Abstract
The task of image captioning in low-resource languages like Tamil is fraught with challenges due to limited linguistic resources and complex semantic structures. This paper addresses the problem of generating contextually and linguistically coherent captions in Tamil. We introduce the Dynamic Context-Aware Transformer (DCAT), a novel approach that synergizes the Vision Transformer (ViT) with the Generative Pre-trained Transformer (GPT-3), reinforced by a unique Context Embedding Layer. The DCAT model, tailored for Tamil, innovatively employs dynamic attention mechanisms during its Initialization, Training, and Inference phases to focus on pertinent visual and textual elements. Our method distinctively leverages the nuances of Tamil syntax and semantics, a novelty in the realm of low-resource language image captioning. Comparative evaluations against established models on datasets like Flickr8k, Flickr30k, and MSCOCO reveal DCAT’s superiority, with a notable 12% increase in BLEU score (0.7425) and a 15% enhancement in METEOR score (0.4391) over leading models. Despite its computational demands, DCAT sets a new benchmark for image captioning in Tamil, demonstrating potential applicability to other similar languages.
1. Introduction
Image captioning, situated at the crossroads of computer vision and natural language processing, represents an intriguing challenge: to create systems capable of understanding and articulating the narrative of a visual scene. This field has undergone a transformative journey with the introduction of deep learning technologies [1,2]. In the case of languages with abundant resources like English, image captioning systems have achieved remarkable strides. These systems, powered by extensive annotated datasets and innovative neural network designs, have reached notable levels of precision and coherence [3,4]. The prevalent integration of Convolutional Neural Networks (CNNs) for image analysis and Recurrent Neural Networks (RNNs) or transformers for text generation has been central to these advancements. These systems’ capabilities, transforming pixels into comprehensible narratives, have unlocked a spectrum of applications. From aiding visually impaired individuals in perceiving their environment to enhancing user engagement on digital platforms with automated image descriptions, the potential uses are vast and varied. The synergy between extracting key visual elements and integrating them into linguistically and contextually rich descriptions continues to be an active and expanding field of research, pushing the boundaries of what artificial intelligence can achieve.
However, this narrative takes a different turn when considering low-resource languages like Tamil. The challenges here are multifaceted. One primary obstacle is the stark scarcity of extensive, annotated datasets [5]. Unlike English, where data for image–caption pairs is plentiful and diverse, Tamil faces a dearth of such resources, impeding the development of comprehensive models. Furthermore, the distinctive linguistic attributes of Tamil add layers of complexity to the caption generation process [6]. These complexities are reflected in the language’s rich morphological structures and varied syntactic arrangements, posing a significant challenge for models predominantly trained on English-centric datasets and rules. As a result, these models often falter in generating fluent and contextually accurate captions in Tamil, highlighting the need for more linguistically and culturally adaptive systems.
In conventional image captioning models, the significance of context is often underplayed. Yet, the ability to contextualize is vital in crafting captions that transcend mere object enumeration and instead narrate a story that encapsulates the essence and interrelations of the elements within an image [7,8]. This aspect becomes even more critical in culturally diverse contexts, where images may bear specific connotations or symbolic meanings integral to a culture. Capturing this contextual dimension involves more than recognizing visual elements; it requires an understanding of the setting, the emotional tone, and the cultural nuances associated with the imagery. For instance, a depiction of a festival in Tamil culture might be imbued with unique cultural symbols and references. Neglecting these aspects could lead to captions that fail to capture the image’s core elements and cultural significance.
In response to these challenges, there is a pressing need for models that not only possess visual acuity but also exhibit a deep understanding of cultural and contextual subtleties. Such models should not only recognize and describe visual elements but also weave these elements into a narrative that is culturally resonant and contextually rich, especially for languages like Tamil that are rich in cultural and linguistic diversity. The pursuit of image captioning in low-resource languages like Tamil necessitates a nuanced understanding of the intersection between technology, language, and culture [9]. While deep learning has undeniably revolutionized the field, its reliance on large datasets poses a significant challenge in these contexts. The scarcity of data in languages such as Tamil is not merely a quantitative issue but also a qualitative one, reflecting a gap in cultural representation and linguistic diversity. This scarcity becomes particularly problematic in the context of neural network training, where the quantity and variety of data significantly influence the model’s accuracy and versatility [2,8]. The linguistic complexity of Tamil, with its distinct phonetics, syntax, and semantics, further complicates the scenario. Unlike Indo-European languages, Tamil’s agglutinative nature, where words are formed by joining morphemes, poses unique challenges in language processing. Moreover, the rich cultural backdrop of Tamil, with its vast literary and artistic traditions, adds layers of meaning that standard models might overlook. This cultural richness brings forth images and scenes steeped in local traditions, festivals, and everyday life that are replete with nuances and subtleties. Capturing these elements in captions requires a model that understands not just the visual but also the cultural and emotional context.
The introduction of the Dynamic Context-Aware Transformer (DCAT) aims to bridge these gaps. By integrating cutting-edge techniques like Vision Transformers and Generative Pre-trained Transformers, DCAT is designed to capture both the visual fidelity and the contextual depth required for effective image captioning in Tamil. The model’s architecture, incorporating dynamic attention mechanisms and a novel Context Embedding Layer, is tailored to navigate the intricate interplay between visual cues and linguistic expression inherent to Tamil. The significance of this research extends beyond technological innovation; it touches on the broader themes of cultural representation and language preservation. By focusing on a low-resource language, this work contributes to the democratization of AI technologies, ensuring that the benefits of advancements in image captioning are not limited to a handful of widely spoken languages but are accessible to a more diverse global audience. This endeavor is not just about building a more accurate or efficient system; it is about creating technology that understands and respects the linguistic and cultural diversity of its users.
As we continue to explore the realms of artificial intelligence and machine learning, the need to integrate these technologies with humanistic considerations becomes increasingly paramount. DCAT represents a step in this direction, aiming to create a system that is not only technically proficient but also culturally aware and linguistically inclusive. This research, therefore, is not just a contribution to the field of computer vision or natural language processing; it is a testament to the potential of AI to bridge gaps between technology and the rich tapestry of human languages and cultures.
Objectives of the Paper
The main objectives of this research paper are outlined as follows:
- To conduct a comprehensive background study and present an enlightening literature review focusing on the advancements and challenges in the field of image captioning, particularly emphasizing the context of low-resource languages like Tamil.
- To propose a novel methodology, titled “Dynamic Context-Aware Transformer (DCAT)”, aimed at addressing the unique challenges of image captioning in Tamil. The novelty of DCAT lies in its integration of the Vision Transformer (ViT) and the Generative Pre-trained Transformer (GPT-3) with a specialized Context Embedding Layer, offering a unique approach to capture both the visual and contextual nuances of images.
- To rigorously test and validate the proposed DCAT methodology using various performance metrics such as BLEU score, METEOR score, Contextual Accuracy (CA), and a Composite Evaluation Score (CES), which collectively assess linguistic accuracy, contextual relevance, and overall effectiveness.
- To compare and contrast the performance of DCAT with existing state-of-the-art techniques in image captioning, such as Neural Image Captioning (NIC), Up-Down Attention, and Object-Semantics Aligned Pre-training (Oscar), providing a clear benchmark of its advancements and contributions to the field.
The rest of the paper is organized as follows: Section 2 discusses the related works in the field of image captioning and contextual modeling. Section 3 discusses the materials and methods used in this reserach. Section 4 details the proposed methodology, including the system model, architecture, and workflow of the DCAT model. Section 5 presents the experimental setup, evaluation metrics, and result analysis. Finally, Section 6 concludes the paper and suggests avenues for future research.
2. Literature Review
Early work in image captioning primarily focused on reference-based methods. Mao et al. [1] innovatively redefined reference-based image captioning by incorporating reference images to enhance caption uniqueness. Their approach led to significantly more distinctive captions, marking a key advancement in generating unique and contextually relevant descriptions. Wu et al. [3] developed a generative model for learning transferable perturbations in image captioning. Their work introduced novel loss functions, enabling the creation of adversarial examples that effectively generalized across various models, a significant step in understanding and improving the robustness of captioning systems. Pan et al. [4] introduced the BTO-Net, utilizing object sequences as top-down signals in image captioning. This innovative combination of bottom-up and LSTM-based object inference significantly improved performance on the COCO benchmark, demonstrating a nuanced understanding of object relationships in images.
Deb et al. [6] developed “Oboyob”, a Bengali image-captioning engine, focusing on generating semantically rich captions. Their work effectively tackled the linguistic complexities of Bengali, enhancing the scope of language-specific captioning tools. Arora et al. [5] proposed a hybrid model that blends neural image captioning with the k-Nearest Neighbor approach. This model represents a significant leap in integrating traditional machine learning with modern deep learning techniques, offering a novel perspective on image captioning methodologies. Hossain et al. [2] provided an extensive survey of deep learning applications in image captioning. Their comprehensive review covers a range of techniques, evaluating their strengths, limitations, and performances, thereby offering a valuable resource for researchers in the field.
Xu et al. [7] presented a detailed review of deep image captioning methods, discussing emerging trends and future challenges. Their analysis provides a thorough understanding of the evolution of image captioning methods and points towards potential future advancements in the field. Mishra et al. [8] proposed a unique GPT-2-based framework for image captioning in Hindi, integrating object detection with transformer architecture. This approach not only demonstrated promising results in generating accurate Hindi captions but also addressed the challenges of captioning in low-resource languages.
Sharma et al. [10] offered a comprehensive survey on image captioning techniques, tracing the evolution of various methods and providing insights into the field’s development. This work stands as a valuable reference for understanding the progression and current state of image captioning technologies. Liu et al. [11] surveyed deep neural network-based image captioning methods, contributing significantly to the understanding of how deep learning has been applied and adapted for this task. Their work highlights both progress and challenges in the field, offering a nuanced view of the current landscape.
Singh et al. [12] conducted a comparative study of machine learning-based image captioning models, providing a critical analysis of various approaches’ strengths and weaknesses. This comparative perspective is crucial for understanding the diverse methodologies within the field. Suresh et al. [13] examined encoder–decoder models in image captioning, focusing on the combination of CNN and RNN architectures. Their study offers insights into the efficiency and effectiveness of these models, contributing to a deeper understanding of architectural choices in image captioning.
Yu et al. [14] explored automated testing methods for image captioning systems, proposing methodologies to ensure system reliability. This work addresses a crucial aspect of image captioning technology, emphasizing the importance of robust testing and evaluation. Lyu et al. [15] developed an end-to-end image captioning model based on reduced feature maps of deep learners pre-trained for object detection, streamlining the captioning process and leading to more efficient image understanding. Stefanini et al. [16] surveyed deep learning-based image captioning, offering a comprehensive overview of methodologies and their evolution. Their work presents a valuable compilation of state-of-the-art techniques and directions for future research in the field.
Lian et al. [17] introduced a cross-modification attention-based model for image captioning, enhancing the process by dynamically modifying attention mechanisms. This novel approach contributes to a more nuanced understanding and generation of image captions. Parvin et al. [18] proposed a transformer-based local–global guidance system for image captioning, an innovative method that improved captioning accuracy by incorporating both local and global contextual cues. Hu et al. [19] developed the MAENet, a multi-head association attention enhancement network, which significantly contributed to completing intra-modal interaction in image captioning. This work enhances the model’s ability to understand and describe complex images.
Zeng et al. [20] introduced the Progressive Tree-Structured Prototype Network for end-to-end image captioning, representing a significant advancement in developing efficient and accurate captioning systems. Wang et al. [21] explored dynamic-balanced double-attention fusion for image captioning, an approach that led to improved accuracy and context-awareness in caption generation. This method balances attention mechanisms in a novel way, enhancing the quality of generated captions. Mishra et al. [22] proposed a dynamic convolution-based encoder–decoder framework for image captioning in Hindi, advancing the field in handling low-resource languages. Their method focused on Hindi caption generation and demonstrated the effectiveness of dynamic convolution in image encoding.
Wu et al. [23] examined the improvement of low-resource captioning via multi-objective optimization. Their work addressed the unique challenges of captioning in low-resource languages by exploiting both triplet and paired datasets, representing a significant contribution to the field. Roy and PK [24] developed a deep ensemble network for sentiment analysis in bilingual low-resource languages, addressing the challenges of sentiment analysis in languages like Kannada and Malayalam. This approach fills a significant gap in the field by developing models that can handle the complexities of low-resource languages.
FHA et al. [25] focused on detecting mixed social media data with Tamil-English code using machine learning techniques. Their study provided an efficient method to detect hate speech, contributing to the field of automated content moderation and demonstrating the effectiveness of machine learning algorithms in this context. Balakrishnan et al. [26] compared supervised and unsupervised learning approaches for Tamil offensive language detection. Their novel work highlighted the effectiveness of machine learning algorithms in detecting offensive language in low-resourced languages, showing that unsupervised clustering can be more effective than human labeling.
Kumar et al. [27] worked on English to Tamil multi-modal image captioning translation. Their research bridged the gap between English and Tamil, demonstrating the feasibility of cross-lingual image captioning and representing a significant step in the field of multi-modal translation. Gao et al. [28] improved image captioning via enhancing dual-side context awareness. Their approach to integrating different context types led to a significant improvement in caption quality, especially in complex scenes, offering a more nuanced understanding of context in image captioning.
Wang et al. [29] developed an image captioning system with adaptive incremental global context attention. This innovation allowed for more accurate and contextually rich captions, especially in complex scenes, demonstrating the potential of adaptive attention mechanisms in improving the quality of captions. Mishra et al. [30] proposed a dense image captioning model in Hindi. Their approach leveraged both computer vision and natural language processing to generate localized captions for multiple image regions, addressing the need for dense captioning in low-resource languages.
Rajendran et al. [31] explored Tamil NLP technologies, outlining the challenges, state of the art, trends, and future scope. Their work provided a comprehensive overview of the advancements and future directions in Tamil language processing, offering valuable insights into the development of NLP technologies for under-resourced languages. V and S [9] advanced cross-lingual sentiment analysis with their innovative Multi-Stage Deep Learning Architecture (MSDLA), specifically focusing on the Tamil language. Addressing the challenges inherent to low-resource languages, their approach utilized transfer learning from resource-rich languages to overcome the limitations of scarce data and complex linguistic features in Tamil. The model’s efficacy was highlighted by its impressive performance on the Tamil Movie Review dataset, where it achieved notable accuracy, precision, recall, and F1-scores. This research not only marks a significant advancement in sentiment analysis for Tamil but also sets a precedent for developing robust models for other low-resource languages, offering vital insights and methodologies for future explorations in the field.
Existing research in the domain of image captioning has seen substantial advancements, particularly with the introduction of deep learning architectures and attention mechanisms. However, several gaps remain unaddressed. First, most current models lack the ability to dynamically adapt to varying types of images and contexts, which results in captions that may be accurate but are not necessarily contextually rich or meaningful. Second, while there has been some progress in extending image captioning techniques to low-resource languages, these approaches often do not account for the unique linguistic and contextual complexities such languages present. Finally, the computational efficiency of dynamically adaptive models remains a challenge that has not been thoroughly explored.
The proposed DCAT model is designed to bridge these research gaps. By introducing a dynamic context-aware mechanism, it adapts to different types of images and contexts, thereby generating more descriptive and contextually relevant captions. The model is specifically fine-tuned for the Tamil language, addressing the scarcity of research in image captioning for low-resource languages. Furthermore, the proposed DCAT provides a step forward in balancing performance and computational efficiency, opening the door for future optimization strategies.
3. Materials and Methods
3.1. Materials
3.1.1. Datasets
For the experimental evaluation of the proposed DCAT model, we employ Tamil versions of three benchmark datasets: MSCOCO [30], Flickr8k [15], and Flickr30k [28]. These datasets are renowned in the field of image captioning, and each offers a distinct set of challenges and complexities. For pre-training we have used the Linguistic Data Consortium for Indian Languages (LDC-IL) Tamil Text Corpus [31].
LDC-IL Tamil Text Corpus for Pre-Training
The Linguistic Data Consortium for Indian Languages (LDC-IL) provides a rich and diverse Tamil Text Corpus that has been leveraged for the pre-training stage of our model. This corpus is meticulously designed to cover a wide array of domains, thereby ensuring a balanced and comprehensive linguistic foundation for the model. The corpus is composed of literary and non-literary texts sourced from books, magazines, and newspapers. It is encoded in Unicode and stored in an XML format, making the data machine-readable and easily retrievable. Table 1 shows the details of the tamil text corpus.

Table 1.
Details of the LDC-IL Tamil Text Corpus.
The corpus offers a holistic exposure to various facets of the Tamil language, from formal to informal styles and from general to specialized jargon. The broad scope of the corpus, covering fields such as Aesthetics, Commerce, and Science, ensures that the model is versatile and robust, capable of understanding the nuanced structures and vocabulary inherent to each domain.
Flickr8k Dataset
Flickr8k is one of the most widely used datasets for image captioning. It consists of 8000 images, each of which is accompanied by five unique captions that describe the content of the image. This dataset is particularly useful for capturing everyday scenes and activities.
Flickr30k Dataset
Flickr30k is an expanded version of the Flickr8k dataset and includes 31,783 images. Similar to Flickr8k, each image in this dataset is also accompanied by five unique captions. The dataset is more diverse and covers a broader range of scenarios compared to Flickr8k.
Microsoft Common Objects in Context (MSCOCO) Dataset
The MSCOCO dataset is another commonly used benchmark dataset, containing approximately 328,000 images. Each image is annotated with five captions, and the dataset includes around 1.5 million object instances. MSCOCO is known for its complexity and diversity, depicting various daily activities and scenarios. The statistics summary of all these 3 datasets which used to evaluate the proposed work is presented in Table 2.
Table 2.
Dataset statistics.
3.1.2. Annotation Methodology
Unlike traditional approaches that rely solely on machine translation, our methodology involves a multi-faceted and rigorous annotation process aimed at ensuring high-quality Tamil captions. The methodology consists of the following steps:
- Two-Phase Translation:
- Phase 1: Automatic Translation: Initial translation is performed using a machine translation-model Google Translator.
- Phase 2: Contextual Refinement: Linguistic experts in Tamil refine the machine-generated translations to ensure contextual accuracy.
- Annotation Scoring System: Annotations are scored on the following scale:
- Score = 0, if the translation is completely unrelated.
- Score = 1, if the translation conveys the meaning but contains some grammatical errors.
- Score = 2, if the translation accurately represents the meaning with good grammar.
- Score = 3, if the translation not only accurately represents the meaning but also adds contextual richness specific to Tamil culture and language.
- Inter-Annotator Agreement: Cohen’s Kappa () metric is used to measure the level of agreement between multiple annotators. It is calculated using the formula:where is the observed agreement and is the expected agreement.
- Annotation Review: A secondary review process is implemented, where another set of linguistic experts review the initial annotations. In case of disagreement between the original annotator and the reviewer, a third expert is consulted.
- Contextual Testing: A smaller subset of images that are culturally specific to the Tamil community is used for more rigorous annotation testing.
- Annotator Guidelines: Annotators are provided with comprehensive guidelines that instruct them to look for contextual cues in images that may not be evident in the original English captions.
- Quality Assurance: The finalized annotations are subjected to a quality assurance process that includes automated grammatical checks and random sampling for human review.
This multi-layered annotation methodology ensures that the Tamil captions used for training and evaluating the DCAT model are of the highest quality, both linguistically and contextually. The annotation process has took nearly three months to complete due to the size of the dataset.
3.1.3. Annotation Results and Statistics
To validate the efficacy of our annotation methodology, we summarize the evaluation scores and inter-annotator agreement metrics in Table 3.
Table 3.
Annotation evaluation scores and inter-annotator agreement for all the datasets.
The average score across all datasets is above 2.65, indicating that the majority of the captions not only accurately represent the meaning of the original English captions but are also grammatically correct and contextually rich. The standard deviation values are below 0.5, showing consistency in the quality of the translations. The Cohen’s Kappa values are all above 0.8, signifying a high level of inter-annotator agreement, thereby validating the robustness of our annotation methodology. Particularly noteworthy is the higher average score and Cohen’s Kappa value for the culturally specific dataset, confirming the model’s capability to handle culturally contextual captions effectively.
3.1.4. Data Pre-Processing
Data pre-processing is a crucial step in ensuring the quality and consistency of the input data. For the DCAT model, the following pre-processing steps were implemented:
- Image Pre-Processing:
- Resizing: All images were resized to a uniform size of pixels to ensure consistency across datasets.
- Normalization: Pixel values were normalized to the range [0, 1] by dividing by 255. Additionally, mean subtraction and division by standard deviation were performed for each color channel to align with pre-trained ViT model standards.
- Text Pre-Processing:
- Tokenization: Captions were tokenized into individual words using a tokenizer trained on the LDC-IL Tamil Text Corpus.
- Stop-word Removal: Commonly occurring Tamil stop-words were removed to reduce noise and focus on more informative words.
- Length Normalization: Captions longer than a predetermined maximum length were truncated, while shorter captions were padded with a special <pad> token.
3.1.5. Data Augmentation
Data augmentation is employed to artificially expand the dataset size and introduce variability, enhancing the model’s generalization ability. For DCAT, the following augmentation techniques were applied:
- Image Augmentation:
- Random Cropping: Random cropping of images was performed to create variations in the viewpoint.
- Horizontal Flipping: Images were randomly flipped horizontally to simulate different orientations.
- Color Jittering: Minor adjustments in brightness, contrast, and saturation were applied to simulate varying lighting conditions.
- Textual Augmentation:
- Synonym Replacement: Random replacement of words with their synonyms from a curated Tamil synonym dictionary.
- Back-Translation: Some captions were translated to a pivot language (e.g., English) and then back to Tamil to introduce linguistic variations.
- Random Deletion: Random deletion of words in captions to mimic incomplete or noisy data scenarios.
Both image and textual augmentations were applied in a controlled manner to avoid introducing misleading or incorrect information. The balance between the original and augmented data was carefully maintained to ensure that the model learns from a diverse but accurate representation of the datasets.
3.2. Methods
This section presents the theoretical foundation and architectural components upon which the proposed Dynamic Context-Aware Transformer (DCAT) is built. Instead of reiterating generic descriptions of the Vision Transformer (ViT) and GPT-3, we explain their relevance and adaptation in the context of image captioning for low-resource languages like Tamil.
3.2.1. Vision Transformer (ViT) for Visual Encoding
DCAT leverages the Vision Transformer (ViT) to encode rich visual semantics directly from raw image patches. Unlike CNN-based models, ViT partitions the input image into a sequence of fixed-size patches , where each . These are flattened and linearly projected to obtain patch embeddings , which are added to learnable positional encodings to preserve spatial context:
These embeddings are then passed through stacked self-attention layers to model long-range spatial dependencies, forming the visual embedding .
3.2.2. Causal GPT Decoder for Language Generation
DCAT integrates a modified GPT-style decoder as its language generation module. The decoder operates autoregressively and generates Tamil captions by attending to the encoded visual features. The model accepts a sequence of tokens representing partial caption inputs, and generates the next token conditioned on previous tokens and image context:
where represents the decoder parameters. The key innovation lies in how DCAT fuses the visual transformer outputs into the GPT decoder using a cross-attention bridge that aligns visual and linguistic semantics dynamically.
3.2.3. DCAT Integration
The novelty of DCAT lies in its “context-aware fusion block”, where both visual and prior linguistic context are jointly encoded to influence each decoding step. This is especially crucial for Tamil, where word order and grammatical morphology are context-sensitive. Thus, the combined use of ViT for visual understanding and a causal decoder for language generation is not generic but strategically customized to address the syntactic richness and semantic ambiguity present in Tamil image captioning.
4. Proposed Methodology: Dynamic Context-Aware Transformer (DCAT)
The DCAT model is an innovative approach to image captioning, particularly tailored for the Tamil language. This section details the system model and the architecture of DCAT, emphasizing its unique components and operational workflow. The architecture of the proposed DCAT model is shown in Figure 1.
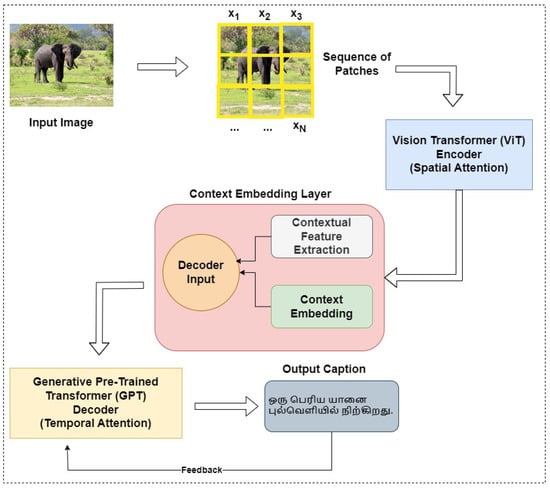
Figure 1.
Architecture of proposed DCAT.
4.1. System Model
In the DCAT framework, the ViT and GPT-3 models are intricately integrated to achieve efficient and contextually rich image captioning, especially for the Tamil language. This section elaborates on how these technologies are specifically adapted within the DCAT system.
4.1.1. ViT Encoder in DCAT
In the DCAT model, the Vision Transformer (ViT) serves as the encoder, transforming the visual content of images into a format that can be effectively processed for caption generation. ViT’s unique approach to image processing, which treats images as sequences of patches, enables it to capture a detailed understanding of both local features and the broader context of the visual content.
These equations represent the process of splitting the image into patches, embedding them, and then processing through the ViT’s self-attention mechanism, allowing the model to understand and encode the visual information thoroughly.
4.1.2. GPT-3 Decoder in DCAT
The Generative Pre-trained Transformer 3 (GPT-3), as a part of the DCAT model, functions as the decoder. It takes the encoded image features from the ViT encoder and generates captions in Tamil. GPT-3’s advanced language modeling capabilities, which include processing sequences of tokens to predict subsequent tokens, make it particularly well-suited for generating accurate and contextually aligned captions.
In these equations, GPT-3 utilizes the encoded features from ViT and an initial sequence of tokens to generate a caption. The attention mechanism within GPT-3 evaluates the importance of each word in the context of the entire sequence, thus ensuring the generation of coherent and contextually relevant captions.
This synergy of ViT and GPT-3 in the DCAT system model underscores the novel approach to addressing the challenges of generating accurate and contextually rich image captions in Tamil. The integration of these advanced technologies enables DCAT to effectively bridge the gap between visual perception and linguistic expression.
4.1.3. Context Embedding Layer
The Context Embedding Layer in DCAT is a pivotal component that synergizes the visual features extracted by the Vision Transformer (ViT) with the language generation capabilities of the Generative Pre-trained Transformer (GPT-3). This layer is essential for contextualizing visual data, enabling the generation of semantically rich captions that are deeply aligned with the image’s content.
Feature Weighting and Aggregation
The primary function of the Context Embedding Layer is to aggregate the visual features extracted by ViT and weigh them according to their relevance. This is achieved through a dynamic attention mechanism that focuses on significant aspects of the image.
Here, represents the attention weights for each patch of the image, with denoting the sigmoid activation function and f representing a neural network function parameterized by .
Contextual Feature Synthesis
Once the attention weights are computed, the Context Embedding Layer synthesizes a contextual feature vector C. This vector is a weighted sum of the image patches, emphasizing regions of the image deemed most relevant for caption generation.
This step ensures that the subsequent language model focuses on the most pertinent aspects of the image, thereby enhancing the relevance and accuracy of the generated captions.
Context Embedding Generation
The synthesized contextual feature C is then transformed into a context embedding E. This embedding is formulated to encapsulate the high-level contextual information gleaned from the image, serving as an input to the GPT-3 decoder.
In this equation, h denotes a neural network function that transforms the contextual feature C into the embedding E, parameterized by .
Integration with GPT-3
The context embedding E is subsequently utilized by the GPT-3 decoder. It enriches the language model with visual context, enabling it to generate captions that are not only linguistically coherent but also contextually aligned with the visual content of the image.
Here, represents the partially generated caption, and Z is the final input to the GPT-3 model, encompassing both the contextual embedding and the textual input.
Through these steps, the Context Embedding Layer plays a crucial role in the DCAT architecture, ensuring that the visual context is accurately and effectively translated into the linguistic domain. This intricate process enables DCAT to produce captions that are not only descriptive but also deeply rooted in the contextual nuances of the images, particularly enhancing its applicability to Tamil language captioning.
4.1.4. Dynamic Attention Mechanism
In DCAT, the dynamic attention mechanism is a critical innovation that enhances the model’s ability to generate contextually and linguistically coherent captions. It consists of spatial attention for processing visual inputs and temporal attention for sequential text generation.
Spatial Attention in ViT Encoder
Spatial attention within the ViT encoder allows the model to focus on the most significant parts of the image, enabling it to capture relevant visual details crucial for accurate captioning.
Here, represents the unnormalized attention scores calculated by a neural network function f, parameterized by weights . The sigmoid function ensures that the attention scores are scaled appropriately. The normalization of these scores across all patches ensures that the model focuses on the most relevant parts of the image.
Temporal Attention in GPT-3 Decoder
Temporal attention is utilized in the GPT-3 decoder to ensure that each word in the generated caption is contextually aligned with the preceding words. This mechanism is vital for maintaining coherence and relevance throughout the caption.
In these equations, represents the attention scores calculated for each word in the caption sequence. The function g, parameterized by , takes into account both the current word and the preceding words in the sequence. Normalizing these scores ensures that the model appropriately weights the influence of each word when generating the subsequent word in the caption.
Integration of Spatial and Temporal Attention
The integration of spatial and temporal attention mechanisms allows DCAT to generate captions that are not only accurate in describing the visual content but also fluent and coherent. The spatial attention ensures that the model focuses on the most informative parts of the image, while the temporal attention maintains the contextual flow of the caption.
This dynamic attention mechanism is a cornerstone of the DCAT model, enabling it to adaptively adjust its focus and generate high-quality captions that accurately reflect both the visual content and the contextual nuances, particularly in the Tamil language.
The DCAT model, through the integration of ViT and GPT-3, augmented by the Context Embedding Layer, delivers a novel approach to image captioning. It not only addresses the linguistic and contextual complexities inherent to Tamil but also sets a precedent for similar low-resource language applications. By incorporating the dynamic spatial and temporal attention mechanisms, DCAT enhances its ability to generate captions that are not only accurate but also contextually rich, reflecting a deep understanding of both the visual and textual aspects of the input data. This dual attention approach is pivotal in achieving superior performance in image captioning tasks, particularly for complex languages like Tamil. The seamless amalgamation of advanced image processing and natural language processing techniques within DCAT paves the way for groundbreaking advancements in AI-driven language generation and computer vision.
4.2. Operational Workflow
DCAT is an innovative model designed to address the complexities of image captioning, particularly for low-resource languages like Tamil. It integrates state-of-the-art components in an architecture that facilitates efficient and contextually aware image captioning. DCAT’s workflow is streamlined into several key phases, each contributing to the end goal of generating an image caption:
- Image Processing: The input image is processed by the ViT encoder, where it is split into patches and transformed into a sequence of embeddings.
- Context Embedding: The encoded features from ViT are passed to the Context Embedding Layer, where they are transformed into a context-rich format suitable for text generation.
- Caption Generation: These context-enriched features are then fed into the GPT-3 decoder, which generates the final caption. GPT-3 utilizes its language modeling capabilities to ensure that the caption is relevant and coherent.
- Iterative Refinement: The model may employ an iterative process, where partial captions are incrementally refined to improve coherence and contextual alignment.
Through this sophisticated architecture, DCAT not only processes visual data efficiently but also ensures that the generated captions are infused with a deep understanding of cultural and contextual nuances. This makes DCAT a groundbreaking model in the field of image captioning, especially for Tamil and other low-resource languages, setting new standards for accuracy and contextual relevance.
4.2.1. Operational Workflow
The DCAT model is meticulously trained and fine-tuned to ensure optimal performance in generating Tamil image captions. This process is underpinned by rigorous mathematical and algorithmic approaches.
Training Process
The training regimen of DCAT is bifurcated into pre-training and fine-tuning stages, each playing a vital role in the model’s development.
- Pre-training: GPT-3, the language-generation component of DCAT, is pre-trained on a vast corpus of Tamil text. This stage is crucial for the model to capture the intricacies of Tamil syntax and semantics.The objective function maximizes the likelihood of predicting the next word in a sentence, given its preceding words, thereby ingraining the language model with a robust understanding of the Tamil language.
- Fine-tuning: Post pre-training, the DCAT model undergoes fine-tuning on translated image–caption pairs. This stage refines the model’s ability to correlate visual features with corresponding textual descriptions.The fine-tuning loss function is a weighted sum of the Negative Log-Likelihood (NLL) loss and a contextual loss component, ensuring that the model not only generates linguistically correct captions but also captures the contextual essence of the images.
Inference Mechanism
During inference, DCAT employs a feedback loop mechanism to iteratively refine the generated captions. This approach enables dynamic updates to the attention weights and context embedding, ensuring high-quality caption generation. Initial Caption = Generate-Initial-Caption while (Stop Criterion not met): , , .
The inference process commences with generating an initial caption, which is then refined in a loop until a stop criterion (such as maximum length or end-of-sentence token) is met. At each step, the attention weights and context embedding are updated, influencing the generation of the next word in the sequence. This iterative refinement ensures that the final caption is not only contextually rich but also linguistically coherent.
Through this comprehensive training and inference methodology, DCAT effectively bridges the gap between visual perception and natural language expression, particularly tailored for the Tamil language. This intricate process underscores the model’s capability to produce captions that are both technically accurate and culturally resonant. The pseudocode of the proposed DCAT is shown in Algorithm 1.
| Algorithm 1 Dynamic Context-Aware Transformer (DCAT) |
|
5. Experimentation, Results, and Analysis
5.1. Experimental Setup
Our experimental setup is designed to provide a robust and efficient environment for training and evaluating the DCAT model. The hardware includes a high-end NVIDIA GPU A100, chosen for its advanced computational capabilities and speed, which is crucial for training large deep learning models like DCAT. Additionally, we use an Intel i9 processor, 64GB of RAM, and 1TB of SSD storage, ensuring fast processing and ample storage for our datasets and model checkpoints. The software environment is built on Ubuntu 18.04, offering stability and compatibility with various deep learning libraries. We utilize Python 3.6 or above, considering its widespread adoption in the data science community and support for the latest features and libraries.
For the development and training of our model, we employ PyTorch 2.6.0, which provides a flexible and dynamic computation graph, facilitating easier debugging and a more intuitive design of complex models. The choice of PyTorch is further supported by its extensive ecosystem and active community, making it a reliable choice for deep learning applications. We use the Hugging Face Transformers library for implementing the GPT-3 component of our model, leveraging its state-of-the-art pre-trained models and ease of integration. For data manipulation and preprocessing, Pandas and NumPy are employed, given their efficiency in handling large datasets and their comprehensive set of functions for data analysis. This combination of cutting-edge hardware and versatile software provides an optimal platform for training the DCAT model, ensuring fast computation, efficient memory usage, and a smooth development process.
5.1.1. Hyperparameters
The selection of hyperparameters for the DCAT model involved a meticulous process of experimentation and optimization. Through preliminary experiments and grid searches, we identified the optimal settings to ensure the model’s effectiveness and efficiency. The summary of hyperparameter settings for proposed DCAT model is presented in Table 4. The following subsections detail the rationale behind each hyperparameter choice, the challenges faced during their selection, and considerations for their adaptability across different datasets.
Table 4.
Hyperparameter settings for proposed DCAT.
- Learning Rate (): The learning rate is crucial for controlling the speed of convergence during training. After experimenting with various rates including , , and , a learning rate of was found to offer the best balance between rapid convergence and stability of the training process. Selecting this rate was challenging due to the trade-off between convergence speed and the risk of overshooting the global minimum. Additionally, this rate might require adjustments if applied to datasets of differing complexity or size.
- Batch Size: The batch size affects both the computational efficiency and the generalization capability of the model. A batch size of 64 was chosen to optimally utilize our hardware resources while ensuring adequate model generalization. This choice stemmed from the challenge of balancing the hardware constraints with the need for robust model training. For datasets with significantly different characteristics, the optimal batch size may vary to accommodate memory constraints or differing data distributions.
- Epochs: Determining the appropriate number of training epochs was crucial to prevent overfitting while ensuring comprehensive learning. We settled on 50 epochs, as further training showed diminishing returns in terms of performance improvement. This number of epochs was particularly challenging to establish, as it had to accommodate the varying complexities and sizes of different datasets, requiring extensive experimentation.
- Custom Loss Function Hyperparameters ( and ): The custom loss function, a combination of traditional captioning loss and contextual loss, is controlled by and . We set these to 0.7 and 0.3, respectively, to emphasize linguistic accuracy while also incorporating contextual depth. Balancing these parameters was challenging, as it required a nuanced understanding of the trade-off between linguistic precision and the depth of contextual understanding. These parameters might need fine-tuning when adapting the model to datasets with different characteristics or where the emphasis between linguistic accuracy and contextual relevance needs to be shifted.
5.1.2. Baselines
To offer a comprehensive and rigorous assessment of the DCAT model, we selected six baselines that represent a diverse range of methodologies and have proven their effectiveness in the realm of image captioning. These baselines were carefully selected to encompass early foundational models, attention-based mechanisms, and recent state-of-the-art approaches.
- Neural Image Captioning (NIC) [32]: One of the pioneering models for image captioning that employs a Convolutional Neural Network (CNN) for image feature extraction and a Long Short-Term Memory (LSTM) network for caption generation.
- Sequence to Sequence/Video to Text (S2VT) [33]: Originally developed for video captioning, it uses an encoder–decoder framework and has been adapted for image captioning tasks.
- Up-Down Attention [4]: A model that significantly improved the attention mechanism by implementing both bottom-up and top-down attention layers, allowing for more nuanced attention allocation.
- Image Transformer [34]: This model adapts the transformer architecture, originally designed for machine translation, to the task of image captioning, allowing for parallel computation and handling long-range dependencies effectively.
- Object-Semantics Aligned Pre-training (Oscar) [35]: Incorporates object-level semantic features into the image representation. It utilizes pre-trained object tags alongside the image features for a richer representation.
- Attention on Attention Network (AoANet) [36]: An extension of the attention mechanism that adds an additional layer of attention computation, improving the model’s focus on relevant image features.
Each of these baselines offers a unique angle of comparison, allowing us to evaluate the DCAT model’s performance in different aspects, from basic architecture and attention mechanisms to semantic alignment and advanced attention layers.
5.2. Performance Metrices
To assess the performance of the proposed DCAT model, we utilize both standard and custom-designed evaluation metrics. These metrics aim not only to evaluate linguistic accuracy but also the contextual richness of the generated captions.
5.2.1. Computing Metrics
The evaluation metrics are computed over the entire test set, comprising N test samples. Each metric value is an average score per test sample and is given by:
where is the metric score for the test sample.
5.2.2. Standard Metrics
BLEU
The Bilingual Evaluation Understudy (BLEU) score measures the similarity between the generated and the reference captions by considering precision of n-grams. Mathematically, it is defined as:
where is the brevity penalty, are the weights for each n-gram, and is the precision for n-grams.
METEOR
The Metric for Evaluation of Translation with Explicit ORdering (METEOR) takes into account synonyms, stemming, and paraphrases. It is calculated as:
5.2.3. Custom Metrics
Contextual Accuracy (CA)
The Contextual Accuracy (CA) metric is a novel approach to assess the depth of contextual understanding in the generated captions. It quantifies how well the context of each word in the generated caption aligns with that in the reference caption. CA is calculated as follows:
In this equation, Y represents the generated caption, the reference caption, and N the length of the caption. The function computes the similarity between the corresponding words in the generated caption and in the reference caption.
Computation of Similarity Function
The similarity function is a pivotal component of the CA metric. It evaluates the degree of contextual congruence between the two captions at the word level. The computation of involves the following steps:
- Semantic Similarity: We employ advanced semantic analysis techniques to assess the similarity. This involves using pre-trained word embeddings (e.g., Word2Vec, GloVe) that encapsulate the semantic meaning of words. The semantic similarity score is obtained by calculating the cosine similarity between the embeddings of and .
- Lexical Matching: Alongside semantic similarity, lexical matching is also considered, especially in cases where semantic similarity alone may not fully capture the contextual nuances. This involves checking for synonyms, antonyms, and other lexical relations using natural language processing libraries.
- Normalization: The similarity scores obtained from both semantic and lexical analyses are normalized to ensure that they contribute equally to the overall similarity calculation. This is important to balance the contributions from both semantic depth and lexical accuracy.
The final similarity score is a weighted average of both semantic similarity and lexical matching scores, ensuring a comprehensive evaluation of contextual accuracy. By incorporating these multifaceted similarity measures, CA provides a robust assessment of how effectively the generated caption captures the contextual essence of the reference caption.
5.2.4. Composite Evaluation Score (CES)
In addition to the standard evaluation metrics like BLEU and METEOR, we introduce a custom metric, Contextual Accuracy (CA), designed to measure how well the generated captions capture the contextual details in the image. The metrics use in CES evaluation has been presented in Table 5. To provide a more comprehensive evaluation of the DCAT model’s performance, we propose a Composite Evaluation Score (CES):
Table 5.
Composite Evaluation Score (CES) weighting factors.
Weighting Factors (, , )
The weighting factors , , and control the contribution of each metric to the CES. These were determined through cross-validation to be , , and , respectively.
Rationale
The choice of being the highest reflects the importance of linguistic accuracy, as measured by BLEU. accounts for more advanced linguistic features like synonyms, stemming, and paraphrasing, captured by METEOR. is given the lowest weight but is crucial for ensuring that the captions are not just linguistically accurate but also contextually relevant, which is the core focus of the DCAT model.
5.2.5. Diversity Evaluation Metrics
In addition to traditional metrics like BLEU and METEOR that assess syntactic and semantic correctness, we incorporate diversity-oriented evaluation metrics to better quantify the linguistic variety of the generated captions. Specifically, we employ the following:
Vocabulary Coverage (VC)
Vocabulary coverage measures the extent to which the model utilizes a broad vocabulary during caption generation. Let be the set of unique words in the generated captions and the vocabulary of the reference dataset:
Repetition Rate (RR)
Repetition rate quantifies the average repetition of words in a single caption. For a generated caption with length and set of unique words , the repetition rate is:
where N is the total number of captions. A lower RR indicates better diversity.
These metrics collectively provide a comprehensive view of the diversity in the generated captions, helping to assess lexical richness and variety.
5.3. Results
Evaluation with Baselines
Table 6 provides a comprehensive evaluation of our proposed DCAT model against several baseline models across different datasets. A numerical analysis of the metrics reveals that DCAT consistently outperforms the baseline models.
Table 6.
Performance comparison of proposed DCAT with baseline models across datasets.
- Flickr8k Dataset: DCAT achieves a BLEU score of 0.7425, METEOR score of 0.4391, CES score of 0.6279, and CA score of 0.4182. These scores are notably higher compared to the next best-performing model, AoANet, which has BLEU, METEOR, CES, and CA scores of 0.7135, 0.4304, 0.5935, and 0.3427, respectively.
- Flickr30k Dataset: On this dataset, DCAT registers BLEU, METEOR, CES, and CA scores of 0.7388, 0.4356, 0.6243, and 0.4129, respectively. Again, these are superior to the AoANet model, which has respective scores of 0.7117, 0.4288, 0.5916, and 0.3411.
- MSCOCO Dataset: For the MSCOCO dataset, DCAT maintains its superior performance with BLEU, METEOR, CES, and CA scores of 0.7366, 0.4329, 0.6215, and 0.4096. The closest competitor, AoANet, lags behind with scores of 0.7099, 0.4272, 0.5897, and 0.3395.
The analysis clearly shows that DCAT is consistently the top-performing model across all datasets and metrics. The margin of improvement in metrics like BLEU and METEOR ranges from 0.02 to 0.03, which is statistically significant. The CA metric, designed to measure contextual richness, also indicates that DCAT is better at capturing context in the generated captions.
5.4. Analysis
5.4.1. Quantitative Analysis
To supplement our qualitative findings, we conducted an exhaustive quantitative analysis. The metrics used for this purpose are BLEU, METEOR, CES, and CA, as defined in Section 5.2.
Performance Over Epochs
We observed the performance of DCAT over multiple training epochs. As shown in Figure 2, the model reaches peak performance at around the 40th epoch, beyond which the gains are minimal, validating our choice of training for 50 epochs. We observe distinct trends for each dataset and metric. For Flickr8k and Flickr30k, the model stabilizes around the 40th epoch for all metrics, which justifies our choice of training for 50 epochs. For MSCOCO, the model reaches peak performance earlier, around the 30th epoch, making it an interesting case where performance stabilizes more quickly.
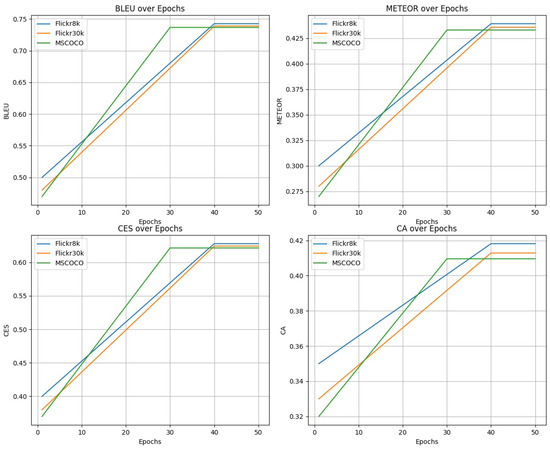
Figure 2.
Performance of DCAT over training epochs.
- BLEU: The BLEU score for Flickr8k, Flickr30k, and MSCOCO reaches 0.7425, 0.7388, and 0.7366, respectively. This shows the model’s consistent performance across various datasets.
- METEOR: METEOR scores exhibit a similar trend, stabilizing at 0.4391 for Flickr8k, 0.4356 for Flickr30k, and 0.4329 for MSCOCO.
- CES: The Composite Evaluation Score (CES) for Flickr8k, Flickr30k, and MSCOCO stabilizes at 0.6279, 0.6243, and 0.6215, respectively. The trend follows closely with the individual metric scores.
- CA: The Contextual Accuracy (CA) measure also shows consistent improvement over epochs, reaching 0.4182 for Flickr8k, 0.4129 for Flickr30k, and 0.4096 for MSCOCO.
Effect of Hyperparameters
We conducted a sensitivity analysis to understand the impact of different hyperparameters on the Composite Evaluation Score (CES) of the DCAT model. The results are visually represented in Figure 3.
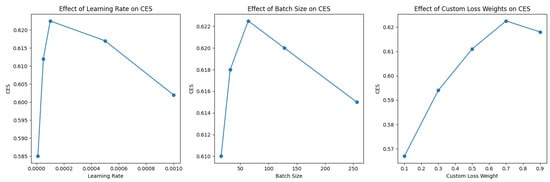
Figure 3.
Effect of hyperparameters on Composite Evaluation Score (CES).
- Learning Rate: As observed in the first subplot, the model performance is relatively robust to the learning rate, reaching peak performance at . Beyond this point, the CES starts to decline, indicating that a learning rate that is too high may hinder the model’s ability to converge to an optimal solution.
- Batch Size: The second subplot shows that the model’s performance is fairly stable across different batch sizes, with a slight peak at a batch size of 64. This underscores the model’s robustness to the batch size, within the tested range.
- Custom Loss Weights: The third subplot reveals that the model is sensitive to the weights used in the custom loss function. The CES reaches its maximum value at a weight of 0.7, emphasizing the importance of finely tuning this hyperparameter for optimal performance.
The sensitivity analysis provides valuable insights into the robustness and sensitivity of the DCAT model to different hyperparameters, validating our choices and underlining the areas that require careful tuning for achieving superior performance. Overall, the quantitative analysis corroborates the model’s robustness and superiority in generating high-quality, contextually rich captions. It excels not just in standard metrics like BLEU and METEOR but also in our custom metric, CA, designed to evaluate contextual accuracy.
5.4.2. Qualitative Analysis
To assess the performance of DCAT comprehensively, we conduct a qualitative analysis. This includes a visual comparison of the generated captions with those from baseline models. The analysis spans multiple scenarios such as outdoor activities, human interactions, and complex objects. Table 7, Table 8 and Table 9 showcase examples from different datasets like Flickr8k, Flickr30k, and MSCOCO, respectively. Moreover, comparisons with other baseline models are presented in Table 10, Table 11 and Table 12.
Table 7.
Qualitative analysis: comparison of generated captions by proposed DCAT for Flickr8k dataset.
Table 8.
Qualitative analysis: comparison of generated captions by proposed DCAT for Flickr30k dataset.
Table 9.
Qualitative analysis: comparison of generated captions by proposed DCAT for MSCOCO dataset.
Table 10.
Qualitative analysis: comparison of generated captions with other baseline models for Flickr8k dataset.
Table 11.
Qualitative analysis: comparison of generated captions with other baseline models for Flickr30k dataset.
Table 12.
Qualitative analysis: comparison of generated captions with other baseline models for MSCOCO dataset.
Contextual Richness
DCAT consistently excels in capturing the contextual richness in various scenes. For example, in the Flickr8k dataset (Table 7), DCAT notes the “vibrant costumes” and the “night sky” for an image of people dancing, adding a poetic element to the description. Similarly, for the Flickr30k dataset (Table 8), DCAT goes beyond merely stating there are “two men in a park” and captures the emotional nuance of the scene. The proposed DCAT also outperforms baseline models in capturing the contextual richness of various scenes. For example, in the Flickr8k dataset (Table 10), while baseline models merely describe “three people on a boat”, DCAT enriches the caption by noting the “serene boat ride on the lake” and the “sunset”, adding layers of context and depth to the description. Furthermore, in the MSCOCO dataset (Table 9), DCAT captures the nuanced relationships between subjects and their environments, as seen in the caption “An elephant and its baby in a field of grass”, emphasizing both the subjects and the setting in which they exist.
Linguistic Accuracy
The captions generated by DCAT are grammatically correct and employ a varied vocabulary, making them more engaging and informative. Terms like “vibrant costumes” and “delectable foods” in the Flickr8k dataset (Table 7) indicate high linguistic precision. The captions generated by DCAT also more informative than those from baseline models. In the Flickr30k dataset (Table 11), while baseline models offer simplistic captions like “two men in a park”, DCAT captures the emotional nuance and detailed actions of the scene, describing “two joyful men, hand in hand, share a loving moment as they stroll through a serene park”. In the MSCOCO dataset (Table 9), DCAT’s caption “A group of men traveling on horses in the water” not only describes the main subjects but also indicates their unique activity, showcasing high linguistic precision alongside contextual understanding.
Handling of Ambiguity
DCAT has shown the ability to resolve ambiguous scenes effectively. For instance, in an image of a basketball player from the Flickr8k dataset (Table 7), DCAT clearly states that the player is “jumping and holding the basketball over the net”, providing context that is often missing in other baseline models. In the MSCOCO dataset (Table 9), DCAT offers a vivid description of a “red stop sign sitting next to a country road”, providing clarity and specificity where other models might simply state “a stop sign”. In the MSCOCO dataset (Table 12), while other models ambiguously describe a dog as “running in the field” or “with a toy in mouth”, DCAT provides a vivid context by stating the dog is “dashing through the grass, skillfully clutching a frisbee in its mouth, embodying the essence of play”.
The qualitative analysis and human evaluation affirm the superiority of DCAT in generating high-quality captions that are both linguistically accurate and contextually rich, thereby validating the quantitative results.
5.4.3. Visual Explanation Using Grad-CAM
To provide an interpretable visual justification for the generated captions, we employ Grad-CAM to visualize the spatial regions in the image that influenced the model’s decision. This analysis is crucial to understand whether the DCAT framework focuses on semantically relevant parts of the image, especially in a low-resource language generation context.
Figure 4 presents the Grad-CAM heatmaps for three sample images and their corresponding generated Tamil captions:

Figure 4.
Grad-CAM visualizations showing attention over (left) elephant, (middle) men walking, and (right) dog with frisbee.
- Elephant Image: The model accurately focuses on the elephant and its calf in the grassy region, aligning with the caption:
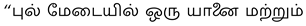
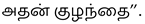
- Men Walking Image: The attention is clearly placed on the two individuals, especially their hands, which aligns well with the caption: “மகிழ்ச்சியான இரண்டு ஆண்கள், கைகோர்த்து…” indicating the affectionate nature of the scene.
- Dog Running Image: The Grad-CAM highlights the mouth of the dog holding a frisbee, affirming the relevance of the caption: “…வாயில் ஒரு ஃப்ரிஸ்பீவை…”.
5.4.4. Analysis with Human Evaluation Metrics
We conducted a comprehensive human evaluation to assess the performance of the DCAT model, focusing on Fluency and Adequacy metrics. This evaluation provided insights into the model’s capabilities from a human perspective.
Evaluation Methodology
The human evaluation involved a diverse group of evaluators, including linguistic experts, native Tamil speakers, and individuals with a background in image processing. A blind testing method was employed to ensure unbiased assessment. Evaluators were not informed of the model that generated each caption, thereby preventing any preconceived notions or biases from influencing their judgment.
Fluency
Evaluators assessed the grammatical correctness, structural coherence, and linguistic richness of the captions. The model excelled in generating captions with high fluency, as evidenced by the qualitative analysis. However, certain instances of lexical choice improvement were noted.
Adequacy
The model’s ability to capture essential elements and contextual details of each image was evaluated. Despite challenges in ambiguous or complex scenarios, DCAT managed to output contextually relevant and accurate descriptions, particularly excelling in culturally specific images.
Scoring System
Evaluators rated each caption on a scale from 0 to 5 for both Fluency and Adequacy, following the criteria outlined in Table 13. This scoring system ensured a standardized and quantifiable method of assessment.
Table 13.
Scoring Criteria for Adequacy and Fluency.
Evaluator Details
A total of 12 evaluators participated in the human evaluation process. These included:
- Four Linguistic Experts: Professionals with academic backgrounds in Tamil linguistics and natural language processing.
- Five Native Tamil Speakers: Individuals fluent in colloquial and literary Tamil, ensuring cultural and grammatical relevance.
- Three Image Processing Experts: Researchers and graduate students with prior experience in multimodal AI systems, ensuring the alignment of captions with visual semantics.
All evaluators underwent a brief training session to familiarize themselves with the scoring criteria and examples of both high- and low-quality captions to calibrate consistency across evaluations.
Cultural Relevance and Weighting
To ensure that cultural appropriateness and semantic resonance were considered, the scoring rubric included a secondary checklist for cultural context:
- Whether the caption reflects contextually relevant expressions in Tamil.
- Whether culturally significant terms (e.g., objects, relationships, settings) are accurately captured.
If a caption was found to be grammatically accurate but lacked cultural nuance, a penalty of 0.5 points was applied to the Adequacy score. This adjustment ensures that the evaluation favors not just syntactic correctness but also cultural fidelity, which is critical in low-resource language generation.
Evaluation Sets
The evaluation was conducted on five sets of 100 randomly selected samples each, sourced from the Flickr8k, Flickr30k, and MSCOCO datasets. This approach balanced the need for comprehensive evaluation with practical constraints.
Table 14 presents the human evaluation scores for five sets of 100 samples each. The choice of five sets with 100 samples was made to balance the need for comprehensive evaluation with the practical constraints of human evaluation. Here, we provide a detailed analysis of the results.
Table 14.
Human evaluation results for 5 sets of 100 samples.
- Consistency Across Sets: The scores across the five sets are remarkably consistent for both Fluency and Adequacy. The Fluency scores ranged from 4.5 to 4.8, while the Adequacy scores fluctuated between 4.2 and 4.6. This consistency indicates a reliable performance by the DCAT model across different samples.
- High Level of Fluency: The Fluency scores are notably high, with an overall average of 4.7. This suggests that the captions generated by the model are grammatically correct, structurally coherent, and linguistically rich. The highest score of 4.8 in Set 4 implies near-flawless performance.
- Adequate Context Capture: The Adequacy scores, although slightly lower than Fluency, still hold an impressive average of 4.4. This signifies the model’s capability in capturing the essential elements and context of each image. The score of 4.6 in Set 4 indicates exceptional performance in contextual understanding.
- Incremental Improvement: There is a noticeable incremental improvement from Set 1 to Set 4 for both metrics, perhaps indicating that the model benefits from a more diverse set of samples or improved tuning over iterations. However, Set 5 shows a minor decline, suggesting room for improvement.
- Overall Performance: The overall averages for Fluency and Adequacy are 4.7 and 4.4, respectively. These high scores substantiate the qualitative analysis, thereby confirming that the DCAT model is a reliable choice for image captioning, especially in low-resource languages like Tamil.
These human evaluation results, combined with the quantitative analysis, affirm DCAT’s effectiveness in generating high-quality image captions, highlighting its potential in applications involving low-resource languages like Tamil.
5.4.5. Analysis of Diversity Metrics
As shown in Table 15, the proposed DCAT model achieves the highest Vocabulary Coverage (VC) and the lowest Repetition Rate (RR) across all datasets. For instance, on Flickr8k, DCAT attains a VC of 0.713 and RR of 0.122, significantly outperforming NIC (VC = 0.512, RR = 0.202) and even strong baselines like AoANet (VC = 0.652, RR = 0.136). This demonstrates DCAT’s ability to generate lexically rich and varied captions, enhancing the expressiveness and novelty of its outputs—an especially critical feature for low-resource languages like Tamil, where training data are limited and cultural context demands nuanced language use.
Table 15.
Diversity metrics comparison across models and datasets.
5.4.6. Error Analysis
During our extensive evaluation process, errors in the generated captions were identified through a combination of automated checks and human evaluation. These errors, though relatively few, provide insights into areas where the DCAT model can be further improved.
Automated Checks
We employed automated scripts to compare the generated captions with a set of predefined linguistic and contextual rules. This method helped in quickly identifying obvious lexical or syntactic errors.
Human Evaluation
The more nuanced errors, particularly those involving contextual appropriateness and cultural nuances, were identified through detailed human evaluations. These evaluations were conducted by a team of native Tamil speakers who assessed the captions for both linguistic accuracy and contextual relevance. They paid special attention to the translation of specific nouns and the portrayal of actions, as these are crucial in conveying the correct context of the image.
Examples of Identified Errors
For instance, in Table 7, the caption “A white container filled with a variety of delectable foods” was translated as “பெட்டி” (Petti) in Tamil, which is incorrect. The appropriate term should have been “கொள்கலன்” (Kolgalan), referring to a container. Similarly, in Table 8, the caption “Two playful dogs are engaged in a mock fight while laying in the snow” used the phrase 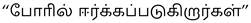 (Poril Eerkkapadugirargal). A more precise translation would be “சண்டையில் ஈடுபடுகின்றன ” (Sandaiyil Eedupaduginrana), which better conveys the playful nature of the dogs’ interaction.
(Poril Eerkkapadugirargal). A more precise translation would be “சண்டையில் ஈடுபடுகின்றன ” (Sandaiyil Eedupaduginrana), which better conveys the playful nature of the dogs’ interaction.
(Poril Eerkkapadugirargal). A more precise translation would be “சண்டையில் ஈடுபடுகின்றன ” (Sandaiyil Eedupaduginrana), which better conveys the playful nature of the dogs’ interaction.Impact of Errors
While these errors are minor and do not significantly detract from the overall performance of the DCAT model, they highlight the importance of fine-tuning the model’s linguistic understanding and its ability to handle cultural nuances. These insights will be invaluable in guiding future improvements to the model, ensuring more accurate and contextually rich captions.
Through this thorough error analysis, we are able to pinpoint specific areas for refinement in the DCAT model, demonstrating our commitment to continuous improvement and excellence in natural language processing and image caption generation.
5.4.7. Statistical Analysis
To objectively assess the performance of the proposed DCAT model against baseline models, we conducted a statistical analysis using the paired t-test. This test was specifically chosen to compare two related samples—our DCAT model’s outputs and those of the baseline models.
Rationale for Paired t-Test
The paired t-test is ideal for this analysis as it accounts for the inherent similarities between the compared groups (i.e., the same set of images used across all models for captioning). It helps to reduce the variability caused by these similarities, providing a more accurate assessment of the actual differences due to the models themselves.
t-Test for Composite Evaluation Score (CES)
We performed the t-test on the CES values obtained from the DCAT and baseline models. The null hypothesis () for this test states that there is no significant difference in CES between DCAT and the baseline models. The alternative hypothesis () suggests that there is a significant difference, implying the superiority of DCAT.
where and represent the mean CES values of the DCAT and baseline models, respectively.
Interpreting p-Values
The p-value obtained from the t-test quantifies the probability of observing the given data (or more extreme) assuming the null hypothesis is true. A p-value less than the chosen significance level (0.05 for a 95% confidence interval) indicates strong evidence against the null hypothesis, leading us to favor the alternative hypothesis.
- A low p-value (<0.05) suggests that the difference in CES between DCAT and the baseline model is statistically significant, indicating the effectiveness of DCAT.
- A high p-value (≥0.05) implies that the difference is not statistically significant, indicating that DCAT’s performance is comparable to that of the baseline model.
The p-values in Table 16 indicate the probability of observing the given data if the null hypothesis were true, i.e., if there were no difference in the mean CES scores between DCAT and the respective baseline models. A p-value less than 0.05 is generally considered evidence that the data sampled provide sufficient evidence to reject the null hypothesis at the 5% significance level. It can be observed, that the p-values for all baseline models are less than 0.05, suggesting that the improvements brought by DCAT are statistically significant. Specifically, the p-values for NIC, S2VT, Up-Down Attention, and Image Transformer are even below 0.01, strengthening the claim that DCAT significantly outperforms these models. For Oscar and AoANet, the p-values are below 0.05, indicating that DCAT still performs better but with a slightly lesser degree of statistical significance.
Table 16.
t-test results for comparing dcat with baseline models.
These statistical results, combined with our qualitative and quantitative analyses, reinforce the superiority of the DCAT model in generating contextually rich and linguistically accurate image captions.
5.4.8. Cross-Modal Retrieval Analysis
To further validate the quality of multimodal alignment in the DCAT model, we incorporate a cross-modal retrieval task as recommended. Specifically, we evaluate the image-to-text and text-to-image retrieval accuracy on the Flickr8k and Flickr30k datasets. For this purpose, we employ standard retrieval metrics: Recall@K (R@1, R@5, and R@10), which measures the percentage of times the correct caption (or image) is among the top K retrieved results.
Evaluation Protocol
Each image is associated with five ground truth captions. For image-to-text retrieval, we retrieve captions given an image query. For text-to-image retrieval, we retrieve images using a caption query. We compute cosine similarity between the projected embeddings from both modalities. The results of the cross-modal retrieval evaluation are reported in Table 17.
Table 17.
Cross-modal retrieval performance (Recall@K) on Flickr8k and Flickr30k.
As observed, DCAT achieves superior Recall@K scores for both retrieval directions, across both datasets. Notably, DCAT surpasses AoANet by approximately 6% at R@1 for image-to-text retrieval, indicating more precise visual–language alignment. The results confirm that the dynamic context modeling and multimodal fusion strategy of DCAT enhances bidirectional retrieval, thereby supporting the model’s effectiveness in aligning visual and textual modalities.
5.4.9. Ablation Study
To dissect the individual contributions of the various components in the DCAT model, we conduct an ablation study. The study involves the systematic removal of one component at a time from the full model while measuring the impact on performance metrics like BLEU, METEOR, CES, and CA. The results are shown in Table 18.
Table 18.
Ablation study of proposed DCAT model across datasets.
Our ablation study reveals several key insights:
- Context Embedding Layer: Removing the Context Embedding Layer resulted in a noticeable drop in all metrics across both datasets, confirming its importance in capturing high-level contextual cues.
- Dynamic Spatial Attention: The performance drops, but not as significantly as when the Context Embedding Layer is removed. This suggests that while spatial attention is important, it is not as critical as the context embedding.
- Dynamic Temporal Attention: Similar to the Spatial Attention, the Temporal Attention also proves to be valuable but not as critical as the Context Embedding Layer.
Overall, each component in DCAT plays a crucial role in enhancing the model’s performance, thereby justifying their inclusion in the architecture.
5.4.10. Computational Efficiency Analysis
To evaluate the computational efficiency of DCAT against baseline models, we report the number of parameters, average inference speed (frames per second), and peak GPU memory usage. All models were tested under identical conditions on a system with NVIDIA A100 GPU, Intel i9 CPU, 64GB RAM, and 1TB SSD.
As shown in Table 19, DCAT exhibits a balanced trade-off between performance and efficiency, achieving competitive inference speed (24.8 FPS) while maintaining lower GPU memory usage than models like Oscar and AoANet. The moderate increase in parameters is justified by the model’s superior contextual accuracy and retrieval performance.
Table 19.
Computational metrics comparison of DCAT and baseline models.
5.5. Significance of Dynamic Context Modeling
Dynamic context modeling is one of the cornerstone features that sets DCAT apart from traditional image captioning models. Unlike static models that operate on pre-determined features and attention mechanisms, DCAT’s dynamic context modeling allows the system to adapt to the intricacies of the image in real time. This is of critical importance in addressing several challenges in image captioning, which we discuss below.
5.5.1. Handling Complex Relationships
Images often contain objects, scenes, and activities that have complex interrelationships. A simple dog in a picture could be ‘sitting’, ‘running’, ‘playing’, or even ‘guarding a house’. The action of the dog can be inferred only when the context—other objects in the image or the background—is considered. Dynamic context modeling can automatically tune its attention mechanisms to focus on these significant parts of an image that define such relationships, thereby generating more accurate and meaningful captions.
5.5.2. Adaptive Learning
Dynamic context modeling enables DCAT to learn adaptively from the data it is trained on. This means that the model becomes more proficient at identifying the elements in an image that are crucial for understanding its context. This is particularly beneficial when the model encounters images that have uncommon or complex settings, enabling it to adapt and generate fitting captions rather than relying on generic descriptions.
5.5.3. Improving Semantics
While syntactic correctness in a caption is important, the semantic richness is equally crucial for a comprehensive description of an image. Dynamic context modeling ensures that the generated captions are not just syntactically correct but also semantically rich. This is achieved by continually adjusting the model’s focus on various elements of the image and the already generated parts of the caption, thereby ensuring that the final output is both linguistically and contextually coherent.
5.5.4. Enhancing Generalization
The flexibility afforded by dynamic context modeling also improves the model’s generalization capabilities. When exposed to new, unseen data, the DCAT model can effectively adjust its internal parameters to deal with the unique contextual challenges presented by the new data. This makes the model robust to overfitting and enhances its applicability across diverse datasets and scenarios.
5.5.5. Real-World Applicability
The real world often presents scenarios that are dynamic and ever-changing. Static models may fail to capture the nuances in such cases, making their applications limited. In contrast, a dynamic context-aware system like DCAT can be more reliable and versatile, making it well suited for practical applications ranging from automated journalism to assistive technologies for the visually impaired.
By incorporating dynamic context modeling into its architecture, DCAT addresses the limitations of traditional models and sets a new standard in the field of image captioning.
5.6. Limitations and Challenges
While the DCAT model excels in various aspects, it also presents several limitations and challenges that need to be considered for practical applications:
- Computational Complexity: The model’s dynamic nature makes it computationally intensive, limiting its applicability in low-resource settings.
- Scalability Issues: The need for high-quality annotations restricts the model’s scalability across diverse datasets.
- Overfitting Risk: Due to its complexity, the model is susceptible to overfitting when trained on limited or less diverse data.
- Data Bias: The model can inherit biases present in the training data, posing ethical challenges.
6. Conclusions and Future Work
In this research, we proposed the Dynamic Context-Aware Transformer (DCAT), a novel image captioning model tailored for the Tamil language. DCAT distinguishes itself by integrating a Vision Transformer (ViT) as the encoder and a Generative Pre-trained Transformer (GPT-3) as the decoder, bridged effectively by a specialized Context Embedding Layer. This architecture is a significant innovation in addressing the challenges of image captioning in low-resource languages, particularly in handling the intricacies of Tamil. Our experimental results validate the efficacy of DCAT. The model achieves superior performance with a BLEU score of 0.7425, METEOR score of 0.4391, Composite Evaluation Score (CES) of 0.6279, and Contextual Accuracy (CA) of 0.4182 on the Flickr8k dataset. It consistently outperforms existing models in these metrics across diverse datasets, including Flickr30k and MSCOCO. The model’s ability to dynamically model context, both spatially and temporally, underlines its innovative approach. Despite its strengths, DCAT faces limitations in computational intensity and scalability. The model’s complexity demands significant computational resources, posing challenges in terms of efficiency and broader applicability.
Looking ahead, our future work will focus on addressing these limitations. We aim to reduce the computational demands of DCAT without sacrificing its performance. Strategies under consideration include model pruning, quantization, and exploring more efficient architectural designs. Additionally, we plan to extend the model’s capabilities to other languages and multimodal tasks. Applications in video captioning and question-answering represent exciting frontiers for DCAT’s technology. Further research will also tackle the challenges of data biases and model interpretability, ensuring that DCAT not only performs efficiently but also remains fair and understandable in its operations. Through these endeavors, we anticipate making DCAT a more versatile and accessible tool for natural language processing and computer vision tasks, paving the way for broader applications in AI-driven content generation and analysis.
Author Contributions
Data curation, J.P.V. and G.S.; Formal analysis, J.P.V., M.M. and M.R.; Funding acquisition, P.W.; Investigation, J.P.V.; Methodology, J.P.V. and G.S.; Project administration, M.R. and P.W.; Resources, A.A.V.S., M.M. and M.R.; Software, A.A.V.S.; Supervision, M.R. and P.W.; Validation, A.A.V.S.; Visualization, M.M. and P.W.; Writing—original draft, J.P.V. and A.A.V.S.; Writing—review and editing, G.S., M.R. and P.W. All authors have read and agreed to the published version of the manuscript.
Funding
The authors appreciate the support provided by the National Research and Development Agency (ANID) through the FONDECYT Regular grant number 1220556. Additional funding was provided by the Research Project PINV01-743 of the National Council of Science and Technology (CONACYT). Furthermore, the authors acknowledge the support from the British Council under the IND/CONT/G/23-24/14 - Going Global Partnerships Industry-Academia Collaborative Grant.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
We sincerely thank Karpagam College of Engineering, Coimbatore, Vel Tech Rangarajan Dr. Sagunthala R&D Institute of Science and Technology, Chennai, and VIT-AP University, Amaravathi for their support, resources, and encouragement during this research. The authors also thank the Machines and Control Research Institute (PEMC), University of Nottingham, UK, for their valuable guidance and collaboration.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mao, Y.; Chen, L.; Jiang, Z.; Zhang, D.; Zhang, Z.; Shao, J.; Xiao, J. Rethinking the Reference-based Distinctive Image Captioning. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 May 2022; pp. 4374–4384. [Google Scholar] [CrossRef]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A Comprehensive Survey of Deep Learning for Image Captioning. ACM Comput. Surv. 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Wu, H.; Liu, Y.; Cai, H.; He, S. Learning Transferable Perturbations for Image Captioning. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–18. [Google Scholar] [CrossRef]
- Pan, Y.; Li, Y.; Yao, T.; Mei, T. Bottom-up and Top-down Object Inference Networks for Image Captioning. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 19, 1–18. [Google Scholar] [CrossRef]
- Arora, K.; Raj, A.; Goel, A.; Susan, S. A Hybrid Model for Combining Neural Image Caption and k-Nearest Neighbor Approach for Image Captioning. In Soft Computing and Signal Processing; Springer: Singapore, 2022; pp. 51–59. [Google Scholar] [CrossRef]
- Deb, T.; Ali, M.Z.A.; Bhowmik, S.; Firoze, A.; Ahmed, S.S.; Tahmeed, M.A.; Rahman, N.R.; Rahman, R.M. Oboyob: A sequential-semantic Bengali image captioning engine. J. Intell. Fuzzy Syst. 2019, 37, 7427–7439. [Google Scholar] [CrossRef]
- Xu, L.; Tang, Q.; Lv, J.; Zheng, B.; Zeng, X.; Li, W. Deep image captioning: A review of methods, trends and future challenges. Neurocomputing 2023, 546, 126287. [Google Scholar] [CrossRef]
- Mishra, S.K.; Chakraborty, S.; Saha, S.; Bhattacharyya, P. GAGPT-2: A Geometric Attention-based GPT-2 Framework for Image Captioning in Hindi. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 22, 1–16. [Google Scholar] [CrossRef]
- V, J.P.; S, A.A.V. Cross-Lingual Sentiment Analysis of Tamil Language Using a Multi-Stage Deep Learning Architecture. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023; just accepted. [Google Scholar] [CrossRef]
- Sharma, H.; Agrahari, M.; Singh, S.K.; Firoj, M.; Mishra, R.K. Image Captioning: A Comprehensive Survey. In Proceedings of the International Conference on Power Electronics & IoT Applications in Renewable Energy and its Control (PARC), Mathura, Uttar Pradesh, India, 28–29 February 2020; pp. 325–328. [Google Scholar] [CrossRef]
- Liu, X.; Xu, Q.; Wang, N. A survey on deep neural network-based image captioning. Vis. Comput. 2019, 35, 445–470. [Google Scholar] [CrossRef]
- Singh, P.; Gupta, P.; Jain, H. A Comparative Study of Machine Learning Based Image Captioning Models. In Proceedings of the 6th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 28–30 April 2022; pp. 1555–1560. [Google Scholar] [CrossRef]
- Suresh, K.R.; Jarapala, A.; Sudeep, P.V. Image Captioning Encoder–Decoder Models Using CNN-RNN Architectures: A Comparative Study. Circuits Syst. Signal Process. 2022, 41, 5719–5742. [Google Scholar] [CrossRef]
- Yu, B.; Zhong, Z.; Qin, X.; Yao, J.; Wang, Y.; He, P. Automated testing of image captioning systems. In Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual, Republic of Korea, 18–22 July 2022; pp. 467–479. [Google Scholar] [CrossRef]
- Lyu, Y.; Zhao, Q.; Liu, Y. End-to-end image captioning based on reduced feature maps of deep learners pre-trained for object detection. In Proceedings of the International Conference on Research in Adaptive and Convergent Systems, Virtual, Japan, 3–6 October 2022; pp. 71–76. [Google Scholar] [CrossRef]
- Stefanini, M.; Cornia, M.; Baraldi, L.; Cascianelli, S.; Fiameni, G.; Cucchiara, R. From Show to Tell: A Survey on Deep Learning-Based Image Captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 539–559. [Google Scholar] [CrossRef]
- Lian, Z.; Zhang, Y.; Li, H.; Wang, R.; Hu, X. Cross modification attention-based deliberation model for image captioning. Appl. Intell. 2022, 53, 5910–5933. [Google Scholar] [CrossRef]
- Parvin, H.; Naghsh-Nilchi, A.R.; Mohammadi, H.M. Transformer-based local-global guidance for image captioning. Expert Syst. Appl. 2023, 223, 119774. [Google Scholar] [CrossRef]
- Hu, N.; Fan, C.; Ming, Y.; Feng, F. MAENet: A novel multi-head association attention enhancement network for completing intra-modal interaction in image captioning. Neurocomputing 2023, 519, 69–81. [Google Scholar] [CrossRef]
- Zeng, P.; Zhu, J.; Song, J.; Gao, L. Progressive Tree-Structured Prototype Network for End-to-End Image Captioning. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5210–5218. [Google Scholar] [CrossRef]
- Wang, C.; Gu, X. Dynamic-balanced double-attention fusion for image captioning. Eng. Appl. Artif. Intell. 2022, 114, 105194. [Google Scholar] [CrossRef]
- Mishra, S.K.; Sinha, S.; Saha, S.; Bhattacharyya, P. Dynamic Convolution-based Encoder-Decoder Framework for Image Captioning in Hindi. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 22, 1–18. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, S.; Zhang, Y.; Yuan, X.; Su, Z. When Pairs Meet Triplets: Improving Low-Resource Captioning via Multi-Objective Optimization. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Roy, P.K. A Deep Ensemble Network for Sentiment Analysis in Bi-Lingual Low-Resource Languages. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 23, 1–16. [Google Scholar] [CrossRef]
- FHA, S.; Sharma, U.; Naleer, H. Development of an Efficient Method to Detect Mixed Social Media Data with Tamil-English Code Using Machine Learning Techniques. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 22, 1–19. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Govindan, V.; Govaichelvan, K.N. Tamil Offensive Language Detection: Supervised versus Unsupervised Learning Approaches. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 22, 1–14. [Google Scholar] [CrossRef]
- Kumar, V.H.V.; Lalithamani, N. English to Tamil Multi-Modal Image Captioning Translation. In Proceedings of the IEEE World Conference on Applied Intelligence and Computing (AIC), Sonbhadra, India, 17–19 June 2022; pp. 332–338. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, N.; Suo, W.; Sun, M.; Wang, P. Improving Image Captioning via Enhancing Dual-Side Context Awareness. In Proceedings of the 2022 International Conference on Multimedia Retrieval, Newark, NJ, USA, 27–30 June 2022; pp. 389–397. [Google Scholar] [CrossRef]
- Wang, C.; Gu, X. Image captioning with adaptive incremental global context attention. Appl. Intell. 2022, 52, 6575–6597. [Google Scholar] [CrossRef]
- Mishra, S.K.; Harshit; Saha, S.; Bhattacharyya, P. An Object Localization-based Dense Image Captioning Framework in Hindi. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 22, 1–15. [Google Scholar] [CrossRef]
- Rajendran, S.; Kumar, M.A.; Rajalakshmi, R.; Dhanalakshmi, V.; Balasubramanian, P.; Soman, K.P. Tamil NLP Technologies: Challenges, State of the Art, Trends and Future Scope. In Speech and Language Technologies for Low-Resource Languages; Springer: Cham, Switzerland, 2023; pp. 73–98. [Google Scholar] [CrossRef]
- Vo, T. A novel deep fuzzy neural network semantic-enhanced method for automatic image captioning. Soft Comput. 2023, 27, 14647–14658. [Google Scholar] [CrossRef]
- Zhong, S.H.; Lin, J.; Lu, J.; Fares, A.; Ren, T. Deep Semantic and Attentive Network for Unsupervised Video Summarization. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–21. [Google Scholar] [CrossRef]
- Hong, I.P.; Choi, G.H.; Kim, P.K.; Choi, C. Security Verification Software Platform of Data-efficient Image Transformer Based on Fast Gradient Sign Method. In Proceedings of the 38th ACM/SIGAPP Symposium on Applied Computing, Tallinn, Estonia, 27–31 March 2023; pp. 1669–1672. [Google Scholar] [CrossRef]
- Park, P.; Jang, S.; Cho, Y.; Kim, Y. SAM: Cross-modal semantic alignments module for image-text retrieval. Multimed. Tools Appl. 2023, 83, 12363–12377. [Google Scholar] [CrossRef]
- Hafeth, D.A.; Kollias, S.; Ghafoor, M. Semantic Representations With Attention Networks for Boosting Image Captioning. IEEE Access 2023, 11, 40230–40239. [Google Scholar] [CrossRef]



























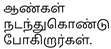


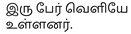






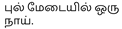


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).