1. Introduction
Rolling bearings, which are crucial components of mechanical equipment, are prone to various types of damage due to their long running time and harsh working environment [
1]. If damaged components cannot be detected and replaced promptly, outcomes include disruption of the normal operation of the mechanical equipment, lower production efficiency, and even serious consequences such as substantial economic losses and casualties [
2]. Accurate, real-time detection and diagnosis of the operating condition of rolling bearings is therefore essential [
3].
In fault diagnosis (FD), vibration signals are widely used as effective diagnostic signals due to their ability to quickly and accurately reflect equipment operating conditions [
4,
5,
6]. Traditional FD methods mainly rely on signal-decomposition techniques such as feature mode decomposition [
7], all time-scale decomposition [
8] and Blaschke mode decomposition [
9]. These methods identify fault types by analyzing the characteristics of the vibration signal, but they heavily rely on empirical knowledge and are difficult to interpret for people without relevant expertise [
10]. Compared to signal-decomposition methods, deep learning techniques have been more widely researched and applied in industry because they do not require a priori knowledge and have superior feature-extraction capability [
11,
12]. For instance, Chang et al. [
13] proposed an FD model combining a one-dimensional convolutional neural network (CNN) with a two-dimensional improved ResNet-50, which utilizes multi-modal information to enhance the robustness of the model. Han et al. [
14] proposed the MT-ConvFormer FD model, which utilizes multi-task learning to extract fault information. Song et al. [
15] proposed an FD model based on multimodal data fusion and the subtraction-average-based optimizer to address the challenge of poor model generalization with small samples by combining CNN and support vector machines. Although these approaches effectively improve FD results by introducing various mechanisms, they also require extensive parameter calculations, leading to increased consumption of storage and computational resources.
In recent years, the rapid development of embedded components and digital twin technology have provided new solutions for FD in rolling bearings in special operating scenarios [
16]. Due to the advantages of edge computing, such as fast transmission and low latency, the lightweight FD methods for rolling bearings have attracted significant attention in recent research [
17]. To enable real-time diagnosis, Fan et al. [
18] proposed a lightweight, multi-scale, multi-attention feature fusion network that significantly enhances fault feature identification. Wang et al. [
19] proposed an AUTO-CNN architectural design method, aiming to achieve a balance between accuracy and use of computational resources. Teta et al. [
20] designed a lightweight CNN and fine-tuned it using the energy-valley optimizer. Wang et al. [
21] proposed a lightweight FD model that integrates frequency-slice wavelet transform with an improved neural-transformer that emphasizes the global capture of important fine-grained information. Xie et al. [
22] designed a lightweight pyramid attention residual network for fault diagnosis under changing operating conditions. However, while the above methods have the advantages of their light weights and the promising results they achieve through different technical approaches, they are over-reliant on global information and neglect to utilize the information extracted at different stages for a more comprehensive diagnosis. Although lightweight models offer advantages such as low computational cost and high diagnostic speed, they face several challenges in practical applications. For instance, issues such as limited fault data and noise interference in real-world scenarios significantly hinder the practical deployment of lightweight models [
23,
24,
25,
26].
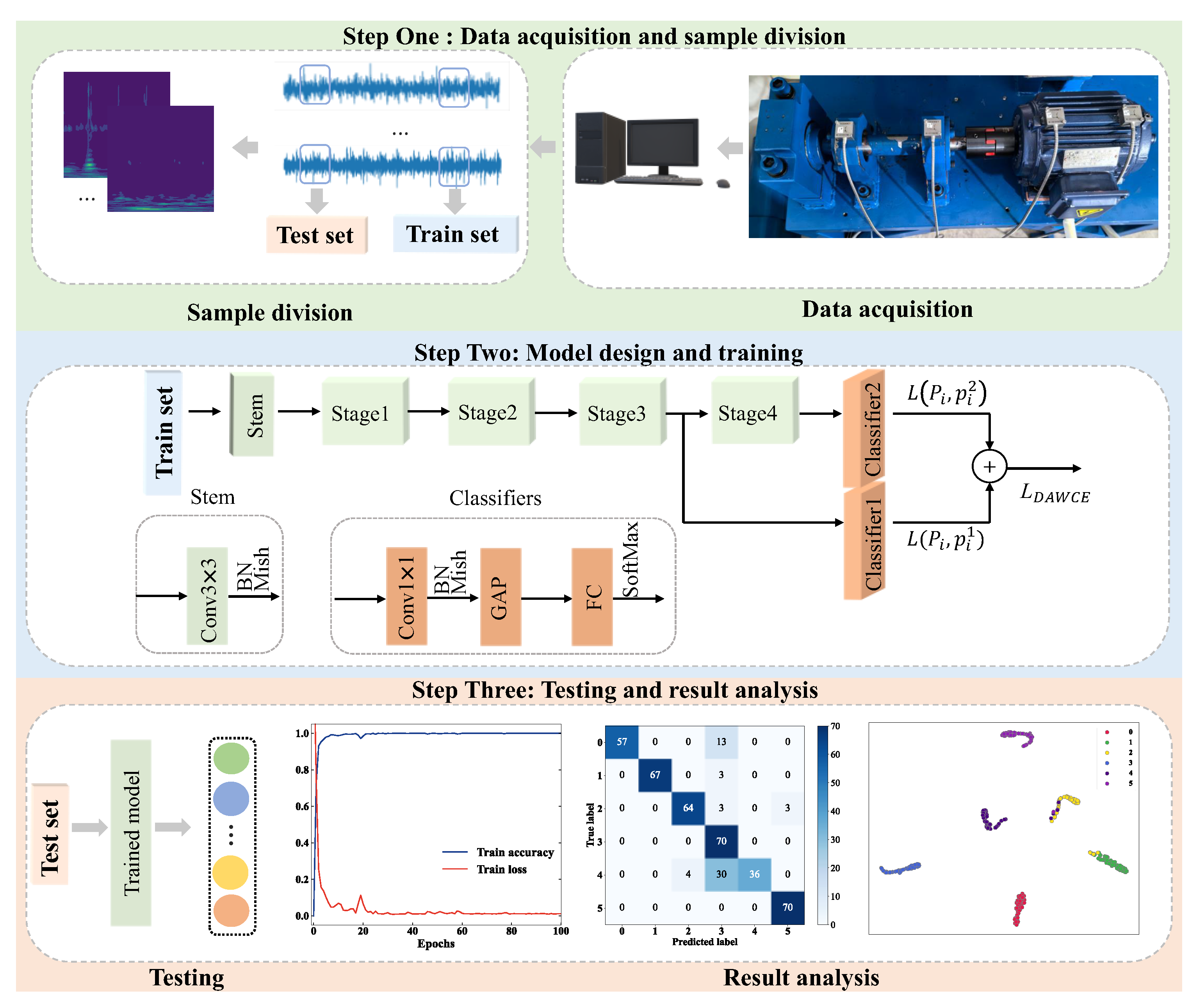
Aiming to address the challenges of achieving light weight, high accuracy, strong robustness to noise, and real-time responsiveness in practical industrial applications, we propose HFDF-EffNetV2, a lightweight FD model, with the following main contributions:
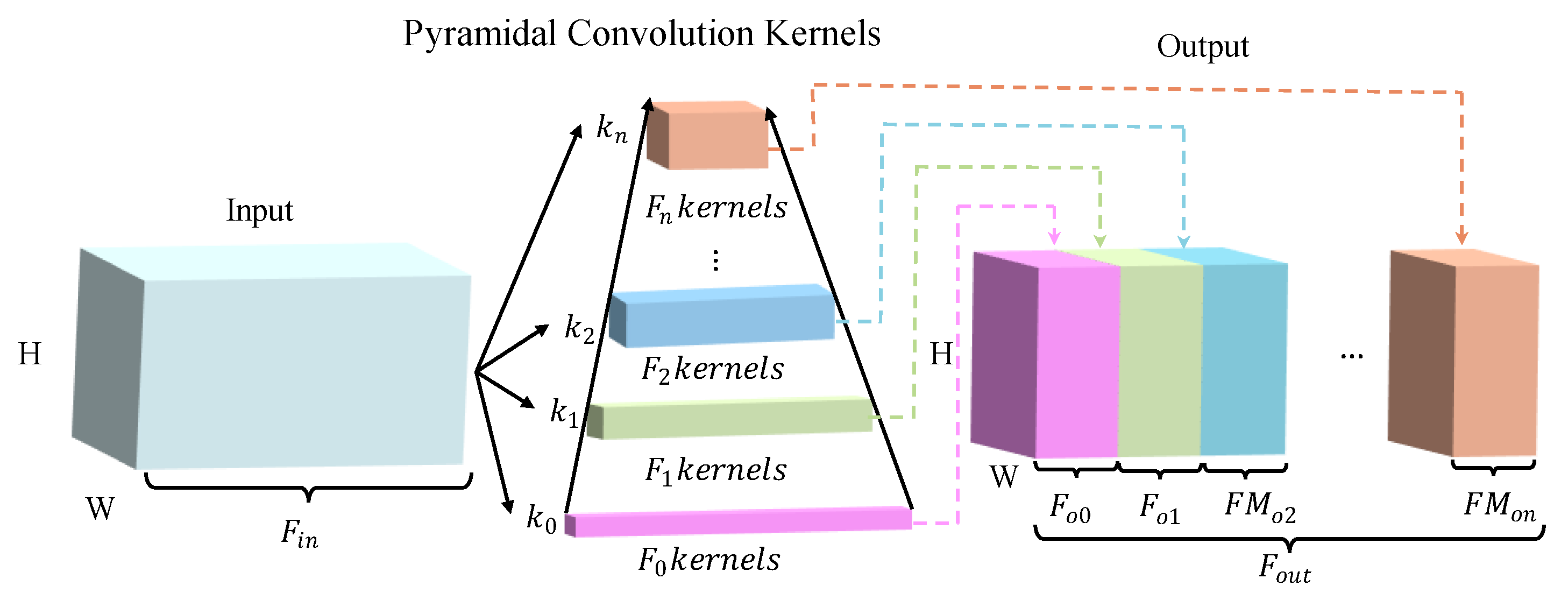
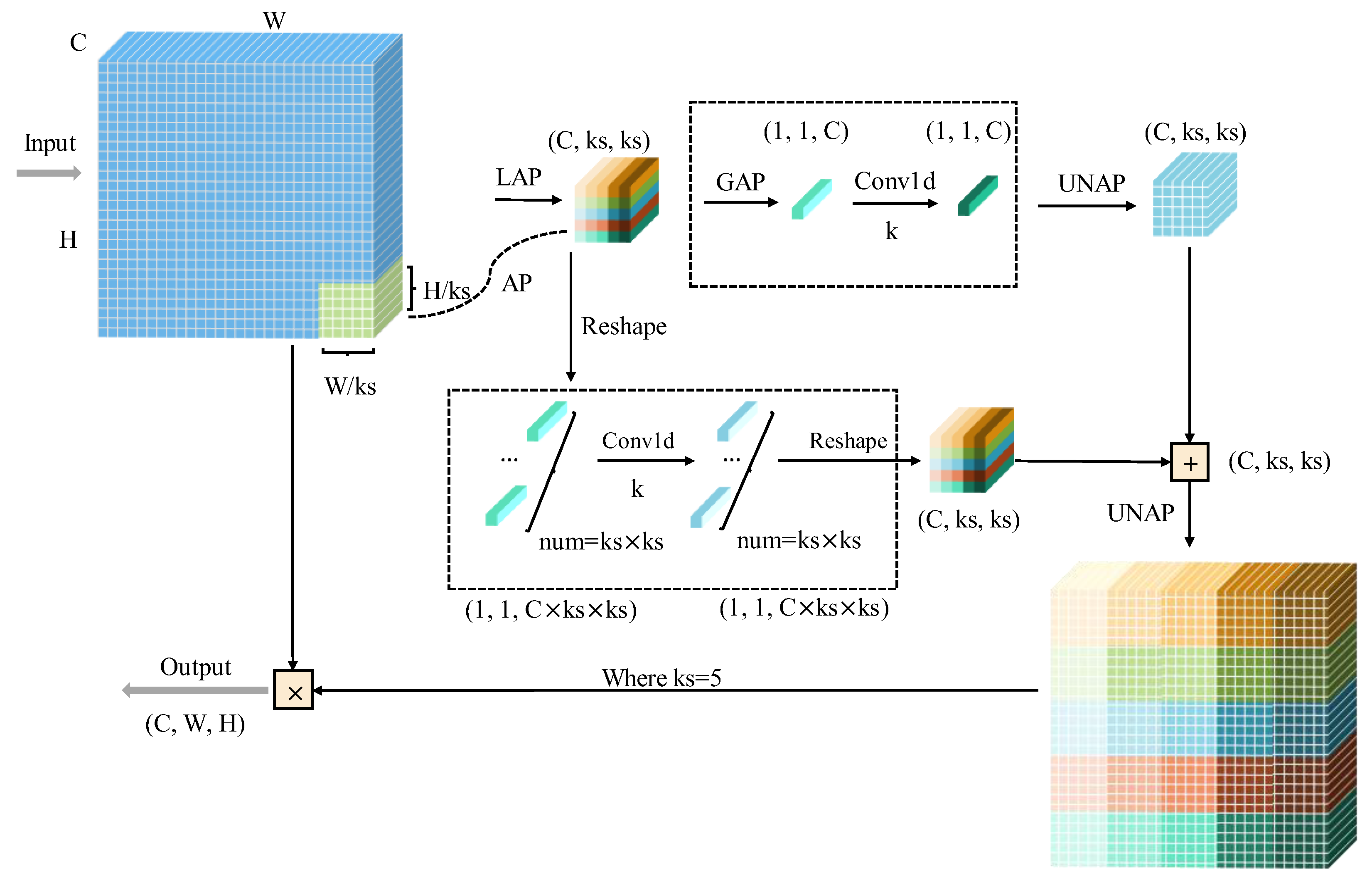
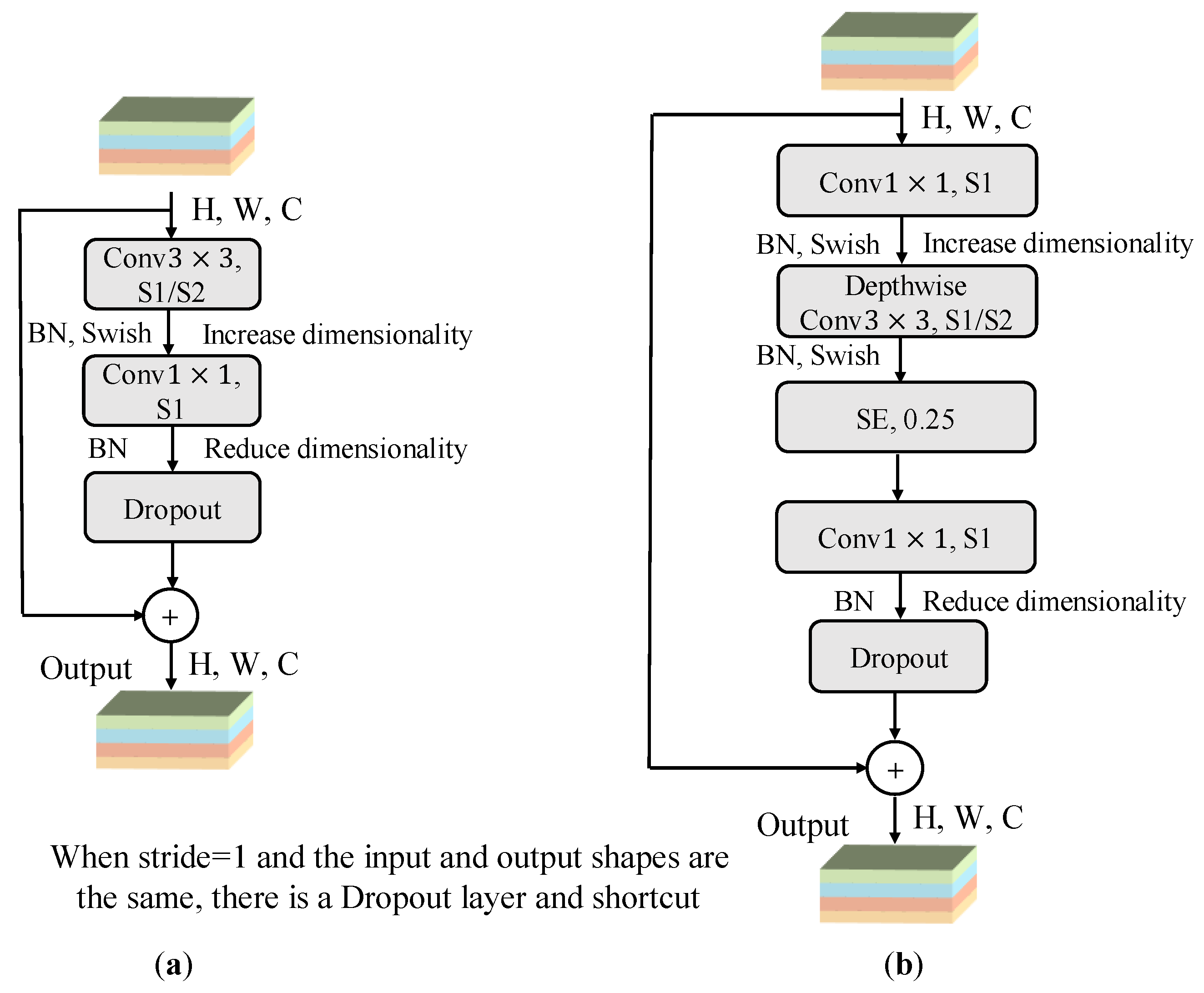
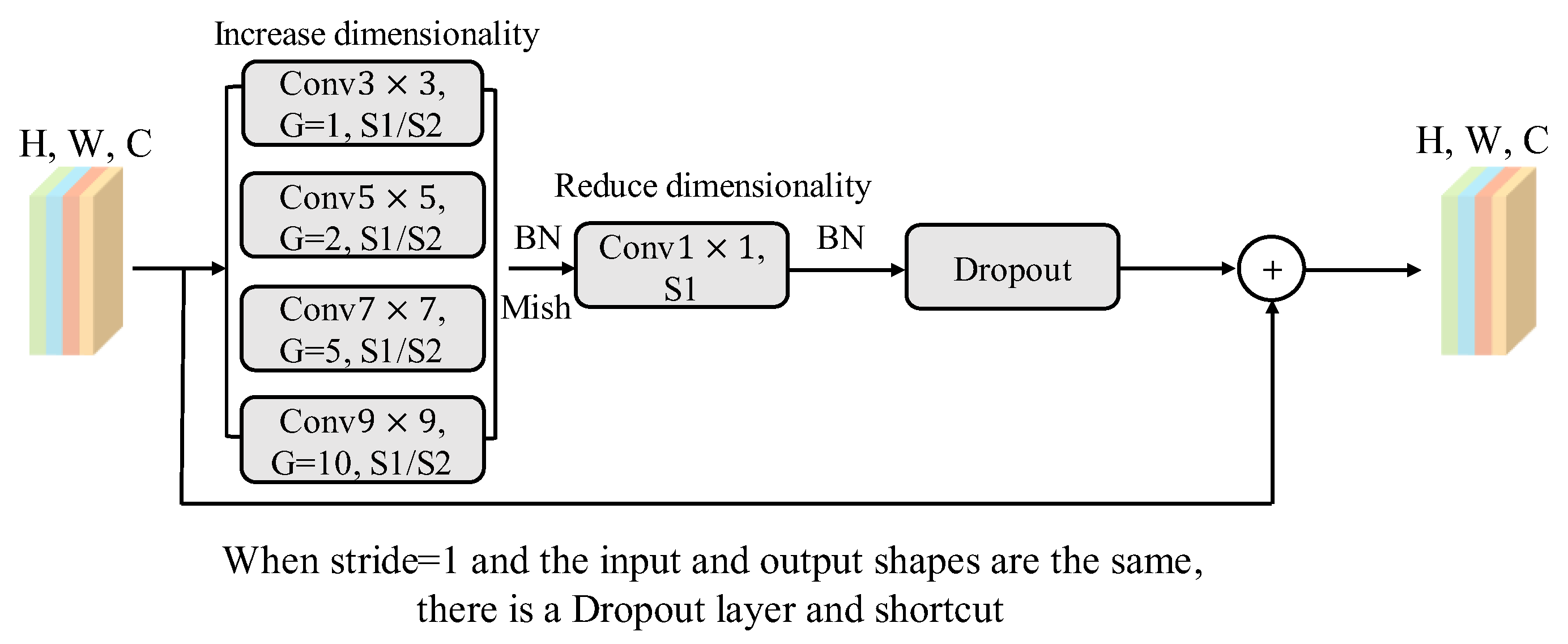
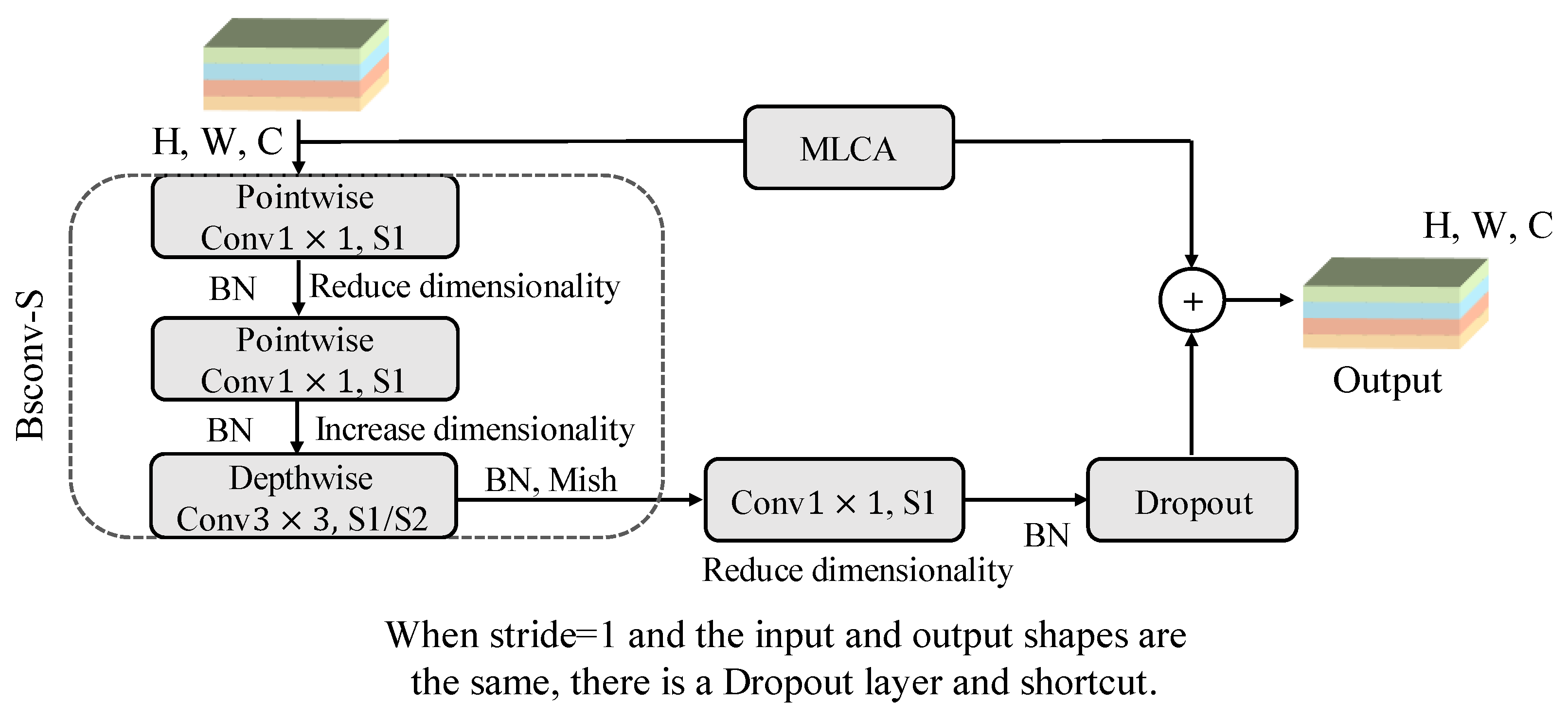
The improved EfficientNetV2 was constructed based on multiplicity factors combined with the Mish activation function. Additionally, Fused-MBPyConv and BSMBConv-MLCA were designed to combine multi-scale shallow features with multi-dimensional deep features for efficient extraction of representative fault features from time-frequency feature maps (FMs).
The hierarchical fine-grained decision fusion (HFDF) strategy is proposed to perform weight updating in phases to alleviate the tendency of the lightweight model to fall into local overfitting when dealing with confusable fault types and small samples.
The proposed model was evaluated under noisy and small-sample conditions and compared with six other models. The results indicate that the proposed model outperforms these others in terms of robustness to noise and stability while remaining lightweight.
The remainder of this study is structured as follows.
Section 2 presents the materials and methods;
Section 3 describes the results, providing detailed architectural parameters;
Section 4 discusses the robustness to noise and stability of HFDF-EffNetV2 in two cases;
Section 5 concludes this study.
4. Discussion
To systematically evaluate applicability in engineering of HFDF-EffNetV2 and the characteristics related to its light weight, this study conduced a series of comparative experiments using the CWRU bearing dataset [
40] and a self-constructed bearing experimental dataset, aiming to validate the model’s performance in terms of light weight, robustness to noise, and stability with small samples. Six advanced lightweight models were selected for comparison, including EfficientNetV2-S [
35], ResNet-18 [
41], RepViT [
42], SqueezeNet [
43], MPNet [
44], and MobileNetV3 [
45]. Additionally, ablation experiments were conducted on the CWRU bearing dataset to evaluate the effectiveness of the three improved methods. To ensure the reliability of the results, all experiments were repeated five times, and the average value was taken as the final result.
4.1. Experimental Hyperparameter Settings and Evaluation Metrics
Data preprocessing and model training were performed using a deep learning framework on PyTorch 3.11.1 based on the PyCharm platform. The system configuration was as follows: Windows 11, AMD Ryzen 7945HX CPU @ 2.5 GHz, NVIDIA GeForce RTX 4060 GPU (NVIDIA, Santa Clara, CA, USA). The experimental hyperparameters were set as in
Table 4.
“Parameters” represents the total number of parameters that the model needs to train, and “time” refers to the time taken for diagnosis with a batch size of 16. These metrics were used to assess the model’s complexity and diagnostic speed. In addition, accuracy, precision (P), recall (R), and F1 score were used to evaluate the diagnostic performance of the model, as calculated in Equations (14)–(17), below:
where
,
,
, and
are the number of true positives, true negatives, false positives, and false negatives, respectively.
4.2. Case 1: CWRU Bearing Dataset
In the experiment, data from the drive-end part of the CWRU bearing dataset with a motor load of 0 horsepower (HP), a speed of 1797 r/min, and a sampling frequency of 12 kilohertz (kHz) were used. The data were divided into four states: normal, inner-ring faults, outer-ring faults, and rolling-ball faults, with single-point fault diameters corresponding to 0.1778 mm (mm), 0.3556 mm, and 0.5334 mm. To ensure the capture of critical fault features, the sample length was set to 1024 data points, with an overlap window of 512, covering approximately 2.5 turns of bearing rotation. The data points were calculated as shown in Equation (18), below:
where
is the number of data points collected per revolution;
is the sampling frequency; and
is the bearing speed under the corresponding operating condition.
The raw vibration signals were standardized, and then the CWT was applied to generate a total of 2000 samples. Each class contained 130 training samples and 70 test samples, with the detailed composition of the dataset shown in
Table 2.
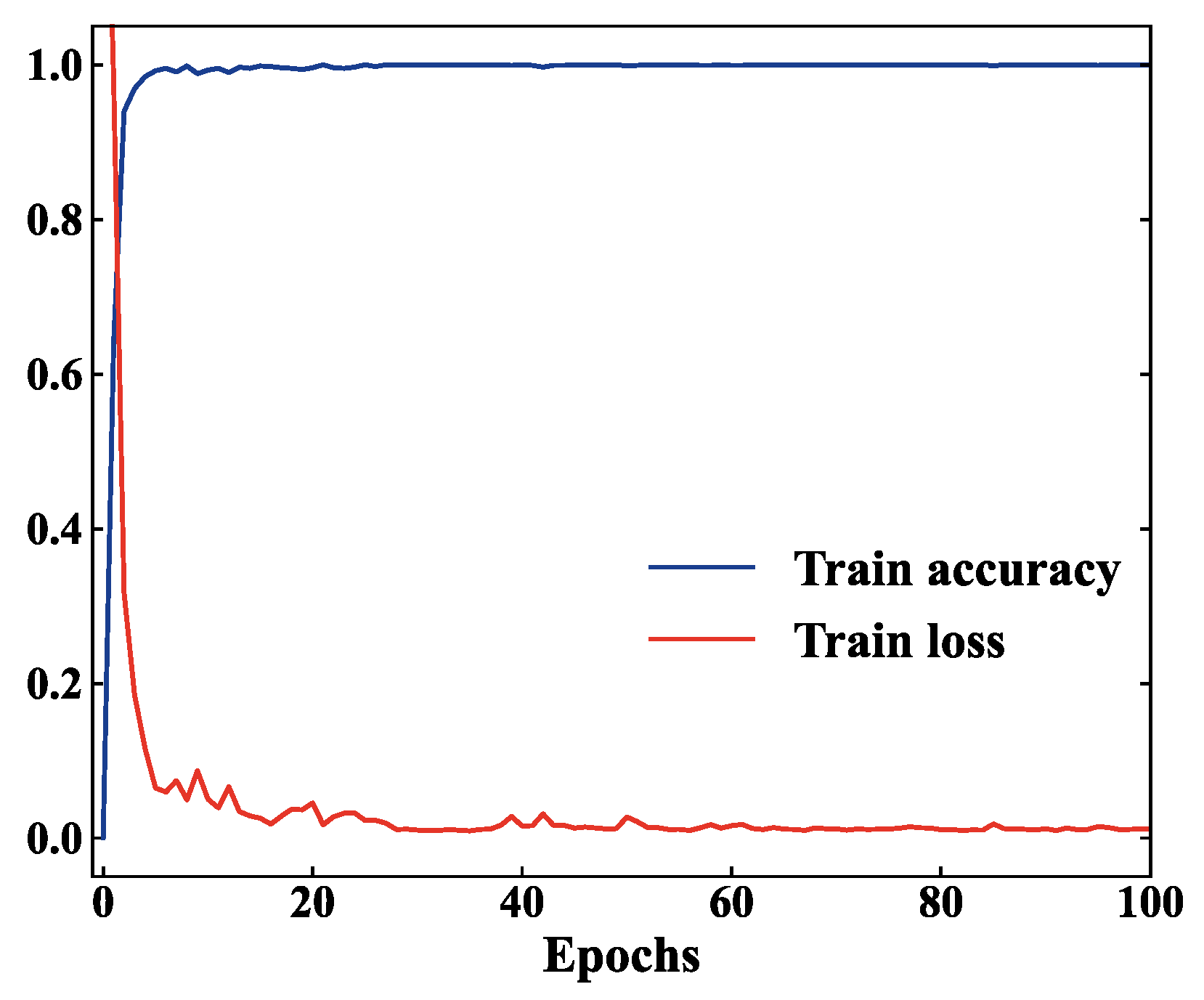
4.2.1. Model Training
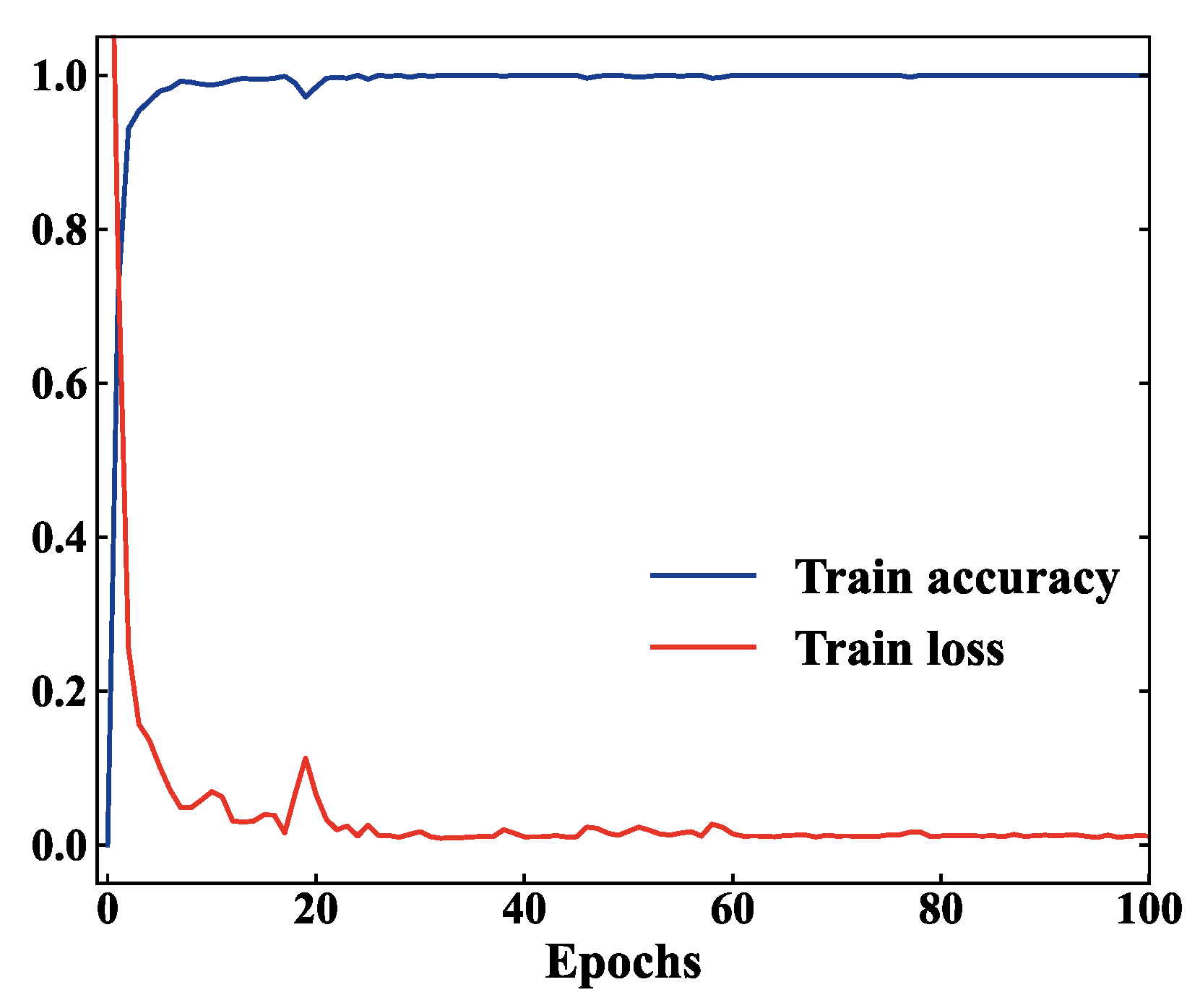
The training curves of HFDF-EffNetV2 are shown in
Figure 8, where it can be observed that, after a few iterations, the training accuracy reached 100% and the training loss rapidly decreased to around 0.1. Although the loss curve fluctuated several times during the subsequent training, it ultimately converged steadily to 0.011. This indicates that the DAWCE loss function helped the model learn effective fault features, gradually reducing the error and causing it to converge towards optimization.
4.2.2. Comparison and Analysis of Model Diagnostic Performance
Table 5 presents the experimental results for the weight and diagnostic evaluation metrics of different models. The proposed model and EfficientNetV2-S both reached 100% accuracy, P, R, and F1, making them the best diagnostic performers among all compared models. Moreover, with the same optimal diagnostic performance as EfficientNetV2-S, the proposed model was significantly lighter-weight, reducing the number of parameters and the diagnostic time by 91% and 35%, respectively. While the proposed model’s parameters and diagnostic time are not optimal, the model’s performance was good. For example, the model has slightly more parameters than SqueezeNet (by 1.12 million (M)), but the time is 23% shorter. The time is slightly longer than that of ResNet-18 (by 1.14 milliseconds (ms)), but the number of parameters is significantly lower, by 83%. In summary, HFDF-EffNetV2 achieved optimal diagnostic performance while still maintaining an excellent lightweight profile, an outcome that validates the effectiveness and advancement of the model design.
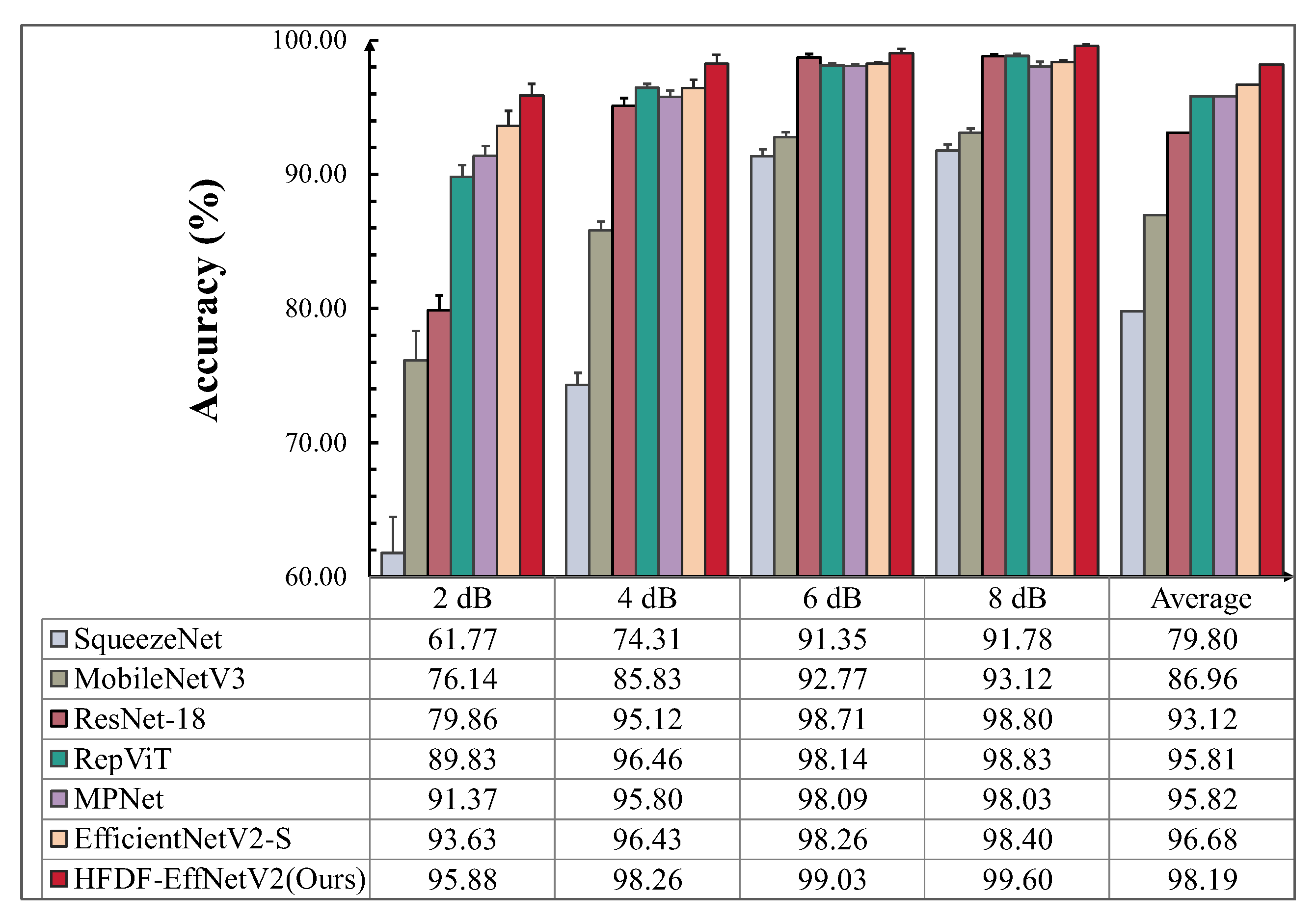
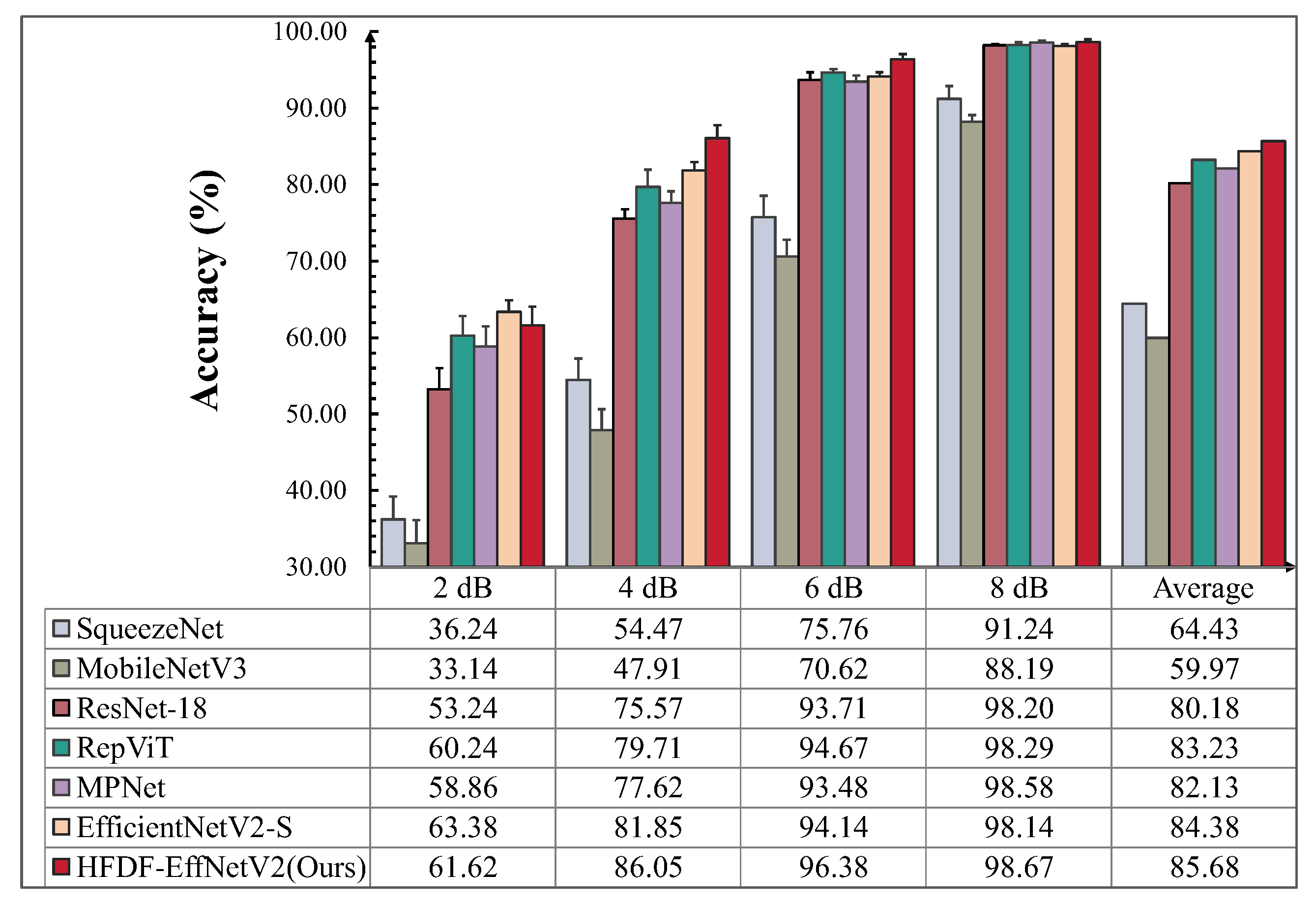
4.2.3. Model Comparison Experiments and Analysis Under Noise Interference
According to Equation (13), GWN with varying SNRs was added to the test set signals to evaluate the robustness of the model to noise. The experimental results are shown in
Figure 9.
After noise was added, the proposed model achieved an average accuracy of 98.19%, which is 18.39%, 11.23%, 5.07%, 2.38%, 2.37%, and 1.51% higher than the six comparison models. Furthermore, the proposed model performed optimally under the same noise intensity compared to the other models. As the noise intensity increased, the accuracy decreased by only 3.72%, which is 1.05% less than the decrease observed in the next-best model, EfficientNetV2-S. At 2 dB, the accuracies of SqueezeNet and MobileNetV3 dropped dramatically, to 61.77% and 76.14%, respectively; these values were 34.11% and 19.74% lower than that of the proposed model, showing a significant gap. ResNet-18, RepViT, and MPNet performed well at 6 dB and 8 dB but poorly at 2 dB, with their accuracies lower than that of the proposed model by 16.02%, 6.05%, and 4.51%, respectively. EfficientNetV2-S, which had the greatest number of parameters, performs=ed well, though its accuracy was slightly lower than that of the proposed model, by 2.25%, at 2 dB. The results show that there is a relationship between the model’s noise resistance and its parameter count. More importantly, optimizing the model architecture to enhance its feature extraction capabilities can significantly improve the robustness of the model under noise interference.
4.2.4. Visualization and Analysis Under Noise Interference
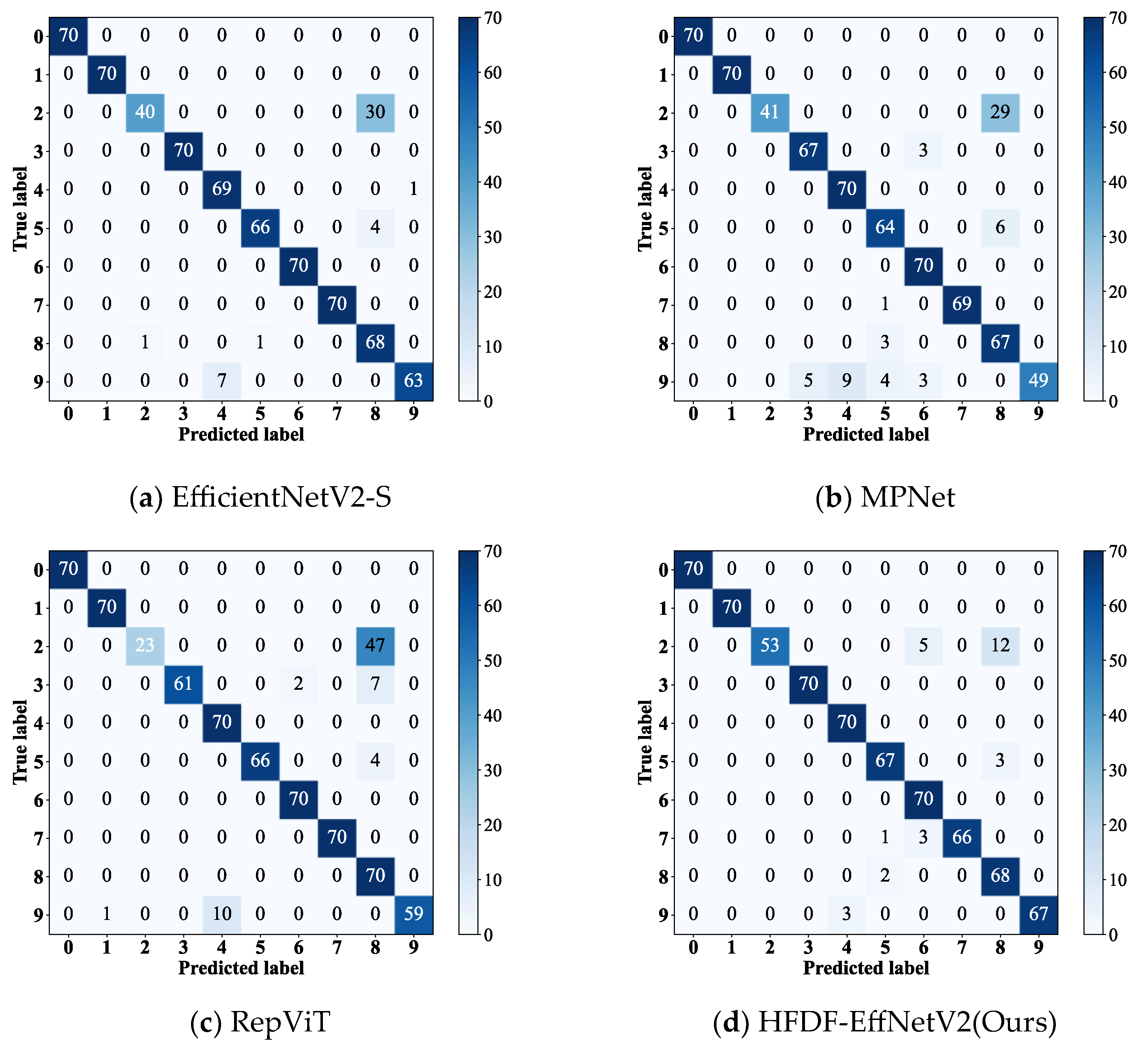
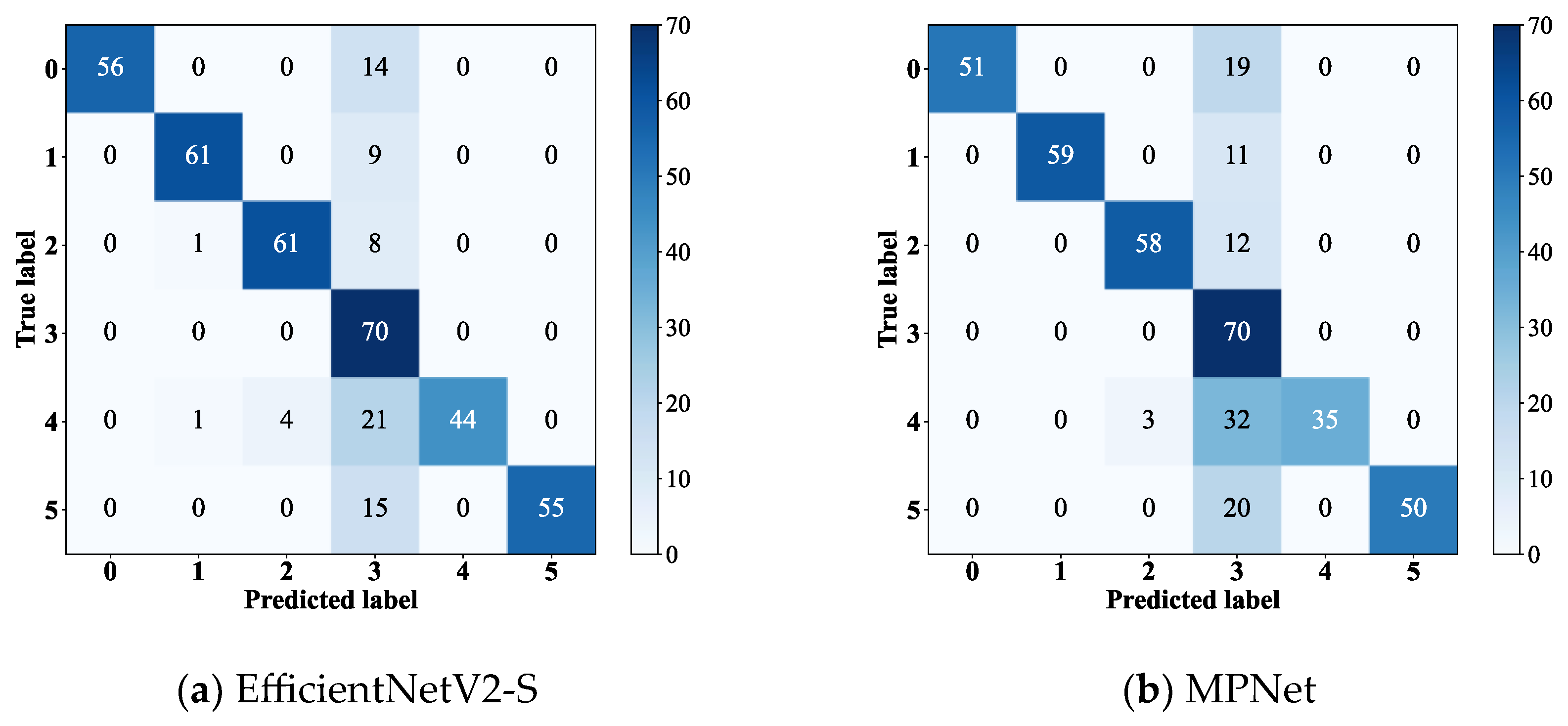
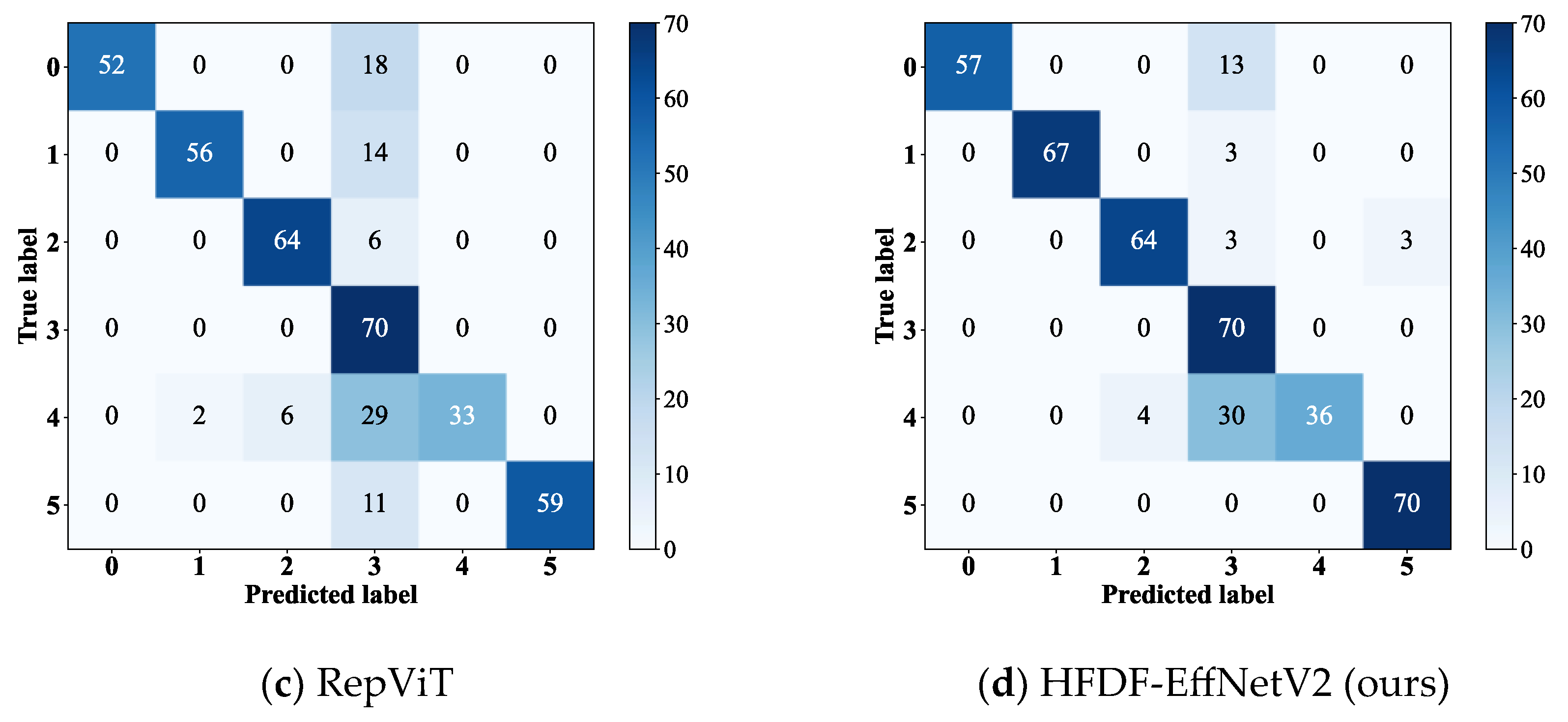
To compare the diagnostic performance of the models under noise interference for different fault types with a simulated SNR of 2 dB, this experiment visualized the confusion matrices of EfficientNetV2-S, RepViT, and MPNet, which performed better in the noise experiments, alongside HFDF-EffNetV2, as shown in
Figure 10.
All models exhibited varying levels of misclassification in diagnosing fault label 2, with the number of misclassified samples for EfficientNetV2-S, RepViT, and MPNet being 30, 29, and 47, respectively, while the proposed model misclassified only 17 samples. Additionally, RepViT and MPNet exhibited poor diagnostic performance (P) for fault label 9, achieving only 70% and 84%, respectively. Although the performance of the proposed model was not optimal for all fault types, its diagnostic P reached 100% for fault labels 0, 1, 3, 4, and 6, and exceeded 94% for fault labels 5, 7, 8, and 9. The results show that HFDF-EffNetV2 significantly improves diagnostic P for samples with confusable fault types.
4.2.5. Comparative Experiments and Analysis with Small Sample Sizes
Due to the difficulty of obtaining large amounts of fault data in practical engineering applications, this experiment evaluated the diagnostic performance of HFDF-EffNetV2 with small sample sets by dividing the samples based on the total length of the sampled vibration signals and creating three datasets (A, B, and C) of different sizes. The number of training samples in datasets A, B, and C was 100, 200, and 300, respectively, while the number of test samples was fixed at 700.
The experimental results are shown in
Table 6. ResNet-18 performed well, with an average accuracy of 98.55%, which is only 0.14% lower than that of the proposed model. EfficientNetV2-S, RepViT, and MPNet, which exhibited relatively good performance in the noise-interference experiments, showed instability when the training data were scarce, with average accuracies lower than that of the proposed model by 2.68%, 6.06%, and 2.72%, respectively. In contrast, the accuracies of SqueezeNet and MobileNetV3 were significantly lower than that of the proposed model, at 10.89% and 7.74%, respectively. On dataset A, the accuracies of all six comparison models decreased significantly, demonstrating that the models failed to extract effective fault features. Although the accuracy of the proposed model decreased compared to those of the other two training datasets on dataset A, it still remained above 98%, which was higher than those of the other six models by 6.35%, 0.09%, 12.69%, 16.12%, 6.09%, and 14.49%, respectively. The results indicate that HFDF-EffNetV2 is less influenced than the other models by the number of training samples and that its performance remains stable across varying sample sizes.
4.2.6. Visualization and Analysis with Small Sample Sizes
To further analyze the feature extraction performance of the model with small samples sizes, this experiment utilized the t-distributed stochastic neighbor embedding (t-SNE) technique to visualize the FD results of ResNet-18, EfficientNetV2-S, MPNet, and the proposed model on dataset A. This approach also allowed for the visualization of the clustering and separation of the extracted fault features after dimensionality reduction.
The visualization results are presented in
Figure 11. The separation of fault features extracted by MPNet and EfficientNetV2-S for samples with fault labels 2, 4, 5, 8, and 9 was insufficiently clear, which could lead to misclassification of fault samples. In contrast, ResNet-18 demonstrated better clustering and separation of features than the previous two models, but the clustering centers for fault labels 4 and 5 were relatively close. Although the proposed model yielded a small number of misclassifications, the clustering and separation of fault features across different samples were satisfactory, highlighting its excellent feature extraction.
4.3. Case 2: Self-Constructed Bearing Experimental Dataset
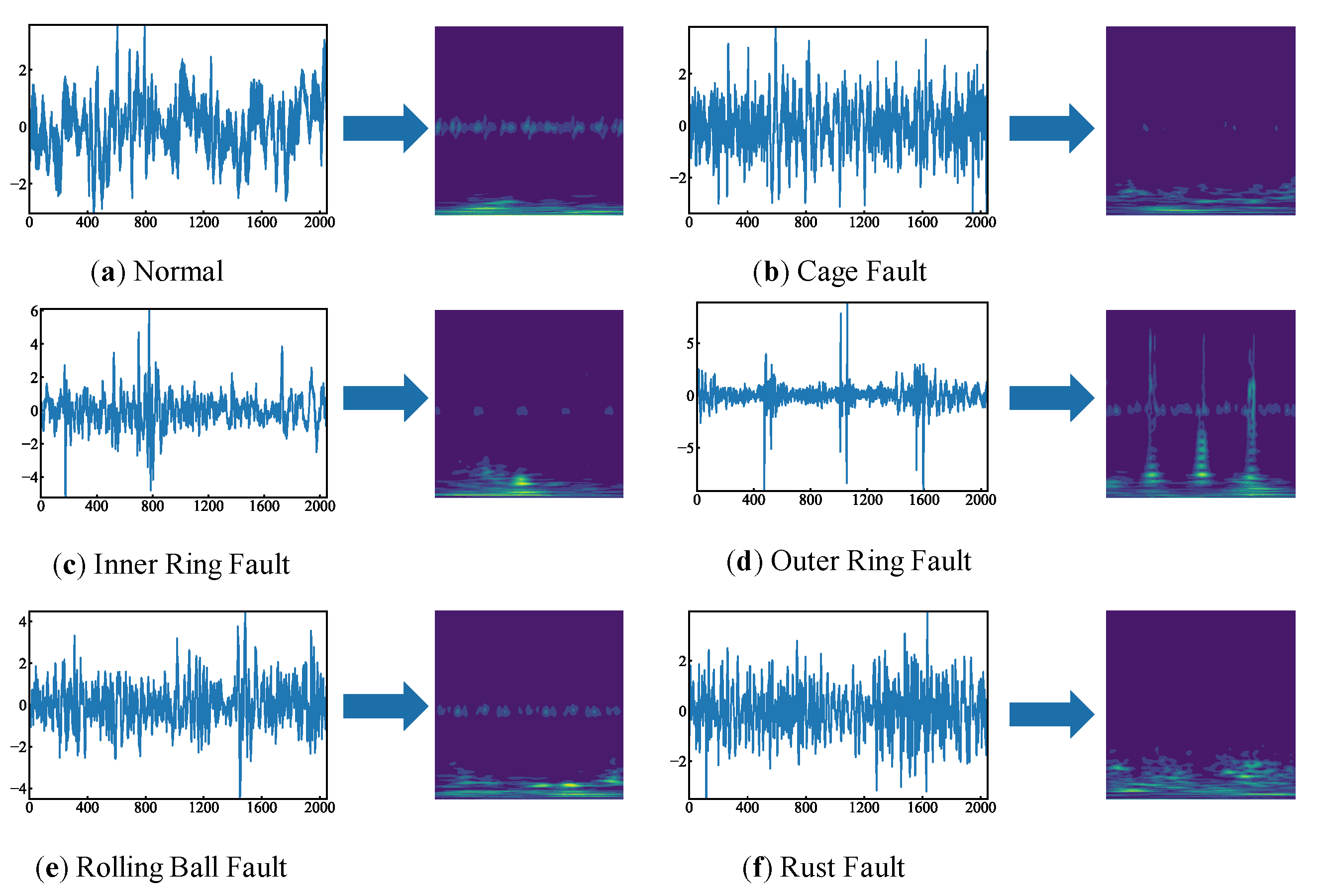
The self-constructed bearing experimental platform primarily consisted of 6206 rolling bearings, a 0.55 kW three-phase asynchronous motor, 1C330ET three-axis vibration and temperature integrated sensors, and couplings, as illustrated in
Figure 12. Based on the common faults of rolling bearings in real industrial scenarios, cage faults, inner-ring faults, outer-ring faults, rolling-ball faults, and rust faults were simulated through wire cutting and saltwater immersion, as shown in
Figure 13. At a speed of 800 r/min and a sampling frequency of 25.6 kHz, approximately 250,000 datapoints were collected for each fault type. To ensure that a single sample would contain fault information for at least one full revolution, the overlap window was set to 1024 and the sample length was set to 2048, as calculated using Equation (18). The time-frequency FM, obtained after standardizing the original signal and performing the CWT, is shown in
Figure 14. The dataset samples were configured to remain the same as in Case 1, as presented in
Table 7.
4.3.1. Model Training
The training curves of HFDF-EffNetV2 are shown in
Figure 15. The model started at 71.5% accuracy at the first iteration and then improved significantly, reaching 99.23% at the 7-th iteration and achieving 100% training accuracy after 100 iterations. Although there were significant fluctuations in the loss curves at the beginning of the model’s training, the loss values began to converge steadily to 0.01 after 20 iterations, indicating that the model’s weight updates tended to stabilize.
4.3.2. Model Diagnostic Performance Comparison and Analysis
Table 8 presents the experimental results for the lightweight and diagnostic evaluation metrics of different models. The proposed model achieved 100% in four diagnostic evaluation metrics, accuracy, P, R, and F1, demonstrating the best performance among all the compared models. Although the proposed model was not optimal in terms of parameters and diagnostic time, it improved all of the diagnostic evaluation metrics by 2.33% and reduced the time by 29% compared to the best small model of SqueezeNet. Additionally, there was only a 0.04 ms time difference between the proposed model and ResNet-18, but the number of parameters was only 17% of the number in ResNet-18.
4.3.3. Model-Comparison Experiments and Analysis Under Noise Interference
Consistent with the noise-interference experiment in Case 1, GWN with different SNRs was added to the test set signals. The experimental results are shown in
Figure 16.
After noise was added, the proposed model still maintained the highest average accuracy, surpassing the other six models by 25.71%, 21.25%, 5.5%, 3.55%, 2.45%, and 1.3%, respectively. As the level of noise interference increased, the accuracies of all models decreased significantly. At 4 dB, SqueezeNet and MobileNetV3 exhibited the largest accuracy gaps with the proposed model, at 38.14% and 31.58%, respectively. Comparatively, ResNet-18, MPNet, and RepViT exhibited slightly better noise resistance than SqueezeNet and MobileNetV3, with deficits of 10.48%, 8.43%, and 6.34% relative to the proposed model, respectively. Although the accuracy of the proposed model was suboptimal at 2 dB, 1.76% lower than the accuracy of EfficientNetV2-S, it showed a notable improvement at 4 dB, surpassing that of EfficientNetV2-S by 4.2%. In summary, these findings suggest that models with larger parameter counts are more resilient to severe noise interference but that an optimal design can also improve the model’s robustness to noise.
4.3.4. Visualization and Analysis Under Noise Interference
In order to show the diagnostic results of the models for different fault types with a simulated SNR of 4 dB, this experiment visualized the confusion matrices of EfficientNetV2-S, RepViT, MPNet, and the proposed model.
The visualization results are shown in
Figure 17, where the diagnostic P of the proposed model is 100% for fault labels 3 and 5 and 89% for fault labels 0, 1, and 2. Compared to EfficientNetV2-S, MPNet, and RepViT, which correctly diagnosed all samples with fault label 3, the diagnostic P for fault label 5 differed significantly from that of the proposed model, with differences of 22%, 28%, and 16%, respectively. In addition, all models performed poorly in the diagnosis of fault label 4. Despite the proposed model having eight more misclassified samples compared to the model with the fewest (EfficientNetV2-S), HFDF-EffNetV2 performed better overall. The result demonstrates that the HFDF strategy effectively mitigates the issue of the lightweight model falling into local overfitting.
4.3.5. Comparative Experiments and Analysis Under Small Samples Conditions
Consistent with the experimental setup in Case 1, this experiment was conducted with three different dataset sizes (A, B, and C), where the numbers of training samples were 100, 200, and 300, respectively, and the number of test set samples was fixed at 700.
The experimental results are presented in
Table 9 and demonstrate that the proposed model achieves optimal diagnostic accuracy across different datasets. ResNet-18 performed excellently, with an average accuracy only 0.5% lower than that of the proposed model. EfficientNetV2-S and MPNet performed well on datasets B and C, but exhibited poor performance on dataset A, resulting in average accuracies 2.76% and 3.26% lower than those of the proposed model, respectively. RepViT, SqueezeNet, and MobileNetV3 exhibited poor performance overall, with average accuracies 5.96%, 8.95%, and 10.69% lower than those of the proposed model, respectively. As the number of training samples decreased, the accuracy of the proposed model decreased slightly by 2.59%, for a value 0.49% higher than that of ResNet18, the model with the smallest decrease. However, it remained more stable compared to the other five models, which showed decreases of 5.1%, 6.02%, 12.3%, 5.28%, and 13.78%. The results indicate that HFDF-EffNetV2 improves the ability to perceive the relationships between different channels in the input FM and that it continues to capture key information from important channels even with small sample sizes.
4.3.6. Visualization and Analysis with Small Sample Sizes
In this experiment, the t-SNE technique was employed to visualize the FD results of ResNet-18, EfficientNetV2-S, MPNet, and the proposed model in a small-sample experiment using dataset A.
The visualization results are shown in
Figure 18. While MPNet and EfficientNetV2-S were effective in clustering and separating the features of fault labels 0, 3, 4, and 5; the clustering and separation of the features for fault labels 1 and 2 were not fully formed, indicating insufficient perception of the differences between fault types, which could result in the misclassification of fault samples. Compared to ResNet-18, the proposed model exhibited more distinct separation for fault labels 1 and 2, with misclassification occurring for only a few samples. The results indicate that HFDF-EffNetV2 effectively establishes a clear classification boundary, demonstrating stronger feature clustering and discriminative ability.
4.4. Analysis of Experimental Results in Two Cases
The results of the comparison experiments conducted demonstrate that the model architecture design significantly influences diagnostic performance. The lightweight architectures of SqueezeNet and MobileNetV3 constrain their capacity to capture salient local fault features, leading to poor robustness. ResNet-18 employs a simple architecture that achieves the fastest diagnostic time, but its limited depth compromises robustness to noise. While the multi-branch architectures of RepViT and MPNet enable effective capture of fault features with enhanced robustness to noise, such architectures inevitably reduce diagnostic speed. EfficientNetV2-S possesses a large model capacity, enabling it to capture deeper fault information and exhibit strong robustness to noise. However, this complexity also makes it sensitive to the size of the training dataset and results in the slowest diagnostic performance. In contrast, although HFDF-EffNetV2 is slightly slower than ResNet-18 and has a marginally higher parameters than SqueezeNet, it utilizes a lightweight multi-branch structure combined with a fine-grained feature extraction and decision fusion approach, significantly enhancing diagnostic accuracy.
4.5. Ablation Experiment and Analysis
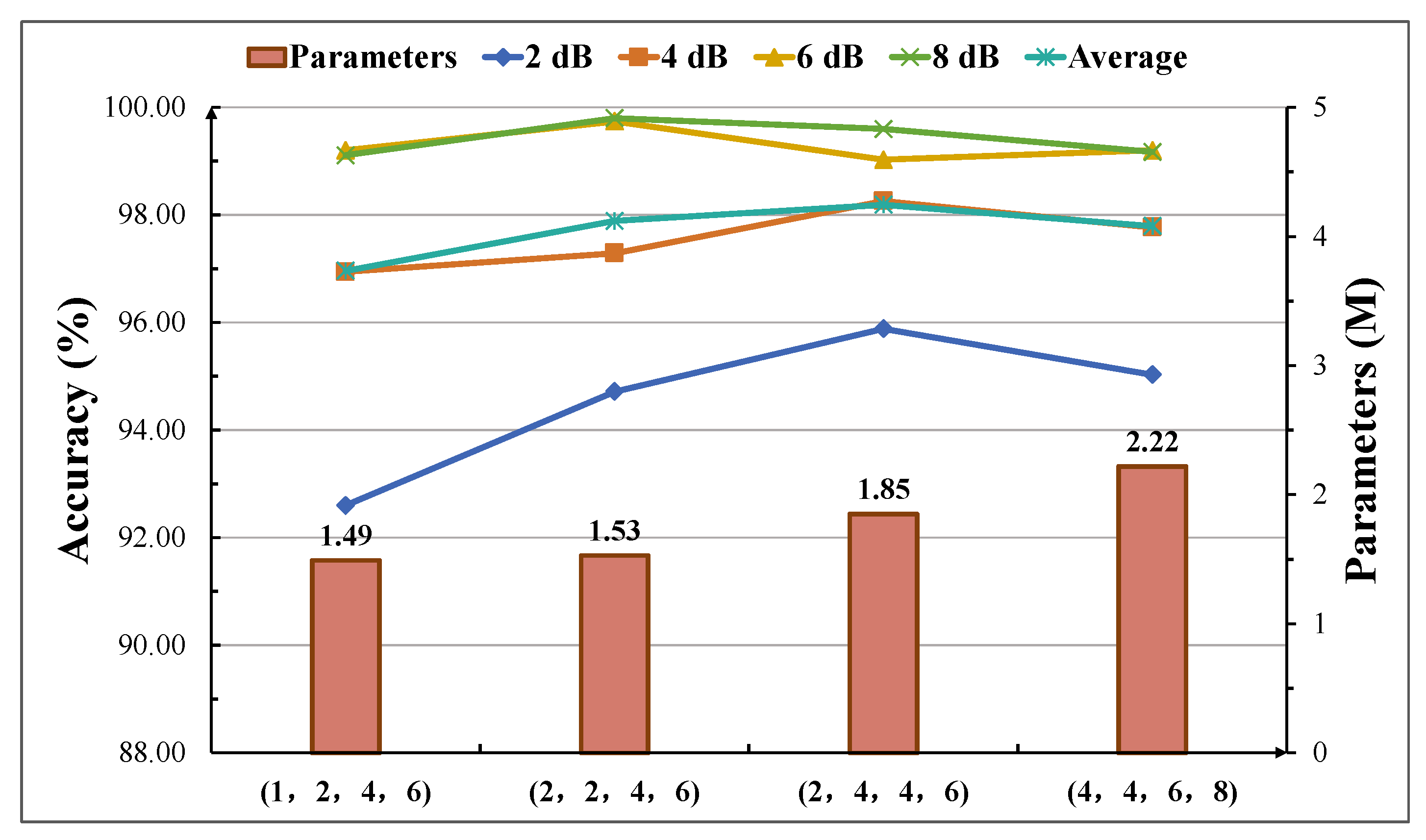
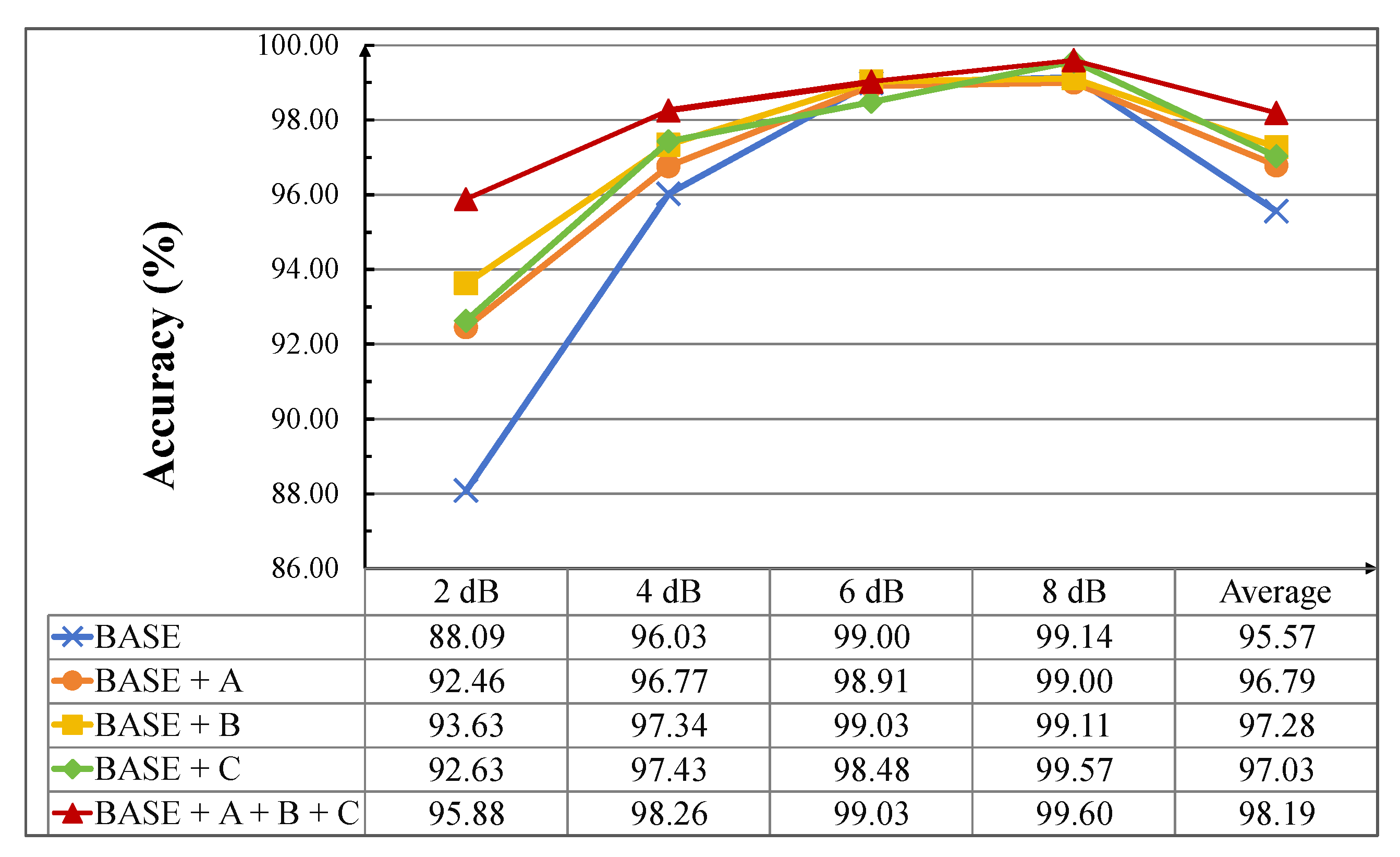
Since the construction of HFDF-EffNetV2 involved multiple methods, ablation experiments were conducted on the CWRU bearing dataset to more intuitively visualize the impact of each method on the model’s diagnostic performance. As shown in
Table 10, The BASE refers to the model constructed based on EfficientNetV2-S. The BASE + A and BASE + B models incorporated the methods of Fused-MBPyConv and BSMBConv-MLCA, respectively. The BASE + C model employed the HFDF strategy, and the BASE + A + B + C represents the proposed model.
The experimental results are presented in
Figure 19 and demonstrate that the application of the three improvement methods significantly enhanced the diagnostic accuracies under strong noise interference. At 2 dB, the accuracy of the BASE + A + B + C was improved by 7.79% compared to the BASE. At 4 dB, BASE + C with the HFDF strategy applied showed improvements of 1.4%, 0.66%, and 0.09% compared to BASE, BASE + A, and BASE + B, respectively. At 6 dB and 8 dB, all models showed improved performance, making the relative improvement of the three enhanced methods compared to BASE non-significant. However, the average accuracies of the three enhanced methods were increased by 1.22%, 1.71%, and 1.46%, respectively, compared to BASE. Overall, all three improvement methods were effective in enhancing the model’s performance under noise interference, with the most significant contributions coming from the application of BSMBConv-MLCA.
5. Conclusions
This study addresses the challenge of achieving real-time and high-accuracy FD on platforms with limited computational resources by proposing a lightweight model called HFDF-EffNetV2.
In noise-interference experiments on the CWRU bearing dataset and a self-constructed bearing dataset, the average accuracy of the proposed model increased by 1.51%, 5.07%, 2.38%, 18.39%, 2.37%, and 11.23% and by 1.3%, 5.5%, 2.45%, 21.25%, 3.55%, and 25.71%, compared to EfficientNetV2-S, ResNet-18, RepViT, SqueezeNet, MPNet, and MobileNetV3, respectively. With small sample sizes, the proposed model outperformed these six models in average accuracy by 2.68%, 0.14%, 6.06%, 10.89%, 2.72%, and 7.74% and by 2.76%, 0.5%, 5.96%, 8.95%, 3.26%, and 10.69%, respectively. These results show that the Fused-MBPyConv and BSMBConv-MLCA proposed in this study achieved deeply coupled resolution of cross-scale fault features while maintaining light weight through feature fusion via staged channel-compression transformations. The HFDF strategy enables global integrated FD with cross-level fault feature relationships through multi-stage information fusion.
Although the proposed model achieved excellent diagnostic results in preliminary experiments and has 1.85 M parameters and faster diagnosis time compared with other lightweight models, which verifies its potential for real-time and highly accurate deployment on edge devices, the model may still be limited by the hardware configurations on resource-constrained edge devices. Indeed, in actual equipment operation, rolling bearings may experience fault types never before encountered by the models. Therefore, future research will combine signal processing with threshold-independent open-set identification strategies to enhance the diagnostic capabilities of the proposed model for unknown faults and evaluate its performance across different edge devices and real-world environments.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}