3.2.2. Algorithm Implementation Steps
Data coding: First, the traffic conflict data are encoded to extract the type and severity of the conflict:
(Rear-End, RE): {RE-Min, RE-Mod, RE-Sev}
(Lane-change, LC): {LC-Min, LC-Mod, LC-Sev}
(Cross, CR): {CR-Min, CR-Mod, CR-Sev}
Here, (Rear-End, RE) denotes a rear-end collision; Min, Mod, and Sev signify the varying degrees of severity associated with such incidents, namely, minor collisions, moderate collisions, and severe collisions. {RE-Min} indicates a minor rear-end collision, {RE-Mod} refers to a moderate rear-end collision, and {RE-Sev} represents a severe rear-end collision. (Lane-change, LC) pertains to lane-change conflicts; {LC-Min}, {LC-Mod}, and {LC-Sev} correspondingly denote minor, moderate, and severe lane-change conflicts. (Crossing, CR) signifies intersectional conflicts; {CR-Min}, {CR-Mod}, and {CR-Sev}, respectively, illustrate the spectrum of severity from minor to moderate to severe crossing conflicts.
Construct a composite transaction: Splice the encoded conflict events with the corresponding driving behavior sequence to form a “driving behavior–traffic conflict” composite transaction.
Frequent item set mining: Use the FP-Growth algorithm to mine frequent item sets.
Association rule generation: Generate association rules based on frequent item sets.
Based on a comprehensive synthesis of data derived from driving simulation experiments and real-world road observations, consider the following 10 sample composite transactions:
{TS↑, LK↓,LC↑, LC-Sev}
{TS↑, LK↑, HS↑, RE-Mod}
{LK↓, AS↑, CR-Sev}
{TS↑, LK↓, RE-Min}
{TS↑, LK↑, LC↑, LC-Mod}
{TS↑, LK↓, LC↑, LC-Sev}
{LK↓, AS↑, CR-Sev}
{TS↑, LK↑, HS↑, RE-Mod}
{TS↑, LK↓, RE-Min}
{TS↑, LC↑, LC-Min}
where TS↑ indicates speeding, LK↓ indicates a short headway, LC↑ indicates frequent lane changes, HS↑ indicates sudden braking, and AS↑ indicates rapid acceleration.
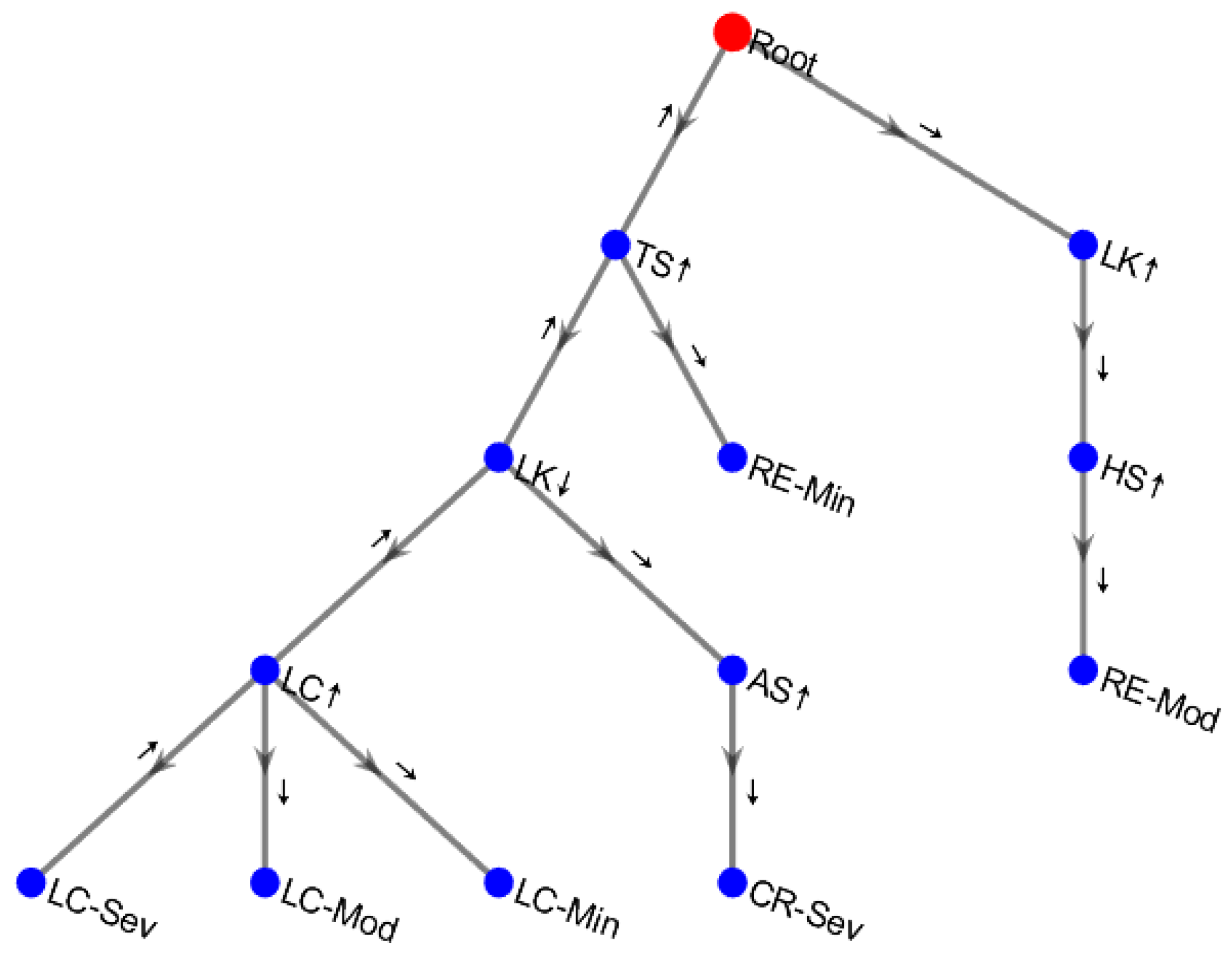
Step 1: Build the FP-Tree
First, count the support of each item, as presented in
Table 8.
Then, build the FP-Tree in descending order of support, as shown in
Figure 10.
Step 2: Mining frequent patterns from the FP-Tree
First, take LC-Sev as an example. Its conditional pattern base is {TS↑, LK↓, LC↑:2}.
Then, through recursive mining, the following frequent patterns are obtained.
{TS↑, LK↓, LC↑, LC-Sev}:2
{TS↑, LK↓, LC-Sev}:2
{TS↑, LC↑, LC-Sev}:2
{LK↓, LC↑, LC-Sev}:2
{TS↑, LC-Sev}:2
{LK↓, LC-Sev}:2
{LC↑, LC-Sev}:2
Step 3: Generate association rules.
For instance, for the rule {TS↑, LK↓, LC↑} → {LC-Sev}:
This rule meets the requirements of the minimum support and minimum confidence thresholds.
Frequent pattern mining aims to identify those driving behavior combinations that frequently co-occur and are closely associated with traffic conflicts, derived from a vast array of driving behavior and traffic conflict data. These combinatorial patterns are crucial for understanding the underlying causes of accidents, predicting traffic conflicts, and formulating targeted safety measures. By excavating frequent patterns, one can uncover behavioral combinations such as “speeding + short headway distance + frequent lane changes”, which exhibit a strong correlation with specific types and severities of traffic conflicts. This directly supports the research objective of reducing traffic accidents on mountainous roads and enhancing overall road safety conditions. It assists transportation management authorities in pinpointing key driving behaviors that warrant monitoring and intervention, thereby facilitating proactive prevention at the source of traffic incidents.
In the FP-Growth algorithm, recursive mining serves as a pivotal step in uncovering frequent patterns. Upon the completion of constructing the FP-Tree, the algorithm embarks on its exploration by commencing with the least frequent behaviors and proceeding in reverse order. Taking “LC-Sev” (severe lane-change conflict) as an illustrative example, we first identify its conditional pattern base—this encompasses other driving behavior sequences associated with “LC-Sev”, along with their respective occurrence frequencies, such as {TS↑, LK↓, LC↑:2}.
Subsequently, a conditional FP-Tree is constructed based on this conditional pattern base; further mining is then conducted within this newly established tree structure. The process of recursive mining perpetually reiterates this cycle, yielding new frequent patterns at each iteration. Each identified frequent pattern represents a potential combination of driving behaviors that could precipitate specific traffic conflicts.
Through recursive mining, the algorithm adeptly extracts all meaningful frequent patterns from the data comprehensively and profoundly. These patterns illuminate the latent relationships among various driving behaviors and their correlations with traffic conflicts—providing crucial data support for subsequent endeavors to generate association rules, assess risks, and formulate safety strategies.
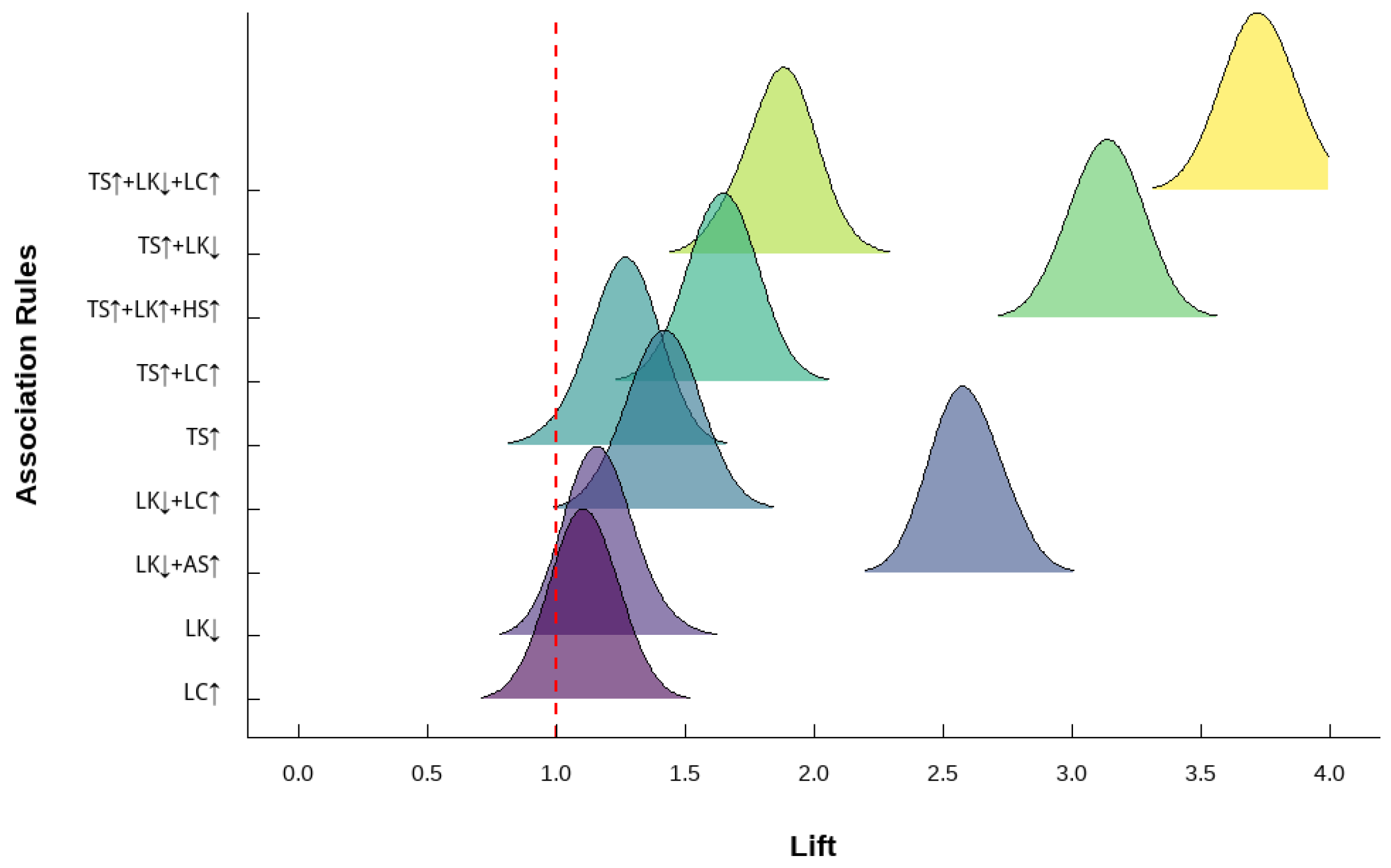
After the calculation, the following key association rules are obtained:
{TS↑, LK↓, LC↑} → {LC-Sev}, sup = 0.2, conf = 1, lift = 5
{TS↑, LK↑, HS↑} →{RE-Mod}, sup = 0.2, conf = 1, lift = 5
{LK↓, AS↑} →{CR-Sev}, sup = 0.2, conf = 1, lift = 5
{TS↑, LK↓} →{RE-Min}, sup = 0.2, conf = 0.5, lift = 2.5
The above rules reflect the strong association between different combinations of driving behaviors and specific types of traffic conflicts. For example, Rule 1 states that a combination of speeding, short headway, and frequent lane changes is likely to result in severe lane-change conflicts; Rule 2 indicates that a combination of speeding, long headway, and sharp braking is likely to cause moderate rear-end collisions.
In the next section, these rules are further evaluated and interpreted to identify the most practical patterns of high-risk driving behavior.
3.2.4. Key Driving Behavior Pattern Recognition
Based on the association rules mined by the FP-Growth algorithm and combined with the enhancement degree and significance test, this paper identifies a series of key driving behavior patterns highly correlated with traffic conflicts, which mainly include the following:
(1) In the mode of speeding + short headway + frequent lane change (TS↑ + LK↓ + LC↑), the probability of lane-change conflict is 3.72 times the average level, and the severity is also high. This indicates that frequent lane changes are very likely to cause vehicle track interleaving and lateral collision under the conditions of overspeeding and short-distance following.
(2) In the mode of overspeed + long front time + sudden braking (TS↑ + LK↑ + HS↑), the probability of rear-end collision is 3.15 times the average level, and most of these collisions are of moderate severity. This indicates that even if the time distance is long, the sudden braking when speeding easily causes the rear car to have no time to react, resulting in a rear-end collision.
(3) In the mode of short headway + rapid acceleration (LK↓ + AS↑), the probability of cross collision is 2.58 times the average level, and most of the collisions are serious. This indicates that rapid-acceleration overtaking is more likely to cause serious collisions at intersections under the condition of short following.
(4) In the mode of speeding + frequent lane change (TS↑ + LC↑), the increase degree in this mode is relatively low (1.86), but it is still the mode associated with a high incidence of rear-end collisions, mostly of a slight degree of seriousness. These results indicate that speeding and lane changing are common causes of traffic flow disorder and potential accidents, and they significantly reduce traffic efficiency, even if no accidents are caused.
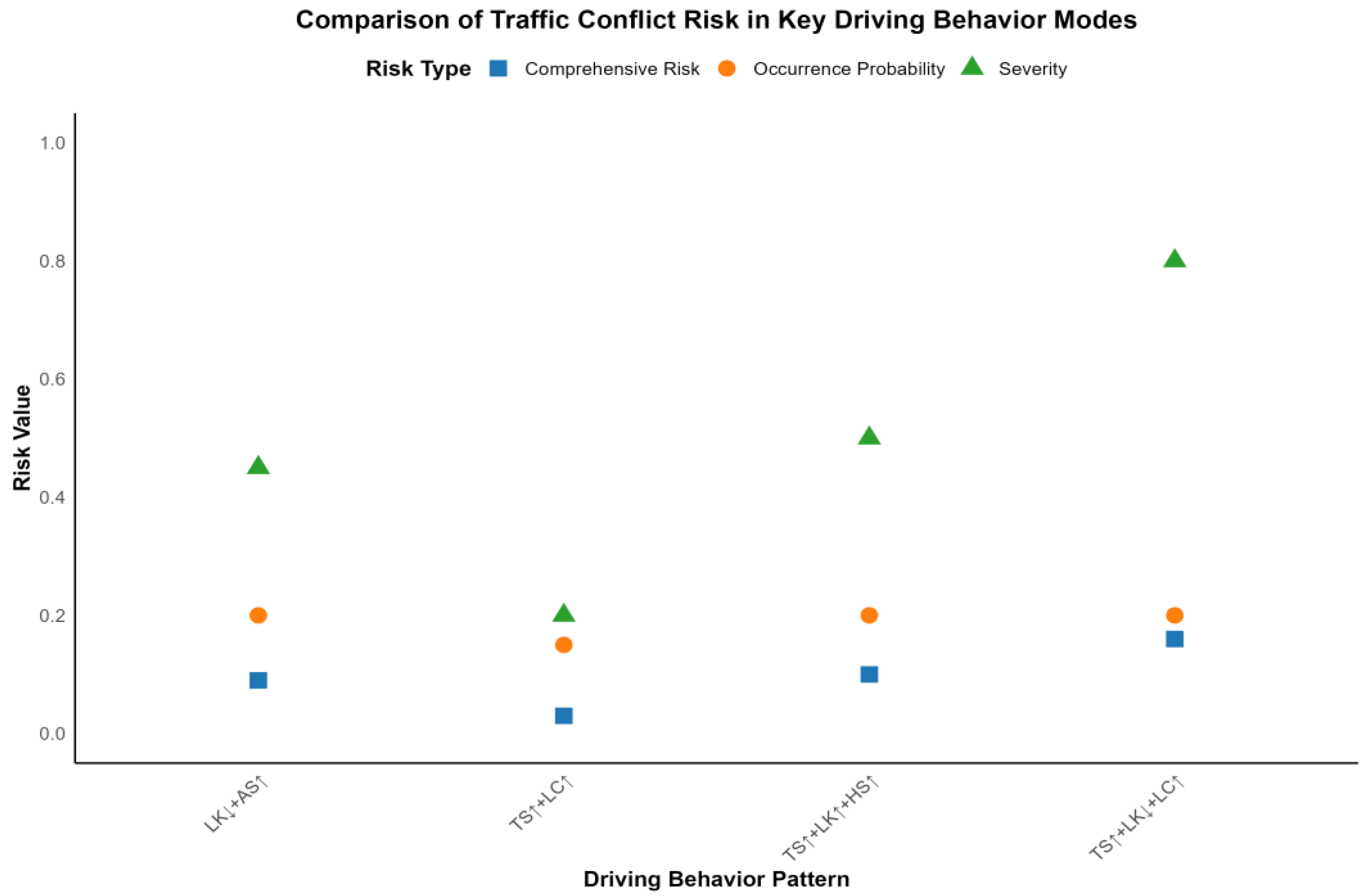
Figure 12 shows the comparison of traffic conflict risks for the above four types of key driving behavior patterns. It can be seen that the mode of “TS↑ + LK↓ + LC↑” has the highest comprehensive risk and that the probability and severity of traffic conflicts are significantly higher than for the other modes, such that it is the illegal behavior that traffic management departments should focus on monitoring and severely crack down on. Other modes, such as “TS↑ + LK↑ + HS↑” and “LK↓ + AS↑”, also have higher comprehensive risks, which are especially likely to lead to accidents of higher severity, which should cause drivers’ vigilance and strengthen legal constraints. Although the “TS↑ + LC↑” mode mostly causes minor collisions, due to its high incidence, it should also be targeted through publicity and education, traffic organization optimization, and other means.
In summary, the FP-Growth algorithm is used to mine association rules from the composite transaction data of driving behavior and traffic conflict and to screen strong association rules through methods such as enhancement degree and confidence tests [
42,
43], which can effectively identify key driving behavior patterns that cause traffic conflict and realize the prevention and control of traffic accidents from the source of driving behavior. These high-risk driving behavior patterns and the types and severity of conflicts induced by them can be used to guide drivers to improve their safety awareness and correct their driving habits and provide a basis for traffic safety publicity and education. At the same time, this information can also guide the traffic management department to reduce the risk rate of accidents and improve the road environment.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}