
Approach to Enhancing Panoramic Segmentation in Indoor Construction Sites Based on a Perspective Image Segmentation Foundation Model


Abstract
1. Introduction
- (1)
- This study improves panoramic segmentation performance in complex indoor construction sites by leveraging SAM, a foundation model for perspective image segmentation.
- (2)
- To enable accurate object extraction in indoor construction images, filtering algorithms were developed for iterative SAM execution, along with a labeling algorithm that assigns semantic labels to objects based on predictions from a target model.
- (3)
- The method is validated through quantitative and qualitative evaluations on real construction site datasets, confirming its applicability and practical value in real environments.
2. Literature Review
2.1. Panoramic Image Segmentation in Indoor Construction Site
2.2. Plane Segmentation with Panoplane360
2.3. Segment Anything Model
2.4. Automatic Mask Generation Model
3. SAM-Based Approach to Improve Panoramic Image Segmentation in Indoor Construction Environments
3.1. Object Extract
3.1.1. Adjustment of Input Parameters
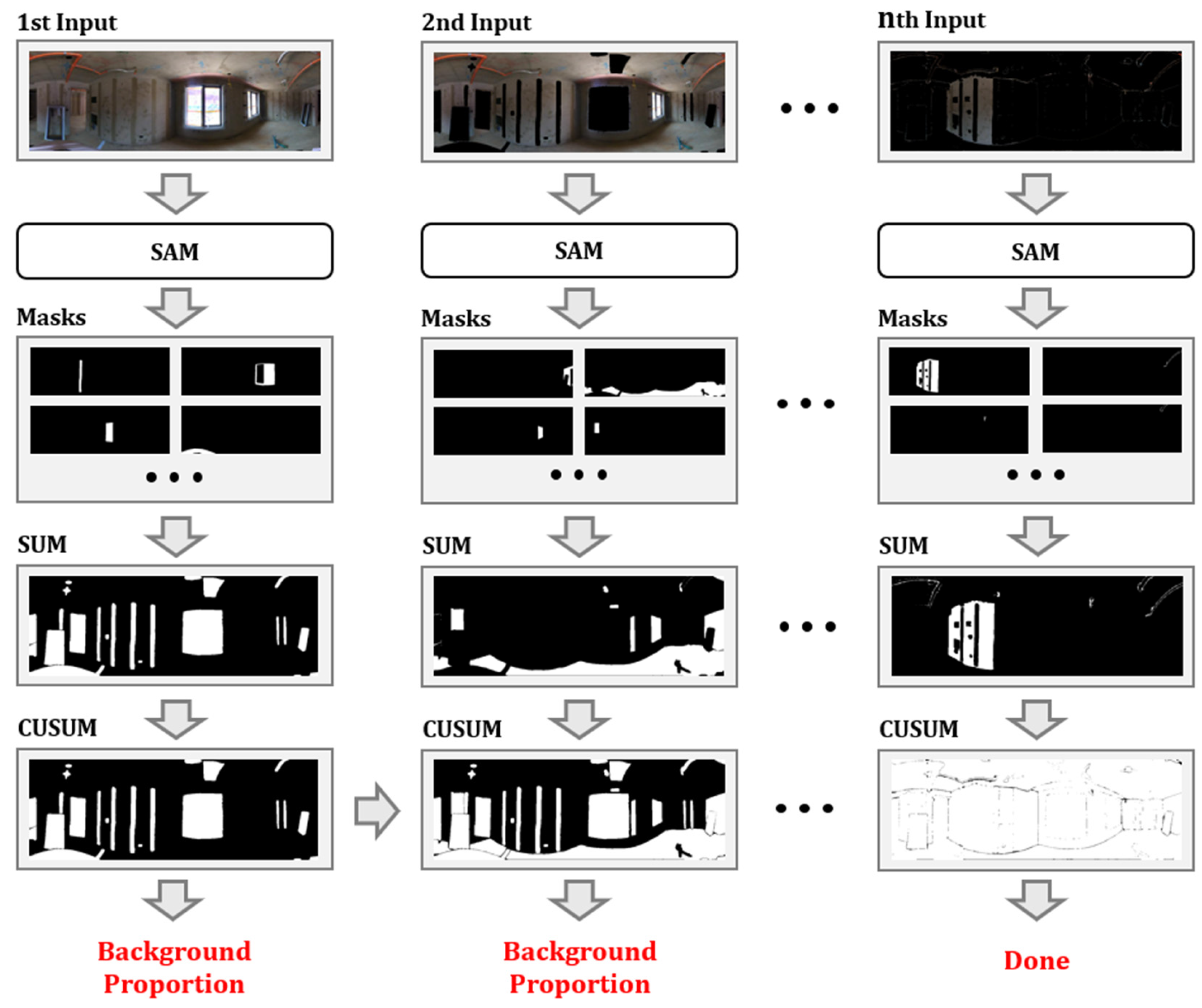
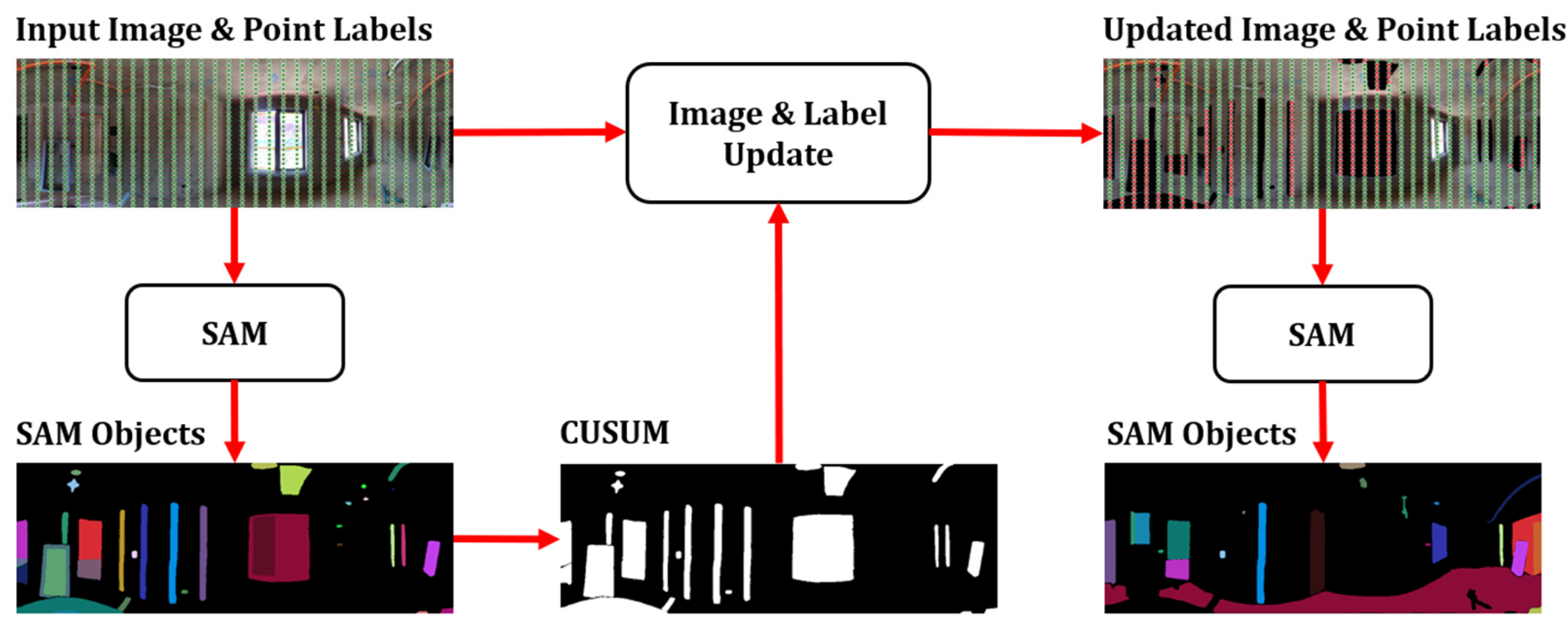
3.1.2. Updating Input Images and Point Labels
| Algorithm 1: Iterative input image update with cumulative mask |
| Input: Input image I of size H × W, Cumulative mask Mcusum Output: Next input image Inext 1: Generate object masks: M ← SamAutomaticMaskGenerator(I) 2: Sort masks by stability score: M ← Sort(M, stability score) 3: Initialize sum mask Msum ← 0H×W 4: for each mask Mseg∈ M do 5: Update current mask: Msum ← Msum+ Mseg 6: end for 7: Update cumulative mask: Mcusum ← Mcusum+ Msum 8: Update input image by masking detected areas: Inext ← I × (1 − BinaryMask(Mcusum)) 9: Return Inext |
| Algorithm 2: Input point label update with cumulative mask |
| Input: Cumulative mask Mcusum of size H × W, Input points P = (wi, hi) Output: Updated point labels L 1: for each point (w, h) ∈ P satisfying Valid do 2: Update label: L[w, h] ← 1 − Mcusum[h, w] 3: (If the Mcusum value is 1, set label to 0; otherwise, set it to 1) 4: end for 5: Return L |
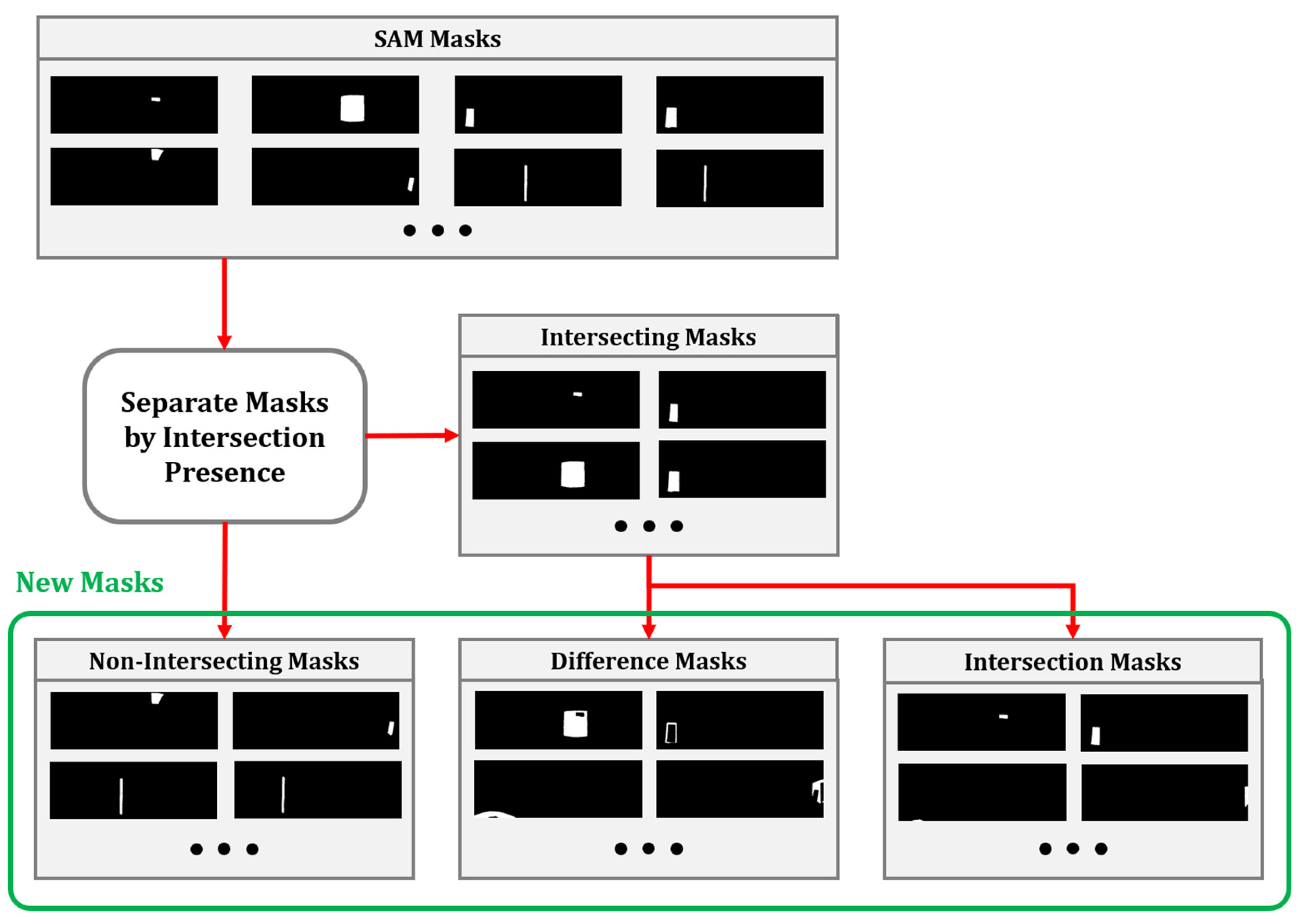
3.1.3. Handling Duplicate and Overlapping Objects
| Algorithm 3: Mask overlap resolution and intersection division |
| Input: Sorted list of masks M Output: Updated list of masks Mnew 1: Step 1: Duplicate Mask Removal 2: for each pair of masks (m1, m2) ∈ M do 3: Compute IoU: iou ← IoU(m1, m2) 4: if iou > 0.85 then 5: Remove m2 6: end if 7: end for 8: Step 2: Separate Masks Based on Intersection 9: Initialize Minter, Mnon-inter 10: for each mask m1 ∈ M do 11: if m1 intersects any m2 ∈ M where m1 ≠ m2 then 12: Add m1 to Minter 13: else 14: Add m1 to Mnon-inter 15: end if 16: end for 17: Step 3: Process and Combine Masks 18: Extract intersection regions: I ← GetIntersections(Minter) 19: if I is not empty then 20: Perform set difference: D ← ComputeSetDifference(Minter, I) 21: else 22: Set D ← ∅ 23: end if 24: Combine all masks: Mnew ← Mnon-inter + I + D 25: Return Mnew |
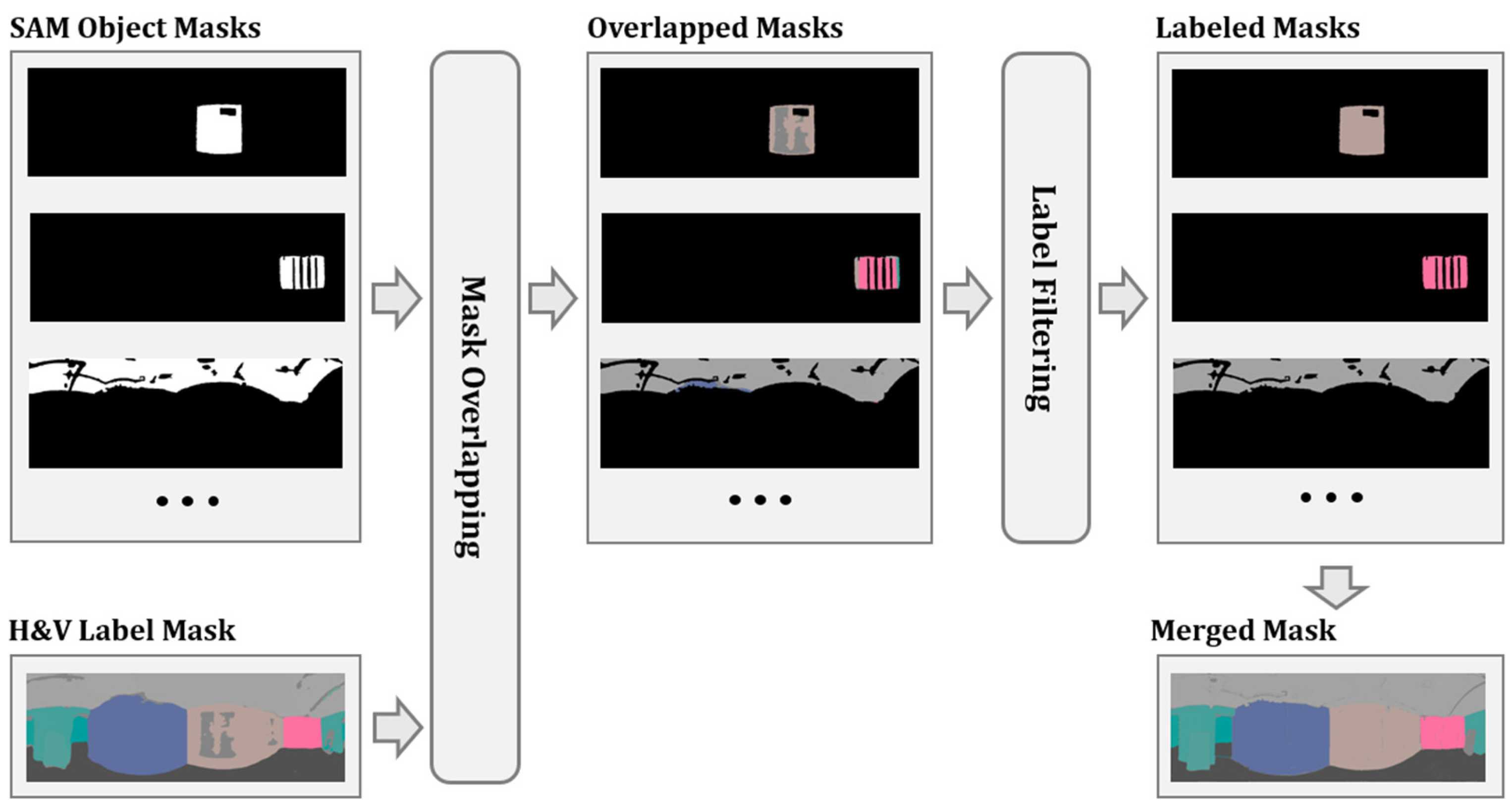
3.2. Label Extraction and Labeling
| Algorithm 4: Object mask assignment and merging |
| Input: List of object masks Mobj, label mask L of size H × W Output: Merged labeled masks Mmerged 1: Step 1: Overlapping masks and Filter Labeled masks 2: Initialize enhanced label mask Lenhanced ← 0H × W 3: Initialize labeled mask list Mlabeled ← ∅ 4: for each object mask Mi∈ Mobj do 5: Compute object mask area: Ai 6: Compute label overlap: Loverlap ← Mi · L 7: Extract label and compute frequencies: L, C ← UniqueCounts(Lvalid) 8: Select dominant label: Ldom ← L[arg max C] 9: Get dominant label count: Cdom ← max C 10: if Cdom ≥ Ai/3 then 11: Assign dominant label: Mlabeled ← Mi · Ldom 12: Append Mlabeled to Mlabeled 13: Update enhanced label mask: Lenhanced ← Lenhanced + Mlabeled 14: end if 15: end for 16: Step 2: Merge Object Masks Based on the Same Labels 17: Extract sorted unique labels: Lsorted ← SortByFrequency(Lenhanced) 18: Initialize merged mask list Mmerged ← ∅ 19: for each label L ∈ Lsorted do 20: Initialize merged mask Mmerged ← 0H × W 21: for each labeled mask Mlabeled ∈ Mlabeled do 22: if L ∈ Mlabeled then 23: Mmerged ← Mmerged + Mlabeled 24: end if 25: end for 26: Append Mmerged to Mmerged 27: end for 28: Return Mmerged |
4. Experimental Study
4.1. Dataset Description
4.2. Evaluation Methods
4.3. Quantitative Analysis
4.4. Qualitative Analysis
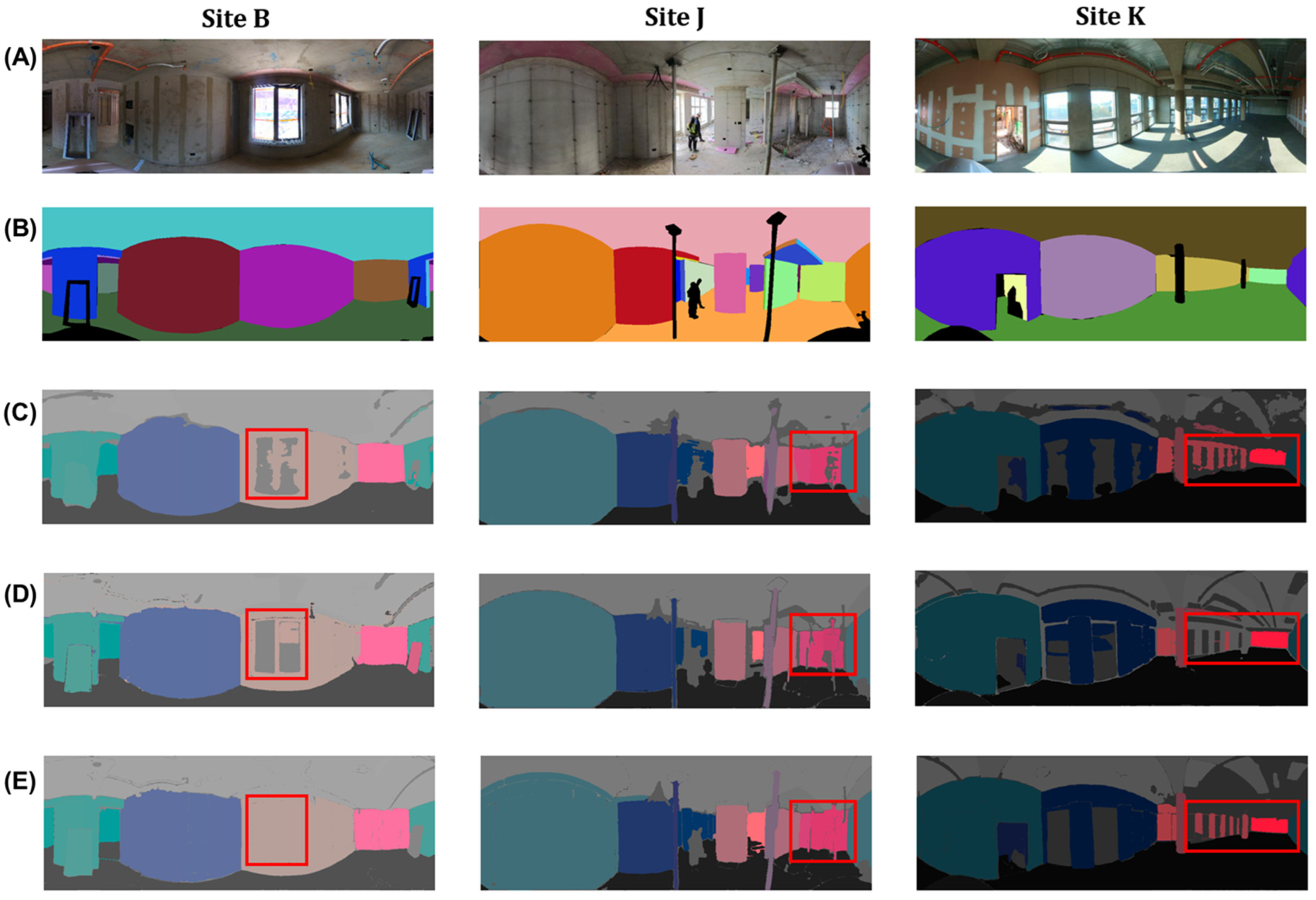
4.4.1. Plane Segmentation Mask
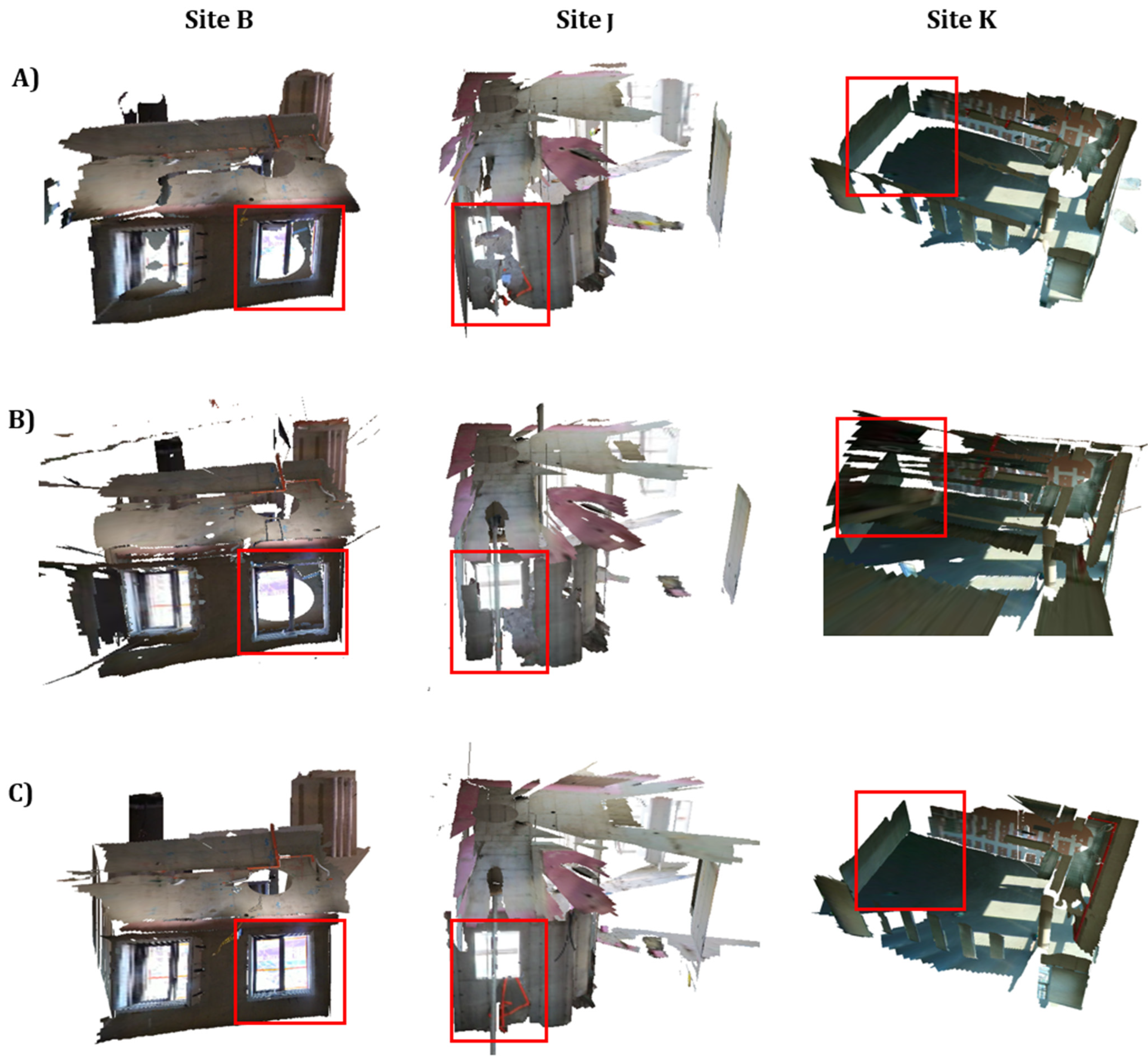
4.4.2. 3D Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Erazo-Rondinel, A.A.; Melgar, M.A. Exploring the Benefits of 360-Degree Panoramas for Construction Project Monitoring and Control. In Proceedings of the 1st International Online Conference on Buildings, Online, 24–26 October 2024. [Google Scholar]
- Fang, X.; Li, H.; Wu, H.; Fan, L.; Kong, T.; Wu, Y. A fast end-to-end method for automatic interior progress evaluation using panoramic images. Eng. Appl. Artif. Intell. 2023, 126, 106733. [Google Scholar] [CrossRef]
- Wei, Y.; Akinci, B. Panorama-to-model registration through integration of image retrieval and semantic reprojection. Autom. Constr. 2022, 140, 104356. [Google Scholar] [CrossRef]
- Kang, M.; Yoon, S.; Kim, T. Computer Vision-Based Adhesion Quality Inspection Model for Exterior Insulation and Finishing System. Appl. Sci. 2024, 15, 125. [Google Scholar] [CrossRef]
- Li, D.; Liu, J.; Feng, L.; Cheng, G.; Zeng, Y.; Dong, B.; Chen, Y.F. Towards automated extraction for terrestrial laser scanning data of building components based on panorama and deep learning. J. Build. Eng. 2022, 50, 104106. [Google Scholar] [CrossRef]
- Ekanayake, B.; Wong, J.K.-W.; Fini, A.A.F.; Smith, P. Computer vision-based interior construction progress monitoring: A literature review and future research directions. Autom. Constr. 2021, 127, 103705. [Google Scholar] [CrossRef]
- Zhang, C.; Shen, J. Object Detection and Instance Segmentation in Construction Sites. In Proceedings of the 2024 3rd Asia Conference on Algorithms, Computing and Machine Learning, Shanghai, China, 22–24 March 2024; pp. 184–190. [Google Scholar]
- Pokuciński, S.; Mrozek, D. Object Detection with YOLOv5 in Indoor Equirectangular Panoramas. Procedia Comput. Sci. 2023, 225, 2420–2428. [Google Scholar] [CrossRef]
- Regona, M.; Yigitcanlar, T.; Xia, B.; Li, R.Y.M. Opportunities and Adoption Challenges of AI in the Construction Industry: A PRISMA Review. J. Open Innov. Technol. Mark. Complex. 2022, 8, 45. [Google Scholar] [CrossRef]
- Tang, S.; Huang, H.; Zhang, Y.; Yao, M.; Li, X.; Xie, L.; Wang, W. Skeleton-guided generation of synthetic noisy point clouds from as-built BIM to improve indoor scene understanding. Autom. Constr. 2023, 156, 105076. [Google Scholar] [CrossRef]
- Ying, H.; Sacks, R.; Degani, A. Synthetic image data generation using BIM and computer graphics for building scene understanding. Autom. Constr. 2023, 154, 105016. [Google Scholar] [CrossRef]
- Lee, H.; Jeon, J.; Lee, D.; Park, C.; Kim, J.; Lee, D. Game engine-driven synthetic data generation for computer vision-based safety monitoring of construction workers. Autom. Constr. 2023, 155, 105060. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, X.; Liu, J.; Cheng, G. Automated layout generation from sites to flats using GAN and transfer learning. Autom. Constr. 2024, 166, 105668. [Google Scholar] [CrossRef]
- Goyal, M.; Mahmoud, Q.H. A Systematic Review of Synthetic Data Generation Techniques Using Generative AI. Electronics 2024, 13, 3509. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Wang, B.; Chen, Z.; Li, M.; Wang, Q.; Yin, C.; Cheng, J.C.P. Omni-Scan2BIM: A ready-to-use Scan2BIM approach based on vision foundation models for MEP scenes. Autom. Constr. 2024, 162, 105384. [Google Scholar] [CrossRef]
- Teng, S.; Liu, A.; Situ, Z.; Chen, B.; Wu, Z.; Zhang, Y.; Wang, J. Plug-and-play method for segmenting concrete bridge cracks using the segment anything model with a fractal dimension matrix prompt. Autom. Constr. 2025, 170, 105906. [Google Scholar] [CrossRef]
- Peng, H.; Liao, Y.; Li, W.; Fu, C.; Zhang, G.; Ding, Z.; Huang, Z.; Cao, Q.; Cai, S. Segmentation-aware prior assisted joint global information aggregated 3D building reconstruction. Adv. Eng. Inform. 2024, 62, 102904. [Google Scholar] [CrossRef]
- Sun, C.; Hsiao, C.-W.; Wang, N.-H.; Sun, M.; Chen, H.-T. Indoor panorama planar 3d reconstruction via divide and conquer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11338–11347. [Google Scholar]
- Zheng, Z.; Lin, C.; Nie, L.; Liao, K.; Shen, Z.; Zhao, Y. Complementary bi-directional feature compression for indoor 360deg semantic segmentation with self-distillation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 4501–4510. [Google Scholar]
- Gao, S.; Yang, K.; Shi, H.; Wang, K.; Bai, J. Review on Panoramic Imaging and Its Applications in Scene Understanding. IEEE Trans. Instrum. Meas. 2022, 71, 1–34. [Google Scholar] [CrossRef]
- Yu, H.; He, L.; Jian, B.; Feng, W.; Liu, S. PanelNet: Understanding 360 Indoor Environment via Panel Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 878–887. [Google Scholar]
- Gkitsas, V.; Sterzentsenko, V.; Zioulis, N.; Albanis, G.; Zarpalas, D. Panodr: Spherical panorama diminished reality for indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3716–3726. [Google Scholar]
- Shen, Z.; Lin, C.; Liao, K.; Nie, L.; Zheng, Z.; Zhao, Y. PanoFormer: Panorama transformer for indoor 360° depth estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 195–211. [Google Scholar]
- Anagnostopoulos, I.; Pătrăucean, V.; Brilakis, I.; Vela, P. Detection of walls, floors, and ceilings in point cloud data. In Proceedings of the Construction Research Congress 2016, San Juan, Puerto Rico, 31 May–2 June 2016; pp. 2302–2311. [Google Scholar]
- Shen, Z.; Zheng, Z.; Lin, C.; Nie, L.; Liao, K.; Zheng, S.; Zhao, Y. Disentangling orthogonal planes for indoor panoramic room layout estimation with cross-scale distortion awareness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17337–17345. [Google Scholar]
- Zhong, Y.; Zhao, D.; Cheng, D.; Zhang, J.; Tian, D. A Fast and Precise Plane Segmentation Framework for Indoor Point Clouds. Remote Sens. 2022, 14, 3519. [Google Scholar] [CrossRef]
- Holz, D.; Holzer, S.; Rusu, R.B.; Behnke, S. Real-time plane segmentation using RGB-D cameras. In Proceedings of the RoboCup 2011: Robot Soccer World Cup XV 15, Istanbul, Turkey, 5-11 July 2012; pp. 306–317. [Google Scholar]
- Yao, H.; Miao, J.; Zhang, G.; Chu, J. 3D layout estimation of general rooms based on ordinal semantic segmentation. IET Comput. Vis. 2023, 17, 855–868. [Google Scholar] [CrossRef]
- Maalek, R.; Lichti, D.D.; Ruwanpura, J. Robust Classification and Segmentation of Planar and Linear Features for Construction Site Progress Monitoring and Structural Dimension Compliance Control. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-3/W5, 129–136. [Google Scholar] [CrossRef]
- Hammad, A.W.A.; Rey, D.; Akbarnezhad, A. A cutting plane algorithm for the site layout planning problem with travel barriers. Comput. Oper. Res. 2017, 82, 36–51. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, K.; Ma, C.; Reiß, S.; Peng, K.; Stiefelhagen, R. Bending reality: Distortion-aware transformers for adapting to panoramic semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16917–16927. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Initial Value | Variation | Conditional Variation |
|---|---|---|---|
| points_per_side | 32 | +4 | |
| stability_score_thresh | 0.97 | −0.002 | |
| pred_iou_thresh | 0.85 | −0.01 | |
| min_mask_region_area | 100 |
| Label | Site | Panoplane360 | SAM+Pano (No Algorithm) | Ours (Proposed) |
|---|---|---|---|---|
| H_plane | Site B | 0.563 | 0.657 | 0.733 |
| Site J | 0.572 | 0.607 | 0.665 | |
| Site K | 0.377 | 0.375 | 0.527 | |
| Total | 0.504 | 0.546 | 0.642 | |
| V_plane | Site B | 0.538 | 0.616 | 0.650 |
| Site J | 0.512 | 0.556 | 0.616 | |
| Site K | 0.508 | 0.542 | 0.552 | |
| Total | 0.519 | 0.571 | 0.606 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Yoon, S.; Kang, M.; Kim, T. Approach to Enhancing Panoramic Segmentation in Indoor Construction Sites Based on a Perspective Image Segmentation Foundation Model. Appl. Sci. 2025, 15, 4875. https://doi.org/10.3390/app15094875
Han J, Yoon S, Kang M, Kim T. Approach to Enhancing Panoramic Segmentation in Indoor Construction Sites Based on a Perspective Image Segmentation Foundation Model. Applied Sciences. 2025; 15(9):4875. https://doi.org/10.3390/app15094875
Chicago/Turabian StyleHan, Juho, Sebeen Yoon, Mingyun Kang, and Taehoon Kim. 2025. "Approach to Enhancing Panoramic Segmentation in Indoor Construction Sites Based on a Perspective Image Segmentation Foundation Model" Applied Sciences 15, no. 9: 4875. https://doi.org/10.3390/app15094875
APA StyleHan, J., Yoon, S., Kang, M., & Kim, T. (2025). Approach to Enhancing Panoramic Segmentation in Indoor Construction Sites Based on a Perspective Image Segmentation Foundation Model. Applied Sciences, 15(9), 4875. https://doi.org/10.3390/app15094875