This section presents the proposed malware detection framework in a formalized structure, followed by four distinct experimental configurations designed to evaluate the contribution and interaction of its core components. Before a detailed analysis of the experiments, we outline the structural relationship between the experimental setups and the proposed framework. The experiments were designed as follows: (i) graph-based node embedding, achieved through Node2Vec or GraphSAGE to understand topological and semantic features from API and DLL graphs; (ii) contextual refinement of embeddings through the GAT, which assigns importance weights to neighboring nodes using attention coefficients; and (iii) final classification using either a custom hybrid CNN-GRU-3 model, optimized for sequential pattern recognition, or an ensemble of traditional ML classifiers. The experiments were designed as follows:
Each of the four experiments explores different configurations of these components to assess their individual and combined contributions. Specifically, Experiment 1 evaluates the baseline performance of Node2Vec and GraphSAGE embeddings using CNN-GRU-3 and ensemble classifiers without GAT. Experiment 2 measures the standalone classification capability of GAT and its integration with initial embeddings. Experiment 3 corresponds to the proposed framework, where GAT refines the embeddings, and CNN-GRU-3 performs classification. Experiment 4 analyzes GAT solely as a feature extractor prior to classification. This experimental design allows for a modular and comparative evaluation of each architectural component and demonstrates how their integration leads to the performance gains achieved by the whole framework.
4.5. Proposed Framework
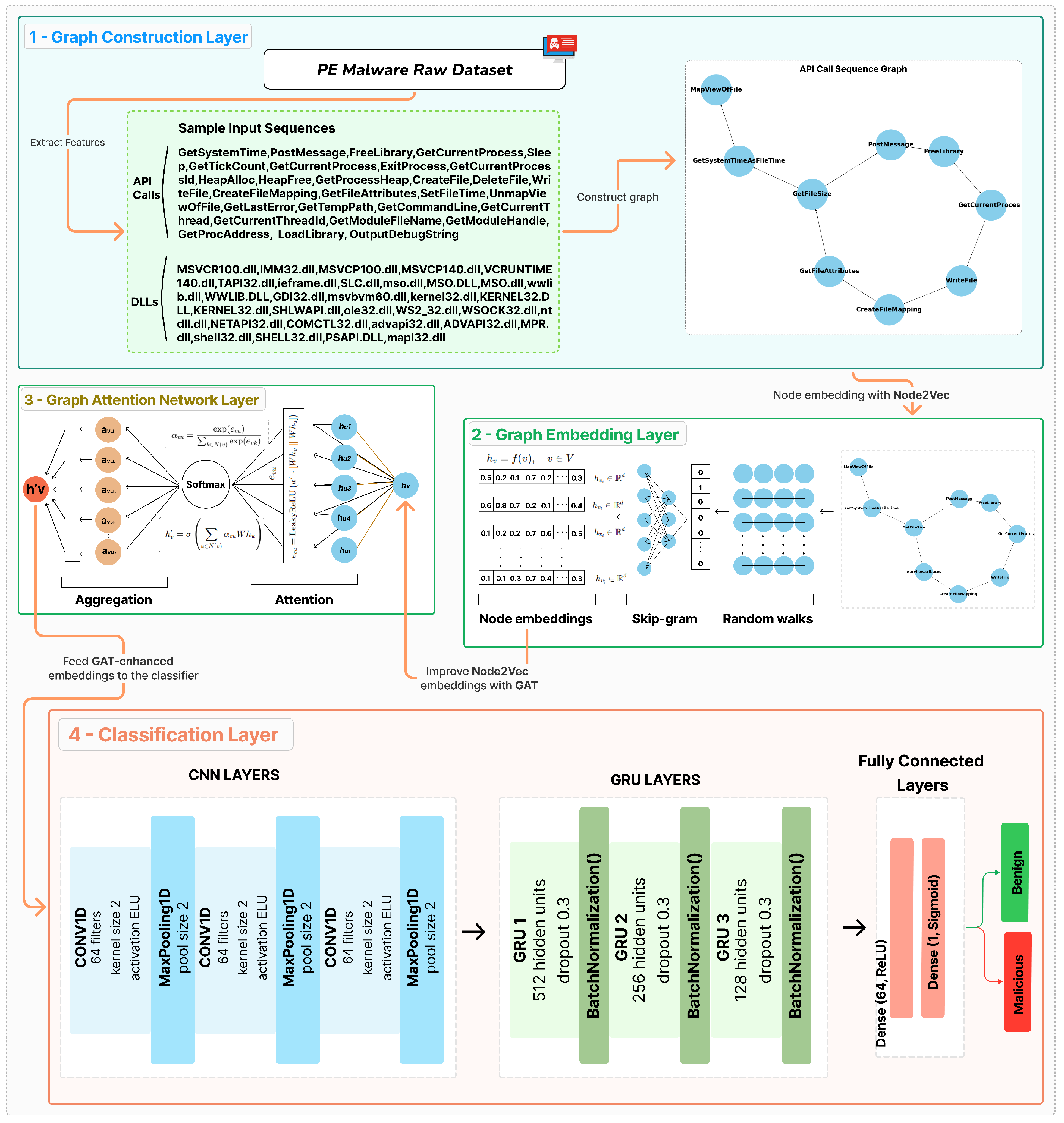
This work presents a novel malware detection framework that integrates graph-based methodologies with DL approaches. The proposed model uses Node2Vec, GAT, and CNN-GRU-3 in a novel structure to exploit structural and contextual relationships in malware data. The overall proposed framework is shown in
Figure 4, and the pseudocode is given in Algorithm 3. The model aims to extract and enhance semantic features from API call sequences and DLL information. First, the graph is constructed using API call sequences and DLL information, where nodes represent API calls or DLLs and edges represent interactions between them. Then, initial node embeddings are generated using Node2Vec via random walks that understand structural relationships in the graph. The embeddings are enhanced using GAT by applying attention mechanisms to improve contextual relationships. Finally, the GAT-enhanced embeddings are fed into the CNN-GRU-3 model, which performs the final classification to detect malware.
| Algorithm 3. Pseudocode for Node2Vec + GAT + CNN-GRU-3 Training Pipeline |
- 1:
Input: Graph , Dimensions d, Walks per node r, Walk length l, Context size k, Return parameter p, In-out parameter q, Number of epochs n - 2:
Output: Predicted class labels - 3:
function Node2VecEmbedding() - 4:
= PreprocessModifiedWeights() - 5:
- 6:
Initialize as Empty - 7:
for to r do - 8:
for each node do - 9:
= Node2VecWalk(, u, l) - 10:
Append to - 11:
end for - 12:
end for - 13:
f = StochasticGradientDescent(k, d, ) - 14:
return f - 15:
end function - 16:
function GAT(f, Adjacency Matrix A, Attention Parameters W, a) - 17:
Initialize attention coefficients: - 18:
Normalize attention coefficients: - 19:
Update node embeddings: - 20:
return Z - 21:
end function - 22:
function TrainCNNGRU3(Z, Y, n) - 23:
Input Z - 24:
Pass Z through convolutional layers: - 25:
Conv1D: 64 filters, kernel size 3, activation ELU, then MaxPooling1D - 26:
Conv1D: 64 filters, kernel size 3, activation ELU, then MaxPooling1D - 27:
Conv1D: 64 filters, kernel size 3, activation ELU, then MaxPooling1D - 28:
Flatten the output of convolutional layers - 29:
Pass through GRU layers: - 30:
GRU1: 512 hidden units, dropout 0.3 - 31:
GRU2: 256 hidden units, dropout 0.3 - 32:
GRU3: 128 hidden units, dropout 0.3 - 33:
Fully connected layers: - 34:
Dense1: 64 units, dropout 0.3, activation ReLU - 35:
Dense2: 1 unit, activation Sigmoid - 36:
Compile model with Adam optimizer, binary crossentropy loss - 37:
Train model for n epochs using Z and labels Y - 38:
return trained model and predictions - 39:
end function
|
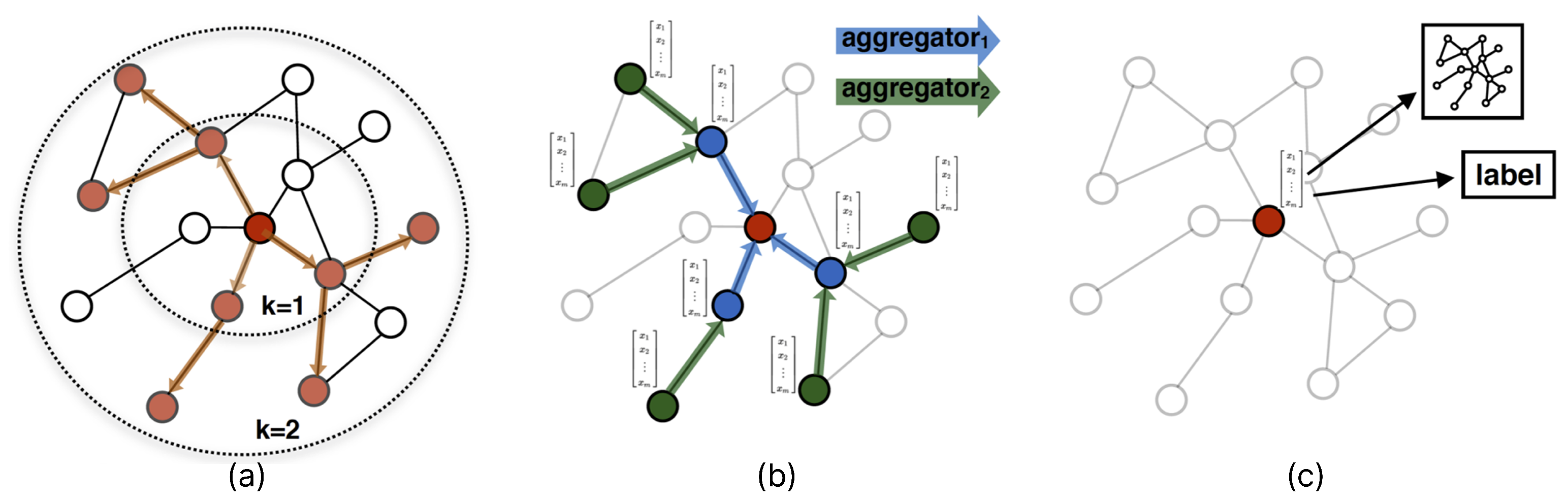
GAT’s attention mechanism improves Node2Vec embeddings by weighting the information from each node’s neighbors with attention coefficients () to make them more contextual. While Node2Vec understands node relationships with random walks, these embeddings only carry structural information. GAT, on the other hand, provides semantic enrichment of embeddings by calculating the importance of nodes to their neighbors (). This process enables each node to create a more meaningful representation in its context. This contextual enrichment is evaluated with higher accuracy rates by DL classifiers. The effectiveness of the proposed model is evaluated through multiple experimental setups, where it is also compared with other graph embedding and classification techniques. The results show that the proposed Node2Vec + GAT + CNN-GRU-3 model achieves the highest accuracy of 0.9961 and outperforms other tested configurations. This achievement is due to the combination of Node2Vec’s effective structural embedding, GAT’s contextual enhancement of embeddings with an attention mechanism, and CNN-GRU-3’s sequential modeling capabilities.
4.6. Performance Metrics
This study uses various metrics to evaluate the performance of malware detection models. Accuracy (Equation (
17)) determines the overall success of the model. At the same time, Recall (Equation (
18)) and (Equation (
19)) Precision metrics are used to measure how much malware was correctly detected and how much of the detected malware was malicious, respectively. F-measure (Equation (
20)) is a measure obtained by combining recall and precision in a balanced manner, indicating the balanced success of the model. Cohen’s Kappa (Equation (
21)) evaluates the reliability of the model against random guesses. At the same time, Mean Absolute Error (MAE) (Equation (
22)) is used to measure how much the model’s predictions deviate from the true values. Using these metrics together provides a more comprehensive assessment of the model’s performance in malware detection.
True Positive (
) are true positive predictions and are cases where the model correctly detects malware; False Negative (
) are cases where the model misses the malware, i.e., does not detect it despite being malicious; True Negative (
) are cases where the model correctly classifies a benign software as benign; and False Positive (
) are cases where a benign software is incorrectly classified as malicious.
represents the observed agreement between raters or classifiers.
represents the expected agreement between raters or classifiers based on chance.
indicates perfect agreement between raters or classifiers.
indicates agreement equivalent to what would be expected by chance.
indicates agreement worse than what would be expected by chance.
where
N is the total number of samples,
is the actual value and
is the value predicted by the model.
4.7. Results and Evaluation
In this study, the Node2Vec + GAT + CNN-GRU-3 model proposed for malware detection was developed and compared with other methods to analyze its performance. The hyperparameters for DL models (CNN and GRU) were determined empirically based on iterative experimentation and validation performance. The CNN block uses three convolutional layers with 64 filters and ELU activation, effectively capturing local spatial features. The GRU block consists of 3 layers with decreasing hidden units (512, 256, 128) and a dropout rate of 0.3 to prevent overfitting, optimized using the Adam optimizer with a learning rate of 0.0001. For the ensemble learning models (Random Forest and XGBoost), hyperparameter tuning was performed using grid search, exploring combinations of key parameters such as the number of estimators, maximum depth, and learning rate. The best-performing configurations, as shown in
Table 4, were selected based on cross-validation accuracy.
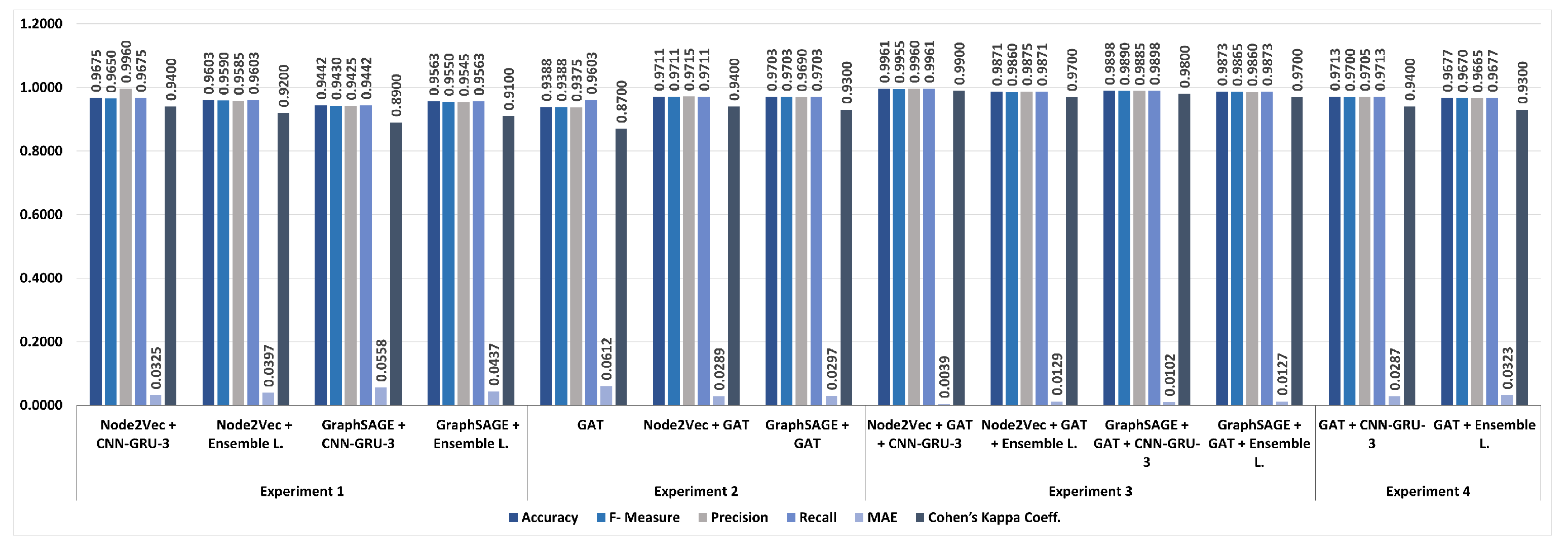
As a result of the experiments conducted with different embedding techniques (Node2Vec and GraphSAGE), contextual enhancement methods (GAT), and classifiers (CNN-GRU-3, Ensemble Learning), it is seen that our proposed model provides the highest accuracy compared to all other combinations. While implementing this study, the NetworkX [
46] library was used to convert API calls and DLL information into a graph structure. While the graph nodes represent API calls and DLLs, the edges represent the relationships between these elements (e.g., call order or dependencies). We applied the Node2Vec and GraphSAGE methods to create embeddings of the nodes. For this purpose, we used node2vec and stellargraph [
47] (Python 3.6 version was preferred for StellarGraph library support in the study) libraries. To further improve the obtained embeddings, we used the GAT model for contextual enrichment with attention mechanisms; the PyTorch Geometric [
48] library was preferred for GAT. Finally, we designed a custom CNN-GRU hybrid model to classify the improved embeddings; we used TensorFlow/Keras libraries at this stage. During the whole process, we also used Pandas, NumPy, and Scikit-learn libraries extensively for data processing and analysis. Training and testing operations were performed in the Google Colab environment using L4 GPU, 53.0 GB system RAM, 22.5 GB GPU RAM, and 235.7 GB disk capacity. This integrated approach combined both graph-based features and the power of DL models to detect malware with high accuracy rates.
Node2Vec + GAT + CNN-GRU-3 model outperforms other Node2Vec and GraphSAGE-based models and models that use GAT as an independent classifier or use GAT for contextual enhancement, with an accuracy value of 0.9961. This result shows that the proposed model benefits from the random walk method of Node2Vec to provide a strong initial embedding, the attention mechanism of GAT to enhance contextual relationships, and the capabilities CNN-GRU-3 to model sequential data.
Table 5 presents the performance results of Node2Vec and GraphSAGE embeddings with CNN-GRU-3 and ensemble learning.
When Node2Vec and GraphSAGE node embedding methods were classified with custom CNN-GRU-3 and Ensemble Learning classifiers, respectively, the best result was obtained from the Node2Vec + CNN-GRU-3 hybrid model. The Node2Vec + CNN-GRU-3 model performed better with 0.9675 accuracy, indicating that the random walk approach of Node2Vec is more effective when combined with the powerful sequential and local information extraction capabilities of CNN-GRU-3.
Table 6 shows the performance results obtained using the GAT classifier and Node2Vec/GraphSAGE embeddings. The GAT model was evaluated both as a standalone classifier and combined with Node2Vec and GraphSAGE embeddings. According to the results, the Node2Vec + GAT model gave the best result with 0.9711 accuracy. When the results were examined, it was seen that the attention mechanism of GAT could process the contextual information more effectively when combined with Node2Vec embeddings. After improving the node embeddings of Node2Vec and GraphSAGE with GAT, they were classified with CNN-GRU-3 and ensemble learning classifiers. The results are shown in
Table 7. GAT was used as a contextual enhancer, and the resulting embeddings were given to CNN-GRU-3 and ensemble learning classifiers. Node2Vec + GAT + CNN-GRU-3 (proposed model) gave the best result among all groups with 0.9961 accuracy. In
Table 8, GAT embeddings are classified with CNN-GRU-3 and ensemble learning. The GAT + CNN-GRU-3 model showed better performance than ensemble learning with 0.9713 accuracy. This situation revealed that CNN-GRU-3 is more effective compared to ensemble learning.
The Node2Vec + CNN-GRU-3 model proved to be an effective initial embedding technique with an accuracy value of 0.9675 for Node2Vec, one of the components of the proposed model. However, when not combined with GAT and CNN-GRU-3, this model could not adequately handle contextual and sequential relationships. The Node2Vec + GAT model showed that GAT’s attention mechanism enriched the embeddings contextually with an accuracy of 0.9711. However, it performed less than the proposed model because it did not understand the sequential information with CNN-GRU-3. The GraphSAGE + GAT + CNN-GRU-3 model provided high performance with an accuracy of 0.9898 even when GraphSAGE was used instead of Node2Vec. This configuration was not as successful as the Node2Vec + GAT + CNN-GRU-3 configuration because Node2Vec can better understand contextual information with the random walk method. As seen in
Figure 5, the models’ performance comparison reveals the proposed framework’s superiority. The performance comparison of the models, as shown in
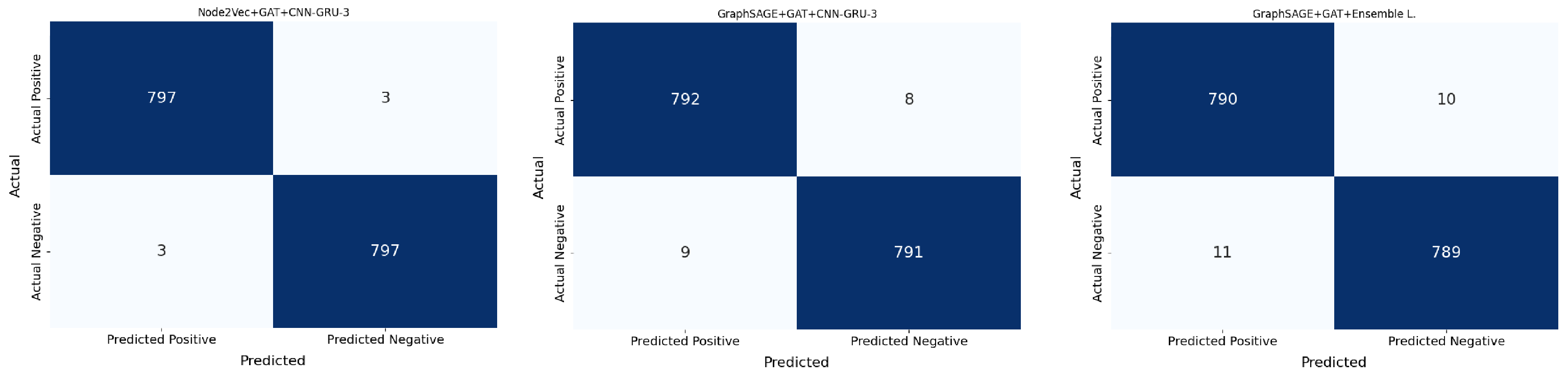
Figure 5, highlights the superiority of the proposed framework. The confusion matrix of the three models that achieved the highest accuracy is given in
Figure 6.
The proposed Node2Vec + GAT + CNN-GRU-3 model achieved a highly balanced classification, with only 3 false positives and 3 false negatives out of 1600 test samples. In contrast, the GraphSAGE + GAT + CNN-GRU-3 configuration resulted in slightly more errors (8 false negatives and 9 false positives), while the GraphSAGE + GAT + Ensemble Learning model showed the highest number of misclassifications (10 false negatives and 11 false positives). The proposed Node2Vec + GAT + CNN-GRU-3 model achieved the highest accuracy (0.9961) in all experiments. This proves the effectiveness of the model’s integration of graph-based contextual information and DL. Recall and F-measure values were higher in the experiments where GAT was used as an embedding improvement method. This is because GAT optimizes contextual relationships and reveals meaningful relationships between nodes. The MAE value of the proposed model (0.02%) is lower than other models. This shows that the model’s error rate in malware detection is relatively low. The Node2Vec + GAT + CNN-GRU-3 model obtained a high value of 0.98 with Cohen’s Kappa. This supports the classification stability and overall accuracy of the model. Considering Experiment 1, it was observed that the accuracy and recall rates were lower in these experiments where Node2Vec and GraphSAGE embeddings were used without improvement with GAT. In particular, the generalization success of the GraphSAGE + Ensemble model was limited. When Experiment 2 was evaluated, contextual information extraction increased in these experiments, where GAT was used as a classifier. However, since the initial embeddings were not directly improved, the accuracy rates were lower compared to the embedding improvement method. When Experiments 3 and 4 were evaluated, the model’s accuracy and generalization success increased significantly in the experiments where GAT was used as the embedding improvement method. This result shows the effect of the contextual enrichment provided by the attention mechanism of GAT on Node2Vec and GraphSAGE embeddings. The graphs in
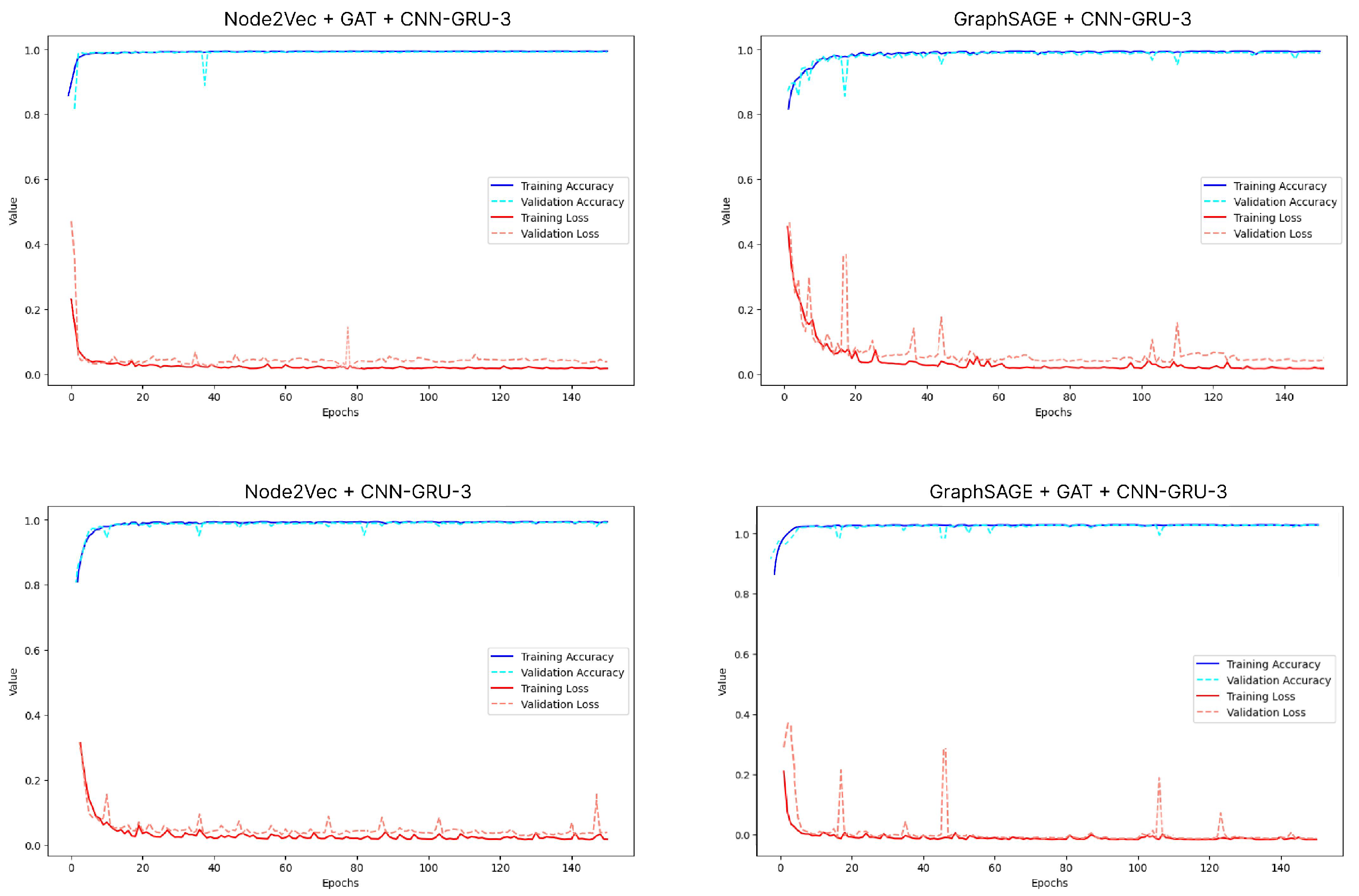
Figure 7 show the performances of Node2Vec + GAT + CNN-GRU-3, GraphSAGE + CNN-GRU-3, Node2Vec + CNN-GRU-3, and GraphSAGE + GAT + CNN-GRU-3 models during the training and validation processes.
The performance evaluation of the models shows that the proposed Node2Vec + GAT + CNN-GRU-3 model outperforms other approaches in terms of accuracy and stability. Achieving an accuracy of 0.9961, this model benefits from the effective use of Node2Vec embeddings, which better understand structural relationships, and GAT’s attention mechanism, which improves the contextual relevance of these embeddings. When combined with the sequential modeling capabilities of the CNN-GRU-3 classifier, the proposed framework achieves a better generalization ability compared to alternatives such as GraphSAGE + GAT + CNN-GRU-3 and Node2Vec + CNN-GRU-3, which show slightly lower accuracy and more fluctuating validation loss. When we examine different GAT scenarios, the scenarios where GAT is used as an embedding enhancement method have shown superior results, especially in performance metrics such as accuracy, precision, recall, and MAE, compared to those used as a classifier. The main reason for this difference is that the initial embeddings created with Node2Vec and GraphSAGE are contextually enriched with attention coefficients by GAT. This improvement of the embeddings has increased the generalization ability of the classification models (CNN-GRU-3, ensemble learning) by making the complex relationships in API calls and DLL information more meaningful. In cases where GAT is used directly as a classifier, the contextual information is only processed during the classification. The initial embeddings are not improved, so MAE is higher, and recall is relatively low. The results show that GAT offers a more effective approach to malware detection when used as an embedding enhancement method.




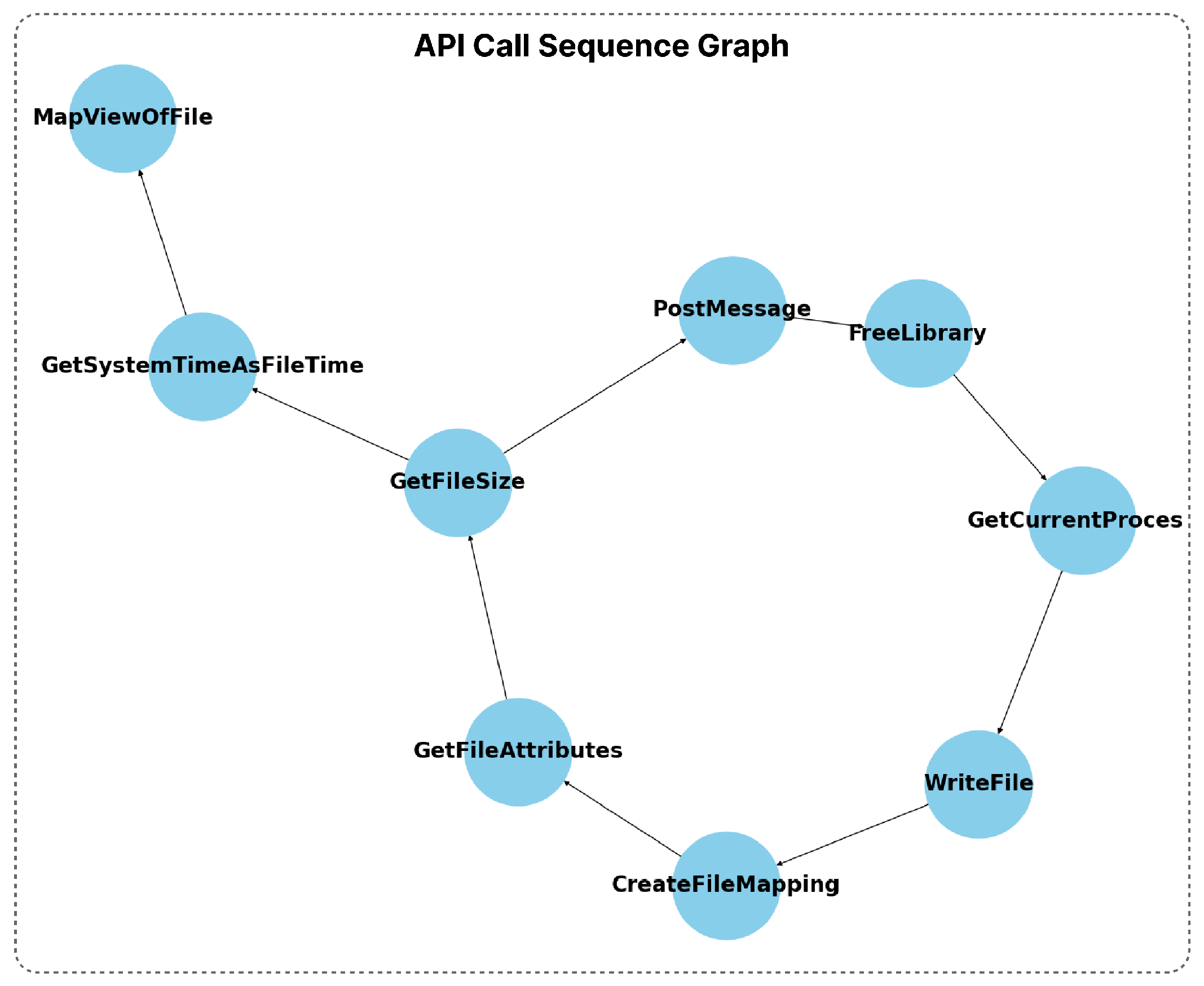

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}