1. Introduction
The application of fuzzy logic [
1] has significantly advanced artificial intelligence by incorporating human-like uncertainty into computational decision-making. This approach has been particularly integrated in the modeling and control of nonlinear systems with the Takagi–Sugeno (T-S) fuzzy model [
2]. By decomposing a complex nonlinear system into a collection of linearized subsystems interconnected through fuzzy inference, the T-S model provides a structured framework for system identification and control. Recent studies [
3,
4,
5] have explored and extended the capabilities of T-S fuzzy models in recent years.
The approach developed in [
6] can be considered as a generalized version of the T-S method. This technique is designed to be computationally efficient, realizing enhanced model accuracy on the basis of parameter weighting. In [
7], the method was further developed to accommodate multivariable systems. Compared to the original T-S model [
2], these approaches demonstrate high accuracy in modeling nonlinear systems.
On the other hand, the authors of [
8] introduced an enhanced T-S fuzzy modeling approach that uses multidimensional membership functions (MDMFs) to improve system identification. Their method eliminates a limitation of the conventional fuzzy inference method based on 1DMFs that can lead to suboptimal placement of fuzzy rules when modeling nonlinear multivariable systems. In contrast, the adoption of MDMFs enhances system identification while requiring fewer fuzzy rules. A genetic algorithm (GA) is integrated to optimize the MDMFs in combination with the T-S approach for modeling and system identification. Experimental results demonstrate that this method achieves lower identification errors compared to the traditional T-S model while reducing the number of fuzzy rules.
Despite advances in the use of MDMFs in fuzzy models, their application in nonlinear multivariable systems remains limited. One major limitation is the challenge of properly tuning membership functions in complex systems, which can lead to reduced accuracy of system identification and control. In this paper, we address this gap by proposing an approach based on MDMFs defined through fuzzy clustering algorithms.
Other algorithms have been developed to facilitate this task, such as the one proposed in [
9], which optimizes the placement of MDMFs using a new algorithm based on the inertia matrix. In [
10], collaborative fuzzy clustering (CFC) was applied to the identification of multiple-input multiple-output (MIMO) systems.
Different adjustment algorithms have been explored through several methods in order to determine the parameters of MDMFs (antecedents) and the T-S model (consequents). One such approach is the application of GAs [
8,
11,
12]; in this approach, the GA is used for optimizing the T-S antecedents and the T-S identification method [
2] is used to estimate the consequents.
In addition to the optimization of MDMFs, fuzzy clustering algorithms have been developed to obtain fuzzy rules for the best separation of data in clustering problems. Examples of these algorithms are fuzzy C-means (FCM) [
13,
14,
15], fuzzy possibilistic c-means [
16], Gustafson–Kessel (GK) [
17,
18,
19], Gath–Geva (GG) [
20], and other approaches [
21].
The K-means approach to clustering was initially proposed by S. Lloyd in 1957 [
22] as a technique for modulation via coded impulses. However, it was James MacQueen [
23] who finished defining it and assigned the current name ten years later. The fuzzy K-means clustering algorithm was created by J. Bezkek and his team [
24], who developed it in 1984.
In 1978, Gustafson and Kessel [
17] proposed a fuzzy clustering algorithm with fuzzy covariances. This algorithm can better estimate the precision of mixed densities.
In 1989, Gath and Geva presented their own fuzzy clustering algorithm, which aims to perform fuzzy clustering without a priori knowledge of the number of clusters necessary to classify the set of samples. The validity of membership in these clusters is based on performance measures using the criteria of hypervolume and density [
25].
In [
26], the authors proposed a fuzzy-based controller for sink selection and clustering in wireless sensor networks. Their proposed method considers the capacity of sink nodes to optimize data transmission and prevent packet loss. Furthermore, a fuzzy-based controller is designed to select cluster heads by reducing the number of fuzzy rules using the R-implications method, which decreases the complexity and energy consumption of the system. Simulation results demonstrate that this approach enhances network lifetime, reduces packet loss, and improves energy efficiency compared to traditional clustering techniques.
In [
27], an anti-swing control method for overhead crane systems was developed by integrating the clustering salp swarm algorithm (CSSA) with a fuzzy PID controller. The proposed approach enhances population diversity and improves convergence accuracy by introducing clustering techniques into the original salp swarm algorithm (SSA). Similarly, a fuzzy control approach based on the extraction and reduction of fuzzy rules through the FCM clustering algorithm was presented in [
28]. This method optimizes a self-tuning fuzzy proportional–derivative controller by reducing the number of fuzzy rules while maintaining control accuracy. The authors demonstrated the effectiveness of these approaches through simulation experiments, showing superior performance compared to conventional fuzzy and PID controllers in mitigating overhead crane oscillations along with improved control precision.
A fuzzy tuning approach for the controller parameters of a parallel manipulator based on clustering analysis was proposed in [
29]. The new technique improves tracking performance throughout the robot workspace by identifying specific configurations that represent different levels of load inertia. Using the FCM clustering algorithm, inertial data are classified and representative cluster centers are determined to enable efficient tuning of the controller parameters for arbitrary configurations. The results obtained from a prototype demonstrate the effectiveness of this methodology in improving control quality without requiring complex real-time computations.
The authors of [
30] presented a hybrid approach combining a fuzzy logic controller (FLC) and FCM to enhance the asset management of power transformers. Their proposed methodology provides diagnoses and prognoses of incipient power transformer faults using a system that incorporates critical parameters such as dissolved gas analysis, interfacial tension, etc. Their study used a dataset consisting of 200 transformer tests for verification, demonstrating that the fuzzy clustering approach can effectively classify insulation conditions into four clusters ranging from healthy insulation to insulation that is nearing the end of its useful life.
In [
31] the authors demonstrated target recognition capability in remote sensing images acquired by a small UAV using fuzzy clustering techniques. To facilitate improved object detection and localization, the fuzzy clustering algorithm was applied to construct an intelligent target recognition model that effectively segments and classifies remote sensing data. The performance of the proposed system was verified through simulation experiments, demonstrating its effectiveness and robustness.
In [
32], the authors proposed a fuzzy control framework for aircraft engines by integrating dynamic clustering modeling with robust control strategies. Their approach utilizes a hierarchical clustering technique to optimize the number of fuzzy rules, ensuring accurate representation of the engine’s dynamic behavior while maintaining computational efficiency. Experimental verification through hardware-in-the-loop (HIL) tests demonstrated the effectiveness of the proposed model, achieving improved engine performance with reduced settling times and overshoots.
In another method presented in [
33], the authors introduced an advanced clustering-based fuzzy segmentation technique for medical image processing, specifically brain magnetic resonance imaging (MRI) segmentation. By incorporating spatial constraints and local membership matrix information, the proposed algorithm enhances traditional fuzzy C-means (FCM) clustering to achieve greater noise resistance and segmentation accuracy.
In this work, different fuzzy clustering techniques are considered, allowing for the construction of clusters with undetermined limits. These methods allow a specific sample to belong to several different clusters, with the respective relationships determined by degrees of membership.
In other words, the main essence of fuzzy clustering is not only to consider the membership of a sample in a certain cluster, but to consider the degree to which it belongs to each of the clusters obtained in the application. The latter represents a great advantage when it comes to representing all the complexity that a set of samples can offer in a real data collection.
Additionally, we evaluate the advantages that fuzzy clustering methodologies can provide in the context of control engineering. Our aim is to obtain a more effective controller by classifying samples of the system to be controlled.
The main contributions of this paper can be summarized as follows:
Development of a novel method for identifying and controlling nonlinear systems using MDMFs.
Integration of fuzzy clustering algorithms to optimize the generation of MDMFs, leading to a reduced number of fuzzy rules while maintaining model accuracy.
A demonstration of the effectiveness of the proposed approach using the example of a thermal mixing tank system.
The rest of this paper is structured as follows:
Section 2 provides a brief description of the T-S identification method based on 1DMFs inference;
Section 3 presents fuzzy control based on multidimensional membership functions, where these functions are adjusted by fuzzy clustering algorithms; finally,
Section 4, uses an illustrative example of a thermal mixing tank system to demonstrate the advantages of our proposed fuzzy clustering methods over traditional fuzzy approaches.
2. T-S Identification Method
The identification methodology for T-S fuzzy models is formulated as an optimization problem in which the nonlinear system parameters are estimated by minimizing a quadratic performance index [
2]. However, the conventional T-S identification approach becomes ineffective when triangular membership functions overlap in pairs, leading to a T-S matrix that is rank-deficient and consequently non-invertible [
6]. To overcome this limitation, a generalized T-S identification framework incorporating a parameter weighting strategy was proposed in [
6,
7] to enhance the robustness of the estimation process.
The above method is based on the identification of nonlinear functions that can be expressed as a set of difference equations by the following IF–THEN rules for an
nth order system:
where
are the system outputs,
are the system inputs, and
are measurable variables, hereinafter referred to as fuzzy variables. The term
denotes the
th fuzzy rule, while the parameters
and
are coefficients associated with the output and input values, respectively.
In this fuzzy framework,
j designates the fuzzy variable index and
denotes the fuzzy rule index associated with the corresponding fuzzy variable. Under this denotation, the fuzzy estimation of the output is provided by
where
in which
represents the membership function associated with the fuzzy set
. In the context of the parameter weighting method, it is assumed that an initial affine linear estimation model is available, i.e., that a preliminary estimation of the following parameters is known:
To obtain this first estimation, the classical least squares method can be applied to the set of data in the system. This estimation can then be utilized as reference parameters for all the T-S fuzzy model subsystems:
Then, the fuzzy model parameters can be obtained by minimizing
where
Y represents the output data,
X represents the fuzzy input/output data, and
P stands for the parameters of the fuzzy model.
As explained in [
6,
7], the matrix
is non-invertible due to the linear dependency among the columns of X, which makes direct computation of the parameter vector P via the classical expression
infeasible. To overcome this limitation, a factor
is introduced. This parameter quantifies the confidence degree associated with the initially estimated parameters; its inclusion ensures that the extended matrix
maintains full rank even if the triangular membership functions overlap in pairs. Thus, the vector
P can be determined by isolating it from Equation (
6):
In the case where the state variables are measurable [
7], Equation (
1) can also be represented by a set of discrete state-space models:
Thus, fuzzy identification can be accomplished with state models [
7] using similar formulations to Equations (
2) and (
3).
Note that in the T-S identification method the fuzzy rules weights are inherently determined by the inference of 1DMFs . In this work, we propose MDMFs to solve this problem.
3. Fuzzy Control Based on Multidimensional Membership Functions Adjusted by Fuzzy Clustering Algorithms
This work presents a new method that for the identification, modeling, and control of nonlinear systems described by the T-S model. The proposed method uses MDMFs and different clustering methods to adjust these functions, achieve a better fit of these functions, and even reduce the number of membership functions necessary to achieve adequate control of the nonlinear system.
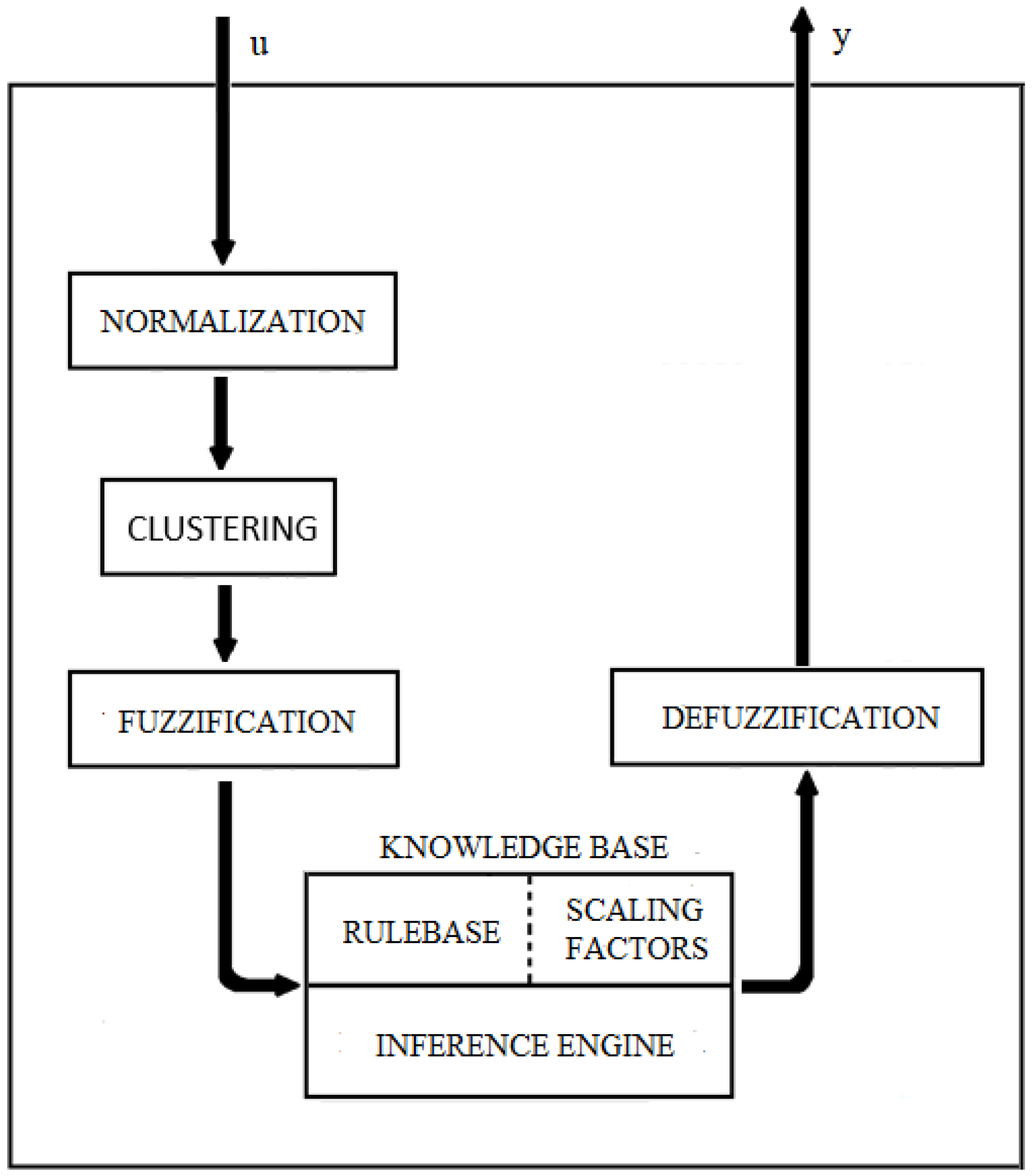
Figure 1 shows the control process using clustering techniques, illustrating the basic structure of a fuzzy system.
The approach proposed in this work for multidimensional fuzzy sets
is described below. The fuzzy variable is defined as follows:
and the MDMF is defined as
. For each multidimensional fuzzy set, a central point
must be designed. This central point is defined by clustering methods in order to select points that produce a greater separation between the datasets. In this work, the dataset used for the clustering process corresponds to the set of measured input–output samples collected from the system under study.
The concept of distance should also be defined, as there are several ways to define it [
34]. The distance is needed in order to establish the proximity of a certain sample with respect to the central points of the membership functions, which is related to the degree of membership regarding each of the rules. Clustering techniques further determine and define this distance depending on which technique was selected during the design phase. In addition, the multidimensional membership rules are determined based on the clustering method and the parameters chosen to calculate them. Thus, the form of these membership rules changes according to the methodology used.
The fuzzy model of the system with
rules is represented as follows:
which becomes
where
To obtain a fuzzy controller based on MDMFs, it is possible to design a controller and observer for each fuzzy rule using any controller and observer design methodology that meets the desired robustness, precision, and speed conditions. In this work, the incremental state model is used [
35], as it has the advantage of introducing an integral action, which in turn allows a steady-state error of zero to be maintained in fuzzy T-S control based on MDMFs. The discrete LQR method and the optimal state observer are also applied, as defined in [
35]. Nonlinear systems can be treated using the T-S fuzzy model based on MDMFs when the multidimensional fuzzy variable is known
.
Recalling the fuzzy model of the system with
rules previously presented in (
10), the difference equation associated with each output can be transformed into a state model with an affine term, as follows:
This means that
where
,
, and
.
Grouping the whole system in a unique model, the following equation is obtained:
which can be represented as follows:
Then, the multivariate state model with independent terms and
rules is represented as follows:
Furthermore, the following incremental state model can be obtained in each fuzzy rule [
35]:
Next, a discrete LQR method for the fuzzy incremental state based on MDMFs is applied. For each rule, we seek to minimize the following cost index J based on the incremental state fuzzy matrices:
where the
and
matrices must be symmetric and positive definite [
6].
The fuzzy controller based on MDMFs is defined as follows:
Because the state
is not usually accessible, a fuzzy state observer is needed:
Calculation of the observation matrix H proceeds in the same way as in [
35] for each fuzzy rule defined by MDMFs, using the following optimal observer:
Estimation of the incremental state can be obtained by means of the state observer shown in (
24). Estimation of the state [
35] is shown in (
25):
3.1. Fuzzy Clustering
Initially, a set of n samples
and a number K of clusters is used. In this way, a fuzzy cluster is considered as a fuzzy subset in X, defined as shown below:
The degree of fuzzy membership for each cluster k is represented as follows:
In this way,
shows the degree of membership of a sample i with respect to a cluster k. In general,
satisfies the conditions provided in (
27):
The results of applying a fuzzy clustering methodology are collected in a partition matrix U =
that shows all the degrees of membership of the samples with respect to each cluster [
36]. To calculate this matrix, the concept of distance to the centers of the clusters is applied, which depends exclusively on the fuzzy clustering method being used.
3.1.1. FCM Clustering Algorithm
The FCM algorithm [
24] is based on the minimization of a cost index, described in (
28):
where
is a vector of cluster prototypes (more commonly known as centers), which have to be obtained through the algorithm. Here, D is the norm of the squared distance of the inner product, as described in (
30):
Statistically, (
30) can be viewed as a measure of the total variance of
from
. The minimization of this equation represents a nonlinear optimization problem that can be solved using a wide variety of methods, from minimization of grouped coordinates to the use of genetic algorithms. The most popular method is a Picard iteration through the first-order conditions for stationary points, also known as the FCM algorithm.
The stationary points can be found using Lagrange multipliers
, as provided in (
31):
Next, the gradients of
with respect to U, V, and
must be set to zero. If
and m > 1, then
can minimize (
32) only if (
32) and (
33) hold:
The FCM algorithm uses the standard Euclidean norm as a distance, meaning that clusters take the form of hyperspheres. Therefore, it can only detect clusters with the same shape and orientation, as the common choice of the norm-inducing matrix is either
or can be chosen an
diagonal matrix that contains the different variances in the direction of the coordinate axes of X, as shown in (
34):
Additionally, A can be defined as the inverse matrix of the
covariance matrix,
, with F defined in (
35):
In the simulations developed in
Section 4, the direct application of this algorithm could induce errors in the case of multidimensional systems.
In order to avoid this problem, the data must be normalized before applying this algorithm. In this way, the distances to the center of the clusters are relative and the distances on the axis of the dimensions with a lower range of values are not neglected. Normalization of the data is carried out as shown in (
36):
After the data have been normalized and the algorithm has been applied, the centers of the clusters must be denormalized, as the FCM algorithm will not have the previously normalized data.
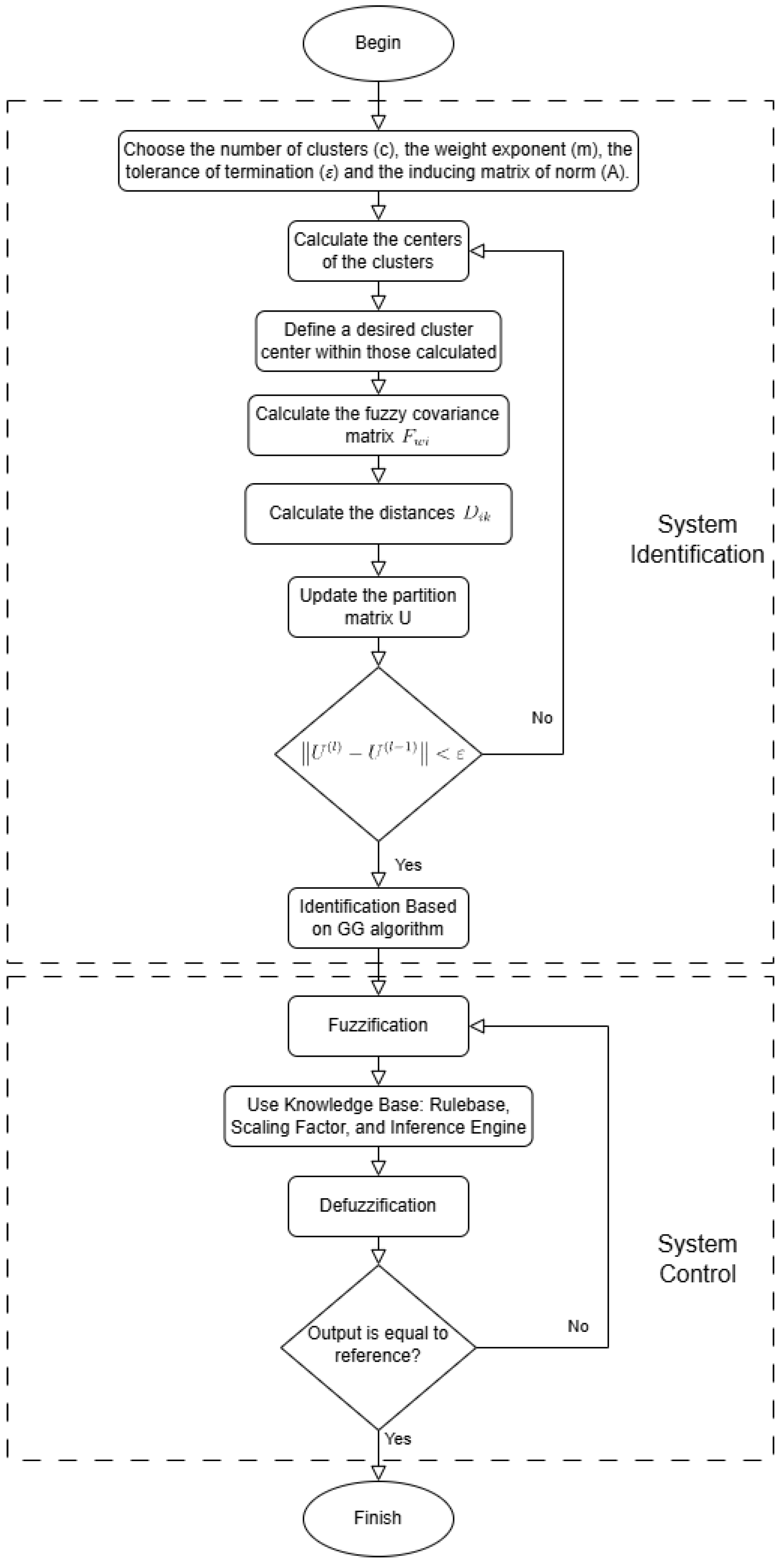
The FCM algorithm used in this work is shown in
Figure 2, and is defined as follows.
- -
Step 1: Given a dataset X, choose the number of clusters 1 < c < N, the weight exponent m > 1, the tolerance of termination , and the inducing matrix of norm A. Initialize the partition matrix randomly such that has arbitrary values.
- -
Step 2: Normalize the data to avoid errors due to differences in the ranges of the different dimensions.
- -
Step 3: Calculate the centers of the clusters such that:
where l is the current iteration number of the algorithm.
- -
Step 4: Define a desired cluster center within the calculated centers in order to force its value. This center will be the same in all iterations.
- -
Step 5: Calculate the distances of the samples to the centers of the clusters such that:
- -
Step 6: Update the partition matrix U such that
- -
Step 7: Repeat steps 3, 4, 5, and 6 for
until fulfilling
- -
Step 8: Denormalize the obtained cluster centers in order to properly place them within the ranges of the different dimensions.
After the centers have been obtained using the algorithm, it is necessary to include fuzzification based on the FCM formulas for the T-S and fuzzy controller identification stages. The fuzzification process for each sample is as follows:
3.1.2. Fuzzy GK Clustering Algorithm
The standard FCM algorithm was extended by Gustafson and Kessel (GK) [
17] by employing an adaptive norm distance, with the aim of detecting clusters of different geometric shapes within a dataset. In this way, each cluster has its own norm-inducing matrix
that produces its own inner product norm, as shown in (
42):
The matrices
are used as optimization variables, and allow each cluster to adapt the distance to the topological structure of the data. The objective function of the GK algorithm is defined by (
43):
However, this equation cannot be minimized directly with respect to
, as it is linear in
. This means that J can be made as small as desired simply by making
less positive definite. To obtain a feasible solution,
must be somehow bounded. To optimize the shape of the cluster while keeping its volume constant, we can vary the determinant of the matrix
such that
where
is adjusted for each cluster. Using the Lagrange multiplier method, we obtain
where
is the fuzzy covariance matrix in cluster i, defined in (
46)
Note that substituting (
45) and (
46) into (
42) provides a distance determined by the quadratic norm between
and the cluster center
, where the covariance is determined by the degrees of membership in U.
The fuzzy GK clustering algorithm is outlined in
Figure 3, which provides a structured flowchart of its main stages. The individual steps are as follows.
- -
Step 1: Given a dataset X, choose the number of 1 < c < N clusters, the weight exponent m > 1, the termination tolerance , and the norm inducing matrix A. Initialize the partition matrix randomly such that has arbitrary values.
- -
Step 2: Calculate the cluster centers as specified below, where l is the number of the current iteration of the algorithm.
- -
Step 3: Determine one of the obtained centers as the chosen center. This center will be the same in all iterations.
- -
Step 4: Calculate the covariance matrix of the clusters such that
- -
Step 5: Add a scaled identity matrix
- -
Step 6: Extract the eigenvalues
and eigenvectors
, find
, and set
- -
Step 7: Reconstruct
with the following form:
- -
Step 8: Calculate the distances
- -
Step 9: Update the partition matrix U as follows:
- -
Step 10: Repeat the above steps until fulfilling
After the centers and the covariance matrix F have been obtained by the algorithm, it is necessary to include a fuzzification based on the GK formulas for the T-S identification and fuzzy controller stages. The fuzzification process for each sample proceeds as follows:
3.1.3. Fuzzy Clustering GG Algorithm
The fuzzy clustering of maximum likelihood estimates (FMLE) algorithm employs the fuzzy maximum likelihood estimation-based rule as the distance [
25], as follows:
Note that unlike the GK algorithm, this distance involves an exponential term, meaning that it decreases faster than the induced product norm. Here,
describes the fuzzy covariance matrix in cluster i, the calculation of which is shown in (
58):
The degrees of membership
are interpreted as the a posteriori probability of selecting cluster i given sample
. Gath and Geva determined in their research [
25] that the FMLE algorithm is capable of determining clusters of different shapes, sizes, and densities. The covariance matrix of the cluster is used in conjunction with an exponential distance, and the clusters are not constrained by their volume. However, this algorithm is much less robust, requiring a good initialization. Depending on the exponential distance, it can become unstable and provide erroneous results or alternatively converge to a near-optimal local point.
The use of a central fuzzy rule to determine a desirable working point has been considered in the same way as in common fuzzy clustering methods. The GG algorithm [
25] used in this work is summarized below and illustrated in the flowchart shown in
Figure 4.
- -
Step 1: Given a dataset X, choose the number of 1 < c < N clusters, the weight exponent m > 1, and the termination tolerance . Initialize the partition matrix U using a robust method.
- -
Step 2: Calculate the cluster centers as follows, where l is the current iteration number of the algorithm:
- -
Step 3: Set one of the obtained clusters as the desired fuzzy rule. This center will be the same in all iterations.
- -
Step 4: Calculate the fuzzy covariance matrix of the cluster:
- -
Step 5: Calculate the distances
in the following form:
with the following a priori probability:
- -
Step 6: Update the partition matrix U with the terms
- -
Step 7: Repeat the above steps until fulfilling
After obtaining the centers, covariance matrix F, and a priori probability
using algorithm, it is necessary to include a fuzzification based on the GG formulae for the T-S identification and fuzzy controller stages. The fuzzification process for each sample is as follows:
4. Thermal Mixing Tank System
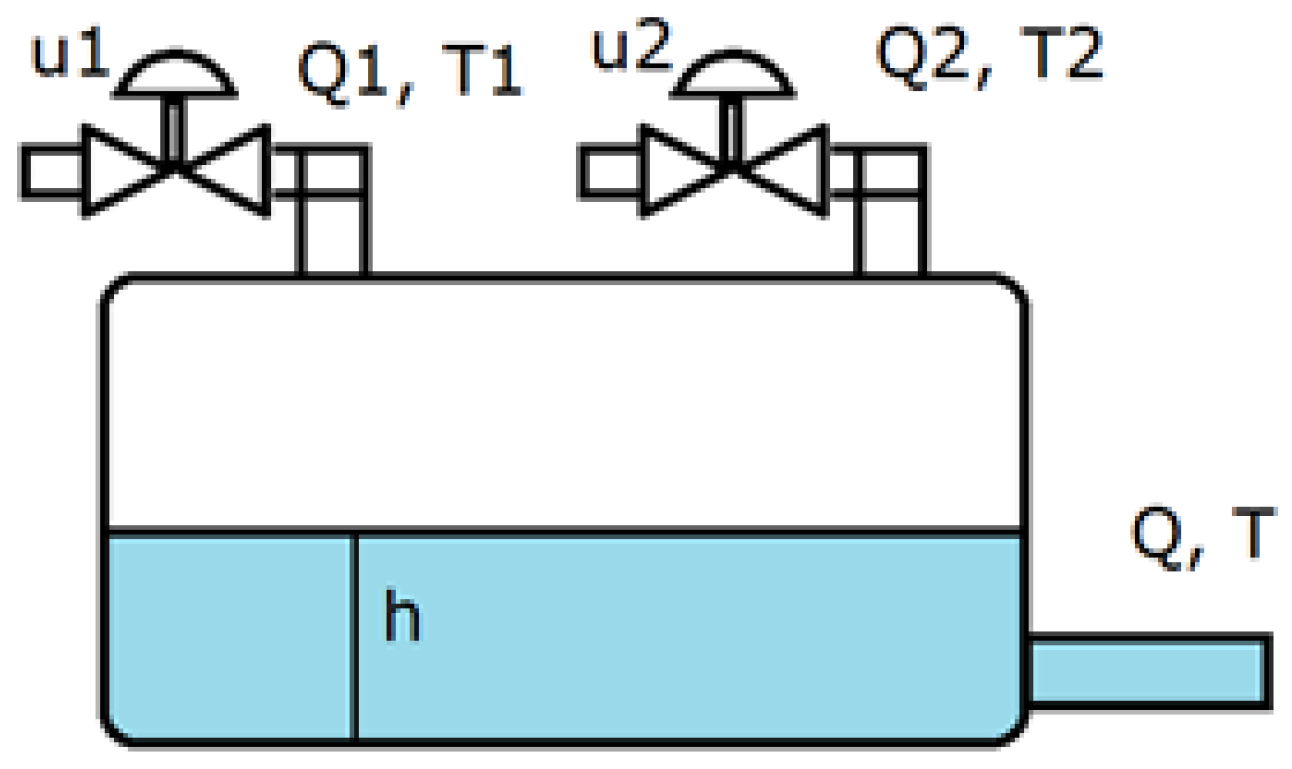
In order to check the effectiveness of each of the methods developed in this work, we investigated the modeling, identification, and control of a thermal mixing tank system consisting of a tank, two fluid inlets with different flow rates and temperatures, and a water outlet.
The studied system is multivariable and nonlinear with a pure time delay, allowing this example to show the advantages and disadvantages of the different methods mentioned above. However, it should be noted that these methods can be applied to any multivariable nonlinear system.
The thermal mixing tank is shown in
Figure 5. The inlet pipes allow for the flow of fluids at two different fixed temperatures (
,
), and their flow rates (
,
) can be adjusted by opening or closing two valves (
,
). The flow rate and outlet temperature (
,
) depend on the inertia of the system and the energy and mass flow of the inlet pipes. The simplified dynamic model representing the inlet flow rates is provided in (
66):
Additionally, due to the location and technology of the flow meter, a delay in the reading of the outflow is considered such that only the flow
in the outflow pipe can be measured, which represents the measured flow delayed by
with respect to the outflow. The relationship between these two signals is described in (
67):
Furthermore, thermal losses proportional to the temperature difference between the inside
and outside
of the mixing tank are modeled, which acts as a disturbance of the system. The dynamic model is represented by (
68)
where h is the tank fluid height,
is the gain of the dynamic system of the inlet flow
,
is the gain of the dynamic system of the input flow
,
is the pole of the dynamic system of the inlet flow
,
is the pole of the dynamic system of the inlet flow rate
,
is the discharge coefficient of the outflow
,
is the pure delay of the inlet flow
,
is the pure delay of the inlet flow
,
is the pure delay of the outflow measurement
, A is the cross-sectional area of the tank,
is the discharge coefficient of the outlet flow Q,
is the opening range of valve 1, and
is the opening range of valve 2.
In order to obtain an open-loop dataset of the system, we carried out a simulation covering long period of time during which random signals were introduced in both input variables and in such a way that the largest range of operation of the nonlinear system was covered.
A sampling time of 0.5 s was chosen for the simulation.
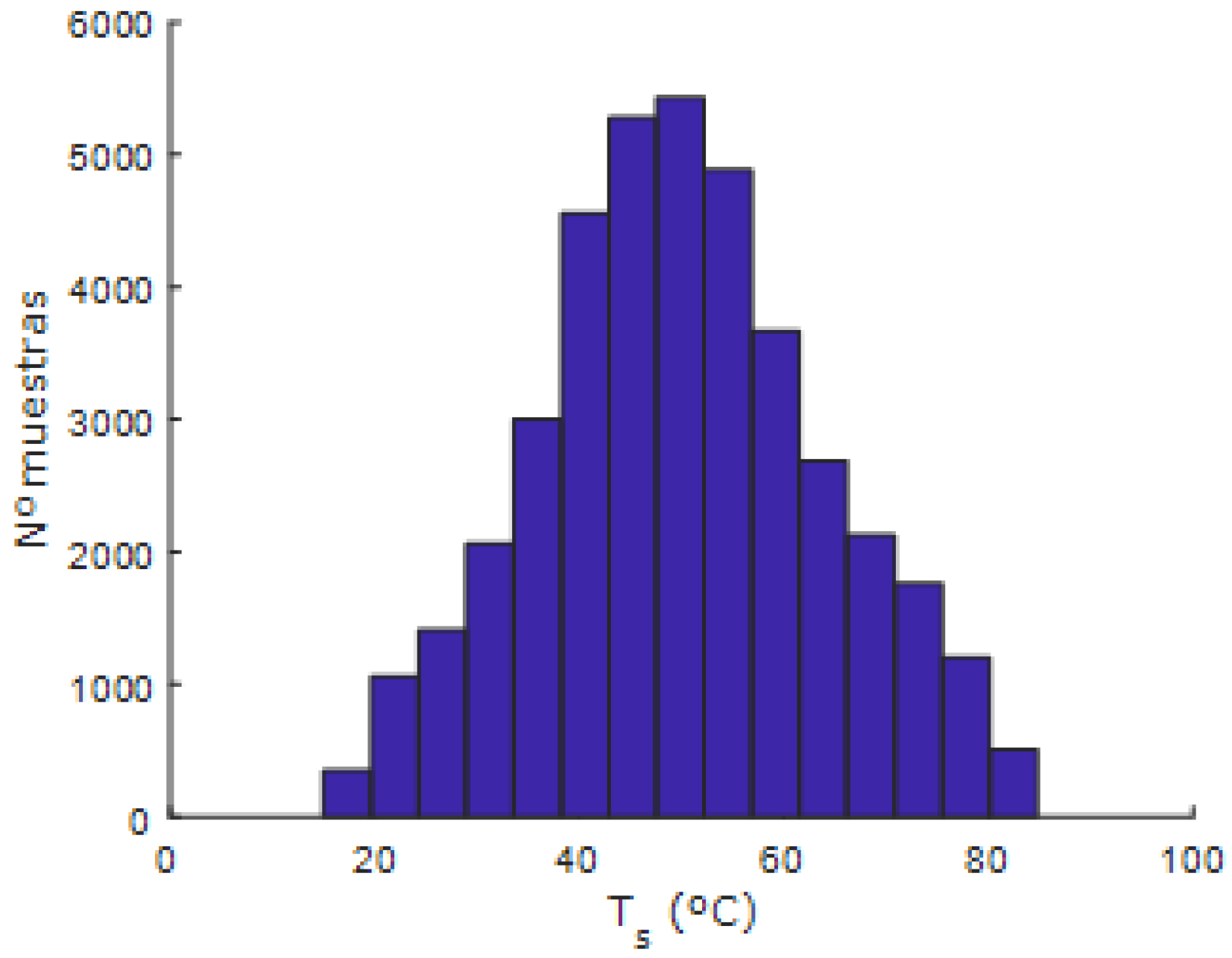
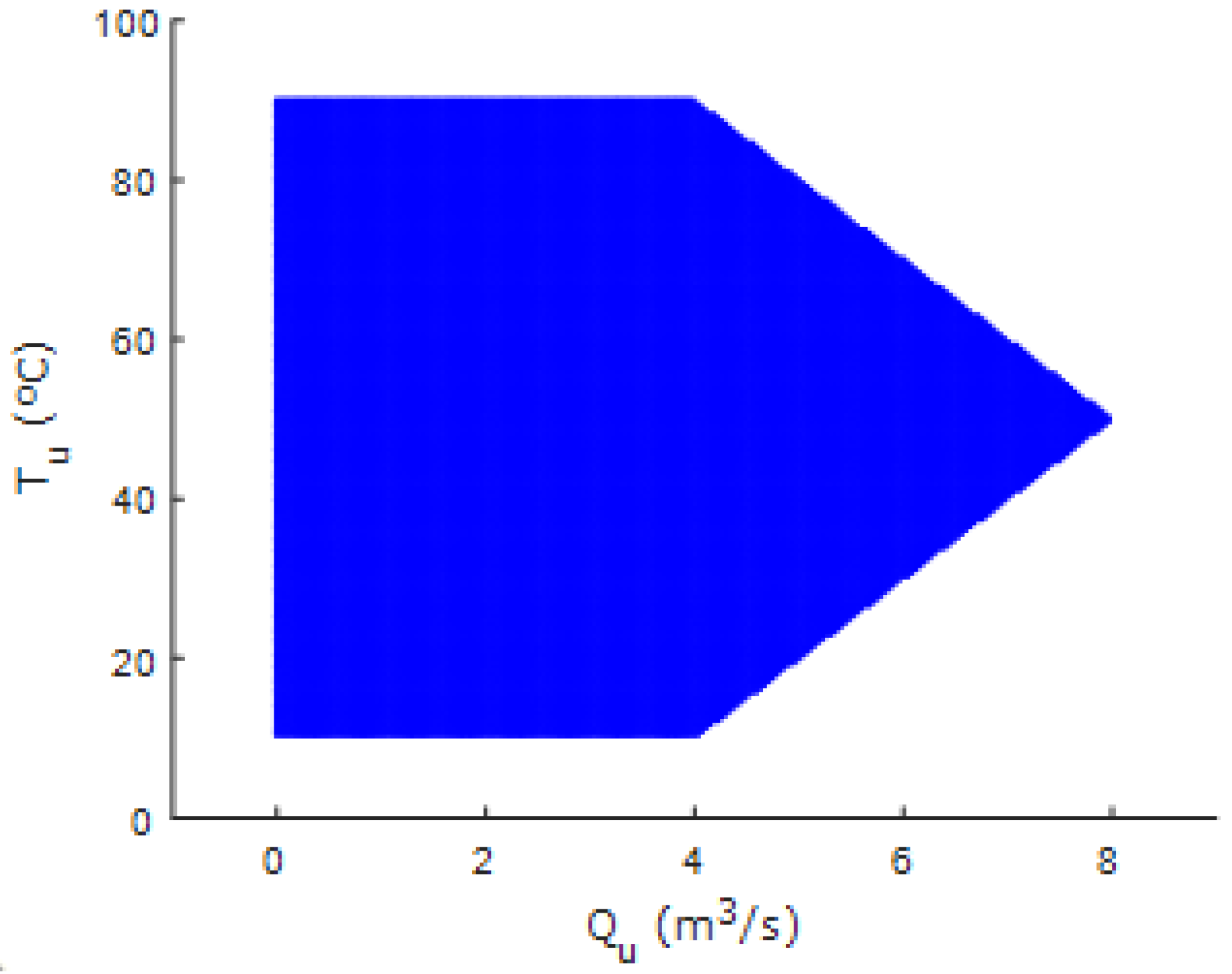
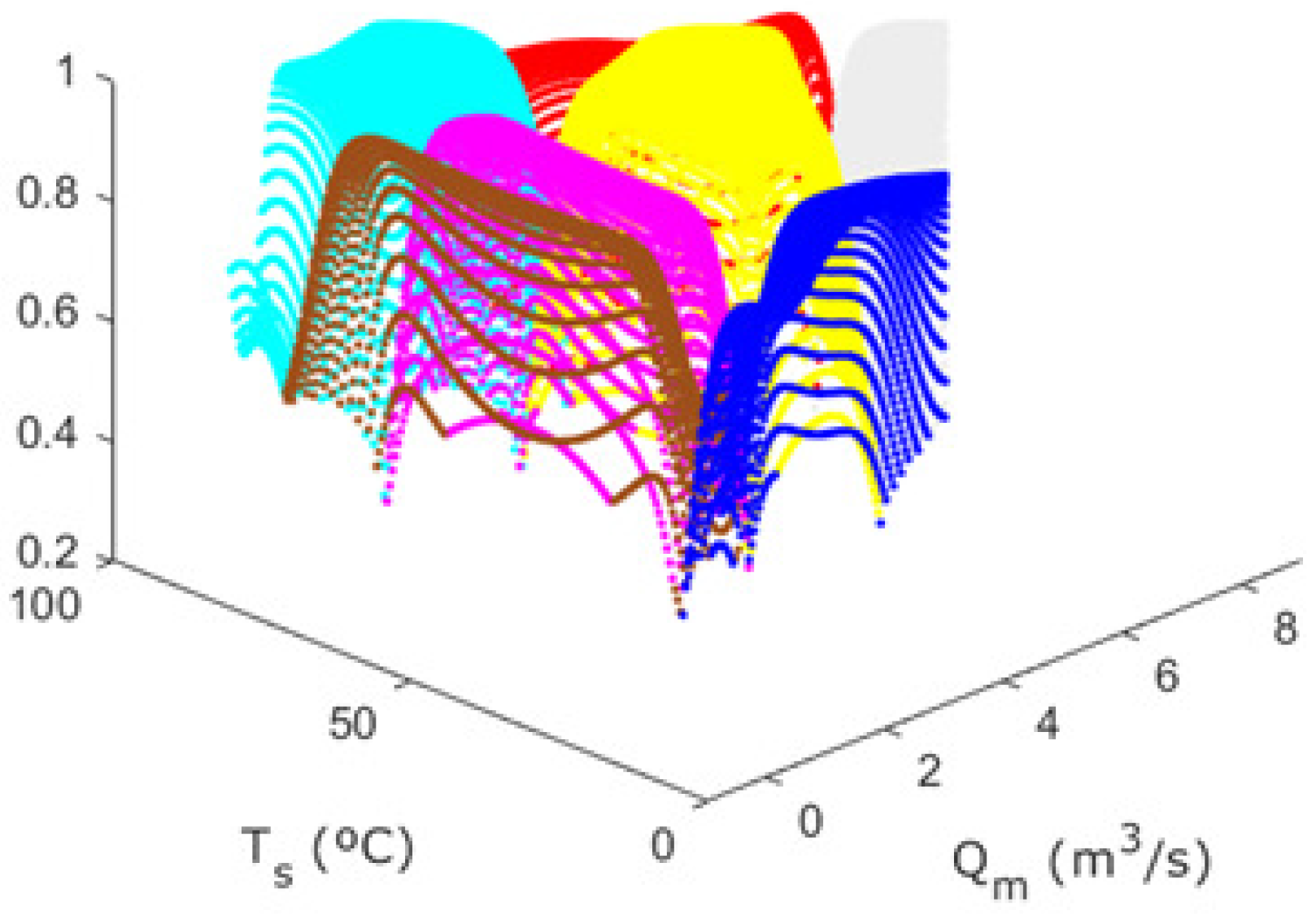
Figure 6 shows the temperature versus the output flow rate. As can be seen, the working range area is between 10–90 ° for the temperature and 0–7
/s for the flow rate.
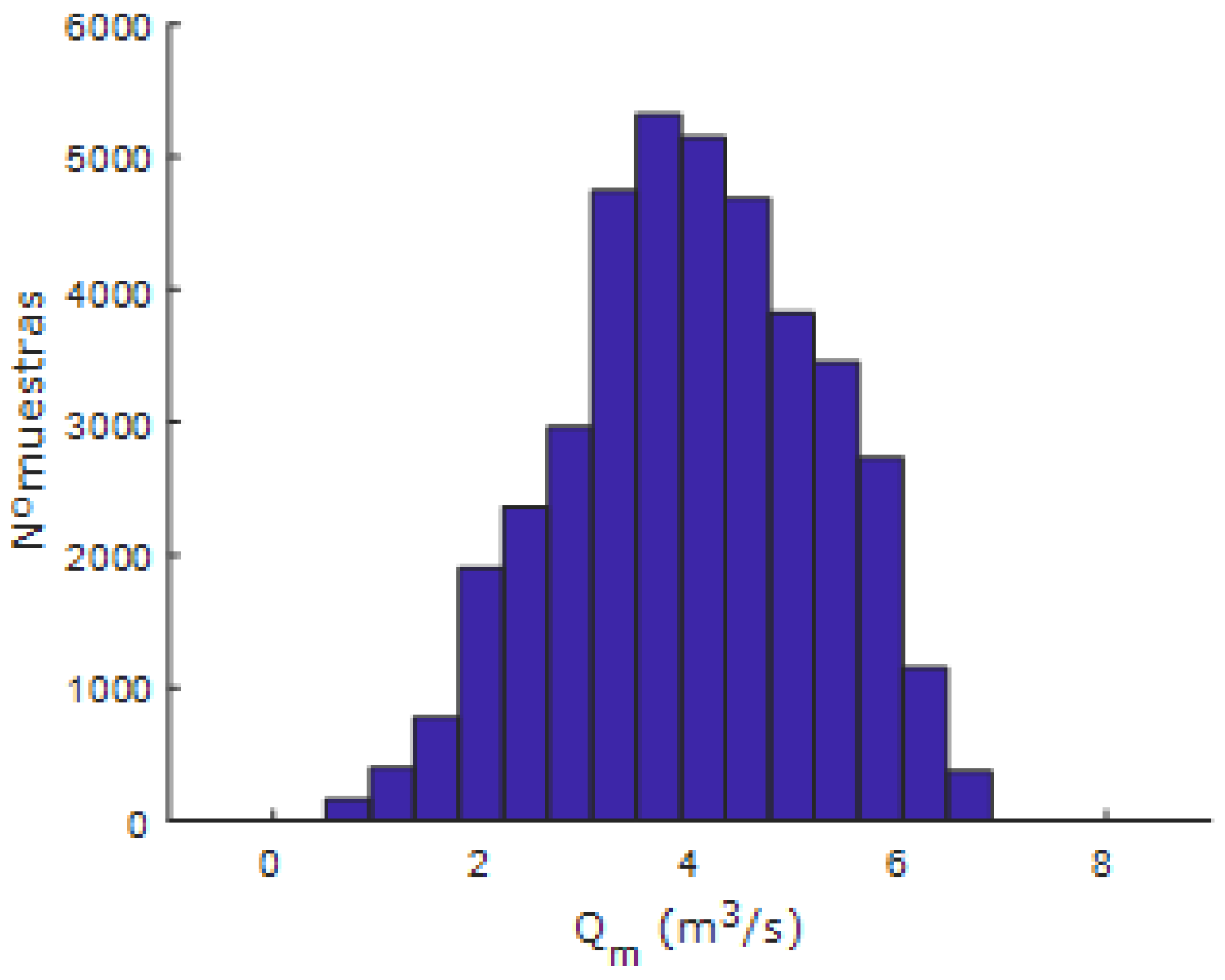
Figure 7 and
Figure 8 represent the histograms of the temperature and flow rate samples of the simulated data, respectively. It can be seen from these histograms that the working range of the thermal mixing tank system is covered, with a higher concentration of data around the central area, which is the desired nominal operating point.
Uniformly distributed data were generated in order to calculate fuzzy clusters that are not affected by the accumulation of data in any particular area and that cover the entire workspace independently of the data obtained through the open-loop system simulation. These data, called uniform data, were artificially originated by covering the entire workspace area of the thermal mixing tank, and were spaced a very small distance apart. The representation of these uniform data is shown in
Figure 9.
4.1. Fuzzy Modeling and Control Based on One-Dimensional Membership Functions
First, the modeling, identification, and fuzzy control based on one-dimensional membership functions is established, as detailed in
Section 2.
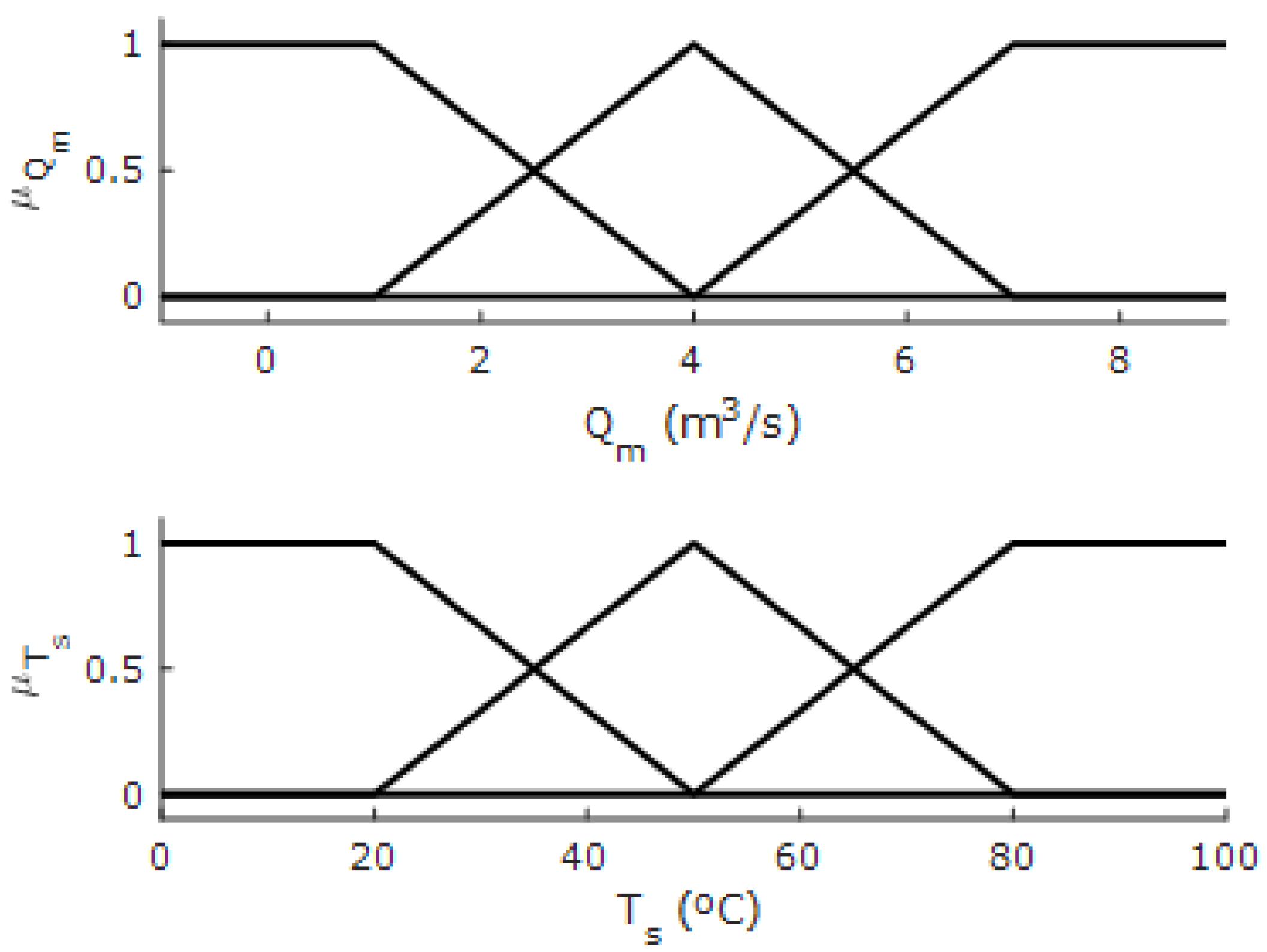
After generating the data as shown in the previous section, we next proceed to determine the membership functions in order to generate the fuzzy system, as shown in
Figure 10.
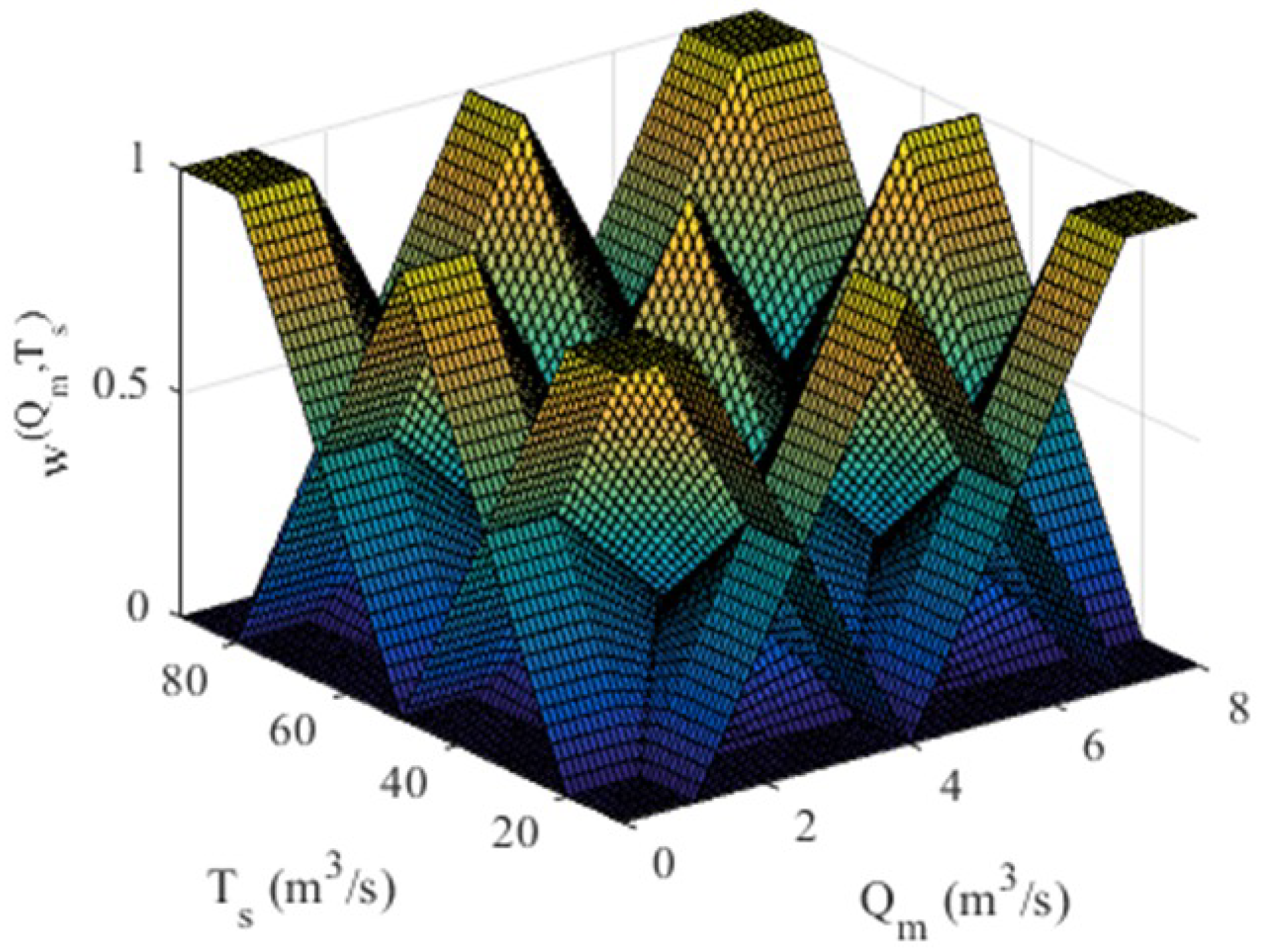
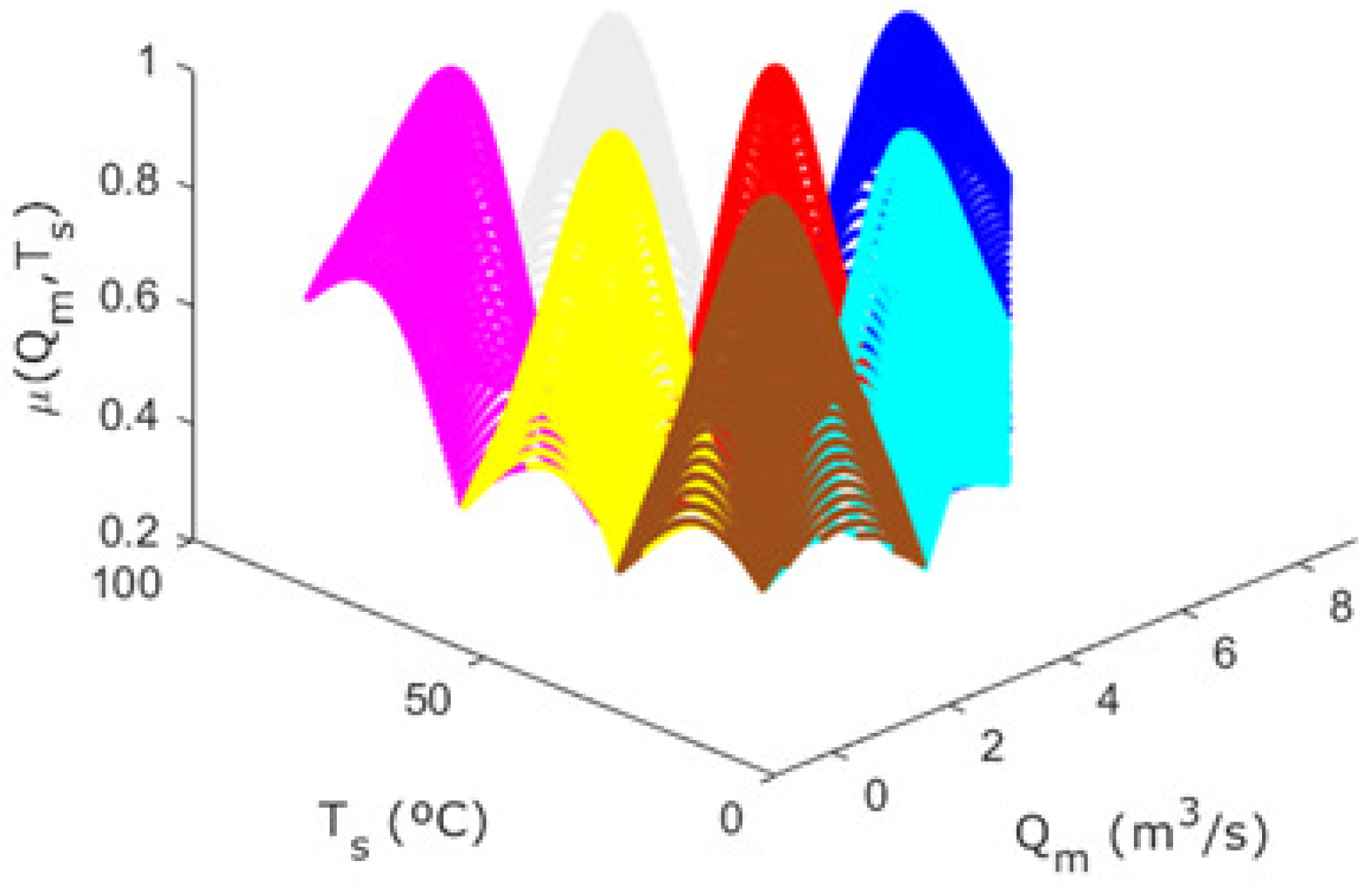
Through the fuzzy inference process, a total of nine rules are obtained, as shown in
Figure 11.
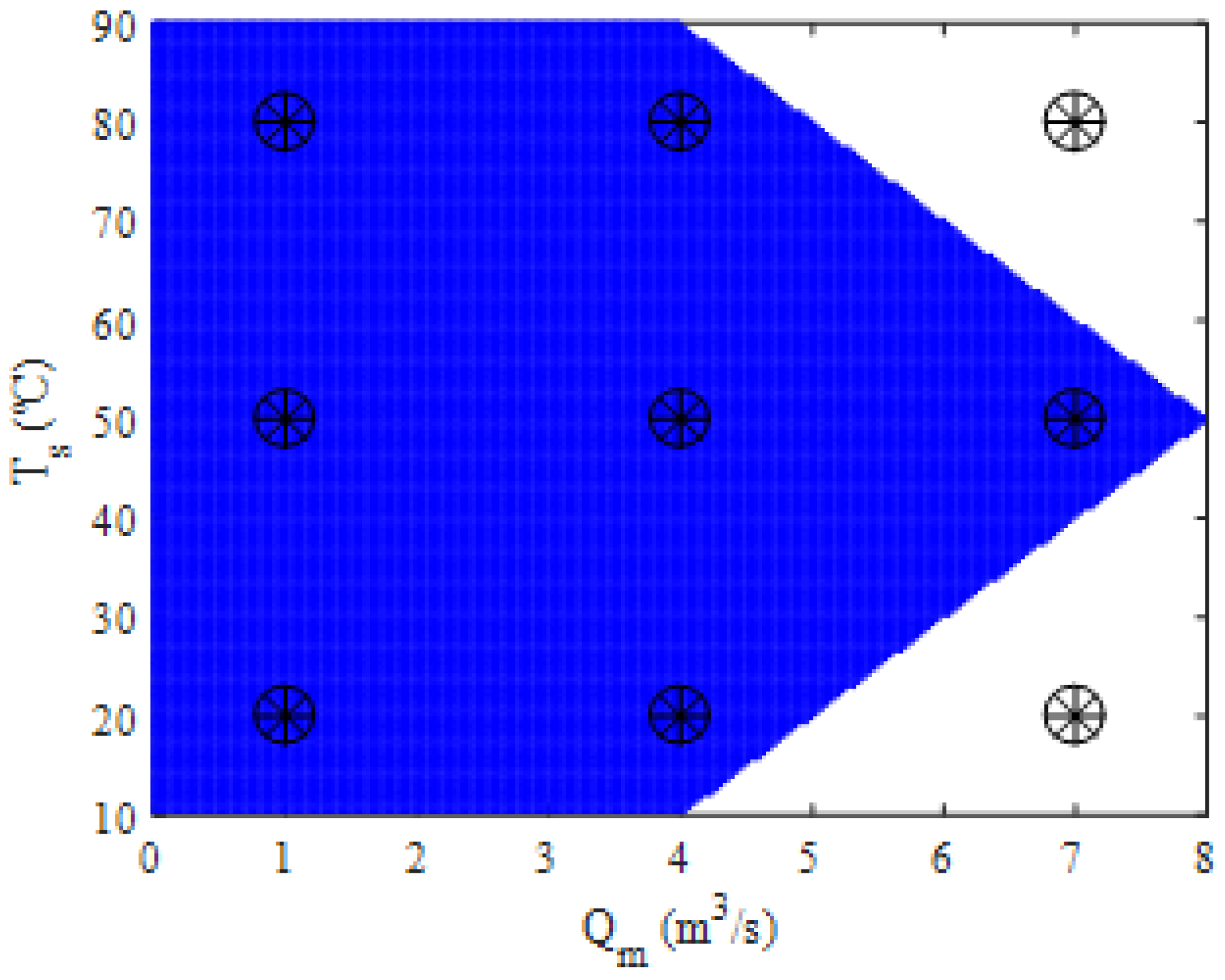
Figure 12 shows the projections of the centers of the fuzzy rules obtained by the fuzzy inference process onto the workspace of the thermal mixing tank system. It can be seen that the top right [7.80] and bottom right [7.20] rules do not cover a significant working space and that samples requiring these fuzzy rules are rarely obtained. This is because working with flow rates requires the inlet valves to be opened, which causes the liquids to mix and the outlet temperature to be close to the average of the inlet temperatures.
The mean square error method is used here to comparison of the effectiveness of the different methodologies.
To identify the nonlinear system, the generalized T-S identification method is used. A least-squares identification of the linearized system at the nominal working point is performed using the
= 10
−6 parameter. As a result, the following identification errors are obtained:
Based on the parameters identified for the nonlinear system, the incremental state model is obtained for each fuzzy rule [
35]. Next, the incremental state model obtained for the central rule is provided as follows:
where
For each fuzzy rule, the state feedback matrix is calculated using the discrete LQR method. The Q and R matrices used in the design are detailed below:
The feedback matrix
obtained in the central rule is as follows:
The state observer in each fuzzy rule is obtained by means of the optimal state observer. The matrix
obtained in the central rule is
Figure 13 and
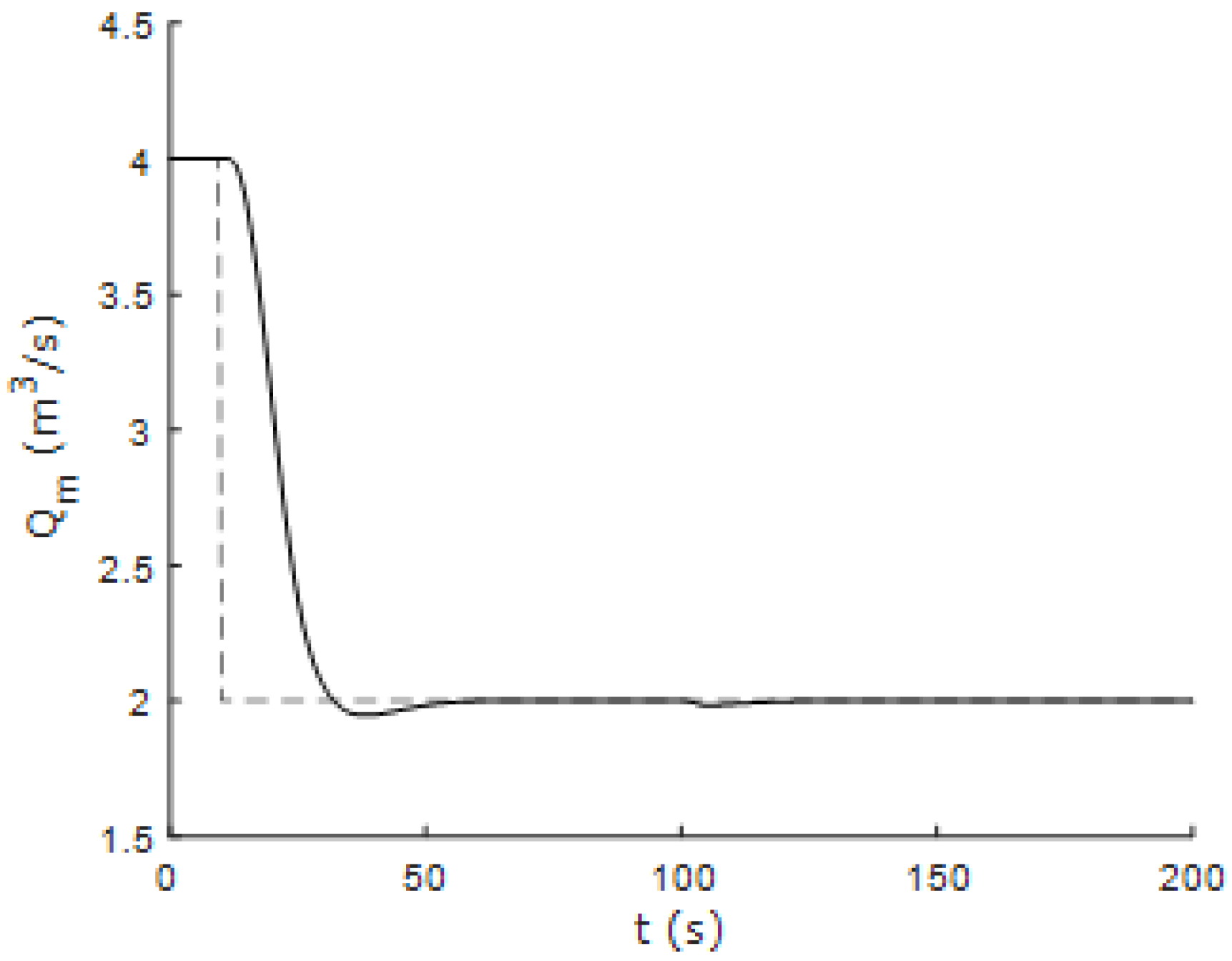
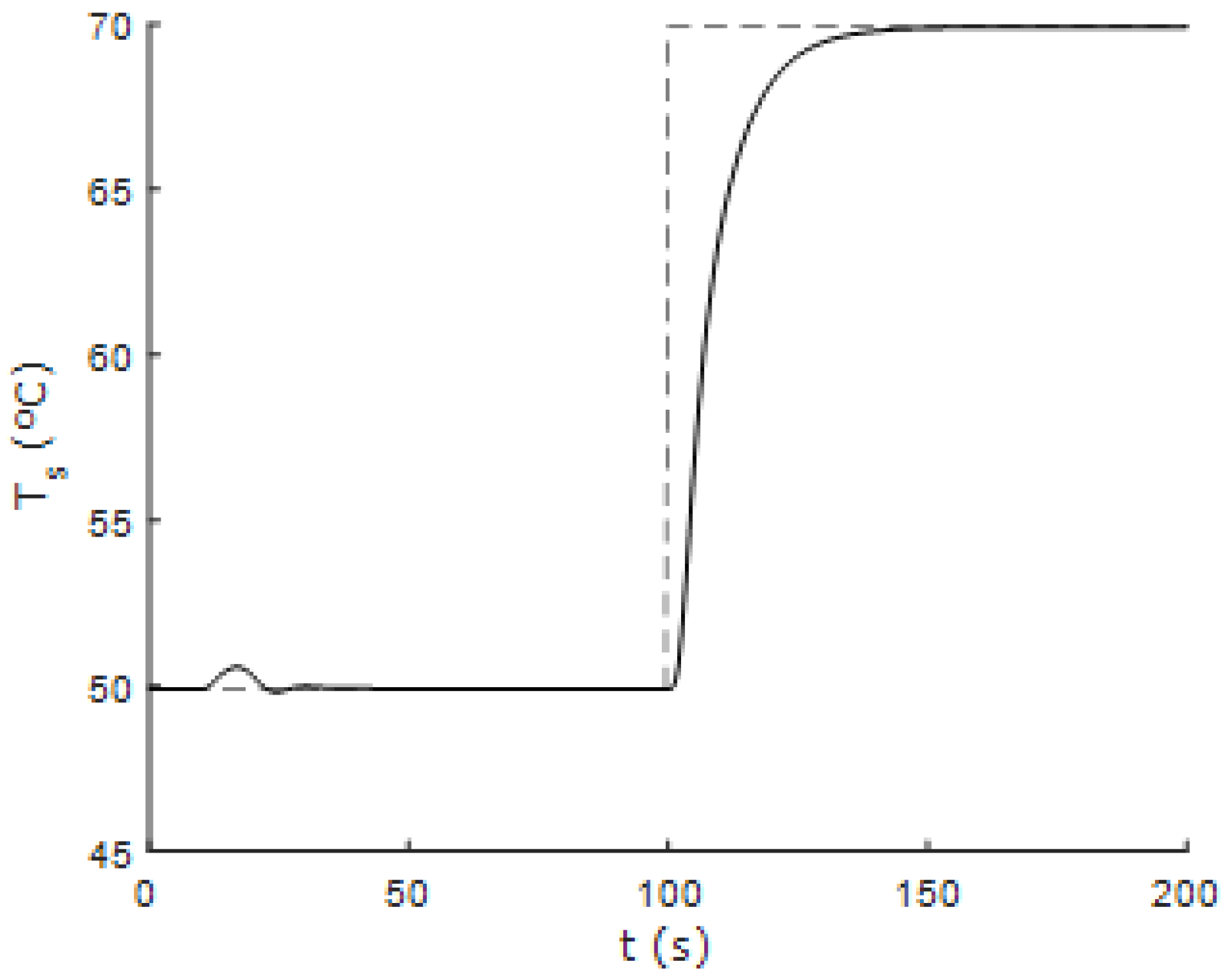
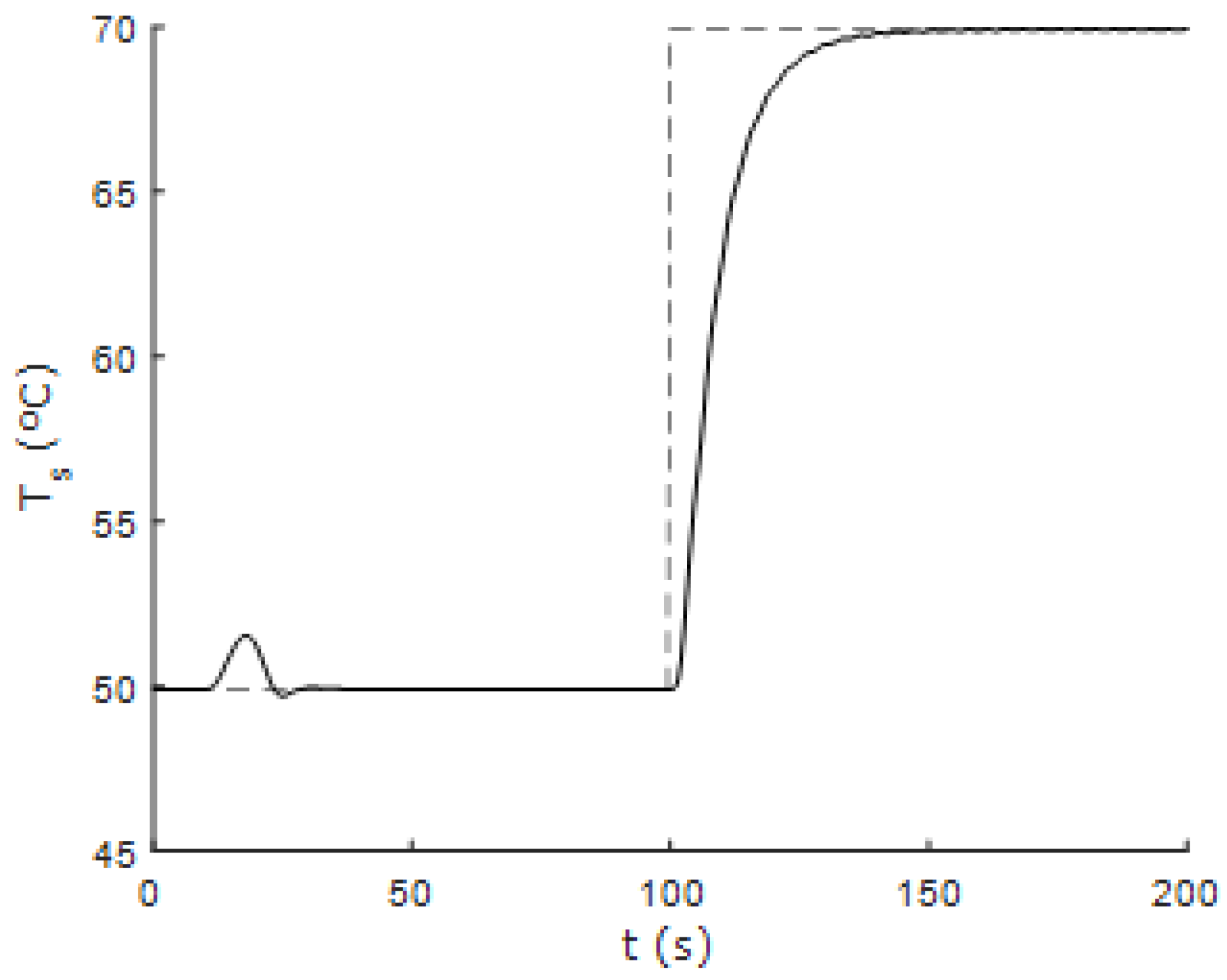
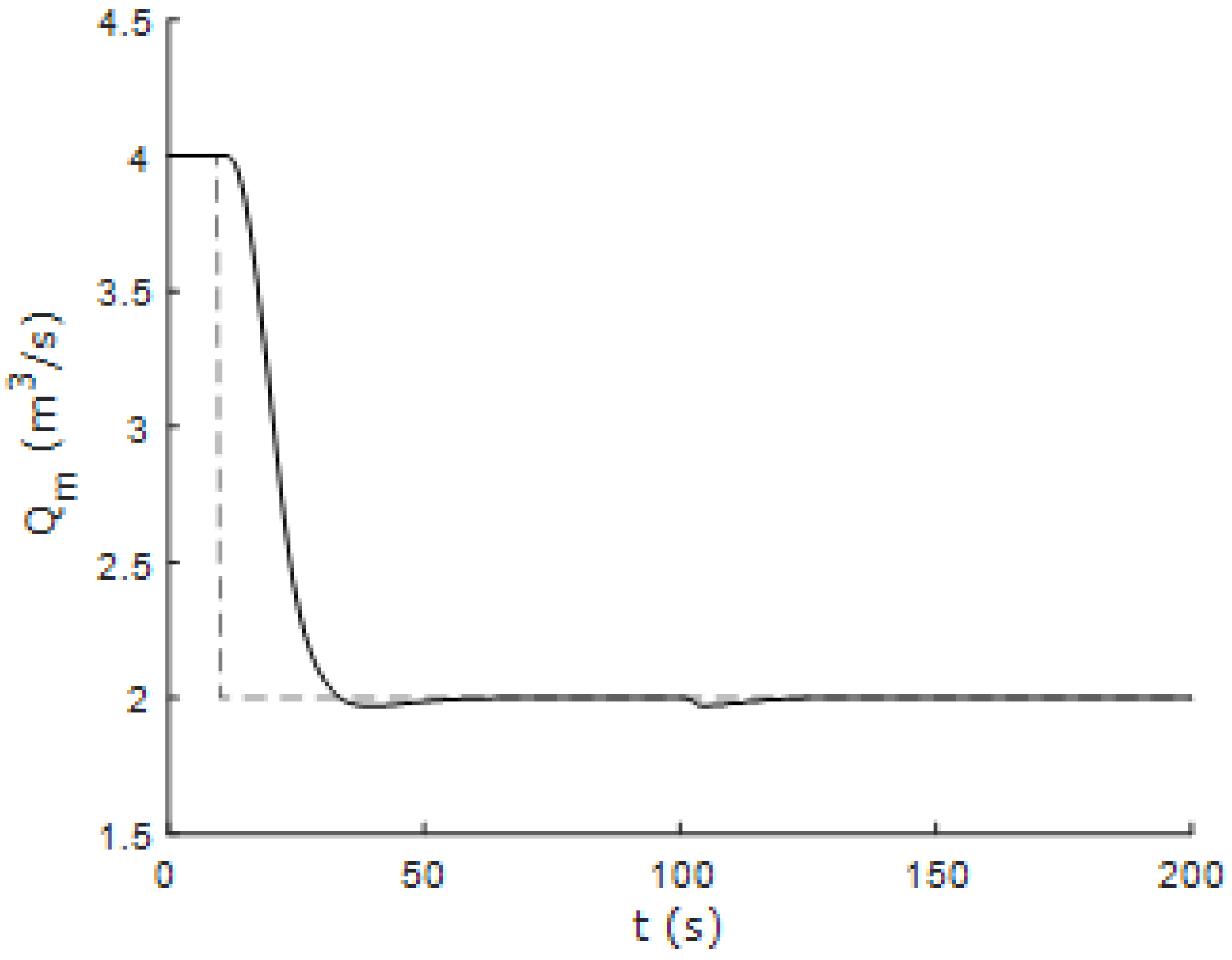
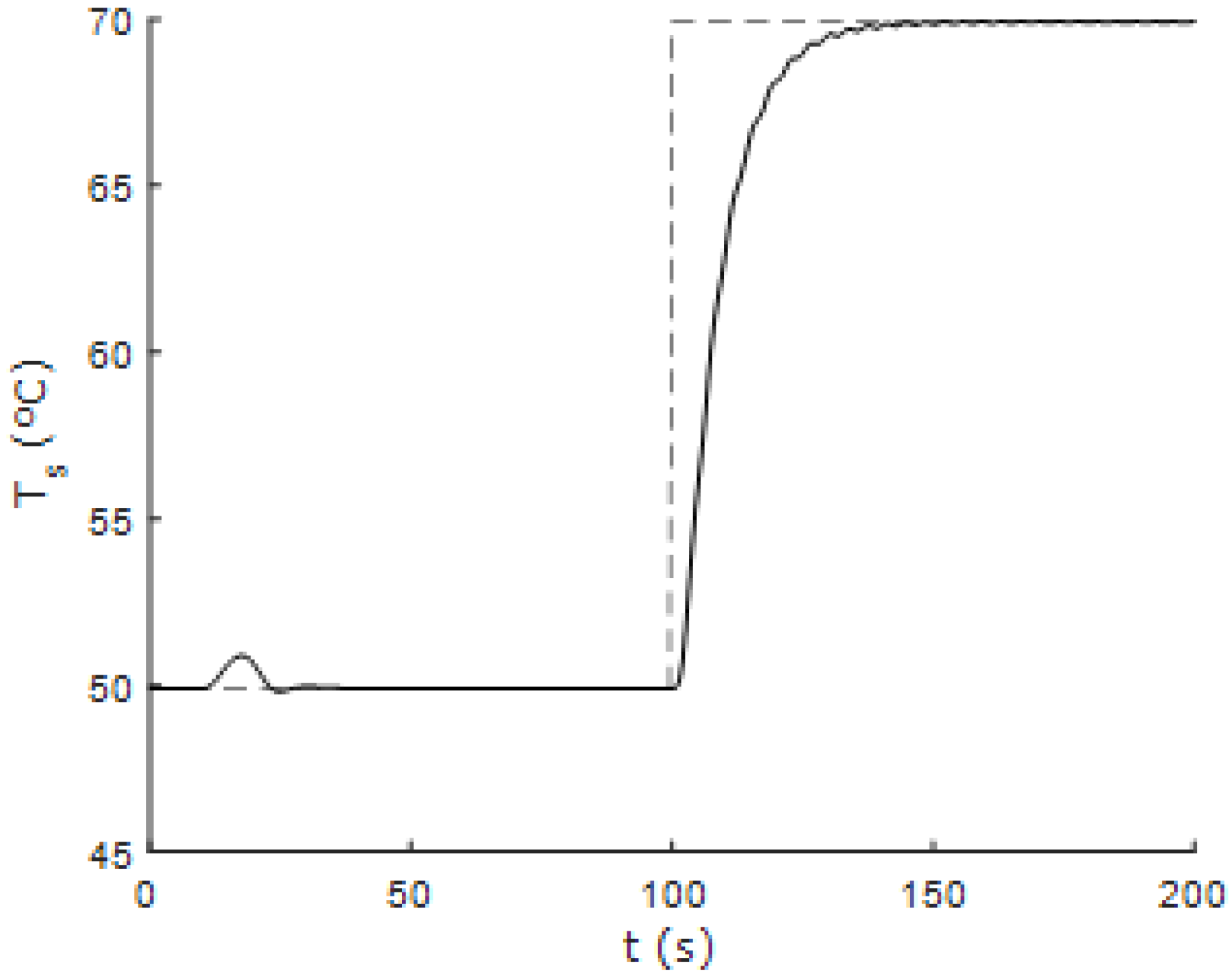
Figure 14 show the response of the controlled system using the 1DMF method based on the fuzzy incremental state model using one-dimensional membership functions when the system is subjected to changes in the reference values of flow and temperature. Furthermore,
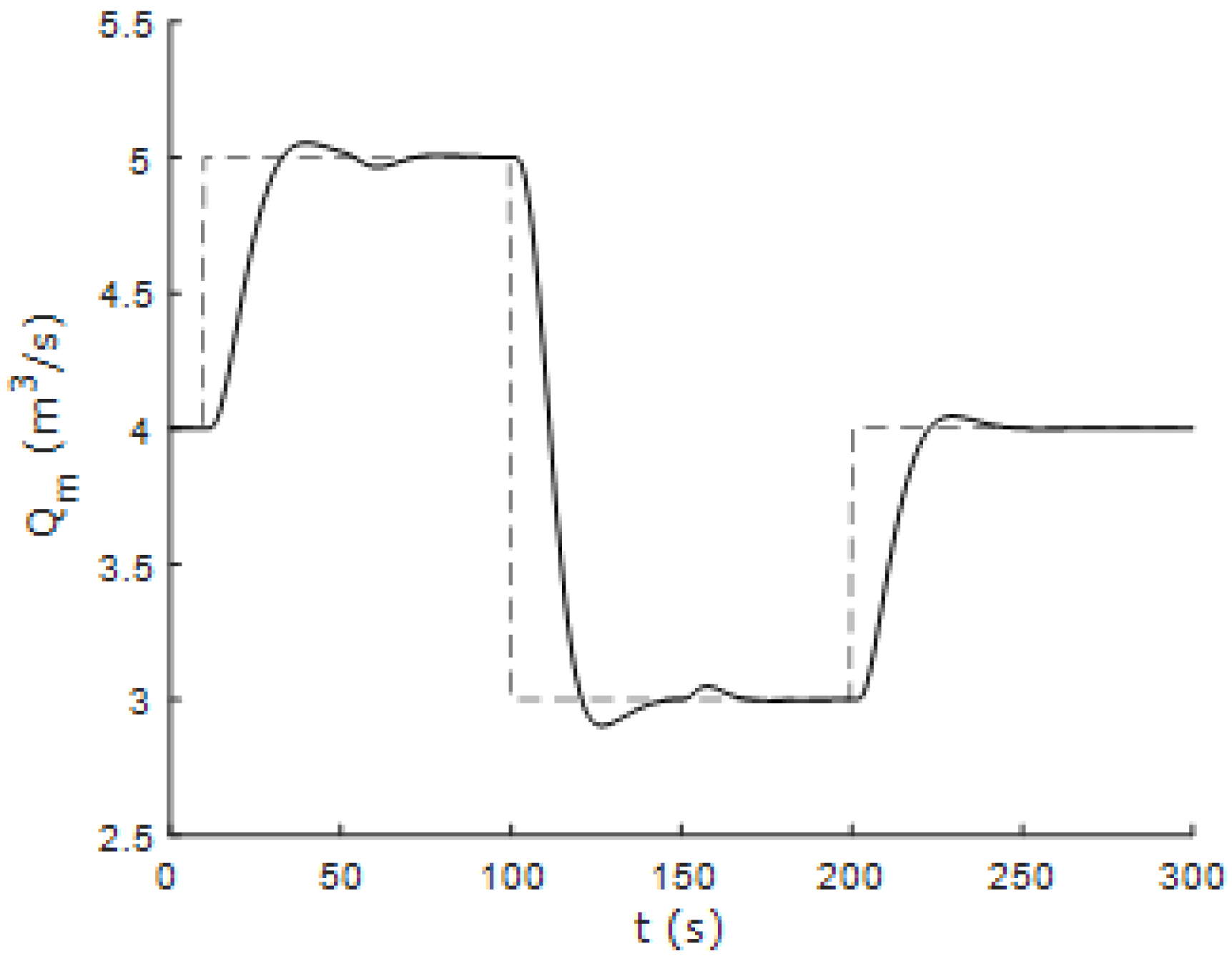
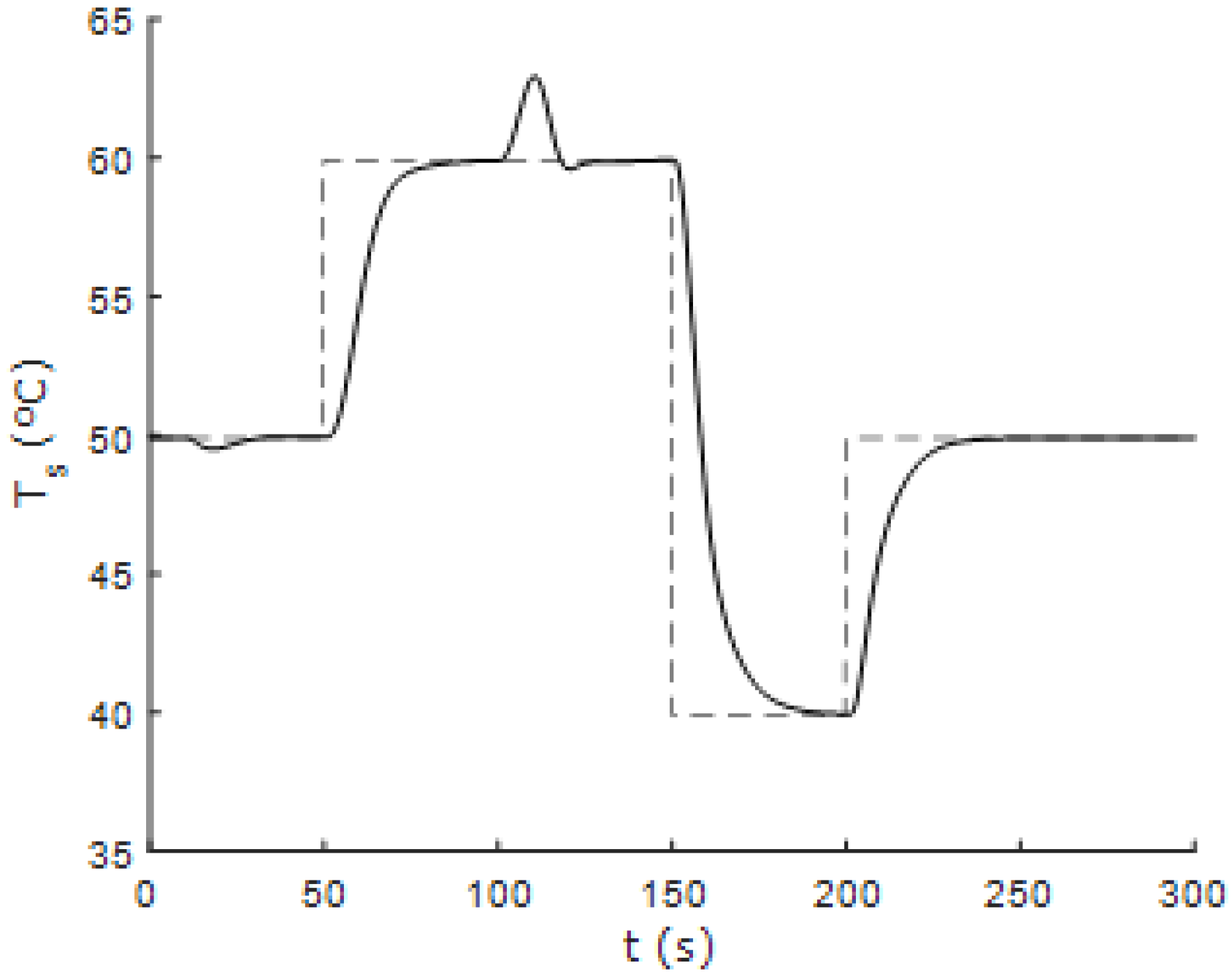
Figure 15 and
Figure 16 show the response of the controlled system to successive changes in the reference signals. It can be seen that the fuzzy controller performs correctly in areas away from the nominal operating point.
The traditional method based on one-dimensional membership functions is a suitable methodology for nonlinear control of the thermal mixing tank system. However, this method includes rules that have no relevance to the identification or control of this system. In order to reduce this set of unnecessary rules, methods based on MDMFs are proposed below.
4.2. Fuzzy Modeling and Fuzzy Control Based on MDMFs Fitted by the FCM Algorithm
This section describes modeling, identification, and fuzzy T-S control based on MDMFs tuned by means of the FCM algorithm and applied to the same example of a thermal mixing tank system.
In order to test whether there is any improvement in the nine rules specified by the traditional method in
Section 4.1, we selected seven fuzzy rules defined by MDMFs. Becasue the design objective for the MDMFs is that they should cover the full working range of the thermal mixing tank system, the uniform data discussed above are used for the FCM algorithm. It should be noted that the data have been normalized to avoid the weight of the temperature in the distances being much larger than the weight of the flow rate due to the numerical difference between these two ranges.
The performance of this algorithm was tested with different values of the m parameter, which indicates the degree of overlap between the membership functions. As this parameter is increased, the slopes of the functions become smoother, which is not desirable.
After several trials, a value of
was selected, resulting in the MDMFs shown in
Figure 17 at the conclusion of the FCM algorithm. The results of the FCM algorithm produce normalized centers that do not correspond to the workspace of the system under study. Therefore, both of the MDMFs must be denormalized in order to be represented on the workspace of the system.
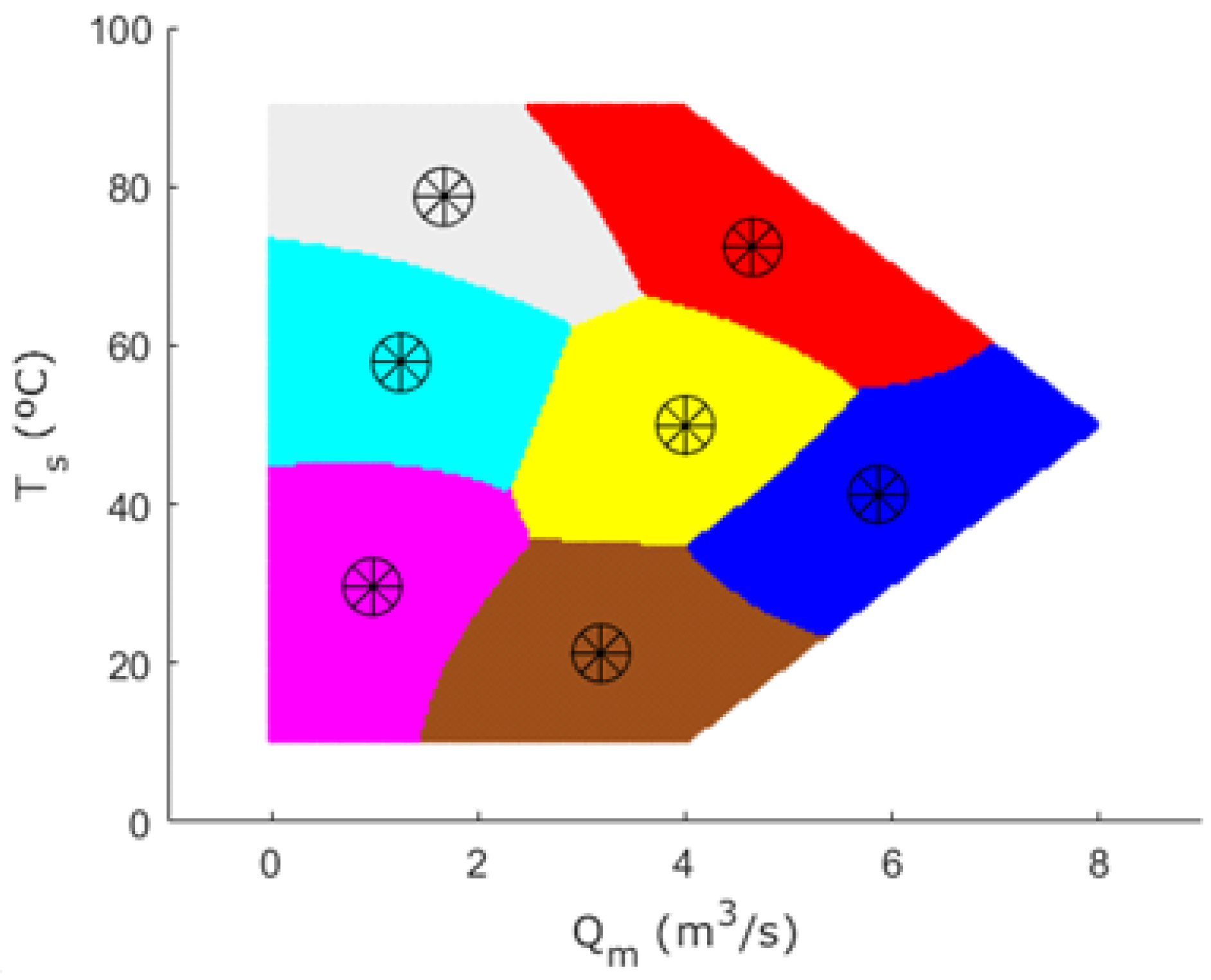
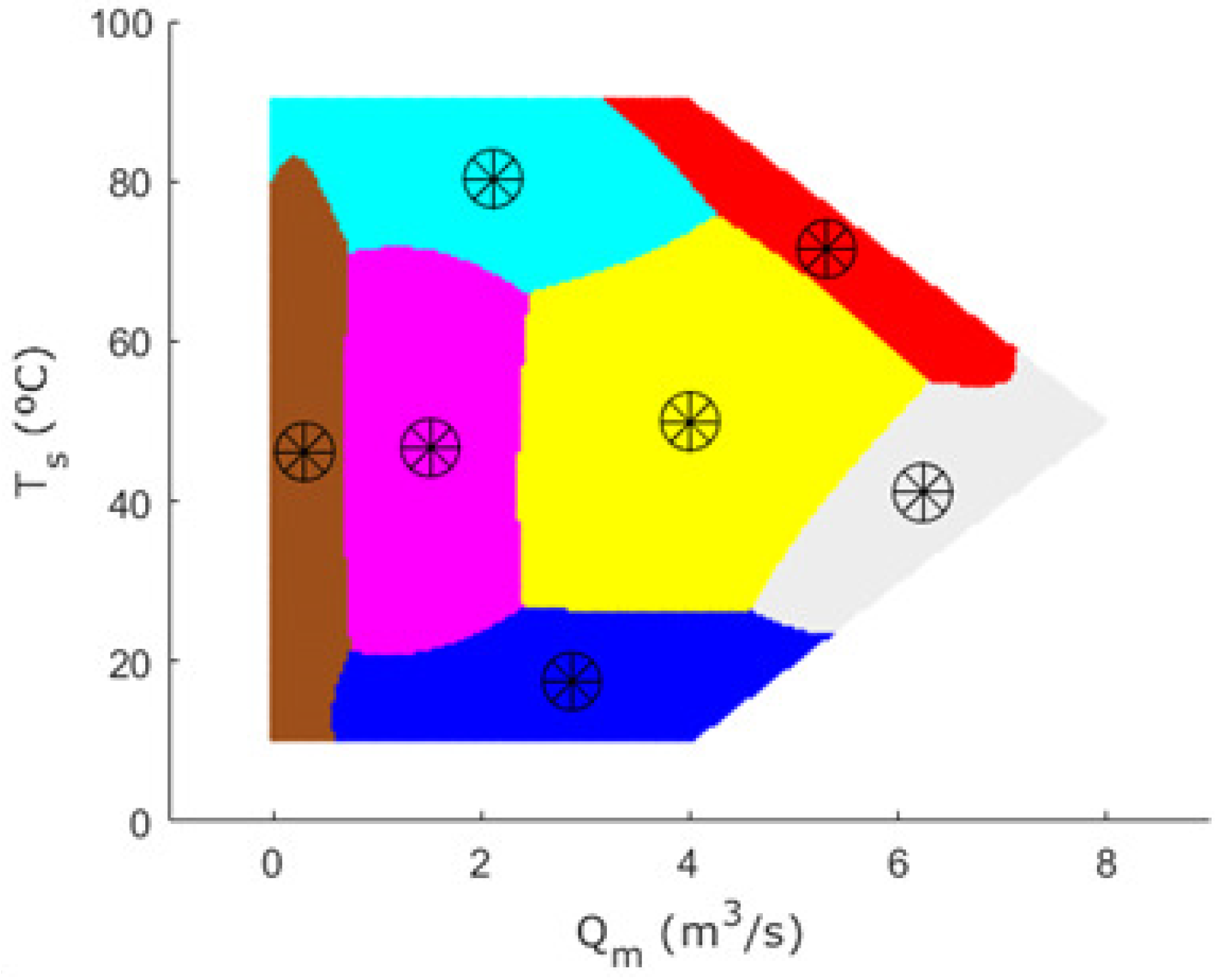
Figure 18 shows the areas of the workspace that are best represented by the different clusters obtained by the FCM algorithm. The centers of the clusters are also shown in the locations determined by the algorithm.
One of the cluster centers was intentionally located at point (4, 50), as this is the nominal operating point of the thermal mixing tank system.
When performing traditional identification by means of the membership functions fitted with the FCM algorithm, the following identification errors are obtained based on the open-loop data of the thermal mixing tank system:
It can be seen that these errors are smaller than those obtained in the previous section. Moreover, this accuracy level was reached with two fewer rules than required when using one-dimensional membership functions, allowing us to affirm an improvement in the modeling and identification of the system. However, having to normalize and then denormalize the samples in order to use this method is a problem that needs to be taken into account.
The following fuzzy vector variable z(k) is defined for all methodologies based on MDMFs:
As in the previous section, the incremental state model obtained for the central rule is
where
The C matrix is the same as in the 1DMFs. The state feedback matrix is calculated using the same algorithm as in
Section 4.1. The Q and R matrices used in the design are the same as in the previous algorithm. The feedback matrix
obtained in the central rule is
The state observer in each fuzzy rule is again obtained using the optimal state observer method, as in
Section 4.1. The matrix
obtained in the central rule is
Figure 19 and
Figure 20 show the response of the system based on the fuzzy incremental state model using MDMFs defined by the FCM method when the system is subjected to changes in the reference values of flow and temperature. Furthermore,
Figure 21 and
Figure 22 show the response of the controlled system to successive changes in the reference signals. It can be seen that the fuzzy controller performs correctly in areas far from the nominal operating point.
This method also achieves efficient control of the thermal mixing tank system by using fewer fuzzy rules. On the other hand, the process of normalizing and denormalizing the data in order to use the FCM algorithm can be very prone to error, and special care needs to be taken in this respect.
4.3. Fuzzy Modeling and Control Based on MDMFs Fitted by the GK Algorithm
In this section, we establish modeling, identification, and fuzzy T-S control based on MDMFs adjusted by means of the GK algorithm.
Seven clusters are chosen in order to check whether there is any improvement over the seven rules specified in the FCM algorithm. Uniform samples are used in order to avoid modifications in the position of the cluster centers due to the massive clustering of data in certain parts of the working area. It should be noted that the samples do not need to be normalized, which represents an immediate advantage over the FCM algorithm. The parameter is used in the same way as previously.
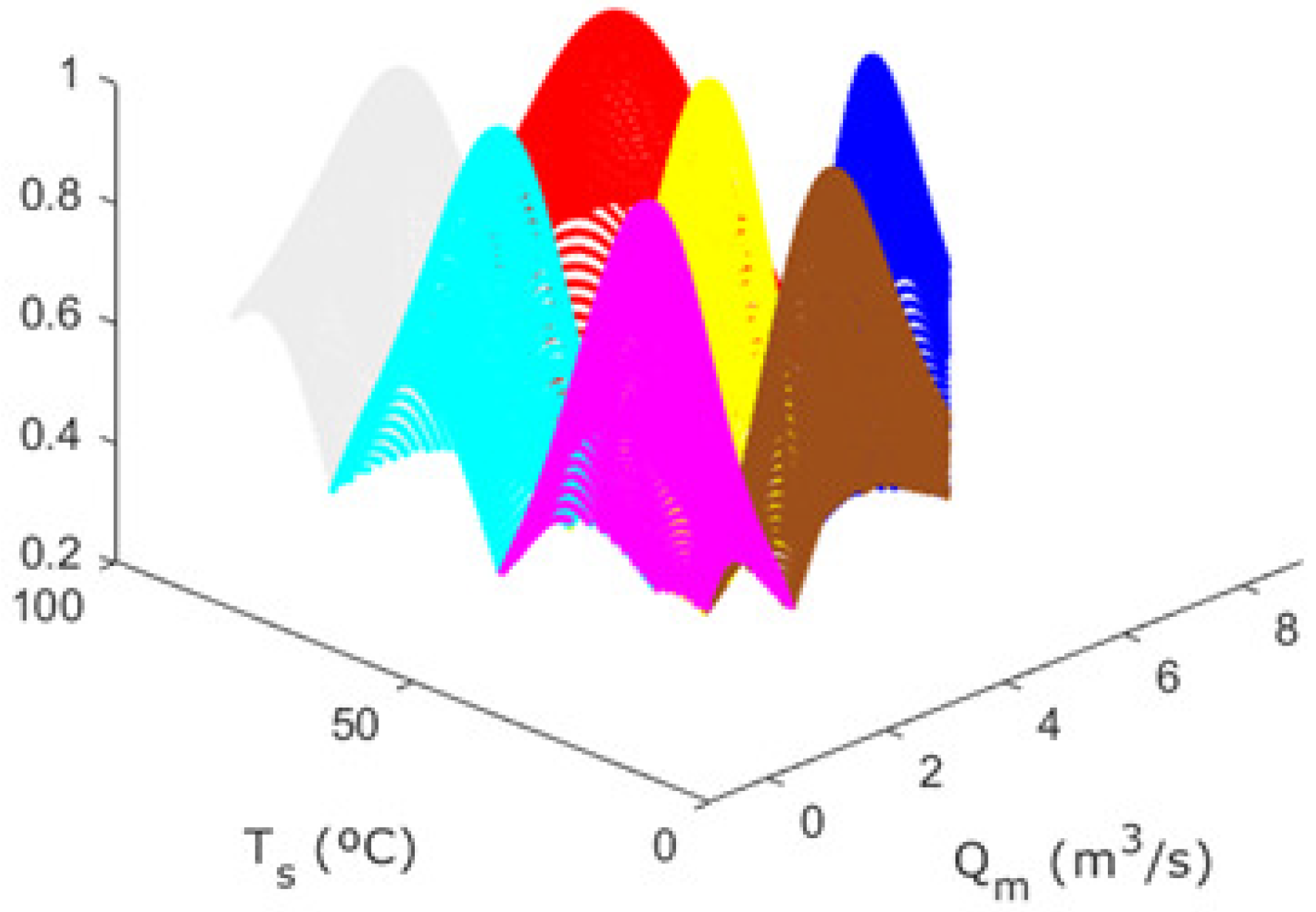
Figure 23 shows the shapes of the MDMFs obtained after applying the GK algorithm.
Figure 24 shows the set of samples of the system and their membership in the most representative cluster. The centers of the clusters are shown in the locations determined by the algorithm.
One of the cluster centers was deliberately located at the point (4, 50), as this is the nominal working point of the system.
When using traditional identification by means of membership functions adjusted with the GK algorithm, the following identification errors are obtained based on the open-loop data of the thermal mixing tank system:
It can be observed that the ratios of these errors are lower than those obtained using the FCM algorithm. Furthermore, it is not necessary to normalize and denormalize the samples and cluster centers, allowing us to affirm that this system represents a great advantage with respect to the FCM algorithm.
Recalling the incremental state model obtained in (
78), the matrices are
and the C matrix is the same as in the previous methods. The Q and R matrices used in the design are also the same ones used before. The feedback matrix
obtained in the central rule is
The state observer in each fuzzy rule is again obtained by means of the optimal state observer. The matrix obtained in the central rule is
Figure 25 and
Figure 26 show the response of the system controlled using MDMFs defined by the GK method when the system is subjected to changes in the reference values of flow and temperature. Furthermore,
Figure 27 and
Figure 28 show the response of the controlled system to successive changes in the reference signals. It can be seen that the fuzzy controller performs correctly in areas away from the nominal operating point.
This method is valid for identification and control; in addition, it has has fewer rules than the traditional method. It can be observed that the errors are smaller than those obtained for the methods in the previous section. Moreover, it is not necessary to normalize and denormalize the samples in order to apply this algorithm, making it the best solution among the studied methods for fuzzy control based on MDMFs.
4.4. Fuzzy Modeling and Control Based on MDMFs Fitted by the GG Algorithm
This section establishes the modeling, identification, and fuzzy control of T-S based on MDMFs fitted by means of the GG algorithm.
To check whether there is any improvement over the seven rules specified in the previous section, we again used seven clusters. Uniform samples were used in order to avoid changes in the position of the cluster centers due to the massive clustering of data in certain parts of the working area.
Figure 29 shows the shapes of the MDMFs obtained after applying the GG algorithm.
Figure 30 shows the set of samples of the system and their membership in the cluster that best represents them. The centers of the clusters are also depicted in order to show where the algorithm determined that they should be located.
We deliberately located one of the cluster centers at the point (4, 50), as this is the nominal working point of the system.
When performing T-S identification by means of the membership functions fitted with the GG algorithm, the following identification errors were obtained based on the open-loop data of the thermal mixing tank system:
Recalling the incremental state model obtained in (
78), the matrices are
The C matrix is the same as in previous methods, and the Q and R matrices are also the same. The feedback matrix
obtained in the central rule is
The state observer in each fuzzy rule is again obtained by the optimal state observer method. The matrix
obtained in the central rule is
Figure 31 and
Figure 32 show the response of the system controlled by the GG algorithm when the system is subject to changes in the reference values of the flow and temperature. Furthermore,
Figure 33 and
Figure 34 show the response of the controlled system to successive changes in the reference signals. It can be seen that the fuzzy controller acts correctly in areas far from the nominal operating point.
It should be noted that the samples do not need to be normalized, which represents an immediate advantage over the FCM algorithm. However, having to rely on a more robust algorithm to determine a non-random initial participation matrix means that the GG algorithm is at a disadvantage with respect to the GK algorithm.
It can be seen that the errors are greater than those obtained using the GK method. Moreover, from an intuitive point of view, the form of the clusters does not seem very suitable for generating MDMFs, which makes it the worst solution among those proposed in this work.
5. Comparison of Clustering Methods for Fuzzy System Modeling
The identification results obtained for the thermal mixing tank system using the four proposed methods (one-dimensional membership functions, FCM algorithm, GK algorithm, and GG algorithm are summarized below, with the root mean squared error (RMSE) calculated for each of the four methods. The obtained results are summarized in
Table 1.
The FCM fuzzy clustering algorithm offers an improvement over results obtained using 1DMFs, achieving better control of the system with a reduced number of rules. On the other hand, the process of data normalization and denormalization required by the FCM algorithm can be very susceptible to errors, and special care must be taken in this aspect.
The GK fuzzy clustering algorithm has a lower identification error than the FCM algorithm with the same reduced number of rules; moreover, it is not necessary to normalize the data, which makes it the best option with respect to other methods.
Regarding the GG algorithm, the main drawback is that it requires an initial participation matrix, meaning that it requires previous execution of another fuzzy clustering algorithm. Furthermore, this algorithm presents a higher identification error than the GK algorithm. Finally, from an intuitive point of view, the shape of the obtained clusters does not seem very suitable for the generation of MDMFs. For these reasons, this algorithm is the worst solution of those proposed in this work for the modeling, identification, and fuzzy control of nonlinear systems.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}