

Few-Shot Object Detection for Remote Sensing Images via Pseudo-Sample Generation and Feature Enhancement


Abstract
1. Introduction
2. Related Work
2.1. Few-Shot Object Detection
2.2. Few-Shot Object Detection in Remote Sensing Images
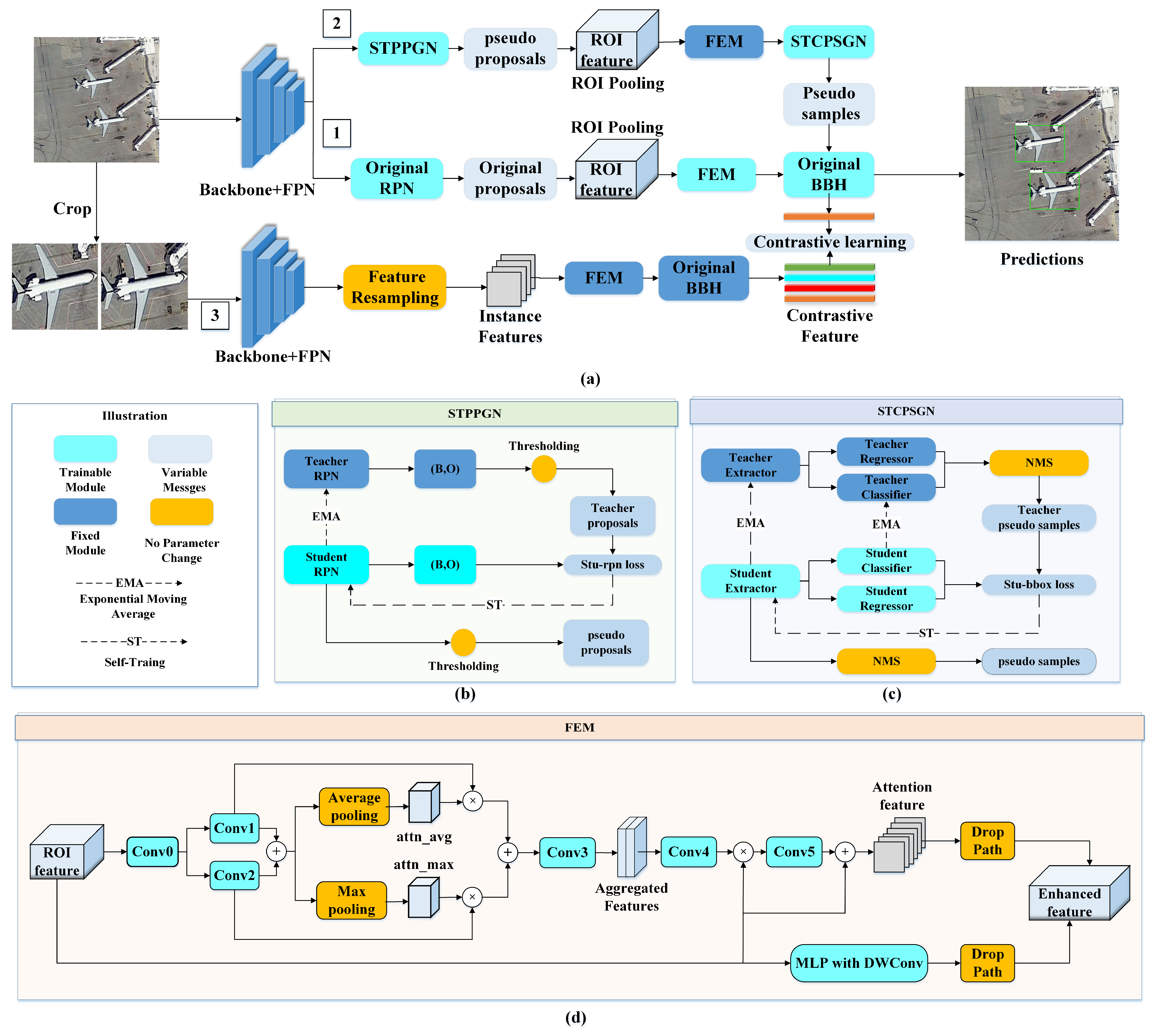
3. Method
3.1. Problem Setting
3.2. Method Architecture
3.3. Self-Training-Based Pseudo-Proposal Generation Network
3.4. Self-Training-Based Confident Pseudo-Sample Generation Network
3.5. Feature Enhancement Module
3.6. Overall Loss Function
4. Experiments
4.1. Dataset and Implementation
4.2. Evaluation Metrics
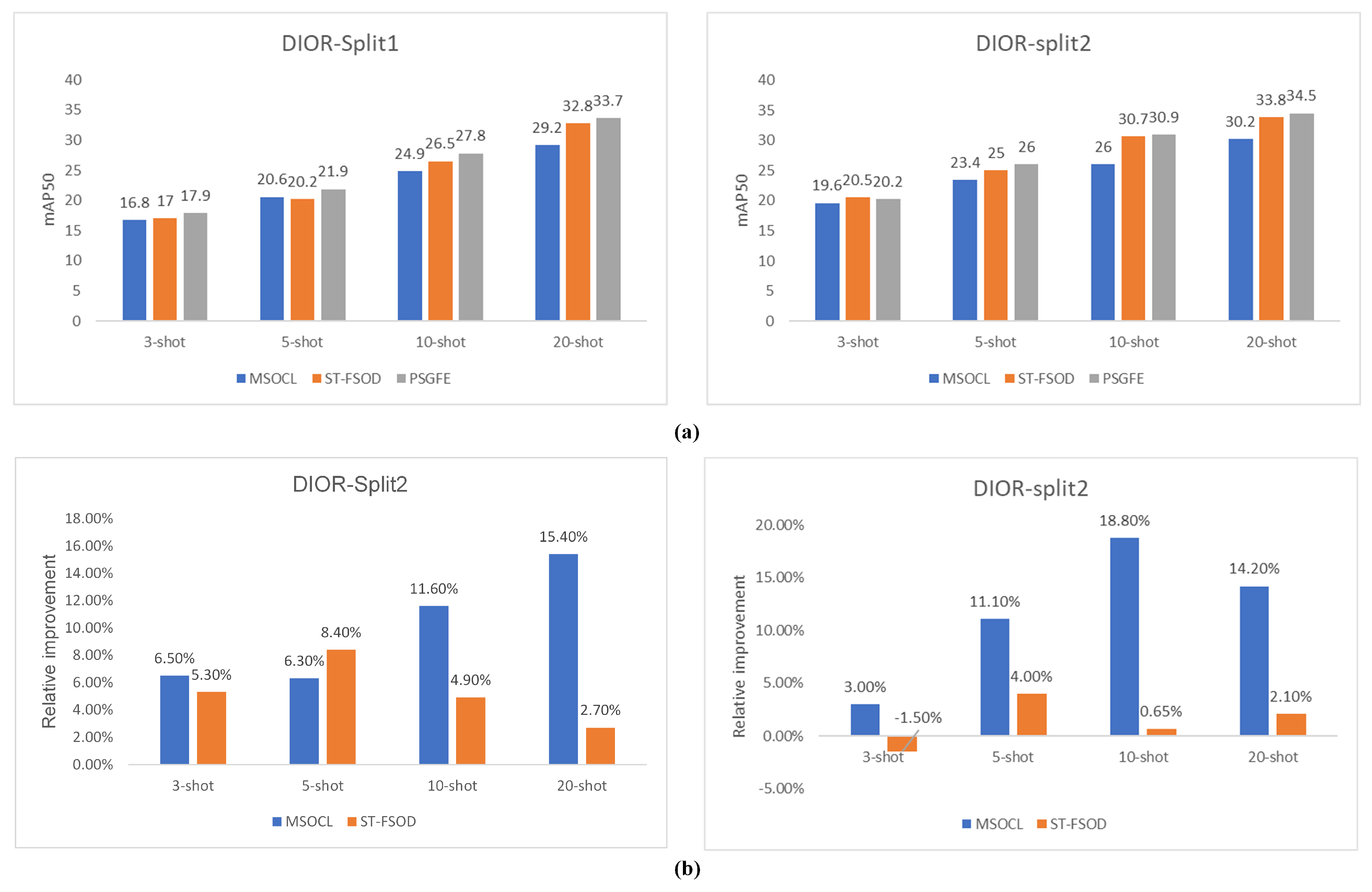
4.3. Quantitative Results on DIOR Datasets
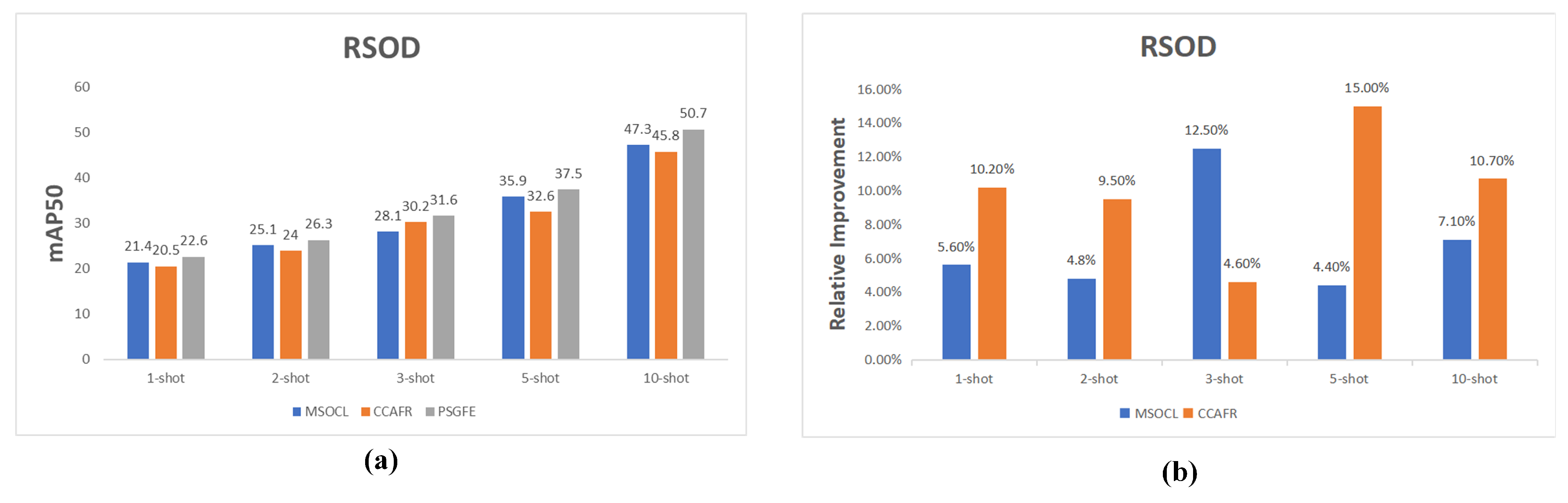
4.4. Quantitative Results on RSOD Datasets
4.5. Qualitative Results
4.6. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, K.; Li, W.; Lei, S.; Chen, J.; Jiang, X.; Zou, Z.; Shi, Z. Continuous remote sensing image super-resolution based on context interaction in implicit function space. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Liu, N.; Celik, T.; Li, H.C. MSNet: A multiple supervision network for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Anbarasan, M.; Muthu, B.; Sivaparthipan, C.B.; Sundarasekar, R.; Kadry, S.; Krishnamoorthy, S.; Dasel, A.A. Detection of flood disaster system based on IoT, big data and convolutional deep neural network. Comput. Commun. 2020, 150, 150–157. [Google Scholar] [CrossRef]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Zhang, J.; Xing, M.; Sun, G.C.; Li, N. Oriented Gaussian function-based box boundary-aware vectors for oriented ship detection in multiresolution SAR imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, L.; Murray, N.; Koniusz, P. Kernelized few-shot object detection with efficient integral aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19207–19216. [Google Scholar]
- Yang, H.; Cai, S.; Sheng, H.; Deng, B.; Huang, J.; Hua, X.S.; Zhang, Y. Balanced and hierarchical relation learning for one-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7591–7600. [Google Scholar]
- Huang, P.; Han, J.; Cheng, D.; Zhang, D. Robust region feature synthesizer for zero-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7622–7631. [Google Scholar]
- Wu, S.; Pei, W.; Mei, D.; Chen, F.; Tian, J.; Lu, G. Multi-faceted distillation of base-novel commonality for few-shot object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 578–594. [Google Scholar]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. LSTD: A low-shot transfer detector for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Bronstein, A.M. RepMet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5197–5206. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Lu, X.; Sun, X.; Diao, W.; Mao, Y.; Li, J.; Zhang, Y.; Fu, K. Few-shot object detection in aerial imagery guided by text-modal knowledge. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–19. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature enhancement network for object detection in optical remote sensing images. J. Remote Sens. 2021, 2021. [Google Scholar] [CrossRef]
- Liu, Y.; Pan, Z.; Yang, J.; Zhou, P.; Zhang, B. Multi-Modal Prototypes for Few-Shot Object Detection in Remote Sensing Images. Remote Sens. 2024, 16, 4693. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, J.; Huang, Z.; Wan, H.; Chang, P.; Li, Z.; Xing, M. FSODS: A lightweight metalearning method for few-shot object detection on SAR images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Fan, Q.; Tang, C.K.; Tai, Y.W. Few-shot object detection with model calibration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 720–739. [Google Scholar]
- Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-shot object detection on remote sensing images via shared attention module and balanced fine-tuning strategy. Remote Sens. 2021, 13, 3816. [Google Scholar] [CrossRef]
- Gao, H.; Wu, S.; Wang, Y.; Kim, J.Y.; Xu, Y. Fsod4rsi: Few-shot object detection for remote sensing images via features aggregation and scale attention. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4784–4796. [Google Scholar] [CrossRef]
- Li, J.; Tian, Y.; Xu, Y.; Hu, X.; Zhang, Z.; Wang, H.; Xiao, Y. MM-RCNN: Toward few-shot object detection in remote sensing images with meta memory. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 7352–7362. [Google Scholar]
- Chen, J.; Qin, D.; Hou, D.; Zhang, J.; Deng, M.; Sun, G. Multiscale object contrastive learning-derived few-shot object detection in VHR imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, F.; Shi, Y.; Xiong, Z.; Zhu, X.X. Few-shot object detection in remote sensing: Lifting the curse of incompletely annotated novel objects. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Serre, T.; Wolf, L.; Bileschi, S.; Riesenhuber, M.; Poggio, T. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 411–426. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, Canada, 18–22 June 2023; pp. 16794–16805. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta R-CNN: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 9577–9586. [Google Scholar]
- Lu, X.; Diao, W.; Mao, Y.; Li, J.; Wang, P.; Sun, X.; Fu, K. Breaking immutable: Information-coupled prototype elaboration for few-shot object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023; Volume 37, pp. 1844–1852. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 456–472. [Google Scholar]
- Wang, X.; Huang, T.E.; Gonzalez, J.; Yu, F. Frustratingly simple few-shot object detection. In Proceedings of the 37th International Conference on Machine Learning (ICML), Online, 13–18 June 2020; pp. 9919–9928. [Google Scholar]
- Wu, A.; Han, Y.; Zhu, L.; Yang, Y. Universal-prototype enhancing for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 19–25 June 2021; pp. 9567–9576. [Google Scholar]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. DefRCN: Decoupled Faster R-CNN for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 19–25 June 2021; pp. 8681–8690. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Lin, S.; Wang, K.; Zeng, X.; Zhao, R. Explore the power of synthetic data on few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 638–647. [Google Scholar]
- Nguyen, K.; Todorovic, S. A self-supervised GAN for unsupervised few-shot object recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3225–3231. [Google Scholar]
- Li, X.; Deng, J.; Fang, Y. Few-shot object detection on remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Xiao, Z.; Qi, J.; Xue, W.; Zhong, P. Few-shot object detection with self-adaptive attention network for remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4854–4865. [Google Scholar] [CrossRef]
- Cheng, G.; Yan, B.; Shi, P.; Li, K.; Yao, X.; Guo, L.; Han, J. Prototype-CNN for few-shot object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–10. [Google Scholar] [CrossRef]
- Xiao, Y.; Lepetit, V.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3090–3106. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Hu, H.; Zhao, J.; Zhu, H.; Yao, R.; Du, W.L. Few-shot object detection via context-aware aggregation for remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, R.; Zeng, Y.; Wu, J.; Wang, Y.; Zhang, X. Few-shot object detection of remote sensing image via calibration. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Ma, S.; Hou, B.; Wu, Z.; Li, Z.; Guo, X.; Ren, B.; Jiao, L. Automatic aug-aware contrastive proposal encoding for few-shot object detection of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Wei, C.; Sohn, K.; Mellina, C.; Yuille, A.; Yang, F. Crest: A class-rebalancing self-training framework for imbalanced semi-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 10857–10866. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 16–20 June 2020; pp. 10687–10698. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 11976–11986. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Araslanov, N.; Roth, S. Self-supervised augmentation consistency for adapting semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 15384–15394. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Zhu, P.; Jia, X.; Tang, X.; Jiao, L. Generalized few-shot object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2023, 195, 353–364. [Google Scholar] [CrossRef]
- Miao, W.; Zhao, Z.; Geng, J.; Jiang, W. Few-shot object detection based on contrastive class-attention feature reweighting for remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 2800–2814. [Google Scholar] [CrossRef]
- Shmelkov, K.; Schmid, C.; Alahari, K. Incremental learning of object detectors without catastrophic forgetting. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3400–3409. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split | Novel Classes | Base Classes | ||||
|---|---|---|---|---|---|---|
| 1 | airplane | ground track field | expressway toll station | harbor | airport | rest |
| 2 | golf course | tennis court | storage tank | dam | vehicle | rest |
| Method | Split1 | Split2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Shot | 3 | 5 | 10 | 20 | 3 | 5 | 10 | 20 |
| RepMet [11] | 5.2 | 5.6 | 5.9 | 6.8 | 5.5 | 5.7 | 7.4 | 7.8 |
| MPSR [30] | 12.9 | 16.2 | 22.7 | 28.8 | 14.7 | 15.9 | 21.0 | 24.7 |
| FsDet [40] | 12.9 | 14.5 | 19.4 | 21.7 | 14.4 | 18.3 | 22.0 | 25.0 |
| P-CNN [39] | 14.5 | 14.9 | 18.9 | 22.8 | 16.5 | 18.8 | 23.3 | 28.8 |
| TFA [31] | 5.4 | 7.6 | 8.6 | 10.7 | 4.3 | 7.6 | 15.3 | 19.6 |
| FSCE [21] | 15.1 | 18.2 | 23.3 | 27.4 | 12.8 | 17.0 | 21.5 | 27.3 |
| G-FSOD [50] | 14.1 | 15.8 | 20.7 | 22.7 | 16.0 | 23.3 | 26.2 | 32.1 |
| MSOCL [22] | 16.8 | 20.6 | 24.9 | 29.2 | 19.6 | 23.4 | 26.0 | 30.2 |
| ST-FSOD [23] | 17.0 | 20.2 | 26.5 | 32.8 | 20.5 | 25.0 | 30.7 | 33.8 |
| Ours | 17.9 | 21.9 | 27.8 | 33.7 | 20.2 | 26.0 | 30.9 | 34.5 |
| Method/Shot | 1 | 2 | 3 | 5 | 10 |
|---|---|---|---|---|---|
| Meta-RCNN [28] | 2.7 | 4.7 | 11.4 | 32.7 | 42.7 |
| TFA [31] | 12.0 | 18.8 | 20.9 | 22.7 | 35.6 |
| FSCE [21] | 19.5 | 25.6 | 28.0 | 28.4 | 43.7 |
| CCAFR [51] | 20.5 | 24.0 | 30.2 | 32.6 | 45.8 |
| SAAN [38] | 4.7 | 9.0 | 10.5 | 34.1 | 44.0 |
| MSOCL [22] | 21.4 | 25.1 | 28.1 | 35.9 | 47.3 |
| Ours | 22.6 | 26.3 | 31.6 | 37.5 | 50.7 |
| Baseline | PSGM | FEM | mAP50 | |
|---|---|---|---|---|
| 10-Shot | 20-Shot | |||
| ✓ | × | × | 24.9 | 29.2 |
| ✓ | ✓ | × | 26.3 | 32.8 |
| ✓ | × | ✓ | 25.6 | 31.9 |
| ✓ | ✓ | ✓ | 27.8 | 33.7 |
| Branch 1 | Branch 2 | Branch 3 | mAP50 | |
|---|---|---|---|---|
| Case1 | ✓ | × | × | 30.7 |
| Case2 | ✓ | ✓ | × | 31.6 |
| Case3 | ✓ | × | ✓ | 31.3 |
| Case4 | ✓ | ✓ | ✓ | 31.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Chen, D.; Zhong, C. Few-Shot Object Detection for Remote Sensing Images via Pseudo-Sample Generation and Feature Enhancement. Appl. Sci. 2025, 15, 4477. https://doi.org/10.3390/app15084477
Huang Z, Chen D, Zhong C. Few-Shot Object Detection for Remote Sensing Images via Pseudo-Sample Generation and Feature Enhancement. Applied Sciences. 2025; 15(8):4477. https://doi.org/10.3390/app15084477
Chicago/Turabian StyleHuang, Zhaoguo, Danyang Chen, and Cheng Zhong. 2025. "Few-Shot Object Detection for Remote Sensing Images via Pseudo-Sample Generation and Feature Enhancement" Applied Sciences 15, no. 8: 4477. https://doi.org/10.3390/app15084477
APA StyleHuang, Z., Chen, D., & Zhong, C. (2025). Few-Shot Object Detection for Remote Sensing Images via Pseudo-Sample Generation and Feature Enhancement. Applied Sciences, 15(8), 4477. https://doi.org/10.3390/app15084477