Optical Flow Odometry with Panoramic Image Based on Spherical Congruence Projection

 ,
,
Abstract
1. Introduction
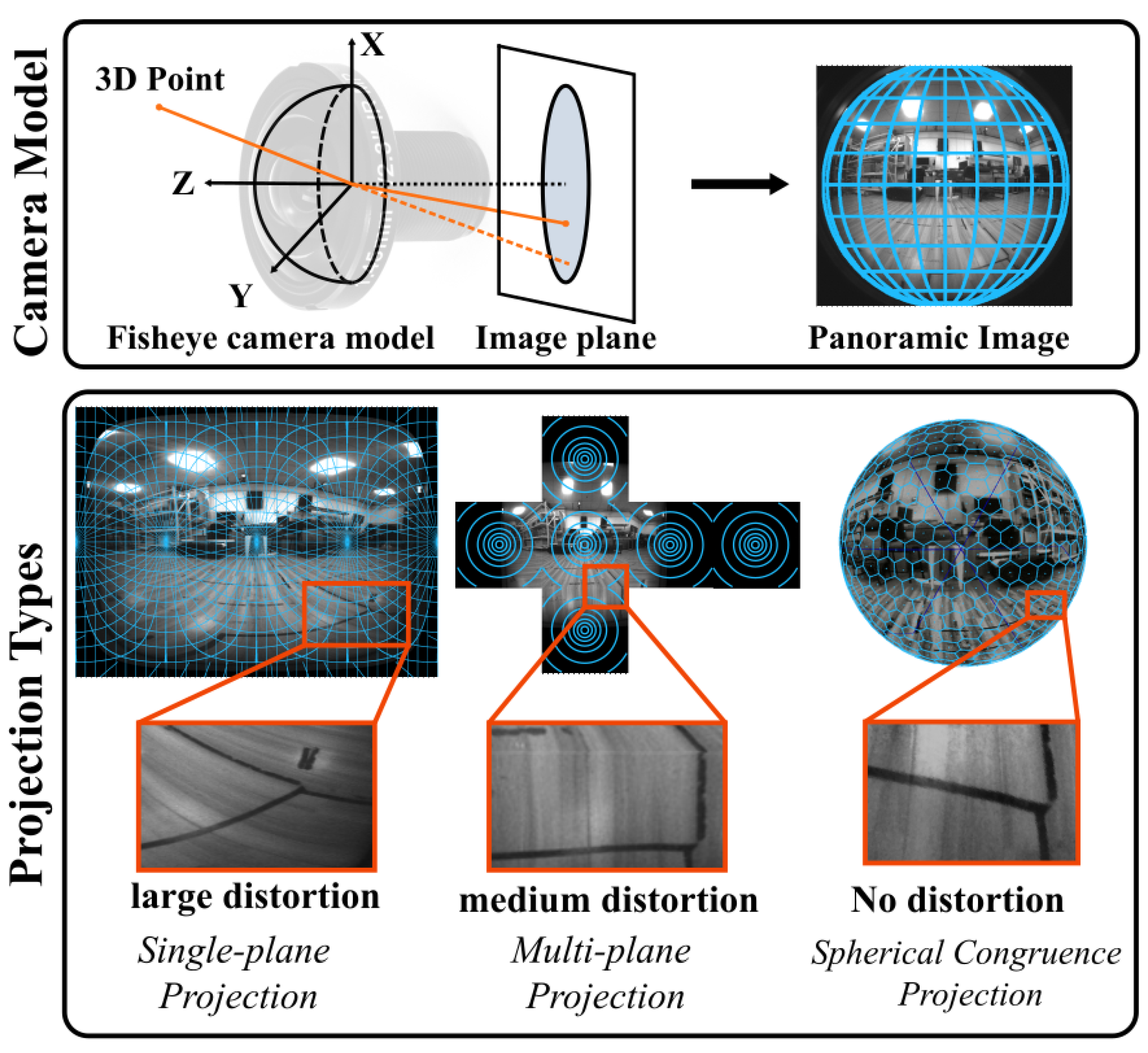
- We propose a spherical congruence projection method that provides a globally consistent, distortion-free representation of panoramic images. Unlike traditional ERP or multi-plane projections, SCP preserves pixel-wise scale and topology on the spherical surface, offering a unified and geometry-preserving alternative for downstream tracking tasks.
- We introduce a dense optical flow tracking framework tailored for spherical imagery. To the best of our knowledge, this is the first system to perform dense pixel–motion estimation directly on a spherical pixel structure. Our method integrates a nonorthogonal gradient operator specifically adapted to the sphere, enabling smooth and spatially consistent flow fields over the entire 360° FoV.
- We present a fully integrated visual odometry pipeline that combines spherical projection and dense flow tracking into a real-time system. Extensive experiments on both public and custom datasets demonstrate that our method not only achieves superior accuracy under high-speed motion but also offers improved robustness compared to existing fisheye and panoramic odometry methods.
2. Related Work
2.1. Panoramic Image-Based Feature Tracking
2.2. Panoramic Image-Based Odometry
3. Materials and Methods
3.1. Spherical Mapping and Pixelation
3.2. Spherical Congruence Projection
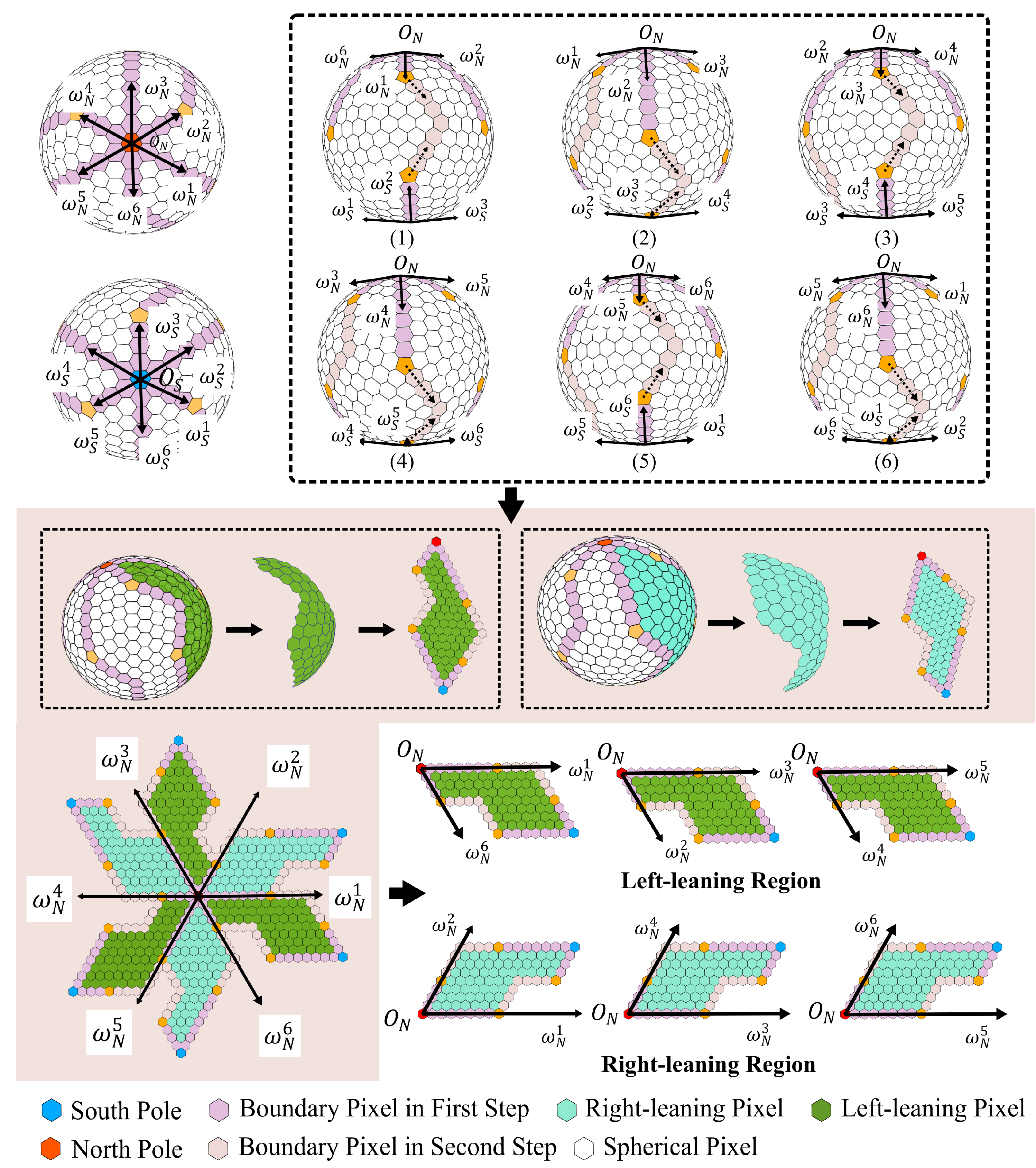
3.2.1. Spherical Pixel Segmentation
3.2.2. Pixel Storage
3.3. SCP-VO Method
3.4. Integration with Inertial Odometry
4. Experiments and Discussion
4.1. Datasets
4.2. Comparative Experimental Results
4.3. Ablation Experiments on Gradient Operator
4.4. Optical Flow Continuity Examination
4.5. Ablation Experiments on FOV
4.6. Ablation Experiments on Keypoint Numbers
4.7. Runtime Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, H.; Zhou, Y.; Yang, K.; Yin, X.; Wang, Z.; Ye, Y.; Yin, Z.; Meng, S.; Li, P.; Wang, K. PanoFlow: Learning 360° backslashcirc Optical Flow for Surrounding Temporal Understanding. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5570–5585. [Google Scholar] [CrossRef]
- Kinzig, C.; Miller, H.; Lauer, M.; Stiller, C. Panoptic Segmentation from Stitched Panoramic View for Automated Driving. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 3342–3347. [Google Scholar]
- Li, Y.; Yabuki, N.; Fukuda, T. Measuring visual walkability perception using panoramic street view images, virtual reality, and deep learning. Sustain. Cities Soc. 2022, 86, 104140. [Google Scholar] [CrossRef]
- Gao, S.; Yang, K.; Shi, H.; Wang, K.; Bai, J. Review on panoramic imaging and its applications in scene understanding. IEEE Trans. Instrum. Meas. 2022, 71, 1–34. [Google Scholar] [CrossRef]
- Scaramuzza, D.; Martinelli, A.; Siegwart, R. A flexible technique for accurate omnidirectional camera calibration and structure from motion. In Proceedings of the Fourth IEEE International Conference on Computer Vision Systems (ICVS’06), New York, NY, USA, 4–7 January 2006; IEEE: Piscataway, NJ, USA, 2006; p. 45. [Google Scholar]
- Chen, H.; Wang, K.; Hu, W.; Yang, K.; Cheng, R.; Huang, X.; Bai, J. PALVO: Visual odometry based on panoramic annular lens. Opt. Express 2019, 27, 24481–24497. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Qin, Z.; Shan, J.; Lu, M. Panoramic SLAM from a multiple fisheye camera rig. ISPRS J. Photogramm. Remote Sens. 2020, 159, 169–183. [Google Scholar] [CrossRef]
- Wang, Y.; Cai, S.; Li, S.J.; Liu, Y.; Guo, Y.; Li, T.; Cheng, M.M. CubemapSLAM: A piecewise-pinhole monocular fisheye SLAM system. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 34–49. [Google Scholar]
- Ramezani, M.; Khoshelham, K.; Fraser, C. Pose estimation by omnidirectional visual-inertial odometry. Robot. Auton. Syst. 2018, 105, 26–37. [Google Scholar] [CrossRef]
- Seok, H.; Lim, J. Rovo: Robust omnidirectional visual odometry for wide-baseline wide-fov camera systems. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6344–6350. [Google Scholar]
- Yoon, Y.; Chung, I.; Wang, L.; Yoon, K.J. Spheresr: 360deg image super-resolution with arbitrary projection via continuous spherical image representation. In Proceedings of the EEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 5677–5686. [Google Scholar]
- Lee, Y.; Jeong, J.; Yun, J.; Cho, W.; Yoon, K.J. Spherephd: Applying cnns on a spherical polyhedron representation of 360deg images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9181–9189. [Google Scholar]
- Gao, X.; Shi, Y.; Zhao, Y.; Wang, Y.; Wang, J.; Wu, G. CAPDepth: 360 Monocular Depth Estimation by Content-Aware Projection. Appl. Sci. 2025, 15, 769. [Google Scholar] [CrossRef]
- Aguiar, A.; Santos, F.; Santos, L.; Sousa, A. Monocular visual odometry using fisheye lens cameras. In Proceedings of the Progress in Artificial Intelligence: 19th EPIA Conference on Artificial Intelligence, EPIA 2019, Vila Real, Portugal, 3–6 September 2019; Proceedings, Part II 19. Springer: Berlin/Heidelberg, Germany, 2019; pp. 319–330. [Google Scholar]
- Lee, U.G.; Park, S.Y. Visual Odometry of a Mobile Palette Robot Using Ground Plane Image from a Fisheye Camera. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 43, 431–436. [Google Scholar] [CrossRef]
- Eder, M.; Shvets, M.; Lim, J.; Frahm, J.M. Tangent images for mitigating spherical distortion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12426–12434. [Google Scholar]
- Huang, H.; Yeung, S.K. 360vo: Visual odometry using a single 360 camera. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23—27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 5594–5600. [Google Scholar]
- Kitamura, R.; Li, S.; Nakanishi, I. Spherical FAST corner detector. In Proceedings of the 2015 IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 2–5 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2597–2602. [Google Scholar]
- Williamson, D.L. Integration of the barotropic vorticity equation on a spherical geodesic grid. Tellus 1968, 20, 642–653. [Google Scholar] [CrossRef]
- Zhao, Q.; Feng, W.; Wan, L.; Zhang, J. SPHORB: A fast and robust binary feature on the sphere. Int. J. Comput. Vis. 2015, 113, 143–159. [Google Scholar] [CrossRef]
- Guan, H.; Smith, W.A. BRISKS: Binary features for spherical images on a geodesic grid. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4516–4524. [Google Scholar]
- Zhang, Y.; Song, J.; Ding, Y.; Yuan, Y.; Wei, H.L. FSD-BRIEF: A distorted BRIEF descriptor for fisheye image based on spherical perspective model. Sensors 2021, 21, 1839. [Google Scholar] [CrossRef] [PubMed]
- Lourenço, M.; Barreto, J.P.; Vasconcelos, F. sRD-SIFT: Keypoint detection and matching in images with radial distortion. IEEE Trans. Robot. 2012, 28, 752–760. [Google Scholar] [CrossRef]
- Gava, C.C.; Hengen, J.M.; Taetz, B.; Stricker, D. Keypoint detection and matching on high resolution spherical images. In Proceedings of the Advances in Visual Computing: 9th International Symposium, ISVC 2013, Rethymnon, Crete, Greece, 29–31 July 2013; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2013; pp. 363–372. [Google Scholar]
- Cruz-Mota, J.; Bogdanova, I.; Paquier, B.; Bierlaire, M.; Thiran, J.P. Scale invariant feature transform on the sphere: Theory and applications. Int. J. Comput. Vis. 2012, 98, 217–241. [Google Scholar] [CrossRef]
- Chen, Z.; Li, J.; Wu, K. 360ORB-SLAM: A Visual SLAM System for Panoramic Images with Depth Completion Network. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024. [Google Scholar]
- Wang, Z.; Yang, K.; Shi, H.; Li, P.; Gao, F.; Bai, J.; Wang, K. LF-VISLAM: A SLAM Framework for Large Field-of-View Cameras With Negative Imaging Plane on Mobile Agents. IEEE Trans. Autom. Sci. Eng. 2023, 21, 6321–6335. [Google Scholar] [CrossRef]
- Yuan, H.; Liu, T.; Zhang, Y.; Jiang, Z. Panoramic Direct LiDAR-assisted Visual Odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Seok, H.; Lim, J. ROVINS: Robust omnidirectional visual inertial navigation system. IEEE Robot. Autom. Lett. 2020, 5, 6225–6232. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, K.; Shi, H.; Li, P.; Gao, F.; Wang, K. LF-VIO: A visual-inertial-odometry framework for large field-of-view cameras with negative plane. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4423–4430. [Google Scholar]
- Wang, D.; Wang, J.; Tian, Y.; Fang, Y.; Yuan, Z.; Xu, M. PAL-SLAM2: Visual and visual–inertial monocular SLAM for panoramic annular lens. ISPRS-J. Photogramm. Remote Sens. 2024, 211, 35–48. [Google Scholar] [CrossRef]
- Scaramuzza, D.; Martinelli, A.; Siegwart, R. A toolbox for easily calibrating omnidirectional cameras. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 5695–5701. [Google Scholar]
- Yang, Y.; Gao, Z.; Zhang, J.; Hui, W.; Shi, H.; Xie, Y. UVS-CNNs: Constructing general convolutional neural networks on quasi-uniform spherical images. Comput. Graph. 2024, 122, 103973. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VIO-Method | Index | ID01 * | ID05 * | ID07 * | ID02 ** | ID03 ** | ID04 ** | ID06 ** | ID08 ** | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | ||
| SCP -VIO | RPEt (%) | 1.70 | 0.90 | 1.17 | 0.63 | 1.10 | 0.52 | 1.35 | 0.82 | 2.14 | 1.66 | 0.10 | 0.53 | 1.11 | 0.56 | 1.24 | 0.75 |
| RPEr (deg/m) | 1.03 | 0.56 | 0.41 | 0.22 | 0.51 | 0.30 | 0.57 | 0.41 | 0.49 | 0.39 | 0.48 | 0.35 | 0.71 | 0.58 | 5.97 | 5.91 | |
| ATE (m) | 0.98 | 0.38 | 0.20 | 0.08 | 0.19 | 0.08 | 0.33 | 0.13 | 0.37 | 0.11 | 0.22 | 0.08 | 0.11 | 0.06 | 0.19 | 0.09 | |
| LF -VIO | RPEt (%) | 2.69 | 1.88 | 1.40 | 0.90 | 1.11 | 0.48 | 1.37 | 0.99 | 1.16 | 0.76 | 0.95 | 0.44 | 1.12 | 0.59 | 1.30 | 0.78 |
| RPEr (deg/m) | 1.21 | 0.66 | 0.42 | 0.29 | 0.51 | 0.27 | 0.49 | 0.32 | 0.49 | 0.26 | 0.50 | 0.38 | 0.62 | 0.50 | 5.92 | 5.86 | |
| ATE (m) | 0.98 | 0.38 | 0.27 | 0.13 | 0.21 | 0.08 | 0.39 | 0.15 | 0.27 | 0.11 | 0.31 | 0.13 | 0.11 | 0.06 | 0.25 | 0.08 | |
| VINS -MONO | RPEt (%) | 3.72 | 2.47 | 1.70 | 1.05 | 5.47 | 3.67 | 1.66 | 1.13 | 2.38 | 1.85 | 1.56 | 0.89 | 3.54 | 2.31 | 3.37 | 2.66 |
| RPEr (deg/m) | 1.45 | 1.12 | 0.46 | 0.26 | 0.51 | 0.25 | 0.43 | 0.29 | 0.43 | 0.27 | 0.52 | 0.40 | 0.48 | 0.30 | 6.17 | 6.12 | |
| ATE (m) | 1.34 | 0.50 | 0.36 | 0.14 | 2.85 | 0.65 | 0.52 | 0.21 | 0.71 | 0.30 | 0.42 | 0.13 | 1.49 | 0.18 | 0.47 | 0.19 | |
| VIO-Method | Index | ID01 | ID02 | ID03 | ID04 |
|---|---|---|---|---|---|
| CI | CI | CI | CI | ||
| SCP -VIO | RPEt (%) | [1.629,1.971] | [1.272,1.423] | [2.028,2.232] | [0.052,0.161] |
| RPEr (deg/m) | [1.033,1.121] | [0.531,0.606] | [0.458,0.523] | [0.450,0.505] | |
| ATE (m) | [0.963,0.982] | [0.325,0.344] | [0.372,0.393] | [0.213,0.223] | |
| LF -VIO | RPEt (%) | [2.550,2.837] | [1.278,1.455] | [1.092,1.222] | [0.916,0.982] |
| RPEr (deg/m) | [1.162,1.263] | [0.458,0.515] | [0.466,0.510] | [0.421,0.536] | |
| ATE (m) | [0.935,0.996] | [0.376,0.398] | [0.261,0.276] | [0.304,0.321] | |
| VINS -MONO | RPEt (%) | [3.524,3.923] | [1.557,1.761] | [2.205,2.397] | [1.492,1.625] |
| RPEr (deg/m) | [1.364,1.545] | [0.421,0.606] | [0.406,0.451] | [0.491,0.550] | |
| ATE (m) | [1.300,1.377] | [0.501,0.533] | [0.690,0.729] | [0.406,0.423] | |
| VIO Method | Index | ID05 | ID06 | ID07 | ID08 |
| CI | CI | CI | CI | ||
| SCP -VIO | RPEt (%) | [1.112,1.222] | [1.042,1.174] | [1.060,1.149] | [1.169,1.307] |
| RPEr (deg/m) | [0.400,0.455] | [0.637,0.774] | [0.482,0.533] | [5.422,6.509] | |
| ATE (m) | [0.192,0.204] | [0.108,0.120] | [0.187,0.199] | [0.178,0.193] | |
| LF -VIO | RPEt (%) | [1.326,1.478] | [1.081,1.219] | [1.069,1.150] | [1.231,1.374] |
| RPEr (deg/m) | [0.393,0.442] | [0.563,0.682] | [0.478,0.524] | [5.381,6.451] | |
| ATE (m) | [0.261,0.281] | [0.108,0.120] | [0.201,0.214] | [0.246,0.259] | |
| VINS -MONO | RPEt (%) | [1.612,1.793] | [3.271,3.813] | [5.132,5.809] | [3.119,3.627] |
| RPEr (deg/m) | [0.434,0.479] | [0.442,0.512] | [0.482,0.529] | [5.581,6.750] | |
| ATE (m) | [0.347,0.370] | [1.437,1.496] | [2.795,2.910] | [0.448,0.481] |
| VIO-Method | Index | RS01 | RS02 | RS03 | RS04 | RS05 | RS06 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | ||
| SCP -VIO | RPEt (%) | 1.863 | 1.240 | 1.831 | 1.299 | 2.041 | 1.267 | 2.344 | 1.473 | 1.953 | 1.095 | 2.929 | 2.021 |
| RPEr (deg/m) | 2.292 | 1.938 | 2.648 | 2.271 | 2.245 | 1.776 | 2.578 | 2.122 | 2.444 | 2.030 | 2.934 | 2.483 | |
| ATE (m) | 0.153 | 0.046 | 0.095 | 0.037 | 0.139 | 0.067 | 0.131 | 0.064 | 0.163 | 0.050 | 0.301 | 0.153 | |
| LF -VIO | RPEt (%) | 2.382 | 1.584 | 2.622 | 1.933 | 2.548 | 1.674 | 2.609 | 1.655 | 2.446 | 1.478 | 2.954 | 1.841 |
| RPEr (deg/m) | 2.206 | 1.853 | 2.833 | 2.385 | 2.872 | 2.382 | 2.720 | 2.261 | 2.598 | 2.087 | 2.951 | 2.467 | |
| ATE (m) | 0.191 | 0.062 | 0.185 | 0.067 | 0.149 | 0.058 | 0.156 | 0.058 | 0.191 | 0.081 | 0.169 | 0.064 | |
| VINS -MONO | RPEt (%) | 2.758 | 1.660 | 2.641 | 1.861 | 2.559 | 1.728 | 2.480 | 1.703 | 2.376 | 1.599 | 2.668 | 1.874 |
| RPEr (deg/m) | 2.301 | 1.922 | 2.924 | 2.459 | 2.768 | 2.311 | 2.956 | 2.479 | 2.792 | 2.346 | 2.992 | 2.575 | |
| ATE (m) | 0.239 | 0.116 | 0.202 | 0.083 | 0.148 | 0.069 | 0.127 | 0.047 | 0.119 | 0.041 | 0.145 | 0.045 | |
| VIO Method | Index | RS07 | RS08 | RS09 | RS10 | RS11 | RS12 | ||||||
| RMSE | std | RMSE | std | RMSE | std | RMSE | std | RMSE | std | RMSE | std | ||
| SCP -VIO | RPEt (%) | 2.342 | 1.662 | 2.693 | 1.841 | 2.297 | 1.464 | 2.667 | 1.795 | 2.999 | 2.058 | 3.155 | 2.193 |
| RPEr (deg/m) | 3.283 | 2.936 | 3.384 | 2.753 | 2.808 | 2.349 | 3.736 | 3.171 | 1.417 | 1.094 | 1.075 | 0.736 | |
| ATE (m) | 0.140 | 0.047 | 0.189 | 0.075 | 0.158 | 0.065 | 0.201 | 0.076 | 0.228 | 0.081 | 0.293 | 0.087 | |
| LF -VIO | RPEt (%) | 3.736 | 2.357 | 3.109 | 2.093 | 2.709 | 1.847 | 3.537 | 2.302 | 3.562 | 2.447 | 3.261 | 2.268 |
| RPEr (deg/m) | 3.004 | 2.459 | 3.240 | 2.616 | 3.194 | 2.764 | 3.875 | 3.255 | 3.709 | 3.165 | 1.981 | 1.334 | |
| ATE (m) | 0.352 | 0.073 | 0.191 | 0.066 | 0.168 | 0.042 | 0.155 | 0.069 | 0.220 | 0.080 | 0.283 | 0.085 | |
| VINS -MONO | RPEt (%) | 2.963 | 2.245 | 3.174 | 2.221 | 2.458 | 1.708 | 3.543 | 2.496 | 3.410 | 2.373 | 3.420 | 2.351 |
| RPEr (deg/m) | 3.129 | 2.766 | 3.326 | 2.696 | 2.475 | 2.017 | 3.809 | 3.223 | 3.679 | 3.092 | 2.034 | 1.333 | |
| ATE (m) | 0.191 | 0.048 | 0.176 | 0.052 | 0.206 | 0.085 | 0.136 | 0.053 | 0.187 | 0.074 | 0.312 | 0.186 | |
| VIO-Method | Index | RS01 | RS02 | RS03 | RS04 | RS05 | RS06 |
|---|---|---|---|---|---|---|---|
| CI | CI | CI | CI | CI | CI | ||
| SCP -VIO | RPEt (%) | [1.676,2.051] | [1.635,2.028] | [1.852,2.230] | [2.144,2.543] | [1.788,2.117] | [2.651,3.207] |
| RPEr (deg/m) | [1.930,2.486] | [2.305,2.991] | [1.981,2.510] | [2.290,2.866] | [2.139,2.749] | [2.593,3.276] | |
| ATE (m) | [0.149,0.157] | [0.092,0.099] | [0.133,0.145] | [0.126,0.137] | [0.159,0.168] | [0.289,0.314] | |
| LF -VIO | RPEt (%) | [2.145,2.618] | [2.334,2.910] | [2.299,2.780] | [2.376,2.842] | [2.222,2.669] | [2.698,3.209] |
| RPEr (deg/m) | [2.003,2.581] | [2.477,3.188] | [2.517,3.227] | [2.626,3.287] | [2.282,2.913] | [2.609,3.293] | |
| ATE (m) | [0.185,0.197] | [0.179,0.191] | [0.145,0.154] | [0.151,0.160] | [0.184,0.198] | [0.164,0.174] | |
| VINS -MONO | RPEt (%) | [2.508,3.008] | [2.362,2.920] | [2.302,2.815] | [2.253,2.707] | [2.139,2.614] | [2.418,2.917] |
| RPEr (deg/m) | [2.012,2.591] | [2.555,3.292] | [2.425,3.111] | [2.402,3.038] | [2.444,3.141] | [2.649,3.336] | |
| ATE (m) | [0.229,0.249] | [0.195,0.208] | [0.142,0.154] | [0.123,0.130] | [0.115,0.122] | [0.139,0.153] | |
| VIO Method | Index | RS07 | RS08 | RS09 | RS10 | RS11 | RS12 |
| CI | CI | CI | CI | CI | CI | ||
| SPC -VIO | RPEt (%) | [2.092,2.592] | [2.442,2.944] | [2.088,2.506] | [2.389,2.945] | [2.691,3.306] | [2.837,3.472] |
| RPEr (deg/m) | [2.842,3.725] | [2.009,3.759] | [2.473,3.143] | [3.244,4.227] | [1.349,2.370] | [0.755,1.139] | |
| ATE (m) | [0.127,0.248] | [0.182,0.196] | [0.152,0.164] | [0.193,0.209] | [0.220,0.236] | [0.284,0.302] | |
| LF -VIO | RPEt (%) | [3.364,4.106] | [0.283,0.339] | [2.447,2.970] | [3.179,3.894] | [3.185,3.939] | [2.930,3.592] |
| RPEr (deg/m) | [2.617,3.391] | [2.893,3.586] | [2.803,3.585] | [3.369,4.381] | [3.222,4.196] | [1.787,2.176] | |
| ATE (m) | [0.366,0.403] | [0.186,0.197] | [0.164,0.172] | [0.149,0.162] | [0.213,0.228] | [0.274,0.292] | |
| VIN -MONO | RPEt (%) | [2.637,3.289] | [2.883,3.466] | [2.226,2.691] | [3.165,3.922] | [3.046,3.774] | [3.074,3.767] |
| RPEr (deg/m) | [2.727,3.531] | [2.972,3.680] | [2.200,2.749] | [3.320,4.297] | [3.205,4.154] | [1.837,2.230] | |
| ATE (m) | [0.189,0.211] | [0.269,0.292] | [0.198,0.214] | [0.131,0.141] | [0.180,0.194] | [0.231,0.347] |
| VIO-Method | Gauss | = 10 | = 25 | = 50 | |||
|---|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | ||
| SCP-VIO | RPEt (%) | 2.250 | 1.705 | 2.320 | 1.762 | 2.829 | 2.081 |
| RPEr (deg/m) | 1.058 | 0.585 | 0.943 | 0.589 | 1.132 | 0.609 | |
| ATE (m) | 0.485 | 0.201 | 0.634 | 0.283 | 1.067 | 0.431 | |
| LF-VIO | RPEt (%) | 2.539 | 1.851 | 2.982 | 2.242 | 3.578 | 2.829 |
| RPEr (deg/m) | 0.851 | 0.466 | 1.179 | 0.654 | 1.002 | 0.618 | |
| ATE (m) | 1.129 | 0.430 | 0.581 | 0.293 | 0.698 | 0.403 | |
| VINS-MONO | RPEt (%) | 4.512 | 3.097 | \ | \ | \ | \ |
| RPEr (deg/m) | 0.985 | 0.505 | \ | \ | \ | \ | |
| ATE (m) | 1.487 | 0.703 | \ | \ | \ | \ | |
| Operator Type | Index | ID01 | ID02 | ID04 | RS01 | RS02 | RS03 | RS04 | |
|---|---|---|---|---|---|---|---|---|---|
| LK operator | RPEt (%) | RMSE | 1.733 | 1.548 | 0.976 | 1.894 | 1.844 | 2.302 | 2.615 |
| std | 0.891 | 1.039 | 0.543 | 1.243 | 1.236 | 1.548 | 1.759 | ||
| RPEr (deg/m) | RMSE | 1.275 | 0.566 | 0.479 | 2.416 | 2.649 | 2.813 | 2.633 | |
| std | 0.825 | 0.473 | 0.350 | 2.074 | 2.269 | 2.363 | 1.932 | ||
| SCP operator | RPEt (%) | RMSE | 1.703 | 1.348 | 0.997 | 1.863 | 1.831 | 2.041 | 2.344 |
| std | 0.900 | 0.819 | 0.533 | 1.240 | 1.299 | 1.267 | 1.473 | ||
| RPEr (deg/m) | RMSE | 1.026 | 0.569 | 0.478 | 2.292 | 2.648 | 2.245 | 2.578 | |
| std | 0.559 | 0.406 | 0.354 | 1.938 | 2.271 | 1.776 | 2.122 | ||
| Index | a | b | RPEt (%) | RPEr (deg/m) | ATE (m) | |||
|---|---|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | |||
| 1 | 2 | 4 | 3.514 | 2.174 | 9.901 | 9.796 | 1.357 | 0.554 |
| 2 | 3 | 6 | 3.297 | 2.117 | 9.954 | 9.850 | 1.142 | 0.444 |
| 3 | 4 | 8 | 3.786 | 2.702 | 9.541 | 9.442 | 1.128 | 0.461 |
| 4 | 5 | 10 | 3.085 | 2.021 | 9.935 | 9.835 | 0.983 | 0.376 |
| 5 | 6 | 12 | 3.084 | 2.096 | 9.943 | 9.841 | 1.028 | 0.438 |
| 6 | 7 | 14 | 4.338 | 3.119 | 9.952 | 9.840 | 1.059 | 0.395 |
| 7 | 8 | 16 | 3.563 | 2.736 | 9.968 | 9.856 | 1.124 | 0.440 |
| 8 | 9 | 18 | 3.502 | 2.307 | 9.936 | 9.838 | 1.232 | 0.505 |
| Field of View | 165° | 140° | 120° | 100° | 80° | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | RMSE | Std | |
| RPEt (%) | 1.831 | 1.299 | 2.064 | 1.422 | 2.088 | 1.457 | 2.341 | 1.669 | 2.523 | 1.789 |
| RPEr (deg/m) | 2.648 | 2.271 | 2.777 | 2.374 | 2.624 | 2.213 | 2.610 | 2.190 | 2.650 | 2.293 |
| ATE (m) | 0.095 | 0.037 | 0.117 | 0.052 | 0.112 | 0.046 | 0.103 | 0.042 | 0.222 | 0.141 |
| Keypoints Number | RPEt (%) | RPEr (deg/m) | ATE (m) | |||
|---|---|---|---|---|---|---|
| RMSE | Std | RMSE | Std | RMSE | Std | |
| 100 | 1.946 | 1.080 | 1.071 | 0.579 | 1.079 | 0.414 |
| 200 | 1.922 | 1.045 | 1.052 | 0.566 | 0.886 | 0.318 |
| 400 | 1.828 | 0.957 | 1.104 | 0.590 | 0.838 | 0.307 |
| 600 | 1.820 | 0.983 | 1.067 | 0.582 | 0.949 | 0.357 |
| 800 | 1.854 | 1.004 | 1.062 | 0.589 | 0.926 | 0.350 |
| VIO-Method | Spherical Mapping Time (s) | Feature Extraction Time (s) | Optical Flow Tracking Time (s) |
|---|---|---|---|
| SCP-VIO | 0.2266 | 0.0378 | 0.0129 |
| LF-VIO | \ | 0.0292 | 0.0132 |
| VINS-MONO | \ | 0.0323 | 0.0130 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Y.; Xiao, Y.; Zhang, J.; Zou, X.; Luo, Y.; Yang, Y. Optical Flow Odometry with Panoramic Image Based on Spherical Congruence Projection. Appl. Sci. 2025, 15, 4474. https://doi.org/10.3390/app15084474
Xie Y, Xiao Y, Zhang J, Zou X, Luo Y, Yang Y. Optical Flow Odometry with Panoramic Image Based on Spherical Congruence Projection. Applied Sciences. 2025; 15(8):4474. https://doi.org/10.3390/app15084474
Chicago/Turabian StyleXie, Yangmin, Yao Xiao, Jinghan Zhang, Xiaofan Zou, Yujie Luo, and Yusheng Yang. 2025. "Optical Flow Odometry with Panoramic Image Based on Spherical Congruence Projection" Applied Sciences 15, no. 8: 4474. https://doi.org/10.3390/app15084474
APA StyleXie, Y., Xiao, Y., Zhang, J., Zou, X., Luo, Y., & Yang, Y. (2025). Optical Flow Odometry with Panoramic Image Based on Spherical Congruence Projection. Applied Sciences, 15(8), 4474. https://doi.org/10.3390/app15084474