1. Introduction
In today’s era of booming multimedia content creation, video editing has become a core element in shaping engaging visual experiences. However, the existing video-editing technologies are gradually revealing multiple limitations when faced with the ever-growing user demands and complex editing tasks.
Traditional video editing means, such as manual cutting, splicing and processing based on simple filters [
1,
2,
3], are rather inadequate when it comes to handling complex video object-level editing and precise local modifications of videos. These methods, which often rely on cumbersome manual operations [
4,
5], are not only inefficient but also struggle to ensure the accuracy and consistency of the editing effects. Moreover, for example, when attempting to modify the detailed features of specific objects in a video (such as changing the texture, shape or color of an object), traditional methods require a huge amount of time for frame-by-frame processing, and are prone to creating obvious visual differences between adjacent frames, which will disrupt the coherence of the video [
6,
7]. Even some advanced traditional video editing software is liable to cause problems like blurry edges and unnatural color transitions when dealing with complex local editing requirements, seriously affecting the visual quality of the edited video.
With the extensive application of deep learning technology in the field of computer vision, the video editing field has also embraced new development opportunities. Specifically, Ruder et al. [
8] put forward a method for transferring the image style to video sequences. Based on the static image style transfer technology, it solves problems such as flickering and discontinuity in videos by introducing new initialization and loss functions. Dong et al. [
9] came up with a CNN-based video style transfer approach. It drew on the principle of image style transfer, applied artistic styles to each frame of the video, and generated videos that conformed to the target style by extracting content and style features. However, these processing methods based on neural networks not only have high computational complexity and large resource consumption but also are slow in speed when dealing with long videos or big data, and show poor adaptability to complex dynamic scenes.
Peebles et al. [
10] presented the GANgealing algorithm, which is used to solve the problem of dense visual alignment. Users only need to label or edit on a single image, and then the editing effect can be easily applied to videos of the same category through forward propagation. However, this method relies on the Gan model [
11], which may lead to deviations in the learned correspondences. Similarly, Liu et al. [
12] proposed a sketch-based face video editing framework, which can apply sketch editing to key frames and then propagate the sketch-editing effect to the entire video. Tzaban et al. [
13] make use of the characteristics of StyleGAN [
14] and the learning of motion tendencies by neural networks to solve the problem of temporal consistency in video face editing to some extent through the coordinated work of six components such as temporally consistent alignment and encoder inversion. However, the two methods mentioned above are both limited by StyleGAN and have problems such as difficulty in generating personalized results, poor local-region processing, and artifact generation.
Kasten et al. [
15] put forward an innovative framework—LNA (Layered Neural Atlases). This method realizes the control of the global scene during the video editing process by decompos-ing video frames into multiple layers and using neural networks to model each layer. Inspired by the research on LNA, Huang et al. [
16] proposed an Inter-active Neural Network Video Editing framework (INVE), which allows users to easily specify editing areas (such as object replacement or modification) in videos. However, both of these two methods have relatively high computational costs and weak gener-alization abili-ties. Especially in scenes with complex motion changes, there may be certain distortion or unnatural effects.
It can be seen that although deep learning models have achieved certain progress in the video editing direction, there are still significant deficiencies when dealing with local areas. Against this background, drawing on some image editing methods based on diffusion models [
17,
18,
19] and attempting to apply them to video editing has pro-vided a brand-new idea for video editing.
Specifically, while recent diffusion-based video editing frameworks have shown some progress in video editing, they still face challenges in achieving precise localized edits with fine-grained spatial consistency. For example, CVPR 2024’s CCEdit [
20] highlights that existing methods often lack explicit mechanisms for aligning local semantic features across frames, leading to inconsistencies when modifying small objects or textures. This limitation is further underscored by SIGGRAPH Asia 2024’s I2VEdit [
21], which demonstrates that even state-of-the-art models struggle to propagate localized image edits to videos without introducing motion artifacts or texture mismatches.
Chen et al. [
22] put forward a new editing form called imitative editing. Users only need to simply mark the area they want to edit in the source image and provide a reference image containing the desired editing effect. Then the editing system can automatically identify the relevant content and accurately apply it to the editing area of the source image. This method is especially suitable for handling modifications of local details and fine editing of complex objects.
Despite the effectiveness of this imitative editing method in image processing, directly applying image editing methods to video editing presents numerous challenges. In this paper, we propose an innovative video editing method. This method combines the local image editing method with CoDeF (Content Deformation Field) [
23] to achieve more precise, more meticulous editing operations on the local content of videos while maintaining temporal consistency.
Specifically, we first produce the canonical image by utilizing the content deformation field. During this process, by deeply analyzing and modeling the video content, the static content in the video is aggregated into the canonical image, while the temporal deformation information from the canonical image to each video frame is accurately recorded.
Subsequently, after generating the canonical image, we apply the local editing module to edit it. By taking advantage of its powerful local editing capabilities, specific local areas in the canonical image are finely modified according to the editing areas specified by users and the reference images. This editing method fully exploits the advantages of analog editing in dealing with local details and can achieve precise editing of tiny objects and complex areas in the canonical image, such as modifying the local texture of an object or adding local components or other subtle features.
Ultimately, we use the learned temporal deformation field to propagate the effect of the edited canonical image to the entire video.
The main contributions of this research are reflected in the following aspects. Firstly, a brand-new video editing framework that combines the image editing method based on the diffusion model with CoDeF is put forward, providing an innovative solution for the fine local editing of videos. Moreover, through the meticulously designed model structure and training strategies, the performance of video editing in handling fine local tasks is remarkably enhanced. It can precisely edit tiny objects and detailed areas in videos while maintaining consistency with the surrounding environment. Last but not least, through extensive experiments and validations, it is proved that this method is superior to the existing methods in terms of the quality of fine local video editing, temporal consistency, and user satisfaction, providing strong support and impetus for the development of video editing technology in the direction of fine local editing.
In practical applications, our approach meets critical demands in industries such as film post-production and e-commerce video creation. For instance, as shown in EffiVED [
24], there is a growing need for tools enabling efficient video editing that balances accuracy and computational efficiency—especially for real-time interactive platforms. Our method directly addresses this challenge by enabling precise control over structural integrity and appearance changes. It builds on the objectives of recent studies such as the 2024 arXiv preprint “Video Diffusion Models: A Survey” [
25], which emphasize the need for scalable solutions in complex editing scenarios.
3. Materials and Methods
3.1. Framework Design Motivation and Method Comparisons
The core challenge in video editing tasks is to ensure temporal consistency while preserving spatial accuracy. Among existing approaches, single-modality learning methods rely exclusively on visual information: traditional GAN/CNN frameworks excel at learning local features for high-quality regional editing but fall short in temporal modeling, leading to inter-frame inconsistencies and imprecise control over editing regions. In contrast, Implicit Neural Representation (INR)-based methods maintain strong spatio-temporal coherence, making them well-suited for style transfer and global modifications. However, they struggle to achieve high-precision local edits and exhibit suboptimal performance with complex user inputs (e.g., text-guided editing).
End-to-end Transformer and large-scale diffusion-based video editing methods offer robust global feature modeling to maintain video consistency, applicable to tasks like style transfer and reconstruction with long-range temporal dependency capture. Yet these approaches suffer from high computational costs and poor real-time performance. Moreover, constrained by the global nature of Transformer modeling, their fine-grained control over local regions remains insufficient, complicating precise localized editing.
To address the gap where existing methods fail to simultaneously meet the dual requirements of “video spatio-temporal consistency” and “precise local-region modification”, this study proposes a region-aware cross-modal learning framework. The framework integrates the strengths of CoDeF and diffusion-based local editing: it leverages CoDeF for temporal consistency modeling to enhance video-editing coherence, employs a dualbranch diffusion architecture for high-precision local editing control, and incorporates cross-modal information from reference images to mitigate the controllability limitations of single-modality approaches. Key indicator comparisons show that traditional GAN/CNN methods achieve high spatial accuracy but low temporal consistency, with editing controllability dependent on training. Transformer/diffusion models exhibit high temporal consistency but moderate spatial accuracy, limited editing controllability, and high computational costs. By contrast, our method achieves superior performance in spatial accuracy, temporal consistency, and editing controllability with moderate computational overhead.
3.2. Framework Overview
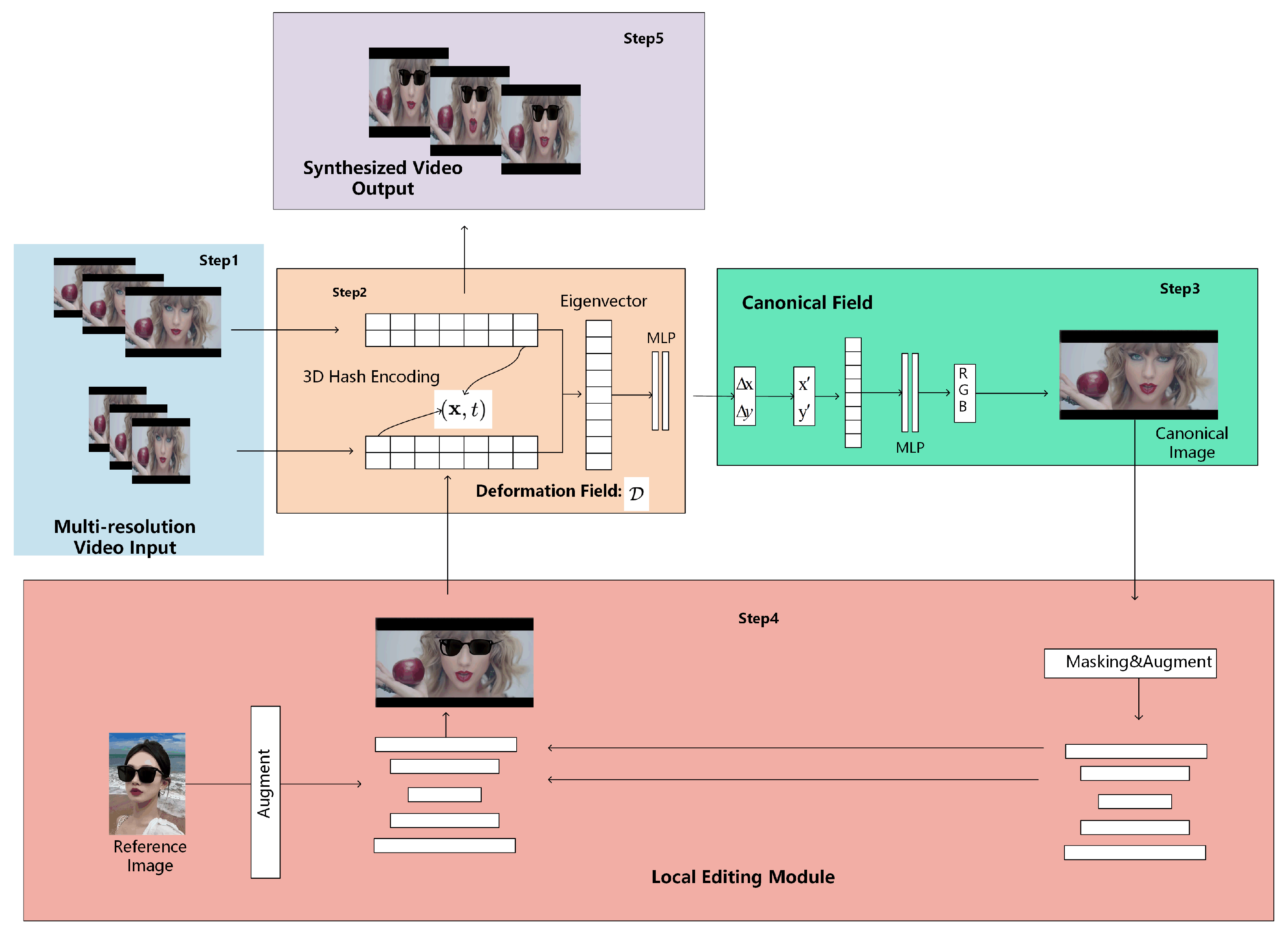
As shown in
Figure 1, the overall framework is mainly composed of three key steps: generating the canonical image, which serves as a stable reference representation with certain pre-defined characteristics (such as a standard scale, orientation, or color space relevant to the video content), conducting local editing on the canonical image, and leveraging the temporal deformation field to propagate the editing effect to the entire video. These three steps are intricately interconnected. The generation of the canonical image provides the basis for local editing, and the local editing in turn informs the creation of the temporal deformation field, which is then used to propagate the editing effect across the entire video, forming a seamless and complete video-editing process. This process can effectively handle various editing requirements in videos, especially the precise modification of local details.
Our video reconstruction pipeline consists of multiple steps, taking a multi-resolution video sequence as input and outputting a synthesized video. First, features are extracted from video frames at different resolutions (Step 1), and spatio-temporal information is mapped to a normalized coordinate space using 3D hash encoding and deformation fields (Step 2). The Canonical Field is then utilized to compute the RGB colors of normalized pixels (Step 3). Next, the Local Editing Module is applied (Step 4): the generated canonical image serves as the source image, which undergoes masking and augmentation operations. By integrating provided reference images, the canonical image is enhanced and edited to enable precise style transfer and content adjustment. Finally, a high-quality reconstructed video is produced (Step 5).
To enhance the clarity of the video editing workflow and elevate methodological transparency, we hereby present the following pseudocode. Algorithm 1 delineates the core operations of our framework, forging a seamless link between theoretical elaborations and procedural logic. It sequentially unfolds critical stages: commencing with input data loading, multi-scale feature extraction, and content deformation field computation, then advancing to canonical image generation, local editing application, and final frame reconstruction. Each step aligns with the technical specifics expounded in corresponding sections, offering readers a structured roadmap to thoroughly grasp the entire video editing pipeline.
| Algorithm 1 Video Editing Pipeline |
Require: Input video frames , Reference image
Ensure: Edited video frames - 1:
Step 1: Load input video and reference image - 2:
- 3:
- 4:
Step 2: Extract Multi-Scale Features - 5:
for
do - 6:
- 7:
end for - 8:
Step 3: Compute Content Deformation Fields (CoDeF) - 9:
for
do - 10:
- 11:
end for - 12:
Step 4: Compute Canonical Image - 13:
- 14:
Step 5: Apply Local Editing - 15:
for
do - 16:
- 17:
end for - 18:
Step 6: Reconstruct Frames with Deformation Fields - 19:
for
do - 20:
- 21:
end for - 22:
Step 7: Save the Edited Video - 23:
|
3.3. Generate the Canonical Image
3.3.1. Train the Model Based on Video Frames
When dealing with video data, we are faced with the following task: Given a video V composed of multiple frames, and its frame sequence is represented as . Our goal is to train an implicit deformable model that can accurately fit the features and change patterns of these frames.
This model is primarily built from two coordinate-based multi-layer perceptrons (MLPs), namely the deformation field D and the canonical field C. The deformation field D takes on the main responsibility of transforming and adjusting the coordinate information within video frames. By leveraging the input coordinate data, it is capable of outputting the corresponding deformed coordinates, thereby effectively depicting the shape-changes and displacements of objects or scenes across different frames in the video.
On the other hand, the canonical field C is dedicated to extracting the canonical information from the video frames. This canonical information can be regarded as a representation encapsulating some common features, basic patterns, or internal structures inherent in the video content. It can harmonize and standardize the relevant information across different frames, enabling the model to better understand and learn the overall semantic and structural information of the video.
Through the coordinated operation of these two key components, the implicit deformable model can effectively fit and analyze the video V, laying a solid foundation for subsequent video-editing tasks.
3.3.2. The Definition and Processing of the Canonical Field
In the CoDeF method, the Canonical Content Field is utilized to unify the dynamic content of a video into a static, time-independent coordinate system. The introduction of the Canonical Content Field imparts consistency to the content representation across video frames. This, in turn, enables efficient video editing with temporal consistency.
The Canonical Content Field
C is a continuous representation of all the flattened textures in a video, specified by the function:
This function maps a two-dimensional position
to a color vector
. Put simply, for each position coordinate within the video frame, the corresponding color value can be retrieved via the Canonical Content Field.
During the model-training process, to accelerate the training and enable the network to capture high-frequency details, the multi-resolution hash encoding is introduced:
It is introduced to convert the coordinate
X into a feature vector. Here,
L is the number of layers of multiresolution, and
F is the feature dimension of each layer.
Specifically, the coordinates
X of the canonical field are fed into the
multi-resolution hash encoder to generate high-dimensional features:
Such an operation is beneficial for the model in capturing high-frequency details.
are the features obtained by linearly interpolating
X at the
i-th resolution.
By performing linear interpolation on the coordinates at multiple resolutions, different features are obtained. This enables the network to capture the high-frequency details in the data more comprehensively and meticulously. Consequently, it can enhance the model’s ability to represent and process the data. After obtaining the high-dimensional features, a Multi-Layer Perceptron (MLP) is used to generate RGB values from the high-dimensional features:
By doing so, the model can comprehend and handle various detailed information in the video more comprehensively and meticulously. As a result, it provides more accurate data support for subsequent video reconstruction and processing tasks. The ultimate goal is to achieve better results. For instance, when processing videos with complex textures or fast-moving objects, this multi-resolution hash encoding technology can enable the model to better capture subtle changes and features, thereby enhancing the quality and accuracy of video processing.
3.3.3. The Construction and Function of the Deformation Field
The Deformation Field is one of the key constituents of the CoDeF method. Its main function is to forge a pixel-level correspondence between video frames and the canonical field. This mapping relationship serves a dual purpose: it unifies the content representation of video frames and lays a solid foundation for the propagation of edits. Through the construction and optimization of the Deformation Field, the content within video frames can be effectively aggregated into the static canonical field. Simultaneously, the edited content can be efficiently propagated back to each frame, thereby achieving temporally-consistent video editing effects.
The deformation field
is a three-dimensional mapping function that characterizes the spatial relationship between video frames and the canonical image. Its function is to translate the coordinates of a pixel
x in a video frame and the time frame index
t into the corresponding coordinates
in the canonical image. It is defined as:
The input is
, where
represents the pixel coordinates in a video frame, and
represents the time-index of the frame. The output is
, which represents the pixel coordinates in the canonical image.
In the implementation of the deformation field, the first step is to perform feature extraction on the pixel coordinates
of the video frames. In order to efficiently represent the spatial and temporal information at different resolutions, a multi-resolution hash encoder is used:
From the high-dimensional feature space to the specific coordinate transformation, learning needs to be carried out through a small multi-layer perceptron (MLP). Specifically, the MLP takes the encoded feature
as input and outputs the pixel coordinates
in the canonical image:
Here, the structure of the MLP is relatively simple, but its learning ability is sufficient to adapt to the nonlinear transformation relationship between the video frame and the canonical field.
3.3.4. Optimization and Acquisition of Canonical Images
The goal of generating the canonical image is to find a global static representation that can incorporate all the core content of the video frames, while ensuring semantic consistency between frames and reconstruction quality. The training of the model is achieved by minimizing the objective function
. This objective function corresponds to the
loss between the true color and the predicted color
at a given coordinate
. Its mathematical expression is:
This means that during the training process, the model endeavors to make the predicted color as close as possible to the true color, thereby improving the accuracy of the reconstructed video. Specifically, here
represents the color value of the pixel
x in the video frame
t;
represents the pixel value reconstructed from the canonical content field
C through the temporal deformation field
.
To prevent model overfitting and improve the generalization ability and stability of the model, additional regularization terms are introduced.Among them, the flow-guided consistency loss
assumes a pivotal role, and the total loss is calculated as:
where
is a hyperparameter used to balance different loss terms. The value of the regularization parameter
in the loss function
L is determined by whether the optical flow of the video sequence is extracted during the preprocessing stage. When the optical flow data of the video sequence is extracted in the preprocessing stage,
is selected. This approach assigns equal importance to the reconstruction loss (
) and the flow-guided consistency loss (
), thereby effectively preventing overfitting and enhancing generalization ability. Such balanced weighting enables the model to optimize for both accurate reconstruction and meaningful flow field generation simultaneously. Empirical verification shows that this equal-weight strategy ensures stable training, while efficiently avoiding overfitting and maintaining the model’s robust generalization capability. When the optical flow data of the video sequence is not extracted during the preprocessing stage,
is adopted.
After completing the optimization of the content deformation field, the process of obtaining the canonical image is relatively simple yet crucial. By setting the deformation of all points to zero, from the perspective of the deformation field, all points are mapped into a unified canonical space. The image within this space is precisely the canonical image.
3.4. Local Editing Module
After obtaining the canonical image through the above methods, the next step is to utilize the local editing module to edit it with the help of a pre-trained diffusion model, so as to achieve the goal of video editing. As shown in
Figure 2, the local editing module is based on a meticulously de-signed dual diffusion model architecture. This architecture is mainly composed of two important components: the source image U-Net and the correlation auxiliary U-Net.
The selection of reference data typically involves user-supplied reference images containing the desired texture or content. These images undergo a preprocessing pipeline to ensure compatibility with the subsequent editing framework. First, non-square images are padded to square dimensions to standardize their geometry. Second, they are resized to the target resolution while strictly preserving the aspect ratio to avoid spatial distortion. Additionally, data augmentation techniques—including Gaussian blur and random perspective transformation—are applied to enhance feature robustness and model generalization. Finally, style and content features are extracted using a CLIP visual encoder, and these features are projected into a dimensional space compatible with the UNet architecture through a linear resampler, ensuring seamless integration with the downstream network. Collectively, these steps facilitate the effective extraction and utilization of reference image features for precise manipulation of source images.
If multiple similar objects appear in the video, our current method relies entirely on user-specified regions to constrain editing. That is, the user manually selects the target object to be edited. No automatic instance segmentation is applied at this stage. However, in future work, we plan to explore the integration of instance segmentation techniques to better distinguish between visually similar and spatially close objects, thereby improving localization accuracy and edit precision.
3.4.1. Preparation of Canonical Image Input
Before performing local editing, it is necessary to clearly specify the area to be edited in the canonical image. This operation is accomplished by creating a white mask. The area exactly covered by the mask is the part that the subsequent model will process. As shown in
Figure 3, if one wants to change the texture of the apple in the image alone, the user can draw a white mask on the apple part of the canonical image. At the same time, the user needs to provide a reference image. This reference image should embody the user’s expected visual effect for the edited area. Taking the apple-texture modification as an example, the reference image can be a photo of a green tangerine, and its texture style can provide a clear editing direction for the model.
3.4.2. Local Editing Processing
The source image U-Net first acquires the canonical image and its mask. The source image U-Net is initialized based on the inpainting model of Stable Diffusion-1.5, and its input is a tensor containing 13 channels.
The 4-channel image latent representation: It governs the diffusion process that gradually evolves from initial random noise to the final output latent code. This process is the core link in generating the specific content of the edited area. The 1-channel binary mask: It serves as a clear marker, precisely indicating the specific area in the source image where the content needs to be regenerated. The 4-channel background latent representation: It contains information related to the background of the area in the source image that is not covered by the mask. Such information is crucial for maintaining the coherence and consistency of the background of the image after editing. Together with the 4-channel image latent representation and the 1-channel binary mask, these components work in concert to ensure the proper generation and refinement of the edited content while maintaining the overall integrity of the image.
In addition, there is the depth map which is converted into a 4-channel depth latent representation after projection processing. Its primary function is to furnish the model with the requisite shape information, assisting the model in better performing reasonable and accurate content-filling operations based on the original shape of the objects in the source image during the editing process. The Correlation Auxiliary U-Net is another vital component within the local editing module. Its core task is to extract the multi-level features of the reference image. It is initialized with the Stable Diffusion-1.5 model and takes the 4-channel latent representation of the reference image as input, delving deep into the visual information within. It not only focuses on the surface information of the image but delves deep into different levels of the image, comprehensively analyzing the reference image from the macroscopic structure to the microscopic details.
To effectively transfer these extracted reference features to the Source Image U-Net, a special attention mechanism is adopted. In the specific calculation process, the for-mula is as follows:
During the middle and upper layer stages of the Source Image U-Net, the keys and values of the Correlation Auxiliary U-Net are concatenated with the corresponding parts of the Source Image U-Net.
and
represent the keys and values of the Correlation Auxiliary U-Net respectively;
and
represent the keys and values of the Source Image U-Net.
In this way, the Source Image U-Net can fully leverage the content in the reference image to complete the synthesis of the masked area in the source image. For example, when editing an object in the source image, if the reference image contains specific texture or shape features of a similar object, the Correlation Auxiliary U-Net extracts these features and transmits them to the Source Image U-Net through the attention mechanism. This enables the Source Image U-Net to generate an object part in the masked area of the source image that is similar to that in the reference image while also coordinating with the overall source image. This ensures that the edited image is more visually natural and realistic. As a result, the accuracy and quality of the editing are improved.
3.5. Deformation Field Propagation
After completing the editing of the canonical image, in order to efficiently and accurately propagate the editing results to all frames of the entire video, we use the Deformation Field to achieve the conversion process from the canonical image to the video frames.
The deformation field
ensures that each pixel in the video can precisely obtain the edited color value from the canonical image by describing the mapping relationship between each pixel
X in the video frame and the corresponding coordinate
in the canonical image. Through the inverse mapping
of the deformation field, we can propagate the content of the edited canonical image back to each frame of the video:
represents the color value of the pixel
X in the video frame;
represents the color value of the pixel
in the edited canonical image;
is the inverse mapping of the deformation field, which maps the pixel coordinate
X in the video frame to the coordinate
in the canonical image.
This mapping process ensures that each pixel in the video frame can obtain the edited content through the canonical image, and can avoid the jumping or flickering phenomena between frames.
However, in cases where the object undergoes drastic shape or appearance changes, the current method may become less stable. In such cases, we suggest that future work could incorporate additional constraints or adaptive warping techniques to improve temporal consistency. These techniques are not applied in the current implementation.
4. Results
4.1. Experimental Setup
This experiment aims to evaluate the effectiveness and performance of our pro-posed approach, which combines the image editing method based on the diffusion model with CoDeF, in the context of video editing. The key focus is on demonstrating how our method effectively propagates edits across video sequences while maintaining spatial and temporal coherence.
During the training process, we set the initial learning rate to 0.001 with a background loss weight of 0.003. The model is trained for 10,000 iterations in total. To ensure stable convergence, we implement a multi-stage learning rate decay schedule, with rate adjustments at steps 2500, 5000, and 7500. Model checkpoints are saved every 2000 steps for model selection and evaluation purposes.
We conducted the experiments on a high-performance computing platform equipped with a single NVIDIA A100 GPU, utilizing a CUDA-accelerated environ-ment. This robust infrastructure ensures the capability to handle large-scale video data and perform complex computations required by our model.
In validating our approach, we employed a video dataset designed for diversity and representativeness, encompassing a broad spectrum of real-world scenarios. This intentional variety ensures experimental outcomes reflect generalized performance across applications rather than overfitting to niche domains. The evaluation dataset comprises video samples with varied motion dynamics and visual aesthetics. Clip lengths range from 40 to 120 frames, and editing tasks span color adjustments, texture synthesis, and object manipulations. These examples were curated to thoroughly assess the model’s capacity to maintain temporal coherence across diverse editing requirements.Through appropriate tuning of training parameters, the duration of optimization can be flexibly adjusted within a range of 3 to 20 min.
This study utilizes publicly available datasets under appropriate licenses, ensuring compliance with data privacy regulations. No personally identifiable information (PII) is processed throughout the research. For qualitative assessments involving human contributions, informed consent was obtained where applicable. Our work adheres to ethical guidelines, emphasizing responsible AI practices and measures to prevent misuse.
4.2. Editing Results
To evaluate the effectiveness of our approach, we conducted experiments on various videos, demonstrating its ability to edit local content components and transfer textures to specific regions.
Figure 4 illustrates the editing results, where we showcase two representative cases to highlight the flexibility and robustness of our method.
In the first row of
Figure 4, we used a source video featuring a woman holding a red apple and speaking without any accessories. A canonical image was extracted from the video, and a reference image of a woman wearing sunglasses was provided. By editing the canonical image to include sunglasses, our method propagated this modification across the entire video sequence. The resulting edited video demonstrates a smooth and temporally coherent transfer of the accessory (sunglasses), where all frames depict the woman wearing sunglasses while maintaining consistency with the original video’s motion and content.
In the second row of
Figure 4, we performed texture transfer by using a reference image of a green tangerine. The canonical image was edited to replace the texture of the red apple with that of the green tangerine. This modification was then propagated across the entire video sequence. The resulting video frames show that the red apple is consistently replaced by the green tangerine across all frames, preserving the spatial alignment and the natural motion of the hand and object.
By editing a single canonical frame, our method successfully disseminates modifications across the entire video sequence while maintaining spatiotemporal coherence. This demonstrates the efficacy of our approach in handling localized edits. Two cases serve as evidence that our approach supports a wide range of edits, from adding new visual features (e.g., sunglasses) to replacing object textures (e.g., apple to green tangerine). This versatility underscores the generalizability of our method to various video-editing tasks. The results show that by simply providing different reference images, users can achieve highly customized edits, which offers significant flexibility and control.
4.3. Comparison to Prior Arts
To thoroughly validate the performance of our proposed local video editing method, we selected several state-of-the-art methods for comparison. Specifically, we selected AnyV2V [
41], StableVideo [
37], and MotionDirector [
45] as competitors, as they represent prominent approaches in video editing. AnyV2V: Known for its versatility in video-to-video translation tasks, this method is centered around maintaining temporal consistency across frames. StableVideo: A method that places emphasis on stability during video editing, particularly for long-term temporal coherence. MotionDirector: Renowned for dealing with complex motion edits, it focuses on modifying motion trajectories while preserving realism in spatial domains. Each of these competing methods has its own unique strengths in the realm of video editing. These methods were chosen because they address the challenges of local edits and texture transfer. Their focus closely aligns with our objectives. By comparing with these approaches, we can showcase the distinct advantages of our method in handling fine-grained edits and maintaining temporal coherence.
4.3.1. Qualitative Experiment
To further evaluate the effectiveness of our method, we carried out detailed demonstrations to contrast the qualitative performance of our method with the selected competitors.
Figure 5 and
Figure 6 display the visual results. These figures provide clear visual evidence for a direct comparison of the qualitative performance among different methods.
As shown in
Figure 5, the source video depicts a woman speaking, and the goal is to modify her hairstyle to match the medium-length wavy red hair from the reference image. This task requires not only an accurate transfer of color and shape but also the preservation of natural motion and temporal consistency across frames.
Among the compared methods, AnyV2V achieves a reasonable color transformation; however, it struggles with structural accuracy, resulting in distorted hair shapes that fluctuate across frames. These inconsistencies render the edited hairstyle appear unnatural and unstable. Overall, these issues limit its ability to produce high-quality, natural-looking hairstyle modifications. StableVideo, on the other hand, ensures better temporal coherence, preventing flickering or erratic movements, but it is deficient in making precise edits. As a result, the final output exhibits an incomplete hairstyle transformation where significant details, such as the wavy texture and proper shape, are missing. Such limitations in achieving accurate and detailed transformations reduce the overall quality of the edited video. MotionDirector performs better in preserving motion dynamics, but the edited region contains overly artificial textures that contrast starkly with the original scene, reducing the realism of the output. Consequently, the lack of natural-looking textures undermines the authenticity of the final output.
In contrast, our method effectively captures the fine details of the hairstyle, including the distinctive wave patterns and vibrant red tones, while ensuring a natural blend with the original video. The structural accuracy of the modified hair remains intact, and the transitions between frames are handled smoothly, eliminating any undesirable temporal artifacts. As a result, the subject’s movement appears seamless. The modification looks both visually convincing and is naturally integrated into the scene.
As shown in
Figure 6, this example centers on replacing the texture of an orange colliding with water in the source video with that of a watermelon, using a reference image as guidance. This transformation is particularly challenging as it requires precise texture alignment, consistent lighting adaptation, and seamless interaction with the surrounding water to maintain realism.
AnyV2V struggles significantly in this task, resulting in severe artifacts and inconsistent texture mapping across frames. The resulting output exhibits noticeable distortions and flickering, making the transformation visually unstable. These flaws seriously compromise the quality and visual integrity of the texture-replacement result. StableVideo demonstrates superior performance in temporal consistency, avoiding erratic changes in texture, but the transfer remains incomplete. Residual patterns of the original orange texture are still present, unable to achieve a full and convincing transformation. Such incomplete transfer significantly reduces the believability of the modified video. MotionDirector successfully applies the watermelon texture, but it introduces unnatural lighting variations and abrupt transitions between frames, making the edited object seem out of place in the scene. These unnatural visual elements undermine the overall authenticity of the edited scene.
Our proposed method, however, excels in maintaining realistic texture replacement. It also ensures harmonious integration with the original video dynamics. The watermelon texture is transferred smoothly onto the orange while preserving crucial visual details such as reflections, shadows, and interactions with the water. Additionally, our approach prevents flickering and ensures that the changes remain consistent across frames. This results in a natural and visually cohesive output, where the new texture appears as an inherent part of the original video rather than an artificial overlay.
4.3.2. Quantitative Results
To the best of our knowledge, in the field of video editing, there is still a lack of widely recognized metrics to comprehensively evaluate the performance of different methods [
37,
46]. However, in order to compare the advantages and disadvantages of the method we proposed with other methods as objectively as possible, in combination with previous studies, we have comprehensively considered several key metrics, including user study metrics: Motion Alignment (MA), Appearance Alignment (AA), Editing Quality (EQ), Temporal Consistency (TC). Motion Alignment (MA) serves to assess the congruence of motion in edited videos with respect to the motion intent encapsulated in the reference image, focusing on the conformity of object movements to predefined editing objectives. Appearance Alignment (AA) quantifies the degree of visual correspondence between edited videos and the reference image, encompassing attributes such as color consistency, texture fidelity, and object-shape preservation. Editing Quality (EQ) provides a holistic assessment of visual integrity in edited outputs, evaluating parameters including sharpness, absence of artifacts, and perceptual naturalness. Temporal Consistency (TC) measures the spatiotemporal coherence of edits across frame sequences, ensuring seamless transitions and the absence of abrupt or unnatural visual discrepancies over time.
These metrics are crucial as they cover different aspects of video editing quality, from the alignment of motion and appearance to the overall editing quality and temporal consistency. Through comparison, we have found that our results surpass those of other methods in local video editing.
To ensure a robust evaluation, we conducted a user study with 50 participants, each evaluating 20 videos. For each case, the participants viewed the source video and the reference image before being presented with four edited videos in random order. They rated each video on a Likert scale from 1 to 5 for each metric.The scores were computed by aggregating participant ratings and normalizing them to a 100-point scale for better comparability.
The results are shown in
Table 1. Our method achieved the best performance in all aspects of the human evaluation. It also obtained the best results in other perceptual index evaluations. These outcomes prove that our proposed method has superior editing capabilities.
4.4. Ablation Study
To validate the importance of canonical image editing, we conducted an ablation study. The results are shown in
Figure 7.
Figure 7a represents the effect of propagation after editing the canonical image, and
Figure 7b,c,d respectively demonstrate the effects of propagation along the deformation field after editing the first frame, a random frame, and the last frame. Observations reveal that in
Figure 7b,d, the eyes of the person are always open, and in
Figure 7c, the eyes of the person are always closed. This indicates that the canonical image can not only store the static shape information of the video object but also represent the motion information of the video object. Analysis shows that by observing
Figure 7b–d, there are significant artifacts and afterimages at the edges of the fingers and hair, and some parts are blurred.
The above ablation experiments demonstrate that the canonical image can significantly support the local editing module in performing editing operations. Simultaneously, it ensures the consistency of video processing and the accuracy and consistency of motion information, further enhancing the quality of video editing.
To further validate the effectiveness of the canonical image in supporting local editing, we conducted additional quantitative experiments. We evaluated the editing quality using LPIPS, PSNR, and FID scores on a dataset of videos. The results in
Table 2 demonstrate that utilizing the canonical image significantly improves perceptual similarity and reduces artifacts in edited frames. We conducted 20 experiments to validate the contribution of the canonical image in supporting the local editing module. The results demonstrate that the canonical image effectively retains structural and semantic information, enabling more stable and accurate edits compared to direct frame-wise editing approaches.
5. Discussion and Conclusions
In this research, we introduce a cohesive framework that combines image-based local editing with the CoDeF (Content Deformation Fields) methodology to enable high-fidelity video editing. By capitalizing on the canonical image representation inherent in video sequences, our approach allows for precise localized modifications with minimal user intervention—requiring only a reference image and an editing mask as inputs. Critically, edited content is propagated across the entire video sequence while preserving temporal consistency, a key challenge in dynamic visual processing. Comprehensive experimental evaluations demonstrate that our method surpasses state-of-the-art techniques across diverse video editing tasks, establishing it as a robust and efficient solution.
Notwithstanding its merits, the proposed approach has notable limitations. The local editing module may encounter difficulties in regions where the reference image contains ambiguous semantic elements, potentially leading to inconsistent results. Additionally, managing extremely complex scenes with overlapping motions or intricate textures remains a technical hurdle. Future investigations could prioritize enhancing the model’s discriminative capabilities through advanced learning architectures—such as adaptive attention mechanisms—and integrating domain-specific prior knowledge to improve performance in challenging scenarios. Beyond technical refinements, this framework holds substantial promise for cross-disciplinary applications, including augmented reality (AR), virtual reality (VR), and video game content generation. Further explorations might focus on domain-adaptive optimizations to extend its utility to interactive media production, automated content creation pipelines, and intelligent video analytics systems.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}