
PBD-YOLO: Dual-Strategy Integration of Multi-Scale Feature Fusion and Weak Texture Enhancement for Lightweight Particleboard Surface Defect Detection


Abstract
1. Introduction and Literature Review
- (1)
- Existing improvement schemes based on YOLO primarily emphasize making the model lightweight or optimizing a single scale, which is unsatisfactory for detecting multi-scale defects that co-occur. When multi-scale defects coexist within a single scene, such as large oil pollution and small shavings, conventional feature fusion methods tend to dilute the features of smaller objects within the deep network [17,18]. This dilution can lead to missed detections.
- (2)
- The texture features of weak scratch defects are rarely detected. More attention tends to be directed toward defects with strong significance and notable grayscale, such as glue spots, shavings, and oil stains. This focus can be attributed to the shortcomings of existing methods, which lack an effective mechanism for enhancing edge features. The conventional convolutional operations within deep networks have a limited capacity to preserve the edge information [19,20], leading to reduced confidence in detecting defects with weaker features.
- (1)
- Based on the YOLOv10 algorithm architecture, an improved algorithm, PBD-YOLO, is proposed for particleboard surface defect detection. PBD-YOLO improves the mAP and the recall while guaranteeing the original network’s real-time performance.
- (2)
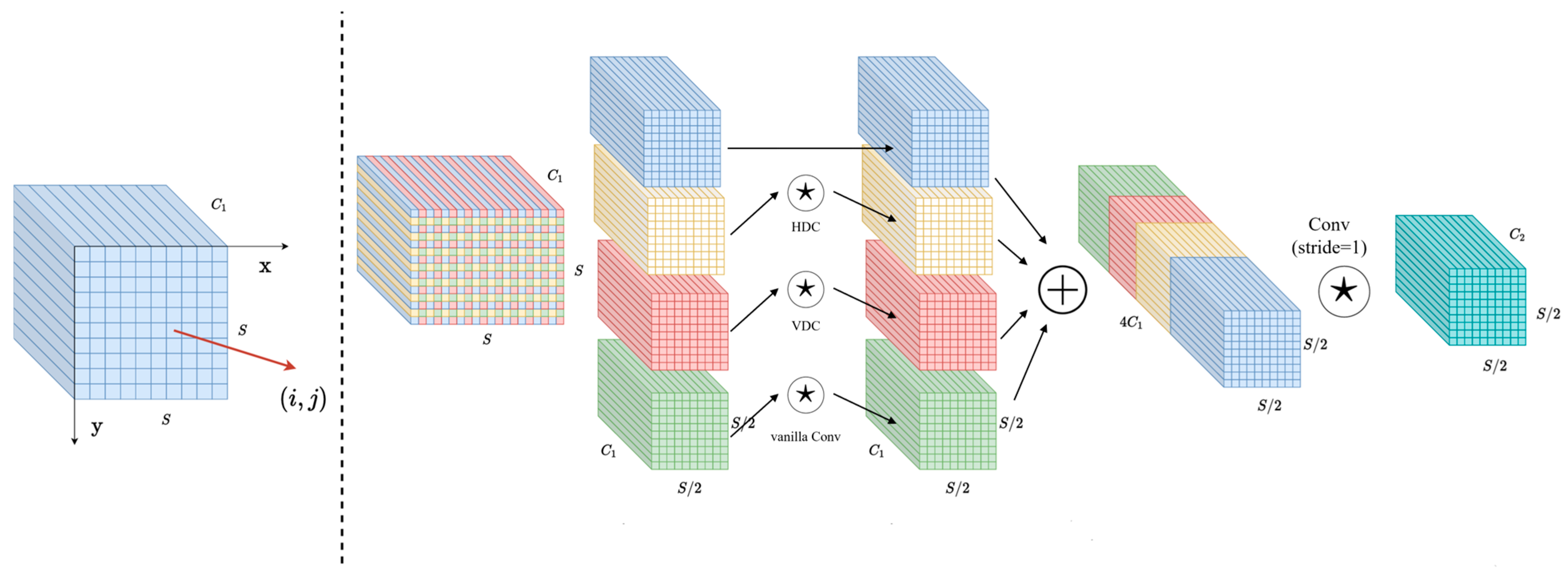
- The PBD-YOLO algorithm introduces the Space to Depth and Difference Enhance Convolution (SPDDEConv) module, which utilizes spatial partitioning, multi-branch difference convolution, and a channel fusion strategy [21,22]. This approach aims to retain more information during the down-sampling process and sharply enhance the edge texture characteristics of defects on the surface of particleboard. As a result, it improves the model’s ability to detect defects, particularly those with weak features.
- (3)
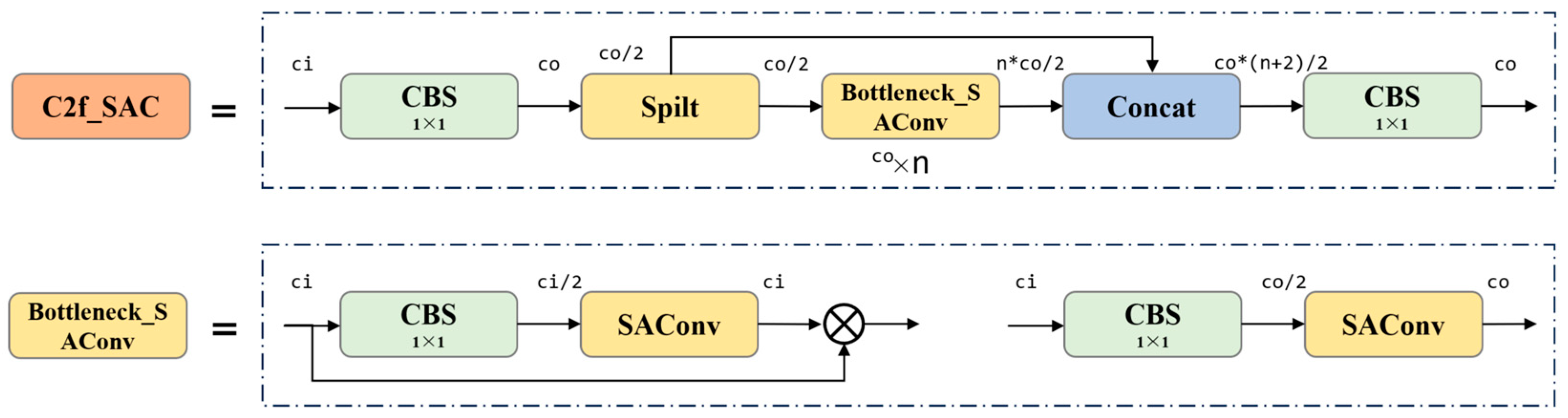
- The PBD-YOLO algorithm also introduces the Switchable Atrous Convolution (SAC) within the C2f feature extraction module. SAC looks twice at the input features with different atrous rates, and the outputs are combined via switches. Additionally, the ShareSepHead module is designed to merge feature maps of varying sizes from the neck by sharing weights. This design enhances the model’s adaptability to multi-scale defects on the particleboard surface and improves its robustness when simultaneously detecting multiple targets of different scales.
2. Materials and Methods
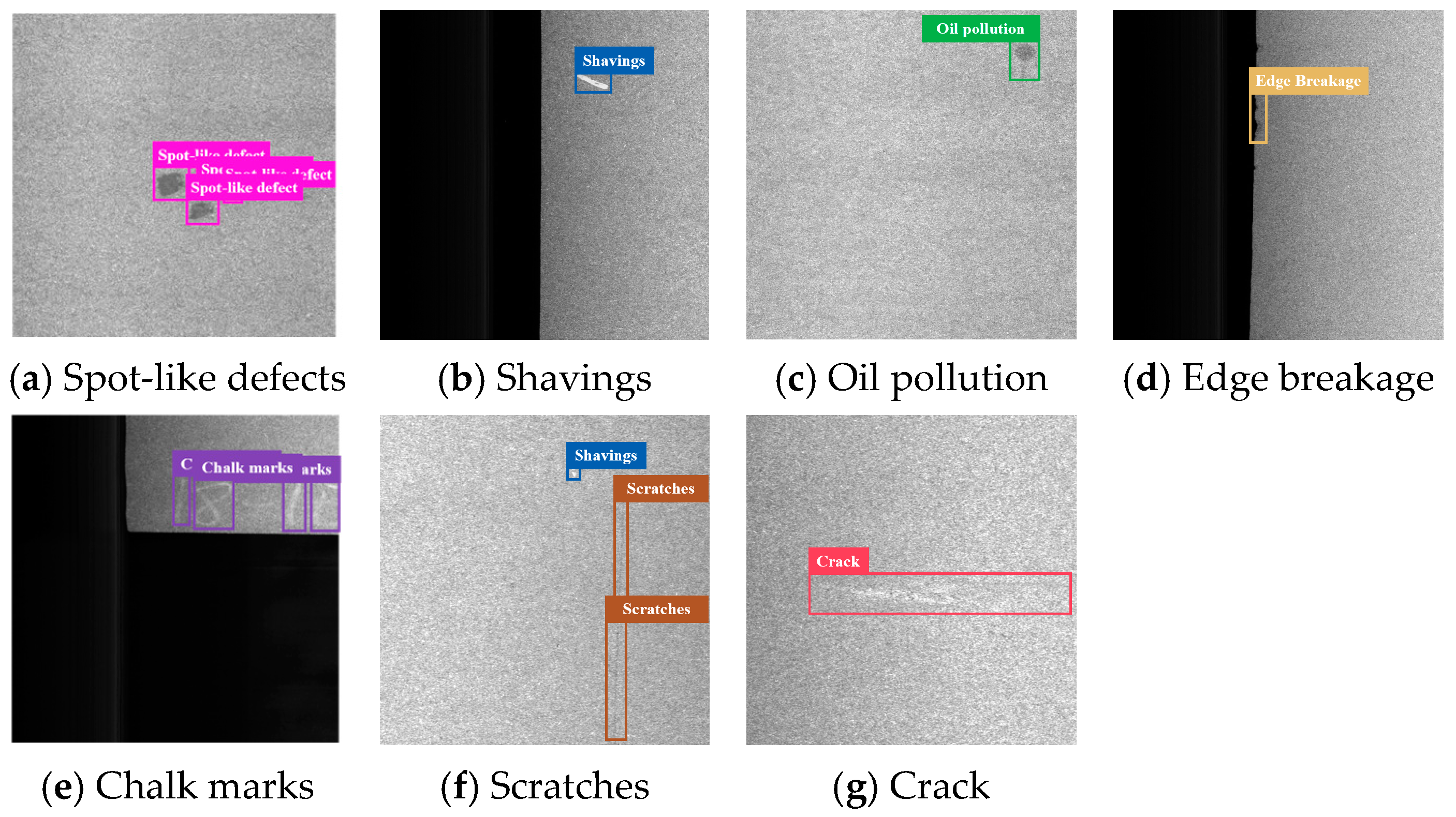
2.1. Materials
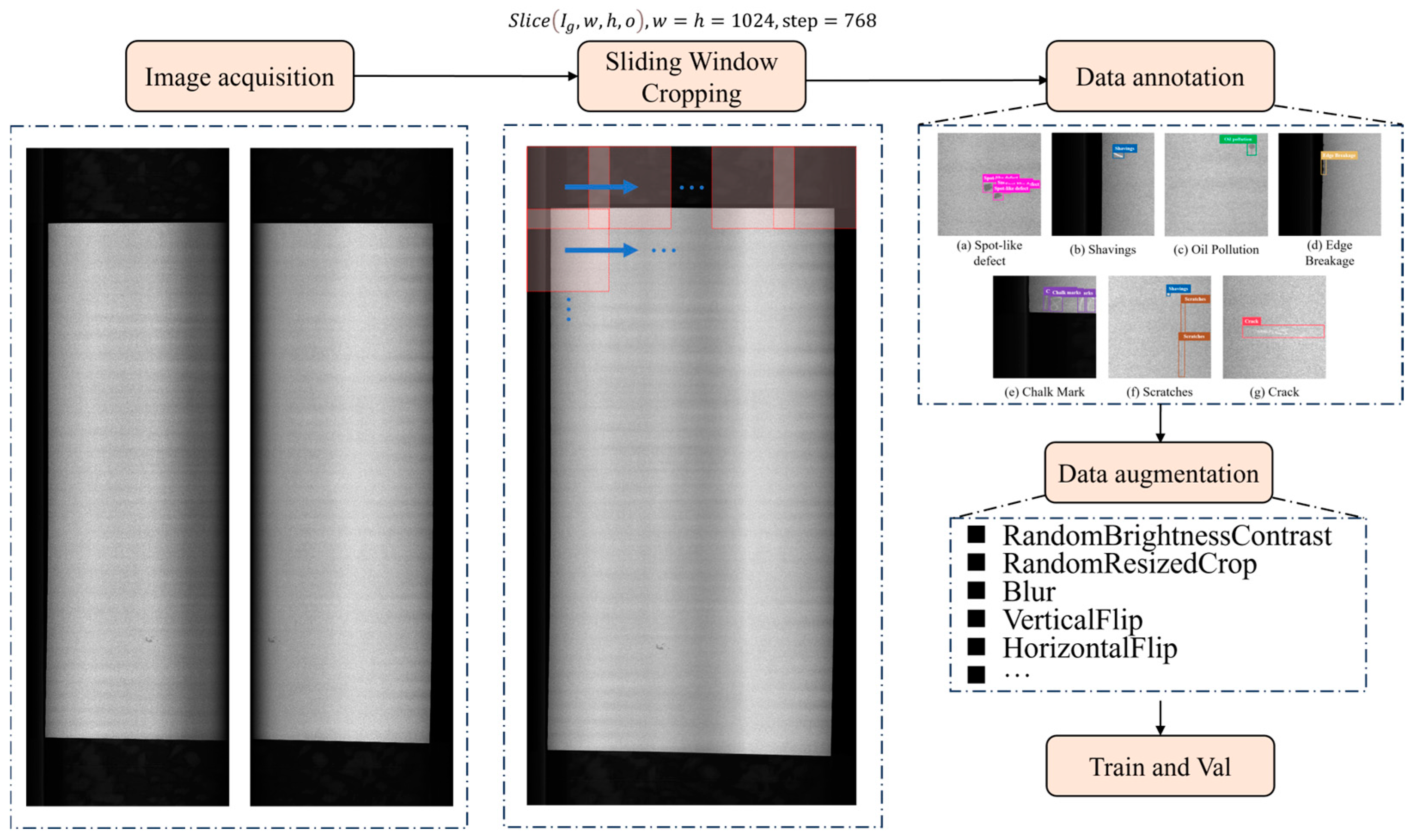
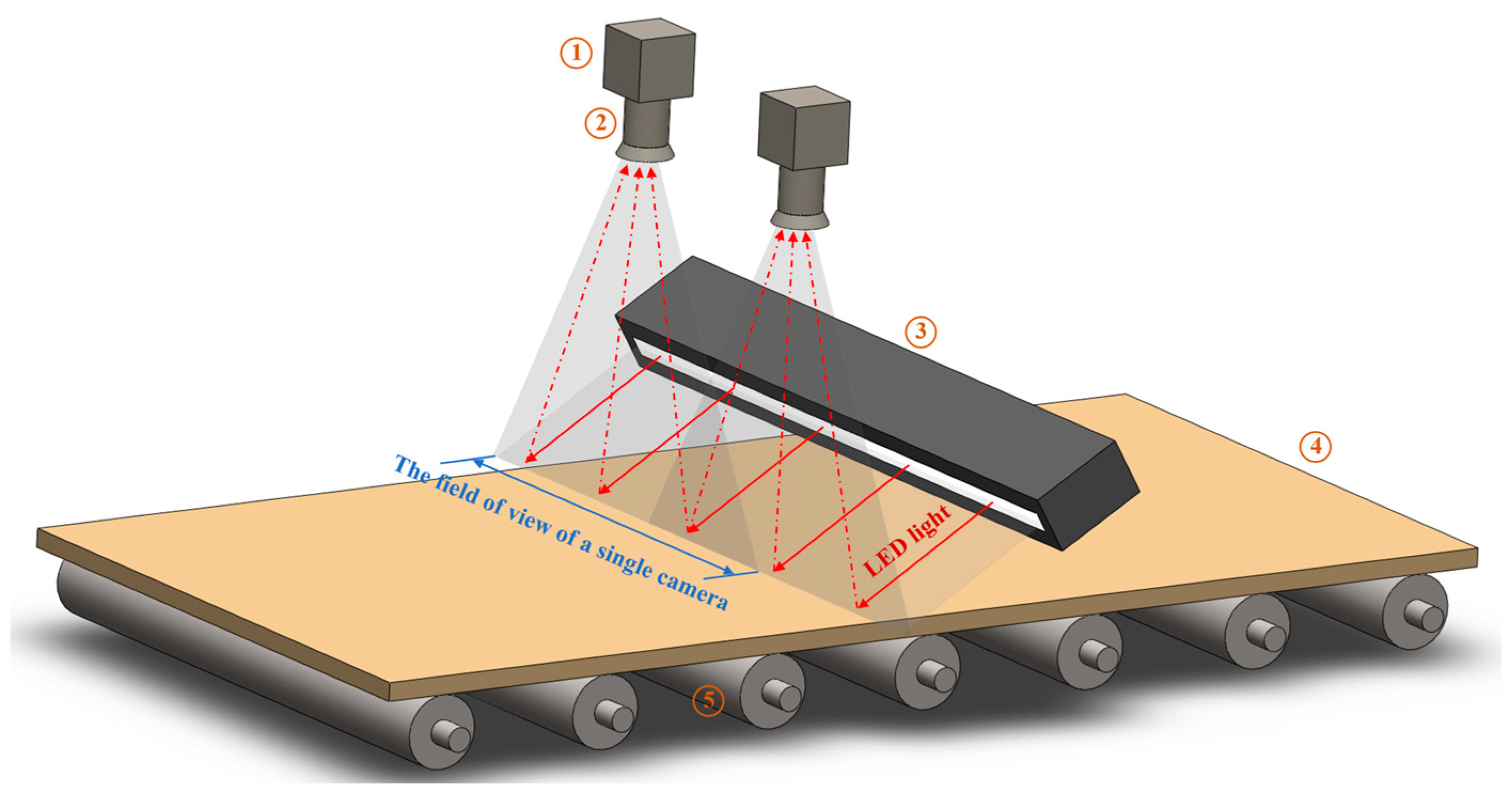
2.2. Image Acquisition and Procession
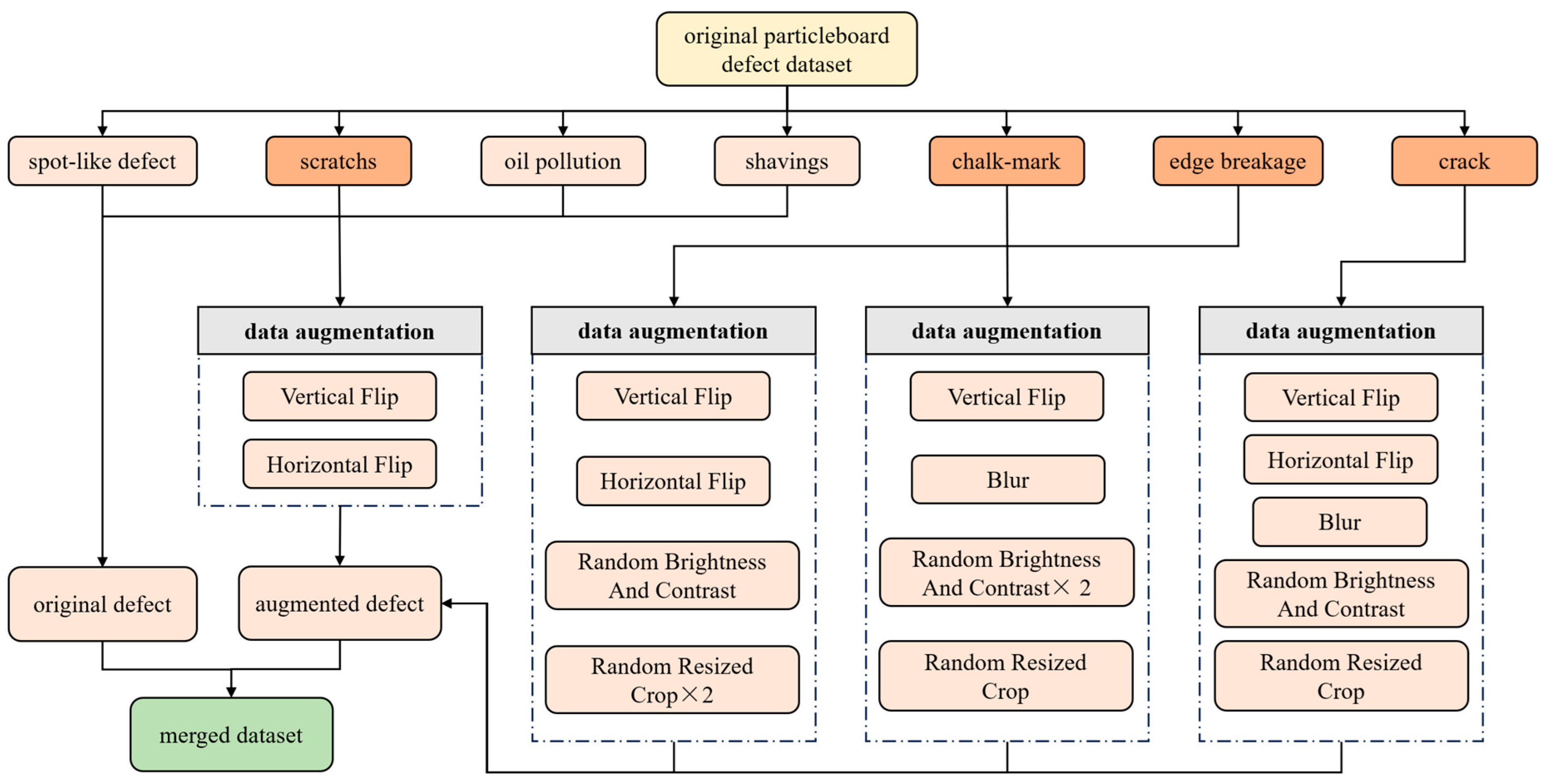
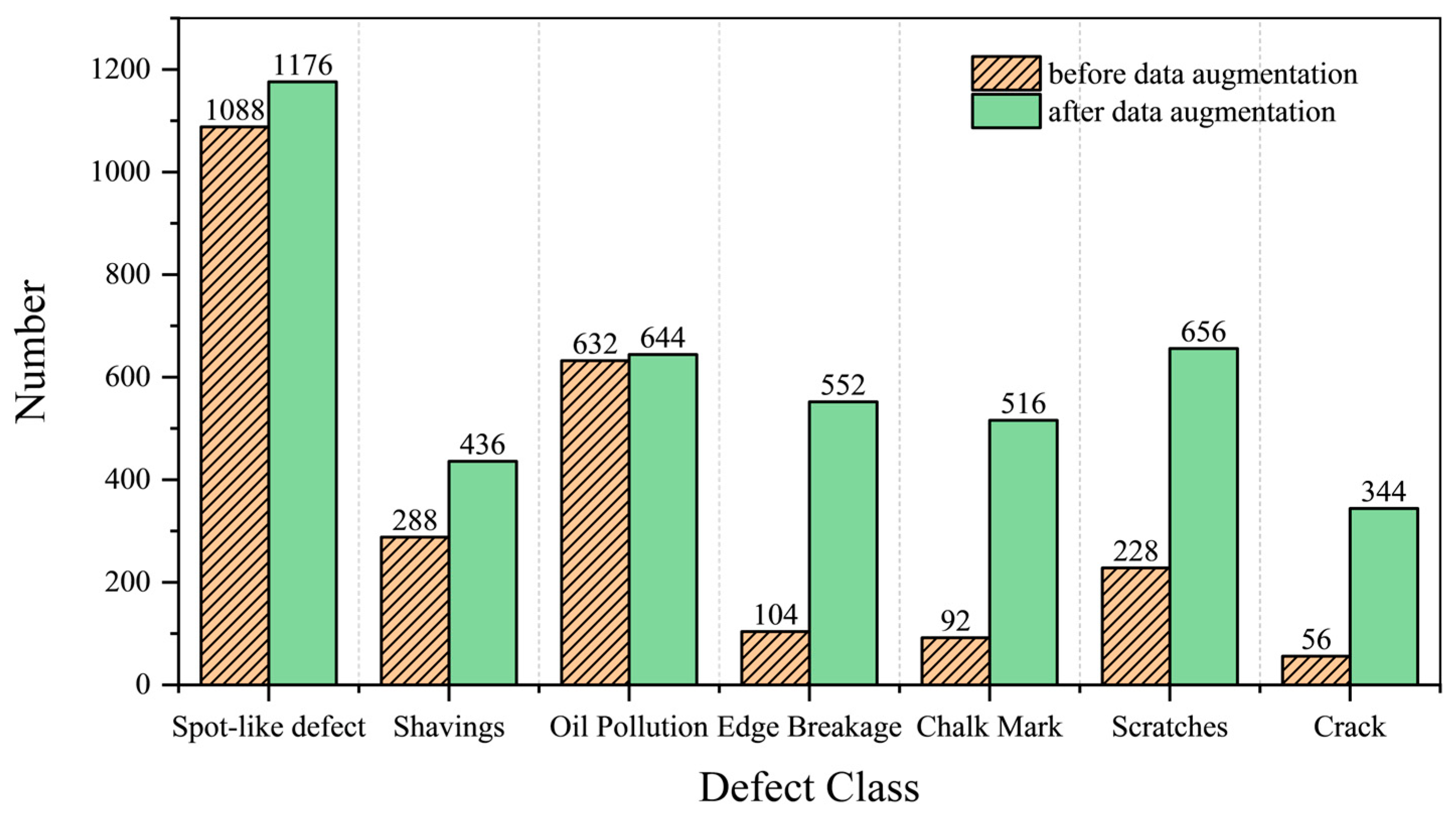
2.3. Data Augmentation Method
2.4. PBD-YOLO Algorithm Architecture
2.4.1. ShareSepHead Detection Head
2.4.2. C2f_SAC Module
2.4.3. SPDDEConv Module
2.5. Algorithm Evaluation Metrics
3. Experiment and Results
3.1. Experimental Details
3.2. Results of Data Augmentation
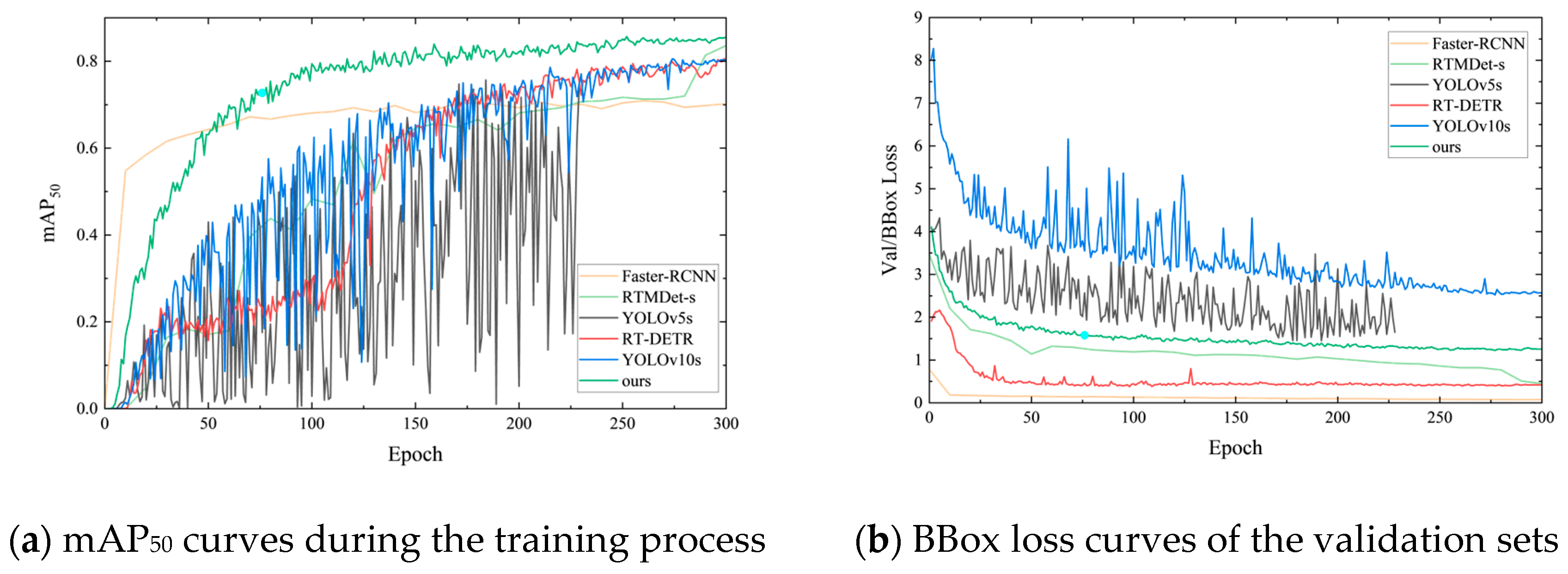
3.3. Results of Comparative Experiment
3.4. Results of Ablation Experiment
4. Discussion
4.1. Discussion of Comparative Experimental Results
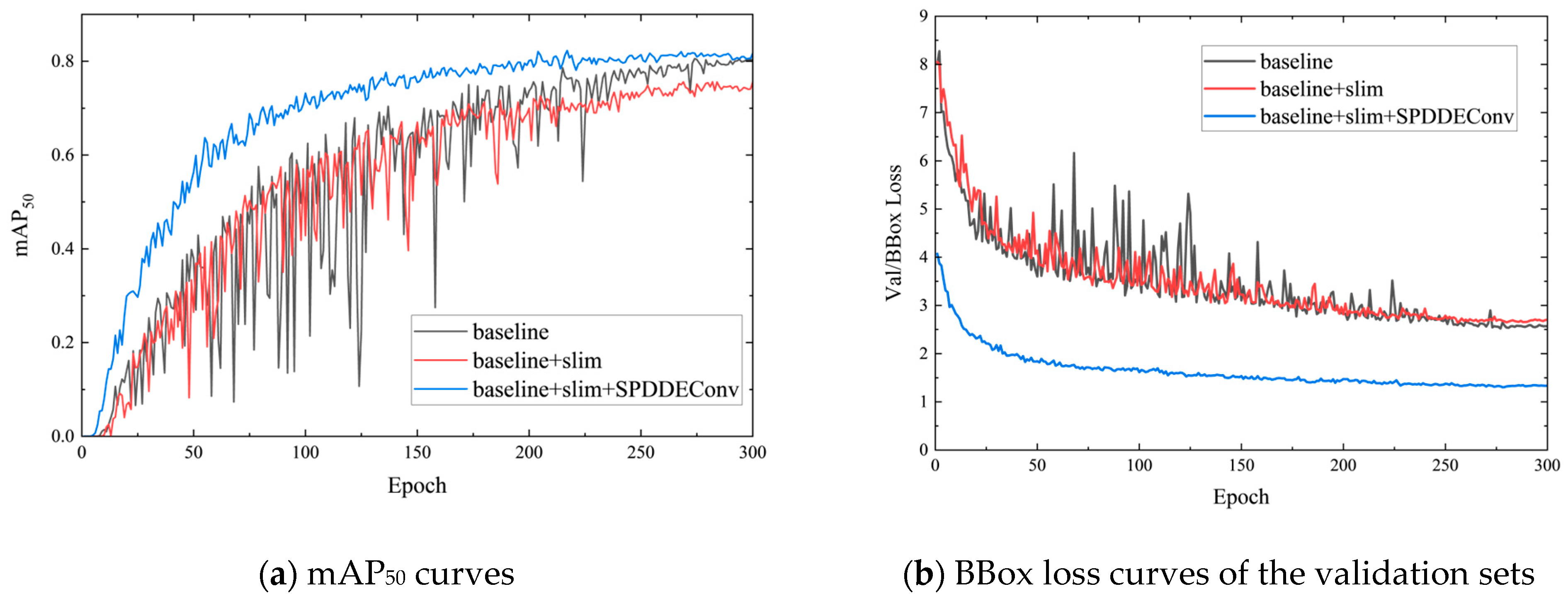
4.2. Discussion of Ablation Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| PBD-YOLO | Particleboard Defect-You Only Look Once |
| SPDDEConv | Space to Depth and Difference Enhance Convolution |
| ShareSepHead | Share Separated Head |
| SAC | Switchable Atrous Convolution |
| C2f_SAC | C2f module with Switchable Atrous Convolution |
| CBAM | Convolutional block attention module |
| ANN | Artificial neural networks |
| DFL | Distribution focal loss |
| HDC | Horizontal difference convolution |
| VDC | Vertical difference convolution |
| mAP | Mean average precision |
| IoU | Intersection over union |
| BBox | Bounding box |
References
- Yang, L.; Mao, S.; Lu, T.; Du, G. Review and Outlook of Technology Development in China’s Particleboard Industry. Chin. J. Wood Sci. Technol. 2024, 38, 1–12. [Google Scholar] [CrossRef]
- You, J.; Hu, S.; Jin, Z. A Brief Analysis of China’s Artificial Board Industry. Green China 2024, 16, 56–61. [Google Scholar] [CrossRef]
- Yang, Y. Application of Machine Vision in Particleboard Surface Defect Detection:Status and Recommendations. China Wood-Based Panels 2024, 31, 33–37. [Google Scholar]
- Zhou, H.; Yu, W.; Zhang, M.; Liu, Y.; Yang, Y.; Xi, S.; Xie, C.; Shen, Y. Development of Intelligent Control and Testing of Particleboard Quality. World For. Res. 2023, 36, 75–79. [Google Scholar] [CrossRef]
- Zhao, Z.; Ge, Z.; Jia, M.; Yang, X.; Ding, R.; Zhou, Y. A Particleboard Surface Defect Detection Method Research Based on the Deep Learning Algorithm. Sensors 2022, 22, 7733. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Xu, Z.; Bian, E.; Yu, C.; Gao, F.; Cao, Y. Particleboard Surface Defect Inspection Based on Data Augmentation and Attention Mechanisms. In Proceedings of the 2022 27th International Conference on Automation and Computing (ICAC), Bristol, UK, 1–3 September 2022; pp. 1–6. [Google Scholar]
- Wang, C.; Liu, Y.; Wang, P. Extraction and Detection of Surface Defects in Particleboards by Tracking Moving Targets. Algorithms 2019, 12, 6. [Google Scholar] [CrossRef]
- Zhu, H.; Zhou, S.; Zeng, Y.; Li, S.; Liu, X. Detection Model of Wood Surface Defects Based on Improved YOLOv5s. Chin. J. Wood Sci. Technol. 2023, 37, 8–15. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Wang, F.; Wei, B.; Li, L. A Comprehensive Review of One-Stage Networks for Object Detection. In Proceedings of the 2021 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xi’an, China, 17–20 August 2021; pp. 1–6. [Google Scholar]
- Zhang, H.; Wang, Y.; Yu, C. Research on Key Technology of Online Detection for Particleboard. In Proceedings of the 2021 IEEE International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 27–29 August 2021; pp. 512–515. [Google Scholar]
- Zhao, Z.; Yang, X.; Zhou, Y.; Sun, Q.; Ge, Z.; Liu, D. Real-Time Detection of Particleboard Surface Defects Based on Improved YOLOV5 Target Detection. Sci. Rep. 2021, 11, 21777. [Google Scholar] [CrossRef]
- Wang, W.; Dang, Y.; Zhu, X.; Guan, Y.; Shen, T.; Cang, Z. Detecting Method for Particleboard Surface Defects Based on the Lite-YOLOv5s Model. Chin. J. Wood Sci. Technol. 2023, 37, 58–67. [Google Scholar] [CrossRef]
- Wang, C.; Liu, Y.; Wang, P.; Lv, Y. Research on the Identification of Particleboard Surface Defects Based on Improved Capsule Network Model. Forests 2023, 14, 822. [Google Scholar] [CrossRef]
- Zha, J.; Chen, X.; Wang, W.; Guan, Y.; Zhang, J. Small Defect Detection Algorithm of Particle Board Surface Based on Improved YOLOv5s. Comput. Eng. Appl. 2024, 60, 158–166. [Google Scholar]
- Guan, Y.; Wang, W.; Shen, T.; Li, J.; Wang, B. Surface defect detection method of particleboard based on improved YOLOv5s model. Appl. Innov. Technol. 2024, 5, 104–112. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer. In Proceedings of the International Conference on Learning Representations (ICLR), Virtually, 6 October 2021; pp. 1–26. [Google Scholar]
- Hu, W.; Wang, T.; Wang, Y.; Chen, Z.; Huang, G. LE–MSFE–DDNet: A Defect Detection Network Based on Low-Light Enhancement and Multi-Scale Feature Extraction. Vis. Comput. 2022, 38, 3731–3745. [Google Scholar] [CrossRef]
- Shao, L.; Zhang, E.; Duan, J.; Ma, Q. Enriched Multi-Scale Cascade Pyramid Features and Guided Context Attention Network for Industrial Surface Defect Detection. Eng. Appl. Artif. Intell. 2023, 123, 106369. [Google Scholar] [CrossRef]
- Lin, Q.; Zhou, J.; Ma, Q.; Ma, Y.; Kang, L.; Wang, J. EMRA-Net: A Pixel-Wise Network Fusing Local and Global Features for Tiny and Low-Contrast Surface Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 2504314. [Google Scholar] [CrossRef]
- Pu, M.; Huang, Y.; Liu, Y.; Guan, Q.; Ling, H. EDTER: Edge Detection with Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1392–1402. [Google Scholar]
- Sunkara, R.; Luo, T. No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Grenoble, France, 19–23 September 2022; Amini, M.-R., Canu, S., Fischer, A., Guns, T., Kralj Novak, P., Tsoumakas, G., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 443–459. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.-M. DEA-Net: Single Image Dehazing Based on Detail-Enhanced Convolution and Content-Guided Attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- Akyon, F.C.; Onur Altinuc, S.; Temizel, A. Slicing Aided Hyper Inference and Fine-Tuning for Small Object Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 6–19 October 2022; pp. 966–970. [Google Scholar]
- Zhang, Y.; Kang, B.; Hooi, B.; Yan, S.; Feng, J. Deep Long-Tailed Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10795–10816. [Google Scholar] [CrossRef]
- Tang, Z.; Li, S. External Defects of Particleboard and Their Countermeasures. China For. Prod. Ind. 2005, 32, 26–28. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. In Proceedings of the Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024 (NeurIPS 2024), Vancouver, BC, Canada, 10–15 December 2024; pp. 1–21. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Newry, UK, 2016; Volume 29, pp. 1–9. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Curran Associates, Inc.: Newry, UK, 2020; Volume 33, pp. 21002–21012. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016; pp. 1–13. [Google Scholar]
- Qiao, S.; Chen, L.-C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10208–10219. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4476–4484. [Google Scholar]
- Yu, S.; Xue, G.; He, H.; Zhao, G.; Wen, H. Lightweight Detection of Ceramic Tile Surface Defects on Improved YOLOv8. Comput. Eng. Appl. 2024, 60, 88–102. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An Empirical Study of Designing Real-Time Object Detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Bany Muhammad, M.; Yeasin, M. Eigen-CAM: Visual Explanations for Deep Convolutional Neural Networks. SN Comput. Sci. 2021, 2, 47. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, C.; Zhao, L.; Qu, X.; Gao, X. A Method of Particleboard Surface Defect Detection and Recognition Based on Deep Learning. Wood Mater. Sci. Eng. 2025, 20, 50–61. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar]
- Bai, D.; Li, G.; Jiang, D.; Yun, J.; Tao, B.; Jiang, G.; Sun, Y.; Ju, Z. Surface Defect Detection Methods for Industrial Products with Imbalanced Samples: A Review of Progress in the 2020s. Eng. Appl. Artif. Intell. 2024, 130, 107697. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | mAP50 | mAP50–95 | Recall | Parameters | Time |
|---|---|---|---|---|---|
| Faster R-CNN | 0.702 | 0.445 | 0.541 | 84.7 M | 25.10 ms |
| YOLOv5s | 0.736 | 0.492 | 0.703 | 18.6 M | 3.08 ms |
| RTMDet-s | 0.836 | 0.566 | 0.676 | 39.03 M | 54.20 ms |
| RT-DETR-ResNet50 | 0.793 | 0.583 | 0.776 | 86.1 M | 8.10 ms |
| YOLOv10s | 0.801 | 0.575 | 0.684 | 15.9 M | 3.15 ms |
| PBD-YOLO (ours) | 0.856 | 0.609 | 0.814 | 14.1 M | 3.16 ms |
| Algorithm | Slim | ShareSepHead | SPDDEConv | C2f_SAC | mAP50 | mAP50–95 | Recall | Parameters | Time |
|---|---|---|---|---|---|---|---|---|---|
| A | - | - | - | - | 0.804 | 0.575 | 0.684 | 15.9 M | 3.15 ms |
| B | √ | - | - | - | 0.756 | 0.529 | 0.690 | 9.8 M | 2.04 ms |
| C | √ | √ | - | - | 0.828 | 0.562 | 0.779 | 9.8 M | 1.73 ms |
| D | √ | - | √ | - | 0.817 | 0.571 | 0.743 | 11.5 M | 2.18 ms |
| E | √ | - | - | √ | 0.794 | 0.559 | 0.731 | 11.1 M | 2.84 ms |
| F | √ | √ | √ | - | 0.823 | 0.551 | 0.766 | 10.8 M | 2.21 ms |
| G | √ | - | √ | √ | 0.847 | 0.603 | 0.795 | 15.6 M | 3.16 ms |
| H | √ | √ | - | √ | 0.845 | 0.599 | 0.793 | 12.5 M | 2.58 ms |
| I | √ | √ | √ | √ | 0.856 | 0.609 | 0.814 | 14.1 M | 3.16 ms |
| Defect Class | mAP50 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | |
| Spot-like defects | 0.756 | 0.762 | 0.843 | 0.838 | 0.789 | 0.843 | 0.837 | 0.872 | 0.832 |
| Shavings | 0.800 | 0.713 | 0.862 | 0.747 | 0.819 | 0.804 | 0.905 | 0.828 | 0.837 |
| Oil pollution | 0.452 | 0.441 | 0.444 | 0.415 | 0.448 | 0.460 | 0.544 | 0.509 | 0.573 |
| Edge breakage | 0.954 | 0.891 | 0.963 | 0.964 | 0.936 | 0.959 | 0.964 | 0.961 | 0.961 |
| Chalk marks | 0.587 | 0.823 | 0.903 | 0.894 | 0.897 | 0.887 | 0.901 | 0.915 | 0.919 |
| Scratches | 0.868 | 0.756 | 0.823 | 0.914 | 0.741 | 0.863 | 0.831 | 0.881 | 0.903 |
| Cracks | 0.939 | 0.903 | 0.955 | 0.949 | 0.926 | 0.948 | 0.947 | 0.951 | 0.970 |
| Defect Class | Recall | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | E | F | G | H | I | |
| Spot-like defects | 0.595 | 0.770 | 0.785 | 0.770 | 0.754 | 0.803 | 0.689 | 0.852 | 0.820 |
| Shavings | 0.588 | 0.571 | 0.801 | 0.667 | 0.762 | 0.714 | 0.902 | 0.762 | 0.759 |
| Oil pollution | 0.295 | 0.375 | 0.425 | 0.276 | 0.381 | 0.339 | 0.46 | 0.446 | 0.503 |
| Edge breakage | 0.900 | 0.833 | 0.933 | 0.933 | 0.906 | 0.967 | 0.933 | 0.967 | 0.933 |
| Chalk marks | 0.750 | 0.750 | 0.732 | 0.786 | 0.821 | 0.826 | 0.807 | 0.786 | 0.857 |
| Scratches | 0.773 | 0.694 | 0.829 | 0.829 | 0.657 | 0.771 | 0.830 | 0.794 | 0.883 |
| Cracks | 0.889 | 0.833 | 0.944 | 0.944 | 0.833 | 0.944 | 0.944 | 0.944 | 0.944 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Chai, Z.; Dai, H.; Yan, L.; Cheng, P.; Yang, J. PBD-YOLO: Dual-Strategy Integration of Multi-Scale Feature Fusion and Weak Texture Enhancement for Lightweight Particleboard Surface Defect Detection. Appl. Sci. 2025, 15, 4343. https://doi.org/10.3390/app15084343
Guo H, Chai Z, Dai H, Yan L, Cheng P, Yang J. PBD-YOLO: Dual-Strategy Integration of Multi-Scale Feature Fusion and Weak Texture Enhancement for Lightweight Particleboard Surface Defect Detection. Applied Sciences. 2025; 15(8):4343. https://doi.org/10.3390/app15084343
Chicago/Turabian StyleGuo, Haomeng, Zheming Chai, Huize Dai, Lei Yan, Pengle Cheng, and Jianhua Yang. 2025. "PBD-YOLO: Dual-Strategy Integration of Multi-Scale Feature Fusion and Weak Texture Enhancement for Lightweight Particleboard Surface Defect Detection" Applied Sciences 15, no. 8: 4343. https://doi.org/10.3390/app15084343
APA StyleGuo, H., Chai, Z., Dai, H., Yan, L., Cheng, P., & Yang, J. (2025). PBD-YOLO: Dual-Strategy Integration of Multi-Scale Feature Fusion and Weak Texture Enhancement for Lightweight Particleboard Surface Defect Detection. Applied Sciences, 15(8), 4343. https://doi.org/10.3390/app15084343