
A Semi-Supervised Single-Image Deraining Algorithm Based on the Integration of Wavelet Transform and Swin Transformer


Abstract
1. Introduction
2. Related Work and Theory
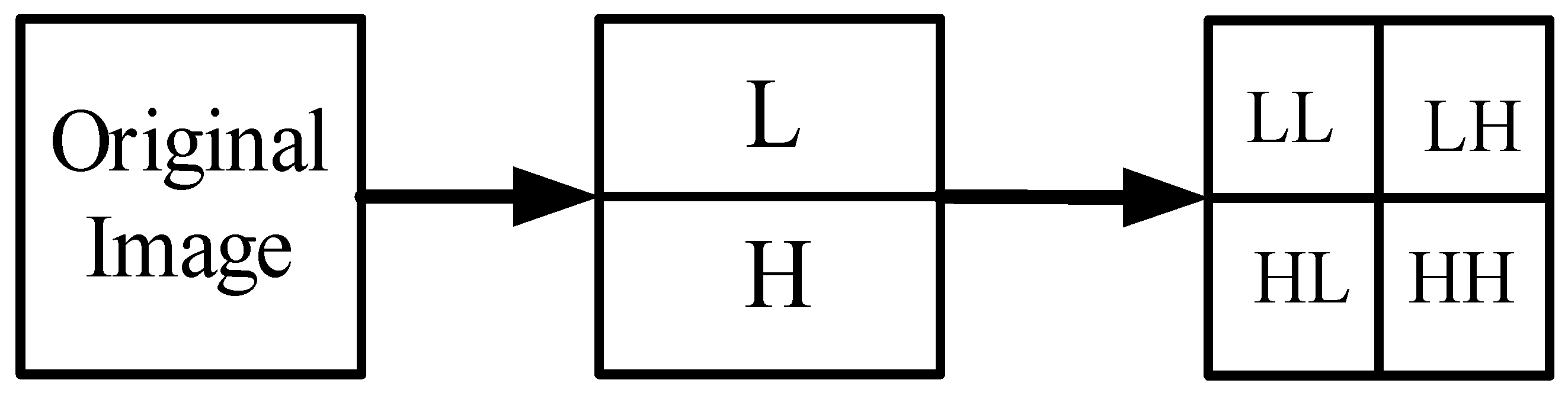
2.1. Wavelet Transform
2.2. Attention Mechanism
2.3. Theoretical Analysis
2.3.1. Working Mechanism of Wavelet Transform
- Frequency domain analysis characteristics: as a time-frequency analysis tool, wavelet transform can analyze signals in both time (or space) and frequency domains. Unlike Fourier transform, it has localization and multi-resolution properties, allowing it to extract image details at different scales, which is crucial for detecting rain streaks in deraining tasks. Rain streaks, as high-frequency noise, are concentrated in certain areas of the image and are captured in high-frequency components (HL, HH). Wavelet transform breaks the image into different scales, enabling focused processing of rain streaks while preserving background details by separating components from high-frequency small scales to low-frequency large scales.
- Correlation between high-frequency components and rain streaks: since rain streaks are typically vertical or diagonal, they manifest as high-frequency features in the HL and HH sub-bands during wavelet decomposition, making them easier to capture. In contrast, the low-frequency sub-bands (LL, LH) retain horizontal details and background information. Deraining targets high-frequency subbands to remove or suppress rain streaks. The image is then restored using the inverse wavelet transform, combining all subbands to reconstruct the rain-free image. Since low-frequency subbands remain unaffected, the image structure is preserved, ensuring clarity and retention of original details.
- Wavelet coefficient thresholding in practical applications: After extracting high-frequency rain streak features using wavelet transform, thresholding techniques can be further applied to suppress noise. Rain streaks, being sparse signals in high-frequency components, can be extracted, and irrelevant noise can be suppressed by setting an appropriate threshold. This method leverages the sparsity and locality of the signal, effectively reducing interference with the image background and enhancing deraining performance.
2.3.2. Working Mechanism of Attentional Mechanisms
- Channel and spatial attention mechanisms: the channel attention mechanism adaptively adjusts the weights of feature channels to focus on important rain streak information while suppressing irrelevant ones. It captures global information through average pooling and generates weights via convolution, prioritizing channels with stronger rain streak features and adjusting to different rain conditions. The spatial attention mechanism weights the significance of different image regions, creating an attention map that highlights areas with concentrated rain streaks. It combines global and local information through max-pooling and average-pooling, ensuring that rain streaks are processed in key regions while preserving details in others.
- Synergistic effect of channel and spatial attention: the spatial and channel attention mechanisms apply weighting to the feature map from different dimensions, with channel attention focusing on feature channels and spatial attention on regions. Combining these mechanisms creates a synergistic effect in deraining tasks. Channel attention prioritizes rain-related information, while spatial attention focuses on important regions to ensure accurate rain streak removal and preserve image details. In a multi-branch network, both attention mechanisms work together to enhance feature gathering, improving feature map learning and ultimately enhancing the quality of the derained image.
2.3.3. Combined Advantages of Wavelet Transform and Attention Mechanisms
- Fine feature extraction and rain streak attention: the wavelet transform captures multi-scale details and high-frequency features of the image, while the attention mechanism enhances the focus on these high-frequency rain streaks. This combination allows the model to effectively remove rain streaks while preserving background details, avoiding excessive smoothing.
- Rain removal and detail recovery: in the process of removing rain streaks, especially in the high-frequency part, the background details may be affected. Wavelet transform provides an efficient decomposition, while the attention mechanism can help the model to recognize and recover the details lost in the rain removal process. For example, the spatial attention mechanism enables better retention of background information, while the channel attention mechanism helps to remove rain streaks without losing important image details.
- Improved generalization and inter-domain adaptability: the attention mechanism’s adaptive weighting, combined with the wavelet transform, boosts the model’s performance across various complex rainy scenes. It also addresses inter-domain differences between synthetic and real data, improving the model’s robustness and stability in real-world conditions.
3. Methodology
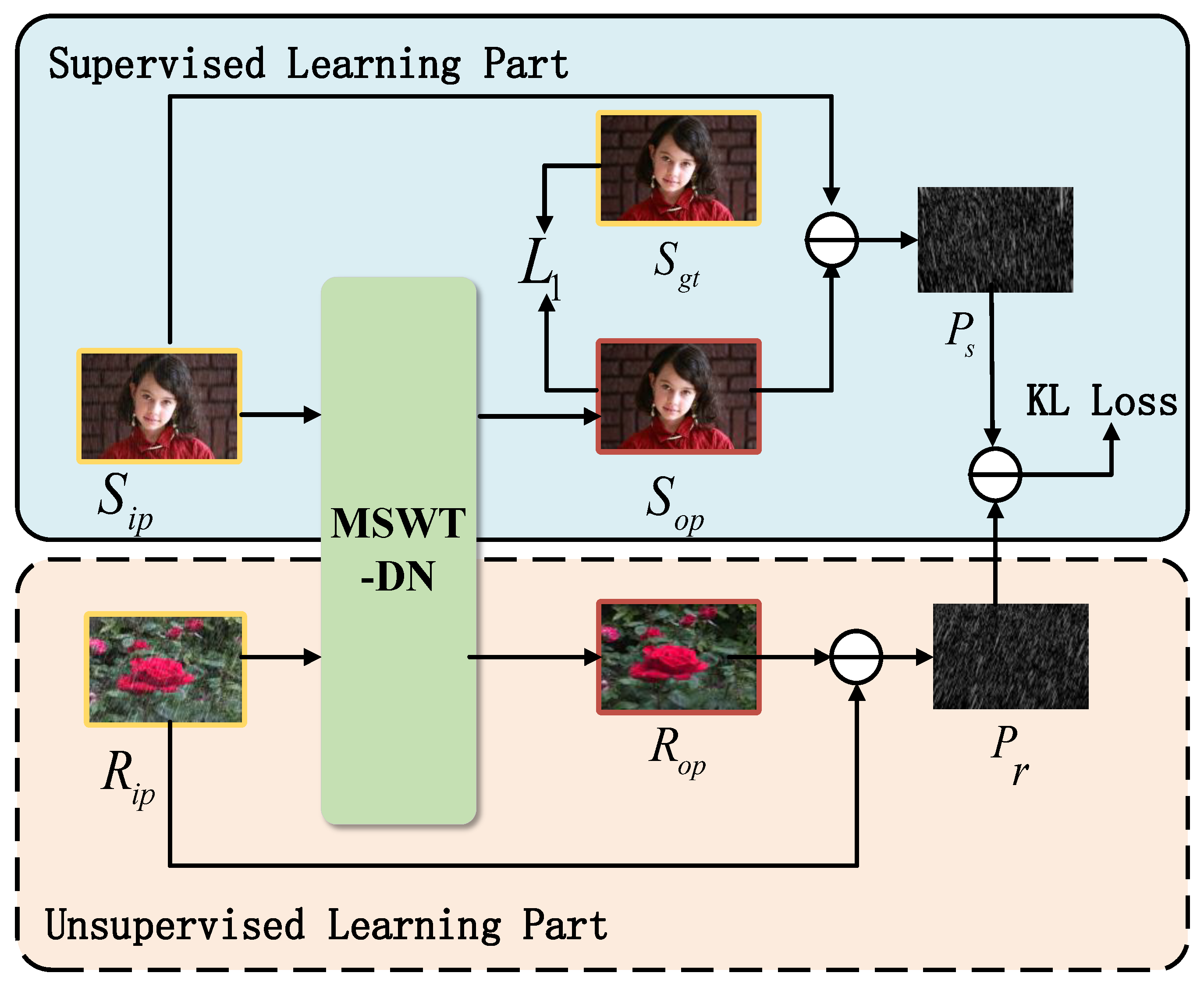
3.1. Overall Network Framework
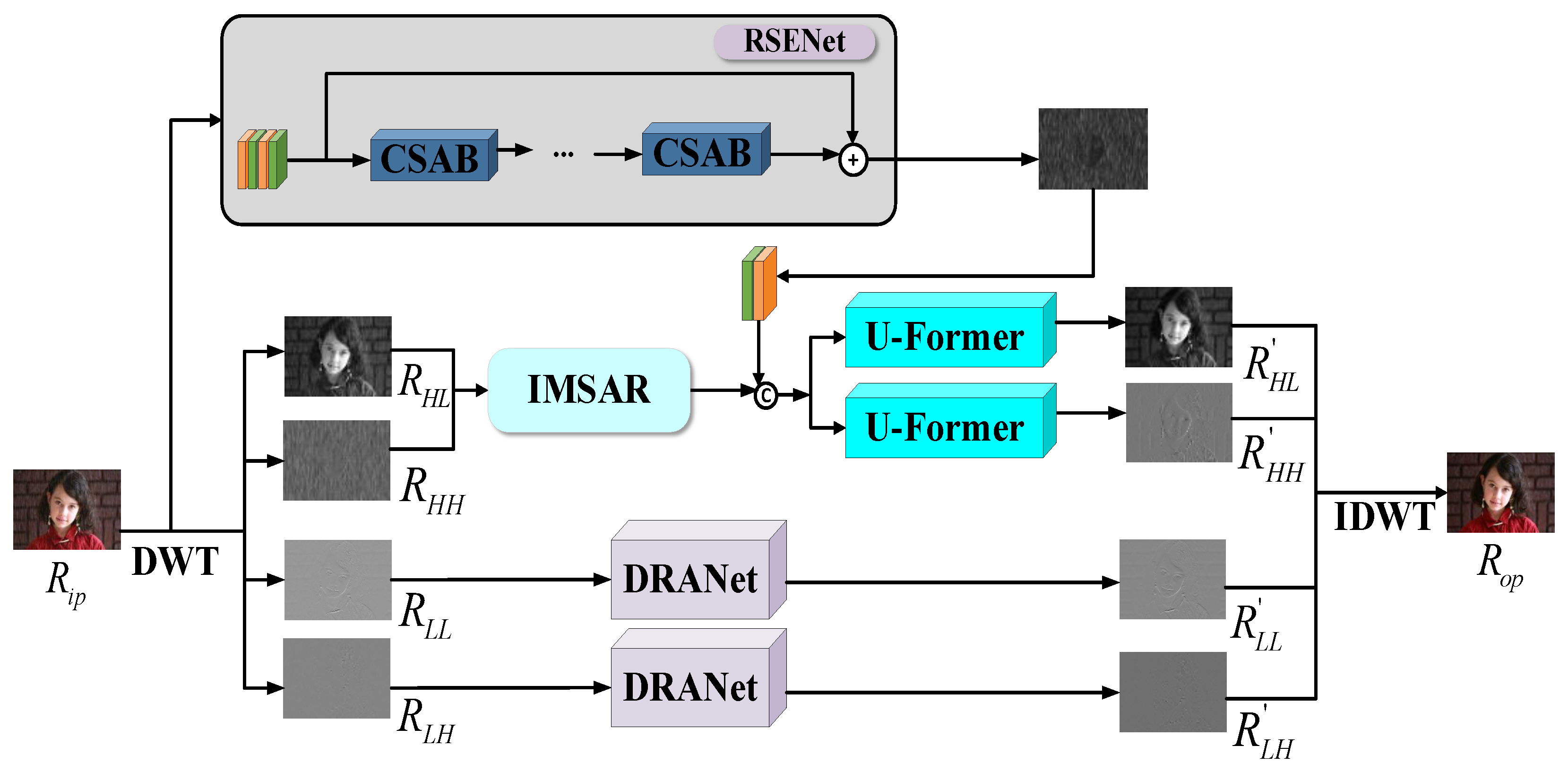
3.2. MSWT-DN Structure
3.2.1. Introduction to Network Components
3.2.2. Multi-Scale Wavelet Transform
3.2.3. Model Parameter Analysis
3.3. Rain Streak Extraction Network (RSENet)
3.3.1. Channel Attention Mechanism
3.3.2. Spatial Attention Mechanism
3.4. Improved Multi-Scale Attention Residual Module (IMSAR)
3.5. U-Former Deraining Subnetwork
3.5.1. Self-Attention Mechanism
3.5.2. STB
3.6. Residual Detail Restoration Network (DRANet)
3.7. Component Complementarity Analysis
3.7.1. Analysis of RSENet
3.7.2. Analysis of IMSAR
3.7.3. Analysis of U-Former
3.7.4. Analysis of DRANet
3.8. Model Optimization and Deployment Strategies
- Model pruning: by removing redundant or unimportant parameters, model pruning can significantly reduce storage requirements and improve inference speed without significantly affecting performance. This makes the model more suitable for real-time deployment, especially in devices with limited computing resources.
- Quantization: quantization reduces memory usage and computational overhead by reducing the precision of weights and activations (for example, converting floating point numbers to low-precision integers). It is particularly suitable for devices with limited hardware capabilities, which can speed up computation and save memory.
- Adaptive computing: adaptive computing allows the model to dynamically adjust the amount of computation based on the complexity of the input. For simple inputs, the model uses fewer layers or modules, thereby reducing computational requirements; for complex inputs, the full model is used to maintain high accuracy, which helps optimize the use of computing resources.
- Hardware acceleration: using GPU, TPU or AI-specific hardware (such as NPU) to accelerate the inference process can significantly improve computing efficiency, especially for real-time applications and resource-constrained devices.
3.9. Loss Function
3.9.1. Supervised Loss
3.9.2. Unsupervised Loss
3.9.3. Total Loss Function
4. Experiments
4.1. Experimental Environment and Parameter Configuration
4.2. Datasets
4.3. Evaluation Metrics
4.4. Ablation Study
4.4.1. Ablation of Network Structure
4.4.2. Ablation of Network Modules
4.4.3. Ablation of Loss Function
4.5. Comparison Experiments
4.5.1. Comparative Experiments with FFT and DCT
- Experimental design
- 2.
- Experimental results and conclusions
4.5.2. Results on Synthetic Datasets
- Quantitative Comparison
- 2.
- Qualitative Comparison
4.5.3. Results on Real Datasets
- Quantitative Comparison
- 2.
- Qualitative Comparison
5. Limitations and Areas of Discussion
- Enhance robustness under extreme rainfall conditions: the performance of the current model drops significantly under heavy rainfall conditions. In the future, the performance of the model under severe weather conditions can be improved by introducing more targeted rainfall features or designing more specialized modules. In addition, combining temporal information (such as the temporal model of video frames) may also effectively improve the performance of the model in dynamic and real-time applications.
- Optimize computational efficiency: the computational overhead of the model is large, which limits its deployment in low-resource devices. To solve this problem, in the future, we could explore optimization techniques such as model pruning, quantization, and knowledge distillation to improve its efficiency in real-time applications by reducing model parameters and accelerating the inference process. Adaptive computing technology can also be used as an effective means to dynamically adjust the computational amount of the model according to the complexity of the input and reduce unnecessary computational consumption.
- Multimodal data fusion: future research could explore the fusion of multimodal data (such as depth maps, infrared images, etc.), which will provide more contextual information for the model and help to more accurately separate raindrop traces from background elements, especially in complex backgrounds and severe weather conditions, further improving the robustness of the model.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, L.; Liu, R.; Zhang, X.; Zhong, W.; Fan, X. Video deraining via temporal aggregation-and-guidance. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–6. [Google Scholar]
- Yan, W.; Tan, R.T.; Yang, W.; Dai, D. Self-aligned video deraining with transmission-depth consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 11966–11976. [Google Scholar]
- Kulkarni, A.; Patil, P.W.; Murala, S. Progressive subtractive recurrent lightweight network for video deraining. IEEE Signal Process. Lett. 2021, 29, 229–233. [Google Scholar] [CrossRef]
- Li, M.; Cao, X.; Zhao, Q.; Zhang, L.; Meng, D. Online rain/snow removal from surveillance videos. IEEE Trans. Image Process. 2021, 30, 2029–2044. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Li, D.; Luo, W.; Ren, W.; Liu, W. Enhanced Spatio-Temporal Interaction Learning for Video Deraining: Faster and Better. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1287–1293. [Google Scholar] [CrossRef] [PubMed]
- Yue, Z.; Xie, J.; Zhao, Q.; Meng, D. Semi-supervised video deraining with dynamical rain generator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 642–652. [Google Scholar]
- Yang, W.; Tan, R.T.; Wang, S.; Fang, Y.; Liu, J. Single image deraining: From model-based to datadriven and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4059–4077. [Google Scholar] [CrossRef]
- Cherian, A.K.; Poovammal, E.; Philip, N.S.; Ramana, K.; Singh, S.; Ra, I.H. Deep Learning Based Filtering Algorithm for Noise Removal in Underwater Images. Water 2021, 13, 2742. [Google Scholar] [CrossRef]
- Zhou, W.; Ye, L. UC-former: A multi-scale image deraining network using enhanced transformer. Comput. Vis. Image Underst. 2024, 248, 104097. [Google Scholar] [CrossRef]
- Fu, X.; Liang, B.; Huang, Y.; Ding, X.; Paisley, J. Lightweight Pyramid Networks for Image Deraining. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1794–1807. [Google Scholar] [CrossRef]
- Chen, X.; Pan, J.; Dong, J. Bidirectional Multi-Scale Implicit Neural Representations for Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; IEEE: New York, NY, USA, 2024; pp. 25627–25636. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 17683–17693. [Google Scholar]
- Zhang, Z.; Wei, Y.; Zhang, H.; Yang, Y.; Yan, S.; Wang, M. Datadriven single image deraining: A comprehensive review and new perspectives. Pattern Recognit. 2023, 143, 109740. [Google Scholar] [CrossRef]
- Guo, Q.; Sun, J.; Juefei-Xu, F.; Ma, L.; Xie, X.; Feng, W.; Liu, Y.; Zhao, J. Efficientderain: Learning pixel-wise dilation filtering for high-efficiency single-image deraining. Proc. AAAI Conf. Artif. Intell. 2021, 35, 1487–1495. [Google Scholar] [CrossRef]
- Huang, H.; Yu, A.; He, R. Memory Oriented Transfer Learning for Semi-supervised Image Deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 7732–7741. [Google Scholar]
- Yasarla, R.; Sindagi, V.A.; Patel, V.M. Syn2real transfer learning for image deraining using gaussian processes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2723–2733. [Google Scholar]
- Jiang, N.; Luo, J.; Lin, J.; Chen, W.; Zhao, T. Lightweight Semi-supervised Network for Single Image Rain Removal. Pattern Recognit. 2023, 137, 109277. [Google Scholar] [CrossRef]
- Chen, X.; Pan, J.; Jiang, K.; Li, Y.; Huang, Y.; Kong, C. Unpaired Deep Image Deraining Using Dual Contrastive Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 2017–2026. [Google Scholar]
- Yang, Y.; Wu, X.D.; Du, K. T-shaped image dehazing network based on wavelet transform and attention mechanism. J. Hunan Univ. 2022, 49, 61–68. [Google Scholar]
- Ahn, N.; Jo, S.Y.; Kang, S.J. EAGNet: Elementwise Attentive Gating Network-Based Single Image De-Raining with Rain Simplification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 608–620. [Google Scholar] [CrossRef]
- Luo, Z.; Sun, Z.; Zhou, W.; Wu, Z.; Kamata, S.I. Rethinking ResNets: Improved stacking strategies with high-order schemes for image classification. Complex Intell. Syst. 2022, 8, 3395–3407. [Google Scholar] [CrossRef]
- Lin, X.; Ma, L.; Sheng, B.; Wang, Z.J.; Chen, W. Utilizing two-phase processing with FBLS for single image deraining. IEEE Trans. Multimed. 2021, 23, 664–676. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA, 2018; pp. 7132–7141. [Google Scholar]
- Han, Y.; Feng, L.; Gao, J. A new end-to-end framework based on non-local network structure and spatial attention mechanism for image rain removal. Int. J. Comput. Appl. 2022, 44, 1083–1091. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; IEEE: New York, NY, USA, 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations; ICLR: Singapore, 2020. [Google Scholar]
- Miclea, A.V.; Terebes, R.M.; Meza, S.; Cislariu, M. On Spectral-Spatial Classification of Hyperspectral Images Using Image Denoising and Enhancement Techniques, Wavelet Transforms and Controlled Data Set Partitioning. Remote Sens. 2022, 14, 1475. [Google Scholar] [CrossRef]
- Xinyi, L. Deep Learning Based Single Image Deraining: Datasets, Metrics and Methods; Fujian Normal University: Fuzhou, China, 2023. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3943–3956. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind“ image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Venkatanath, N.; Praneeth, D.; Bh, M.C.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the 2015 Twenty-First National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Li, P.; Jin, J.; Jin, G.; Fan, L.; Gao, X.; Song, T.; Chen, X. Deep Scale-space Mining Network for Single Image Deraining. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, LA, USA, 19–20 June 2022; pp. 4275–4284. [Google Scholar]
- Xiao, J.; Fu, X.; Liu, A.; Wu, F.; Zha, Z.J. Image De-Raining Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12978–12995. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Lu, J.; Chen, H.; Wu, X.; Chen, X. Dilated Convolutional Transformer for High-Quality Image Deraining. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Vancouver, BC, Canada, 17–24 June 2023; pp. 4199–4207. [Google Scholar]
- Zhou, W.; Ye, L.; Wang, X. Residual Contextual Hourglass Network for Single-Image Deraining. Neural Process. Lett. 2024, 56, 63. [Google Scholar] [CrossRef]
- Cui, X.; Wang, C.; Ren, D.; Chen, Y.; Zhu, P. Semi-supervised image deraining using knowledge distillation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8327–8341. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Input | MSWT-DN | MSWT-SSIDA |
|---|---|---|---|
| NIQE | 13.72 | 12.83 | 11.55 |
| PIQE | 10.65 | 9.93 | 9.16 |
| Evaluation Algorithms | Rain1200 | Rain1400 | ||
|---|---|---|---|---|
| PSNR | SSIM | NIQE | PIQE | |
| Removal of wavelet transform | 31.31 | 0.906 | 13.58 | 10.34 |
| Removal of RSENet | 32.47 | 0.913 | 13.65 | 10.11 |
| Removal of IMARM | 31.89 | 0.904 | 13.93 | 10.26 |
| Removal of U-Former | 31.96 | 0.911 | 13.89 | 10.18 |
| Removal of channel space attention | 29.62 | 0.876 | 14.06 | 10.54 |
| MSWT-SSIDA | 34.86 | 0.961 | 11.52 | 9.13 |
| Title 1 | Rain1200 | Rain1400 | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| Q1 | 32.17 | 0.915 | 31.04 | 0.895 |
| Q2 | 33.64 | 0.922 | 32.38 | 0.913 |
| Q3 | 34.88 | 0.963 | 32.57 | 0.956 |
| Frequency Method | Rain1200 | Rain1400 | RealRain | |||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | NIQE | PIQE | |
| FFT | 33.36 | 0.944 | 32.10 | 0.936 | 13.20 | 10.40 |
| DCT | 33.28 | 0.940 | 32.05 | 0.930 | 13.11 | 10.29 |
| MSWT | 34.86 | 0.961 | 32.55 | 0.953 | 11.52 | 9.13 |
| Comparison Algorithms | Rain1200 | Rain1400 | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| DARAGNet | 32.68 | 0.890 | 31.44 | 0.885 |
| DSMNet | 32.93 | 0.891 | 31.67 | 0.923 |
| IDT | 33.88 | 0.893 | 32.12 | 0.890 |
| RCHNet | 34.04 | 0.912 | 32.58 | 0.955 |
| MOSS | 34.15 | 0.927 | 32.25 | 0.906 |
| LSNet | 34.37 | 0.930 | 32.46 | 0.927 |
| SSID_KD | 34.53 | 0.944 | 32.38 | 0.923 |
| MSWT-SSIDA | 34.86 | 0.961 | 32.55 | 0.953 |
| Metrics | DARAGNet | DSMNet | IDT | RCHNet | MOSS | LSNet | SSID_KD | MSWT- SSIDA |
|---|---|---|---|---|---|---|---|---|
| NIQE | 13.88 | 13.74 | 13.69 | 13.61 | 12.46 | 12.17 | 11.79 | 11.52 |
| PIQE | 10.63 | 10.41 | 10.16 | 9.85 | 9.72 | 9.53 | 9.46 | 9.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Y.; Liu, X. A Semi-Supervised Single-Image Deraining Algorithm Based on the Integration of Wavelet Transform and Swin Transformer. Appl. Sci. 2025, 15, 4325. https://doi.org/10.3390/app15084325
Hao Y, Liu X. A Semi-Supervised Single-Image Deraining Algorithm Based on the Integration of Wavelet Transform and Swin Transformer. Applied Sciences. 2025; 15(8):4325. https://doi.org/10.3390/app15084325
Chicago/Turabian StyleHao, Yu, and Xiaoyan Liu. 2025. "A Semi-Supervised Single-Image Deraining Algorithm Based on the Integration of Wavelet Transform and Swin Transformer" Applied Sciences 15, no. 8: 4325. https://doi.org/10.3390/app15084325
APA StyleHao, Y., & Liu, X. (2025). A Semi-Supervised Single-Image Deraining Algorithm Based on the Integration of Wavelet Transform and Swin Transformer. Applied Sciences, 15(8), 4325. https://doi.org/10.3390/app15084325