1. Introduction
Speaker change detection (SCD) is an important task in audio processing, particularly for applications such as speech segmentation, speaker diarization, and automatic transcription. Accurate detection of speaker transitions is critical in multi-person conversations, especially in meeting scenarios, where challenges such as overlapping speech and background noise can make correct detection difficult.
Traditional SCD methods rely on audio features, including pitch, Mel Frequency Cepstral Coefficient (MFCC), and cepstral coefficients, with various approaches such as metric-based and neural network-based methods. However, these approaches often underperform in complex acoustic environments such as those with low signal-to-noise ratios or simultaneous speech. Other multi-modal approaches to SCD have been explored, but they face practical limitations. Their approaches rely on ground-truth transcripts, which are often impractical in real-world scenarios due to transcription errors and limited availability. Another issue is that binary cross-entropy loss (BCE loss) is used as the main objective function, which causes models to fail to learn useful features from imbalanced data. Usually, an SCD dataset contains many negative samples (no change points) and fewer positive samples (change points); it has imbalanced features.
To address these challenges, we propose an end-to-end multi-modal SCD model with a self-attention layer based on large pre-trained models and enhance it with focal loss to mitigate the issue of imbalanced data. The model employs a pre-trained large audio model to extract acoustic features from raw audio and a large language model (LLM) to derive semantic and contextual information from transcripts generated by an automatic speech recognition (ASR) system. By leveraging both modalities in a practical, real-world setting, this approach enhances detection accuracy in challenging acoustic conditions while avoiding the reliance on manually annotated transcripts. Furthermore, this study investigates the impact of different configurations, including audio-only, text-only, and multi-modal setups, to evaluate their effectiveness in SCD. A comparison between BCE loss and different focal loss configurations is carried out. Additionally, we explore different fine-tuning strategies, examining the impact of updating the pre-trained models to optimize performance while balancing computational efficiency. The evaluation is conducted using the multi-talker meeting corpus [
1], a widely recognized dataset in speech and audio processing research. Experimental results showed that updating the pre-trained model’s parameters during the training significantly outperformed freezing them for all modalities. Compared to the text-only model, the audio-only model outperforms it in various settings, and the multi-modal configuration surpasses both. The self-attention layer introduced in the approach effectively improved the F1-score compared to the model without using it for various modalities. The proposed approach outperforms the baselines and also outperforms previous approaches enhanced with multi-modals.
The rest of the work is organized as follows: (i)
Section 2 reviews related studies on SCD, including multi-modal approaches. (ii)
Section 3 presents the approach, including task formalization and the proposed model. (iii)
Section 4 provides details on the experiments, including model setup, data statistics, baselines, and a discussion of the results. (iv)
Section 5 describes a discussion related to the obtained results. (v)
Section 6 discusses the limitations of the approach and potential future directions. (vi)
Section 7 concludes the work with a summary of the key findings.
2. Related Work
Existing approaches to SCD problems can be categorized into two groups: (i) unsupervised approaches; (ii) supervised approaches.
Most unsupervised approaches are considered metric-based methods that calculate the discrepancy between two consecutive frames or segments. A change point is detected if the distance between the two segments exceeds a predefined threshold; otherwise, it is considered that no change point exists. In this direction, one of the simplest metric-based approaches [
2] is to use a distance function, such as Kullback–Leibler (KL) divergence [
3], to measure the similarity between two consecutive segments modeled with Gaussian mixture models (GMMs). It is very sensitive to a predefined threshold and difficult to generalize to unseen audio data. Early methods to SCD are the combination of GMMs with Bayesian information criterion (BIC) [
4,
5,
6]. Specifically, each segment will be modeled with separate GMMs (referred to as two speaker models), and two consecutive segments will be modeled with a GMM (referred to as a single speaker model). BIC is used to calculate a score that estimates how well these GMMs will predict the given segments. Generalized Likelihood Ratio (GLR) [
7] can also be applied with GMMs. It measures the likelihood ratio between two distributions of these segments. Studies have shown that using neural network-based speaker embeddings [
8,
9] outperforms traditional audio features such as mel-frequency cepstral coefficients (MFCCs), pitch, and filter banks in SCD. In the work [
10], the authors applied a neural network to calculate speaker embeddings at the frame level, such as d-vector, and used it with metric-based segmentation to detect speaker changes. It achieved a fast and effective SCD model using deep speaker vectors.
In the supervised direction, many machine learning methods have been applied to SCD, including conditional random field (CRF) [
11], which was applied to speaker detection and tracking. In their work, the authors proposed a variational CRF training algorithm for SCD, and it outperforms GMM-based methods; however, it requires knowing the speaker number in the audio in advance. In addition to traditional models, various neural networks [
12,
13] have been applied to SCD in recent years.
In the work [
13], the author proposed an end-to-end SCD approach which also covers overlap speaker change issues. They consider this as a multi-label classification task, which is performed with permutation-invariant training. SincNet [
14] and bidirectional Long Short-Term Memory (LSTM) were applied on short audio chunks with higher temporal resolution. The authors reported that their results are better on both voice activity detection and audio segmentation.
Beyond SCD-specific methods, several studies have contributed important insights into improving ASR systems more generally. In a practical application, Grossinho et al. [
15] developed a multi-modal ASR system for speech therapy that integrates audio and visual cues, demonstrating improved recognition in noisy environments. Dziadzio et al. [
16] showed that language models trained on speech transcripts significantly outperform those trained on written texts, even when using smaller corpora. Wanumen and Florez [
17] highlighted how architectural choices in phoneme recognition systems affect performance, especially when combining modular components. To address noise robustness, Deng [
18] introduced a Bayesian framework that unifies front-end and back-end compensation techniques.
In recent developments, studies on SCD based on pre-training technologies have become more frequent. In the work [
12], the authors proposed a model for speaker embeddings, which was pre-trained on three conditions: (i) gender classification; (ii) contrastive loss; (iii) triplet loss. Then, the model takes two audio segments (2 s) and feeds them into a classification layer to identify whether they belong to a speaker or more. During the training process, the pre-trained model is not trained; only the classification part is fine-tuned for low-latency SCD in broadcast news. The text-based and multi-modal-based SCD approach is another promising research direction [
19,
20,
21,
22]. For the text-based approach, Anidjar et al. [
19], proposed a text-only speaker change detection method using word embeddings. Instead of relying on audio, the model uses fixed-length text windows and predicts speaker changes based on semantic similarity. The authors performed tests on Hebrew conversations, it achieved strong performance and generalized well to unseen speakers. The approach is useful in settings where audio is unavailable or not suitable.
Zhao et al. [
20] present a text-based SCD method that does not rely on audio signals. The authors propose a hierarchical recurrent neural network (RNN) architecture with static sentence-level attention, allowing the model to effectively incorporate surrounding context when determining speaker changes in text transcripts. The model processes dialogue in two levels: an LSTM encodes individual sentences, and another LSTM handles the sequence of sentence representations. A static attention mechanism helps the model focus on informative parts of the context. Experiments on a large dataset of TV talk show transcripts demonstrate that the method outperforms traditional and non-attention neural models, especially in settings where only textual data are available.
For the multi-modal approach, in the work [
21], the authors use the Transformer-Transducer (T-T) model to train a model to turn the audio into speaker turn augmented transcriptions, in which they added a special symbol in the transcriptions to indicate speaker turn for the next training process. Then, they used these transcriptions with a speaker turn symbol as training data and retrain with the previously obtained ASR model, then train a new model with a token-level loss function.
Anidjar et al. [
22] propose a hybrid approach to speaker change detection by combining both speech and text-based features. The authors use a Transformer-based model to detect speaker changes in ASR-generated transcripts, while also incorporating audio cues like speaker embeddings. By evaluating multiple fusion strategies (early, late, and hybrid fusion), the work demonstrates that joint modeling of audio and text outperforms using either modality alone. The method achieves strong results on broadcast news datasets, highlighting the complementary nature of acoustic and textual features in SCD.
Another multi-modal approach was introduced by Jung et al. [
23], a state-of-the-art multi-modal SCD model that combines both audio and text features using an encoder-decoder architecture. Instead of aligning speaker embeddings with individual words, the authors extract X-vector embeddings from 1.5 s audio windows, allowing for more robust speaker representation. The model architecture features modality-specific encoders (a BERT-based encoder for text and a CNN-based encoder for audio), followed by a Transformer decoder that performs multi-modal fusion and prediction. The system is trained using ASR-generated transcripts, not gold-standard text, making it suitable for real-world deployment. It outputs token-level speaker change predictions and is trained with a binary cross-entropy loss. An evaluation of the AMI dataset shows that the model outperforms previous single-modal and multi-modal baselines.
The last two previous works are compared with the proposed approach in this study. The main difference of our model is the use of large pre-trained models for both text and audio modalities, along with the application of a self-attention layer to enhance audio feature extraction. To address the data imbalance issue, which is inherent to the speaker change detection task, we employ focal loss to further improve the model’s performance.
3. Approach
3.1. Problem Formalization
Speaker change detection aims to find the time points in an audio stream where the speaker changes. Formally, we are given an input sequence of audio features , where is the audio feature vector at time frame or segment t, and T is the total number of frames or segments. The task is to predict a binary label sequence , where if a speaker change occurs at frame or segment t, and otherwise.
The goal is to find a function , parameterized by , that minimizes the difference between the predicted labels and the true labels .
3.2. Multi-Modal SCD Model
Speaker change detection in audio streams can be addressed using a multi-modal approach that integrates audio and text data.
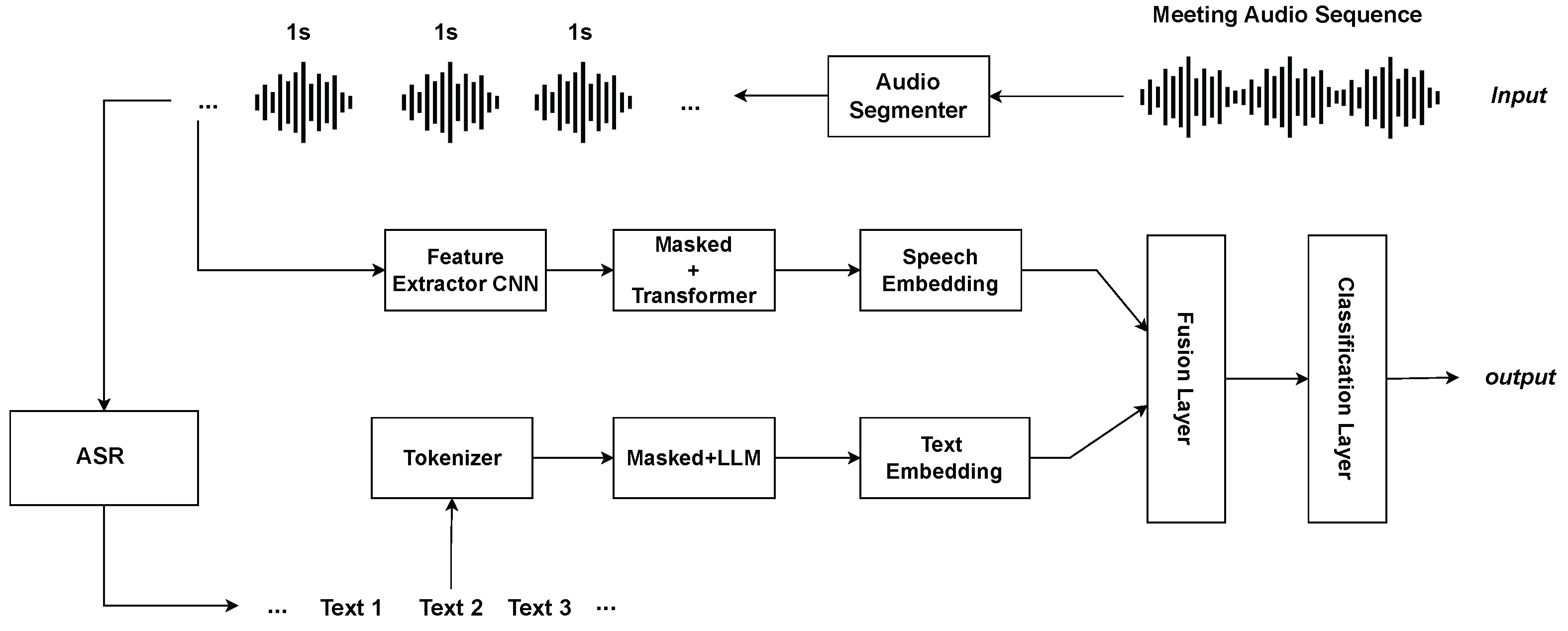
Figure 1 illustrates the proposed multi-modal SCD model, which uses both audio and text to find when speakers change during a meeting. First, the multi-talker meeting audio is split into 1 s pieces. These pieces go through a pre-trained model that learns important sounds (using CNN and Transformer), and it creates a speech feature embedding, a short summary of each audio piece. The audio is converted into text using an automatic speech recognition system, rather than using ground-truth transcripts, which makes the approach more practical. The text is split into tokens and processed with a pre-trained language model to create a text embedding. Both the speech and text embeddings are then combined in a fusion layer. After that, a classification layer uses the combined information to decide whether a speaker change happens at each time step.
This model employs two pre-trained large models: (i) large audio models to extract acoustic features from raw audio; (ii) large language model to derive semantic information from the transcript. The combination of these modalities enhances the accuracy of detecting speaker transitions.
3.2.1. Audio Feature Extraction
In the model, audio features are extracted using the pre-trained Wav2Vec2 encoder, which transforms raw audio signals into contextualized hidden representations. Given a 1 s raw audio waveform segment represented as a vector
, where
L is the number of audio samples (e.g.,
for 16 kHz sampling), we pass this input through the Wav2Vec2 encoder to obtain a sequence of feature vectors:
where
T is the number of time frames after subsampling by the encoder, and
is the dimensionality of each feature vector.
To enhance this representation, we further apply a self-attention mechanism that enables the model to re-weight the importance of different time steps based on their relevance to speaker change detection. The attention-enhanced audio representation is computed using the output of Equation (
1):
To convert the temporal sequence
into a fixed-size vector suitable for classification, we apply mean pooling across the time dimension to the output of the attention layer:
This final vector serves as the aggregated audio embedding, capturing both global and locally attended information from the original speech segment. It is used either directly (in audio-only mode) or concatenated with text embeddings (in multi-modal mode) for downstream classification.
3.2.2. Text Feature Extraction
The audio is segmented into 1 s intervals, and an automatic speech recognition (ASR) system is applied to generate transcripts for each segment, rather than relying on ground truth transcriptions, which are impractical for real-world applications. The text processing leverages a pre-trained large language model, Bert [
24], and its contextual embeddings. The transcript is tokenized and input into Bert, producing embeddings for each token. The embedding of the
[CLS] token is selected to represent the sentence’s semantic content:
where
encapsulates the overall meaning of the text.
3.2.3. Feature Fusion and Classification
To integrate audio and text modalities, a simple concatenation is performed between the two. The resulting audio and text embeddings are then concatenated:
where
is the fusion embedding obtained by concatenating the embeddings from the text and audio extraction modules.
The final audio representation serves as input to a fully connected neural network for classification. The classifier consists of three linear layers with decreasing dimensions. Each linear transformation is followed by layer normalization to stabilize training and improve generalization. Non-linearity is introduced using the ReLU activation function, and dropout regularization is applied after each hidden layer to mitigate overfitting. The final output is passed through a sigmoid activation function to produce a probability score for the classification task.
To optimize the model, we employ focal loss, which is designed to address class imbalance by down-weighting well-classified examples and focusing more on hard-to-classify instances. Given the predicted probability and the ground-truth label, the focal loss is computed as follows:
where
is the binary cross-entropy loss,
represents the predicted probability for the true class,
is a weighting factor that balances the contribution of positive and negative samples, and
controls the down-weighting of easy examples.
By combining structured feature extraction with a classification strategy, the model effectively learns meaningful audio representations while addressing class imbalance in the dataset.
4. Experiments
4.1. Model Setup
The model utilizes pre-trained Wav2Vec2 and Bert, specifically wav2vec2-base and bert-base-cased variants. Training employs the AdamW optimizer with a learning rate scheduler, ensuring stable updates and effective convergence. The base model components (Wav2Vec2 and Bert) use a learning rate of , while the classifier has a higher learning rate of . A weight decay of is applied for regularization. To enhance stability, a warmup ratio of is used, meaning the learning rate gradually increases during the first 10% of total training steps before following a linear decay. Training is conducted for 10 epochs, with the total number of training steps computed as the product of the number of epochs and the length of the training dataloader. Additionally, a random seed is set to ensure reproducibility across experiments.
The classifier is designed to process the features with a hidden size of 768. The head of self-attention is set to 8. The classifier consists of three fully connected layers with 512 and 256 hidden units, each followed by layer normalization, ReLU activation, and dropout (0.4), leading to a final output layer for classification.
Each of the three configurations, multi-modal, text-only, and audio-only, supports two training modes: (i) a freeze mode (F); (ii) a non-freeze mode (NF). In freeze mode, all Wav2Vec2 and Bert parameters are fixed, and only the classification layers are trained. In non-freeze mode, the configurations differ as follows: both base models with their classification layers are trained. For the focal loss of the model, is set to 0.31, and is set to 2.0. For convenience in naming, we use eMD to refer to the proposed approach. Using the different settings described above, we define two versions of eMD: (i) A multi-modal model without self-attention and cross-attention layers, which consists only of the three fully connected layers mentioned earlier for classification. This model is denoted as eMD. (ii) A model with self-attention layers, which enhances feature interaction. This version is denoted as eMD
4.2. Baselines
To check how well the proposed models work, we compare them with these baselines:
(i) Neural Network (NN) Baseline: This model takes a flattened vector of 13-dimensional MFCC features as input. It has fully connected layers with non-linear activation functions. Then, a sigmoid output layer predicts the chance of a speaker change. This baseline captures feature patterns in each segment but does not model time relations between segments.
(ii) Bidirectional Long Short-Term Memory (BiLSTM): This model takes sequences of 13-dimensional MFCC feature vectors. Its bidirectional structure helps capture both past and future time relations. BiLSTM outputs are pooled over time to form a fixed-size representation. Then, a fully connected layer with a sigmoid activation is used for classification.
(iii) Fine-Tuned Approach with Multilayer Perceptron (MLP): This model is a strong baseline similar to this work. It uses only audio and has a single linear classification layer. It is referred to as Wav2Vec2-MLP.
4.3. Dataset Statistics
Experiments were conducted using the AMI meeting corpus [
1], a well-established audio dataset commonly utilized in speech and audio processing research. The AMI corpus provides a diverse collection of meeting recordings with noisy data, interrupted data, etc., allowing for the evaluation of the model under a variety of conditions and scenarios. The dataset used for training and evaluating the multi-modal speaker change detection model is detailed in two tables.
Table 1 presents the overall statistics of the training dataset, which includes 137 meetings with an average of 790.99 change points per meeting. The dataset exhibits an average of 306.61 overlap points, indicating instances of simultaneous speech, and an average of 3.99 speakers per meeting. The average length of each meeting is 34.11 min, with a total duration of 4673.69 min. The class distribution shows that 30.85% of the data are positive instances (indicating speaker changes), while 69.15% are negative instances (no speaker changes).
Table 2 provides statistics for the test set, covering eight meetings identified by specific IDs (e.g., EN2002a, EN2002b, etc.). It reports the total number of change points, overlap points, and speakers per meeting, as well as the audio length in minutes. For example, the EN2002a meeting has 1366 change points, 678 overlaps, 4 speakers, and a duration of 43.90 min. The test set averages 821.31 change points, 328.19 overlaps, 3.94 speakers, and 33.38 min per meeting. Additionally, the class distribution for each meeting is provided, with percentages for positive (P) and negative (N) classes. On average, 31.40% of the test set instances are positive, and 68.60% are negative, reflecting a similar imbalance to the training set. These statistics highlight the complexity and variability of the dataset, which are particularly due to overlapping speech and the distribution of speaker changes.
4.4. Pre-Processing
The pre-processing pipeline is designed to prepare audio data from the AMI meeting corpus for speaker change detection tasks. We use the standard split of the AMI dataset into training and test sets, as provided by the Hugging Face datasets library, and load corresponding metadata files. For each meeting, the audio is segmented into fixed-length chunks, typically 1 s using librosa. Each segment is then labeled as a speaker change or not based on its temporal overlap with annotated change points. The segments are then standardized to exactly 16,000 samples by zero-padding or truncation, ensuring consistent input size for downstream modeling.
Each audio segment is fed into the whisper-base model, used as the ASR system to obtain transcripts from audio. The hyperparameters for the Whisper model are set as follows: temperature is set to 0, best_of is set to 1, and beam_size is set to 5. To generate text embeddings, we use the bert-base-cased model, a case-sensitive pre-trained language model (PLM) trained on a large collection of English texts. No additional text normalization is applied to the transcripts.
4.5. Evaluation Metrics
Several metrics are employed to assess the performance of the baseline and proposed methods. The false alarm rate (FAR) measures the proportion of incorrect speaker change detections, which is calculated as the ratio of false positives to all non-change points:
The missed detection rate (MDR) evaluates the frequency of undetected speaker changes, which is determined as the ratio of false negatives to all true change points:
The Hit rate measures how well the model correctly identifies actual speaker change points.
Additionally, precision is used to indicate the accuracy of detected speaker changes, recall assesses the ability to identify all true speaker changes, and the F1-score provides a balanced measure of precision and recall. These metrics collectively offer a comprehensive evaluation of the model’s effectiveness in speaker change detection. It should be noted that the average results (Precision, Recall, F1-score, FAR, and MDR) reported below are calculated using the Macro method.
4.6. Results
4.6.1. Results of eMD Model
Table 3 and
Table 4 detail the performance of the
eMD model for SCD using freeze and non-freeze models across three modalities: Text, Audio, and Multi-modal.
The Multi-modal approach consistently outperformed single modality configurations in both the freeze and non-freeze settings. For instance, in the freeze models, the Multi-modal modality achieved a Hit Rate of 79.88% in meeting EN2002a (45.51% P, 54.49% N), compared to 72.28% for Text and 78.34% for Audio. In the non-freeze models, the Multi-modal Hit Rate reached 82.98% in EN2002d (40.20% P, 59.80% N), surpassing Text (70.43%) and Audio (82.26%) modalities. The non-freeze models exhibited marked improvements over freeze models, particularly in Audio and Multi-modal settings. The FAR in Audio modality decreased from a range of 19.08–40.48% in freeze models to 8.32–25.99% in the non-freeze models. Similarly, the Multi-modal MDR reduced from 20.12–30.53% (freeze) to 17.02–33.33% (non-freeze), indicating enhanced detection accuracy.
The class imbalance significantly impacted the Text modality in the freeze models, resulting in elevated MDR and reduced Hit Rates. For example, in meeting ES2004b (25.46% P, 74.54% N), the Text modality recorded an MDR of 43.72% and a Hit Rate of 56.28%, reflecting a bias toward the majority negative class. This imbalance compromised the detection of speaker changes. The non-freeze models, particularly Multi-modal, effectively addressed these challenges. In ES2004b, the Multi-modal non-freeze model improved the Hit Rate to 72.53% and reduced the MDR to 27.47%, demonstrating the advantage of adaptive learning and multi-modal integration in handling imbalanced distributions.
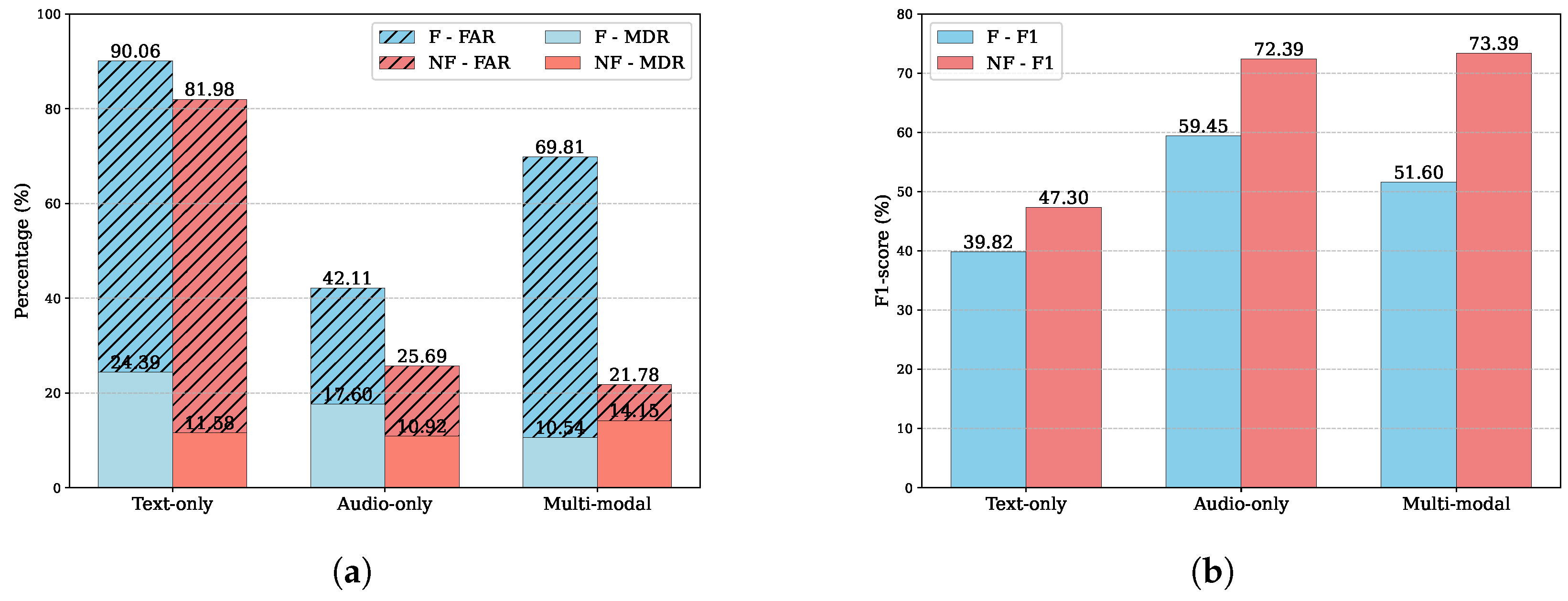
Figure 2 compares the performance of the freeze (F) and non-freeze (NF) models across three setups of the
eMD model: text-only, audio-only, and multi-modal. In
Figure 2a, the stacked bar chart shows the average FAR and MDR. The hatched bars represent FAR, while the solid bars represent MDR. The light blue bars correspond to freeze mode, and the red bars correspond to non-freeze mode. Generally, the multi-modal configuration shows a lower FAR and MDR compared to the text-only and audio-only setups. All non-freeze models outperform the freeze models in all three settings. In the audio-only mode, it can be seen that the FAR decreases significantly from 31.49% to 25.98%, while the MDR drops from 25.24% to 16.93%.
Figure 2b shows the averaged results of F1-scores. The text-only configuration achieves an F1-score of 54.22% with freeze and 55.26% with non-freeze. The audio-only configuration records an F1-score of 60.51% under freeze and 62.58% under non-freeze. The multi-modal configuration performs best, with an F1-score of 70.54% for freeze and 70.91% for non-freeze. The results demonstrate that the multi-modal approach outperforms both text-only and audio-only configurations, with a slight improvement in the non-freeze mode.
4.6.2. Results of eMD Model
Table 5 and
Table 6 show the results of the
eMD model. It applies a self-attention layer only to the multi-modal and audio-only configuration, as previous experiments showed that adding self-attention to the text-only models did not improve performance. In the freeze (F) mode (
Table 5), where feature extraction layers remain unchanged, the audio-only setup outperforms the text-only setup. This suggests that audio inherently provides more informative cues for speaker change detection than text. The multi-modal setup performs best, leveraging both modalities to achieve the highest Hit Rates across all meetings.
In the non-freeze (NF) mode
Table 6, where feature extraction layers are fine-tuned, overall performance improves. The text-only model sees a reduction in FAR from 87–92% to 77–87%, and MDR drops to 9.07% in the best case. The audio-only model continues to outperform the text-only model, with FAR decreasing to 16.80% (IS1009c) and 17.23% (IS1009b), and MDR remaining below 14%. The multi-modal approach remains the most effective, maintaining FAR around 20% and MDR between 9 and 16%. The multi-modal setup achieves the most significant improvements across the most imbalanced meetings (TS3003c, IS1009c, ES2004b). Fine-tuning substantially reduces FAR, dropping from 57.93% to 21.06% in TS3003c, from 76.07% to 14.04% in IS1009c, and from 78.26% to 21.97% in ES2004b. These results suggest that utilizing both text and audio in a fine-tuned model can help reduce the impact of class imbalance, making multi-modal processing a promising approach for speaker change detection in imbalanced scenarios.
The precision, recall, and F1-score for the
eMD and
eMD models are reported in
Appendix A.
Figure 3 compares the performance of freeze (F) and non-freeze (NF) models across three setups of the
eMD model: text-only, audio-only, and multi-modal. In
Figure 3a, the stacked bar chart shows the average FAR and MDR. The hatched bars represent FAR, while the solid bars represent MDR. The light blue bars correspond to freeze mode, and the red bars correspond to non-freeze mode. It is clearly shown that
eMD uses the attention layer; the fine-tuned model (NF) reduces both FAR and MDR significantly compared to the freeze model. For example, the multi-modal model with freeze mode achieves a high FAR of 69.81% and a low MDR of 10.54; however, the fine-tuned (the red bar) trade-off between these two rates reduces the false alarm from 69.81% to 21.78%.
Figure 3b reports the F1-score for these models, and it shows that the highest F1-score 73.39% was obtained by the multi-modal model with NF.
4.6.3. Optimization Parameters for Focal Loss
In order to test how focal loss [
25] influences the model’s performance in the SCD imbalanced situation, we predefined various values of parameters of focal loss, such as
and
. The former
is a weighting factor that balances class importance in imbalanced datasets. A lower
(<0.5) gives more weight to the majority class (non-change points), while a higher
(>0.5) gives more weight to the minority class (speaker change points).
is a focusing parameter that reduces the weight of easy samples, making the model focus more on hard-to-classify examples. A higher
increases this effect, but too high a value can cause training instability.
We selected a highly imbalanced meeting from the training set to analyze different parameter combinations and reduce training time.
Figure 4 presents the curves for different combinations of values of
and
. Traditional binary cross-entropy (BCE) loss is also included for comparison and is denoted as BCEloss.
Figure 4a,b illustrate how the FAR and MDR change with different values of
and
. It can be observed that
and
, when using BCEloss, achieve comparably low FAR scores. Among them, the loss function, when
, becomes weighted BCE loss, which performs slightly better than the others. From
Figure 4b, it can be seen that
with BCEloss results in a higher MDR compared to other settings.
Figure 4c displays F1-scores across different settings, clearly showing that focal Loss outperforms BCEloss. When
(orange curve) and
, the model achieves the highest F1-score. These values are chosen for focal Loss, and the final model is trained using this configuration, denoted as eMD
.
4.6.4. Comparison with Baselines
The performance of the
eMD and
eMD models is evaluated in
Table 7, which indicates improvements of up to 2.73% in the F1-score over the baseline Wav2vec-MLP. The comparison includes baseline models: Neural Network (NN), Long Short-Term Memory (LSTM), and Wav2vec-MLP. The NN struggles with a high missed detection rate, while LSTM shows improvement but remains weak in detecting speaker changes. Wav2vec-MLP provides a stronger baseline with higher precision, though it still misses some detections.
The eMD model, tested in audio-only and multi-modal modes, improves recall compared to Wav2vec-MLP, but its false alarm rate increases. The multi-modal setup of eMD offers a slight recall boost over the audio-only version, with similar false alarm rates, suggesting limited additional benefit. The eMD model, incorporating attention, further enhances recall in both audio-only and multi-modal modes, reducing missed detections despite a higher false alarm rate. The multi-modal eMD configuration performs best, achieving the lowest missed detection rate (14.15%) and highest recall (85.85%) among all models, with an F1-score of 73.39%, surpassing Wav2vec-MLP’s overall score.
Compared to the baselines, eMD multi-modal approach stands out, leveraging attention and multi-modal data to outperform Wav2vec-MLP, with notable improvements in recall (it is similar to the hit rate, an important metric for SCD, because it measures how well the model captures actual speaker change points) and reduced missed detections.
4.6.5. Comparison with Previous Work
Table 8 compares the proposed approach with previous multi-modal methods and a pitch-based approach. However, a direct comparison is not possible due to differences in experimental settings. For instance, Zhao et al. [
21] use a custom definition of precision and recall, making the task easier. Other studies apply forgiveness collars when identifying change points. Despite these differences,
Table 8 shows that the proposed approach performs competitively and achieves better results than previous multi-modal methods.
4.7. Visualization of Attention Layer
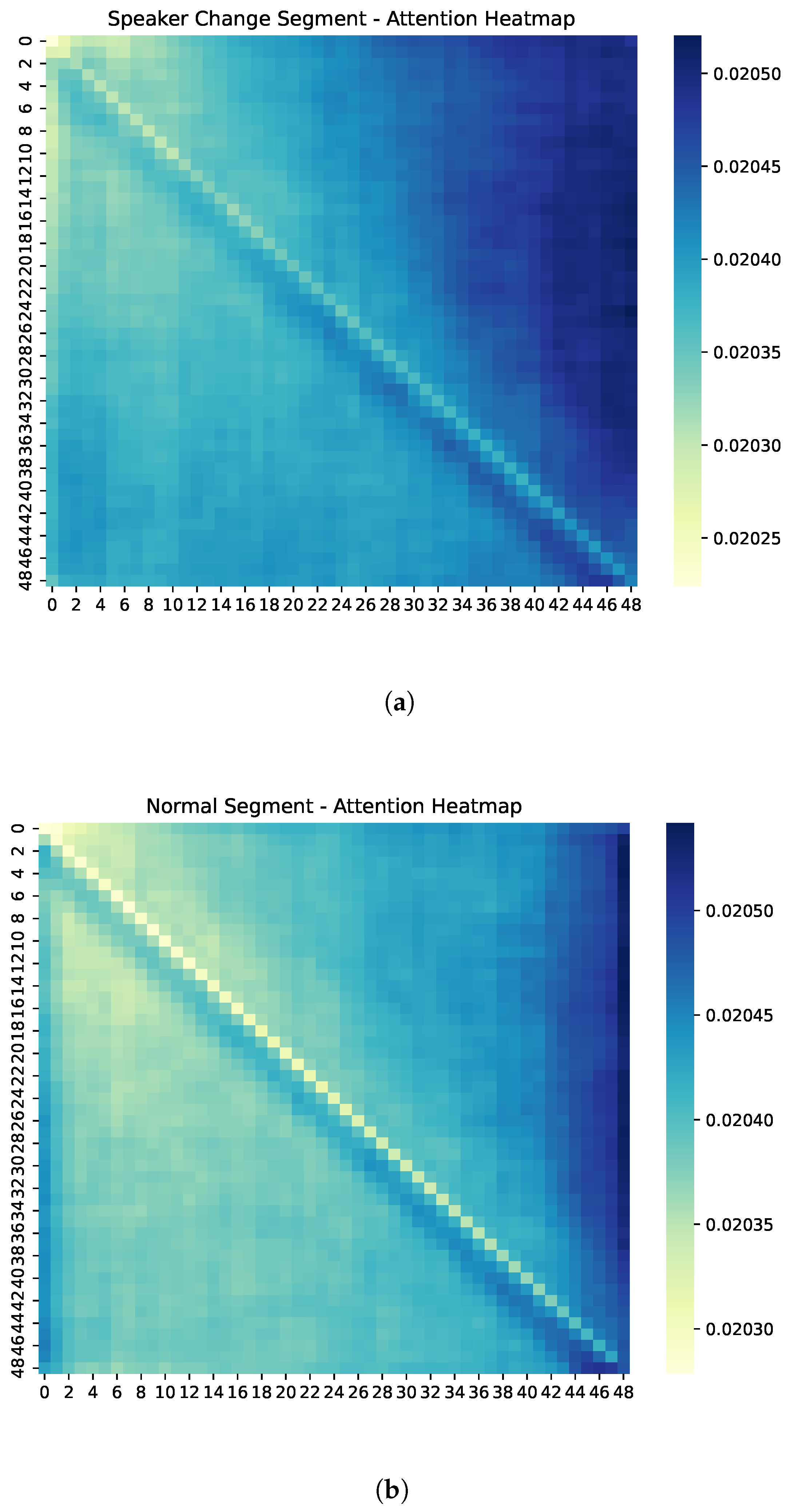
Figure 5 presents the average intra-segment self-attention maps for two types of audio segments: those containing speaker changes (
Figure 5a) and those without speaker changes (
Figure 5b). Each attention matrix is of size 50 × 50, reflecting attention weights between 50 temporal frames (approximately one frame every 20 milliseconds in a 1 s segment).
Notably, the attention map for speaker change segments exhibits more diffuse and scattered patterns. The attention weights are distributed more broadly across off-diagonal regions, indicating that the model attends to a wider temporal context when a speaker transition is occurring. This suggests increased uncertainty or contextual reevaluation during such transitions.
In contrast, normal segments show strongly diagonal attention patterns, meaning each frame primarily attends to itself and its immediate neighbors. This reflects temporal stability and high model confidence when no speaker change is detected.
These patterns align with our entropy-based analysis, which showed statistically higher attention entropy in speaker change segments. As shown in
Figure 6, the attention entropy is significantly higher in speaker change segments compared to normal ones. The result shows that speaker change segments tend to have significantly higher attention entropy, suggesting that the model distributes attention more broadly when detecting transitions. This further supports the hypothesis that the model attends more diffusely under speaker transition conditions.
5. Discussion
The results across various configurations of the proposed eMD and eMD models demonstrate consistent improvements in SCD. These gains can be attributed to three key design choices: multi-modal integration, fine-tuning of PLM, and the use of self-attention layers in combination with focal loss.
Multi-modal integration proved to be effective across all settings. Models that jointly processed audio and text consistently outperformed those relying on a single modality. This advantage was especially apparent in imbalanced data scenarios, where speaker change points were rare. While audio captures acoustic variations, text offers semantic information, forming a more complete signal for identifying transitions.
Fine-tuning the PLM further enhanced performance, particularly for the audio and multi-modal configurations. Models with the unfrozen pre-trained model adapted more effectively to the data, reducing both the FAR and MDR. These improvements were reflected in the overall F1-scores, suggesting that trainable backbones are more effective at capturing the complex interaction patterns and overlapping speech dynamics characteristic of multi-talker meetings.
Introducing self-attention into the architecture, as in eMD, further boosted performance. The attention mechanism enabled the model to weigh temporal features more flexibly, particularly around potential speaker transitions. Attention visualizations revealed clear distinctions in how the model processed speaker change versus normal segments. In speaker change segments, attention was distributed more broadly across time, suggesting increased uncertainty and the need for wider contextual integration. Normal segments, on the other hand, showed tightly focused attention patterns, indicating greater temporal stability. Higher attention entropy in speaker change segments indicates that the model is actively attending to a broader temporal context, which helps it capture the complex and distributed cues necessary for accurately detecting speaker transitions.
Focal loss optimization played a critical role in improving performance under imbalance. By assigning more weight to challenging examples and reducing the influence of easy negatives, the model achieved better recall and a stronger balance between false alarms and missed detections. This was particularly helpful in cases where standard loss functions failed to adequately address the rarity of speaker change events.
6. Limitations
Despite the effectiveness of our approach, there are several limitations that could impact performance. First, we rely on a hard alignment between text and audio, which may introduce errors when transcription and audio segmentation are not perfectly synchronized. This can lead to misaligned speaker change points, affecting downstream processing. Second, the pre-trained Bert model used in our approach does not inherently contain speaker information. As a result, the textual representation lacks explicit speaker cues, which could otherwise improve the detection of speaker transitions.
A more effective approach would involve a joint model that simultaneously performs automatic speech recognition and speaker change detection, reducing alignment errors. Alternatively, a stacked model architecture, where ASR is followed by SCD in a sequential manner, could improve robustness by leveraging intermediate speech representations. These models can be integrated with pre-trained audio models to further improve performance. Future research should investigate joint modeling of automatic speech recognition and speaker change detection to improve alignments between text and audio, or use hidden embeddings from a pre-trained ASR model to improve SCD performance.
7. Conclusions
In this work, we proposed a multi-modal speaker change detection (SCD) approach that integrates audio and text information to improve detection. The proposed method leverages pre-trained large-scale models for feature extraction and incorporates a self-attention mechanism to refine contextual representations. The features are combined and passed through a fully connected classification network with layer normalization and dropout to make the model more stable. The model also uses focal loss to handle the class imbalance of the data.
We tested the model on a speaker change detection task, using audio–text pairs from a multi-talker meeting dataset. The experiments included comparing multi-modal and single-modal models, checking the effect of fine-tuning pre-trained models, and testing the impact of self-attention layers. The results show important findings. The multi-modal approach works better than single-modality models, which shows that audio and text together help detect speaker changes. Fine-tuning pre-trained models makes a much better model, as opposed to freezing them. Updating the pre-trained model’s parameters during training gives a 21% improvement in the multi-modal setting. Adding a self-attention layer improves feature learning, which boosts performance by about 2%, compared to a model without it. We have compared attention entropy between speaker change and non-change segments and found that entropy is higher during speaker changes. This suggests that the model attends to a broader temporal context when detecting speaker transitions, helping it capture subtle and distributed cues. Higher attention entropy in these segments reflects more adaptive and effective attention behavior for speaker change detection in multi-talker meetings.
Despite these improvements, the approach has certain limitations. There is a reliance on hard alignment between ASR-generated text and audio segments. The text information is first used symbolically, then it is turned into embeddings, which lack speaker-specific information, reducing their effectiveness in capturing speaker transitions based solely on textual cues.
To address these limitations, future research should explore jointly performing automatic speech recognition and speaker change detection to reduce alignment errors. Alternatively, a stacked ASR-to-SCD pipeline could leverage intermediate ASR representations for better speaker change detection.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}