1. Introduction
The integration of Artificial Intelligence (AI) into education has introduced new approaches for evaluating student engagement, particularly in Science, Technology, Engineering, Arts, and Mathematics (STEAM) programs. This paper explores the development of an AI-based text sentiment analysis system designed to evaluate learning engagement levels by analyzing textual data from students, such as responses, feedback, and discussions. By utilizing natural language processing techniques, this system aims to provide educators with actionable insights to enhance teaching strategies and foster a more interactive and effective STEAM learning environment.
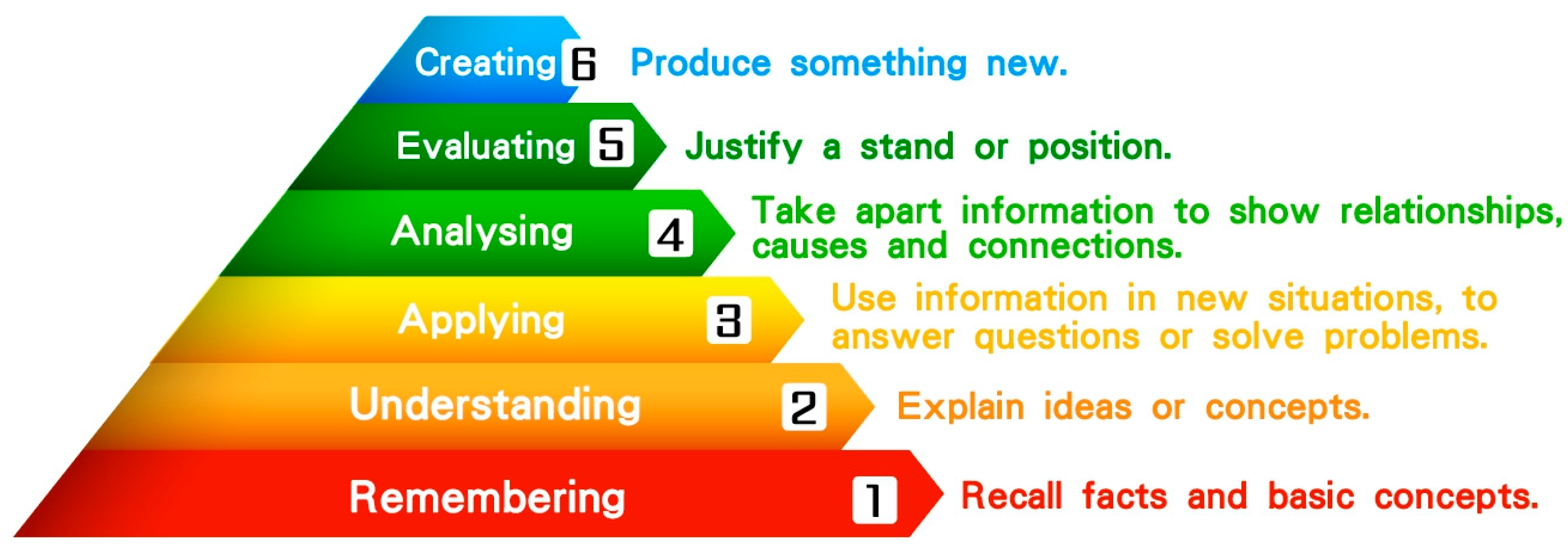
Bloom’s taxonomy, introduced in 1956, originally categorized learning objectives into six ascending levels. A recent study [
1] updated the taxonomy to encompass these levels: remembering, understanding, applying, analyzing, evaluating, and creating, as illustrated in
Figure 1. According to Bloom’s framework, the highest level of learning is the ability to produce original work. This study adopted this framework to design its research objectives [
1].
STEM integrates the disciplines of science, technology, engineering, art, and mathematics, and STEAM education assists in developing problem-solving skills by fostering cross-disciplinary integration [
2,
3]; hands-on STEM activities designed through 6E orientation can help enhance technological literacy [
3]. Computational thinking (CT) is designed to train problem-solving methods, help students understand the nature of the problem, and develop possible solutions to complex problems. These solutions are then presented in a manner that can be understood by computers, humans, or both [
4]. Therefore, the main focus of CT is to learn to program problems, solve them systematically, and practice creativity [
5,
6]. To reach the sixth level of Bloom’s learning goals, the students must be able to create their own products [
1]. Further, inquiry-based learning involves asking questions, making observations, conducting research to discover information that has been recorded, developing experimental methods and tools for data collection, collecting, analyzing, and interpreting data, outlining possible explanations, and creating predictions for future research. This helps learners explore learning topics, achieve deeper learning, and create their own work [
7].
Text sentiment analysis, also known as opinion mining or emotion AI, involves studying people’s opinions, sentiments, evaluations, appraisals, attitudes, and emotional states, such as happiness, fear, and surprise, etc. [
8]. Sentiment analysis is a valuable tool for gaining insights from social networks [
9] and has been widely applied in various domains, including assessing learning engagement in STEAM education, analyzing social media trends in financial markets [
10], evaluating customer satisfaction [
11], and measuring employee engagement during digital transformation [
12].
Learning engagement is crucial for enhancing learning performance, as highly engaged students are more likely to actively participate in class, understand and retain information, and achieve superior learning outcomes. An AI-based sentiment analysis system can evaluate learners’ engagement by analyzing the sentiments expressed in their written feedback, forum posts, or other textual communications. Therefore, the purpose of this study is to develop an AI-based sentiment analysis system to evaluate learners’ engagement levels in education.
2. Literature Review
2.1. Learning Engagement
In many constructivist approaches to teaching and learning, group work and collaboration are encouraged so that students can actively learn and share ideas in groups or among peers to deepen their understanding of the subject matter [
13]. This approach to learning through collaboration and assistance can therefore be applied to different types of learning, such as problem-based learning [
5,
14], project-based learning, and inquiry-based learning [
7]; collaborative learning is also widely used in STEM education research as the main method of curriculum delivery [
13,
14,
15,
16,
17]. A technology acceptance model for high school STEM action learning was proposed, and it was found that social influence directly affects the intention to use STEM, meaning that community interaction has a significant impact on STEM teaching and learning activities. Therefore, this study adopted a cooperative learning approach for the design of lesson plans.
Among the indicators for assessing the effectiveness of cooperative learning, learning engagement is important [
18,
19,
20]. According to the definition of engagement [
21], the measurement of engagement can be divided into three dimensions: behavioral, affective, and cognitive. Behavioral engagement represents the extent to which students actively participate in learning activities. These indicators include the amount of time spent on learning activities or the extent to which they interact with other people and are usually measured by observable behaviors. Cognitive engagement represents the extent to which students expend brainpower to understand the content of the curriculum and is assessed by motivation, self-regulation, or deep learning [
22]. Luo et al. (2020) [
22] determined behavioral, affective, and cognitive engagement measures by observing interactive behaviors of students during STEM activities. Beyond observation, we employed a learning engagement questionnaire that assessed three dimensions—affective, behavioral, and cognitive engagement—through eight statements rated on a Likert scale [
23]. The questionnaire demonstrated adequate reliability, with Cronbach’s alpha values ranging from 0.71 to 0.80. A previous study developed an Online Student Engagement Scale (OSES) to determine the actual level of student engagement in learning [
24]. The OSES has been rigorously tested for its reliability and validity. The scale consists of 16 questions divided into four dimensions: skills, affect, engagement, and performance. The “skills” questions focus on how students interact with the content, the “emotions” questions focus on how to make the content interesting and useful, and the “engagement” questions focus on how students interact with others. The “performance” questions focused on test scores. Questionnaires are usually administered at the end of the learning process, so their accuracy is easily influenced by students’ personal factors and lack of objectivity. Therefore, methods to assess real-time participation by recording behaviors during the learning process have also been developed. The earliest measures of real-time engagement were based on log files generated from online learning systems, which provided detailed information about the timing, frequency, antecedents, and outcomes of learning activities and allowed researchers to examine which types of learning activities caused changes in student engagement.
2.2. Engagement Assessment
The second-generation real-time engagement assessment was recorded using physiological or neurological sensors. The sensor data analysis method focused on analyzing the data collected by various sensors during the learning process to assess engagement. Commonly used sensors included electroencephalograms, electrocardiograms [
25], pressure sensors [
26], eye-tracking [
27], and skin potentials [
28]. The physiological data collected by these sensors can be converted and validated to represent the learners’ real-time learning data. However, the wearing of certain devices may cause discomfort and affect the learning outcomes of the students; thus, third-generation automatic recognition technologies that use advanced computational techniques (e.g., deep learning models) are used to estimate an individual’s learning engagement by analyzing facial expressions or body postures [
29,
30,
31]. However, the computer vision-based approach has limitations. First, because the process of training the classifier relies on manual judgment, there is no guarantee that errors caused by manual judgment can be excluded; second, a single feature cannot represent the total learning engagement. For example, facial expressions can be used to measure emotional engagement [
29] and cognitive engagement [
30], whereas skin potential shows a moderate correlation between cognitive engagement and behavioral engagement [
28].
In previous collaborative learning studies, participants’ conversations and actions were recorded through video, and their behaviors were coded to analyze their learning performance. Because this study adopts a cooperative learning approach, it is necessary to deal with situations where multiple subjects interact at the same time. Therefore, this study proposes the development of a speech recognition system that records student interactions during collaborative learning through audio recording, which is automatically converted into text by the speech recognition system and encoded with fuzzy comparisons based on a set of keywords. The advantage of using speech recognition is that the learning process can be recorded without affecting the subject’s activity, and the collation of research data through speech recognition and AI can significantly improve the accuracy and reduce possible errors of manual recognition. Current studies adopted various deep learning networks, such as a recurrent neural network (RNN) coupled with an attention mechanism, to develop a prompted-enhanced sentiment analysis [
32] or aspect-based sentiment system [
33].
However, to compensate for the fact that speech recognition may not represent the full range of engagement, previous studies coded engagement by analyzing participant interactions in video recordings [
34]. The coding of engagement in the video was guided by behaviors outlined in the study’s definition [
35] and those associated with instructional behavioral engagement [
36], which identifies whether the participant is actively engaged by observing behavioral actions. In summary, measuring engagement through speech recognition provides an objective measure that does not interfere with student learning and is an efficient and effective measurement tool [
25]. A review of past research suggests that it is appropriate to measure learning engagement with physiological signals, such as gestures and speech sounds, and that there is no research that uses speech recognition of text followed by text analysis techniques to provide a measure of learning engagement.
2.3. Our Contributions
This research presents the design and implementation of a novel system that integrates artificial intelligence (AI) voice recognition, natural language processing (NLP), and sentiment analysis to evaluate learners’ emotional engagement based on textual data derived from learning sheets and real-time discussions. The study employed a structured methodology for collecting and processing educational text data, utilizing learning sheets completed by 129 first- and second-year university students during a two-week computational thinking (CT) course. The researchers introduced a participation recognition system that leverages AI speech-to-text conversion and emotion scoring to assess real-time engagement during student discussions. We provide empirical evidence of the system’s effectiveness through an analysis of students’ learning texts, which yields a dictionary of feelings and engagement indicators. Although sentiment analysis has been widely applied in other domains, this work uniquely adapts it to the STEAM education context, focusing on CT and inquiry-based learning. By linking learners’ textual responses and emotional scores to their perceptions of course utility, the researchers bridged the gap between emotional engagement and educational outcomes, thus contributing to the growing body of research on AI-enhanced pedagogy.
3. Research Methodology
In this study, we propose an AI-based text sentiment analysis system to evaluate learners’ engagement in STEAM education within a Computational Thinking (CT) and inquiry-based learning curriculum. The system comprises four integrated models: (1) AI Voice Recognition Model: Using the Google Voice Recognition API, this model converts student discussion audio into text for engagement analysis. (2) Word-Breaking Model: Using Jieba Chinese Natural Language Processing, this model segments text into keywords and removes stop words to prepare data for sentiment analysis. (3) Keyword Analysis Model: This model filters and analyzes keywords, labels them as high- or low-participation, and generates matrices and word clouds to identify engagement patterns. (4) Emotion Analysis Model: This model uses various sentiment dictionaries to calculate positive and negative emotion scores per sentence (Equations (1)–(3)) and aggregates these into participation scores. The purpose of this study is to provide educators with a tool to assess and enhance emotional engagement in STEAM by correlating sentiment with perceived course helpfulness, as validated through university student data.
3.1. Data Collection Method
In this study, the computational thinking (CT) concept combined with an inquiry-based learning curriculum and learning sheets was designed to collect learning experiences; the learning sheets were used as input for the subsequent development of a text–emotion analysis model. The input variable is the user’s response to the learning sheet (Learning Sheet Q2), and the output variable is whether the learner thinks the CT course learning activity is helpful (Learning Sheet Q3), with “Yes” indicating that it is helpful and “No” indicating that it is not. The course was conducted for first- and second-year university students over a two-week period. The course content was CT and inquiry-based learning (Python fundamentals), and the study sheets were completed after the course. In total, 129 learning texts were collected. The study sheets were designed as follows.
3.2. Computational Thinking + Inquiry Learning #1 (Python Fundamentals) Learning Sheet Training
In the first course, students were given tasks to complete the following learning sheets using the Foundations of Computational Thinking (Python) learning sheet. This was used to train the basic concepts of CT. Students were asked to answer these questions. Students were also given discussion topics and inquiry-based learning methods to discuss their answers with each other. The design of the learning sheet is shown in
Table 1.
Prg #D refers to Program 4 in our design learning activity. In the coding practice class, the teacher first teaches and demonstrates several programs. Then, the students are required to complete the result of Program Example 4 and fill out the learning sheet. The goal of this program is to allow the user to input a number n and then display the left half of a triangle. For example, if the user enters 3, the program will display three rows of the left half of a triangle.
The learning sheet consists of three main sections: 1. Program Objectives and Tasks: The goals and tasks that the program needs to accomplish. 2. Computational Thinking (CT) Steps: The four steps of computational thinking (breaking down the problem, pattern recognition, abstraction, and algorithm). 3. Learning Reflections: Open-ended questions, including: Q1: Explain your CT steps. Q2: Describe your learning experience. Q3: Evaluate your own learning outcomes.
In the second section focusing on computational thinking, the first column lists the four CT steps, the second column is for learners to record their analysis based on these steps, and the third column contains a reference demo provided by the teacher.
3.3. Participation Recognition System for AI Voice Recognition/Text Emotion Recognition System for Creative Education
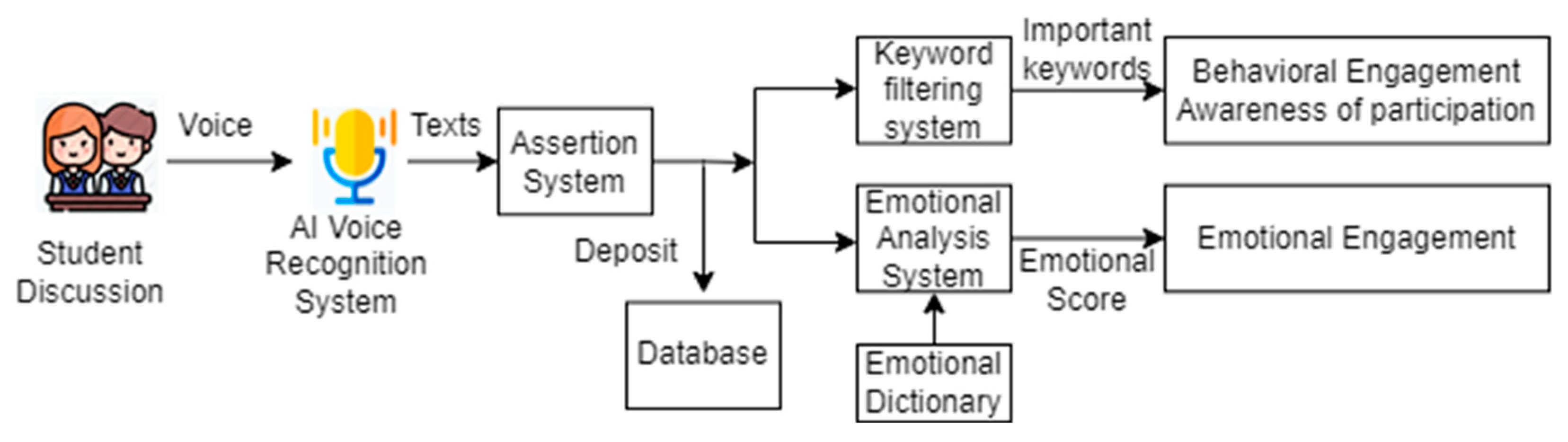
We created a participation recognition system that integrates AI speech and emotion recognition for creative education. The system was used to calculate and analyze the engagement level of real-time learning in STEAM education. The entire system architecture is shown in
Table 2 and
Figure 2. It includes the following modules.
- (1)
AI voice recognition system: By linking to the Google Voice Recognition API, it converted the student discussion process voice into text.
- (2)
Word-breaking system: Through natural language processing (NLP) technology, Jieba Chinese word-breaking technology was used to break the entire sentence. Thus, it could be turned into keywords that were analyzed and stored in the back-end web database (MySQL).
- (3)
Keyword analysis system: After obtaining the word breaks, the keywords were manually labeled as high- and low-participation groups through the keyword filtering system. Then, using keyword analysis technology, we analyzed important keywords. This study adopted keyword analysis technology that used word segmentation techniques to break text into meaningful words. After removing stop words, the frequency of each word was calculated to analyze important keywords, and finally, a word cloud was created based on these frequencies.
- (4)
Emotion analysis system: After the keywords were extracted, the students’ emotions of each sentence were analyzed through the emotion analysis system, combined with the emotion dictionary, and the positive and negative emotion scores of each sentence were calculated; the emotion scores of each student’s sentences were summed up to obtain the emotion participation score of each student.
Table 2.
System environment.
Table 2.
System environment.
Win10 + Apache Web Server
Python, Anaconda, TensorFlow, Keras, Jieba, NLP module.
Front-end HTML, JavaScript, PHP programs
Back-end MySQL database, Flask Web Services |
Figure 2.
AI speech recognition/emotion recognition system architecture.
Figure 2.
AI speech recognition/emotion recognition system architecture.
In the AI voice recognition system, the subject entered their student number information at the beginning of the experiment. At the beginning of the experiment, the participants entered their student numbers into the AI voice recognition system. The recording then began, and the system converted the subject’s speech into text. After input, the system converted the subject’s speech content into text. The system immediately stored the recognized text in the back-end web database. The system also analyzed the user’s emotions during the conversation. This was used as the analysis information for the participation level.
3.4. Keyword Extraction
In this study, we performed keyword selection after word-breaking by referring to the procedure in [
37]. The system used the NLP suite, and Jieba was used for word extraction analysis to compare its effectiveness. (1) First, we used Jieba to break the words. Some unnecessary stop words (such as symbols [ ], 、, <, >) were removed before clearing the data. (2) A list of results after word breaks was created by blanking. (3) Sentences were manually marked as high- or low-participation and provided to the system. (4) Keywords were filtered using various methods in Python. The keyword count was converted into a matrix. (5) Keyword analysis was performed using word clouds.
3.5. Emotional Engagement Level Calculation
After systematic word determination using the NLP package, the keywords in each sentence were compared with the sentiment dictionary using the Chinese Sentiment dictionary [
38] and NTUSD (National Taiwan University Sentiment Dictionary) [
39] to determine the number of positive and negative words in each sentence. The NTUSD is a dictionary of Chinese words published in 2006 and is available free of charge for academic use. The dictionary includes 11,088 semantic words in both simplified and traditional Chinese, including 2812 positive and 8276 negative words. The dictionary is labeled as positive or negative only, with no distinction between intensity or other additional information [
40].
Another emotion dictionary integrates the China HowNet emotional dictionary with other words [
39,
41] through web crawling containing a total of 7376 positive words and 12,646 negative words. The original text is in simplified Chinese. After converting it into traditional Chinese, it was used as another emotion dictionary.
In this study, the sentiment calculation formula [
40] was modified. As in Equations (1)–(3),
denotes the negative score of the
Ci sentence;
is the frequency of negative words of the
Ci sentence.
denotes the negative score of the
Ci sentence;
is the frequency of positive words of the
Ci sentence. Equation (1) calculates the negative score of a sentence in the learner discussion after converting speech to text. Equation (2) calculates the positive score of a learner’s sentence. Equation (3) calculates the sentiment score
to present positive or negative intention for the sentence. The sentiment score was then used as indicators of learners’ immediate emotional engagement levels.
The emotion corpus is based on the NTUSD (National Taiwan University Sentiment Dictionary), published in 2006, which provides 2812 positive and 8276 negative Chinese words and is widely utilized for academic sentiment analysis in Chinese texts. However, its static nature and potential lack of intensity gradation limited its applicability to our dynamic, education-focused dataset. To address this limitation, we supplemented it with another sentiment dictionary (containing 7376 positive and 12,646 negative words), thereby enhancing coverage and ensuring greater relevance to contemporary language use among students.
The sentiment calculation formula was modified to align with the objectives of evaluating learners’ emotional engagement in STEAM education using text from learning sheets and real-time discussions. The original formula determined emotions using binary classification, labeling them solely as positive or negative. To address this, we made several adjustments: we incorporated the frequency and relative proportion of positive and negative words within each sentence into the calculation, and by setting a threshold value, we used the quantified emotion scores to classify the polarity of the emotions. This approach enables us to assess and infer each student’s emotional engagement.
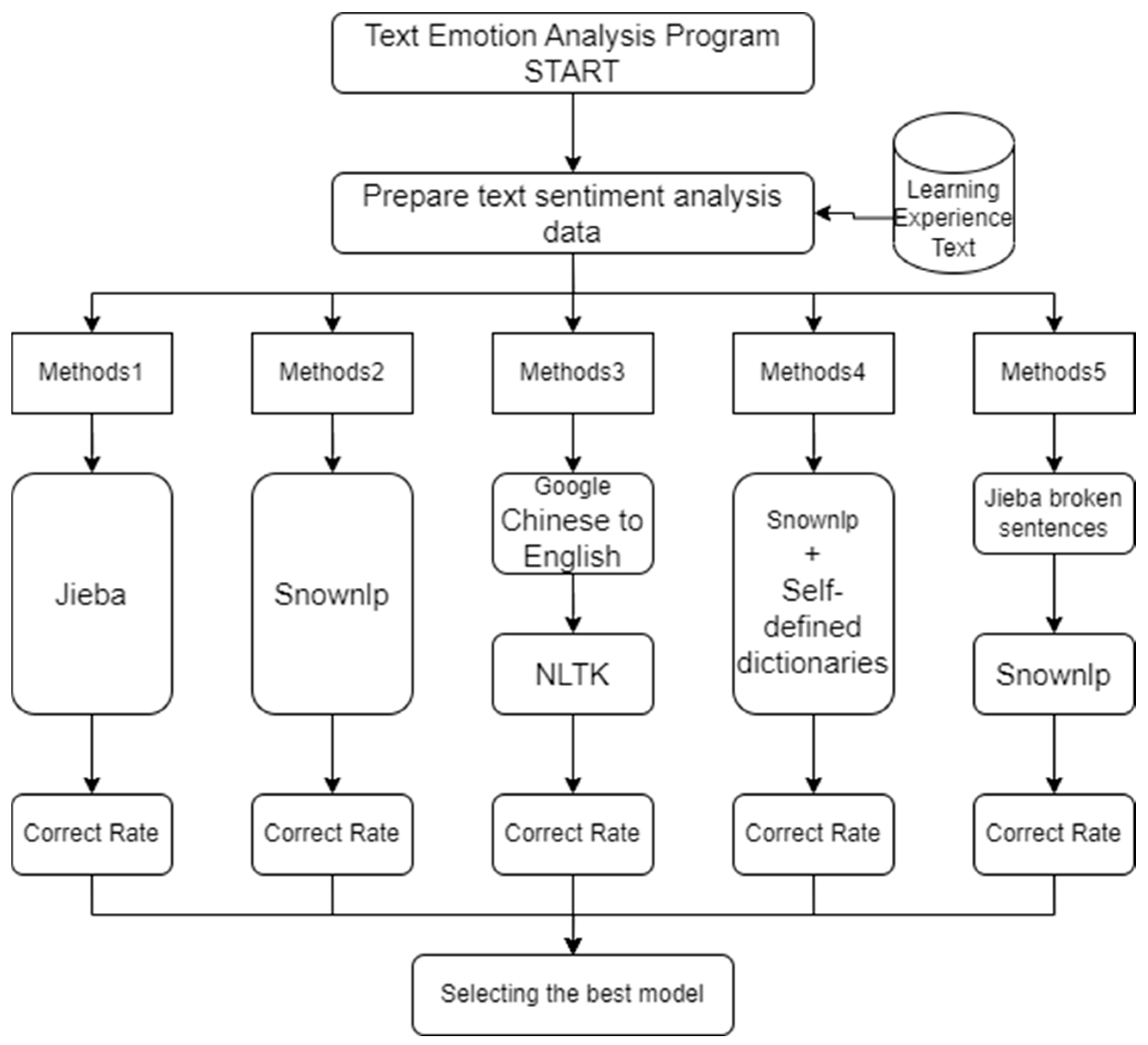
3.6. Research and Analysis Process
The research and analysis process is shown in
Figure 3. Model A is the original SnowNLP method, Model B is Jieba, and Model C is NLTK. This study proposes two models to improve the original SnowNLP method: Model D is SnowNLP retrained with a self-constructed emotion dictionary, and Model E is the SnowNLP + Jieba method. Finally, the accuracy of the different models was analyzed to determine the best model. The Python implementations of Jieba (
https://github.com/fxsjy/jieba, accessed on 1 January 2025), SnowNLP (
https://github.com/isnowfy/snownlp, accessed on 1 January 2025), and NLTK (
https://github.com/nltk/nltk, accessed on 1 January 2025) are available on GitHub.
4. Results and Analysis
In this study, a total of 129 learning texts were collected from first- and second-year university students over a two-week period, as noted in the data collection methods subsection. The experiments were conducted on a desktop computer equipped with an Intel Core i7-9700 processor (8 cores, 3.0 GHz base frequency), 16 GB of DDR4 RAM, and an NVIDIA GeForce GTX 1660 Ti GPU with 6 GB of VRAM. This setup provided adequate computational power for natural language processing (NLP) tasks, including word-breaking using various toolkits (Jieba, SnowNLP, and NLTK), keyword extraction, and emotion analysis. The data processing pipeline included several stages, and we report approximate times based on the system described above. (a) Speech-to-text conversion: Using the Google Voice Recognition API, converting student discussion audio (averaging 5 min per session) to text took approximately 10–15 s per recording, depending on audio quality and network latency. (b) Word-breaking with Jieba: Processing the 129 learning texts (approximately 645–903 sentences) using the Jieba Chinese word-breaking technology took about 2–3 min in total, including stop-word removal. (c) Keyword extraction and analysis: Generating the keyword matrix and word clouds for the entire dataset required approximately 5–7 min, with manual labeling of high/low-participation groups adding an additional 1–2 h of human effort. (d) Emotion analysis: Calculating emotion scores using the combined Chinese Sentiment Dictionary (7376 positive, 12,646 negative words) and NTUSD (2812 positive, 8276 negative words) took roughly 3–4 min for the full dataset, as the system compared keywords against the dictionaries and computed scores per sentence using Equations (1)–(3).
The back-end web database used MySQL 8.0 and was hosted locally on the same machine, with a storage capacity of approximately 50 MB for raw text, segmented keywords, and emotion scores. The AI voice recognition system processed real-time audio input via a standard USB microphone (sampling rate: 44.1 kHz). This study analyzed the high-frequency keywords associated with positive and negative emotions in learning experiences. Keywords that appeared more than 10 times were selected and sorted to create the word cloud.
Model training for the emotion analysis system utilized popular NLP toolkits rather than a machine learning classifier due to the reliance on predefined sentiment dictionaries, which reduced computational overhead while maintaining accuracy for this exploratory study.
4.1. Effect of Sentiment Dictionaries on Model Accuracy
In this study, two different sentiment dictionaries were used to analyze model correctness: Method 1 used the NTUSU sentiment dictionary, and Method 2 used an online sentiment dictionary. The results show that the accuracy rate of Method 1 was higher than that of Method 2. A comparison of the accuracy rates is shown in
Table 3. Because the original model does not use a sentiment dictionary, the accuracy rate is not different when using different sentiment dictionaries. In Models D and E, the accuracy rate was improved by 23.26% and 7.75%, respectively, using NTUSU’s sentiment dictionary. This indicates that a more suitable emotion dictionary will help improve the emotion discrimination accuracy. Therefore, the development of an effective sentiment analysis model can be facilitated by creating a dictionary suitable for students’ learning emotions.
4.2. Analysis of the Accuracy of the Different Models
After the first part of the analysis, NTUSU was used as the sentiment dictionary to analyze the accuracy rates of the five text-based sentiment analysis models. A comparison of the accuracy rates of the different models is presented in
Table 4. The results of this study showed that the accuracy rates of Models D and E were higher than those of the original models. The best model is Model E, a hybrid model combining the SnowNLP and Jieba assertions, with a 95.35% accuracy rate. This shows that the hybrid model proposed in this study is effective for analyzing learners’ emotions. Further analysis of the model improvement showed that the hybrid model (Model E) improved 55.04% over the original SnowNLP model, 7.75% over the Jieba model (Model B), and 6.2% over the retrained SnowNLP model (Model D) using the NTUSU emotion dictionary.
The accuracy rates of the different models are plotted as shown in
Figure 4. Both models proposed in this study have better accuracy than the original model, and the hybrid model is the best model, with 95.35% accuracy.
4.3. Keyword Analysis and Word Cloud Analysis
This study used the best model (Model E) to analyze the keywords after breaking the words of learning experiences, and finally created a word cloud analysis. In this study, we analyzed the top keywords for positive and negative emotions in learning experiences. Keywords with more than 10 occurrences were selected and sorted in the following order. The most frequently used keywords for positive emotions were 1, thinking (18); 2, logic (17); 3, easy (16), 4, practical (13); and 5, interesting (11). This shows that if teaching materials or courses are designed to help students think, build logic, and do it in a practical, fun, and easy way, it will help students build positive emotions and increase their engagement in learning. The most frequently used keywords for negative emotions were 1, problem (30); 2, mistake (18); 3, not (10); and 4, error (10). This shows that if learners have problems during the learning process, such as making mistakes or errors in execution results, or if the results are not as expected or wanted, they will have negative emotions and therefore will reduce their participation in learning. The summary of keyword analysis is summarized in
Table 5.
Through word cloud analysis method, the positive and negative keywords of the learners’ learning experiences are made into a word cloud, as shown in
Figure 5 and
Figure 6.
4.4. Discussions
The system’s performance in different educational settings (e.g., online vs. in-person classes) may yield different results. Both settings benefit from the system’s ability to analyze verbal and textual engagement. Online classes can leverage its compatibility with virtual platforms, while in-person settings excel with direct audio capture and immediate interaction. However, online performance might suffer from network instability or noisier audio inputs, whereas in-person settings avoid these issues but require physical presence. The in-person environment can be influenced by external noises such as multiple students talking at once, background music, and simultaneous conversations between teachers and students. Therefore, using post-production manual labeling might be necessary to achieve better results. The rule-based emotion scoring and small dataset limit adaptability in both settings, although manual labeling is more manageable in person with teacher oversight.
The sentiment analysis model’s biases originate from its static dictionary, manual processes, limited sample size, and insufficient contextual depth. Mitigation strategies encompass refining the dictionary, enhancing natural language processing sophistication, standardizing labeling procedures, and expanding data diversity. While the current system is suitable for the manuscript’s STEAM context, these proposed improvements would enhance its reliability across various educational settings, balancing feasibility with the study’s resource constraints, such as mid-range hardware capabilities.
Adapting the system for non-STEAM subjects involves reconfiguring input prompts, updating the sentiment dictionary, refining keywords, adjusting scoring, and aligning with classroom dynamics. These changes leverage its existing architecture—voice/text analysis and emotion scoring—making it versatile for assessing engagement in subjects such as literature, history, or languages, provided that subject-specific tweaks are applied. Further pilot studies in these areas would validate its effectiveness beyond STEAM.
5. Conclusions
This study developed a textual sentiment analysis model utilizing five models: Model A is the original SnowNLP method, Model B is Jieba, and Model C is NLTK. This study proposed two models to improve the original SnowNLP method. Model E is the SnowNLP + Jieba method for comparison and analysis. The study analyzed (1) the effect of sentiment dictionaries on the accuracy of the models, (2) the accuracy of the different models, and (3) the extracted keywords.
First, the effect of sentiment dictionaries on model accuracy showed that different sentiment dictionaries significantly affect model accuracy, and NTUSU is a relatively good sentiment dictionary for learning sentiment discrimination and can improve model accuracy. Second, the accuracy of the different models was analyzed. The results of this study show that the best model was Model E, a hybrid model combining the SnowNLP and Jieba assertions, with an accuracy rate of 95.35%. The best model was used to determine the keywords of positive and negative emotions. This shows that if teaching materials or courses are designed in a way that helps students think, build logic, and do it in a practical and fun way, it will help students build positive emotions and increase their participation in learning. Third, the most frequent keywords for negative emotions were problem, error, not, and mistake. This shows that learners who have problems during the learning process, such as making mistakes or errors and obtaining results that are not what they expected, will have negative emotions and, therefore, lower learning engagement.
5.1. Practical Implications
The advantages of formative assessment include the system’s capacity to provide real-time feedback to optimize teaching, personalize learning paths, and enhance student self-regulation. However, its challenges include limited data accuracy in noisy or multi-learner environments, potential privacy violations through continuous emotion monitoring, and the risk of weakening the emotional bond between teachers and students during direct interactions owing to overreliance on AI feedback. The application of an AI system evaluation in summative assessments can efficiently process large-scale data and enhance evaluation objectivity. However, challenges arise from the weak correlation between emotion and learning performance, difficulties in accurately assessing knowledge mastery, and complexities in capturing the trajectory of emotional changes in long texts for academic evaluations. Furthermore, future research could examine the correlation between sentiment data and learning performance. In conclusion, the AI-based text sentiment analysis system demonstrates innovative potential in formative assessment, with its dynamic feedback characteristics aligned closely with the teaching objectives. However, the application of summative assessments should be approached with caution, and the correlation between emotional data and academic performance requires further clarification.
5.2. Limitation and Prospective Research
This study suggests that the development of an emotion dictionary for the learning domain, together with the proposed hybrid SnowNLP+Jieba model, is effective for further improving the correct discrimination of learning emotions. By identifying the keywords that affect learning emotions, the researcher can design a more appropriate curriculum to enhance positive emotions, which in turn will increase engagement and improve learning effectiveness.
Future studies may combine AI-based sentiment analysis with data from additional measures, such as physiological sensors or computer vision techniques, to provide a more holistic view of student engagement. Conducting longitudinal studies to assess the long-term impact of the AI-based sentiment analysis system on learning engagement and outcomes would offer more comprehensive insights. This study employs a binary classification approach to analyze learning engagement. Future research can utilize other deep learning models—such as Convolutional Neural Networks (CNN), Long Short-Term Memory networks (LSTM), or large language models (LLMs)—to explore the relationships among text sentiment scores, learning outcomes, and levels of learning engagement, as well as to perform prediction or classification.
In addition, teaching styles and methods can impact the effectiveness of an AI-based sentiment analysis system in STEAM education by shaping the quantity, quality, and emotional texture of the text data. Inquiry-based, project-based, and hands-on approaches tend to generate richer, more actionable data, thereby boosting the AI’s ability to measure engagement accurately. However, lecture-based or less interactive methods might challenge the system with sparse or ambiguous inputs. For optimal performance, the AI must be trained on diverse, context-aware datasets tailored to STEAM’s unique blend of creativity and problem-solving, and it should adapt to the nuances that each teaching approach brings to student expression and engagement.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}