1. Introduction
The frequency spectrum, essential for wireless communications, is a limited resource that has become increasingly congested [
1,
2,
3]. Cognitive radio (CR) dynamically allocates communication for secondary users (SUs) in parts of the spectrum, known as spectrum holes, where primary users (PUs) are absent [
4,
5,
6]. Several techniques exist for spectrum sensing, including energy detection, feature detection, Nyquist and sub-Nyquist methods, and multi-bit and one-bit compressive sensing. More recently, machine learning models have been employed to detect the presence of PUs [
7,
8]. Across these methods, noise can adversely affect the accurate detection of PUs, impacting the efficient use of the spectrum. In multi-user systems, the distance between users significantly influences the noise levels. Thus, predicting the noise level in the received signal and understanding user distances is fundamental for optimizing spectrum efficiency.
In communication systems, noise refers to any unwanted or random interference that compromises the quality of a transmitted signal. Noise can distort the original information being transmitted, leading to errors, diminished signal clarity, and reduced communication performance [
9]. Almost all communication channels and systems encounter noise, which can originate from various sources. The noise level can be influenced by several factors, including transmitted power, path loss, shadow fading, multipath fading, and the distance between users. In addition to these factors, additive white Gaussian noise is a type of noise that exists across all frequencies [
10]. This noise is characterized by its randomness and uniform energy distribution throughout the frequency spectrum. White Gaussian noise is a common model for representing random background noise in communication systems. By predicting noise levels, one can more effectively optimize system parameters and frequency allocation [
11].
The distance between users is an important factor that influences signal quality and, consequently, spectrum efficiency. In spectrum sensing, the strength of the received signal depends on the distance between the transmitter and receiver. Predicting these distances helps to adjust the transmission power levels: users closer to the transmitter require lower power for reliable communication, while users farther away need higher power [
12]. This power control optimizes energy efficiency and minimizes interference. Especially in systems with limited resources, such as bandwidth, predicting distances is fundamental for effective resource allocation. Users closer to the transmitter can be assigned greater bandwidth and consequently higher data rates, while those farther away might be allocated smaller bandwidths to improve the signal quality at the same transmission power level. Additionally, distance prediction is essential for providing location-based services. The distance between users can also impact the performance of artificial intelligence models used to increase spectrum efficiency. By estimating distances, services like navigation, location-based advertisements, and emergency services can be offered.
To predict noise and distances between users, regression models and deep learning architectures are recommended [
13]. Regression models are a class of machine learning algorithms designed to predict continuous numerical values based on input data. These models play a crucial role in various fields, including economics, finance, healthcare, and natural sciences. They allow for the analysis and forecasting of trends, relationships, and outcomes by learning from historical data. Among the most common traditional machine learning regression approaches are support vector regression (SVR) (an extension of support vector machines to regression), decision trees and random forests [
14], linear regression (one of the simplest yet most widely used regression techniques), and ridge and lasso regression (variants of linear regression). In more robust regression approaches, convolutional neural networks (CNNs), initially designed for image analysis, can be adapted for regression tasks [
15]. More recently, transformer, designed for forecasting, has shown promise for regression activities [
16].
In this article, we propose the use of regression models to predict noise levels and distances based on spectrum sensing signals. During our study, we generated a dataset that considers important parameters, including a wide range of noise power densities, an extensive sensing area, and power leakage from the PUs. We compared both traditional and deep learning models for prediction purposes. Furthermore, we evaluated the results using various metrics. Our proposed method has shown promising results, with a correlation coefficient exceeding 0.98 for noise and over 0.82 for distance. Additional metrics also indicate that our method is effective in predicting noise levels and distances between users. Such predictive capability can be important in designing communication systems to enhance spectrum efficiency.
This article is organized as follows: in
Section 2, related works about the prediction of noise levels and distances between users in a communication system are presented; in
Section 3, the proposed methodology for data generation, training, and evaluation is described; in
Section 4, the experiments conducted and the results achieved are presented; the discussions related to the experiments are presented in
Section 5; lastly, in
Section 6, the conclusions are presented.
Contributions
The main contributions of this paper can be summarized as follows: (1) the use of the transformer model, one of the newest and most robust networks, which achieved good results for distance prediction even with a limited architecture; (2) for noise prediction, the classical regression methods presented excellent results, achieving a correlation coefficient greater than 0.98, demonstrating a high level of similarity between the predictions and real values; (3) since the current models used for spectrum sensing are very sensitive to signal quality, the proposed approach can help in designing better communication systems based on artificial intelligence models by providing prior information.
3. Methods
This section presents the proposed methods for data generation and noise and distance predictions.
3.1. System Model
The use of generated data simulating PU signals is proposed in spectrum sensing to predict the noise level of the sensed signal and the initial and final distances between users. For this, the methodology is divided as follows: (1) database generation, where the signals that represent PUs are generated [
1,
2]; (2) training the proposed regression models [
22,
23]; and (3) evaluation of the trained models for predicting noise level and distance [
13,
24]. At the end of the process, it is expected that the models will be able to predict the level of noise and the initial and final distances between the PU and SU during the sensing period.
The dataset utilized for training the proposed regression models comprises signal data, noise levels, and distances between the users. Initially, the SU and PU are positioned within the area , moving randomly for a duration of . During this time, signals are sensed, and data on noise levels () as well as initial () and final () distances are collected. These collected data are then used to train and test the proposed regression models. To validate the effectiveness of the method in predicting noise levels and distances, various metrics are calculated.
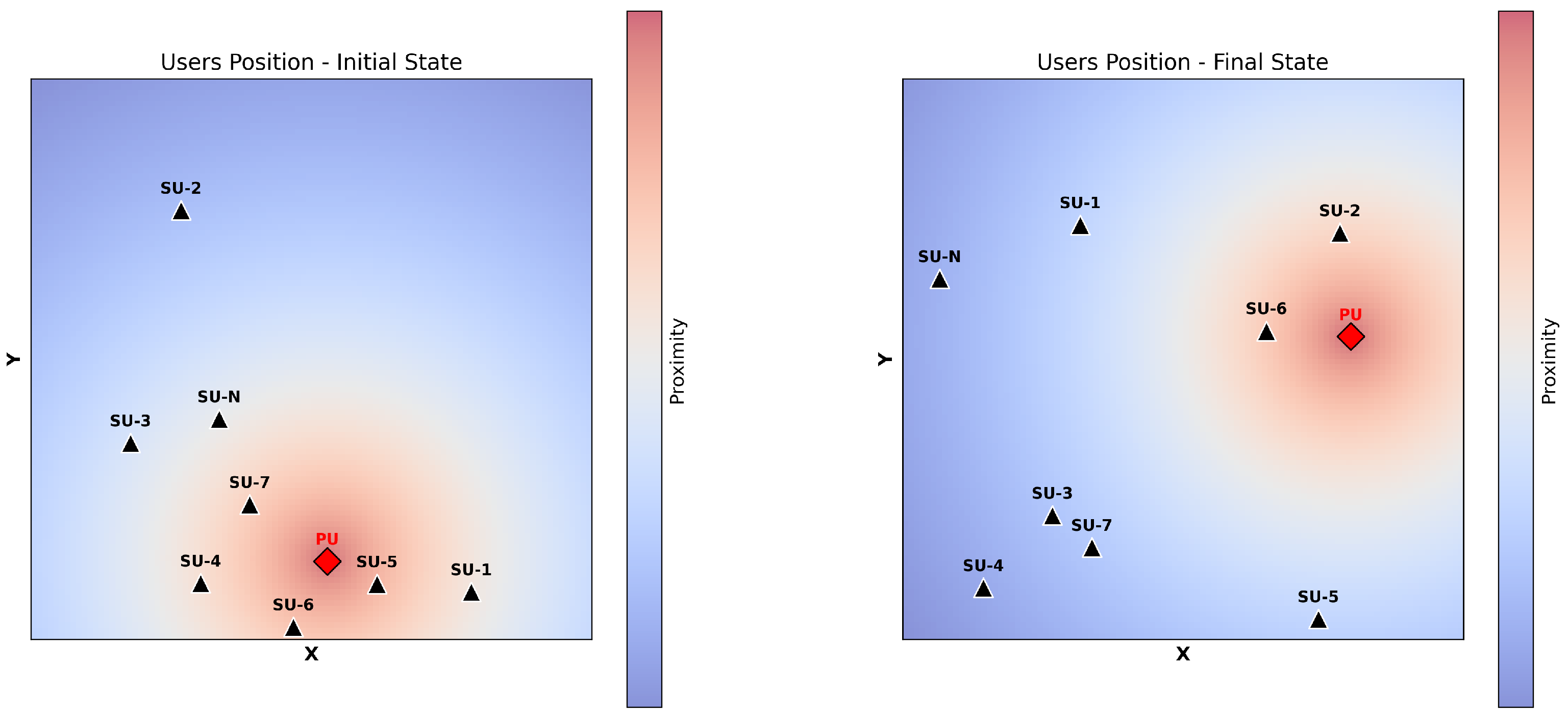
Figure 1 illustrates the representation of the environment just described. The initial state (left) is an example of how users can be positioned within the area, while the final state (right) demonstrates the change in position after
. The PU, marked by a red diamond, and the SUs, represented by black triangles, are randomly positioned within the area. In the initial state, the heatmap represents the distance of each SU from the PU, with warmer (red) areas indicating closer proximity and cooler (blue) areas showing greater distances. In the final state, we can observe that the PU and SUs have changed positions, and the distances between the SUs may also vary during the observation period.
The output of step (1) is expected to be the signals that represent the PU, the associated noise level for each signal, and the initial and final distances during the sensing. Using this information, two regression models are trained: one for noise level prediction and another for initial and final distance predictions. In step (2), some classical machine learning regression models are employed, including random forest, decision tree, extra trees, XGBosst, LightGBM, SVR, and transformer. The output of this step consists of predicted values for noise level and distances given a test dataset. Lastly, in step (3), several metrics are used to evaluate the best models for these tasks.
3.2. Data Generation
In the spectrum sensing process, the decision on the channel condition is binary, involving two hypotheses:
and
[
25]. Here,
represents the hypothesis in which the PU is present, while
represents the absence of the PU [
2]. For the purposes of this paper, we will only consider hypotheses involving the presence of the PU. We assume that
SU and a single PU are moving at a speed
v, with their starting positions randomly chosen within a given area. As a result, the users’ locations change over a time interval of
. Additionally, we are considering a multi-channel system with
bands, each having a bandwidth of
. Furthermore, we assume that the PU can utilize
consecutive bands [
1]. Therefore, the received signal of the
i-th SU on the
j-th band at time
n can be described as
where
and
is the additive white Gaussian noise (AWGN), whose noise power density is
, mean zero, and standard deviation
. With
being the proportion of power leaked to adjacent bands,
represents the bands occupied by the PU and
indicates the bands affected by the leaked power of the PU.
In the expression
, a simplified path loss model is utilized, which can be written as follows:
where
and
denote the path-loss exponent and path-loss constant, respectively. Here,
represents the Euclidean distance between the PU and SU
i at time
n. The shadow fading of the channel, indicated by
, between the PU and SU
i at time
n in decibels (dB) can be described by a normal distribution with a mean of zero and a variance of
. The term
P denotes the power transmitted by the PU within a specified frequency band. Furthermore, the multipath fading factor, denoted as
, is modeled as an independent zero-mean circularly symmetric complex Gaussian (CSCG) random variable. Moreover, the data transmitted at time
n, represented by
, have an expected value of one [
1,
2].
3.3. Regression Models
The machine learning regression models used to predict interference and distance between the PU and SUs are random forest, decision tree, extra trees, XGBoosting, LightGBM, SVR, and transformer.
3.3.1. Random Forest
Random forest consists of a collection of trees denoted as
. Here,
x represents an input vector of length
q, containing a correlated random vector
X, while
refers to independent and identically distributed random vectors. In the context of regression, assume that the observed data are drawn independently from the joint distribution of
, where
Y represents the numerical outcome. This dataset includes
-tuples, namely
[
26]. The prediction of the random forest regression is the unweighted average over the collection
3.3.2. Decision Tree
In the context of regression, the decision tree is based on recursively partitioning the input feature space into regions and then assigning a constant value to each region. This constant value serves as the prediction for any data point that falls within that region. Assume that
X is the input data,
Y the target variable, and
represents the parameters that define the splits in the decision tree [
27]. Let
be the predicted value for
Y given input
X and parameter
. Given a set of
n training samples
, where
, the decision tree regressor seeks to find optimal split
that minimizes the sum of square differences between the predicted value and the actual target value. The prediction for a given
X can be represented as
where
N is the number of leaf nodes (regions) in the tree,
is the constant value associated with the leaf node
, and
is an indicator function that equals 1 if
X falls within the region
and 0 otherwise.
3.3.3. Extra Trees
The extra trees approach follows the same step-by-step process as random forest, using a random subset of features to train each base estimator [
26], although the best feature and the corresponding value for splitting the node are randomly selected [
28]. Random forest uses a bootstrap replica to train the model, while, with extra trees, the whole training dataset is used to train each regression tree [
29].
3.3.4. XGBoosting
XGBoosting (XGB) is a highly optimized distributed gradient boosting library. It employs a recursive binary splitting strategy to identify the optimal split at each stage, leading to the construction of the best possible model [
30]. Due to its tree-based structure, XGB is robust to outliers and, like many boosting methods, is effective in countering overfitting, making model selection more manageable. The regularized objective of the XGB model during the
tth training step [
31] is illustrated in Equation (
5). Here,
represents the loss, which quantifies the disparity between the prediction of the imputed missing value
and the corresponding ground truth
.
where
is the regularizer representing the complexity of the
kth tree.
3.3.5. LightGBM
LightGBM (LGBM) is the gradient boosting decision tree (GBDT) algorithm with gradient-based one-side sampling (GOSS) and exclusive feature bundling (EFB). The GOSS technique is employed within the context of gradient boosting, utilizing a training set consisting of
n instances {
}, where each instance
represents an
s-dimensional vector in space
. In every iteration of gradient boosting, we compute the negative gradients of the loss function relative to the model’s output, resulting in {
}. These training instances are then arranged in descending order, based on the absolute values of their gradients, and we select the top-
instances with the largest gradient magnitudes to constitute a subset A [
32]. For the complementing set
, comprising
of instances characterized by smaller gradients, a random subset B is extracted, sized at
. The division of instances is subsequently determined by the estimated variance gain concerning vector
over the combined subset
, where
where
,
,
,
, and
is the coefficient used to normalize the the sum of the gradients over
B back to the size of
.
3.3.6. SVR
Given
n training data
,
, and
represents the space of the input patterns [
33]. The goal of the
-SVR is to find a function that exhibits a maximum deviation of
or less from the target value
obtained during training while also maintaining a minimal degree of fluctuation or variability. This function can be described as
where
denotes dot product in
.
3.3.7. Transformer
A transformer model consists of an encoder and a decoder, each composed of multiple layers of self-attention and feed-forward neural networks. The base structure of a transformer is the self-attention mechanism. Given an input sequence, the self-attention computes a weighted sum of the values. Multi-head attention is used to capture different aspects of relationships. Let the input of a transformer layer be
, where
n is the number of tokens and
d is the dimension of each token. Then, one block layer can be a function
defined by [
34]
where Equations (
8)–(
10) refer to attention computation, and Equations (
11) and (
12) refer to the feed-forward network layer.
is the row-wise softmax function,
is the layer normalization function, and
the activation function.
Q,
K,
V, and
,
,
,
,
are the training parameters in the layer [
34]. In
Figure 2, the architecture of the proposed transformer is displayed.
3.4. Evaluation Metrics
The metrics used for evaluation of the regression models are the mean square error, mean absolute error, root mean square error, mean absolute percentage error, R-square, and correlation coefficient [
35].
Mean square error (
) [
35]:
where
n is the number of data points in the dataset,
represents the actual target value of the
i-th data point, and
represents the predicted value of the
i-th data point.
Mean absolute error (
) [
35]:
where
denotes the absolute value.
Root mean square error (
) [
35]:
Mean absolute percentage error (
) [
35]:
R-square (
) [
24]:
where
represents the sum of squared differences between the actual target values and the predicted values.
represents the total sum of squares, which is the sum of squared differences between the actual target values and their mean.
Correlation coefficient [
36]:
The correlation coefficient is given by the Pearson correlation coefficient:
where
is the mean of the actual target values and
is the mean of the predicted values.
5. Discussion
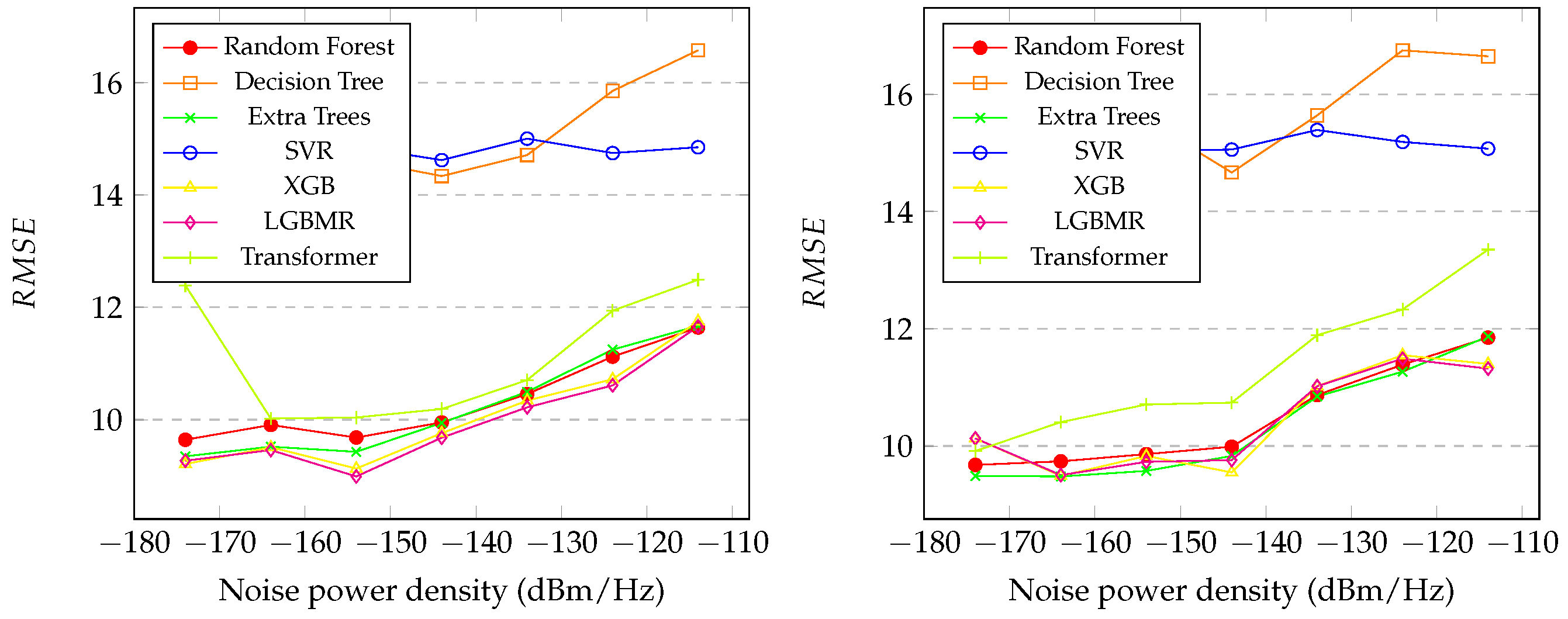
In
Section 4.3, the results for noise prediction were presented, and several important aspects need to be highlighted. In
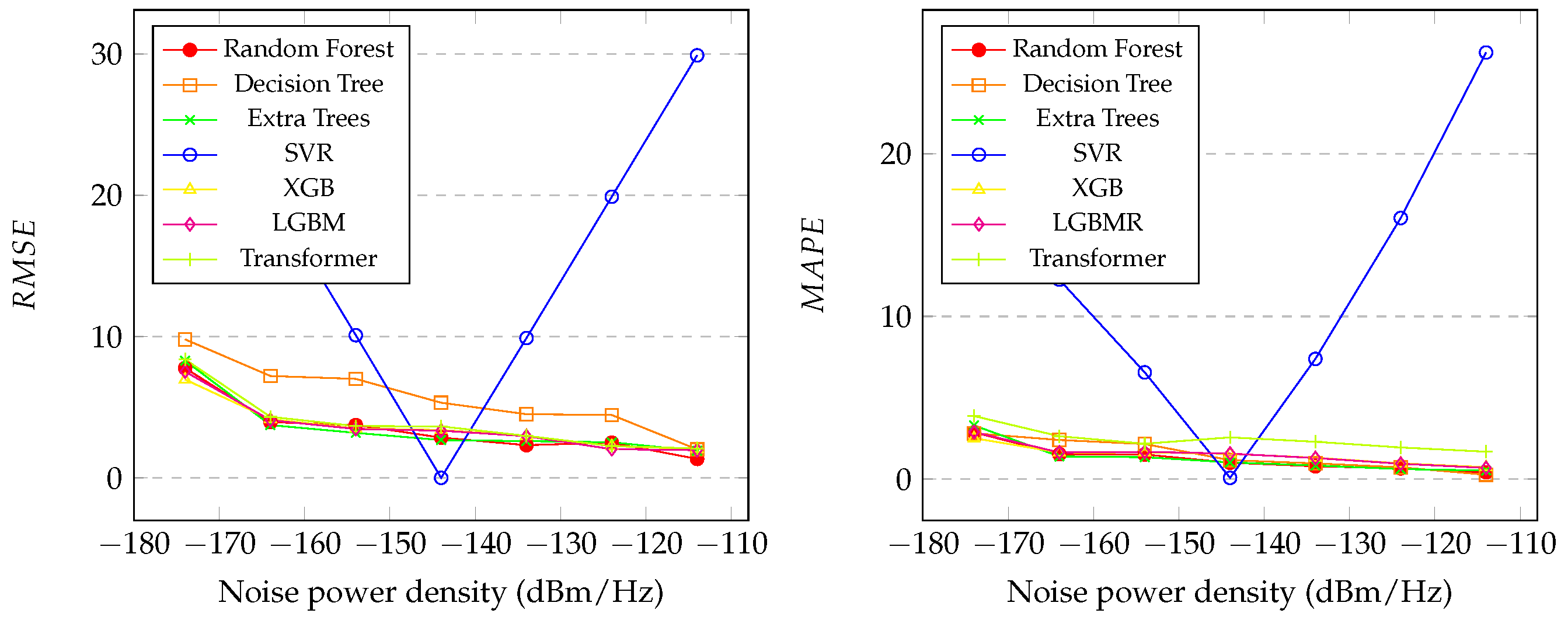
Figure 3 (left), it is noticeable that the models achieved similar performance, except for decision tree and SVR. Interestingly, the best performance occurred at the highest levels of noise, except for SVR, which specialized in a single noise level,
dBm/Hz.
Figure 3 (right) and
Figure 4 (left and right) exhibit similar characteristics to
Figure 3 (left). The overall results for random forest, XGB, LGBM, transformer, and extra trees are similar across all the metrics, with random forest and XGB performing particularly well, as demonstrated in
Table 6. In contrast, SVR exhibited poor performance overall. Additionally, the correlation coefficients reveal that random forest, XGB, LGBM, and extra trees achieved strong correlations between the predicted and real noise values (
Table 6). Due to the limited computational resources and the large amount of generated data, it was not possible to enhance the robustness of the transformer architectures. Furthermore, a search for optimal hyperparameter values for all the models could be a proposed enhancement for the work.
In
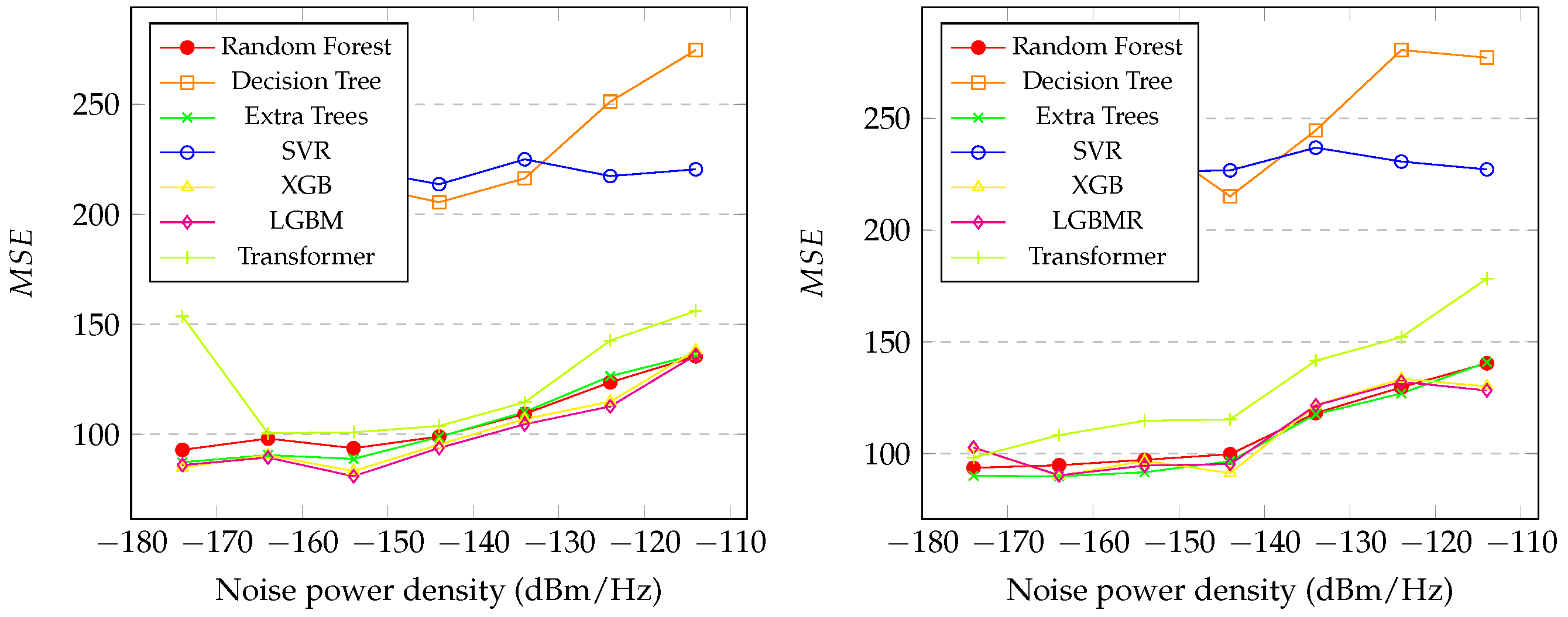
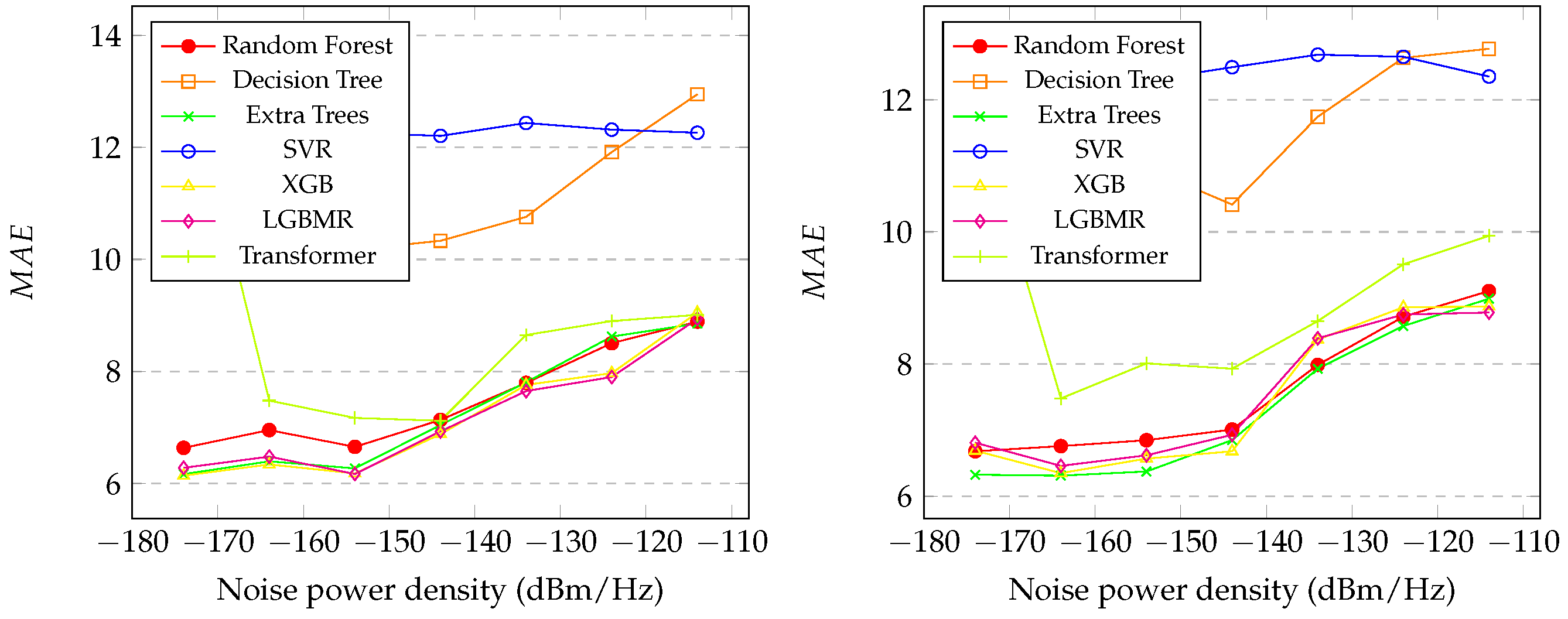
Section 4.4, the results for the initial and final distance predictions were presented, and several notable observations arise. In
Figure 5, it is evident that extra trees and LGBM achieved the highest performance. Unlike the noise prediction, the best performance for both distance predictions occurred at the lowest levels of noise for all the models, which was expected. The behavior of predicting the initial distance mirrors that of predicting the final distance, as indicated in
Figure 5,
Figure 6,
Figure 7 and
Figure 8. The general results for random forest, XGB, LGBM, transformer, and extra trees exhibit similarity across all the metrics, with extra trees, transformer, and LGBM slightly outperforming in almost all the metrics for both the initial and final distances, as shown in
Table 7 and
Table 8, respectively. In contrast, decision tree and SVR showed poor performance overall. Moreover, the correlation coefficients reveal that the predicted distances exhibited indices greater than
in relation to the real values in both distances, initial and final. An interesting factor is that, in the initial distance prediction, the
values for the XGB and LGBM models returned ’inf’. More studies are needed to understand what happened.
6. Conclusions
In this paper, a noise and distance prediction method based on spectrum sensing signals using regression models was proposed. The conducted experiments have shown that the proposed methods hold promise for predicting noise levels, as well as the initial and final distances between the PU and SU. The correlation coefficient value for XGB is the highest and closest to one (
Table 6), indicating a strong correlation between the predicted and actual noise values in the test database. As a result, the proposed methods can greatly benefit various applications, especially in telecommunication and networking, enabling the design of communication systems that meet appropriate requirements for ensuring reliable and efficient data transfer.
Additionally, the predictions for the initial and final distances between the PUs and SUs are presented as results. The conducted experiments have demonstrated that the proposed methods show promise in predicting distances between users. The correlation coefficient values for transformer are the highest, exceeding
(
Table 7 and
Table 8), which implies a good level of correlation between the predicted distances and the actual distances in the test database. It is important to highlight that the number of possible noise levels is limited to seven (
to
dBm/Hz), while the number of possible distances is unknown since the distance was chosen randomly within a certain range of the area. Therefore, there may be a difference in performance between the two approaches. Hence, the proposed methods hold the potential to benefit numerous applications, including signal attenuation and path loss, interference and frequency reuse, fading and multipath effects, localization and tracking, and power control.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}