
Monocular Vision-Based Depth Estimation of Forward-Looking Scenes for Mobile Platforms



Abstract
1. Introduction
- (1)
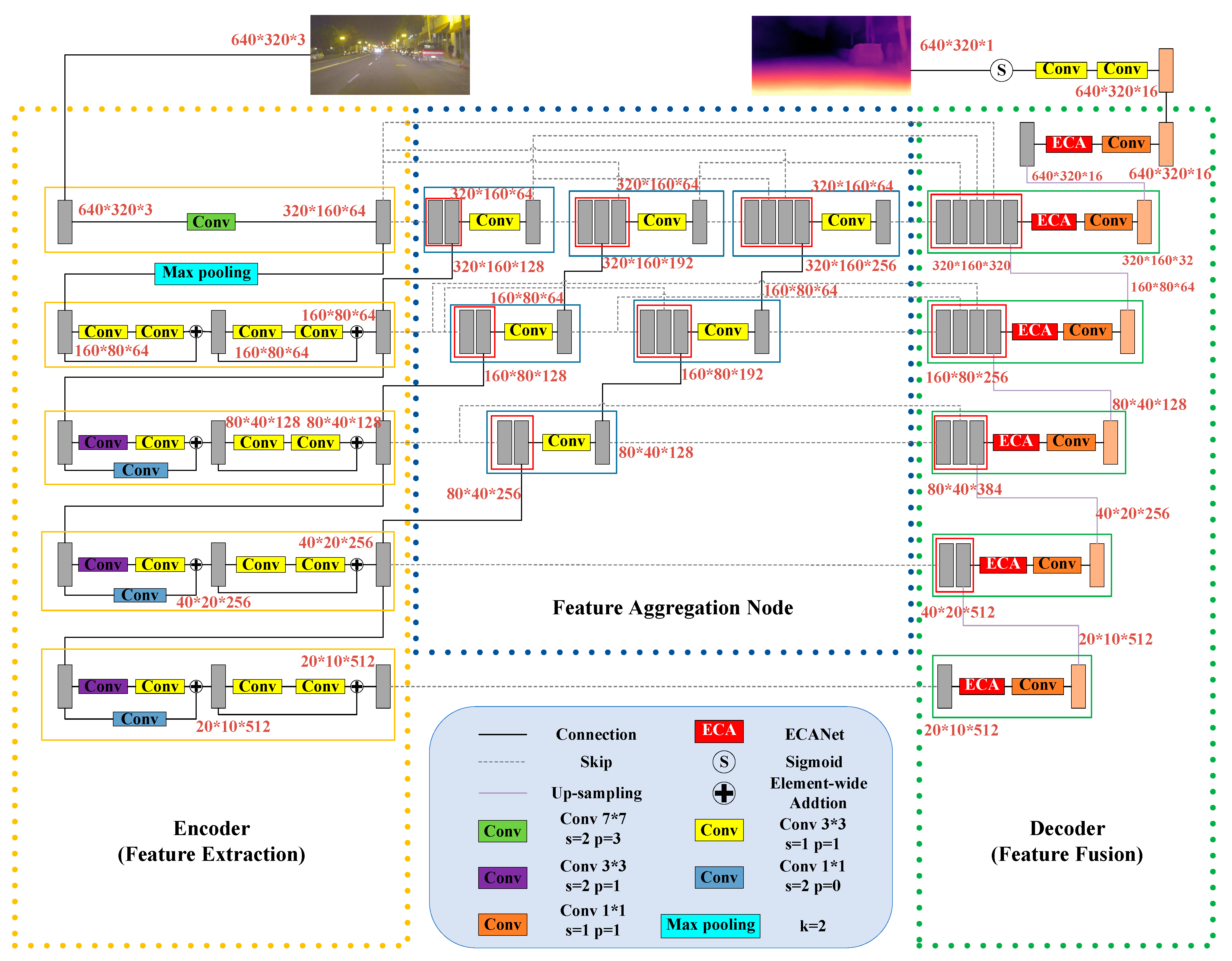
- An intermediate module that incorporates multi-layer feature aggregation nodes is proposed to further integrate feature maps with varying resolutions. This module enhances the multiscale fusion effects of feature maps at different levels and helps prevent the loss of important semantic and detailed information.
- (2)
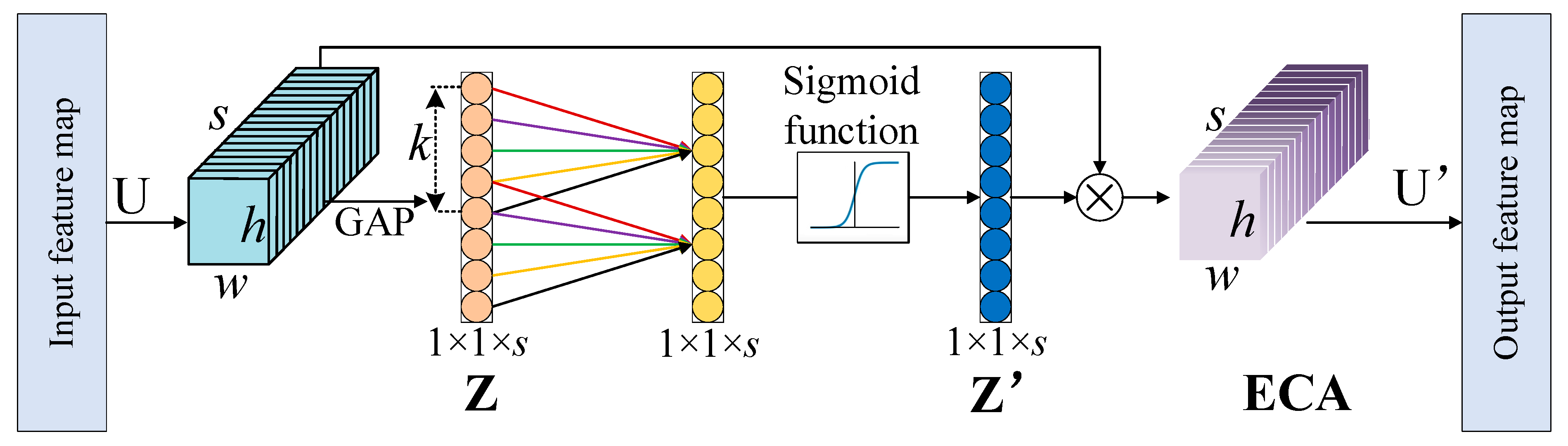
- To enhance the weights of significant channels for extracting more prominent features and thereby improving the accuracy of depth estimation, the Efficient Channel Attention Module (ECANet) is integrated into the proposed network.
- (3)
- We conducted experiments using both the KITTI dataset, which was a public dataset and constructed in a real environment, and the virtual simulation dataset based on the AirSim simulation environment. These datasets encompass various lighting conditions and application scenarios. The related experimental results demonstrate that the proposed method has been initially validated and shows promising performance when compared to the original Monodepth2.
2. Methodology
2.1. Re-Projection
2.2. Depth Estimation Network
2.3. Attention Mechanism
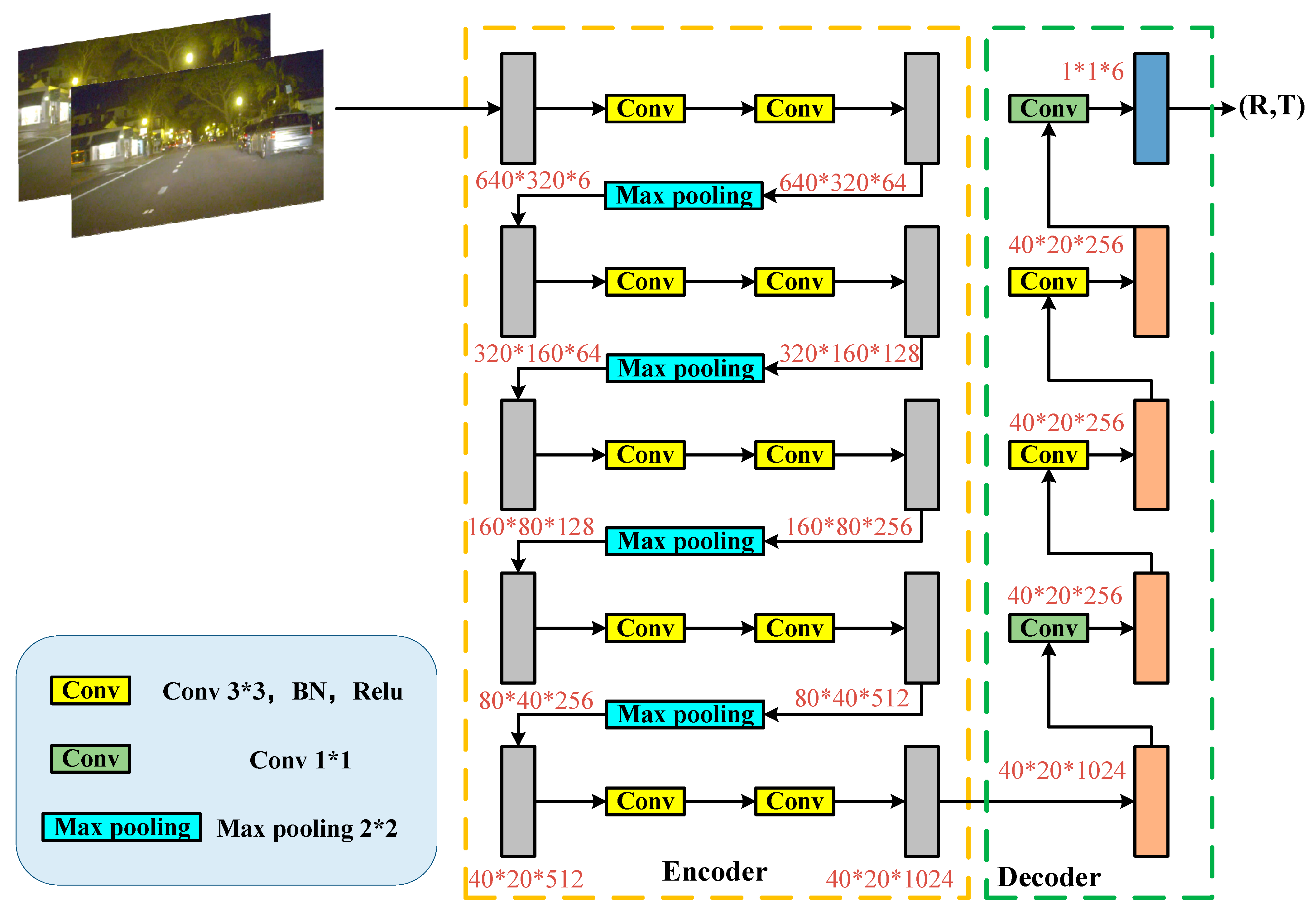
2.4. Pose Estimation Network
2.5. Loss Function
3. Experiment
3.1. Performance Evaluation for AGVs
3.2. Performance Evaluation for UAVs
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Wang, J.; Zhang, W.; Zhan, Y.; Guo, S.; Zheng, Q.; Wang, X. A survey on deploying mobile deep learning applications: A systemic and technical perspective. Digit. Commun. Netw. 2022, 8, 1–7. [Google Scholar] [CrossRef]
- Gong, T.; Zhu, L.; Yu, F.R.; Tang, T. Edge intelligence in intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8919–8944. [Google Scholar] [CrossRef]
- Raj, R.; Kos, A. A comprehensive study of mobile robot: History, developments, applications, and future research perspectives. Appl. Sci. 2022, 12, 6951. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef] [PubMed]
- Milburn, L.; Gamba, J.; Fernandes, M.; Semini, C. Computer-Vision Based Real Time Waypoint Generation for Autonomous Vineyard Navigation with Quadruped Robots. In Proceedings of the 2023 IEEE International Conference on Autonomous Robot Systems and Competitions, Tomar, Portugal, 26–27 April 2023; pp. 239–244. [Google Scholar]
- Chen, L.; Li, Y.; Huang, C.; Li, B.; Xing, Y.; Tian, D.; Li, L.; Hu, Z.; Na, X.; Li, Z.; et al. Milestones in autonomous driving and intelligent vehicles: Survey of surveys. IEEE Trans. Intell. Veh. 2022, 8, 1046–1056. [Google Scholar] [CrossRef]
- Lu, Y.; Xue, Z.; Xia, G.S.; Zhang, L. A survey on vision-based UAV navigation. Geo-Spat. Inf. Sci. 2018, 21, 21–32. [Google Scholar] [CrossRef]
- Opromolla, R.; Fasano, G. Visual-based obstacle detection and tracking, and conflict detection for small UAS sense and avoid. Aerosp. Sci. Technol. 2021, 119, 107167. [Google Scholar] [CrossRef]
- Zhang, C.; Cao, Y.; Ding, M.; Li, X. Object depth measurement and filtering from monocular images for unmanned aerial vehicles. J. Aerosp. Inf. Syst. 2022, 19, 214–223. [Google Scholar] [CrossRef]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8445–8453. [Google Scholar]
- Fan, L.; Wang, J.; Chang, Y.; Li, Y.; Wang, Y.; Cao, D. 4D mm Wave radar for autonomous driving perception: A comprehensive survey. IEEE Trans. Intell. Veh. 2024, 9, 4606–4620. [Google Scholar] [CrossRef]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Deliry, S.I.; Avdan, U. Accuracy of unmanned aerial systems photogrammetry and structure from motion in surveying and mapping: A review. J. Indian Soc. Remote Sens. 2021, 49, 1997–2017. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, Y.; Tong, K.; Chen, H.; Yuan, Y. Review of visual simultaneous localization and mapping based on deep learning. Remote Sens. 2023, 15, 2740. [Google Scholar] [CrossRef]
- Mertan, A.; Duff, D.J.; Unal, G. Single image depth estimation: An overview. Digit. Signal Process. 2022, 123, 103441. [Google Scholar] [CrossRef]
- Poggi, M.; Tosi, F.; Batsos, K.; Mordohai, P.; Mattoccia, S. On the synergies between machine learning and binocular stereo for depth estimation from images: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5314–5334. [Google Scholar] [CrossRef] [PubMed]
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular depth estimation using deep learning: A review. Sensors 2022, 22, 5353. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Garratt, M.A.; Anavatti, S.G.; Abbass, H.A. Towards real-time monocular depth estimation for robotics: A survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16940–16961. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 2014 Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; p. 27. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7 June 2015; pp. 5162–5170. [Google Scholar]
- Huang, B.; Zheng, J.Q.; Nguyen, A.; Tuch, D.; Vyas, K.; Giannarou, S.; Elson, D.S. Self-supervised generative adversarial network for depth estimation in laparoscopic images. In Proceedings of the 24th International Conference on Medical Image Computing and Computer Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 227–237. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Liu, J.; Kong, L.; Yang, J.; Liu, W. Towards better data exploitation in self-supervised monocular depth estimation. IEEE Robot. Autom. Lett. 2023, 9, 763–770. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Seif, G.; Dimitrios, A. Edge-Based Loss Function for Single Image Super-Resolution. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1468–1472. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Index | Formula |
|---|---|
| Absolute relative error Abs Rel | |
| Square relative error Sq Rel | |
| Root mean square error RMSE | |
| Root mean square logarithmic error RMSE log | |
| Threshold accuracy | |
| thr Acc | thr = 1.25, 1.252, 1.253 |
| Method | Abs_Rel | Sq_Rel | RMSE | RMSE_Log | Thr Acc (thr = 1.25) | Thr Acc (thr = 1.252) | Thr Acc (thr = 1.253) |
|---|---|---|---|---|---|---|---|
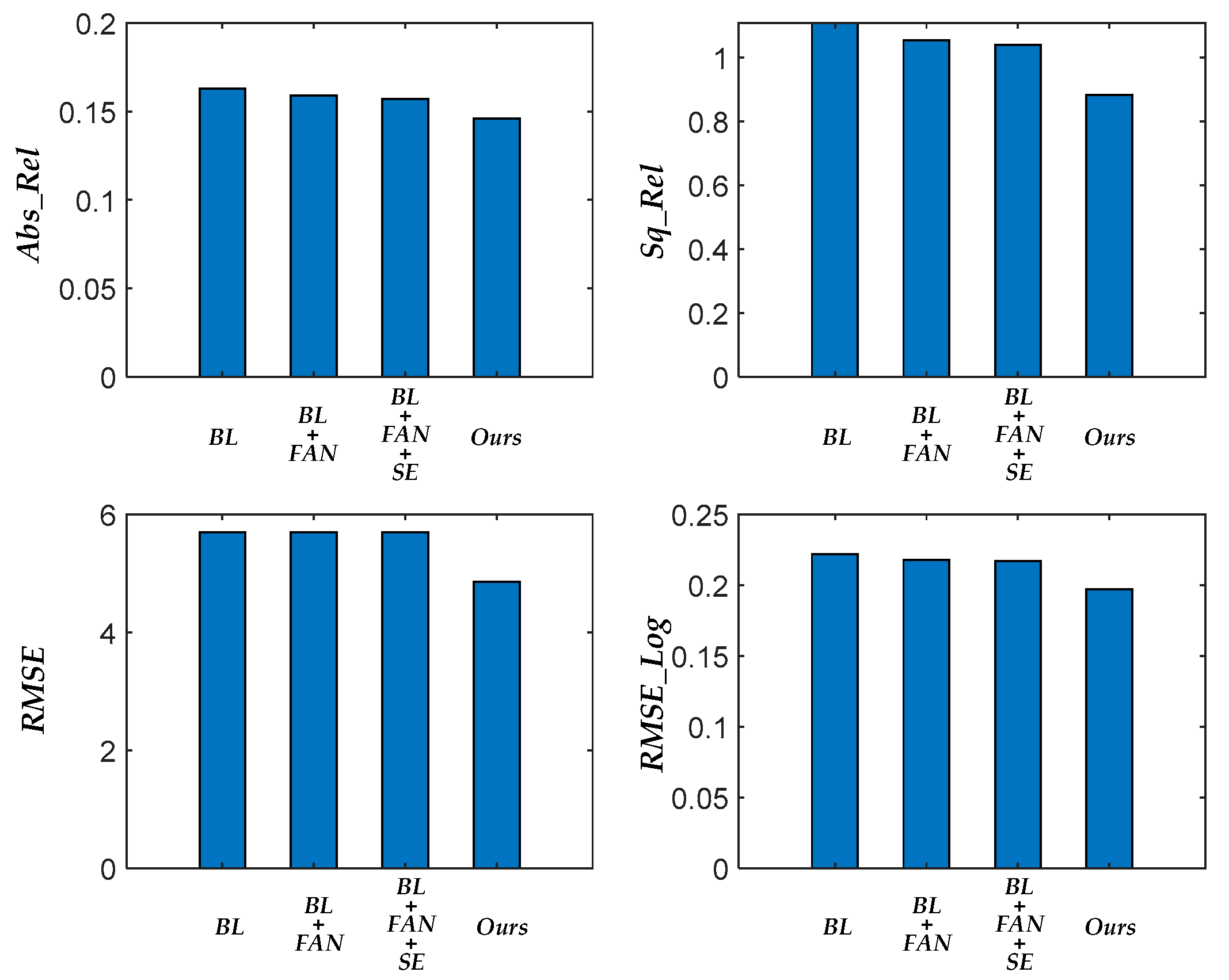
| Proposed | 0.146 | 0.883 | 4.857 | 0.197 | 0.792 | 0.954 | 0.988 |
| HR-Depth | 0.157 | 1.039 | 5.698 | 0.217 | 0.751 | 0.941 | 0.985 |
| Monodepth2 | 0.163 | 1.108 | 5.699 | 0.222 | 0.750 | 0.931 | 0.982 |
| Test Sample | Method | Abs_Rel | Sq_Rel | RMSE | RMSE_Log | Thr Acc (thr = 1.25) | Thr Acc (thr = 1.252) | Thr Acc (thr = 1.253) |
|---|---|---|---|---|---|---|---|---|
| AirSim_Mountain | Proposed | 0.211 | 1.241 | 5.493 | 0.321 | 0.783 | 0.943 | 0.982 |
| HR-Depth | 0.218 | 1.392 | 5.864 | 0.395 | 0.771 | 0.940 | 0.979 | |
| Monodepth2 | 0.229 | 1.503 | 6.104 | 0.461 | 0.773 | 0.924 | 0.978 | |
| AirSim_CityRoad | Proposed | 0.242 | 1.364 | 5.790 | 0.355 | 0.779 | 0.942 | 0.980 |
| HR-Depth | 0.253 | 1.472 | 5.941 | 0.432 | 0.776 | 0.941 | 0.978 | |
| Monodepth2 | 0.256 | 1.577 | 6.077 | 0.515 | 0.772 | 0.939 | 0.977 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Ding, M.; Li, S. Monocular Vision-Based Depth Estimation of Forward-Looking Scenes for Mobile Platforms. Appl. Sci. 2025, 15, 4267. https://doi.org/10.3390/app15084267
Wei L, Ding M, Li S. Monocular Vision-Based Depth Estimation of Forward-Looking Scenes for Mobile Platforms. Applied Sciences. 2025; 15(8):4267. https://doi.org/10.3390/app15084267
Chicago/Turabian StyleWei, Li, Meng Ding, and Shuai Li. 2025. "Monocular Vision-Based Depth Estimation of Forward-Looking Scenes for Mobile Platforms" Applied Sciences 15, no. 8: 4267. https://doi.org/10.3390/app15084267
APA StyleWei, L., Ding, M., & Li, S. (2025). Monocular Vision-Based Depth Estimation of Forward-Looking Scenes for Mobile Platforms. Applied Sciences, 15(8), 4267. https://doi.org/10.3390/app15084267