1. Introduction
With the rapid growth of text data in the era of information explosion, it has become essential to efficiently process and organize this information. Text classification, a core task in natural language processing (NLP), aims to automatically assign text to predefined categories [
1,
2]. Text classification is crucial not only for the efficient management of large-scale text data but also for its wide application in fields such as sentiment analysis [
3], spam filtering, and news recommendation [
4]. Therefore, text classification remains a key and important research topic.
With the rise in deep learning, text classification models have made substantial progress in recent years. Traditional machine learning methods, such as support vector machine (SVM) [
5] and naive Bayes [
6], remain effective in certain scenarios. However, with improvements in computing power and algorithm optimization, deep learning models have demonstrated greater potential in processing complex semantic information. Initially, researchers borrowed convolutional neural networks (CNNs) from computer vision and applied them to text classification tasks. Through the sliding window operation in the convolutional layer, CNNs effectively capture local features in the text, aiding in the identification of keywords and phrases, particularly in short text classification tasks [
7,
8].
Subsequently, recurrent neural networks (RNNs) were introduced to process sequence information, enabling the better capture of contextual dependencies in text [
9]. However, traditional RNNs face the problem of vanishing and exploding gradients when processing long sequences, limiting their ability to model long texts. To address this issue, long short-term memory (LSTM) and gated recurrent units (GRUs) were proposed [
10]. They successfully captured long-term dependencies in text through gating mechanisms, performed well in text classification tasks, and became essential tools for processing sequence information.
With the advent of pre-trained models, deep learning-based text classification technology has made significant advancements. Pre-trained language models, such as BERT and GPT, have acquired extensive semantic knowledge by pre-training on large-scale corpora [
11,
12,
13]. In text classification tasks, these models are initially trained on large-scale data to accumulate corpus knowledge and are subsequently fine-tuned to achieve optimal performance for specific tasks, significantly advancing the development of text classification technology. In recent years, contrastive learning, an emerging technology, has garnered significant attention in text classification [
14]. By enabling the model to learn the similarities and differences between samples, its understanding of semantic information is enhanced, thereby improving text classification performance [
15,
16]. Although existing contrastive learning methods have made progress, they still have notable shortcomings, primarily related to insufficient data utilization. Existing methods, such as autoencoders [
17], contrastive learning based on dropout layers [
18], and document metadata contrastive learning [
19,
20], although effective, do not fully address the problem of data scarcity, resulting in limited robustness in model training.
This study aims to address the aforementioned problems and focuses on improving data enhancement methods. By designing four effective text enhancement strategies (symbol insertion, affirmative auxiliary verbs, double negation, and repeated punctuation insertion), two types of data enhancement strategies are proposed: affirmative enhancement and negation transformation. Affirmative enhancement replaces the predicate verb with affirmative auxiliary verbs to adjust the sentence’s positive semantics, while negation transformation alters the sentence’s meaning by adding negative words before nouns and verbs. These data enhancement strategies can transform the data at a deeper level, thereby significantly increasing the volume of training data. To address the challenges posed by false data, we also introduce an instance weighting method to mitigate the impact of sampling bias on model training by assigning weights to each sample. By using complementary models to generate sample weights and adjusting training data accordingly, we can effectively filter out biased data and ensure a balanced distribution, thereby improving the model’s generalization and robustness.
2. Related Work
In this section, we present the related work, including that on text data augmentation and contrastive learning.
Text data augmentation enhances the training samples by modifying existing data to generate new data. Onan et al. [
21] proposed simple text augmentation strategies, such as synonym replacement, random insertion, and random deletion, to improve performance on text classification tasks. Ding et al. [
22] proposed a data augmentation approach based on words with paradigmatic relations. The effectiveness of this approach was demonstrated across six text categorization tasks using convolutional or recurrent neural networks. Zhao et al. [
23] proposed an unsupervised text augmentation approach to address the problem of consistency training. Kesgin et al. [
24] proposed an automatic text augmentation strategy based on an automated search architecture, which enhanced the model’s generalization ability through the automatic combination of augmentation strategies.
Contrastive learning distinguishes between similar and dissimilar data points by learning the features of different samples. A growing number of contrastive learning methods have emerged in recent years. Zhang et al. [
25] proposed debiased contrastive learning, which corrects the sampling of identically labeled data points without knowledge of the true labels. It demonstrates superior performance in vision, language, and reinforcement learning tasks. Wang et al. [
26] proposed a contrastive learning framework that did not require specific task-relevant invariant prior knowledge. The framework constructed separate embedding spaces to capture feature variations and invariants. Zhou et al. [
27] proposed parametric contrastive learning with parameterized learning centers to address the problem of learning from unbalanced data. Garg et al. [
28] proposed an augmented contrastive learning approach to improve learning performance by understanding the distributional differences between weak and strong images.
3. Method
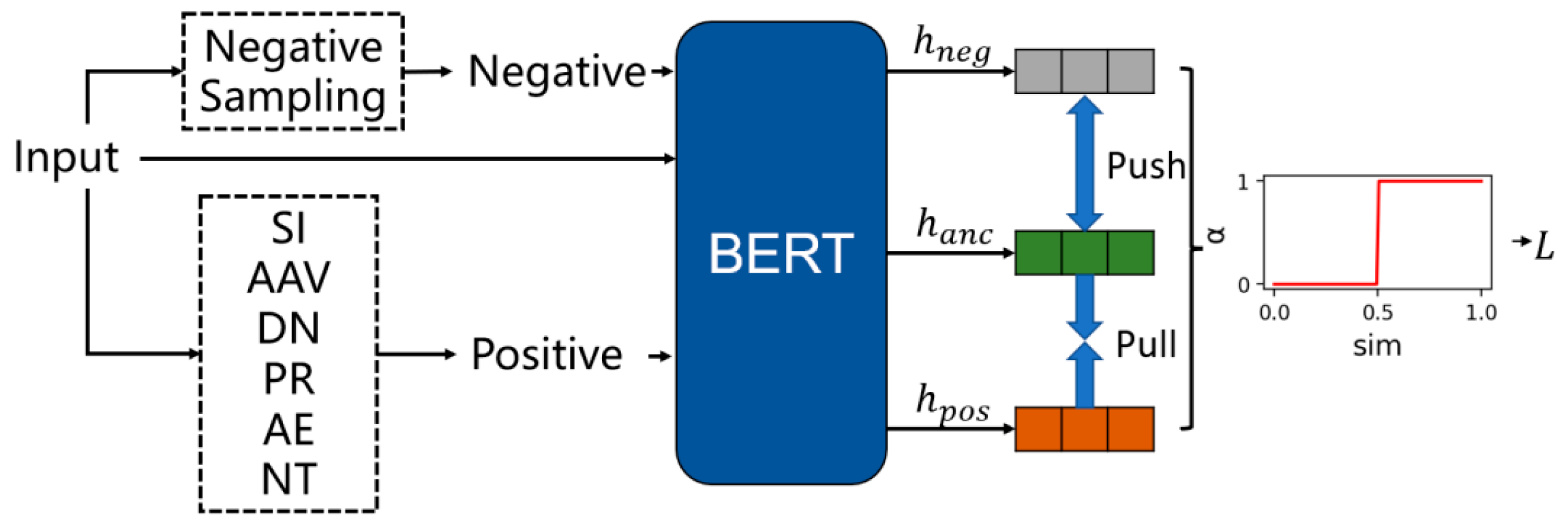
The model we propose is obtained by pre-training based on BERT. Our proposed method is shown in
Figure 1:
First, we pre-train an unsupervised contrastive learning model based on BERT using unlabeled data to enable the model to capture semantic features. Subsequently, we perform text classification training on labeled data by adding a classification layer.
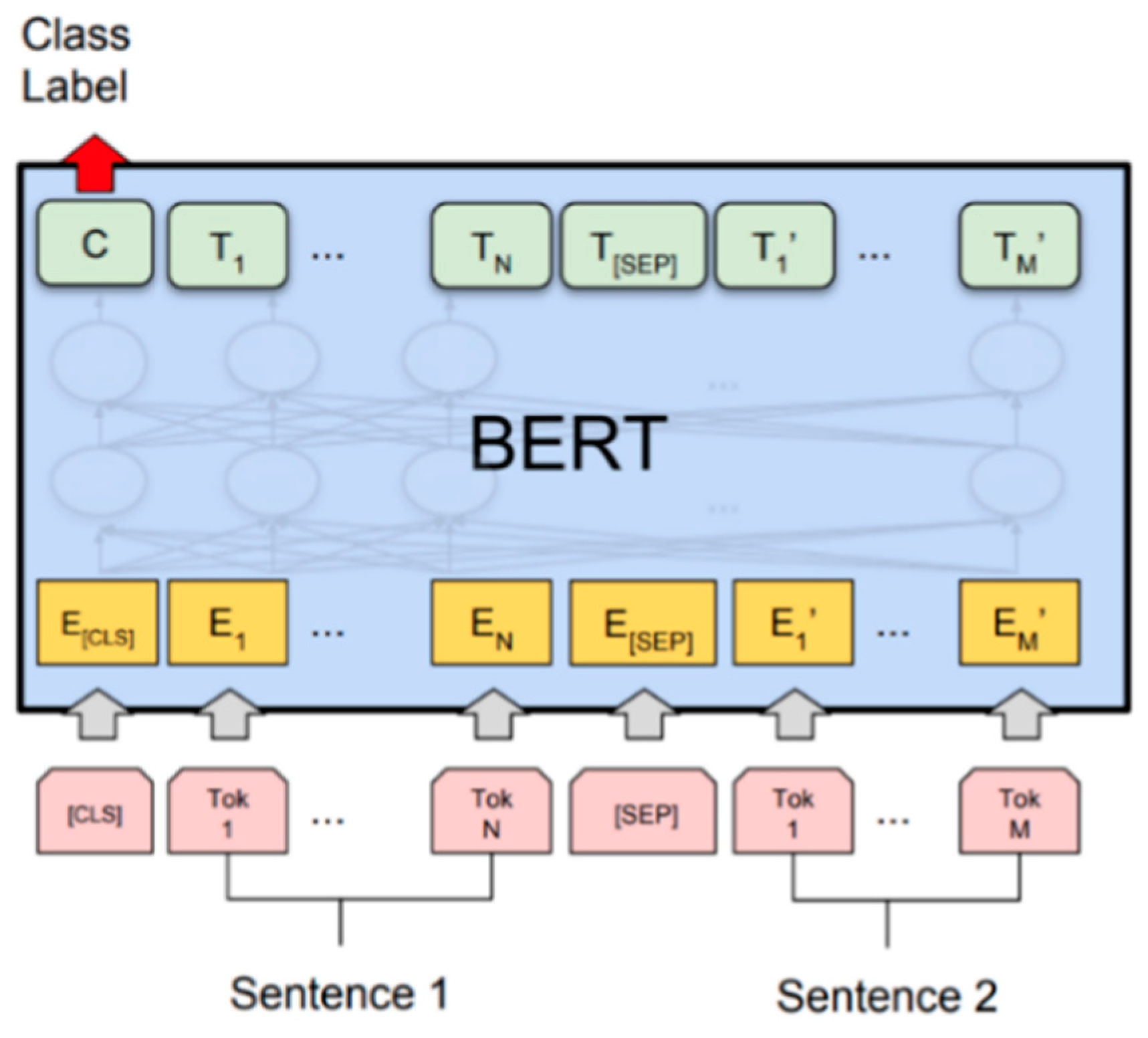
3.1. BERT
In this section, we will introduce the core part of contrastive learning training—the BERT model. BERT (Bidirectional Encoder Representations from Transformers) [
29] is a pre-trained language model proposed by Google and based on the Transformer [
30] architecture. Unlike traditional unidirectional language models, BERT uses bidirectional context modeling. When predicting the current word, it considers the contextual information before and after the word, which gives BERT stronger expression and understanding capabilities. The BERT model structure is shown in
Figure 2:
The BERT model consists of a multi-layer Transformer encoder, including a self-attention mechanism and a feedforward neural network. The model input is a piece of text, which is passed through the embedding layer to obtain the word vector, then through the multi-layer Transformer encoder to extract features and model the context, and finally outputs the representation of the sentence. The Transformer encoder consists of two key components:
- (1)
Multi-head attention mechanism: This mechanism effectively models the context information through the self-attention model, helping the model to understand the relationship between each word in the context.
- (2)
Feedforward neural network layer: This is used to further process the output of the attention layer and enhance the expressiveness of the model through nonlinear transformation.
where
is the trainable weight matrix.
The feedforward neural network reintegrates the attentional output through two fully connected layers:
where
are trainable weight matrices and
are bias vectors.
3.2. Data Augmentation
Contrastive learning pre-training is a powerful self-supervised learning method that can provide rich semantic information for sentence-level semantic representation models. In contrastive learning, positive samples are pairs of samples from the same category. Data augmentation is a common technique that aims to expand the dataset by generating more training samples by applying random transformations or perturbations to the original samples. Contrastive learning learns meaningful representations by comparing the similarities between positive and negative samples. In our study, the positive sample data augmentation strategies used for sentence pre-training are as follows:
- (1)
Symbol Insertion (SI): Symbols usually do not carry specific meanings and only change the structure of the sentence. We generate positive samples by inserting commas between the main and subordinate clauses, repeating existing punctuation marks, or swapping periods and exclamation marks.
- (2)
Affirmative Auxiliary Verbs (AAV): We fine-tune the meaning of sentences by adding affirmative auxiliary verbs to the sentences. We design some auxiliary verbs, such as “must”, “have to”, etc., and insert them into the sentences. This method is more radical than inserting punctuation marks.
- (3)
Double Negation (DN): Double negation refers to the use of two negative words in the same sentence. For example, the original sentence “I like anyone” can be transformed into “I don’t dislike anyone”, changing the semantics of the sentence through double negation.
- (4)
Punctuation Repeat Insertion (PR): We randomly select punctuation marks (such as periods, semicolons, question marks, etc.) and insert them into sentences to increase the sense of a pause or the separation of sentences.
In addition, we also propose two more radical sentence enhancement methods:
- (1)
Affirmation Enhancement (AE): This is an active generative method that enhances the certainty of sentences by slightly adjusting the meaning of sentences. We first collect affirmative auxiliary verbs such as “must”, “can’t help”, “have to”, and randomly select an auxiliary verb to modify the predicate verb of the sentence. For example, the original sentence “he went to the meeting” can be transformed into “he must go to the meeting” through affirmation enhancement, emphasizing the necessity of the action.
- (2)
Negation Transformation (NT): Negation transformation is a harmful data enhancement method that changes semantics. By adding negative words (such as “not”) before nouns and verbs, the tone of the sentence is changed to express a negative or negative meaning. For example, the original sentence “She likes chocolate” can be transformed into “She doesn’t like not eating chocolate” through negative transformation, which is transformed into a negative attitude towards chocolate.
It should be noted that negative transformation may change the sentiment tendency of the original sentence, making it more negative or positive. In practice, the decision to use negative transformation enhancement methods must be made according to the specific task and context.
3.3. Contrasting Learning Pre-Training Loss
In order to effectively solve the problem of negative sample sampling bias, we propose a new solution, that is, no longer being limited to sampling negative samples from the current batch of positive samples, but instead sampling from the entire sample space. This can better capture the global characteristics of the sample distribution and reduce the impact of sampling bias. However, the extracted negative samples may contain examples with semantically similar positive samples (i.e., false negative samples), which poses certain challenges to model training.
To alleviate this problem, we propose an instance weighting approach to penalize erroneous negative samples. Since we cannot access true labeling or semantic similarity, we utilize a complementary model to generate weights for each negative sample. This paper uses the state-of-the-art GTE model [
31] as the complementary model. Given a negative sample representation
from
or
and a sentence representation
from BERT, we utilize GTE to generate weights
, which are calculated as follows:
where
is the hyperparameter of the instance weighting threshold and
is the cosine similarity score of the two sample semantic vectors. In this way, negative samples with higher semantic similarity to the original sentence representation will be treated as erroneous negative samples and penalized by assigning a weight of 0 to them. Based on the weights, we optimize the sentence representation using a debiased cross-entropy contrast learning loss function, calculated as follows:
where
is the temperature hyperparameter. Our framework follows the GTE approach and utilizes dropout to augment the positive samples
.
Doing so can penalize erroneous negative samples and improve the distinction between positive samples. This helps to improve the representation and generalization of the model.
3.4. Classification and Training
After pre-training the model, we obtain an encoder model with a large corpus. Here, we further connect the fully connected layer for multiple classifications later:
We then use the cross-entropy loss function to train the classification network:
4. Experiment
In this section, we design experiments to demonstrate the effectiveness of the proposed model. First, we introduce the dataset used, the experimental environment, and the comparison method, and then we present the overall experimental results and the ablation experiments, respectively.
4.1. Datasets
We use three sets of Chinese text datasets that we crawl and clean ourselves, corresponding to three different application scenarios: food reviews, takeaway service reviews, and movie and TV reviews. Among them, the food dataset and the takeaway dataset are both binary classification tasks, with labels divided into “positive” and “negative”; the movie and TV review dataset is a four-category task, corresponding to four sentiment levels of “very good”, “general preference”, “general deviation”, and “very bad”. In the process of constructing the dataset, we strictly de-duplicate the original text data, remove redundant and templated content, and use a combination of regular rules and manual review to complete the cleaning of noisy text and label correction. In addition, we balance the sample distribution to avoid category bias in the model during the training phase and improve the objectivity and comparability of the experimental results. Each dataset is divided into training set, validation set, and test set. The specific sample number and category distribution are listed in
Table 1 for subsequent experimental reproduction and comparison.
4.2. Experimental Environment
This study uses an NVIDIA A100 Tensor Core GPU as the deep learning experimental environment, Python 3.8, and Pytorch 1.13, and the model hyperparameter configuration is shown in
Table 2.
4.3. Comparison Methods
In order to verify the effectiveness of our proposed model, we have selected the following comparison methods for comparison experiments:
- (1)
CRNN [
32] (convolutional recurrent neural network): This is a text classification method that combines convolutional neural network (CNN) and recurrent neural network (RNN). CNN is mainly used to extract local features, while RNN is good at capturing contextual dependency information in sequences. CRNN can simultaneously model the local structure and global semantics of text, so it is widely used in various text classification tasks. This paper selects CRNN as the baseline method because it represents the classic deep learning text classification architecture, performs stably on multiple standard datasets, and has good reference value.
- (2)
AEDA [
33] (An Easier Data Augmentation): This is a lightweight data augmentation method that increases data diversity by randomly inserting punctuation marks into the input text, thereby improving the generalization ability of the model. It has the advantages of a simple operation and there being no need for additional labels, and has been verified to have certain effects in multiple text classification tasks. Therefore, this paper selects AEDA as a comparison method to evaluate the actual effect of traditional text augmentation technology in this task.
- (3)
LFCN [
34] (Label-Fusion Convolutional Network): This is a neural network structure that integrates label information and deep representation. It is often combined with pre-trained language models (such as BERT) and CNN to improve the model’s modeling ability for text semantics. LFCN represents a typical architecture of a class of BERT and CNN fusion models, with strong feature extraction capabilities. This paper uses it as a comparison baseline to verify the advantages of the proposed model in the deep fusion of semantic information.
4.4. Overall Results
The following experiments were conducted on three datasets for the four baselines as well as for our proposed model, and we measured the model effect on four common metrics of classification: accuracy (ACC), precision (P), recall (R), and F1.
CRNN: The model achieved an accuracy of 80.54%, with relatively high precision (83.96%) but a lower recall (61.04%) and F1 score (62.55%).
AEDA and DBSCAN: Both results were identical, suggesting that AEDA may not have significantly improved the model performance. The accuracy was 75.7%, with precision, recall, and F1 score values of approximately 37.85%, 50%, and 43.08%, respectively.
Ours: Achieved the best performance in terms of accuracy, with a value of 85.14%. It performed well in precision (86.12%) and recall (72.01%), resulting in a high F1 score of 85.96%. This indicates that the proposed model is highly effective in categorizing food-related texts.
CRNN: The model achieved an accuracy of 75.18%, with precision, recall, and F1 scores of 72.53%, 68.97%, and 69.99%, respectively.
AEDA and LFCN: Both performed similarly, with an accuracy of 66.58%. The precision, recall, and F1 scores were approximately 33.29%, 50%, and 39.96%, respectively.
Ours: Achieved superior performance in terms of accuracy, with a value of 84.71%. It exhibited high precision (85.67%), recall (79.36%), and a high F1 score of 81.35%. This indicates that the proposed model is particularly effective in classifying takeout-related texts.
CRNN: The model achieved an accuracy of 67.18%, with precision, recall, and F1 scores of 37.96%, 41.24%, and 37.82%, respectively.
AEDA and LFCN: Both performed similarly, with an accuracy of 47.35%, and precision, recall, and F1 scores of approximately 11.83%, 25%, and 16.06%, respectively.
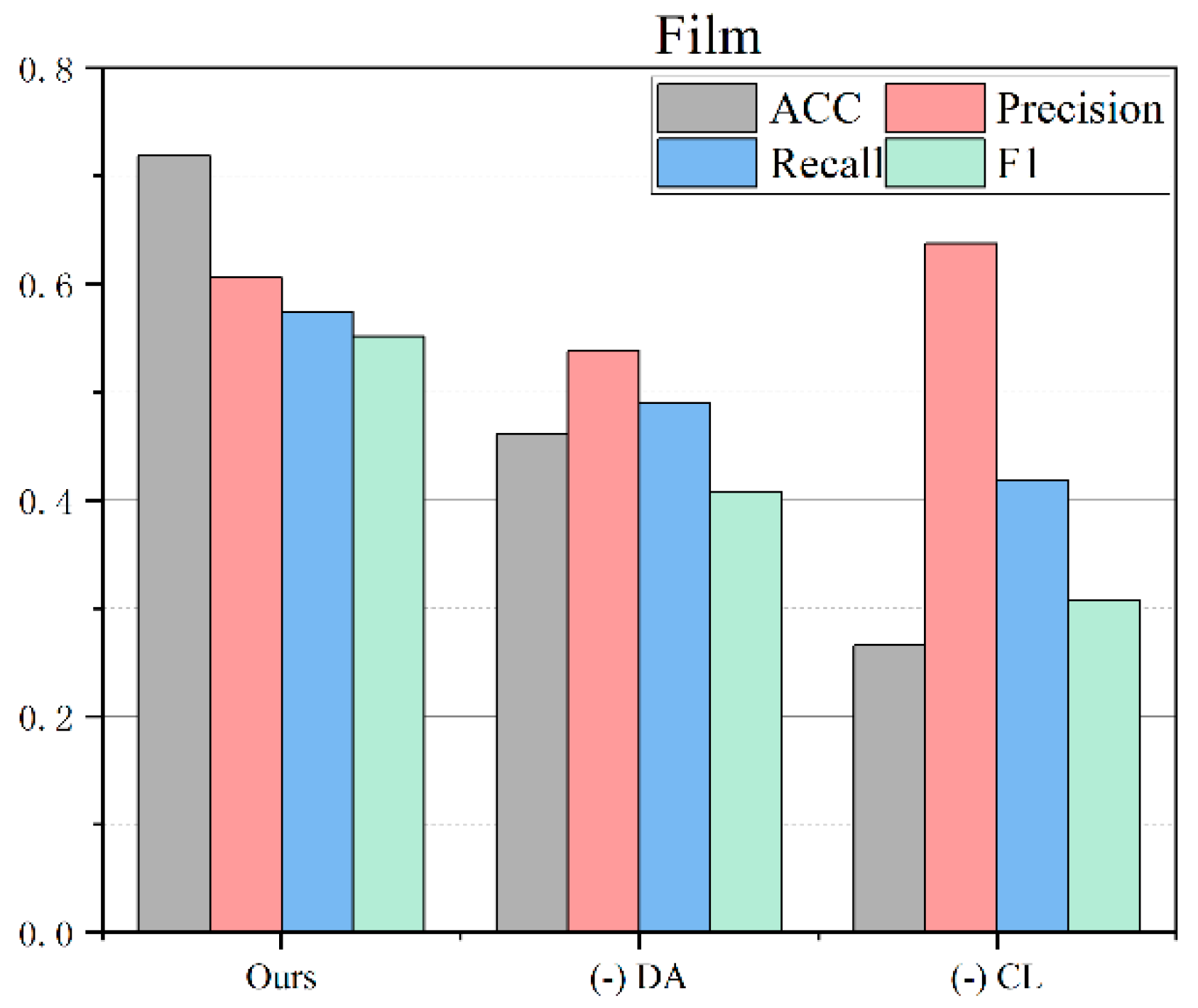
Ours: Performed significantly better in terms of accuracy, with a value of 71.85%, and exhibited high precision (60.58%) and recall (57.42%), resulting in a competitive F1 score of 55.15%. This indicates that the proposed model is highly effective in four-category classification tasks.
The proposed model consistently outperforms the baseline across all three datasets, demonstrating its robustness.
Although AEDA is a data enhancement technique, it does not significantly improve the results of these experiments. In the LFCN model, integrating BERT with CNN does not provide a significant advantage in these specific tasks. The proposed model, which performs best across all metrics, with the highest accuracy and competitive precision, recall, and F1 scores, demonstrates its effectiveness in text categorization tasks. The model’s effectiveness is attributed to the proposed data enhancement technique, which, on one hand, better utilizes the existing data. On the other hand, the weighting of instances helps to filter out invalid data more effectively, leading to improved model training.
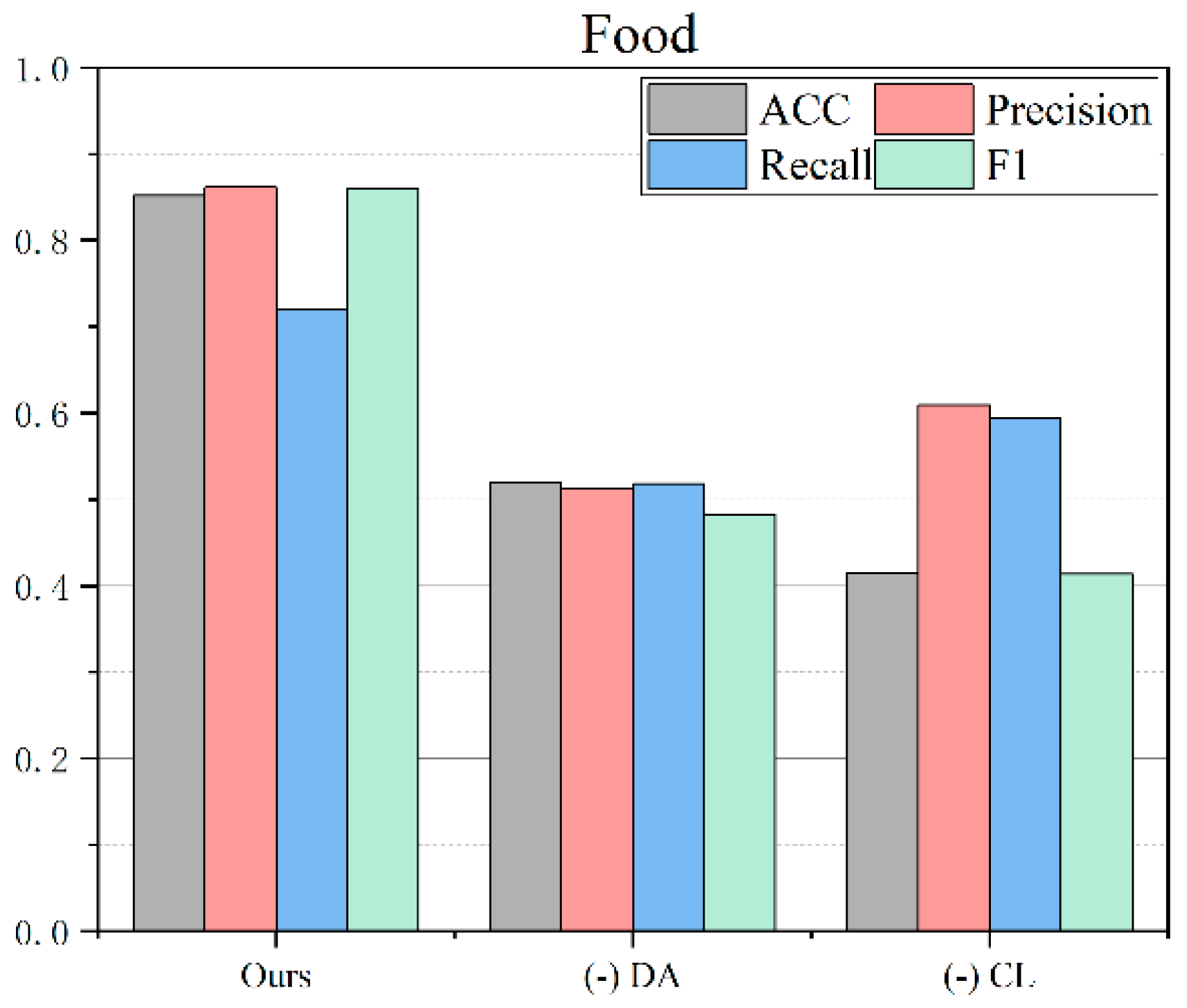
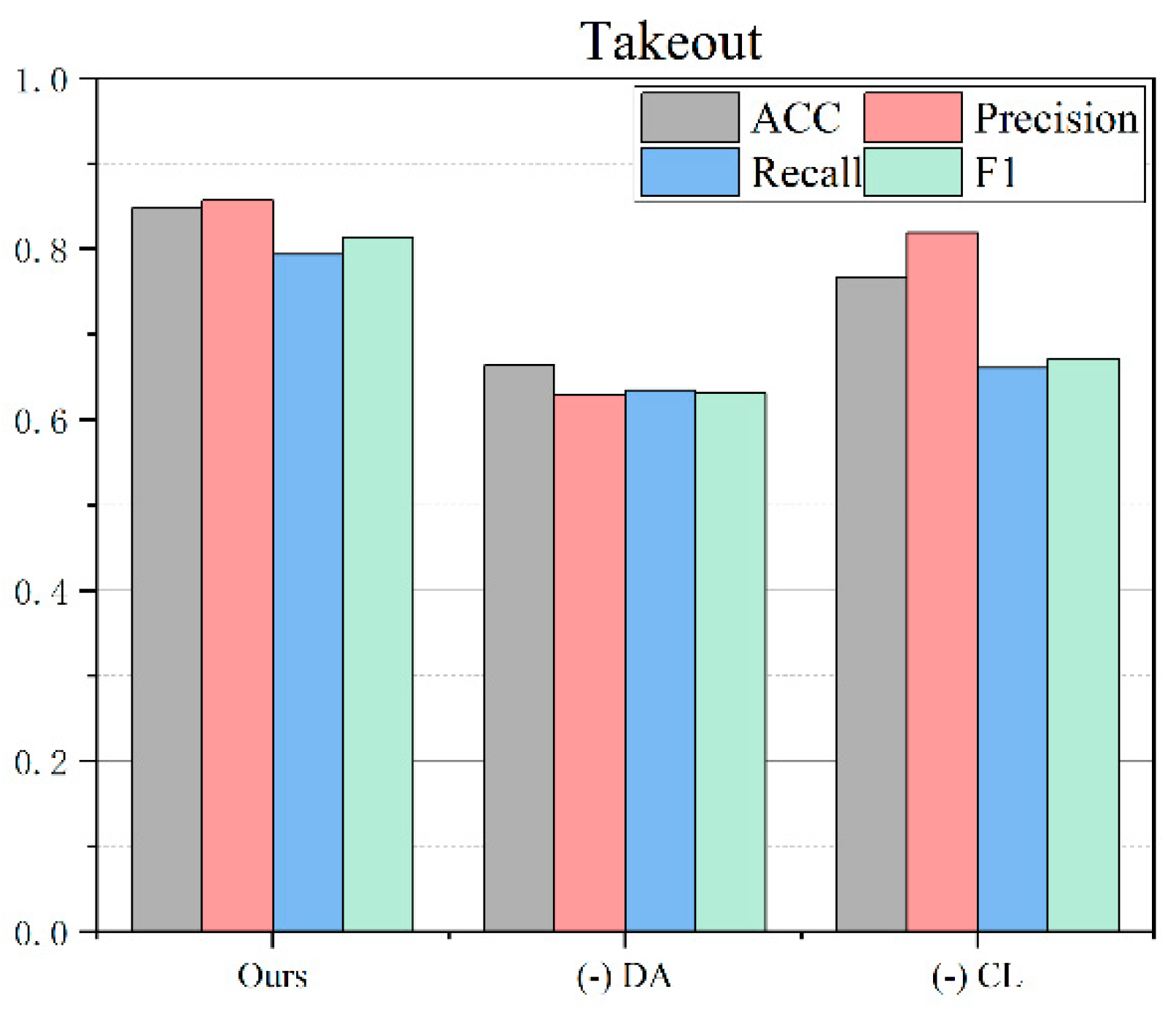
4.5. Ablation Study
In this study, we design two ablation models, one of which involves (1) removing data augmentation and the other involves (2) removing contrastive learning, and compare them with the complete proposed model to analyze the contribution of each key module to the classification effect. By comparing the performance of each model on three datasets, we can systematically evaluate the importance of data augmentation and contrastive learning in improving text classification performance. The ablation results for the three datasets are shown in
Figure 3,
Figure 4 and
Figure 5:
- (1)
Ours (proposed model):
This model is a complete framework that combines a contrastive learning pre-training model, data augmentation, and instance clustering, aiming to improve text classification performance. The model shows significant advantages on the food dataset, achieving high accuracy, precision, recall, and F1 value. Although the performance on the movie and takeaway datasets is not as good as the food dataset, it still achieves relatively good results, verifying the effectiveness and generalization ability of the model.
- (2)
Remove data augmentation:
This ablation model removes the data enhancement strategy based on the proposed model. Data enhancement plays a key role in contrastive learning. It helps to improve the generalization ability of the model by introducing noisy negative samples in positive samples and optimizing them. The experimental results show that after removing data enhancement, the classification performance of the model on various datasets decreases significantly. On the food dataset, the accuracy (ACC) after removing data enhancement is 0.5198, the precision (Precision) is 0.5131, the recall rate (Recall) is 0.5178, and the F1 value is 0.482, which is significantly lower than the proposed model. On the movie and takeaway datasets, removing data enhancement also leads to similar performance degradation, further proving the importance of data enhancement on the model effects.
- (3)
Remove contrastive learning:
This ablation model removes the contrastive learning part based on the proposed model and directly uses the BERT pre-trained parameters for text classification. Contrastive learning helps to learn more semantically meaningful text representations by introducing positive sample enhancement and optimizing noisy negative samples similarly to positive samples. The experimental results show that after removing contrastive learning, the classification performance of the model also shows a significant decline. On the food dataset, the accuracy (ACC) after removing contrastive learning is 0.4143, the precision (Precision) is 0.6089, the recall rate (Recall) is 0.5942, and the F1 value is 0.4131, which is significantly lower than the proposed model. On the movie and takeaway datasets, the model without contrastive learning also shows similar performance degradation.
In summary, the experimental results show that the proposed contrastive learning text classification pre-trained model performs better than other models on these datasets, and data augmentation and contrastive learning are the key factors to improve the model performance. Removing these two important parts will lead to a significant decrease in the model classification performance, which further verifies the effectiveness and advantages of our proposed method.
5. Discussion
In this study, we propose a contrastive learning text classification pre-training model that combines data augmentation and instance weighting, aiming to solve the core problem of “insufficient data utilization” in existing contrastive learning methods. By designing two strategies, positive augmentation and negative transformation, we semantically expand the original text to generate more diverse and challenging training samples. Different from the traditional random augmentation method, we introduce semantic control in the augmentation process to make the generated samples closer to the real distribution in terms of their content. At the same time, considering the problem that noise or “false negative samples” may be introduced in the augmentation process, we propose an instance weighting mechanism and introduce a complementary model to evaluate the sample quality, thereby effectively suppressing the negative impact of harmful samples on model training. This design greatly improves the effectiveness and expressiveness of training data while maintaining the basic idea of contrastive learning.
From the experimental results, this method has achieved better results than baseline models such as CRNN, AEDA, and LFCN on three real datasets of food, takeout, and film. It not only significantly improves the accuracy, but also performs well in indicators such as precision, recall, and F1 that measure classification ability. Especially in the ablation experiment, removing the data augmentation or contrastive learning module will lead to a significant drop in model performance, further verifying that the synergy of these two technologies is crucial to the model effect. In future research, we plan to further expand this research from multiple directions. On the one hand, we will explore more refined semantic enhancement strategies, such as context reconstruction methods based on large language models, to improve the quality and diversity of the enhanced samples in semantic expression; on the other hand, we will consider introducing an attention mechanism to dynamically optimize the instance weighting strategy, so that the model can more effectively identify and suppress the interference of noise samples during training, thereby enhancing the overall robustness. We will also try to apply this research method to more challenging task scenarios such as multi-label classification and cross-language text classification to evaluate its adaptability and promotion potential in complex applications.
6. Conclusions
This study proposes a text classification method based on a contrastive learning pre-training model, and verifies the effectiveness of the model through comparative experiments and ablation experiments. We use the contrastive learning method to train the pre-trained model so that the model can learn the deep semantic features of text data, so that similar texts become closer in the embedding space, while the distance between different texts becomes farther. We conduct classification training on supervised data and compare it with the existing text classification models. The experimental results show that the proposed model outperforms the traditional model in multiple indicators such as accuracy, precision, recall, and F1 score, showing its excellent performance. Further ablation experiments show that removing the positive sample enhancement strategy and contrasting pre-training parameters will lead to a significant decline in model performance, proving the key role of these two strategies in improving the model. In particular, the positive sample enhancement strategy significantly improves the performance of the model on different tasks by optimizing the relationship between similar texts. The model proposed in this paper not only performs well on a variety of datasets, but also has broad application potential in practice.
Author Contributions
Methodology, X.L.; Software, X.L.; Validation, J.C.; Resources, Q.H.; Data curation, X.L.; Writing—original draft, X.L.; Writing—review & editing, J.C.; Supervision, Q.H.; Project administration, Q.H.; Funding acquisition, J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Jiangxi Provincial Natural Science Foundation, grant number 20242BAB20126.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tsirmpas, D.; Gkionis, I.; Papadopoulos, G.T.; Mademlis, I. Neural natural language processing for long texts: A survey on classification and summarization. Eng. Appl. Artif. Intell. 2024, 133, 108231. [Google Scholar] [CrossRef]
- Taha, K.; Yoo, P.D.; Yeun, C.; Homouz, D.; Taha, A. A comprehensive survey of text classification techniques and their research applications: Observational and experimental insights. Comput. Sci. Rev. 2024, 54, 100664. [Google Scholar] [CrossRef]
- Liu, J.; Li, K.; Zhu, A.; Hong, B.; Zhao, P.; Dai, S.; Wei, C.; Huang, W.; Su, H. Application of deep learning-based natural language processing in multilingual sentiment analysis. Mediterr. J. Basic Appl. Sci. 2024, 8, 243–260. [Google Scholar] [CrossRef]
- Shang, F.; Shi, J.; Shi, Y.; Zhou, S. Enhancing e-commerce recommendation systems with deep learning-based sentiment analysis of user reviews. Int. J. Eng. Manag. Res. 2024, 14, 19–34. [Google Scholar]
- Manoharan, G.; Dharmaraj, A.; Sheela, S.C.; Naidu, K.; Chavva, M.; Chaudhary, J.K. Machine learning-based real-time fraud detection in financial transactions. In Proceedings of the 2024 International Conference on Advances in Computing, Communication and Applied Informatics (ACCAI), Chennai, India, 9–10 May 2024; pp. 1–6. [Google Scholar]
- Alam, N.; Zaki, S.A.; Ahmad, S.A.; Singh, M.K.; Azizan, A. Machine learning approach for predicting personal thermal comfort in air conditioning offices in Malaysia. Build. Environ. 2024, 266, 112083. [Google Scholar] [CrossRef]
- Ai, W.; Wei, Y.; Shao, H.; Shou, Y.; Meng, T.; Li, K. Edge-enhanced minimum-margin graph attention network for short text classification. Expert Syst. Appl. 2024, 251, 124069. [Google Scholar] [CrossRef]
- Zhao, L.; Lee, S.W. Integrating Ontology-Based Approaches with Deep Learning Models for Fine-Grained Sentiment Analysis. Comput. Mater. Contin. 2024, 81, 1855–1877. [Google Scholar] [CrossRef]
- Mienye, I.D.; Swart, T.G.; Obaido, G. Recurrent neural networks: A comprehensive review of architectures, variants, and applications. Information 2024, 15, 517. [Google Scholar] [CrossRef]
- Uluocak, I.; Bilgili, M. Daily air temperature forecasting using LSTM-CNN and GRU-CNN models. Acta Geophys. 2024, 72, 2107–2126. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Q.; Kong, X.; Xiong, J.; Ni, S.; Cao, D.; Niu, B.; Chen, M.; Li, Y.; Zhang, R.; et al. Fine-tuning large language models for chemical text mining. Chem. Sci. 2024, 15, 10600–10611. [Google Scholar] [CrossRef]
- Wan, M.; Safavi, T.; Jauhar, S.K.; Kim, Y.; Counts, S.; Neville, J.; Suri, S.; Shah, C.; White, R.W.; Yang, L.; et al. Tnt-llm: Text mining at scale with large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 5836–5847. [Google Scholar]
- Liu, Y.; Huang, L.; Giunchiglia, F.; Feng, X.; Guan, R. Improved graph contrastive learning for short text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 18716–18724. [Google Scholar]
- Lian, Y.; Tang, H.; Xiang, M.; Dong, X. Public attitudes and sentiments toward ChatGPT in China: A text mining analysis based on social media. Technol. Soc. 2024, 76, 102442. [Google Scholar] [CrossRef]
- Pan, J.S.; Wang, X.; Yang, D.; Li, N.; Huang, K.; Chu, S.C. Flexible margins and multiple samples learning to enhance lexical semantic similarity. Eng. Appl. Artif. Intell. 2024, 133, 108275. [Google Scholar] [CrossRef]
- Wu, W.; Sun, Z.; Song, Y.; Wang, J.; Ouyang, W. Transferring vision-language models for visual recognition: A classifier perspective. Int. J. Comput. Vis. 2024, 132, 392–409. [Google Scholar] [CrossRef]
- Gao, D.; Chen, K.; Chen, B.; Dai, H.; Jin, L.; Jiang, W.; Ning, W.; Yu, S.; Xuan, Q.; Cai, X. LLMs-based machine translation for E-commerce. Expert Syst. Appl. 2024, 258, 125087. [Google Scholar] [CrossRef]
- Sakr, A.; Torki, M.; El-Makky, N.M. AlexUNLP-STM at NADI 2024 shared task: Quantifying the Arabic Dialect Spectrum with Contrastive Learning, Weighted Sampling, and BERT-based Regression Ensemble. In Proceedings of the Second Arabic Natural Language Processing Conference, Bangkok, Thailand, 16 August 2024; pp. 735–741. [Google Scholar]
- Giner-Miguelez, J.; Gómez, A.; Cabot, J. Using Large Language Models to Enrich the Documentation of Datasets for Machine Learning. arXiv 2024, arXiv:2404.15320. [Google Scholar]
- Hou, G.; Cao, S.; Ouyang, D.; Wang, N. Label-template based Few-Shot Text Classification with Contrastive Learning. arXiv 2024, arXiv:2412.10110. [Google Scholar]
- Onan, A.; Balbal, K.F. Improving Turkish text sentiment classification through task-specific and universal transformations: An ensemble data augmentation approach. IEEE Access 2024, 12, 4413–4458. [Google Scholar] [CrossRef]
- Ding, B.; Qin, C.; Zhao, R.; Luo, T.; Li, X.; Chen, G.; Xia, W.; Hu, J.; Tuan, L.A.; Joty, S. Data augmentation using llms: Data perspectives, learning paradigms and challenges. In Proceedings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 1679–1705. [Google Scholar]
- Zhao, C.; Sun, X.; Feng, R. Multi-strategy text data augmentation for enhanced aspect-based sentiment analysis in resource-limited scenarios. J. Supercomput. 2024, 80, 11129–11148. [Google Scholar] [CrossRef]
- Kesgin, H.T.; Amasyali, M.F. Advancing NLP models with strategic text augmentation: A comprehensive study of augmentation methods and curriculum strategies. Nat. Lang. Process. J. 2024, 7, 100071. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, H.; Zhu, X.; Chen, Y. Deep Contrastive Clustering via Hard positive sample Debiased. Neurocomputing 2024, 570, 127147. [Google Scholar] [CrossRef]
- Wang, S.; Sui, Y.; Wang, C.; Xiong, H. Unleashing the Power of Knowledge Graph for Recommendation via Invariant Learning. In Proceedings of the ACM on Web Conference 2024, Singapore, 13–14 May 2024; pp. 3745–3755. [Google Scholar]
- Zhou, Y.; Gao, C.; Zhou, J.; Ding, W.; Shen, L.; Lai, Z. OCI-SSL: Open Class-Imbalanced Semi-Supervised Learning with Contrastive Learning. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 3779–3792. [Google Scholar] [CrossRef]
- Garg, S.; Setlur, A.; Lipton, Z.; Balakrishnan, S.; Smith, V.; Raghunathan, A. Complementary benefits of contrastive learning and self-training under distribution shift. Adv. Neural Inf. Process. Syst. 2024, 36, 11621–11673. [Google Scholar]
- Zalte, J.; Shah, H. Contextual classification of clinical records with bidirectional long short-term memory (Bi-LSTM) and bidirectional encoder representations from transformers (BERT) model. Comput. Intell. 2024, 40, e12692. [Google Scholar] [CrossRef]
- Do, N.Q.; Selamat, A.; Fujita, H.; Krejcar, O. An integrated model based on deep learning classifiers and pre-trained transformer for phishing URL detection. Future Gener. Comput. Syst. 2024, 161, 269–285. [Google Scholar] [CrossRef]
- Rowland Yeo, K.; Gil Berglund, E.; Chen, Y. Dose optimization informed by PBPK modeling: State-of-the art and future. Clin. Pharmacol. Ther. 2024, 116, 563–576. [Google Scholar] [CrossRef]
- Prakash, P.; Hanumanthaiah SK, Y.; Mayigowda, S.B. CRNN model for text detection and classification from natural scenes. IAES Int. J. Artif. Intell. 2024, 13, 839. [Google Scholar] [CrossRef]
- Kim, H.S.; Lee, J.H. Need Text Data Augmentation? Just One Insertion Is Enough. Int. J. Fuzzy Log. Intell. Syst. 2024, 24, 83–92. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, G.; Zhang, L.; Shen, X.; Luo, S. An effective multi-modal adaptive contextual feature information fusion method for Chinese long text classification. Artif. Intell. Rev. 2024, 57, 233. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}