1. Introduction
An intelligent tutoring system (ITS) is an educational tool that leverages artificial intelligence and big data technologies to provide personalized learning support and services to learners [
1]. With the rapid development of AI technologies, educational intelligent agents such as ITSs are gaining increasing attention in the field of education, as they can offer tailored learning paths and personalized learning resources based on learners’ interests, preferences, and characteristics. An ITS represents a significant area of mutual empowerment between AI and education, serving as an effective means to promote large-scale personalized learning and achieve precise workload reduction and efficiency enhancement, thereby facilitating the digital transformation of education. Research focusing on the three key elements of the learning process, scenarios, subjects, and services, should be conducted on the unobtrusive perception and intelligent recognition of learning scenarios, the cognitive tracking and attribution inference of learning subjects, and the dynamic and precise adaptation of learning services. This will lead to the formation of a technical system where “learning scenarios are computable, learning subjects are comprehensible, and learning services are adaptable”, thereby constructing an intelligent tutoring system [
2].
A recommendation system is an information filtering system that utilizes algorithms and data to provide users with personalized content, products, or services [
3]. As an integral part of modern information technology, recommendation systems deeply analyze users’ historical behavior data and item characteristics to offer suggestions that align with their interests and preferences. Recommendation systems are mainly classified into content-based recommendation, collaborative filtering recommendation, and hybrid recommendation. They are widely applied in e-commerce, social media, content platforms, education, and other fields to enhance user experience and increase user engagement. The latest recommendation systems leverage advanced technologies such as big data and artificial intelligence, significantly promoting the development of recommendation systems in both academia and industry. Education is a key development area for recommendation systems providing intelligent and personalized services for learning path planning, personalized learning, high-quality learning resource recommendation, social learning, etc. These services can effectively improve learners’ learning experiences and educational quality, making them an important component of intelligent tutoring systems and a significant research direction for educational intelligent agents as well as a field worthy of in-depth study.
A knowledge graph represents knowledge in a graph format and is used to describe entities and their relationships with each other. It is an important research direction in the field of artificial intelligence. A knowledge graph typically consists of entities and relationships, enabling the efficient representation of complex interconnected information. The technical framework for constructing a knowledge graph can be divided into three levels: the information extraction layer, the knowledge integration layer, and the knowledge processing layer. The information extraction layer is responsible for extracting entities and relationships from multiple data sources; the knowledge integration layer processes knowledge from different sources, resolving data conflicts and redundancy issues; and the knowledge processing layer further processes and optimizes the extracted and integrated knowledge. A knowledge graph is an intelligent and efficient means of organizing knowledge, which not only helps users quickly and accurately obtain the information they need but also plays a significant role in multiple fields, including search engines, recommendation systems, question-answering systems, natural language processing, and intelligent assistants. Well-known knowledge graphs include Google Knowledge Graph, Wikidata, DBpedia, ConceptNet, FreeBase, and YAGO. The combination of knowledge graphs and recommendation systems has provided a strong impetus for the rapid development of intelligent tutoring systems, given the powerful capabilities of knowledge graphs in knowledge representation [
4].
The application of knowledge graphs in the field of recommendation systems has become increasingly widespread and deep. User needs can be better understood through structured knowledge representation that includes rich contextual information and multi-dimensional features, thereby enhancing the accuracy and relevance of recommendations. Various types of auxiliary information are utilized to better identify users’ latent interests and item characteristics to improve the accuracy of recommendation algorithms. In recent years, recommendation systems based on knowledge graphs have garnered widespread attention from both academia and industry by fully leveraging the hidden information in graph-structured data, achieving a series of research results that not only improve recommendation accuracy but also enhance the interpretability of recommendation results. To fully exploit the auxiliary information in knowledge graphs, existing research primarily adopts propagation-based methods to integrate representations of entities and relationships as well as higher-order connection patterns to achieve more personalized recommendations. A common implementation of this approach is based on graph neural network technology. Wang et al. [
5] proposed the RippleNet model, which introduced a preference propagation mechanism in knowledge graphs for the first time. It automatically and iteratively extends users’ latent preferences along the connections in the knowledge graph, thereby propagating user preferences across the set of knowledge entities. Wang et al. [
6] proposed the Knowledge Graph Attention Network (KGAT) model, which explicitly models higher-order connections in knowledge graphs in an end-to-end manner. The KGAT model recursively propagates information from a node’s neighbors (including users, items, or attributes) to refine the node’s embedding representation and includes an attention mechanism to differentiate the importance of neighbors. Wang et al. [
7] proposed the Collaborative Knowledge-Aware Attentive Network (CKAN), which explicitly encodes collaborative signals through collaborative propagation and naturally integrates them with knowledge associations. The CKAN effectively fuses collaborative information with knowledge information, demonstrating significant superiority. Inspired by the effectiveness of contrastive learning in extracting supervisory signals from data, Ding et al. [
8] focused on exploring contrastive learning in knowledge-aware recommendation (KGR) and proposed a multi-level, interactive contrastive learning mechanism. Unlike traditional contrastive learning methods that contrast nodes in two generated graph views, KGIC’s interactive contrastive mechanism performs layer-by-layer self-supervised learning by contrasting layers within the graph. Subsequently, a large number of propagation-based iterative update models have been proposed, such as KGRec [
9] and EditKG [
10]. Lin et al. [
11] proposed a new framework called BoxGNN, which performs message aggregation through combinations of logical operations to merge higher-order signals. The integration of knowledge graphs and recommendation systems in the field of education is a highly promising direction.
The recommendation system based on knowledge graphs has achieved certain successes in the field of learning resource recommendation, making progress in areas such as courses, exercises, academic papers, books, and learning peers. Zhang et al. [
12] proposed the Knowledge Group Aggregation Network (KGAN) model, which naturally projects learner behavior and course graphs into a unified space, effectively alleviating challenges such as interaction sparsity, course relevance, and intention diversity in course recommendation. Jin et al. [
13] introduced the MC-DRER exercise recommendation model for online problem-solving, which constructs a knowledge graph in the field of programming and establishes associations between exercises and their knowledge points, enabling the recommendation method to handle relationships between knowledge points. Although knowledge-graph-based recommendation systems have led to some progress in personalized learning, there are still two urgent issues in the field of personalized learning resource recommendation: (1) A significant amount of research has focused on the representation of learning resources but neglected the representation of learners. (2) The aggregation strategies for multi-source heterogeneous information are relatively simplistic, which can easily lead to information loss and the failure to distinguish the importance of different neighboring entities. We assume that in a certain intelligent education recommendation scenario, there is a set of M learners and a set of N learning resources. Based on the implicit feedback of learners in historical records, we can obtain a learner–resource interaction matrix, where r
ij indicates that learner i has interacted with learning resource j, and otherwise, r
ij = 0. Additionally, we organize auxiliary information into the form of a knowledge graph, where each knowledge triple (h,r,t) represents a relationship between the head entity h and the tail entity t, and E and R are the sets of entities and relationships in the knowledge graph, respectively. Our objective is to learn a predictive function.
This paper proposes a learner-enhanced personalized learning resource recommendation model (LKGA) to effectively mitigate the challenges posed by the aforementioned issues. This specific work includes three aspects: First, by extracting collaborative signals from users, the learning resources clicked by learners who have clicked the same resource are considered potential collaborative signals and merged with the original learning resource features to form the initial entity set for learners. Explicitly encoding the collaborative information in potential learner–learning resource interactions naturally integrates these signals with knowledge propagation. Second, during the entity aggregation process, an attention mechanism is employed to distinguish the different semantic expressions of each tail entity, thereby treating the contributions of different neighbors differently. Third, initial connections are added during each hop of the learner’s aggregation process, and including the information from the first hop in every subsequent hop can effectively reduce information loss, thereby further enhancing the representation capability of learners.
In summary, our contributions include the following:
- (1)
We propose a novel, end-to-end, personalized learning resource recommendation model, LKGA, which more comprehensively represents the original entity sets of learners and learning resources by simultaneously considering user collaborative signals and learning resource collaborative signals. The model facilitates embedding representations by naturally combining collaborative propagation between learners and learning resources with knowledge graph propagation.
- (2)
Furthermore, the model effectively distinguishes the semantic differences of tail entities by fully leveraging the attention mechanism and reduces information loss by adding initial connections during the aggregation process. This helps to focus on the important roles of key neighbors and further enhances the effective representation capability of learners, allowing for deeper expression of the latent meanings of learners in the vector space.
- (3)
We conducted experiments on educational datasets, and the extensive experimental results demonstrated that the LKGA model achieved the best performance across multiple evaluation metrics, fully validating the effectiveness of our proposed method.
In the remainder of this paper, we will comprehensively review related work in
Section 2 and point out the two issues present in the current research. We describe in detail our proposed LKGA method in
Section 3, and we describe how we conducted extensive experiments and thoroughly analyze the experimental results in
Section 4. We discuss the experimental results from multiple perspectives in
Section 5. Finally,
Section 6 summarizes the entire paper, drawing conclusions and outlining future research directions.
2. Related Work
Below, we review related work from two aspects: recommendation algorithms based on knowledge graph representation learning and personalized services for intelligent education. The recommendation algorithms based on knowledge graph representation learning are categorized from the perspective of technological development into embedding-based methods, path-based methods, and propagation-based methods. This study is considered a development of the propagation-based methods from a technological viewpoint. The personalized services for intelligent education analyze the application of intelligent recommendation technology as the core key technology for intelligent guidance systems aimed at personalized learning. The focus is on learning resource recommendation via knowledge graphs.
2.1. Recommendation Algorithms Based on Knowledge Graph Representation Learning
With the rapid development of artificial intelligence and big data technologies, recommendation systems have been widely applied in various fields. Knowledge graphs, as an efficient method of knowledge representation and organization, provide rich semantic information and structured knowledge for recommendation systems, significantly enhancing the accuracy and interpretability of recommendations. In recent years, recommendation algorithms based on knowledge graph representation learning have gradually become a research hotspot. These algorithms enhance the representation capabilities of users and items by integrating entity and relationship information from knowledge graphs, thereby achieving more precise personalized recommendations. Wang et al. [
5] proposed Ripple Network, an end-to-end framework that naturally integrates knowledge graphs into recommendation systems. It automatically and iteratively expands users’ potential interests along the links in the knowledge graph, stimulating the propagation of user preferences, and superimposes multiple “ripples” activated by users’ historical clicked items to form a preference distribution of users for candidate items, thereby predicting the final click probability. These algorithms can be classified into three categories based on the ways in which knowledge graph information is utilized in existing research: embedding-based methods, path-based methods, and propagation-based methods.
2.1.1. Embedding-Based Methods
The core idea of embedding-based methods is to map entities and relationships in the knowledge graph into a low-dimensional vector space, thereby enhancing the representation capabilities of items or users by leveraging rich auxiliary information. For example, the CKE model proposed by Zhang et al. [
14] learns item embeddings with the participation of the knowledge graph, effectively linking items to entities and relationships in the knowledge graph by fusing collaborative filtering and knowledge graph embeddings. Shi et al. [
15] proposed a Knowledge Graph Embedding Attention Network model, which introduces the translation distance method into high-order knowledge propagation, effectively embedding knowledge into a set of triples and achieving efficient fusion of collaborative information and auxiliary knowledge. These methods can transform complex knowledge graph structures into compact vector representations through embedding learning, facilitating subsequent recommendation task processing.
However, embedding-based methods also have some limitations. Firstly, these methods often struggle to capture high-order relationships between entities because they primarily focus on direct embeddings of entities and relationships, ignoring complex path information and multi-hop relationships in the knowledge graph. Secondly, the learned entity embeddings may not be entirely suitable for recommendation tasks, as there may be a discrepancy between the objectives of embedding learning and recommendation tasks. Additionally, embedding methods may face challenges in computational efficiency and storage costs when dealing with large-scale knowledge graphs.
2.1.2. Path-Based Methods
Path-based methods provide additional guidance for recommendation tasks by exploring various patterns connecting entities in knowledge graphs. The core of these methods lies in leveraging path information within knowledge graphs to capture complex relationships between entities. For example, Yu et al. [
16] proposed a method based on heterogeneous information networks, which combines heterogeneous relationship information for each user and utilizes user implicit feedback data along with personalized recommendation models to deliver high-quality recommendation results. Zhao et al. [
17] introduced a knowledge graph recommendation algorithm tailored for a multi-path recurrent neural network encoder, which fully considers the correlations between paths and can better capture semantic information within the knowledge graph.
However, in real-world scenarios, decomposing complex user–item connection patterns into individual linear paths may lead to information loss. This is because relationships in knowledge graphs are often multi-hop and non-linear, and path-based methods may not fully preserve these complex relationships. Furthermore, optimizing path selection and recommendation objectives poses a challenge, as the number and complexity of paths can increase dramatically with the scale of the knowledge graph, leading to prohibitively high computational costs.
2.1.3. Propagation-Based Methods
Propagation-based methods refine entity representations by aggregating embeddings of multi-hop neighbors in the knowledge graph, starting from the user’s initial records. These methods are typically implemented using graph neural network technology, effectively leveraging the structured information in the knowledge graph. For example, the KGNN-LS model employs graph convolutional neural networks to obtain the representations of items by aggregating their neighboring nodes, thereby enhancing the use of relationships in the knowledge graph and improving recommendation accuracy [
18]. Guan et al. [
19] proposed a knowledge-graph-based exercise recommendation method, KG4Ex, where the knowledge graph includes three key entities (knowledge concepts, students, and exercises) and their interrelationships, which can be used to recommend suitable exercises. These methods, through multi-hop propagation, can capture implicit relationships between users and items, thereby enhancing the personalization of recommendations.
However, propagation-based methods also present some challenges. Firstly, these methods often involve substantial computational load, especially when dealing with large-scale knowledge graphs, as the training and inference processes of graph neural networks can consume significant computational resources. Secondly, to reduce computational costs, random sampling methods are often used to select neighbor nodes, but this may lead to information loss, thereby affecting the accuracy and completeness of recommendation results. Additionally, the issue of information decay during the propagation process needs to be addressed through appropriate design, such as introducing residual connections to preserve original information.
In recent years, recommendation algorithms based on knowledge graphs have also been evolving with the continuous development of deep learning and graph neural network technologies. For example, in the latest research, Zhang et al. [
20] proposed a novel recommendation model called KGLN based on graph neural networks. This model first merges node features in the graph using a single-layer neural network then adjusts the aggregation weights of neighboring entities by incorporating influencing factors and iterates from a single layer to multiple layers to capture multi-order associated entity information. Finally, it integrates entity and user functionalities to generate recommendation scores, thereby improving the accuracy and effectiveness of personalized recommendations. In addition, Wang et al. [
21] began exploring the integration of large language models (LLMs) with knowledge graphs, leveraging their powerful language generation capabilities and knowledge comprehension abilities to provide richer contextual information for recommendation systems.
2.2. Personalized Learning Services for Intelligent Education
Personalized learning services for intelligent education aim to leverage artificial intelligence technology to provide learners with a tailored educational experience [
22]. Based on learners’ individual learning needs and characteristics, various advanced technologies such as big data and artificial intelligence are employed to achieve differentiated teaching, personalized learning, refined management, data-driven research, and intelligent services.
Traditional personalized learning services primarily rely on teachers’ observations, judgments, and students’ learning performance to adjust teaching methods, learning content, learning pace, and other aspects. For example, teachers will provide more guidance and practice for students who are slower in their learning progress, while for those who are faster, teachers may offer additional extracurricular learning resources to help them consolidate and expand their knowledge. However, this approach has certain limitations, such as insufficient teacher resources and the low accessibility of personalized services. Traditional personalized services rely heavily on teachers’ subjective judgments, and teachers’ time and energy are limited, making it difficult to grasp each student’s learning data in real time. This results in significant deficiencies in both the efficiency and effectiveness of traditional personalized services.
Personalized learning services in the field of intelligent education are undergoing a transition from a traditional “experience-driven” approach to a “data-driven” one. Initially, the concept of personalized learning was vague, primarily relying on educational psychology theories and teachers’ individual judgments. Although these practices exhibited a certain degree of personalization, they lacked universality and systematicity. With the rise of big data and artificial intelligence technologies, Guo et al. [
23] proposed that the deep integration of data-driven approaches and AI technologies is key to promoting the realization of personalized educational services. The seamless integration of learner profiling, generative AI, and adaptive recommendation will make personalized learning more scientific, precise, intelligent, and diversified. Maghsudi et al. [
24] delved into the role and implementation mechanism of data-driven personalized learning in the process of educational modernization. The process involves collecting, modeling, analyzing, and providing feedback on student data, then constructing personalized learner profiles using digital portraits, and ultimately designing personalized learning plans and services based on these digital portraits of learners.
Furthermore, with breakthroughs in multimodal data collection and deep learning algorithms, the construction of precise and personalized learning services using multimodal data such as voice, video, and physiological signals has become a new topic in the field of education. Intelligent personalized services dynamically generate precise learning resource recommendations by collecting and analyzing students’ learning behavior data, as well as multimodal data such as emotions and expressions, to tailor personalized learning paths for students. Sajja et al. [
25] developed an AI-based learning analysis tool. It utilizes GPT-4 to analyze students’ emotional states (stress, curiosity, confusion, excitement, etc.) and cognitive progress based on their questions while also recording interactions between students and the AI assistant. This tool quantifies learning preferences to model students’ learning behaviors, aiding in the dynamic adjustment of recommendation strategies to achieve personalized learning.
Gounder et al. [
26] proposed an intelligent tutoring system that integrates students’ cognition, learning preferences, and learning styles through artificial intelligence technology; dynamically adjusts learning tasks and resources; and customizes personalized learning plans for students. The research results show that when learning content and strategies match students’ cognition and learning styles, their comprehension, memory, and academic performance are effectively improved. Gligorea et al. [
27] discussed how to use adaptive learning technology to provide students with a tailored learning experience and enhance learning outcomes and academic performance. They pointed out that artificial intelligence (AI) and machine learning (ML) algorithms can dynamically adjust the difficulty and depth of learning content based on students’ knowledge mastery and learning progress, creating personalized learning paths for students while incorporating a real-time feedback mechanism. Eden et al. [
28] proposed an AI-based intelligent assistant system (AIIA) aimed at supporting personalized and adaptive learning in higher education. This system deeply integrates with learning management systems (LMSs) using technologies such as natural language processing (NLP) and large language models. Its personalized learning services include dynamic learning resource generation, adaptive learning paths, immediate real-time feedback and assessment, and emotional support, thereby achieving a highly personalized learning experience.
Regarding learning resource recommendation via knowledge graphs, Ma et al. [
29] proposed a new method for recommending learning resources through a knowledge graph and learning-style clustering. In this method, a knowledge graph is constructed based on a general ontology model, and graph embedding algorithms and graph matching processes are applied to optimize the efficiency of graph computation in order to identify similar learning resources. Wang et al. [
30] introduced a learning resource recommendation model based on a Collaborative Knowledge Graph Attention Network (CKALR). This model constructs knowledge graphs using the attributes of teaching resources, naturally integrating the explicit collaborative signals between learners and learning resources with the auxiliary knowledge in the graph. An attention mechanism is employed to accurately capture the implicit personal preferences inherent in learners’ past interaction information, further enriching the feature representation of both learners and learning resources. Niu et al. [
31] employed a recommendation algorithm that combines knowledge graphs and collaborative filtering. They collected and modeled implicit data from online courses and compared the impact of video and text learning resources on user learning needs with different weights in order to gain deeper insights into the differing contributions of video and text learning resources in meeting learning needs. Dong et al. [
32] proposed the MkEGC framework for learning resource recommendation, treating the recommendation process as a Markov decision process. They constructed a dual-knowledge graph convolutional network that operates in both the learning resource knowledge and learner knowledge domains. Hierarchical and attention weighting strategies were designed to effectively extract latent hierarchical information from the knowledge graphs.
Despite the progress made since the introduction of knowledge-graph-based recommendation systems in personalized learning, two pressing issues remain in the realm of personalized learning resource recommendation: (1) Much of the research has focused on the representation of learning resources while neglecting the representation of learners. (2) The strategies for aggregating multi-source heterogeneous information tend to be overly simplistic and can result in information loss and the failure to differentiate the significance of various neighboring entities. Our work differs from existing studies by proposing a novel, end-to-end, personalized learning resource recommendation model called LKGA. This model simultaneously attends to user collaborative signals and learning resource collaborative signals, providing a more comprehensive representation of the original entity sets of learners and learning resources. The natural combination of collaborative propagation between learners and learning resources with knowledge graph propagation aids in embedding representations. Furthermore, while some studies utilize relatively simple attention mechanisms and do not fully consider the diversity among various types of information, our model effectively leverages the attention mechanism to distinguish the semantic differences of tail entities. Adding initial connections during the aggregation process effectively reduces information loss. This approach highlights the important role of key neighbors and can further enhance the effective representation capability of learners, allowing for deeper expression of the latent meanings of learners in the vector space.
3. Materials and Methods
Now, we introduce the proposed LKGA model framework in detail. As shown in
Figure 1, LKGA mainly consists of four components: firstly, the collaborative propagation layer, which propagates collaborative information through interactions between learners and learning resources; secondly, the knowledge graph propagation layer, which disseminates information through the knowledge graph; thirdly, the knowledge-aware embedding layer, which utilizes an attention mechanism to learn knowledge-based weights within the same set of entities and generates weighted representations of the entities; and finally, the prediction layer, which includes a novel aggregation method to aggregate representations of learners and learning resources from different propagation layers and outputs the predicted click-through rate.
We assume a scenario of intelligent educational recommendation where there are a set of M learners and a set of N learning resources . Based on the implicit feedback of learners in their historical records, we can obtain a learner–resource interaction matrix, , where indicates that the learner has interacted with the learning resource , and otherwise, . Additionally, we organize auxiliary information into a knowledge graph, , where each knowledge triplet, , represents a relationship, , existing between the head entity and the tail entity , with and being the sets of entities and relationships in the knowledge graph. Our goal is to learn a prediction function, , where represents the predicted probability and denotes the model parameters of the function .
3.1. Collaborative Propagation Layer
Firstly, we extract the learning resources that directly interact with the learners from the interaction graph between learners and learning resources.
Afterwards, we continue to explore higher-order collaborative signals among learners’ interactions. We believe that if two learners are connected through an auxiliary node, it indicates that there is also an indirect relationship between them. That is to say that learners who have interacted with the same learning resources as the target learner share similarities, and the learning resources they have interacted with can be considered higher-order collaborative information for the target learner. The specific formula is as follows:
and
represent learners similar to the target learner and the learning resources they have interacted with, respectively. We include the learning resources interacted with by learners similar to the target learner as part of the initial set for the target learner. Therefore, the final initial set for the learner is represented as
Here, “+” represents the merging operation. Then, after entity alignment,
, these learning resources are aligned with the knowledge graph, which can be represented as follows:
Similarly, we believe that learners who interact with the same learning resource also contribute to the feature representation of the learning resource due to their similar behavioral preferences. Therefore, we consider other learning resources interacted with by the same learner collaborative signals for recommending learning resources, and the formula is represented as follows:
Combining the collaborative information set and the alignment set of learning resources, the initial set of learning resources is represented as
As shown in
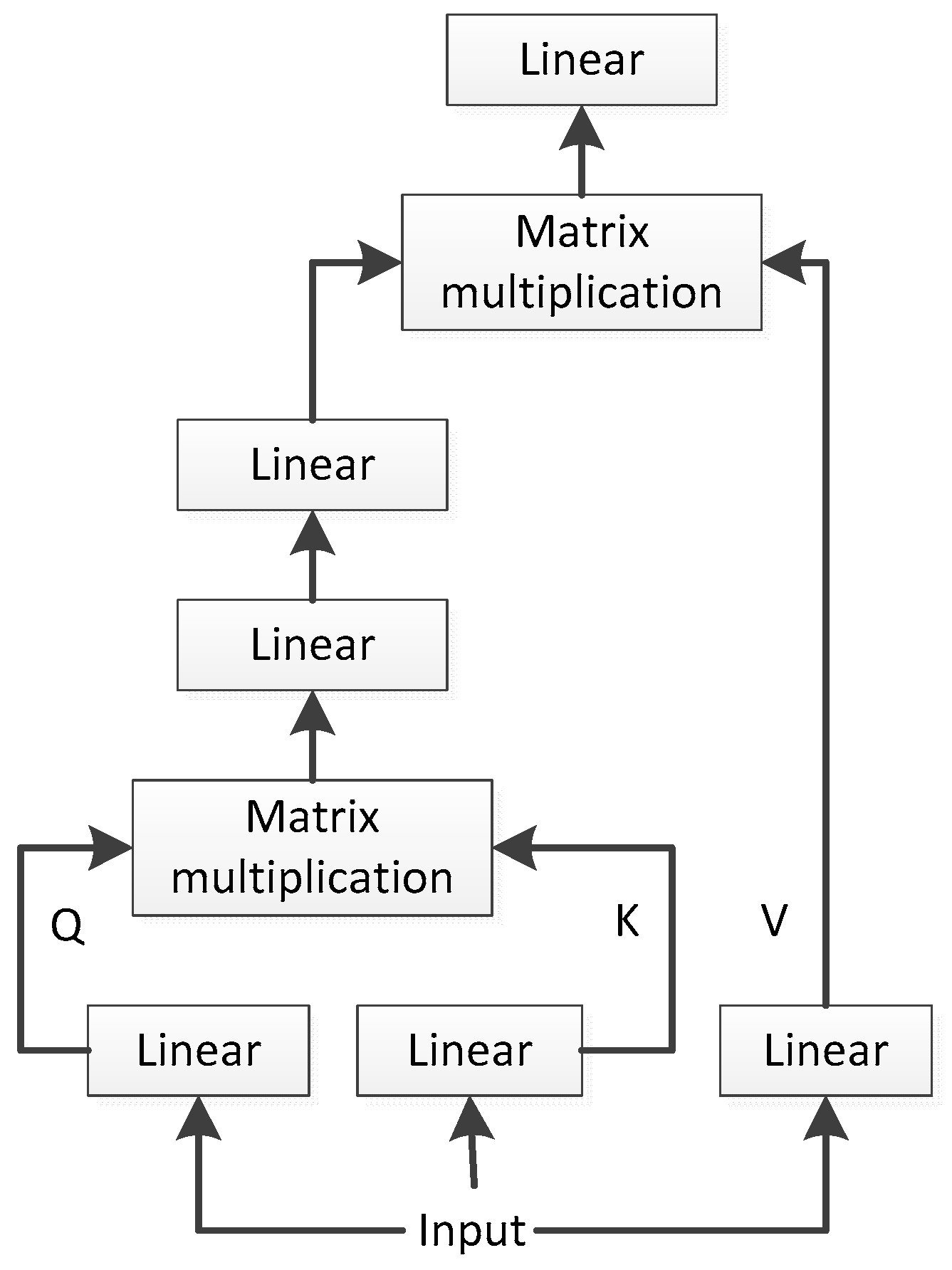
Figure 2, the multi-head attention mechanism allows the model to concurrently focus on different parts of the input across multiple subspaces. This enables the model to simultaneously capture various features and relationships. By concatenating or averaging the outputs of multiple attention heads, the multi-head attention mechanism can represent the input information more richly, thereby enhancing the model’s expressive capability. The multi-head attention mechanism can identify complex relationships and patterns within the input data, as each attention head can focus on different features or information. In tasks such as natural language processing and computer vision, models that utilize the multi-head attention mechanism typically perform better than those using a single attention head, leading to overall performance improvements. By attending to different parts of the input, the multi-head attention mechanism can more comprehensively utilize the input information, thus reducing information loss and enhancing the model’s robustness. In summary, the multi-head attention mechanism enhances LKGA’s flexibility and expressive power through parallel processing and diversified attention, leading to superior performance in complex tasks.
3.2. Knowledge Graph Propagation Layer
In a knowledge graph, entities are connected through relationships, and by propagating knowledge along the connections in the graph, we can obtain expanded entity sets and triples, which effectively enhance the latent representations of learners and learning resources. The entity sets for learners,
, and learning resources,
, are recursively defined as
where
represents the distance from the initial entity set, and the subscript notation
is a unified placeholder for either the learner
or learning resource
. Given the definition of the entity set, we define the set of triples in the
-th layer for the learner
and learning resource
as follows:
The construction of the LKGA model using knowledge graphs as auxiliary information is of great significance because neighboring entities can be regarded as intuitive extensions of learner preferences and learning resource characteristics. Through deep propagation based on knowledge graphs, high-order information about the interaction between learners and learning resources based on the knowledge graph can be captured, thereby effectively enhancing the model’s ability to represent learners and learning resources using latent vectors. By simultaneously focusing on user collaborative signals and learning resource collaborative signals, we provide a more comprehensive representation of the original entity sets for learners and learning resources. The natural combination of collaborative propagation between learners and learning resources with knowledge graph propagation aids in embedding representations. Our approach employs a careful design to filter the entities being propagated based on collaborative signals in contrast to the indiscriminate propagation of knowledge graphs found in existing research.
3.3. Knowledge-Aware Embedding Layer
We propose an attention mechanism that integrates entity and relation information, generating attention weights for tail entities while considering the semantic associations among the head, relation, and tail entities, to account for the different meanings of tail entities when they have different semantic associations.
denotes the
-th triple in the
-th layer of triples, and the attention embedding of the tail entity is represented as follows:
where
,
, and
represent the representations of the head entity, relation entity, and tail entity of the
-th tuple, respectively.
denotes the attention weight, which we implement through a neural network similar to the attention mechanism, with the following formula:
where
is a nonlinear activation function, and
is the final activation function,
.
denotes the concatenation operation, and
,
, and
as well as
,
, and
are all trainable weights and biases. Finally, the function
normalizes the weights:
Ultimately, the set of triples in the
-th layer for a learner or learning resource can be represented as
The subscript
is a placeholder for either a learner or a learning resource.
represents the number of triples in the set
. The entities in the initial set have strong associations with the original learner and learning resource and best reflect the learner’s preferences and the description of the learning resource. The initial entity sets for learners and learning resources are represented as follows:
The learning resource
has related entities in its original representation, which are the nodes closest to the learning resource itself in the latent semantic space. We represent them as
We know that information tends to decay during transmission. We augment the representation of each layer’s output for the learner with the initial set to ensure that the final embedding retains a portion of its initial embedding and supplements the subtle differences between the input and output. After the knowledge-aware attention embedding, we obtain the attention-weighted representations of the learner and the learning resource:
3.4. Prediction Layer
The representation in each layer can be interpreted as hierarchical latent influences that emphasize different high-order connections and preference similarities. By emphasizing different high-order connections and preference similarities, we implement three types of aggregation operations to aggregate the multiple representations in Formulas (17) and (18) into a single vector for the representation of learners and learning resources.
3.4.1. Sum Aggregation
Sum aggregation involves concentrating the sum of multiple vectors as an input, followed by a nonlinear transformation.
where
is the nonlinear transformation function, and
and
are the weights and biases trained by the model. We use the same notation and nonlinear transformation function for the remaining two aggregators.
3.4.2. Pooling Aggregation
Pooling aggregation is similar to the pooling operation in convolutional neural networks, where the maximum value among multiple vectors is taken, followed by a nonlinear transformation:
3.4.3. Concatenation Aggregation
Concatenation aggregation concatenates the vector representations in a set into a single vector representation and then applies a nonlinear transformation to it. The specific operation is as follows:
where
, and
denotes the concatenation operation.
Since the aggregated vector representations of the learner and the learning resource require the same dimensions for further computation, we select a balanced combination of multiple representations for the aggregator. We use
to denote the aggregated vector of the learner and
to denote the aggregated vector of the learning resource. Finally, we compute the inner product of the representations to predict the learner’s preference score for the learning resource.
3.5. Loss Function
We extract the same number of negative samples as positive samples for each learner to balance the number of positive and negative samples and ensure the training effect of the model. Finally, we have the following loss function for the LKGA model:
where
is the cross-entropy loss,
denotes the set of positive learner–learning resource pairs, and
denotes the opposite (i.e., the set of negative pairs).
is the parameter set of the model, and
and
are the embedding tables for all entities and relations, respectively.
is the L2 regularization function adjusted by the parameter
.
4. Experiment and Result Analysis
4.1. Dataset and Evaluation Metrics
We used the Book-Crossing dataset to test the effectiveness of our proposed model. This dataset includes nearly 1.15 million books and 139,746 book rating data (ranging from 0 to 10) in the Book-Crossing community, with a sparsity of 0.9994.
Table 1 shows the statistics of the dataset. In the experimental scenario of click-through rate prediction, we used the model trained on the training set to predict the probability of each interaction in the test set. In this study, we used the AUC and F1 metrics to evaluate our model, with higher values indicating better performance. Books are an extremely important learning resource, playing a significant role in education, culture, psychology, and social interaction. They are a valuable resource of human wisdom and experience. The learning of specialized books often has a prerequisite relationship; for example, one must have a foundational understanding of programming languages before studying books on data structures. This kind of prerequisite relationship also exists in recommendations for topics like news and e-commerce, which have certain discrepancies.
4.2. Comparison Models
To validate the effectiveness of the proposed LKGA, we compared it with four types of recommendation methods—the collaborative-filtering-based method (BPRMF [
33]), the embedding-based method (CKE [
14]), the path-based method (PER [
16]), and propagation-based methods (RippleNet [
5], KGNN-LS [
18], KGAT [
6], CKAN [
7], KGIN [
34], CAKR [
35], KGG [
36], KCNR [
37], KGIE [
38])—described below:
BPRMF [
33] is a classic CF method that utilizes pairwise matrix factorization for implicit feedback and is optimized using the Bayesian Personalized Ranking loss.
CKE [
14] is a representative embedding-based model that integrates collaborative filtering modules with structural, textual, and visual knowledge embeddings of items into a unified Bayesian framework.
PER [
16] is a typical path-based method that treats collaborative filtering as a heterogeneous information network and extracts latent features based on meta-paths to represent connections between users and items along different types of relational paths.
RippleNet [
5] is an advanced propagation-based model that employs a memory-like network and propagates users’ latent preferences in the KG to enrich user representations.
KGNN-LS [
18] is a method that applies a trainable function to compute user-specific item embeddings. It then utilizes a graph neural network to generate personalized item embeddings. Additionally, label smoothing is employed to regularize the edge weights, thereby enhancing the inductive bias.
KGAT [
6] is also an advanced propagation-based model that integrates a UIG and KG into a homogeneous unified graph called a CKG. Compared to KGCN, KGAT utilizes an attention mechanism to distinguish the importance of neighbors in the CKG during the propagation process.
CKAN [
7] is an advanced propagation-based model that utilizes a heterogeneous propagation strategy to explicitly encode these two types of information and applies a knowledge-aware attention mechanism to distinguish the contributions of different knowledge neighbors.
KGIN [
34] is proposed to explore the intentions behind user–item interactions using auxiliary item knowledge. Each intent is modeled as a careful combination of KG relationships, encouraging the independence of different intents to achieve better model capability and interpretability. A new information aggregation scheme is designed for the GNN, which recursively integrates sequences of relationships with long-range connectivity.
CAKR [
35] is a new method that optimizes feature interaction between items and their corresponding entities in the knowledge graph and includes a feature crossover unit incorporating an attention mechanism to enhance the recommendation performance.
KGG [
36] is a recommendation method that combines users’ local interest features and global interest features, efficiently exploring users’ preference levels toward target users by learning users’ local and global interest features through a knowledge graph convolutional neural network and a generative adversarial network.
KCNR [
37] is a knowledge-aware enhanced network for domain-informed recommendation, which acquires different knowledge neighbors by propagating within the knowledge graph and utilizes a knowledge-aware attention network to distinguish and aggregate the contributions of different neighbors in the knowledge graph, thereby enriching user profiles. The information complementarity module automatically shares potential interactive features between items and entities, achieving information complementarity between items and entities.
KGIE [
38] is a novel graph neural network recommendation model based on interactive embeddings, which utilizes the knowledge graph and user–item interaction matrix to extract latent information, improves the aggregation method, and optimizes overall performance. The interactive embeddings are merged with users through a convolutional neural network and independently participate in the aggregation of domain information, providing more contextual information for recommendations.
4.3. Experimental Setup
This experiment was conducted on a Windows operating system using the PyCharm Community Edition 2022 integrated development environment, with Python 3.7 as the programming language. Libraries such as torch 1.10.0, torchvision 0.11.0, and numpy 1.19.5 were utilized. The hardware environment consisted of a 24-core Intel Core i9-10920X CPU @ 3.5 GHz (Intel, Santa Clara, CA, USA), an NVIDIA GeForce RTX 3090 Ti, 64 GB of RAM, a 1 TB solid-state drive, and a 4 TB hard disk drive (Nvidia, Santa Clara, CA, USA). In terms of dataset division, we split the dataset into a 6:2:2 ratio (training set–validation set–test set). We adjusted the parameters based on baseline models and existing experience. We meticulously tuned parameters such as the number of iterations, batch size, number of propagation layers, learning rate, L2 weight, hidden-layer dimensions, user triplet size, book triplet size, and information aggregation method. Xavier initialization was used for model parameters, and ADAM was employed as the optimizer. The number of epochs was set to 10, and the batch size was set to 1024. Our learning rate and L2 regularization coefficient were set to 0.002 and 10−5, respectively, and the embedding dimension was set to 64.
4.4. Performance Comparison
Table 2 presents the AUC and F1 values for each model. Through performance comparison analysis, we can see that our method achieved the best performance on the Book-Crossing dataset in terms of the evaluated metrics.
The path-based methods performed the worst in experiments on the Book-Crossing dataset, even worse than the classic collaborative filtering method, BPRMF, indicating that the experimental results of path-based methods were heavily dependent on the choice of paths.
The propagation-based method combines the semantic representations of entities and relationships with path connectivity, and its effectiveness is superior to the first two methods. Experimental data showed that RippleNet improved the AUC metric by 10.1% compared to PER.
KGAT captures the differential importance of different neighbor nodes during the propagation process through an attention mechanism, which positively contributes to improving the performance of knowledge graph representation learning models. Its results showed an improvement of 0.6% and 0.4% in the AUC and F1 metrics, respectively, compared to RippleNet. This indicates that the attention mechanism could effectively identify important neighbor nodes and assign more flexible weight distributions, thereby better mining the hidden semantic information in the knowledge graph.
Although RippleNet, KGNN-LS, KGAT, CKAN, KGIN, CAKR, KGG, KCNR, KGIE, and LKGA are all propagation-based recommendation methods, their performance on the Book-Crossing dataset varied significantly. This is primarily due to the unique characteristics of different datasets. During the process of information propagation, while useful information is obtained, noise is also introduced. Finding a balance between acquiring useful information and reducing noise is a direction for the continuous optimization of models. It is difficult to find a propagation-based method that performs well across all datasets, which also serves as the starting point for our ongoing research into personalized learning resource recommendation models based on knowledge graphs.
CKAN, CAKR, and our model all involve attention mechanisms to varying degrees to improve the performance of the models in tasks such as recommendation. The CAKR model focuses on information sharing between items and their corresponding entities. Compared to KGAT, the model’s performance is improved to some extent, indicating that enhancing user and item representations is crucial for recommendation tasks.
Our model fully leveraged collaborative signals to learn rich representations of books and learners and utilized initial connections to ensure information decay during the propagation process. This demonstrated that combining collaborative signals in the user–item interaction graph with auxiliary information in the knowledge graph was key to improving recommendation performance.
4.5. Ablation Study
To verify the significant contributions of the main components in our model, we compared our model with the following variants:
First, we created a variant, LKGA
w/
o learner, without collaborative signals from learners, in which we removed the collaborative signals from learners and only used the books that learners directly interacted with as the initial set of entities. Second, we removed the initial connections to create
; in this variant, we removed the initial connections in the embedding generation of each layer. The experimental results are shown in
Figure 3, from which we can draw the following conclusions.
- (1)
Compared to our model, removing the collaborative signals from learners led to a decrease in model performance. This fact demonstrates that relying solely on the direct interaction information of learners limited the model’s effectiveness, and introducing collaborative signals served as a supplementary means to help the model capture learners’ interests and preferences.
- (2)
Removing initial connections resulted in poorer performance, as each layer introduced a certain degree of loss and distortion to the input information, leading to a gradual decrease in the richness and effectiveness of the original information. Retaining the original information through initial connections effectively mitigated information loss.
- (3)
We can observe that the impact of removing collaborative signals was greater than that of removing initial connections, which also proves that the selection of initial entities had a significant impact on model performance. When the selection of initial entities could represent learners’ preferences as much as possible, even without initial connections, good results could be achieved with reasonable parameter settings.
In summary, collaborative representation learning provided an effective way to model high-order connectivity relationships between learners and books, enabling the model to more accurately depict learner preferences and book characteristics. This refined representation learning is key to improving recommendation performance and helps build more intelligent and personalized recommendation systems.
Furthermore, considering the potential impact of irrelevant entities on model performance, we introduced an attention mechanism that dynamically adjusted the importance of different neighboring entities, effectively avoiding the interference of irrelevant information.
4.6. Impact of Hyperparameters
4.6.1. The Impact of Embedding Dimensions
We investigated the effect of different embedding dimensions on the model’s recommendation performance. For computational convenience, we used the same embedding dimension for both entities and relations.
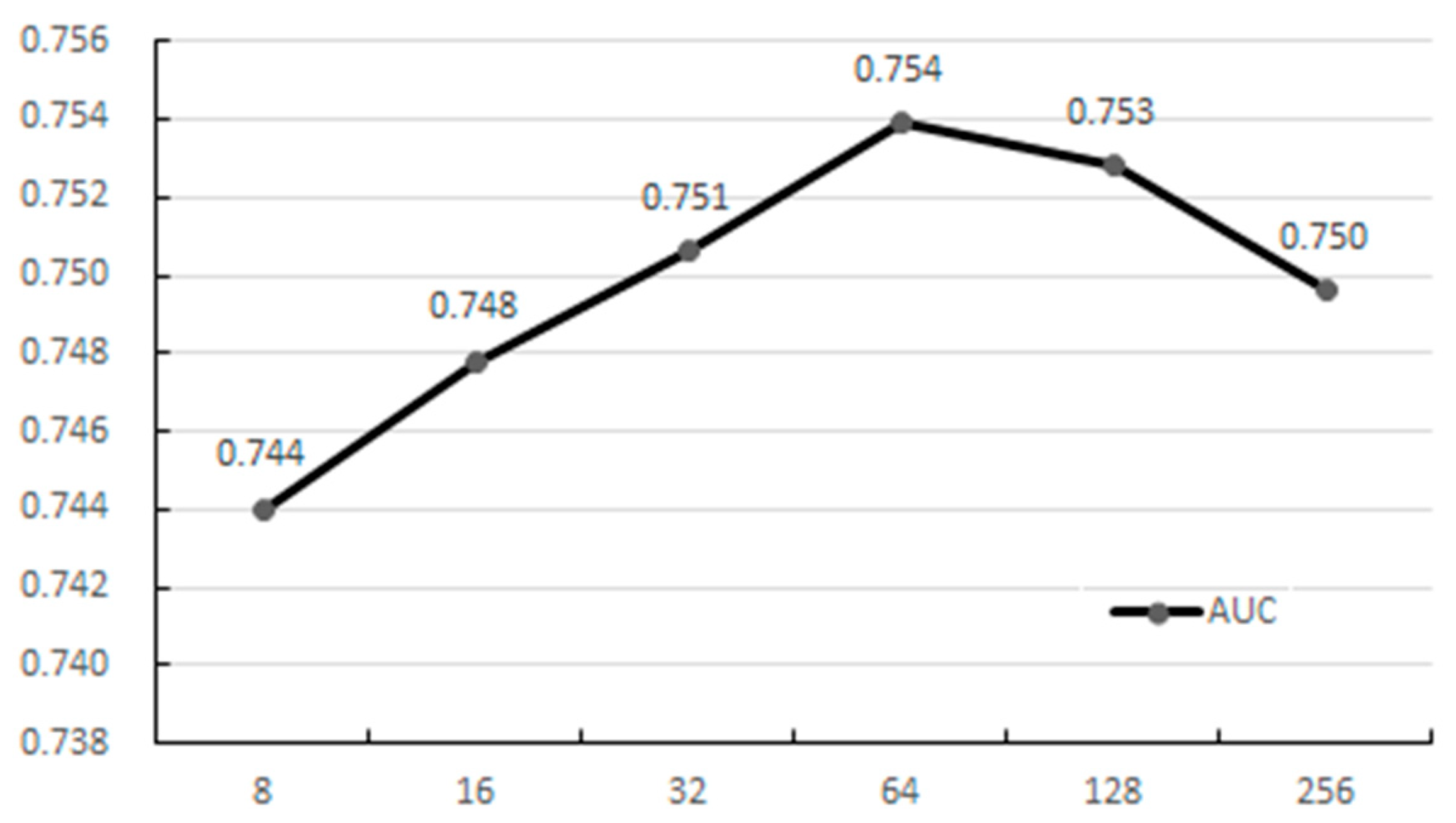
Figure 4 presents a comparison of the effects using different embedding dimensions. We can observe that increasing the embedding dimension within a certain range improved the model’s recommendation performance, but when the dimension was increased to 128, the performance started to decline. The main reason for this phenomenon was the trade-off between positive and negative information. Although increasing the number of layers provided more auxiliary information, which was beneficial for mining deeper semantic connections between entities, it also introduced more noise. When the amount of noise exceeded that of the auxiliary information, the model’s performance deteriorated.
4.6.2. The Impact of Model Depth
The depth of the model represents the maximum number of layers for knowledge propagation. We set the range of layers, D, to {1, 2, 3, 4} to explore the changes in model metrics. To better distinguish the subtle variations in metrics among different layer settings, we used four decimal places for precision. In
Table 3, we present a comparison of the effects of different layer settings on the performance of the dataset. It can be observed that the best results were achieved when D = 3, and further, stacking more layers led to worse performance. The main reason for this phenomenon was the trade-off between positive and negative information. Although increasing the number of layers provided more auxiliary information, which was beneficial for mining deeper semantic connections between entities, it also introduced more noise. When the amount of noise exceeded that of the auxiliary information, the model’s performance declined.
5. Discussion
The introduction of advanced knowledge graphs in learning resource recommendation systems significantly enhances the accuracy and personalization of recommendations. Traditional recommendation systems [
14,
16,
33] primarily rely on collaborative filtering and content-based filtering methods; however, these approaches often face issues of data sparsity and cold starts. Knowledge graphs integrate structured and unstructured data to construct a rich semantic relationship network, which better captures the potential connections between learning resources and the knowledge background of learners. This not only improves the precision of recommendations but also provides effective resource suggestions during the early stages of a learner’s journey, thereby alleviating cold start problems. Through knowledge graphs, we can offer highly personalized resource recommendations for different learners. For instance, if a learner already possesses a high level of knowledge in a particular domain, the system can recommend more advanced learning resources; conversely, for beginners, the system can suggest foundational introductory resources. This personalized recommendation not only enhances learners’ learning efficiency but also enriches their learning experience and satisfaction.
In this paper, we propose a novel knowledge-graph-based personalized learning resource recommendation model. By extracting collaborative signals from users, we treat the learning resources clicked by learners who have clicked the same resource as potential collaborative signals, concatenating them with the original features of the learning resources to form the learner’s original entity set. Secondly, during the entity aggregation process, each tail entity has a different semantic representation, and we use an attention mechanism to differentiate the importance of different neighboring entities. Finally, we incorporate residual connections in each hop of the learner’s aggregation, adding information from the first hop to ensure that no information is lost. Our experimental results show that the knowledge-graph-based recommendation system outperforms traditional methods [
36,
37,
38] in terms of both accuracy and user satisfaction.
Intelligent tutoring systems and other educational agents have garnered widespread attention in the field of education, as they can provide personalized services to learners [
1]. Learning resource recommendation, particularly knowledge-graph-based learning resource recommendation, has led to continuous research progress as an important component of intelligent tutoring systems. Another significant advantage of knowledge graphs is their interpretability. Traditional recommendation systems often operate as “black boxes”, making it difficult for users to understand the basis of the recommendations. In contrast, knowledge graphs can clearly demonstrate the relationships between learning resources and the logic behind the recommendations, helping learners understand the reasons for the system’s suggestions, thereby enhancing user trust in the system. This transparency is particularly important in the education sector, as it assists teachers and students in better planning their learning paths.
The LKGA model can be further expanded to various scenarios such as course recommendation, micro-course recommendation, paper recommendation, learning path recommendation, exercise recommendation, peer recommendation, teacher recommendation, and the integration of multiple personalized educational resources. It is necessary to construct knowledge graphs for different recommendation scenarios and utilize these knowledge graphs as auxiliary information to enhance the performance of recommendations. As an important module of intelligent tutoring systems, the intelligence of the recommendation system plays a crucial role in the personalization of these systems. This requires a deep understanding of educational resources and learners, which can be achieved by collecting vast amounts of data on learners and learning resources, allowing for a comprehensive understanding of the current learning status of learners in order to better serve them.
Although this study achieved certain results, like all propagation-based knowledge graph recommendation models, it also involved a fixed-size next hop during the knowledge propagation process, which may introduce noise. Further optimization by adopting dynamically sized neighbors could potentially improve the practical effectiveness of the recommendations. However, determining the appropriate number of dynamic neighbors is not straightforward and poses certain challenges for data processing. Typically, the knowledge propagation process does not exceed three hops, but it is reasonable to assume that there are auxiliary pieces of information that can be utilized beyond three hops. Exploring how to use multimodal data to address the information aggregation deficiencies caused by knowledge propagation is also a worthwhile area of research.






{kind=link}
{kind=link}
{kind=link}
{kind=link}