
Neighborhood Deviation Attack Against In-Context Learning

Abstract
1. Introduction
- We propose a text-only MIA method against ICL, revealing its inherent privacy risks. Our method combines neighbor sample generation and MIA techniques to achieve higher stability and accuracy.
- We conduct experiments on multiple datasets and LLMs, demonstrating the effectiveness of our approach in judging whether a specific sample belongs to the ICL example used by LLM.
- We conduct an extensive study on the factors that affect attack performance and analyze the possible causes of these effects. These influencing factors include the hyperparameters of the attack method and the structure of the attack model.
- We explore potential defense strategies to mitigate the privacy risks of LLM in ICL. These strategies include reducing the memory of LLM for ICL examples and limiting the deviation caused by the output.
2. Related Work
2.1. Membership Inference Attack Against Machine Learning
2.2. Membership Inference Attack Against Large Language Model
2.3. In-Context Learning
3. Preliminaries
3.1. Large Language Model
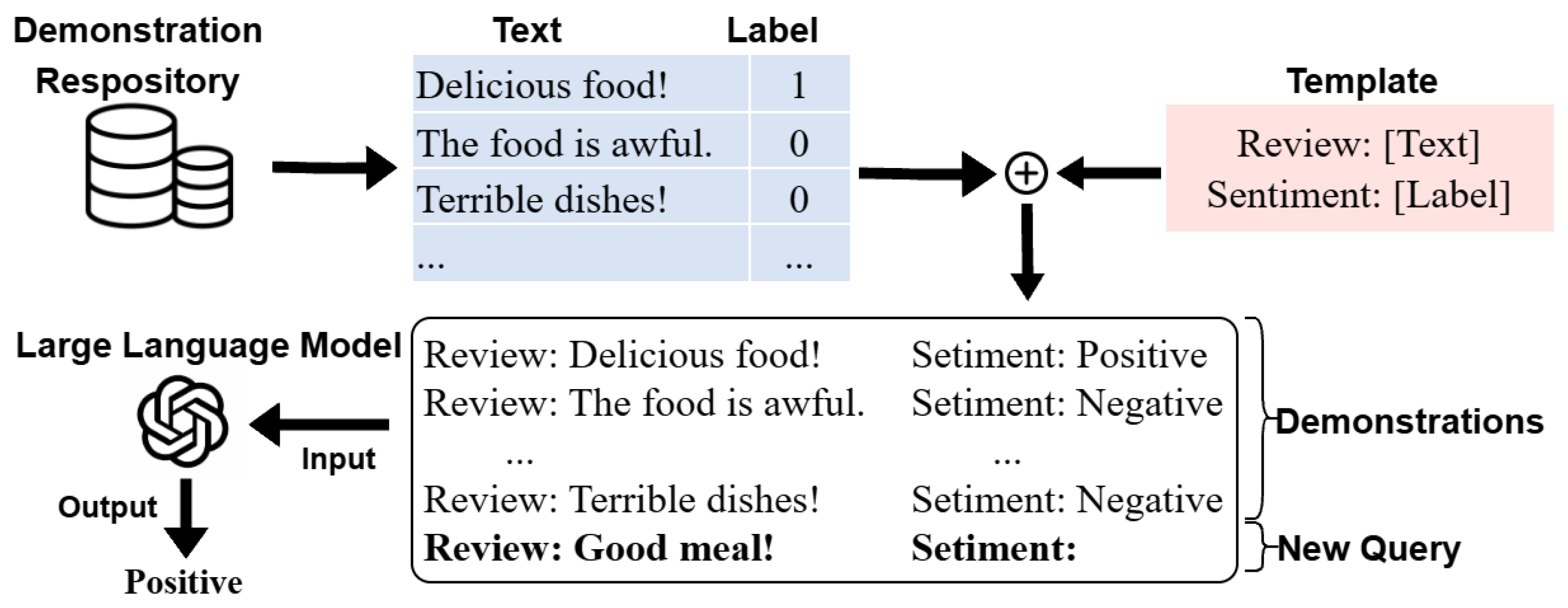
3.2. In-Context Learning
- “Review: Delicious food! Sentiment: Positive”.
- “Review: The food is awful. Sentiment: Negative”.
- “Review: Terrible dishes! Sentiment: Negative”.
3.3. Membership Inference Attack
4. Proposed Algorithm
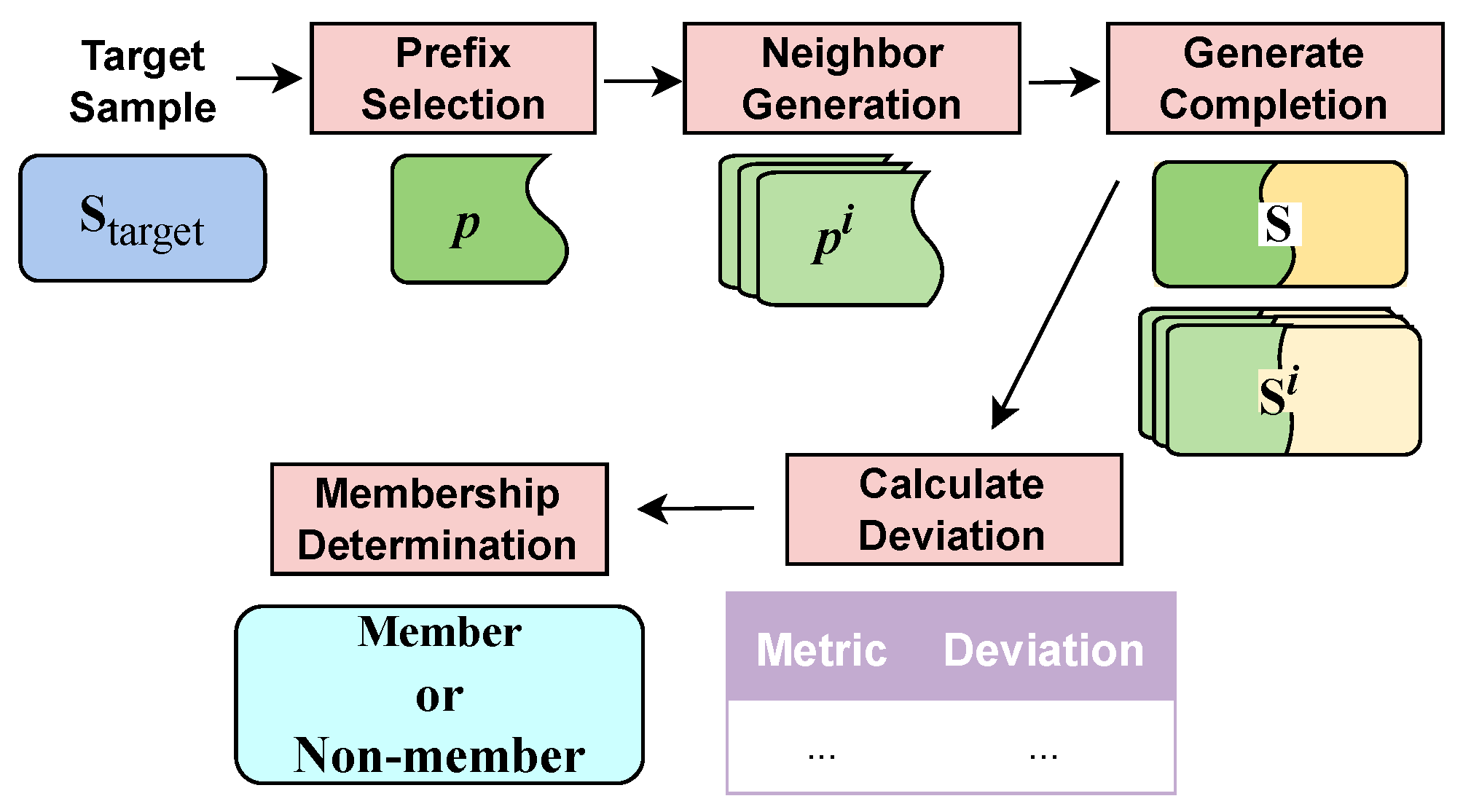
4.1. Method Overview
| Algorithm 1 Neighbor Deviation Attack. |
| Input: target sample , LLM , attack model , number of neighbors N, metric calculation function Output: Membership status (Member or Non-Member)
|
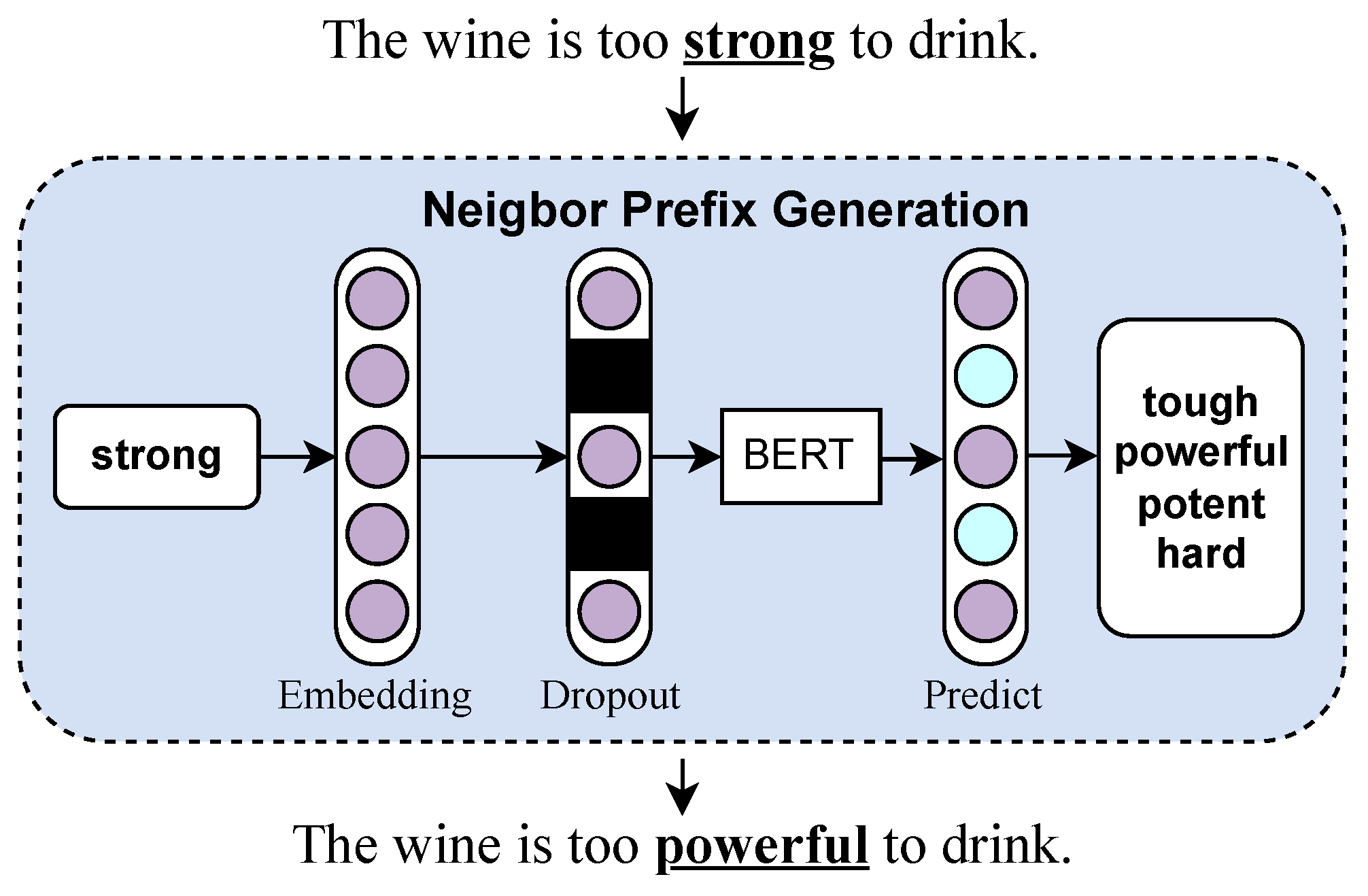
4.2. Neighbor Prefix Generation
4.3. Predictive Completion
4.4. Metric Deviation Calculation
4.5. Membership Determination
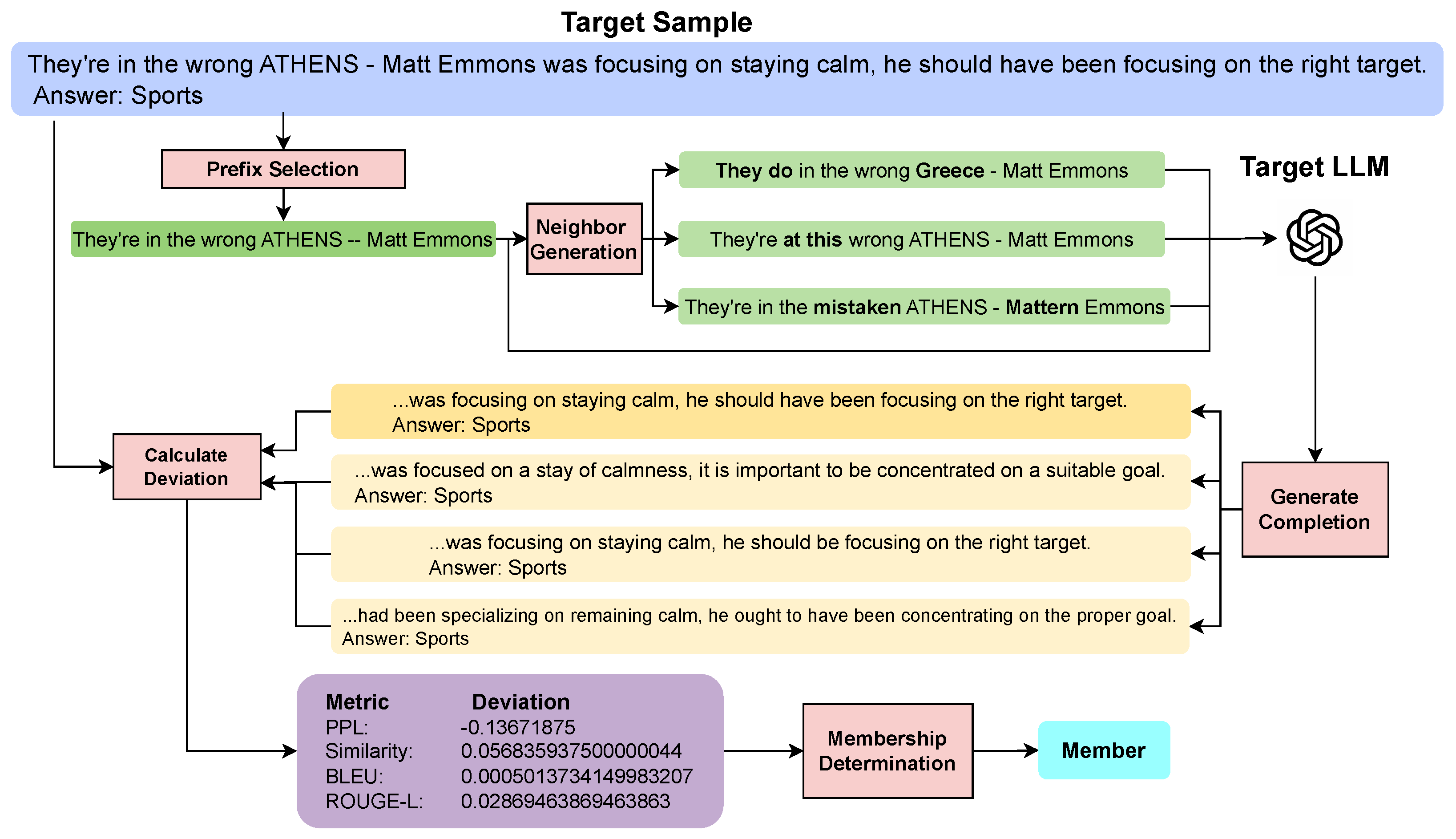
4.6. Workflow Example
5. Experiments
5.1. Experimental Basis
5.2. Evaluation Metrics
5.3. Comparative Methods
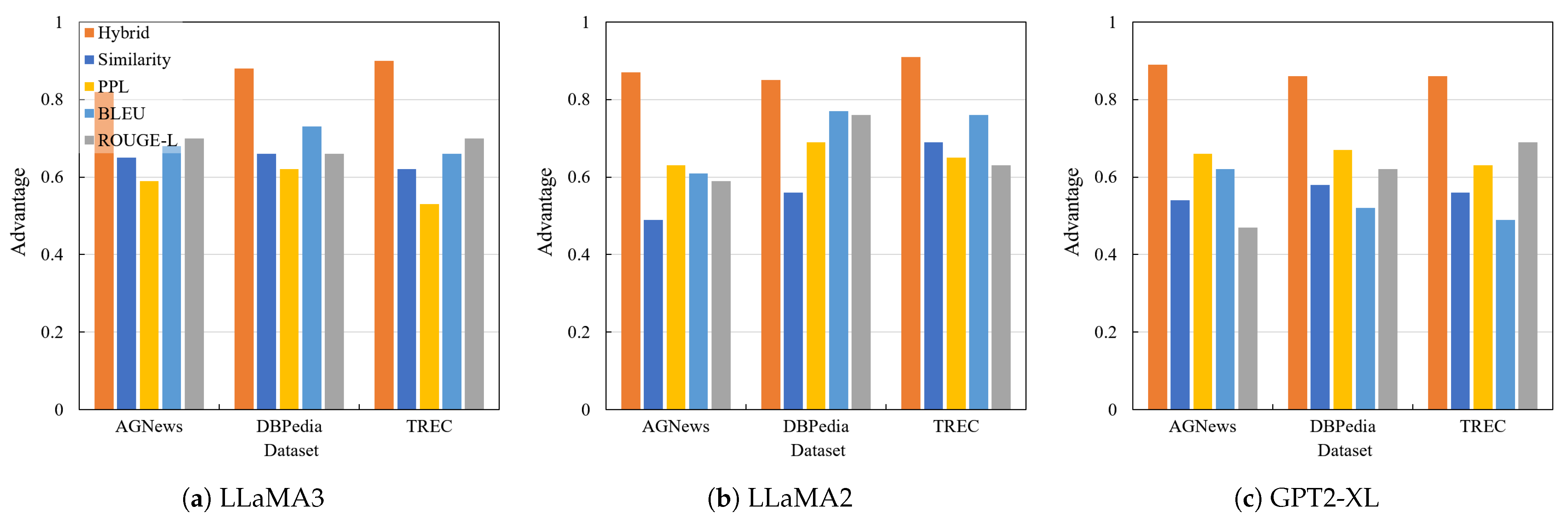
5.4. Results
5.5. Ablation Experiments
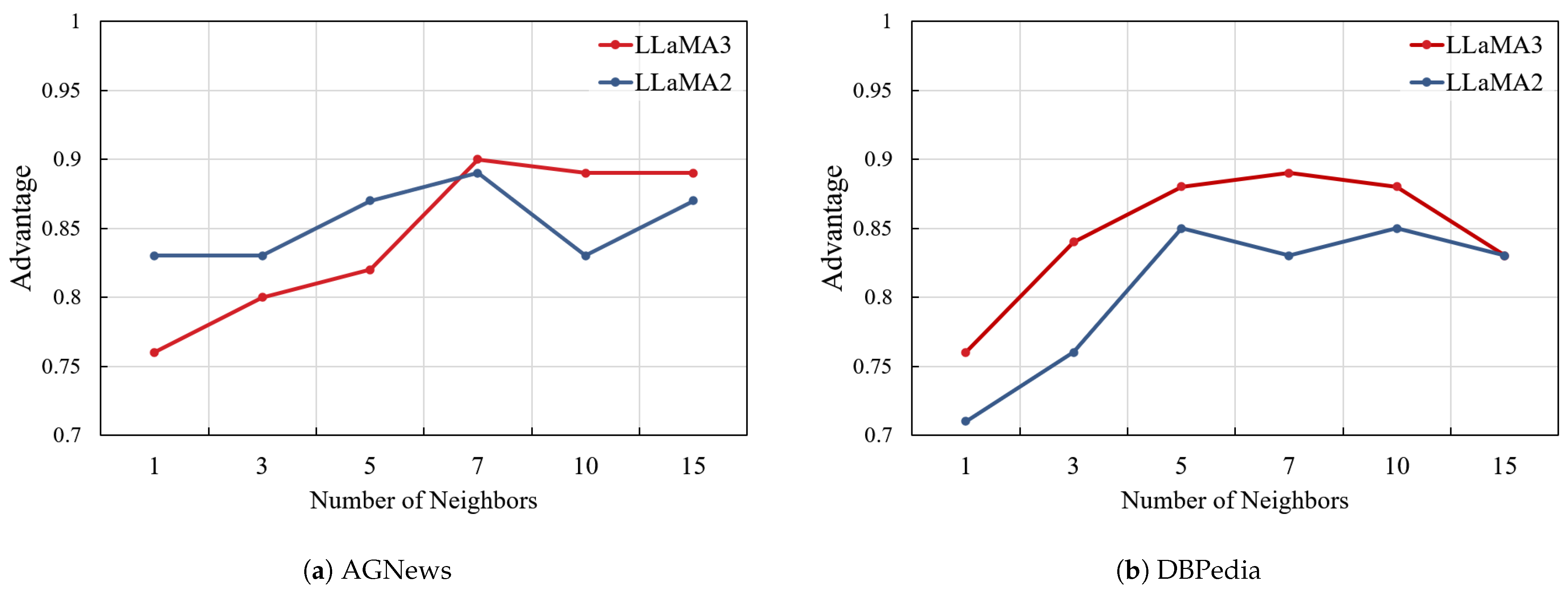
5.5.1. Number of Neighbors
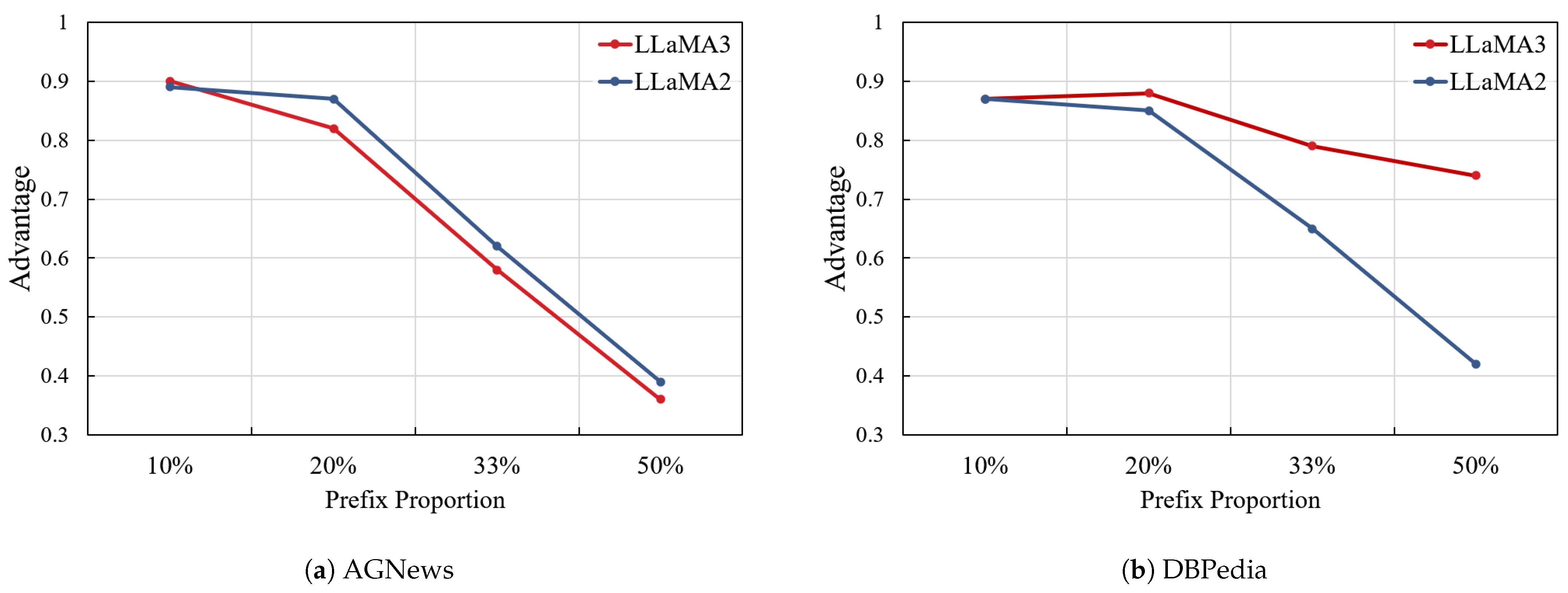
5.5.2. Prefix Proportion
5.5.3. Number of Replacement
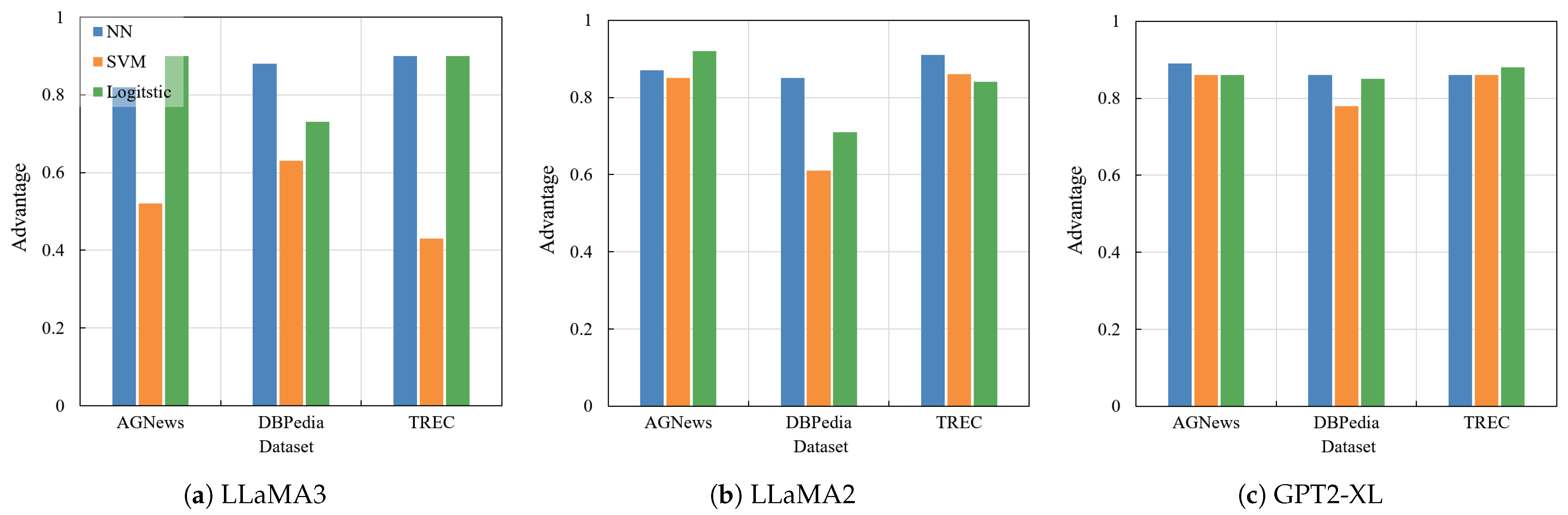
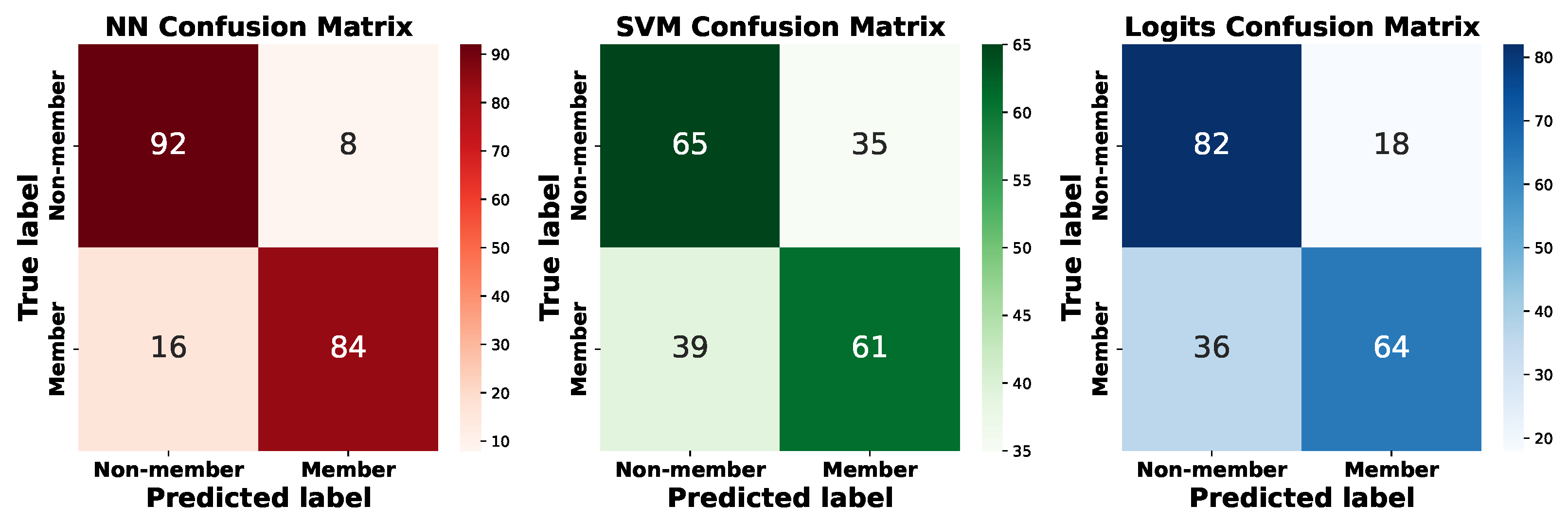
5.5.4. Attack Model
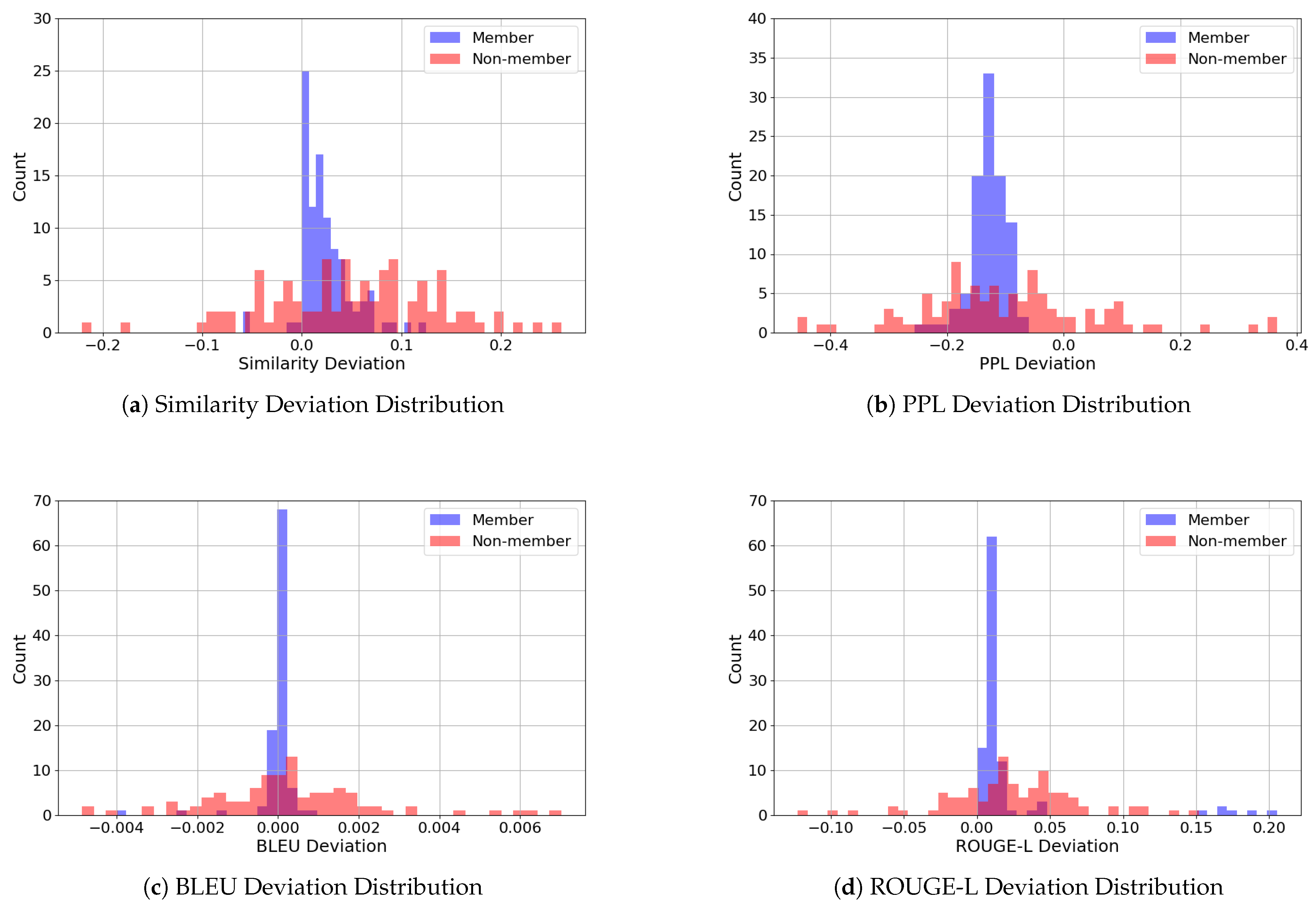
5.5.5. Distribution of Metric Deviation
6. Potential Defenses
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Hadi, M.U.; Al-Tashi, Q.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; et al. A survey on large language models: Applications, challenges, limitations, and practical usage. Authorea Prepr. 2023, 3. [Google Scholar] [CrossRef]
- Rao, A.; Kim, J.; Kamineni, M.; Pang, M.; Lie, W.; Succi, M.D. Evaluating ChatGPT as an adjunct for radiologic decision-making. medRxiv 2023. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Liu, X.Y.; Wang, G.; Yang, H.; Zha, D. FinGPT: Democratizing Internet-scale Data for Financial Large Language Models. In Proceedings of the NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, New Orleans, LA, USA, 15 December 2023. [Google Scholar]
- Wu, S.; Irsoy, O.; Lu, S.; Dabravolski, V.; Dredze, M.; Gehrmann, S.; Kambadur, P.; Rosenberg, D.; Mann, G. Bloomberggpt: A large language model for finance. arXiv 2023, arXiv:2303.17564. [Google Scholar]
- Wang, X.; Anwer, N.; Dai, Y.; Liu, A. ChatGPT for design, manufacturing, and education. Procedia CIRP 2023, 119, 7–14. [Google Scholar] [CrossRef]
- Fraiwan, M.; Khasawneh, N. A review of chatgpt applications in education, marketing, software engineering, and healthcare: Benefits, drawbacks, and research directions. arXiv 2023, arXiv:2305.00237. [Google Scholar]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Ma, J.; Li, R.; Xia, H.; Xu, J.; Wu, Z.; Liu, T.; et al. A survey on in-context learning. arXiv 2022, arXiv:2301.00234. [Google Scholar]
- Duan, H.; Dziedzic, A.; Yaghini, M.; Papernot, N.; Boenisch, F. On the privacy risk of in-context learning. arXiv 2024, arXiv:2411.10512. [Google Scholar]
- Ren, K.; Meng, Q.R.; Yan, S.K.; Qin, Z. Survey of artificial intelligence data security and privacy protection. Chin. J. Netw. Inf. Secur. 2021, 7, 1–10. [Google Scholar]
- Hu, H.; Salcic, Z.; Sun, L.; Dobbie, G.; Yu, P.S.; Zhang, X. Membership inference attacks on machine learning: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 235. [Google Scholar] [CrossRef]
- Huang, W.; Wang, Y.; Chen, C. Privacy Evaluation Benchmarks for NLP Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 2615–2636. [Google Scholar]
- Das, B.C.; Amini, M.H.; Wu, Y. Security and privacy challenges of large language models: A survey. ACM Comput. Surv. 2025, 57, 152. [Google Scholar] [CrossRef]
- Ko, M.; Jin, M.; Wang, C.; Jia, R. Practical membership inference attacks against large-scale multi-modal models: A pilot study. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 4871–4881. [Google Scholar]
- Fu, W.; Wang, H.; Gao, C.; Liu, G.; Li, Y.; Jiang, T. Practical membership inference attacks against fine-tuned large language models via self-prompt calibration. arXiv 2023, arXiv:2311.06062. [Google Scholar]
- Shi, W.; Ajith, A.; Xia, M.; Huang, Y.; Liu, D.; Blevins, T.; Chen, D.; Zettlemoyer, L. Detecting Pretraining Data from Large Language Models. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3–18. [Google Scholar]
- Rahimian, S.; Orekondy, T.; Fritz, M. Sampling Attacks: Amplification of Membership Inference Attacks by Repeated Queries. arXiv 2020, arXiv:2009.00395. [Google Scholar]
- Hayes, J.; Melis, L.; Danezis, G.; De Cristofaro, E. LOGAN: Membership Inference Attacks Against Generative Models. Proc. Priv. Enhancing Technol. 2019, 1, 133–152. [Google Scholar] [CrossRef]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 739–753. [Google Scholar]
- Wu, B.; Chen, C.; Zhao, S.; Chen, C.; Yao, Y.; Sun, G.; Wang, L.; Zhang, X.; Zhou, J. Characterizing membership privacy in stochastic gradient langevin dynamics. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6372–6379. [Google Scholar]
- Ye, J.; Maddi, A.; Murakonda, S.K.; Bindschaedler, V.; Shokri, R. Enhanced membership inference attacks against machine learning models. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 3093–3106. [Google Scholar]
- Ullah, N.; Aman, M.N.; Sikdar, B. meMIA: Multi-level Ensemble Membership Inference Attack. IEEE Trans. Artif. Intell. 2025, 6, 93–106. [Google Scholar] [CrossRef]
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Erlingsson, U.; et al. Extracting training data from large language models. In Proceedings of the 30th USENIX security symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021; pp. 2633–2650. [Google Scholar]
- Mireshghallah, F.; Goyal, K.; Uniyal, A.; Berg-Kirkpatrick, T.; Shokri, R. Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 8332–8347. [Google Scholar]
- Mattern, J.; Mireshghallah, F.; Jin, Z.; Schoelkopf, B.; Sachan, M.; Berg-Kirkpatrick, T. Membership Inference Attacks against Language Models via Neighbourhood Comparison. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Feng, Q.; Kasa, S.R.; Yun, H.; Teo, C.H.; Bodapati, S.B. Exposing privacy gaps: Membership inference attack on preference data for LLM alignment. arXiv 2024, arXiv:2407.06443. [Google Scholar]
- Xie, R.; Wang, J.; Huang, R.; Zhang, M.; Ge, R.; Pei, J.; Gong, N.; Dhingra, B. ReCaLL: Membership Inference via Relative Conditional Log-Likelihoods. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 8671–8689. [Google Scholar]
- Wang, Z.; Liu, G.; Yang, Y.; Wang, C. Membership Inference Attack against Long-Context Large Language Models. arXiv 2024, arXiv:2411.11424. [Google Scholar]
- Wen, R.; Li, Z.; Backes, M.; Zhang, Y. Membership inference attacks against in-context learning. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, Salt Lake City, UT, USA, 14–18 October 2024; pp. 3481–3495. [Google Scholar]
- Truex, S.; Liu, L.; Gursoy, M.E.; Yu, L.; Wei, W. Demystifying membership inference attacks in machine learning as a service. IEEE Trans. Serv. Comput. 2019, 14, 2073–2089. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Sun, T.; Shao, Y.; Qian, H.; Huang, X.; Qiu, X. Black-box tuning for language-model-as-a-service. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 20841–20855. [Google Scholar]
- Mo, Y.; Liu, J.; Yang, J.; Wang, Q.; Zhang, S.; Wang, J.; Li, Z. C-ICL: Contrastive in-context learning for information extraction. arXiv 2024, arXiv:2402.11254. [Google Scholar]
- Zhang, K.; Lv, A.; Chen, Y.; Ha, H.; Xu, T.; Yan, R. Batch-ICL: Effective, Efficient, and Order-Agnostic In-Context Learning. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 10728–10739. [Google Scholar]
- Jiang, G.; Ding, Z.; Shi, Y.; Yang, D. P-ICL: Point in-context learning for named entity recognition with large language models. arXiv 2024, arXiv:2405.04960. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent abilities of large language models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 11048–11064. [Google Scholar]
- Zhou, W.; Ge, T.; Xu, K.; Wei, F.; Zhou, M. BERT-based lexical substitution. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3368–3373. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28. [Google Scholar]
- Li, X.; Roth, D. Learning question classifiers. In Proceedings of the COLING 2002: The 19th International Conference on Computational Linguistics, Taipei, Taiwan, 26 August–30 August 2002. [Google Scholar]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Nguyen, D.; Luo, W.; Vo, B.; Nguyen, L.T.; Pedrycz, W. Con2Vec: Learning embedding representations for contrast sets. Knowl.-Based Syst. 2021, 229, 107382. [Google Scholar] [CrossRef]
- Ni, J.; Abrego, G.H.; Constant, N.; Ma, J.; Hall, K.; Cer, D.; Yang, Y. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. In Findings of the Association for Computational Linguistics: ACL 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Martin, J.H.; Jurafsky, D. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Pearson/Prentice Hall: Upper Saddle River, NJ, USA, 2009; Volume 23. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Yeom, S.; Giacomelli, I.; Fredrikson, M.; Jha, S. Privacy risk in machine learning: Analyzing the connection to overfitting. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 268–282. [Google Scholar]
- Liu, N.F.; Lin, K.; Hewitt, J.; Paranjape, A.; Bevilacqua, M.; Petroni, F.; Liang, P. Lost in the Middle: How Language Models Use Long Contexts. Trans. Assoc. Comput. Linguist. 2024, 12, 157–173. [Google Scholar] [CrossRef]
- Freitag, M.; Al-Onaizan, Y. Beam Search Strategies for Neural Machine Translation. arXiv 2017, arXiv:1702.01806. [Google Scholar] [CrossRef]
- Holtzman, A.; Buys, J.; Forbes, M.; Bosselut, A.; Golub, D.; Choi, Y. Learning to Write with Cooperative Discriminators. arXiv 2018, arXiv:1805.06087. [Google Scholar] [CrossRef]
- Holtzman, A.; Buys, J.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. arXiv 2019, arXiv:1904.09751. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Method | Target | Attack Content | Training Data | Target Model | ||
|---|---|---|---|---|---|---|
| Sample | Distribution | Structure | Parameter | |||
| Shadow Attack [19] | ML Model | Training Data | ✓ | ✓ | ✓ | × |
| Sampling Attacks [20] | ML Model | Training Data | × | ✓ | ✓ | × |
| LOGAN [21] | Generative Model | Training Data | × | × | ✓ | ✓ |
| Nasr et al. [22] | ML Model | Training Data | × | × | ✓ | × |
| Wu et al. [23] | ML Model | Training Data | ✓ | × | × | ✓ |
| Truex et al. [33] | ML Model | Training Data | ✓ | × | × | × |
| Ye et al. [24] | ML Model | Training Data | ✓ | ✓ | × | × |
| MEMIA [25] | ML Model | Training Data | × | ✓ | × | × |
| Carlini et al. [26] | LLM | Training Data | × | × | × | × |
| Mireshghallah et al. [27] | Masked LM | Training Data | × | ✓ | × | × |
| Mattern et al. [28] | LM | Training Data | ✓ | × | × | × |
| PREMIA [29] | LLM | Training Data | × | ✓ | × | × |
| RECALL [30] | LLM | Training Data | ✓ | × | × | × |
| Wang et al. [31] | LLM | Context Content | × | × | × | × |
| Wen et al. [32] | LLM | ICL Samples | × | × | × | × |
| Our Work * | LLM | ICL Samples | × | × | × | × |
| Model | Attack Method | Dataset | ||
|---|---|---|---|---|
| AGNews | DBPedia | TREC | ||
| LLaMA3 | GAP | 0.49 | 0.40 | 0.35 |
| RA | 0.89 | 0.72 | 0.83 | |
| NDA | 0.82 | 0.83 | 0.91 | |
| LLaMA2 | GAP | 0.36 | 0.42 | 0.38 |
| RA | 0.82 | 0.62 | 0.82 | |
| NDA | 0.87 | 0.85 | 0.91 | |
| GPT2-XL | GAP | 0.47 | 0.25 | 0.15 |
| RA | 0.89 | 0.84 | 0.86 | |
| NDA | 0.89 | 0.86 | 0.85 | |
| Model | Number of Replacement | Dataset | |
|---|---|---|---|
| AGNews | DBPedia | ||
| LLaMA2 | 1 | 0.87 | 0.85 |
| 2 | 0.8 | 0.72 | |
| 3 | 0.71 | 0.72 | |
| LLaMA3 | 1 | 0.82 | 0.88 |
| 2 | 0.9 | 0.85 | |
| 3 | 0.86 | 0.84 | |
| Train | Test | |||
|---|---|---|---|---|
| LLaMA2&TREC | LLaMA2&AGNews | GPT2-XL&TREC | GPT2-XL&AGNews | |
| LLaMA2&TREC | / | 0.76 | 0.87 | 0.83 |
| LLaMA2&AGNews | 0.88 | / | 0.82 | 0.91 |
| GPT2-XL&TREC | 0.92 | 0.80 | / | 0.77 |
| GPT2-XL&AGNews | 0.88 | 0.90 | 0.83 | / |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, D.; Yang, Z.; Zheng, L.; Jin, B.; Xu, H.; Li, Y.; Xu, B.; Peng, K. Neighborhood Deviation Attack Against In-Context Learning. Appl. Sci. 2025, 15, 4177. https://doi.org/10.3390/app15084177
Hou D, Yang Z, Zheng L, Jin B, Xu H, Li Y, Xu B, Peng K. Neighborhood Deviation Attack Against In-Context Learning. Applied Sciences. 2025; 15(8):4177. https://doi.org/10.3390/app15084177
Chicago/Turabian StyleHou, Dai, Zhenkai Yang, Lei Zheng, Bo Jin, Huan Xu, Ying Li, Bo Xu, and Kai Peng. 2025. "Neighborhood Deviation Attack Against In-Context Learning" Applied Sciences 15, no. 8: 4177. https://doi.org/10.3390/app15084177
APA StyleHou, D., Yang, Z., Zheng, L., Jin, B., Xu, H., Li, Y., Xu, B., & Peng, K. (2025). Neighborhood Deviation Attack Against In-Context Learning. Applied Sciences, 15(8), 4177. https://doi.org/10.3390/app15084177