
Focusing 3D Small Objects with Object Matching Set Abstraction

 , and
, and
Abstract
1. Introduction
2. Related Work
2.1. Three-Dimensional Object Detection
2.2. Small Object Detection
2.3. Set Abstraction Algorithms
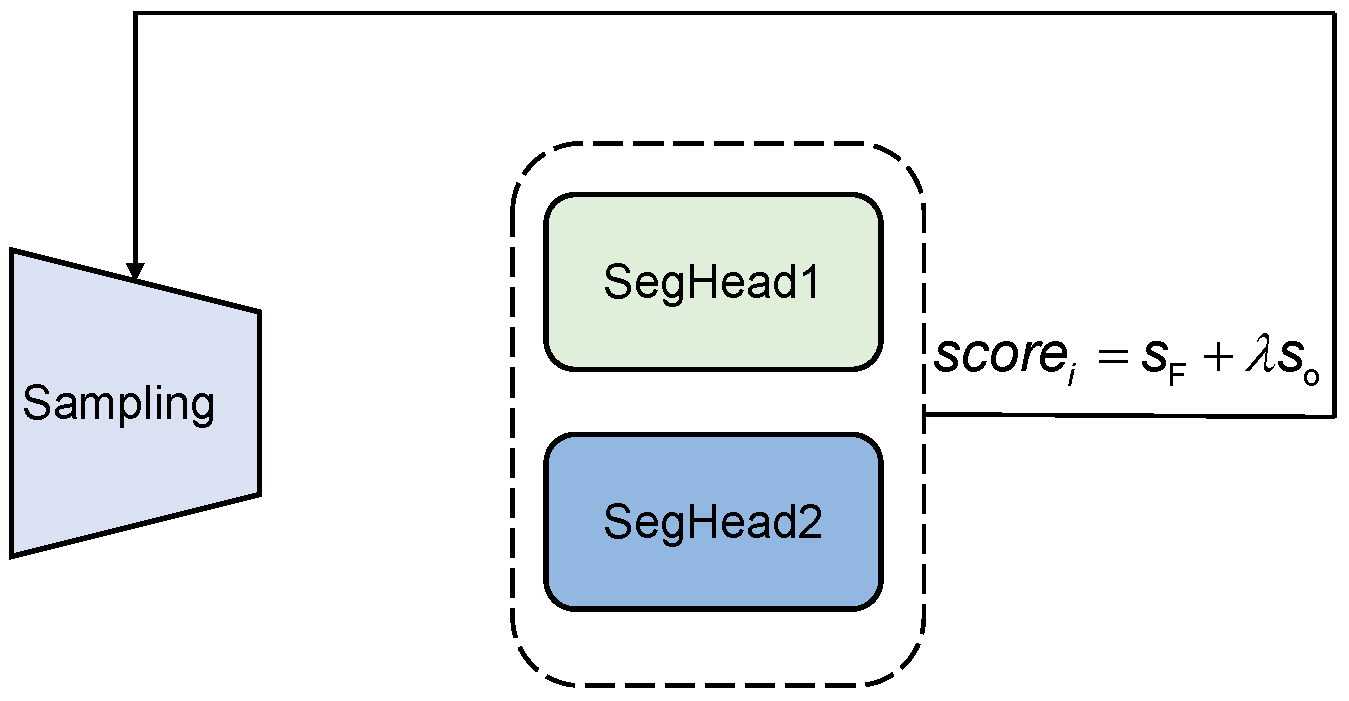
3. Methodology
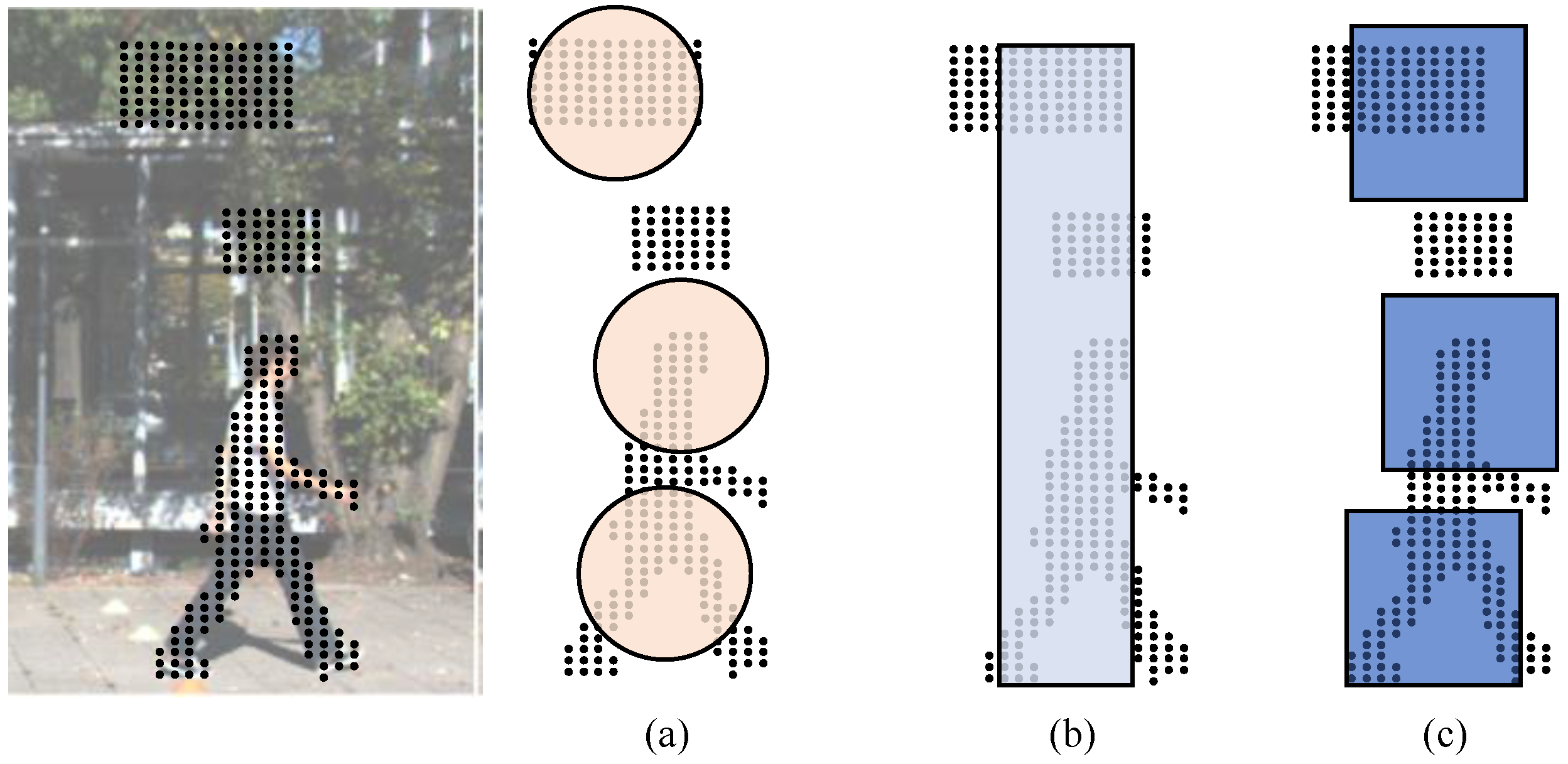
3.1. Focus-Based Sampling
3.2. Cube Query
4. Experiments
4.1. Implementation Details
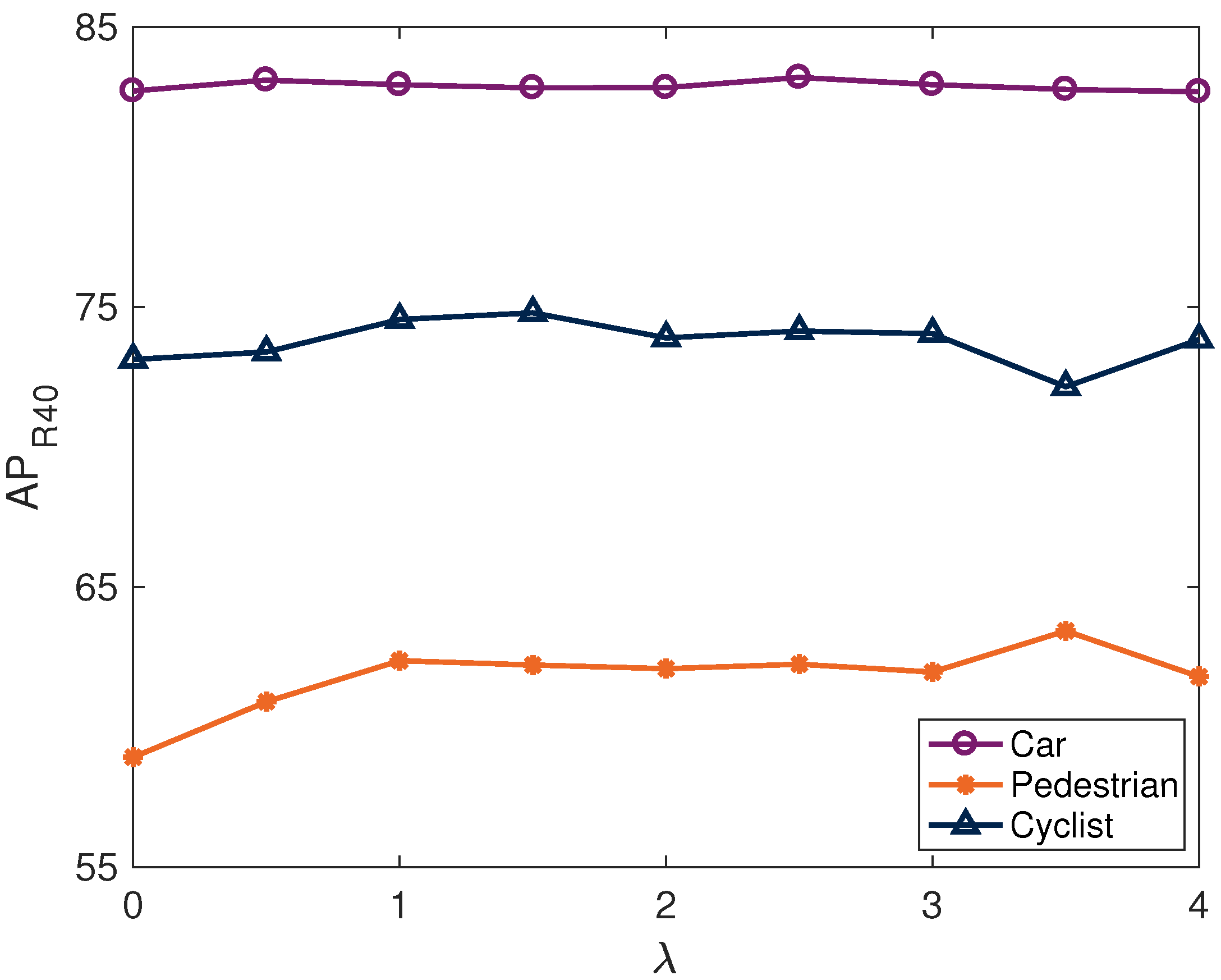
4.2. Ablation Studies
4.3. Main Experiments
4.4. Quantitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D object detection for autonomous driving: A comprehensive survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Drobnitzky, M.; Friederich, J.; Egger, B.; Zschech, P. Survey and systematization of 3D object detection models and methods. Vis. Comput. 2024, 40, 1867–1913. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Song, Z.; Wei, H.; Jia, C.; Xia, Y.; Li, X.; Zhang, C. VP-net: Voxels as points for 3D object detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5701912. [Google Scholar]
- Chen, Y.; Yu, Z.; Chen, Y.; Lan, S.; Anandkumar, A.; Jia, J.; Alvarez, J.M. Focalformer3D: Focusing on hard instance for 3D object detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 8360–8371. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D object detection and tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11779–11788. [Google Scholar]
- Chi, X.; Liu, J.; Lu, M.; Zhang, R.; Wang, Z.; Guo, Y.; Zhang, S. BEV-SAN: Accurate bev 3D object detection via slice attention networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17461–17470. [Google Scholar]
- Wang, Y.; Deng, J.; Hou, Y.; Li, Y.; Zhang, Y.; Ji, J.; Ouyang, W.; Zhang, Y. CluB: Cluster Meets BEV for LiDAR-Based 3D Object Detection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2024; Volume 36. [Google Scholar]
- Li, Z.; Lan, S.; Alvarez, J.M.; Wu, Z. BEVNeXt: Reviving Dense BEV Frameworks for 3D Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 20113–20123. [Google Scholar]
- Li, J.; Luo, C.; Yang, X. PillarNeXt: Rethinking network designs for 3D object detection in LiDAR point clouds. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17567–17576. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-based 3D single stage object detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11037–11045. [Google Scholar]
- Fan, L.; Yang, Y.; Wang, F.; Wang, N.; Zhang, Z. Super sparse 3D object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12490–12505. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Xie, X.; Han, J. Towards large-scale small object detection: Survey and benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar] [CrossRef] [PubMed]
- Bosquet, B.; Cores, D.; Seidenari, L.; Brea, V.M.; Mucientes, M.; Del Bimbo, A. A full data augmentation pipeline for small object detection based on generative adversarial networks. Pattern Recognit. 2023, 133, 108998. [Google Scholar] [CrossRef]
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. Neurocomputing 2023, 530, 150–164. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Zhang, Y.; Gao, Y.; Zhao, Z.; Feng, H.; Zhao, T. Context Feature Integration and Balanced Sampling Strategy for Small Weak Object Detection in Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6009105. [Google Scholar] [CrossRef]
- Cui, L.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Zhang, L.; Shao, L.; Xu, M. Context-aware block net for small object detection. IEEE Trans. Cybern. 2020, 52, 2300–2313. [Google Scholar] [CrossRef] [PubMed]
- Gao, T.; Niu, Q.; Zhang, J.; Chen, T.; Mei, S.; Jubair, A. Global to Local: A Scale-Aware Network for Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615614. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, H.; Huang, Q.; Han, Y.; Zhao, M. DsP-YOLO: An anchor-free network with DsPAN for small object detection of multiscale defects. Expert Syst. Appl. 2024, 241, 122669. [Google Scholar] [CrossRef]
- Ye, T.; Qin, W.; Zhao, Z.; Gao, X.; Deng, X.; Ouyang, Y. Real-Time Object Detection Network in UAV-Vision Based on CNN and Transformer. IEEE Trans. Instrum. Meas. 2023, 72, 2505713. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef] [PubMed]
- Tang, S.; Zhang, S.; Fang, Y. HIC-YOLOv5: Improved YOLOv5 For Small Object Detection. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 6614–6619. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Z.; Zhang, J.; Tao, D. SASA: Semantics-augmented set abstraction for point-based 3D object detection. In Proceedings of the 36th AAAI Conference on Artificial Intelligence (AAAI-22), Online, 22 February–1 March 2022; Volume 36, pp. 221–229. [Google Scholar]
- Jhong, S.Y.; Chen, Y.Y.; Hsia, C.H.; Wang, Y.Q.; Lai, C.F. Density-Aware and Semantic-Guided Fusion for 3D Object Detection using LiDAR-Camera Sensors. IEEE Sens. J. 2023, 23, 22051–22063. [Google Scholar] [CrossRef]
- Huang, Z.; Zheng, Z.; Zhao, J.; Hu, H.; Wang, Z.; Chen, D. PSA-Det3D: Pillar set abstraction for 3D object detection. Pattern Recognit. Lett. 2023, 168, 138–145. [Google Scholar] [CrossRef]
- Li, X.; Wang, C.; Zeng, Z. WS-SSD: Achieving faster 3D object detection for autonomous driving via weighted point cloud sampling. Expert Syst. Appl. 2024, 249, 123805. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, Y.; Tang, X.; Sun, H. Boundary-aware set abstraction for 3D object detection. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–7. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, D.; Wang, Y.; Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, , 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D object proposal generation and detection from point cloud. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10526–10535. [Google Scholar]
- Jiang, T.; Song, N.; Liu, H.; Yin, R.; Gong, Y.; Yao, J. VIC-Net: Voxelization information compensation network for point cloud 3D object detection. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13408–13414. [Google Scholar]
- Tong, G.; Peng, H.; Shao, Y.; Yin, Q.; Li, Z. ASCNet: 3D object detection from point cloud based on adaptive spatial context features. Neurocomputing 2022, 475, 89–101. [Google Scholar] [CrossRef]
- Zhang, Y.; Hu, Q.; Xu, G.; Ma, Y.; Wan, J.; Guo, Y. Not all points are equal: Learning highly efficient point-based detectors for 3D lidar point clouds. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18931–18940. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. IPOD: Intensive point-based object detector for point cloud. arXiv 2018, arXiv:1812.05276. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from RGB-D data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast encoders for object detection from point clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12689–12697. [Google Scholar]
- Wang, Z.; Jia, K. Frustum ConvNet: Sliding frustums to aggregate local point-wise features for amodal 3D object detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1742–1749. [Google Scholar]
- Zhou, D.; Fang, J.; Song, X.; Liu, L.; Yin, J.; Dai, Y.; Li, H.; Yang, R. Joint 3D instance segmentation and object detection for autonomous driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1836–1846. [Google Scholar]
- Zhang, Y.; Huang, D.; Wang, Y. PC-RGNN: Point cloud completion and graph neural network for 3D object detection. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI-21), Online, 2–9 February 2021; Volume 35, pp. 3430–3437. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Car | Pedestrian | Cyclist | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | Easy | Moderate | Hard | |
| Baseline (Ball Query) | 91.18 | 82.94 | 80.34 | 60.65 | 57.53 | 51.30 | 91.10 | 72.02 | 67.64 |
| Model A (FocS + Ball Query) | 90.37 | 80.49 | 77.75 | 62.02 | 58.10 | 50.96 | 92.16 | 72.50 | 66.96 |
| Model B (Cube Query) | 91.09 | 82.72 | 79.75 | 59.09 | 58.92 | 52.26 | 92.27 | 73.13 | 67.20 |
| Model C (FocS + Pillar Query) | 88.66 | 78.97 | 78.24 | 66.63 | 60.58 | 55.01 | 88.67 | 72.19 | 67.77 |
| Model D (Two SA Layers) | 91.25 | 82.68 | 80.15 | 66.93 | 59.90 | 54.03 | 91.46 | 71.74 | 67.03 |
| OMSA (FocS + Cube Query) | 91.53 | 82.81 | 80.25 | 69.59 | 62.47 | 56.77 | 92.41 | 73.24 | 68.85 |
| Method | Representation Format | Type | Car | ||
|---|---|---|---|---|---|
| Easy | Moderate | Hard | |||
| VoxelNet [4] | Voxel | One-stage | 81.97 | 65.46 | |
| SECOND [5] | Voxel | One-stage | 87.43 | 76.48 | 69.10 |
| PointRCNN [33] | Point | Two-stage | 88.88 | 78.63 | 77.38 |
| PV-RCNN [34] | Voxel + Point | Two-stage 92.57 | 84.83 | 82.69 | |
| 3DSSD [14] | Point | One-stage | 89.71 | 79.45 | 78.67 |
| VIC-Net [35] | Voxel + Point | Two-stage | 89.58 | 84.40 | 78.86 |
| ASCNet [36] | Point | Two-stage | - | 83.33 | - |
| IA-SSD [37] | Point | One-stage | - | 79.57 | - |
| OMSA | Point | One-stage | 91.53 | 82.81 | 80.25 |
| Method | Representation Format | Type | Pedestrian | Cyclist | ||||
|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |||
| VoxelNet [4] | Voxel | One-stage | 57.86 | 53.42 | 48.87 | 67.17 | 47.65 | 45.11 |
| 3DSSD [14] | Point | One-stage | 54.64 | 44.27 | 40.23 | 82.48 | 64.10 | 56.90 |
| IA-SSD [37] | Point | One-stage | - | 58.91 | - | - | 71.24 | - |
| OMSA | Point | One-stage | 69.59 | 62.47 | 56.77 | 92.41 | 73.24 | 68.85 |
| Method | Representation Format | Type | Car | ||
|---|---|---|---|---|---|
| Easy | Moderate | Hard | |||
| VoxelNet [4] | Voxel | One-stage | 77.47 | 65.11 | 57.73 |
| SECOND [5] | Voxel | One-stage | 84.65 | 75.96 | 68.71 |
| IPOD [38] | Point | Two-stage | 79.75 | 72.57 | 66.33 |
| AVOD + Feature Pyramid [39] | Point + RGB | Two-stage | 81.94 | 71.88 | 66.38 |
| Frustum PointNets [40] | Point + RGB | Two-stage | 81.20 | 70.39 | 62.19 |
| PointPillars [41] | Voxel | One-stage | 82.58 | 74.31 | 68.99 |
| PointRCNN [33] | Point | Two-stage | 86.96 | 75.64 | 70.70 |
| F-ConvNets [42] | Point | Two-stage | 85.88 | 76.51 | 68.08 |
| PV-RCNN [34] | Voxel + Point | Two-stage | 90.25 | 81.43 | 76.82 |
| 3DSSD [14] | Point | One-stage | 88.36 | 79.57 | 74.55 |
| Joint [43] | Point | Two-stage | 87.74 | 78.96 | 74.30 |
| PC-RGNN [44] | Point | Two-stage | 89.13 | 79.90 | 75.54 |
| ASCNet [36] | Point | Two-stage | 88.48 | 81.67 | 76.93 |
| IA-SSD [37] | Point | One-stage | 88.34 | 80.13 | 75.04 |
| OMSA | Point | One-stage | 87.28 | 76.18 | 71.81 |
| Method | Representation Format | Type | Pedestrian | Cyclist | ||||
|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |||
| VoxelNet [4] | Voxel | One-stage | 39.48 | 33.69 | 31.51 | 61.22 | 48.39 | 44.37 |
| SECOND [5] | Voxel | One-stage | 45.31 | 35.52 | 33.14 | 75.83 | 60.82 | 53.67 |
| IPOD [38] | Point | Two-stage | 56.92 | 44.68 | 42.39 | 71.40 | 53.46 | 48.34 |
| AVOD + Feature Pyramid [39] | Point + RGB | Two-stage | 50.80 | 42.81 | 40.88 | 64.00 | 52.18 | 46.61 |
| Frustum PointNets [40] | Point + RGB | Two-stage | 51.21 | 44.89 | 40.23 | 71.96 | 56.77 | 50.39 |
| PointPillars [41] | Voxel | One-stage | 51.45 | 41.92 | 38.89 | 77.10 | 58.65 | 51.92 |
| PointRCNN [33] | Point | Two-stage | 47.98 | 39.37 | 36.01 | 74.96 | 58.82 | 52.53 |
| F-ConvNets [42] | Point | Two-stage | 52.37 | 45.61 | 41.49 | 79.58 | 64.68 | 57.03 |
| PV-RCNN [34] | Voxel + Point | Two-stage | 52.17 | 43.29 | 40.29 | 78.60 | 63.71 | 57.65 |
| ASCNet [36] | Point | Two-stage | 42.00 | 35.76 | 33.69 | 78.41 | 65.10 | 57.87 |
| IA-SSD [37] | Point | One-stage | 46.51 | 39.03 | 35.60 | 78.35 | 61.94 | 55.70 |
| OMSA | Point | One-stage | 52.26 | 50.41 | 38.20 | 79.53 | 62.30 | 55.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, L.; Song, N.; Hu, J.; Han, H.; Han, X.; Xiong, F. Focusing 3D Small Objects with Object Matching Set Abstraction. Appl. Sci. 2025, 15, 4121. https://doi.org/10.3390/app15084121
Guo L, Song N, Hu J, Han H, Han X, Xiong F. Focusing 3D Small Objects with Object Matching Set Abstraction. Applied Sciences. 2025; 15(8):4121. https://doi.org/10.3390/app15084121
Chicago/Turabian StyleGuo, Lei, Ningdong Song, Jindong Hu, Huiyan Han, Xie Han, and Fengguang Xiong. 2025. "Focusing 3D Small Objects with Object Matching Set Abstraction" Applied Sciences 15, no. 8: 4121. https://doi.org/10.3390/app15084121
APA StyleGuo, L., Song, N., Hu, J., Han, H., Han, X., & Xiong, F. (2025). Focusing 3D Small Objects with Object Matching Set Abstraction. Applied Sciences, 15(8), 4121. https://doi.org/10.3390/app15084121