Abstract
Multimodal summarization (MS) generates text summaries from multimedia articles with textual and visual content. Therefore, MS can suffer from the multimodal factual inconsistency problem, where the generated summaries may distort or deviate from both the textual and visual content in the original multimodal input. Existing MS approaches mainly focus on improving the degree of word overlap between output summaries and reference summaries while ignoring the factual inconsistency problem. In this work, we propose a fact-aware multimodal summarization model (FactMS) to improve the multimodal factual consistency of MS. Specifically, we extract the factual information in the textual and visual modalities and remove the text knowledge with low correlation with the visual input. A dual heterogeneous knowledge graph is then proposed to learn the intra-modality factual information in both textual and visual content. By fusing the multimodal factual information in the decoding stage, summaries with better factual consistency are generated. In addition, we propose an automatic method for evaluating visual factual consistency in MS based on the text-image consistency. Extensive experiments conducted on three real-world datasets demonstrate that FactMS achieves an excellent performance of multimodal factual consistency and has a comparable performance in terms of word overlap.
1. Introduction
At present, new articles published on the web contain multimodal content such as text and images. Hence, a great deal of attention has been paid to the multimodal summarization (MS) task, which strives to generate a summary of the multimodal article [1,2,3]. However, if there is a deviation between the generated summary and the facts, it may lead to public distrust of the content generated by the AI system. These risks prompt us to focus our research on consistency between multimodal summaries and facts.
The factual inconsistency problem has been studied in text-only summarization tasks [4,5,6,7], where the generated summary is supposed to be consistent with the textual article. However, there is currently no work focusing on the factual consistency of MS. MS can also suffer from factual inconsistency problems that are more severe than those in text-only summarization since MS generates the summary from both the textual and visual modalities. The summaries generated by the existing MS models can distort or deviate from the meaning of the textual and visual content in the original documents, since they mainly focus on obtaining a high degree of word overlap with the textual content and do not consider consistency between the textual and visual input. As shown in Figure 1, without considering the factual information of the visual content, the summary at the top contains the sentence eight French died, which is abstracted from the helicopter collision event in the textual content. This summary deviates from the main idea of the multimodal content, since helicopter collision event is not reflected in the visual content and is not the main content when taking the two modalities as a whole. That is to say, the summary deviates from the visual input, which represents a visual inconsistency problem. Therefore, it is a great challenge to generate a multimodal factual consistency summary for the multimodal article, since the summary should be consistent to different modalities simultaneously.

Figure 1.
An example of the multimodal factual inconsistency problem in MS. The blue part indicates important textual knowledge. The pink part indicates the textual fact errors. The green part indicates the phenomenon of visual inconsistency, i.e., a deviation from the article’s main point due to the lack of visual knowledge.
Due to the heterogeneous nature of the textual and visual content, existing models for factual consistency in text-only summarization cannot be directly extended to MS. Moreover, the facts in different modalities may complement or conflict with each other. Therefore, it is nontrivial to learn the factual knowledge from different modalities and effectively fuse them into improve the multimodal factual consistency of MS. Meanwhile, the correlation and complementary characteristics of the multimodal content also provide clues to enhance the factual consistency in MS. The textual content can be represented as a correlated knowledge graph: the nodes are named entities or relation types, and edges connect the relation tuples (e.g., Chelsea and Paris Saint Germain are entity nodes, and adversary and team member are relation nodes).
Similarly, for the visual modality, correlated objects can also be connected and become a component of a visual knowledge graph. The graph representation is effective at learning factual information from each modality of content.
Moreover, the graphs of different modalities are correlated with each other, which presents a cross-modality correlation to learn the inter-modality factual information of the multimodal content.
To address the problem, we take advantage of intra- and inter-modality correlation to improve the multimodal factual consistency in MS. Accordingly, a framework of fact-aware MS via heterogeneous knowledge graph (FactMS) is proposed.
First, to learn the factual information from each modality, a dual heterogeneous knowledge graph is proposed to model the intra-modality factual knowledge of both textual and visual modalities.
Then, a CLIP [8] model fine-tuned on the summary data is employed to filter the textual factual information that deviates from the visual input. Finally, a cross-modality knowledge interactor is proposed to learn the inter-modality factual knowledge representation, which aims to reduce the conflict between modalities, and then supplement and highlight the crucial information.
To evaluate FactMS, we performed experiments on three multimodal summarization datasets. The metrics based on tuple relations and natural language information are used to evaluate the textual factual consistency. In addition, to evaluate the visual factual consistency between generated summaries and visual input, we propose an automatic evaluation index of visual factual consistency based on image-text matching. Human evaluation experiments are conducted to better evaluate the factual consistency with multimodal content, which tests user satisfaction in both consistency and fluency. Experiment results show that FactMS has improved the existing advanced methods by an average of about 2–5 percentage points in terms of indicators for measuring multimodal factual consistency. At the same time, while ensuring that the summary similarity does not decrease, it effectively reduces the distortion of key facts in the generated summary.
Our main contributions are as follows:
- We define and analyze the problem of multimodal factual inconsistency in MS, and an automatic visual factual consistency evaluation method for MS is proposed.
- We propose a novel framework named FactMS to learn the factual information from different modalities and fuse them to generate multimodal fact-aware summaries for multimodal articles.
- Experimental results on large-scale MS datasets demonstrate that FactMS achieves an excellent performance of multimodal factual consistency and also obtains a comparable performance in terms of word overlap.
2. Related Work
Our research is mainly based on previous studies on multimodal summarization and factual consistency of text summarization.
- Text Summarization
Automatic text summarization involves generating a succinct and coherent summary that retains the essential information and overarching meaning of the original text [9]. Numerous methods of text summarization have been proposed [10,11,12,13,14,15]. Lewis et al. [13] presented a denoising autoencoder called BART designed for pretraining sequence-to-sequence models. This approach proves particularly effective when subsequently fine-tuned for text generation tasks. Thakkar et al. [15] introduced a pioneering domain feature miner, crafted by conceptualizing the feature mining problem as a clustering issue. Three recently formulated empirical observations are incorporated to enhance the effectiveness of summarizing textual data. Joshi et al. [11] proposed sentence topic embeddings and sentence content embeddings for capturing long-range semantic dependencies and structural content information in texts. Chatterjee et al. [10] introduced the DEPSYM++ simplifier, designed to perform four distinct types of simplification on sentences within the input text. These simplifications are tailored to address the presence of appositive clauses, relative clauses, conjoined clauses, and passive voice. Those methods strive in every possible way to maximally utilize textual data to generate summaries.
- Multimodal Summarization
Multimodal summarization aims to generate the crucial part of the multimodal input. In recent years, the generation of text summarization from multimodal data, including text, vision, and audio has been extensively studied [16,17,18]. A substantial body of research has concentrated on integrating visual data to enhance the quality of text summarization [1,2,3,19,20,21,22]. Chen and Zhuge [1] proposed a multimodal attention mechanism to generate text summaries by combining visual and text information. Li et al. [2] introduced a multimodal sentence summarization task that creates a condensed text summary from a long sentence and its corresponding image. Li et al. [3] used a multimodal selective gate network to encourage the encoder to focus on the important information of the input text. These studies are mainly devoted to improving the word overlap between the generated summary and the reference summary (i.e., ROUGE), which ignores factual inconsistency (Zhang et al. [19]).
- Factual Consistency of Text Summarization
Nearly 30% of the summaries generated by abstractive text summary models have faithfulness problems such as distortion and fabrication [4]. With the development of abstractive text summarization, the problem of factual consistency has received increasing attention in recent years. Cao et al. [4] proposed a dual attention decoder, which integrates source sentences and factual descriptions to improve the factual consistency of text summarization. Huang et al. [6] treated subjects and objects as nodes to construct a graph transformer [23], introducing factual consistency information to enhance the model’s semantic understanding of entity interaction with a multi-choice cloze reward. Zhu et al. [7] used a graph attention network [24] to learn a feature representation of the entity relation in the source article and employ a factual accuracy model designed to refine the generated summary. By regarding the factual inconsistency problem as natural language inference and fact checking, Kryscinski et al. [5] proposed the weakly supervised factual consistency metric FactCC, which is widely used to study factual consistency of text summarization. The current studies on factual consistency mainly focus on text-only summarization, which is not directly adaptable to the multimodal consistency in MS.
3. Problem Formulation
Given an article and the corresponding images , our aim is to generate a fact-aware summary by learning the factual information from both of the modalities, where L, N, , and M denote the number of sentences in the article, the number of tokens in the article, the number of tokens in the summary, and the number of images, respectively. The multimodal factual information consists of two parts: textual factual knowledge and visual factual knowledge . The output summary Y is expected to have a sufficient lexical overlap with the annotated summary and a high degree of multimodal factual consistency with article X and images I.
4. Fact-Aware Multimodal Summarization
To retrieve and integrate multimodal factual information and effectively fuse it to the generation of factual summaries, we propose a novel model FactMS, which can learn the factual knowledge and its latent correlation among different modalities. The framework is shown in Figure 2. FactMS comprises a vision-based text content filter, a dual heterogeneous knowledge graph, a cross-modality knowledge interaction, a text encoder, and a summary decoder. The dual heterogeneous knowledge graphs are utilized to learn the multimodal factual knowledge from the input of text and images. Then, due to the heterogeneity of the multimodal data, the factual knowledge representations of the two modalities are fused through the cross-modality knowledge interaction process. Finally, the summary decoder generates summaries by exploiting the correlation between text and multimodal factual knowledge.
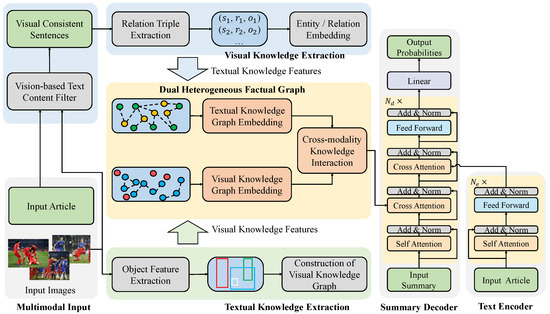
Figure 2.
The architectural framework of FactMS. The vision-based text content filter is utilized to generate visually consistent sentences. The dual heterogeneous knowledge graph is proposed to model the multimodal factual knowledge. The crucial information in multimodal input is supplemented and enhanced in the cross-modality knowledge interaction. The multimodal factual knowledge is integrated into the generation process of fact-aware summaries.
4.1. Vision-Based Text Content Filter
To avoid the interference of the text content which is extremely deviated from visual input on the generation of summaries, a CLIP [8] model fine-tuned on the MS data is employed to filter the textual factual information that deviates from the visual input. Specifically, for each article X, we set the summary Y and each corresponding image as M summary image pairings. Given a set of N summary image pairings, for an input article X, we calculate the cosine similarity between sentences and images , and take the maximum between sentence and all M images as the final score of sentence . Only sentences with scores higher than the threshold are taken for the subsequent extraction process of text knowledge, where is a hyperparameter.
4.2. Dual Heterogeneous Knowledge Graph
The generated summary is supposed to be factually consistent with both text and images in the multimodal data. Usually, the fact-related objects in both text and images correlate with each other, which provides clues for learning the factual knowledge from both modalities. It is necessary to introduce multimodal factual knowledge into MS and consider the heterogeneity between different modalities. Therefore, we propose a dual heterogeneous knowledge graph to model the correlation of factual knowledge in text and images, as the Figure 3. Concretely, the relation triples in the article represent the primary text knowledge information, and the relation between objects in the images can be considered as the primary visual knowledge information.

Figure 3.
An example of the construction of textual and visual knowledge graphs.
4.2.1. Textual Knowledge Graph
Textual Relation triples can represent the factual knowledge in the textual modality. To extract the relation triples from the input article, an ERNIE-based [25] relation extraction model fine tuned on the DuIE dataset [26] is employed. Each relational triple comprises a subject, an object, and the relationship between them. Then, the textual knowledge graph is constructed, in which each subject, object, and relation is denoted as a node. If a relation node r is between a subject node and an object node o, two edges, and , are added.
Since the extracted relation types are fixed, a learnable one-hot embedding matrix embeds relation nodes. For each entity node, the average embedding of its tokens is used as the initial embedding of the node [27]. Then, we employ a graph attention network (GAT) [24] to obtain the final representation of all nodes. The node feature is calculated by a weighted average of its neighbors:
where denotes concatenation, K represents the multi-head number, is the set of the neighborhood of node i, and are trainable parameters, and are activation functions. This process can be simply expressed as follows:
4.2.2. Visual Knowledge Graph
Objects and scenes in visual content can be considered as visual factual knowledge. For the input images, we employ a pretrained bottom-up attention model [28] as the object extractor, which employs a Faster R-CNN [29] initialized with ResNet-101 [30] to obtain the object representation. Each object has a 2048-dimension feature and a bounding box location.
We regard the objects and scenes in an image as the visual knowledge elements. Nodes in the visual knowledge graph contain two types: individual objects and scenes composed of multiple objects. The representation of an individual object is calculated as follows:
where is the feature extracted by the object extractor, is a trainable parameter matrix, and is the activation function.
A scene comprises a certain number of objects representing the interactive relationship between these objects. As shown in Figure 1, several players celebrating a goal and a football and the shooting player in the images can be regarded as scenes containing rich visual knowledge information. We calculate the Intersection over Union (IoU) of bounding boxes between objects. Objects whose IoU is greater than the threshold are connected to form a scene. First, a graph attention network is employed to update the features of each object in a scene:
Then, we use an average layer to obtain a representation of the scene:
Note that the factor in Equation (6) ensures that is the average of the w object features, effectively normalizing the scene representation by the number of objects in the image [31]. Finally, a representation of all nodes in the visual knowledge graph is obtained.
4.3. Cross-Modality Knowledge Interaction
The interaction of factual knowledge elements between modalities can complement and enhance the crucial information in the multimodal content. Specifically, entities and relations in the article correlate to objects and scenes in the image, which can be exploited to learn the cross-modality representation to capture and enhance facts from both modalities. Thus, a cross-modality knowledge encoder is employed to fuse the two types of knowledge information via transformer attention layers [32]. The input of the attention layer can be regarded as query (), key (), and value (). The output is a weighted sum of , where the weight comes from and . The calculation process is as follows:
where denotes the dimension of the queries and the keys. If , , and are all the same, it is called self-attention [32]. If comes from one modality, and come from another modality, it denotes cross-attention [33,34], which can fuse the knowledge information of one modality into another modality. The feed-forward network layer constitutes a position-wise fully connected module:
where is the input of the layer, , , , are trainable parameters, and is the activation function.
The cross-modality knowledge encoder is a stack of cross-attention (CrossAttn), self-attention (SelfAttn), and feed-forward network (FFN) layers with layer normalization (LN). The visual knowledge features fused with textual knowledge are calculated as follows:
Similarly, fused with visual knowledge, the textual knowledge features can be obtained. Finally, the fused multimodal knowledge features are obtained as the integration of knowledge information in the two modalities:
4.4. Fact-Aware Summary Generation
As shown in Figure 2, a transformer [32] encoder–decoder structure is employed as the multimodal summary generator to combine the textual and visual knowledge information and generate a multimodal factual consistency summary.
4.4.1. Text Encoder
Assuming is the embedding (including position embedding) of an input article , the output of the text encoder is calculated as follows:
Finally, we take as the output of the encoder, where denotes the number of layers of the text encoder.
4.4.2. Summary Decoder
The summary decoder fuses the knowledge information learned from both modalities to generate the output summary. It utilizes the text encoder output , the cross-modality knowledge features , and the first p tokens embedding to compute the distribution of the vocabulary for the token. For brevity, we omit below. First, we obtain the self-attention output:
Then, before the feed-forward network layer, two cross-attention layers are employed to receive and , respectively:
Before attending , the summary decoder first attends , because can prompt the summary decoder to focus on the crucial part of the source article [35].
After layers of decoder, the output of all p tokens is obtained. is used to calculate the vocabulary distribution of the next token:
where is a trainable parameter matrix. is then used to compute the cross-entropy loss.
5. Experiment Setup
5.1. Dataset
We conducted experiments utilizing three multimodal summarization datasets: Daily Mail, CNN, and MHHF. Additional statistical information pertaining to these datasets is available in Table 1.

Table 1.
Statistics of the proposed dataset.
The Daily Mail and CNN datasets from MM-AVS [36] were sourced from the respective websites of Daily Mail and CNN. This dataset constitutes a comprehensive multimodal resource that encompasses documents, summaries, images, captions, and titles. It facilitates a robust comparison between multimodal summarization methods and traditional text-based approaches. HCSCL-dataset [19] is a Chinese multimodal summarization dataset. The textual data comprises diverse news articles sourced from TTNews [37] and THUCNews [38], spanning categories such as sports, entertainment, society, etc. Each article is accompanied by three pertinent images, with captions demonstrating the utmost relevance to the respective news titles.
5.2. Evaluation Metrics
5.2.1. Textual Factual Consistency Metric
To evaluate the textual factual consistency, FactCC [5] is employed as an evaluation metric. The source article and generated summary are fed into a binary classification model, and a score between 0 and 1 is output. A higher FactCC score indicates better factual consistency. Following previous work, we adopt back-translation and synonymous rewriting methods to generate consistent samples. Then, we adopt pronoun swapping, name entity swapping, and sentence negation methods to generate inconsistent samples. Finally, the FactCC model is fine-tuned using the generated sentences.
A relation triple usually reflects a fact to some degree, so we extract the relation triples from the reference and generated summaries, respectively. Thus, they are used to calculate the factual accuracy. The DuIE dataset [26] is used to train the relation extraction model based on the pretrained model ERNIE [25]. Assume and are the relation tuple sets in the generated summary and the reference summary, respectively. and are the name entity sets in the generated summary and the reference summary, respectively. The relation accuracy rate (RAR) and entity accuracy rate (EAR) are as follows:
5.2.2. Visual Factual Consistency Metric
For visual factual consistency, we argue that the output summary should cover as much visual input as possible and avoid deviation from the visual content. The matching score between the generated summary and the input image meets this requirement well [39]. Therefore, obtaining the CLIP model fine-tuned on the MS data as mentioned before, we define the summary-image consistency score (SICS) as the automatic visual factual consistency metric as follows:
where Y is the generated summary, is the input image, and M is the number of input images.
5.2.3. Word Overlap Metric
As two standard metrics in the field of text generation for automatic evaluation, ROUGE [40] and BLEU [41] are utilized to assess the degree of overlap between the generated summary and the reference summary. A higher score means a higher overlap, which denotes better fluency of the generated summaries.
5.3. Baselines
We compared our model to existing MS models and traditional text-only summarization models.
- Multimodal Summarization Models:
MSMO: a model which defines the multimodal summarization output task and applies an attention mechanism on text and image to generate textual summary with relative images [42]. HOW2: the first model proposed to generate a textual summary with video content [17]. MOF: a model with multimodal output, which considers image accuracy as another loss [43]. MSE: a model which proposes a selective mechanism that uses multimodal signals to select important information [3]. VMSMO: the first one to explore the video-based multimodal summarization with multimodal output [44]. HCSCL: a model which improves the quality of MS by considering the hierarchical cross-modality semantic correlation [19].
- Text-only Summarization Models:
S2S: a stable standard sequence-to-sequence architecture using an RNN encoder–decoder with a global attention mechanism [45]. PG: a sequence-to-sequence framework combined with attention mechanism and pointer network [46]. FTSum: a dual-attention model proposed to integrate fact description into the summary generation process to enhance the factual consistency [4].
5.4. Implementation Details
We set in the transformer [32] structure used in our experiment. The multi-head number is set to 6. The GAT has two graph attention layers and eight multi-heads. The hidden state sizes in GAT are 96 and 256 for text and images, respectively. The dropout rate is 0.3 in GAT and 0.1 in transformer. The alpha parameter is 1.0 in ELU and 0.2 in LeakyReLU. We initialize the word embeddings utilizing the BERT model [47] bert-base-chinese to initialize the parameters of our embedding matrix, which has a size of 21,128 and a dimension of 768. Image objects are selected based on a bottom-up attention model [28], with a confidence threshold of greater than 0.55. Each object is characterized by a 2048-dimensional feature vector. Each object is represented by a 2048-dimensional vector. The IoU threshold between objects is 0.2. is set to 0.95 in the vision-based text content filter, and we ensure that the number of remaining sentences is not less than half of the total. We employ an Adam [48] optimizer with the initial learning rate set to 3 × 10−4 multiplied by 0.9 every 16 epochs. The batch size is set to 8.
6. Results and Analysis
6.1. Word Overlap Evaluation
Table 2 shows the ROUGE and BLEU performance of the baseline models and FactMS on the HCSCL-dataset test set, measuring the degree of word overlap between the generated summaries and target summaries. Although FactMS introduces a large amount of textual and visual factual knowledge in the hope of enhancing factual consistency, it is still comparable to the most advanced MS model in terms of word overlap metrics. FactMS achieves the highest ROUGE-2 score (29.04), ROUGE-L score (41.87), BLEU-3 score (25.52), and BLEU-4 score (23.65). This indicates that FactMS retains the ability to generate fluent text summaries while focusing on the factual consistency problem.
Table 2.
Comparison of FactMS with baselines on HCSCL-dataset.
To comprehensively evaluate FactMS, we conducted comparative analyses with other methods on both the Daily Mail and CNN datasets. As shown in Table 3, FactMS consistently outperforms all metrics on the CNN dataset and surpasses other baselines on the Daily Mail dataset in terms of ROUGE-2 and ROUGE-L scores. These findings provide robust evidence that the superior performance of our model on the HCSCL dataset is not an isolated case, thereby validating the effectiveness of the proposed dual heterogeneous knowledge graph.
Table 3.
Comparison of FactMS with baselines on Daily Mail and CNN dataset.
6.2. Textual Faithfulness Evaluation
As displayed in Table 4, FactMS achieves better textual factual consistency than all the baseline models. Specifically, the performance of FactMS is better than all advanced MS baselines in average FactCC score (FactCCavg) and the percentage of FactCC scores greater than 0.9 (FactCC>0.9), which shows that FactMS has the best average and maximum ability to output summaries with textual factual consistency. In addition to having the best scores of FactCC, FactMS also achieves 19.41 RAR and 24.92 EAR, which are 6.21 and 0.7 higher than the best performance in MS baselines, respectively. The results indicate that the extraction and fusion of the textual and visual knowledge information effectively improve the textual factual consistency of MS. FactMS can greatly alleviate the problem of generating textual fact errors, which benefits from the attention to the factual knowledge information in both the textual and visual modalities.
Table 4.
Comparison of FactMS with baseline on faithfulness evaluation metrics.
6.3. Visual Faithfulness Evaluation
We report SICSmax and SICSavg for evaluation of visual factual consistency. FactMS has the best SICS, as shown in Table 4, which indicates that the summaries generated by FactMS are more consistent with the input images. On one hand, it benefits from the visual consistent information provided by the vision-based text content filter. On the other hand, it benefits from the extraction and fusion of visual knowledge and textual knowledge. To further evaluate the performance of FactMS in visual faithfulness, for each selected summary, three volunteers are employed to collate and observe the object and scene information extracted from the input images to obtain the object’s behavior, relationship, and scene events as visual information and count the quantity. Similarly, is quantified as the subject–predicate relationship and the described events in the output summary. represents the amount of cross-modality information matched in and . A higher indicates that the output summary is more consistent with the visual input, and more visual-related information can be obtained from the textual input.
6.4. Ablation Study
Two ablation experiments are designed to analyze the effects of the textual knowledge graph and the visual knowledge graph on word overlap and faithfulness. The result is shown in Table 5. We can see that the model has better performances in multimodal factual consistency with the dual heterogeneous graph. Textual knowledge improves textual factual consistency more than visual knowledge, but it is the opposite in the consistency of visual facts. That is to say, by fusing visual knowledge information only, the model will generate more fluency and informativeness but less reliability and factual consistency. It demonstrates that integrating textual and visual knowledge information helps generate both fact-aware and fluency summaries.
Table 5.
The ablation results for FactMS. VK represents visual knowledge and TK represents textual knowledge.
6.5. Human Evaluation
To further evaluate FactMS’s performance, we randomly select 100 multimodal articles from our test dataset for human evaluation. Three volunteers manually evaluate the summaries generated by FactMS, MSMO, MSE, MAtt, and human-written summaries (Target). To evaluate word overlap, volunteers score between 1 (worst) and 5 (best) on informativeness (Inf) and fluency (Flu). Inf means whether the summary represents the crucial information from the source article, and Flu means whether the summary is grammatically correct. As shown in Table 6, the Inf and Flu scores of FactMS outperform all baselines and are close to the target. The Visionp of FactMS is better than other baselines and closest to the target. This improvement benefits from the vision-based text content filter and the fusion of textual and visual knowledge information by FactMS.
Table 6.
Human evaluation results of informativeness, fluency, and vision precision scores.
6.6. Case Study
Figure 4 shows examples of the output summaries of FactMS and several baseline MS models. The green symbol indicates that the summary is consistent with the image or text, while the red indicates inconsistency. Compared with existing MS studies, FactMS generates summaries with better multimodal factual consistency due to the integration of textual and visual multimodal factual knowledge.

Figure 4.
Examples of the multimodal input and the summaries generated by FactMS and MS baselines.
6.7. Discussion
If the image is completely unrelated to the textual content, our vision-based text content filter would not find matching objects or scenes. Consequently, the model’s cross-modality fusion would de-emphasize visual features, effectively defaulting to a text-focused summary. In such cases, the generated summary would rely more heavily on textual facts while assigning minimal weight to the irrelevant image data.
6.8. Limitations
Although the FactMS model has achieved good results on the three multimodal datasets, its performance may be data-dependent. Specifically, most of these datasets come from news media, and inevitably have a bias towards the angle or subject of media coverage; in scenarios dominated by sports news, the model is better at identifying sports-related entities and actions, but may require further fine-tuning and adaptation in other fields (such as medical and government affairs). In addition, since media data often has tendencies, if the image content is inconsistent with the actual news topic, it may bring noise and bias to the model. Therefore, future work will consider a wider and more diverse range of multimodal data sources, and introduce external knowledge bases and more rigorous fact verification modules during the training phase to reduce bias propagation and improve the robustness of the system.
7. Conclusions
In this paper, we define and analyze the multimodal factual inconsistency problem in the multimodal summarization task. To address this problem, we propose a fact-aware multimodal summarization model via a vision-based text content filter and a dual heterogeneous knowledge graph, which fuses factual knowledge in both textual and visual modalities to generate summaries. Experiment results show that our model is effective in producing summaries that are consistent with the multimodal content. Our model differs from the text-only summarization models, which aim to make summaries consistent with the text content only. It is also different from the existing MS works, which only focus on the informativeness and fluency of summaries. By extracting textual and visual knowledge and exploiting the correlation between multimodal content, we can enhance multimodal factual consistency in multimodal summarization.
Author Contributions
Conceptualization, C.L. and M.Z.; methodology, C.L. and M.Z.; software, H.Y. and M.Z.; validation, C.L., H.Y. and M.Z.; formal analysis, M.Z.; investigation, M.Z.; resources, C.L.; data curation, C.L.; writing—original draft preparation, M.Z.; writing—review and editing, C.L. and M.Z.; visualization, H.Y. and M.Z.; supervision, C.L.; project administration, C.L.; funding acquisition, C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, J.; Zhuge, H. Abstractive text-image summarization using multi-modal attentional hierarchical rnn. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4046–4056. [Google Scholar]
- Li, H.; Zhu, J.; Liu, T.; Zhang, J.; Zong, C. Multi-modal Sentence Summarization with Modality Attention and Image Filtering. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 4152–4158. [Google Scholar]
- Li, H.; Zhu, J.; Zhang, J.; He, X.; Zong, C. Multimodal sentence summarization via multimodal selective encoding. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 5655–5667. [Google Scholar]
- Cao, Z.; Wei, F.; Li, W.; Li, S. Faithful to the original: Fact aware neural abstractive summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Kryscinski, W.; McCann, B.; Xiong, C.; Socher, R. Evaluating the Factual Consistency of Abstractive Text Summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 9332–9346. [Google Scholar]
- Huang, L.; Wu, L.; Wang, L. Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5094–5107. [Google Scholar]
- Zhu, C.; Hinthorn, W.; Xu, R.; Zeng, Q.; Zeng, M.; Huang, X.; Jiang, M. Enhancing Factual Consistency of Abstractive Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 718–733. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. Text Summarization Techniques: A Brief Survey. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2017, 8, 397. [Google Scholar] [CrossRef]
- Chatterjee, N.; Agarwal, R. Studying the effect of syntactic simplification on text summarization. IETE Tech. Rev. 2023, 40, 155–166. [Google Scholar]
- Joshi, A.; Fidalgo, E.; Alegre, E.; Fernández-Robles, L. DeepSumm: Exploiting topic models and sequence to sequence networks for extractive text summarization. Expert Syst. Appl. 2023, 211, 118442. [Google Scholar]
- Liu, S.; Cao, J.; Yang, R.; Wen, Z. Key phrase aware transformer for abstractive summarization. Inf. Process. Manag. 2022, 59, 102913. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Zhang, M.; Zhou, G.; Yu, W.; Liu, W. FAR-ASS: Fact-aware reinforced abstractive sentence summarization. Inf. Process. Manag. 2021, 58, 102478. [Google Scholar] [CrossRef]
- Thakkar, H.K.; Sahoo, P.K.; Mohanty, P. DOFM: Domain feature miner for robust extractive summarization. Inf. Process. Manag. 2021, 58, 102474. [Google Scholar]
- Li, H.; Zhu, J.; Ma, C.; Zhang, J.; Zong, C. Multi-modal summarization for asynchronous collection of text, image, audio and video. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1092–1102. [Google Scholar]
- Palaskar, S.; Libovickỳ, J.; Gella, S.; Metze, F. Multimodal abstractive summarization for how2 videos. arXiv 2019, arXiv:1906.07901. [Google Scholar]
- Khullar, A.; Arora, U. MAST: Multimodal Abstractive Summarization with Trimodal Hierarchical Attention. arXiv 2020, arXiv:2010.08021. [Google Scholar]
- Zhang, L.; Zhang, X.; Pan, J. Hierarchical cross-modality semantic correlation learning model for multimodal summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 11676–11684. [Google Scholar]
- Zhang, Z.; Meng, X.; Wang, Y.; Jiang, X.; Liu, Q.; Yang, Z. Unims: A unified framework for multimodal summarization with knowledge distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 11757–11764. [Google Scholar]
- Zhang, L.; Zhang, X.; Guo, Z.; Liu, Z. CISum: Learning Cross-modality Interaction to Enhance Multimodal Semantic Coverage for Multimodal Summarization. In Proceedings of the 2023 SIAM International Conference on Data Mining (SDM), SIAM, Paul Twin Cities, MN, USA, 27–29 April 2023; pp. 370–378. [Google Scholar]
- Zhang, L.; Zhang, X.; Han, L.; Yu, Z.; Liu, Y.; Li, Z. Multi-task hierarchical heterogeneous fusion framework for multimodal summarization. Inf. Process. Manag. 2024, 61, 103693. [Google Scholar] [CrossRef]
- Koncel-Kedziorski, R.; Bekal, D.; Luan, Y.; Lapata, M.; Hajishirzi, H. Text Generation from Knowledge Graphs with Graph Transformers. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Sun, Y.; Wang, S.; Feng, S.; Ding, S.; Pang, C.; Shang, J.; Liu, J.; Chen, X.; Zhao, Y.; Lu, Y.; et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv 2021, arXiv:2107.02137. [Google Scholar]
- Li, S.; He, W.; Shi, Y.; Jiang, W.; Liang, H.; Jiang, Y.; Zhang, Y.; Lyu, Y.; Zhu, Y. Duie: A large-scale chinese dataset for information extraction. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Dunhuang, China, 9–14 October 2019; pp. 791–800. [Google Scholar]
- Zhang, L.; Zhang, X.; Zhou, Z.; Huang, F.; Li, C. Reinforced adaptive knowledge learning for multimodal fake news detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 16777–16785. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Fu, H.; Wang, J.; Chen, J.; Ren, P.; Zhang, Z.; Zhao, G. Dense Multi-Agent Reinforcement Learning Aided Multi-UAV Information Coverage for Vehicular Networks. IEEE Internet Things J. 2024, 11, 21274–21286. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Zhang, L.; Zhang, X.; Li, C.; Zhou, Z.; Liu, J.; Huang, F.; Zhang, X. Mitigating Social Hazards: Early Detection of Fake News via Diffusion-Guided Propagation Path Generation. In Proceedings of the ACM Multimedia, Melbourne, Australia, 28 October–1 November 2024. [Google Scholar]
- Dou, Z.Y.; Liu, P.; Hayashi, H.; Jiang, Z.; Neubig, G. Gsum: A general framework for guided neural abstractive summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4830–4842. [Google Scholar]
- Fu, X.; Wang, J.; Yang, Z. Multi-modal summarization for video-containing documents. arXiv 2020, arXiv:2009.08018. [Google Scholar]
- Hua, L.; Wan, X.; Li, L. Overview of the NLPCC 2017 shared task: Single document summarization. In Proceedings of the National CCF Conference on Natural Language Processing and Chinese Computing, Dalian, China, 8–12 November 2017; Springer: Cham, Switzerland, 2017; pp. 942–947. [Google Scholar]
- Sun, M.; Li, J.; Guo, Z.; Yu, Z.; Zheng, Y.; Si, X.; Liu, Z. Thuctc: An efficient chinese text classifier. GitHub Repos. 2016. [Google Scholar]
- Zhang, L.; Zhang, X.; Zhou, Z.; Zhang, X.; Wang, S.; Philip, S.Y.; Li, C. Early Detection of Multimodal Fake News via Reinforced Propagation Path Generation. IEEE Trans. Knowl. Data Eng. 2024, 37, 613–625. [Google Scholar] [CrossRef]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–15 July 2002; pp. 311–318. [Google Scholar]
- Zhu, J.; Li, H.; Liu, T.; Zhou, Y.; Zhang, J.; Zong, C. MSMO: Multimodal summarization with multimodal output. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4154–4164. [Google Scholar]
- Zhu, J.; Zhou, Y.; Zhang, J.; Li, H.; Zong, C.; Li, C. Multimodal summarization with guidance of multimodal reference. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9749–9756. [Google Scholar]
- Li, M.; Chen, X.; Gao, S.; Chan, Z.; Zhao, D.; Yan, R. VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles. arXiv 2020, arXiv:2010.05406. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- UzZaman, N.; Bigham, J.P.; Allen, J.F. Multimodal summarization of complex sentences. In Proceedings of the 16th International Conference on Intelligent User Interfaces, Palo Alto, CA, USA, 13–16 February 2011; pp. 43–52. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).