
Big Data-Driven 3D Visualization Analysis System for Promoting Regional-Scale Digital Geological Exploration

 , , , and
, , , and
Abstract
1. Introduction
2. Related Works
2.1. Resource Integration and Task Scheduling in Heterogeneous Clouds
2.2. Progress in Heterogeneous Geological Data Integration
2.3. Progress in Large-Scale Geological Data Rendering
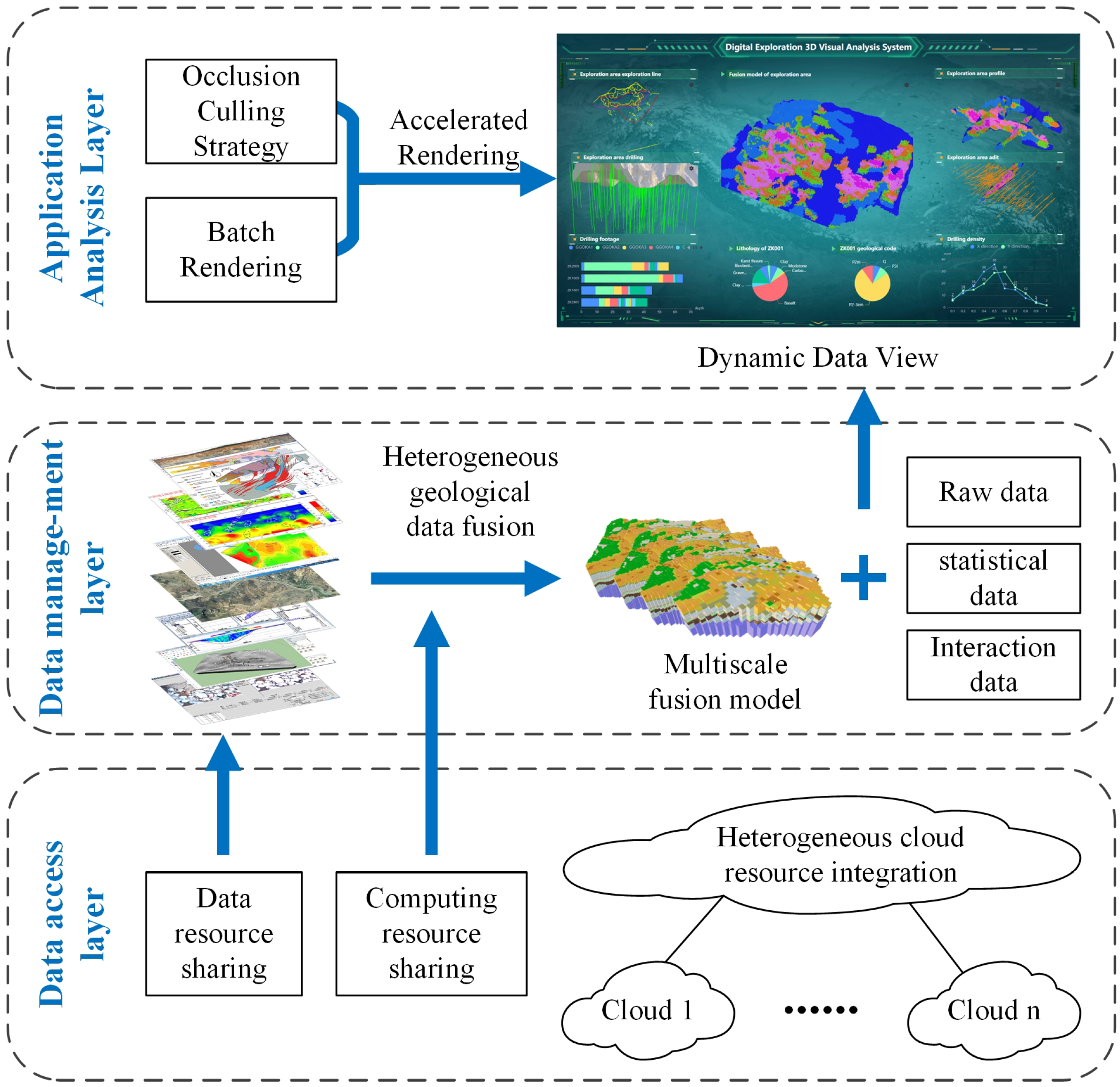
3. System Architecture and Key Technologies
3.1. CMMN-Based Heterogeneous Cloud Resource Integration and Scheduling
3.1.1. Heterogeneous Cloud Resource Integration Framework
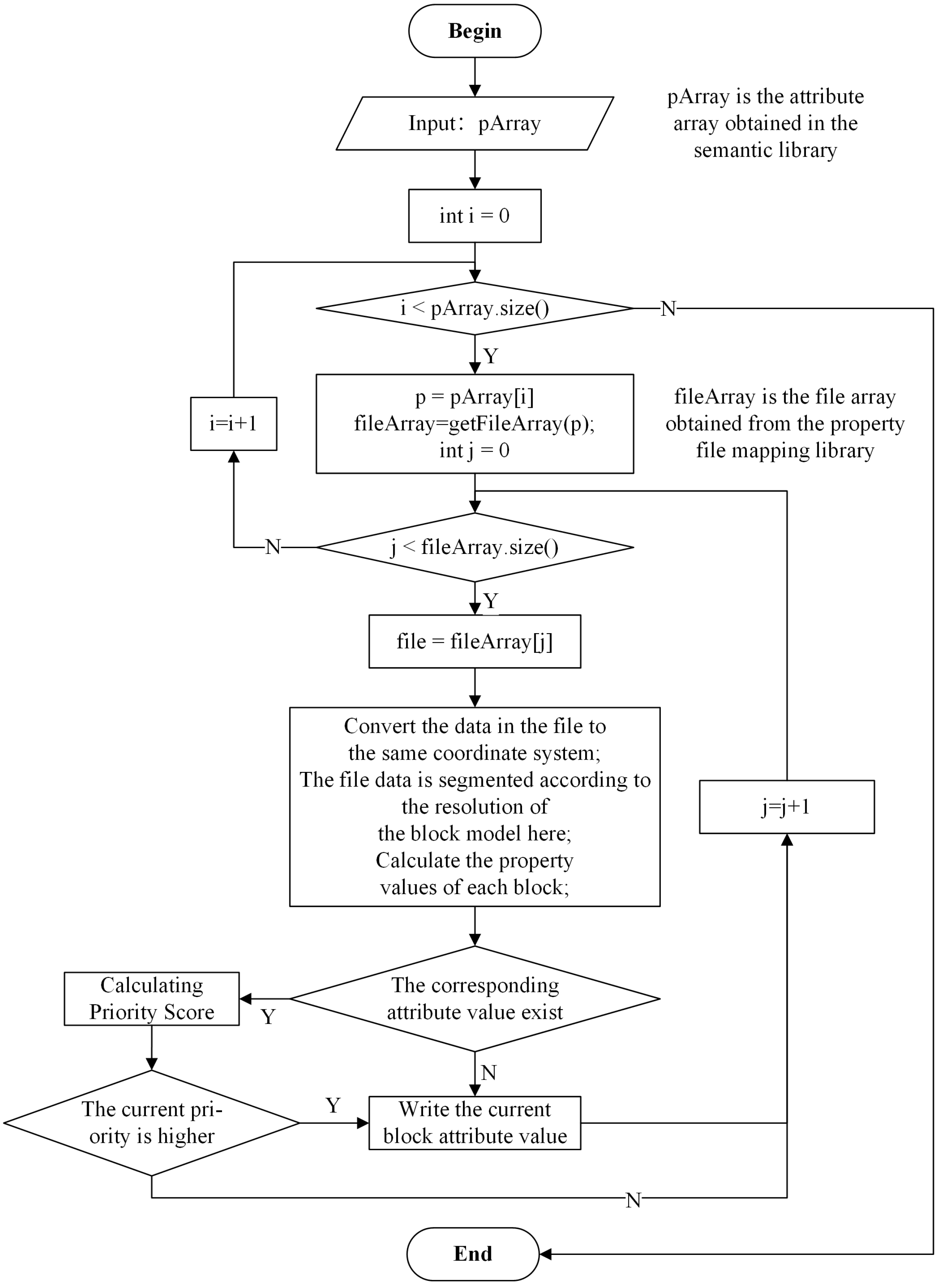
3.1.2. Task Scheduling Optimization Based on CMMN Algorithm
| Algorithm 1: Improved CMMN. |
 |
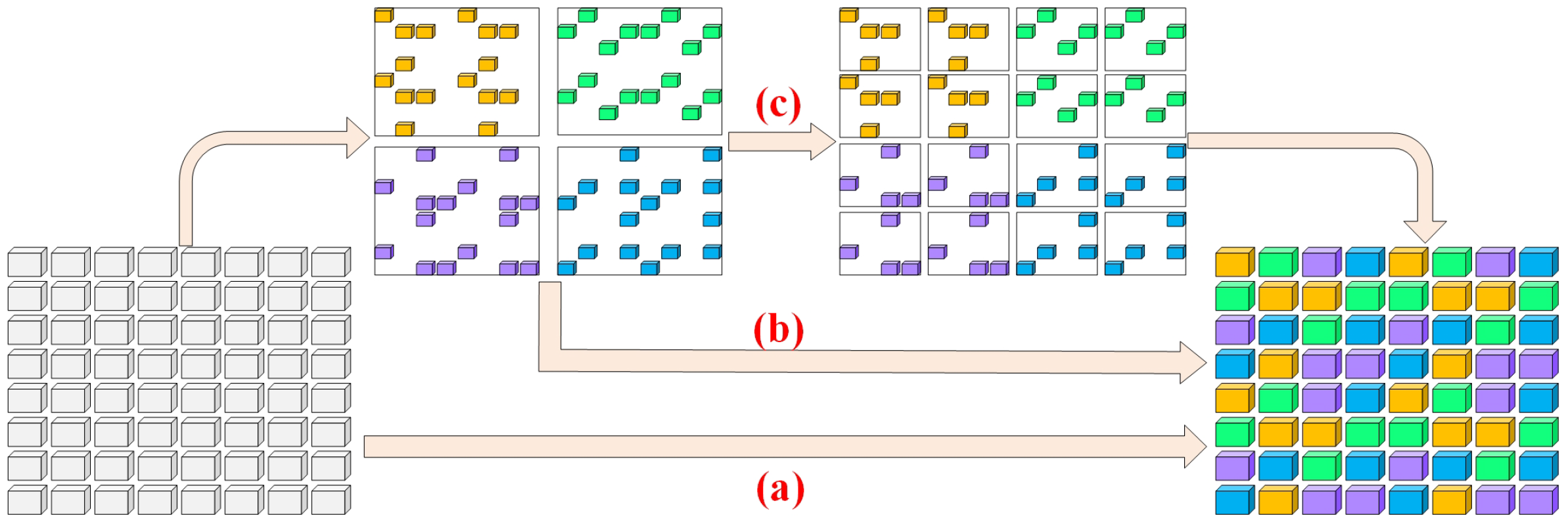
3.2. Dynamic Integration of Heterogeneous Geological Data via Block Models
3.2.1. Block Model-Based Heterogeneous Geological Data Fusion
3.2.2. Modular Approach for Dynamic Data View Generation
3.3. Rendering Optimization Strategy for 3D Visual Analytics
3.3.1. Occlusion Culling Strategy
3.3.2. Batch Rendering Strategy
4. Experiments and Results
4.1. Task Scheduling Performance Analysis
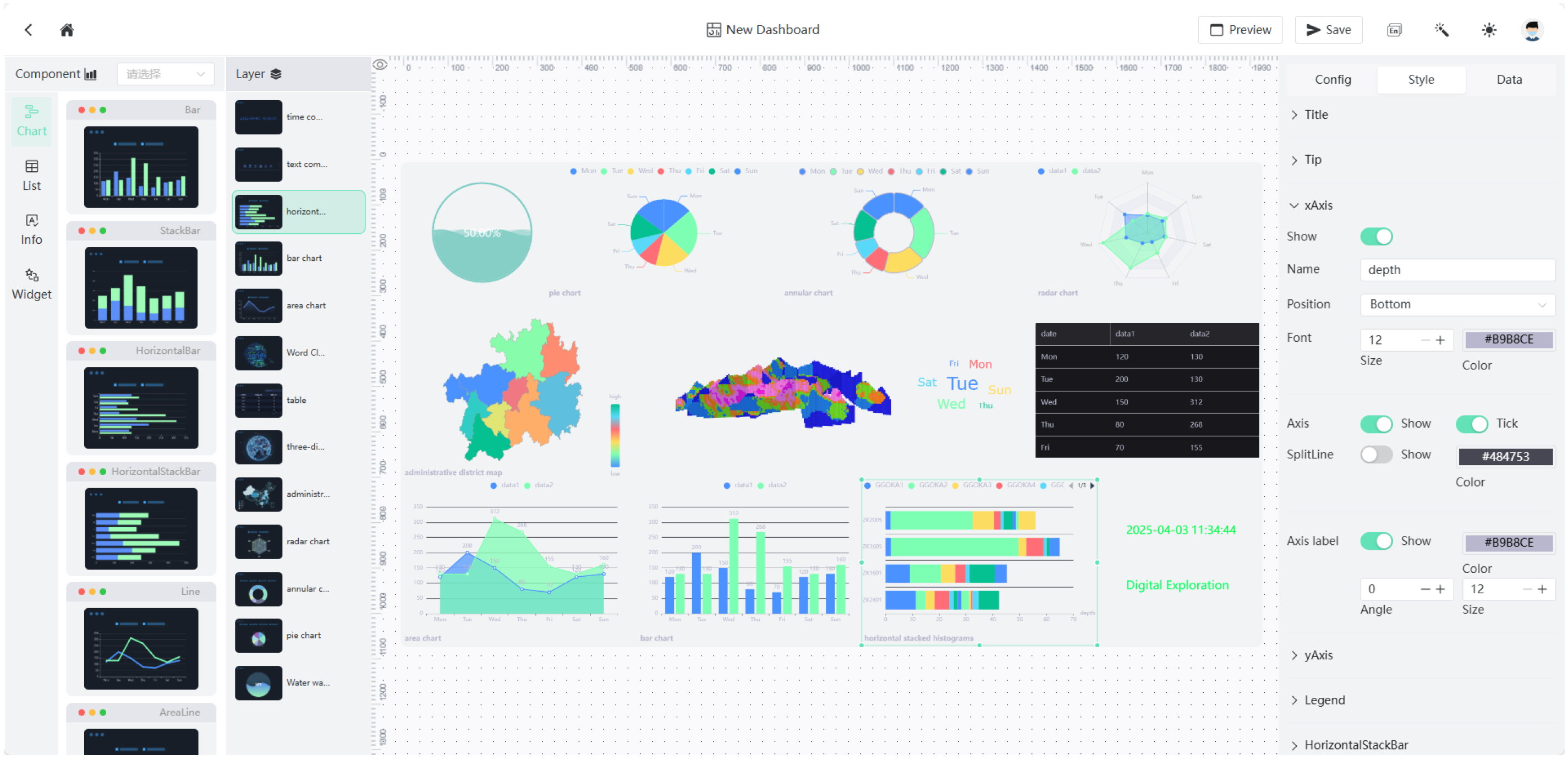
4.2. Dynamic Data View Generation
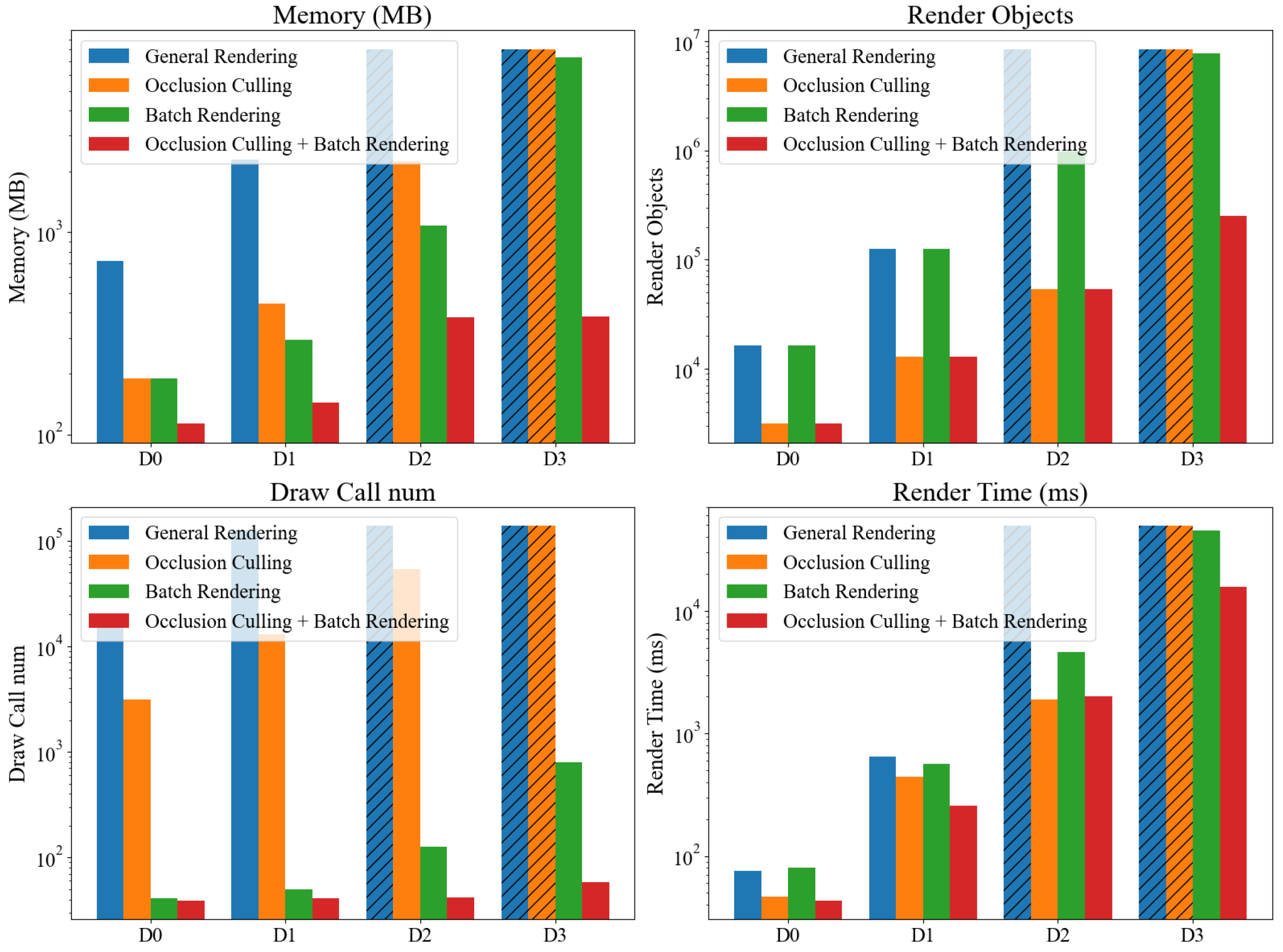
4.3. Rendering Performance Optimization
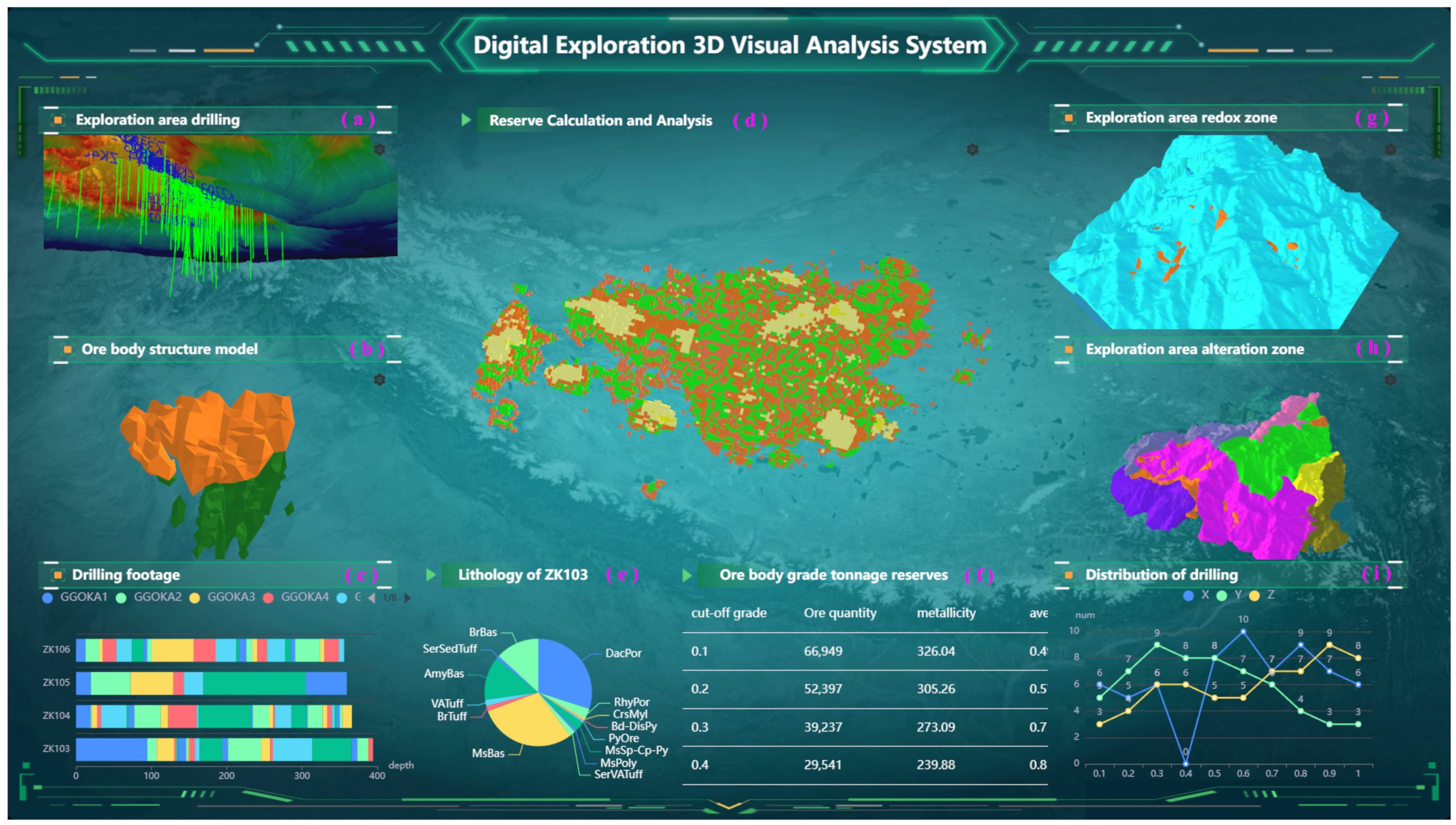
4.4. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, Q.; Wu, C. Experimental research and progress on intelligent mineral exploration based on big data. Earth Sci. Front. 2024, 31, 350–367. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, X.; Zhou, Q.; Tian, Y.; Zhang, Z.; Li, J.; Li, Y.; Xu, K. Digital exploration and digital transformation of the geological and mineral exploration industry. Guizhou Geol. 2021, 38, 119–128. [Google Scholar]
- Huang, Z.; Shi, Z. Digital exploration practices and exploration in the Mázōngling bauxite mining area, Zheng’an County, Guizhou Province. Eng. Technol. Res. 2023, 8, 1–4. [Google Scholar] [CrossRef]
- Wu, C.; Zhou, Q.; Xu, k.; Zhang, X.; Kong, C.; Li, Y.; Yang, B.; Zhang, S.; Yuan, L. A review study of the prospecting process of Datangpo manganese ore used for big data prediction. Guizhou Geol. 2022, 39, 189–204. [Google Scholar]
- Zhao, P.; Chen, Y. Digital geosciences and quantitative mineral exploration. J. Earth Sci. 2021, 32, 269–275. [Google Scholar] [CrossRef]
- Tavani, S.; Billi, A.; Corradetti, A.; Mercuri, M.; Bosman, A.; Cuffaro, M.; Seers, T.; Carminati, E. Smartphone assisted fieldwork: Towards the digital transition of geoscience fieldwork using LiDAR-equipped iPhones. Earth Sci. Rev. 2022, 227, 103969. [Google Scholar] [CrossRef]
- Wu, C. Can big data and geoinformatics promote the quantitative phase of geology? Earth Sci. 2022, 47, 3913–3914. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, C.; Zhou, Q.; Weng, Z.; Yuan, L.; He, K.; Zhang, Q.; Yang, B. Three-dimensional geological modeling of manganese deposits based on exploration big data and data market. Bull. Geol. Sci. Technol. 2020, 39, 12–20. [Google Scholar] [CrossRef]
- Tian, Y.; Wu, C.; Weng, Z.; Liu, G.; Zhang, Z.; Chen, Q. Discussion on key technologies of geological big data visualization. Bull. Geol. Sci. Technol. 2020, 39, 29–36. [Google Scholar] [CrossRef]
- Maljers, D.; Stafleu, J.; Van der Meulen, M.; Dambrink, R. Advances in constructing regional geological voxel models, illustrated by their application in aggregate resource assessments. Neth. J. Geosci. 2015, 94, 257–270. [Google Scholar] [CrossRef]
- Yang, H.Q.; Chu, J.; Wu, S.; Zhu, X.; Qi, X.; Chiam, K. Advancing geological modelling and geodata management: A web-based system with AI assessment in Singapore. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2025, 19, 218–232. [Google Scholar]
- Liu, G.; Wu, C.; He, Z.; Weng, Z.; Que, X.; Tian, S.; Li, Y. Research on data models for expression and storage management of geological spatiotemporal big data. Bull. Geol. Sci. Technol. 2020, 39, 164–174. [Google Scholar] [CrossRef]
- Di Curzio, D.; Castrignanò, A.; Fountas, S.; Romić, M.; Rossel, R.A.V. Multi-source data fusion of big spatial-temporal data in soil, geo-engineering and environmental studies. Sci. Total Environ. 2021, 788, 147842. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Liu, G.; Chen, Q.; Zhao, L.; Shize, X.; Qing, L.; Junjie, Z. Key technologies and applications of 3D spatial data management system for mining based on multi-source data integration and WebGIS. Softw. Guide 2023, 22, 18–28. [Google Scholar] [CrossRef]
- Wu, C.; Liu, G.; Zhou, Q.; Zhang, X.; Xu, K. Basic issues in the integrated application of geological big data. Bull. Geol. Sci. Technol. 2020, 39, 1–11. [Google Scholar] [CrossRef]
- Zhang, Y.H.; Wen, C.; Zhang, M.; Xie, K.; He, J.B. Fast 3d visualization of massive geological data based on clustering index fusion. IEEE Access 2022, 10, 28821–28831. [Google Scholar] [CrossRef]
- Slawik, M.; Zilci, B.I.; Demchenko, Y.; Baranda, J.I.A.; Branchat, R.; Loomis, C.; Lodygensky, O.; Blanchet, C. CYCLONE unified deployment and management of federated, multi-cloud applications. In Proceedings of the 2015 IEEE/ACM 8th International Conference on Utility and Cloud Computing (UCC), Limassol, Cyprus, 7–10 December 2015; pp. 453–457. [Google Scholar] [CrossRef]
- Castañé, G.G.; Xiong, H.; Dong, D.; Morrison, J.P. An ontology for heterogeneous resources management interoperability and HPC in the cloud. Future Gener. Comput. Syst. 2018, 88, 373–384. [Google Scholar] [CrossRef]
- Yang, C.T.; Chen, S.T.; Cheng, W.H.; Chan, Y.W.; Kristiani, E. A heterogeneous cloud storage platform with uniform data distribution by software-defined storage technologies. IEEE Access 2019, 7, 147672–147682. [Google Scholar] [CrossRef]
- Panda, S.K.; Jana, P.K. Efficient task scheduling algorithms for heterogeneous multi-cloud environment. J. Supercomput. 2015, 71, 1505–1533. [Google Scholar] [CrossRef]
- Chen, W.; Xie, G.; Li, R.; Bai, Y.; Fan, C.; Li, K. Efficient task scheduling for budget constrained parallel applications on heterogeneous cloud computing systems. Future Gener. Comput. Syst. 2017, 74, 1–11. [Google Scholar] [CrossRef]
- Panda, S.K.; Jana, P.K. An energy-efficient task scheduling algorithm for heterogeneous cloud computing systems. Clust. Comput. 2019, 22, 509–527. [Google Scholar] [CrossRef]
- Behera, I.; Sobhanayak, S. Task scheduling optimization in heterogeneous cloud computing environments: A hybrid GA-GWO approach. J. Parallel Distrib. Comput. 2024, 183, 104766. [Google Scholar] [CrossRef]
- Olierook, H.K.; Scalzo, R.; Kohn, D.; Chandra, R.; Farahbakhsh, E.; Clark, C.; Reddy, S.M.; Müller, R.D. Bayesian geological and geophysical data fusion for the construction and uncertainty quantification of 3D geological models. Geosci. Front. 2021, 12, 479–493. [Google Scholar] [CrossRef]
- Zhuang, C.; Zhu, H.; Wang, W.; Liu, B.; Ma, Y.; Guo, J.; Liu, C.; Zhang, H.; Liu, F.; Cui, L. Research on urban 3D geological modeling based on multi-modal data fusion: A case study in Jinan, China. Earth Sci. Inform. 2023, 16, 549–563. [Google Scholar] [CrossRef]
- Wu, J.; Han, W.; Chen, J.; Wang, S. Improving Geological Remote Sensing Interpretation via Optimal Transport-Based Point–Surface Data Fusion. Remote Sens. 2023, 16, 53. [Google Scholar] [CrossRef]
- Sjöbergh, J.; Li, X.; Goebel, R.; Tanaka, Y. A visualization-analytics-interaction workflow framework for exploratory and explanatory search on geo-located search data using the meme media digital dashboard. In Proceedings of the 2015 19th International Conference on Information Visualisation, Barcelona, Spain, 22–24 July 2015; pp. 300–309. [Google Scholar] [CrossRef]
- Stehle, S.; Kitchin, R. Real-time and archival data visualisation techniques in city dashboards. Int. J. Geogr. Inf. Sci. 2020, 34, 344–366. [Google Scholar] [CrossRef]
- Farmanbar, M.; Rong, C. Triangulum city dashboard: An interactive data analytic platform for visualizing smart city performance. Processes 2020, 8, 250. [Google Scholar] [CrossRef]
- Wu, L.; Hou, J.; Zhu, Y.; Li, Y. Research on the sharing technology of large-scale 3D geological models based on 3D Tiles. Comput. Tech. Geophys. Geochem. Explor. 2024, 46, 242–250. [Google Scholar] [CrossRef]
- Xu, D.; Peng, H.; Xiao, J.; Yang, Q.; Li, S.; Liu, H. Key technologies and applications of integrated management for urban full-space 3D model data. Bull. Geol. Sci. Technol. 2023, 42, 388–397. [Google Scholar] [CrossRef]
- Li, F.; Gao, C.; Liu, Y.; Huang, K.; Pan, M.; Chen, X.; Yuan, Y. Integrated multi-scale reservoir data representation and indexing for reservoir data management and characterization. Comput. Geosci. 2020, 138, 104433. [Google Scholar] [CrossRef]
- Graciano, A.; Rueda, A.J.; Feito, F.R. Real-time visualization of 3D terrains and subsurface geological structures. Adv. Eng. Softw. 2018, 115, 314–326. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Cloud Completion Time (ms) | Average Cloud Utilization | ||||
|---|---|---|---|---|---|---|
| CMMN | Optimized | Improvement | CMMN | Optimized | Improvement | |
| 100 × 4 | 60,583.98 | 59,528.53 | 1.77% | 0.9644 | 0.9685 | 0.43% |
| 200 × 8 | 37,110.81 | 36,367.85 | 2.04% | 0.9385 | 0.9496 | 1.18% |
| 300 × 12 | 26,606.16 | 26,029.34 | 2.22% | 0.9302 | 0.9351 | 0.53% |
| 400 × 16 | 21,091.38 | 20,655.71 | 2.11% | 0.9210 | 0.9299 | 0.97% |
| 500 × 20 | 17,500.01 | 17,109.37 | 2.28% | 0.9171 | 0.9215 | 0.48% |
| 600 × 24 | 14,910.70 | 14,519.72 | 2.69% | 0.9093 | 0.9141 | 0.53% |
| 700 × 28 | 13,171.05 | 12,823.78 | 2.71% | 0.9039 | 0.9123 | 0.93% |
| 800 × 32 | 11,747.93 | 11,436.66 | 2.72% | 0.9040 | 0.9094 | 0.60% |
| 900 × 36 | 10,528.38 | 10,258.25 | 2.63% | 0.9081 | 0.9119 | 0.42% |
| 1000 × 40 | 9636.75 | 9399.24 | 2.52% | 0.9012 | 0.9054 | 0.47% |
| Datasets | Basic Rendering | Occlusion Culling | Batch Rendering | Both |
|---|---|---|---|---|
| D0 | 724 | 189 | 189 | 113 |
| D1 | 2281 | 444 | 295 | 144 |
| D2 | Out of memory | 2241 | 1080 | 382 |
| D3 | Out of memory | Out of memory | 7325 | 384 |
| Datasets | Basic Rendering | Occlusion Culling | Batch Rendering | Both |
|---|---|---|---|---|
| D0 | 16,406 | 3131 | 16,406 | 3131 |
| D1 | 126,067 | 12,892 | 126,067 | 12,892 |
| D2 | Out of memory | 53,876 | 983,021 | 53,863 |
| D3 | Out of memory | Out of memory | 7,743,278 | 251,885 |
| Datasets | Basic Rendering | Occlusion Culling | Batch Rendering | Both |
|---|---|---|---|---|
| D0 | 16,419 | 3144 | 41 | 39 |
| D1 | 126,080 | 12,905 | 50 | 41 |
| D2 | Out of memory | 53,876 | 126 | 42 |
| D3 | Out of memory | Out of memory | 801 | 58 |
| Datasets | Basic Rendering | Occlusion Culling | Batch Rendering | Both |
|---|---|---|---|---|
| D0 | 75.5 | 61.7 | 80.3 | 58.26 |
| D1 | 651.6 | 563.8 | 568.8 | 388.3 |
| D2 | Out of memory | 2969.7 | 1585.6 | 3148.1 |
| D3 | Out of memory | Out of memory | 44,961 | 25,753.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Wu, J.; Chen, G.; Liu, G.; Zhang, X. Big Data-Driven 3D Visualization Analysis System for Promoting Regional-Scale Digital Geological Exploration. Appl. Sci. 2025, 15, 4003. https://doi.org/10.3390/app15074003
Tian Y, Wu J, Chen G, Liu G, Zhang X. Big Data-Driven 3D Visualization Analysis System for Promoting Regional-Scale Digital Geological Exploration. Applied Sciences. 2025; 15(7):4003. https://doi.org/10.3390/app15074003
Chicago/Turabian StyleTian, Yiping, Jiongqi Wu, Genshen Chen, Gang Liu, and Xialin Zhang. 2025. "Big Data-Driven 3D Visualization Analysis System for Promoting Regional-Scale Digital Geological Exploration" Applied Sciences 15, no. 7: 4003. https://doi.org/10.3390/app15074003
APA StyleTian, Y., Wu, J., Chen, G., Liu, G., & Zhang, X. (2025). Big Data-Driven 3D Visualization Analysis System for Promoting Regional-Scale Digital Geological Exploration. Applied Sciences, 15(7), 4003. https://doi.org/10.3390/app15074003