1. Introduction
Machine learning models can be used to predict pavement performance in terms of rutting and fatigue cracking. The use of autonomous trucks in this research further includes the aspects of different later wander modes, lane width variations that are directly linked to the behaviour of autonomous trucks. Autonomous trucks are bound to bring new challenges to current the transport infrastructure system, specifically on the impact of autonomous trucks on pavements. Autonomous trucks can be programmed by the manufacturers to a controlled lateral path within the highway lane. It has been proposed to use the zero lateral wander to improve traffic efficiency and safety [
1]. However, this type of lateral wander has detrimental implications on the pavement. An alternative option is to use uniform wander mode where the channelized loading from autonomous trucks can be minimized by uniformly distributing the lateral paths within the lane [
2]. The performance of uniform wander mode can be further increased by adding the truck platooning function, which works in favour of increased fuel efficiency for autonomous trucks [
3]. Machine learning is part of the artificial intelligence types used in performance prediction modelling of impacts on pavements. Traditional methods for performance evaluation of pavements require complicated calculations and procedures to analyse the data and results. With the provision of a vast variety of available data, predictions based on pavement material properties, traffic details and environmental details can be made. Therefore, the model structure is designed based on the quantitative relationship between input variables and output variables, thereby developing the machine learning model [
4].
The concept of machine learning is used to analyse large data and performance predictions of future pavement performance parameters based on training the algorithm. Machine learning is trained through the examples generated through various iterations of data and developing the relationship between input and output variables [
5]. The artificial neural network (ANN) is composed of several interconnected processing units present in layer forms (input layers, hidden layers, output layer). The ANN is composed of three different types, consisting of the recurrent neural network (RNN), convolutional neural network (CNN) and multi-layer perception neural network (MLPNN), with hidden layers greater than one being part of the deep neural network [
6].
A variety of parameters related to autonomous trucks in terms of traffic speed, lateral wander options, tire types and axle configurations are taken into account. Furthermore, the aforementioned parameters are combined, and their effect on rutting and fatigue damage is evaluated using the data obtained from finite element modelling. The use of machine learning models for fatigue cracking and rutting progression of pavement based on numerous input parameters can significantly reduce the calculation time and quantity of data needed for analysis, since these models are fundamentally proficient for their role in pattern recognition, classification, data identification and predictions [
7].
For fatigue cracking predictions, transfer functions are employed for alligator cracking and longitudinal cracking [
8]. The term Stress Intensity Factor (SIF) has been used previously for performing cracking analysis of asphalt pavements [
9]. Semi-analytical finite element modelling in conjunction with neural networks is performed for evaluating SIF. The neural network models are then trained to yield the SIF based on semi-analytical finite element modelling.
In the existing research, different machine learning models have not been optimized with the k-fold technique, and their prediction capability has not been measured with an extensive range of input and output variables. Moreover, the performance of each model is measured by comparing it with the relevant laboratory results for material behaviour. However, in this research, the mechanical behaviour of the pavement is evaluated by using finite element modelling; therefore, the parameters used are validated beforehand. Thus, in this research, the predictive performance using the finite element modelling is further reinforced by using the machine learning models which serves as a research gap in the current research.
This research provides an alternative option for predicting pavement performance in terms of rutting and fatigue cracking that has previously been predicted using finite element modelling. The addition of further prediction using machine learning models increases the prediction accuracy of the preexisting output variables. Therefore, in the previous research, only the prediction of certain pavement distress mechanisms has been performed directly using machine learning algorithms with a narrow range of input variables. Moreover, this research also integrates the autonomous trucks and their corresponding parameters including lane width variations, lateral wander modes and asphalt thickness variations into machine learning models. Therefore, a wide range of input variables associated with autonomous trucks are included, and evaluation of the prediction accuracy of different machine learning models is performed.
The novelty of this research consists of integrating the machine learning algorithms in predicting the performance indicators of flexible pavements in terms of rutting and fatigue cracking from the preexisting data consisting of input variables and already evaluated output variables. Since finite element modelling can be used to predict the performance of flexible pavements, the use of machine learning algorithms can be included to perform similar predictions but in a fraction of time. Therefore, the focus of this research is to evaluate the performance of different machine learning algorithms available, compare their performance in predictions and outline the best-performing algorithm.
4. Methodology
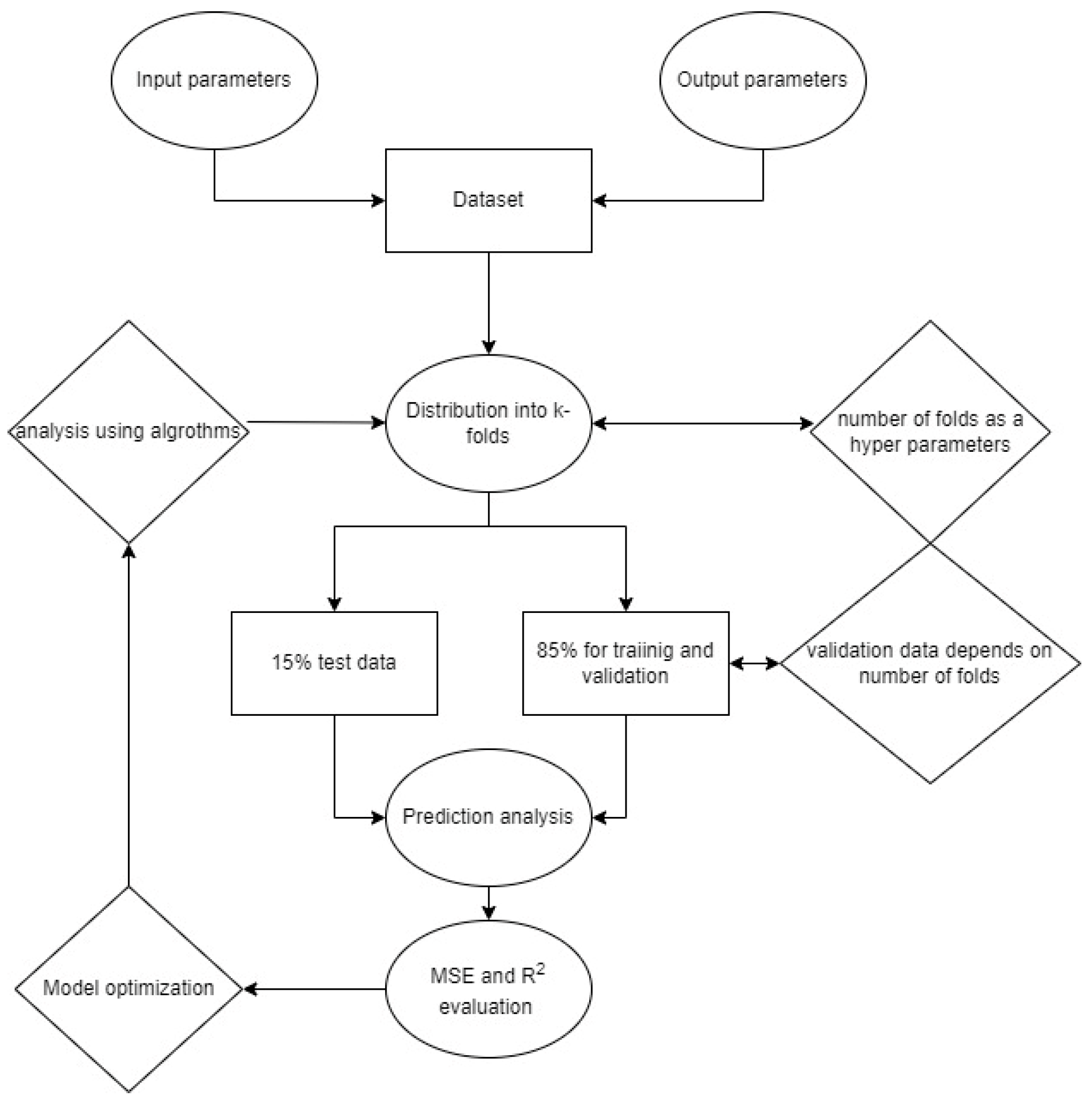
A total of 350 data points have been selected with input and output parameters. Input parameters include axle loading type, total truck load in GWT, lateral wander modes (Uniform and Zero wander), lane width variations (3.75 m and 4.2 m), asphalt layer thickness variations (16 cm and 20 cm) and tire footprint type (dual tire, single wide tire). Output parameters include fatigue life reduction in years, number of passes to fatigue damage, rut depth and number of passes to reach rut depth of 6 mm. For larger data, three forms of data treatment are used to achieve the optimized model for prediction against actual values. This includes training of 70% data, where the first remaining 15% of the data is validated and the last remaining 15% of the data is tested. A brief summary of this research is shown in
Figure 1.
Since the quantity of data points is less and the actual data is validated, the k-fold cross-validation technique is used where the prediction of models is analysed by dividing the data into k subsets or folds. According to the type of algorithm (random forest, decision tree, gradient boosting, K-neighbour, SVR, LightGBM and CatBoost), the number of folds may vary based on the capability of these individual models to predict the results.
As observed from
Figure 2, test data are kept at 15%, and the remaining 85% is kept for validation and training. The amount of data used for validation varies with the number of folds used for each algorithm tested. If there are nine folds for the decision tree algorithm, then 95% of the data is used for validation, and 5% is used for training. Furthermore, number of k-folds are used as a hyperparameter, and the optimum number of folds for each algorithm is evaluated based on the highest prediction strength of each model. Each algorithm possesses a different number of folds and corresponding MSE and R
2 values through iterations. The model is further optimized during prediction analysis where two different metrics are used to evaluate model performance including mean square error and R
2. The MSE values for each algorithm and their corresponding number of folds are averaged and shown in the
Section 6.
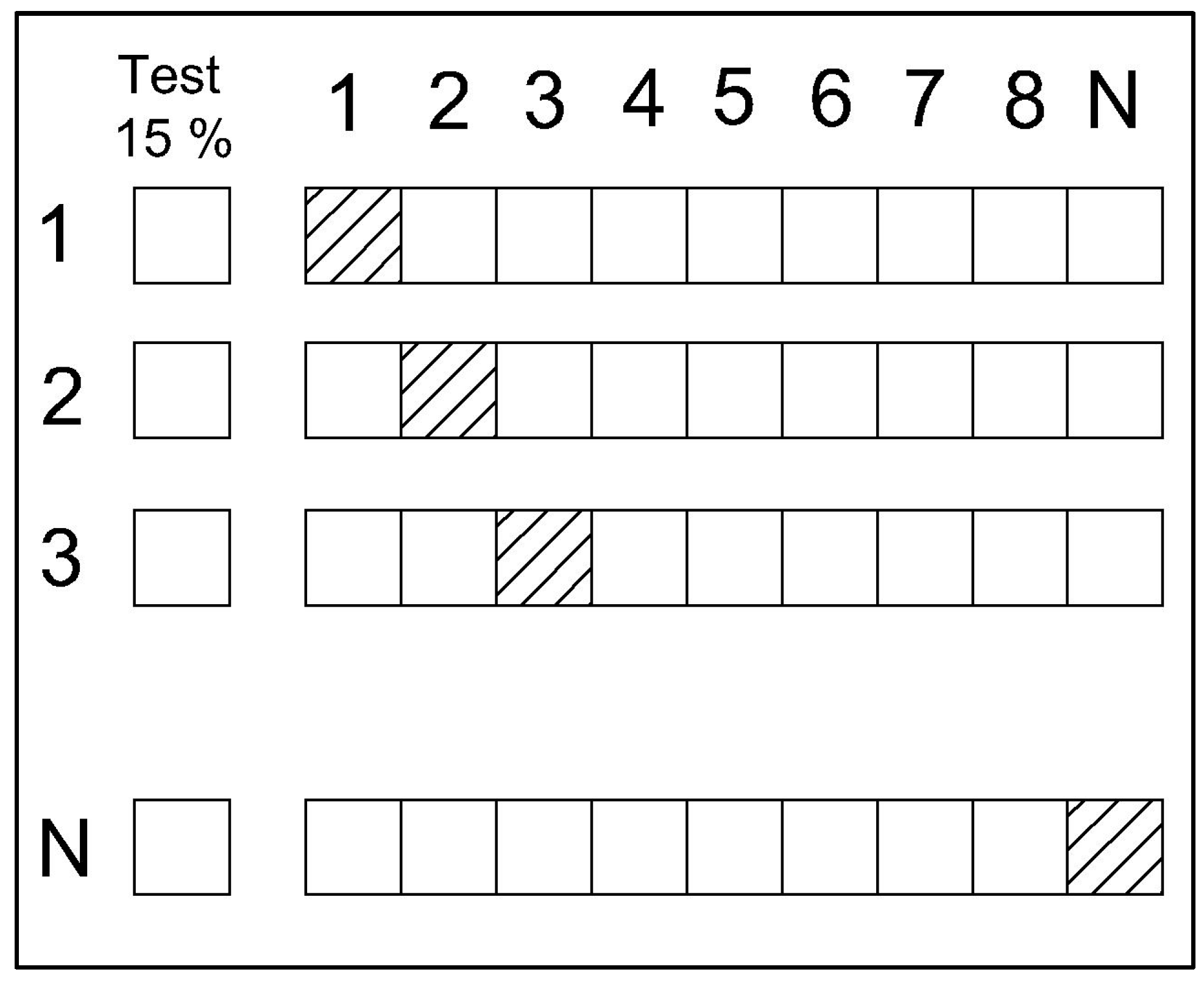
Data analysis based on k-fold validation is shown in
Figure 3. As observed, the test data fold amount is kept at 15%. The data arrangement ranges from zero to N number of folds. Each algorithm optimizes and selects a specific number of folds to increase prediction accuracy for the test, validation and training data. Out of each fold, the training and validation data from each subfold are selected to ensure that all the parameters are included in the data analysis part. Furthermore, all the boxes corresponding to each fold are evaluated, and an optimized number of folds are formed with their corresponding MSE and R
2 values. The shaded portion corresponds to each instance the specific dataset for training and validation was selected for each fold number. Therefore, the hyperparameters optimization related to the fold prediction optimization is carried out to calculate the optimum number of folds for each algorithm, including random forest, SVR, gradient boosting, decision tree, K-neighbour, LightGBM and CatBoost.
4.1. Hyperparameter Optimization
Optimization of hyperparameters using each model is performed where the number of folds is provided, and the optimum number of folds is calculated for each model type used. The range of hyperparameters is chosen based on the number of iterations required for reaching a minimum MSE value; therefore, the following commands are used to calculate the optimum number of folds for hyperparameter optimization. Hyperparameters affect the performance of models in terms of calculated MSE values, with the optimum hyperparameter consisting of the least number of folds for accuracy and time efficiency.
4.1.1. Linear Regression
Number of k-folds = list(range(2, 11)), ‘fit_intercept’: [True, False], ‘copy_X’: [True, False], ‘n_jobs’: [None, −1], ‘positive’: [False, True]
For linear regression, the number of folds between two and eleven is addressed, and parameters including ‘fit_intercept’, ‘copy_X’, ‘n_jobs’ and ‘positive’ are used to optimize the model.
4.1.2. Decision Tree
Number of k-folds = list(range(2, 11)), ‘criterion’: [“squared_error”, “friedman_mse”, “absolute_error”, “poisson”], ‘splitter’: [“best”, “random”], ‘max_depth’: range(3, 26), ‘max_features’: [None, “auto”, “sqrt”, “log2”], ‘min_impurity_decrease’: [0.0, 0.1, 0.2]
For the decision tree algorithm, the number of folds was from two to eleven, and parameters including “squared_error”, “friedman_mse”, ‘splitter’, ‘max_features’ and ‘min_impurity_decrease’ are used to optimize the number of folds with higher prediction accuracy.
4.1.3. Random Forest
Number of k-folds = list(range(2, 11)), ‘criterion’: [“squared_error”, “absolute_error”, “poisson”], ‘max_depth’: [None] + list(range(3, 16))
For the random forest algorithm, the number of folds ranged from two to eleven, with “squared_error”, “absolute_error” and “poisson” used for optimization of number of folds.
4.1.4. Gradient Boosting
Number of k-folds = list(range(2, 11)), ‘learning_rate’: [0.001, 0.01, 0.1, 0.2, 0.3], ‘max_depth’: [3, 4, 5, 6], ‘min_samples_split’: [2, 5, 10], ‘max_features’: [None, ‘sqrt’, ‘log2’], ‘tol’: [1 × 10−4, 1 × 10−3, 1 × 10−2], ‘criterion’: [‘friedman_mse’, ‘squared_error’, ‘mse’]
For gradient boosting, the number of folds ranged from two to eleven, with parameters including ‘learning_rate’, ‘max_depth’, ‘max_features’ and ‘mse’ used for optimization.
4.1.5. KNN Regression
Number of k-folds = list(range(2, 11)), ‘n_neighbors’: [3, 5, 7, 9], ‘weights’: [‘uniform’, ‘distance’], ‘algorithm’: [‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’], ‘leaf_size’: [20, 30, 40], ‘p’: [1, 2, 3], ‘metric’: [‘euclidean’, ‘manhattan’, ‘chebyshev’, ‘minkowski’]
For KNN regression, the number of k-folds ranged from two to eleven, with parameters including ‘n_neighbors’, weights’, ‘leaf_size’ and ‘metric’ used for further optimization.
4.1.6. SVR
Number of k-folds = list(range(2, 11)), ‘kernel’: [‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’], ‘degree’: [2, 3, 4], ‘gamma’: [‘scale’, ‘auto’, 0.1, 1.0], ‘coef0’: [0.0, 0.1, 0.5], ‘C’: [0.1, 1.0, 10.0]
For SVR, the number of k-folds also ranged from two to eleven, with optimization parameters including ‘kernel’, ‘degree’, ‘gamma’, ‘coef0’ and ‘C’.
5. Data Visualization
In this research, the prediction performance of the models based on fatigue life reduction in years, maximum passes to rut at 6 mm, number of passes to fatigue damage and rut depth at 1.3 million passes is analysed based on the input data used. Different numbers of folds for each model using the k-fold cross-validation technique have been developed.
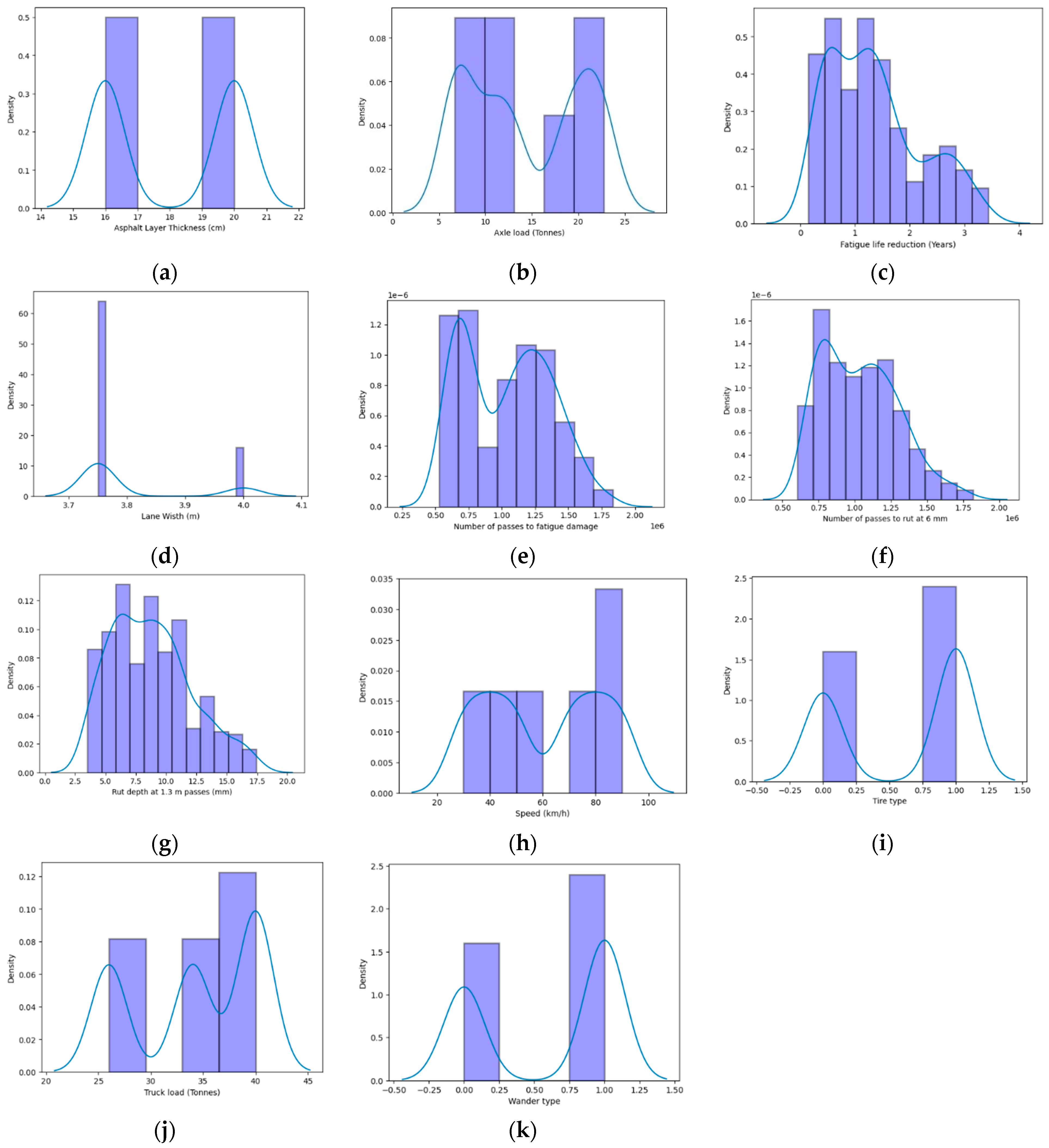
The visualization of data and existing patterns in data are presented. The relationship of input variables and their dependence on each other as well as dependence on output variables are analysed. Frequency of various proportions of input data values including tire types, speed, truck load, axle load, lane width and asphalt layer thickness is evaluated. Furthermore, the frequency and type of input variables used in whole input data series are visualized.
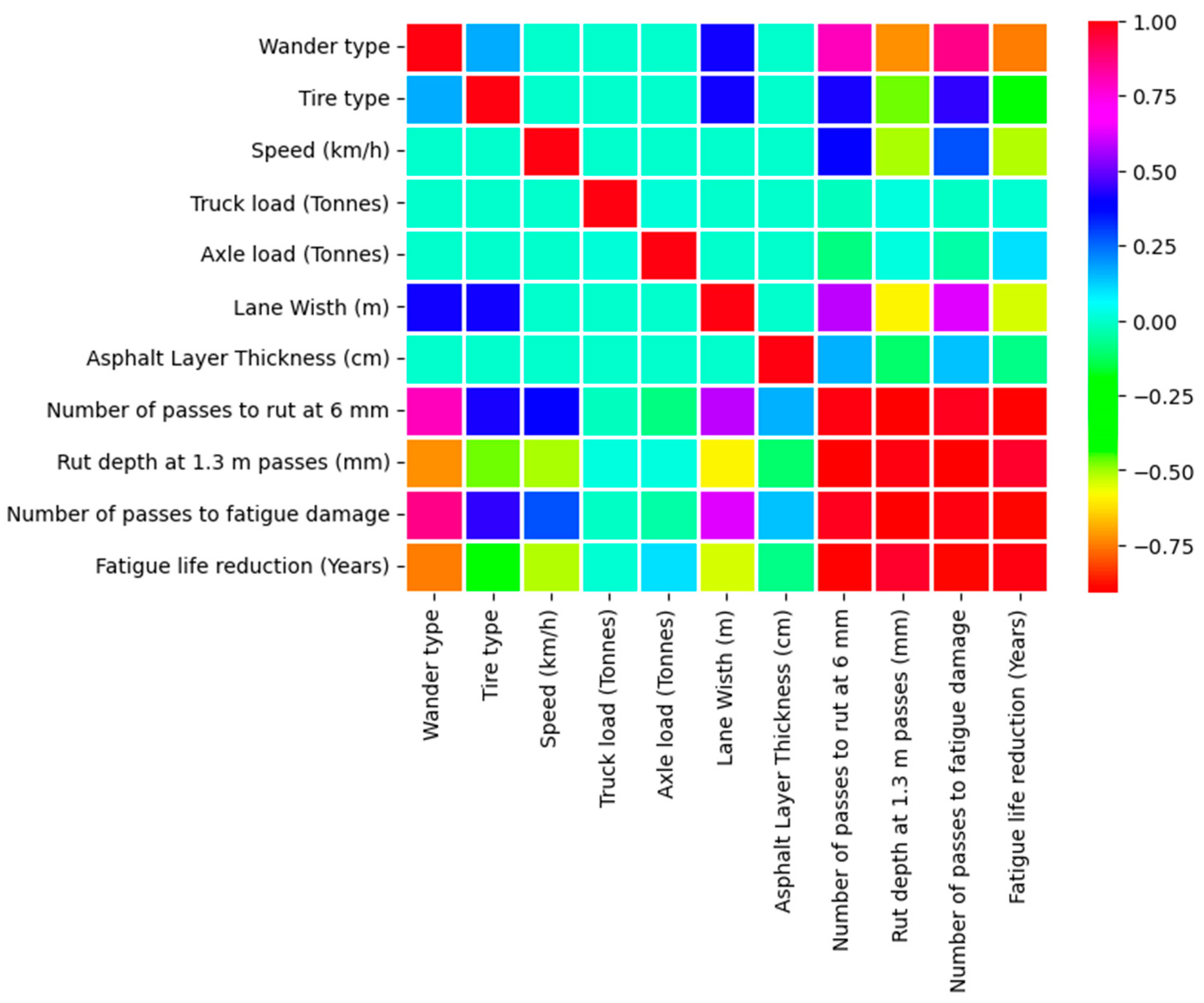
Figure 4 shows the correlation of parameters with a certain degree of dependence based on the colour schemes. Wander type has the highest influence on fatigue life reduction in years. The switch to zero wander mode increases the fatigue life reduction. Furthermore, the increase in speed leads to a decrease in fatigue life reduction, with a correlation value of −0.52. The lane width increment and its relationship with tire type is also visualized. Asphalt layer thickness is not directly related to speed, axle loading and lane width variations. Number of passes to rut depth and number of passes to fatigue damage show the highest relevance with a value of 0.98. The number of passes to fatigue damage and fatigue life reduction behave coherently with a value of −0.89, since fatigue life will decrease with increase in the factor of fatigue life reduction. In terms of rut depth progression, wander type has the highest significance with a factor of −0.72 when switched to uniform wander mode, since the rut depth would decrease. The second most significant parameter affecting the rut depth parameter is the lane width with a factor of −0.59, followed by speed with a value of −0.51.
Correlations of input and output parameters are shown in
Figure 5. Furthermore, the relevance of output parameters among one another and the input parameters among one another can be observed. Wander type and fatigue life reduction are inversely related to each other, and the fatigue life reduction would decrease when the uniform wander mode is used. Asphalt layer thickness and number of passes to fatigue and rut depth at 6 mm are in the range of 0.25 with increase in the number of passes at lower asphalt thickness values. Speed has higher significance than the axle load in terms of number of passes to fatigue damage and number of passes to rut depth at 6 mm. Wander type has the highest significance on all the output parameters, since the use of uniform wander or zero wander would significantly affect the pavement distress. Axles load variation does not create a significant difference between rutting and fatigue damage-related output parameters. Lane width increment also affects the rutting and fatigue damage significantly, and the damage increases with reduction in lane width.
Graphical data visualization of input and output parameters is shown in
Figure 6.
Figure 6a shows the arrangement of asphalt thickness variation in the data used for analysis. The asphalt thickness values ranging from 20 cm to 14 cm are used with decrement of 20 cm, and finite element analysis based on previous research has shown that the ideal use of asphalt layer thickness at 16 cm using 4.2 m of lane width; therefore, most data remain in the vicinity of 16 cm and 20 cm.
According to
Figure 6b, based on three different truck types used, the axle load values are used with variations of 6.7 T, 10.6 T, 22.7 T, 7.3 T, 18.7 T, 13 T and 21 T. The frequency of data consisting of axle load greater than 20 T and between 6.7 T and 17 T is higher than that of 18.7 T.
As shown in
Figure 6c, fatigue life reduction is provided in terms of the number of reduced years in fatigue life. In most of the scenarios, fatigue life reduction remains at 0.8 years and 1.2 years, individually calculated under each axle. In some instances, where a zero wander mode is used with dual tires at low speeds, the fatigue life reduction reaches 3.3 years.
Since the lane width of 4 m as shown in
Figure 6d was found to be ideal for reduced pavement distress for autonomous trucks, only two data variations are provided, consisting of the base scenario of 3.75 m and 4 m.
Based on the effect of parameters including speed, axle type and lateral wander mode type, most of the reduced number of passes to fatigue damage can increase to 1.7 million where zero wander mode is used at low speeds. In the case of a uniform wander mode, the magnitude decreases to 62,000 passes, showing a major shift in the
Figure 6e.
As observed from
Figure 6f, the highest frequency of data entries exists at 75,000 passes due to the usage of zero wander mode. When uniform wander mode is used as the data move towards the right, a lower number of passes are needed to reach the similar rut depth of 6 mm. In the case of a zero wander mode, around 1.75 million passes are required to reach the rut depth of 6 mm, exhibiting the lowest frequency of data entry.
As observed from
Figure 6g, rut depth values are input, ranging from as low as 3.3 mm in cases of uniform wander modes to 17.2 mm in cases of slow speeds at zero wander mode with axle load of 22.7 T. Furthermore, the use of dual tire and zero wander mode significantly increases the rut depth; however, the highest frequency of rut depth inputs remains in the vicinity of 6 mm and 8 mm.
Speed values ranging from 30 km/h to 90 km/h are used for the input data in
Figure 6h. However, the higher frequency of speed values at 90 km/h is utilized for assessing the variations in rut depth and fatigue damage values at normal operating speeds.
As observed from
Figure 6i, the single wide tire and dual tire types are used for input. The bar line on the left indicates the use of a dual wheel setup, since the single wheel setup is going to be beneficial for the pavement distress; therefore, further data entries for a single wide tire are included for detailed analysis of pavement distress.
As observed from
Figure 6j, three different truck types are used for input and analysis based on their GWT. A class-1 type truck has a GWT of 40 T with 5 axles; a class-2 type truck has a GWT of 26 T with 2 axles; and a class-3 type truck has a GWT of 34 T with 4 axles. Since the class-1 type truck has more axles, and it is the truck with the highest percentage in the traffic mix, the frequency of data consisting of class-1 trucks is higher than other two types.
As observed in
Figure 6k, data from two lateral wander modes consisting of uniform wander and zero wander modes are included. Since the uniform wander mode performs better than the zero wander mode, it has more data entries for comparisons with other parameters.
6. Results
Prediction of output variables using all the models along with MSE and R
2 values is presented. Each model uses a specified number of folds based on the extent of output variables. For number of passes to fatigue and rut damage, the MSE increases for all the models; however, when rut depth and fatigue life reduction are evaluated, the MSE stays the minimum. Furthermore, the data scatter for predicted values and actual values is shown along the perfect prediction line.
Figure 7 shows the performance prediction in terms of fatigue life reduction for different models.
Figure 7a shows comparison of actual calculated and predicted values using the decision tree algorithm. Fatigue life reduction in terms of reduced number of years as a result of zero wander mode are predicted based on the input data. As observed, a total of nine optimized folds are developed using the k-fold technique, and the maximum proficiency of the model was contained against the nine folds. All the folds generate an MSE of 0.00. However, Fold 9 kept the predicted values closer to the actual values.
Figure 7b shows the comparison of values using the gradient boost. As observed, the predicted values lie closer to the centre line, and all folds exhibit the same performance. A total of nine folds have been developed for further optimization of this algorithm.
Figure 7c shows the comparison of predicted reduced fatigue life in number of years and actual fatigue life reduction as used in input using the KNN algorithm. As observed, the predicted values for all the folds are scattered with MSE of 0.04 among all the folds. KNN shows lower performance prediction efficiency as compared to other analysed models.
In
Figure 7d, linear regression has been used to evaluate the prediction performance for reduced life in number of years as a result of fatigue damage. A certain pattern can be observed for all the folds analysed using linear regression. Based on the prediction performance evaluation, linear regression yields the minimum MSE of 0.05 for Fold 9 and Fold 3. However, the overall predictive performance of linear regression model is less than that of the K-neighbour algorithm.
In
Figure 7e, the random forest algorithm has been used to evaluate the correlation of predicted values with actual values. This algorithm yields the MSE of 0.00 for the majority of folds. However, the scatter in prediction is higher than that of the gradient boosting algorithm.
In
Figure 7f, SVR has been used to predict the reduction in fatigue life in years. SVR only requires a total of five folds to perform optimization for a model. Furthermore, SVR yields the MSE of 0.00 for all the folds considered. However, the data scatter is higher than that of the gradient boosting model.
Prediction of reduced fatigue life and comparison with actual values are shown in
Figure 7g. As observed, the minimum MSE is obtained at 0.000 and R
2 of 1.0000. CatBoost regression outperforms other models in terms of prediction accuracy and matching with the actual values for fatigue life reduction in number of years.
Figure 7h above shows the comparison of predicted and actual values using LightGBM. As observed, the model yields accurate results with MSE of 0.001 and R
2 of 0.999. LightGBM is the second-best machine learning model after CatBoost.
MSE and R
2 values for prediction of fatigue life reduction in years are shown in
Table 1. As observed, the highest MSE is shown by linear regression with a value of 0.056 and a corresponding lowest R
2 value of 0.9023. Furthermore, CatBoost regression exhibits the highest prediction performance among other models with an MSE of 0.000 and R
2 of 1.000. Gradient boost and LightGBM exhibit the least scatter in predicted data values showing close correspondence to the actual values. However, decision tree, random forest, KNN and SVR also depict good prediction capabilities.
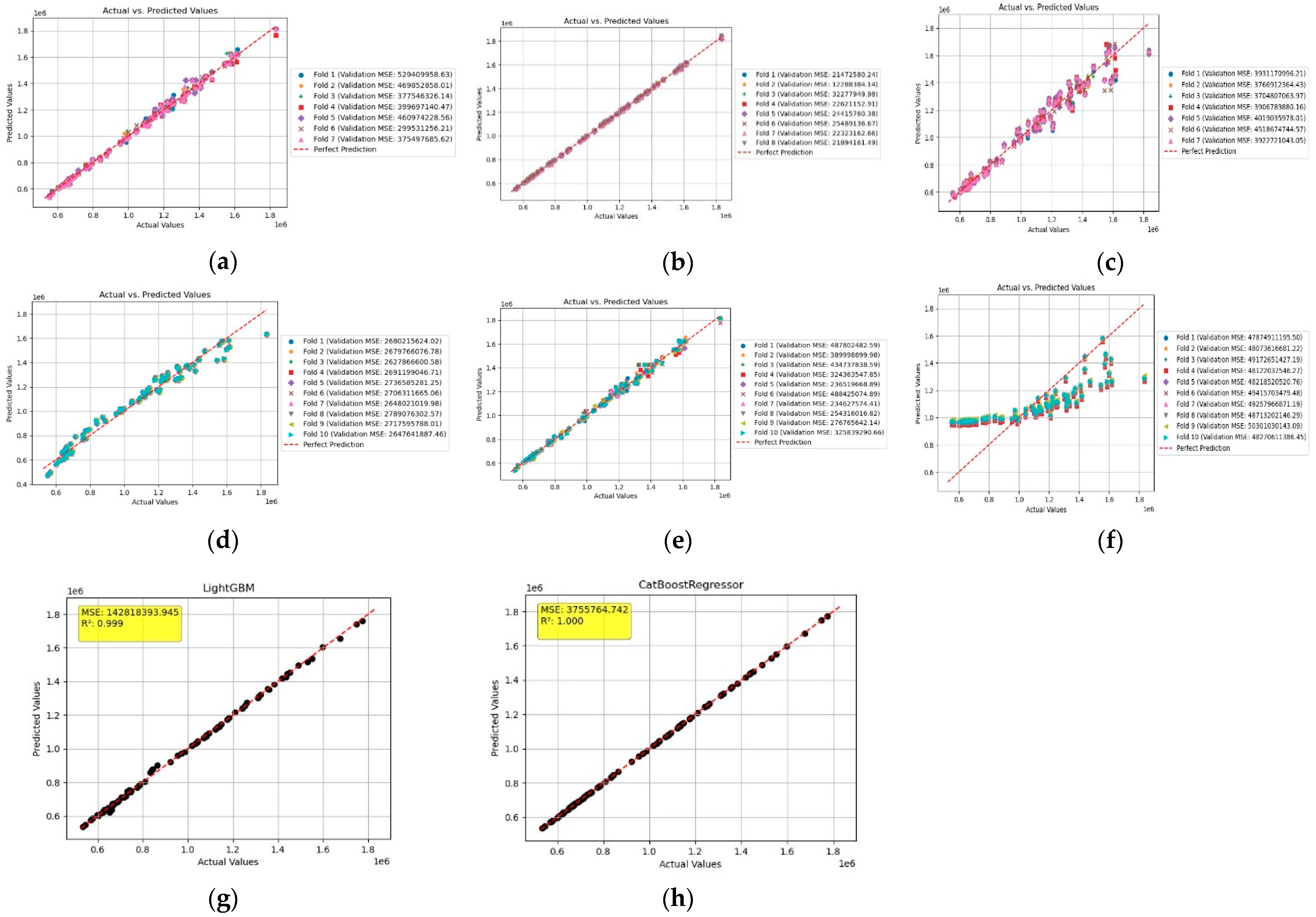
Figure 8 shows the performance prediction in terms of number of passes to fatigue damage for different models.
Figure 8a shows the comparison of MSE for predicted and actual values in terms of number of passes to fatigue damage using the decision tree algorithm. Higher magnitude of MSE values correspond to an increased number of passes to fatigue damage in the range of millions. A total of seven folds have been developed. Fold 6 yields the minimum MSE of 299,531,256.21. The decision tree algorithm exhibits increased prediction performance with little scatter at higher number of passes to fatigue.
In
Figure 8b, comparison of predicted and actual values is shown using gradient boost. As observed, predicted values stayed on the perfect prediction line exhibiting no scatter. A total of eight folds have been developed. Fold 2 yields the least MSE of 12,288,384.14. Gradient boost outperforms other models with reduced scatter.
In
Figure 8c, predicted values are compared against the actual values using the K-neighbour algorithm. Increase in scatter from the actual values can be observed at a higher number of passes. A total of seven folds have been developed, with Fold 7 yielding the minimum MSE of 3,922,721,043.05.
In
Figure 8d, predicted values are compared against the actual values using linear regression. Scatter from linear regression is slightly reduced when compared to K-neighbour. Furthermore, MSE has been further reduced to 2,627,866,600.58 at Fold 3. The scatter increases as the number of passes are increased
In
Figure 8e, predicted values are compared against the actual values using random forest. A total of 10 folds have been developed, with Fold 7 exhibiting the least MSE of 234,627,574.41. Scatter in predicted values is better than that of KNN and linear regression. Predicted value are at the perfect prediction line at a lower number of passes; however, increase in scatter can be observed at passes more than 1.2 × 10
6.
In
Figure 8f, predicted values are compared against actual values using SVR. As observed, SVR shows the highest scatter and offset in predicted values when compared to actual values among other algorithms. Fold 4 exhibits the least MSE of 48,122,037,546.27.
Performance of LightGBM based on predicted and actual values is shown in
Figure 8g. As observed, LightGBM shows overall accurate prediction capacity with slight scatter in prediction along the intermediate and higher number of passes due to non-linear behaviour of asphalt mixture related to fatigue damage. LightGBM yields MSE of 1.428 × 10
8 and R
2 of 0.999.
Predicted and actual values for CatBoost regression are shown in
Figure 8h. As observed, predicted values stay on the perfect prediction line exhibiting highest prediction performance among other models. Least MSE of 3.755 × 10
6 is observed with R
2 of 1.000.
Comparisons of MSE and R
2 values for number of passes to fatigue damage have been shown in
Table 2. As observed, CatBoost exhibits the least MSE of 3.755 × 10
6 and maximum R
2 of 1.000, followed by LightGBM with MSE of 1.428 × 10
8 and R
2 of 0.999. SVR, however, exhibits the highest MSE of 4.874 × 10
10 and R
2 of 0.5375.
Figure 9 shows the performance prediction in terms of number of passes to reach rut depth of 6 mm for different models.
Figure 9a shows the prediction capability of the decision tree algorithm for maximum number of passes to reach rut depth of 6 mm for zero wander mode. Since the number of passes are in the range of a million in some instances, these graphs have been developed and scaled accordingly to exhibit higher MSE values. A total of nine folds for the decision tree algorithm have been developed, and Fold 3 exhibits the least MSE among other folds, with a magnitude of 454,458,547.
Figure 9b shows the prediction of values in terms of number of passes to reach rut depth of 6 mm using gradient boosting. As observed, a total of 10 folds have been developed to further optimize the prediction model. Least MSE is observed at Fold 7, with a value of 22,056,971.7. The graph shows the least amount of data scatter among other algorithms used. Furthermore, the predictive performance of the gradient boosting model surpasses the decision tree algorithm.
In
Figure 9c, the predicted values have been plotted against the actual values using the KNN algorithm. Increased data scatter can be observed at a higher number of passes, where rut depth suddenly increases leading to increased prediction deficiency for this model. Least MSE has been observed by Fold 4, with an MSE of 6,335,127,849.05.
Figure 9d shows linear regression being used to predict the values. The scatter pattern is the same as that of the KNN algorithm where scatter increases at a higher number of passes. However, the extent of scatter is less than that of KNN. A total of 10 folds have been developed for model optimization. Least MSE stays at 4,351,218,590.71, which outperforms the prediction capability of the KNN algorithm.
In
Figure 9e, predicted values for number of maximum passes to rut depth at 6 mm are shown using random forest. A total of 10 folds have been developed for model optimization. As observed, the random forest algorithm outperforms KNN and linear regression models, exhibiting an MSE of 350,754,482.9.
In
Figure 9f, SVR has been used to predict the values for maximum passes to rut depth at 6 mm. As observed, significant increase in data scatter occurs when compared to other algorithms. A total of 10 folds were developed. Fold 3 exhibits the least MSE of 29,456,518,554.68 among other folds. However, the MSE of SVR is significantly higher than other models.
Figure 9g shows the comparison of predicted and actual values for decreased number of passes as a result of fatigue damage. As observed, CatBoost performs well with higher accuracy than other models, yielding the lowest MSE of 5,934,373.659 and R
2 of 1.000. All the data points stay on the perfect prediction line.
Predicted and actual values from LightGBM are shown in
Figure 9h. LightGBM shows overall good performance, with slight scatter in data at mid-range and high-range values. At intermediate and higher numbers of passes, some discrepancy between the predicted and actual values can be observed. However, LightGBM yields MSE of 240,337,676.967 and R
2 of 0.997.
Comparison of MSE and R
2 values for maximum number of passes to reach rut depth of 6 mm is shown in
Table 3. As observed, CatBoost exhibits the least MSE of 5.934 × 10
6 among other models and a maximum R
2 of 1.000. Furthermore, the highest MSE exists for SVR, corresponding to a related R
2 of 0.5656. However, gradient boosting, random forest and LightGBM provide significant prediction capabilities, with R
2 of 0.9995, 0.9893 and 0.997, respectively, among other algorithms.
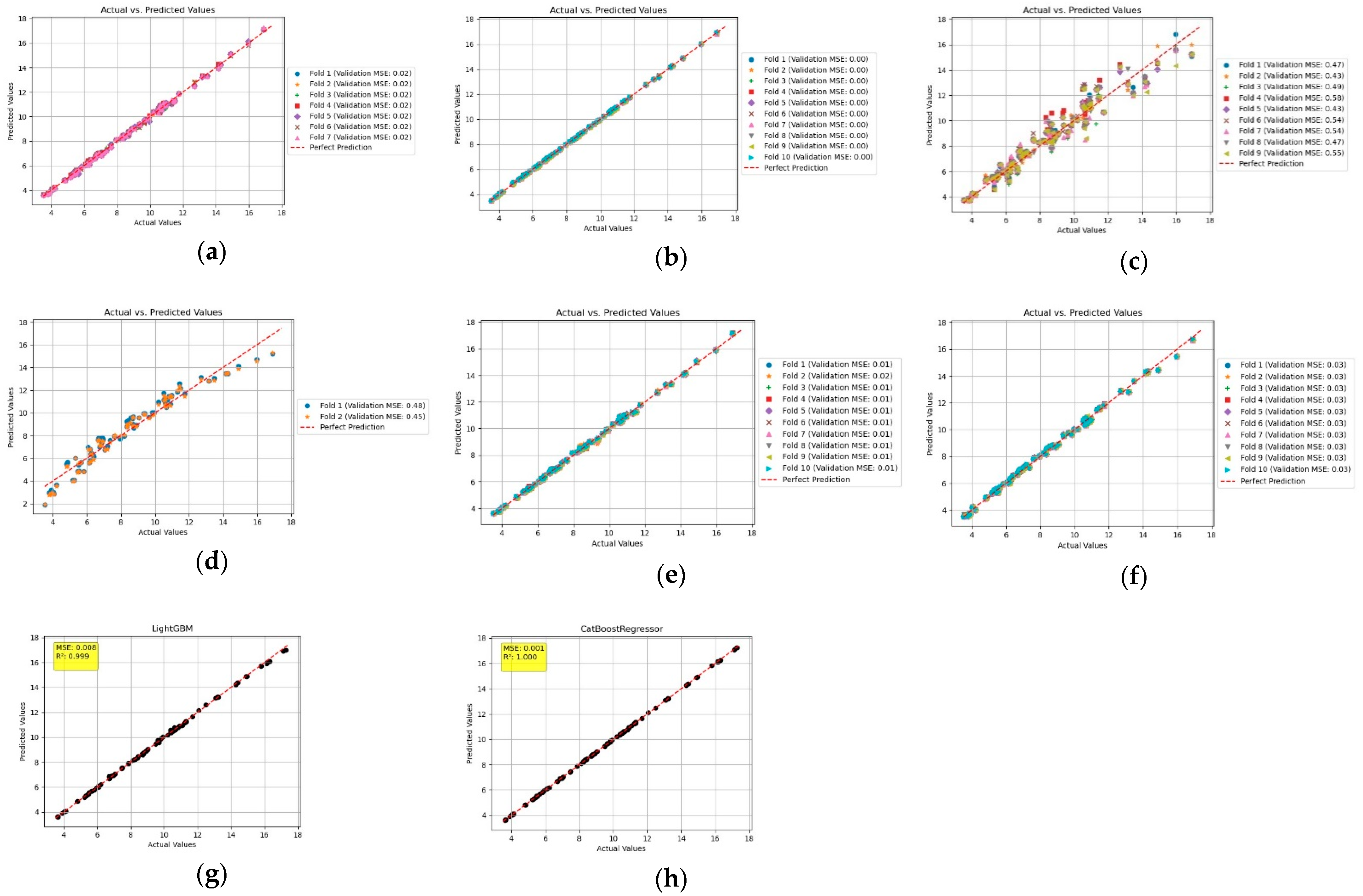
Figure 10 shows the prediction performance in terms of rut depth at 1.6 million passes for different models. In
Figure 10a, predicted and actual rut depth values based on the number of passes have been shown using the decision tree algorithm. A total of seven folds have been developed, with all folds exhibiting the MSE of 0.02. As observed, predicted values stay closer to the perfect prediction line.
In
Figure 10b, gradient boosting has been used to evaluate the predicted and actual values for rut depth. A total of 10 folds have been developed, and all folds exhibit the MSE of 0.00. Gradient boosting outperforms the decision tree algorithm in terms of proximity of data points to the perfect prediction line.
In
Figure 10c, the KNN algorithm has been used to compare the predicted value against the actual values. A total of nine folds have been used for model optimization. Fold 2 and Fold 5 exhibit the least MSE of 0.43. However, the data scatter for predicted values is significantly higher than other models. The data scatter increases at higher rut depth values.
In
Figure 10d, linear regression has been used to predict the values for rut depth under specified passes and lateral wander type used. Only two folds have been developed for model optimization, and increase in folds did not enhance the model’s prediction capability. Fold 2 exhibits the minimum MSE of 0.45. As observed, the predicted values stay closer to the perfect prediction line around intermediate rut depth values; however, the scatter increases at lower and higher rut depth values. This model outperforms the KNN, but the predictive performance is less than that of gradient boosting and decision tree.
In
Figure 10e, the random forest algorithm has been used to predict the values for rut depth based on the input data. A total of 10 folds have been developed for model optimization. Minimum MSE of 0.01 is obtained. Data scatter for random forest corresponds to that of the gradient boosting and decision tree algorithms.
In
Figure 10f, SVR has been used to predict the values for rut depth. A total of 10 folds have been used. As observed, data scatter stays closer to the perfect prediction line, leading to an MSE of 0.03 for all the folds. Data scatter increases at higher rut depth values.
Predicted and actual values for rut depth at 1.3 million passes using LightGBM are shown in
Figure 10g. As observed, the model exhibits good prediction accuracy, with predicted values staying on the perfect prediction line; however, slight offset from the perfect prediction line can be observed at higher rut depth values. LightGBM exhibits MSE of 0.008 and R
2 of 0.999.
Figure 10h shows the predicted and actual values using the CatBoost regression. CatBoost outperforms other models in terms of the least MSE of 0.001 and R
2 of 1.000. As observed, the values stay on the perfect prediction line, with no offset even at higher rut depth values.
MSE and R
2 for all the models based on rut depth prediction performance have been shown in
Table 4. As observed, CatBoost outperforms other models, with the least MSE of 0.001 and corresponding R
2 of 1.000. KNN exhibits larger offset of predicted values, with an MSE of 0.499082 and corresponding R
2 of 0.9452. Prediction performance of LightGBM stays closer to gradient boosting, with MSE of 0.008 and R
2 of 0.999.
7. Discussion
In this research, different machine learning algorithms have been used to perform performance predictions of asphalt pavement in terms of fatigue damage and rutting. Furthermore, the relationship and dependency between input and output variables have been analysed for 350 data points. K-fold optimization technique has been used to optimize the hyperparameters and the corresponding number of folds for each machine learning algorithm used. The machine learning algorithms used are linear regression, decision tree, random forest, gradient boosting, K-nearest neighbour, SVR, LightGBM and CatBoost. As observed from the results, CatBoost and LightGBM outperform other machine learning models in terms of reduced MSE and R2 values. Furthermore, the hyperparameters for LightGBM and CatBoost can be optimized easily with fewer numbers of folds, leading to time efficiency in performance predictions. The least performance is exhibited by linear regression and in some instances by KNN.
In the case of a higher number of passes used both for fatigue damage and rut depth, scatter in the results for SVR increases significantly. KNN and linear regression are also affected by a higher number of passes, where scatter in predicted values increases beyond 1.2 × 10
6 passes, as shown in
Figure 8c and
Figure 8d, respectively. Decision tree and random forest show better overall performance than the aforementioned models. CatBoost leads to the use of the minimum number of folds required to reach the minimum MSE of 0.001 in cases of rut depth at 1.6 million passes. Furthermore, LightGBM also exhibits a closer performance to CatBoost in terms of reduced MSE. The inclusion of categorial boosting and arrangement of hyperparameters for both of these models leads to higher prediction efficiency when compared to other models.
Predictive performance of LightGBM is followed by gradient boosting and random forest. CatBoost performs best in all scenarios, whether it is the number of passes to fatigue and rut damage or fatigue and rut life reduction in number of years. Both LightGBM and CatBoost are specific implementations of the gradient boosting machine (GBM) algorithm, which builds trees sequentially by correcting the errors of the previous trees. This iterative correction process helps in reducing bias, leading to better performances as observed in
Figure 7g and
Figure 7h, respectively. Moreover, LightGBM and CatBoost employ advanced techniques like histogram-based approaches and categorical feature handling (CatBoost), which significantly improve training speed and accuracy. These models are less prone to overfitting compared to simpler models like decision trees because they include regularization techniques like shrinkage (learning rate), early stopping and pruning. Regularization ensures that the models do not memorize the training data but generalize well to unseen data, which is crucial for achieving lower MSE and higher accuracy.
Linear regression assumes that there is a linear relationship between the input features and the target variables. However, in cases like predicting fatigue and rutting damage, the relationship is likely complex and non-linear with high scatter, as shown in
Figure 9d. Linear models are unable to capture this complexity, leading to lower accuracy, higher scatter in predictions and increased MSE. This explains why linear regression performs poorly in this context.
K-nearest neighbour works by finding the closest neighbours to a given data point and predicting the output based on their values. While this method can work well for simple datasets, it struggles with high-dimensional or large datasets, particularly when there is noise or irrelevant features. The model has no internal mechanism to handle feature interactions or non-linearity, and its predictions can be highly sensitive to the choice of k (the number of neighbours) and the distance metric. Moreover, KNN can suffer from issues such as overfitting or underfitting, especially if the data have many irrelevant or noisy features, as observed in
Figure 10c where the scatter increases with the increase in rut depth magnitude. This leads to reduced prediction accuracy and high variance in its performance.
Decision trees can model complex relationships and non-linear data patterns. However, they have a tendency to overfit the training data if not properly pruned or regularized with less scatter in terms of fatigue life reduction in number of years, as shown in
Figure 7a, and rut depth at 1.6 million passes, as shown in
Figure 10a. While decision trees provide interpretable results and perform well in capturing feature interactions, their performance often degrades when there is noise in the data.
SVR is designed to model non-linear relationships by mapping the input data to a higher-dimensional space via a kernel function. While SVR can capture complex data patterns, it is highly sensitive to hyperparameters such as the choice of kernel, regularization parameters and the trade-off between bias and variance, leading to further deterioration in prediction performance with very high scatter with higher magnitudes of numbers, as shown in
Figure 8f and
Figure 9f. If these parameters are not carefully tuned, SVR can underperform, especially in the presence of noisy data or with large datasets. SVR also requires careful preprocessing, like feature scaling, to perform optimally.
Random forest generally performs better than a single decision tree because it averages multiple trees to reduce variance and overfitting. However, it does not take into account the errors of previous trees in the way that gradient boosting, LightGBM and CatBoost do, leading to less refinement in predictions, which can be observed in
Figure 9e, in terms of number of passes to reach rut depth of 6 mm. While random forest is robust, less prone to overfitting and more interpretable than other models like SVR, it still cannot reach the accuracy of boosting-based methods in terms of predictive power, particularly in complex, high-dimensional datasets. Random forest benefits from the fact that multiple trees are averaged, reducing variance, but it does not have the advantage of boosting, which can systematically focus on difficult-to-predict cases. Gradient boosting models (like LightGBM and CatBoost) tend to perform better because they correct errors from the previous trees, which allows them to make more refined and accurate predictions. These models can be used for a variety of applications based on the availability of input parameters as used in this research; however, the effect of temperature variations as input variables and their correlation with output variables and the resulting fatigue cracking and rutting damage has not be considered as part of this research, including the use of statistical significance of each model type and error distribution in the prediction evaluation for each model which shall be included in the future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}