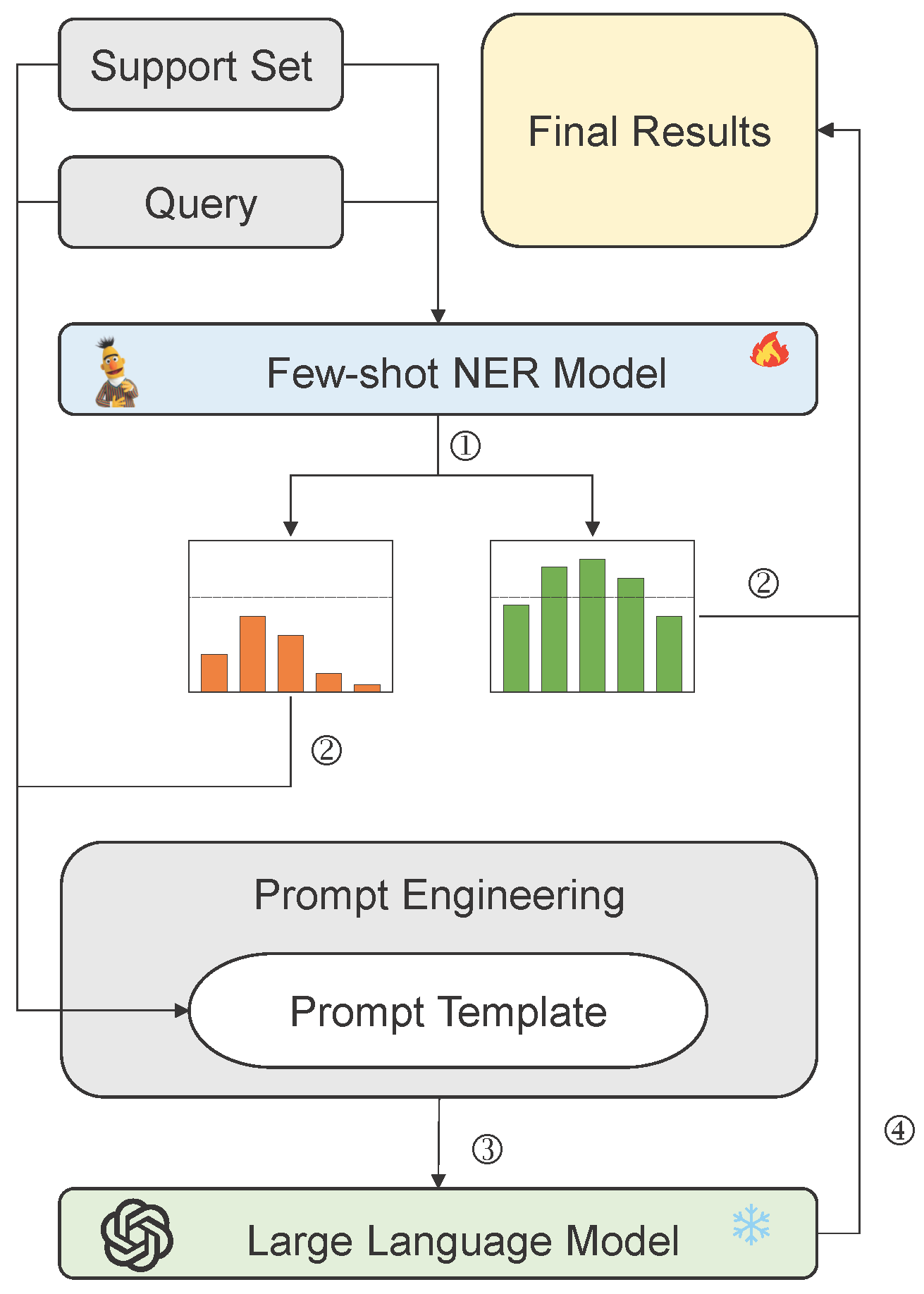
4.2. Experimental Setup
To reduce experimental costs, we sample subsets from the test datasets. For the Few-NERD, we randomly select 100 support sets and 100 query sets are randomly selected. For the CrossNER, we select 200 support sets and 200 query sets in the 1-shot setting, and 100 support sets and 100 query sets in the 5-shot setting. In the main experiments, chain-of-thought prompting, metacognitive prompting, and self-verification prompting are not applied. Experiments related to prompt engineering are discussed in
Section 4.7.
We choose LACNER as the metric learning-based few-shot NER model. In the experiments, LACNER’s hyperparameters and setting are exactly the same as those reported by Xiao et al. [
17]. For LLMs, we employ various open-source models. To expedite inference, we employ vLLM and set the temperature parameter to 0 to ensure accuracy in the generated results. All models, except for DeepSeek-V2.5, which is accessed via an external API, are executed on a single A100 GPU (Nvidia, Santa Clara, CA, USA).
To ensure fairness, we generate three sets of few-show NER model predictions, each using a different random seed, and subsequently feed these predictions into the LLM to minimize randomness. Each experiment is repeated three times, and the average micro-F1 score is reported. We use BGE-large-en-v1.5 as the sentence embedding model. Furthermore, all F1 scores mentioned in this paper refer to micro-F1.
4.4. Analysis of the Impact of Thresholds on Model Performance
By setting threshold
appropriately, uncertain or potentially misclassified samples are redirected to the LLM for re-prediction. The process of appropriately setting the threshold
is detailed in
Appendix A. To validate the effectiveness of the LLM in handling low-confidence predictions, we conduct experiments on the CoNLL-03 using Qwen-2.5-14B. As shown in
Figure 5, we explore two threshold configurations: (1) setting
, where all samples are classified only by LACNER, and (2) setting
, where the LLM re-predicts every entity word identified by LACNER.
Figure 5 demonstrates that for low-confidence predictions,
achieves the higher F1 score than LACNER alone, whereas for predictions with higher confidence, LACNER alone performs better. It shows that when the confidence of prediction is low, the LLM leverages its extensive world knowledge and reasoning capabilities to correct recognition errors. Thus, integrating the LLM with the metric-based few-show NER model enhances overall performance.
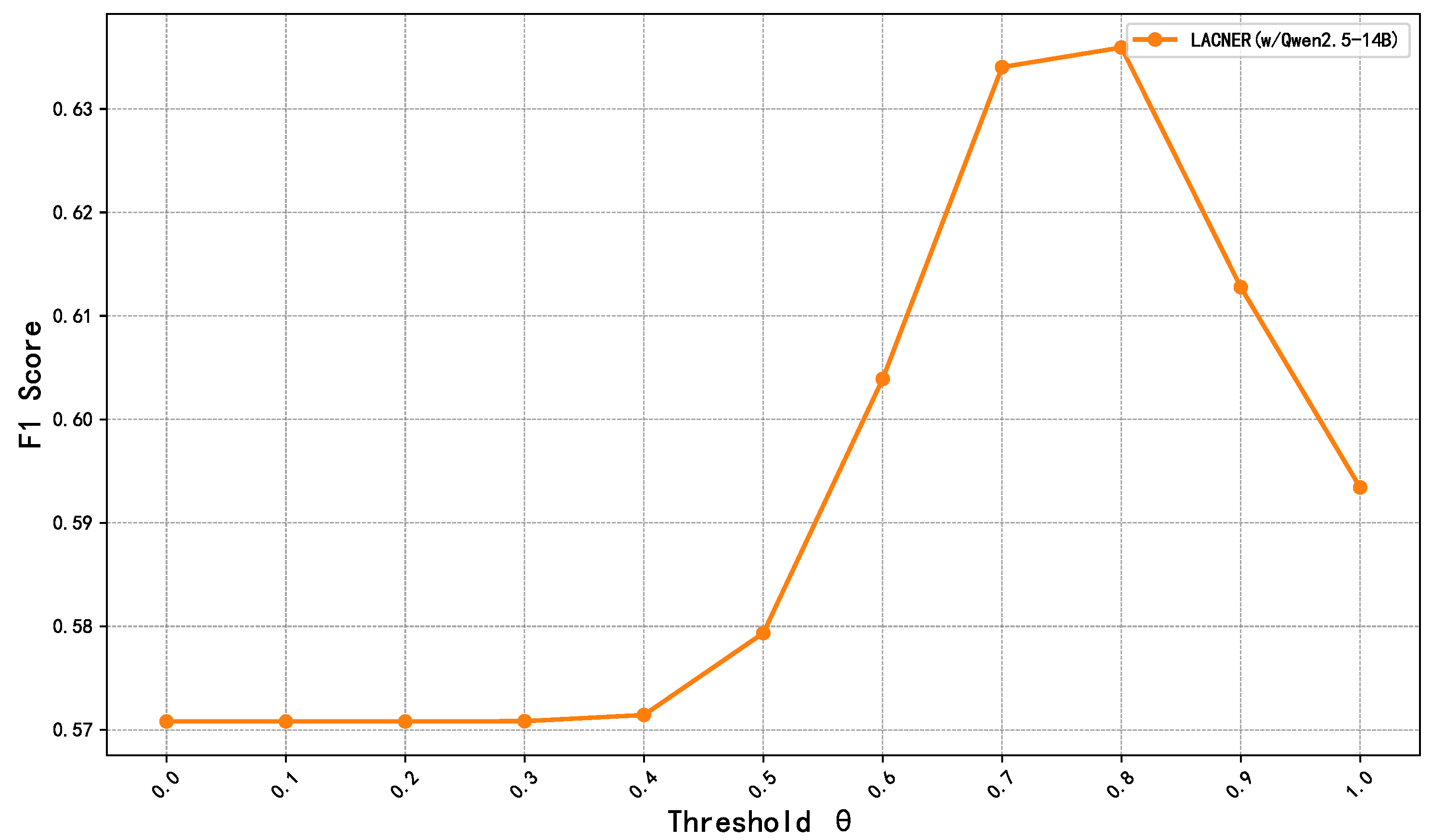
We next analyze the impact of threshold selection on the performance of model. As shown in
Figure 6, we evaluate
by choosing ten threshold points at intervals of 0.1. The results show that as
varies, the F1 score initially rises before declining. At lower thresholds, the LLM corrects many misclassified samples, leading to improved overall performance. However, at higher thresholds, the LLM erroneously modifies correct predictions, resulting in performance degradation. This trend suggests that applying the LLM to high-confidence samples may introduce additional errors, diminishing overall performance. Thus, selecting an optimal threshold is crucial for maximizing the collaborative benefits of both the few-shot NER model and LLM.
4.5. Comparison with Other Methods
In this section, we conduct experiments on various open-source LLMs with different parameters, comparing the performance of different methods and exploring the contributions of various LLM to LACNER. The experimental results are shown in
Table 2 and
Table 3.
As shown in
Table 2, the performance of few-shot NER methods based on the LLM improves significantly with increasing the parameter of the LLM. For example, in the 1-shot setting, when the parameters of the Qwen2.5 series increase from 7B to 14B, the F1 score on all datasets improves. Specifically, Qwen2.5-14B achieves up to 10.84% higher F1 score compared to Qwen2.5-7B. Additionally, DeepSeek-V2.5, which has the largest number of parameters, exhibits the maximum F1 improvement of 24.9% over Llama3.1-8B. It indicates that the larger parameter LLM possess richer world knowledge and stronger reasoning capabilities, leading to better generalization and few-shot learning performance in extremely low-resources.
However, as the number of examples increases, the performance gains of the LLM tend to plateau, meaning the benefit from more examples becomes limited. In contrast, LACNER leverages metric learning to fully capture domain-specific knowledge, and its performance gap with the LLM widens as the number of training samples grows.
Re-identifying low-confidence entity words filtered by LACNER using large models leads to significant improvements across all settings. In the 1-shot setting, compared to using LACNER alone, achieves the F1 improvement ranging from 2.27% to 8.99%, with an average gain of 6.73%. These results indicate that the extensive knowledge and strong reasoning capabilities of the LLM compensate for LACNER’s limitations in representation learning for certain entity types, as well as classification errors due to limited support set examples, thereby enhancing overall performance. In the 5-shot setting, as LACNER learns entity representations more effectively, fewer samples require re-identification by the LLM, leading to smaller performance gains compared to the 1-shot setting. Nevertheless, achieves the average F1 improvement of 3.06%.
Overall, the integration of the LLM enhances LACNER’s performance; both Qwen2.5-14B and DeepSeek-V2.5 significantly boost LACNER’s performance in the 1-shot and 5-shot settings. These findings confirm that the parameter scale and pretraining quality of the LLM significantly impact their generalization and knowledge transfer capabilities in downstream tasks.
Furthermore, compared with LLM Rerank, improves the average F1 score by 3.44% in the 1-shot setting and by 1.55% in the 5-shot setting. It indicates that restricting the scope of predicted labels can enhance the classification accuracy of the LLM. Additionally, the structured prompting approach proposed in this study outperforms the multiple choice prompting used in LLM Rerank by improving the LLM’s understanding of task requirements and providing relevant background knowledge.
Compared with CrossNER, the Few-NERD contains a greater variety of entity labels with finer granularity, a larger labeling space, and higher differentiation complexity. On CrossNER, the LLM performed well in the 1-shot setting, benefiting from their extensive prior knowledge. However, when applied independently to Few-NERD, the LLM demonstrated lower performance, particularly in the INTRA, where the disparity is more pronounced. It suggests that as task complexity and label granularity increase, LLMs face greater challenges.
Although integrating an LLM with LACNER continues to enhance performance, the improvements become increasingly nuanced. Specifically, in the INTRA setting, improves the average F1 score by 1.76% compared to LACNER, while in the INTER setting, it achieves a 1.52% improvement. The disparity in these collaborative improvements narrows, suggesting that as task complexity increases, LLMs face greater challenges.
Finally, compared with LLM Rerank, achieves the average F1 improvement of 0.95% in the INTRA setting and 0.78% in the INTER setting. Moreover, unlike LLM Rerank, it removes the need for manually creating the COT examples.
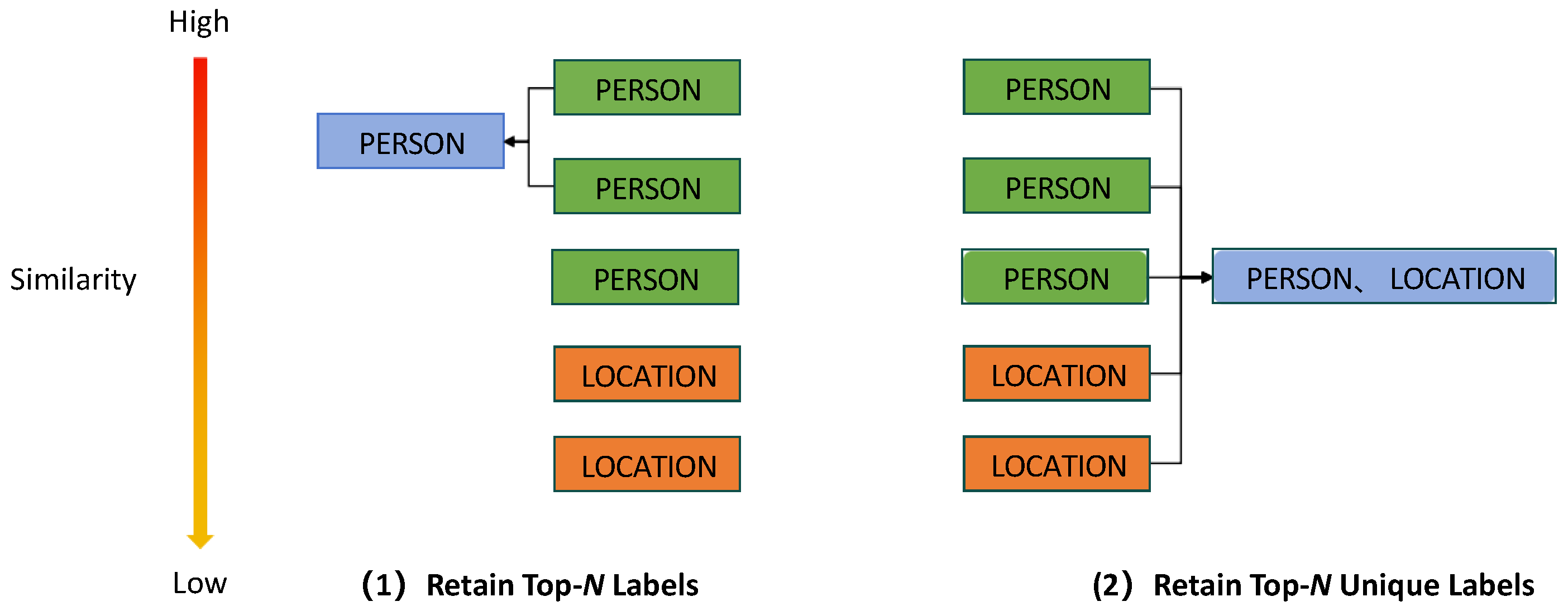
4.6. Analysis of the Impact of Predicted Label Scope on Collaborative Capabilities
As shown in
Table 4, the advantage of Qwen2.5-14B over LACNER gradually decreases as the number of entity types increases. In some cases, LACNER even outperforms Qwen2.5-14B. As the number of entity types grows, distinguishing fine-grained categories with subtle differences becomes more challenging. In contrast, the metric learning-based few-shot NER model, trained on diverse examples, effectively learns to differentiate these subtle nuances. Thus, implementing an appropriate label scope filtering strategy during collaboration is crucial for reducing confusion in the LLM.
Table 5 and
Table 6 present the impact of varying the scope of predicted labels on the Few-NERD and CrossNER.
Table 5 shows that when all entity types are provided, the classification space for the LLM becomes excessively large. Compared to the “retain top-1 label” strategy, performance drops by up to 1.72%, suggesting that limiting the label scope improves model focus. Similarly,
Table 6 reveals a comparable trend in the 5-shot setting of CrossNER, where the “retain top-
N labels” strategy achieves the best performance. This approach prevents the LLM from being overwhelmed by excessive predicted labels while enabling it to reference additional labels when the metric learning-based few-shot NER model’s predictions are uncertain or when test samples lie near cluster boundaries. However, in the 1-shot setting of CrossNER, the significant domain discrepancy between the source and target domains leads to suboptimal representations learned by LACNER. In this case, providing all predicted labels more effectively leverages the LLM’s capabilities.
4.7. Analysis of the Effectiveness of Various Methods in Prompt Design
In this section, we first examine the effectiveness of incorporating type definitions and few-shot examples in our prompt. We then investigate whether prompt engineering can further enhance overall performance.
- (1)
Analysis of the Effectiveness of Type Definitions and Few-Shot Examples in In-Context Learning
Table 7 presents the performance of two strategies—type definitions and few-shot examples—using ablation on the CrossNER. The results show that employing both type definitions and few-shot examples yields the best performance under both 1-shot and 5-shot settings. Specifically, in the 1-shot setting, the combined approach outperforms the baseline (which does not apply these strategies) by 1.8%, while in the 5-shot setting, it achieves the 0.52% improvement. These findings suggest that incorporating both type definitions and demonstrations enhances the model’s comprehension of the task and entity type definitions, thereby improving classification accuracy. However, on the OntoNotes, removing the demonstrations leads to better performance, indicating that noise in these demonstrations may hinder model understanding. When noise exists in the support set, the classification performance of large and small language models is affected to varying degrees. Large language models, which leverage extensive world knowledge, exhibit stronger robustness against noise, whereas smaller models are more prone to noise interference in few-shot setting.
- (2)
Analysis of the Effectiveness of Prompt Engineering
Prompt engineering techniques can further stimulate the model’s reasoning abilities. We evaluate how different zero-shot prompting approaches affect the performance of model.
As shown in
Table 8, metacognitive prompting improves performance by 0.76% in the 1-shot setting and 0.23% in the 5-shot setting compared to our prompt. Emulating human metacognition enhances the model’s ability to comprehend and execute NER tasks more effectively. However, zero-shot CoT and self-verification prompting generally lead to performance degradation. The CoT prompting is originally designed for tasks requiring explicit step-by-step reasoning, such as mathematical or logical problems. In contrast, NER primarily relies on textual semantics and contextual understanding, which do not align perfectly with CoT’s strengths. For self-verification prompting, if the initial prediction is highly uncertain, the mechanism allows the model to reassess and correct errors, explaining its effectiveness on certain datasets (e.g., CoNLL). However, if the model is overly confident in an incorrect prediction, the verification process may reinforce the error by drawing upon the same underlying knowledge base and reasoning patterns. Therefore, for tasks heavily reliant on semantic understanding, such as NER, prompt designs should prioritize enhancing text comprehension.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}