
Vulnerable Road User Detection for Roadside-Assisted Safety Protection: A Comprehensive Survey


Abstract
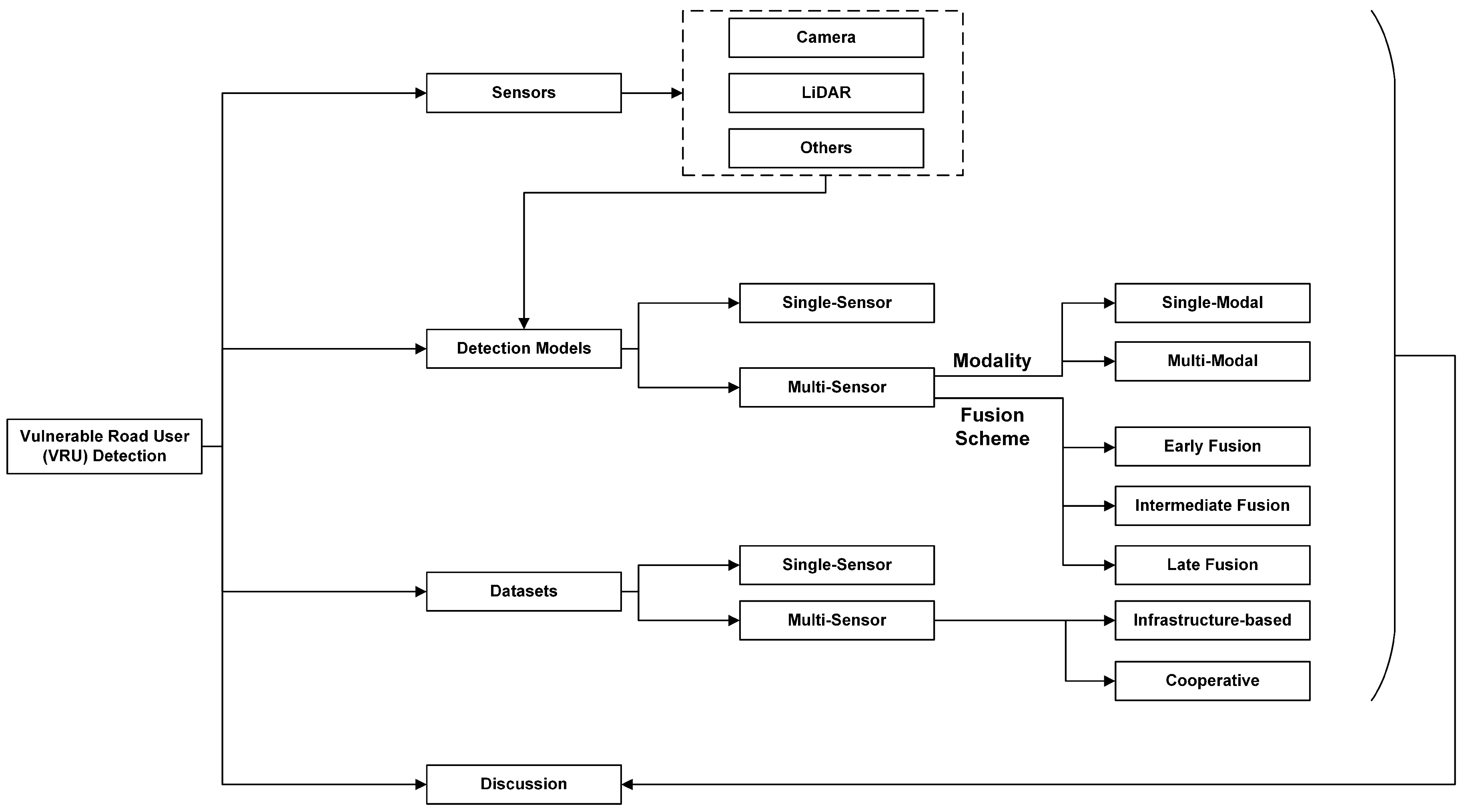
1. Introduction
1.1. Motivation
1.2. Organization
2. Typical Roadside Sensors
3. VRU Detection Models
3.1. Single-Sensor
3.1.1. Camera-Based Detection
3.1.2. LiDAR-Based Detection
3.2. Multi-Sensor
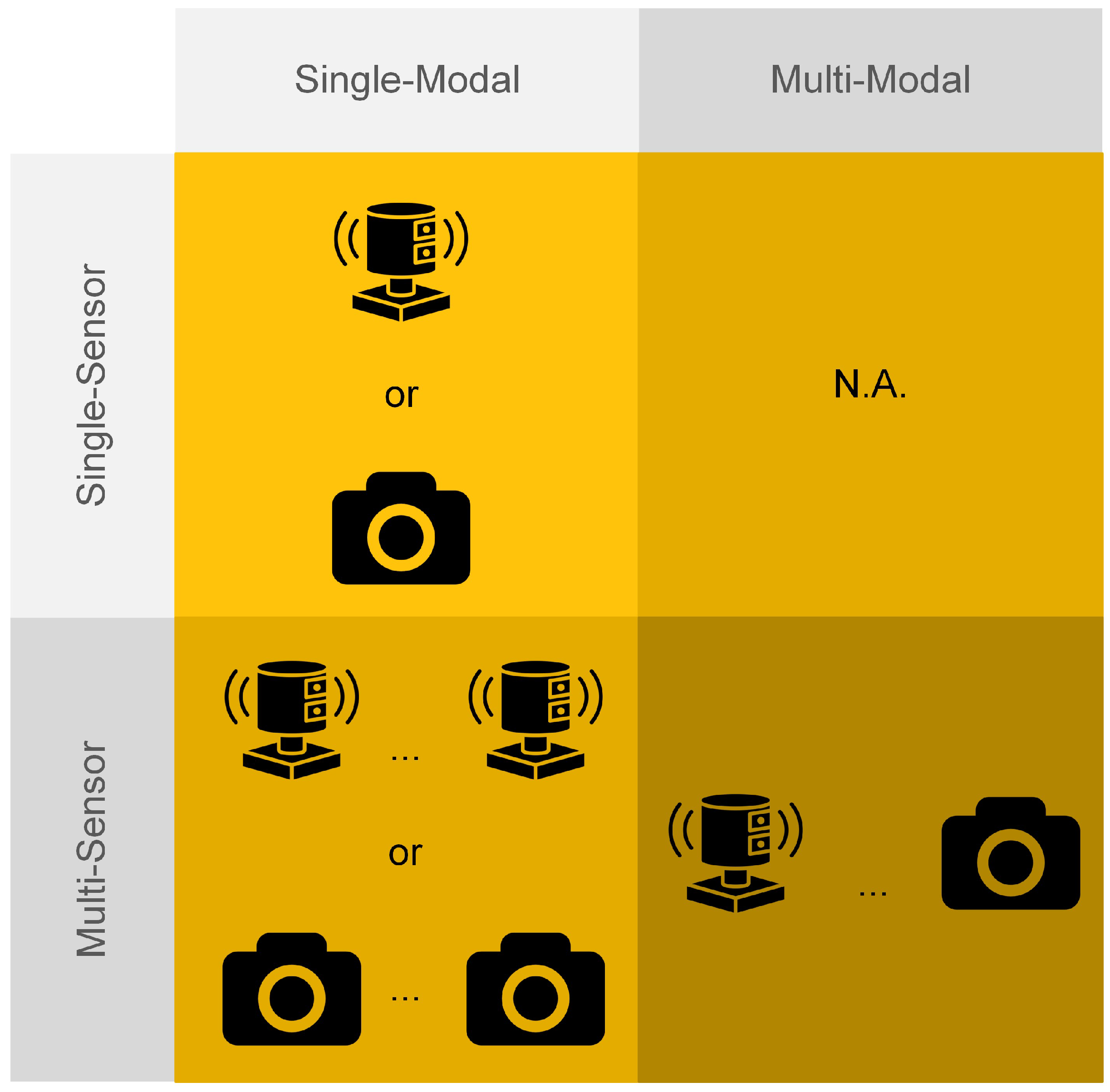
3.2.1. Classification by Modality
- Single-ModalCamera only: Multiple cameras can provide a wider field of view (FOV) and more accurate results in VRU detection, particularly in addressing issues related to illumination and occlusion. Inspired by research in the multiple-camera multi-object tracking (MOT) domain [110], cameras from different directions can be fused to detect and track objects. In this approach, objects are first detected in each camera view, and then their movement is tracked across multiple cameras, which constitutes the fusion in the temporal aspect. This paper, however, focuses only on the detection aspect, meaning that the primary goal of using multiple cameras from different directions is to solve issues of illumination and occlusion to ensure VRUs are detected, rather than performing re-identification and tracking. In this context, detections from different cameras are used to complement one another. Moreover, camera fusion can enhance the detection performance. For example, in InfraDet3D [111], a fusion method for the 3D detection results from two roadside cameras was proposed as one of the baseline approaches. In this method, the detections from two cameras are transformed to the same reference frame and matched within a threshold distance. The merging process involved combining matched detections by choosing the central position and yaw vector of the identified object from the nearest sensor. The dimensions of the merged detections were determined by averaging the measurements from both detectors. In general, camera-only fusion with a post-processing technique is designed to complement the detection results from different cameras and improve the detection accuracy of objects detected simultaneously, thus enhancing the safety of VRUs with greater confidence.In recent years, deep learning-based feature fusion methods for multi-view 3D object detection, such as DETR3D [32] and PETR [33], have been proposed using onboard-collected images. However, their potential performance in roadside detection remains underexplored.LiDAR only: Multiple LiDARs can improve detection accuracy by registering data from different viewpoints to obtain a higher-quality point cloud or by combining detections through late fusion. Meissner et al. [112] established a real-time pedestrian detection network of eight multilayer laser scanners in the KoPER project [113]. The collected data from different sensors are simply registered together. Then, a real-time adaptive foreground extractor was proposed using the Mixture of Gaussian (MoG) [114], and then an improved DBSCAN [112] was achieved by projecting the points to a 2D plane and dividing the clustering area with cells to reduce computation. Limited by the fixed range and the required minimum number of clusters in DBSCAN, when it comes to two pedestrians being very close, it is very challenging to separate them. In InfraDet3D [111], different fusion methods of two LiDARs were proposed as the baseline methods, including early fusion and late fusion. Early fusion of a LiDAR-only setup is to merge numerous point cloud scans generated by various LiDAR sensors at time step t to create a unified and densely populated point cloud, which used Fast Global Registration [115] to register the merged point cloud in the initial transformation and point-to-point Iterative Closest Point (ICP) [116] for the refinement. A late fusion baseline method of LiDAR was also talked about in the paper, which continued to use the same late fusion approach mentioned in camera-only fusion. In this work, pedestrians and cyclists were considered in the detection but not as the main objects. Although not much attention is given to the VRUs, the two fusion methods proposed are very straightforward and computationally cheap, which gives some inspiration for roadside real-time VRU sensing. Additionally, feature-level fusion using multiple LiDARs has been explored. For example, PillarGrid [117] extracts features from two different LiDARs in a pillar-wise manner and fuses them in a grid-wise fashion to enhance detection performance and extend the detection range.
- Multi-ModalRegarding multi-modal sensor fusion, various sensor combinations can be used for detection, including but not limited to cameras and LiDAR or cameras and RADAR. However, this paper primarily focuses on these two common combinations for VRU detection, with other multi-modal fusion methods briefly introduced.Camera and LiDAR: The fusion of camera and LiDAR sensors is one of the most common multi-modal sensor combinations. Cameras provide rich features that are beneficial for classification and detection during the daytime, while LiDAR can detect objects at night and offer more accurate point cloud data without distortion. In recent years, many promising fusion methods using cameras and LiDAR have been proposed. Generic fusion methods are listed in Table 4, with fusion strategies categorized based on pairs of sensor-derived feature types. Each category combines specific types of features from LiDAR and camera sensors; for example, FV/BEV and feature map represent features derived from LiDAR’s FV/BEV and camera’s feature map.In roadside sensor fusion applications, methods have evolved from assigning distinct functions to individual sensors for detection to integrating detections or features from multiple sensors. Shan et al. [4] designed an infrastructure-based roadside unit (IRSU) with two cameras, one LiDAR, and a Cohda Wireless RSU to detect pedestrians in the blind spots of connected and autonomous vehicles (CAVs), providing the CAVs with collision avoidance data. In this setup, the cameras were used for object detection and classification, while LiDAR was used to generate 3D dimensions and orientations. InfraDet3D [111] proposed a camera–LiDAR fusion method where LiDAR detection results were first transformed into the camera coordinate system, and then the detections from both sensors were synchronized based on the distance between the center points of the detected objects. In this method, the camera’s detection served as a supplement to LiDAR detection, employing a late fusion strategy. In CoopDet3D [118], Zimmer et al. extracted features with roadside data from a camera and LiDAR. The features were transformed into a bird’s eye view (BEV) representation. This method outperformed InfraDet3D on the TUMTraf dataset. VBRFusion [119] was proposed for VRU detection at medium to long ranges, based on the DAIR-V2X dataset [107]. VBRFusion enhanced the encoding of point and image feature mapping, as well as the fusion of voxel features, to generate high-dimensional voxel representations. In general, roadside fusion methods are gradually shifting from conventional function fusion approaches to feature fusion methods, aligning with generic LiDAR and camera sensor fusion techniques.Camera and RADAR: The combination of a camera and RADAR as a sensing unit is a cost-effective solution for detection. Similar to LiDAR-based detection models, this category includes both conventional methods and deep learning-based methods for fusing data from cameras and RADAR. Conventional methods often employ weighted averaging and clustering techniques, while deep learning approaches leverage neural networks to improve detection accuracy and robustness [120]. Bai et al. [121] developed a fusion method that capitalizes on the strengths of both cameras and RADAR to detect road users, including VRUs. RADAR detection results provide the distance and velocity of the target by measuring the time delay and phase shift of the echo signal. The camera detects the target’s angle and classification using YOLO V4 [22]. After calibrating the coordinates of both sensors, the results from the two sensors are fused using the nearest-neighbor correlation method. Similarly, in RODNet, RGB images are used to classify and localize objects, while transformed radio frequency images are utilized only for object localization [122]. Liu et al. [123] proposed methods for both single-scan and multi-scan fusion using Dempster’s combination rule to enhance evidence fusion performance. They also employed pre-calibration and the nearest-neighbor correlation method to associate detections from the camera and RADAR. Furthermore, the authors fused the detection results from multiple scans by associating detections from adjacent scans, which improved overall performance. With camera and RADAR fusion, challenging scenarios, particularly those captured under poor lighting conditions, can be detected more accurately.Regarding the DL-based methods, CenterFusion [67] associates RADAR point clouds with image detections, concatenates features from both the camera and RADAR, and recalculates the depth, rotation, and velocity of the objects. CRAFT [68] introduced the Soft-Polar Association and Spatio-Contextual Fusion Transformer to facilitate information sharing between the camera and RADAR. In recent years, inspired by BEV-based 3D detection methods with cameras, BEV-based feature maps have also been generated in camera and RADAR fusion, leveraging RADAR’s precise occupancy information. RCBEV4d [69] extracted spatial–temporal features from RADAR and applied point fusion and ROI fusion with transformed BEV image features. CRN [70] achieved comparable performance to LiDAR detectors on the nuScenes dataset, outperforming them at long distances. RCBEVDet [71] introduced a dual-stream RADAR backbone to capture both local RADAR features and global information, along with a RADAR Cross-Section (RCS)-aware BEV encoder that scatters point features across multiple BEV pixels rather than just one. This method outperformed previous approaches on the nuScenes dataset. In general, RADAR serves as a complementary information source to camera-based 3D detection methods, providing more accurate depth information, especially in adverse weather conditions.Others: Another camera combination involves the fusion of RGB cameras and infrared (IR) cameras, which can significantly improve detection performance, particularly under poor visibility conditions such as adverse weather or nighttime [124,125]. Pei et al. [126] also proposed a multi-spectral pedestrian detector that combines visible-optical (VIS) and infrared (IR) images. This method achieves state-of-the-art (SOTA) performance on the KAIST dataset [127]. When the RGB and infrared cameras share the same field of view (FOV), an image fusion technique can be employed to create a single combined image, making it easier to distinguish VRUs from the background [128].MMPedestron [129] is a novel multi-modal model for pedestrian detection that consists of a unified multi-modal encoder and a detection head. It can fuse data from five modalities (RGB, IR, Depth, LiDAR, and Event) and is extendable to include additional modalities. The data sources can also span multiple domains, such as traffic surveillance, autonomous driving, and robotics. Trained on a unified dataset composed of five public datasets with different modalities, MMPedestron surpasses the existing SOTA models for each individual dataset. This demonstrates the potential of a unified generalist model for multi-sensor perception in pedestrian detection, outperforming sensor fusion models tailored to specific sensor modalities.
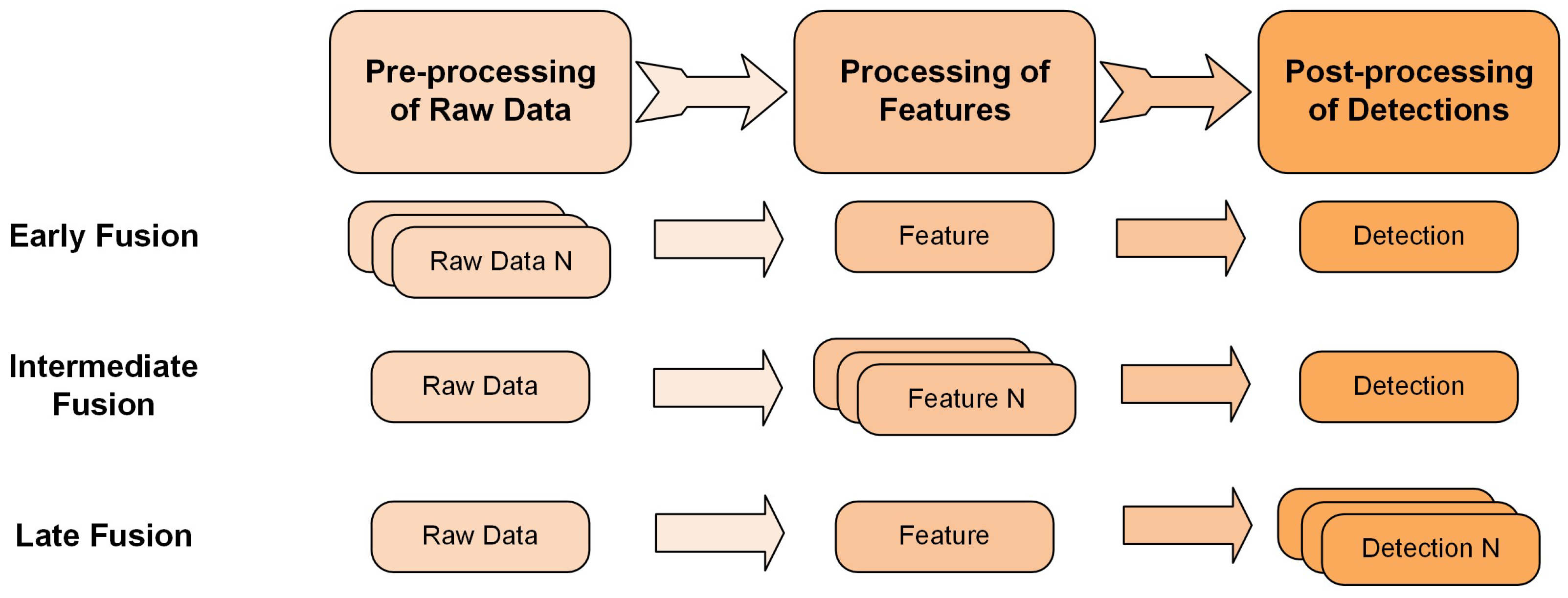
3.2.2. Classification by Fusion Scheme
- Early FusionSharing the raw sensor data with other sensors to extend the perceptual range or point cloud density (multiple LiDARs) and enhance detection accuracy is a logical approach. In line with this strategy, the raw data collected from various sensors is transformed into a unified coordinate system to facilitate subsequent processing [131]. However, this kind of strategy is inevitably sensitive to some issues such as sensor calibration, data synchronization, and communication capacity, which are critical considerations in real-time implementations [132]. For example, with a limited communication bandwidth, it may be viable to transmit limited-resolution image data, but it might not be practical to transmit LiDAR point cloud data in real-time. For instance, a 64-beam Velodyne LiDAR operating at 10 Hz can produce approximately 20 MB of data per second [9].
- Intermediate FusionThe fundamental principle behind IF can be succinctly described as employing deeply extracted features for fusion at intermediate stages within the perception pipeline. IF relies on hidden features primarily derived from deep neural networks, which exhibit greater robustness compared to the raw sensor data utilized in early fusion. Moreover, feature-based fusion approaches typically employ a single detector to produce object perception outcomes, thereby eliminating the necessity of consolidating multiple proposals as required in LF. For example, MVX-Net utilizes the IF strategy to fuse features from 2D images and 3D points or voxels, and it is processed by VoxelNet [8]. Bai et al. also proposed the PillarGrid to fuse the extracted features of two LiDARs to improve the detection accuracy [117].
- Late FusionLate fusion also adopts a natural cooperative paradigm for perception, wherein perception outcomes are independently generated and subsequently fused. Unlike EF, although LF still requires a relative positioning for merging perception results, its robustness to calibration errors and synchronization issues is significantly improved. This is primarily because object-level fusion can be established based on spatial and temporal constraints. Rauch et al. [133] employed the Extended Kalman Filter (EKF) to coherently align the shared bounding box proposals, leveraging spatiotemporal constraints. Moreover, techniques such as Non-Maximum Suppression (NMS) [134] and other machine learning-driven proposal refining methods find extensive applications in LF methodologies for object perception [135].
4. Datasets
4.1. Single-Sensor Datasets
4.2. Multi-Sensor Datasets
5. Discussion
5.1. Detection Models
5.1.1. Challenges
- Real-time ProcessingAs GPU computing performance continues to advance, researchers are developing more complex models and exploring the fusion of diverse data across various modalities and scenarios. The goal is to train robust models with strong generalization capabilities that are not constrained by a single modality or scenario. However, in practical roadside assistance systems, deploying large-scale multi-modal models can be challenging due to limitations in computing performance and communication latency between sensors and the edge computer. Therefore, developing lightweight models that offer robust performance and high tolerance to variations presents a significant research direction in road-assisted detection systems.
- Non-rigid Small 3D Object DetectionGiven the small size of VRUs, accurately detecting them in 3D is inherently more challenging due to the limited information collected by sensors. Relying on a single sensor may not provide sufficient data, making sensor fusion a more effective solution to address the missing features and enhance detection accuracy.Considering the non-rigid characteristic of the VRUs, such as walking, running, sitting and standing, it will be more challenging to detect them compared with rigid objects like vehicles. Compared with 2D detection, there is much less research focusing on this issue in 3D detection with LiDAR, which may be the result of sparse points on VRU itself and most LiDAR’s application in rigid object detection such as for vehicles. However, with the advancement of LiDAR resolution and the ability to capture more detailed VRU gestures, this area presents promising opportunities for future research.
- Domain Generalization from Onboard to RoadsideIn real-world applications, many pre-trained models are directly used for practical purposes, such as roadside surveillance. However, most pre-trained detection models that use point clouds as input are primarily designed and trained for onboard applications. A key question arises: how adaptable are these pre-trained onboard detection models to roadside detection tasks? Typically, when a LiDAR-based detection model trained on onboard datasets is directly applied to roadside data, performance degradation often occurs. This issue falls under domain generalization, where the challenge is ensuring the model performs well despite domain differences between development and deployment data, with minimal additional investment.
5.1.2. Trends and Future Research
- Low-cost Solution for Comparative Resilience to LiDARAn increasing number of studies are exploring multi-camera 3D detection combined with RADAR as an affordable alternative to LiDAR. RADAR provides robust performance under varying lighting conditions and is effective for depth measurement, while cameras deliver high resolution and rich semantic information. Additionally, RADAR demonstrates strong weather robustness, velocity estimation, and long-range detection, offering several advantages over LiDAR [68]. Although RADAR has limitations, such as sparsity, inaccurate measurements, and ambiguity, researchers have proposed RADAR noise filtering modules to enhance detection accuracy [150,151]. Notably, CRAFT [68] achieves a 41.1% mAP on the nuScenes test dataset, with 46.2% AP for pedestrians and 31.0% AP for bicycles. However, none of the existing methods have been specifically tailored for VRU detection. As a result, roadside VRU detection using camera and RADAR fusion remains largely unexplored, representing a promising area for future research.
- Unified Generalist ModelRecently, some researchers have attempted to develop unified detection models that integrate multiple modalities and domains to enhance robustness across various settings. For example, MMPedestron [129] fused data from five modalities across domains, ranging from traffic surveillance to robotics. As a result, it outperforms existing state-of-the-art models on individual datasets. In this context, variations in roadside data, such as tilt angle, mounting height, and resolution, may not pose limitations for a unified model trained with diverse data.
- Tracking by DetectionRecently, a new trend has been combining the detection and tracking module as an end-to-end method to solve the detection and tracking at the same time, which solves VRU occlusion issues while saving the training process and avoiding the complex data association process.
5.2. Datasets
5.2.1. Challenges
- Unclear Definition of VRU SubclassesExisting datasets lack a variety of VRUs, and the VRU subclasses within these datasets are inconsistent, which increases the difficulty of developing detection models. As a result, a clear definition of VRU subclasses is missing, and some rare VRUs do not receive sufficient attention. To facilitate dataset collection, annotation, and the development of corresponding detection models, we propose a standardized classification for most VRU categories, building on previous classifications found in various datasets and the Intersection Safety Challenge hosted by the U.S. Department of Transportation [152]. The detailed VRU classifications are presented in Table 8.
- Insufficient Critical VRU ScenariosMost perception datasets focus on detecting main road users, such as vehicles, while often overlooking critical corner cases, such as high-risk interactions between vehicles and pedestrians [153]. This creates a strong need for real-world or synthetic datasets that adequately represent critical VRU scenarios. Although simulated datasets can generate challenging situations like accidents and occlusions, a comprehensive dataset covering diverse VRU categories and corner cases is still lacking.
5.2.2. Trends and Future Research
- Sensor Placement TestingA quick and precise evaluation of roadside sensor placement before installation is crucial for effective data collection or monitoring. Sensor placement without proper evaluation can be time-consuming and may make it difficult to identify the optimal viewpoint. This is especially critical for VRU detection, where it is essential to select locations that cover sidewalks and crossings while minimizing occlusion. Therefore, evaluating the influence of sensor placement on the view and performance of baseline detection models is necessary to ensure optimal functionality.For instance, Cai et al. (2023) [154] conducted a simulation study comparing various LiDAR placements across multiple intersection scenarios. This approach enabled the evaluation of different placements alongside various detection algorithms, using real-world mirror scenarios for comparison. This study offers valuable insights into sensor placement testing, highlighting how small changes in sensor positioning can significantly impact VRU detection accuracy. Proper sensor placement is thus a key factor in optimizing detection performance and minimizing false negatives, making it an essential aspect of system design.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes * | Subclasses | Reference |
|---|---|---|
| Pedestrian |
| [73,83,85,86,97,105,112,129,131,138,139,141,155,156,157,158,159] |
| Wheelchair |
| [12] |
| Bicycle |
| [10] |
| Non-Motorized Device |
| [13,16,89] |
| Scooter |
| [11] |
| Skateboard | N.A. | [15] |
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sun, C.; Brown, H.; Edara, P.; Stilley, J.; Reneker, J. Vulnerable Road User (VRU) Safety Assessment; Technical Report; Department of Transportation, Construction and Materials Division: Jefferson City, MO, USA, 2023. [Google Scholar]
- California Traffic Safety Quick Stats; California Office of Traffic Safety: Elk Grove, CA, USA, 2021.
- California Quick Crash Facts; California Highway Patrol: Sacramento, CA, USA, 2020.
- Shan, M.; Narula, K.; Wong, Y.F.; Worrall, S.; Khan, M.; Alexander, P.; Nebot, E. Demonstrations of Cooperative Perception: Safety and Robustness in Connected and Automated Vehicle Operations. Sensors 2020, 21, 200. [Google Scholar] [CrossRef] [PubMed]
- Commsignia. Vulnerable Road User (VRU) Detection Case Study. n.d. Available online: https://www.commsignia.com/casestudy/vru (accessed on 23 March 2025).
- Ouster. BlueCity Solution. 2025. Available online: https://ouster.com/products/software/bluecity (accessed on 23 March 2025).
- Ouster. Ouster BlueCity to Power Largest Lidar-Enabled Smart Traffic. 2025. Available online: https://investors.ouster.com/news-releases/news-release-details/ouster-bluecity-power-largest-lidar-enabled-smart-traffic (accessed on 23 March 2025).
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- García-Venegas, M.; Mercado-Ravell, D.A.; Pinedo-Sánchez, L.A.; Carballo-Monsivais, C.A. On the safety of vulnerable road users by cyclist detection and tracking. Mach. Vis. Appl. 2021, 32, 109. [Google Scholar] [CrossRef]
- Gilroy, S.; Mullins, D.; Jones, E.; Parsi, A.; Glavin, M. E-Scooter Rider detection and classification in dense urban environments. Results Eng. 2022, 16, 100677. [Google Scholar] [CrossRef]
- Beyer, L.; Hermans, A.; Leibe, B. DROW: Real-Time Deep Learning-Based Wheelchair Detection in 2-D Range Data. IEEE Robot. Autom. Lett. 2017, 2, 585–592. [Google Scholar] [CrossRef]
- Shimbo, Y.; Kawanishi, Y.; Deguchi, D.; Ide, I.; Murase, H. Parts Selective DPM for detection of pedestrians possessing an umbrella. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 972–977. [Google Scholar] [CrossRef]
- Wang, H.; Li, C.; Zhang, Y.; Liu, Z.; Hui, Y.; Mao, G. A scheme on pedestrian detection using multi-sensor data fusion for smart roads. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–5. [Google Scholar]
- Wu, J.; Xu, H.; Yue, R.; Tian, Z.; Tian, Y.; Tian, Y. An automatic skateboarder detection method with roadside LiDAR data. J. Transp. Saf. Secur. 2021, 13, 298–317. [Google Scholar] [CrossRef]
- Yang, J.; Tong, Q.; Zhong, Y.; Li, Q. Improved YOLOv5 for stroller and luggage detection. In Proceedings of the 2023 4th International Conference on Computer Engineering and Application (ICCEA), Hangzhou, China, 7–9 April 2023; pp. 252–257. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 29th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics. YOLOv5: A State-of-the-Art Real-Time Object Detection System. 2021. Available online: https://docs.ultralytics.com (accessed on 23 March 2025).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12346, pp. 213–229. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. Fcos3d: Fully convolutional one-stage monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 913–922. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Proceedings of the Conference on Robot Learning, PMLR, London, UK, 8–11 November 2022; pp. 180–191. [Google Scholar]
- Liu, Y.; Wang, T.; Zhang, X.; Sun, J. Petr: Position embedding transformation for multi-view 3d object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 531–548. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1477–1485. [Google Scholar]
- Yang, L.; Yu, K.; Tang, T.; Li, J.; Yuan, K.; Wang, L.; Zhang, X.; Chen, P. Bevheight: A robust framework for vision-based roadside 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 21611–21620. [Google Scholar]
- Fan, S.; Wang, Z.; Huo, X.; Wang, Y.; Liu, J. Calibration-free bev representation for infrastructure perception. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 9008–9013. [Google Scholar]
- Shi, H.; Pang, C.; Zhang, J.; Yang, K.; Wu, Y.; Ni, H.; Lin, Y.; Stiefelhagen, R.; Wang, K. CoBEV: Elevating Roadside 3D Object Detection with Depth and Height Complementarity. arXiv 2023, arXiv:2310.02815. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3d lidar using fully convolutional network. arXiv 2016, arXiv:1608.07916. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7652–7660. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Shi, G.; Li, R.; Ma, C. PillarNet: Real-Time and High-Performance Pillar-Based 3D Object Detection. In Computer Vision—ECCV 2022; Lecture Notes in Computer Science; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; Volume 13670, pp. 35–52. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-Voxel Feature Set Abstraction with Local Vector Representation for 3D Object Detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Lu, H.; Chen, X.; Zhang, G.; Zhou, Q.; Ma, Y.; Zhao, Y. SCANet: Spatial-channel attention network for 3D object detection. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1992–1996. [Google Scholar]
- Krispel, G.; Opitz, M.; Waltner, G.; Possegger, H.; Bischof, H. Fuseseg: Lidar point cloud segmentation fusing multi-modal data. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1874–1883. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2774–2781. [Google Scholar]
- Qiao, D.; Zulkernine, F. CoBEVFusion: Cooperative Perception with LiDAR-Camera Bird’s-Eye View Fusion. arXiv 2023, arXiv:2310.06008. [Google Scholar]
- Kim, M.; Kim, G.; Jin, K.H.; Choi, S. Broadbev: Collaborative lidar-camera fusion for broad-sighted bird’s eye view map construction. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 11125–11132. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. Mvx-net: Multimodal voxelnet for 3d object detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7276–7282. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 720–736. [Google Scholar]
- Zhu, H.; Deng, J.; Zhang, Y.; Ji, J.; Mao, Q.; Li, H.; Zhang, Y. Vpfnet: Improving 3d object detection with virtual point based lidar and stereo data fusion. IEEE Trans. Multimed. 2022, 25, 5291–5304. [Google Scholar] [CrossRef]
- Wang, C.; Ma, C.; Zhu, M.; Yang, X. Pointaugmenting: Cross-modal augmentation for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11794–11803. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Xie, L.; Xiang, C.; Yu, Z.; Xu, G.; Yang, Z.; Cai, D.; He, X. PI-RCNN: An efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12460–12467. [Google Scholar] [CrossRef]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–52. [Google Scholar]
- Jiao, Y.; Jie, Z.; Chen, S.; Chen, J.; Ma, L.; Jiang, Y.G. Msmdfusion: Fusing lidar and camera at multiple scales with multi-depth seeds for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 21643–21652. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17182–17191. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1090–1099. [Google Scholar]
- Qin, Y.; Wang, C.; Kang, Z.; Ma, N.; Li, Z.; Zhang, R. SupFusion: Supervised LiDAR-camera fusion for 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 22014–22024. [Google Scholar]
- Nabati, R.; Qi, H. Centerfusion: Center-based radar and camera fusion for 3d object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1527–1536. [Google Scholar]
- Kim, Y.; Kim, S.; Choi, J.W.; Kum, D. Craft: Camera-radar 3d object detection with spatio-contextual fusion transformer. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1160–1168. [Google Scholar] [CrossRef]
- Zhou, T.; Chen, J.; Shi, Y.; Jiang, K.; Yang, M.; Yang, D. Bridging the view disparity between radar and camera features for multi-modal fusion 3d object detection. IEEE Trans. Intell. Veh. 2023, 8, 1523–1535. [Google Scholar] [CrossRef]
- Kim, Y.; Shin, J.; Kim, S.; Lee, I.J.; Choi, J.W.; Kum, D. Crn: Camera radar net for accurate, robust, efficient 3d perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 17615–17626. [Google Scholar]
- Lin, Z.; Liu, Z.; Xia, Z.; Wang, X.; Wang, Y.; Qi, S.; Dong, Y.; Dong, N.; Zhang, L.; Zhu, C. RCBEVDet: Radar-camera Fusion in Bird’s Eye View for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 14928–14937. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Papageorgiou, C.; Poggio, T. A trainable system for object detection. Int. J. Comput. Vis. 2000, 38, 15–33. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31th International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Tarchoun, B.; Jegham, I.; Khalifa, A.B.; Alouani, I.; Mahjoub, M.A. Deep cnn-based pedestrian detection for intelligent infrastructure. In Proceedings of the 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sousse, Tunisia, 2–5 September 2020; pp. 1–6. [Google Scholar]
- Zhou, X.; Zhang, L. SA-FPN: An effective feature pyramid network for crowded human detection. Appl. Intell. 2022, 52, 12556–12568. [Google Scholar] [CrossRef]
- Mammeri, A.; Siddiqui, A.J.; Zhao, Y.; Pekilis, B. Vulnerable road users detection based on convolutional neural networks. In Proceedings of the 2020 International Symposium on Networks, Computers and Communications (ISNCC), Montreal, QC, Canada, 20–22 October 2020; pp. 1–6. [Google Scholar]
- Sharma, D.; Hade, T.; Tian, Q. Comparison Of Deep Object Detectors On A New Vulnerable Pedestrian Dataset. arXiv 2024, arXiv:2212.06218. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Jinrang, J.; Li, Z.; Shi, Y. MonoUNI: A unified vehicle and infrastructure-side monocular 3d object detection network with sufficient depth clues. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 11703–11715. [Google Scholar]
- Huang, C.R.; Chung, P.C.; Lin, K.W.; Tseng, S.C. Wheelchair Detection Using Cascaded Decision Tree. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 292–300. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Sun, Y.; Xu, H.; Wu, J.; Zheng, J.; Dietrich, K.M. 3-D data processing to extract vehicle trajectories from roadside LiDAR data. Transp. Res. Rec. 2018, 2672, 14–22. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. kdd 1996, 96, 226–231. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Kononenko, I. Comparison of inductive and naive Bayesian learning approaches to automatic knowledge acquisition. Curr. Trends Knowl. Acquis. 1990, 8, 190. [Google Scholar]
- Zhao, J.; Xu, H.; Liu, H.; Wu, J.; Zheng, Y.; Wu, D. Detection and tracking of pedestrians and vehicles using roadside LiDAR sensors. Transp. Res. Part C: Emerg. Technol. 2019, 100, 68–87. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 16–18 October 1989; Volume 1, pp. 593–605. [Google Scholar] [CrossRef]
- Song, Y.; Tian, J.; Li, T.; Sun, R.; Zhang, H.; Wu, J.; Song, X. Road-Users Classification Utilizing Roadside Light Detection and Ranging Data; Technical Report, SAE Technical Paper; Society of Automotive Engineers: Warrendale, PA, USA, 2020. [Google Scholar]
- Specht, D.F. Probabilistic neural networks. Neural Netw. 1990, 3, 109–118. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Gong, Z.; Wang, Z.; Yu, G.; Liu, W.; Yang, S.; Zhou, B. FecNet: A Feature Enhancement and Cascade Network for Object Detection Using Roadside LiDAR. IEEE Sens. J. 2023, 23, 23780–23791. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, W.; Qi, Y.; Hu, Y.; Zhang, W. A Common Traffic Object Recognition Method Based on Roadside LiDAR. In Proceedings of the 2022 IEEE 7th International Conference on Intelligent Transportation Engineering (ICITE), Beijing, China, 11–13 November 2022; pp. 436–441. [Google Scholar]
- Zhang, L.; Zheng, J.; Sun, R.; Tao, Y. Gc-net: Gridding and clustering for traffic object detection with roadside lidar. IEEE Intell. Syst. 2020, 36, 104–113. [Google Scholar]
- Blanch, M.R.; Li, Z.; Escalera, S.; Nasrollahi, K. LiDAR-Assisted 3D Human Detection for Video Surveillance. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2024; pp. 123–131. [Google Scholar]
- Shi, H.; Hou, D.; Li, X. Center-Aware 3D Object Detection with Attention Mechanism Based on Roadside LiDAR. Sustainability 2023, 15, 2628. [Google Scholar] [CrossRef]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J. Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 21361–21370. [Google Scholar]
- Wang, Y.; Solomon, J.M. Object dgcnn: 3d object detection using dynamic graphs. Adv. Neural Inf. Process. Syst. 2021, 34, 20745–20758. [Google Scholar]
- Fan, L.; Wang, F.; Wang, N.; Zhang, Z.X. Fully sparse 3d object detection. Adv. Neural Inf. Process. Syst. 2022, 35, 351–363. [Google Scholar]
- Amosa, T.I.; Sebastian, P.; Izhar, L.I.; Ibrahim, O.; Ayinla, L.S.; Bahashwan, A.A.; Bala, A.; Samaila, Y.A. Multi-camera multi-object tracking: A review of current trends and future advances. Neurocomputing 2023, 552, 126558. [Google Scholar] [CrossRef]
- Zimmer, W.; Birkner, J.; Brucker, M.; Nguyen, H.T.; Petrovski, S.; Wang, B.; Knoll, A.C. Infradet3d: Multi-modal 3d object detection based on roadside infrastructure camera and lidar sensors. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; pp. 1–8. [Google Scholar]
- Meissner, D.; Reuter, S.; Dietmayer, K. Real-time detection and tracking of pedestrians at intersections using a network of laserscanners. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 630–635. [Google Scholar]
- Strigel, E.; Meissner, D.; Seeliger, F.; Wilking, B.; Dietmayer, K. The ko-per intersection laserscanner and video dataset. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1900–1901. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE computer society Conference on Computer Vision and pattern recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 246–252. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast Global Registration. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9906, pp. 766–782. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Sensor Fusion IV: Control Paradigms and Data Structures; SPIE: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Bai, Z.; Wu, G.; Barth, M.J.; Liu, Y.; Sisbot, E.A.; Oguchi, K. Pillargrid: Deep learning-based cooperative perception for 3d object detection from onboard-roadside lidar. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 1743–1749. [Google Scholar]
- Zimmer, W.; Creß, C.; Nguyen, H.T.; Knoll, A.C. Tumtraf intersection dataset: All you need for urban 3d camera-lidar roadside perception. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 1030–1037. [Google Scholar]
- Yao, J.; Zhou, J.; Wang, Y.; Gao, Z.; Hu, W. Infrastructure-assisted 3D detection networks based on camera-lidar early fusion strategy. Neurocomputing 2024, 600, 128180. [Google Scholar] [CrossRef]
- Zhou, Y.; Dong, Y.; Hou, F.; Wu, J. Review on millimeter-wave radar and camera fusion technology. Sustainability 2022, 14, 5114. [Google Scholar] [CrossRef]
- Bai, J.; Li, S.; Zhang, H.; Huang, L.; Wang, P. Robust Target Detection and Tracking Algorithm Based on Roadside Radar and Camera. Sensors 2021, 21, 1116. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, Z.; Li, Y.; Hwang, J.N.; Xing, G.; Liu, H. RODNet: A Real-Time Radar Object Detection Network Cross-Supervised by Camera-Radar Fused Object 3D Localization. IEEE J. Sel. Top. Signal Process. 2021, 15, 954–967. [Google Scholar] [CrossRef]
- Liu, P.; Yu, G.; Wang, Z.; Zhou, B.; Chen, P. Object classification based on enhanced evidence theory: Radar–vision fusion approach for roadside application. IEEE Trans. Instrum. Meas. 2022, 71, 5006412. [Google Scholar] [CrossRef]
- Xu, D.; Ouyang, W.; Ricci, E.; Wang, X.; Sebe, N. Learning cross-modal deep representations for robust pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5363–5371. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- Pei, D.; Jing, M.; Liu, H.; Sun, F.; Jiang, L. A fast RetinaNet fusion framework for multi-spectral pedestrian detection. Infrared Phys. Technol. 2020, 105, 103178. [Google Scholar] [CrossRef]
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST multi-spectral day/night data set for autonomous and assisted driving. IEEE Trans. Intell. Transp. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Zhang, Y.; Zeng, W.; Jin, S.; Qian, C.; Luo, P.; Liu, W. When Pedestrian Detection Meets Multi-Modal Learning: Generalist Model and Benchmark Dataset. arXiv 2024, arXiv:2407.10125. [Google Scholar]
- Bai, Z.; Wu, G.; Barth, M.J.; Liu, Y.; Sisbot, E.A.; Oguchi, K.; Huang, Z. A survey and framework of cooperative perception: From heterogeneous singleton to hierarchical cooperation. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15191–15209. [Google Scholar]
- Eshel, R.; Moses, Y. Homography based multiple camera detection and tracking of people in a dense crowd. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Rauch, A.; Klanner, F.; Rasshofer, R.; Dietmayer, K. Car2x-based perception in a high-level fusion architecture for cooperative perception systems. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 270–275. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Arnold, E.; Dianati, M.; de Temple, R.; Fallah, S. Cooperative perception for 3D object detection in driving scenarios using infrastructure sensors. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1852–1864. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar] [CrossRef]
- Braun, M.; Krebs, S.; Flohr, F.; Gavrila, D.M. EuroCity Persons: A Novel Benchmark for Person Detection in Traffic Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1844–1861. [Google Scholar] [CrossRef]
- Neumann, L.; Karg, M.; Zhang, S.; Scharfenberger, C.; Piegert, E.; Mistr, S.; Prokofyeva, O.; Thiel, R.; Vedaldi, A.; Zisserman, A.; et al. NightOwls: A Pedestrians at Night Dataset. In Proceedings of the Computer Vision—ACCV 2018, Perth, Australia, 2–6 December 2018; Jawahar, C.V., Li, H., Mori, G., Schindler, K., Eds.; Springer: Cham, Switzerland, 2019; pp. 691–705. [Google Scholar] [CrossRef]
- Pang, Y.; Cao, J.; Li, Y.; Xie, J.; Sun, H.; Gong, J. TJU-DHD: A Diverse High-Resolution Dataset for Object Detection. arXiv 2020, arXiv:2011.09170. [Google Scholar] [CrossRef] [PubMed]
- Shah, A.; Lamare, J.B.; Anh, T.N.; Hauptmann, A. CADP: A Novel Dataset for CCTV Traffic Camera based Accident Analysis. arXiv 2018, arXiv:1809.05782. [Google Scholar]
- Yongqiang, D.; Dengjiang, W.; Gang, C.; Bing, M.; Xijia, G.; Yajun, W.; Jianchao, L.; Yanming, F.; Juanjuan, L. BAAI-VANJEE Roadside Dataset: Towards the Connected Automated Vehicle Highway technologies in Challenging Environments of China. arXiv 2021, arXiv:2105.14370. [Google Scholar]
- Creß, C.; Zimmer, W.; Purschke, N.; Doan, B.N.; Kirchner, S.; Lakshminarasimhan, V.; Strand, L.; Knoll, A.C. TUMTraf event: Calibration and fusion resulting in a dataset for roadside event-based and RGB cameras. IEEE Trans. Intell. Veh. 2024, 9, 5186–5203. [Google Scholar]
- Ye, X.; Shu, M.; Li, H.; Shi, Y.; Li, Y.; Wang, G.; Tan, X.; Ding, E. Rope3d: The roadside perception dataset for autonomous driving and monocular 3d object detection task. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 21341–21350. [Google Scholar]
- Zimmer, W.; Wardana, G.A.; Sritharan, S.; Zhou, X.; Song, R.; Knoll, A.C. TUMTraf V2X Cooperative Perception Dataset. arXiv 2024, arXiv:2403.01316. [Google Scholar]
- Xiang, H.; Zheng, Z.; Xia, X.; Xu, R.; Gao, L.; Zhou, Z.; Han, X.; Ji, X.; Li, M.; Meng, Z.; et al. V2X-Real: A Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception. arXiv 2024, arXiv:2403.16034. [Google Scholar]
- Li, Y.; Ma, D.; An, Z.; Wang, Z.; Zhong, Y.; Chen, S.; Feng, C. V2X-Sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving. IEEE Robot. Autom. Lett. 2022, 7, 10914–10921. [Google Scholar] [CrossRef]
- Long, Y.; Morris, D.; Liu, X.; Castro, M.; Chakravarty, P.; Narayanan, P. Radar-camera pixel depth association for depth completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12507–12516. [Google Scholar]
- Lin, J.T.; Dai, D.; Van Gool, L. Depth estimation from monocular images and sparse radar data. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10233–10240. [Google Scholar]
- U.S. DOT. ITS—Intersection Safety Challenge; U.S. Department of Transportation: Washington, DC, USA, 2024.
- Yang, L.; Liu, S.; Feng, S.; Wang, H.; Zhao, X.; Qu, G.; Fang, S. Generation of critical pedestrian scenarios for autonomous vehicle testing. Accid. Anal. Prev. 2025, 214, 107962. [Google Scholar] [CrossRef] [PubMed]
- Cai, X.; Jiang, W.; Xu, R.; Zhao, W.; Ma, J.; Liu, S.; Li, Y. Analyzing infrastructure lidar placement with realistic lidar simulation library. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 5581–5587. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar] [CrossRef]
- Ojala, R.; Vepsäläinen, J.; Hanhirova, J.; Hirvisalo, V.; Tammi, K. Novel convolutional neural network-based roadside unit for accurate pedestrian localisation. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3756–3765. [Google Scholar]
- Cong, P.; Zhu, X.; Qiao, F.; Ren, Y.; Peng, X.; Hou, Y.; Xu, L.; Yang, R.; Manocha, D.; Ma, Y. STCrowd: A Multimodal Dataset for Pedestrian Perception in Crowded Scenes. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 19576–19585. [Google Scholar] [CrossRef]
- Song, H.; Choi, I.K.; Ko, M.S.; Bae, J.; Kwak, S.; Yoo, J. Vulnerable pedestrian detection and tracking using deep learning. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–2. [Google Scholar] [CrossRef]

| Sensors | Advantages | Disadvantages | Cost | Durability |
|---|---|---|---|---|
| Monocular Camera | Rich Information (Signs and Objects) | Strong Light Dependence; Poor Environmental Adaptability; Low Ranging Accuracy; Low Privacy; Narrow Field of View (FOV); Limited 3D Information | Low | Moderate |
| LiDAR | Simple Structure; Low Power Consumption; Strong Environmental Adaptability; Extensive FOV; High Accuracy; High Privacy; Rich 3D Information | Insufficient Ability to Read Signs and Distinguish Colors | High | Moderate to Low (moving parts) |
| RADAR | Long Detection Distance; High Accuracy in Object Position and Speed; Strong Environmental Adaptability; High Privacy | Insufficient Accuracy in Object Detection and Classification; Insufficient Ability to Read Signs and Distinguish Colors | Moderate | High |
| Depth Camera | Accurate Depth Perception; Moderate Light Dependence | Insufficient Range and Resolution in Depth; Poor Environmental Adaptability | Moderate | Moderate |
| Infrared Camera (IR) | Low Light Dependence; Strong Environmental Adaptability | Narrow FOV; Insufficient Ability to Read Signs and Distinguish Colors | Moderate | Moderate |
| Fisheye Camera | Extensive FOV; Rich Information (Signs and Objects) | Low Privacy | Moderate | Moderate to Low (lens scratches) |
| Event-based Camera | Robustness to Motion Blur; Low Power Consumption; High Dynamic Range; Minimal Data Rate | Limited Spatial Resolution; Complex Data Processing | High | High |
| Methods | Year | Dimensions | Sensors | |||
|---|---|---|---|---|---|---|
| 2D | 3D | Camera | LiDAR | RADAR | ||
| Faster R-CNN [17] | 2015 | ✓ | ✓ | |||
| SSD [18] | 2016 | ✓ | ✓ | |||
| RetinaNet [19] | 2017 | ✓ | ✓ | |||
| FPN [20] | 2017 | ✓ | ✓ | |||
| YOLO series [21,22,23,24] | - | ✓ | ✓ | |||
| CornerNet [25] | 2018 | ✓ | ✓ | |||
| CenterNet [26] | 2019 | ✓ | ✓ | |||
| ViT [27] | 2021 | ✓ | ✓ | |||
| DETR [28] | 2020 | ✓ | ✓ | |||
| Swin Transformer [29] | 2021 | ✓ | ✓ | |||
| PVT [30] | 2021 | ✓ | ✓ | |||
| FCOS3D [31] | 2021 | ✓ | ✓ | |||
| DETR3D [32] | 2022 | ✓ | ✓ | |||
| PETR [33] | 2022 | ✓ | ✓ | |||
| BEVDepth [34] | 2023 | ✓ | ✓ | |||
| BEVHeight [35] | 2023 | ✓ | ✓ | |||
| CBR [36] | 2023 | ✓ | ✓ | |||
| CoBEV [37] | 2023 | ✓ | ✓ | |||
| VeloFCN [38] | 2016 | ✓ | ✓ | |||
| PIXOR [39] | 2018 | ✓ | ✓ | |||
| VoxelNet [8] | 2018 | ✓ | ✓ | |||
| SECOND [40] | 2018 | ✓ | ✓ | |||
| PointPillars [41] | 2019 | ✓ | ✓ | |||
| CenterPoint [42] | 2021 | ✓ | ✓ | |||
| PillarNet [43] | 2022 | ✓ | ✓ | |||
| PointRCNN [44] | 2019 | ✓ | ✓ | |||
| PV-RCNN [45] | 2020 | ✓ | ✓ | |||
| PV-RCNN++ [46] | 2023 | ✓ | ✓ | |||
| MV3D [47] | 2017 | ✓ | ✓ | ✓ | ||
| AVOD [48] | 2018 | ✓ | ✓ | ✓ | ||
| Cont Fuse [49] | 2018 | ✓ | ✓ | ✓ | ||
| SACNet [50] | 2019 | ✓ | ✓ | ✓ | ||
| FuseSeg [51] | 2020 | ✓ | ✓ | ✓ | ||
| BEVFusion [52] | 2023 | ✓ | ✓ | ✓ | ||
| CoBEVFusion [53] | 2023 | ✓ | ✓ | ✓ | ||
| BroadBEV [54] | 2024 | ✓ | ✓ | ✓ | ||
| MVXNet [55] | 2019 | ✓ | ✓ | ✓ | ||
| 3D-CVF [56] | 2020 | ✓ | ✓ | ✓ | ||
| VPF-Net [57] | 2022 | ✓ | ✓ | ✓ | ||
| PointAugmenting [58] | 2021 | ✓ | ✓ | ✓ | ||
| PointFusion [59] | 2018 | ✓ | ✓ | ✓ | ||
| PI-RCNN [60] | 2020 | ✓ | ✓ | ✓ | ||
| EPNet [61] | 2020 | ✓ | ✓ | ✓ | ||
| MSMDFusion [62] | 2023 | ✓ | ✓ | ✓ | ||
| PointPainting [63] | 2020 | ✓ | ✓ | ✓ | ||
| DeepFusion [64] | 2022 | ✓ | ✓ | ✓ | ||
| TransFusion [65] | 2022 | ✓ | ✓ | ✓ | ||
| SupFusion [66] | 2023 | ✓ | ✓ | ✓ | ||
| CenterFusion [67] | 2021 | ✓ | ✓ | ✓ | ||
| CRAFT [68] | 2023 | ✓ | ✓ | ✓ | ||
| RCBEV4d [69] | 2023 | ✓ | ✓ | ✓ | ||
| CRN [70] | 2023 | ✓ | ✓ | ✓ | ||
| RCBEVDet [71] | 2024 | ✓ | ✓ | ✓ | ||
| Category Based on Feature Extraction Method | Methods | Pros | Cons |
|---|---|---|---|
| Front view (FV)-based | VeloFCN [38] | Good for detecting VRUs in foreground of the scenario. | Struggles with occlusions and side or distant VRUs. |
| Bird’s eye view (BEV)-based | PIXOR [39] | Comprehensive view of surroundings, improved occlusion handling. | Loss of fine-grained details in crowded environments. |
| Voxel-based | VoxelNet [8], SECOND [40], PointPillars [41], CenterPoint [42], FecNet [102], PillarNet [43] | Effective for large-scale, structured objects. | Struggles with small or non-rigid objects, such as VRUs. |
| Point-based | PointRCNN [44], PV-RCNN [45], PV-RCNN++ [46] | Best for small, non-rigid objects, better occlusion handling. | Computationally expensive, slower inference. |
| Category Based on Feature Extraction Method | Methods | Comments |
|---|---|---|
| FV/BEV- and feature map-based | MV3D [47], AVOD [48], Cont Fuse [49], SACNet [50], FuseSeg [51], BEVFusion [52], CoBEVFusion [53], BroadBEV [54] | BEV provides spatial context for VRUs, and camera feature maps enhance object classification; FV may not be as robust as BEV for VRU detection, especially for detecting VRUs that might be occluded or outside the direct front-view. |
| Voxel- and feature map-based | MVXNet [55], 3D-CVF [56], VPF-Net [57], PointAugmenting [58] | Voxel grid provides depth but lacks high resolution for fine VRU detection. Combined with feature maps, detection improves but may struggle in cluttered environments. |
| Point- and feature map-based | PointFusion [59], PI-RCNN [60], EPNet [61], MSMDFusion [62] | Precise 3D spatial data from LiDAR combined with camera’s semantic information helps detect VRUs, even in occlusions or complex environments. |
| Point- and mask-based | PointPainting [63] | Combines precise depth information with semantic segmentation for accurate VRU detection, especially in occlusions or partial visibility scenarios. |
| Deep feature-based | DeepFusion [64], TransFusion [65], SupFusion [66] | Advanced fusion of high-level features from both sensors leads to the best detection of VRUs, especially in dynamic or complex scenes. |
| Datasets | Data Source | Object Class | Content |
|---|---|---|---|
| Caltech [138] |
|
|
|
| CityPersons [139] |
|
|
|
| EuroCity Persons [140] |
|
|
|
| NightOwls [141] |
|
|
|
| TJU-DHD [142] |
|
|
|
| CADP [143] |
|
|
|
| BGVP [86] |
|
|
|
| Datasets | Data Source | Synchronization | Object Class | Content |
|---|---|---|---|---|
| BAAI-VANJEE [144] |
| 20% synchronized |
|
|
| DAIR-V2X-I [107] |
| Yes |
|
|
| TUMTraf Intersection Dataset [118] |
| Yes |
|
|
| LLVIP [125] |
| Yes |
|
|
| TUMTraf Event [145] |
| Yes |
|
|
| MMPD [129] |
| Yes |
|
|
| Datasets | Data Source | Synchronization | Object Class | Content |
|---|---|---|---|---|
| Rope3D [146] |
| Yes |
|
|
| DAIR-V2X-C [107] |
| Yes |
|
|
| TUMTraf V2X Cooperative Perception Dataset [147] |
| Yes |
|
|
| V2X-Real [148] |
| Yes |
|
|
| V2X-SIM [149] |
| Yes |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wei, C.; Wu, G.; Barth, M.J. Vulnerable Road User Detection for Roadside-Assisted Safety Protection: A Comprehensive Survey. Appl. Sci. 2025, 15, 3797. https://doi.org/10.3390/app15073797
Zhang Z, Wei C, Wu G, Barth MJ. Vulnerable Road User Detection for Roadside-Assisted Safety Protection: A Comprehensive Survey. Applied Sciences. 2025; 15(7):3797. https://doi.org/10.3390/app15073797
Chicago/Turabian StyleZhang, Ziyan, Chuheng Wei, Guoyuan Wu, and Matthew J. Barth. 2025. "Vulnerable Road User Detection for Roadside-Assisted Safety Protection: A Comprehensive Survey" Applied Sciences 15, no. 7: 3797. https://doi.org/10.3390/app15073797
APA StyleZhang, Z., Wei, C., Wu, G., & Barth, M. J. (2025). Vulnerable Road User Detection for Roadside-Assisted Safety Protection: A Comprehensive Survey. Applied Sciences, 15(7), 3797. https://doi.org/10.3390/app15073797