
PRNet: 3D Object Detection Network-Based on Point-Region Fusion


Abstract
1. Introduction
- (1)
- This study introduces a novel point-region fusion module (PRF) designed to integrate region-specific features from images with corresponding point clouds, thereby enhancing the performance of the fusion process.
- (2)
- This study develops an image feature fusion module (IF-Fusion), which ingeniously combines image feature maps of various sizes. This approach is specifically aimed at preserving the features of small objects while augmenting the overall expressive capability of the point cloud features.
- (3)
- Experimental results based on the KITTI benchmark demonstrate that the proposed method achieves significant advancements over previous fusion networks. This underscores the efficacy and innovative nature of the proposed approach in the realm of point cloud object detection.
2. Related Work
2.1. Methods Based on Single-Modality
2.2. Methods Based Multi-Modality Fusion
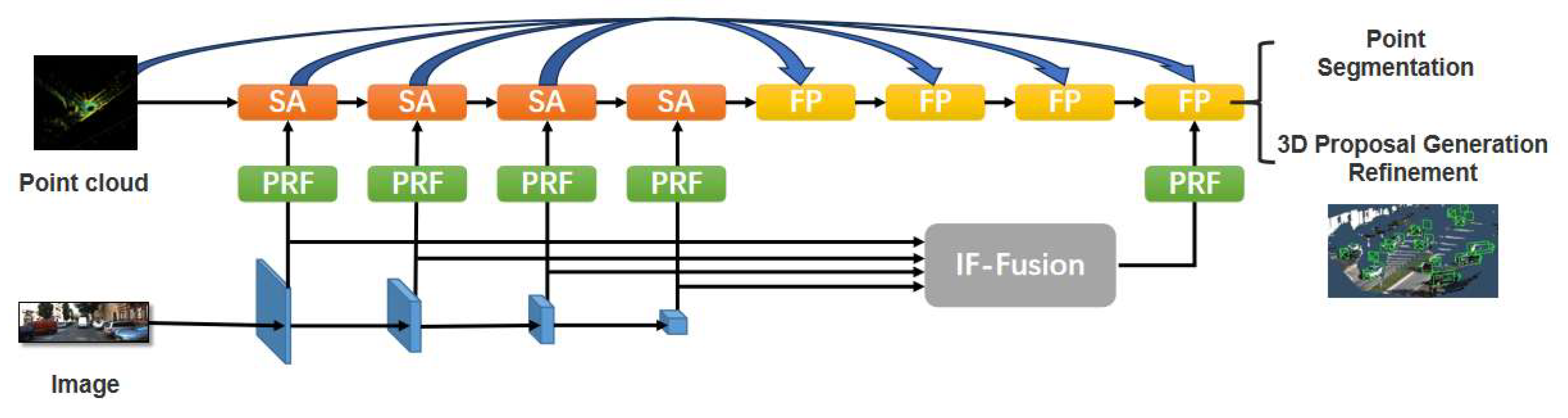
3. PRNet Framework
3.1. Feature Extractors for Point Cloud and Image
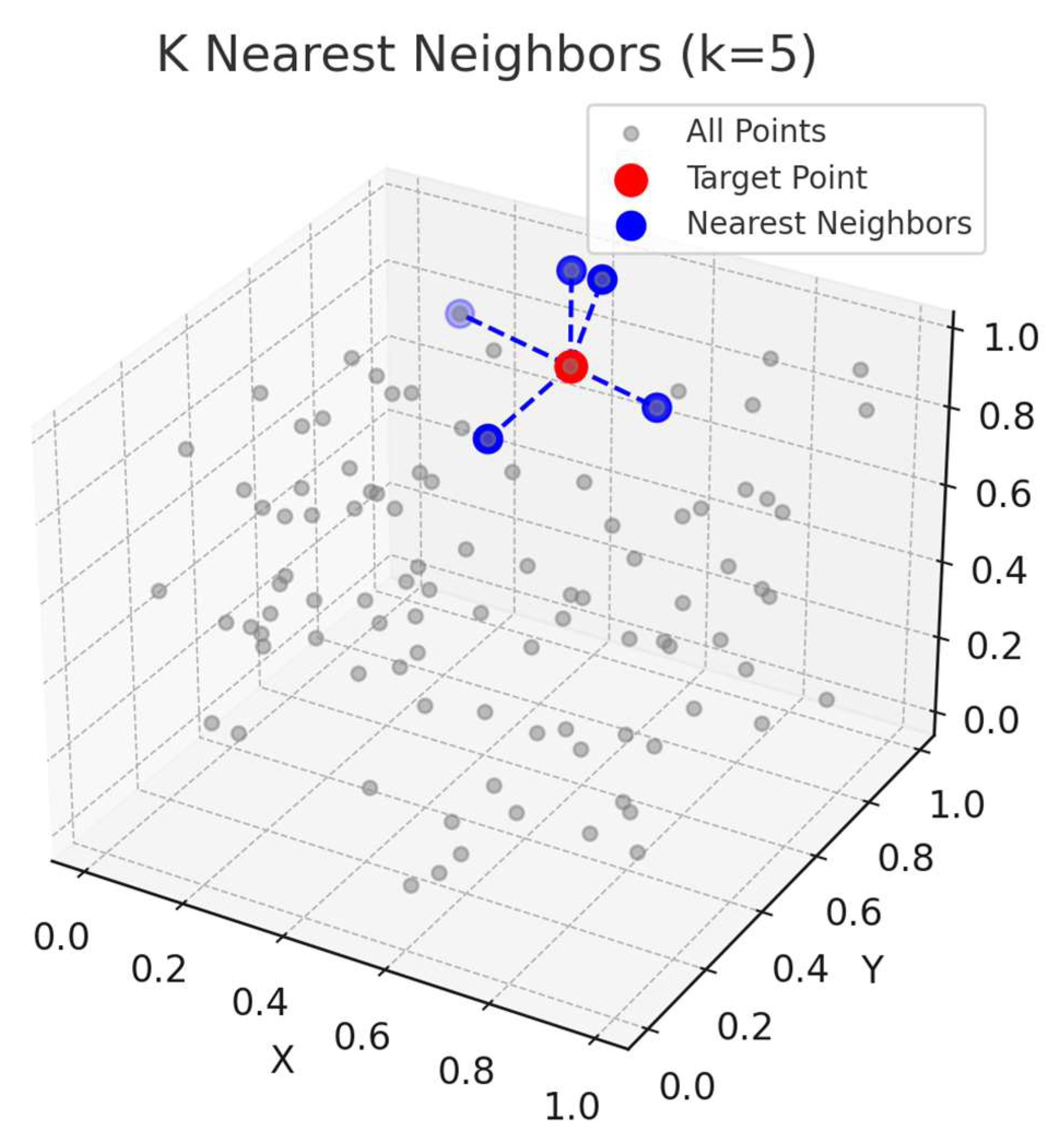
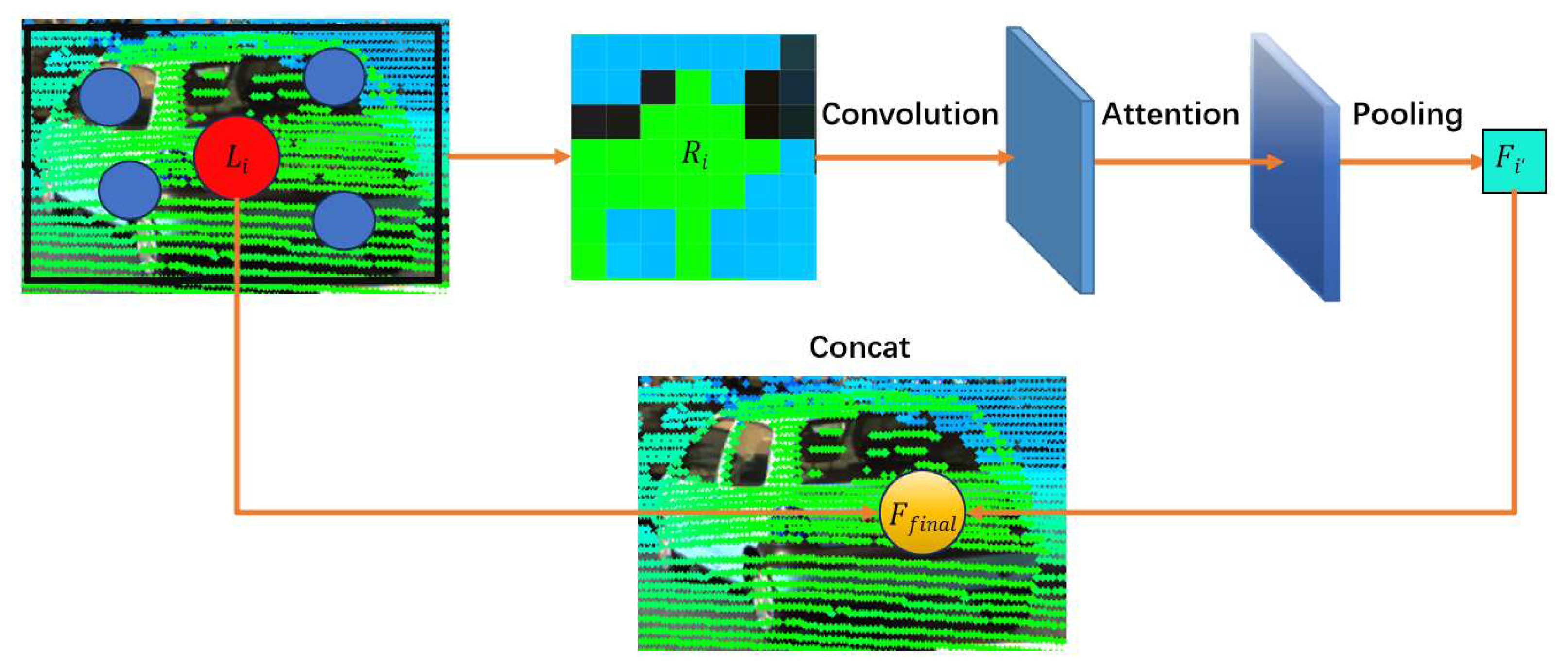
3.2. PRF Module
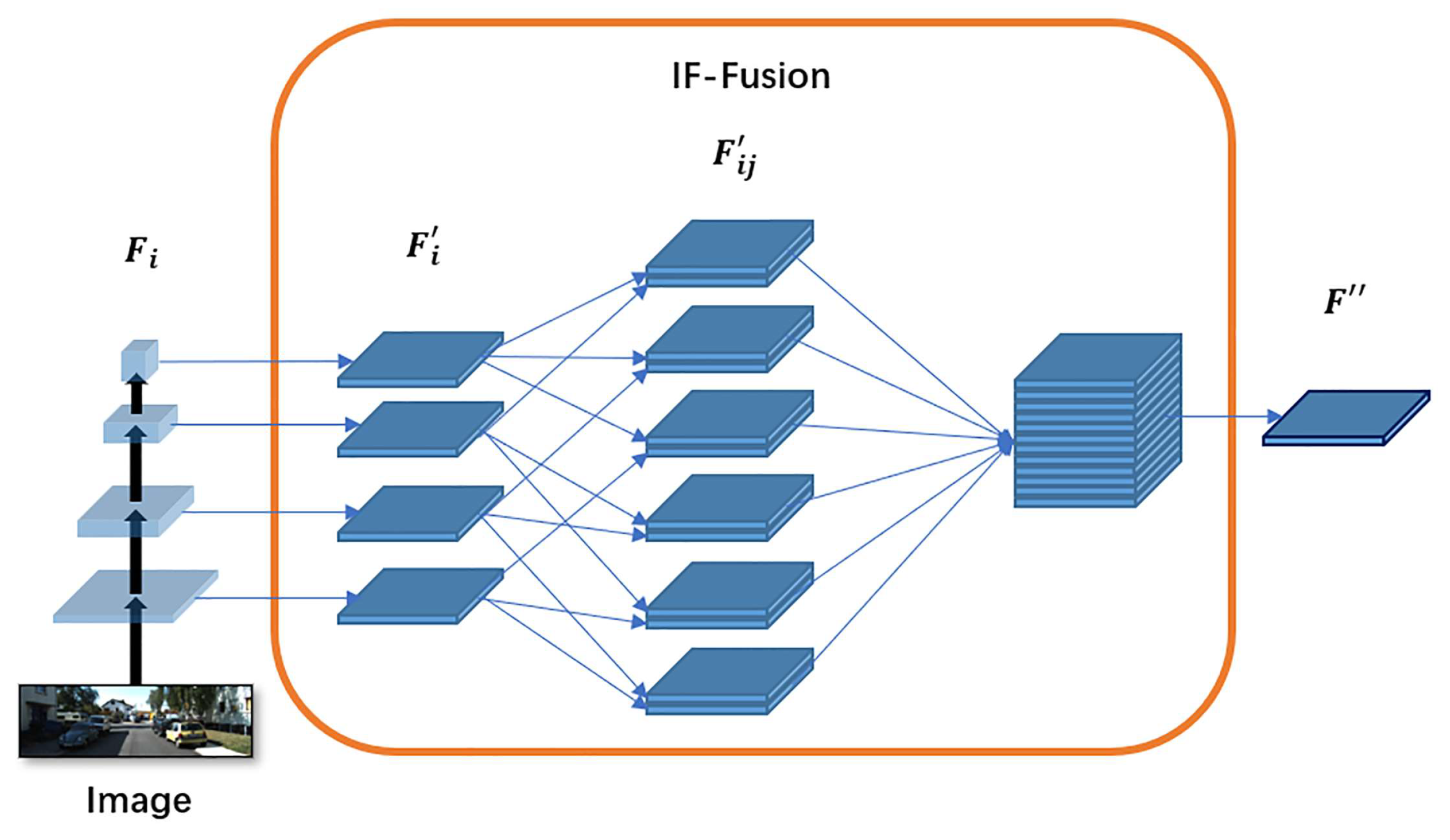
3.3. IF-Fusion
3.4. Computational Complexity Analysis
4. Experiment and Result
4.1. 3D Detection
4.2. The Effect of PRF Module
4.3. The Effect of IF-Fusion
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 3354–3361. [Google Scholar]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep learning for lidar point clouds in autonomous driving: A review. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Ataer-Cansizoglu, E.; Taguchi, Y.; Ramalingam, S.; Garaas, T. Tracking an RGB-D camera using points and planes. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2 December 2013; pp. 51–58. [Google Scholar]
- Kim, H.; Kim, J.; Nam, H.; Park, J.; Lee, S. Spatiotemporal Texture Reconstruction for Dynamic Objects Using a Single RGB-D Camera. Comput. Graph. Forum 2021, 40, 523–535. [Google Scholar]
- Wang, Z.; Zhan, W.; Tomizuka, M. Fusing bird’s eye view lidar point cloud and front view camera image for 3d object detection. 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Fidler, S.; Urtasun, R. 3d object proposals using stereo imagery for accurate object class detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1259–1272. [Google Scholar] [PubMed]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In Computer Vision–ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XV 16; Springer International Publishing: New York, NY, USA, 2020; pp. 35–52. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Drobnitzky, M.; Friederich, J.; Egger, B.; Zschech, P. Survey and systematization of 3D object detection models and methods. Vis. Comput. 2024, 40, 1867–1913. [Google Scholar] [CrossRef]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3d bounding box estimation using deep learning and geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7074–7082. [Google Scholar]
- Li, B.; Ouyang, W.; Sheng, L.; Zeng, X.; Wang, X. Gs3d: An efficient 3d object detection framework for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1019–1028. [Google Scholar]
- Shi, X.; Ye, Q.; Chen, X.; Chen, C.; Chen, Z.; Kim, T.K. Geometry-based distance decomposition for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15172–15181. [Google Scholar]
- Cai, Y.; Li, B.; Jiao, Z.; Li, H.; Zeng, X.; Wang, X. Monocular 3d object detection with decoupled structured polygon estimation and height-guided depth estimation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 10478–10485. [Google Scholar]
- Ma, X.; Zhang, Y.; Xu, D.; Zhou, D.; Yi, S.; Li, H.; Ouyang, W. Delving into localization errors for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4721–4730. [Google Scholar]
- Liu, X.; Xue, N.; Wu, T. Learning auxiliary monocular contexts helps monocular 3D object detection. Proc. AAAI Conf. Artif. Intelligence 2022, 36, 1810–1818. [Google Scholar] [CrossRef]
- You, Y.; Wang, Y.; Chao, W.L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv 2019, arXiv:1906.06310. [Google Scholar]
- Qian, R.; Garg, D.; Wang, Y.; You, Y.; Belongie, S.; Hariharan, B.; Campbell, M.; Weinberger, K.Q.; Chao, W.L. End-to-end pseudo-lidar for image-based 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5881–5890. [Google Scholar]
- Guo, X.; Shi, S.; Wang, X.; Li, H. Liga-stereo: Learning lidar geometry aware representations for stereo-based 3d detector. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3153–3163. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Li, J.; Sun, Y.; Luo, S.; Zhu, Z.; Dai, H.; Krylov, A.S.; Ding, Y.; Ling, S. P2v-rcnn: Point to voxel feature learning for 3d object detection from point clouds. IEEE Access 2021, 9, 98249–98260. [Google Scholar] [CrossRef]
- Li, J.; Luo, S.; Zhu, Z.; Dai, H.; Krylov, A.S.; Ding, Y.; Shao, L. 3D IoU-Net: IoU guided 3D object detector for point clouds. arXiv 2020, arXiv:2004.04962. [Google Scholar]
- Sun, P.; Wang, W.; Chai, Y.; Elsayed, G.; Bewley, A.; Zhang, X.; Sminchisescu, C.; Anguelov, D. Rsn: Range sparse net for efficient, accurate lidar 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5725–5734. [Google Scholar]
- Fan, L.; Xiong, X.; Wang, F.; Wang, N.; Zhang, Z. Rangedet: In defense of range view for lidar-based 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2918–2927. [Google Scholar]
- Liang, Z.; Zhang, Z.; Zhang, M.; Zhao, X.; Pu, S. Rangeioudet: Range image based real-time 3d object detector optimized by intersection over union. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7140–7149. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Wang, Y.; Fathi, A.; Kundu, A.; Ross, D.A.; Pantofaru, C.; Funkhouser, T.; Solomon, J. Pillar-based object detection for autonomous driving. In Computer Vision–ECCV 2020, 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16; Springer International Publishing: New York, NY, USA, 2020; pp. 18–34. [Google Scholar]
- Kuang, H.; Wang, B.; An, J.; Zhang, M.; Zhang, Z. Voxel-FPN: Multi-scale voxel feature aggregation for 3D object detection from LIDAR point clouds. Sensors 2020, 20, 704. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 1201–1209. [Google Scholar]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-ensembling single-stage object detector from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14494–14503. [Google Scholar]
- Xu, Q.; Zhong, Y.; Neumann, U. Behind the curtain: Learning occluded shapes for 3d object detection. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2893–2901. [Google Scholar] [CrossRef]
- Qian, R.; Lai, X.; Li, X. BADet: Boundary-aware 3D object detection from point clouds. Pattern Recognit. 2022, 125, 108524. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle detection from 3d lidar using fully convolutional network. arXiv 2016, arXiv:1608.07916. [Google Scholar]
- Yang, B.; Liang, M.; Urtasun, R. Hdnet: Exploiting hd maps for 3d object detection. In Proceedings of the Conference on Robot Learning, PMLR. Zürich, Switzerland, 29–31 October 2018; pp. 146–155. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 1–8. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. Mvx-net: Multimodal voxelnet for 3d object detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: New York, NY, USA, 2019; pp. 7276–7282. [Google Scholar]
- Hong, D.S.; Chen, H.H.; Hsiao, P.Y.; Fu, L.C.; Siao, S.M. CrossFusion net: Deep 3D object detection based on RGB images and point clouds in autonomous driving. Image Vis. Comput. 2020, 100, 103955. [Google Scholar]


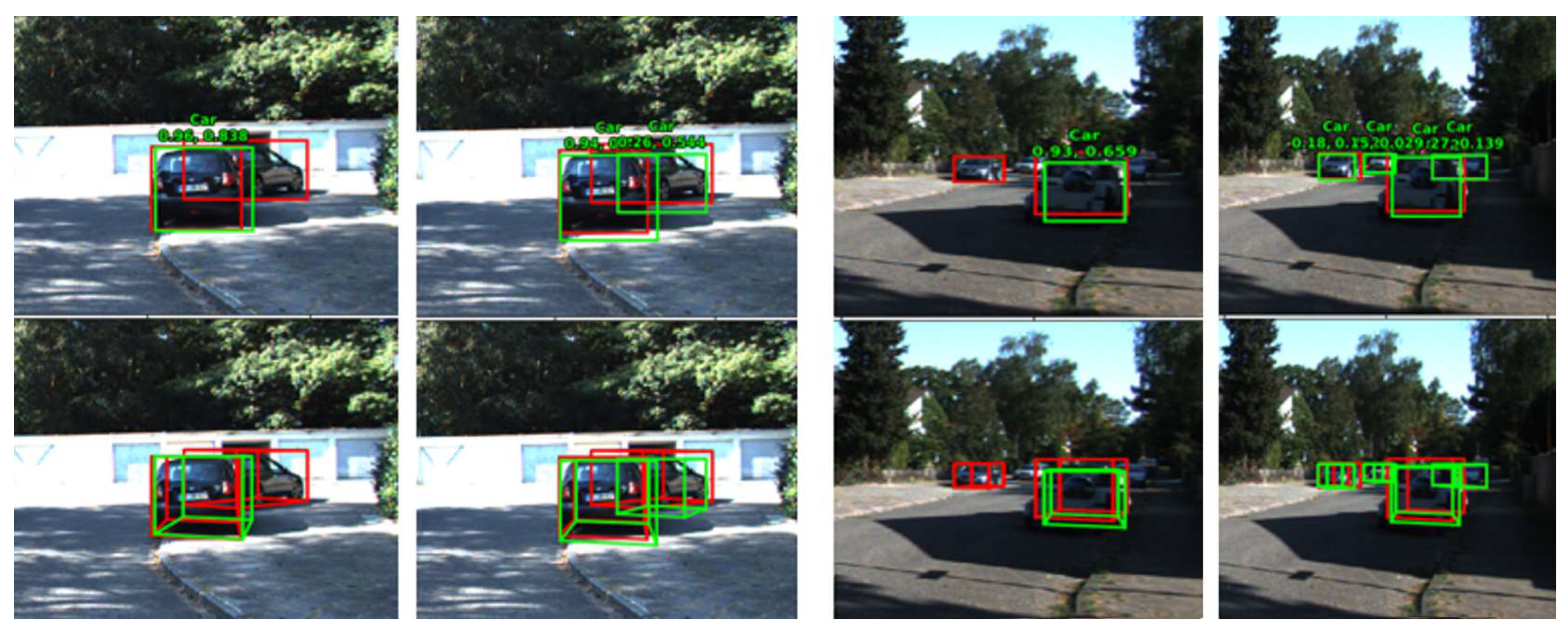


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP3D (%) | APBEV (%) | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |
| F-PointNet | 81.20 | 70.39 | 62.19 | 88.70 | 84.00 | 75.33 |
| F-ConvNet | 85.88 | 76.51 | 68.08 | 89.69 | 83.08 | 74.56 |
| MV3D | 71.09 | 62.35 | 55.12 | 86.02 | 76.90 | 68.49 |
| AVOD-FPN | 81.94 | 71.88 | 66.38 | 88.53 | 83.79 | 77.90 |
| ContFuse | 82.54 | 66.22 | 64.04 | 88.81 | 85.83 | 77.33 |
| CrossFusion | 83.20 | 74.50 | 67.01 | 88.39 | 86.17 | 78.23 |
| CLOCs | 87.50 | 76.68 | 71.20 | 92.60 | 88.99 | 81.74 |
| PI-RCNN | 84.59 | 75.82 | 68.39 | - | - | - |
| VPFNet | 88.51 | 80.97 | 76.74 | - | - | - |
| SFD | 91.73 | 84.76 | 77.92 | 95.64 | 91.85 | 86.83 |
| Ours | 91.95 | 80.56 | 78.08 | 95.75 | 88.83 | 88.68 |
| PRF | k_neighbors | AP3D (%) | APBEV (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Average | Easy | Moderate | Hard | Average | ||
| No | - | 88.82 | 78.62 | 76.67 | 81.37 | 94.76 | 87.25 | 85.40 | 89.14 |
| Yes | 3 | 90.70 | 79.68 | 77.24 | 82.54 (+1.17) | 95.15 | 88.40 | 86.28 | 89.94 (+0.80) |
| 4 | 91.06 | 79.94 | 77.69 | 82.90 (+1.53) | 94.69 | 88.33 | 86.34 | 89.79 (+0.65) | |
| 5 | 90.88 | 79.84 | 77.65 | 82.79 (+1.42) | 95.11 | 88.40 | 86.43 | 89.98 (+0.84) | |
| Sensor | PRF | IF-Fusion | AP3D (%) | APBEV (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |||
| Lidar | × | × | 88.82 | 78.62 | 76.67 | 94.76 | 87.25 | 85.40 |
| Lidar + Image | √ | × | 90.70 | 79.68 | 77.24 | 95.15 | 88.40 | 86.28 |
| Lidar + Image | × | √ | 90.70 | 81.10 | 79.00 | 94.79 | 88.08 | 86.10 |
| Lidar + Image | √ | √ | 91.95 | 80.56 | 78.08 | 95.75 | 88.83 | 86.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Guo, Y.; Hu, H. PRNet: 3D Object Detection Network-Based on Point-Region Fusion. Appl. Sci. 2025, 15, 3759. https://doi.org/10.3390/app15073759
Fu Y, Guo Y, Hu H. PRNet: 3D Object Detection Network-Based on Point-Region Fusion. Applied Sciences. 2025; 15(7):3759. https://doi.org/10.3390/app15073759
Chicago/Turabian StyleFu, Yufei, Yuhao Guo, and Hui Hu. 2025. "PRNet: 3D Object Detection Network-Based on Point-Region Fusion" Applied Sciences 15, no. 7: 3759. https://doi.org/10.3390/app15073759
APA StyleFu, Y., Guo, Y., & Hu, H. (2025). PRNet: 3D Object Detection Network-Based on Point-Region Fusion. Applied Sciences, 15(7), 3759. https://doi.org/10.3390/app15073759