
Navigation Map Construction Based on Semantic Segmentation and Multi-Submap Integration



Abstract
1. Introduction
- The method does not rely on dense depth estimation, and reconstructs only the road surface and obstacles, omitting complex three-dimensional (3D) environmental reconstruction, and generates a lightweight 2D grid map, which can provide a directly parsable input for path-planning algorithms.
- A method is proposed to construct a global coordinate map even in the absence of GNSS signals.
- A multi-submap management module is proposed, in which multiple submaps are used to represent relatively larger environments. The submaps are classified based on the vehicle’s position, ensuring efficient memory allocation for each submap.
- Real-time map storage and retrieval functions are implemented, ensuring that the generated global coordinate maps are reusable and support subsequent mapping tasks.
2. Related Works
2.1. Visual SLAM
2.2. Vision-Based Navigation Map Construction
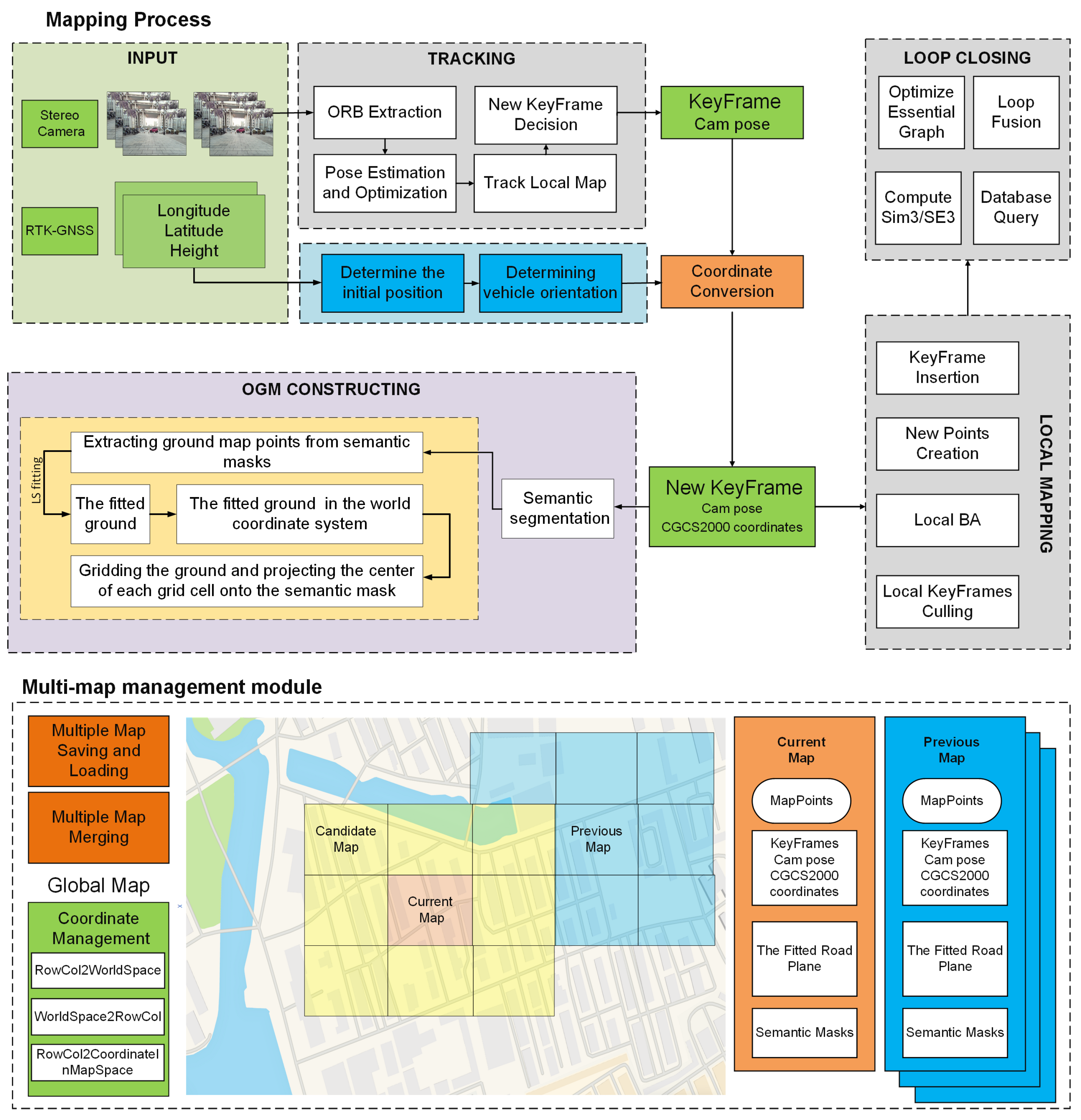
3. System Overview
4. Methods
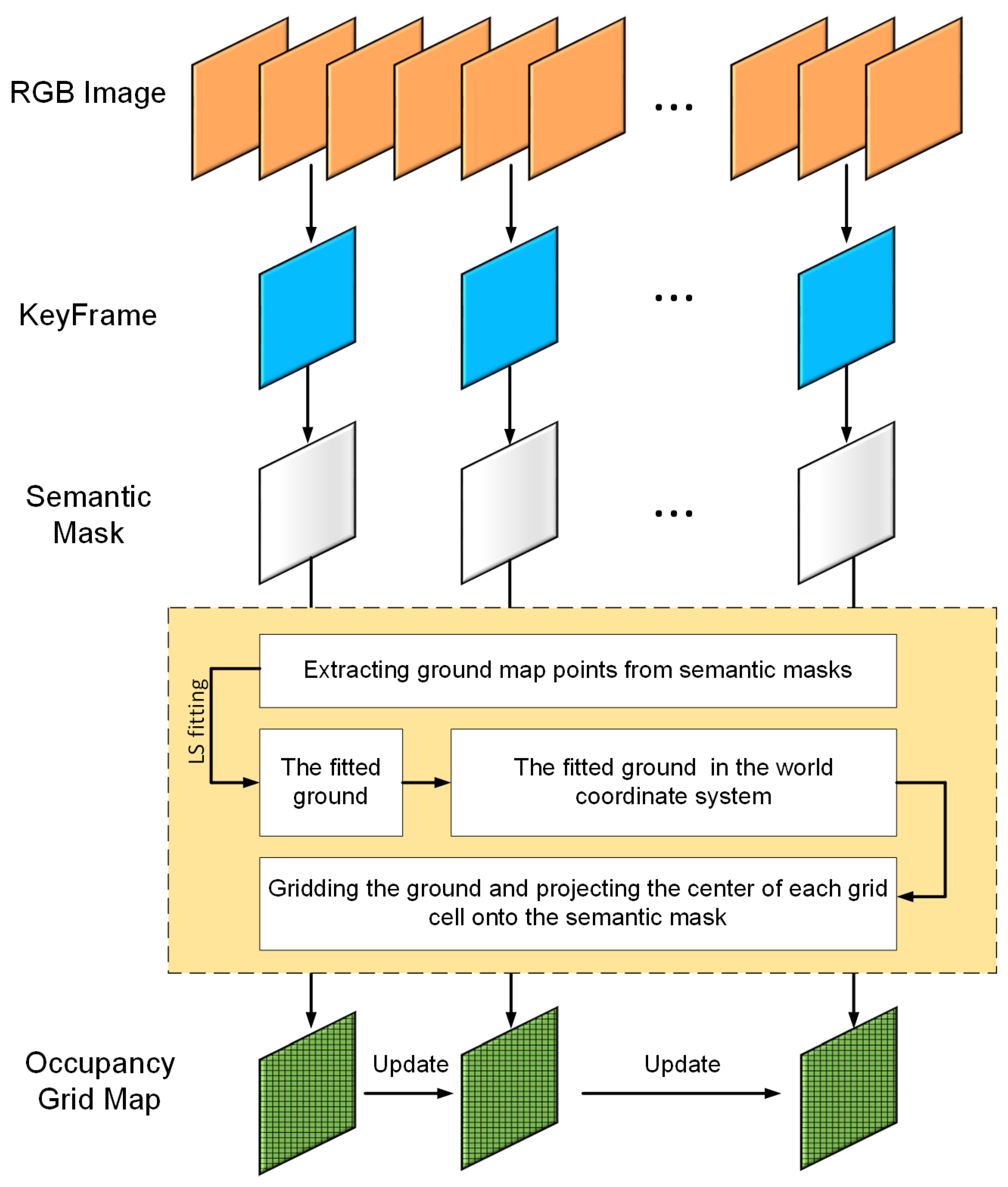
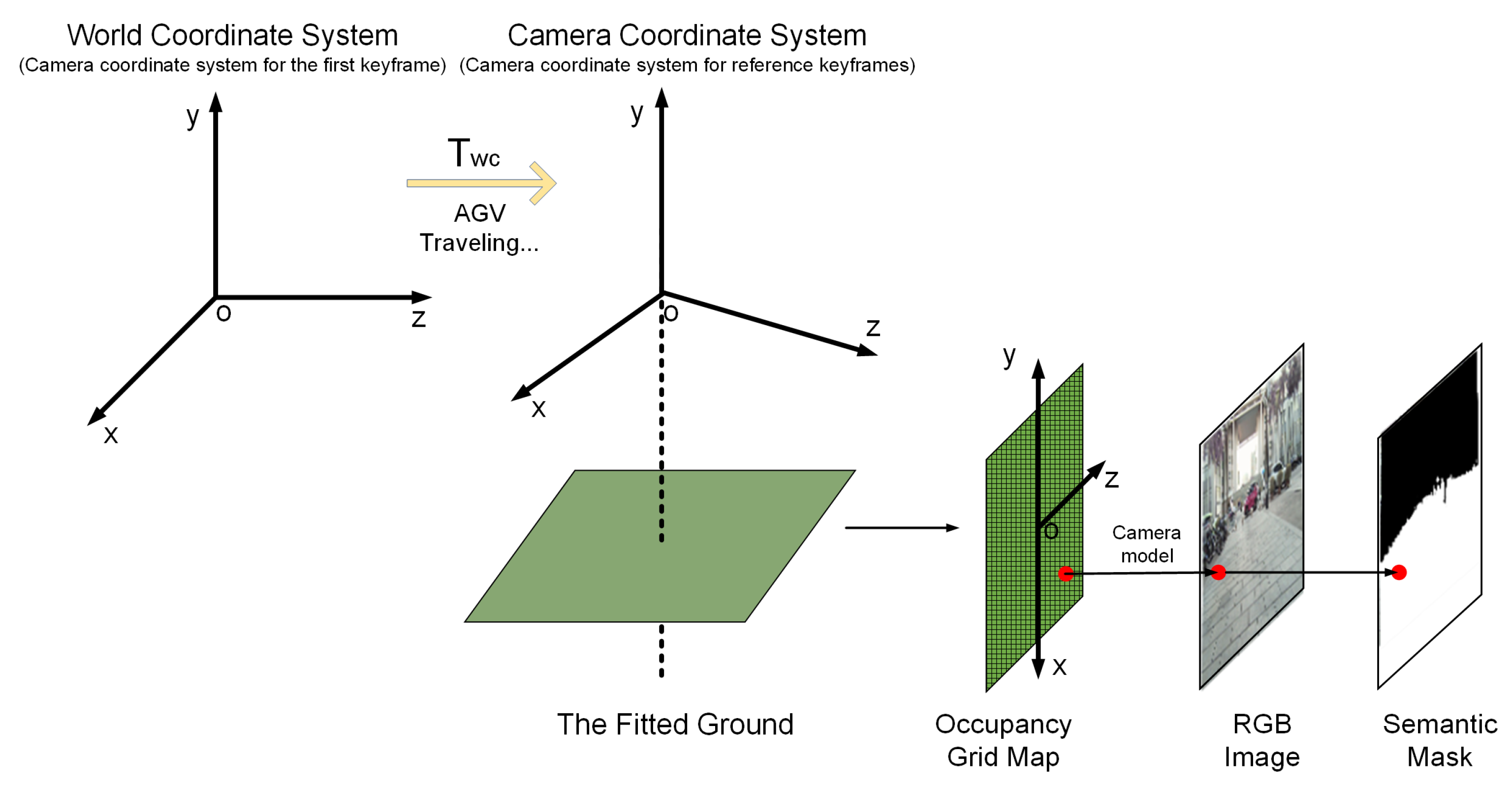
4.1. Incremental Ground Position Estimation
| Algorithm 1 Incremental Calculation of Fitted Ground Plane Parameters |
|
4.2. Multi-Submap Fusion Mapping Method for Outdoor Environment
4.2.1. Map Update Strategy for a Single Submap
| Algorithm 2 Submap Update Using KeyFrame Observations |
|
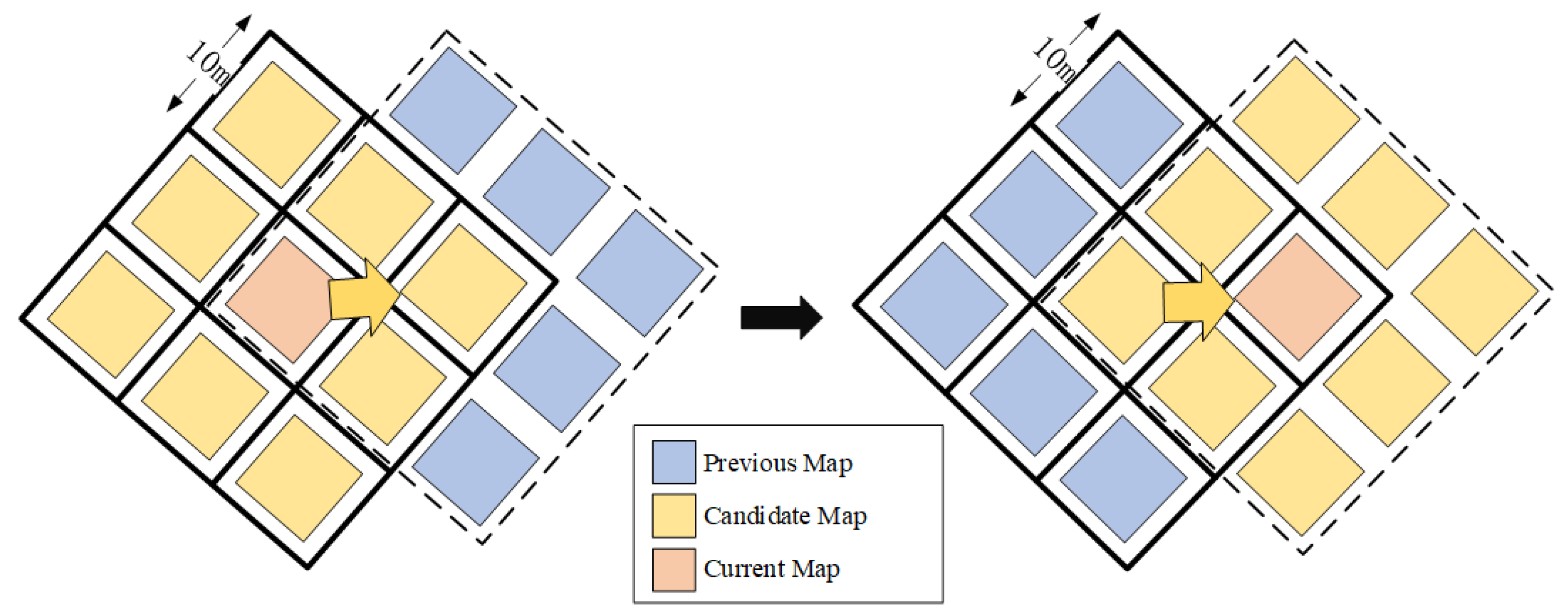
4.2.2. The Multi-Submap Management Module
5. Experimental Results
5.1. Experimental Setup and Environment
5.2. Experimental Results Analysis
5.2.1. Evaluation of Obstacle Reconstruction in the Scene
5.2.2. Evaluation of Road Surface Reconstruction in the Scene
6. Discussion
6.1. Performance Comparison

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Comparison Based on RMSE | ||||||
|---|---|---|---|---|---|---|
| Method | RMSE (m) | |||||
| Scene 1 | Scene 2 | Scene 3 | Scene 4 | Scene 5 | Total | |
| CroCo-Stereo [34] | 0.285 | 0.314 | 0.296 | 0.311 | 0.330 | 0.307 |
| ACVNet [35] | 0.455 | 0.398 | 0.427 | 0.379 | 0.443 | 0.420 |
| PCVNet [36] | 0.650 | 0.673 | 0.612 | 0.675 | 0.710 | 0.637 |
| CREStereo [27] | 0.472 | 0.411 | 0.521 | 0.439 | 0.490 | 0.467 |
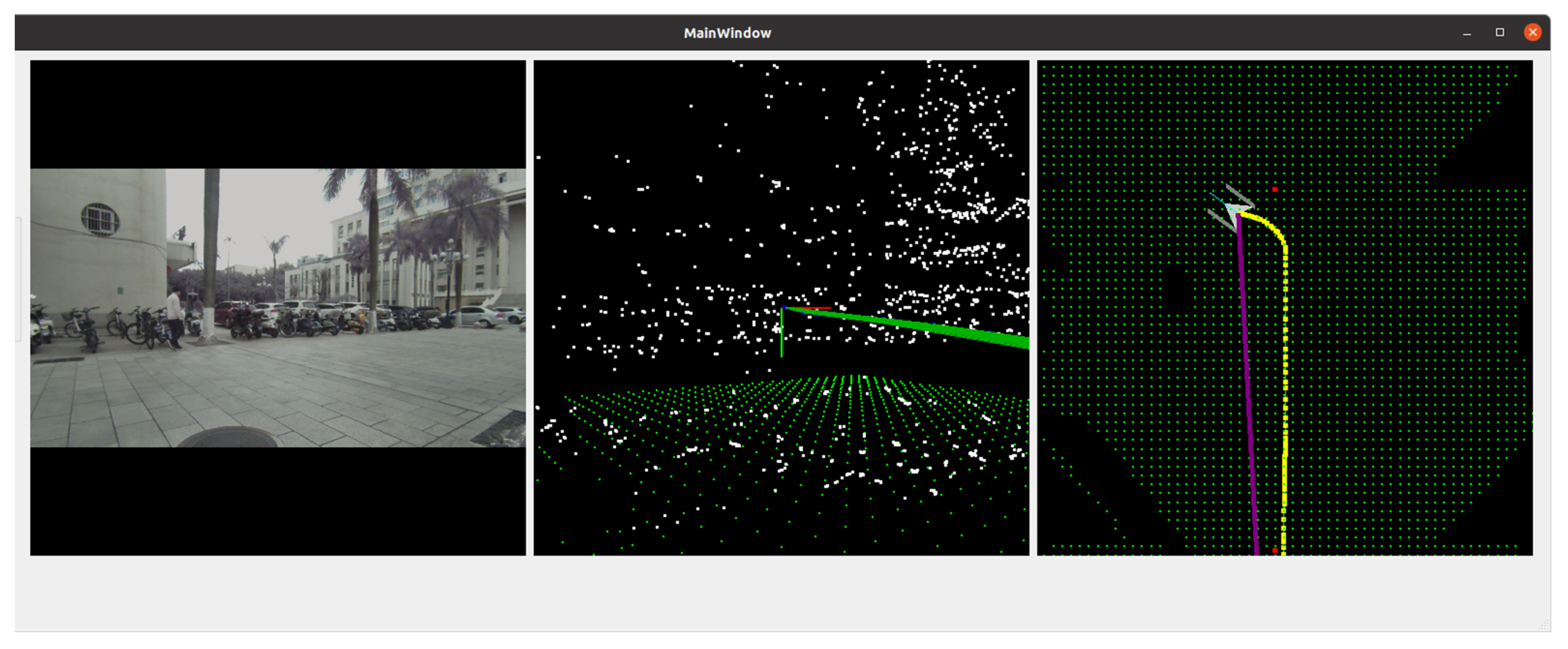
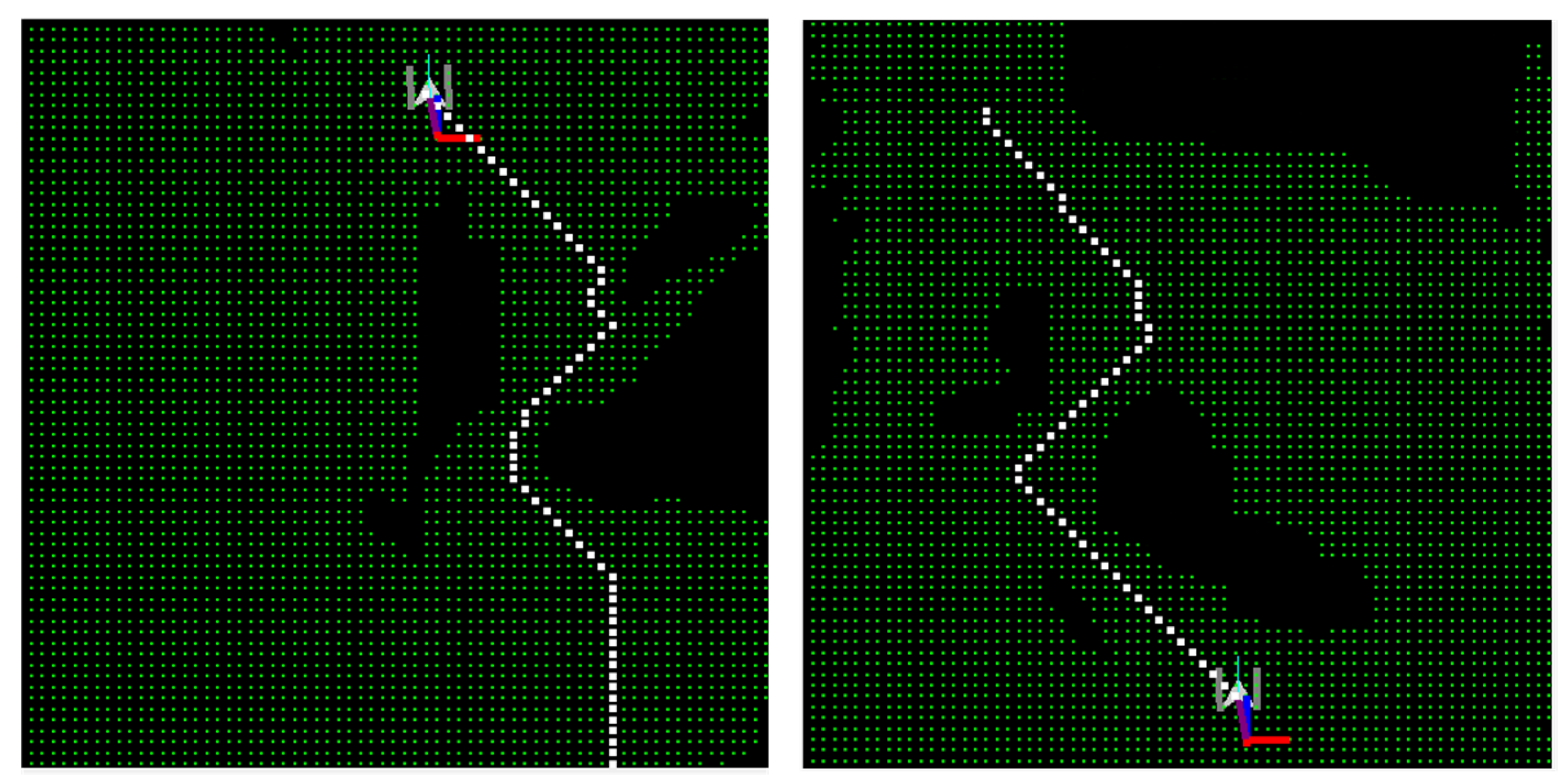
6.2. Example Application
6.3. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Viswanathan, D.G. Features from accelerated segment test (fast). In Proceedings of the 10th Workshop on Image Analysis for Multimedia Interactive Services, London, UK, 6–8 May 2009; pp. 6–8. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Cham, Switzeraland, 2010; pp. 778–792. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Cheng, J.; Zhang, L.; Chen, Q.; Hu, X.; Cai, J. A review of visual SLAM methods for autonomous driving vehicles. Eng. Appl. Artif. Intell. 2022, 114, 104992. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzeraland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. Semanticfusion: Dense 3d semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Runz, M.; Buffier, M.; Agapito, L. Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar]
- Tosi, F.; Bartolomei, L.; Poggi, M. A survey on deep stereo matching in the twenties. Int. J. Comput. Vis. 2025, 1–32. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, H.; Qi, X.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Fully convolutional networks for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 214–223. [Google Scholar]
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- Liu, C.W.; Wang, H.; Guo, S.; Bocus, M.J.; Chen, Q.; Fan, R. Stereo matching: Fundamentals, state-of-the-art, and existing challenges. In Autonomous Driving Perception: Fundamentals and Applications; Springer: Berlin/Heidelberg, Germany, 2023; pp. 63–100. [Google Scholar]
- Mertan, A.; Duff, D.J.; Unal, G. Single image depth estimation: An overview. Digit. Signal Process. 2022, 123, 103441. [Google Scholar]
- Tsardoulias, E.G.; Iliakopoulou, A.; Kargakos, A.; Petrou, L. A review of global path planning methods for occupancy grid maps regardless of obstacle density. J. Intell. Robot. Syst. 2016, 84, 829–858. [Google Scholar] [CrossRef]
- Lowe, G. Sift-the scale invariant feature transform. Int. J. 2004, 2, 2. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9; Springer: Cham, Switzerland, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Gálvez-López, D.; Tardos, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Cao, S.; Lu, X.; Shen, S. GVINS: Tightly coupled GNSS–visual–inertial fusion for smooth and consistent state estimation. IEEE Trans. Robot. 2022, 38, 2004–2021. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Xiong, L.; Kang, R.; Zhao, J.; Zhang, P.; Xu, M.; Ju, R.; Ye, C.; Feng, T. G-VIDO: A vehicle dynamics and intermittent GNSS-aided visual-inertial state estimator for autonomous driving. IEEE Trans. Intell. Transp. Syst. 2021, 23, 11845–11861. [Google Scholar] [CrossRef]
- Liu, J.; Gao, W.; Hu, Z. Optimization-based visual-inertial SLAM tightly coupled with raw GNSS measurements. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11612–11618. [Google Scholar]
- Zhu, J.; Zhou, H.; Wang, Z.; Yang, S. Improved Multi-sensor Fusion Positioning System Based on GNSS/LiDAR/Vision/IMU with Semi-tightly Coupling and Graph Optimization in GNSS Challenging Environments. IEEE Access 2023, 11, 95711–95723. [Google Scholar]
- Xu, L.; Feng, C.; Kamat, V.R.; Menassa, C.C. An occupancy grid mapping enhanced visual SLAM for real-time locating applications in indoor GPS-denied environments. Autom. Constr. 2019, 104, 230–245. [Google Scholar]
- Chang, Q.; Li, X.; Xu, X.; Liu, X.; Li, Y.; Miyazaki, J. StereoVAE: A lightweight stereo-matching system using embedded GPUs. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 1982–1988. [Google Scholar]
- Li, J.; Wang, P.; Xiong, P.; Cai, T.; Yan, Z.; Yang, L.; Liu, J.; Fan, H.; Liu, S. Practical stereo matching via cascaded recurrent network with adaptive correlation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16263–16272. [Google Scholar]
- Xu, G.; Wang, X.; Ding, X.; Yang, X. Iterative geometry encoding volume for stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21919–21928. [Google Scholar]
- Wu, Z.; Zhu, H.; He, L.; Zhao, Q.; Shi, J.; Wu, W. Real-time stereo matching with high accuracy via Spatial Attention-Guided Upsampling. Appl. Intell. 2023, 53, 24253–24274. [Google Scholar]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. g 2 o: A general framework for graph optimization. In Proceedings of the 2011 IEEE international Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]
- Tsai, R. A versatile camera calibration technique for high-accuracy 3D machine vision metrology using off-the-shelf TV cameras and lenses. IEEE J. Robot. Autom. 1987, 3, 323–344. [Google Scholar] [CrossRef]
- Jiang, Z.; Liu, J.; Wang, F.; Bei, J.; Zhai, X. Research on construction Theory of Global cGcs2000 coordinate Frame. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 167–174. [Google Scholar]
- Liang, Y.; Li, Y.; Yu, Y.; Zheng, L. Integrated lateral control for 4WID/4WIS vehicle in high-speed condition considering the magnitude of steering. Veh. Syst. Dyn. 2020, 58, 1711–1735. [Google Scholar]
- Weinzaepfel, P.; Lucas, T.; Leroy, V.; Cabon, Y.; Arora, V.; Brégier, R.; Csurka, G.; Antsfeld, L.; Chidlovskii, B.; Revaud, J. Croco v2: Improved cross-view completion pre-training for stereo matching and optical flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 17969–17980. [Google Scholar]
- Xu, G.; Cheng, J.; Guo, P.; Yang, X. Attention concatenation volume for accurate and efficient stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12981–12990. [Google Scholar]
- Zeng, J.; Yao, C.; Yu, L.; Wu, Y.; Jia, Y. Parameterized cost volume for stereo matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 18347–18357. [Google Scholar]
- Zhang, W.; Wang, N.; Wu, W. A hybrid path planning algorithm considering AUV dynamic constraints based on improved A* algorithm and APF algorithm. Ocean Eng. 2023, 285, 115333. [Google Scholar] [CrossRef]



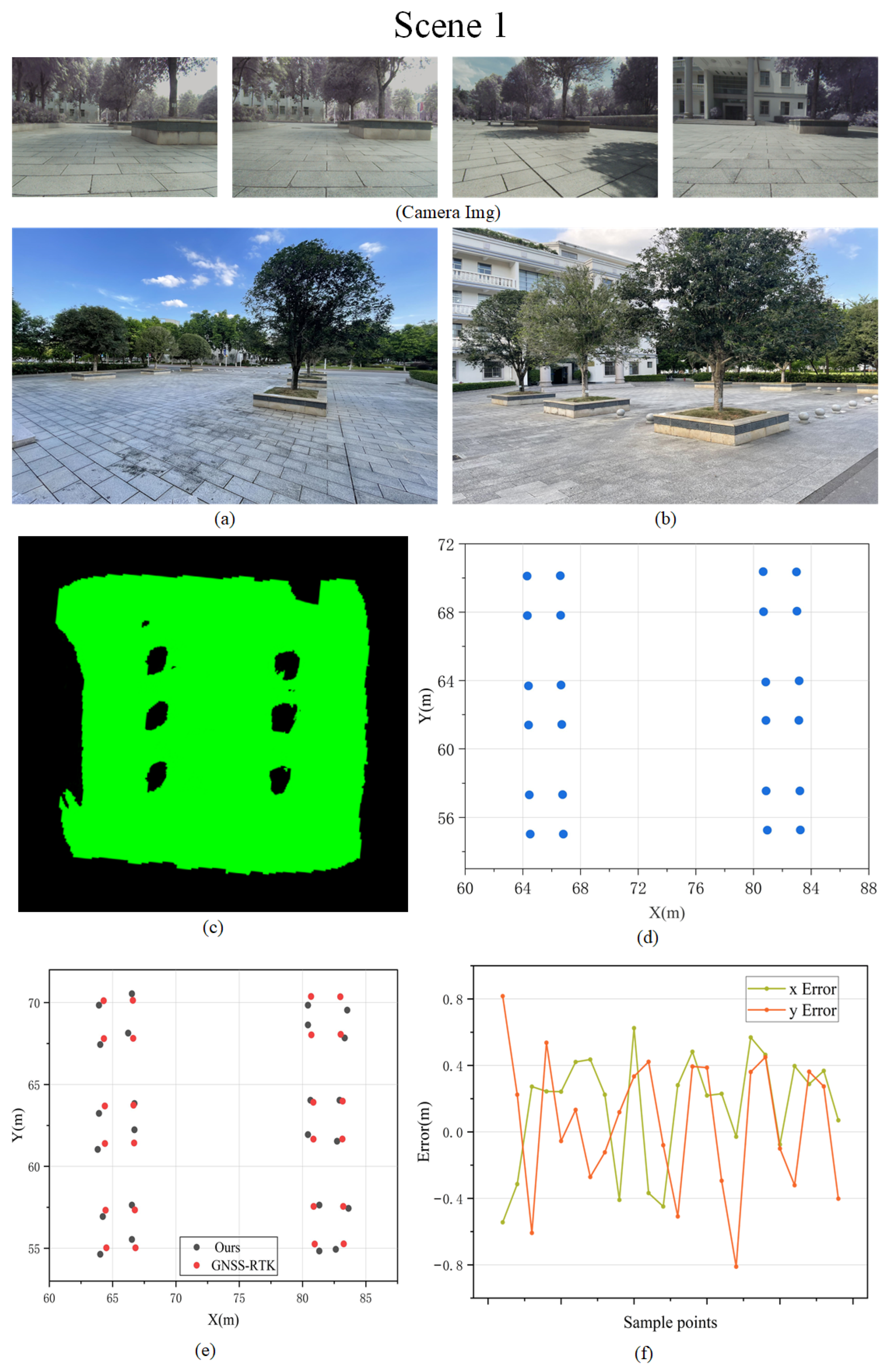
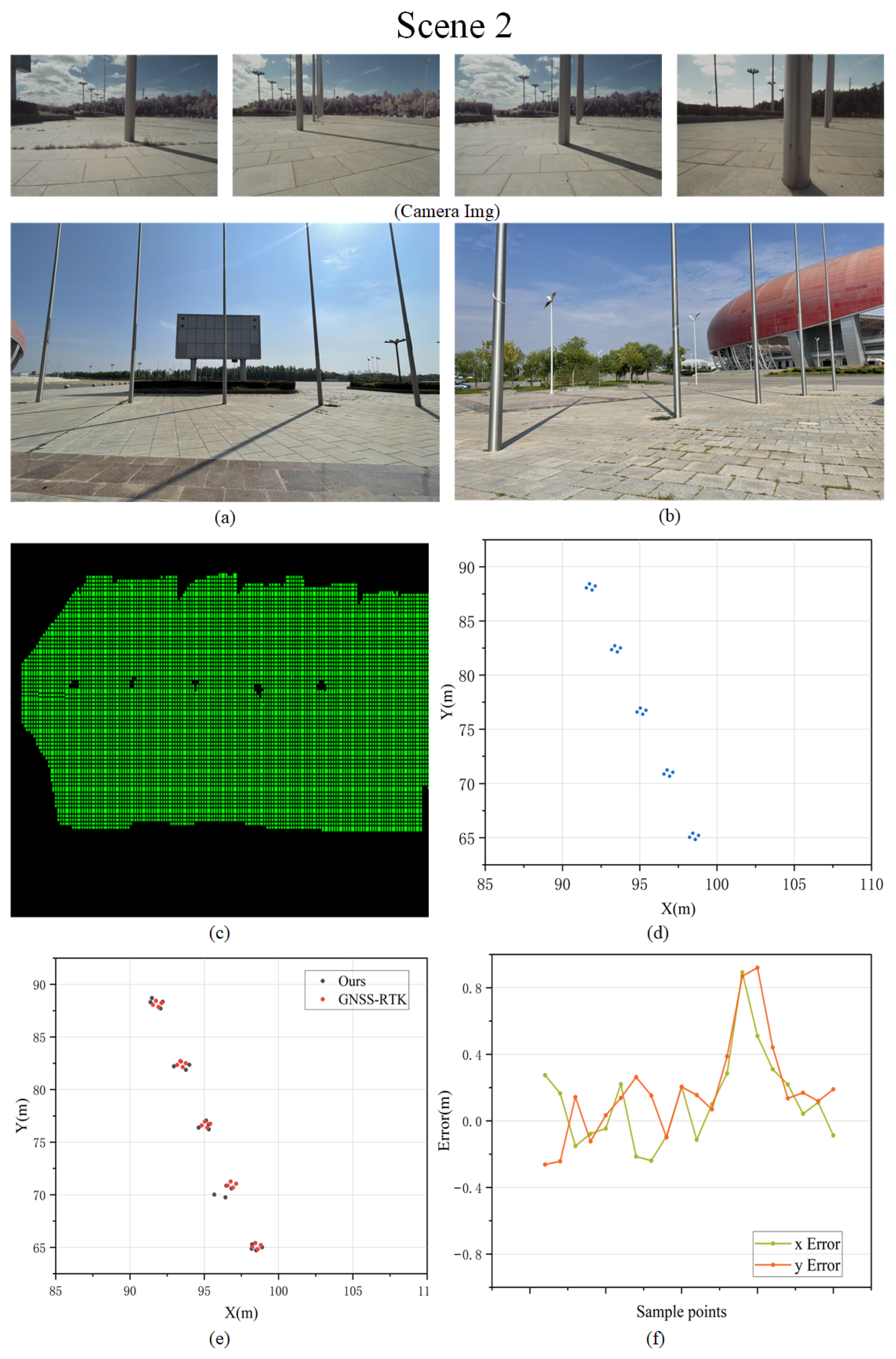
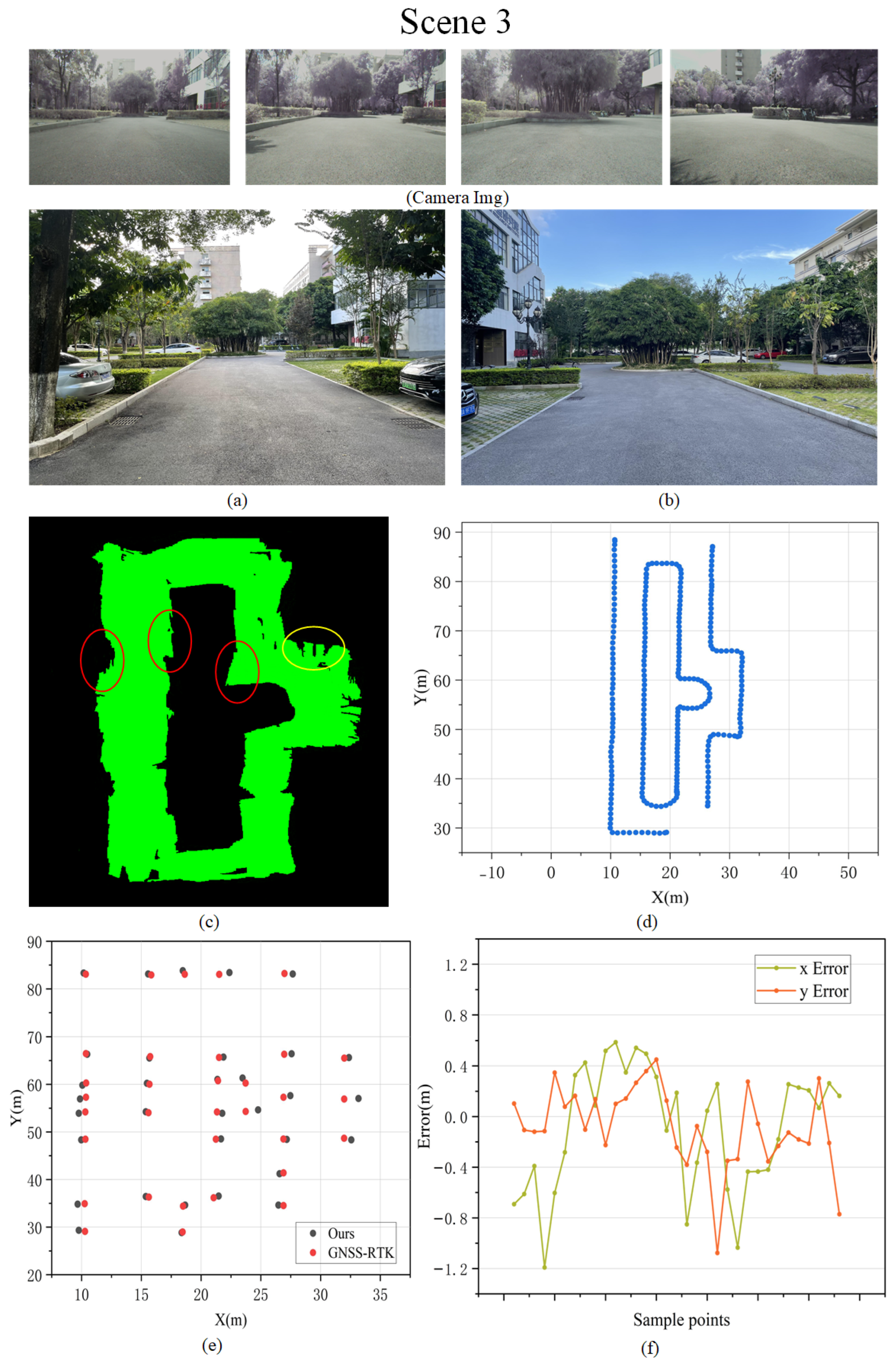
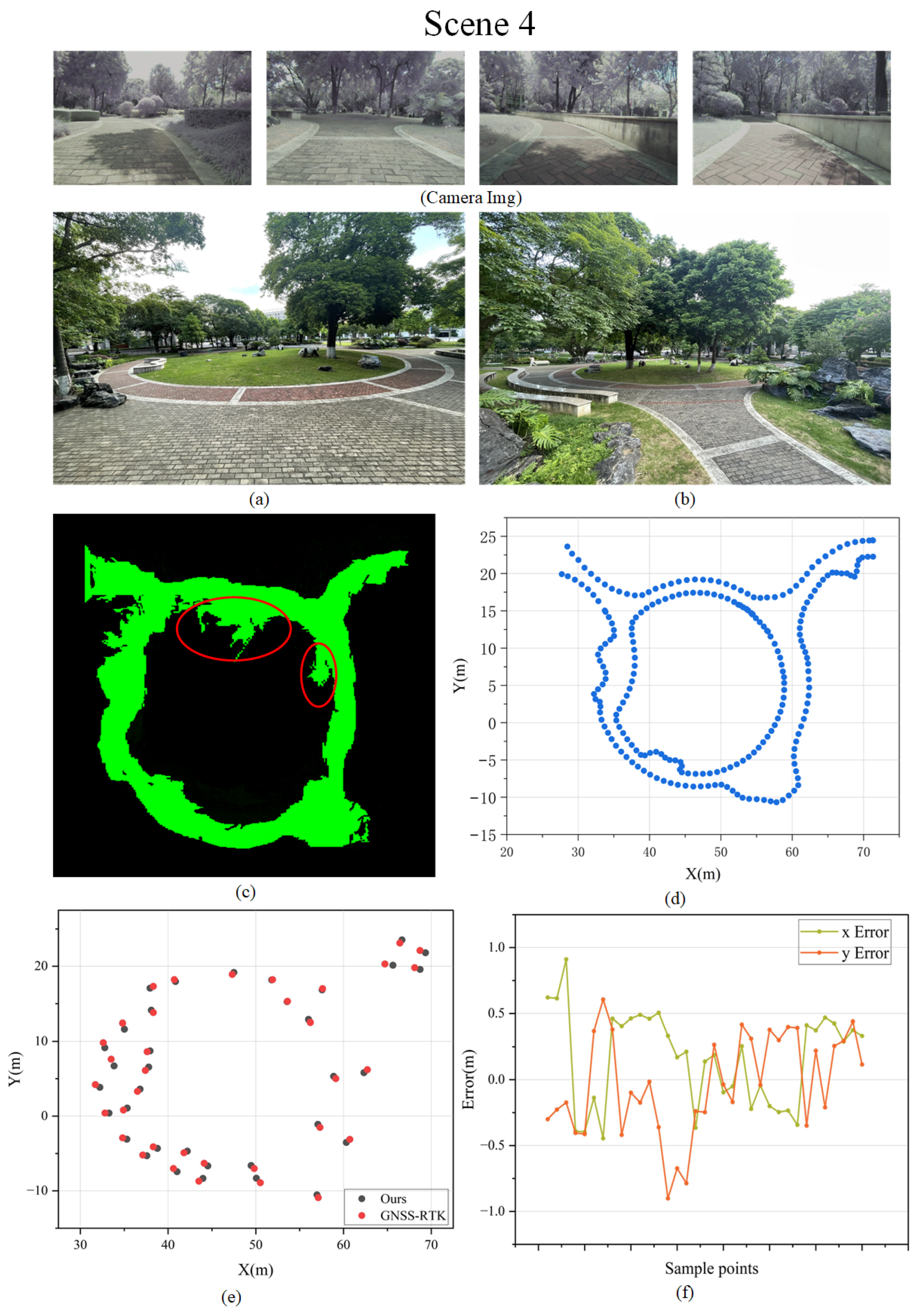

| RMSE in Mapping Experiment | ||||
|---|---|---|---|---|
| Scene | Map Scale () | RMSE (m) | ||
| Position x | Position y | Total | ||
| Scene 1 | 900 | 0.367 | 0.404 | 0.386 |
| Scene 2 | 1200 | 0.288 | 0.347 | 0.319 |
| Scene 3 | 2100 | 0.485 | 0.325 | 0.413 |
| Scene 4 | 3000 | 0.387 | 0.378 | 0.382 |
| Method | CroCo-Stereo | ACVNet | PCVNet | CREStereo | Ours (FCN) |
| Time (ms) | 2151 | 693 | 101 | 1361 | 96 |
| GPU memory (GB) | 2.85 | 3.2 | 1.21 | 1.26 | 1.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Huang, C.; Yu, J.; Luo, H. Navigation Map Construction Based on Semantic Segmentation and Multi-Submap Integration. Appl. Sci. 2025, 15, 3725. https://doi.org/10.3390/app15073725
Li G, Huang C, Yu J, Luo H. Navigation Map Construction Based on Semantic Segmentation and Multi-Submap Integration. Applied Sciences. 2025; 15(7):3725. https://doi.org/10.3390/app15073725
Chicago/Turabian StyleLi, Gang, Chen Huang, Jian Yu, and Hao Luo. 2025. "Navigation Map Construction Based on Semantic Segmentation and Multi-Submap Integration" Applied Sciences 15, no. 7: 3725. https://doi.org/10.3390/app15073725
APA StyleLi, G., Huang, C., Yu, J., & Luo, H. (2025). Navigation Map Construction Based on Semantic Segmentation and Multi-Submap Integration. Applied Sciences, 15(7), 3725. https://doi.org/10.3390/app15073725