
Enhanced Blind Separation of Rail Defect Signals with Time–Frequency Separation Neural Network and Smoothed Pseudo Wigner–Ville Distribution



Abstract
1. Introduction
2. Methodology of Time–Frequency Separation Neural Network
2.1. Basic Blind Source Separation Problem and Typical Solutions
2.2. Time–Frequency Analysis of AE Signals Using Smoothed Pseudo Wigner–Ville Distribution
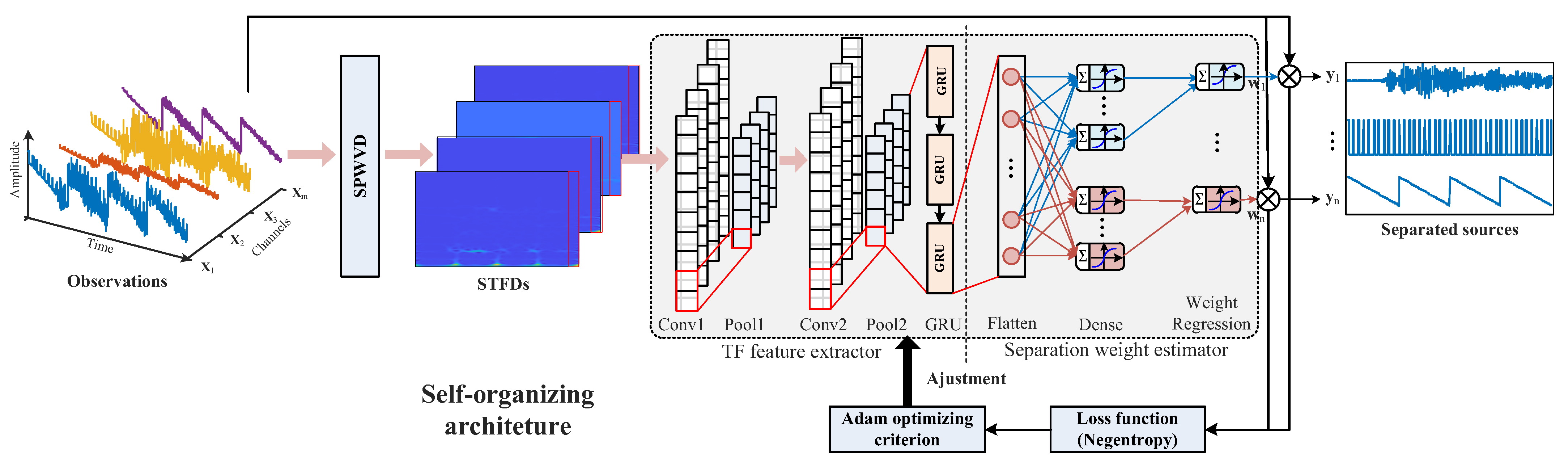
2.3. Enhanced Defect Detection with a Time–Frequency Separation Neural Network
2.3.1. TF Feature Extractor
2.3.2. Separation Weight Estimator and Loss Function
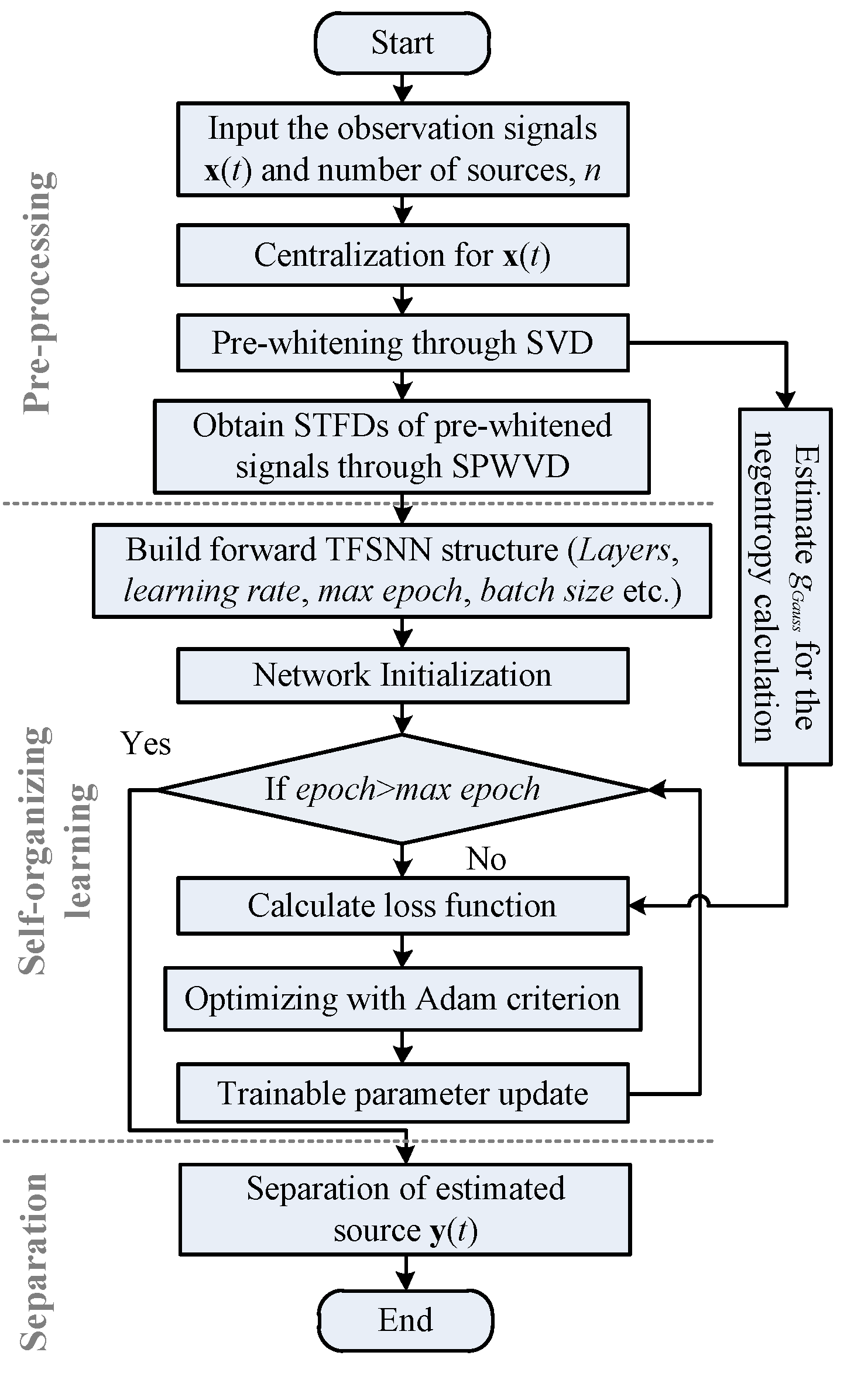
2.3.3. Overall Procedure of the Proposed TFSNN Method
- Precise representation of the time–frequency spectrogram for the mixture signals. Firstly, a superior time–frequency analysis, namely SPWVD, is combined as a pre-processing technique. SPWVD is an improved version of TFA, which can both suppress the cross-item interference and retain a high-resolution spectrogram. In this way, the characteristics of sources can be represented in a more accurate manner.
- Sufficient exploitation of the inherent time–frequency characteristics for the AE signals: To cooperate with the STFDs, 1D-CNN and GRU structures were introduced in the TFSNN to extract and exploit the dominant characteristics from AE signals’ TF representation.
- High accuracy and stable acquisition of the separation weights with the self-organizing network: The above learned features were provided to the separation regressor, and the optimization process can be achieved using powerful network optimizers such as Adam rather than a traditional quasi-Newton method. Hence, it can avoid oscillation and provide a faster convergence and higher accuracy.
3. Experiments and Datasets
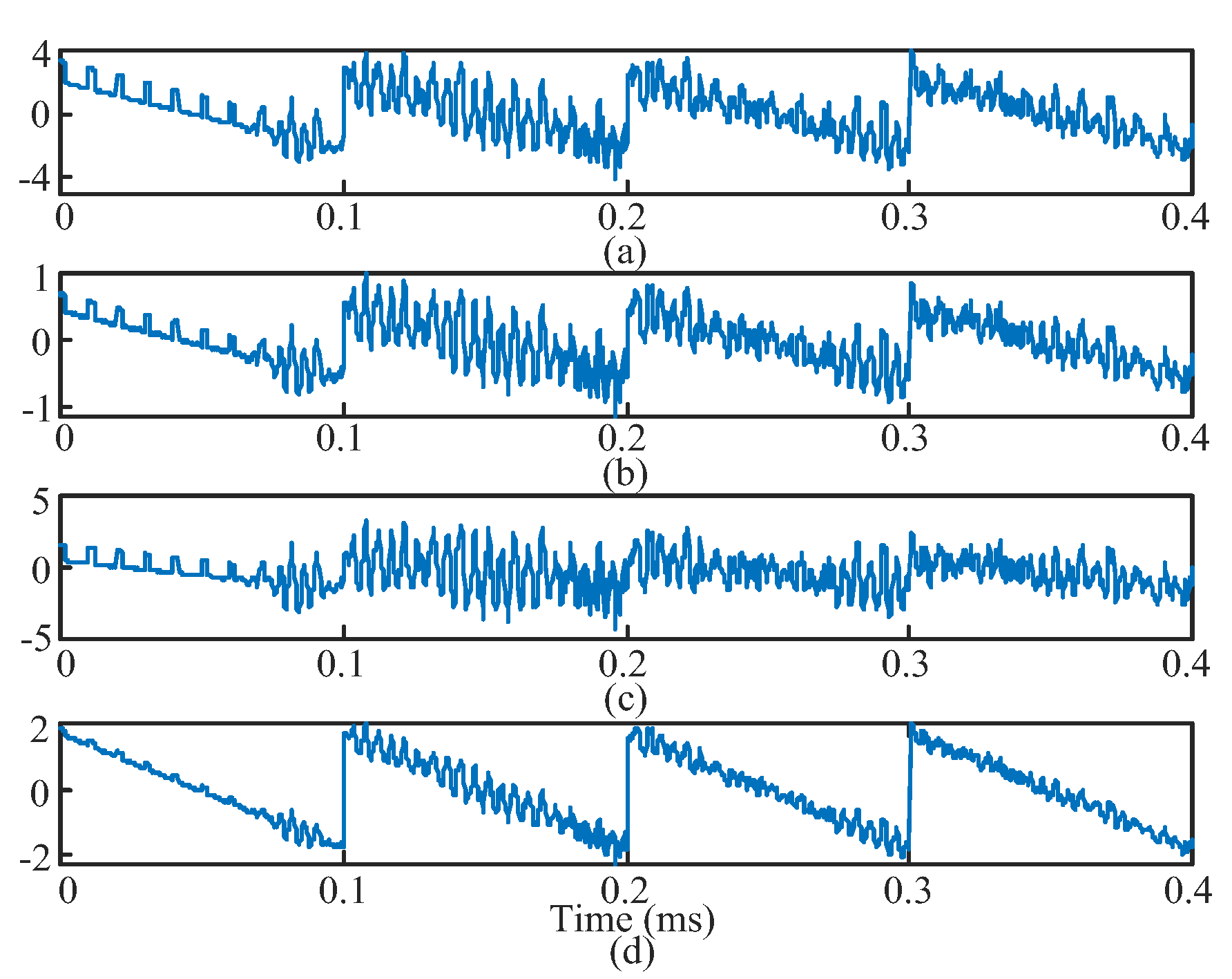
3.1. Case 1: Validation with Generated Interferences and Four-Channel Simulations
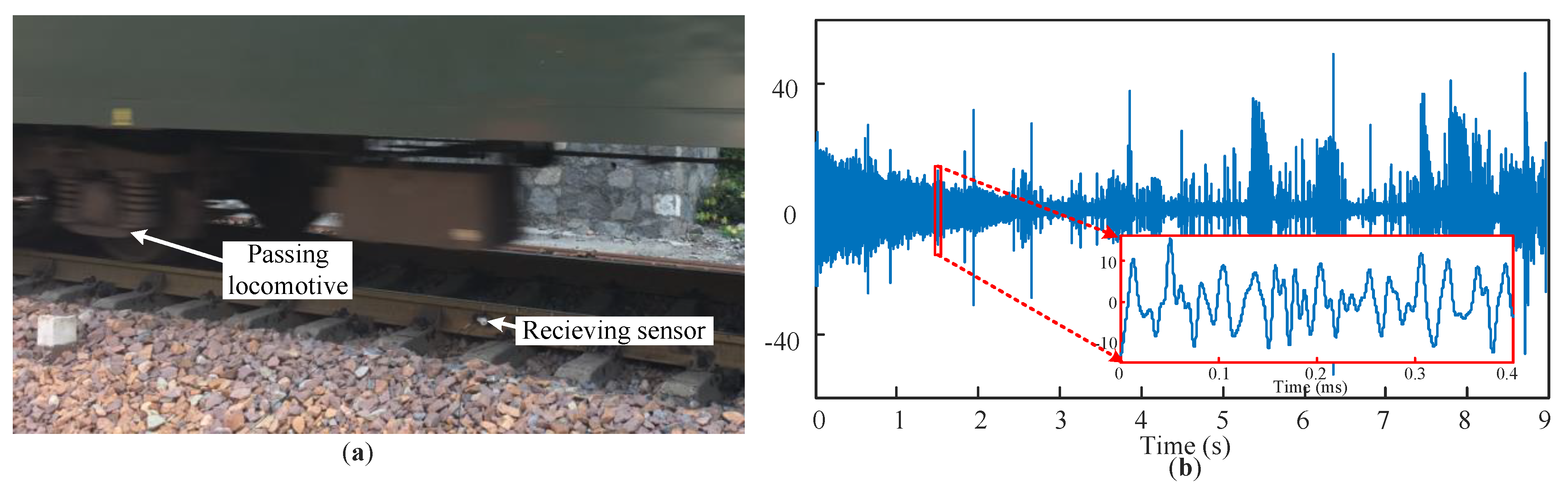
3.2. Case 2: Validation with Rail Crack Signals and Actual Additive Railway Noises
4. Results
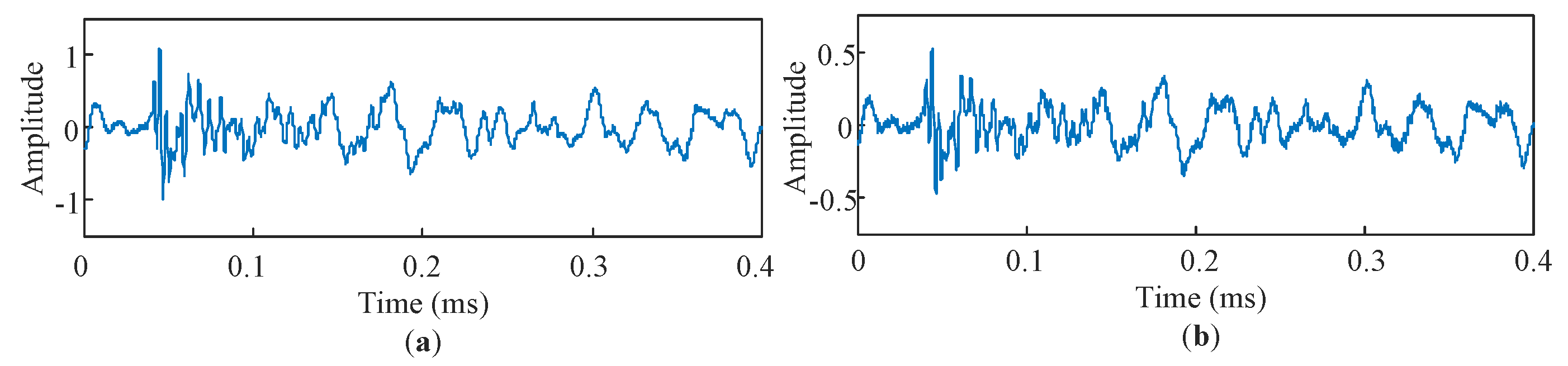
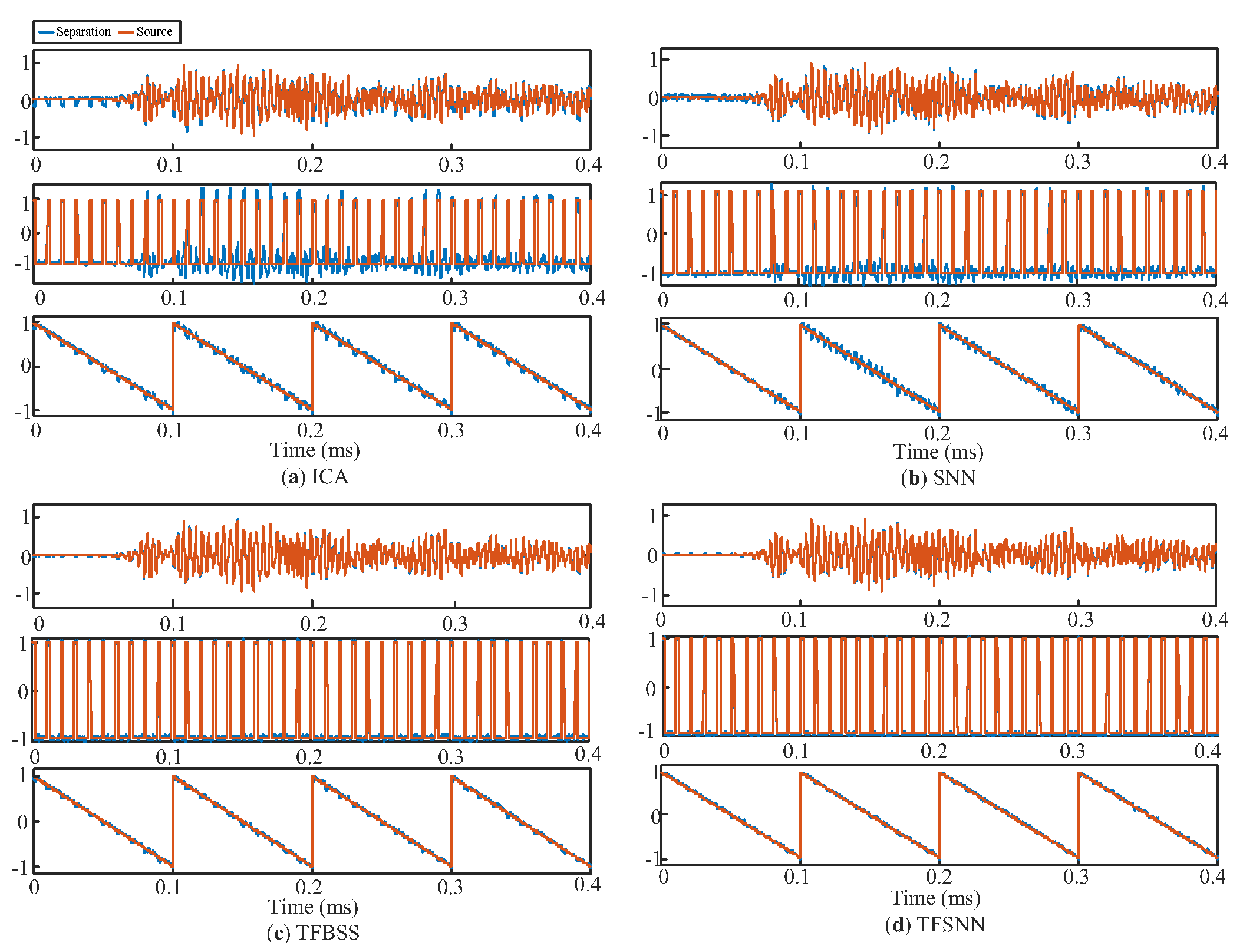
4.1. Defect Separation Performance with Simulated Test Signals
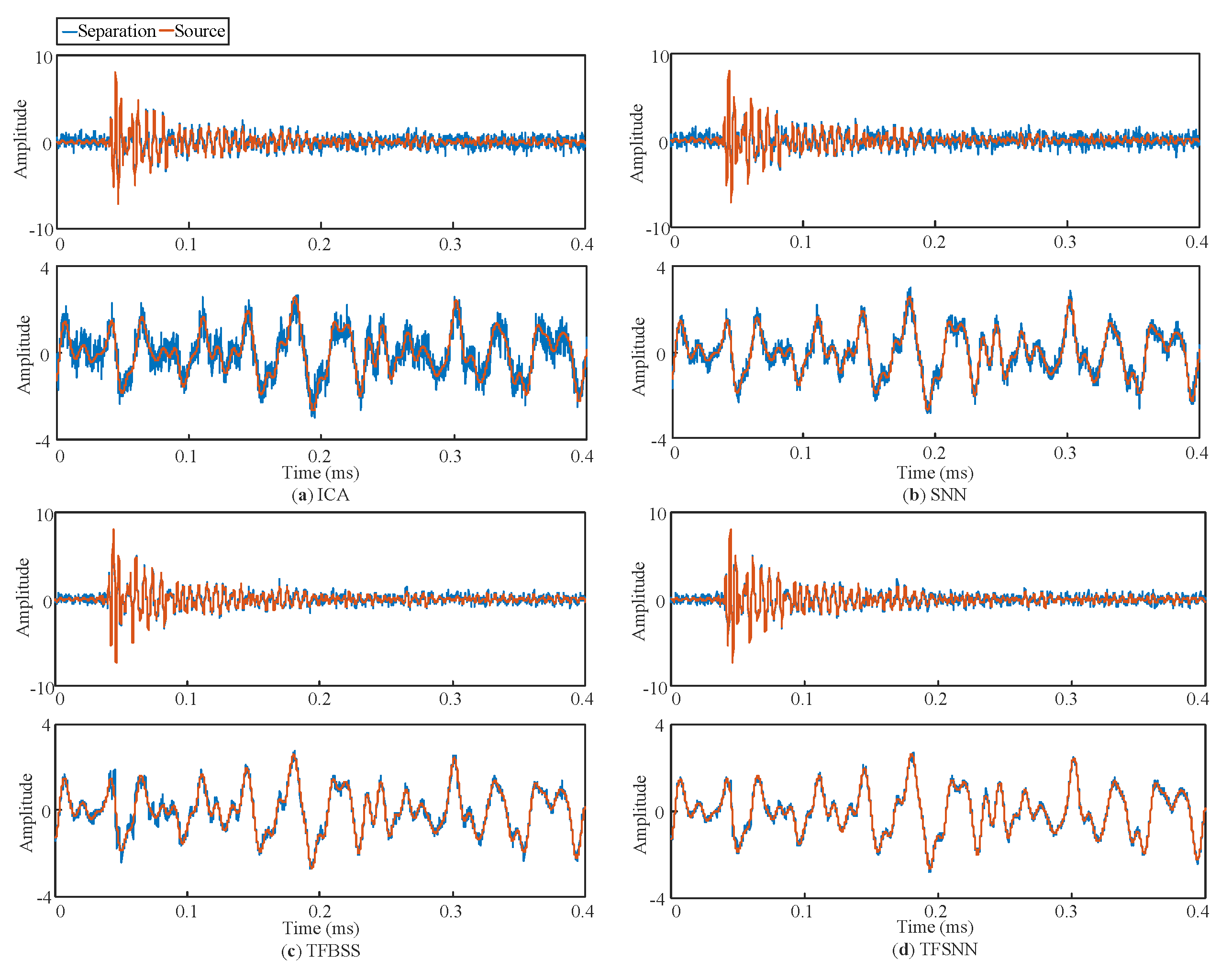
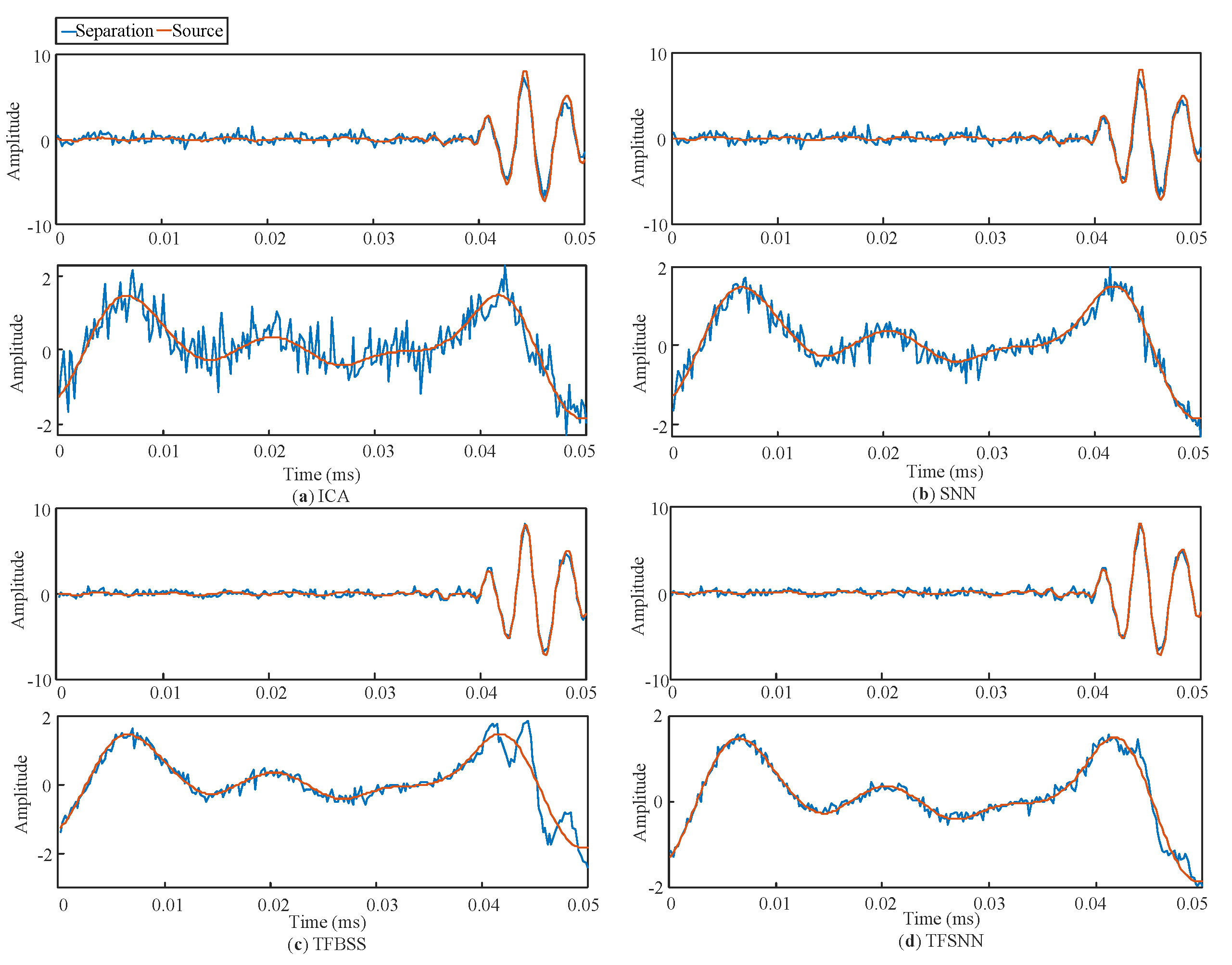
4.2. Defect Separation Performance with Experimentally Acquired Railway Noise Signals
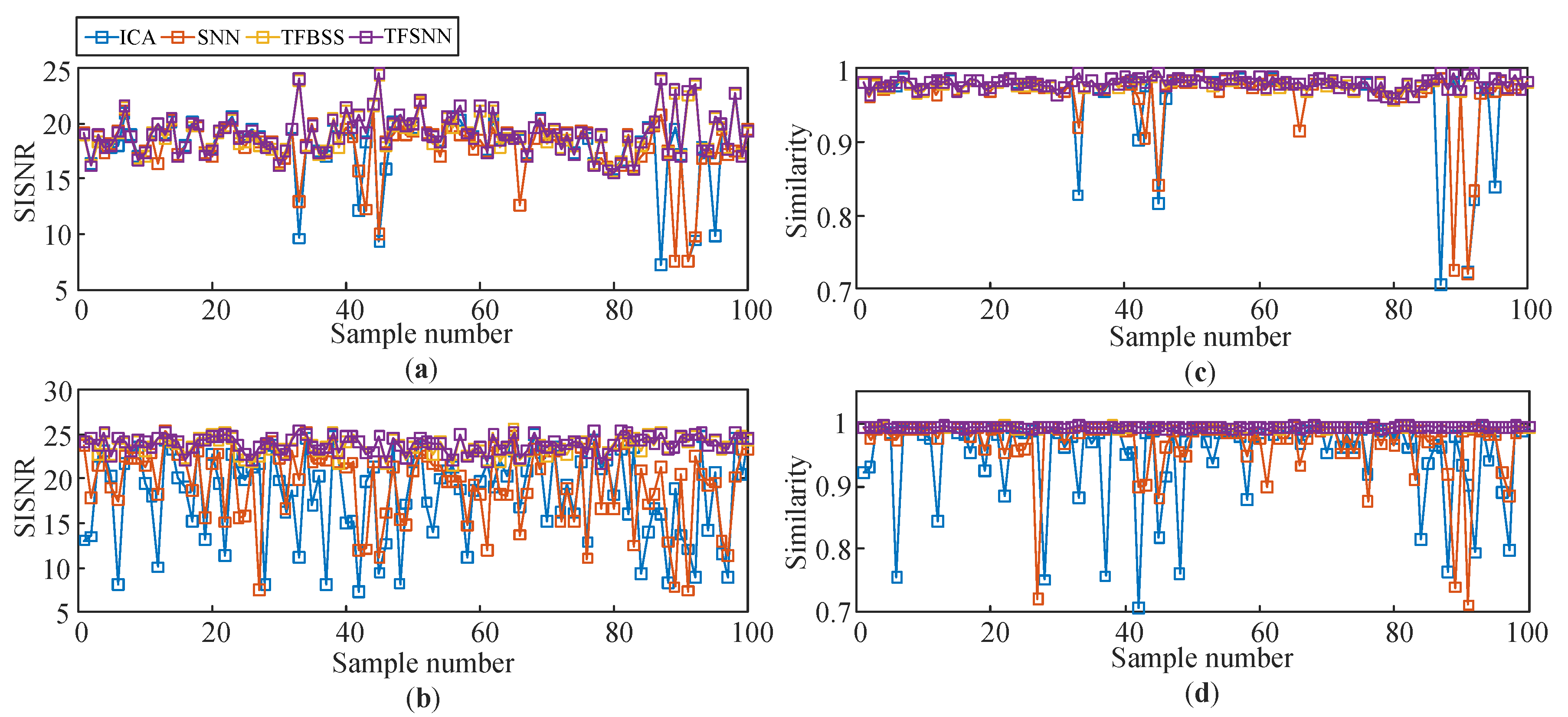
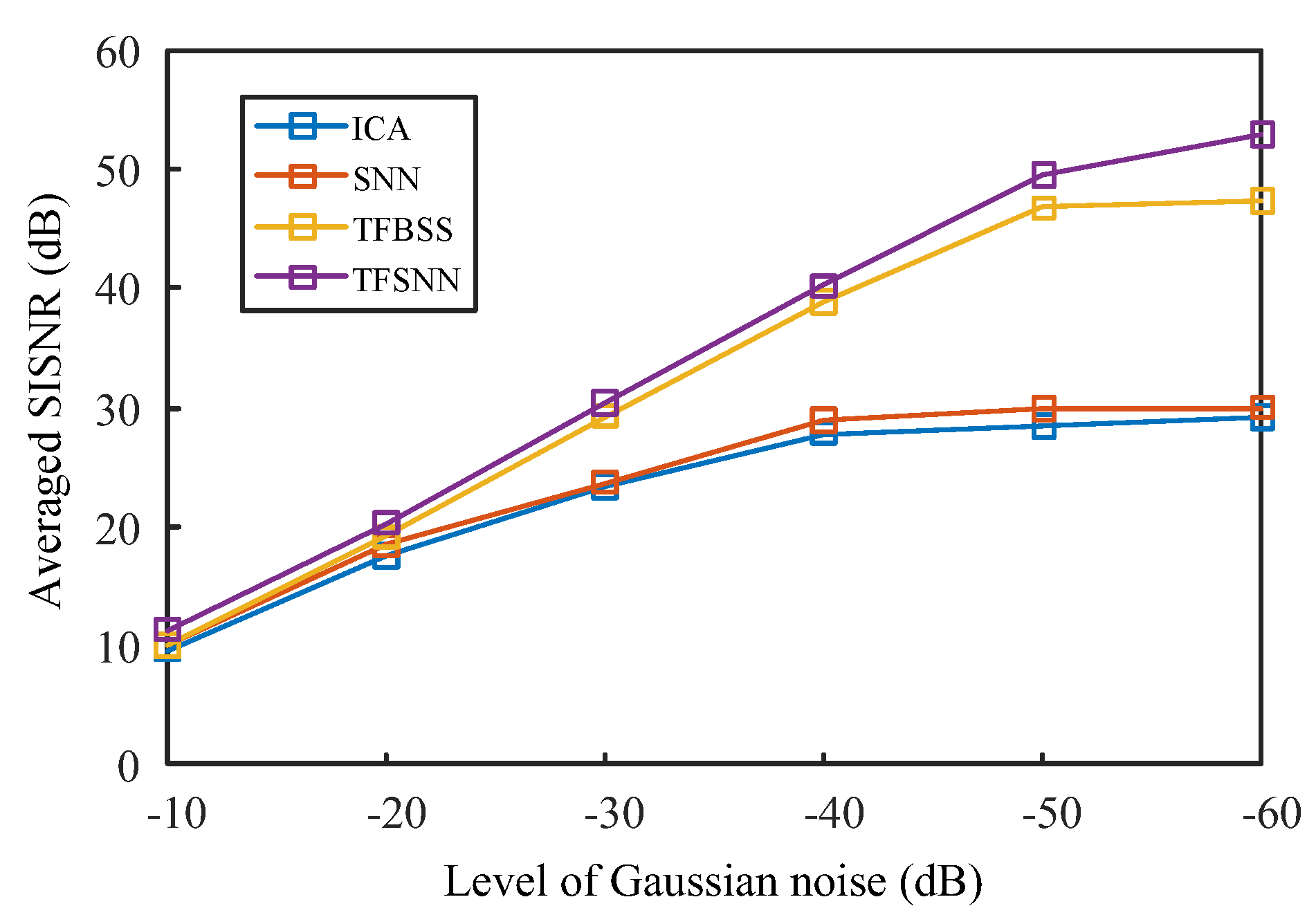
4.3. Systematic Assessment of Comparative Methods with Test Sets and Stability Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alahakoon, S.; Sun, Y.; Spiryagin, M.; Cole, C. Rail flaw detection technology for safer, reliable transportation: A review. J. Dyn. Syst. Meas. Control 2018, 140, 020801. [Google Scholar]
- Wang, K.; Zhang, X.; Song, S.; Wang, Y.; Shen, Y.; Wilcox, P.D. Rail Steel Health Analysis Based on a Novel Genetic Density-based Clustering Technique and Manifold Representation of Acoustic Emission Signals. Appl. Artif. Intell. 2021, 36, 1012–1030. [Google Scholar]
- Li, Z.R.; Liu, Z.L.; Zuo, M.J. Homotypic multi-source mixed signal decomposition based on maximum time-shift kurtosis for drilling pump fault diagnosis. Mech. Syst. Signal Process. 2024, 221, 111724. [Google Scholar]
- Gurve, D.; Krishnan, S. Separation of Fetal-ECG Fr om Single-Channel Abdominal ECG Using Activation Scaled Non-Negative Matrix Factorization. IEEE J. Biomed. Health Inform. 2020, 24, 669–680. [Google Scholar]
- Luo, Z.; Li, C.; Zhu, L. A Comprehensive Survey on Blind Source Separation for Wireless Adaptive Processing: Principles, Perspectives, Challenges and New Research Directions. IEEE Access 2018, 6, 66685–66708. [Google Scholar]
- Yu, Y.; Wang, W.; Han, P. Localization based stereo speech source separation using probabilistic time-frequency masking and deep neural networks. EURASIP J. Audio Speech Music Process. 2016, 2016, 7. [Google Scholar]
- Maddirala, A.K.; Shaik, R.A. Separation of Sources from Single-Channel EEG Signals Using Independent Component Analysis. IEEE Trans. Instrum. Meas. 2017, 10, 2775358. [Google Scholar]
- Mohanaprasad, K.; Singh, A.; Sinha, K.; Ketkar, T. Noise reduction in speech signals using adaptive independent component analysis (ICA) for hands free communication devices. Int. J. Speech Technol. 2019, 22, 169–177. [Google Scholar]
- Jian, J.; Wang, L.; Lu, Z.R. Enhancing second-order blind identification for underdetermined operational modal analysis through bandlimited source separation. J. Sound Vib. 2024, 572, 118179. [Google Scholar]
- Chowdhury, J.H.; Shihab, M.; Pramanik, S.K.; Hossain, M.S.; Ferdous, K.; Shahriar, M. Separation of Heartbeat Waveforms of Simultaneous Two-Subjects Using Independent Component Analysis and Empirical Mode Decomposition. IEEE Microw. Wirel. Technol. Lett. 2024, 34, 1059–1062. [Google Scholar]
- Wang, K.; Hao, Q.; Zhang, X.; Tang, Z.; Wang, Y.; Shen, Y. Blind source extraction of acoustic emission signals for rail cracks based on ensemble empirical mode decomposition and constrained independent component analysis. Measurement 2020, 157, 107653. [Google Scholar]
- Ansari, S.; Alatrany, A.S.; Alnajjar, K.A.; Khater, T.; Mahmoud, S.; Al-Jumeily, D.; Hussain, A.J. A survey of artificial intelligence approaches in blind source separation. Neurocomputing 2023, 561, 126895. [Google Scholar]
- Isomura, T.; Tpyoizumi, T. Multi-context blind source separation by error-gated Hebbian rule. Sci. Rep. 2019, 9, 7127. [Google Scholar]
- Liu, S.; Wang, B.; Zhang, L. Blind Source Separation Method Based on Neural Network with Bias Term and Maximum Likelihood Estimation Criterion. Sensors 2021, 21, 973. [Google Scholar] [CrossRef]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar]
- Sinha, R.; Rollwage, C.; Doclo, S. Variants of LSTM cells for single-channel speaker-conditioned target speaker extraction. EURASIP J. Audio Speech Music Process. 2024, 2024, 16. [Google Scholar]
- Lee, K.J.; Lee, B. End-to-End Deep Learning Architecture for Separating Maternal and Fetal ECGs Using W-Net. IEEE Access 2022, 10, 39782–39788. [Google Scholar]
- Li, Y.; Ramli, D.A. Advances in Time-Frequency Analysis for Blind Source Separation: Challenges, Contributions, and Emerging Trends. IEEE Access 2023, 11, 137450–137474. [Google Scholar]
- Massar, H.; Drissi, T.B.; Nsiri, B.; Miyara, M. Advancements in Blind Source Separation for EEG Artifact Removal: A comparative analysis of Variational Mode Decomposition and Discrete Wavelet Transform approaches. Appl. Acoust. 2025, 228, 110300. [Google Scholar]
- Cheng, W.; Jia, Z.; Chen, X.; Han, L.; Zhou, G.; Gao, L. Underdetermined convolutive blind source separation in the time–frequency domain based on single source points and experimental validation. Meas. Sci. Technol. 2020, 31, 095001. [Google Scholar]
- Benkedjouh, T.; Zerhouni, N.; Rechak, S. Tool wear condition monitoring based on continuous wavelet transform and blind source separation. Int. J. Adv. Technol. 2018, 97, 3311–3323. [Google Scholar]
- Morovati, V.; Kazemi, M.T. Detection of sudden structural damage using blind source separation and time–frequency approaches. Smart Mater. Struct. 2016, 25, 055008. [Google Scholar]
- Elouaham, S.; Nassiri, B.; Dliou, A.; Zougagh, H.; El Kamoun, N.; El Khadiri, K.; Said, S. Combination time-frequency and empirical wavelet transform methods for removal of composite noise in EMG signals. TELKOMNIKA Telecommun. Comput. Electron. Control 2023, 21, 1373–1381. [Google Scholar]
- Sun, H.; Fang, L.; Guo, J. A fault feature extraction method for rotating shaft with multiple weak faults based on underdetermined blind source signal. Meas. Sci. Technol. 2018, 29, 125901. [Google Scholar]
- Liu, J.; Zhang, K.; Wang, Z. Identification Method for Railway Rail Corrugation Utilizing CEEMDAN-PE-SPWVD. Sensors 2024, 24, 8058. [Google Scholar] [CrossRef]
- Long, H.; Zhao, S.; Sun, Y.; Zhang, Y.; Yang, X. Diagnosis of Al-CFRTP TA-FSLW defect using acoustic emission signal based on SPWVD and ResNet. Measurement 2024, 231, 114667. [Google Scholar]
- Wang, K.; Zhang, X.; Wan, F.; Chen, R.; Zhang, J.; Wang, J.; Yang, Y. Wheel Defect Detection Using Attentive Feature Selection Sequential Network with Multidimensional Modeling of Acoustic Emission Signals. IEEE Trans. Instrum. Meas. 2023, 72, 2529514. [Google Scholar]
- Pang, L.; Tang, Y.; Tan, Q.; Liu, Y.; Yang, B. A MLE-based blind signal separation method for time–frequency overlapped signal using neural network. EURASIP J. Adv. Signal Process. 2022, 2022, 121. [Google Scholar]
- Zhang, X.; Feng, N.; Zou, Z.; Wang, Y.; Shen, Y. An investigation on rail health monitoring using acoustic emission technique by tensile test. In Proceeding of Instrumentation and Measurement Technology Conference (I2MTC), Pisa, Italy, 11–14 May 2015. [Google Scholar]
- Wang, K.; Zhang, X.; Hao, Q.; Wang, Y.; Shen, Y. Application of improved Least-Square Generative Adversarial Networks for Rail Crack Detection by AE Technique. Neurocomputing 2019, 332, 236–248. [Google Scholar]
- Zhang, X.; Cui, Y.; Wang, Y.; Sun, M.; Hu, H. An improved AE detection method of rail defect based on multi-level ANC with VSS-LMS. Mech. Syst. Signal Process. 2018, 99, 420–433. [Google Scholar]
- Jonathan, R.; Wisdom, S.; Erdogan, H.; Hershey, J.R. SDR-Half-Baked or Well Done? In Proceedings of the 2019 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP). Brighton, UK, 12–17 May 2019. [Google Scholar]
- Luo, Y.; Mesgarani, N. Tasnet: Time-domain audio separation network for real-time single-channel speech separation. arXiv 2018, arXiv:1711.00541. [Google Scholar]
- Kautský, V.; Koldovský, Z.; Adal, T. Double Nonstationarity: Blind Extraction of Independent Nonstationary Vector/Component from Nonstationary Mixtures Performance Analysis. IEEE Trans. Signal Process. 2024, 72, 3228–3241. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Crack | Square Pulse | Ramp |
|---|---|---|---|
| ICA | 10.6537 | 12.5581 | 20.1588 |
| SNN | 15.3378 | 13.4418 | 20.7815 |
| TFBSS | 24.0757 | 29.3030 | 25.0376 |
| TFSNN | 26.5158 | 32.2905 | 28.2357 |
| Algorithm | Crack | Square Pulse | Ramp |
|---|---|---|---|
| ICA | 0.9470 | 0.9723 | 0.9952 |
| SNN | 0.9854 | 0.9947 | 0.9958 |
| TFBSS | 0.9980 | 0.9994 | 0.9984 |
| TFSNN | 0.9982 | 0.9997 | 0.9992 |
| Algorithm | Averaged SISNR | Averaged Similarity | ||
|---|---|---|---|---|
| Defect | Railway Noise | Defect | Railway Noise | |
| ICA | 18.0983 ± 2.8019 | 18.2298 ± 5.0321 | 0.9657 ± 0.048 | 0.9509 ± 0.0678 |
| SNN | 17.8321 ± 2.4989 | 19.5157 ± 4.302 | 0.9663 ± 0.0419 | 0.9673 ± 0.0513 |
| TFBSS | 18.9886 ± 1.8957 | 23.7881 ± 1.0311 | 0.9784 ± 0.008 | 0.9832 ± 0.0017 |
| TFSNN | 19.1102 ± 1.8263 | 23.9424 ± 0.9326 | 0.9796 ± 0.007 | 0.9935 ± 0.0014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Wang, K.; Yang, Y.; Cao, Y.; You, Y. Enhanced Blind Separation of Rail Defect Signals with Time–Frequency Separation Neural Network and Smoothed Pseudo Wigner–Ville Distribution. Appl. Sci. 2025, 15, 3546. https://doi.org/10.3390/app15073546
Zhang M, Wang K, Yang Y, Cao Y, You Y. Enhanced Blind Separation of Rail Defect Signals with Time–Frequency Separation Neural Network and Smoothed Pseudo Wigner–Ville Distribution. Applied Sciences. 2025; 15(7):3546. https://doi.org/10.3390/app15073546
Chicago/Turabian StyleZhang, Mingxiang, Kangwei Wang, Yule Yang, Yaojia Cao, and Yong You. 2025. "Enhanced Blind Separation of Rail Defect Signals with Time–Frequency Separation Neural Network and Smoothed Pseudo Wigner–Ville Distribution" Applied Sciences 15, no. 7: 3546. https://doi.org/10.3390/app15073546
APA StyleZhang, M., Wang, K., Yang, Y., Cao, Y., & You, Y. (2025). Enhanced Blind Separation of Rail Defect Signals with Time–Frequency Separation Neural Network and Smoothed Pseudo Wigner–Ville Distribution. Applied Sciences, 15(7), 3546. https://doi.org/10.3390/app15073546