
Classification of Properties in Human-like Dialogue Systems Using Generative AI to Adapt to Individual Preferences


Abstract
Featured Application
Abstract
1. Introduction
2. Methods
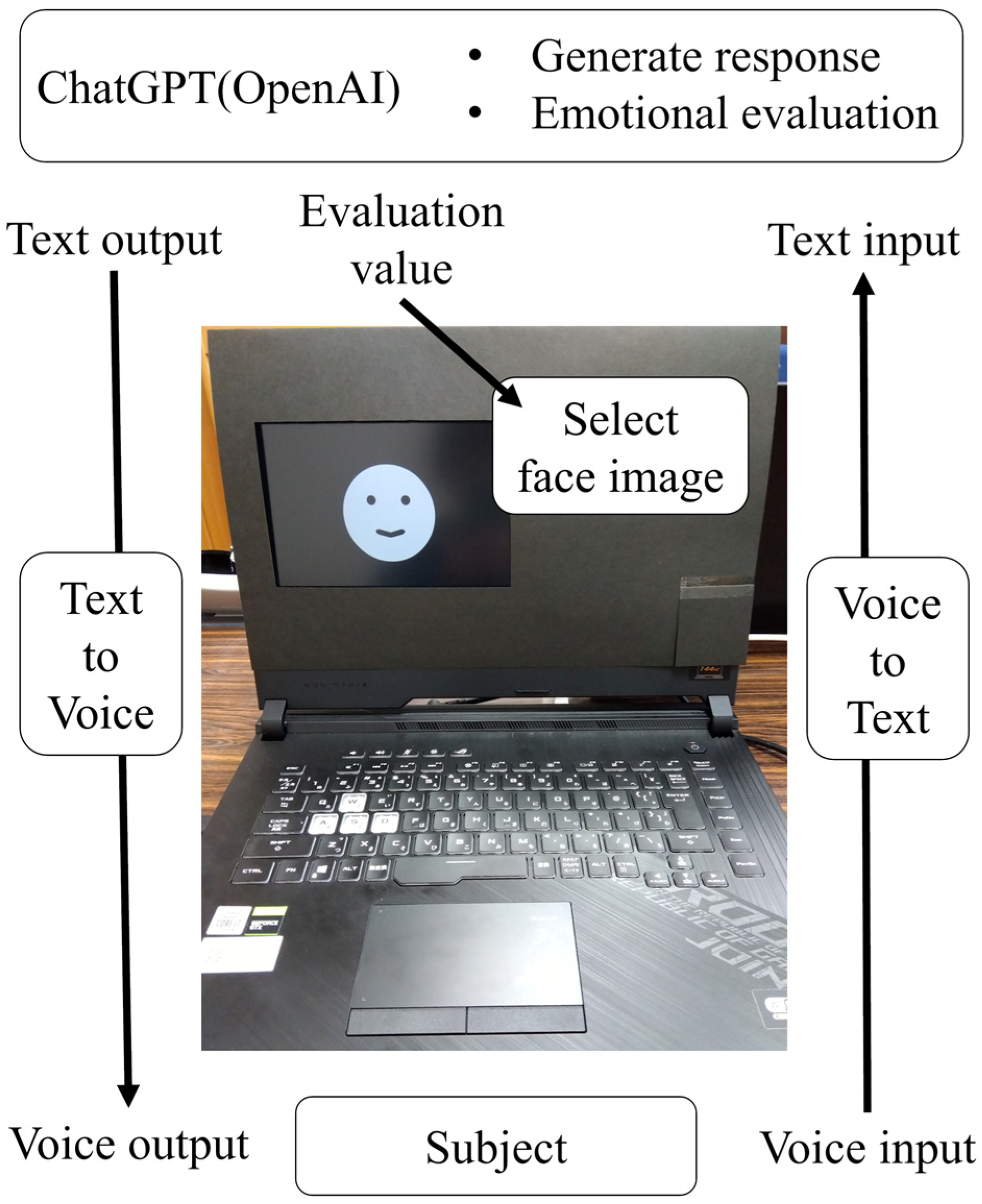
2.1. Dialogue System
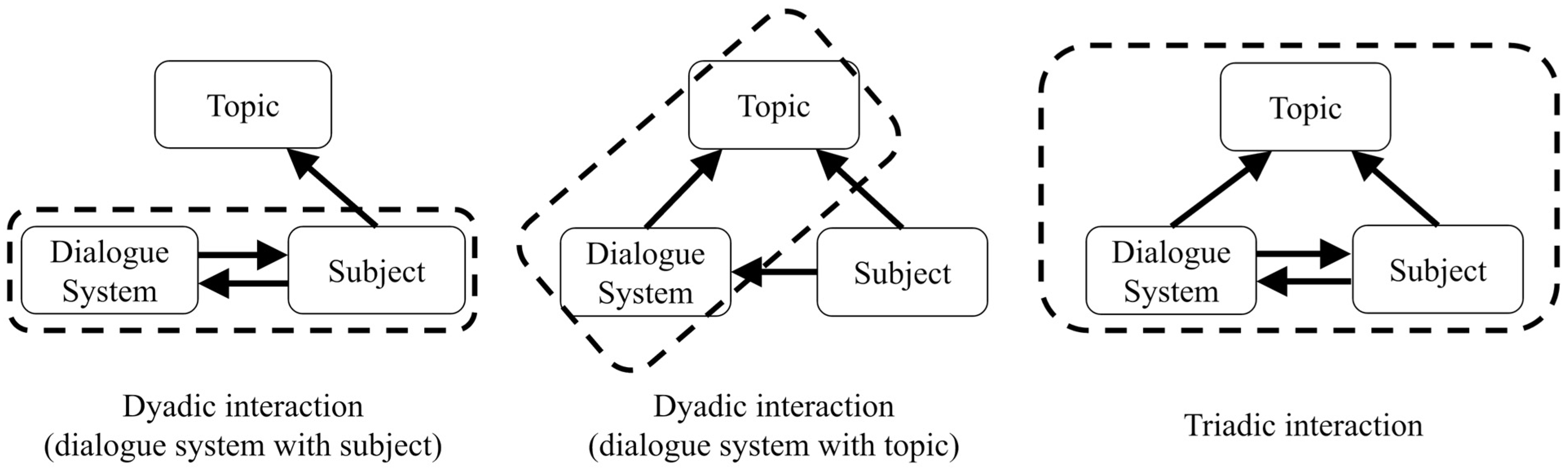
2.2. Settings of Dyadic and Triadic Interactions
2.3. Topic
2.4. General Algorithms
2.5. Questionnaire
2.6. Subject
2.7. Experimental Procedure
- The subject inputs any voice, such as hello, into the system.
- The dialogue system announces a topic and starts a dialogue.
- After five minutes, the system announces the end of a dialogue and asks the subject to fill out the post-dialogue questionnaire.
3. Results
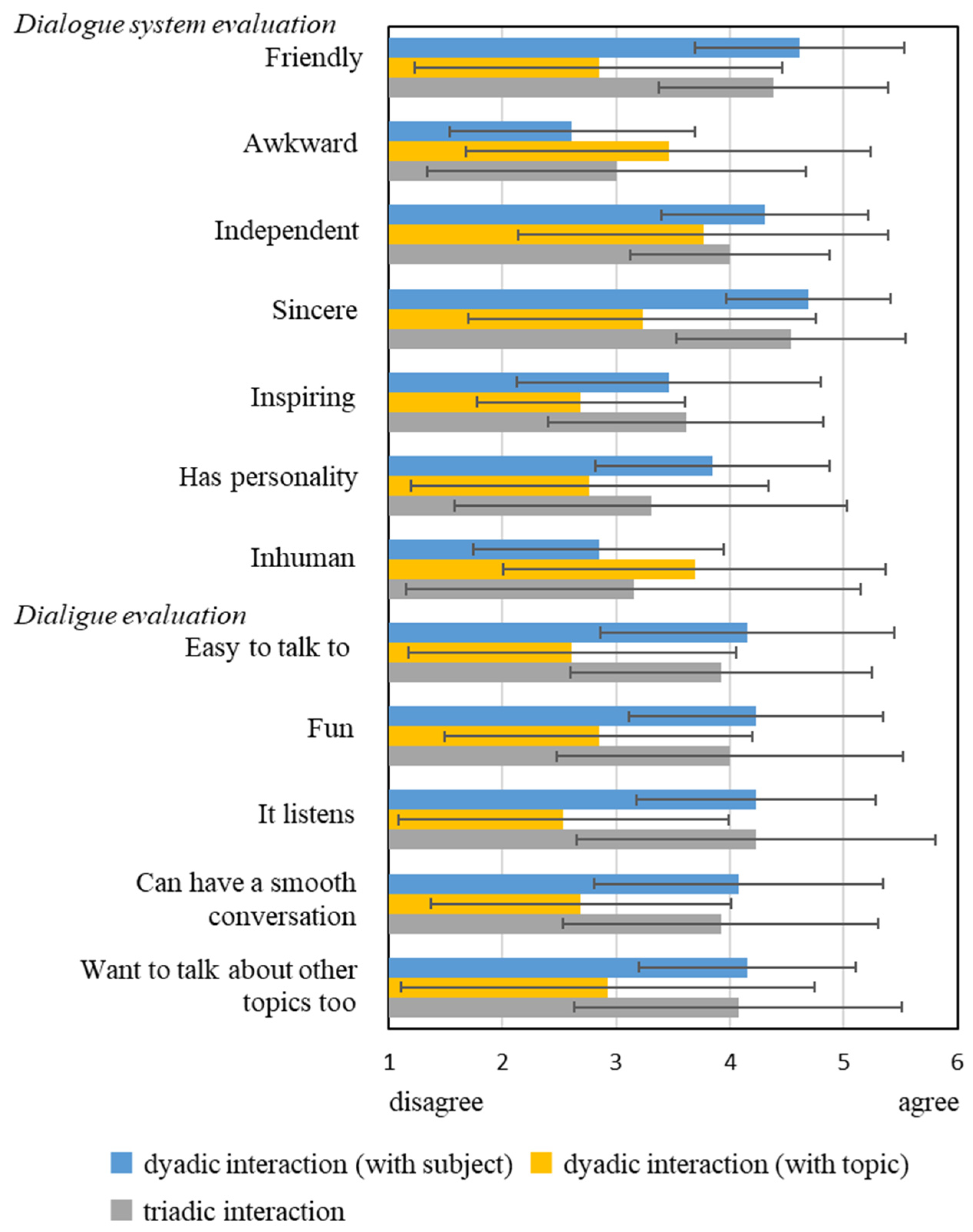
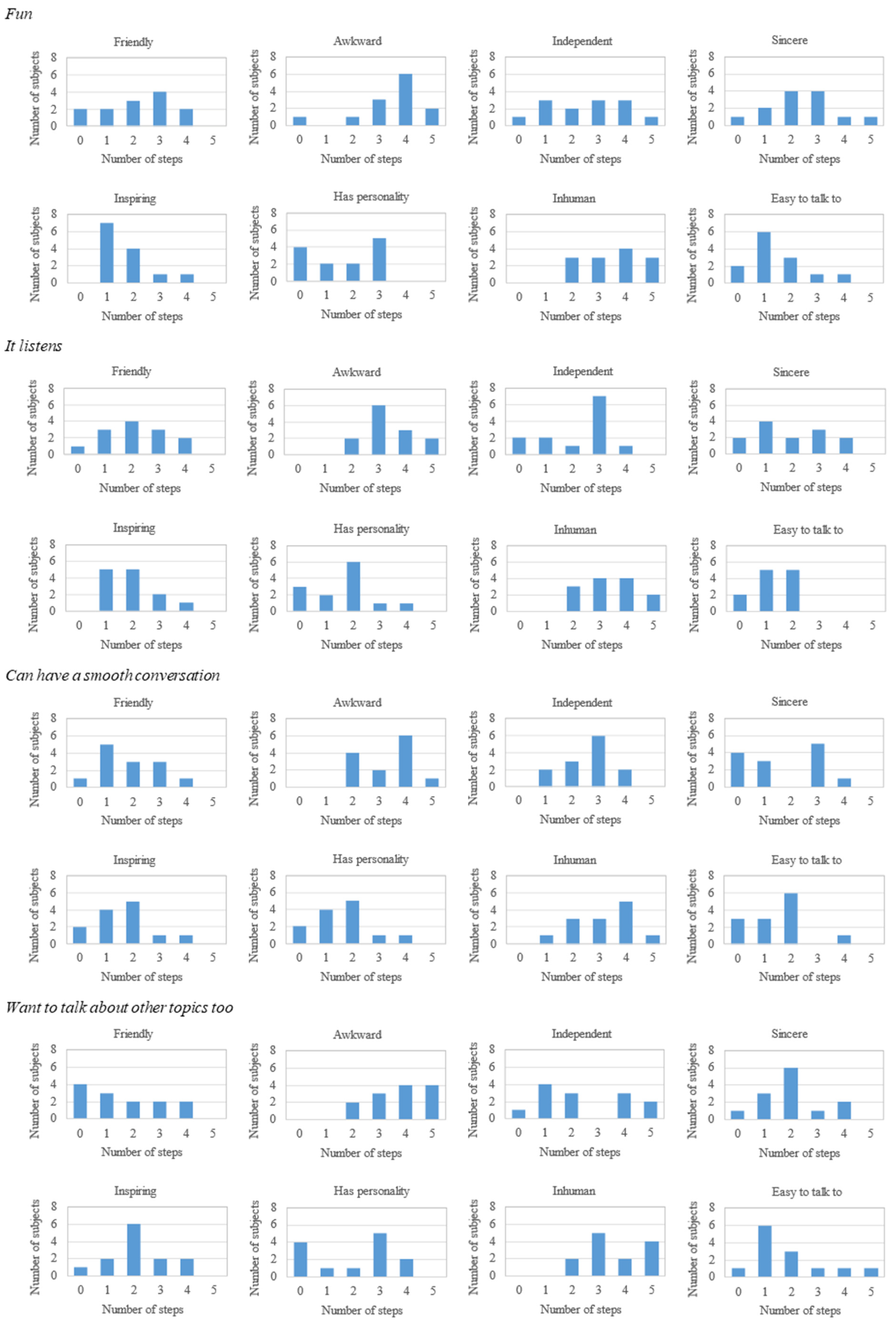
3.1. Questionnaire Results
3.2. Analysis of Links Between Evaluations of the System and the Dialogue
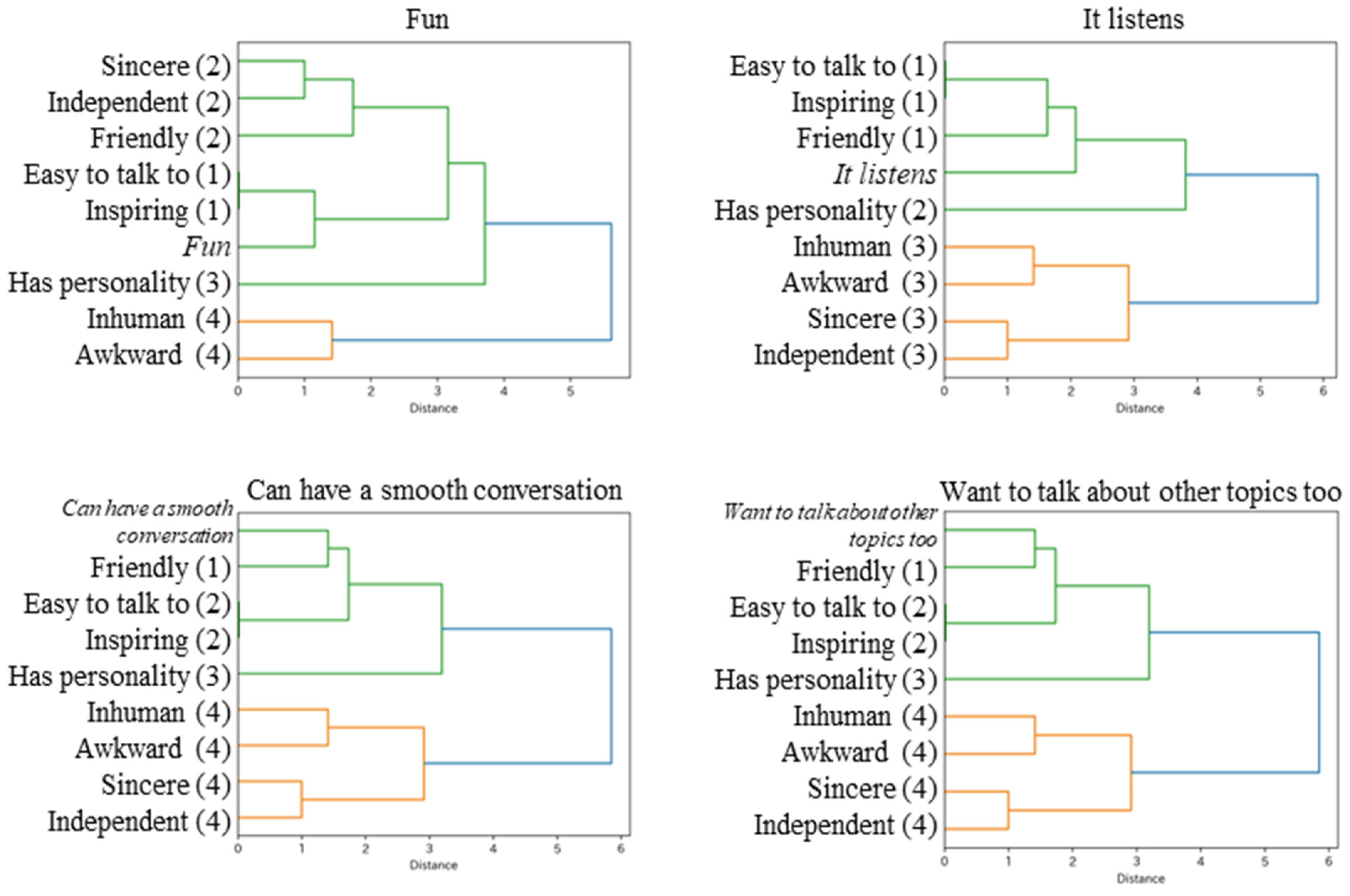
3.3. The Classification of the System Evaluation Items
4. Discussion
- The “Inspiring” item was developed to evaluate an attractiveness factor of a friend that provides positive inspiration [28]. The “Inspiring” item was only related to the “Fun” from the dialogue category. In other words, dialogues with an inspiring partner were fun. This is a reasonable result of a literal interpretation of “Inspiring”. The property of inspiration was evaluated through the item “Inspiring”.
- The “Easy to talk to” item was developed to evaluate a sense of security. An interpersonal relationship with a sense of security means a relaxed relationship without worries or barriers. As shown in previous research on friendships, the sense of security is the most fundamental attractiveness factor of a friend, and the survey item “Easy to talk to” best reflects this [28]. The “Easy to talk to” item was related to three dialogue evaluations, except for “Can have a smooth conversation”. The result indicates that the item was most commonly related to positive evaluations, as it was the most frequent and generally relational among the subjects. It is also natural that a sense of security is a fundamental element of the relationship with the system. Similarly to interpersonal relationships, the property of a sense of security was evaluated through the item “Easy to talk to”.
- The “Friendly” item was developed with the expectation that a friendly system would be evaluated positively as a dialogue partner. The “Friendly” item was related to “Can have a smooth conversation”, which indicates dialogue capabilities, and “Want to talk about other topics too”, which indicates a wish to continue the relationship, but not to “Fun” or “It listens”, which involve feelings. It seems that the “Friendly” item was interpreted as being collaborative, which refers to the system’s dialogue capability to make dialogue easy for the subjects. Compared with being friendly, being collaborative is a more plausible expectation for the system. The property of collaboration was evaluated through the item “Friendly”.
- The “Independent” item was developed to evaluate a sense of distance, an attractiveness factor of a friend that maintains a moderate distance [28]. The “Independent” item was related to “Fun”, “It listens”, and “Want to talk about other topics too” among some subjects. In other words, dialogues with an independent partner made some subjects feel good and caused a wish to continue. This is a reasonable result for an interpretation of “Independent” as maintaining a moderate distance, similar to the case of human friends. The property of a sense of distance was evaluated through the item “Independent”.
- The “Has personality” item was developed with reference to a survey about impressions of robots [29]. The words “Has personality” are reasonably interpreted literally regarding systems. The “Has personality” item was related to three dialogue evaluations, except for “Can have a smooth conversation”, among some subjects. It is natural that some subjects preferred a partner with a personality. The property of personality was evaluated through the item “Has personality”.
- The “Sincere” item was developed to evaluate the attractiveness factor of a friend. Sincerity is an important factor in lasting friendships [28]. However, the “Sincere” item was not related to “Want to talk about other topics too”, which indicates a wish to continue the relationship. It was related to “Can have a smooth conversation” and “It listens” among some subjects, but not to “Fun”. When the dialogue system listened well and responded fluently, the system was evaluated as sincere. Unlike in interpersonal relationships, “Sincere” in the system was interpreted in terms of reliability rather than trust. Considering that an attentive attitude and conversational ability were evaluated individually through the word sincere, the “Sincere” item is referred to as seriousness. The property of seriousness was evaluated through the item “Sincere”.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Folstad, A.; Skjuve, M.; Brandtzaeg, P.B. Different chatbots for different purposes: Towards a typology of chatbots to understand interaction design. Internet Sci. 2019, 11551, 145–156. [Google Scholar] [CrossRef]
- Durante, Z.; Huang, Q.; Wake, N.; Gong, R.; Park, J.S.; Sarkar, B.; Taori, R.; Noda, Y.; Terzopoulos, D.; Choi, Y.; et al. Agent AI: Surveying the horizons of multimodal interaction. arXiv 2024, arXiv:2401.03568. [Google Scholar]
- Zhang, J.; Oh, Y.J.; Lange, P.; Yu, Z.; Fukuoka, Y. Artificial Intelligence Chatbot Behavior Change Model for Designing Artificial Intelligence Chatbots to Promote Physical Activity and a Healthy Diet: Viewpoint. J. Med. Internet Res. 2020, 22, e22845. [Google Scholar] [CrossRef]
- Ayedoun, E.; Hayashi, Y.; Seta, K. Adding Communicative and Affective Strategies to an Embodied Conversational Agent to Enhance Second Language Learners’ Willingness to Communicate. Int. J. Artif. Intell. Educ. 2019, 29, 29–57. [Google Scholar] [CrossRef]
- Herrmann-Werner, A.; Festl-Wietek, T.; Junne, F.; Zipfel, S.; Madany Mamlouk, A. “Hello, my name is Melinda”—Students’ views on a digital assistant for navigation in digital learning environments; A qualitative interview study. Front. Educ. 2021, 5, 541839. [Google Scholar] [CrossRef]
- Kosinski, M. Evaluating large language models in theory of mind tasks. Proc. Natl. Acad. Sci. USA 2024, 121, e2405460121. [Google Scholar] [CrossRef]
- Jones, C.R.; Bergen, B.K. People cannot distinguish GPT-4 from a human in a Turing test. arXiv 2024, arXiv:2405.08007. [Google Scholar]
- Zhou, H.; Huang, M.; Zhang, T.; Zhu, X.; Liu, B. Emotional chatting machine: Emotional conversation generation with internal and external memory. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LU, USA, 2–7 February 2018; pp. 730–738. [Google Scholar]
- Nißen, M.; Rüegger, D.; Stieger, M.; Flückiger, C.; Allemand, M.; v Wangenheim, F.; Kowatsch, T. The effects of health care chatbot personas with different social roles on the client-chatbot bond and usage intentions: Development of a design codebook and web-based study. J. Med. Internet Res. 2022, 24, e32630. [Google Scholar] [CrossRef] [PubMed]
- Miyanishi, T.; Hirayama, J.; Kanemura, A.; Kawanabe, M. Answering mixed type questions about daily living episodes. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4265–4271. [Google Scholar] [CrossRef]
- Rapp, A.; Curti, L.; Boldi, A. The human side of human-chatbot interaction: A systematic literature review of ten years of research on text-based chatbots. Int. J. Hum. Comput. Stud. 2021, 151, 102630. [Google Scholar] [CrossRef]
- Kätsyri, J.; Förger, K.; Mäkäräinen, M.; Takala, T. A review of empirical evidence on different uncanny valley hypotheses: Support for perceptual mismatch as one road to the valley of eeriness. Front. Psychol. 2015, 6, 390. [Google Scholar]
- Svenningsson, N.; Faraon, M. Artificial intelligence in conversational agents: A study of factors related to perceived humanness in chatbots. In Proceedings of the 2019 2nd Artificial Intelligence and Cloud Computing Conference, Kobe, Japan, 21–23 December 2019; pp. 151–161. [Google Scholar] [CrossRef]
- Ahmad, R.; Siemon, D.; Gnewuch, U.; Robra-Bissantz, S. Designing personality-adaptive conversational agents for mental health care. Inf. Syst. Front. 2022, 24, 923–943. [Google Scholar] [CrossRef]
- Reeves, B.; Nass, C. The Media Equation: How People Treat Computers, Television, and New Media Like Real People and Places; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Ho, A.; Hancock, J.; Miner, A.S. Psychological, relational, and emotional effects of self-disclosure after conversations with a chatbot. J. Commun. 2018, 68, 712–733. [Google Scholar] [CrossRef]
- Okada, Y.; Kimoto, M.; Iio, T.; Shimohara, K.; Shiomi, M. Two is better than one: Apologies from two robots are preferred. PLoS ONE 2023, 18, e0281604. [Google Scholar] [CrossRef]
- Hill, J.; Ford, W.R.; Farreras, I.G. Real conversations with artificial intelligence: A comparison between human-human online conversations and human-chatbot conversations. Comput. Hum. Behav. 2015, 49, 245–250. [Google Scholar] [CrossRef]
- Mou, Y.; Xu, K. The media inequality: Comparing the initial human-human and human-AI social interactions. Comput. Hum. Behav. 2017, 72, 432–440. [Google Scholar] [CrossRef]
- Brandtzaeg, P.B.; Folstad, A. Why people use chatbots. Internet Sci. 2017, 10673, 377–392. [Google Scholar] [CrossRef]
- Abe, K.; Quan, C.; Cao, S.; Luo, Z. Subjective evaluation of dialogues with dyadic and triadic interactions using a ChatGPT-based dialogue system. In Proceedings of the 2024 Joint 13th International Conference on Soft Computing and Intelligent Systems and 25th International Symposium on Advanced Intelligent Systems (SCIS&ISIS), Himeji, Japan, 9–12 November 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Gao, T.; McCarthy, G.; Scholl, B.J. The Wolfpack Effect: Perception of Animacy Irresistibly Influences Interactive Behavior. Psychol. Sci. 2010, 21, 1845–1853. [Google Scholar] [CrossRef]
- Kanakogi, Y.; Okumura, Y.; Inoue, Y.; Kitazaki, M.; Itakura, S. Rudimentary Sympathy in Preverbal Infants: Preference for Others in Distress. PLoS ONE 2013, 8, e65292. [Google Scholar] [CrossRef]
- Imaizumi, T.; Takahashi, K.; Ueda, K. Influence of appearance and motion interaction on emotional state attribution to objects: The example of hugging shimeji mushrooms. Comput. Hum. Behav. 2024, 161, 108383. [Google Scholar] [CrossRef]
- Loeffler, D.; Schmidt, N.; Tscharn, R. Multimodal expression of artificial emotion in social robots using color, motion and sound. In Proceedings of the 2018 ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 5–8 March 2018; pp. 334–343. [Google Scholar] [CrossRef]
- Jacka, R.E.; Garrodb, O.G.B.; Yu, H.; Caldarac, R.; Schyns, P.G. Facial expressions of emotion are not culturally universal. Proc. Natl. Acad. Sci. USA 2012, 109, 7241–7244. [Google Scholar] [CrossRef]
- Tomasello, M. Becoming Human: A Theory of Ontogeny; Belknap Press of Harvard University Press: Cambridge, MA, USA, 2021. [Google Scholar]
- Nishiura, M.; Daibo, I. The relationships between attraction of same-sex friend and relationship-maintenance motivation in the light of personal importance. Jpn. J. Interpers. Soc. Psychol. 2010, 10, 115–123. (In Japanese) [Google Scholar] [CrossRef]
- Chidori, H.; Matsuzaki, G. Impression for the robot that the purpose of communication. In Proceedings of the 59th Annual Conference of Japanese Society for the Science of Design, Sapporo, Japan, 22–24 June 2012; (In Japanese) [Google Scholar] [CrossRef]
- Yokotani, K.; Takagi, G.; Wakashima, K. Advantages of virtual agents over clinical psychologists during comprehensive mental health interviews using a mixed methods design. Comput. Hum. Behav. 2018, 85, 135–145. [Google Scholar]
- Ortega-Bolaños, R.; Bernal-Salcedo, J.; Germán Ortiz, M.; Galeano Sarmiento, J.; Ruz, G.A.; Tabares-Soto, R. Applying the ethics of AI: A systematic review of tools for developing and assessing AI-based systems. Artif. Intell. Rev. 2024, 57, 110. [Google Scholar] [CrossRef]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.S.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef] [PubMed]
- Sundar, S.S. Rise of Machine Agency: A Framework for Studying the Psychology of Human–AI Interaction (HAII). J. Comput. Mediat. Commun. 2020, 25, 74–88. [Google Scholar] [CrossRef]
- Sano, T.; Horii, T.; Abe, K.; Nagai, T. Temperament estimation of toddlers from child–robot interaction with explainable artificial intelligence. Adv. Robot. 2021, 35, 1068–1077. [Google Scholar] [CrossRef]
- Ring, L.; Shi, L.; Totzke, K.; Bickmore, T. Social support agents for older adults: Longitudinal affective computing in the home. J. Multimodal User Interfaces 2015, 9, 79–88. [Google Scholar] [CrossRef]
- Wang, Y.; Song, W.; Tao, W.; Liotta, A.; Yang, D.; Li, X.; Gao, S.; Sun, Y.; Ge, W.; Zhang, W.; et al. A systematic review on affective computing: Emotion models, databases, and recent advances. Inf. Fusion 2022, 83–84, 19–52. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dialogue progression | Interactions | ||
| Dyadic interaction (with subject) | Dyadic interaction (with topic) | Triadic interaction | |
| Respond to what a subject says. If a subject goes off-topic, follow the subject. Ex. Subject “What do you like?”, System “One of my absolute favorite hobbies is traveling. Exploring new places and experiencing different cultures brings me so much joy!” | Read out the prepared sentences one at a time and do not respond to what a subject says. Ex. Subject “What do you like?”, System “Both oranges and apples have their own wonderful qualities!” | Respond topically to what a subject says. If a subject goes off-topic, the system sometimes points it out. Ex. Subject “What do you like?”, System “I enjoy both oranges and apples, but my choice depends on my mood or the season. They’re both nutritious and delicious fruits, don’t you think?” | |
| Start | Neutral level facial expression image is displayed, and a standard phrase is announced, e.g., “Hello. The first topic is which is a better fruit, orange or apple?” | ||
| Subject turn | Some voice input, e.g., “I like an orange. I think, an orange is better”. | ||
| Processing | Prompt for a response: Respond to a subject input in a polite tone with approximately 25 words. Prompt for emotional evaluation: Rate happiness and sadness on a scale of 100 about “a subject input and a generated response”. The difference in numbers between the degree of happiness and sadness is changed to five levels and used to select a face image. | All response texts and face image selections are prepared in advance. The generated sentences about topics are cut into appropriate lengths, and face images are selected in the same way as the others, except for subject inputs. | Prompt for a response: Respond topically to a subject input in a polite tone of approximately 25 words on a topic. Prompt for emotional evaluation: Rate happiness and sadness on a scale of 100 about “a subject input and a generated response”. The difference in numbers between the degree of happiness and sadness is changed to five levels and used to select a face image. |
| System turn | A selected face image is displayed, and a response text is read out. | ||
| Repeat Subject turn, Processing and System turn for 5 min. | |||
| End | A standard phrase is announced, “Thank you. That’s all for this topic. Please fill out the questionnaire. Please talk to me after you’ve finished”. | ||
| Evaluation Item | Setting | |||
|---|---|---|---|---|
| Dyadic Interaction (with Subject) | Dyadic Interaction (with Topic) | Triadic Interaction | ||
| System | Friendly | 5 | 3 | 4 |
| Awkward | 3 | 5 | 3 | |
| Independent | 4 | 4 | 4 | |
| Sincere | 4 | 4 | 5 | |
| Inspiring | 5 | 2 | 5 | |
| Has personality | 5 | 2 | 2 | |
| Inhuman | 2 | 5 | 4 | |
| Easy to talk to | 5 | 2 | 5 | |
| Dialogue | Fun | 4 | 2 | 5 |
| It listens | 4 | 2 | 6 | |
| Can have a smooth conversation | 4 | 2 | 4 | |
| Want to talk about other topics too | 4 | 2 | 4 | |
| Dialogue Evaluation | Generally Relational | Individually Relational | Non-Relational | Non-Relational |
|---|---|---|---|---|
| Fun | Inspiring Easy to talk to | Independent Has personality | Friendly Sincere | |
| It listens | Easy to talk to | Independent Sincere Has personality | Friendly Inspiring | |
| Can have a smooth conversation | Friendly | Sincere | Easy to talk to | Independent Inspiring Has personality |
| Want to talk about other topics too | Friendly Easy to talk to | Independent Has personality | Sincere | Inspiring |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abe, K.; Quan, C.; Cao, S.; Luo, Z. Classification of Properties in Human-like Dialogue Systems Using Generative AI to Adapt to Individual Preferences. Appl. Sci. 2025, 15, 3466. https://doi.org/10.3390/app15073466
Abe K, Quan C, Cao S, Luo Z. Classification of Properties in Human-like Dialogue Systems Using Generative AI to Adapt to Individual Preferences. Applied Sciences. 2025; 15(7):3466. https://doi.org/10.3390/app15073466
Chicago/Turabian StyleAbe, Kaori, Changqin Quan, Sheng Cao, and Zhiwei Luo. 2025. "Classification of Properties in Human-like Dialogue Systems Using Generative AI to Adapt to Individual Preferences" Applied Sciences 15, no. 7: 3466. https://doi.org/10.3390/app15073466
APA StyleAbe, K., Quan, C., Cao, S., & Luo, Z. (2025). Classification of Properties in Human-like Dialogue Systems Using Generative AI to Adapt to Individual Preferences. Applied Sciences, 15(7), 3466. https://doi.org/10.3390/app15073466