
Conditional GAN-Based Two-Stage ISP Tuning Method: A Reconstruction–Enhancement Proxy Framework

Abstract
1. Introduction
- 1.
- Propose ReEn-GAN and build an AI-assisted ISP tuning process for CV tasks based on a proxy method. The system uses ReEn-GAN as a two-stage proxy to fit the entire ISP and its parameters, and reversely optimizes the proxy parameters through the evaluation indicators of CV tasks and applies them to the existing ISP, greatly simplifying the process of manual tuning ISP;
- 2.
- Utilize the prior knowledge of ISP to decompose the ISP pipeline into two processes: reconstruction and enhancement. By using an alternating network structure and loss functions of the two-stage proxies, the problems of significant changes in image color and texture that result from parameter adjustments, parameter interference and proxy training difficulties in the end-to-end proxy method are solved;
- 3.
- Verify the feasibility of using ReEn-GAN for auto-tuning in CV scenes such as image denoising and object detection, as well as the impact of different loss functions and pyramid pooling module (PPM) additions on proxy tuning performance.
2. Related Works
3. Methods
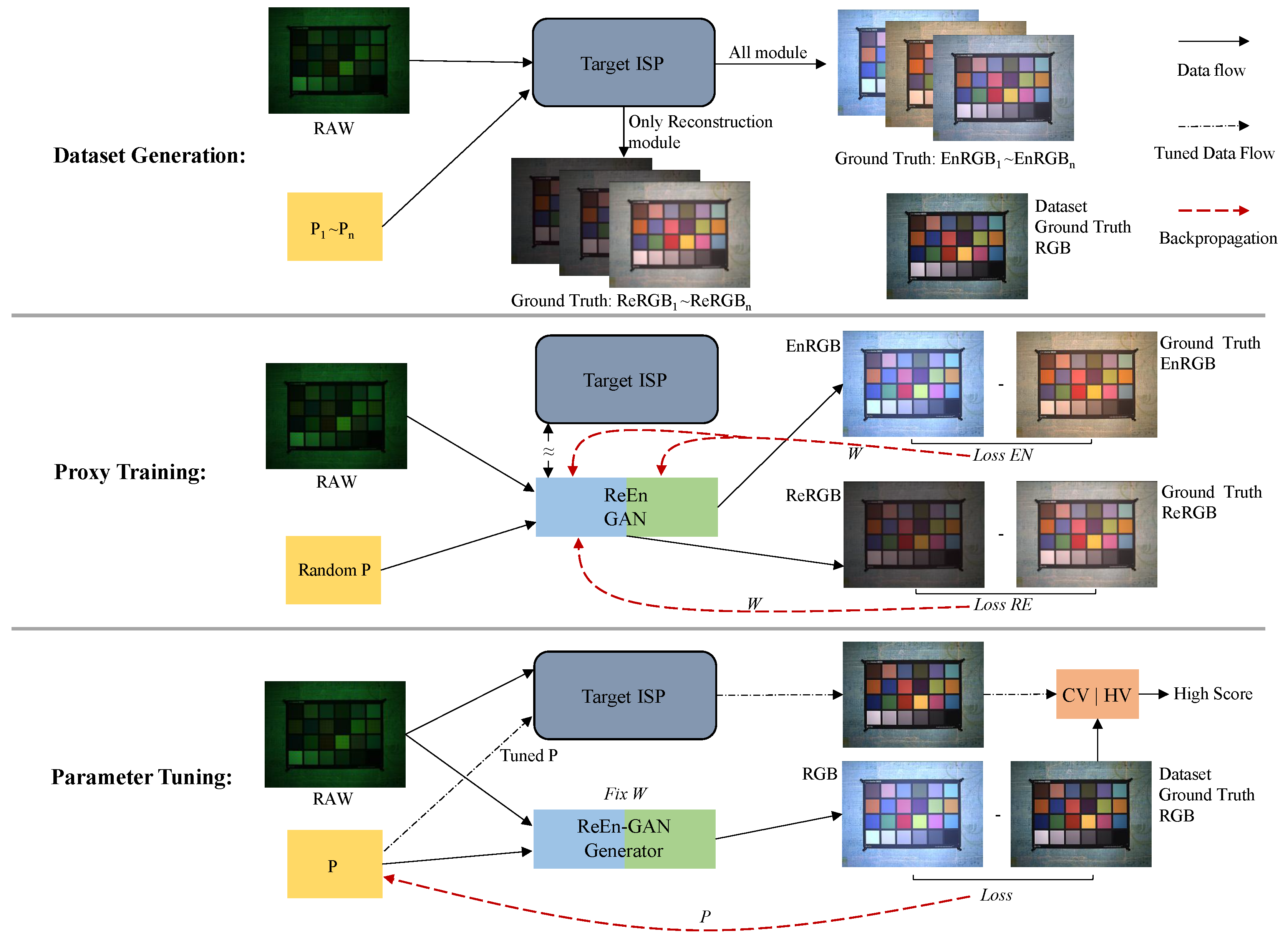
3.1. Overall Proxy Tuning Process
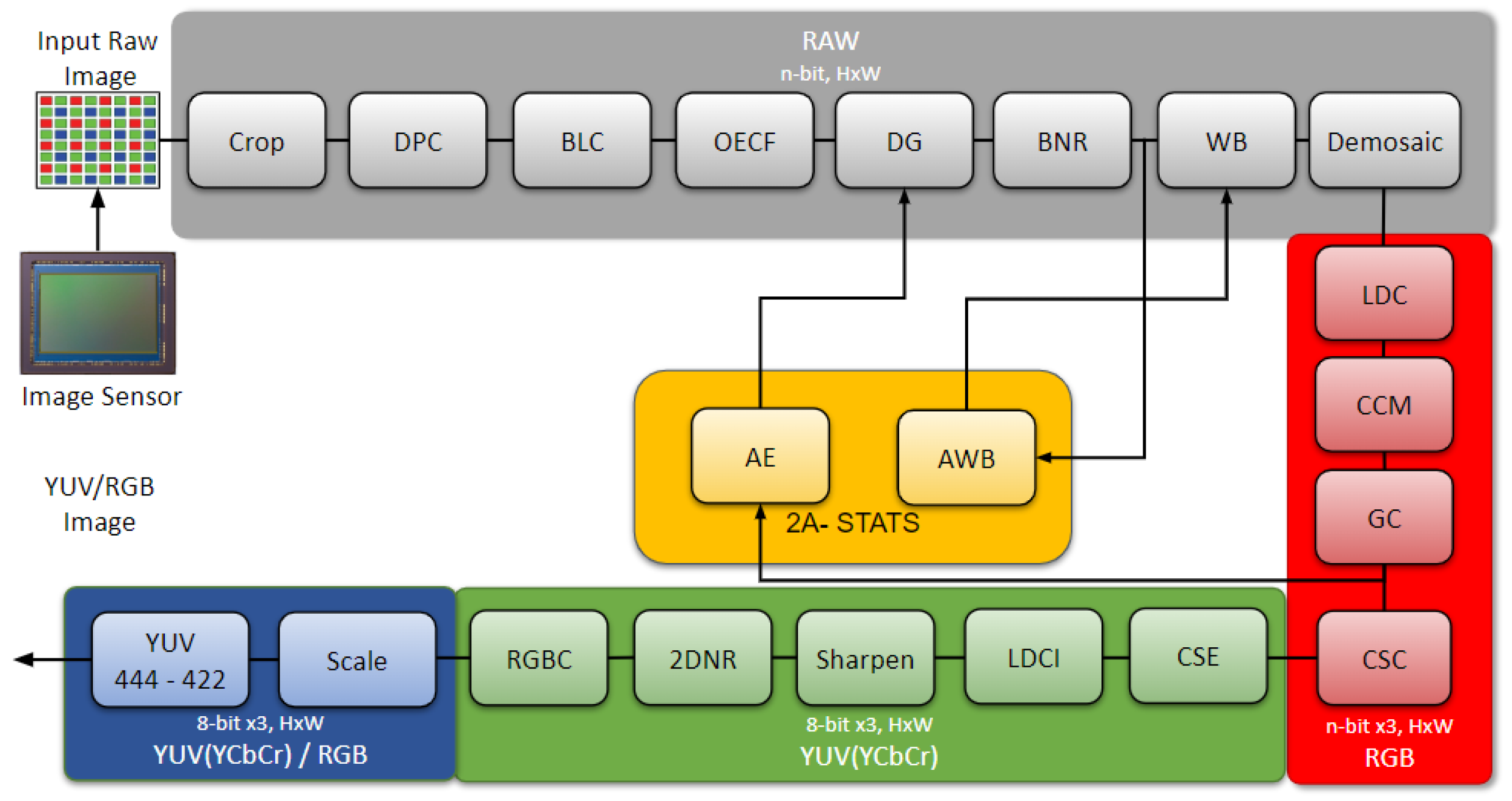
3.2. Reconstruction Stage
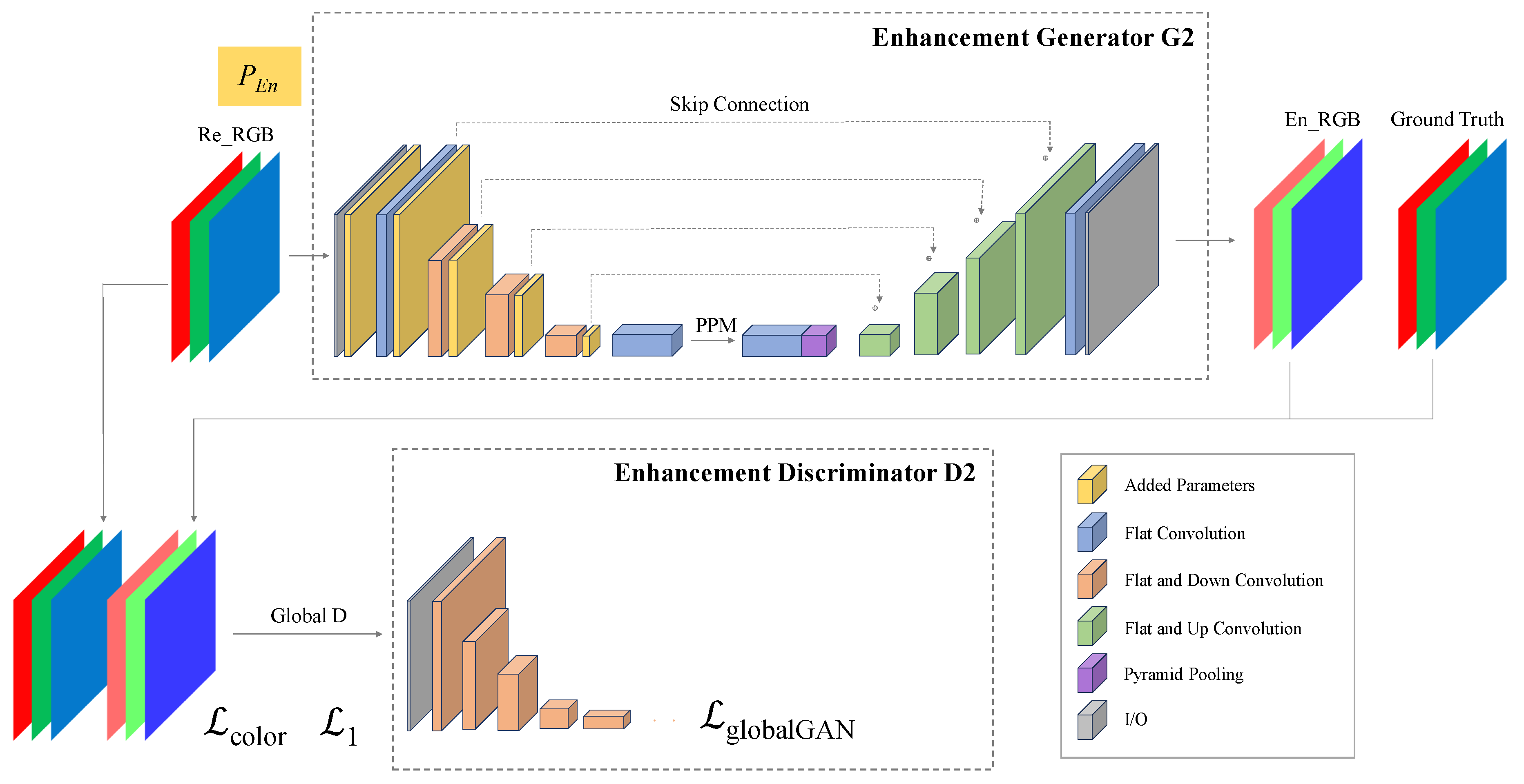
3.3. Enhancement Stage
3.4. Loss Function
3.5. Proxy Training and Tuning Scheme
4. Experiments
4.1. Experimental Environment and Dataset
4.2. Data Generation and ISP Tuning Preparation
4.3. Proxy Performance Experiment
4.4. Denoising Tuning Experiment
4.5. Object Detection Tuning Experiment
4.6. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ISP | Image Signal Processor |
| CV | Computer Vision |
| HV | Human Vision |
| PPM | Pyramid Pooling Module |
| BLC | Black Level Correction |
| BNR | Bayer Noise Reduction |
| AWB | Auto White Balance |
| CSE | Color Saturation Enhancement |
| LDCI | Local Dynamic Contrast Improvement |
| 2DNR | Two-dimensional Noise Reduction |
References
- Brown, M.S. Understanding the In-Camera Image Processing Pipeline for Computer Vision. In Proceedings of the IEEE Computer Vision and Pattern Recognition-Tutorial, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Guo, Y.; Wu, X.; Luo, F. Learning Degradation-Independent Representations for Camera ISP Pipelines. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2023; pp. 25774–25783. [Google Scholar]
- Wu, C.T.; Isikdogan, L.F.; Rao, S.; Nayak, B.; Gerasimow, T.; Sutic, A.; Ain-kedem, L.; Michael, G. VisionISP: Repurposing the Image Signal Processor for Computer Vision Applications. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4624–4628. [Google Scholar] [CrossRef]
- Yang, C.; Kim, J.; Lee, J.; Kim, Y.; Kim, S.S.; Kim, T.; Yim, J. Effective ISP Tuning Framework Based on User Preference Feedback. Electron. Imaging 2020, 32, 1–5. [Google Scholar] [CrossRef]
- IEEE Std 1858-2016; IEEE Standard for Camera Phone Image Quality. IEEE: New York, NY, USA, 2017; pp. 1–146. [CrossRef]
- IEEE P2020 Automotive Imaging. 2018, pp. 1–32. Available online: https://ieeexplore.ieee.org/document/8439102 (accessed on 13 November 2024).
- Microsoft. Microsoft Teams Video Capture Specification, 4th ed.; Microsoft: Redmond, WA, USA, 2019. [Google Scholar]
- Wueller, D.; Kejser, U.B. Standardization of Image Quality Analysis–ISO 19264; Society for Imaging Science and Technology: Scottsdale, AZ, USA, 2016. [Google Scholar]
- Yahiaoui, L.; Horgan, J.; Deegan, B.; Yogamani, S.; Hughes, C.; Denny, P. Overview and Empirical Analysis of ISP Parameter Tuning for Visual Perception in Autonomous Driving. J. Imaging 2019, 5, 78. [Google Scholar] [CrossRef] [PubMed]
- Molloy, D.; Deegan, B.; Mullins, D.; Ward, E.; Horgan, J.; Eising, C.; Denny, P.; Jones, E.; Glavin, M. Impact of ISP Tuning on Object Detection. J. Imaging 2023, 9, 260. [Google Scholar] [CrossRef] [PubMed]
- Yoshimura, M.; Otsuka, J.; Irie, A.; Ohashi, T. DynamicISP: Dynamically Controlled Image Signal Processor for Image Recognition. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 12820–12830. [Google Scholar]
- Zhou, J.; Glotzbach, J. Image Pipeline Tuning for Digital Cameras. In Proceedings of the 2007 IEEE International Symposium on Consumer Electronics, Irving, TX, USA, 20–23 June 2007; pp. 1–4. [Google Scholar] [CrossRef]
- Tseng, E.; Yu, F.; Yang, Y.; Mannan, F.; Arnaud, K.S.; Nowrouzezahrai, D.; Lalonde, J.F.; Heide, F. Hyperparameter optimization in black-box image processing using differentiable proxies. ACM Trans. Graph. 2019, 38, 27:1–27:14. [Google Scholar] [CrossRef]
- Liang, Z.; Cai, J.; Cao, Z.; Zhang, L. CameraNet: A Two-Stage Framework for Effective Camera ISP Learning. IEEE Trans. Image Process. 2021, 30, 2248–2262. [Google Scholar] [CrossRef] [PubMed]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 12–15 December 2011; pp. 2546–2554. [Google Scholar]
- Nishimura, J.; Gerasimow, T.; Sushma, R.; Sutic, A.; Wu, C.T.; Michael, G. Automatic ISP Image Quality Tuning Using Nonlinear Optimization. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2471–2475. [Google Scholar] [CrossRef]
- Tseng, E.; Mosleh, A.; Mannan, F.; St-Arnaud, K.; Sharma, A.; Peng, Y.; Braun, A.; Nowrouzezahrai, D.; Lalonde, J.F.; Heide, F. Differentiable Compound Optics and Processing Pipeline Optimization for End-to-end Camera Design. ACM Trans. Graph. 2021, 40, 1–19. [Google Scholar] [CrossRef]
- Mosleh, A.; Sharma, A.; Onzon, E.; Mannan, F.; Robidoux, N.; Heide, F. Hardware-in-the-Loop End-to-End Optimization of Camera Image Processing Pipelines. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7526–7535. [Google Scholar] [CrossRef]
- Portelli, G.; Pallez, D. Image Signal Processor Parameter Tuning with Surrogate-Assisted Particle Swarm Optimization. In Artificial Evolution; Idoumghar, L., Legrand, P., Liefooghe, A., Lutton, E., Monmarché, N., Schoenauer, M., Eds.; Springer: Cham, Switzerland, 2020; pp. 28–41. [Google Scholar]
- Xu, F.; Liu, Z.; Lu, Y.; Li, S.; Xu, S.; Fan, Y.; Chen, Y.K. AI-assisted ISP hyperparameter auto tuning. In Proceedings of the 2023 IEEE 5th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hangzhou, China, 11–13 June 2023; pp. 1–5. [Google Scholar]
- Robidoux, N.; Seo, D.E.; Ariza, F.; García Capel, L.E.; Sharma, A.; Heide, F. End-to-end High Dynamic Range Camera Pipeline Optimization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6293–6303. [Google Scholar] [CrossRef]
- Qin, H.; Han, L.; Wang, J.; Zhang, C.; Li, Y.; Li, B.; Hu, W. Attention-Aware Learning for Hyperparameter Prediction in Image Processing Pipelines. In European Conference on Computer Vision; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 271–287. [Google Scholar]
- Santos, C.F.G.D.; Arrais, R.R.; Silva, J.V.S.D.; Silva, M.H.M.D.; Neto, W.B.G.d.A.; Lopes, L.T.; Bileki, G.A.; Lima, I.O.; Rondon, L.B.; Souza, B.M.D.; et al. ISP Meets Deep Learning: A Survey on Deep Learning Methods for Image Signal Processing. ACM Comput. Surv. 2025, 57, 1–44. [Google Scholar] [CrossRef]
- Liu, G.H.; Wei, Z. Image Retrieval Using the Fused Perceptual Color Histogram. Comput. Intell. Neurosci. 2020, 2020, 8876480. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.; Wang, B. An image retrieval algorithm based on improved color histogram. In Journal of Physics: Conference Series; IOP Publishing Ltd.: Bristol, UK, 2019; Volume 1176, p. 022039. [Google Scholar] [CrossRef]
- Furgala, Y.; Velhosh, A.; Velhosh, S.; Rusyn, B. Using Color Histograms for Shrunk Images Comparison. In Proceedings of the 2021 IEEE 12th International Conference on Electronics and Information Technologies (ELIT), Lviv, Ukraine, 5–7 May 2021; pp. 130–133. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Nilsson, J.; Akenine-Möller, T. Understanding SSIM. arXiv 2020, arXiv:2006.13846. [Google Scholar]
- Korhonen, J.; You, J. Peak signal-to-noise ratio revisited: Is simple beautiful? In Proceedings of the 2012 Fourth International Workshop on Quality of Multimedia Experience, Melbourne, Australia, 5–7 July 2012; pp. 37–38. [Google Scholar] [CrossRef]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Čadík, M.; Herzog, R.; Mantiuk, R.; Mantiuk, R.; Myszkowski, K.; Seidel, H.P. Learning to Predict Localized Distortions in Rendered Images. Comput. Graph. Forum 2013, 32, 401–410. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to See in the Dark. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3291–3300. [Google Scholar] [CrossRef]
- Wei, Z. Raw Bayer Pattern Image Synthesis with Conditional GAN. arXiv 2021, arXiv:2110.12823. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K. DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3297–3305. [Google Scholar]
- Infinite-ISP. Available online: https://github.com/10x-Engineers/Infinite-ISP (accessed on 23 December 2024).
- Abdelhamed, A.; Lin, S.; Brown, M.S. A High-Quality Denoising Dataset for Smartphone Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. (IJRR) 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Parameter | Default Value | Min Value | Max Value |
|---|---|---|---|---|
| BLC | R sat * | 4095 | 1 | |
| Gr sat * | 4095 | 1 | ||
| Gb sat * | 4095 | 1 | ||
| B sat * | 4095 | 1 | ||
| BNR | R std dev s * | 1 | 0 | 12 |
| R std dev r | 0.1 | 0 | R std dev s | |
| G std dev s * | 1 | 0 | 12 | |
| G std dev r | 0.08 | 0 | G std dev s | |
| B std dev s * | 1 | 0 | 12 | |
| B std dev r | 0.1 | 0 | B std dev s | |
| Sharpen | sharpen sigma | 5 | 1 | 12 |
| sharpen strength | 1 | 0 | 8 | |
| 2DNR | wts * | 10 | 1 | |
| AWB | underexposed pecentage | 5 | 0 | 16 |
| overexposed pecentage | 0.1 | 0 | 16 | |
| percentage | 3.5 | 0 | 16 | |
| CSE | saturation gain | 1.5 | 0 | 8 |
| LDCI | clip limit * | 1 | 1 | 5 |
| Methods | SSIM | HC | Params/M | FLOPs/G |
|---|---|---|---|---|
| End-to-End Proxy [20] | 0.965 | 0.954 | 8.7 | 66.72 |
| Proposed Proxy | 0.967 | 0.978 | 14.29 | 116.58 |
| Methods | PSNR | SSIM |
|---|---|---|
| Random-Param | 16.72 | 0.527 |
| Default-Param | 22.17 | 0.795 |
| BM3D 1 | 25.89 | 0.806 |
| Hand-tuned | 27.86 | 0.873 |
| End-to-End Proxy [20] | 33.54 | 0.892 |
| Proposed Proxy | 33.76 | 0.908 |
| Method | mAP@0.5/% | True Positives | False Negatives | F1 Score | AP@0.5/% | ||
|---|---|---|---|---|---|---|---|
| Car | Person | Bicycle | |||||
| Random Param | 74.2 | 4628 | 1957 | 82.1 | 75.2 | 73.1 | 74.4 |
| Default Param | 79.6 | 5024 | 1561 | 86.3 | 80.7 | 77.9 | 80.4 |
| Hand-tuned Param | 83.4 | 5276 | 1309 | 88.6 | 83.4 | 85.2 | 81.6 |
| End-to-End Proxy [20] | 90.8 | 5751 | 834 | 93.1 | 91.4 | 90.7 | 90.3 |
| Proposed Proxy | 92.0 | 5841 | 744 | 93.9 | 92.2 | 92.4 | 91.5 |
| + | + | +PPM | Proxy SSIM | Proxy HC | Tuning PSNR | Tuning SSIM |
|---|---|---|---|---|---|---|
| 0.917 | 0.892 | 30.39 | 0.825 | |||
| ✓ | 0.948 | 0.937 | 32.53 | 0.867 | ||
| ✓ | 0.924 | 0.946 | 31.45 | 0.846 | ||
| ✓ | 0.921 | 0.904 | 31.02 | 0.832 | ||
| ✓ | ✓ | ✓ | 0.967 | 0.978 | 33.76 | 0.908 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, P.; Ye, J. Conditional GAN-Based Two-Stage ISP Tuning Method: A Reconstruction–Enhancement Proxy Framework. Appl. Sci. 2025, 15, 3371. https://doi.org/10.3390/app15063371
Zhan P, Ye J. Conditional GAN-Based Two-Stage ISP Tuning Method: A Reconstruction–Enhancement Proxy Framework. Applied Sciences. 2025; 15(6):3371. https://doi.org/10.3390/app15063371
Chicago/Turabian StyleZhan, Pengfei, and Jiongyao Ye. 2025. "Conditional GAN-Based Two-Stage ISP Tuning Method: A Reconstruction–Enhancement Proxy Framework" Applied Sciences 15, no. 6: 3371. https://doi.org/10.3390/app15063371
APA StyleZhan, P., & Ye, J. (2025). Conditional GAN-Based Two-Stage ISP Tuning Method: A Reconstruction–Enhancement Proxy Framework. Applied Sciences, 15(6), 3371. https://doi.org/10.3390/app15063371