2.1. The Fundamentals of RRT Algorithm
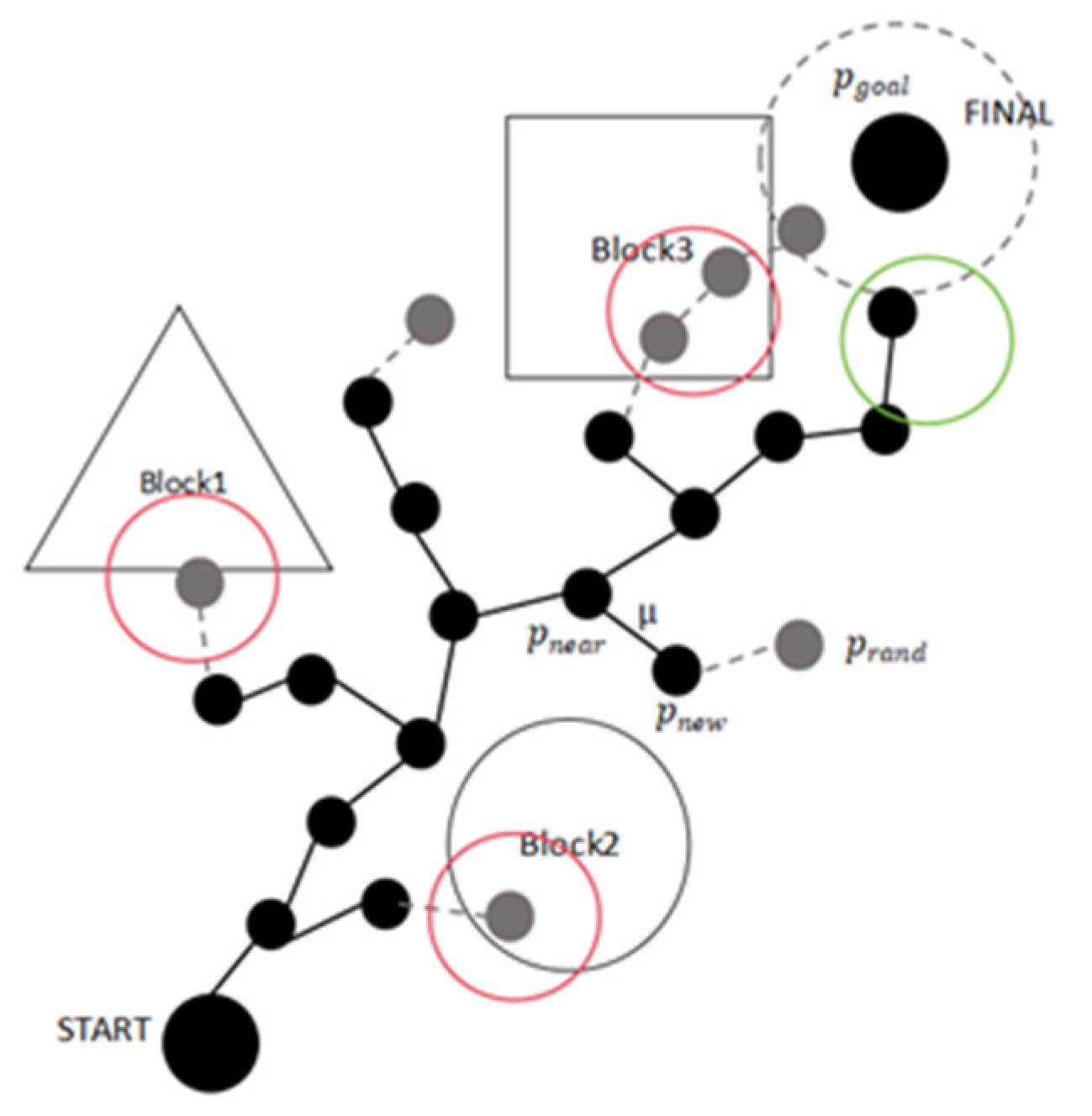
In the field of autonomous driving, the Rapidly Exploring Random Tree (RRT) algorithm based on sampling planning is widely used for path planning. The idea is to treat the initial node as the root node and, through a finite number of random samples, increase the leaf nodes to generate a randomly expanding tree. When the leaf nodes of the random tree reach the target point or target area, an optimal or suboptimal collision-free path can be found from the initial node to the target point within the tree. As shown in
Figure 1, the green area represents the final path points, the red area indicates obstacle collision detection, the gray dashed area is the reachable region, and
represents the step size.
The RRT algorithm has strong search capabilities, and as long as there is a feasible path in the environment, the RRT algorithm can find a feasible path. However, the traditional RRT algorithm, while exhibiting strong randomness, also introduces several drawbacks. For example, the direction of growth of the random tree during expansion is quite random, leading to low search efficiency, slow convergence speed, and issues such as lack of stability and deviation from the optimal solution in dynamic environments.
To optimize the traditional RRT algorithm, this paper proposed a variable steering angle strategy that integrates Kalman filtering with the RRT algorithm and incorporates collision detection. This approach filters redundant particles through Kalman filtering, thereby enhancing search efficiency and accuracy.
2.2. Variable Steering Angle Strategy
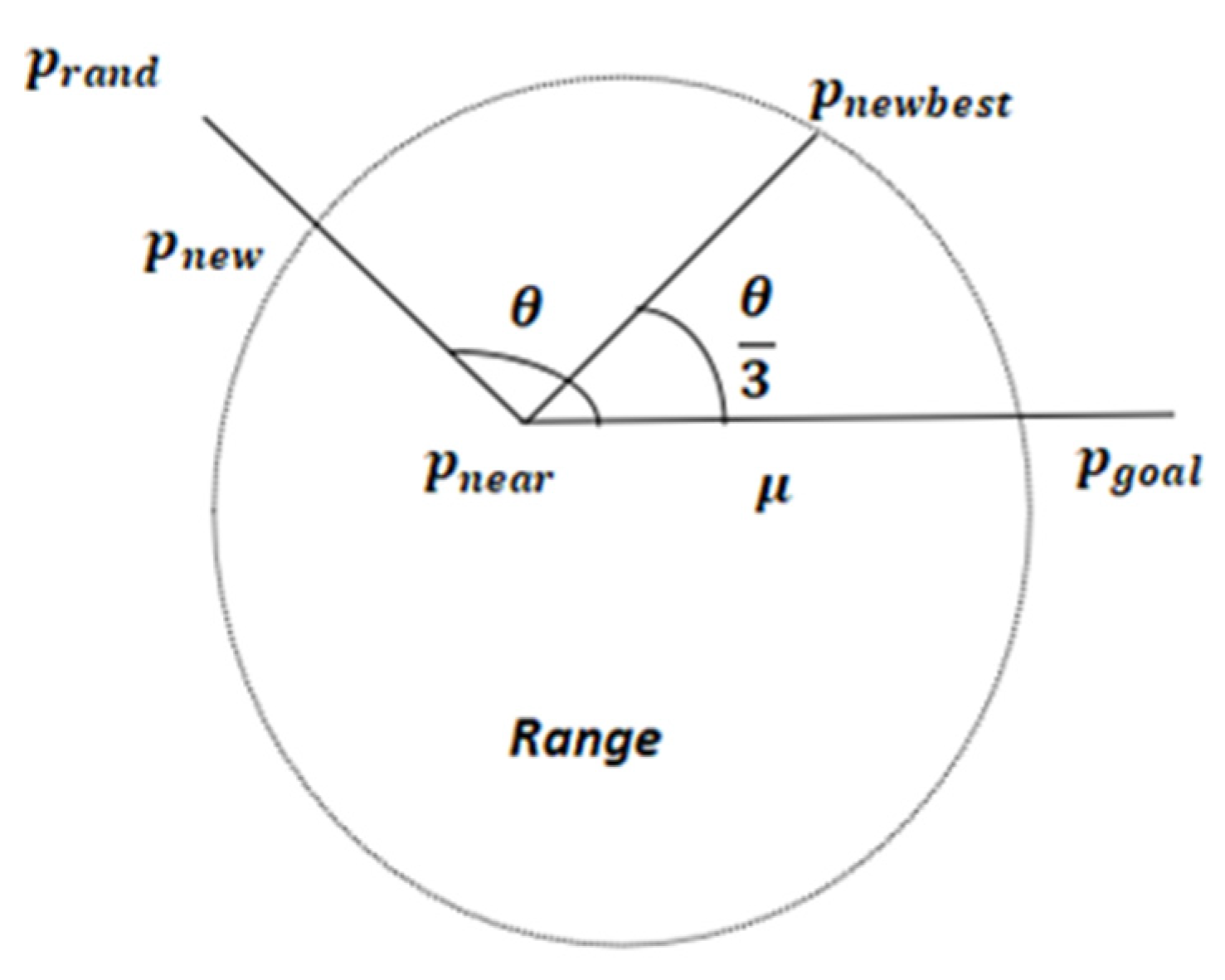
The principle behind the variable steering angle strategy is to prevent the search tree from growing in a reverse direction. This strategy is based on the concept of RRT node extension. When the sampling area narrows down to a specific range, the growth of new branches, without constraints on the steering angle, may deviate from the target point, creating unnecessary branches and generating a large number of redundant search nodes. As a result, search efficiency and accuracy are reduced. However, blindly pursuing high directionality can also lead to local oscillations, which in turn reduces search efficiency. This article introduces a variable steering angle strategy, the principles of which are illustrated in
Figure 2.
In the Range region, after the random tree child node
finds the closest point
in the tree, a new child node
is generated according to the preset step size
. If the distance between two points is less than
, then
is taken as the new search node; if the distance between two points is greater than
, then
passes the collision detection, and at this point, the angle
is greater than 90° between the connecting line of
,
and the connecting line between
,
, then it means that the tree branching sub-node There is a reverse growth situation where, in order to solve this problem, the steering angle
is changed to one-third of the original to generate a new child node,
, as a child node of this search tree. The formula for updating the steering angle is shown in Equation (1).
In the above equation, when
, no steering angle processing is required; otherwise, the steering angle is updated to one-third of the original. Defining
as the updated step size, q as the sum of the normalized vectors of the new child node’s outward extension, and
as the child node after the variable steering angle strategy, the new node generation equations are as follows:
2.3. Collision Detection and Kalman Filter Redundancy Point Elimination
Although the algorithm has been improved by the variable steering angle strategy proposed in this paper, the path searched for the first time may still contain more redundant points, which produces oscillations and unnecessary bit position adjustments during path planning. In this paper, based on the Kalman filtering algorithm, the current node passes through the collision detection, and then the step lengths between the node and the node are compared, in which nodes with larger step lengths are filtered out through the Kalman gain until nodes with larger step lengths are no longer passed through this point for searching. There is no more searching through this point at this stage, and instead the prediction state of the next steering is adjusted.
Kalman Filtering is an autoregressive filtering method based on the minimum variance criterion, and its core principle originates from Bayesian filtering theory. The mathematical expressions are shown in Equations (5) and (6).
In the above equation,
is the state of the environment in which the robot is located at time t, A is the state transition matrix, B is the input control matrix, y_t is the observation value of the environment by the robot at time t,
is the input noise, and
is the observation noise. H is the observation matrix, as shown in Equation (7).
The observation matrix maps the system state to the observation space and describes how the system state affects the measurements. The dimension of H is , where p is the number of observation variables and n is the number of state variables. The observation matrix H describes which state variables in the state vector contribute to the measurements.
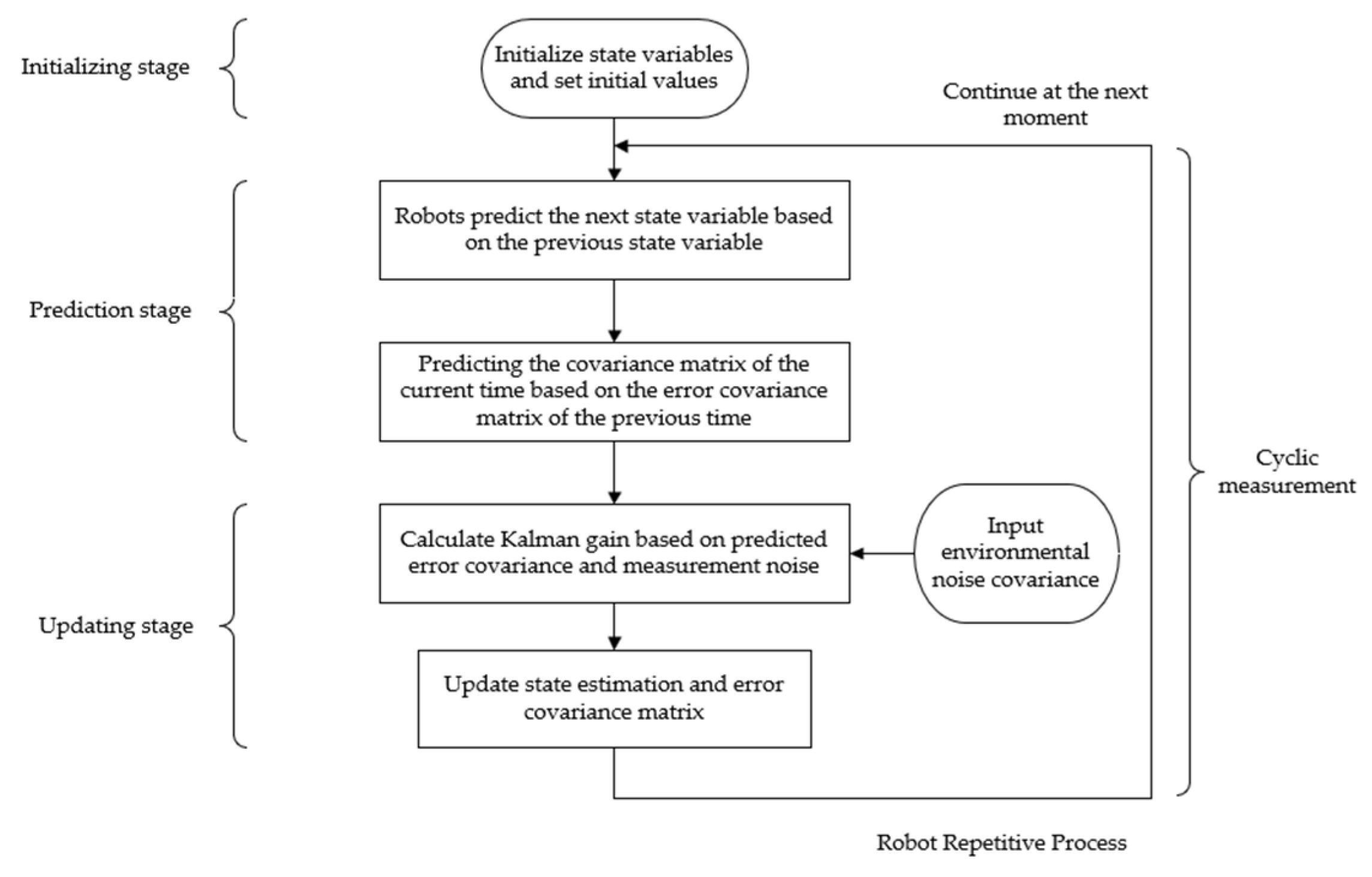
The robot predicts the next state and error covariance based on a known dynamic model and then calculates the Kalman gain based on the predicted error covariance and measurement noise. The Kalman gain formula is shown in Equation (8).
In the above equation, R represents the covariance matrix of the node measurement noise, is the covariance matrix of the nth node a priori estimation, is the transpose of the measurement matrix H, and is the Kalman gain of the nth time. Under the assumption of constant time, the robot’s state is updated based on the measurements, and the target movement point is determined, significantly reducing the computational time complexity of the random tree during the search.
The flowchart of the Kalman filter algorithm is shown in
Figure 3.
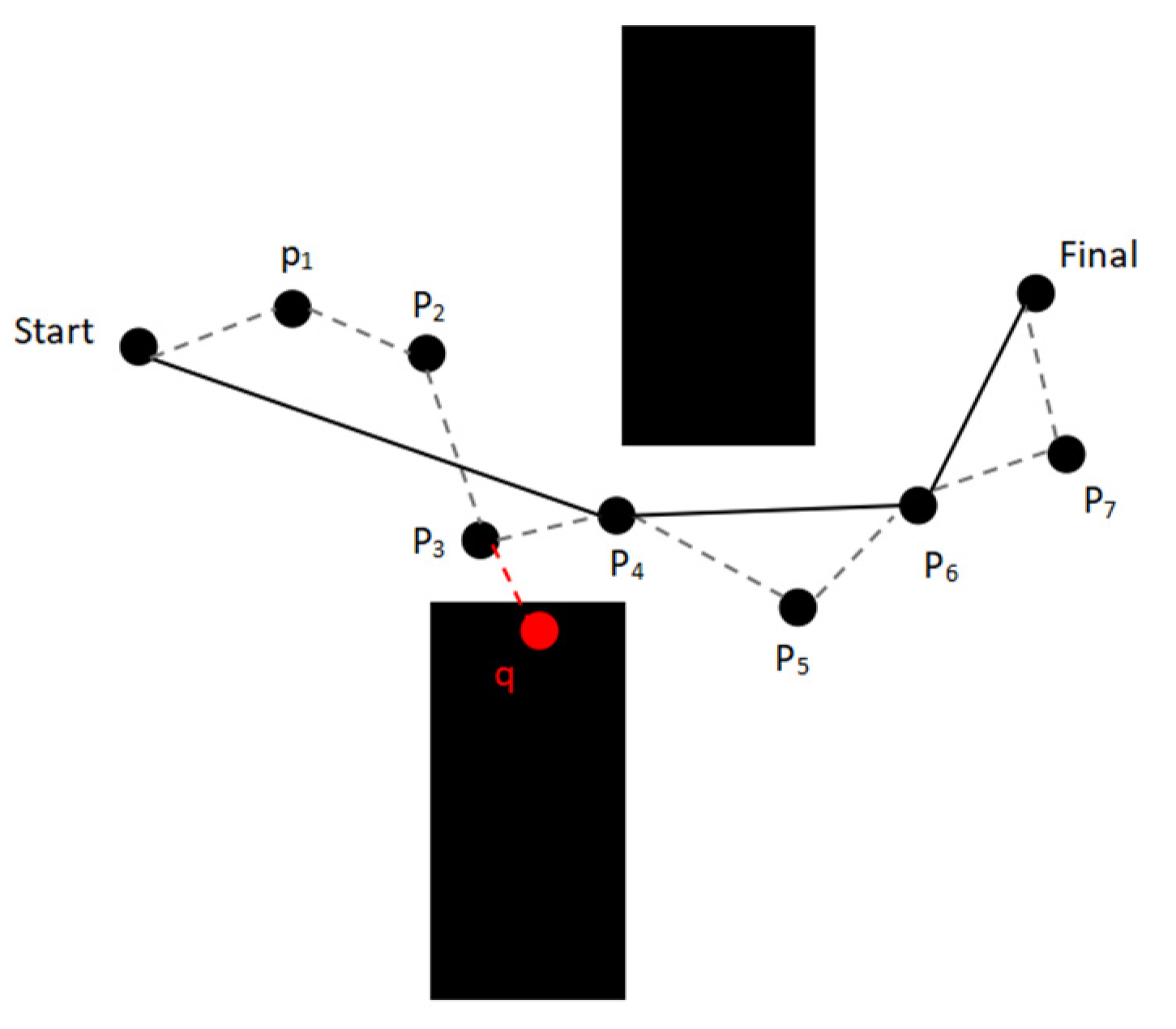
Redundant points in path planning refer to unnecessary nodes between the starting point and the target point. Removing these points can make the path simpler while reducing the number of node observation pose, thereby improving search efficiency. Based on the fundamental principles of the Kalman filter algorithm, this paper estimates the node states through the mapping of the observation matrix H, predicting the future position of the nodes and evaluating the necessity of the nodes. The principle of redundant node elimination based on the Kalman filter is shown in
Figure 4.
As shown below, the black node Start is the starting point, Final is the target point, and points are the path planning points, with a total of seven points. The black solid line is the Kalman filtered path: , and the gray dashed line is the initial path, where it can be seen that the number of nodes between the start point and the target point is reduced significantly, which shortens the frequency of nodes adjusting their own position in path planning. q is the collision detection node of node , which adjusts its position through collision detection, and combines with the variable steering angle strategy to get the next child node .
In the process of path planning, in addition to ensuring the path is optimal, it is also essential to guarantee the smoothness of the path. The higher the smoothness, the higher the controllability. This paper uses Bezier curves for path smoothness optimization. Bezier curves can generate smooth, continuous curves, reducing sharp corners and discontinuities in the path, while also avoiding unnatural movements or acceleration changes. In robot path planning, smooth paths can reduce sudden changes in the robot’s motion, thereby improving the stability and accuracy of movement.
In this paper, a second-order Bezier curve is used to give three control points,
,
and
, where
and
form a first-order Bézier curve while
and
form a first-order Bézier curve, i.e:
On the basis of generating two first-order points through Equation (9), a second-order Bessel point
is generated through Equation (10).
to obtain a second-order Bezier curve:
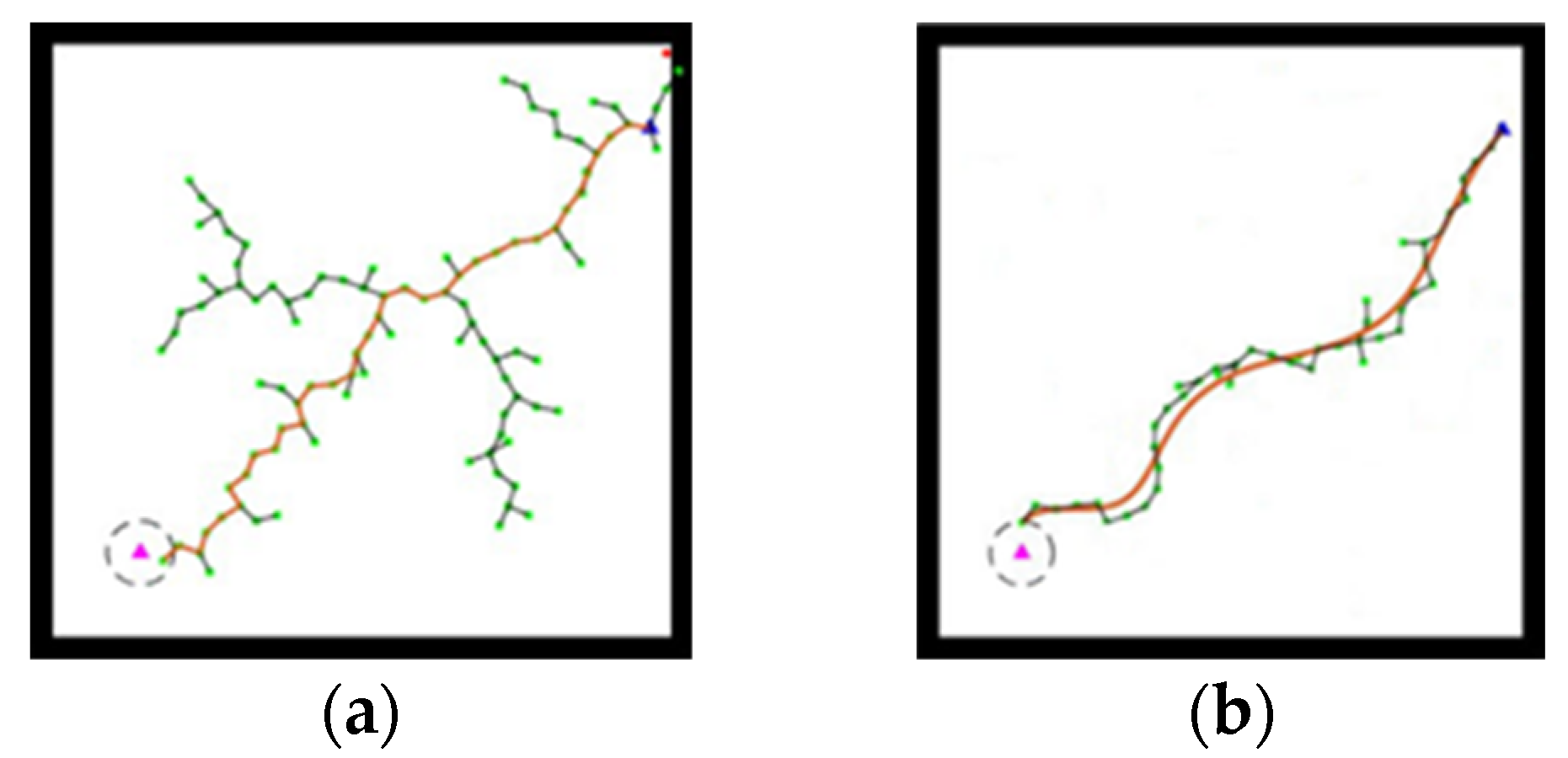
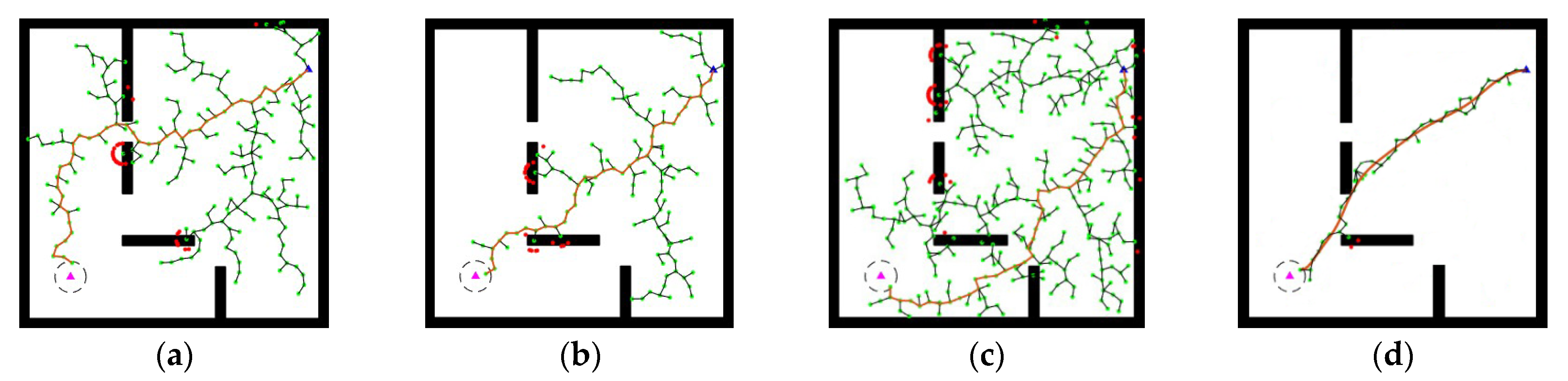
With t taken at equal intervals from 0 to 1, the path of the final curve after second-order Bezier smoothing is shown in
Figure 5. In this figure, the time values from (a) to (d) are 0.182 s, 0.479 s, 0.708 s, and 1 s.
2.4. Improved RRT Algorithm Framework Model
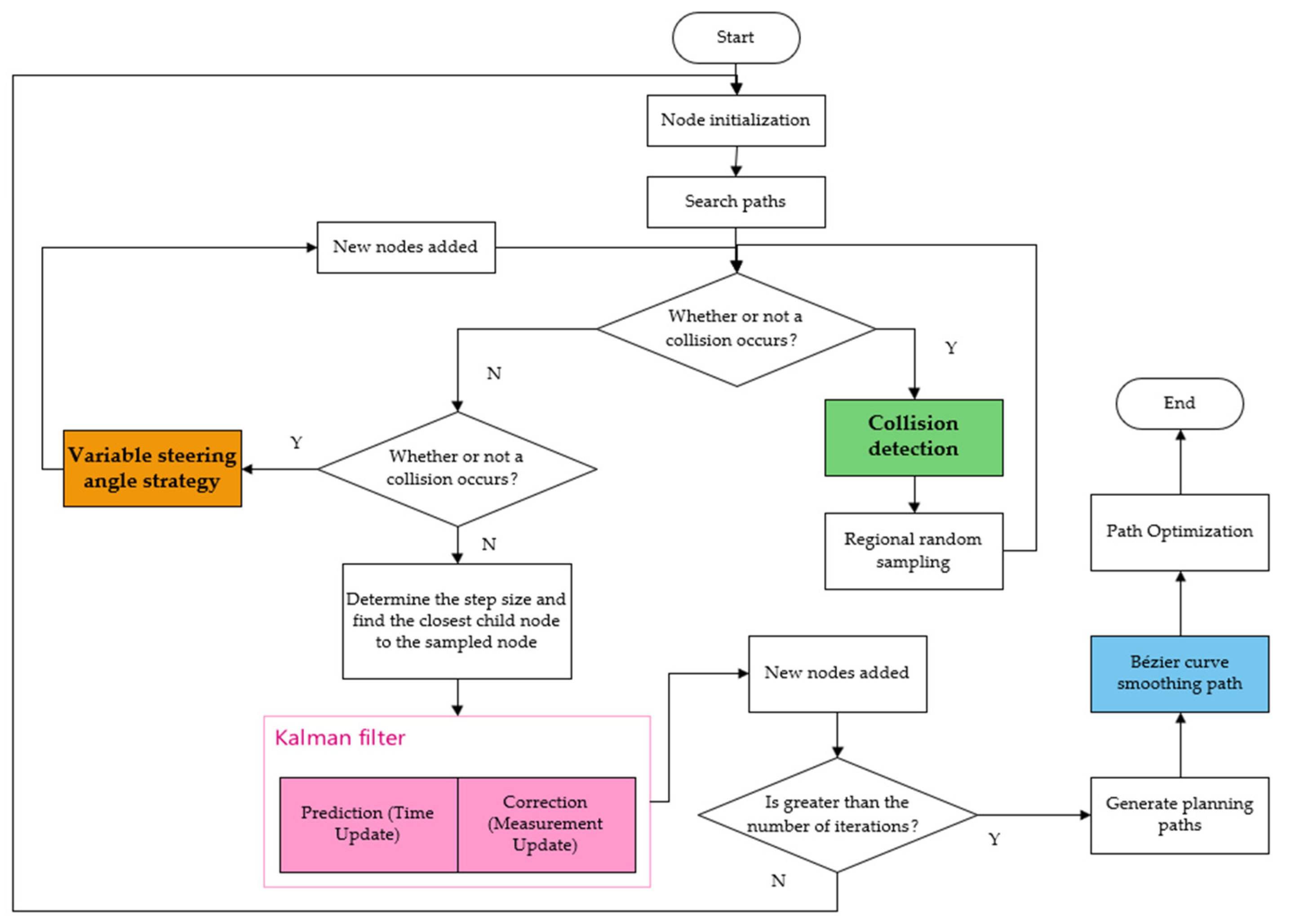
The improved RRT-KF algorithm is built on the traditional RRT algorithm, making it more efficient in searching across various environments by incorporating strategies such as steering angle change, redundant point removal based on Kalman filtering, collision detection, and path smoothing using Bezier curves. Starting from the initial point, the algorithm finds the nearest point and then expands toward a random point. At this stage, the steering angle change strategy adjusts the step size and direction during expansion to avoid the phenomenon of nodes growing in reverse, dynamically adjusting the steering angle to increase the algorithm’s flexibility and prevent the algorithm from stalling. During the node growth process, collision detection is used to ensure that the planned path does not pass through obstacles, and the steering angle change strategy helps accurately and quickly lock onto the forward direction. During path generation, unnecessary points may appear between nodes, affecting the path length and efficiency. Based on traditional redundant point removal, Kalman filtering is used to observe and predict the future target position of nodes, determining whether a node is redundant and removing it accordingly. With the smoothing effect of the second-order Bezier curve, the final node can reach the target point along a smooth path, providing a theoretical foundation for the practical application of this algorithm. The pseudocode of the algorithm is shown in Algorithm 1.
| Algorithm 1: Improved RRT-KF Algorithm |
| 1. RRT-KF () |
| [node(start)] |
| // Finding the nearest node |
| // Steering angle change strategy |
| 5. if not collision check () // Collision detection |
| 6. update Kalman filter () |
| 7. float distance = calculateDistance (nodes[i], nodes[j]) // The distance is measured based on the observation matrix H |
| 8. if (distance
) delete node (nodes, nodeCount) |
| 9. nodes[i] = nodes[i+1] |
| 10. nodeCount — // Redundant point elimination based on Kalman filter |
| 11. tree.append () |
| 12. if distance ( |
| 13. path |
| 14. smoothed path// Bezier curve path smoothing |
| 15. return SmoothedPath |
In the above algorithm, given the starting point is and the target point is , the algorithm begins by searching for nearby child node from . Using child node as the parent node, the algorithm compares the angle between nodes and to determine if a collision has occurred through the pose. The Kalman filter state of the node is updated, and the distance of the node is checked to see if it lies within the observation values, thus removing redundant points. Finally, the path is smoothed using a Bezier curve, and the SmoothedPath is returned.



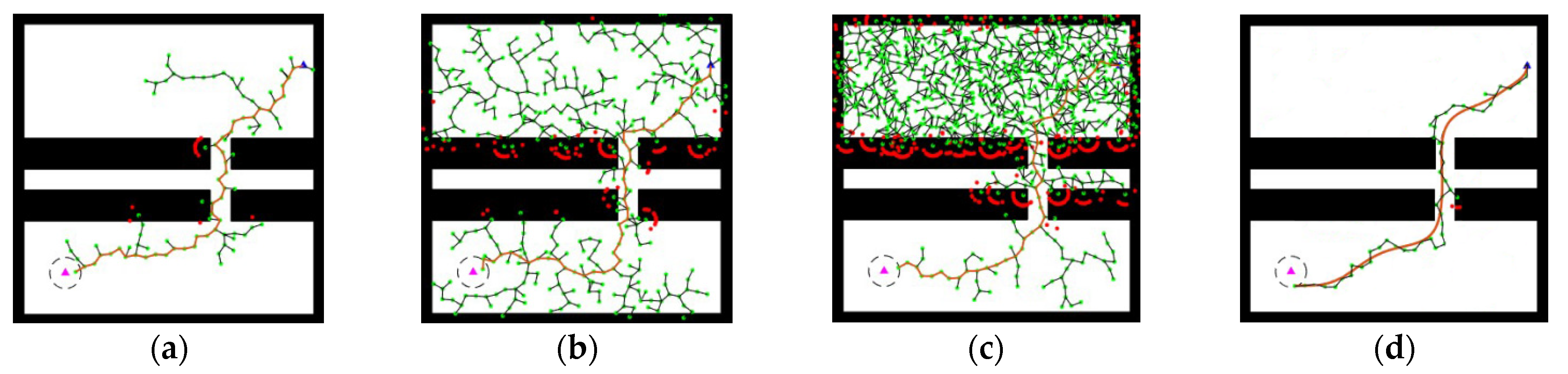
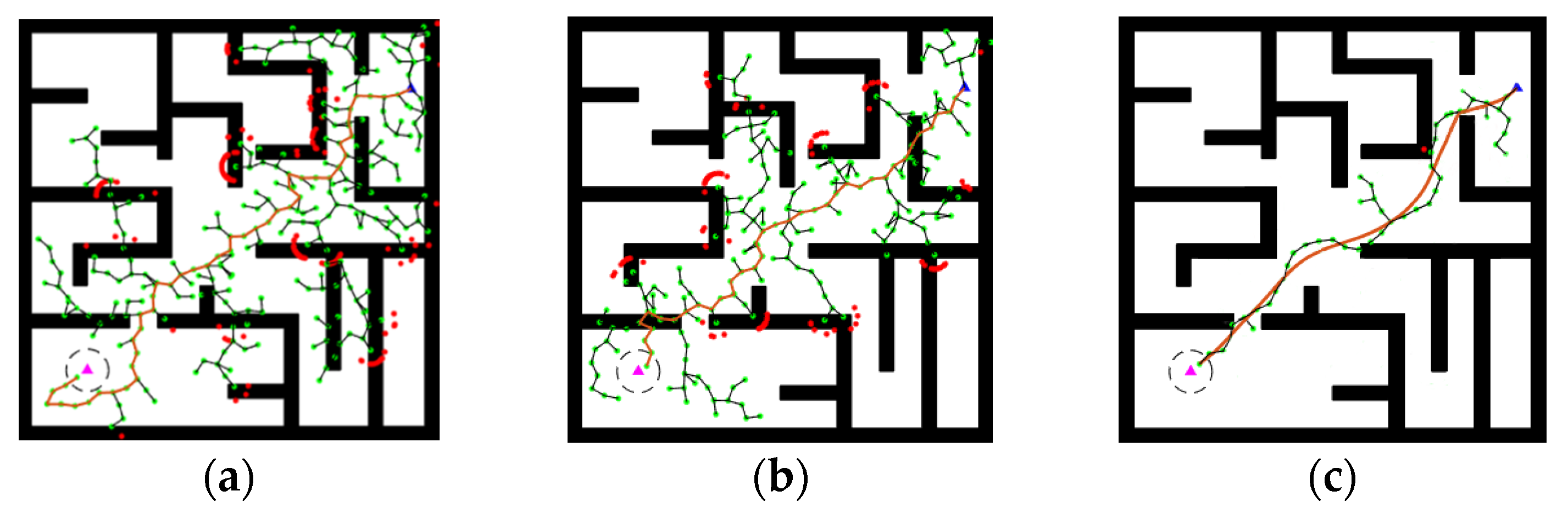
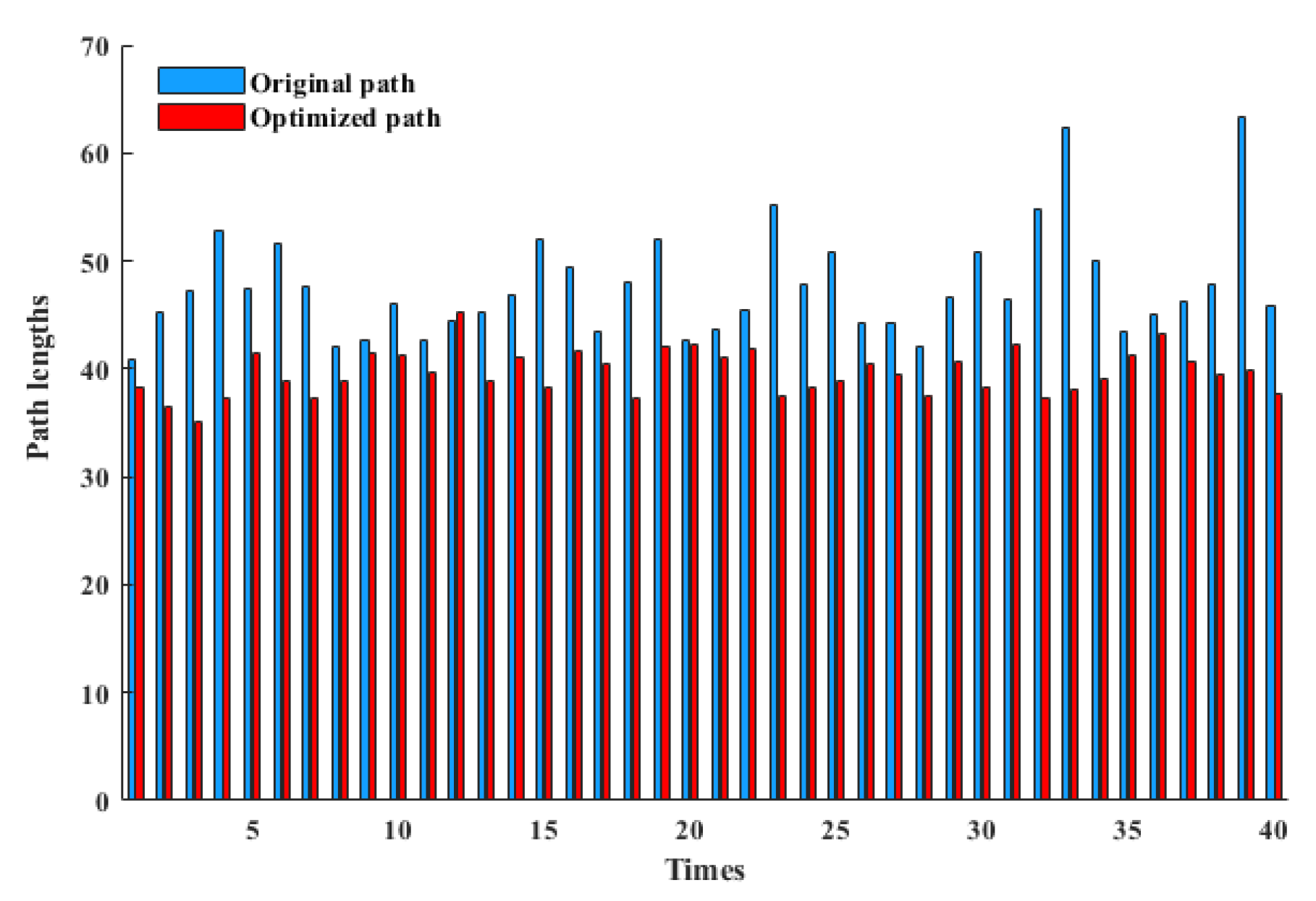




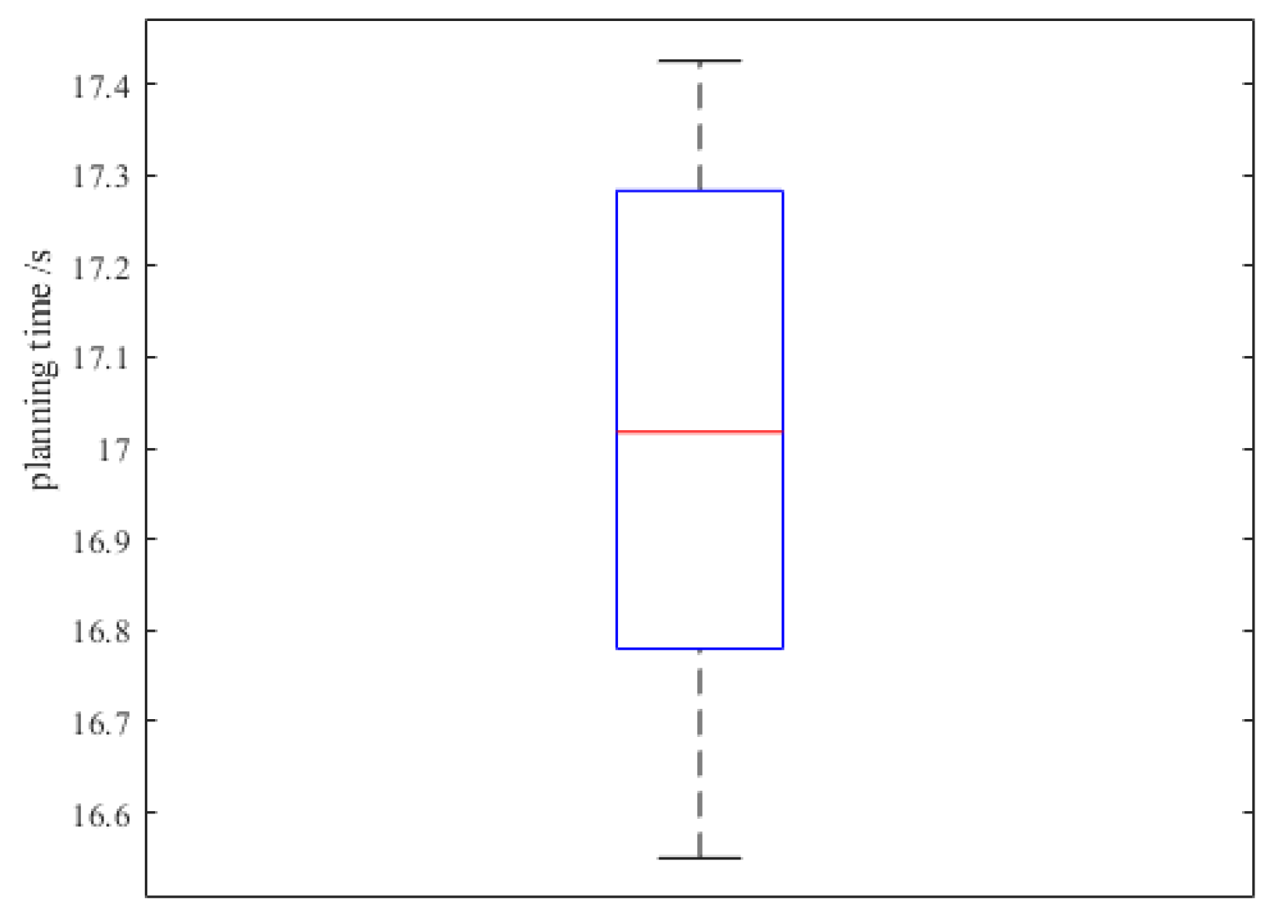

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}