
Voronoi-GRU-Based Multi-Robot Collaborative Exploration in Unknown Environments


Abstract
1. Introduction
- 1.
- An Innovative Decision-Making Framework: We propose V-R-MATD3, a hierarchical framework that, for the first time, combines Voronoi-driven spatial decomposition with GRU-augmented MATD3 for multi-robot exploration. The Voronoi partitioning allocates non-overlapping regions to eliminate redundant coverage, while the enhanced MATD3 algorithm leverages Voronoi-constrained action spaces and dual critic networks to optimize collaborative policies. The GRU layers model sequential state transitions, ensuring temporally coherent decision-making.
- 2.
- Development of a Multi-Robot RL Toolkit: We develop an open-source toolkit compatible with the ROS and Gazebo platforms for multi-robot reinforcement learning. By adjusting the Cartographer framework, we achieve high-precision joint map construction, ensuring data quality during accelerated training.
- 3.
- Design of a Prior-Guided Adaptive Hybrid Reward (PGAHR) Function: We propose a hybrid reward function, termed PGAHR, which combines dynamically adjusted intrinsic rewards with fixed extrinsic rewards. This function incorporates prior knowledge to maximize overall rewards and enhance learning efficiency. Specifically, we simplify the state space by subsampling the LiDAR measurements, and we reduce the robot’s action space using a spatial segmentation technique, which helps avoid excessive proximity between robots and contributes to maximizing the reward.
2. Background
2.1. Preliminaries
- LiDAR: A laser-based sensor used to measure distances, used in this work for mapping and obstacle detection.
- Global Plan: The optimal path from the start to the goal computed using algorithms like A* [37], considering static obstacles and map constraints, as well as serving as a reference trajectory for navigation systems.
- A*: A heuristic search algorithm that efficiently finds minimum-cost paths by combining the actual traversal cost () and the estimated remaining cost () [38], being widely used in robotics for global path planning.
- Local Plan: Short-term path planning that handles immediate obstacles and dynamics, optimizing robot movement.
- TEB [39]: Timed Elastic Band, a local planner that optimizes robot trajectories as elastic bands, balancing path smoothness, obstacle clearance, and kinematic constraints, as well as supporting dynamic obstacle avoidance through receding-horizon optimization.
- Cartographer [40]: A graph-based SLAM system that uses submaps and loop closure detection for consistent 2D/3D mapping, supporting multi-sensor fusion (LiDAR and IMU) for robust localization.
- Multi-Robot Map Merge: The process of combining maps from multiple robots to create a unified map, essential for cooperative navigation.
- Optional Goal Set: A set of possible goals that robots can choose from, used in task allocation and planning.
- Relative Position: The position of one robot relative to another, based on coordinate systems, critical for coordination.
- Target Point: A specific point that a robot needs to reach, used in path planning and navigation.
2.2. Problem Statement
- 1.
- Exploration Time Steps (T): The total number of navigation operations (each considered a step), thus indicating the efficiency of the reinforcement learning strategies.
- 2.
- Coverage Rate (): The proportion of environment explored at time step t, calculated aswhere represents the cumulative area explored by agent i from to . An unknown area is considered fully explored when it is entirely enclosed by detected obstacles.
- 3.
- Exploration Time (): The total time spent completing the exploration task, distinct from the number of time steps (T), thus reflecting the overall efficiency of the process.
3. Methodology
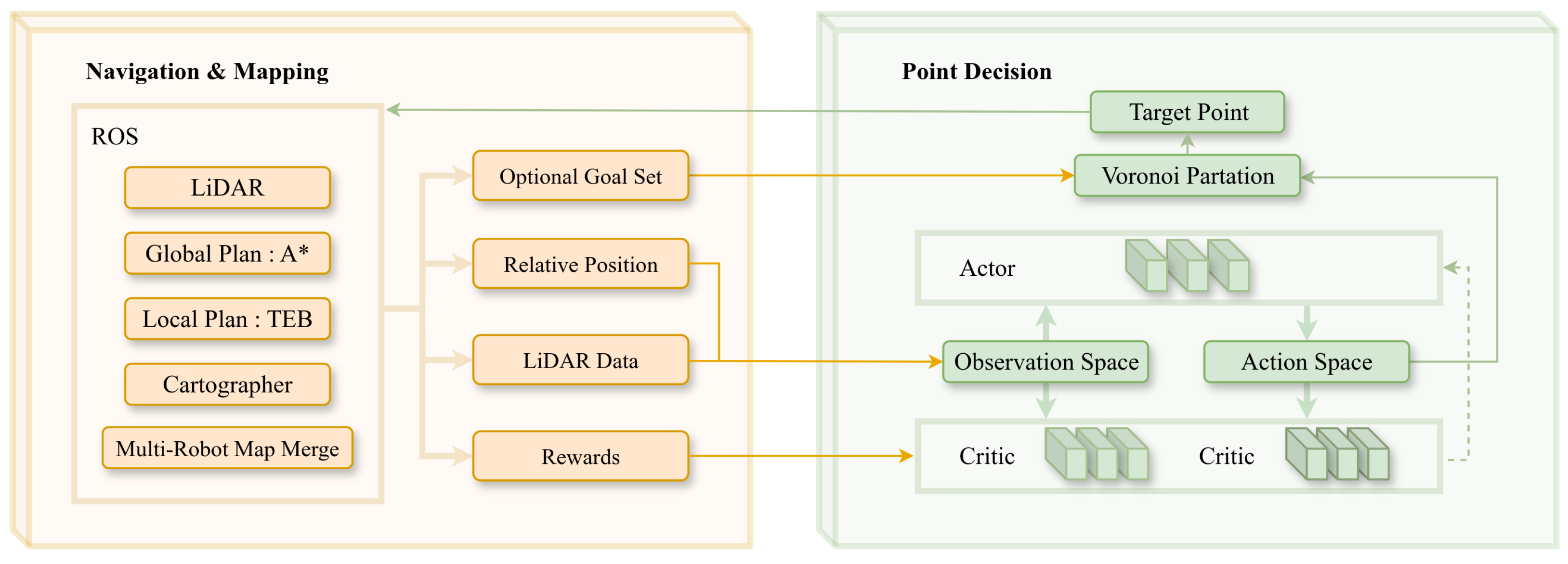
3.1. Framework
3.2. V-R-MATD3 Strategy
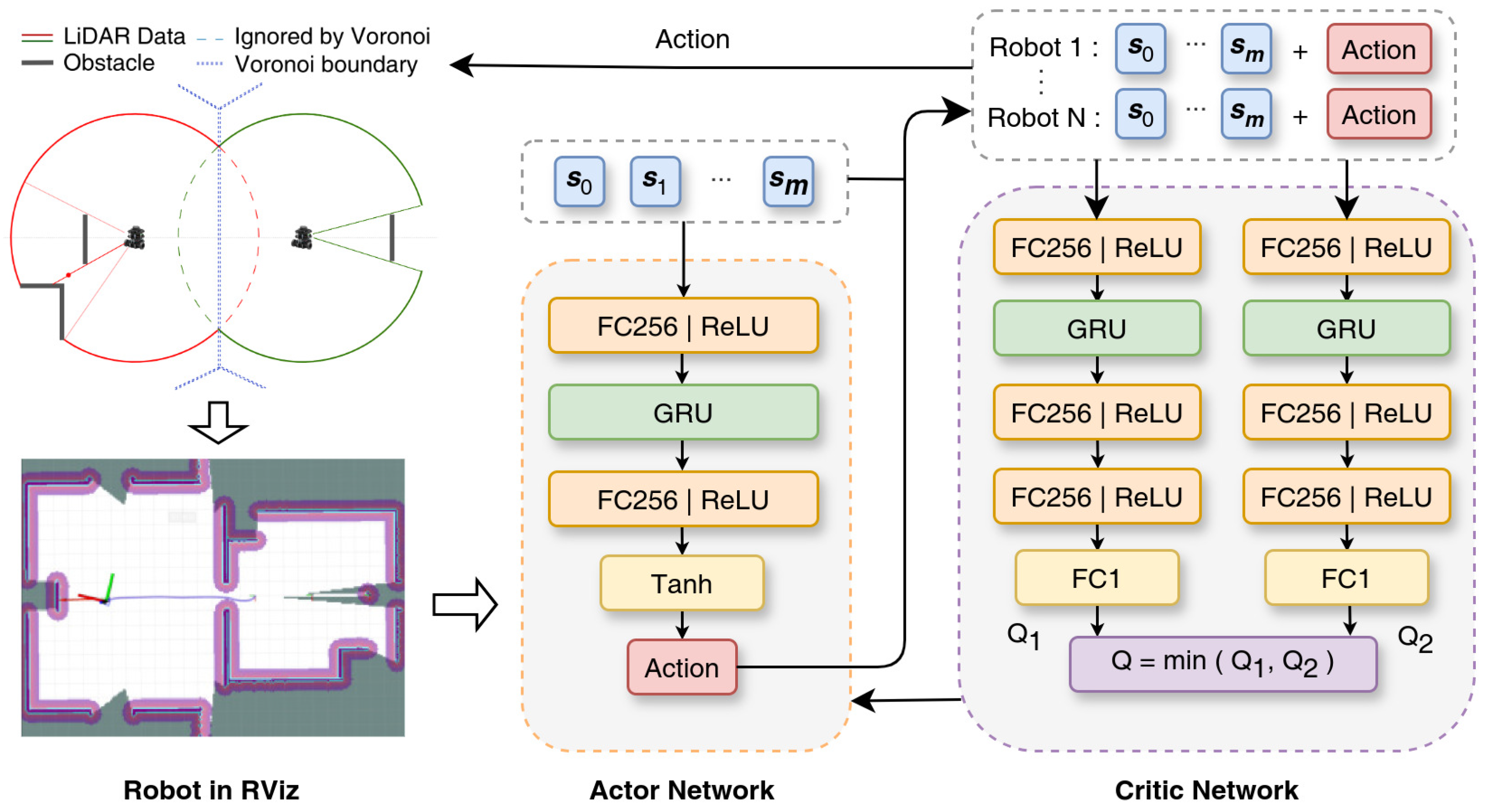
3.2.1. Observation and Action Spaces
3.2.2. Network Architecture
3.2.3. MATD3 Algorithm
3.2.4. Reward Shaping
| Algorithm 1 Multi-robot Exploration based on V-R-MATD3 |
|
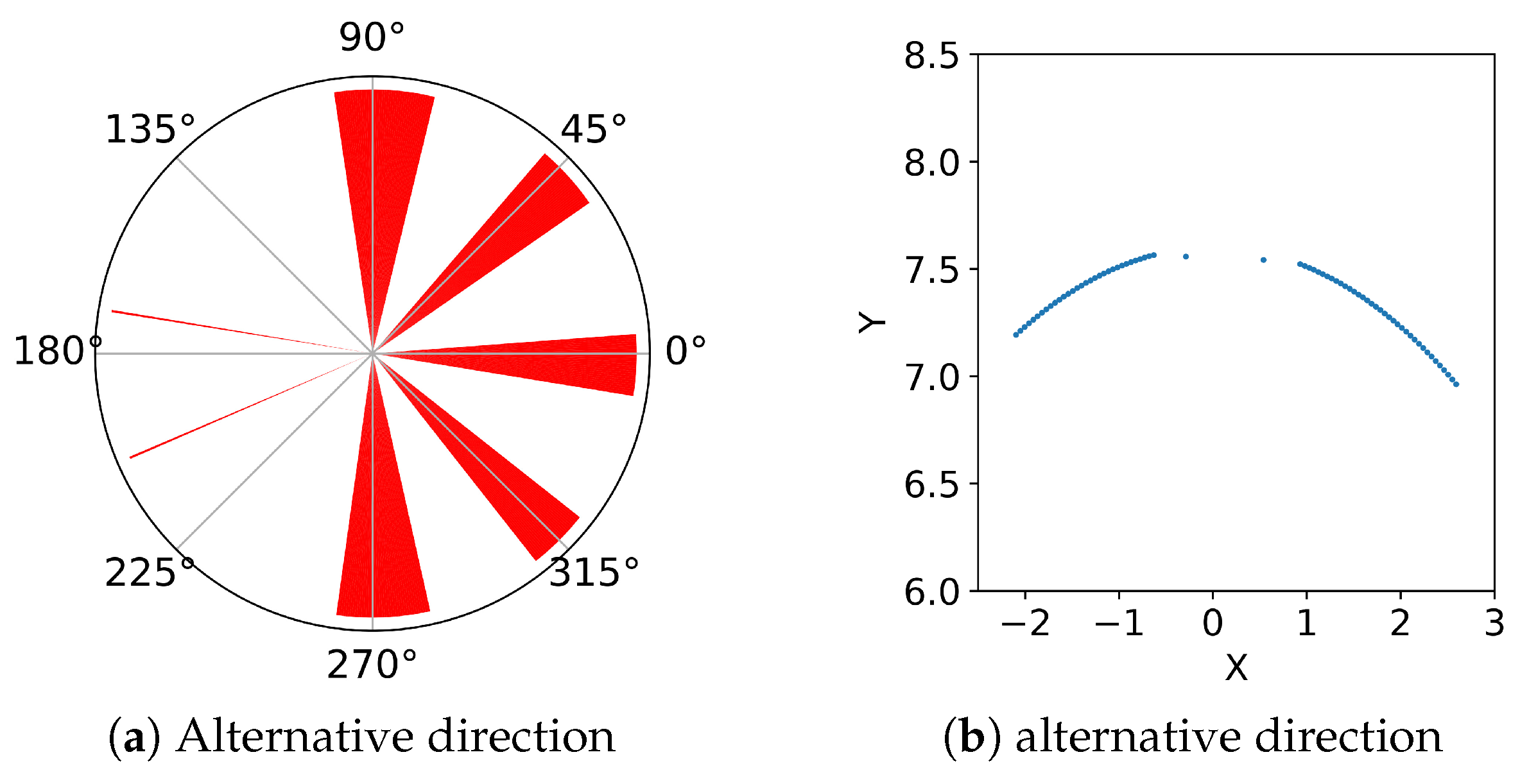
3.3. Action Space Transformation
4. Experiments and Discussion
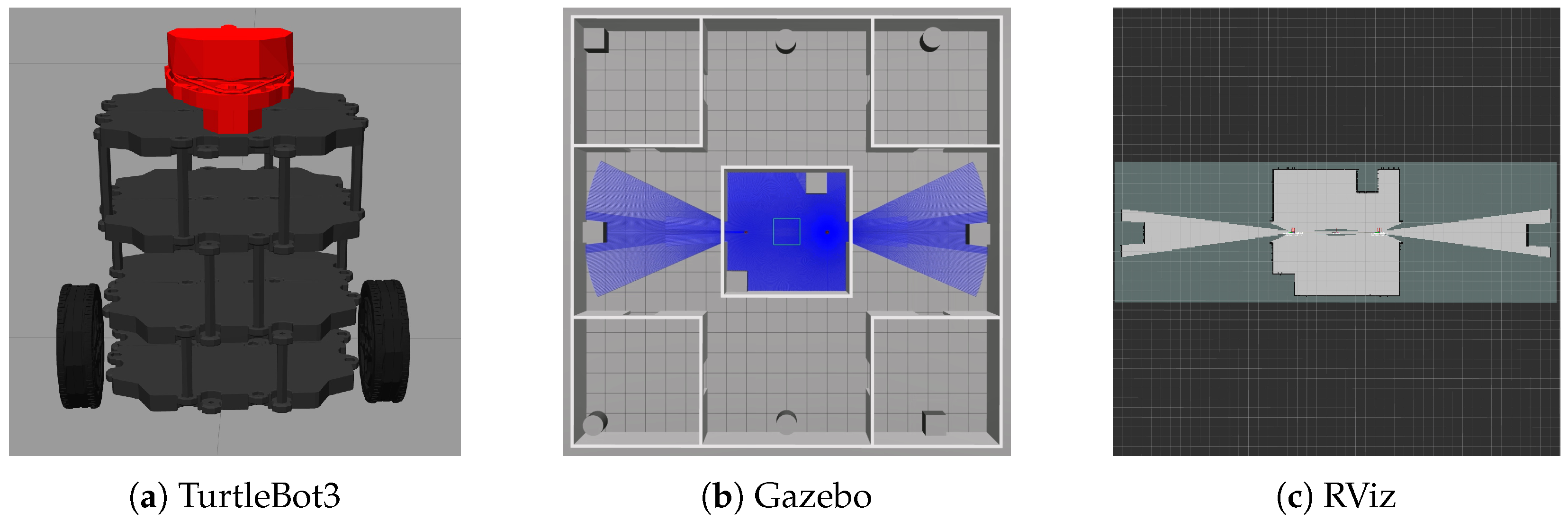
4.1. Experimental Setup
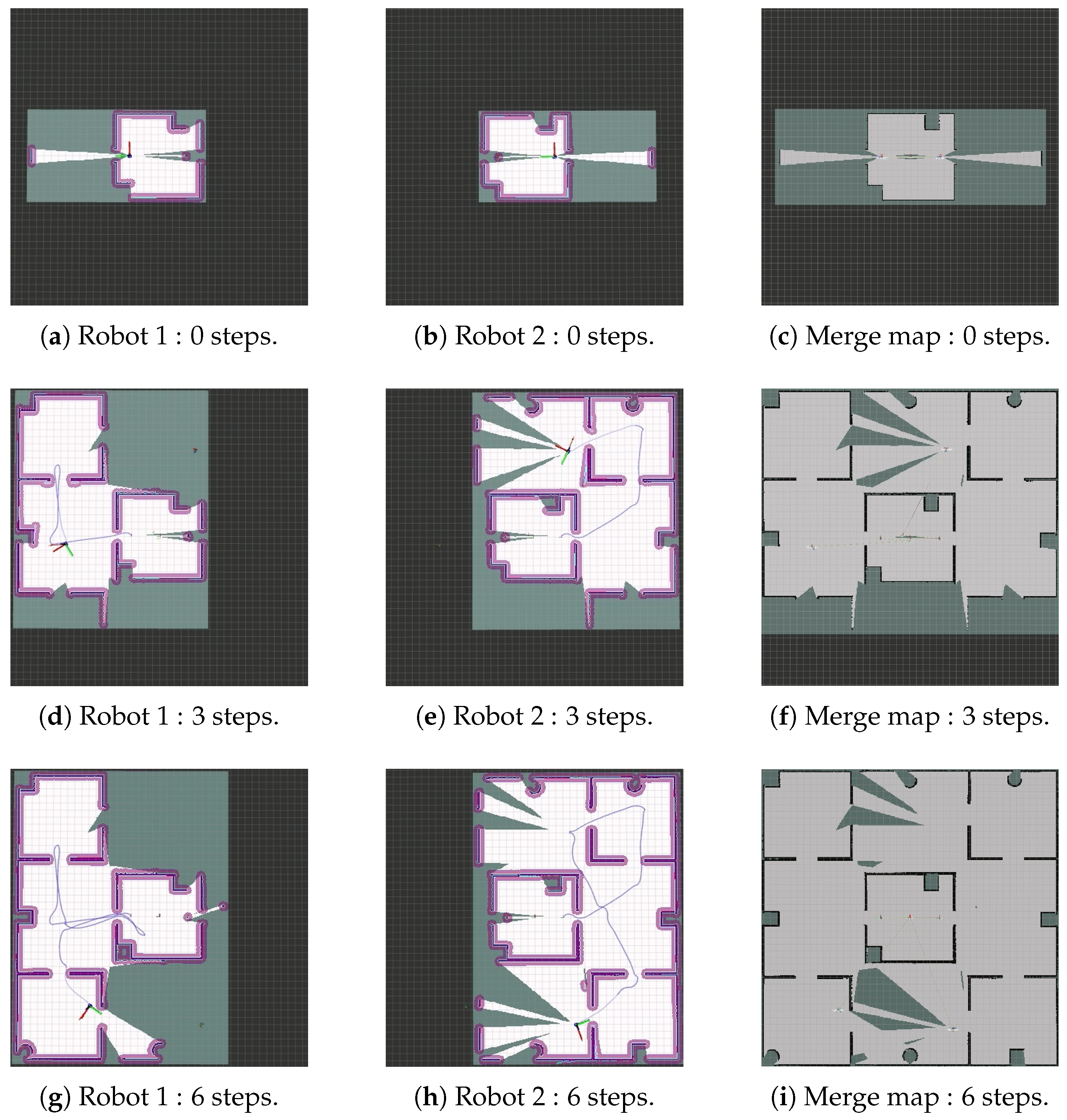
4.2. Development of Motion Planning and Map Merging
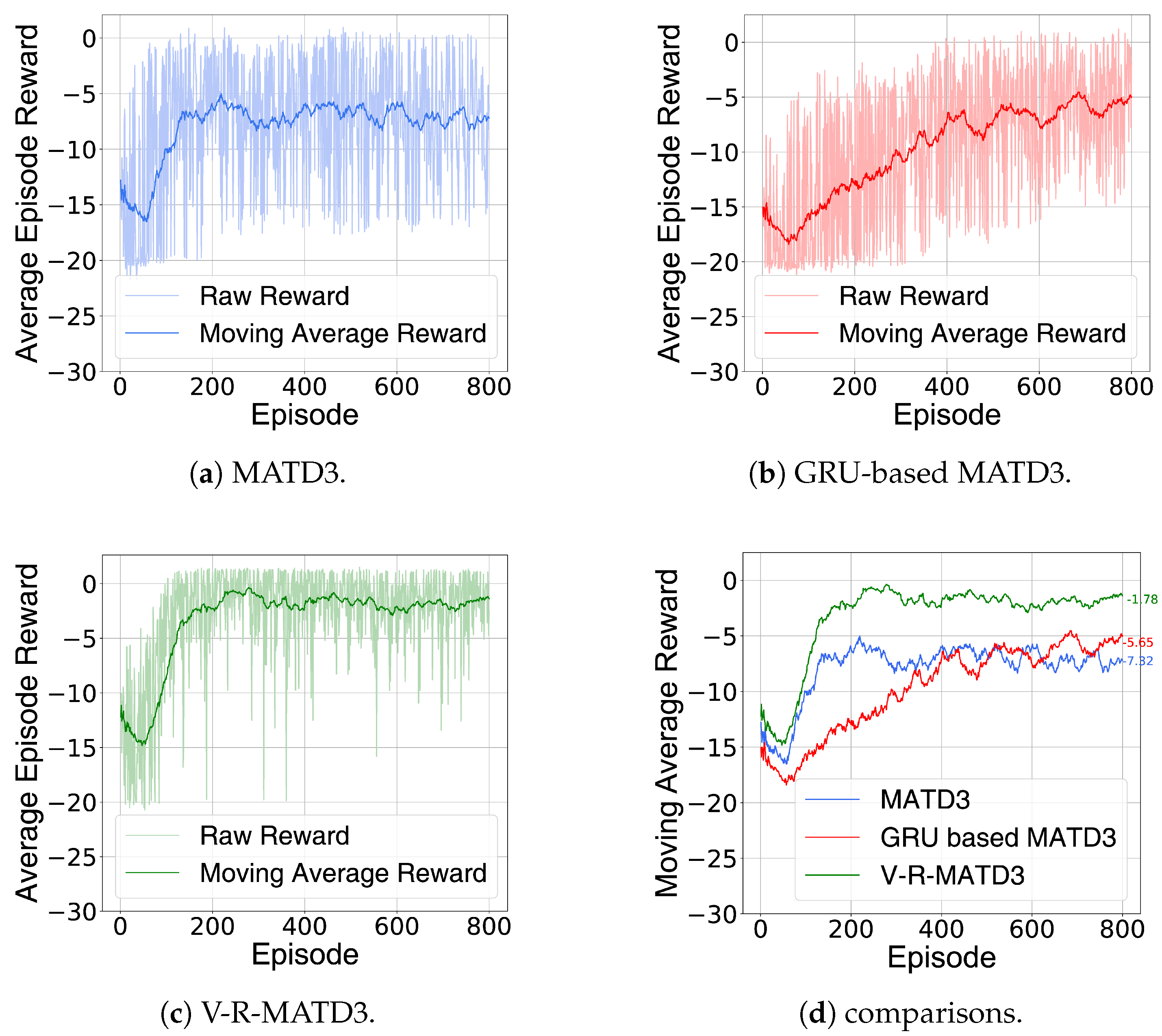
4.3. Ablation Study
4.3.1. Training Process
4.3.2. Testing Process
4.4. Comparison with Existing Methods
5. Conclusions
- Centralized computation limits flexibility in the robotic system: Our approach utilizes a centralized decision-making and distributed execution architecture, which is widely adopted due to its global optimality. However, it faces scalability issues as the number of robots increases and encounters communication bottlenecks. A distributed architecture could address these problems [47], but RL inference has high computational complexity and is resource-intensive. If a distributed approach were adopted, each robot would require high performance [48]. Due to hardware limitations in our lab, we initially chose the centralized decision-making model. Future work will explore the efficiency of distributed solutions in multi-robot systems.
- Lack of real-world experiments: Our experiments were conducted in the high-fidelity Gazebo simulation environment [1]. While this environment considers many dynamic factors, it still deviates significantly from the real world. We plan to conduct experiments with real robots in real environments and utilize domain randomization to mitigate the Sim–Real gap [49].
- Insufficient robustness to dynamic obstacles and robot failures: The experiments in this paper were conducted in a static environment, which is ideal and rarely prone to faults. Previous studies have explored the need for the reallocation of coverage areas in the event of system failures [8,50]. Additionally, communication failures are a key research area. Reference [51] discusses multi-robot coordination in communication-limited environments. Our future work will investigate emergency mechanisms for communication failures, considering establishing communication protocols that only activate when necessary in limited communication scenarios.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, J.; Niu, H.; Carrasco, J.; Lennox, B.; Arvin, F. Voronoi-based multi-robot autonomous exploration in unknown environments via deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 14413–14423. [Google Scholar] [CrossRef]
- Zhang, H.; Cheng, J.; Zhang, L.; Li, Y.; Zhang, W. H2GNN: Hierarchical-hops graph neural networks for multi-robot exploration in unknown environments. IEEE Robot. Autom. Lett. 2022, 7, 3435–3442. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, S.; Xie, Y.; Zheng, S.; Shi, P.; Rudas, I.; Cheng, X. Deep Reinforcement Learning-Based Mapless Navigation for Mobile Robot in Unknown Environment with Local Optima. IEEE Robot. Autom. Lett. 2024, 10, 628–635. [Google Scholar] [CrossRef]
- Poudel, L.; Elagandula, S.; Zhou, W.; Sha, Z. Decentralized and centralized planning for multi-robot additive manufacturing. J. Mech. Des. 2023, 145, 012003. [Google Scholar] [CrossRef]
- Peng, Y.; Hu, Y.; Ai, C. Modeling and simulation of cooperative exploration strategies in unknown environments. Complex Syst. Model. Simul. 2023, 3, 343–356. [Google Scholar] [CrossRef]
- Yan, X.; Zeng, Z.; He, K.; Hong, H. Multi-robot cooperative autonomous exploration via task allocation in terrestrial environments. Front. Neurorobot. 2023, 17, 1179033. [Google Scholar] [CrossRef]
- Liu, Y.; Nejat, G. Robotic urban search and rescue: A survey from the control perspective. J. Intell. Robot. Syst. 2013, 72, 147–165. [Google Scholar] [CrossRef]
- Nair, V.G.; Dileep, M.; Guruprasad, K. Robust Online Multi-robot Simultaneous Exploration and Coverage Path Planning. IEEE Access 2024, 12, 72990–73003. [Google Scholar] [CrossRef]
- Breitenmoser, A.; Schwager, M.; Metzger, J.C.; Siegwart, R.; Rus, D. Voronoi coverage of non-convex environments with a group of networked robots. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 4982–4989. [Google Scholar] [CrossRef]
- Yu, J.; Tong, J.; Xu, Y.; Xu, Z.; Dong, H.; Yang, T.; Wang, Y. Smmr-explore: Submap-based multi-robot exploration system with multi-robot multi-target potential field exploration method. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 8779–8785. [Google Scholar] [CrossRef]
- Wang, D.; Wang, H.; Liu, L. Unknown environment exploration of multi-robot system with the FORDPSO. Swarm Evol. Comput. 2016, 26, 157–174. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Gielis, J.; Shankar, A.; Prorok, A. A critical review of communications in multi-robot systems. Curr. Robot. Rep. 2022, 3, 213–225. [Google Scholar] [CrossRef] [PubMed]
- Lv, Z.; Cheng, C.; Lv, H. Multi-robot distributed communication in heterogeneous robotic systems on 5G networking. IEEE Wirel. Commun. 2023, 30, 98–104. [Google Scholar] [CrossRef]
- Cui, H.; Zhao, G.; Liu, S.; Li, Z. A decentralized dynamic self-triggered control approach to consensus of multiagent systems. IEEE Trans. Syst. Man, Cybern. Syst. 2023, 53, 5772–5783. [Google Scholar] [CrossRef]
- Zhou, B.; Xu, H.; Shen, S. Racer: Rapid collaborative exploration with a decentralized multi-uav system. IEEE Trans. Robot. 2023, 39, 1816–1835. [Google Scholar] [CrossRef]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30, 6379–6390. [Google Scholar]
- Ackermann, J.; Gabler, V.; Osa, T.; Sugiyama, M. Reducing overestimation bias in multi-agent domains using double centralized critics. arXiv 2019, arXiv:1910.01465. [Google Scholar] [CrossRef]
- Fu, J.; Co-Reyes, J.; Levine, S. EX2: Exploration with Exemplar Models for Deep Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar] [CrossRef]
- Matignon, L.; Jeanpierre, L.; Mouaddib, A.I. Coordinated multi-robot exploration under communication constraints using decentralized markov decision processes. AAAI Conf. Artif. Intell. 2012, 26, 2017–2023. [Google Scholar] [CrossRef]
- Papoudakis, G.; Christianos, F.; Rahman, A.; Albrecht, S.V. Dealing with non-stationarity in multi-agent deep reinforcement learning. arXiv 2019, arXiv:1906.04737. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Cham, Switzerland, 2021; pp. 321–384. [Google Scholar] [CrossRef]
- Gupta, J.K.; Egorov, M.; Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. In Proceedings of the Autonomous Agents and Multiagent Systems: AAMAS 2017 Workshops, Best Papers, Revised Selected Papers 16. São Paulo, Brazil, 8–12 May 2017; Springer: Cham, Switzerland, 2017; pp. 66–83. [Google Scholar] [CrossRef]
- Ning, Y.; Li, T.; Yao, C.; Du, W.; Zhang, Y. HMS-RRT: A novel hybrid multi-strategy rapidly-exploring random tree algorithm for multi-robot collaborative exploration in unknown environments. Expert Syst. Appl. 2024, 247, 123238. [Google Scholar] [CrossRef]
- Zhou, C.; Li, J.; Shi, Y.; Lin, Z. Research on multi-robot formation control based on matd3 algorithm. Appl. Sci. 2023, 13, 1874. [Google Scholar] [CrossRef]
- Wong, A.; Bäck, T.; Kononova, A.V.; Plaat, A. Deep multiagent reinforcement learning: Challenges and directions. Artif. Intell. Rev. 2023, 56, 5023–5056. [Google Scholar] [CrossRef]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 1587–1596. [Google Scholar]
- Zhang, F.; Li, J.; Li, Z. A TD3-based multi-agent deep reinforcement learning method in mixed cooperation-competition environment. Neurocomputing 2020, 411, 206–215. [Google Scholar] [CrossRef]
- Padrao, P.; Fuentes, J.; Bobadilla, L.; Smith, R.N. Estimating spatio-temporal fields through reinforcement learning. Front. Robot. AI 2022, 9, 878246. [Google Scholar] [CrossRef]
- Ding, C.; Zhou, Y.; Pu, G.; Zhang, H. Low carbon economic dispatch of power system at multiple time scales considering GRU wind power forecasting and integrated carbon capture. Front. Energy Res. 2022, 10, 953883. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, Z.; Wang, J.; Cao, Z. Multi-robot collaborative hunting in cluttered environments with obstacle-avoiding Voronoi cells. IEEE/CAA J. Autom. Sin. 2024, 11, 1643–1655. [Google Scholar] [CrossRef]
- Lavrenov, R.; Magid, E. Towards heterogeneous robot team path planning: Acquisition of multiple routes with a modified spline-based algorithm. MATEC Web Conf. 2017, 113, 02015. [Google Scholar] [CrossRef]
- Shakya, A.K.; Pillai, G.; Chakrabarty, S. Reinforcement learning algorithms: A brief survey. Expert Syst. Appl. 2023, 231, 120495. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Cao, X.; Xu, Y.; Yao, Y.; Zhi, C. An Improved Hybrid A* Algorithm of Path Planning for Hotel Service Robot. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Wu, J.; Ma, X.; Peng, T.; Wang, H. An improved timed elastic band (TEB) algorithm of autonomous ground vehicle (AGV) in complex environment. Sensors 2021, 21, 8312. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE international Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar] [CrossRef]
- Quigley, M. ROS: An open-source Robot Operating System. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ international Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; pp. 2149–2154. [Google Scholar] [CrossRef]
- Ryu, H.; Shin, H.; Park, J. Multi-agent actor-critic with hierarchical graph attention network. Proc. AAAI Conf. Artif. Intell. 2020, 34, 7236–7243. [Google Scholar] [CrossRef]
- Yu, C.; Velu, A.; Vinitsky, E.; Gao, J.; Wang, Y.; Bayen, A.; Wu, Y. The surprising effectiveness of ppo in cooperative multi-agent games. Adv. Neural Inf. Process. Syst. 2022, 35, 24611–24624. [Google Scholar]
- Umari, H.; Mukhopadhyay, S. Autonomous robotic exploration based on multiple rapidly-exploring randomized trees. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1396–1402. [Google Scholar] [CrossRef]
- Basilico, N.; Amigoni, F. Exploration strategies based on multi-criteria decision making for searching environments in rescue operations. Auton. Robot. 2011, 31, 401–417. [Google Scholar] [CrossRef]
- Chen, L.; Zhao, Y.; Zhao, H.; Zheng, B. Non-communication decentralized multi-robot collision avoidance in grid map workspace with double deep Q-network. Sensors 2021, 21, 841. [Google Scholar] [CrossRef] [PubMed]
- Bashabsheh, M. Comprehensive and Simulated Modeling of a Centralized Transport Robot Control System. Int. J. Adv. Comput. Sci. Appl. 2024, 15. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar] [CrossRef]
- Almadhoun, R.; Taha, T.; Seneviratne, L.; Zweiri, Y. A survey on multi-robot coverage path planning for model reconstruction and mapping. SN Appl. Sci. 2019, 1, 847. [Google Scholar] [CrossRef]
- Zhou, M.; Li, J.; Wang, C.; Wang, J.; Wang, L. Applications of Voronoi Diagrams in Multi-Robot Coverage: A Review. J. Mar. Sci. Eng. 2024, 12, 1022. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Parameter | Value |
|---|---|---|
| Learning rate | 2.5 × | |
| Batch size | B | 64 |
| Discount rate | 0.9 | |
| Hidden layer size | H | 256 |
| Max episode length | 2.5 × | |
| Replay buffer size | 20 | |
| Exploration noise std | 0.3 | |
| Use shared policy | true |
| World I | World II | World III | ||||
|---|---|---|---|---|---|---|
| Steps | MAE 1 | Steps | MAE | Steps | MAE | |
| V-R-MATD3 | 3.67 | −1.0% | 7.69 | 4.2% | 5.42 | −2.3% |
| R-MAPPO | 5.11 | −4.1% | 9.04 | 3.8% | 7.31 | −0.8% |
| MATD3 | 6.80 | −11.8% | 11.58 | −4.7% | 14.10 | 16.8% |
| World I | World II | World III | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Steps | Time (s) | Overlap (%) | Steps | Time (s) | Overlap (%) | Steps | Time (s) | Overlap (%) | |
| Ours | 3.65 | 22.41 | 0.02 | 7.72 | 97.04 | 0.24 | 5.42 | 36.87 | 0.13 |
| MATD3 | 7.14 | 38.03 | 0.10 | 12.40 | 106.35 | 0.31 | 8.73 | 50.03 | 0.17 |
| MAPPO | 9.92 | 42.29 | 0.14 | 18.05 | 114.24 | 0.33 | 11.26 | 44.54 | 0.19 |
| RRT | 24.86 | 89.13 | 0.47 | 55.53 | 153.86 | 0.42 | 43.08 | 85.74 | 0.21 |
| Cost | 56.81 | 62.09 | 0.44 | 148.14 | 151.40 | 0.46 | 95.68 | 98.82 | 0.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Y.; Hou, J.; Ma, P.; Ma, M. Voronoi-GRU-Based Multi-Robot Collaborative Exploration in Unknown Environments. Appl. Sci. 2025, 15, 3313. https://doi.org/10.3390/app15063313
Lei Y, Hou J, Ma P, Ma M. Voronoi-GRU-Based Multi-Robot Collaborative Exploration in Unknown Environments. Applied Sciences. 2025; 15(6):3313. https://doi.org/10.3390/app15063313
Chicago/Turabian StyleLei, Yang, Jian Hou, Peixin Ma, and Mingze Ma. 2025. "Voronoi-GRU-Based Multi-Robot Collaborative Exploration in Unknown Environments" Applied Sciences 15, no. 6: 3313. https://doi.org/10.3390/app15063313
APA StyleLei, Y., Hou, J., Ma, P., & Ma, M. (2025). Voronoi-GRU-Based Multi-Robot Collaborative Exploration in Unknown Environments. Applied Sciences, 15(6), 3313. https://doi.org/10.3390/app15063313