Abstract
As healthcare costs rise due to aging populations and chronic illnesses, optimized care solutions are urgently needed. Gesture recognition and fall detection are critical for intelligent companion robots in healthcare. However, current deep learning models struggle with accuracy and real-time performance in complex backgrounds due to high computational demands. To address this, we propose an improved RT-DETR R18 model tailored for companion robots. This lightweight, efficient design integrates YOLOv9’s ADown module, the RepNCSPELAN4 module, and custom attention-based AdaptiveGateUpsample and AdaptiveGateDownsample modules for enhanced multi-scale feature fusion, reducing weight and complexity while optimizing real-time detection. Experiments show our model achieves a 51.7% reduction in parameters, a 46.7% decrease in GFLOPS, and higher FPS compared to RT-DETR R18, with mAP@0.5, mAP@0.5-0.95, precision, and recall improving to 99.4%, 86.4%, 99.6%, and 99.4%, respectively. Testing in complex indoor environments confirms its high accuracy for gesture recognition and fall detection, reducing manual workload and offering a novel solution for human behavior recognition in intelligent companionship.
1. Introduction
According to forecasts from the United Nations (UN), the world’s population is aging. Globally, the proportion of individuals aged 65 and older has risen from 6% in 1990 to 10% in 2024 [1]. This demographic is expected to grow rapidly, with projections indicating that the number of individuals aged 65 and older will reach 2.2 billion by 2080 [2]. People in this age group face challenges in maintaining independent living and are more susceptible to chronic illnesses [3]. Additionally, the number of individuals living alone is on the rise [4,5]. A white paper published by the Chinese Academy of Social Sciences in 2016 reported that nearly 100 million elderly individuals in China live alone, a number that continues to increase, indicating that over half of the elderly population in China comprises solitary seniors [6]. Known causes of mortality among the elderly include accidental falls, medication noncompliance, and incorrect medication usage [7]. According to the World Health Organization (WHO) data from 2021, falls are the second leading cause of accidental or unintentional injury deaths globally and the primary cause of injury-related fatalities among seniors aged 65 and older in China. The probability of falling and the associated risk of injury or death significantly increase with age. Between 2013 and 2023, the standardized mortality rate for falls among the elderly in China showed a general upward trend [8]. If elderly individuals could issue timely alerts for assistance immediately after a fall, they could receive prompt help, significantly reducing the likelihood of severe injury or death. Consequently, fall detection has emerged as a prominent research focus. Additionally, the WHO reports that there are over 1 billion people with disabilities worldwide [9]. Recent data from the WHO indicates a rising incidence of various diseases, such as diabetes, obesity, and depression, necessitating ongoing monitoring for affected individuals [10]. In recent decades, domestic healthcare expenditures have steadily increased, rising from 4.5% of GDP in 2000 [11] to an average of 7.2% in 2023 [12]. In the coming years, the increasing proportion of elderly individuals in the population, combined with rising per-hour costs in healthcare [13] and investments in related medical technologies, will likely lead to continued growth in healthcare spending. This trend particularly affects individuals of lower socioeconomic status and those with multiple chronic conditions. Furthermore, the aging population and the growing number of patients with chronic illnesses will heighten the demand for healthcare personnel, including registered nurses [14] and physician assistants [15], leading to staffing shortages and increased healthcare burdens [16,17,18].
With the rapid development of technology, intelligent companion robots are playing an increasingly important role in our daily lives. Especially in home and healthcare settings, these robots can provide not only basic care and psychological support [19,20], but also monitor vital signs and the environment to ensure user safety and security [21,22]. Intelligent companion robots assist the elderly and disabled individuals in overcoming various life challenges, enhancing their quality of life while reducing the burden on family members and caregivers. Consequently, the demand for intelligent companion robots is on the rise.
In the development of intelligent companion robots, gesture recognition and fall detection are among the core technologies. Gesture recognition technology enables robots to understand user intentions and respond in real time. Compared to traditional button or touchscreen interactions, gesture recognition offers a more intuitive and natural user experience. Fall detection can monitor users’ posture changes to identify potential anomalies, such as falls or loss of balance, which is crucial for ensuring the safety of the elderly and others requiring care.
The aim of this study is to develop a lightweight, efficient, and high-throughput algorithm for gesture recognition and fall detection that can be deployed on resource-constrained intelligent companion robots. In pursuing this goal, our work focuses on addressing the challenges of accurately recognizing gestures and abnormal human postures in complex, cluttered healthcare environments while maintaining real-time performance.
2. Background and Literature Review
There is limited research on gesture recognition for intelligent companion robots based on deep learning, which typically optimizes and deploys convolutional neural network models [23,24,25]. While there is a greater amount of research on gesture recognition for other types of robots using deep learning, most of these also rely on convolutional neural networks and are often optimized for complex indoor companion environments that are not healthcare-specific [26,27,28,29,30]. Accurately recognizing gestures and abnormal human postures in relatively confined and highly interfered environments may pose challenges.
Similarly, research on fall-detection technologies for intelligent companion robots based on deep learning is scarce, typically relying on key point detection for recognition [31,32]. However, there is substantial research on related fall-detection technologies using deep learning, with mainstream algorithms generally based on key points or CNN for fall detection [33,34,35,36,37,38,39,40]. Since this paper aims to achieve both gesture recognition and fall detection using the same model, there will be challenges regarding the model’s generality.
2.1. Gesture-Recognition and Fall-Detection Methods Based on Classical Machine Learning
In the field of machine learning, classic machine learning methods have been widely applied in gesture recognition and fall detection. For example, Gupta et al. [41] extracted HOG and SIFT features from images, concatenated them, computed the correlation between test and training image matrices, and finally classified the test images using a KNN classifier. Pan et al. [42] proposed using a Gaussian Mixture Model (GMM) for hand segmentation in color images. Fourier descriptors, Hu moments, and Scale-Invariant Feature Transform (SIFT) were used to process the segmented images to extract distinct features. PCA and Linear Discriminant Analysis (LDA) were utilized for dimensionality reduction before classification by a kernel support vector machine (SVM). Saransh et al. [43] developed a gesture recognition system that first employed Gaussian filtering to remove noise from images, then utilized the YCbCr color space for skin color detection, ultimately extracting features based on the hand’s key points. Athira et al. [44] developed a gesture recognition system that independently recognizes sign language, enabling the identification of single-handed static and dynamic gestures, two-handed static gestures, and finger-spelled words in Indian Sign Language (ISL) from real-time video. The system’s gesture recognition module consists of three main stages: preprocessing, feature extraction, and classification. In the preprocessing stage, skin color segmentation is used to extract signs from real-time video; during feature extraction, Zernike moments are employed for keyframe extraction; and the resulting features are classified using support vector machines. Lin et al. [45] utilized Gaussian Mixture Models (GMM) for foreground-background separation, employing changes in acceleration to determine falls. Gunale et al. [46] compared the impacts of five traditional machine learning algorithms—support vector machine, K-nearest neighbors, stochastic gradient descent, decision trees, and gradient boosting—using F-score as a metric for experimental analysis. Experiments show that decision trees perform well in classification tasks, but gradient boosting algorithms perform better in certain complex scenarios. Zhang et al. [47] employed an improved Vibe algorithm to extract human targets, isolating moving individuals and using support vector machines (SVM) to distinguish between falling behaviors and other low-height actions like sitting and lying down.
It is evident that early machine learning-based methods for gesture recognition and fall detection often required developing algorithms tailored to specific environments, resulting in limited applicability and robustness. The design of the algorithm is intricate, and these methods usually recognize only specific gestures or human features in controlled environments, lacking flexibility for deployment and resilience against strong interference. Additionally, their accuracy tends to be lower, which makes it difficult to meet practical production demands. To address these shortcomings, convolutional neural networks (CNNs) have been increasingly used in gesture recognition. CNNs are capable of extracting target features through multiple layers of convolutional and pooling operations, providing high robustness and real-time performance in deep learning models, such as DETRs, which outperform YOLOs in real-time object detection (RT-DETR) and You Only Look Once (YOLO).
2.2. Gesture-Recognition and Fall-Detection Methods Based on Deep Learning
In deep learning, the YOLO algorithm has emerged as the most commonly used method for gesture recognition based on object detection, thanks to its high detection speed, accuracy, user-friendliness, and potential for further enhancements [48,49]. As a CNN-based algorithm, YOLO has been widely adopted in real-world applications and has contributed to the evolution of other CNN-based algorithms. Many researchers have refined YOLO to create more accurate algorithms tailored to specific environments and use cases. For instance, Yang et al. introduced an improved YOLOV8s algorithm for recognizing football referee gestures [50]; Jiang et al. implemented dynamic gesture recognition in medical scenarios using an enhanced YOLOV5 for aviation medical rescue flight simulators [51]; and Meng et al. utilized YOLOV8 for gesture-controlled medical devices [52]. Xu et al. proposed a fall-detection algorithm based on an improved YOLOv8 model for indoor environments [53], while Song et al. presented a home fall-detection algorithm based on an enhanced YOLOv5 [54].
In industrial work environments, where relatively large spaces minimize background interference, these YOLO-based gesture recognition algorithms typically operate in relevant industrial contexts rather than in healthcare settings. The optimizations in these algorithms typically focus on accurately detecting hand targets rather than addressing background interference. While they perform well in industrial settings, the background interference in healthcare environments is more complex and variable, which can greatly impact their recognition accuracy. Although the YOLO-based fall-detection algorithms are somewhat similar to the healthcare environments discussed in this paper, the presence of medical devices and other items complicates their general applicability to gesture recognition tasks.
However, alongside the widespread application and diversification of CNN-based algorithms, we should explore effective yet underdeveloped algorithms to ensure diversity and innovation in relevant academic fields, such as the Transformer-based RT-DETR, which is the focus of this paper. Moreover, despite the extensive application of the YOLO series in industrial production experiments, they still exhibit notable shortcomings. YOLO tends to produce numerous redundant bounding boxes during operation, which need to be eliminated in post-processing through non-maximum suppression (NMS). The choice of NMS hyperparameters can have a significant effect on YOLO’s accuracy and speed [55]. Dai et al. incorporated a dynamic encoder into the DETR model to mimic the Transformer encoder’s attention mechanism, improving the model’s ability to detect small object features [56]. They also introduced an unsupervised pre-training (UP)-DETR model, which accelerates convergence in object detection and helps alleviate the issue of long training times associated with DETR [57].
Unlike the typical industrial work environments encountered in laboratories, healthcare environments are closer to home living situations; however, irregular obstructions (e.g., furniture, pets) scattered around the person and gesture present a significant challenge for YOLO models, which struggle to recognize holistic information. To achieve high precision and recall in healthcare settings while considering factors like cost and training time, it is advisable to shift from YOLO and opt for a lightweight model from the DETR series, such as the real-time end-to-end object-detection model RT-DETR, as the enhanced base model [55]. Unlike YOLO, RT-DETR utilizes a mixed encoder that efficiently processes multi-scale features and performs Intersection over Union (IoU) aware query selection, allowing it to achieve faster speeds with comparable accuracy and outperform YOLO in object detection under complex backgrounds.
2.3. Recent Advances and Motivation for This Work
On the other hand, in healthcare environments, gesture images may contain more distracting objects compared to industrial work environments, including but not limited to objects with colors similar to the hands and complex, variable occlusions. Although RT-DETR offers higher overall resolution than YOLO, it still struggles to differentiate gestures from distracting elements in healthcare settings, indicating a need for improved recognition capabilities tailored to medical contexts. Moreover, the RT-DETR model comprises a large number of parameters. To reduce deployment complexity and improve inference speed, lightweight designs have been implemented to decrease parameter size and computational load. This paper proposes a Lightweight RT-DETR with AUDPN model specifically for gesture recognition and fall detection in healthcare, using the parameter-efficient RT-DETR-R18 model from the RT-DETR series as the foundational model [55].
The main contributions addressing these issues are as follows:
- By integrating the ADown downsampling module and the RepNCSPELAN4 module from YOLOv9 into the RT-DETR model’s backbone, we enhanced its recognition accuracy while reducing computational complexity. This modification enables the model to be deployed on resource-constrained hardware and allows for seamless upgrades without any performance loss.
- To address the accuracy limitations of the feature fusion network, we revisited the structure of RT-DETR R18. We identified that the original upsampling and downsampling processes in the feature fusion stages of RT-DETR R18 relied solely on basic nearest-neighbor interpolation and convolution operations. This approach led to deficiencies in feature selectivity, adaptability, and global information retention. Inspired by attention mechanisms, we developed the AdaptiveGateUpsample and AdaptiveGateDownsample modules. These modules leverage attention mechanisms to address the shortcomings of conventional upsampling and downsampling in terms of feature selectivity, adaptability, and the retention of both local and global information. This results in more precise upsampling and more effective downsampling, enhancing feature representation and model performance. Based on these modules, we constructed the Attentional Up-Downsampling Pyramid Network (AUDPN), an attention-based upsampling and downsampling pyramid structure. This architecture improves multi-scale object-detection capabilities, particularly under challenging conditions such as occlusion and complex lighting, maintaining high detection accuracy and robustness.
- Finally, the practical value of the model was validated through experiments on gesture recognition and human anomaly detection in medical care environments. The model successfully demonstrated its utility by automatically recognizing user gestures and abnormal human postures, combined with gesture-based control and fall posture-detection alarms.
The remainder of this paper is organized as follows: Section 2 discusses the collection and processing of image data, the structure of the Lightweight RT-DETR with AUDPN and its improved modules, and model evaluation metrics. Section 3 explains the results and discussions, including training environments, parameter settings, results from ablation studies and comparative experiments, and the effectiveness of gesture recognition and fall detection. Section 4 provides a summary, limitations, and future work.
3. Materials and Methods
3.1. Data Collection and Preprocessing
The data in this paper is sourced from multiple public datasets, combining parts from each of these datasets. A total of 19,115 images were collected. Hand gestures such as “Call”, “OK”, “Stop”, “Forward”, and “Backwards” in this dataset were drawn from specific subsets within the HaGRID–HAnd Gesture Recognition Image Dataset, namely “call”, “ok”, “plam”, “stop inverted”, and “stop” [58]. The “Fall” gesture in this dataset was sourced from the CAUCAFall and fall-detection-ca3o8_dataset datasets [59,60]. The dataset was divided into training, testing, and validation sets in a 6:3:1 ratio. The data sources for the training, testing, and validation sets are shown in Table 1.

Table 1.
Data Sources for Datasets.
In this paper, we will define the fall posture and five control gestures, with specific definitions of the gestures provided in Table 2. There is currently no internationally or locally recognized standard protocol for gesture recognition in healthcare applications. However, considering that elderly individuals and patients may have difficulty learning new gestures, the most practical approach is to use common, widely recognized gestures rather than requiring users to undergo specific training. Therefore, we selected hand gestures from the HaGRID dataset, which consists of frequently used gestures, including “Call”, “OK”, “Stop”, “Forward”, and “Backwards”. This selection ensures that the robot’s gesture recognition system remains intuitive and easy to use for individuals with cognitive or physical limitations.
Table 2.
Fall Posture and Gesture Definition.
3.2. Design of Lightweight RT-DETR with Attentional Up-Downsampling Pyramid Network
The proposed Lightweight RT-DETR with Attentional Up-Downsampling Pyramid Network model is an improvement based on the lightweight RT-DETR-R18 model [55]. The benchmark model has been further optimized for weight, and to facilitate model deployment, it is implemented using the Ultralytics library. This enables the Lightweight RT-DETR with Attentional Up-Downsampling Pyramid Network to operate within the YOLO framework, simplifying its use, deployment, and optimization. Like traditional neural networks, it comprises four key components: the backbone, neck, decoder, and head. The backbone first extracts shallow features from images through two consecutive convolution operations. In layers P3 to P5, the ADown downsampling operator and the GELAN-based RepNCSPELAN4 module are integrated to reduce model complexity while enhancing deep semantic feature recognition. In the decoder and head sections, the Lightweight RT-DETR with Attentional Up-Downsampling Pyramid Network incorporates newly developed upsampling and downsampling modules (AdaptiveGateUpsample and AdaptiveGateDownsample), enhancing feature expression and model performance. This leads to the construction of an Attentional Up-Downsampling Pyramid Network structure, Attentional Up-Downsampling Pyramid Network (AUDPN), which improves the model’s detection capabilities. Compared to RT-DETR R18, the following improvements have been made:
- We incorporated the ADown downsampling module from YOLOv9 to optimize the backbone, using average pooling to extract feature map dimensions. This reduces model parameters, enhancing its lightweight design. Additionally, ADown can merge its parameters into convolutional layers during inference, further improving efficiency.
- We replaced the feature extraction module in the RT-DETR R18 backbone with the RepNCSPELAN4 module from YOLOv9. This module is more lightweight and offers greater versatility and efficiency for handling complex training tasks.
- We independently developed attention-based upsampling and downsampling modules (AdaptiveGateUpsample and AdaptiveGateDownsample) to replace the original neck upsampling and downsampling modules. These modules leverage attention mechanisms to address the shortcomings of conventional upsampling and downsampling, improving feature selectivity, adaptability, and the retention of both local and global information. As a result, the upsampling becomes more precise, and the downsampling more effective. This led to the creation of a new feature fusion network, the Attentional Up-Downsampling Pyramid Network (AUDPN), which enhances object-detection capabilities.
3.2.1. Adown
The ADown module is a downsampling module derived from YOLOv9. We integrated this module into the RT-DETR R18 backbone by inserting it between convolutional operations. The structure of the ADown module is shown in Figure 1.
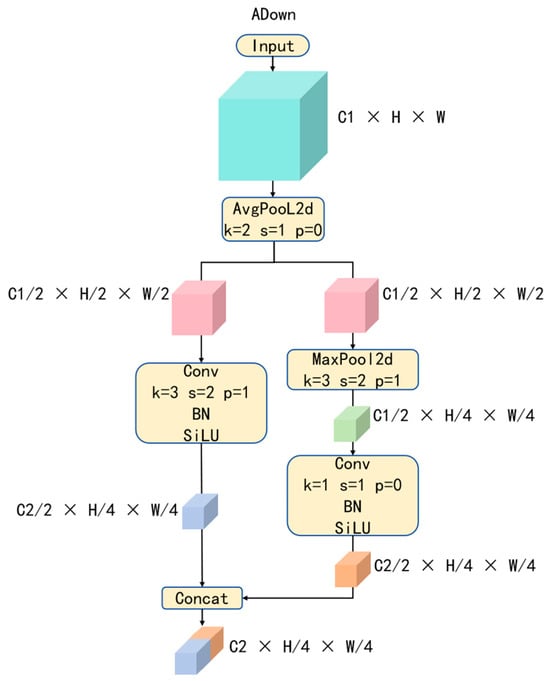
Figure 1.
The Structural Diagram of ADown.
Unlike classic downsampling modules (e.g., max pooling, average pooling, or the combination of large convolution kernels with large strides), ADown introduces two parallel convolution operations [61]. The module first applies average pooling to the image features, extracting global feature information. Then, the channels are divided into two parts, processed separately through a series of operations, including convolution, batch normalization, activation functions, and max pooling. This design aims to extract internal image features after average pooling while retaining the most prominent features of each object. Finally, the outputs of the two parts are concatenated along the channel dimension, fusing multi-scale feature maps and expanding the tensor dimensions to further explore deep semantic information. By incorporating this module, model efficiency is improved without significantly compromising accuracy.
3.2.2. RepNCSPELAN4
RepNCSPELAN4 is derived from the new network architecture called GELAN proposed in YOLOv9, as shown in Figure 2.
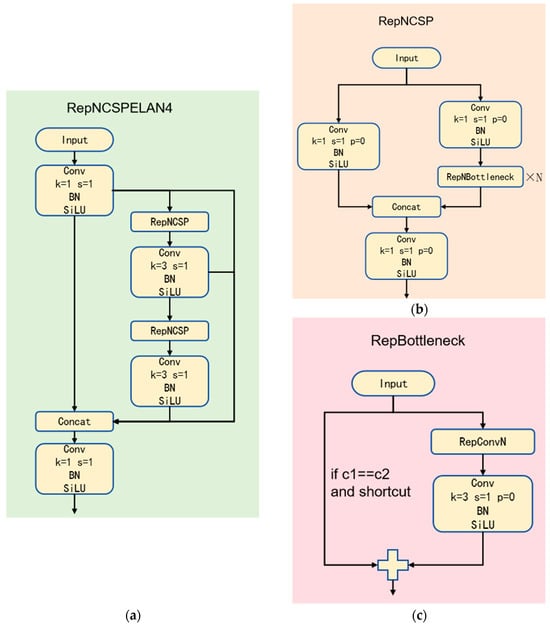
Figure 2.
The Structural Diagram of RepNCSPELAN4. (a) The Overall Structural Diagram of RepNCSPELAN4; (b) The Structural Diagram of RepNCSP; (c) The Structural Diagram of RepNBottleneck.
The authors of RepNCSPELAN4 designed it by combining two neural network architectures: CSPNet with gradient path planning and ELAN [62]. The CSPNet architecture divides the input features into two parts: one part is directly passed to subsequent layers, while the other undergoes complex convolutional processing before fusion. This enhances gradient flow and reduces memory consumption. ELAN, on the other hand, employs multi-branch hierarchical convolutional processing to capture features at different scales. It uses feature aggregation and deep stacking to expand the receptive field and enhance feature representation capabilities [63,64]. The GELAN architecture integrates CSPNet’s split-parallel concept with ELAN’s multi-branch hierarchical convolution approach, improving the model’s performance and flexibility [61]. Consequently, the GELAN structure, which combines the advantages mentioned above, demonstrates strong capabilities in feature extraction and integration, while meeting the demands of complex scenarios. Furthermore, GELAN supports the flexible integration of various computational modules, not limited to convolution operations. This enables the network to adapt flexibly to different tasks and hardware conditions. Its modular design and customizability make the structure more scalable and easier to optimize, meeting diverse application scenarios and performance requirements. These features allow GELAN to maintain high efficiency while offering stronger adaptability and broad application potential. This design makes the RepNCSPELAN4 module a reliable component for real-time applications, enhancing model performance. It provides a new direction for continuous model optimization by replacing the conventional convolution modules in RT-DETR, serving as a core computational unit.
3.2.3. Attentional Up-Downsampling Pyramid Network (AUDPN)
In deep learning, upsampling operations are critical steps in many tasks, such as image segmentation, super-resolution, and generative adversarial networks. Typically, upsampling methods using nn.Upsample include nearest neighbor interpolation and bilinear interpolation. The neck network of RT-DETR R18 employs the nearest neighbor interpolation method for upsampling via nn.Upsample. However, these traditional upsampling methods have certain limitations, leading to less-than-ideal model accuracy. Specifically, conventional upsampling methods (like nearest neighbor and bilinear interpolation) fail to fully utilize contextual information, often resulting in blurred feature maps, especially around edges and details [65,66]. Additionally, these methods apply the same interpolation strategy across all locations, neglecting the fact that different areas may require different treatments. For example, edge regions may need more detail preservation, while flat regions might require smoother transitions.
To overcome these limitations, inspired by attention mechanisms, this paper proposes a new upsampling module—AdaptiveGateUpsample, the structure of which is illustrated in Figure 3.
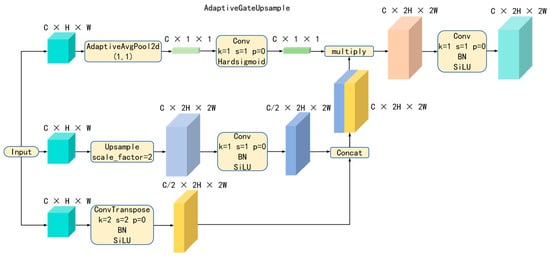
Figure 3.
The Structural Diagram of AdaptiveGateUpsample.
In designing the AdaptiveGateUpsample module, we enhanced information utilization and feature representation during the upsampling process by introducing an adaptive channel attention mechanism [67] and a multi-path upsampling approach. Specifically, we employed global average pooling and a gating mechanism (using 1 × 1 convolutions and a Hardsigmoid activation function) to generate channel attention weights. These weights are used to emphasize important features while suppressing unimportant ones [67,68], making the upsampling process more adaptive. Additionally, we combined transpose convolutions and nearest neighbor interpolation for feature map enlargement through parallel pathways. The advantage of integrating transpose convolutions into the network lies in their ability to adjust parameters via backpropagation during training [69]. Compared to traditional interpolation algorithms, this dynamic and learnable upsampling method yields more reasonable pixel values, resulting in richer detail in the high-resolution feature maps [70]. Therefore, the transpose convolution pathway can better restore detailed information, while the nearest neighbor interpolation pathway provides a quick and straightforward upsampling method. The combination of both, through concatenation and channel attention gating operations, enhances the quality of the feature maps after upsampling.
Moreover, in neural networks, downsampling operations are used to reduce the spatial resolution of feature maps, thereby decreasing computational complexity and increasing the receptive field. RT-DETR R18 employs convolutional operations for downsampling. However, this traditional method has certain limitations that impact the overall performance of the model, such as information loss and lack of adaptability. The lack of adaptability parallels the issues presented by the upsampling module, while information loss manifesting specifically as fixed-size convolution kernels and strides may lead to the loss of important feature information. In particular, large strides in convolution can easily overlook details, and even smaller strides may face the problem of excessive detail but overall inadequacy [71].
To address these issues, we also introduce a channel attention mechanism [67] and propose a new downsampling module—AdaptiveGateDownsample. Its structure is illustrated in Figure 4.
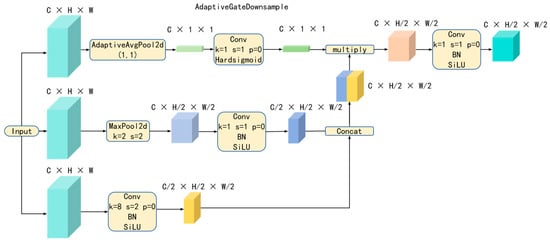
Figure 4.
The Structural Diagram of AdaptiveGateDownsample.
This module integrates an adaptive attention mechanism and a multi-path downsampling strategy, effectively enhancing information utilization and feature representation during the downsampling process. Its design philosophy includes channel attention mechanisms and multi-path downsampling, where the channel attention mechanism is designed similarly to that described earlier: it uses global average pooling and a gating mechanism (via 1 × 1 convolutions and a Hardsigmoid activation function) to generate channel attention weights. These weights are used to emphasize important features while suppressing unimportant ones [67,68].
Regarding the multi-path downsampling design, it combines convolution and max pooling as two downsampling methods to compress the feature maps through parallel paths. In the convolution path, small strides are used for downsampling, which helps retain detailed information, while the max pooling path preserves important regional feature information. By combining both methods through concatenation and channel attention gating operations, the quality of the feature maps after downsampling can be improved.
Consequently, in the neck of the neural network, the self-developed attention-based upsampling and downsampling modules (AdaptiveGateUpsample and AdaptiveGateDownsample) replace the original upsampling and downsampling modules, resulting in a new feature fusion network called the Attentional Up-Downsampling Pyramid Network (AUDPN). This structure retains the advantageous features of the original RT-DETR neck network while enhancing the model’s target-detection capability, particularly in complex environments, maintaining high detection accuracy and robustness. The new network structure, Lightweight RT-DETR with AUDPN, is illustrated in Figure 5. The intelligent companion robot is primarily designed for individual caregiving, meaning that it typically does not operate in environments with multiple people. If a caregiver is consistently present, the need for an autonomous companion robot is significantly reduced. However, in cases where temporary interactions involve multiple individuals, the model integrates an attention-based feature fusion mechanism to enhance its robustness by filtering out irrelevant gestures from background participants. While occasional misclassifications may occur in environments where certain gestures (e.g., “OK”) are widely used, this remains an open research problem that requires further optimization in future work.
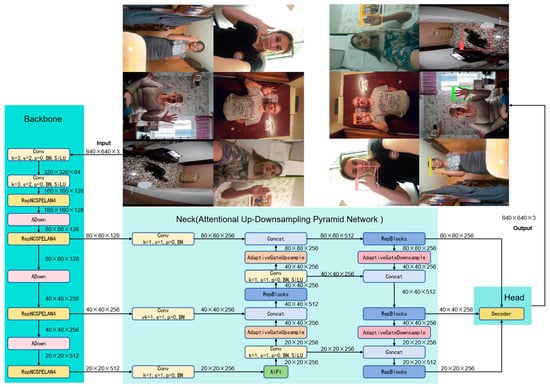
Figure 5.
The Structural Diagram of Lightweight RT-DETR with AUDPN.
3.3. Evaluation Metrics
To evaluate the model’s level of lightweight design and its effectiveness in gesture recognition and fall detection within healthcare environments, this study will utilize precision, recall, GFLOPS (Giga Floating Point Operations per Second), and the number of parameters for model evaluation. Precision measures the accuracy of the model’s target predictions, mAP (mean Average Precision) represents the average accuracy across all detections, and recall indicates the proportion of correctly predicted targets out of the total. Higher values, closer to 1, signify better model performance. GFLOPS reflects the model’s computational complexity, while Params indicate its level of lightweight design—lower values reduce training costs and enhance efficiency. An effective gesture recognition and fall-detection model should maintain high precision and recall while remaining lightweight.
True Positives (TP) denote correctly identified gestures or falls, while False Positives (FP) and False Negatives (FN) represent misidentified or missed cases. The evaluation metrics are calculated as follows:
4. Results
4.1. Training Environment and Hyperparameter Settings
The model in this experiment is trained in an Ubuntu 20.04 environment, running on an Intel(R) Xeon(R) Platinum 8352 V CPU @ 2.10 GHz, an NVIDIA GeForce GTX 4090 GPU, and 24 GB of memory. The software setup includes Python 3.8.10 and PyTorch 2.0.0, with GPU acceleration enabled via CUDA 11.8. The cache setting is disabled, while other parameters remain at default values. The dataset is randomly split into training, testing, and validation sets at a 6:3:1 ratio. For fair and effective performance comparison across models, all experiments follow the parameter settings in Table 3, with pre-trained weights not used to improve accuracy. Input images are uniformly resized to 640 × 640 pixels, and training is conducted with a batch size of 28 per iteration. The training workflow is illustrated in Figure 6.
Table 3.
Model hyperparameter settings.

Figure 6.
Training Process Diagram.
4.2. Ablation Experiments
Ablation experiments were performed on a randomly selected annotated dataset to evaluate the effectiveness of the lightweight design. The outcomes of these experiments are presented in Table 4, while the optimized precision results are detailed in Table 5.
Table 4.
Results of ablation experiments in terms of model lightweighting.
Table 5.
Results of ablation experiments in terms of model-detection accuracy.
Initially, RT-DETR-R18, the most lightweight model in the RT-DETR series, was chosen as the enhanced baseline. The ADown downsampling operator was then incorporated, and the backbone was replaced with the GELAN module, the mAP@0.5 precision improved by 0.3%, while mAP@0.5–0.95 decreased by 0.4%. The recall rate increased by 0.4%, and accuracy decreased by 0.1%. Simultaneously, the parameters, GFLOPS, and weight size were significantly reduced by 53.35%, 51.58%, and 52.85%, respectively, thereby enhancing the model’s lightweight characteristics.
Subsequently, the self-developed downsampling module based on the attention mechanism, AdaptiveGateDownsample, was added to the neck of the network to replace the original downsampling module. This addition addressed the shortcomings of conventional downsampling in terms of feature selectivity, adaptiveness, and global information retention, making the downsampling process more effective. As a result, precision (P) and recall (R) increased by 0.2% and 0.3%, respectively, while mAP@0.5–0.95 improved by 0.5%. Compared to previous experiments, the parameters, GFLOPS, and weight size were reduced by 2.82%, 2.9%, and 2.75%.
Finally, the self-developed upsampling module based on the attention mechanism, AdaptiveGateUpsample, replaced the upsampling module in the neck of the network. This change also addressed the deficiencies of conventional upsampling in terms of feature selectivity, adaptiveness, and global information retention, resulting in more precise upsampling. Consequently, the new feature fusion network, Attentional Up-Downsampling Pyramid Network (AUDPN), was established, enhancing target-detection capability. This led to improvements in mAP@0.5, mAP@0.5–0.95, and precision by 0.1%, 0.2%, and 0.1%, respectively, while the model’s parameters, GFLOPS, and weight size increased by 6.56%, 13.43%, and 6.78%.
The improvements have been completed, and the final Lightweight RT-DETR with AUDPN model demonstrated comprehensive advantages over the baseline model under the experimental conditions of this study. Compared to RT-DETR-R18, its parameters, GFLOPS, and weight size decreased by 51.69%, 46.67%, and 51.04%, while mAP@0.5, mAP@0.5-0.95, precision, and recall increased by 0.4%, 0.3%, 0.2%, and 0.7%, respectively. A visual comparison of the various parameters from the ablation experiments is illustrated in Figure 7 and Figure 8.
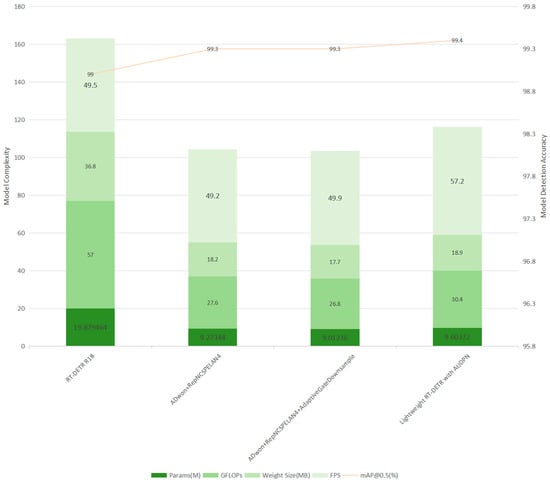
Figure 7.
Partial comparison of Lightweight RT-DETR with AUDPN ablation test parameter quantity indicators.
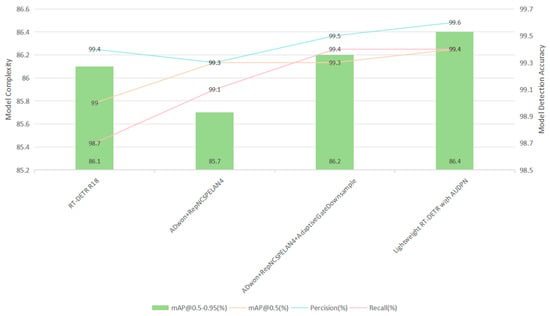
Figure 8.
Partial comparison of Lightweight RT-DETR with AUDPN ablation test performance indicators.
In the established training environment for the Lightweight RT-DETR with AUDPN, the FPS reached 57.2, indicating that the model can perform approximately 57.2 inferences per second. This represents the number of predictions the model can make within 1 s. The real-time detection capability of Lightweight RT-DETR with AUDPN at 57.2 inferences per second meets the requirements for gesture recognition and fall detection, while demonstrating superior accuracy and lightweight design compared to the baseline model. The frame rate of the model significantly impacts its ability to detect gestures dynamically. At 57.2 FPS, the model ensures that even if a gesture is quickly undone (e.g., due to loss of strength or sudden movement), sufficient temporal information is captured for accurate recognition. Compared to lower-frame-rate models, our approach reduces the likelihood of missing rapid gestures, which is critical for real-time healthcare applications.
4.3. Comparative Experiments
As shown in Table 6, a comparison was made between Lightweight RT-DETR with AUDPN and other models of similar parameter scale, such as YOLOv5s, YOLOv6s, YOLOv8s, YOLOv5m, and YOLOv8m, regarding accuracy and lightweight metrics. The parameters of each model, as detailed in Table 6, primarily compare mAP@0.5, precision, recall, Params, and GFLOPS.
Table 6.
Results of each indicator for different models.
The intuitive comparison of various parameters in the comparative experiment is shown in Figure 9.
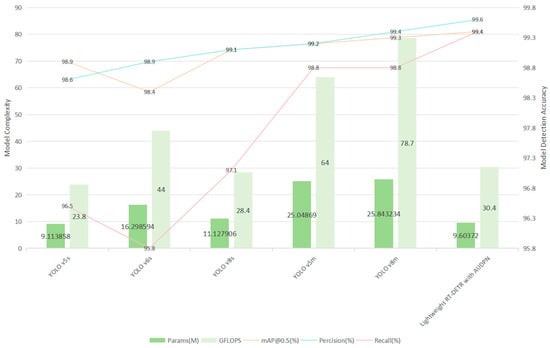
Figure 9.
Partial comparison of different models’ performance indicators.
In terms of model lightweighting, the Lightweight RT-DETR with AUDPN demonstrates significant advantages compared to most other models. Based on model accuracy, Lightweight RT-DETR with AUDPN achieves optimal performance, indicating that this model has reached a relatively optimal level in both deployability and recognition accuracy.
4.4. Performance Evaluation of Lightweight RT-DETR with AUDPN
The ultimate goal of the algorithm proposed in this paper is to apply it to the intelligent companion robot platform to address relevant healthcare resource issues. After completing the training and testing of the Lightweight RT-DETR with AUDPN model, the next step is to deploy this model on the intelligent companion robot platform for performance validation. We selected the Microsoft LifeCam Studio as the visual perception module for the intelligent companion robot platform, specifically the Elite version, which with a resolution of 1080p can rotate 360° horizontally and supports automatic focus functionality. These features ensure that gesture details are clearly captured under various lighting conditions and viewing angles, improving the reliability of keypoint detection for pattern recognition. Figure 10 illustrates this camera.

Figure 10.
Microsoft LifeCam Studio Camera (Microsoft, Redmond, WA, USA).
Considering cost and practical application issues, we chose the Intel Core i7-10870 industrial computer as the processor for the intelligent companion robot. It has 8 GB of memory, an 8-core CPU, and a total solid-state drive capacity of 128 GB, allowing it to stably handle data computation tasks over extended periods. Figure 11 provides a schematic of the industrial computer.

Figure 11.
Industrial Computer.
Based on the aforementioned components, we controlled the industrial computer via NOMACHINE, aligning its installed Ubuntu version with the one mentioned earlier, specifically Ubuntu 20.04. After unifying the Linux system version, we utilized Anaconda to construct an independent deployment environment within Ubuntu. Due to the specific graphics card model of the industrial computer, we could not install CUDA; therefore, the GPU version of PyTorch was not installed, and we opted for the PyTorch CPU version. The deployment environment is summarized in Table 7.
Table 7.
Model hyperparameter settings.
In this deployment environment, code was written in VS Code to perform frame-by-frame inference using the camera, with a confidence threshold adjusted to 0.75 for detecting falls and five hand gestures without obstruction. The results are shown in Figure 12:

Figure 12.
Fall Pose Detection and Gesture Recognition Results.
Additionally, to simulate the potential impact of lighting and object occlusion on gesture recognition and fall pose detection in complex healthcare environments, corresponding experiments were conducted to verify the practicality of the Lightweight RT-DETR with AUDPN algorithm when deployed on the intelligent companion robot platform, as illustrated in Figure 13:

Figure 13.
Fall Pose Detection and Gesture Recognition Results Under Significant Occlusion or Lighting Effects.
This experiment validated the effectiveness and accuracy of Lightweight RT-DETR with AUDPN for detecting falls and recognizing gestures in complex healthcare work environments, demonstrating the model’s potential for deployment and use in experimental settings.
5. Discussion
5.1. Findings
This paper proposes a lightweight object-detection model—Lightweight RT-DETR with AUDPN—specifically designed for intelligent companion robots to enhance performance in gesture-recognition and fall-detection tasks within complex healthcare environments. By incorporating the ADown module from YOLOv9, the RepNCSPELAN4 module, and our self-developed attention-based upsampling and downsampling modules (AdaptiveGateUpsample and AdaptiveGateDownsample), we constructed the Attentional Up-Downsampling Pyramid Network (AUDPN). This design not only reduces the number of parameters compared to RT-DETR R18 but also effectively enhances feature fusion capabilities and overall object-detection accuracy.
Experimental results revealed some unexpected outcomes. In addition to achieving reductions of 51.69% in parameters, 46.67% in GFLOPS, and 51.04% in weight size, the Lightweight RT-DETR with AUDPN model demonstrated improvements in mAP@0.5, mAP@0.5–0.95, precision, and recall by 0.4%, 0.3%, 0.2%, and 0.7%, respectively. Unexpectedly, our model also exhibited a robust performance under conditions of occlusion and low light, suggesting that the integration of attention-based feature fusion not only addresses computational efficiency but also enhances resilience against environmental interference.
5.2. Limitations
Despite the promising performance of the Lightweight RT-DETR with AUDPN, several limitations remain:
- Real-time Performance: Although the model has an FPS of up to 57.2 in the training environment, its FPS will be significantly reduced when deployed on resource-limited devices such as industrial control computers without GPU acceleration. Therefore, if you want to achieve fast and accurate inference, we recommend deploying it on devices with GPU acceleration.
- Task Specificity: The current model is primarily optimized for gesture recognition and fall detection. Its generalization to other object-detection tasks still requires further validation. One limitation of the proposed system is its reliance on commonly used gestures, which, while reducing the cognitive burden on elderly users, may lead to potential gesture misclassification in environments where similar gestures are frequently performed. For example, the “OK” gesture might be misinterpreted in certain social settings where it is commonly used. However, as previously discussed, requiring elderly users to learn custom gestures is impractical, making the adoption of familiar gestures the most viable solution. Future research should explore advanced disambiguation strategies, such as integrating hand keypoint tracking or multi-modal inputs (e.g., combining voice commands with gestures) to improve recognition accuracy in these scenarios.
- Cost Considerations: An important limitation is the potential high cost associated with building and deploying intelligent companion robots. In the context of China’s healthcare system—where cost sensitivity is critical—this could impede widespread adoption despite the model’s technical advantages. The intelligent companion robot used in this paper costs about 10,000 RMB. However, the recommended high-configuration version costs around 20,000 RMB.
5.3. Future Research Directions
Future work should address these limitations and explore several new directions:
- Enhanced Data Diversity: Training and testing the model on more diverse datasets collected from various healthcare centers and home environments could improve adaptability and robustness.
- Model Optimization: Further refinements of the model structure and algorithmic enhancements, potentially drawing inspiration from emerging models like YOLO V11, may boost real-time performance on resource-constrained devices.
- Cost-Reduction Strategies: Research into more cost-effective hardware integration and model-compression techniques will be crucial for reducing the overall expense of intelligent companion robot systems.
- Beneficiary-Centric Applications: Future studies should also focus on long-term pilot deployments in Chinese eldercare facilities and community healthcare centers. The primary beneficiaries of this research include elderly individuals, family caregivers, healthcare providers, and policymakers. Intelligent companion robots equipped with our lightweight model could reduce caregiver burden, enable rapid intervention in emergencies, and ultimately lower healthcare costs by preventing severe injuries.
In summary, while the Lightweight RT-DETR with AUDPN demonstrates significant advancements in both efficiency and detection accuracy, further research is essential to optimize its performance in real-world scenarios and address economic challenges. Our findings not only contribute to the academic discourse on lightweight detection models but also offer practical implications for enhancing healthcare support in China.
6. Conclusions
In this study, we proposed a lightweight object-detection model—Lightweight RT-DETR with Attentional Up-Downsampling Pyramid Network (AUDPN)—specifically designed for intelligent companion robots in healthcare environments. Our approach integrates YOLOv9’s ADown module and RepNCSPELAN4 module with novel attention-based upsampling and downsampling mechanisms (AdaptiveGateUpsample and AdaptiveGateDownsample) to enhance multi-scale feature fusion while reducing computational complexity. Experimental evaluations demonstrated that our model achieves a significant reduction in parameters (51.7%) and GFLOPS (46.7%), while improving detection performance, with increased mAP, precision, and recall. Moreover, the high frame rate (57.2 FPS) ensures robust dynamic gesture recognition even under challenging conditions such as occlusion and low light.
Our results indicate that the proposed model is well-suited for individual caregiving scenarios, where the use of commonly recognized gestures minimizes the training burden on elderly users and patients. Although occasional misclassifications may occur in multi-person environments, the current design effectively balances computational efficiency with high detection accuracy. Nonetheless, challenges such as real-time performance on low-resource devices and the high cost of intelligent companion robots remain. These limitations provide avenues for further research, including advanced disambiguation strategies, model optimization inspired by emerging techniques like YOLO V11, and cost-reduction methods through hardware and algorithmic improvements.
Overall, the Lightweight RT-DETR with AUDPN model contributes to the academic discourse on efficient detection models and offers practical implications for enhancing healthcare support in China and beyond. Future work will focus on refining the model for broader applications, optimizing deployment on resource-constrained devices, and conducting long-term pilot studies to validate its performance in real-world healthcare settings.
Author Contributions
Conceptualization, X.H. and X.S.; Methodology, X.H. and N.L.; Software, X.H.; Validation, X.H., X.F. and Q.Y.; Formal analysis, X.H. and M.W.; Investigation, X.H; Resources, X.H.; Data curation, X.H.; Writing—original draft preparation, X.H.; Writing—review and editing, X.H.; Visualization, X.H.; Supervision, X.H.; Project administration, X.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data that are cited in this article are available in a publicly accessible repository.
Acknowledgments
The authors thank the editor and anonymous reviewers for their helpful comments and valuable suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- United Nations. World Population Prospects—Population Division—United Nations. Available online: https://population.un.org/wpp/ (accessed on 30 December 2024).
- United Nations. World Population Prospects 2024. 2024. Available online: https://www.un.org/development/desa/pd/sites/www.un.org.development.desa.pd/files/undesa_pd_2024_wpp_2024_advance_unedited_0.pdf (accessed on 30 December 2024).
- Babič, F.; Ljiljana, T.M.; Bekić, S.; Holzinger, A. Machine Learning for Family Doctors: A Case of Cluster Analysis for Studying Aging Associated Comorbidities and Frailty. Lect. Notes Comput. Sci. 2019, 11713, 178–194. [Google Scholar] [CrossRef]
- Barry, A.; Heale, R.; Pilon, R.; Lavoie, A. The Meaning of Home for Ageing Women Living Alone: An Evolutionary Concept Analysis. Health Soc. Care Community 2017, 26, e337–e344. [Google Scholar] [CrossRef]
- Finlay, J.M.; Kobayashi, L.C. Social Isolation and Loneliness in Later Life: A Parallel Convergent Mixed-Methods Case Study of Older Adults and Their Residential Contexts in the Minneapolis Metropolitan Area, USA. Soc. Sci. Med. 2018, 208, 25–33. [Google Scholar] [CrossRef]
- Tang, Y. Research on Home-Based Elderly Care Services for Empty Nest Elderly in Rural Communities. Heilongjiang Hum. Resour. Soc. Secur. 2022, 31–33. Available online: https://kns.cnki.net/kcms2/article/abstract?v=VcTOyLYtvEyplYs2_tWdrXhflPLEgFzjNyzOwdcU5owyptMPyHrvZvAgFp6YcrywtbX0wRRnWStjQ1Vm8fYjISEPh7WyVDFdRAMH3oRynHjf9YLi6D49hwKPCNzwz3AmvctwZv0Vy7KUqTW9y5UpXIw7mV9bFAke7w2EZcJXLFMsEL7BWcj2Xg==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Nguyen, H.; Manolova, G.; Daskalopoulou, C.; Vitoratou, S.; Prince, M.; Prina, A.M. Prevalence of Multimorbidity in Community Settings: A Systematic Review and Meta-Analysis of Observational Studies. J. Comorbidity 2019, 9, 2235042X19870934. [Google Scholar] [CrossRef]
- Xie, Q. Research on Fall Detection Based on Deep Learning. Master’s Thesis, Nanjing University of Information Science and Technology, Nanjing, China, 2024; p. 59. Available online: https://link.cnki.net/doi/10.27248/d.cnki.gnjqc.2024.000194 (accessed on 3 January 2025).
- World Health Organization. Disability and Health. Available online: https://www.who.int/zh/news-room/fact-sheets/detail/disability-and-health (accessed on 30 December 2024).
- Santos, N.B.; Bavaresco, R.S.; Tavares, J.E.R.; Ramos, G.d.O.; Barbosa, J.L.V. A Systematic Mapping Study of Robotics in Human Care. Robot. Auton. Syst. 2021, 144, 103833. [Google Scholar] [CrossRef]
- Ba, S.; Hu, L.; Huang, K. Analysis of the Impact of Population Aging on the Life Insurance Industry: Product Structure Optimization and Pricing Strategy Discussion from an Actuarial Perspective. Hainan Financ. 2024, 3–17. Available online: https://kns.cnki.net/kcms2/article/abstract?v=VcTOyLYtvEzwGVKzrQOoARiJPad56hz-dGT3x_bMH9q9-9ZKsxyNlECkQksnIoessgP12TvrIBwqaEeRSH-tzlULjr5g-AW6mfkPZpB6qQSoZ_XdTVwXyu6I_RvTVToLYJvZrK_Ckw3a3diwJCXMDg8avpfEB_pMhrsB1v5o6oqWULjo_UEvDg==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Department of Planning, Development and Information Technology of the People’s Republic of China. Statistical Bulletin on the Development of China’s Health Industry in 2023. 2024. Available online: http://www.nhc.gov.cn/guihuaxxs/s3585u/202408/6c037610b3a54f6c8535c515844fae96.shtml (accessed on 31 December 2024).
- Hooker, R.; Cawley, J.; Everett, C. Predictive Modeling the Physician Assistant Supply: 2010–2025. Public Health Rep. 2011, 126, 708–716. [Google Scholar] [CrossRef]
- Cooper, S.; Fava, D.; Vivas, C.; Marchionni, L.; Ferro, F. ARI: The Social Assistive Robot and Companion. In Proceedings of the 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; pp. 745–751. [Google Scholar] [CrossRef]
- Auerbach, D. Will NP Workforce Grow Future? Med. Care 2012, 50, 606–610. [Google Scholar] [CrossRef]
- Robinson, H.; Macdonald, B.; Broadbent, E. The Role of Healthcare Robots for Older People at Home: A Review. Int. J. Soc. Robot. 2014, 6, 575–591. [Google Scholar] [CrossRef]
- Broekens, J.; Heerink, M.; Rosendal, H. Assistive Social Robots in Elderly Care: A Review. Gerontechnology 2009, 8, 94–103. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-To-End Object Detection with Transformers. In Computer Vision—ECCV 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Bavaresco, R.; Barbosa, J.; Vianna, H.; Büttenbender, P.; Dias, L. Design and Evaluation of a Context-Aware Model Based on Psychophysiology. Comput. Methods Programs Biomed. 2020, 189, 105299. [Google Scholar] [CrossRef]
- D’Onofrio, G.; Fiorini, L.; Hoshino, H.; Matsumori, A.; Okabe, Y.; Tsukamoto, M.; Limosani, R.; Vitanza, A.; Greco, F.R.; Greco, A.; et al. Assistive Robots for Socialization in Elderly People: Results Pertaining to the Needs of the Users. Aging Clin. Exp. Res. 2019, 31, 1313–1329. [Google Scholar] [CrossRef] [PubMed]
- Torta, E.; Oberzaucher, J.; Werner, F.; Cuijpers, R. Attitudes towards Socially Assistive Robots in Intelligent Homes: Results from Laboratory Studies and Field Trials. J. Hum.-Robot Interact. 2013, 1, 76–99. [Google Scholar] [CrossRef][Green Version]
- Simonov, M.; Bazzani, M.; Frisiello, A. Ubiquitous Monitoring & Service Robots for Care. In Proceedings of the 35th German Conference on Artificial Intelligence, Saarbrucken, Germany, 24–27 September 2012; p. 93. [Google Scholar]
- Tan, J.; Chan, W.; Robinson, N.; Croft, E.; Kulic, D. A Proposed Set of Communicative Gestures for Human Robot Interaction and an RGB Image-Based Gesture Recognizer Implemented in ROS. arXiv 2021, arXiv:2109.09908. [Google Scholar] [CrossRef]
- Wada, Y.S.; Lotfi, A.; Mahmud, M.; Machado, P.; Kubota, N. Gesture Recognition Intermediary Robot for Abnormality Detection in Human Activities. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 1415–1421. [Google Scholar] [CrossRef]
- Werner, C.; Kardaris, N.; Koutras, P.; Zlatintsi, A.; Maragos, P.; Bauer, J.M.; Hauer, K. Improving Gesture-Based Interaction between an Assistive Bathing Robot and Older Adults via User Training on the Gestural Commands. Arch. Gerontol. Geriatr. 2020, 87, 103996. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, Y.; Liu, Z. A Dynamic Hand Gesture Recognition Algorithm Based on CSI and YOLOv3. J. Phys. Conf. Ser. 2019, 1267, 012055. [Google Scholar] [CrossRef]
- Zhou, Z.; Han, F.; Wang, Z. Application of Improved SSD Algorithm in Chinese Sign Language Recognition. Comput. Eng. Appl. 2021, 57, 156–161. [Google Scholar]
- Wu, S.; Li, Z.; Li, S.; Liu, Q.; Wu, W. Static Gesture Recognition Algorithm Based on Improved YOLOv5s. Electronics 2023, 12, 596. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, T. Gesture Recognition Based on Improved Faster R-CNN. Inf. Commun. 2019, 44–46. Available online: https://kns.cnki.net/kcms2/article/abstract?v=amOBmv6QLtp-vSJs7CyNIes_FGpIsqWsv9ebKEnCsEexL7hAbjl0WMtBk6dz9w8NvLkLWjM0gQ_u-5sbtrup6rLR3PrPaM73eJlmK4aSSkQqVkQwJ7bu3zEua24wIJLE3dcmqvWWX6PosxikdQG2mT2VTBP1oM4uaNSyKeqPc5lQZdYZp6FBYg==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Niu, Y.; Wu, Y.; Sun, K.; Lu, H.; Zhao, P. Gesture Recognition Detection Based on Lightweight Convolutional Neural Networks. Electron. Meas. Technol. 2022, 45, 91–98. [Google Scholar] [CrossRef]
- Wu, J.; Jiang, L. Intelligent Monitoring System for Elderly Living Alone Based on Ros Service Robots. Electron. Technol. Softw. Eng. 2021, 78–80. Available online: https://kns.cnki.net/kcms2/article/abstract?v=amOBmv6QLtq3OLFyN-QPZfH5Ob75UBpZ48f7KIDiSwA9tTYCkkcnUeV-v_PYufG7SR9IGXRSYtiVavfBKhyADM69nFKecNzmWY3-xQGd1pvPTR6P1PzRJuNY-48JawpYWN3rS2ys2A5SshAg2xmMiV1rOHdtkDOozQbHv-ym1yrbJriyjCDnJw==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Chen, X.; Zhao, Y.; Wang, F.; Cao, X.; Yang, Y. Fall Detection Alarm System for Service Robots Based on Static Image Pose Estimation. Sci. Technol. Innov. Her. 2023, 1–3. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. AAAI Conf. Artif. Intell. 2018, 32, 7444–7452. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Adaptive Spectral Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2018, arXiv:1805.07694. [Google Scholar] [CrossRef]
- Min, W.; Cui, H.; Rao, H.; Li, Z.; Yao, L. Detection of Human Falls on Furniture Using Scene Analysis Based on Deep Learning and Activity Characteristics. IEEE Access 2018, 6, 9324–9335. [Google Scholar] [CrossRef]
- Adhikari, K.; Bouchachia, H.; Nait-Charif, H. Activity Recognition for Indoor Fall Detection Using Convolutional Neural Network. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; IEEE: Berlin/Heidelberg, Germany, 2017; pp. 81–84. [Google Scholar] [CrossRef]
- Xu, S.; Wang, H.; Zhang, H.; Pang, J. A Keypoint-Based Method for Infrared Image Fall Detection. Infrared Technol. 2021, 43, 1003–1007. Available online: https://kns.cnki.net/kcms2/article/abstract?v=amOBmv6QLtqMuhRTYLLOBtlSOeSw7D6sgr9AmhVyzR8nOtjbb5ivJnPFKme0ThCQVeqIgp7q6i84FXSf6qwz5MgTa2-Tj2HFPBA-ELkqOjkQjmZUIrp9EmPXOLBzdqwQpmpM_nsGkgwU4V_5_khO1yqtQz6QizMaT3KMW_UCIsxrBelEC4qtaw==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Chhetri, S.; Alsadoon, A.; Al-Dala’in, T.; Prasad, P.W.C.; Rashid, T.A.; Maag, A. Deep Learning for Vision-Based Fall Detection System: Enhanced Optical Dynamic Flow. Comput. Intell. 2020, 37, 578–595. [Google Scholar] [CrossRef]
- Qi, Y.; Chen, S.; Sun, L. Fall Detection Using Dual-Stream Cnn Based on Improved Vibe Algorithm. Comput. Eng. Des. 2023, 44, 1812–1819. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, X.; Gao, H.; Zeng, Z.; Zhang, Y. Fall Detection Algorithm Based on Convolutional Neural Network and Multi Discriminative Features. J. Comput.-Aided Des. Graph. 2023, 35, 452–462. Available online: https://link.cnki.net/urlid/11.2925.tp.20230410.1444.002 (accessed on 3 January 2025).
- Gupta, B.; Shukla, P.; Mittal, A. K-Nearest Correlated Neighbor Classification for Indian Sign Language Gesture Recognition Using Feature Fusion. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Pan, T.-Y.; Lo, L.-Y.; Yeh, C.-W.; Li, J.-W.; Liu, H.-T.; Hu, M.-C. Real-Time Sign Language Recognition in Complex Background Scene Based on a Hierarchical Clustering Classification Method. In Proceedings of the 2016 IEEE Second International Conference on Multimedia Big Data (BigMM), Taipei, Taiwan, 20–22 April 2016; pp. 64–67. [Google Scholar] [CrossRef]
- Sharma, S.; Jain, S.; Khushboo. A Static Hand Gesture and Face Recognition System for Blind People. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 534–539. [Google Scholar] [CrossRef]
- Athira, P.K.; Sruthi, C.J.; Lijiya, A. A Signer Independent Sign Language Recognition with Co-Articulation Elimination from Live Videos: An Indian Scenario. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 771–781. [Google Scholar] [CrossRef]
- Redmon, C.-Y.; Divvala, S.-M.; Girshick, J.-W.; Farhadi, L.-W.; Huang, C.-L. Vision-Based Fall Detection through Shape Features. In Proceedings of the 2016 IEEE Second International Conference on Multimedia Big Data (BigMM), Taipei, Taiwan, 20–22 April 2016; pp. 237–240. [Google Scholar] [CrossRef]
- Gunale, K.; Mukherji, P. Indoor Human Fall Detection System Based on Automatic Vision Using Computer Vision and Machine Learning Algorithms. J. Eng. Sci. Technol. 2018, 13, 2587–2605. Available online: https://api.semanticscholar.org/CorpusID:189891830 (accessed on 3 January 2025).
- Zhang, F.; Zhu, J. Fall Detection Technology Based on Dual Cameras. Comput. Syst. Appl. 2020, 29, 186–192. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Hu, D.; Zhu, J.; Liu, J.; Wang, J.; Zhang, X. Gesture Recognition Based on Modified Yolov5s. IET Image Process. 2022, 16, 2124–2132. [Google Scholar] [CrossRef]
- Yang, Z.; Shen, Y.; Shen, Y. Football Referee Gesture Recognition Algorithm Based on YOLOv8s. Front. Comput. Neurosci. 2024, 18, 1341234. [Google Scholar] [CrossRef]
- Jiang, L. Application of Visual Gesture Recognition Technology in Simulation Training of Aviation Medicine. Master’s Thesis, North China University of Technology, Beijing, China, 2022; p. 72. Available online: https://link.cnki.net/doi/10.26926/d.cnki.gbfgu.2022.000695 (accessed on 3 January 2025).
- Meng, Q.; Dai, J.; Cha, J.; Xiong, Y.; Si, B. Common Gesture Recognition Based on Yolov8 Algorithm. Mod. Instrum. Med. Treat. 2023, 29, 12–20. Available online: https://kns.cnki.net/kcms2/article/abstract?v=amOBmv6QLtogTJhNnVM9_6PIzl6cqWTLexizIQbvgMjPcu4jI8ysIYLwhOTscKZdHQWfabnOABr9qei9XPZJVwyCN6T9RZJGXMnBGBHpkIUYYBA4NGoB5lrtwuj0cCPHVJhLTS356nSR4pHZwn1wVDWcKY5Bt9jXWX1SmDDBK_7TrsoLr3EIDA==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Song, J.; Xu, H.; Zhu, X.; Huang, X.; Chen, C.; Wang, Z. Oef-Yolo: An Improved Yolov8 Algorithm for Fall Detection. Comput. Eng. 2024, 1–16. [Google Scholar] [CrossRef]
- Zong, Z. Research on Home Fall Detection Based on Improved Yolov5s. Master’s Thesis, Nanchang University, Nanchang, China, 2023; p. 72. Available online: https://link.cnki.net/doi/10.27232/d.cnki.gnchu.2023.003973 (accessed on 3 January 2025).
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-To-End Object Detection with Dynamic Attention. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 2968–2977. [Google Scholar] [CrossRef]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised Pre-Training for Object Detection with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar] [CrossRef]
- Alexander, K.; Karina, K.; Alexander, N.; Roman, K.; Andrei, M. HaGRID—HAnd Gesture Recognition Image Dataset. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024. [Google Scholar] [CrossRef]
- Eraso, J.C.; Muñoz, E.; Muñoz, M.; Pinto, J. Dataset CAUCAFall. Mendeley Data 2022. V4. Available online: https://data.mendeley.com/datasets/7w7fccy7ky/4 (accessed on 3 January 2025).
- Roboflow Universe Projects. Fall Detection Object Detection Dataset and Pre-Trained Model by Roboflow Universe Projects. Roboflow Universe. Available online: https://universe.roboflow.com/roboflow-universe-projects/fall-detection-ca3o8 (accessed on 31 December 2024).
- Wang, C.-Y.; Yeh, I.-H.; Liao, M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Computer Vision—ECCV 2024; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2024; Volume 15089, pp. 1–21. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient Long-Range Attention Network for Image Super-Resolution. In Computer Vision—ECCV 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 649–667. [Google Scholar] [CrossRef]
- Li, Z.; Wu, Y.; Jiang, H.; Lei, D.; Pan, F.; Qiao, J.; Fu, X.; Guo, B. RT-DETR-SoilCuc: Detection Method for Cucumber Germinationinsoil Based Environment. Front. Plant Sci. 2024, 15, 1425103. [Google Scholar] [CrossRef]
- Yu, Y.; Mu, Y. Research on Interpolation Algorithm. Mod. Comput. (Prof. Ed.) 2014, 32–35. Available online: https://kns.cnki.net/kcms2/article/abstract?v=amOBmv6QLtoGbG38vL2mgf5TqgvM6iWToQl_G06TEEaIBPdws4o914lEOKfAuEidvtVVRwV6kbe8ObazAihaaIUXoDzJmck6-pRHgJZhCcVQV3X5wD-o%20fGxu6604b2Erm86IW60USMSdETRY0Oum2GSsVSCy_SLpchQlzZcdFmdL36j7tEpx4w==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Wang, Y.; Zhang, Q.; Li, N. Research on Image Deformation Based on Interpolation Algorithm. Instrum. Anal. Monit. 2014, 19–21. Available online: https://kns.cnki.net/kcms2/article/abstract?v=amOBmv6QLtrRVKzp6PjEtVophzc2kNAEw5su4e_8_FADrlIjACFKJseWyg4CPPFzkVPmFCRzsKBoaCMcDQ_BCn9l0p5pHXtg27HRevzViGAndeduGxKZulNiTlCtpTV0H6awOnTiZ3sx5qHEyvDYR9WPKWPGAilvZdok9ZamrJWw9q59AjkZtw==&uniplatform=NZKPT&language=CHS (accessed on 3 January 2025).
- Hu, J.; Shen, L.; Sun, G. Squeeze-And-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Jiang, W.; Gao, Y.; Yuan, H.; Liu, W. Image Classification Network with Gated Mechanism. Acta Electron. Sin. 2024, 52, 2393–2406. Available online: https://link.cnki.net/urlid/11.2087.TN.20240808.1000.002 (accessed on 3 January 2025).
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Gong, Y.; Shen, X. Smoking Detection Algorithm Based on Yolov3 with Transposed Convolution Fusion. Comput. Meas. Control 2024, 32, 40–46+54. [Google Scholar]
- Gu, Z.; Liu, G.; Shao, C.; Yu, H. Downsampling Algorithm Incorporating Size Receptive Field Mechanism in Deep Detection Methods. Comput. Sci. Explor. 2023, 18, 2727–2737. Available online: https://link.cnki.net/urlid/11.5602.TP.20231122.1143.006 (accessed on 3 January 2025).






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).