Abstract
As a critical task in underground coal mining, personnel identification and positioning in fully mechanized mining faces are essential for safety. Yet, complex environmental factors—such as narrow tunnels, heavy dust, and uneven lighting—pose significant challenges to accurate detection. In this paper, we propose a personnel detection network, MSS-YOLO, for fully mechanized mining faces based on YOLOv8. By designing a Multi-Scale Edge Enhancement (MSEE) module and fusing it with the C2f module, the performance of the network for personnel feature extraction under high-dust or long-distance conditions is effectively enhanced. Meanwhile, by designing a Spatial Pyramid Shared Conv (SPSC) module, the redundancy of the model is reduced, which effectively compensates for the problem of the max pooling being prone to losing the characteristics of the personnel at long distances. Finally, the lightweight Shared Convolutional Detection Head (SCDH) ensures real-time detection under limited computational resources. The experimental results show that compared to Faster-RCNN, SSD, YOLOv5s6, YOLOv7-tiny, YOLOv8n, and YOLOv11n, MSS-YOLO achieves AP50 improvements of 4.464%, 10.484%, 3.751%, 4.433%, 3.655%, and 2.188%, respectively, while reducing the inference time by 50.4 ms, 11.9 ms, 3.7 ms, 2.0 ms, 1.2 ms, and 2.3 ms. In addition, MSS-YOLO is combined with the SGBM binocular stereo vision matching algorithm to provide a personnel 3D spatial position solution by using disparity results. The personnel location results show that in the measurement range of 10 m, the position errors in the x-, y-, and z-directions are within 0.170 m, 0.160 m, and 0.200 m, respectively, which proves that MSS-YOLO is able to accurately detect underground personnel in real time and can meet the underground personnel detection and localization requirements. The current limitations lie in the reliance on a calibrated binocular camera and the performance degradation beyond 15 m. Future work will focus on multi-sensor fusion and adaptive distance scaling to enhance practical deployment.
1. Introduction
Coal resources around the world are an indispensable energy source, representing an economic, clean, and efficient use of fossil energy. It has been determined that in the future, coal resources will still be one of the main energy sources in the world’s energy structure and will be difficult to replace. As the most important working environment in underground coal mines, fully mechanized mining faces usually utilize commonly used coal mining machinery to complete the coal mining process, including scraping, room and pillar cutting, etc. The normal operation of mechanized working faces inevitably requires personnel and equipment to work together, and in the limited space, this can easily lead to personnel exposing themselves to operational risks. Therefore, it is necessary to ensure the safety of personnel in fully mechanized mining faces by means of intelligent detection and monitoring systems, as well as timely warnings of unsafe behaviors and potential accidents in the complex and changeable working face environment.
At present, the methods for detecting and determining the illegal operation and abnormal behavior of personnel in fully mechanized mining faces mainly include the traditional manual monitoring method [1], ultra-wideband wireless communication (UWB) [2], and computer vision detection technology [3]. Among them, the traditional manual inspection and monitoring methods are easily affected by the subjective judgment of personnel, and at the same time, prolonged monitoring work can easily lead to fatigue among the monitoring personnel, reducing their attention and alertness, meaning they may ignore important abnormal situations and fail to send out timely alarm information, thus creating a hidden safety danger. Based on ultra-wideband wireless communication (UWB) technology, which relies on the measurement principle of TOF and TDOA, the time difference of the signals between two ultra-wideband modules is used to calculate the relative distance between the personnel and the laser, allowing to measure the personnel’s position. However, due to the influence of the dust concentration in fully mechanized mining faces, as well as occlusion, the positioning error generated by UWB cannot meet the demand for precise positioning of personnel underground in coal mines. The positioning information obtained by computer vision-based personnel positioning methods is more intuitive and stable. These methods usually use object detection or semantic segmentation algorithms under stereoscopic vision for miners’ feature extraction and then combine the internal and external references of the camera to obtain the personnel’s position information under the working surface. This technology has several advantages: it is non-contact and low-cost, has high accuracy and stability, avoids cumulative errors, etc. Therefore, at present, most fully mechanized mining faces adopt computer vision localization methods for personnel localization.
In previous work, we carried out extensive research on personnel detection in fully mechanized mining faces; developed the DsLMF+ dataset for the detection of coal mine personnel, their postures, and other related objects [4]; and utilized the data to detect miners and their postures in two-dimensional images. The method mainly utilizes the YOLOv7 object detection algorithm to detect and estimate the attitude of the personnel in an image of an integrated mining face captured by an industrial camera. In the course of the study, it was found that the narrow space of the roadway and the dense stacking of equipment limit the working range of miners, and the personnel features are often obscured by equipment such as hydraulic supports and coal mining machines [5]. In addition, the complex spatial structure of the underground environment leads to limited installation of lighting equipment, and the layout of large mechanical equipment in the fully mechanized mining face will block the light sources and form a shadow area. Further, the dynamically changing operating environment during the process of advancing the face makes it difficult to adapt to the original lighting layout, and the coverage of light sources in some areas is insufficient. At the same time, when the coal mining machine’s drum performs high-speed cutting on the coal wall, it produces a large amount of cutting dust that diffuses throughout the roadway. Although high-pressure spray dust-reduction technology [6] is used to eliminate dust, the droplets cannot adequately cover the dust particles, leading to a low combination efficiency between the water mist and dust. Coupled with limited ventilation in the mine, the unsettled water mist accumulates in the confined space, forming a high concentration of water mist in the environment. Therefore, in the complex environment where miners’ features are easily obscured and blurred, traditional target detection algorithms often produce more missed detections and false detections [7], which seriously undermines the accuracy of intelligent identification and monitoring tasks in underground coal mines. The actual working condition of a coal mining face in an underground coal mine is shown in Figure 1.

Figure 1.
Actual working conditions of the fully mechanized mining face in an underground coal mine.
A schematic diagram of the hazardous area for personnel on the fully mechanized mining face is shown in Figure 2. In general, the working area of personnel on the fully mechanized mining face is usually on the outside of the scraper conveyor, and crossing the scraper conveyor to enter the inside is considered illegal operation. Therefore, to address the problem of miners invading dangerous areas for illegal operation, this paper adopts a deep learning-based object detection algorithm for miners’ feature extraction and uses a binocular stereo matching algorithm to calculate the three-dimensional coordinates of the center position of the bounding box where the miners are located. This approach enables personnel localization and lays the foundation for subsequently determining whether the personnel have entered the illegal area or not.

Figure 2.
Diagram of hazardous areas in fully mechanized mining face. The inner area of the enclosing box formed by the red straight line is the danger zone.
Environmental conditions such as heavy dust, water mist, and uneven illumination of the working face during the cutting process of the coal mining machine in the fully mechanized mining face seriously affect image quality and reduce target features, leading to deterioration in the effectiveness of object detection. To solve the problems of blurred target features and difficult feature extraction caused by water mist, dust, and uneven illumination in image data, this paper constructs a personnel detection network architecture, MSS-YOLO, for the complex environment of coal mining face. This architecture is based on the YOLOv8 object detection network, incorporating the characteristics of the environment of the coal mine. It aims to provide stable and real-time personnel detection information for personnel localization at the face. At the same time, combined with the SGBM binocular stereo vision matching method [8], the proposed approach achieves three-dimensional localization of miners in the working face. The main contributions of this paper are as follows:
- To address the omission and misdetection issues of traditional deep learning algorithms in miner localization for an integrated mining face, this paper proposes the MSS-YOLO model. It achieves real-time and stable miner detection under uneven illumination, feature blurring, and varying dust concentrations.
- The proposed MSS-YOLO model integrates a Multi-Scale Edge Enhancement (MSEE) module into the C2f module of YOLOv8 to strengthen edge representation and reduce missed or false detections caused by high dust conditions and jitter. We also construct a lightweight Shared Convolutional Detection Head (SCDH) based on group-normalized shared-weight convolution, which significantly reduces the computational overhead while maintaining accuracy. Furthermore, replacing the SPPF module with a Spatial Pyramid Shared Conv (SPSC) module reduces long-range target feature loss and decreases model redundancy.
- A UCMD coal mine underground miner localization image dataset is constructed by simulating various conditions in a fully mechanized mining face. Based on this dataset, the paper integrates MSS-YOLO with the SGBM binocular stereo vision matching algorithm to solve the 3D spatial positions of miners and verifies its performance in a simulated roadway. Experimental results show that MSS-YOLO detects miners in real time and with high accuracy under different dust concentrations and distances, while the binocular-based localization achieves excellent precision and stability.
The rest of this paper is organized as follows. Section 2 introduces some related work within this topic, and Section 3 outlines the traditional YOLOv8 network. Building on this, the MSS-YOLO network proposed in this paper is described in detail, along with a miner localization method combining MSS-YOLO with SGBM binocular stereo vision matching technology. Additionally, the construction scheme of UCMD for the personnel dataset of the fully mechanized mining face is introduced. The construction of the related experimental platform as well as the experimental demonstration is given in Section 4, and Section 5 discusses and summarizes the research work in this paper. All source code and all data in this article are available upon request.
2. Related Work
Image data-based methods for accurate positioning of personnel in integrated mining faces of coal mines mainly rely on the stability and robustness of personnel detection. Currently, personnel detection algorithms can be categorized into traditional detection methods and deep learning-based personnel detection methods. Traditional image-based personnel detection methods mainly extract features such as the target’s grayscale, texture [9], and color information to complete the detection task. Currently, common traditional people detection algorithms include Viola-Jones [10], HOG+SVM [11], DPM [12], and Soft-NMS [13], etc. Before the advent of deep learning-based people detection algorithms, traditional people detection algorithms could accomplish the people detection task in simple scenarios in a relatively stable manner.
With the development of computer technology and industrial intelligence, the demand for intelligent monitoring of staff status and location under complex working conditions has gradually risen. However, traditional personnel detection methods in complex environments have low detection efficiency, poor real-time performance, and cannot ensure good stability. Therefore, researchers have begun to use deep learning-based object detection algorithms to establish personnel detection models, thus completing the task of personnel detection in industrial application scenarios. Currently, deep learning-based object detection algorithms are generally categorized into two types: region nomination-based and end-to-end methods. Among them, region nomination-based object detection algorithms achieve high-precision object detection by generating candidate regions and performing target classification and localization within these regions. The more mainstream region nomination-based object detection algorithms today are R-CNN [14], Fast R-CNN [15], and SPP-net [16]. End-to-end object detection algorithms generate target categories and bounding boxes directly from the input image without intermediate candidate region nomination steps, which is faster and more efficient. Currently, the more mainstream end-to-end object detection algorithms are YOLO [17], SSD [18], EfficientDet [19], and DETR [20].
In current industrial application environments, deep learning-based personnel detection has achieved remarkable success. Yi Jin et al. [21] proposed an improved Faster R-CNN network for the problem of difficult detection of pedestrians in low-quality images under complex backgrounds and realized the detection of road pedestrians at different time periods. Ahmad Esmaeil Abbasi et al. [22] proposed a road object and pedestrian detection method based on YOLOv8, which solves the problem of missed detection and high false detection rates of pedestrians under foggy conditions by adjusting hyperparameters such as epochs, batch size, and augmentation methods. Zhen Liang et al. [23] proposed a detection model based on improved YOLOv7-Tiny in order to improve the detection accuracy of an object detection algorithm for vehicles and pedestrians in traffic scenes and to solve the problem of small target leakage detection, achieving real-time and highly stable detection on the embedded platform NVIDIA Jetson AGX Xavier. Sanzai Liu et al. [24] proposed a lightweight object detection model integrating GhostNet and YOLOv5s to further improve the accuracy of UAV personnel detection in complex scenarios. This approach addresses the problems of the small size of pedestrians and the difficulty of detecting personnel under different backgrounds and illumination conditions in UAV remote sensing images. Wei-Yen Hsu et al. [25] considered problems such as poor pedestrian detection performance due to the effects of a small percentage of pedestrians in an image and large differences in the aspect ratio of the input image. To overcome these challenges, they proposed the ratio- and scale-aware YOLO (RSA-YOLO) algorithm, which enhances the detection model’s pedestrian detection performance in the VOC 2012 comp4, INRIA, and ETH datasets. Xiangyang Li et al. [26] proposed a novel mask-guided multi-level fusion network (M2FNet) for RGB-T pedestrian detection in order to solve the problem of modal information contamination that is characteristic of RGB-T pedestrian detection methods. They tested it on the KAIST and CVC-14 RGB-T pedestrian detection datasets, which achieved more excellent results. Hong Zhang et al. [27] proposed the MEAG-YOLO model for the timely and accurate detection of the use of workers’ personal protective equipment (PPE) in complex scenarios in substations, which effectively solves the problem of inaccurate detection results caused by traditional algorithms due to different target sizes, complex backgrounds, and multiple model parameters. Yangwei Ying et al. [28] used YOLOX for personnel detection in order to improve the efficiency and level of laboratory safety management and to monitor abnormal behaviors such as smoking and incorrect wearing of personal protective equipment (PPE) such as laboratory coats, hats, masks, and gloves. At the same time, the steps of human key point detection, posture estimation, and behavioral recognition were used to realize the abnormal behavioral discrimination of laboratory personnel. Meanwhile, for other target detection tasks in complex scenarios, scholars have proposed targeted improvements in their respective fields. Yu Wang et al. [29] proposed a multi-target detection algorithm based on the combination of YOLOv5 and Distance Intersection Over Union loss Non-Maximum Suppression (DIOU-NMS) for the omission problem of traditional algorithms when detecting dense small targets under aerial images, which effectively solves the detection performance of dense small targets under complex backgrounds. Dejun Chen et al. [30] proposed a DCAM-YOLOv5 target detection algorithm for use on ground-penetrating radar (GPR), which solves the problems of low accuracy of traditional methods in detecting multiple types of defects in tunnel lining and the difficulty of feature extraction under fuzzy boundaries.
In summary, in various applications in complex industrial environments, the simplicity of deployment, real-time performance, and good target detection of the YOLO series of algorithms have led researchers to make targeted improvements to the algorithms. This has led to mature application of these variants of the structure in most industrial fields, especially in the study of pedestrian detection methods, and the YOLO series has been highly favored by researchers. However, due to the complex environmental characteristics such as high dust, high noise, weak texture, and uneven illumination in the fully mechanized mining faces of underground coal mines, the existing models are insufficient to fully solve the task of personnel detection in a fully mechanized mining face. Therefore, building on our previous research and adopting the YOLOv8 object detection algorithm [31], we built the MSS-YOLO model by designing an MSEE, SCDH, and SPSC modules to carry out the recognition and detection of miners in a fully mechanized mining face. Meanwhile, based on the miner detection results, SGBM binocular stereo vision matching technology is integrated to compute the miners’ 3D spatial coordinates. The specific details of the network architecture and the miner localization method will be mentioned in the following section.
3. Methods
3.1. MSS-YOLO Network Structure
The YOLO framework has been widely used in the field of deep learning-based object detection, and its network structure includes three important components: Backbone, Neck, and Head. The Backbone uses a convolutional module to extract target features. The Neck component adopts a multi-scale feature fusion technique, which is capable of fusing different stages of feature maps from the Backbone to enhance the feature representation. The Head component is responsible for the final object detection and classification task, in which the detection head contains convolutional and deconvolutional layers to generate the detection results. YOLO’s end-to-end detection and efficient inference speed enable it to adapt to most complex industrial scenarios.
However, although YOLO is able to achieve high-precision object detection in different industrial fields, there are still some problems in the task of identifying miners in a fully mechanized mining face. First of all, the complex environment of underground coal mines, such as high water mist, high dust, and uneven lighting, causes motion blurring of personnel features in images, leading to problems such as omission and misdetection in the algorithm. At the same time, due to the influence of the harsh environment, personnel features at long distances are easily confused with background features, which further leads to the failure of the object detection algorithm under these conditions. In addition, the computational resources in underground coal mines are limited, and most of their devices are edge computing devices. Although the mainstream versions of the YOLO object detection framework have gradually included lightweight structure designs, when running on the equipment of a fully mechanized mining face, there are problems of computational overload, high latency, and high power consumption, making it difficult to effectively complete the detection task.
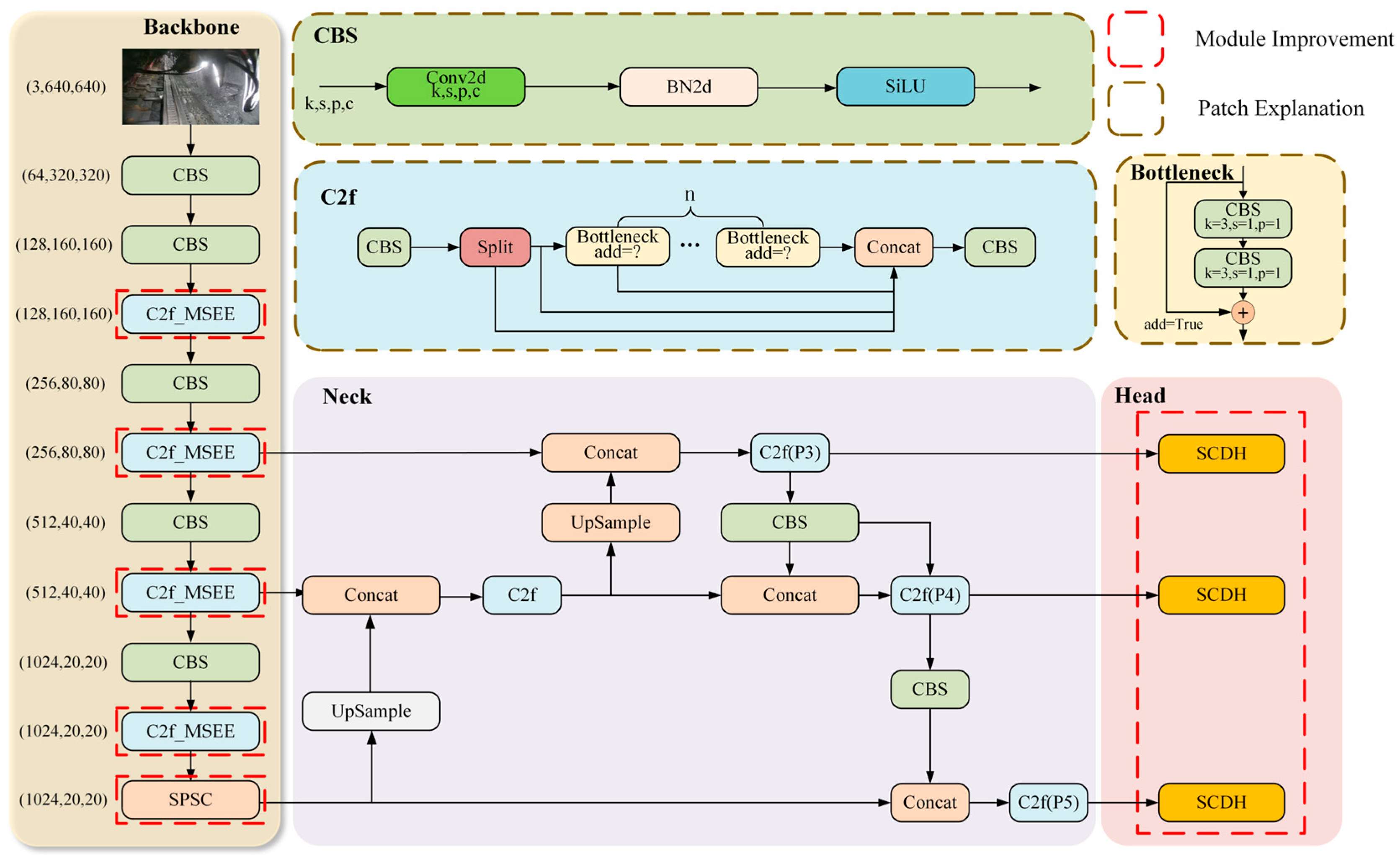
Therefore, to address the above problems, this paper constructs the MSS-YOLO network based on the YOLOv8 network architecture, combined with the target characteristics of the miners in the fully mechanized mining face of the coal mine. The structure of the MSS-YOLO network is shown in Figure 3. Among the features, the designs of the MSEE (M), SCDH (S), and SPSC (S) modules are elaborated in Section 3.1.1, Section 3.1.2, and Section 3.1.3, respectively.
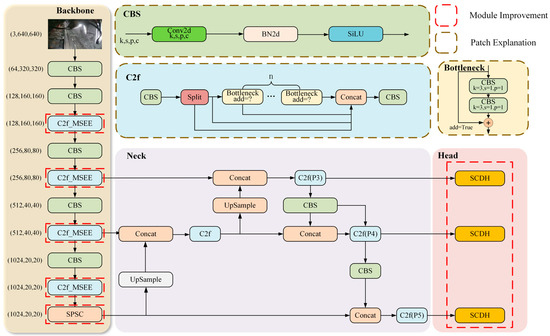
Figure 3.
The architecture of the MSS-YOLO network model.
3.1.1. The Multi-Scale Edge Enhance Module
Due to the high concentration of dust diffusion and uneven illumination in the environment of the fully mechanized mining face in the coal mine, the target features in images are not obvious. As a result, the traditional YOLOv8 detection algorithm struggles to extract miners’ features and is prone to losing target features, leading to omissions, false detections, etc. In order to ensure the stability of miner detection and improve the accuracy of the object detection model in the miner recognition task in the integrated mining face of coal mines, this paper designs an MSEE module. This module is combined with the C2f module to enhance the model’s ability to recognize miner targets of different scales under high dust concentrations and to enhance the expression of edge information.
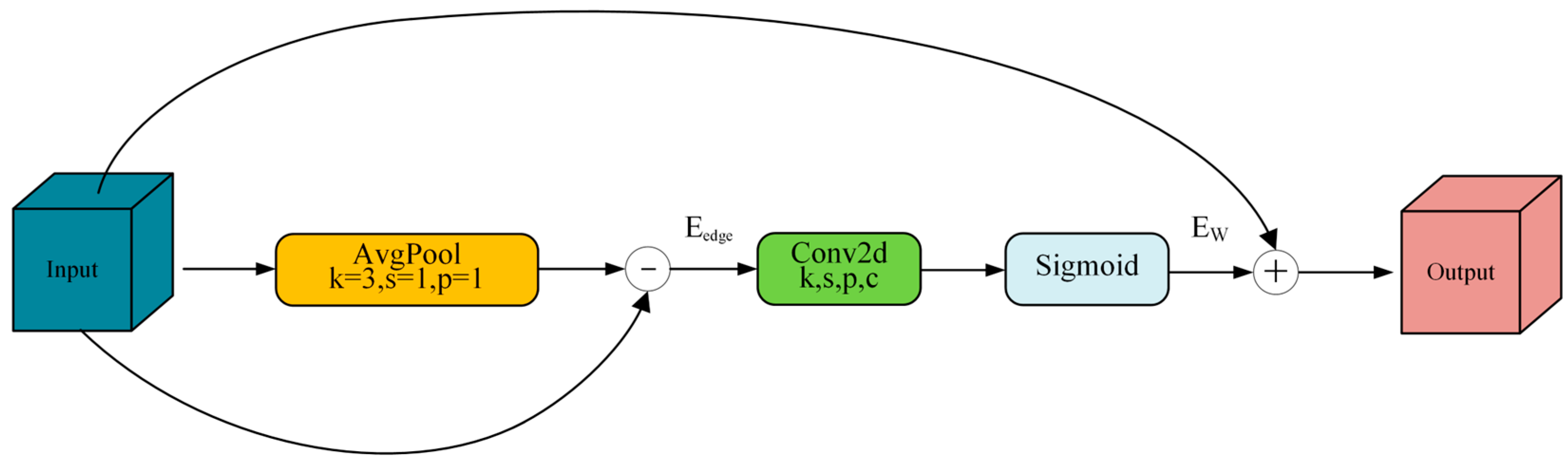
In general, image edge information usually appears in regions with more drastic pixel variations, i.e., locations with large pixel gradient changes. The average pooling operation can smooth the input feature map by applying low-pass filtering to separate high-frequency features. Then, the edge features are obtained by subtracting the low-pass filtered feature map from the original feature map. The calculation formula is shown in Equation (1):
where is the input feature map, is the result after average pooling of , and is the edge feature map. Based on the above theory, in the MSEE module, this paper uses a 3 × 3 average pooling layer to smooth the input features to extract the low-frequency information of the feature map. Then, the original feature map is used to subtract the pooled low-frequency information to obtain the edge information, . Then, a convolutional layer is used to learn the edge information weights, and the output of the extracted edge feature information is weighted by the sigmoid activation function, and the final edge feature weights are calculated as shown in Equation (2):
where is the edge feature weight obtained after the sigmoid operation; is the sigmoid activation function, whose output range is [0, 1]; is the convolution operation; and is the bias term. Then, it is superimposed with the input feature map in the form of residual concatenation to obtain the feature map after enhancing the edge information, which improves the ability of the network to perceive the target edge. The feature Edge Enhancement (EE) module is shown in Figure 4.
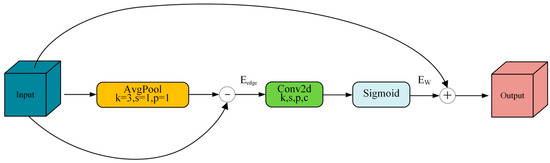
Figure 4.
The feature Edge Enhancement (EE) module.
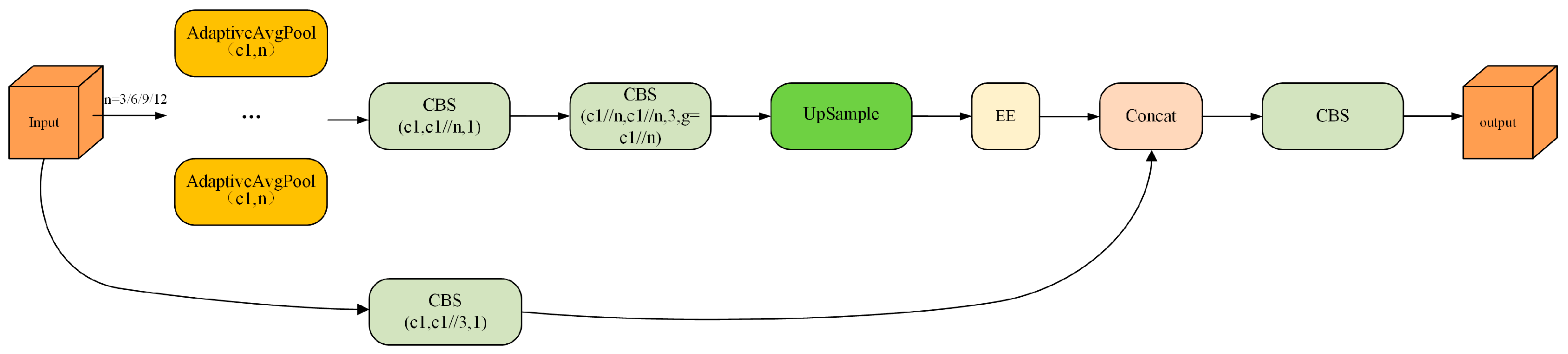
In order to further improve the object detection performance of fuzzy-feature images under harsh conditions, this paper designs four groups of feature branch extraction structures with different scales of 3, 6, 9, and 12 in parallel, based on the pooling layer of AdaptiveAvgPool. This allows the network to capture detailed information at different scales. After applying convolution to the feature maps at different scales, the EE module is used to enhance the edge contour features and details of the target in the image, and then the multi-scale feature maps are spliced together. This compensates for the insufficient extraction of different scales of the edge contour of the network for the coal mine underground and effectively improves the network’s performance in the detection of the weak texture and weak edge targets caused by dense fog and vibration. The structure of the MSEE module is shown in Figure 5.
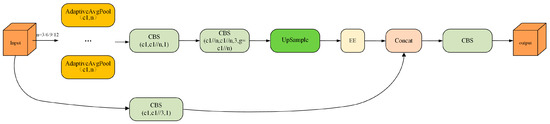
Figure 5.
The structure of the MSEE module.
3.1.2. The Shared Convolutional Detection Head Module
The narrow tunnel, poor lighting conditions, and variable dust concentration in the fully mechanized mining face of the coal mine can lead to poor imaging quality for the images captured by the camera, making it difficult to extract miners’ features and increasing the time required for extraction. Furthermore, when the original YOLOv8n model is used for detection in this environment, due to limited underground computing resources, slow inference speed, and other real-time constraints, it cannot meet the needs of real-time monitoring. Therefore, in order to solve the problem of limited computational resources on the working surface and to improve the model inference speed while guaranteeing the detection accuracy, this paper designs an SCDH module to optimize the model on the basis of the original YOLOv8 detection head structure.
In the SCDH module, Group Normalization (GN) convolution is primarily used to improve the localization and classification performance of the detection head [32]. The structure of the Group Normalization Convolution (Conv_GN) module is shown in Figure 6. In the Conv_GN module, the BN (Batch Normalization) layer in the original CBS module (Figure 3) in the detection head is replaced with a GN layer, which aims to improve the model performance and reduce the complexity by optimizing the consistency of the feature distribution. The traditional BN layer suffers from significant bias in its estimation when the batch size is small, leading to an unstable training process and the introduction of additional noise, which results in significant degradation of the model generalization performance. It is also prone to the problem of insufficient BN when the batch size is too large. In addition, in the inference stage of the model, BN relies on the global statistics accumulated during training, which makes it difficult to adapt to a situation with dynamic input distributions and easily triggers model degradation. GN avoids the network’s dependence on the batch dimension and improves the model’s generalization ability through the normalization strategy of grouping channels, i.e., calculating the mean and variance of each group in the direction of the channel and normalizing them. Among them, the grouping operation can adapt more flexibly to the distributional characteristics of features at different levels and mitigate the risk of overfitting by reducing the parameter coupling in the normalization process. In this paper, the channel dimensions are divided into 16 groups for independent normalization to eliminate the dependence on batch size and enhance the stability during small batch training, while avoiding the resource overhead of maintaining the global mean and variance in the inference phase.

Figure 6.
The structure of the Conv_GN.
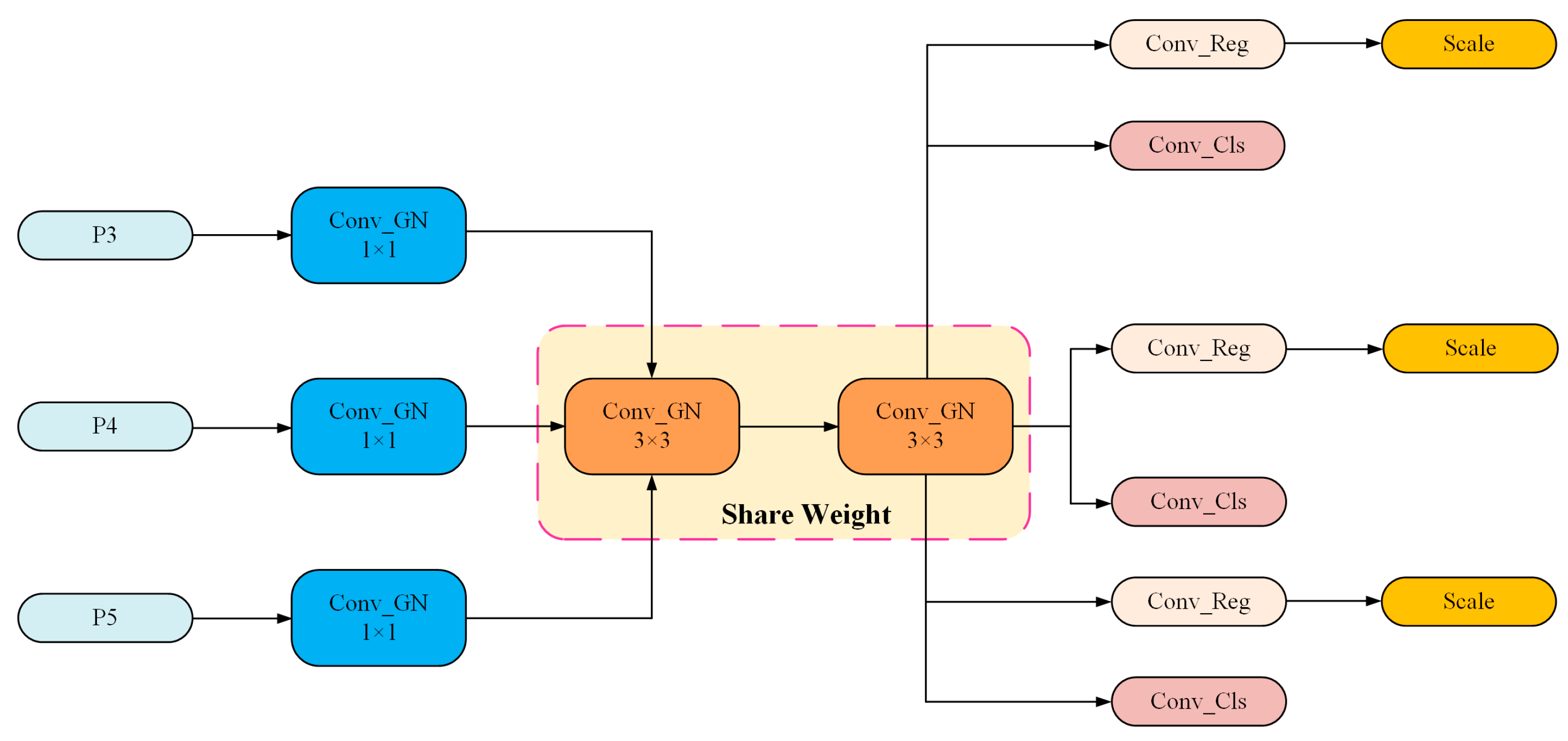
At the same time, weight-sharing convolution is constructed by using the same weight parameter. By constructing this weight-sharing convolution to process features at different locations in the input data, the design ensures that only the feature maps at different scales perform convolution operations, rather than using separate convolution layers for each scale. This design can efficiently deal with feature information at different scales, significantly reduce the number of model parameters, reduce the computational overhead of the model, and greatly accelerate the model inference speed, which ensures that the model still has real-time inference in the case of limited computational resources. In addition, in order to cope with problems such as the inconsistent scale of the target features detected by each detector head, this paper uses the Scale layer to scale the features. The structure of the SCDH module is shown in Figure 7.
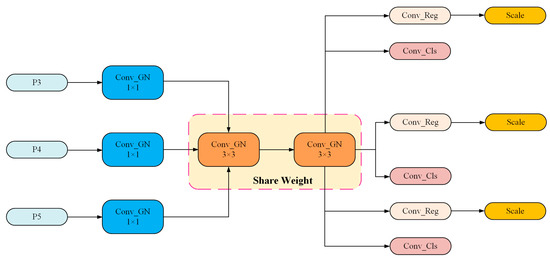
Figure 7.
The structure of the SCDH module.
3.1.3. Spatial Pyramid Shared Conv
Since the pooling operation in the SPPF structure tends to lose detailed information, in the task of personnel detection in mining faces, it is prone to losing the personnel target features in blurred scenes caused by long distances and dust. However, convolution offers higher and more flexible expressive capabilities for feature extraction, and it can better capture the detailed features in images compared with the pooling operation.
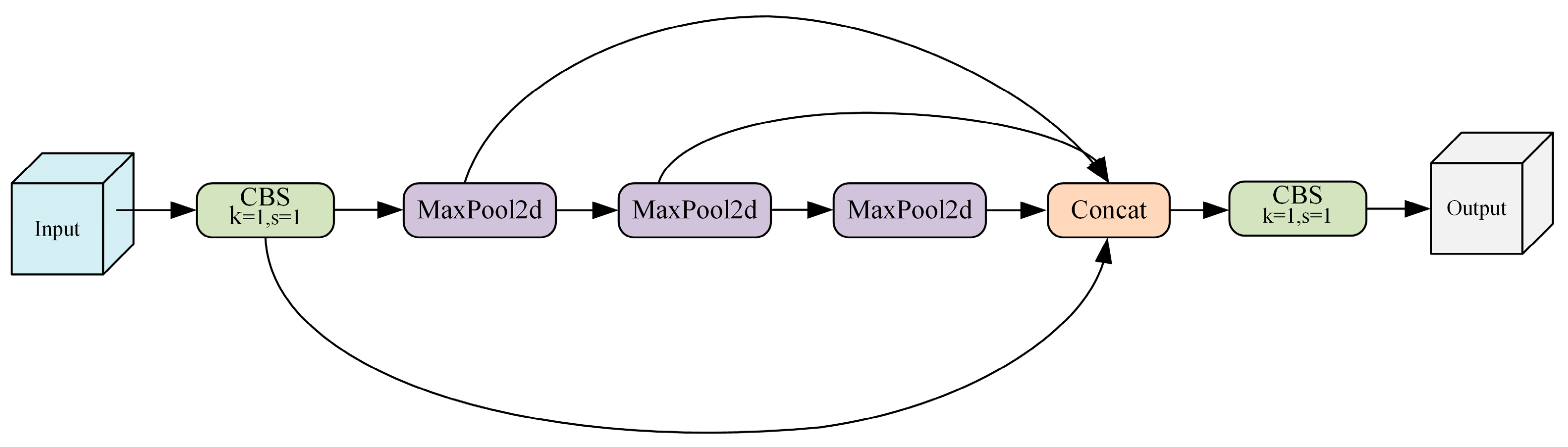
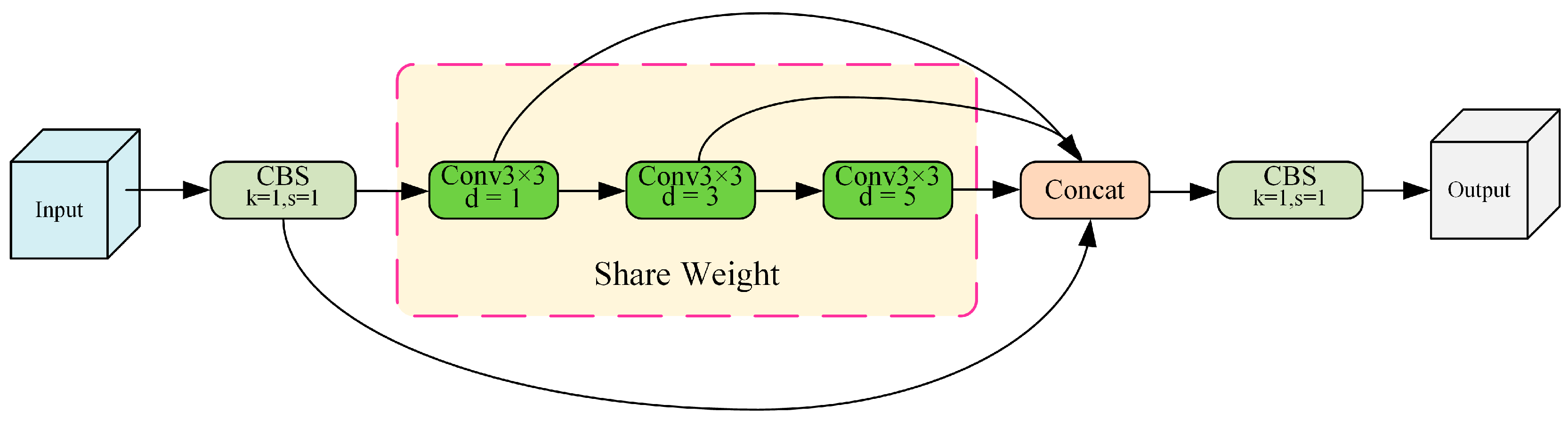
Therefore, in this paper, an SPSC module is designed to replace SPPF based on convolutional operation, aiming to improve the detection performance of the model for long-range targets and ambiguous targets due to dust. Specifically, Conv3×3 with dilation rates d of 1, 3, and 5 is utilized to replace max pooling in the original convolutional SPPF, so that the model extracts features at different scales. This enhances the model’s feature extraction capability for targets of different sizes and between different contextual information. At the same time, weight parameters are shared for Conv3×3 convolutional blocks to reduce model redundancy, lower the number of model parameters, and improve the model inference speed. The structures of the SPPF and SPSC modules are shown in Figure 8 and Figure 9, respectively.
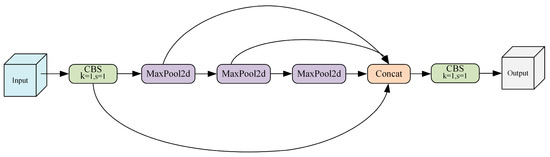
Figure 8.
The structure of the SPPF module.
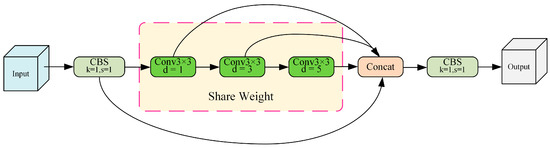
Figure 9.
The structure of the SPSC module.
3.2. Underground Coal Miner Dataset
In order to realize the task of identifying and locating personnel in a fully mechanized mining face underground in coal mines, we combined part of the miner class data in the open dataset DsLMF+, which is our previous open dataset for intelligent identification and classification of anomalies in underground coal mines, and the data of the simulated miners in the Coal Mining Main Laboratory of Xi’an University of Science and Technology (a total of 7675) as the image data. The sensor used to collect the analog miner data was a ZED2i stereo vision camera with a resolution of 1920 × 1080, a baseline of 120 mm, a lens focal length of 4 mm, and a field of view of up to 72° (H) × 44° (V) × 81° (D). In order to ensure the detection stability of the training model in different scenarios and avoid overfitting of the model, the images of the miners in the fully mechanized mining face collected in this dataset contain several different scenarios: low concentration of dust, high concentration of dust, dark environment, overexposed environment, uneven light environment, different distances, and different personnel densities. Some of the acquired images are shown in Figure 10.

Figure 10.
Images of some of the underground personnel captured.
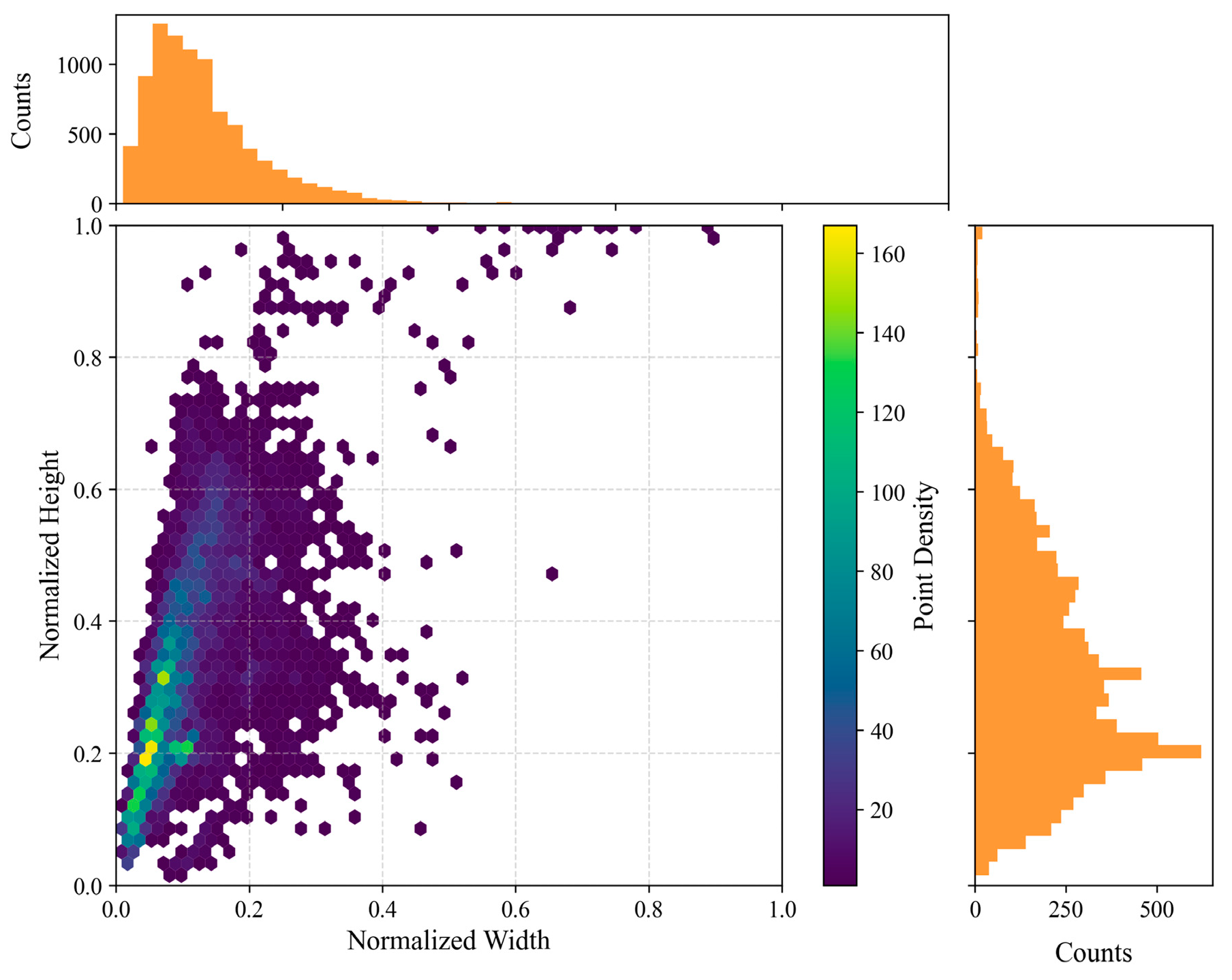
In order to further improve the construction of the dataset, the unlabeled images of miners in the simulated data of the Coal Mining Main Laboratory of Xi’an University of Science and Technology (XUST) were manually annotated using the Labelme tool (5.3.1) (https://github.com/labelmeai/labelme, accessed on 10 September 2023), and the annotated label file format was in YOLO format, with the labels named as Coal_miner. Subsequently, the image data as well as the labeled files were divided in a ratio of 8:2, with the training set containing 6140 sheets and the validation set containing 1535 sheets. The dataset was named UCMD. Meanwhile, to further elaborate the data distribution, this paper summarizes the scatter distribution of the width and height of the normalized bounding box among all the artificial labels in the UCMD dataset. The distribution is shown in Figure 11.
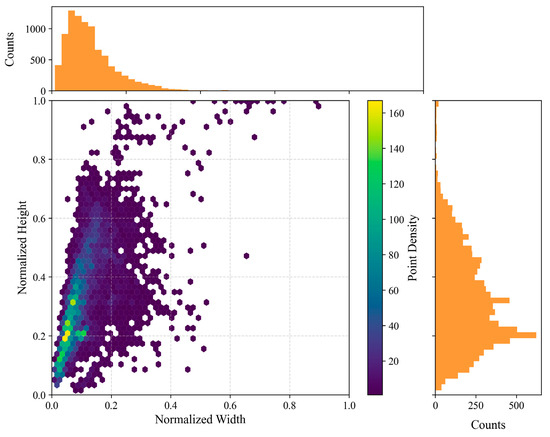
Figure 11.
Heat map of the width and height distribution of the bounding box. The horizontal axis of the heat map represents the normalized width, and the vertical axis represents the normalized height. The orange rectangles represent the histogram of the width distribution and the histogram of the height distribution of the bounding box.
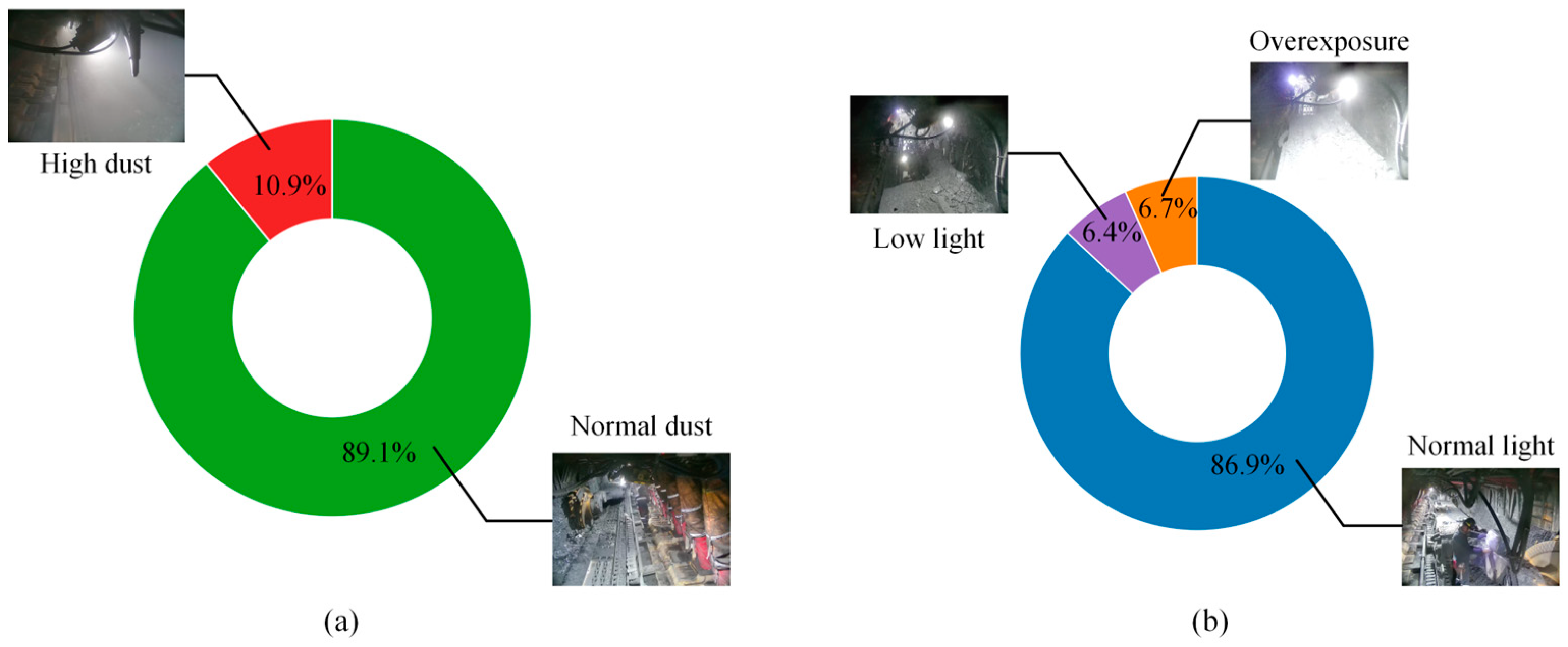
From the scatter distribution of the width and height of the bounding box after the normalization of the UCMD label file in Figure 11, the distribution of the miner label (Coal_miner) is more comprehensive. The width of most of the bounding boxes accounts for about 5% to 10% of the total width of the image, and the height of most of the bounding boxes accounts for about 20% of the total height of the image. There are also some extremely large bounding boxes and very small bounding boxes, which proves the reasonableness of the construction of the UCMD dataset and enables the model to have a certain degree of generalization ability, as well as reducing the risk of overfitting during the training of the network. At the same time, in order to calculate the different distributions of the image data in different environments and conditions, we invited three people from the team who have experience of working in underground coal mines to determine the conditional distribution of the UCMD dataset. If divided based on dust concentration, the total number of images with a high dust concentration is 836, equal to 10.9 percent of the total, and the total number of images with a dust-free or normal dust concentration environment is 6839, or 89.1 percent of the total. If divided by light brightness, the total number of overexposed images is 511 (6.7%), the total number of images in low light is 494 (6.4%), and the total number of images in normal light is 6670 (86.9%). From the frequency statistics of this extreme environment, it can be concluded that the traditional/commonly used visual target detection methods on the surface cannot be directly transplanted and used underground, further illustrating the importance of the proposed MSS-YOLO model. The results of the distribution of different environments are shown in Figure 12.
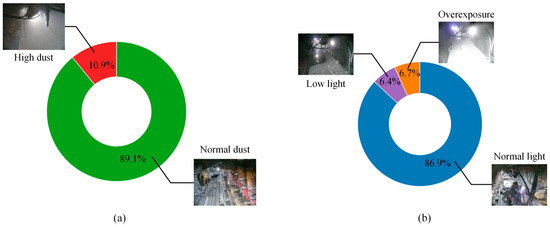
Figure 12.
The results of the distribution of different environments. (a) The distribution of data under different cutting dust conditions; (b) the distribution of data under different light conditions.
3.3. Personnel Localization Method Based on SGBM Stereo Vision Matching Algorithm and MSS-YOLO
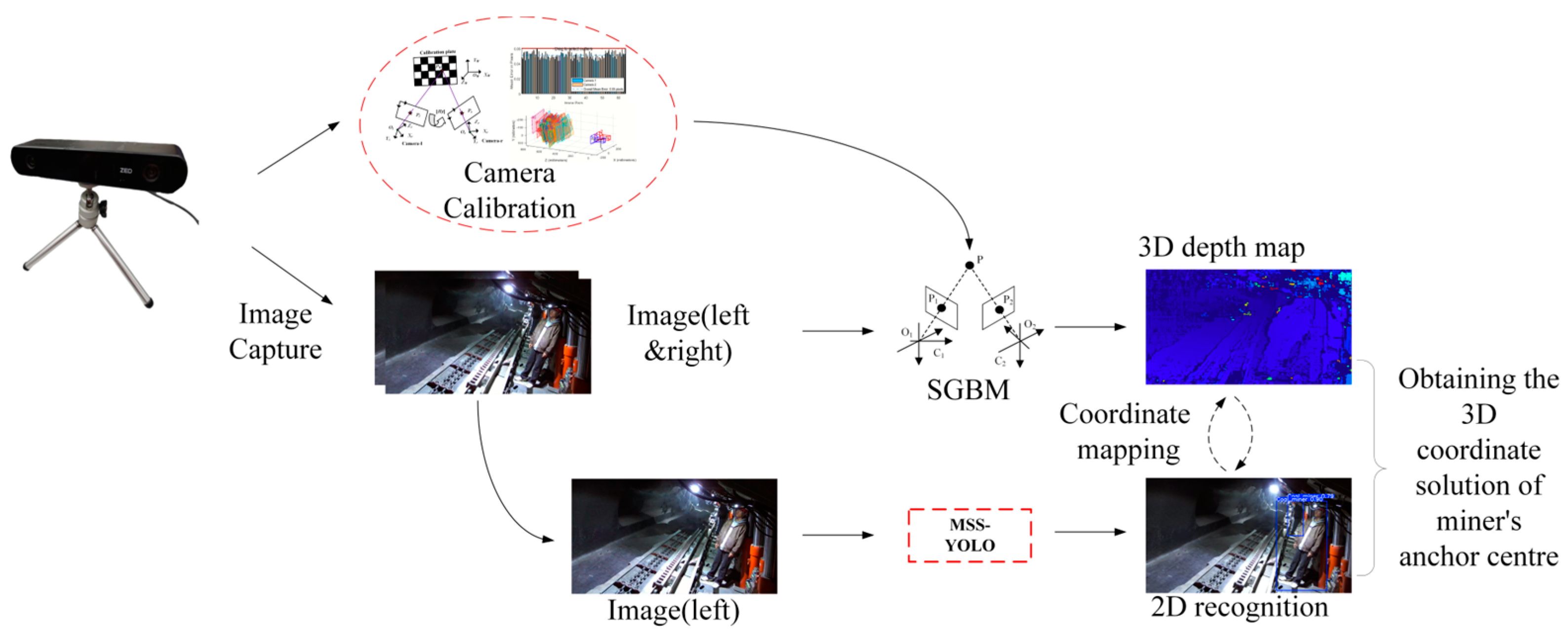
In order to realize the three-dimensional (3D) positioning of personnel, this paper utilized a ZED2i binocular camera for image acquisition; the Matlab2018b camera calibration toolbox was used to calibrate the binocular camera using the checkerboard grid calibration method [33]. The disparity of binocular images was calculated according to the SGBM binocular stereo vision matching method.
Firstly, MSS-YOLO was utilized for underground coal mine personnel recognition on the left view of the ZED2i binocular camera. At the same time, disparity calculation was performed on the binocular view based on the SGBM visual matching algorithm to obtain the 3D spatial information of each pixel under the current frame, which was transformed into a disparity map. The cost calculation method, the global energy function, the cost aggregation and disparity calculation, and the disparity map calculation formulas are shown in Equations (3)–(6) [34], respectively. Finally, the rectangular pixel centers obtained from the miner recognition results on the left view were mapped with the disparity map in order to obtain the 3D spatial coordinate information of the personnel coordinates. The solution flow is shown in Figure 13.
where denotes the basic matching cost, is the disparity value of the current pixel, are pixel coordinates, and denotes a block centred on with a size of 5 × 5.
where is the global energy function, is the weight of the smoothing term, and denotes a pixel in the neighborhood of ).
where is the result of the disparity calculation.
where is the focal length of the camera, is the baseline distance between the left and right cameras, and is the corresponding value in the disparity map.
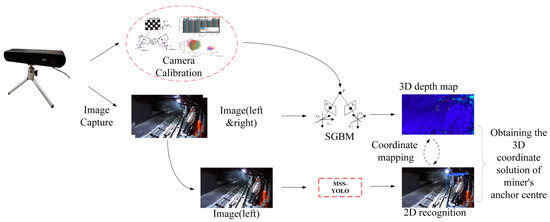
Figure 13.
Flowchart of 3D spatial solution for underground personnel in the fully mechanized mining face.
4. Experiments and Performance
4.1. Training Environment and Parameter Settings
In the software environment of the experiments in this paper, the programming language used was Python 3.8, and the deep learning framework was Pytorch 2.0.0. Meanwhile, CUDA 11.8 and cuDNN 8.7.0 were used as the deep learning acceleration modules. Based on the Windows 10 system, the model training was completed with an Intel® CoreTM i9-13900 K CPU and an NVIDIA GeForce TUF-RTX4080. Regarding the training parameters, the initial learning rate (lr0) was set to 0.01, the final learning rate (lrf) was set to 0.01 times the initial learning rate, the momentum was set to 0.937, the weight decay coefficient was set to 0.0005, and the optimizer was SGD. The maximum number of training epochs was set to 300, the batch size for training samples was set to 32, and the input size of the image was 640 × 640 × 3.
4.2. Experimental Results and Analysis
4.2.1. Experimental Validation of MSS-YOLO-Based Miner Identification
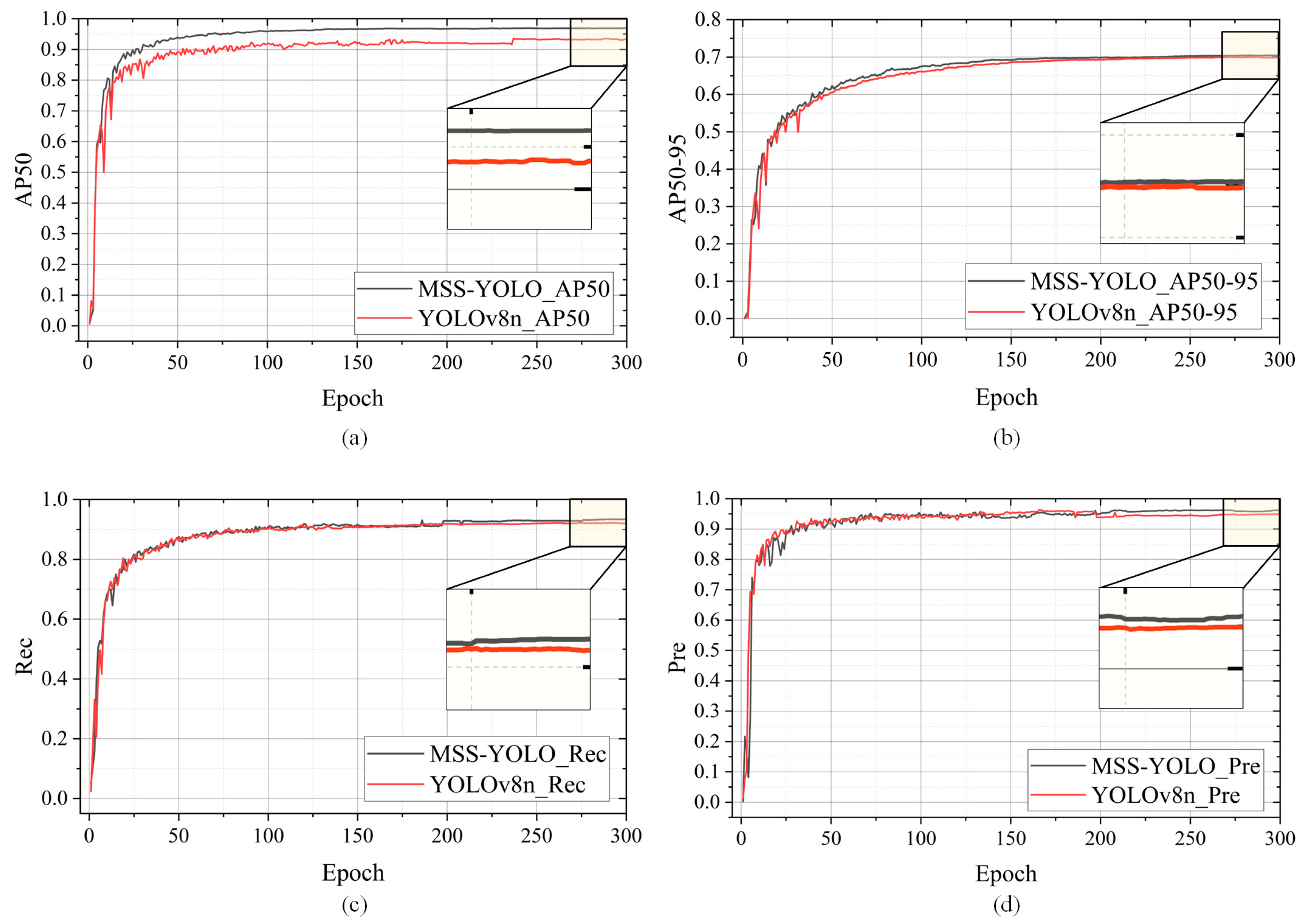
In order to verify the stability and generalization ability of MSS-YOLO for the detection of miners in a coal mining face under different scenarios, this paper utilized a ZED-2i camera to collect a total of 832 personnel images captured at different distances and under different environmental conditions within a simulated tunnel in the coal mine laboratory of Xi’an University of Science and Technology. These images constitute the UCMD test set for model and method validation. In these photos, in order to simulate the actual working conditions of a fully mechanized mining face, a smoke maker, low light, and a mining lamp were used to simulate the real roadway conditions of an underground coal mine. The miner detection results in the fully mechanized mining face were quantitatively analyzed using four commonly used evaluation indexes: Precision (Pre), Recall (Rec), AP50, and AP50-95, where AP50 and AP50-95 refer to the average of the Pre metrics calculated for an IoU threshold of 0.5 and from 0.5 to 0.95 in steps of 0.05, respectively. The variation curves of the performance evaluation metrics of MSS-YOLO and YOLOv8n trained on the UCMD dataset are shown in Figure 14, and the calculation formulas are shown in Equations (7) and (8) [35], respectively.
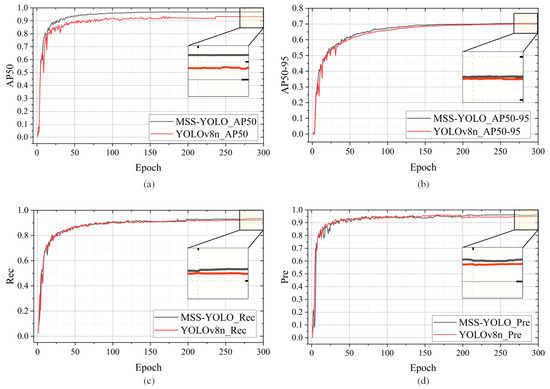
Figure 14.
Variation curves of performance evaluation metrics for MSS-YOLO vs. YOLOv8n trained on the UCMD dataset. (a) Comparison of AP50, (b) comparison of AP50-95, (c) comparison of Rec, and (d) comparison of Pre. The black curve represents the training curve of the original YOLOv8n model, and the red curve represents the training curve of MSS-YOLO. The black line box shows a localized zoom of the curve.
In the formulas, TP, FP, and FN represent the true positives, false positives, and false negatives of the inference results of the miner detection model, respectively. In this paper, TP represents the total number of miners correctly detected by the model, FP represents the total number of miners incorrectly detected by the model as miner targets in the underground coal mine, and FN represents the total number of miners not detected by the model in the underground coal mine.
As can be seen from Figure 14, the AP50, AP50-95, Rec, and Pre metrics of MSS-YOLO converge to 0.96915, 0.70416, 0.93351, and 0.96168, respectively. These values are higher than those of YOLOv8n, which demonstrates that the improved model is able to better satisfy the demand for personnel identification in the integrated mining face of the underground coal mine.
In order to further verify the effectiveness of MSS-YOLO’s improvement of each module of YOLOv8n, a set of ablation experiments were designed in this paper to analyze the effectiveness of the model’s improvement. Taking YOLOv8n as the benchmark model, the results of the ablation experiments are shown in Table 1, where “√” indicates that the module is used and “×” indicates that the module is not used.

Table 1.
Results of ablation experiments.
As can be seen from Table 1, relative to the YOLOv8n benchmark model, MSS-YOLO improves the AP50 metric by 3.655%, AP50-95 by 0.494%, Rec by 1.336%, and Pre by 1.26% and reduces the inference time by 1.2 ms. It is demonstrated that the MSEE module is able to pay attention to the target edges and the local feature information of targets of different sizes and scales when detecting in the poor environment of the fully mechanized mining face in the coal mine. This ensures that the detection of large targets will not be lost, while also improving the accuracy of the detection of small targets. It is also demonstrated that the introduction of the SCDH module ensures that the model utilizes the shared convolution to reduce the number of parameters and better improve the inference speed of the model. At the same time, it is shown that the SPSC module is able to reduce the model redundancy in a significant way, capture the detailed features in the image effectively, and better improve the model’s detection performance for dust and targets at long distances.
To further validate the enhancement in detection performance after model improvement, this paper compared MSS-YOLO with the two-stage algorithm Faster-RCNN [36], the single-stage algorithm SSD, and other mainstream YOLO variants using five quantitative metrics, which are AP50, AP50-95, Recall (Rec), Precision (Pre), and Latency. The validation results are shown in Table 2. At the same time, in order to more intuitively represent the detection results of each algorithm, this paper visualized some of the detection results obtained from the different models, and the collated results are shown in Figure 15.
Table 2.
Comparison of the results of miner identification and detection and evaluation of integrated mining face under different models.

Figure 15.
Partial detection results for different models. The highlighted part in the lower right corner is the zoomed-in result of the part in the yellow box.
As shown in Table 2, compared to SSD, Faster-RCNN, and other mainstream versions of YOLO, MSS-YOLO was able to obtain faster and more stable results on the UCMD dataset under all metrics. Among them, compared with YOLOv11, the values for AP50, AP50-95, and Pre improved by 2.188%, 0.19%, and 1.091%. Although the Rec value was reduced by 0.247%, the inference speed improved by 2.3 ms.
As can be seen from Figure 15, compared with other mainstream algorithms, MSS-YOLO can obtain higher detection confidence in the close detection task and when there is direct interference to the camera from the miner’s lamp, and it can improve the leakage of the other models in the miner detection task at long distances and obtain accurate detection results. In the miner detection task with high dust, it can also obtain miner detection results in a more stable way. To a certain extent, it meets the requirements of personnel detection in the fully mechanized mining face, thus further ensuring the positioning of coal mine personnel and supporting the task of identifying those violating the rules and invading abnormal areas.
4.2.2. Experimental Validation of Personnel Localization Method Based on SGBM Stereo Vision Matching Algorithm + MSS-YOLO
In order to validate the personnel positioning method described in this paper, we simulated the actual situation of a fully mechanized mining face in a coal mine laboratory and conducted experimental validations. Specifically, a cutting dust simulator (A-1000, manufactured by JC Light, Guangdong, China) and a mobile power supply (DC12–24 V, manufactured by CARWANTA, Guangdong, China) were used to replicate a dust-laden environment. With reference to the actual camera arrangement in a fully mechanized mining face, a ZED2i binocular camera was installed on top of the hydraulic bracket. Meanwhile, a digital total station (FX201, Manufactured by SOKKIA, Saitama, Japan) was used to measure the center of the personnel in order to obtain their three-dimensional spatial coordinates under the total station’s coordinate system. The entire experiment was carried out on a platform, as shown in Figure 16.

Figure 16.
Experimental platform for binocular visual localization of miners in the fully mechanized mining face.
In the experiment, the main parameters of the SGBM binocular stereo vision matching algorithm used in this paper were as shown in Table 3. In order to ensure the feasibility of the described method, the experiment was divided into 20 groups for experimental verification according to the dust concentration, personnel distance, and the number of personnel. Among them, groups 1–12 comprised a single person with different concentrations and at different distances up to 10 m from the camera, and groups 13–20 comprised two people at different concentrations and at different distances up to 10 m from the camera. At the same time, in order to unify the coordinate system of the total station and binocular camera and to facilitate the comparison of the positioning results, with the help of the checkerboard, we utilized the position information of the four boundary points of the checkerboard under the left view of the digital total station and binocular camera as the intermediate conversion quantity. Furthermore, we solved the left view of the binocular camera to obtain the rotation matrix R for the total station and the displacement vector T by using PnP (Perspective-n-Point) in order to convert the results obtained by the binocular camera to the total station coordinate system. In this paper, the total station data were taken as the actual true values, and the analysis of the identification and localization results and errors for the 20 groups of people is shown in Table 4.
Table 3.
Values of the main parameters of the SGBM algorithm.
Table 4.
Personnel identification and localization results and error analysis.
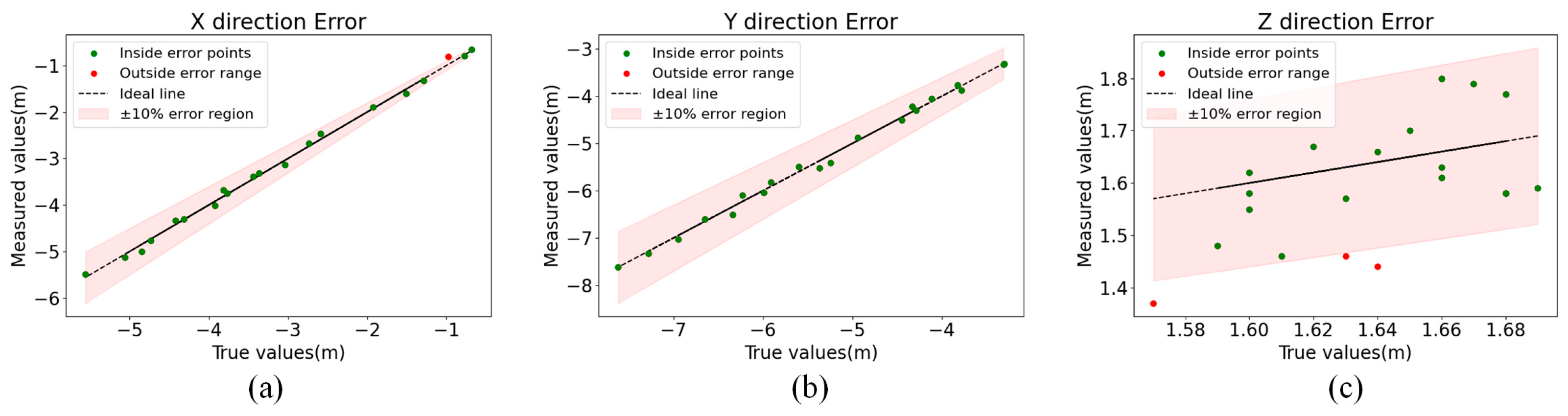
As shown in Table 4, the x- and y-directions have high position measurement accuracy, while the position measurement error in the z-direction is large. In the measurement range of 3–10 m, the measurement errors of the positions in the x-, y-, and z-directions are within 0.170 m, 0.160 m, and 0.200 m, and the average errors are 0.014 m, 0.008 m, and 0.043 m, respectively. At the same time, from the point of view of the measurement distance, the distance measurement error is within 0.185 m, which meets the maximum error for personnel positioning in the coal mine working face. The influence of the positioning method described in this paper on the measurement accuracy of miners in the fully mechanized mining face is shown in Figure 17.
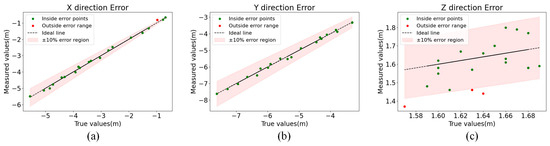
Figure 17.
Personnel identification and localization results and error analysis. (a) The x-axis error, (b) y-axis error, and (c) z-axis error. The black straight line is where the actual ideal miner position is located, green points are measurement points with an error of ±10% or less, and red points are measurement points outside the ±10% error region.
As can be seen from Figure 17, the measurement error of the method described in this paper is mostly within 10% of the actual true value in the x-, y-, and z-axes, which shows good robustness. Meanwhile, in order to further visualize the experimental results, some of the detection results in this paper are shown in Figure 18. The upper right number of the detection anchor box represents the actual distance measured by the method of this paper.

Figure 18.
Miner binocular vision recognition and localization detection results map. (a) Original image data; (b) 3D depth map after being solved by the SGBM algorithm; (c) resultant map of the 3D spatial data of the miner bounding box detection center obtained by the MSS-YOLO fusion SGBM model.
As can be seen from Figure 18, the miner measurement method described in this paper for a fully mechanized mining face has good stability under the conditions of near distance, long distance, low dust concentration, high dust concentration, and direct light exposure from a mine lamp. It can meet the requirements of three-dimensional position measurement of miners in a fully mechanized mining face.
5. Discussion and Conclusions
In this paper, an MSS-YOLO network model has been proposed to address the problems of target leakage detection, false detection, and poor real-time performance under limited computational resources, which are faced by miner identification and localization systems in complex environments such as fully mechanized mining faces with high dust concentrations and uneven illumination in underground coal mines. This model efficiently, rapidly, and stably identifies and detects miner targets. Based on the MSS-YOLO detection results, this paper utilized SGBM binocular stereo vision matching technology to achieve real-time localization of miners in three-dimensional space, and experimental validation was carried out by simulating the roadway, which proved the effectiveness of MSS-YOLO. The specific conclusions are as follows:
- Aiming to address the problems that traditional deep learning algorithms face, such as being prone to target omission and misdetection under the complex working environment of coal mines and the inability to guarantee good real-time performance under limited computational resources, the MSS-YOLO model, suitable for the identification and detection of miners in a fully mechanized mining face, is proposed. Combining part of the miners’ data from the DsLMF+ dataset and miners’ data from different distances and different dust concentrations in a simulated roadway environment of a generalized mining face, we constructed the personnel localization dataset UCMD, which contains 7675 images, and manually labeled the miners. Compared with Faster-RCNN, SSD, and other mainstream versions of the YOLO series, the performance of the proposed MSS-YOLO model is significantly improved, and it is able to accomplish the personnel detection and identification tasks in real time and stably under different lighting, different distances, and different cutting dust concentrations.
- The proposed underground coal mine miner detection network MSS-YOLO was utilized for validation on the UCMD dataset. Compared with the benchmark model YOLOv8n, MSS-YOLO showed improvements of 3.655% on the AP50 metric, 0.494% on AP50-95, 1.336% on Recall, and 1.26% on accuracy and reduced the inference time by 1.2 ms. Although its Rec value was slightly lower than that of YOLOv11n, it outperformed YOLOv11n in all other metrics.
- In order to realize miner localization in the fully mechanized mining face, this paper combined MSS-YOLO and the SGBM binocular stereo vision matching algorithm. Based on the detection results of MSS-YOLO and the binocular vision disparity solution, the three-dimensional spatial coordinates of the center area of the anchor frame, where the miner was located, were located, and experimental validation of this miner localization method was carried out. The experimental results showed that in the measurement range of 3–10 m in 20 groups, the measurement errors of the positions in the x-, y-, and z-directions were within 0.170 m, 0.160 m, and 0.200 m, with an average error of 0.014 m, 0.008 m, and 0.043 m, respectively. Meanwhile, in terms of the measurement distances, the measurement errors of the distances were within 0.185 m, which meets the maximum permitted positioning error for personnel in the working face of the coal mine.
- From the above conclusions, it can be seen that the MSS-YOLO model proposed in this paper is capable of obtaining excellent results under the premise of ensuring good real-time performance in recognizing and detecting miners under the complex background of integrated mining faces in coal mines. However, when the vision sensor operates under extreme conditions such as artificial over-obscuration and severe exposure, it can lead to the loss of most of the features of the target miner, resulting in unstable detection results from MSS-YOLO and problems such as missed and false detections. At the same time, the SGBM binocular stereo vision matching algorithm is also prone to problems such as reduced matching accuracy, discontinuity, and differential leakage under such working conditions, which affects the accuracy of miner positioning. Therefore, in future work, we will focus on discussing and researching image target feature extraction and recovery under extreme coal mine conditions, such as the study of dust degradation modeling based on underground coal mine images and the study of quaternion-based [39] image brightness overexposure and underexposure correction, etc. Meanwhile, for problems such as the insufficient parallax matching solution accuracy of the SGBM binocular stereo vision matching algorithm under extreme conditions, we will study a fast and efficient parallax solving method to optimize and improve the stereo vision matching effect based on the combination of octonion-based transform moments with deep learning [40], in order to further improve the effectiveness of miner identification and localization.
Author Contributions
Conceptualization, W.Y. and X.Z.; methodology, W.Y. and X.Z.; software, Y.W.; validation, Y.W., W.Y. and L.Z.; formal analysis, L.Z.; investigation, T.W.; resources, Y.C.; data curation, Y.W. and J.J.; writing—original draft preparation, W.Y.; writing—review and editing, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work received funding from the National Natural Science Foundation of China, grant number 52104166; the Natural Science Foundation of Shaanxi Province, grant number 2021JLM-03; and the Key R&D project in Shaanxi, grant number 2023-YBGY-063.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The source code and all data are available upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, Z.; Li, C.; Wu, D.; Dai, W.; Geng, S.; Ding, Q. A Wireless Sensor Network Based Personnel Positioning Scheme in Coal Mines with Blind Areas. Sensors 2010, 10, 9891–9918. [Google Scholar] [CrossRef] [PubMed]
- Chen, W. Personnel precise positioning system of coal mine underground based on UWB. J. Phys. Conf. Ser. 2021, 1920, 012115. [Google Scholar] [CrossRef]
- Li, X.; Wang, S.; Liu, B.; Chen, W.; Fan, W.; Tian, Z. Improved YOLOv4 network using infrared images for personnel detection in coal mines. J. Electron. Imaging 2022, 31, 013017. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, X.; Ma, B.; Wang, Y.; Wu, Y.; Yan, J.; Zhang, C.; Wan, J.; Wang, Y.; Huang, M.; et al. An open dataset for intelligent recognition and classification of abnormal condition in longwall mining. Sci. Data 2023, 10, 416. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, S.; Chen, W.; Weng, Z.; Fan, W.; Tian, Z. An Intelligent Vision-Based Tracking Method for Underground Human Using Infrared Videos. Symmetry 2022, 14, 1750. [Google Scholar] [CrossRef]
- Zhang, H.; Han, W.; Xu, Y.; Wang, Z. Analysis on the Development Status of Coal Mine Dust Disaster Prevention Technology in China. J. Healthc. Eng. 2021, 2021, 574579. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Y.; Duan, S.; Pan, H. An efficient detection of non-standard miner behavior using improved YOLOv8. Comput. Electr. Eng. 2023, 112, 109021. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef]
- Zheng, C.; Pei, W.; Yan, Q.; Chong, Y. Pedestrian detection based on gradient and texture feature integration. Neurocomputing 2017, 228, 71–78. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Forsyth, D. Object Detection with Discriminatively Trained Part-Based Models. Computer 2014, 47, 6–7. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Seattle, WA, USA, 27 July 2020. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Jin, Y.; Zhang, Y.; Cen, Y.; Li, Y.; Mladenovic, V.; Voronin, V. Pedestrian detection with super-resolution reconstruction for low-quality image. Pattern Recognit. 2021, 115, 107846. [Google Scholar] [CrossRef]
- Esmaeil Abbasi, A.; Mangini, A.M.; Fanti, M.P. Object and Pedestrian Detection on Road in Foggy Weather Conditions by Hyperparameterized YOLOv8 Model. Electronics 2024, 13, 3661. [Google Scholar] [CrossRef]
- Liang, Z.; Wang, W.; Meng, R.; Yang, H.; Wang, J.; Gao, H.; Li, B.; Fan, J. Vehicle and Pedestrian Detection Based on Improved YOLOv7-Tiny. Electronics 2024, 13, 4010. [Google Scholar] [CrossRef]
- Liu, S.; Cao, L.; Li, Y. Lightweight Pedestrian Detection Network for UAV Remote Sensing Images Based on Strideless Pooling. Remote Sens. 2024, 16, 2331. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Lin, W.-Y. Ratio-and-Scale-Aware YOLO for Pedestrian Detection. IEEE Trans. Image Process. 2021, 30, 934–947. [Google Scholar] [CrossRef]
- Li, X.; Chen, S.; Tian, C.; Zhou, H.; Zhang, Z. M2FNet: Mask-Guided Multi-Level Fusion for RGB-T Pedestrian Detection. IEEE Trans. Multimed. 2024, 26, 8678–8690. [Google Scholar] [CrossRef]
- Zhang, H.; Mu, C.; Ma, X.; Guo, X.; Hu, C. MEAG-YOLO: A Novel Approach for the Accurate Detection of Personal Protective Equipment in Substations. Appl. Sci. 2024, 14, 4766. [Google Scholar] [CrossRef]
- Ying, Y.; Wang, H.; Zhou, H. Research on Abnormal Behavior Monitoring in University Laboratories Based on Video Analysis Technology. Appl. Sci. 2024, 14, 9374. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, X.; Shi, J. YOLOv5-based Dense Small Target Detection Algorithm for Aerial Images Using DIOU-NMS. Radioengineering 2024, 33, 12–22. [Google Scholar] [CrossRef]
- Chen, D.; Xiong, S.; Guo, L. Research on Detection Method for Tunnel Lining Defects Based on DCAM-YOLOv5 in GPR B-Scan. Radioengineering 2023, 32, 299–311. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18-19 April 2024; pp. 1–6. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R.; Zabih, R. A Taxonomy And Evaluation Of Dense Two-Frame Stereo Correspondence Algorithms. Int. J. Comput. Vis. IJCV 2000, 47, 7–42. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, H.; Zhao, Y. Yolov7-sea: Object detection of maritime uav images based on improved yolov7. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 233–238. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Tahiri, M.A.; Amakdouf, H.; El mallahi, M.; Qjidaa, H. Optimized Quaternion Radial Hahn Moments Application to Deep Learning for the Classification of Diabetic Retinopathy. Multimed. Tools Appl. 2023, 82, 46217–46240. [Google Scholar] [CrossRef]
- Tahiri, M.A.; Boudaaoua, B.; Karmouni, H.; Tahiri, H.; Oufettoul, H.; Amakdouf, H.; Qjidaa, H.; Abouhawwash, M.; Askar, S.S.; Sayyouri, M. Octonion-based transform moments for innovative stereo image classification with deep learning. Complex Intell. Syst. 2024, 10, 3493–3511. [Google Scholar] [CrossRef]


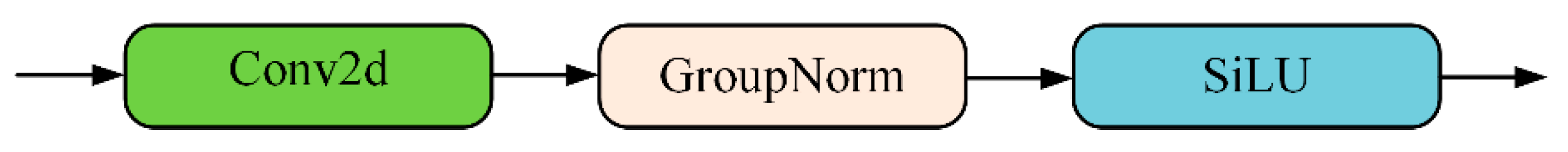




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).