1. Introduction
Time series data refers to a collection of data points associated with specific time components, typically recorded at uniform time intervals [
1]. This type of data reflects the state or magnitude of a particular phenomenon or object over time [
2].
Multivariate Time Series (MTS) is a set of time series that share the same timestamps. At each time point, data is represented as an array of variables or numerical values, essentially forming a collection of multiple univariate time series captured over time [
1]. This data structure enables the analysis of relationships and dynamic changes among variables, serving as a crucial tool for studying complex systems and exploring interactions across various domains. In the evolving field of time series analysis, identifying patterns and dynamic changes is essential for accurate forecasting and deep insights [
3].
Traffic flow data is a typical example of MTS, exhibiting complex temporal characteristics such as long-term trends, seasonality, periodicity, and randomness. For instance, commuting traffic increases during morning and evening rush hours but drops significantly at night; commercial areas may be busier on weekends, while commuter routes experience lower traffic; highway traffic surges during long holidays, whereas urban road traffic decreases; sudden accidents can cause a sharp drop in traffic, followed by a congestion recovery phase.
Additionally, the propagation of traffic flow within a road network is constrained by its topology. Traffic flow is not independently distributed but is influenced by upstream and downstream road segments. There is often a strong correlation between adjacent road segments or regions. Thus, beyond the typical characteristics of MTS data, traffic flow also exhibits complex spatial features.
While analyzing data characteristics, it is essential to consider not only its temporal and spatial properties but also its frequency-domain features. For example, in traffic flow data, the magnitude of different frequency components after time-frequency transformation represents the signal’s energy at various frequencies, while the frequency corresponding to the maximum magnitude indicates the primary traffic cycle. In signal processing and time series analysis, time-domain and frequency-domain methods each have their strengths and limitations. Combining both approaches leverages their complementary advantages, enhancing signal analysis and feature extraction. This integration enables a more comprehensive examination of signals across both time and frequency dimensions, overcoming the limitations of a single analysis method.
Anomalies in traffic flow data often indicate special situations, such as equipment failures or unexpected incidents within specific time periods. Failure to detect these anomalies in a timely and accurate manner may lead to severe consequences. Fast and effective anomaly detection helps identify potential issues early, minimizing unnecessary economic losses [
4]. Therefore, efficiently extracting potential anomalies from data holds significant practical value.
However, specialized anomaly detection methods for traffic flow data remain scarce. Existing studies often adopt a uniform detection approach without fully considering the varying needs of different domains. Moreover, many methods primarily focus on the spatio-temporal characteristics of traffic flow data while overlooking its frequency-domain features, limiting the exploration of periodic patterns. This single-dimensional analysis lacks specificity in handling traffic anomalies, making it challenging to accurately capture complex abnormal patterns.
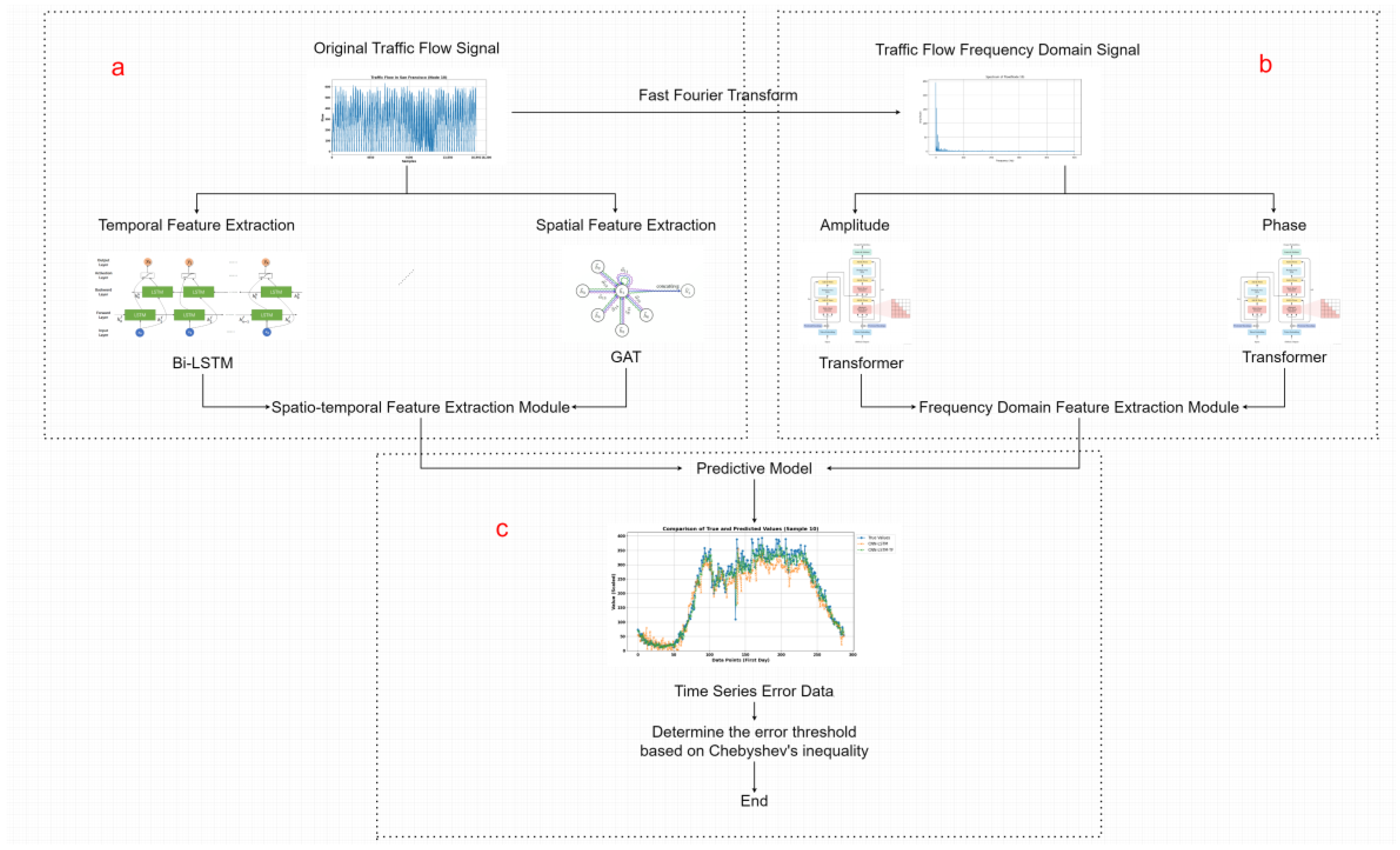
To achieve more precise anomaly detection in traffic flow data, this paper proposes a prediction-based anomaly detection method for traffic flow data with multi-domain feature extraction. The key innovations of this method are as follows:
This method not only focuses on the temporal characteristics of traffic flow data but also fully considers the spatial correlations between the data. By using different models to jointly learn both temporal and spatial features, it enables feature extraction in the time domain. Additionally, recognizing that traffic flow data often exhibits periodicity and may be subject to noise interference, this paper leverages the advantages of frequency-domain analysis (such as periodicity identification and noise suppression) to further explore the frequency-domain characteristics of the data. The model then learns its frequency-domain representation, achieving more comprehensive feature extraction. Experimental results show that prediction models that fully explore data features can significantly improve prediction accuracy.
- 2.
Error Analysis and Threshold Determination
Prediction-based methods are widely used in anomaly detection, relying on the difference between predicted and observed values to identify anomalies. However, determining an appropriate error threshold in existing methods often lacks adaptability and reliability. To address this issue, this paper introduces Chebyshev’s inequality to establish a more scientific and rational threshold for error analysis, thereby enhancing the accuracy and robustness of anomaly detection.
2. Related Work
In real-world monitoring scenarios, traffic flow data collected by sensors is typically unlabeled [
5] and often suffers from incompleteness due to various objective factors, leading to anomalies and missing data. This necessitates anomaly detection models with unsupervised learning capabilities [
6,
7]. Additionally, the high dimensionality, dynamic nature, and complexity of MTS data [
8] make accurately identifying anomalous data a challenging task.
Currently, unsupervised time series anomaly detection methods can be broadly categorized into traditional and deep learning-based approaches. Common traditional methods include statistical approaches (both parametric and non-parametric) as well as reconstruction and clustering techniques based on classical machine learning. In contrast, deep learning-based methods primarily focus on prediction and reconstruction. Statistical methods typically model each variable in MTS data independently, failing to fully leverage the spatial relationships among multiple variables. For highly correlated MTS data, anomaly detection methods based on classical machine learning and deep learning have become the dominant trend in research and application.
Reconstruction-based anomaly detection methods for multivariate time series involve training models to learn latent representations of normal time subsequences, reconstructing the multivariate subsequences, and identifying anomalies by measuring the differences between the reconstructed and original sequences. Principal Component Analysis (PCA) is a classical dimensionality reduction and feature extraction technique [
9]. It detects anomalies by assessing whether a data sample can be effectively reconstructed. If a sample is difficult to reconstruct, its features are likely inconsistent with the overall dataset, indicating it as an anomaly. Aosong et al. [
10] applied an improved PCA-based method to detect faults in chiller sensors. Qu et al. [
11] proposed an optimization approach that minimizes intra-class reconstruction errors while maximizing inter-class reconstruction errors for training samples. Rashidi et al. [
12] introduced a standardized reconstruction error metric, providing a more effective means for accuracy evaluation. Ana et al. [
13] adopted a partially interpretable autoencoder structure to enhance PCA’s data compression and reconstruction capabilities. Dan et al. [
14] developed a novel semi-supervised anomaly detection framework based on reconstruction similarity. Ji et al. [
15] proposed a new anomaly detection framework that integrates statistical analysis with neural network methods.
Clustering-based anomaly detection is a typical unsupervised method that distinguishes anomalies based on three common assumptions: data points that do not belong to any cluster are anomalies, data points far from the cluster centers are anomalies, and data points within sparse or small clusters are anomalies. Aziz et al. [
16] applied K-means clustering to Call Detail Records (CDRs) from both anomaly detection and prediction perspectives, proposing a scalable and efficient anomaly detection method. Rajeshkumar et al. [
17] optimized anomaly detection models by enhancing machine learning classifiers. Wang et al. [
18] introduced an anomaly detection algorithm combining clustering techniques with autoencoder models to identify network traffic anomalies.
With the widespread application potential of deep learning across various fields, deep learning-based time series anomaly detection methods have garnered significant attention. These methods can learn complex nonlinear temporal relationships and high-dimensional representations of time series data. Nallappan et al. [
19] proposed a content-based video retrieval (CBVR) framework for anomaly detection in surveillance videos, leveraging deep learning techniques and HNSW (Hierarchical Navigable Small World) indexing. Iqbal et al. [
20] applied various deep learning models for anomaly detection and time series forecasting and introduced a statistical method to overcome the limitations of high-dimensional time series data. Shafeiy et al. [
21] introduced the pioneering MCN-LSTM technique for real-time water quality monitoring, addressing the challenges of detecting anomalies in complex time series data.
With the continuous optimization of forecasting models and methods, prediction-based anomaly detection techniques have shown significant development potential. Changzhi et al. [
22] applied forecasting methods to detect anomalies in power data. Takahashi et al. [
23] proposed using seasonal thresholds to improve prediction-based detection methods, addressing the challenge of determining error thresholds.
Table 1 presents a comparison of various anomaly detection methods.
With the further advancement of deep learning, predictive models now consider not only the temporal dependencies of samples but also the spatial dependencies, including the network topology of the samples. Kidu et al. [
24] extracted spatio-temporal features from samples to predict and identify driver activities. Ullah et al. [
25] proposed a one-dimensional hybrid CNN-LSTM method to extract spatio-temporal features for detecting pipeline leaks. Tipper et al. [
26] used CNN and LSTM for deepfake video detection. Xiong et al. [
27] introduced a data-augmented SSA-CNN-LSTM framework for fault prediction. Li et al. [
28] introduced a multi-feature extraction neural network model based on Convolutional LSTM for predicting PM2.5 levels in air quality forecasting, achieving effective integration of spatial correlations. Jiawei et al. [
29] proposed a novel detection method based on CNN and LSTM networks to comprehensively explore spatio-temporal information.
In the time domain, the focus is typically on the transient characteristics of a signal, which reflect how the signal changes over time and are suitable for monitoring dynamic variations. In contrast, in the frequency domain, complex time-domain signals are decomposed into components of different frequencies. Analyzing these frequencies effectively identifies and suppresses noise, with an emphasis on the periodic characteristics of the signal. Frequency domain analysis is a method that examines the characteristics of a signal in the frequency domain. Pascale et al. [
30] revealed the differences in the contribution of frequency components to the overall signal at different speeds through the analysis of noise emissions from two distinct motorized sources. Li et al. [
31] proposed a Global Navigation Satellite System (GNSS) spoofing detection method based on frequency domain processing. Combining time domain and frequency domain characteristics provides a more comprehensive perspective, improving the efficiency and accuracy of feature extraction and facilitating a better understanding and analysis of signal characteristics.
Predictive anomaly detection methods typically require the construction of an accurate forecasting model. By comparing the difference between predicted and observed values against a predefined threshold, anomalies can be identified. Based on the literature review, the following key challenges exist in the field of traffic flow anomaly detection:
While traffic flow data share typical characteristics of MTS data, they also exhibit strong spatial dependencies. However, existing methods often fail to account for these spatial properties.
- 2.
Limited consideration of frequency-domain features
Current predictive models primarily focus on time-domain methods, leveraging only temporal and spatial characteristics while overlooking frequency-domain properties. As a result, the feature learning process for MTS data remains incomplete.
- 3.
Uncertainty in error threshold determination
In predictive anomaly detection, setting an appropriate error threshold is challenging. Since error analysis is a crucial step in ensuring detection accuracy, the lack of a reliable threshold selection method can significantly impact the effectiveness of anomaly detection.
Based on the above issues and situation analysis, this paper proposes a prediction-based anomaly detection method for traffic flow data that incorporates multi-domain feature extraction. This method leverages both time-domain and frequency-domain features to comprehensively capture the temporal and spectral characteristics of the data, enabling the construction of an effective time series prediction model. By analyzing the predicted and observed values, the error threshold is determined using Chebyshev’s inequality, and anomalies are detected by checking whether the error falls within the threshold range. This approach enables effective detection of anomalous data points.
4. Experiments and Results
4.1. Datasets
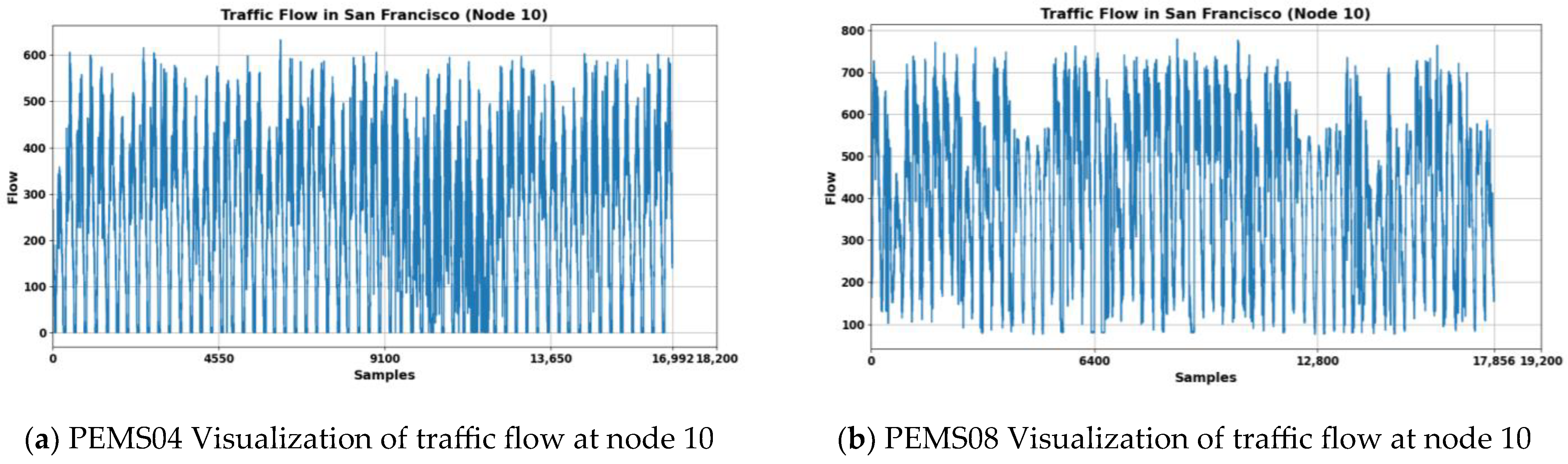
The datasets used in this paper are a set of publicly available datasets provided by the Performance Measurement System (PEMS), a California transportation management system. The PEMS04 used in this paper is data generated by 307 detectors collecting data at 5-min intervals for a total of 59 days. The PEMS08 is data generated by 170 detectors collecting data at 5-min intervals for a total of 62 days. The data collected by each detector at each acquisition contains three dimensions of features: flow, average velocity, and average occupancy. In this paper, we will retain the flow rate component for prediction experiments. The raw traffic of node 10 in both datasets is shown in
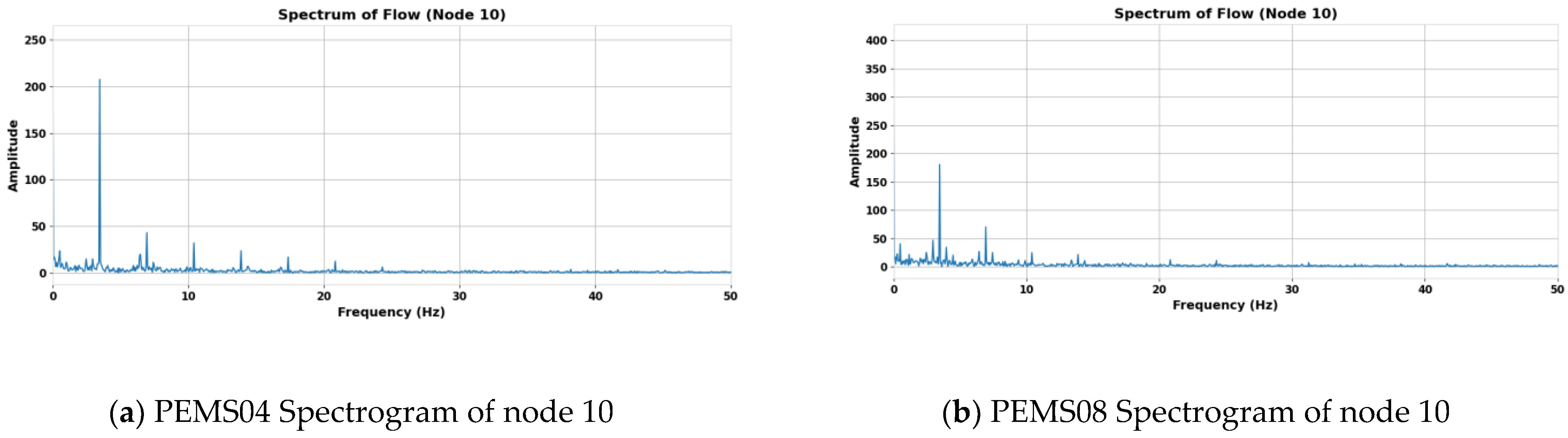
Figure 2a,b, where (a) is the traffic data of node 10 of PEMS04, 16,992 is the quantity collected in 59 days at this node, and (b) is the traffic data of node 10 of PEMS08, 17,856 is the quantity collected in 62 days at this node. In the process of frequency domain feature extraction, we subjected the original traffic flow sequence to FFT, and the spectrograms of node 10 in both datasets after FFT transformation are shown in
Figure 3a,b.
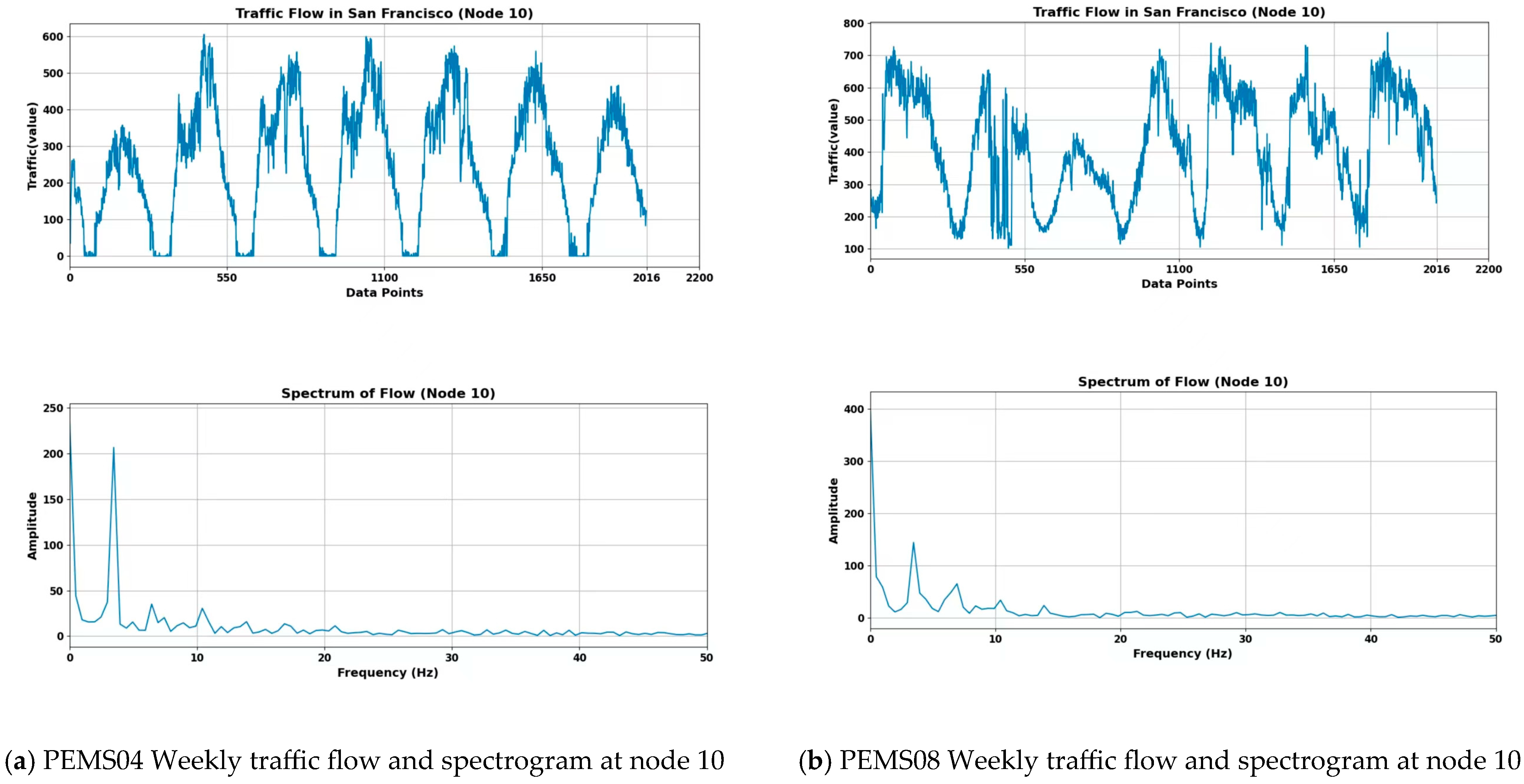
Specifically, the number of samples collected in a day is 288, and we take the traffic flow data of any week to analyze, as shown in
Figure 4a,b. Analyzing from the time domain, it can be seen that a clear periodicity is presented. However, other characteristics presented in the data cannot be obtained from the time domain.
Amplitude represents the strength or energy of a signal at a specific frequency. The greater the amplitude, the more substantial the contribution of that frequency component to the signal. Amplitude is typically used to identify the dominant frequency components of the signal. Phase, on the other hand, indicates the relationship between a specific frequency component and time. Phase information is crucial for understanding the signal’s waveform, periodicity, and time delays. When multiple signals are superimposed, phase differences can cause interference, which can, in turn, affect the final shape of the signal.
4.2. Evaluation Metrics
The anomaly detection method proposed in this paper is based on flow prediction, and the accuracy of detection is related to the accuracy of prediction. The evaluation metrics are all selected as Mean Absolute Error (MAE), Root Mean Square Error (RMSE), Mean Absolute Percentage Error (MAPE). Where: is the observed value, is the predicted value, and n is the total number of samples.
MAE measures the average absolute value of the prediction errors, which represents the average deviation between the predicted values and the true values. The smaller the value, the more accurate the prediction. The calculation formula is as follows:
RMSE calculates the root mean square error, which is the square root of the average of the squared errors. Since squaring amplifies larger errors, RMSE emphasizes the impact of large errors. It is suitable for scenarios that are sensitive to large errors. The smaller the value, the better the model’s fit. The calculation formula is as follows:
MAPE measures the percentage of the error relative to the true values, providing a dimensionless error metric. The smaller the value, the smaller the model’s prediction error. The calculation formula is as follows:
The Nash-Sutcliffe Efficiency (NSE) coefficient is commonly used to quantify the predictive accuracy of simulation models and is widely applied in evaluating hydrological, meteorological, and environmental models. NSE is an indicator of the degree of fit between the model’s predictions and observed values. It calculates the mean square error between the predicted results and the observed values, and compares it to the variance of the observed values. The range of NSE is from −∞ to 1, with a value closer to 1 indicating better model performance. The mathematical expression for NSE is as follows:
where:
is the observed value,
is the predicted value, and
is the mean of the observations.
4.3. Contrasting Models and Ablation Experiments
LSTM has been widely applied in prediction scenarios, primarily for capturing temporal dependencies. In time series forecasting tasks, it can effectively explore the time-varying features of data. For example, Abbass et al. [
32] used LSTM to develop a voltage stability prediction model for power systems, while Wang et al. [
33] proposed an LSTM-based ship fuel consumption prediction model using a self-attention mechanism. To capture both temporal and spatial dependencies simultaneously, CNN is used to capture spatial relationships. The combination of CNN and LSTM has become a common temporal model for traffic flow prediction [
26,
27,
28,
29,
30]. To evaluate the impact of the frequency domain features proposed in this paper on prediction results, the following models were compared:
4.4. Experimental Setup
In the experiment, the data from 59 days in PEMS04 is divided into a training set and a test set, with the first 45 days of data used for model training and the subsequent 14 days used for testing. In PEMS08, the data from 62 days is divided into a training set and a test set, with the first 48 days used for training and the final 14 days used for testing. For each dataset, historical data from 6 time steps (half an hour) is used to predict the traffic flow change in the next time step (5 min).
All deep learning networks in this study are implemented using Pytorch 2.3.1. The model uses the Adam optimizer with a learning rate set to 0.0001, a batch size of 64, and 50 epochs. Additionally, learning rate decay and early stopping strategies are employed to prevent overfitting.
The network parameters of the model proposed in this paper are set as follows: the number of multi-attention heads in the GAT network num_heads is 4; the number of hidden layers num_hid is 6; and the output feature dimension out_c is 6. The number of layers num_layers of Bi-LSTM is 2, the hidden layer dimension hid_c is 16, and the output feature dimension out_c is 6; Transformmer encoder has an output dimension coder_c of 8; the number of encoders and decoders num_coder are both 2, and the number of attention heads num_heads is 4. The convolutional kernel size kernel_size of the CNN is 5 in the comparison and ablation experiments.
4.5. Predicted Results
To verify the advantages of the BI-GAT-TF model proposed in this paper, a comparative experiment was conducted with the CNN-LSTM-TF prediction model. Additionally, to assess the effectiveness of the proposed frequency-domain spatial feature extraction in improving the model’s prediction accuracy, an ablation study was performed by removing the frequency-domain feature extraction module from the BI-GAT-TF model and observing the results. For a more intuitive understanding of the impact of frequency-domain feature extraction on the experimental results, a comparison was also made between the traditional CNN-LSTM model and the CNN-LSTM-TF model.
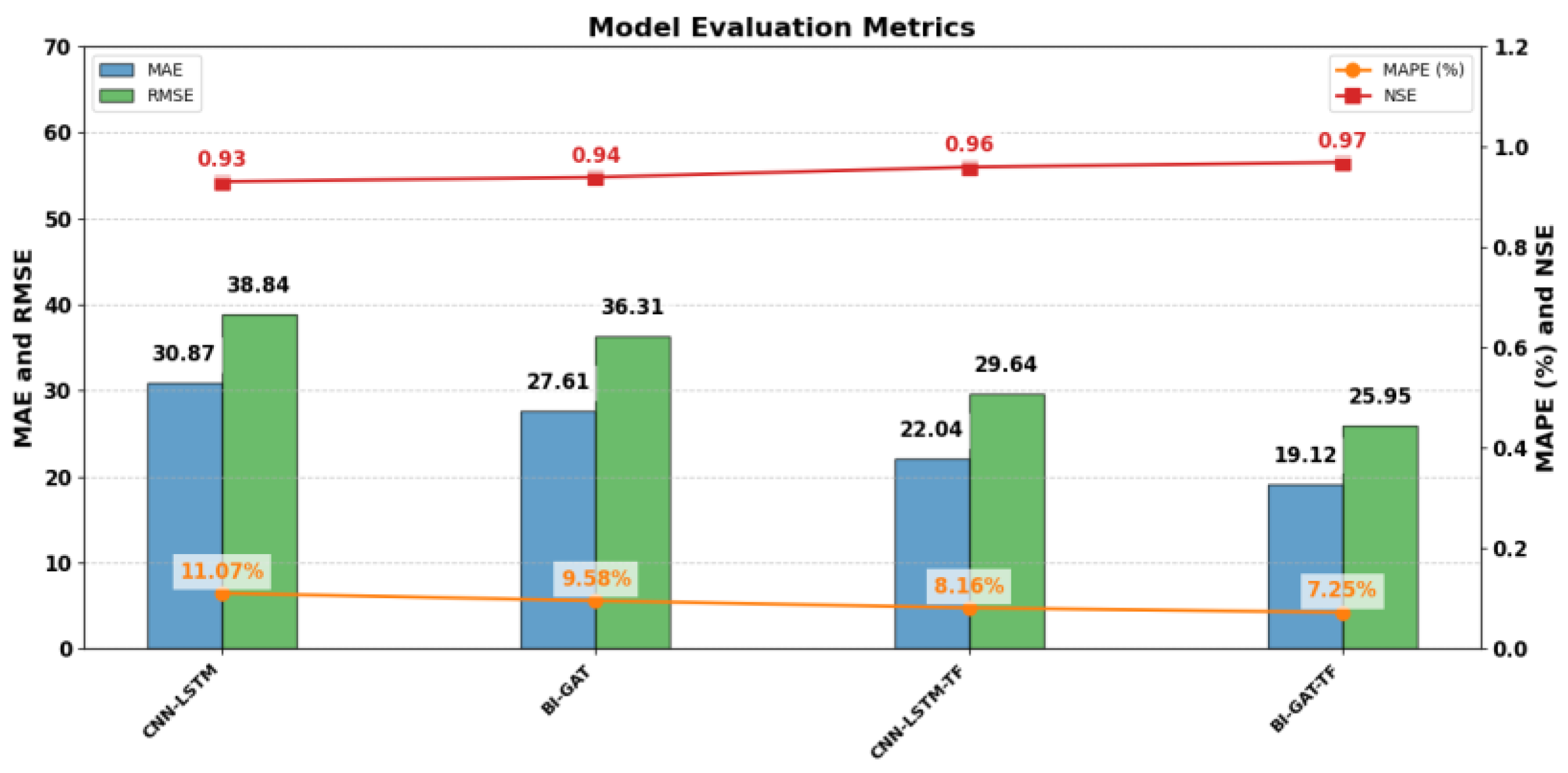
The experimental results comparing the proposed prediction model with the baseline models are shown in
Figure 5 and
Figure 6. From the results, the proposed model achieves the lowest MAE, MAPE (%), and RMSE on both the PEMS04 and PEMS08 datasets. Specifically, in the PEMS04 dataset, the values are 26.05, 12.36, and 37.08, while in the PEMS08 dataset, the values are 19.12, 7.25, and 19.12, respectively. The NSE is also the highest in both datasets, with values of 0.93 and 0.97, respectively. These results indicate that the proposed model achieves optimal performance in terms of prediction error and accuracy. Notably, the experimental results on the PEMS08 dataset outperform those on the PEMS04 dataset. This can be attributed to the fact that the PEMS08 dataset contains a larger number of traffic flow sequences, which provides a longer total sequence length. This increase in sequence length offers a clear advantage in terms of model training and feature extraction. In conclusion, the proposed prediction model demonstrates excellent detection performance on real-world test datasets, achieving more accurate predictions.
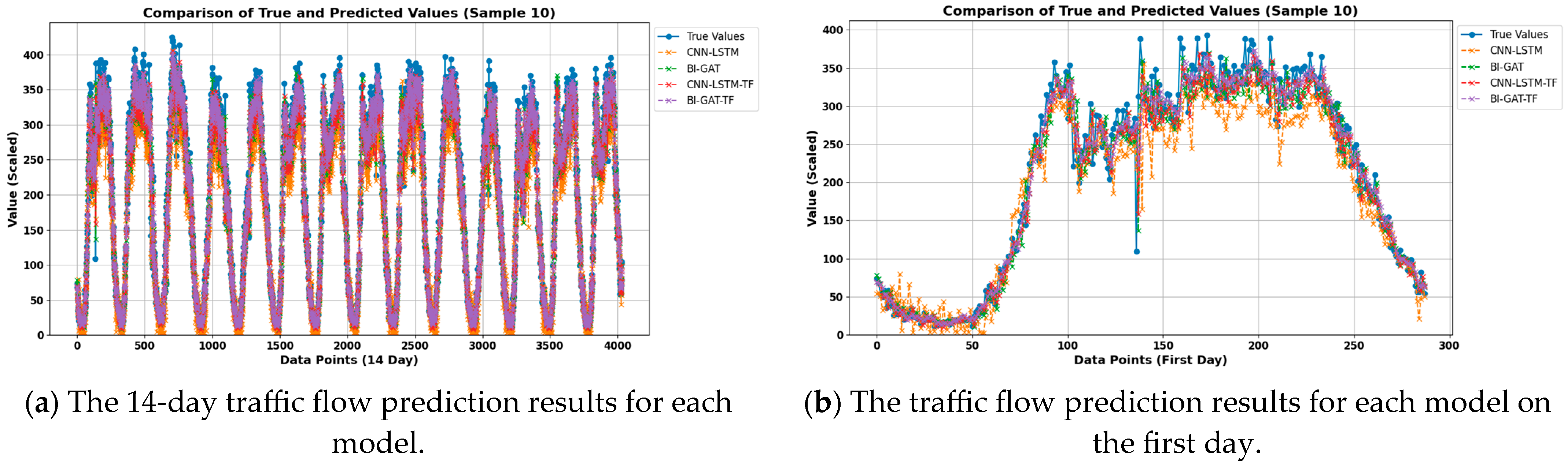
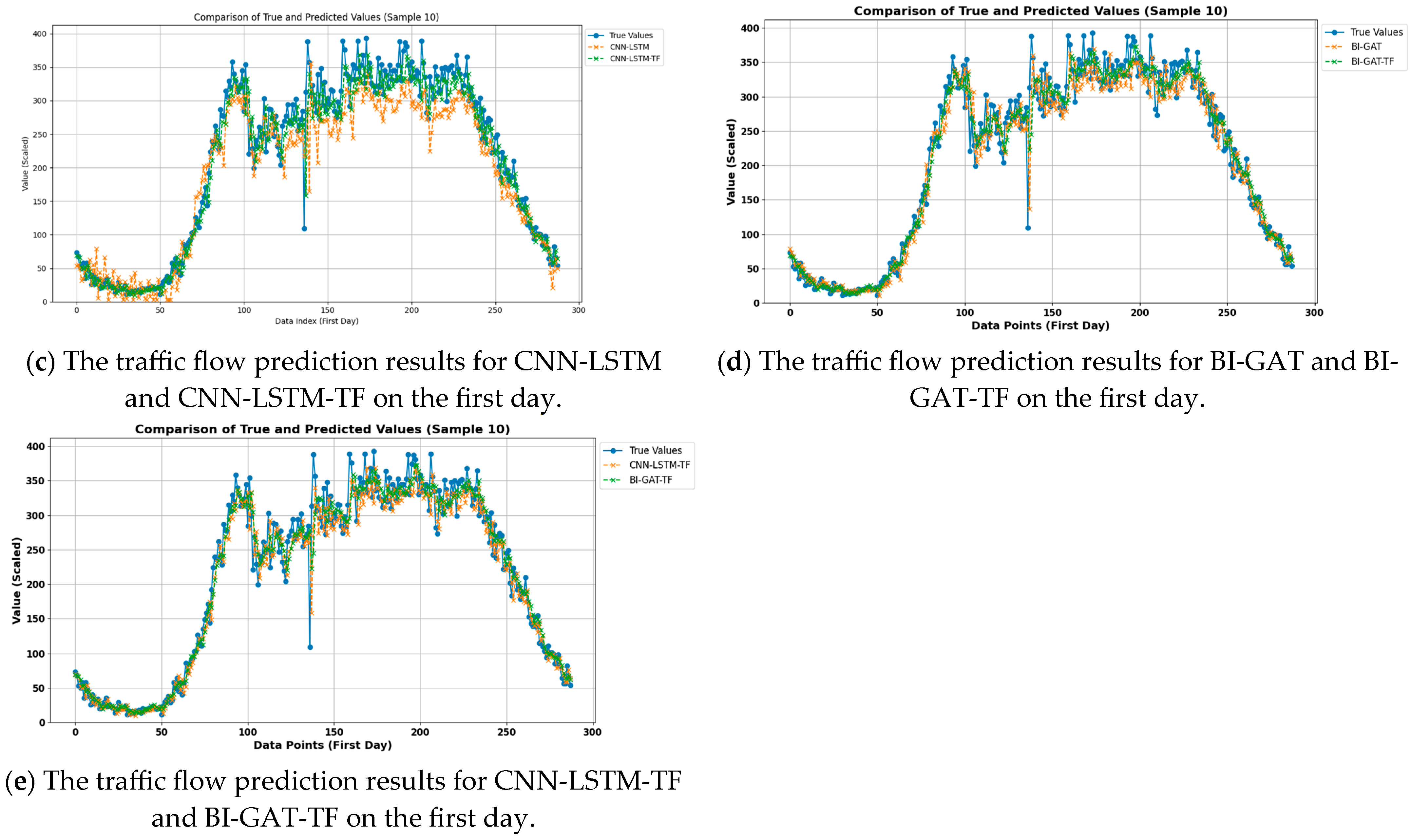
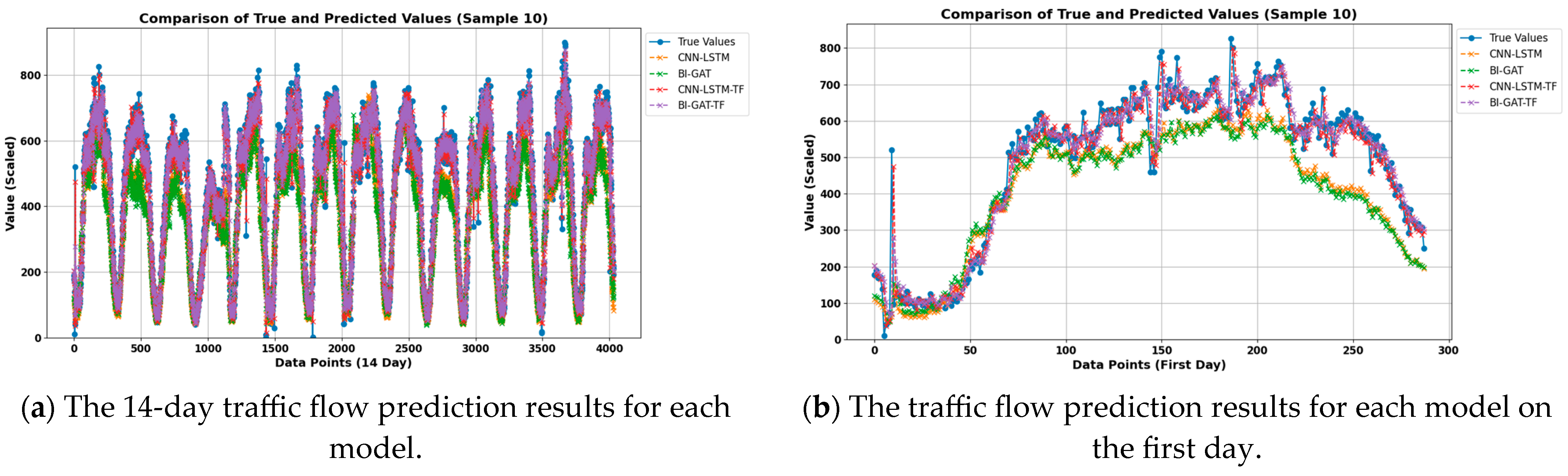
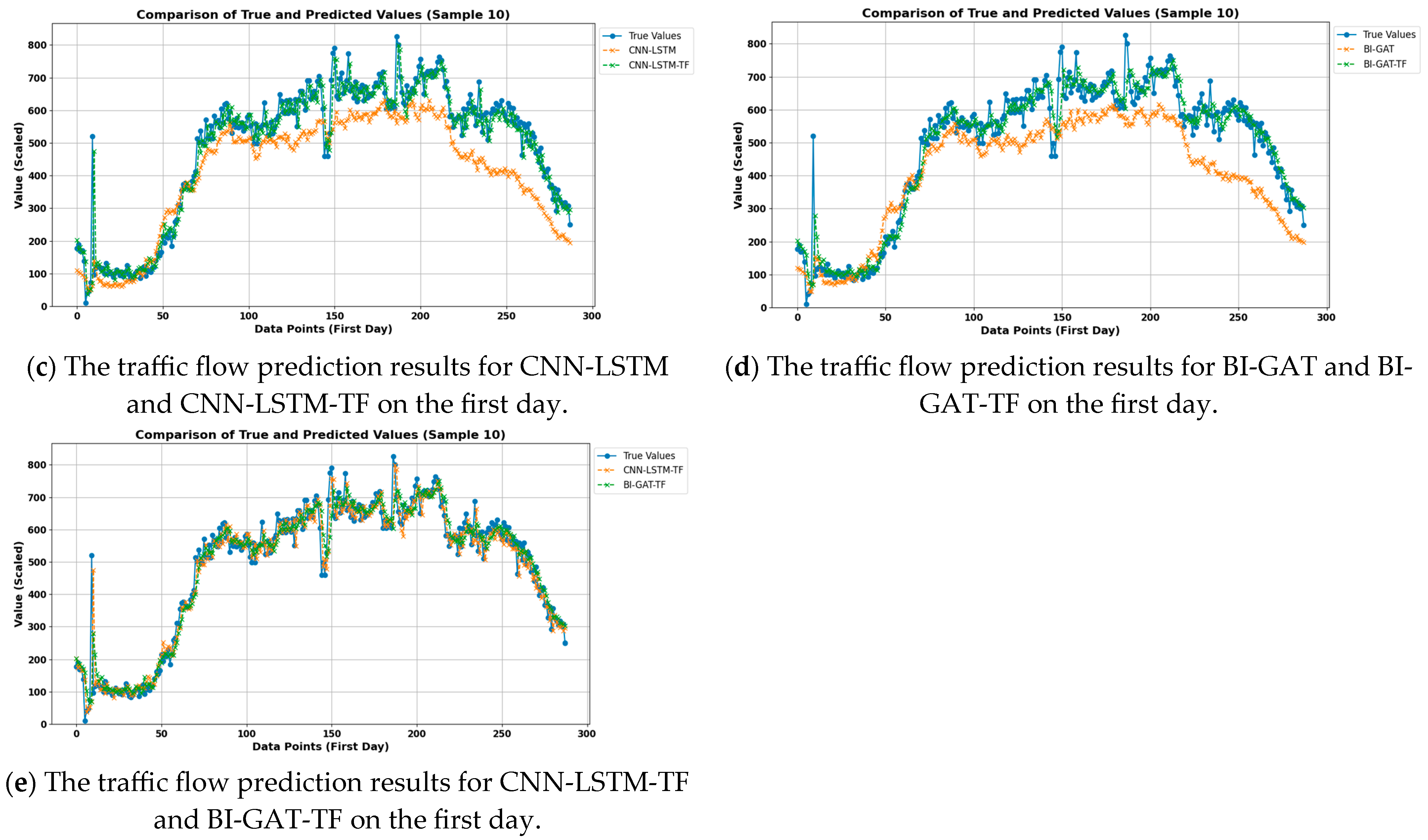
Figure 7 and
Figure 8 show the experimental results for node 10 in the PEMS04 and PEMS08 datasets, respectively. (a) shows the 14-day traffic flow prediction results for each model; (b) shows the traffic flow prediction results for each model on the first day; (c) shows the traffic flow prediction results for CNN-LSTM and CNN-LSTM-TF on the first day; (d) shows the traffic flow prediction results for BI-GAT and BI-GAT-TF on the first day; (e) shows the traffic flow prediction results for CNN-LSTM-TF and BI-GAT-TF on the first day.
As shown in
Figure 7c,d and
Figure 8c,d, the results indicate that the prediction models with the frequency domain feature extraction module are closer to the true data. The results in
Figure 7e and
Figure 8e more clearly demonstrate that the BI-GAT-TF model performs better in terms of fitting compared to CNN-LSTM-TF. This suggests that the proposed model, both in terms of the selected time domain feature extraction model and the idea of frequency domain feature extraction, significantly improves the prediction accuracy of the model.
It is worth noting that, both in the PEMS04 and PEMS08 datasets, there are data points with large fluctuations, such as around noon in PEMS04 (around 12:00) and around 1 AM in PEMS08. At these times, the fitting performance of CNN-LSTM-TF is better than the other three models. However, while analyzing these points, it is important to consider not only the model’s fitting at these points but also whether the data collected at these time points may be anomalous.
4.6. Abnormal Detection Results
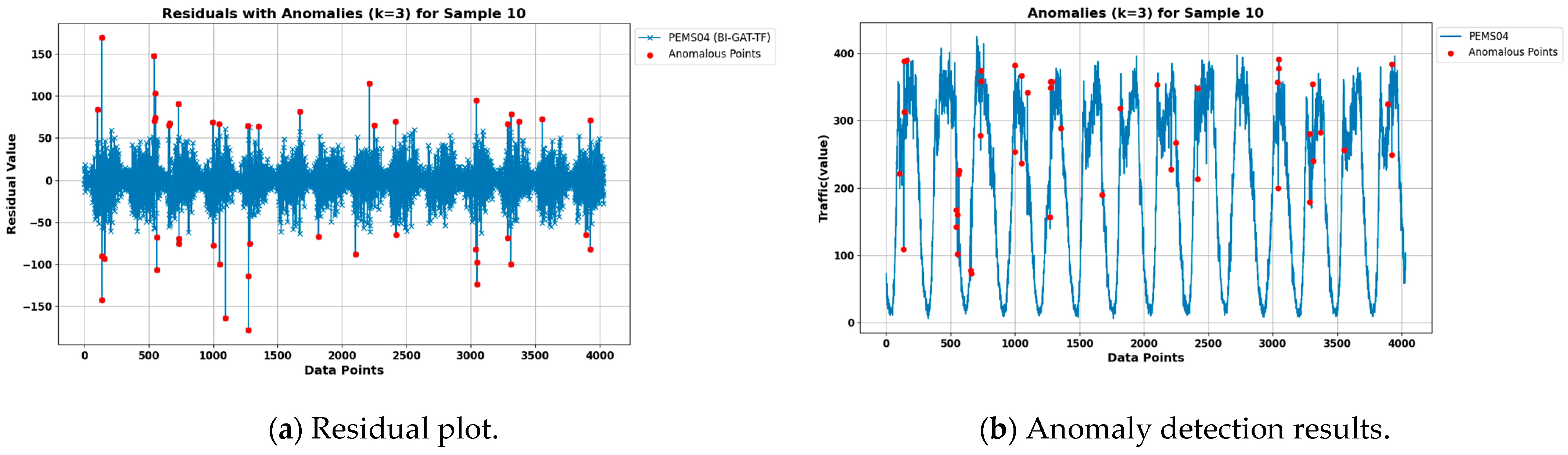
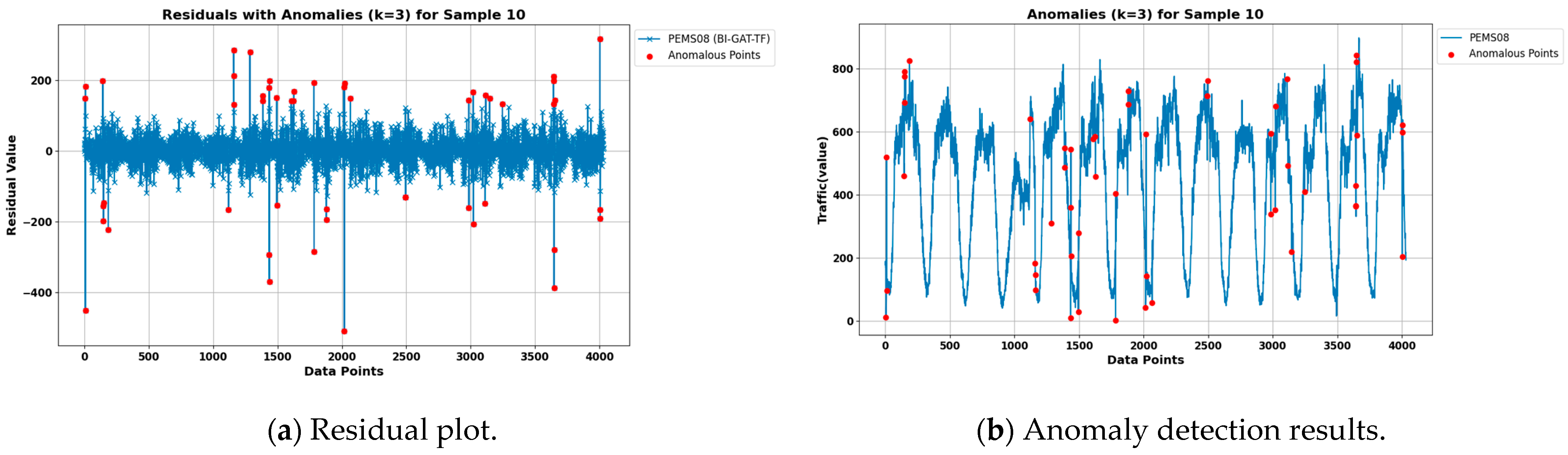
The anomaly detection part first requires determining the error threshold. Set
k to 3. According to Chebyshev’s inequality, an error
exceeding
or
is considered to be an outlier for that data point, i.e., at least
of the errors should fall within the range of
. Combined with the above proposed prediction model, anomaly detection is carried out, and the number of detected anomalies in the PEMS04 and PEMS08 datasets are 46 and 51, respectively. The detection results are shown in
Figure 9 and
Figure 10. Among them,
Figure 9a and
Figure 10a display the residual plots for the two datasets, showing the residual range when
k = 3 and the detected anomalies in the residual plots.
Figure 9b and
Figure 10b show the anomalous points detected in the original traffic flow for the two datasets.
The dataset used in this paper is real traffic flow data, and there is no labeling of anomaly data. In order to more reasonably verify the effectiveness and accuracy of the detection method in this paper, this paper compares the classical unsupervised anomaly detection methods: the Ensemble-based isolated forest method [
34], the reconstruction-based LSTM-VAE [
35] method, and the prediction-based LSTM-NDT [
36] methods, to further validate the accuracy of anomaly detection. Isolation Forest (IF) distinguishes normal and abnormal data by isolation and is suitable for high-dimensional data and large-scale datasets; LSTM-VAE captures temporal dependencies by invoking a combinatorial model that feeds potential variables learned by VAE into LSTM, and finally identifies anomalies by using the reconstruction probabilities; and LSTM-NDT predicts the anomalies by using LSTM data, detects anomalies by computing errors, and introduces an unsupervised nonparametric anomaly thresholding strategy.
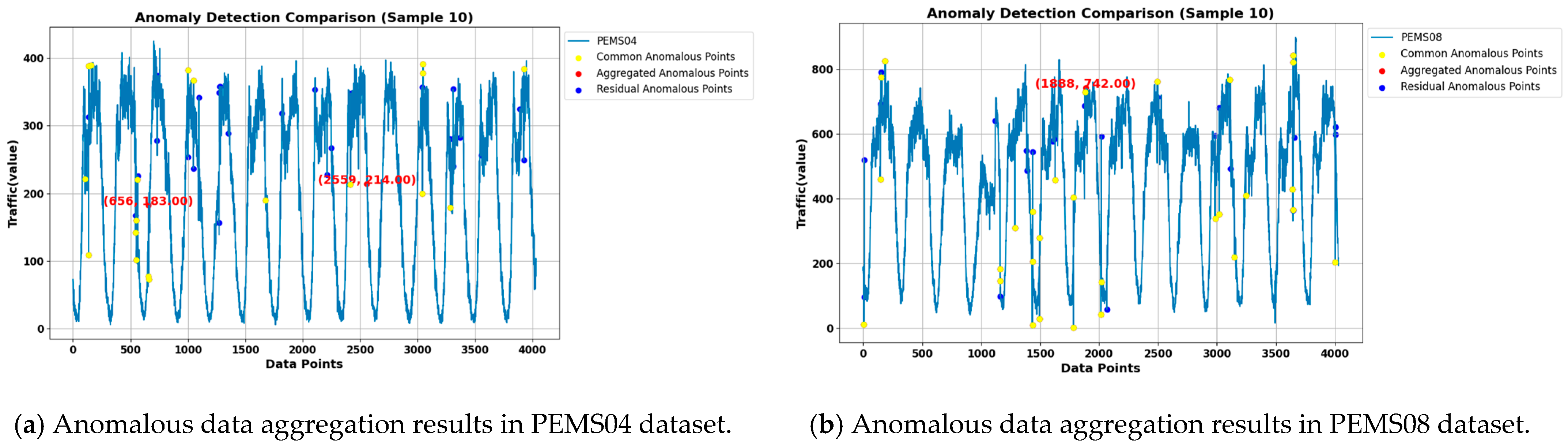
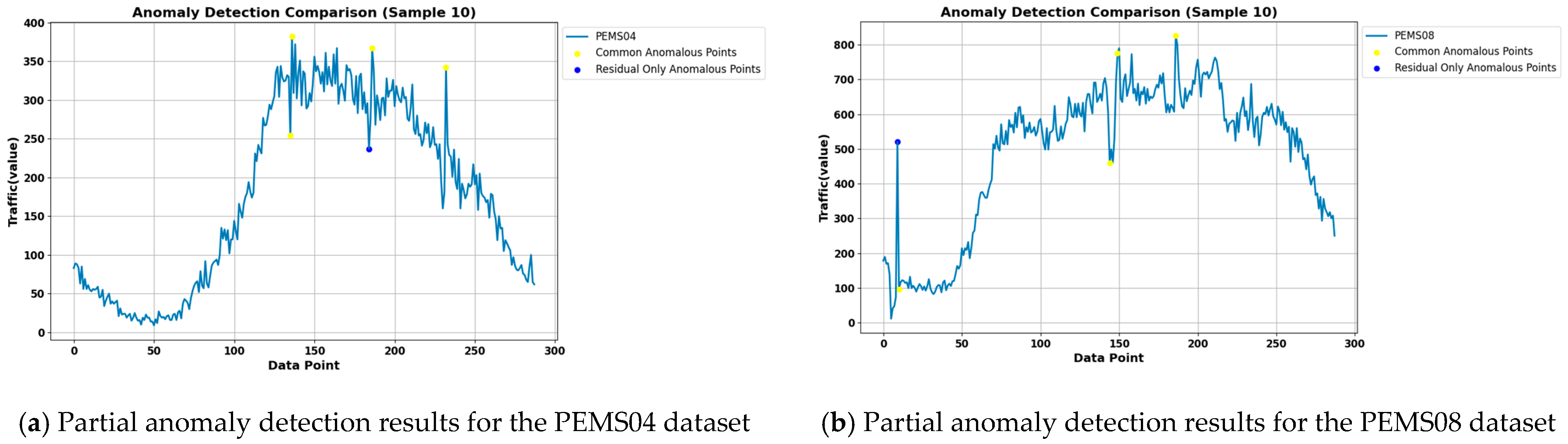
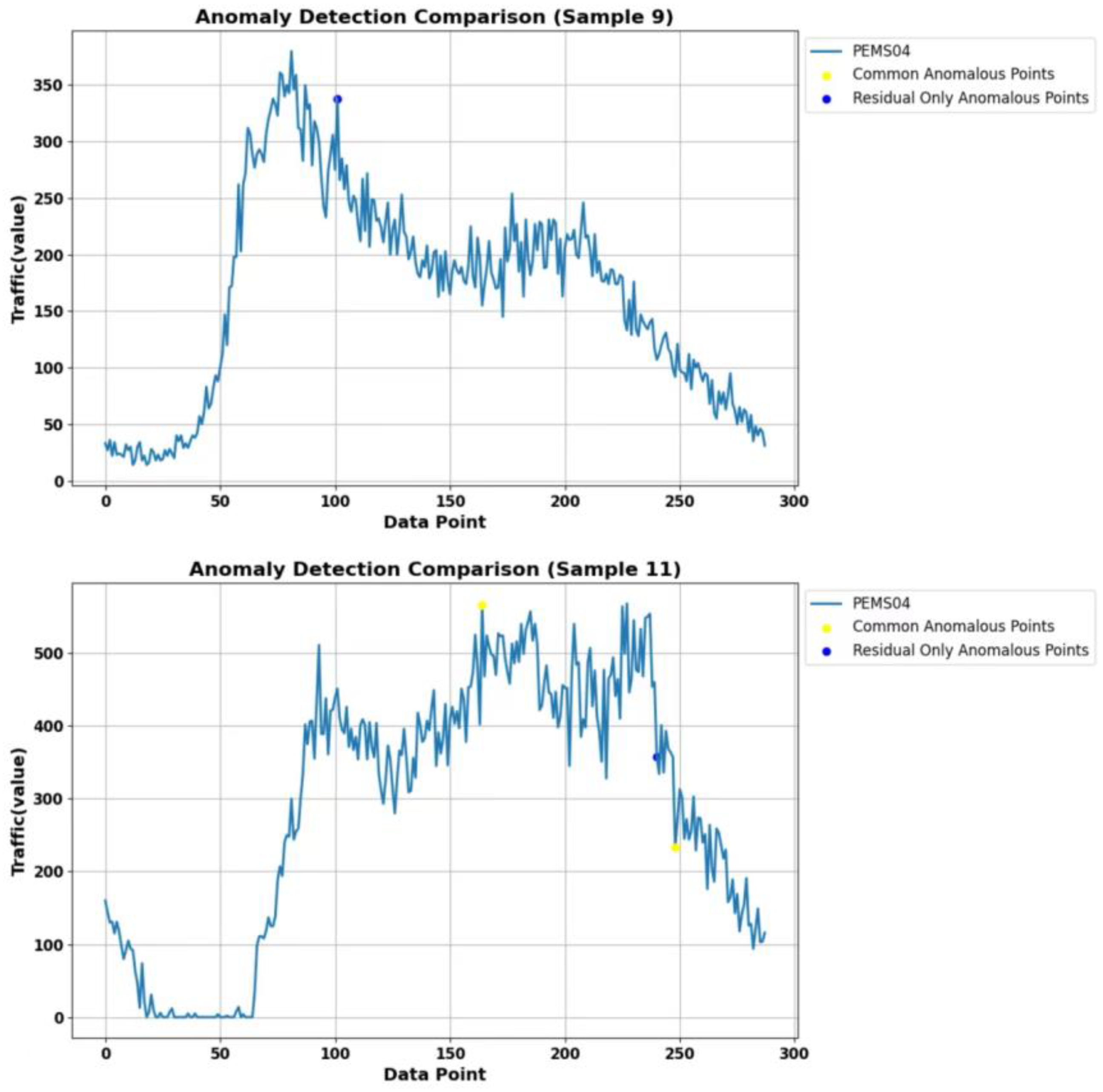
The results of the three methods, Isolation Forest, LSTM-VAE, and LSTM-NDT, are aggregated by the voting method, and at least two methods are set to consider a point as anomalous before it is considered as an anomaly. The anomalies obtained from the aggregation are compared with the anomalies detected in this paper, and the results are shown in
Figure 11. The blue points in the figure are the anomalies detected using the methods in this paper and not detected by the aggregation methods, the yellow points are the common anomalies detected by the aggregation methods and also detected by the methods in this paper, and the red points are the anomalies detected by the aggregation methods and not detected by the methods in this paper.
Analysis of the aggregation results shows that in the PEMS04 dataset, the number of anomalies obtained by the aggregation method is 21, and the number of anomalies obtained by this paper’s detection method is 46. Compared with the anomalies obtained by the aggregation method, this paper’s detection method detected 19 of them, and 2 data points were not detected. In the PEMS08 dataset, the number of anomalies obtained by the aggregation method is 30, and the number of anomalies obtained by the detection method in this paper is 51. Compared with the anomalies obtained by the aggregation method, the detection method in this paper detects 29 of them, and 1 data point is not detected.
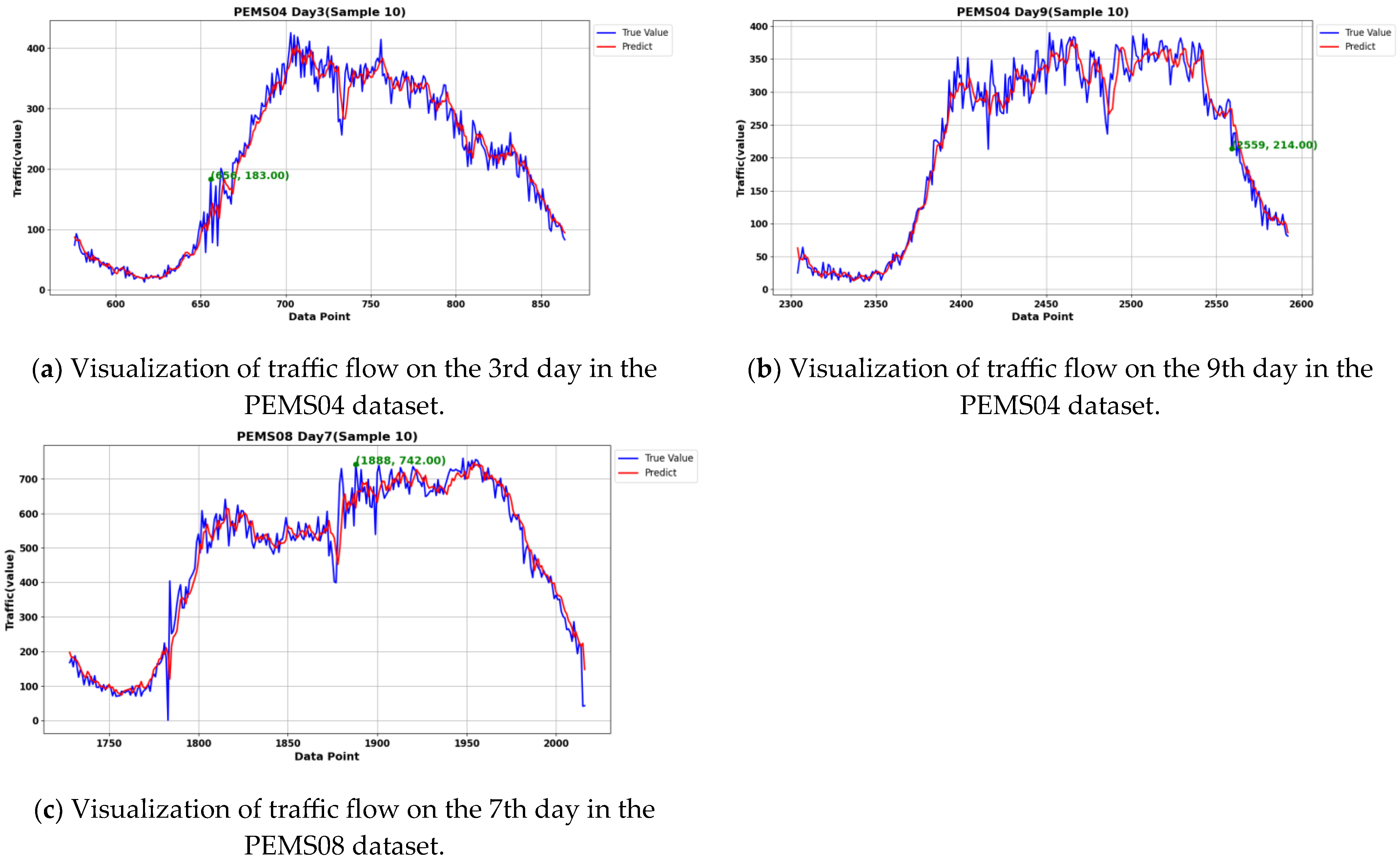
After analysis, the two data points that were not detected in this paper in the PEMS04 dataset were in the time periods of the third and ninth days. Similarly, the one data point in the PEMS08 dataset that appeared to be undetected was in the time period of the seventh day, as shown in
Figure 12.
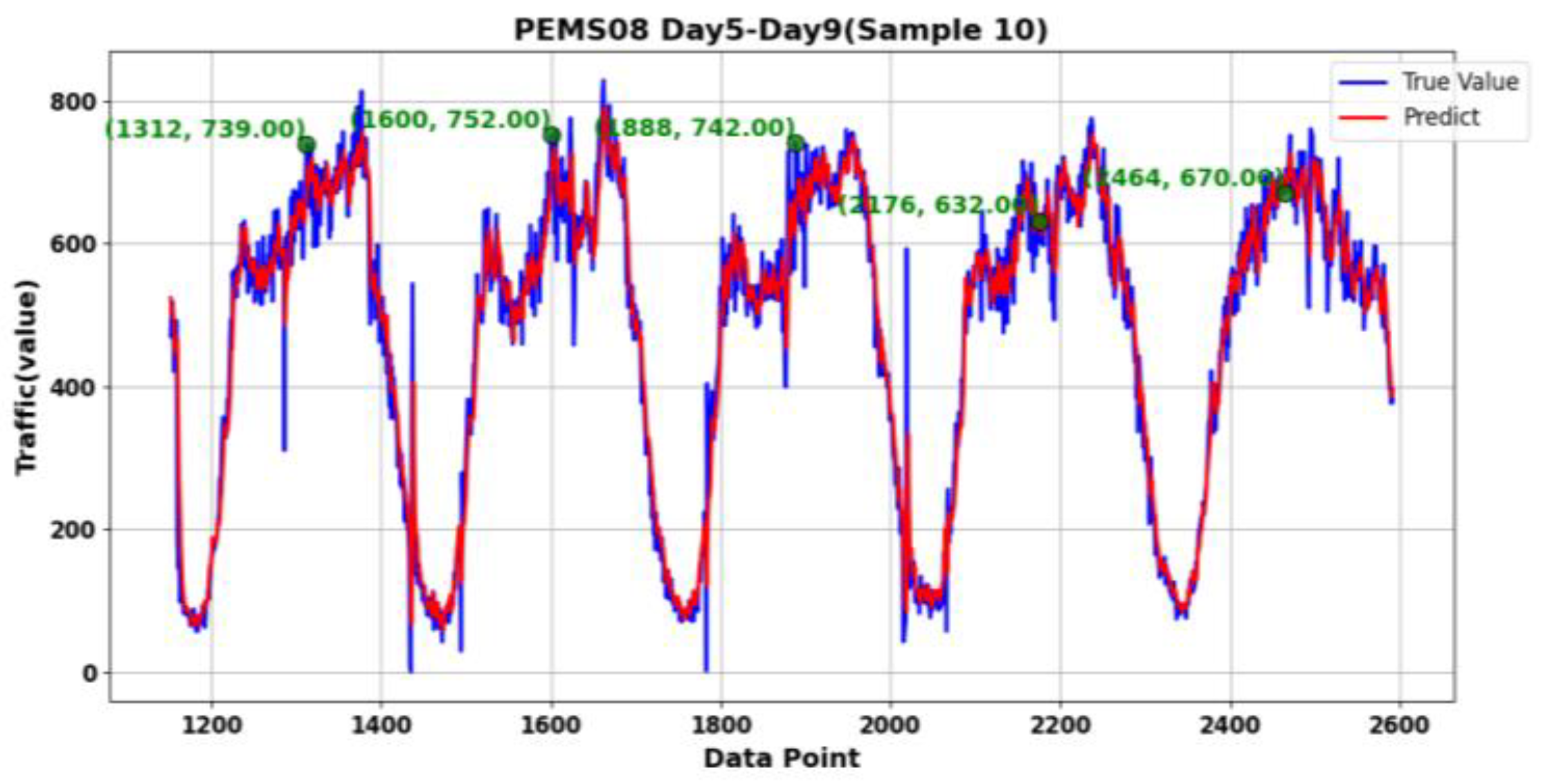
We expanded the time range and visualized the results, as shown in
Figure 13 and
Figure 14. Specifically,
Figure 13a shows the traffic flow from the first to the fifth day in the PEMS04 dataset, while
Figure 13b shows the traffic flow from the seventh to the eleventh day in the PEMS04 dataset.
Figure 14 shows the traffic flow from the fifth to the ninth day in the PEMS08 dataset. The data points in the figures represent the coordinates of the data points that were not detected by our method, as well as the coordinates of the two days before and after each of these points.
Traffic flow data exhibits certain periodic patterns, such as differences in flow during peak periods (morning and evening rush hours) and off-peak periods. It may also display seasonal variations on a daily, weekly, or monthly basis. Additionally, traffic flow between adjacent road sections or intersections is often correlated, with upstream traffic conditions influencing downstream ones. The flow typically changes within a reasonable range. This characteristic can be leveraged to further assess whether the undetected data points are truly anomalies. The undetected data points in the figures, however, do not show any significant abnormalities and remain within a reasonable range of variation.
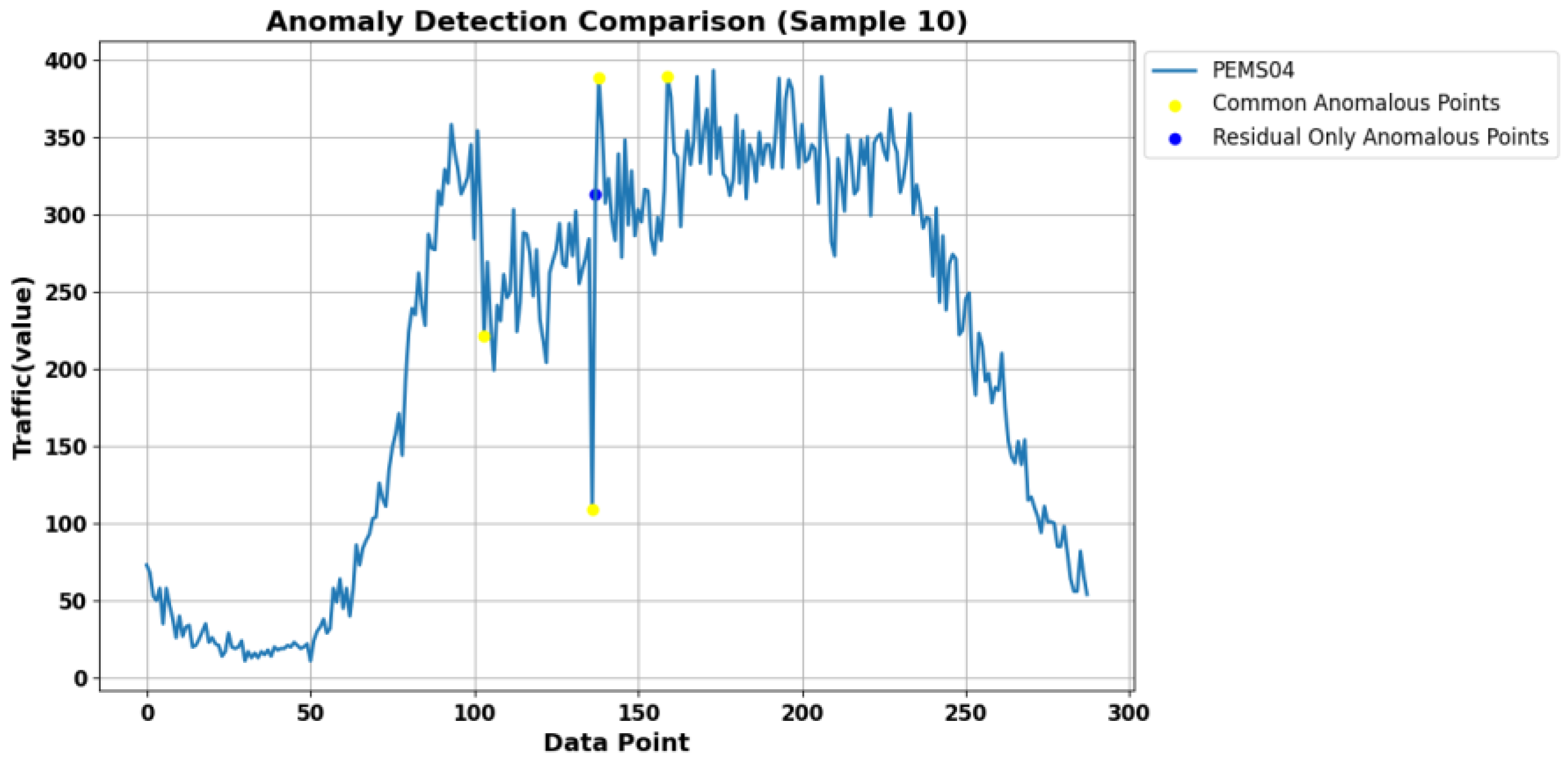
An analysis of the anomalies detected by the proposed method but missed by the aggregation method reveals that the proposed detection method identifies more anomalies with clear abnormal characteristics that do not align with short-term traffic flow changes, as shown in
Figure 15. The reason for this result, aside from the aggregation method causing the loss of a few anomalies, primarily lies in the limitations of the aforementioned anomaly detection methods when handling high-dimensional and time-series data. For instance, the Isolation Forest method assumes that features are independent, but in time-series data, temporal dependencies (such as trends or seasonality) are crucial, and it fails to model these temporal relationships. LSTM-VAE, while effective, requires complex training and substantial time and computational resources, especially for long time series or high-dimensional data. Its training efficiency is relatively low, and when the difference between anomalies and normal data is small, the model may struggle to differentiate between the two. LSTM-NDT assumes that the prediction errors of normal data are small, while those of anomalies are larger. However, by modeling only temporal features, it fails to adequately learn the data’s full characteristics, leading to poor performance of the prediction model and reduced error differentiation ability, which negatively impacts anomaly detection.
Additionally, the proposed detection method in this paper also identifies cases where the difference between two anomalous data points within a short time span is too large, and it classifies the data between these anomalies as abnormal, as shown in
Figure 16. The dataset in this study is collected every 5 min, and based on the analysis of traffic flow variation characteristics, significant changes in traffic flow within a short period may be caused not only by anomalies in data collection but also by the occurrence of unexpected events.
To verify whether the drastic fluctuations in traffic flow during this time period were caused by a sudden event, we analyzed the basic relationship between upstream and downstream traffic flow. The relationship between upstream and downstream traffic flow is highly dynamic and coupled. Upstream flow affects downstream flow through a transmission effect, while downstream flow can also influence upstream flow through a feedback effect. We observed the flow changes of nodes connected to this particular node during this time period, as shown in
Figure 17. From
Figure 17, there were no significant changes in the upstream and downstream traffic flow during this period, making the likelihood of a sudden event minimal. Based on practical considerations, if abnormal data is detected both at the beginning and end of a short data collection period, the data measured during this short period is most likely also abnormal. Thus, the situation where two anomalous data points within a short time frame have a large discrepancy, and the data between these points is also classified as abnormal, aligns better with real-world scenarios. This analysis further validates that the anomaly detection method proposed in this paper has higher accuracy.
5. Conclusions
This paper proposes a traffic flow anomaly detection method based on predictive multi-domain feature extraction. The method reduces prediction errors by constructing a more accurate prediction model and determines the error threshold using Chebyshev’s inequality. Anomalous data points are identified by checking whether the prediction error falls within the threshold range. Experimental results demonstrate that optimizing the prediction model and improving the error analysis method can effectively enhance the accuracy of anomaly detection.
In terms of prediction model improvement, the proposed approach fully leverages the characteristics of traffic flow data and incorporates both time-domain and frequency-domain features for time series modeling. In the time domain, the model captures temporal and spatial correlations of the time series, while in the frequency domain, it extracts amplitude and phase information to learn frequency-related characteristics. Experimental results on the PEMS04 and PEMS08 datasets show that the prediction accuracy of the multi-domain feature extraction model is significantly higher than that of methods relying solely on time-domain features. This conclusion remains valid even when compared with the classical CNN-LSTM model.
In terms of error analysis and error threshold determination, this paper innovatively introduces Chebyshev’s inequality to establish the error threshold. By determining whether the error exceeds this threshold, a more scientific and rational error analysis is achieved, enhancing the accuracy and robustness of anomaly detection. As a result, potential anomalies within the dataset are effectively identified. Finally, a comparison with classical unsupervised anomaly detection methods is conducted to more reasonably validate the accuracy of the proposed method in detecting anomalies within unlabeled datasets.
We also note that the dataset used in this paper has some limitations, such as less missing data, lower proportion of noise, and so on. In the future, we can conduct experiments under the conditions of having clear outlier labels, adding different proportions of noise, etc., comparing more benchmark models, etc., to continuously improve the detection accuracy.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}