YOLO-OHFD: A YOLO-Based Oriented Hair Follicle Detection Method for Robotic Hair Transplantation

Abstract
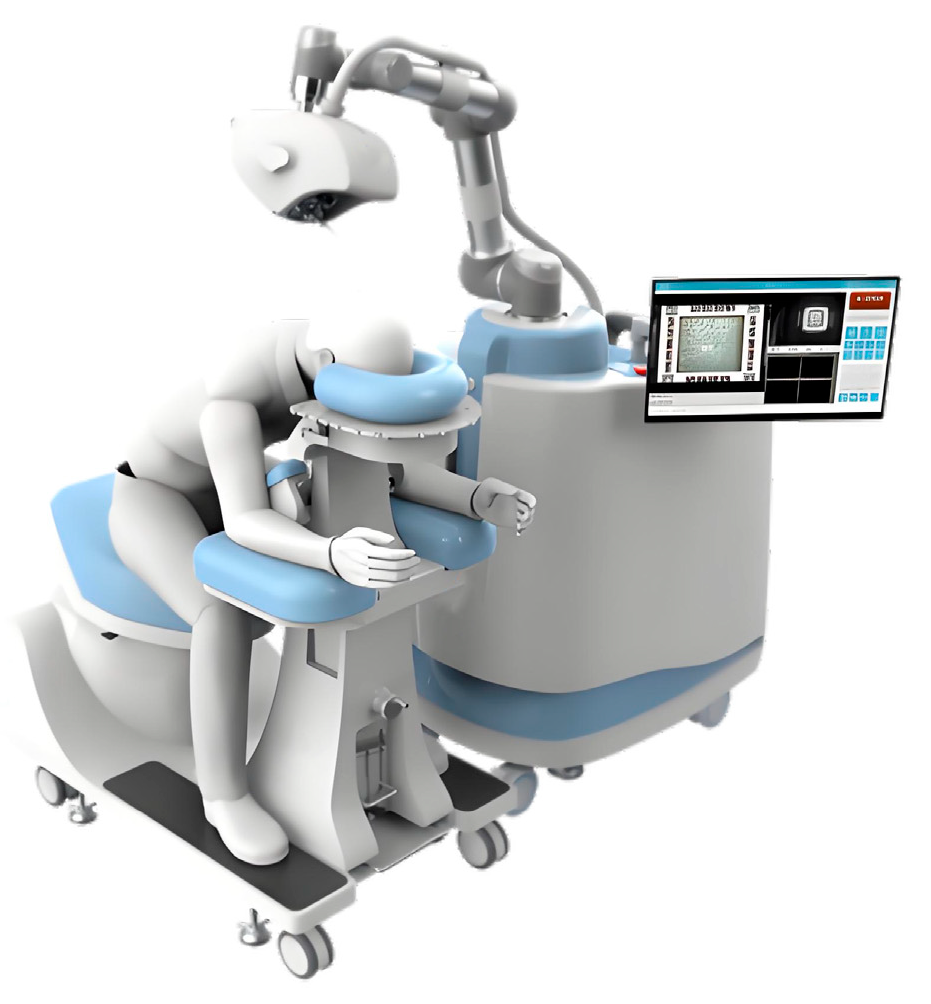
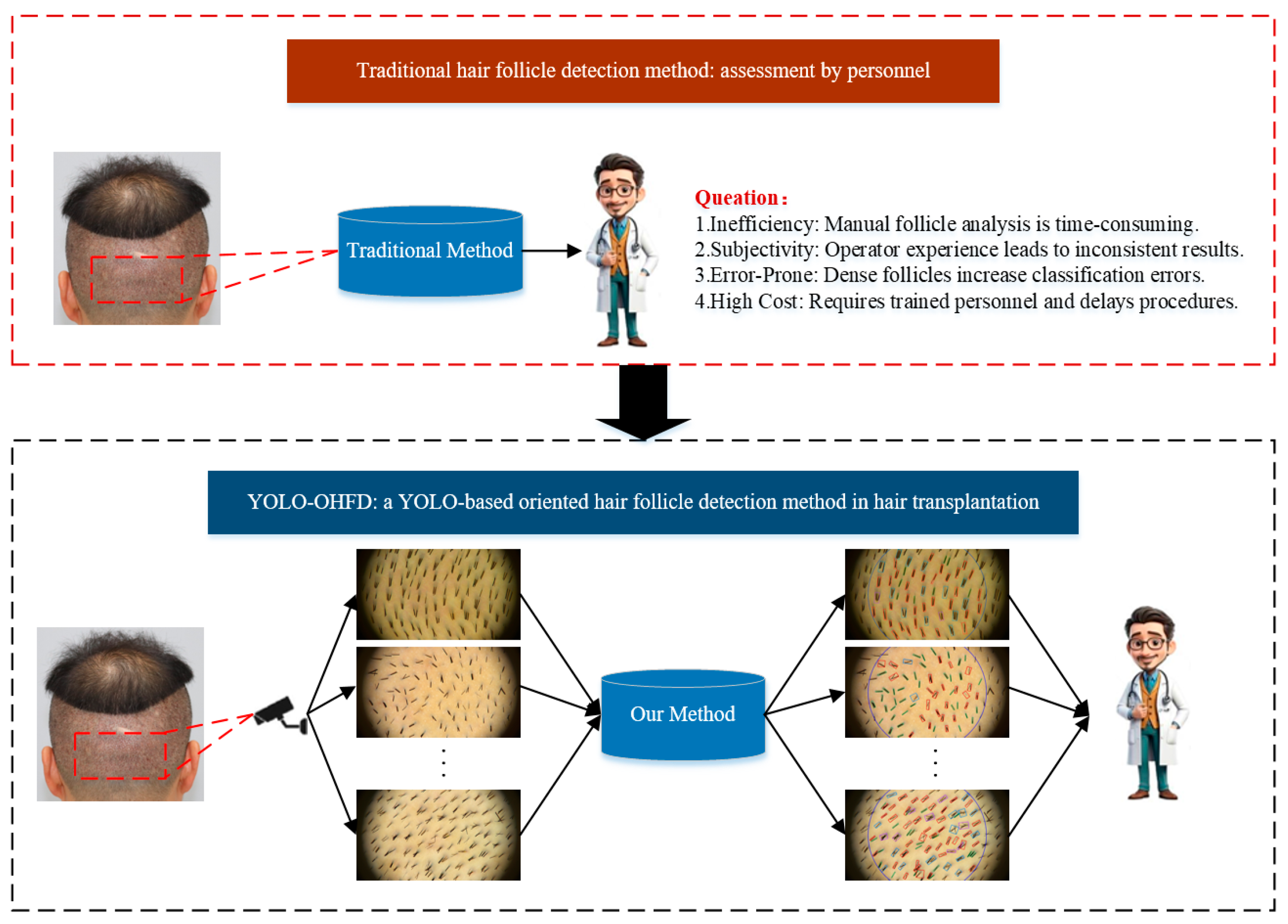
1. Introduction
- An oriented object detection method is introduced for the hair follicle detection task, enabling precise localization of hair follicles and reducing background interference in robot-assisted hair transplantation.
- A YOLO-OHFD framework is proposed, integrating ECA-Res2Block, FAM, and decoupled heads to enhance the network’s accuracy in detecting and classifying hair follicles.
- An OBB-based oriented hair follicle detection dataset is developed, offering a benchmark for evaluating methods designed for hair follicle detection and classification in dermoscopic images.
2. Materials and Methods
2.1. Proposed Method
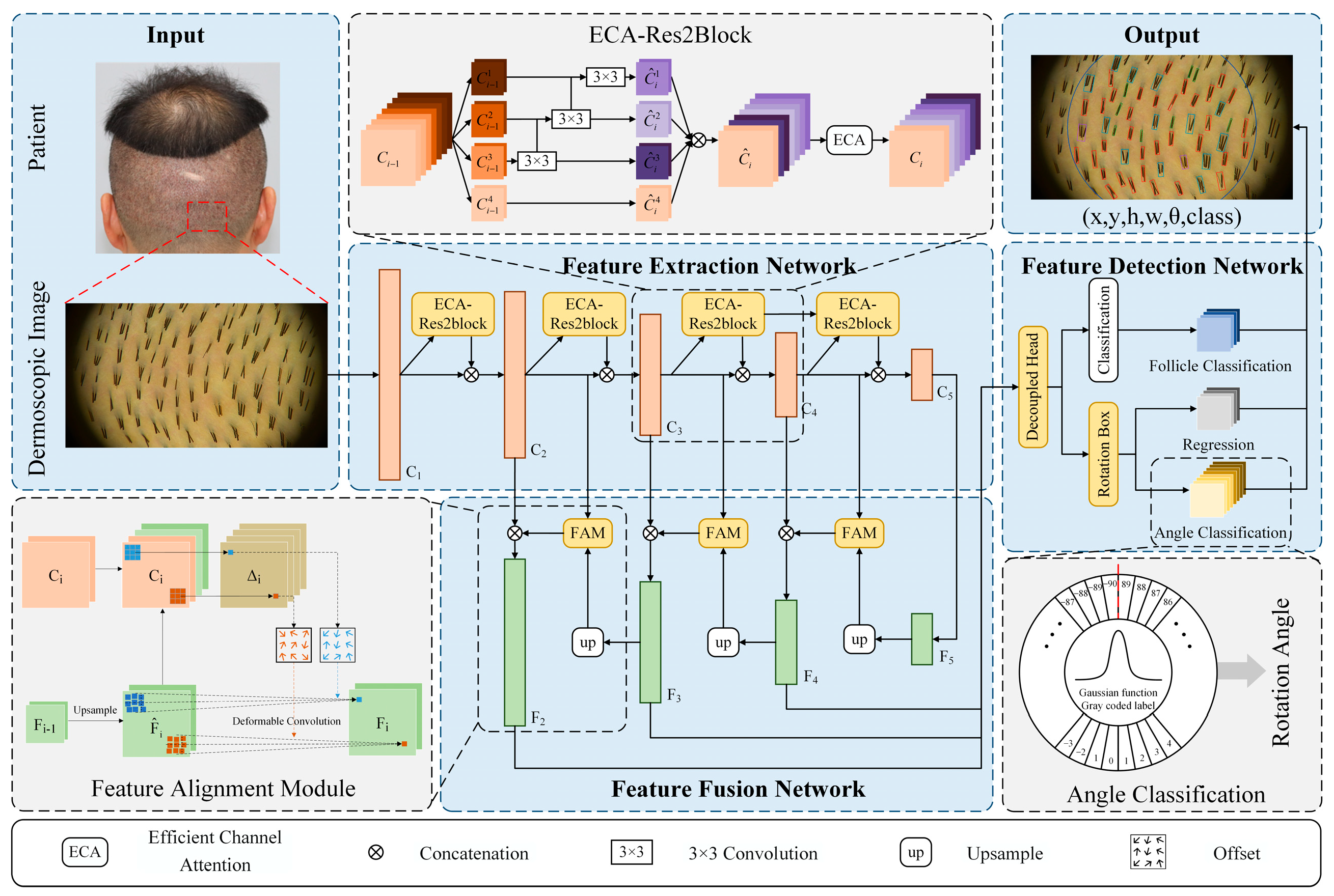
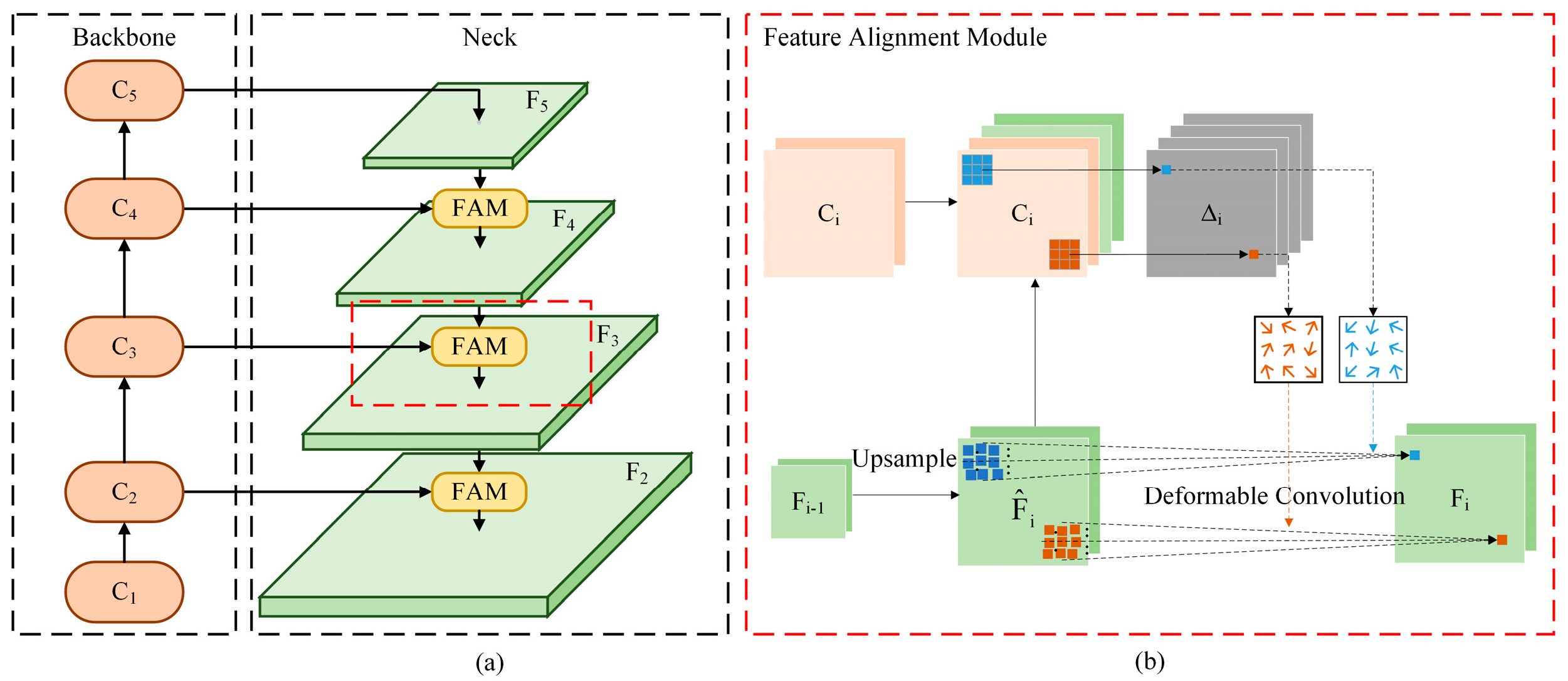
2.2. Structure of YOLO-OHFD
2.2.1. Feature Extraction Network Based on Adaptive Receptive Field
2.2.2. Feature Fusion Network Based on Feature Alignment
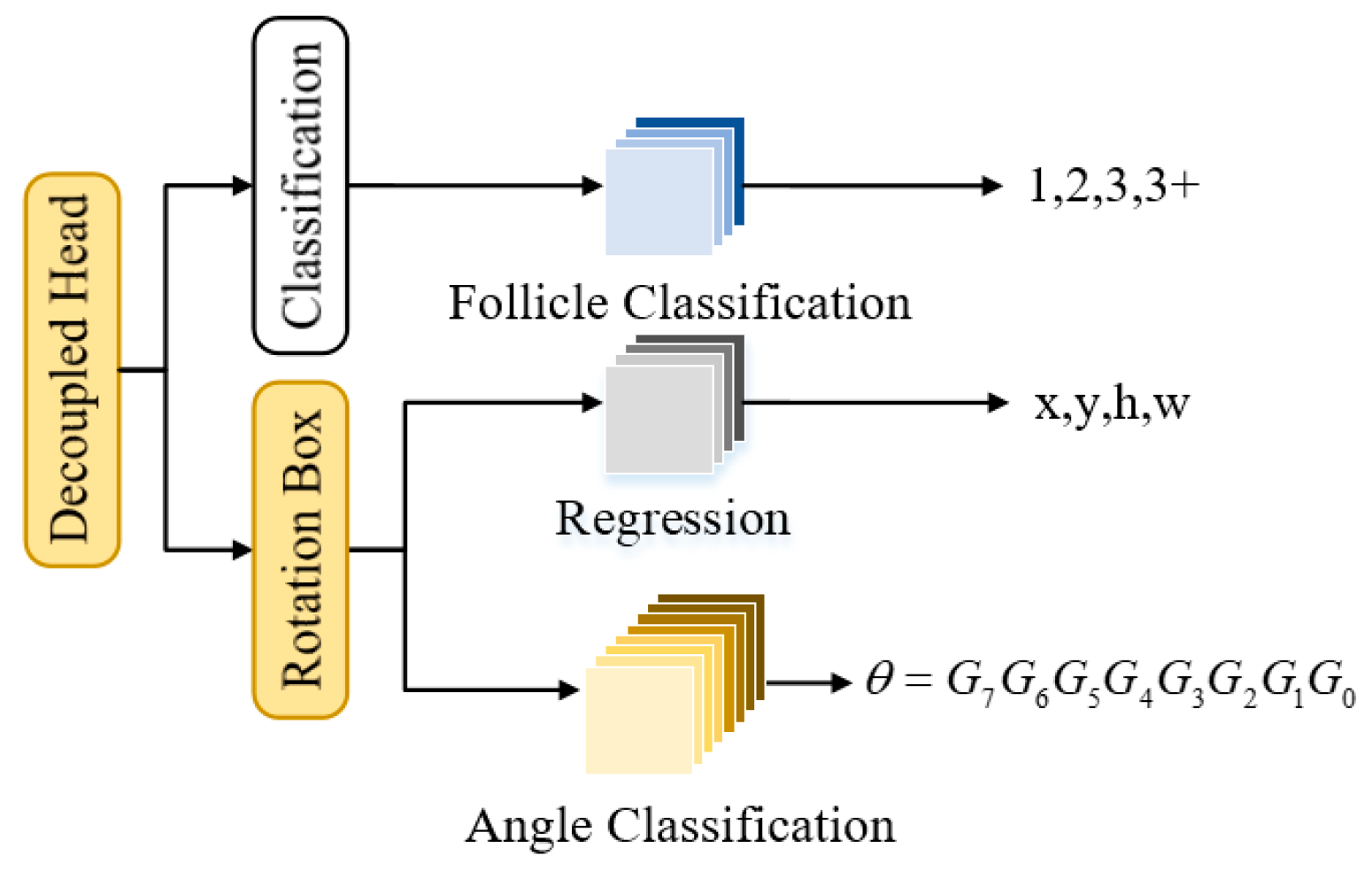
2.2.3. Feature Detection Network Based on Decoupled Heads
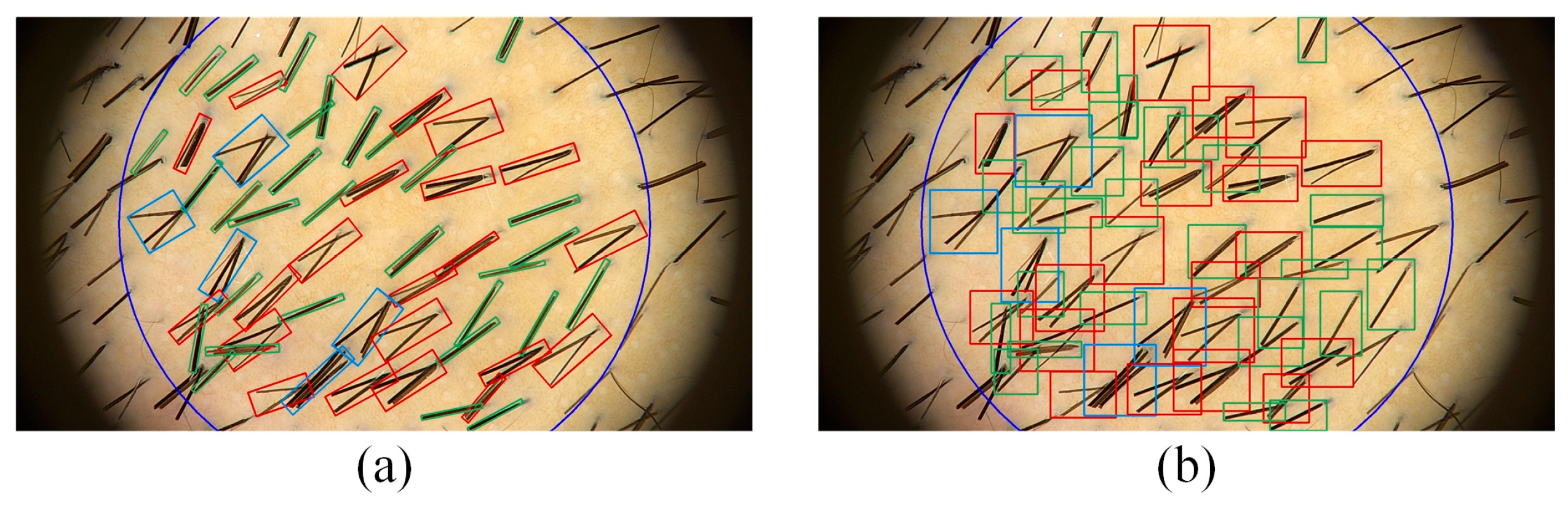
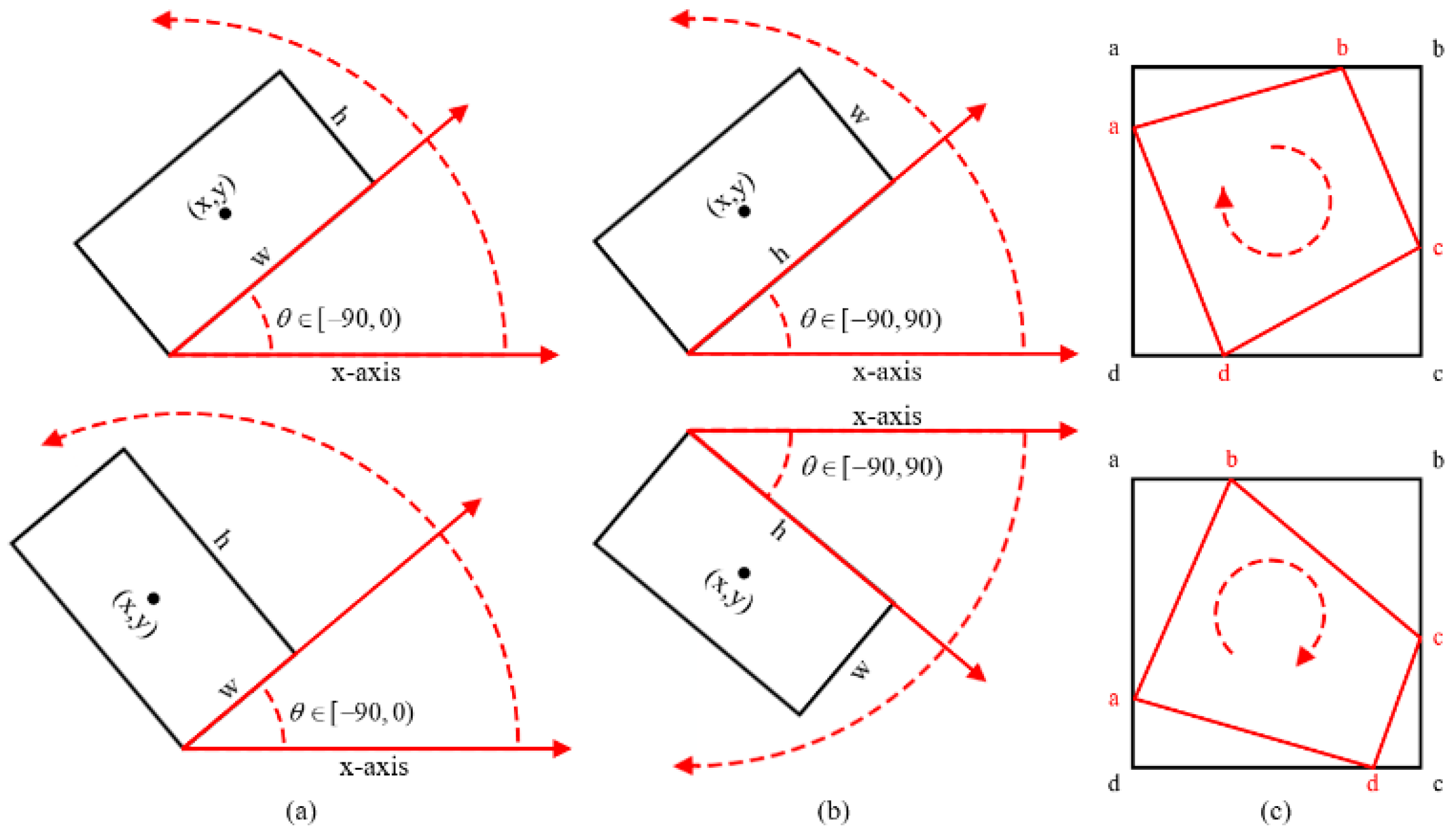
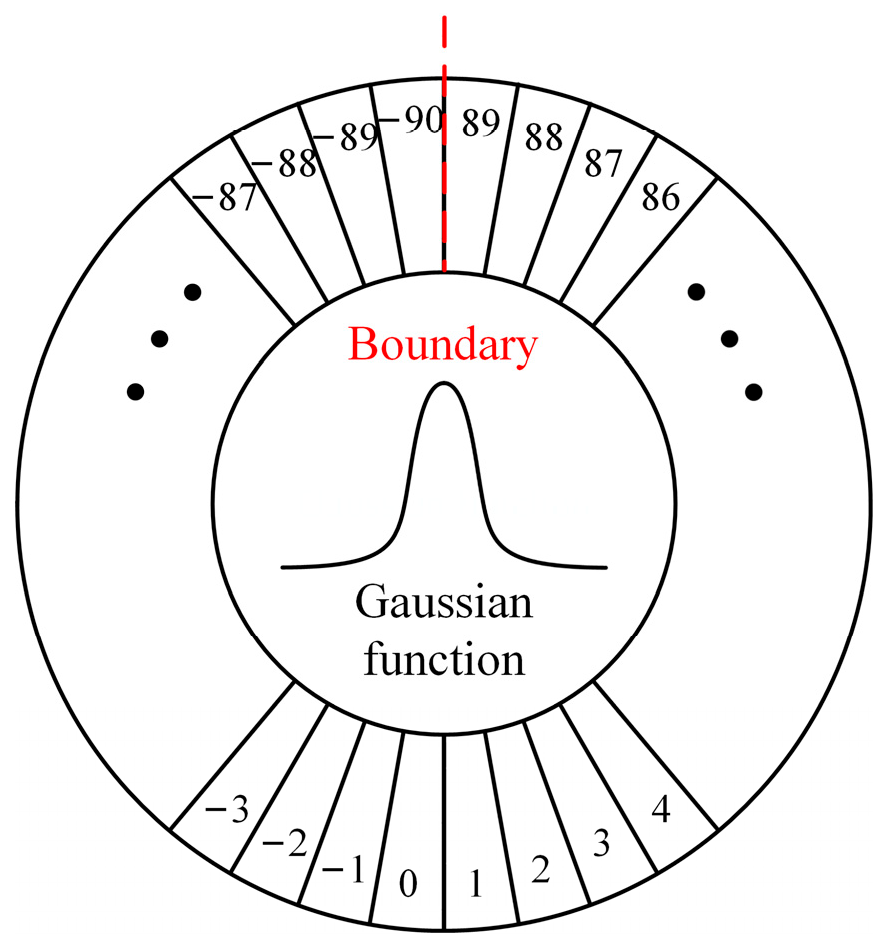
2.2.4. Loss Calculation Based on Oriented Object Detection
3. Experiments
3.1. Experimental Setup
3.1.1. Dataset
3.1.2. Data Preprocessing
3.1.3. Performance Evaluation
3.2. Hyperparameter Selection
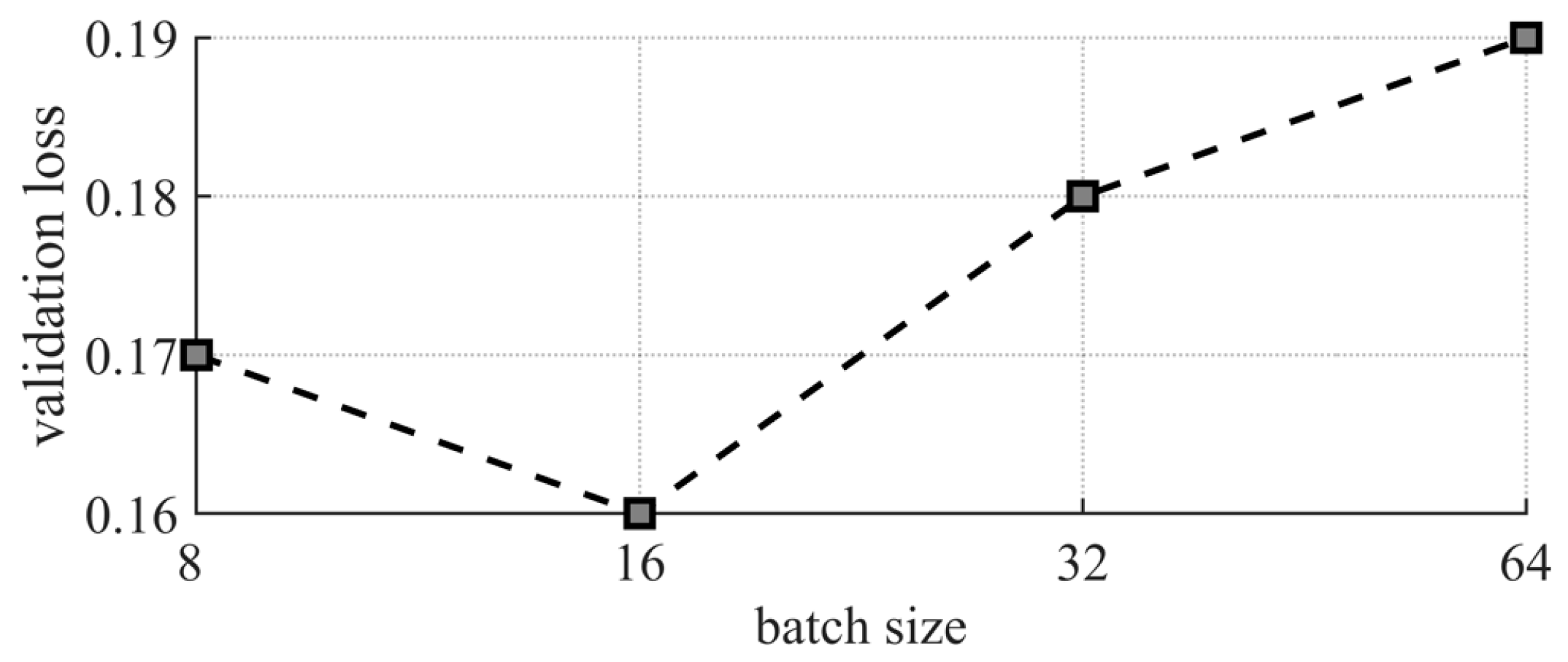
3.2.1. Batch Size Selection
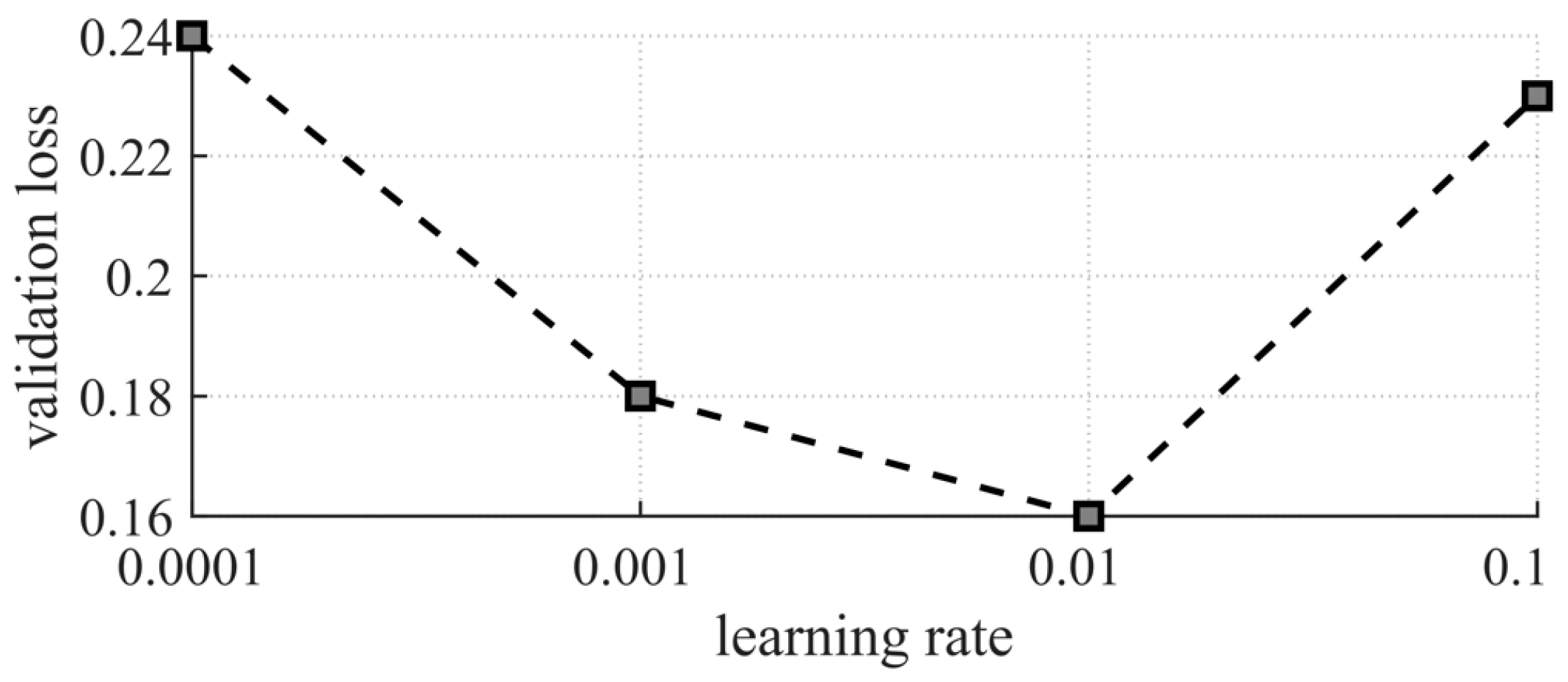
3.2.2. Learning Rate Selection
3.2.3. Window Radius Selection
3.2.4. Other Hyperparameter Selections
3.3. Ablation Experiments
3.3.1. Ablation Experiment of Feature Extraction Network
3.3.2. Ablation Experiment of Feature Fusion Network
3.3.3. Ablation Experiment of Feature Detection Network
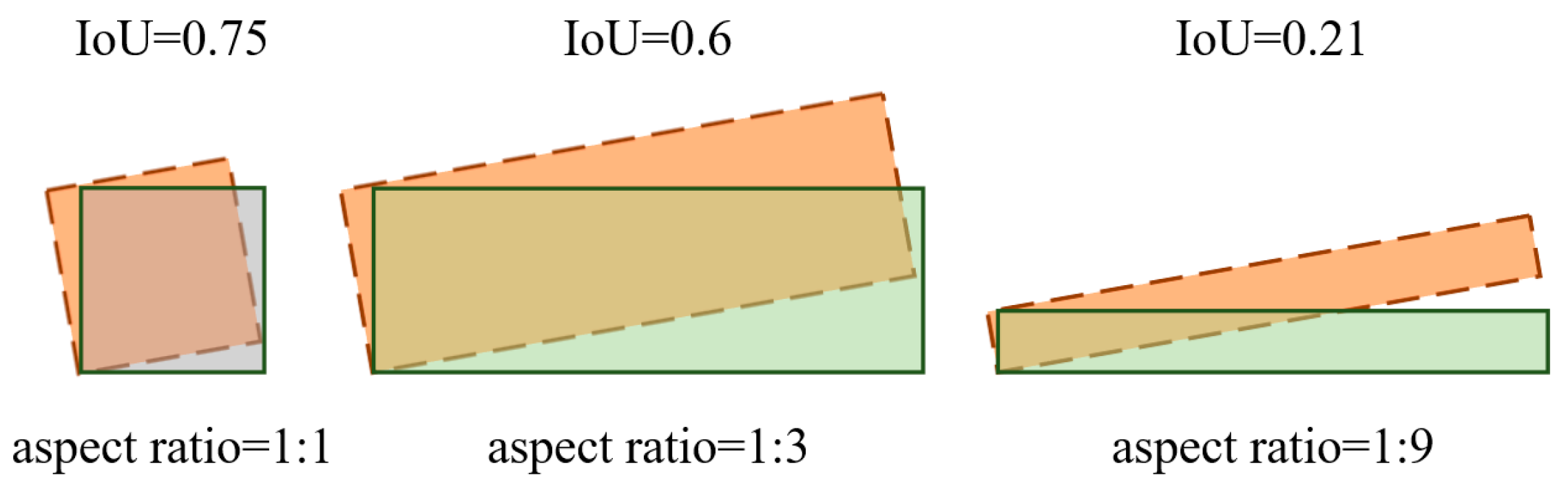
3.3.4. Ablation Experiments of IoU Methods
3.4. Comparison with State-of-the-Art Oriented Object Detection Methods
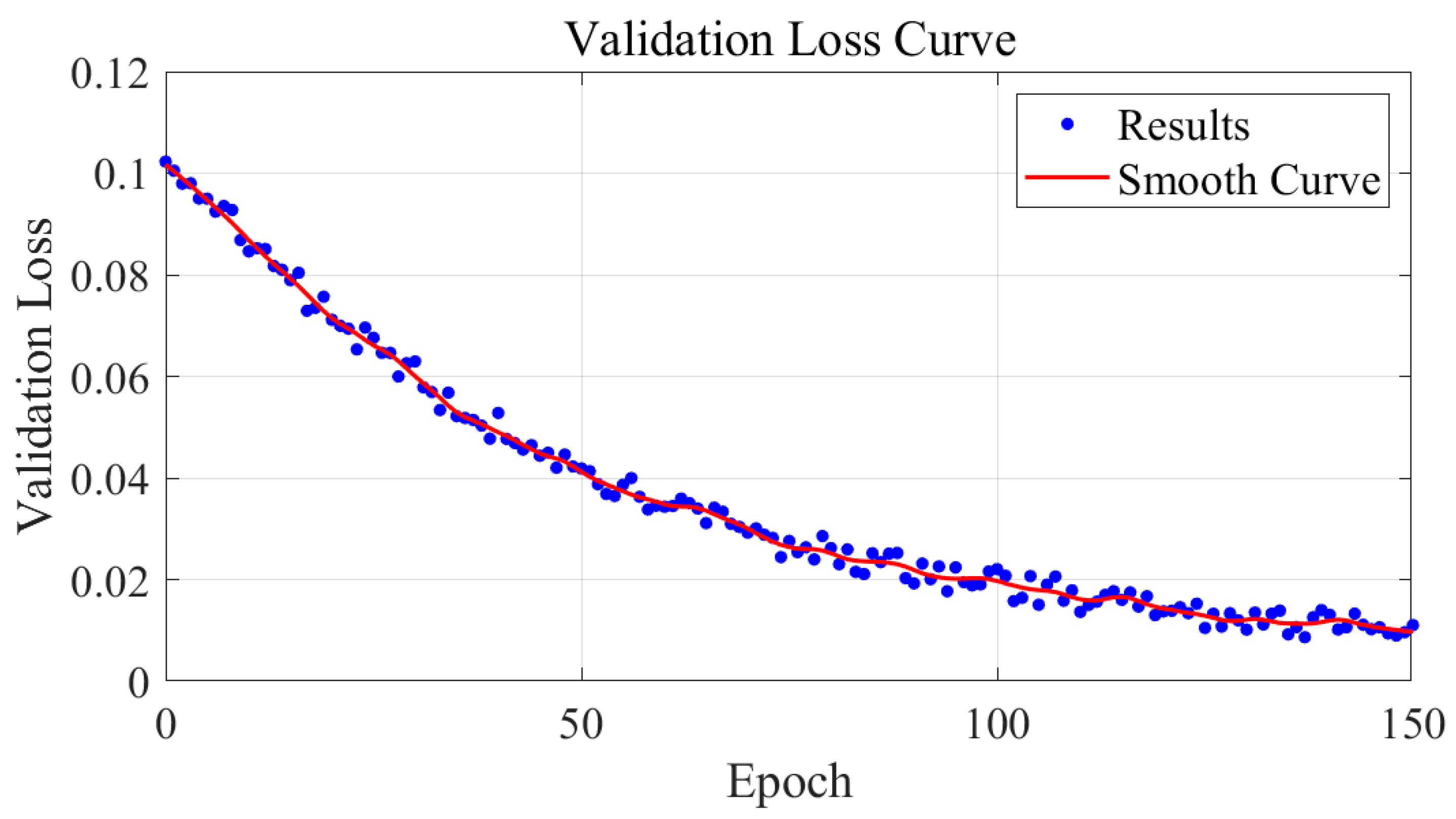
3.5. Training Visualization
4. Discussion
- (1)
- Market Expansion: The increasing prevalence of hair loss globally and the growing acceptance of cosmetic surgery are likely to drive market growth. Robotic systems that can offer high precision and reduced procedural times are particularly well-positioned to capitalize on this trend.
- (2)
- Integration with Other Technologies: Future developments could see the integration of YOLO-OHFD with augmented reality (AR) and virtual reality (VR) systems to enhance surgical planning and outcome visualization, providing surgeons with real-time, enhanced images of the surgical site.
- (3)
- Automation and Learning: Advancements in machine learning could enable these systems to improve their performance over time based on procedural data, potentially leading to fully automated systems that require minimal human oversight.
- (4)
- Technical Challenges: Despite significant advancements, challenges remain, particularly in handling very high-density hair follicles and those with complex orientations. Improvements in image acquisition technologies and real-time processing capabilities are necessary to address these issues.
- (5)
- Regulatory and Ethical Considerations: As with all medical technologies, rigorous testing and regulatory approval are crucial. There are also ethical considerations related to the automation of surgical procedures, including concerns about patient safety and the role of human surgeons.
- (6)
- Customization and Personalization: Future research could also explore how these technologies might be adapted for use in other types of hair, such as body hair, and for patients with varying scalp conditions. Customization to individual patients’ needs and conditions will be crucial for wider adoption.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Rhodes, T.; Girman, C.J.; Savin, R.C.; Kaufman, K.D.; Guo, S.; Lilly, F.R.; Siervogel, R.; Chumlea, W.C. Prevalence of male pattern hair loss in 18–49 year old men. Dermatol. Surg. 1998, 24, 1330–1332. [Google Scholar] [CrossRef] [PubMed]
- Okhovat, J.P.; Marks, D.H.; Manatis-Lornell, A.; Hagigeorges, D.; Locascio, J.J.; Senna, M.M. Association between alopecia areata, anxiety, and depression: A systematic review and meta-analysis. J. Am. Acad. Dermatol. 2023, 88, 1040–1050. [Google Scholar] [CrossRef] [PubMed]
- Bae, T.W.; Jung, Y.C.; Kim, K.H. Needle Transportable Semi-Automatic Hair Follicle Implanter and Image-Based Hair Density Estimation for Advanced Hair Transplantation Surgery. Appl. Sci. 2020, 10, 4046. [Google Scholar] [CrossRef]
- Hoffmann, R. TrichoScan: A novel tool for the analysis of hair growth in vivo. J. Investig. Dermatol. Symp. Proc. 2003, 8, 109–115. [Google Scholar] [CrossRef]
- Vallotton, P.; Thomas, N. Automated body hair counting and length measurement. Skin Res. Technol. 2008, 14, 493–497. [Google Scholar] [CrossRef]
- Shih, H.-C. An unsupervised hair segmentation and counting system in microscopy images. IEEE Sens. J. 2014, 15, 3565–3572. [Google Scholar] [CrossRef]
- Konstantinos, K.A. Hair transplantation—From the ‘ancient’ 4 mm plugs to the latest follicular unit excision technique: 8 decades of painful progress. In Hair Loss: Advances and Treatments; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 25–52. [Google Scholar] [CrossRef]
- Kubaisi, T.A. Acute versus chronic telogen hair loss: A review of the knowledge and recent facts. Al-Anbar Med. J. 2024, 20, 2. [Google Scholar] [CrossRef]
- Bi, X.; Hu, J.; Xiao, B.; Li, W.; Gao, X. IEMask R-CNN: Information-enhanced mask R-CNN. IEEE Trans. Big Data. 2022, 9, 688–700. [Google Scholar] [CrossRef]
- Kim, M.; Kang, S.; Lee, B.-D. Evaluation of automated measurement of hair density using deep neural networks. Sensors 2022, 22, 650. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.-C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 10213–10224. [Google Scholar] [CrossRef]
- Gu, X.; Zhang, X.; Fang, H.; Wu, W.; Lin, J.; Yang, K. A New Dataset for Hair Follicle Recognition and Classification in Robot-Aided Hair Transplantation. In Proceedings of the International Conference on Artificial Neural Networks, Heraklion, Crete, Greece, 23–26 September 2023; pp. 38–49. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Gallucci, A.; Znamenskiy, D.; Pezzotti, N.; Petkovic, M. Hair counting with deep learning. In Proceedings of the 2020 International Conference on Biomedical Innovations and Applications (BIA), Varna, Bulgaria, 24–27 September 2020; pp. 5–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Xian, S.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 2849–2858. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11207–11216. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Sun, X. Point-Based Estimator for Arbitrary-Oriented Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4370–4387. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. ReDet: A Rotation-Equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 2786–2795. [Google Scholar] [CrossRef]
- Mahasin, M.; Dewi, I.A. Comparison of CSPDarkNet53, CSPResNeXt-50, and EfficientNet-B0 backbones on YOLO v4 as object detector. Int. J. Eng. Sci. Inf. Technol. 2022, 2, 64–72. [Google Scholar] [CrossRef]
- Senussi, M.F.; Kang, H.S. Occlusion removal in light-field images using CSPDarkNet53 and bidirectional feature pyramid network: A multi-scale fusion-based approach. Appl. Sci. 2024, 14, 9332. [Google Scholar] [CrossRef]
- Sun, B.; Wang, X.; Li, H.; Dong, F.; Wang, Y. Small-target ship detection in SAR images based on densely connected deep neural network with attention in complex scenes. Appl. Intell. 2023, 53, 4162–4179. [Google Scholar] [CrossRef]
- Xiao, Z.; Yang, G.; Yang, X.; Mu, T.; Yan, J.; Hu, S. Theoretically achieving continuous representation of oriented bounding boxes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–20 June 2024; pp. 16912–16922. [Google Scholar] [CrossRef]
- Tian, S.L.; Xu, K.; Xia, J.; Chen, L. Efficient parallel dynamic overset unstructured grid for flow simulation with moving bodies. AIAA J. 2023, 61, 2135–2166. [Google Scholar] [CrossRef]
- Liu, F.; Chen, R.; Zhang, J.; Xing, K.; Liu, H.; Qin, J. R2YOLOX: A lightweight refined anchor-free rotated detector for object detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Farhadi, A.; Redmon, J. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Epoch | 150 |
| Initial learning rate | 0.01 |
| Batch size | 16 |
| Optimizer | SGD |
| weight_decay | 0.0005 |
| Momentum | 0.937 |
| warmup_epoch | 3.0 |
| warmup_momentum | 0.8 |
| Mosaic | 1.0 |
| CSL theta | 180 |
| Window radius | 2 |
| Method | Class1 | Class2 | Class3 | Class4 | mAp | FPS |
|---|---|---|---|---|---|---|
| CSP + Res | 75.83 | 76.11 | 74.35 | 71.61 | 75.55 | 44.02 |
| CSP + Res2 | 79.76 | 79.19 | 77.39 | 75.18 | 78.91 | 46.19 |
| CSP + Res + ECA | 83.27 | 83.86 | 81.69 | 79.01 | 83.12 | 41.06 |
| CSP + Res2 + ECA | 88.56 | 87.39 | 84.38 | 81.96 | 87.05 | 43.63 |
| CSP + Res + CBAM | 82.96 | 82.37 | 79.25 | 76.95 | 81.83 | 33.26 |
| CSP + Res2 + CBAM | 87.33 | 86.17 | 82.96 | 80.18 | 85.77 | 35.61 |
| CSP + Res + CA | 83.56 | 83.11 | 80.96 | 77.52 | 82.68 | 36.02 |
| CSP + Res2 + CA | 88.17 | 86.89 | 83.62 | 80.76 | 86.51 | 37.96 |
| Method | Class1 | Class2 | Class3 | Class4 | mAp | FPS |
|---|---|---|---|---|---|---|
| FPN | 85.26 | 85.13 | 81.69 | 80.03 | 84.40 | 46.96 |
| FPN + FAM (Conv) | 85.11 | 85.02 | 81.53 | 80.06 | 84.27 | 45.71 |
| FPN + FAM (DCN) | 88.36 | 87.41 | 84.33 | 82.76 | 87.01 | 43.66 |
| Method | Class1 | Class2 | Class3 | Class4 | mAp | FPS |
|---|---|---|---|---|---|---|
| Coupled + Reg | 83.06 | 82.86 | 79.61 | 78.92 | 82.22 | 36.69 |
| Decoupled + Reg | 86.11 | 85.57 | 82.27 | 81.33 | 85.02 | 37.63 |
| Coupled + Cls | 84.13 | 83.71 | 80.89 | 79.96 | 83.22 | 38.03 |
| Decoupled + Cls | 87.98 | 87.13 | 84.01 | 81.36 | 86.66 | 40.93 |
| Coupled + Cls (GCL) | 84.98 | 84.27 | 81.13 | 80.65 | 83.83 | 41.57 |
| Decoupled + Cls (GCL) | 88.49 | 87.31 | 84.31 | 81.89 | 86.98 | 43.71 |
| Method | Class1 | Class2 | Class3 | Class4 | mAp | FPS |
|---|---|---|---|---|---|---|
| IoU | 79.41 | 81.09 | 79.53 | 78.26 | 80.18 | 44.97 |
| GIoU | 81.07 | 82.13 | 80.03 | 78.49 | 81.30 | 44.22 |
| DIoU | 81.19 | 82.31 | 80.02 | 78.63 | 81.43 | 44.13 |
| CIoU | 85.68 | 85.36 | 82.23 | 80.13 | 84.73 | 43.93 |
| EIoU | 88.47 | 87.34 | 84.35 | 81.83 | 86.99 | 43.69 |
| Method | Class1 | Class2 | Class3 | Class4 | mAp | FPS | FLOPS (G) | Paras (M) | MIT (ms) |
|---|---|---|---|---|---|---|---|---|---|
| R2CNN [20] | 55.68 | 54.01 | 52.57 | 50.59 | 54.17 | 9.63 | 163.86 | 60.14 | 103.84 |
| RRPN [21] | 57.02 | 57.04 | 54.55 | 52.96 | 56.46 | 10.01 | 150.25 | 41.22 | 99.90 |
| SCRDet [22] | 62.95 | 62.84 | 60.15 | 58.2 | 62.24 | 16.37 | 74.20 | 39.30 | 61.09 |
| RoI-Trans [23] | 71.92 | 71.14 | 69.96 | 67.53 | 71.05 | 22.65 | 105.17 | 55.13 | 44.15 |
| G.Vertex [24] | 74.58 | 73.94 | 71.26 | 69.44 | 73.52 | 29.66 | 105.43 | 41.13 | 33.72 |
| DRN [25] | 76.22 | 75.61 | 72.8 | 71.34 | 75.17 | 13.58 | 189.81 | 20.65 | 73.64 |
| R3Det [26] | 78.97 | 79 | 77.03 | 74.68 | 78.49 | 12.86 | 132.63 | 41.90 | 77.76 |
| CenterMap [27] | 79.79 | 79.4 | 77 | 74.43 | 78.93 | 33.57 | 130 | 41.11 | 29.79 |
| S2A-Net [28] | 81.62 | 81.74 | 79.84 | 77.8 | 81.23 | 37.51 | 101.51 | 38.62 | 26.66 |
| ReDet [29] | 83.4 | 82.1 | 80.76 | 78.33 | 82.15 | 14.19 | 48.39 | 31.62 | 70.47 |
| YOLO-OHFD | 87.6 | 87.5 | 85.37 | 83.25 | 87.01 | 43.67 | 42.57 | 22.57 | 22.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Liu, X. YOLO-OHFD: A YOLO-Based Oriented Hair Follicle Detection Method for Robotic Hair Transplantation. Appl. Sci. 2025, 15, 3208. https://doi.org/10.3390/app15063208
Wang H, Liu X. YOLO-OHFD: A YOLO-Based Oriented Hair Follicle Detection Method for Robotic Hair Transplantation. Applied Sciences. 2025; 15(6):3208. https://doi.org/10.3390/app15063208
Chicago/Turabian StyleWang, Hui, and Xin Liu. 2025. "YOLO-OHFD: A YOLO-Based Oriented Hair Follicle Detection Method for Robotic Hair Transplantation" Applied Sciences 15, no. 6: 3208. https://doi.org/10.3390/app15063208
APA StyleWang, H., & Liu, X. (2025). YOLO-OHFD: A YOLO-Based Oriented Hair Follicle Detection Method for Robotic Hair Transplantation. Applied Sciences, 15(6), 3208. https://doi.org/10.3390/app15063208