This section will conduct a series of experiments to verify the performance of REU-Net.
3.2. Dataset
The dataset used in this study is the Massachusetts Building Dataset. This publicly available dataset contains 151 high-resolution aerial images, each with a size of 1500 × 1500 pixels, covering an area of approximately 2.25 square kilometers per image, with the entire dataset covering about 340 square kilometers. The data labels are generated by OpenStreetMap and have been manually verified to ensure accuracy.
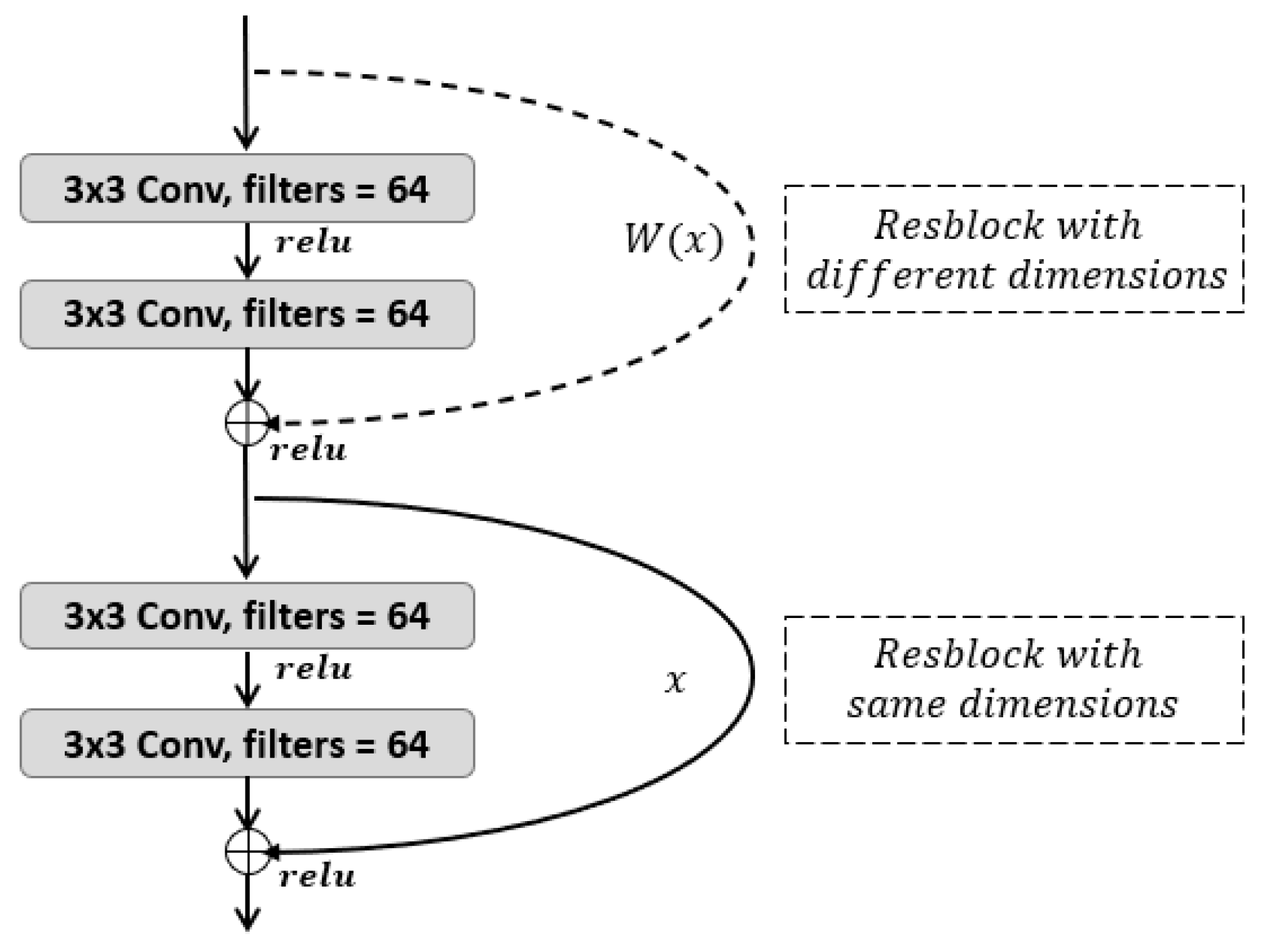
To ensure stable convergence and prevent overfitting, we adopt a learning rate scheduling strategy where the initial learning rate (0.0001) is multiplied by 0.5 every 50 epochs. Although the residual structure increases the network depth, its parameter-efficient design (e.g., identity mapping and 1 × 1 convolutions) avoids significant complexity growth. As a result, the training process remains stable without requiring gradient clipping or adaptive optimizers like AdamW.
To evaluate the effect of image resolution, we trained REU-Net(2EEAM) on the Massachusetts dataset with input sizes of 128 × 128, 256 × 256, and 512 × 512. Performance comparison is shown in
Table 4.
Although increased resolutions (512 × 512) improve MIoU and Border IoU over 256 × 256, their computational cost is much higher than the 256 × 256 baseline. Thus, we selected 256 × 256 as the default resolution to balance accuracy (0.7952 MIoU) and efficiency (48.9 ms per image), making it suitable for real-time applications.
To increase the diversity of the data and improve computational efficiency, the images in the dataset were divided into smaller 256 × 256 pixel patches from the original 1500 × 1500 pixel images. This transformation expanded the dataset from 151 to 3775 images, significantly increasing the variety of building scenes, such as urban buildings along roads, densely arranged small buildings, circular building clusters, lakeside buildings, scattered buildings in dense vegetation, and large buildings under extensive shadows. The images of different scenarios are shown in
Figure 5. In the experiment, the dataset was randomly split into training, testing, and validation sets in a specific ratio, with 3075 images used for training, 350 images for testing, and 350 images for validation.
3.5. Parameter Experiments
We adopted a neural network architecture, REU-UNet(2EEAM), which integrates two EEAM modules, and performed image segmentation on the Massachusetts dataset to determine the optimal weight values for the loss function. To assess the impact of different weight distributions on model performance, we experimented with six parameter combinations (α, β): (0, 1), (0.2, 0.8), (0.4, 0.6), (0.6, 0.4), (0.8, 0.2), and (1, 0), where
is the weight for the Edge-Consistency Loss (
) and
is the weight for the BCE Loss (
). The segmentation results are shown in
Table 7.
When is set to 0.6 and to 0.4, the segmentation results show significant advantages in terms of P, MPA, MIoU, and FWIoU compared to other networks. Therefore, we set to 0.4 and to 0.6 in the total loss function ().
We conducted an ablation study to compare the proposed hybrid loss (BCE + EC) with other common losses. As shown in
Table 8.
It can be found that Dice Loss improves over pure BCE (MIoU: 0.7524 vs. 0.7282) but underperforms BCE + EC due to its focus on regional overlap rather than edge precision. Focal Loss struggles with training stability (fluctuating loss curves) and achieves lower Border IoU (0.7583), likely because it prioritizes hard examples but neglects edge consistency. BCE + EC + Dice shows marginal improvement over BCE + EC but introduces higher complexity. The proposed BCE + EC strikes the optimal balance between edge accuracy (Border IoU: 0.9295) and simplicity.
3.6. Ablation Experiment
In deep learning, ablation studies are an important research method used to better understand network behavior by removing certain parts of the neural network. Robert Long [
25] defines ablation studies as the process of removing parts of a complex neural network and testing its performance to gain deeper insight into the network’s internal mechanisms.
In this section, to determine the optimal network configuration that integrates the attention module for achieving the best performance, we conducted four ablation experiments. Specifically, we compared the segmentation performance of networks with no attention module, and networks with one, two, three, or four EEAM attention modules (i.e., REU-Net, REU-Net(1EEAM), REU-Net(2EEAM), REU-Net(3EEAM), and REU-Net(4EEAM)). The evaluation metrics include the loss values during training and the model’s performance on the Massachusetts dataset (P, MPA, MIoU, and FWIoU) to identify the model with the best overall performance for further comparison experiments.
The data analysis in
Table 9 shows that the proposed REU-Net(2EEAM) demonstrates a significant advantage in network configuration: it outperforms other configurations in terms of metrics, such as P, MPA, MIoU, FWIoU, border IoU, HD, Parameters, FLOPs (the forward computation cost for a single image).
Notably, REU-Net(2EEAM) achieves the highest MIoU (0.7952) and Border IoU (0.9295) with a moderate increase in parameters (35.6 M vs. 34.5 M) and FLOPs (69.3 G vs. 65.2 G). In contrast, the result of 1EEAM shows Insufficient edge enhancement due to limited receptive field coverage, and 3/4EEAM’s results show that Excessive modules introduce redundant computations and over-smooth features, degrading performance (MIoU drops by 7.4% and 8.7%, respectively).
Thus, 2EEAM optimally leverages the trade-off between accuracy and complexity by enhancing critical edge features while avoiding over-parameterization.
To highlight that EEAM enhances edge extraction capabilities and improves the overall accuracy of building segmentation by the model, this paper compares REU-Net(2EEAM) with versions where 2EEAM is replaced by three different attention mechanisms: SE-Net, CBAM, and Transformer.
As clearly shown in
Table 10, REU-Net with 2EEAM outperforms other attention mechanisms in all metrics, demonstrating that 2EEAM significantly contributes to enhancing the model’s segmentation capabilities.
3.7. Comparative Experiments
To evaluate the effectiveness of the proposed improved network REU-UNet(2EEAM), we first selected several classic network models, including FCN8s [
15], SegNet [
24], BiSeNet [
26], DANet [
27], PSPNet [
28], UNet [
16], DeepLabV3+ [
29], UNet++ [
17], MAFF-HRNet [
30], and NPSFF-Net [
31], as well as the REU-Net network without the edge-enhancement attention module for building image segmentation experiments. The results were then compared with those of REU-Net(2EEAM) to systematically validate the improvements in segmentation performance. This comparison aims to systematically validate the performance improvement of the modified network in terms of segmentation accuracy.
Table 11 presents a quantitative comparison of REU-Net(2EEAM) with other classic networks in the building image segmentation task. The experimental results show that traditional networks like FCN8s, SegNet, BiSeNet, and DANet perform poorly in segmentation accuracy metrics. Although PSPNet, UNet, and DeepLabV3+ show some improvements, they still fall short of UNet++. Further observation reveals that MAFF-HRNet, NPSFF-Net, REU-Net, and REU-Net(2EEAM) show more significant progress in segmentation accuracy. Specifically, REU-Net(2EEAM) achieved the best results in key evaluation metrics, such as P, MPA, MIoU, FWIoU, border IoU and HD, with improvements of 0.9408, 0.8641, 0.7952, 0.8897, 0.9295, and 1.0893, respectively, compared to the baseline UNet model. These results strongly demonstrate the superiority of the proposed improved algorithm in terms of accuracy, while also indicating that the implemented network improvement strategy is both reliable and effective.
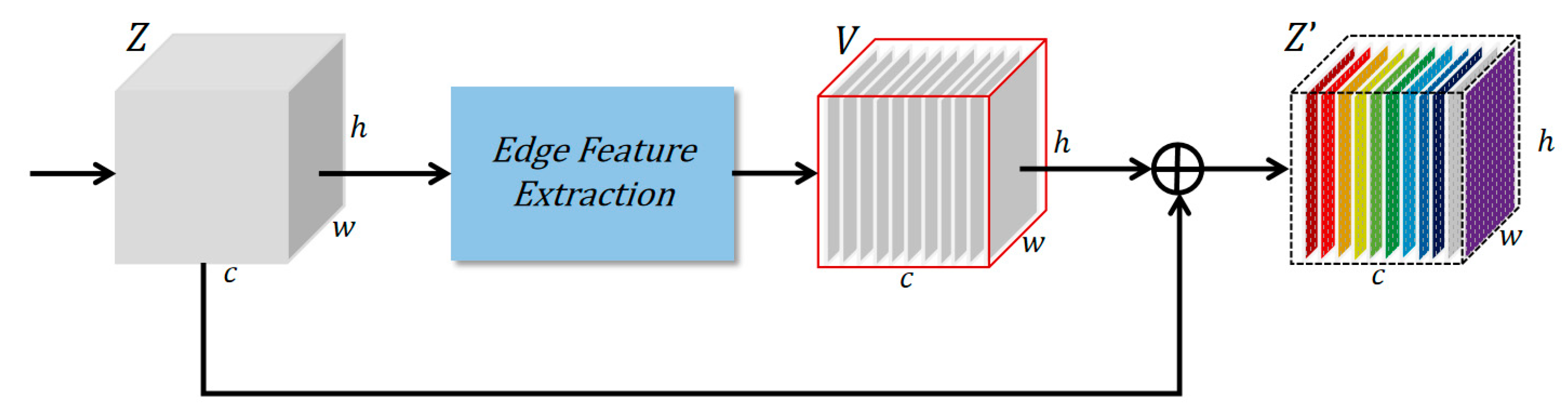
The enhanced segmentation accuracy of REU-Net(2EEAM) compared to other U-Net variants, such as UNet++ or DeepLabV3+, can be attributed to the replacement of traditional 3 × 3 and 1 × 1 convolution blocks with residual blocks (ResBlocks). This modification not only deepens the network architecture but also mitigates the vanishing gradient problem, effectively transferring features from one layer to the next and enabling the extraction of deeper semantic information. Furthermore, direct skip connections are substituted with edge enhancement attention modules. These modules enhance the extraction of building contours and edge information by calculating the difference between positional features and original features, thereby improving segmentation accuracy. Consequently, these improvements enable REU-Net(2EEAM) to achieve superior performance in accurately identifying building edges and enhancing overall segmentation precision.
Figure 7 shows that REU-Net(2EEAM) excels in building segmentation tasks across various scenarios. It demonstrates significant advantages, particularly in complex scenarios where buildings are small, sparsely distributed, and overlap with vegetation. In the first, third, and fourth images, the buildings are small and scattered, with vegetation intertwining with the structures, making accurate segmentation more challenging for the model. By incorporating the attention mechanism, REU-Net(2EEAM) enhances its focus on building edge information, allowing it to clearly segment the building outlines and accurately present their shapes. In contrast, other comparison models, lacking the specific handling of edge information, suffer from a significant shape distortion of the buildings and are more sensitive to image noise, leading to the misidentification of non-existent buildings.
In the second and fifth images, which feature dense clusters of small buildings, REU-Net(2EEAM) accurately segments the clear outlines of the buildings and shows a high success rate in identifying smaller structures. Other comparison models, particularly the FCN8s model, fail to effectively capture the edge details of the buildings, resulting in blurry segmentation and a significant distortion of the building shapes.
In the sixth, seventh, and eighth images, which feature mixed scenes of large and small buildings, REU-Net(2EEAM) also performs exceptionally well. Whether accurately capturing the shape of large buildings or recognizing the details of smaller ones, REU-Net(2EEAM) demonstrates its powerful segmentation capabilities. In contrast, other models fail to effectively distinguish between buildings of different scales in complex architectural structures, resulting in imprecise segmentation.
In summary, REU-Net(2EEAM) successfully improves building segmentation accuracy through enhanced edge information, demonstrating superior performance in complex scenarios compared to other models.
In terms of a detailed comparison, as shown in
Figure 8, the first image demonstrates that REU-Net(2EEAM) accurately identifies the small building, while REU-Net and UNet, although able to segment the building within the frame, lose varying degrees of detail. PSPNet, BiSeNet, and FCN8s completely fail to segment the building.
In the second image, which contains both a large and a small building, the gap between the two buildings is precisely identified by REU-Net(2EEAM). While REU-Net also recognizes it, the boundaries are somewhat blurred. In contrast, UNet, PSPNet, BiSeNet, and FCN8s fail to fully distinguish the boundaries between the two.
Similarly, in the third and fourth images, REU-Net(2EEAM) accurately identifies the gaps between buildings, while the other comparison models fail to fully distinguish the two buildings. This clearly demonstrates that the introduction of the Edge Enhancement Attention Module significantly improves the accuracy of building segmentation by REU-Net(2EEAM).
To validate the generalization capability of REU-Net(2EEAM), we conducted comparative experiments on three remote sensing datasets: Massachusetts Building Dataset (Dataset 1), WHU Building Dataset (Dataset 2), and Inria Aerial Dataset (Dataset 3). The performance of baseline models (UNet, DeepLabV3+, UNet++), recent state-of-the-art models (NPSFF-Net, REU-Net), and REU-Net(2EEAM) is summarized in
Table 12.
As shown in
Table 12, REU-Net(2EEAM) achieves the highest MIoU and Border IoU across all datasets, demonstrating robust generalization. For instance, on Dataset 3 (Inria), it outperforms UNet++ by 13.5% in MIoU and 29.1% in Border IoU, highlighting its ability to adapt to diverse building distributions and resolutions.
The significant improvement in Border IoU (e.g., 0.939 on Inria) is attributed to the Edge Enhancement Attention Module (EEAM), which explicitly extracts directional gradients (Sobel operators) and applies spatial weighting to amplify boundary features. This design effectively suppresses background noise while preserving fine-grained edges.
To evaluate whether REU-Net(2EEAM) is suitable for real-time applications, this paper compares the computational costs of several models, including UNet, DeepLabV3+, UNet++, NPSFF-Net, REU-Net, and REU-Net(2EEAM). The computational cost is assessed across the following dimensions.
Parameters: the number of model parameters (in millions);
FLOPs: the forward computation cost for a single image (in billions of floating-point operations);
Inference Time: the inference time for a single image with a batch size of 1 (in milliseconds);
FPS: Frames Per Second, representing the number of frames processed per second. The calculation formula is as follows: .
The experimental results are presented in
Table 13. For fairness, all inference time measurements were conducted on an NVIDIA RTX 4060Ti GPU with 16 GB of memory. Input images were resized to 256 × 256 pixels, and the batch size was set to 1 to simulate real-time processing scenarios.
As shown in
Table 13, REU-Net(2EEAM) achieves a competitive inference time of 48.9 ms per image (20.5 FPS), which meets the real-time threshold (≤100 ms). Compared to UNet++ (58.1 ms) and DeepLabV3+ (62.7 ms), our model reduces inference latency by 15.8% and 22.0%, respectively, while maintaining higher segmentation accuracy (see
Table 11). The minor increase in FLOPs (69.3 G vs. UNet’s 65.2 G) is attributed to the EEAM’s edge-enhancement operations, but its parameter-efficient design (35.6 M parameters) ensures compatibility with resource-constrained devices.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}