1. Introduction
The rapid advancements in DNA sequencing technologies have significantly enhanced the quality and quantity of genomic data, providing unprecedented opportunities for medical research and personalized healthcare. Large-scale databases such as the National Center for Biotechnology Information (NCBI) [
1] have been established to manage the vast quantities of DNA sequence data generated globally. Furthermore, the increasing public interest in DNA sequencing has spurred the growth of commercial services such as 23 andMe [
2], which offers personalized genomic analysis to individuals. However, this proliferation of genomic data has also introduced critical challenges related to data privacy and security.
DNA sequences contain highly sensitive information, including genetic predispositions to diseases, physical traits, and other personal attributes. This raises significant privacy concerns, as unauthorized access to or misuse of such data could have serious implications [
3]. Recognizing the importance of safeguarding personal data, regulatory frameworks such as the European Union’s General Data Protection Regulation (GDPR) [
4,
5] have been enacted to enforce strict privacy and access rights. These developments have amplified public demand for robust mechanisms to protect DNA sequences, equating their sensitivity to that of other forms of personal data.
To address these concerns, an effective access control mechanism for managing DNA sequence data is imperative. Blockchain technology offers a promising solution due to its decentralized, immutable, and secure characteristics, which inherently prevent data tampering and unauthorized access.
This research proposes a privacy-preserving DNA sequence sharing ecosystem leveraging blockchain technology to enhance data security and autonomy. The ecosystem consists of two interconnected blockchains: a decentralized identity chain and a DNA sharing chain. The decentralized identity chain facilitates the autonomous management of digital identities through the allocation of personal contracts to users. These contracts enable users to register for various services independently of centralized identity providers, ensuring control and autonomy over their digital identities. The DNA sharing chain, in turn, implements an access control mechanism that allows users to define granular access levels for their DNA segments, specifying target groups for data sharing. To ensure trustworthiness, research institutions participating in the ecosystem must undergo government certification and classification.
The primary objective of this ecosystem is to establish a secure and trustworthy environment for DNA sequence sharing, preserving the privacy and autonomy of both individuals and research institutions while advancing medical research. In particular, this work addresses the following research questions: (RQ1) How can blockchain technology be utilized to enable fine-grained, privacy-preserving sharing of DNA sequences among authorized parties? (RQ2) What system architecture and mechanisms are needed to ensure such a solution is scalable, secure, and interoperable with real-world healthcare workflows? To answer these questions, we propose a novel dual-blockchain architecture and implement a working prototype. The main contributions of this work include (1) a two-chain blockchain ecosystem (combining Ethereum and Hyperledger Fabric) that separates identity management from DNA data sharing to improve scalability and privacy; (2) a fine-grained access control mechanism for DNA sequence segments, enabling selective data sharing with granular permissions; (3) an integration of off-chain storage and decentralized identity (DID) to handle large genomic datasets and comply with privacy regulations (e.g., GDPR’s right to erasure); and (4) a comprehensive evaluation and comparison with existing approaches, demonstrating improved throughput (up to 10–20 transactions/s) and robust security features. This design extends prior work in decentralized health data sharing (e.g., Hsieh et al. [
6]) by introducing a two-blockchain architecture and enforcing fine-grained, attribute-level access control, which were not explored in earlier frameworks.
The remainder of this paper is organized as follows:
Section 2 reviews related work on blockchain-based DNA sequence storage and sharing frameworks.
Section 3 details the system design and implementation.
Section 4 presents the performance evaluation and comparative security analysis. Finally,
Section 5 concludes the paper and outlines future research directions.
2. Related Works
The advent of advanced DNA sequencing technologies has facilitated the collection of extensive genomic data, raising significant concerns regarding the privacy and security of sensitive information. Addressing these challenges has been the focus of numerous studies, with blockchain technology emerging as a promising solution due to its decentralized and secure nature.
Shabani [
7] explored the potential application of blockchain and smart contracts to manage access rights to DNA sequence data, highlighting their suitability for automating access control rules in a decentralized manner. This approach underscores blockchain’s potential to bridge the gap between researchers and the public regarding genomic data privacy concerns.
Several studies have proposed blockchain-based frameworks for secure DNA data sharing. Mathur et al. [
8] employed blockchain to secure data transmission among researchers, emphasizing the robustness of blockchain in ensuring data integrity during communication. Neto et al. [
9] introduced a three-layered general framework for DNA sequence storage, aimed at inspiring future research directions. Additionally, various studies [
10,
11,
12] have implemented smart contract-based access control mechanisms to enhance the security and privacy of genomic data sharing. Despite these advancements, the large volume of DNA sequence data presents a significant challenge for on-chain storage. As an alternative, off-chain storage has been identified as a practical and efficient solution to address blockchain’s data scalability challenges [
13]. Eberhardt and Tai [
14] offer early insights into off-chaining computation and data, reinforcing the importance of moving bulky data off-chain to improve performance and scalability. This off-chain approach has been incorporated into many of these frameworks. A notable implementation of off-chain storage is presented by Aung et al. [
15], who integrated multiple heterogeneous offline databases into a private blockchain network. Their approach leveraged an integrator node to facilitate communication between the blockchain network and external databases, demonstrating the feasibility of hybrid solutions in managing large-scale genomic data.
In recent years, blockchain integration in genomic data sharing has continued to evolve. For instance, Albalwy et al. [
16] developed ConsentChain, an Ethereum-based dynamic consent platform for clinical genomics that stores consent preferences on a permissioned blockchain while keeping genomic files off-chain. While ConsentChain improves the granularity of consent management, its reliance on Ethereum introduces performance and cost limitations (transaction throughput and fees) [
17]. A 2022 perspective by Zarchi et al. [
18] proposed a private blockchain coupled with an NFT-based genomic data marketplace to incentivize data sharing, illustrating alternative approaches to encourage genomic data contributions. Furthermore, emerging studies emphasize self-sovereign identity and decentralized storage as key innovations for genomic data privacy—principles that our two-chain ecosystem adopts to empower users and protect sensitive information.
In a related domain, Hsieh et al. [
6] extended the application of blockchain technology to physiological data sharing by adopting a decentralized digital identity framework initially proposed by Yan [
19]. This framework creates personal contracts for individual users, representing their digital identities in a decentralized manner. Users connect to their digital identities via digital wallets, eliminating reliance on traditional centralized identity providers such as Gmail or Facebook. While these studies have advanced the state of blockchain-based solutions for genomic and physiological data sharing, several limitations persist. The scalability of blockchain networks for large-scale genomic data remains a pressing challenge, as does the integration of heterogeneous datasets into cohesive systems. Furthermore, user adoption of decentralized identity frameworks requires addressing usability concerns and interoperability with existing systems. Similar scalability and integration challenges have been observed beyond the biomedical domain as well. For instance, Mourtzis et al. [
20] describe blockchain integration in an industrial metaverse context, highlighting interoperability hurdles. Likewise, Bianchini et al. [
21] propose a resource-oriented blockchain architecture for intertwined supply chains to address data heterogeneity and scalability issues. These studies demonstrate that many challenges in blockchain adoption are common across different fields, reinforcing the broader importance of addressing scalability and seamless data integration. These gaps underscore the need for continued research to refine these technologies and address unresolved issues.
In summary, the novel contributions of this work are as follows: (1) a two-chain blockchain ecosystem (combining Ethereum and Hyperledger Fabric) that separates identity management from DNA data sharing, thereby improving scalability and privacy compared to prior single-chain approaches; (2) a fine-grained access control mechanism for DNA sequence segments, enabling selective data sharing with granular, segment-level permissions (in contrast to the coarser access controls in earlier frameworks); (3) an integration of off-chain storage and decentralized identity (DID) to handle large genomic datasets and comply with privacy regulations (such as GDPR’s “right to erasure”), an approach not combined in previous solutions; and (4) a comprehensive evaluation and comparison with existing approaches, demonstrating improved throughput (up to 10–20 transactions/s for key operations) and robust security features, thus evidencing the efficiency and practicality of the proposed system.
3. System Design and Implementation
This section details the design and implementation of a blockchain-based framework for managing digital identities and securely sharing genomic data. One fundamental design consideration is deciding which data to store on-chain versus off-chain. Given the size and sensitivity of genomic data, storing raw DNA sequences directly on the blockchain would be impractical and costly. Therefore, our architecture stores only essential identity and permission metadata on-chain while keeping the actual DNA sequences in secure off-chain databases. This approach preserves blockchain immutability and auditability for key access information and minimizes on-chain storage costs by leveraging off-chain storage for the bulk of the data [
16,
22]. In the following, we describe the system architecture and components.
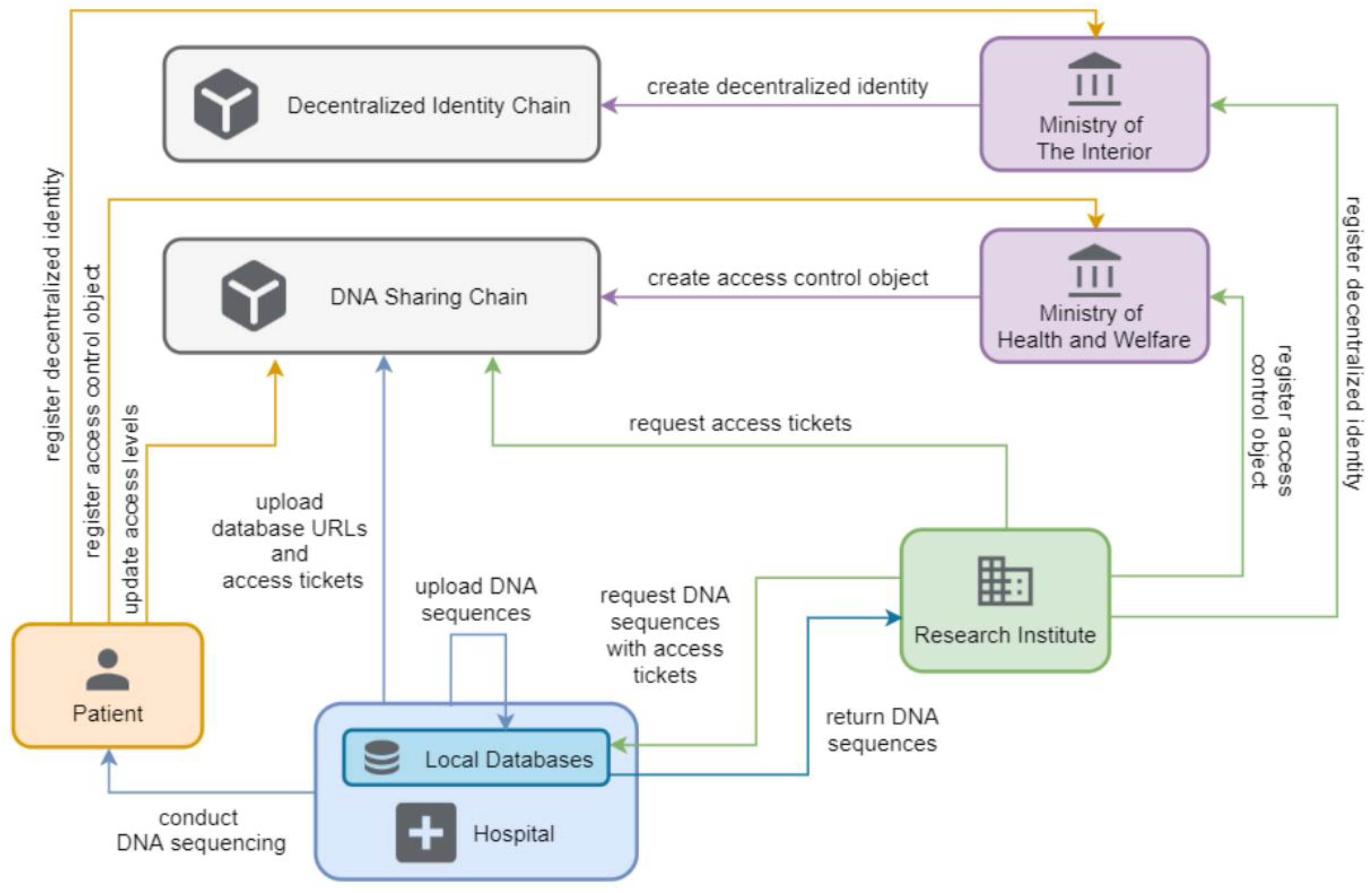
3.1. System Architecture
The proposed system architecture comprises two interdependent blockchains: the decentralized identity chain and the DNA sharing chain, supported by a web-based decentralized application (DApp) for user interaction via browser interfaces. This dual-chain approach ensures efficient management of digital identities and robust execution of access control mechanisms.
Figure 1 provides an overview of the system, delineating its architecture and components.
3.1.1. Decentralized Identity Chain
The decentralized identity chain manages the storage and verification of digital identities and personal materials. Patients and research institutes must register using their ID numbers and wallet addresses, validated by the Ministry of the Interior. Upon successful certification, the Ministry generates a personal contract for each entity, representing their digital identity on the blockchain. These contracts, fully owned and accessible only by their registrars, facilitate the storage of personal data needed for system services.
The decentralized identity chain is based on the blockchain-based decentralized identity framework by Hsieh et al. [
6], with enhancements tailored for the system. Ethereum serves as the underlying platform due to its robust wallet support and immutability.
Identity Manager Contract: This contract manages the creation and binding of decentralized identities. Trusted institutions, such as the Ministry of the Interior, can invoke functions like createUser() to generate new identities. This streamlined process eliminates unbound contracts and ensures data integrity.
Identity Contract: Each user is assigned a unique identity contract, granting them exclusive ownership. Users can securely store and manage personal materials using functions such as addData() and getData(). To enhance privacy, all materials are encrypted with the user’s wallet public key.
3.1.2. DNA Sharing Chain
The DNA Sharing Chain implements the access control mechanism for DNA data sharing. Patients and research institutes, following decentralized identity registration, upload relevant materials for validation by the Ministry of Health and Welfare, which creates access control objects upon certification. These objects maintain the access levels for DNA segments and allow patients to manage permissions. Requests for data access trigger smart contracts that query these objects to generate lists of available data, enabling seamless database interactions.
The DNA sharing chain utilizes Hyperledger Fabric to implement efficient and secure access control. Key-value structures store access control data, enabling streamlined querying and management. We choose Hyperledger Fabric (a private consortium blockchain) for this component because it provides a permissioned environment with modular consensus and no cryptocurrency requirement, making it well-suited for sensitive biomedical data sharing [
23]. Hyperledger Fabric’s design allows for high transaction throughput and fine-grained identity management through its Membership Service, aligning with our trust model [
18].
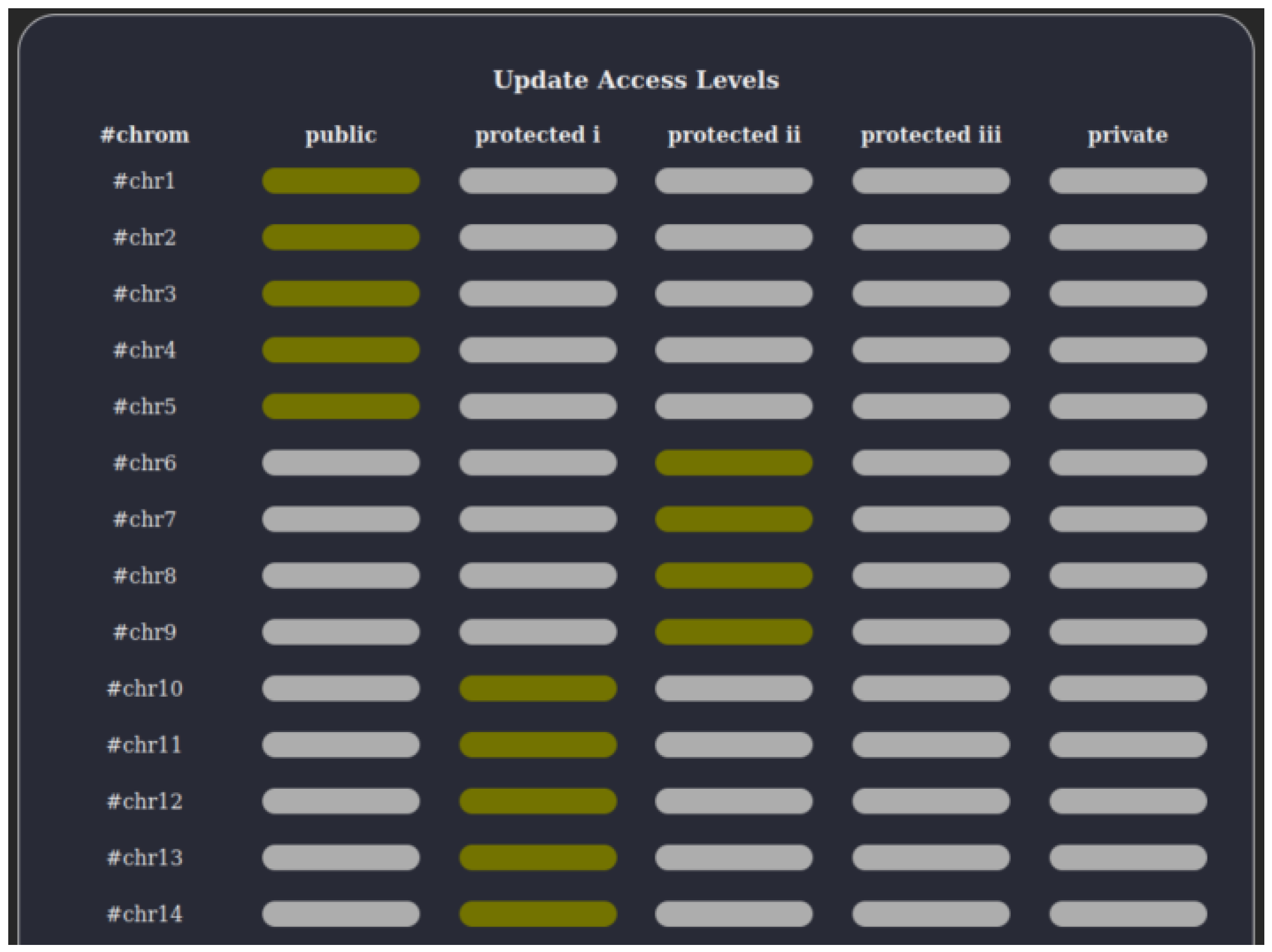
Patient Access Control Contract: This contract manages patient-specific access permissions. Patients can assign access levels to DNA segments using an updateAccessLevelList() function.
Table 1 describes access levels ranging from public (accessible to all research institutes) to private (not accessible).
Research Institute Access Control Contract: Access permissions for research institutes are defined by this contract. Permissions are granted based on hierarchical classifications (
Table 2) and remain immutable after registration.
3.1.3. Off-Chain Data Management
Hospitals and genomic data providers store the actual DNA sequence files in their local databases (off-chain). Each DNA sequence file is associated with an access ticket—a secure reference (e.g., an encrypted URL or index) that is uploaded to the blockchain. By storing only these encrypted pointers on-chain instead of the raw sequences, data owners retain the ability to remove or move the actual data off-chain without cluttering the blockchain. This design satisfies data sovereignty requirements and regulatory “right to deletion” demands, since sensitive sequence data are not permanently written to an immutable ledger [
22]. The blockchain records ensure that any access to the off-chain data is permissioned and auditable via the on-chain tickets.
3.2. Workflow
This architecture leverages Ethereum for decentralized identity management and Hyperledger Fabric for high-performance access control operations. The system employs workflows that ensure secure user interactions through offline signing mechanisms, protecting sensitive keys. Hospitals manage DNA data in off-chain local databases, linking encrypted access tickets to the blockchain for dynamic authorization.
3.2.1. Registering a Decentralized Identity
The registration workflow for decentralized identities is depicted in
Figure 2. Registrants, either individuals or organizations, must submit their type, ID number (or organization number), and wallet address to the Ministry of the Interior. The Ministry verifies these credentials to ensure they have not been previously registered. Upon successful verification, the Ministry generates a unique ID and creates an identity contract for the registrar. Ownership of the identity contract is then transferred to the registrar, granting access to all services associated with the decentralized identity
3.2.2. Uploading and Downloading Personal Materials
The processes for uploading and downloading personal materials to and from the identity contract are illustrated in
Figure 3. To upload materials securely, users must encrypt all data using public keys obtained from their wallet and provide a digitally signed message for storage authorization. The identity contract verifies the signed message before securely storing the materials. For users intending to join the DNA sharing chain, uploading a certificate signing request (CSR) and private key to the identity contract is a mandatory prerequisite.
To download materials, users must specify the desired material name and submit a digitally signed message using their private key. Upon successful verification, the encrypted material is retrieved and can be decrypted with the user’s wallet private key. This dual-process design ensures that sensitive data remain secure throughout both storage and retrieval operations.
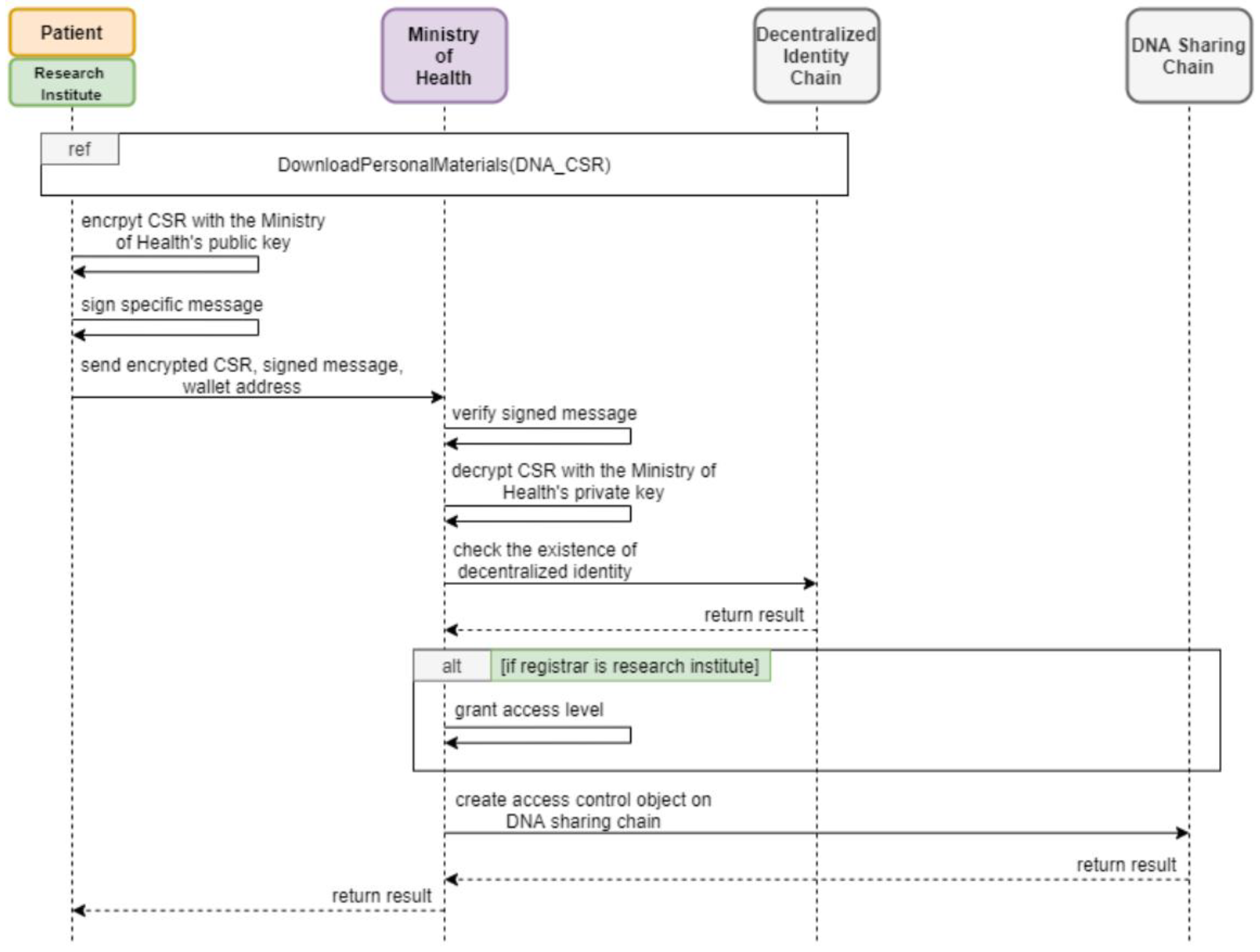
3.2.3. Registering Access Control Objects
The process for registering access control objects, visualized in
Figure 4, involves submitting a CSR, a signed message, and a wallet address. These credentials are re-encrypted with the Ministry of Health and Welfare’s public key for secure transmission. Upon successful validation of the signed message and CSR, the Ministry creates an access control object on the DNA sharing chain. This object, tailored to the registrar’s requirements, governs subsequent data access levels and permissions.
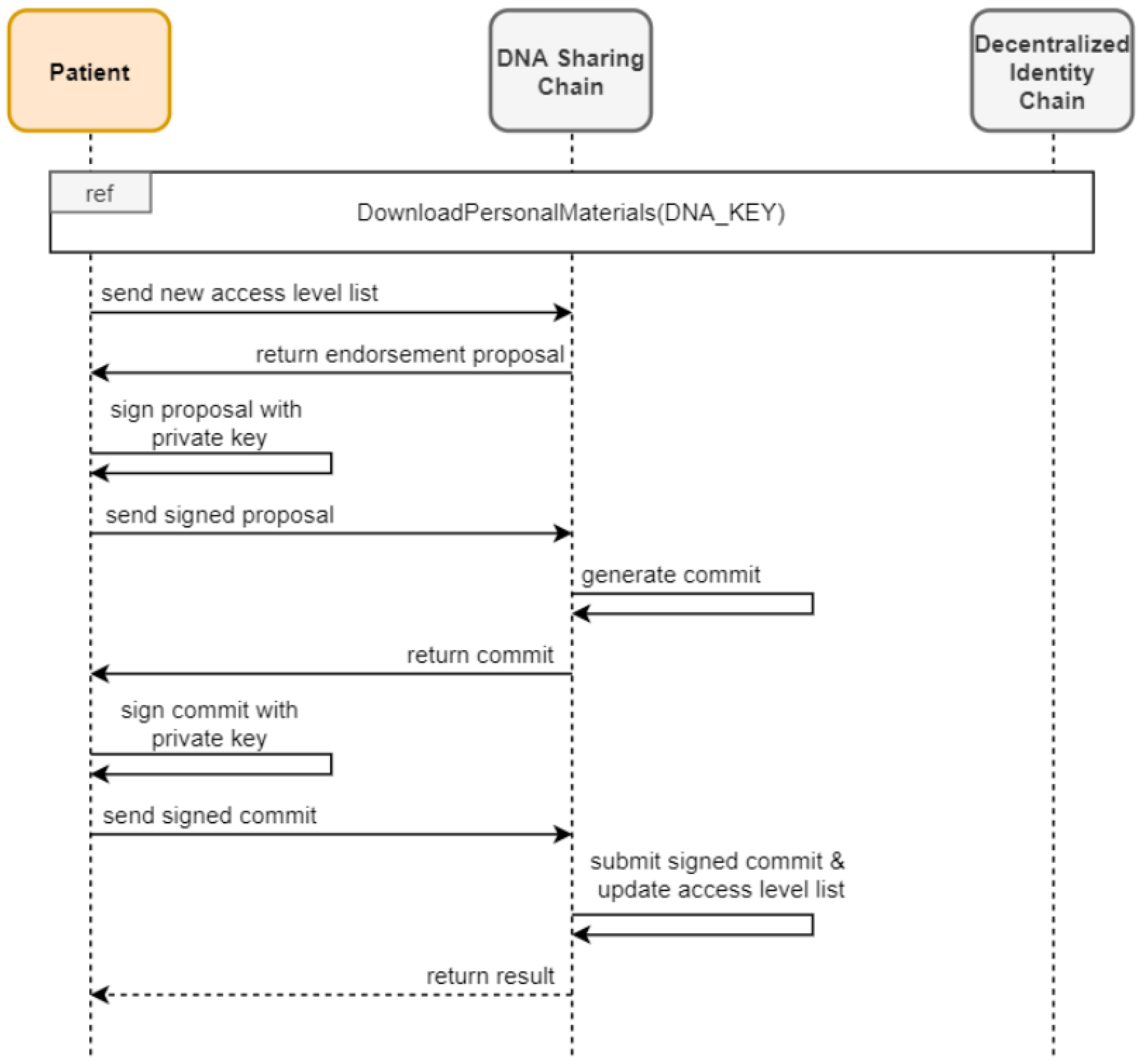
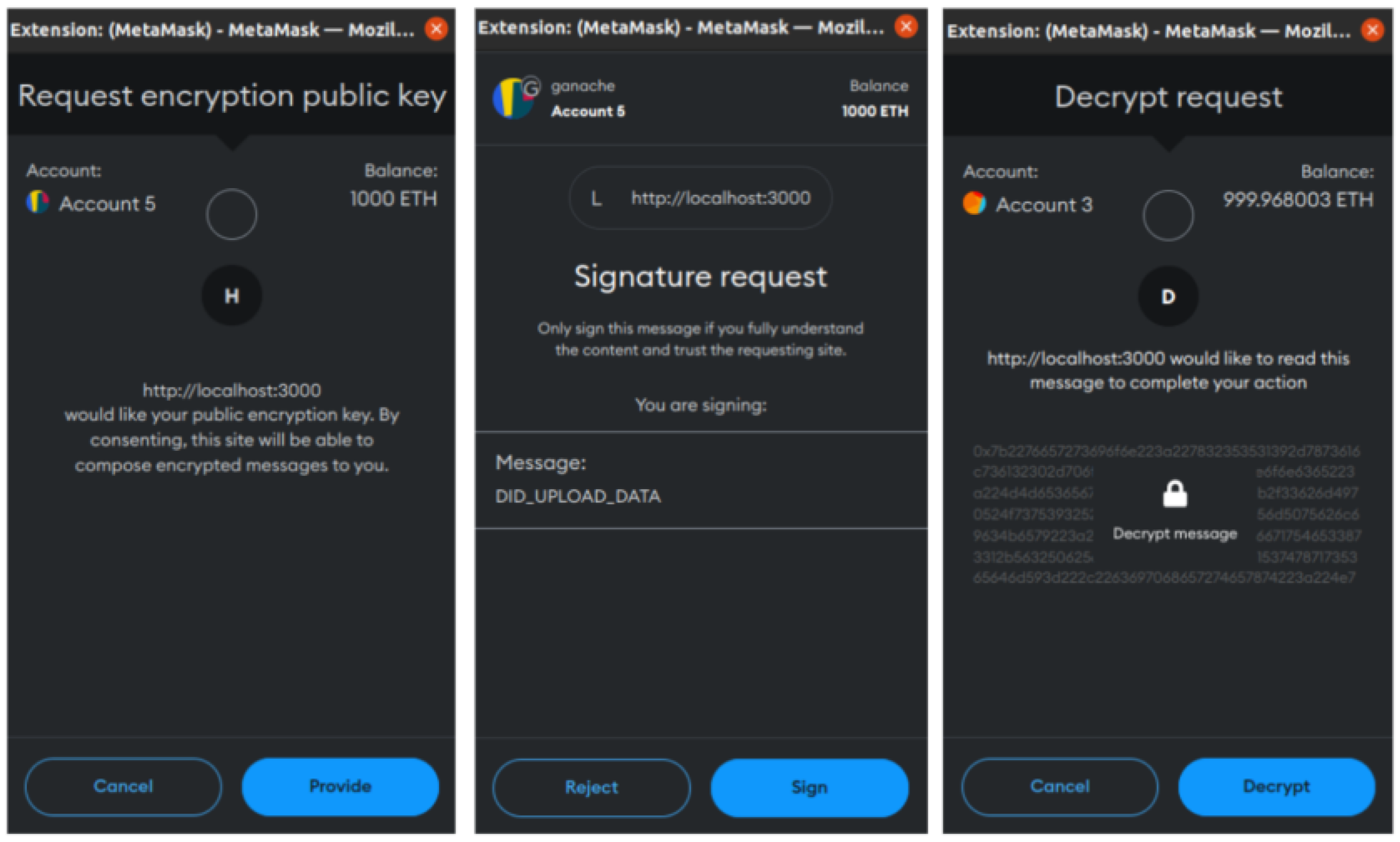
3.2.4. Updating Access Level Lists
To address security concerns associated with direct blockchain interaction, offline signing is implemented for updating access levels, as shown in
Figure 5. The patient retrieves their private key from the identity contract and completes the following three steps:
- 1.
Sign Proposal: Generate and sign a proposal containing the new access level list using the private key.
- 2.
Sign Commit: Submit the signed proposal for verification by endorsers on the DNA sharing chain. Upon acceptance, a signed commit is returned.
- 3.
Submit Commit: Sign and submit the commit to update the access levels on the chain securely.
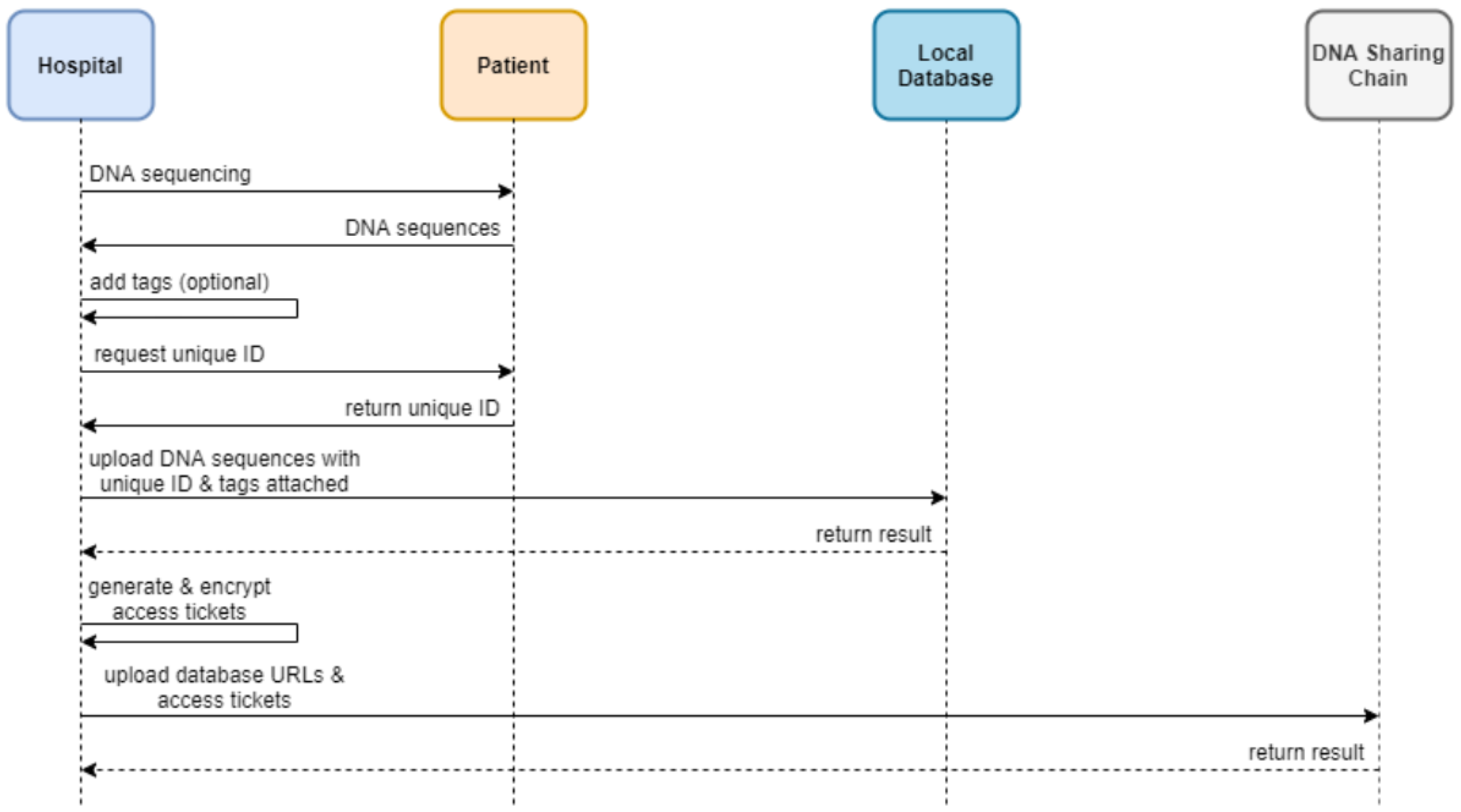
3.2.5. Uploading and Downloading DNA Sequences
The workflow for uploading DNA sequences is illustrated in
Figure 6. Patients provide a unique identifier to the hospital conducting the sequencing. Hospitals may optionally attach tags (e.g., gender or genetic characteristics) to enhance data granularity. The DNA sequences, along with encrypted access tickets, are stored in local databases and linked to the patient’s access control object on the blockchain, with hospitals determining the format and encryption methods.
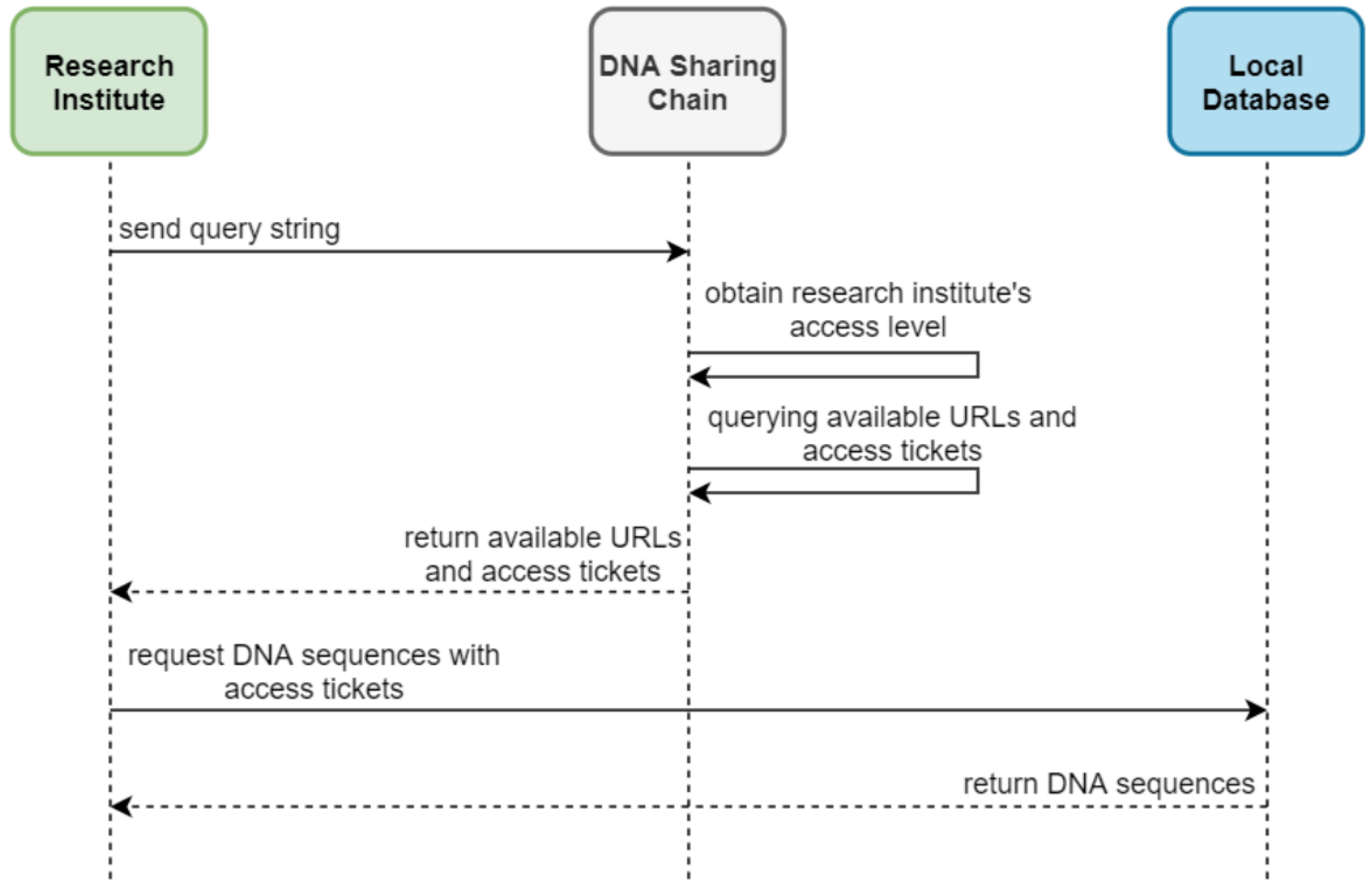
The workflow for downloading DNA sequences is illustrated in
Figure 7. Research institutes query the DNA sharing chain with specific search parameters. The chain evaluates the access levels of both the patient and the institute, filtering available access tickets and corresponding URLs. Authorized tickets enable the institutes to request DNA sequence data directly from hospital databases, ensuring compliance with predefined access control policies.
These workflows demonstrate the secure and efficient integration of decentralized identity and access control mechanisms, leveraging blockchain technologies to ensure data integrity and privacy across all operations. For detailed use case demonstrations, please refer to
Appendix B.
3.3. System Implementation
3.3.1. Decentralized Identity Chain
The registration of decentralized identities is essential for secure access to the ecosystem. As shown in
Figure 8, patients register as “person” users and research institutes as “organization” users by submitting identification numbers and wallet addresses via the MetaMask browser extension. The Ministry of the Interior verifies these details and generates a unique identity contract on the blockchain.
Users manage their decentralized identities through an interface, which allows them to view details, upload encrypted materials, and retrieve data. Materials are encrypted using the wallet’s public key and uploaded with a digitally signed message via MetaMask (
Figure 9). Retrieval involves decrypting materials with the user’s private key. To access the DNA sharing chain, users must upload a certificate signing request (CSR) and private key, stored as “DNA_CSR” and “DNA_KEY” in the identity contract.
3.3.2. DNA Sharing Chain
Registration of Access Control Objects: The registration process requires users to upload a CSR and private key. Patients and research institutes select appropriate access control object types and sign a message to initiate registration. The Ministry of Health and Welfare verifies these details before generating access control objects. Automated tools streamline the process, except for MetaMask-triggered signing.
Updating Access Levels: As shown in
Figure 10, patients manage access levels for DNA segments through a table interface. Offline signing secures updates by signing and submitting transaction proposals. The private key, downloaded from the identity contract, ensures secure authentication. Changes are reflected on the DNA sharing chain upon submission.
Uploading and Downloading DNA Sequences: DNA sequence uploading involves two steps. Patients provide unique IDs to hospitals, which store sequences in local off-chain databases using variant call format (VCF) for efficiency, optionally tagging data with attributes like gender or medical history. Encrypted access tickets are then uploaded to the patient’s access control object on the blockchain. Downloading DNA sequences involves querying, downloading access tickets, and requesting data. Research institutes submit signed queries with optional tags. The DNA sharing chain evaluates permissions and returns authorized tickets and URLs, enabling institutes to securely retrieve data from hospital databases.
This implementation integrates blockchain-based security and access controls to ensure the robust and efficient management of sensitive DNA data.
3.3.3. System Interface and Integration
The system provides an integrated web-based interface (DApp) to interact with both blockchains. Patients and researchers use a single portal where Ethereum transactions (for identity registration and data upload) are initiated via MetaMask prompts, and Hyperledger Fabric chaincode invocations (for updating access lists or querying data) are performed through a backend service using the user’s Fabric digital certificate. To improve performance, our implementation employs offline transaction signing for Fabric operations: users download their Fabric private key (stored on the identity blockchain) and sign transaction proposals locally, which are then submitted directly to the Fabric network. This approach avoids the latency of the official Fabric SDK’s peer-to-peer communication, achieving significantly higher throughput (~10 transactions per second for frequent access updates, as shown in
Section 4.3) compared to the standard SDK (<1 TPS). The DApp interface (e.g.,
Figure 10, access control table) abstracts these technical details, making the dual-blockchain system accessible to non-expert users. (The pseudocode for the chaincode logic implementing these processes is provided in
Appendix A—
Figure A1.)
4. Evaluation
This section presents the evaluation of the proposed system, encompassing performance metrics such as gas consumption and throughput, followed by a comparative analysis with related models and a discussion of security and usability considerations.
4.1. Test Environment
The evaluation was conducted using a system with specifications detailed in
Table 3, which includes an Intel
® Core
TM i5-8250U CPU (1.60 GHz), four cores, 16 GB RAM, and Ubuntu 20.04.5 LTS. Apache JMeter [
24], an open-source performance testing tool, was employed to simulate concurrent and sequential API requests, evaluating the throughput of the decentralized identity chain and DNA sharing chain. For Ethereum-based operations, Truffle Suite [
25] was used for deploying, debugging, and testing smart contracts. Automated testing scripts were constructed to measure gas consumption, leveraging Ganache, an Ethereum test network emulator, for rapid deployment. The DNA sharing chain was implemented using Fablo [
26], which facilitated the efficient setup and configuration of Hyperledger Fabric networks.
4.2. Gas Consumption
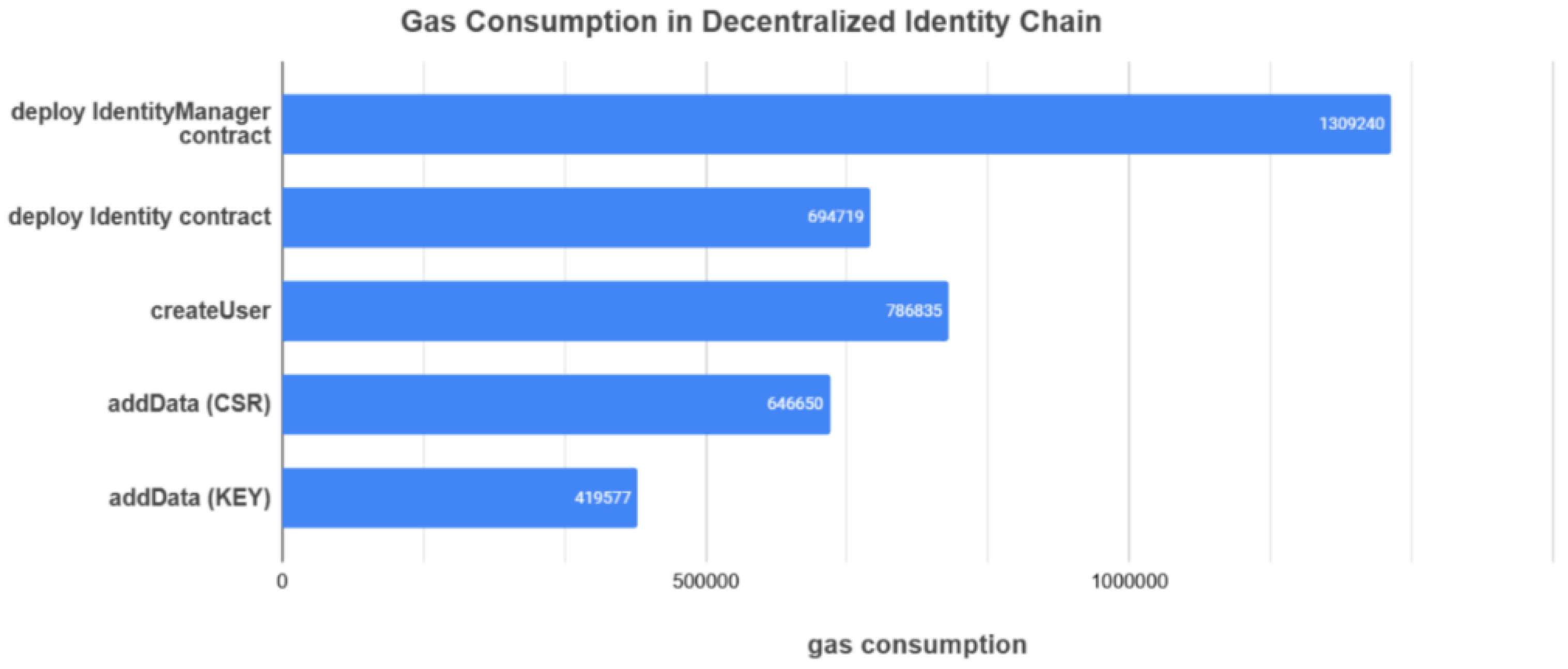
Table 4 outlines the specifications of the test Ethereum network, which was built using Ganache with one node, an in-memory LevelDB state database, auto-mining, and a block time of 0.5 s. Gas, the cost metric for Ethereum operations, was analyzed to assess the computational efficiency of operations. As shown in
Figure 11, gas consumption scales with the complexity of the operation. Deploying the IdentityManager contract required approximately 1300 K gas units, executed once during system initialization. Key user operations, including createUser, addData (CSR), and addData (KEY), consumed 400 K–800 K gas units per operation. Each operation is executed once per user, and the observed gas consumption is within acceptable limits for scalability. By minimizing the amount of data stored on-chain (only small certificates and keys), our design keeps gas costs manageable. For DNA data transactions, Hyperledger Fabric is used (which does not use gas), and only tiny encrypted tickets are written to Ethereum, further containing gas usage.
4.3. Throughput
Decentralized Identity Chain: Throughput, defined as the number of requests handled per second, was measured for core operations in the decentralized identity chain, as depicted in
Figure 12. The results indicate that throughput inversely correlates with the computational complexity of operations. The createUser, addData (CSR), and addData (KEY) operations achieved a maximum throughput of 10–15 requests per second. The getIdentityContractAddress operation, which does not involve transaction submission, processed approximately 20 requests per second. These operations, executed once per user, demonstrate sufficient throughput to accommodate the expected user load.
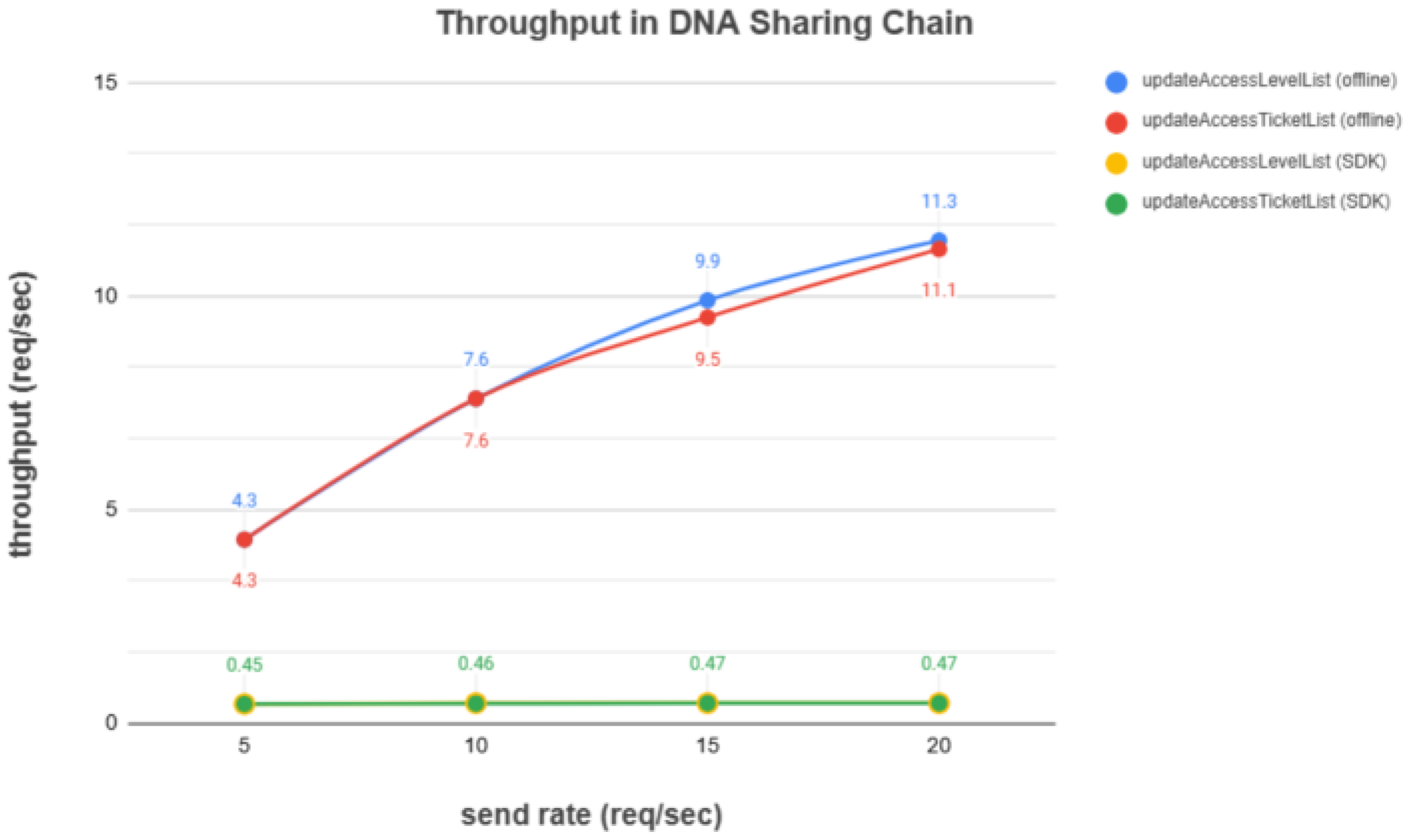
DNA Sharing Chain: Throughput in the DNA sharing chain was evaluated for the updateAccessLevelList and updateAccessTicketList operations, as shown in
Figure 13. Offline signing demonstrated superior performance, achieving approximately 10 requests per second, compared to less than 1 request per second for the official SDK. The discrepancy arises from the official SDK’s reliance on peer node connections and network communication, whereas offline signing enables users to prepare and sign transaction proposals locally before direct submission. In this system, updateAccessLevelList utilizes offline signing for frequent user updates, while the less frequent updateAccessTicketList relies on the official SDK. The observed throughput (up to ~10 TPS for access updates) is sufficient to handle the anticipated user base and significantly higher than what has been reported in purely Ethereum-based approaches (often <5 TPS for complex contracts due to network limitations [
17]).
4.4. Comparative Analysis with Existing Models
Here, we compare the performance and security of our blockchain-based ecosystem with prior genomic data-sharing models. Traditional blockchain solutions for genomic data (e.g., those in [
8,
9,
11,
16]) often face scalability issues due to using a single public blockchain for all operations. For example, the ConsentChain system [
16] built on Ethereum must contend with network congestion and transaction fees, limiting its throughput and cost efficiency for large-scale use [
17]. In contrast, our dual-chain architecture leverages a permissioned Hyperledger Fabric network for data sharing, allowing our DNA chain to achieve dedicated throughput of around 10 transactions/s without gas fees or miner delays. This represents an improvement in performance and scalability, as our private chain can handle frequent access updates internally, whereas an Ethereum-based approach would be constrained by the public chain’s ~15 TPS global limit and incurrence of costs for every transaction [
18].
In terms of access control granularity, previous frameworks typically manage consent or access at the study or record level—for instance, the DWARNA biobanking consent system [
10] treats consent as a binary setting (broad consent yes/no), and ConsentChain allows patients to grant or revoke data access, primarily at the dataset level [
17]. Our system advances this by enabling segment-level access control, where patients can specify permissions for individual regions or types of genetic data. This fine-grained approach is particularly important for genomic data, as it allows the sharing of only relevant genetic markers with researchers (e.g., specific genes related to a study) while keeping more sensitive segments private. Such granularity is not addressed by ConsentChain or DWARNA, which focus on whole-record consent management.
With respect to security and trust, many earlier proposals rely on public blockchain identities or pseudonymous addresses [
9,
11], which, while preserving anonymity, may allow participants of uncertain trustworthiness. Our model explicitly introduces a consortium governance aspect: only government-certified research institutions can join the network, and patients are verified through national ID mechanisms. This design choice reduces the risk of malicious actors compared to open networks, at the cost of requiring a trusted authority to onboard users. We believe this trade-off is suitable for medical data contexts where a level of institutional oversight is expected. Notably, the integration of a decentralized identity (DID) chain (based on [
6]) in our work is a distinguishing factor. The physiological chain system [
6] demonstrated the viability of self-sovereign identities in healthcare; our work builds on this by adding a second blockchain dedicated to data transactions, thereby isolating identity management from data exchange. This two-chain architecture improves upon [
6] by preventing heavy data loads from impacting identity ledger performance and by providing specialized optimization (Fabric’s endorsement policies) for data access workflows.
We also compare our approach to the concept of using blockchain with marketplaces or incentives, as discussed in some recent works. While systems proposing tokenization (e.g., via NFTs) aim to encourage data sharing by monetization, they raise complex ethical and privacy questions (such as valuing personal genomic data). Our ecosystem takes a different path by incentivizing participation through strict privacy guarantees and trust (via government oversight) rather than direct payments. This aligns with the view that participants are more willing to share data when they trust the platform’s security and governance, as opposed to purely financial incentives [
18].
In summary, compared to prior blockchain solutions for genomics, our proposed ecosystem provides enhanced scalability (through a hybrid architecture), finer access control, and a built-in trust model involving government certifications. These novel features position our system as a more practical and secure approach for DNA data sharing in research collaborations.
4.5. Security Vulnerabilities and Mitigation Strategies
Although blockchain technology strengthens data integrity and transparency, it is not immune to security vulnerabilities, especially in biomedical data applications. We analyze potential threats to our system and the mitigation strategies in place:
Blockchain Endpoint Security: One well-known vulnerability is at the user endpoint—if an attacker compromises a user’s device or wallet, they could steal private keys and impersonate that user [
27]. In our system, this risk is mitigated by the use of trusted wallet software (MetaMask (
https://metamask.io/, accessed on 17 February 2025)) for identity transactions and by encouraging users to keep their Fabric private keys secure (e.g., downloaded keys are protected by passwords). We assume users follow best practices; in future work, hardware wallets or multi-factor authentication could be integrated for additional safety.
Smart Contract Vulnerabilities: Bugs or logic flaws in smart contracts/chaincode can lead to exploits. We addressed this by keeping the chaincode logic simple and rigorously testing each function. For example, identity contracts only allow trusted authorities to create new identities, and the Fabric chaincode checks that transactions are properly signed by certified entities. We also benefit from Hyperledger Fabric’s endorsement policies that require multiple peers’ approval for transactions, reducing the risk of a single malicious peer affecting the ledger. Nevertheless, we remain aware that smart contract vulnerabilities in healthcare blockchain systems have been reported [
28]. As a precaution, our contracts were audited for common issues (reentrancy, overflow, improper access control) and deployed on test networks before production.
Network Attacks: Public blockchains face 51% attacks or Sybil attacks on their peer-to-peer networks [
27]. In our consortium blockchain, membership is permissioned—all nodes are known organizations—which largely prevents Sybil attacks (bogus identities cannot simply join). The Ethereum identity chain is public, but identity contracts cannot be created or modified without Ministry approval, limiting the damage a 51% attack could do (an attacker could reorder or censor transactions on Ethereum but not forge a valid identity without the Ministry’s key). Fabric’s ordering service is operated by trusted parties, preventing any single entity from controlling the ledger history. We also implement TLS encryption for all network communications in the Fabric network to prevent eavesdropping or man-in-the-middle attacks between consortium nodes.
Data Confidentiality and Privacy: All personal data stored on the identity chain are encrypted with users’ public keys, and DNA access tickets on-chain are encrypted, so even if the blockchain ledger is publicly accessible, the sensitive content remains unintelligible to unauthorized viewers. Off-chain DNA files are protected by hospital security measures and are only retrieved using access tickets that are issued via on-chain permission checks. If an adversary somehow obtains an access ticket without authorization, the ticket by itself is encrypted and time-limited, rendering it difficult to misuse. To further reduce exposure, our access tickets could be implemented as one-time tokens that are invalidated after use. Additionally, by not storing raw DNA sequences on-chain, we avoid the irreversible exposure of genomic data; if a data breach is detected off-chain, the data can be removed or its link updated, and the blockchain tickets can be revoked, an approach consistent with recommended privacy protection mechanisms [
16].
Integrating Institutional Security: Some security aspects fall outside the blockchain scope. For example, we assume hospitals properly secure their databases and that the governmental authorities managing the certificates remain uncompromised. These are standard operational security concerns; we rely on institutional policies and audits to maintain this trust. Our system’s design, however, makes it easy to pinpoint responsibility (e.g., any data access is logged on the blockchain, so any misuse can be traced to a credential). This transparency serves as a deterrent against insider threats and complements traditional security controls.
By considering known blockchain vulnerabilities and incorporating multiple layers of defense (encryption, permissioned membership, audits, and logging), we aim to create a robust security posture for the DNA sharing ecosystem. We acknowledge that no system is perfectly secure, and ongoing security assessments (including penetration testing and formal verification of smart contracts) will be part of future work to continuously strengthen the platform.
4.6. Usability and Real-World Deployment Challenges
Despite the technical capabilities of the proposed system, there are usability and adoption challenges that must be addressed for real-world success. Blockchain-based applications in healthcare face hurdles in user acceptance; non-expert users often have a low awareness of blockchain and may feel anxiety about using unfamiliar tools [
22]. In our context, patients and clinicians might find managing Ethereum wallets or Fabric certificates daunting. We have taken initial steps to improve usability—for example, the web DApp consolidates all interactions in a single interface, and MetaMask is used, as it is a widely adopted wallet interface—but this still assumes a certain level of technical literacy. In practical deployment, a training or an abstraction layer might be necessary (for instance, hospital IT systems could handle the blockchain interactions so that end users only see a conventional web portal). Simplifying key management (perhaps through custodial wallets or integrating with national health IDs) is an important future direction to enhance user-friendliness.
Another challenge is integration into existing healthcare workflows. Hospitals and research institutes have established processes and databases; adopting our system would require linking those databases to the blockchain infrastructure and ensuring compliance with healthcare data standards. We have designed the system to use standard formats (e.g., VCF for genomic data) and to require minimal on-chain data, which eases integration, but substantial effort in terms of IT support and interoperability will be needed. Moreover, regulatory compliance (beyond GDPR) such as HIPAA in the US must be considered when deploying across jurisdictions. Our design of storing only encrypted, consented pointers on-chain is intended to help with compliance, but a thorough legal review in each deployment scenario is necessary.
The requirement of government authorities (e.g., Ministry of Health) to certify and participate in the network, while a security strength, could slow down adoption. In some regions, obtaining such institutional engagement might be difficult or time-consuming. This introduces a threat to validity in terms of generalizability: the success of our approach in practice relies on a supportive regulatory environment. We mitigate this risk by demonstrating the system in a context (Taiwan’s healthcare system) where such government involvement is plausible, but broader adoption may require adapting the governance model (for instance, using a consortium of major genomic institutions as the trust anchors if government participation is unavailable).
In summary, real-world deployment will require addressing human and organizational factors. We have highlighted the user-centric design elements of our system to improve trust (e.g., giving users full control over their data-sharing settings), which can motivate participation. Still, building sufficient trust will likely require pilot programs. We plan to conduct user studies in the future to gather feedback from both patients and researchers using the system interface, which will guide further refinements in usability. Additionally, incremental rollout in a controlled environment (such as a single hospital network) could help demonstrate the value of the system and catalyze wider adoption. By acknowledging these practical challenges early, we can adapt our approach to ensure that the technology delivers benefits in a real healthcare setting, not just in theory.
5. Conclusions and Future Work
This research proposes a privacy-preserving DNA sequence sharing ecosystem leveraging blockchain technology. The system integrates two distinct blockchain architectures to achieve secure and efficient data management. The decentralized identity chain utilizes a decentralized identity framework that enables users to generate personal contracts representing their digital identities. By managing identities in a decentralized manner, the system eliminates dependence on centralized service providers, significantly reducing the risks of data exposure and tampering. Enhancements in the registration process and the refinement of data access rights within identity contracts further improve the framework’s functionality and autonomy.
The DNA sharing chain incorporates independent smart contracts for managing access control data for patients and research institutes. An innovative access control mechanism allows patients to assign specific access levels to their DNA sequence segments, facilitating selective sharing with trusted entities. This user-centric design promotes a secure, user-friendly environment, fostering patients’ willingness to share DNA data and thereby contributing to the advancement of medical research.
Despite these achievements, the current implementation imposes certain limitations. Registration on the DNA sharing chain is presently restricted to a certificate signing request (CSR) and private key stored within digital identities. Future work will focus on extending registration capabilities to accommodate a broader range of methods, thereby enhancing flexibility. Additionally, plans are underway to support a wider variety of digital wallets within the decentralized application (DApp), optimizing the user experience and broadening accessibility. Furthermore, we will conduct comprehensive security audits and usability testing with real users to identify any vulnerabilities or user experience issues not captured in the prototype evaluation. This will ensure that the ecosystem is not only secure in theory but also practical for widespread adoption in healthcare settings. These future enhancements aim to refine the ecosystem’s usability and scalability, paving the way for more widespread adoption of privacy-preserving blockchain-based solutions in biomedical data sharing and beyond.
Author Contributions
T.-T.-A.N., Y.-H.H., C.-H.T. and S.-M.Y. researched and designed this topic. T.-T.-A.N., Y.-C.L., C.-H.T. and Y.-H.H. worked on the system architecture and workflow. Y.-C.L., C.-H.T. and Y.-H.H. implemented the system. Y.-H.H., C.-H.T. and S.-M.Y. evaluated the system. T.-T.-A.N., Y.-H.H. and S.-M.Y. organized and wrote the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
Acknowledgments
This study was supported by our lab (Distributed Computing SystemLaboratory, National Chiao Tung University, Taiwan): “Identifying Non-Intentional Ad Traffic on the Demand-Side in Display Advertising”.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Pseudocode for DNA Sharing Chaincode
The following pseudocode figure outlines the core logic of the Hyperledger Fabric chaincode for the DNA sharing chain, including access update and query functionalities:
Figure A1.
Pseudocode for DNA sharing chaincode. Explanation: The UpdateAccessLevel function allows a patient to set which types of organizations can access a given DNA segment. The UploadAccessTicket function is used to store an encrypted access token (or pointer) on-chain once the DNA sequence is stored in an off-chain database. The QueryData function is invoked when a research institute queries the blockchain for accessible DNA data; it iterates over patients’ access rules and collects those segments for which the requester’s organization type is permitted. Any optional query filters (such as data tags) would be applied in the matches() check (for simplicity, detailed tag filtering logic is omitted here). The result is a list of encrypted access tickets that the researcher can use to retrieve the data from the off-chain storage. All sensitive outputs are encrypted for the requester to ensure only the authorized party can read the returned tickets. Light Blue (Cyan): Used for comments. Red: Used for string literals. Black: Used for variables, function names, and other identifiers. Bold Black: Used for function calls and event emitters.
Figure A1.
Pseudocode for DNA sharing chaincode. Explanation: The UpdateAccessLevel function allows a patient to set which types of organizations can access a given DNA segment. The UploadAccessTicket function is used to store an encrypted access token (or pointer) on-chain once the DNA sequence is stored in an off-chain database. The QueryData function is invoked when a research institute queries the blockchain for accessible DNA data; it iterates over patients’ access rules and collects those segments for which the requester’s organization type is permitted. Any optional query filters (such as data tags) would be applied in the matches() check (for simplicity, detailed tag filtering logic is omitted here). The result is a list of encrypted access tickets that the researcher can use to retrieve the data from the off-chain storage. All sensitive outputs are encrypted for the requester to ensure only the authorized party can read the returned tickets. Light Blue (Cyan): Used for comments. Red: Used for string literals. Black: Used for variables, function names, and other identifiers. Bold Black: Used for function calls and event emitters.
![Applsci 15 03193 a001]()
Appendix B
Use Case Demonstrations
This appendix presents four key workflows of our blockchain-enabled DNA data-sharing system.
1. Identity Registration Process
Objective: A new user (patient or research institute) registers a decentralized identity, which is verified by the Ministry of the Interior and recorded on the decentralized identity chain.
Key Steps:
Fill Registration Form and MetaMask Signing: The user opens the registration page as shown in
Figure 8, selects their user type (e.g., Person or Organization), and enters an ID number plus a wallet address automatically fetched from MetaMask. When they click Register, MetaMask prompts for transaction confirmation, ensuring the user’s private key securely signs the request.
On-Chain Identity Creation: Upon confirmation, the registration transaction is sent to the IdentityManager contract, where the Ministry’s node verifies the ID. If valid, a unique identity contract is generated and owned by the user.
UI Confirmation: The front end displays the newly created identity details. MetaMask logs the contract interaction, allowing the user to verify that the process is completed on-chain.
2. DNA Data Access Control Setup
Objective: A patient defines who can access specific segments of their DNA data by configuring an access control object on the DNA sharing chain, as shown in
Figure 10.
Key Steps:
Access Control Object Registration: The patient uploads a certificate signing request (CSR) and private key. The Ministry of Health and Welfare certifies the request, creating a new on-chain object to manage permissions.
Assign Permissions: Through a user-friendly table, the patient selects which research institute types (e.g., clinics, medical centers) can view each DNA segment. Clicking Save triggers an update transaction, signed via MetaMask or offline signing.
Blockchain Enforcement: The DNA sharing chain securely stores these permissions, preventing unauthorized edits. Patients can revise or revoke access at any time by submitting another signed transaction.
3. Research Institute Data Request Process
Objective: A registered research institute queries the DNA sharing chain for authorized access to patient data.
Key Steps:
Submit a Query: The institute enters filtering criteria (e.g., patient ID, genetic markers) and signs a transaction via MetaMask to request data access.
Permission Check: The chaincode evaluates the institute’s classification against patients’ access levels. If matched, it generates encrypted access tickets.
Result Display: The front end receives an event indicating which data (if any) the institute can view.
4. Data Retrieval Workflow
Objective: The research institute downloads DNA sequences authorized in the previous step, using the encrypted access tickets.
Key Steps:
Present Access Ticket and Download: The institute’s front end automatically attaches the ticket to a file request to the hospital’s off-chain database. The hospital verifies the ticket (valid signature, correct issuer) before releasing the data.
Off-Chain Transfer and Auditing: The raw DNA file (often in VCF format) is transferred over a secure channel.
References
- National Library of Medicine. Available online: https://www.ncbi.nlm.nih.gov/ (accessed on 17 May 2024).
- 23andme. Available online: https://www.23andme.com/ (accessed on 17 May 2024).
- Heeney, C.; Hawkins, N.; de Vries, J.; Boddington, P.; Kaye, J. Assessing the Privacy Risks of Data Sharing in Genomics. Public Health Genom. 2010, 14, 17–25. [Google Scholar] [CrossRef] [PubMed]
- Regulation (EU) 2016/679 of the European Parliament and of the Council. J. Eur. Union 2016, 679, 2016.
- Hjerppe, K.; Ruohonen, J.; Leppänen, V. The general data protection regulation: Requirements, architectures, and constraints. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference (RE), Jeju, Republic of Korea, 23–27 September 2019; pp. 265–275. [Google Scholar]
- Hsieh, Y.H.; Guan, X.Q.; Liao, C.H.; Yuan, S.M. Physiological-chain: A privacy preserving physiological data sharing ecosystem. Inf. Process. Manag. 2024, 61, 103761. [Google Scholar] [CrossRef]
- Shabani, M. Blockchain-based platforms for genomic data sharing: A decentralized approach in response to the governance problems? J. Am. Med. Inform. Assoc. 2018, 26, 76–80. [Google Scholar] [CrossRef] [PubMed]
- Mathur, G.; Pandey, A.; Goyal, S. Immutable DNA sequence data transmission for next generation bioinformatics using blockchain technology. In Proceedings of the 2nd International Conference on Data, Engineering and Applications (IDEA), Bhopal, India, 28–29 February 2020; pp. 1–6. [Google Scholar]
- Neto, M.M.; Marinho, C.S.D.S.; Coutinho, E.F.; Moreira, L.O.; Machado, J.D.C.; de Souza, J.N. Research opportunities for e-health applications with DNA sequence data using blockchain technology. In Proceedings of the 2020 IEEE International Conference on Software Architecture Companion (ICSA-C), Salvador, Brazil, 16–20 March 2020; pp. 95–102. [Google Scholar]
- Mamo, N.; Martin, G.M.; Desira, M.; Ellul, B.; Ebejer, J.P. Dwarna: A blockchain solution for dynamic consent in biobanking. Eur. J. Hum. Genet. 2020, 28, 609–626. [Google Scholar] [CrossRef] [PubMed]
- Shuaib, K.; Saleous, H.; Zaki, N.; Dankar, F. A layered blockchain framework for healthcare and genomics. In Proceedings of the 2020 IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; pp. 156–163. [Google Scholar]
- Kim, Y.; Park, Y.-H. Blockchain-based model for gene data management using deidentifying scheme. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics Asia (ICCE-Asia), Gangwon, Republic of Korea, 1–3 November 2021; pp. 1–4. [Google Scholar]
- Alghazwi, M.; Turkmen, F.; Van Der Velde, J.; Karastoyanova, D. Blockchain for genomics: A systematic literature review. Distrib. Ledger Technol. Res. Pract. 2022, 1, 1–28. [Google Scholar] [CrossRef]
- Eberhardt, J.; Tai, S. On or off the blockchain? Insights on off-chaining computation and data. In Service-Oriented and Cloud Computing (ESOCC 2017); Springer: Berlin/Heidelberg, Germany, 2017; pp. 3–15. [Google Scholar]
- Aung, S.T.Y.; Pluempitiwiriyawej, C. Blockchain-based implementation for integration of DNA profiles information systems. In Proceedings of the 2020-5th International Conference on Information Technology (InCIT), Chonburi, Thailand, 21–22 October 2020; pp. 110–115. [Google Scholar]
- Albalwy, F.; Brass, A.; Davies, A. A blockchain-based dynamic consent architecture to support clinical genomic data sharing (ConsentChain): Proof-of-concept study. JMIR Med. Inform. 2021, 9, e27816. [Google Scholar] [CrossRef] [PubMed]
- Oliva, A.; Kaphle, A.; Reguant, R.; Sng, L.M.; Twine, N.A.; Malakar, Y.; Wickramarachchi, A.; Keller, M.; Ranbaduge, T.; Chan, E.K.; et al. Future-proofing genomic data and consent management: A comprehensive review of technology innovations. GigaScience 2024, 13, giae021. [Google Scholar] [CrossRef] [PubMed]
- Zarchi, G.; Sherman, M.; Gady, O.; Herzig, T.; Idan, Z.; Greenbaum, D. Blockchains as a means to promote privacy-protecting, access-availing, incentive-increasing, ELSI-lessening DNA databases. Front. Digit. Health 2023, 4, 1028249. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.-Y. Self-Sovereign Identity Based Personal Information Security Control Infrastructure—A Case Study of e-Portfolio Ecosystem. Master’s Thesis, National Yang Ming Chiao Tung University, Hsinchu City, Taiwan, 2022. [Google Scholar]
- Mourtzis, D.; Angelopoulos, J.; Panopoulos, N. Blockchain integration in the era of industrial metaverse. Appl. Sci. 2023, 13, 1353. [Google Scholar] [CrossRef]
- Bianchini, D.; De Antonellis, V.; Garda, M.; Melchiori, M. Resource-oriented approach for effective blockchain integration in intertwined supply chains. In Proceedings of the International Conference on Database and Expert Systems Applications (DEXA), Bangkok, Thailand, 25–27 August 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 18–33. [Google Scholar]
- Transformational Bioinformatics—“Genomic Data Privacy in the Era of Decentralised Systems”. Available online: https://bioinformatics.csiro.au/blog/genomic-data-privacy-in-the-era-of-decentralised-systems-a-perspective/#:~:text=all%20informed%20consent%20states%20for,for%20data%20access%20and%20use (accessed on 17 May 2024).
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains. In Proceedings of the 13th EuroSys Conference, Porto, Portugal, 23–36 April 2018; pp. 1–15. [Google Scholar]
- Apache Jmeter. Available online: https://jmeter.apache.org/ (accessed on 17 May 2024).
- Truffle Suite. Available online: https://archive.trufflesuite.com/ (accessed on 17 May 2024).
- Github—Fablo. Available online: https://github.com/hyperledger-labs/fablo/ (accessed on 17 May 2024).
- Wenhua, Z.; Qamar, F.; Abdali, T.A.N.; Hassan, R.; Jafri, S.T.A.; Nguyen, Q.N. Blockchain Technology: Security Issues, Healthcare Applications, Challenges and Future Trends. Electronics 2023, 12, 546. [Google Scholar] [CrossRef]
- Kasyapa, M.S.; Vanmathi, C. Blockchain integration in healthcare: A comprehensive investigation of use cases, performance issues, and mitigation strategies. Front. Digit. Health 2024, 6, 1359858. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}