
Fiber Sensing in the 6G Era: Vision Transformers for ϕ-OTDR-Based Road-Traffic Monitoring


Abstract
1. Introduction
2. Deep-Learning-Based Traffic Parameter Estimation
2.1. Vision Transformer Architecture
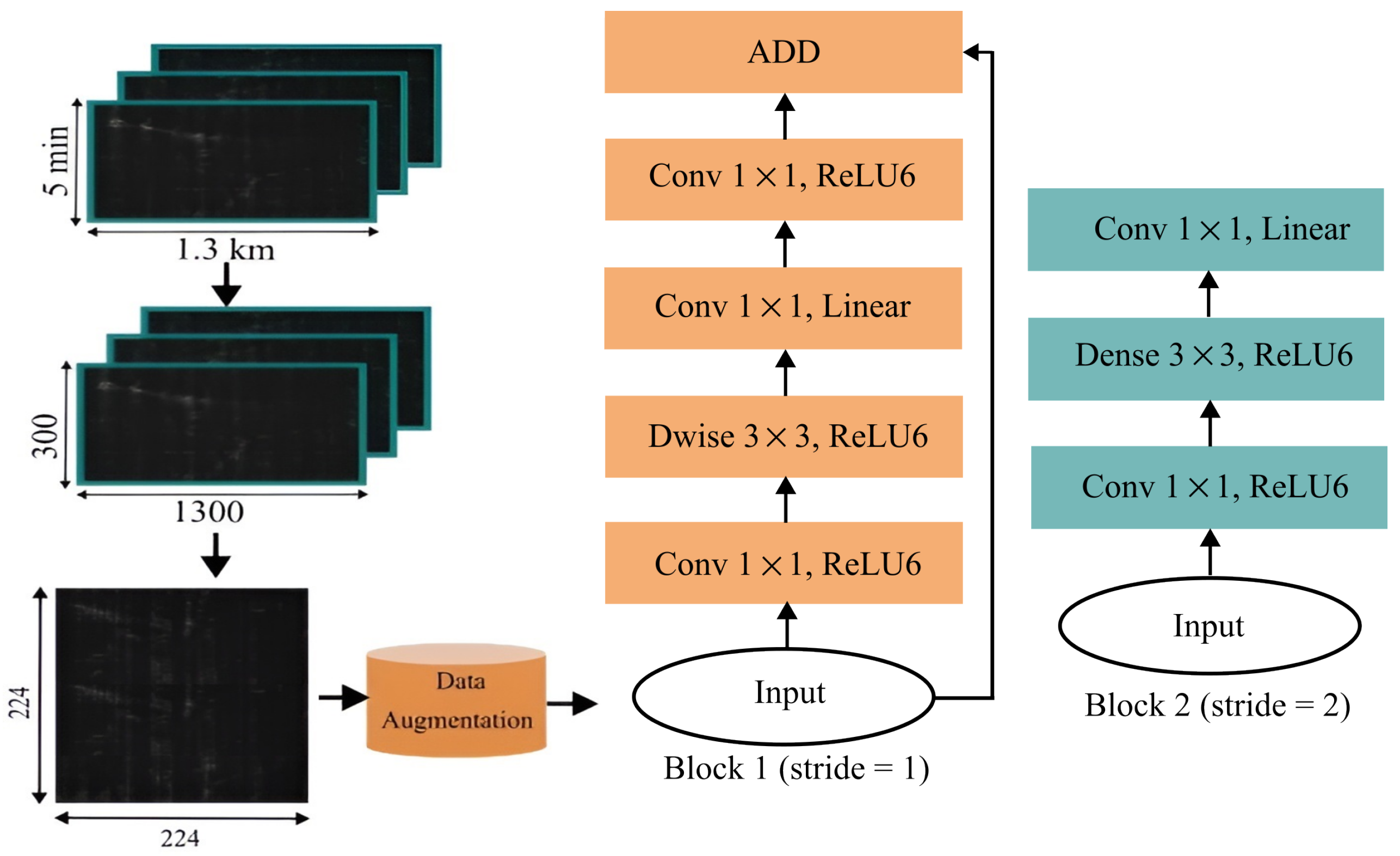
2.2. MobileNetV2 Architecture
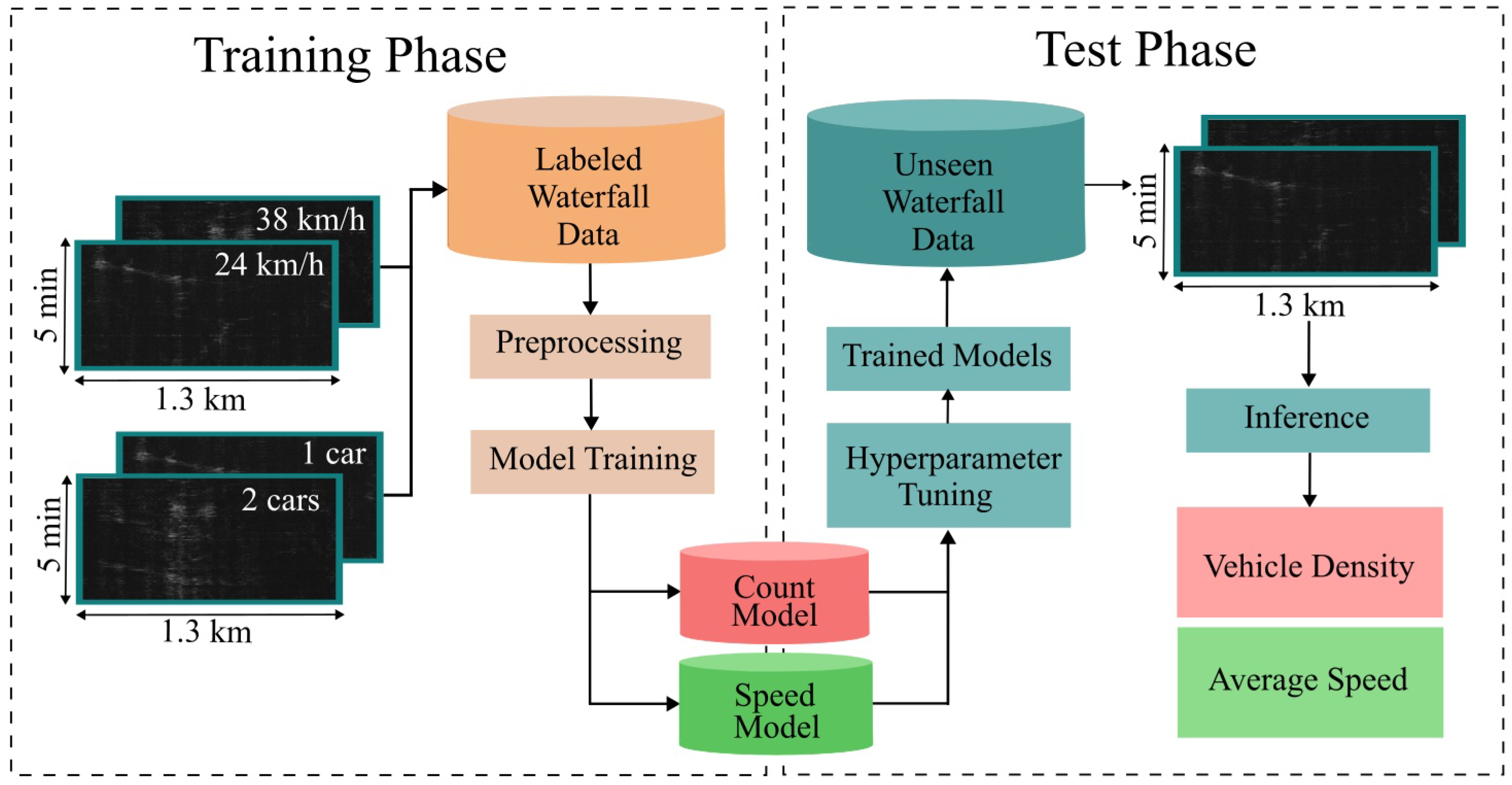
2.3. Preparation, Training, and Performance Evaluation
2.3.1. Image Preprocessing and Data Augmentation
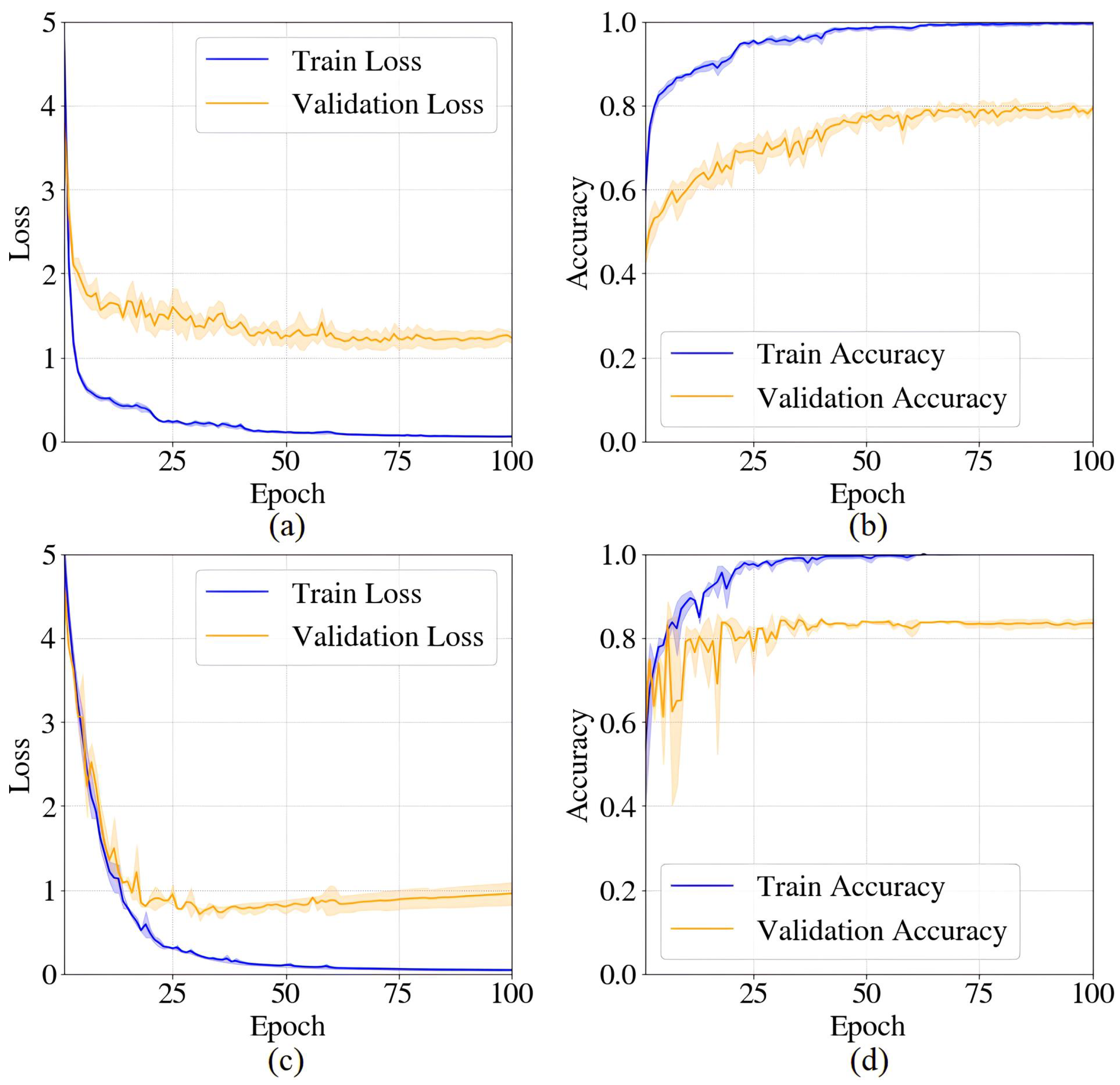
2.3.2. Model Training and Performance Evaluation
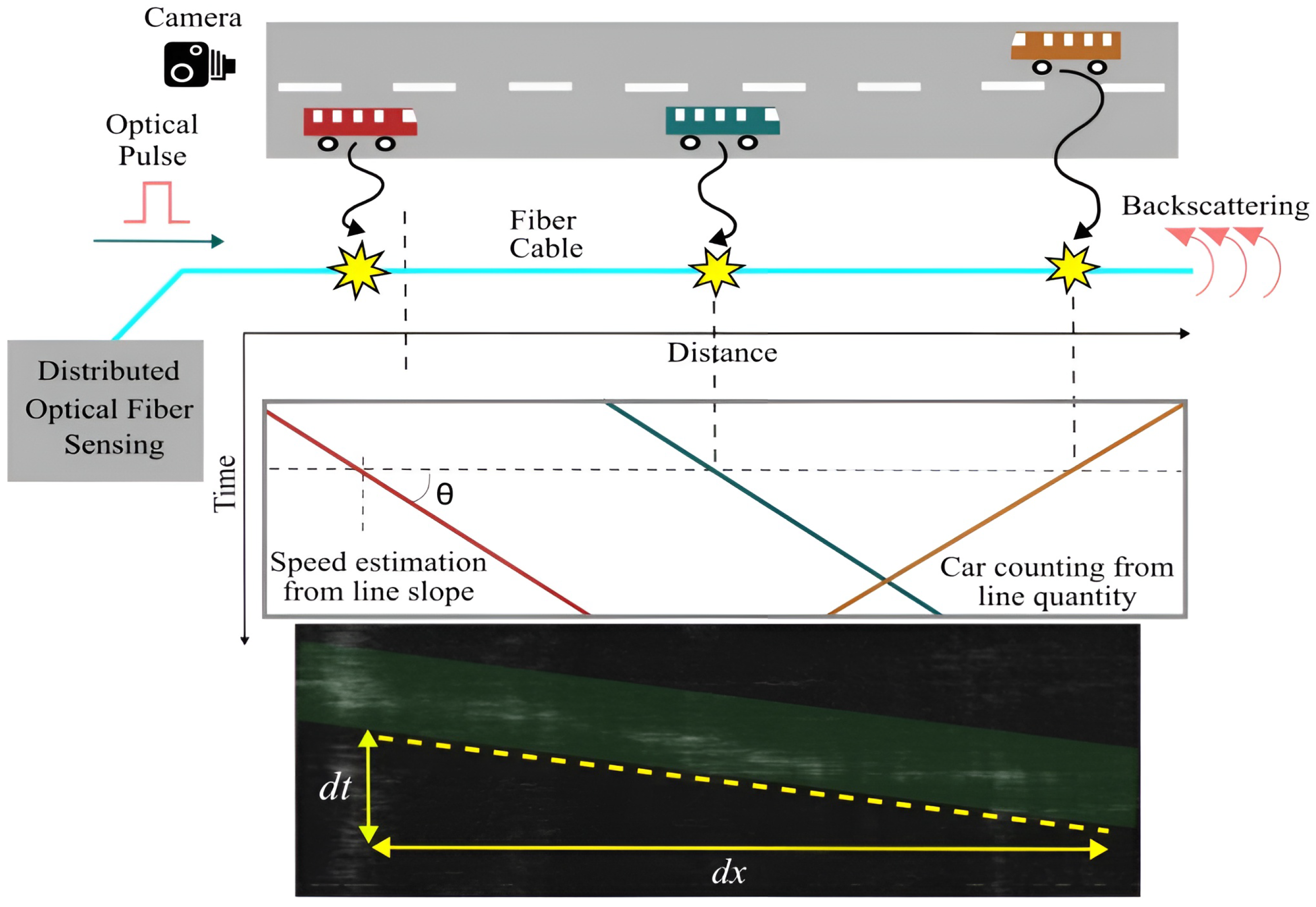
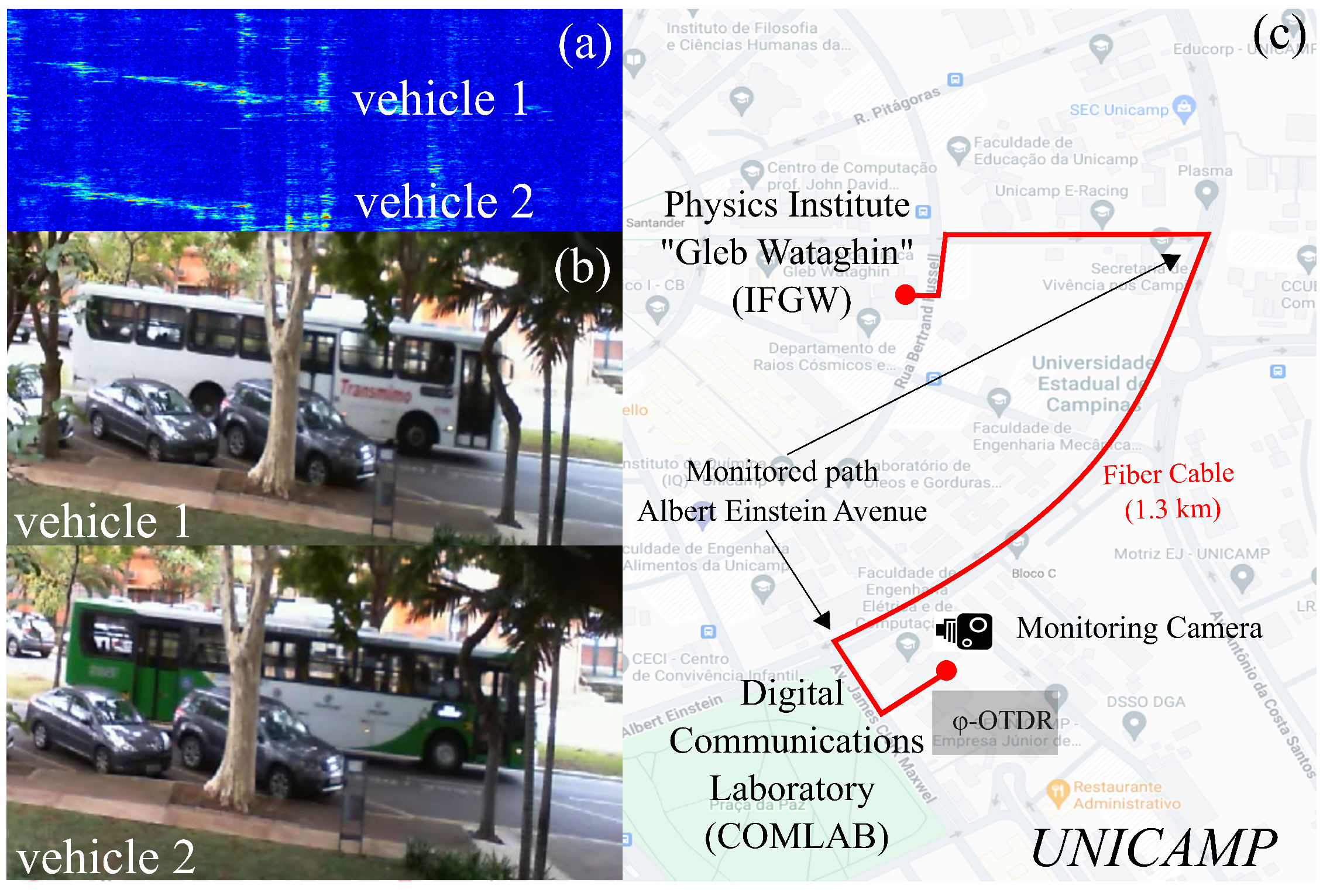
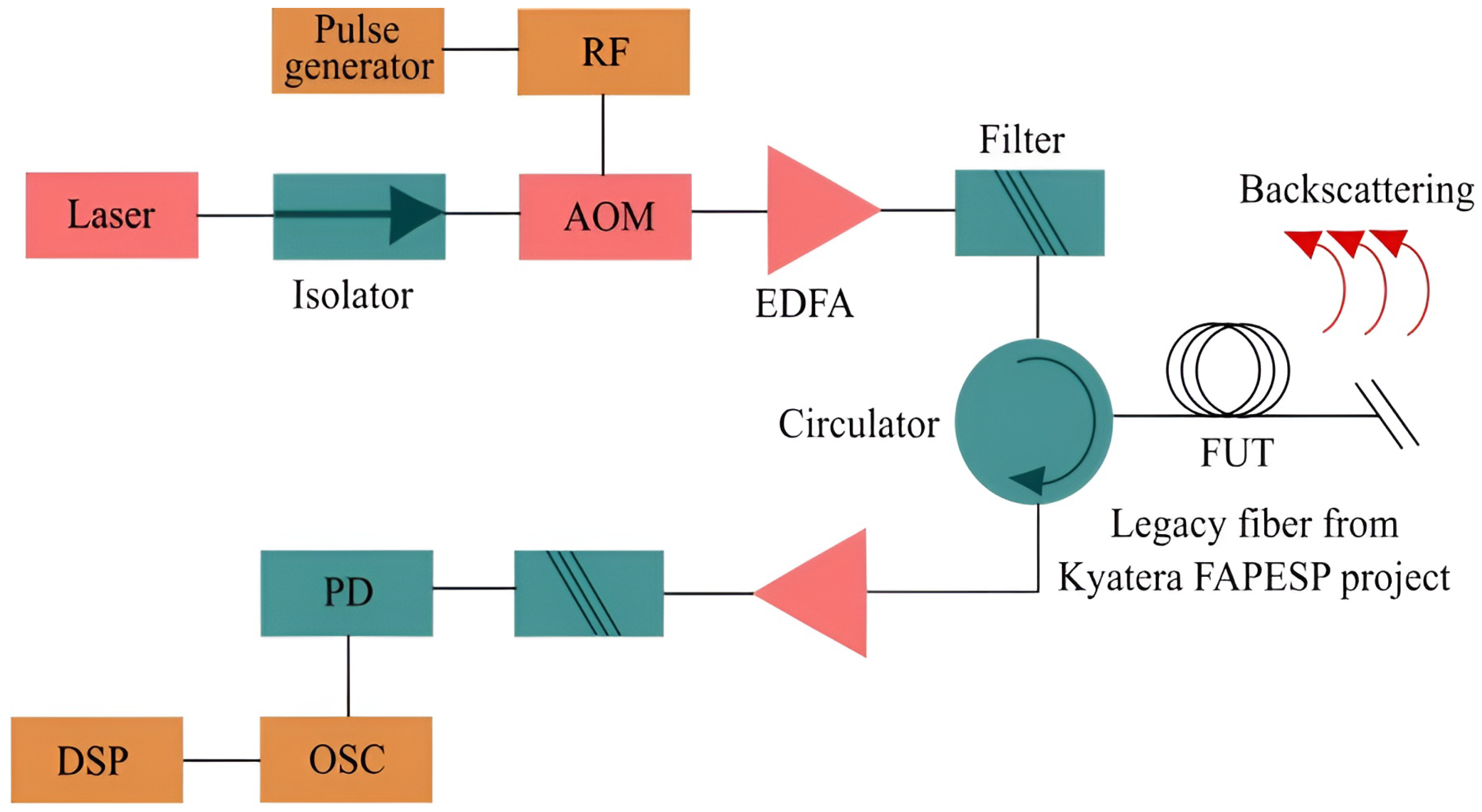
3. Experimental Setup
3.1. -OTDR Setup
3.2. Camera Setup
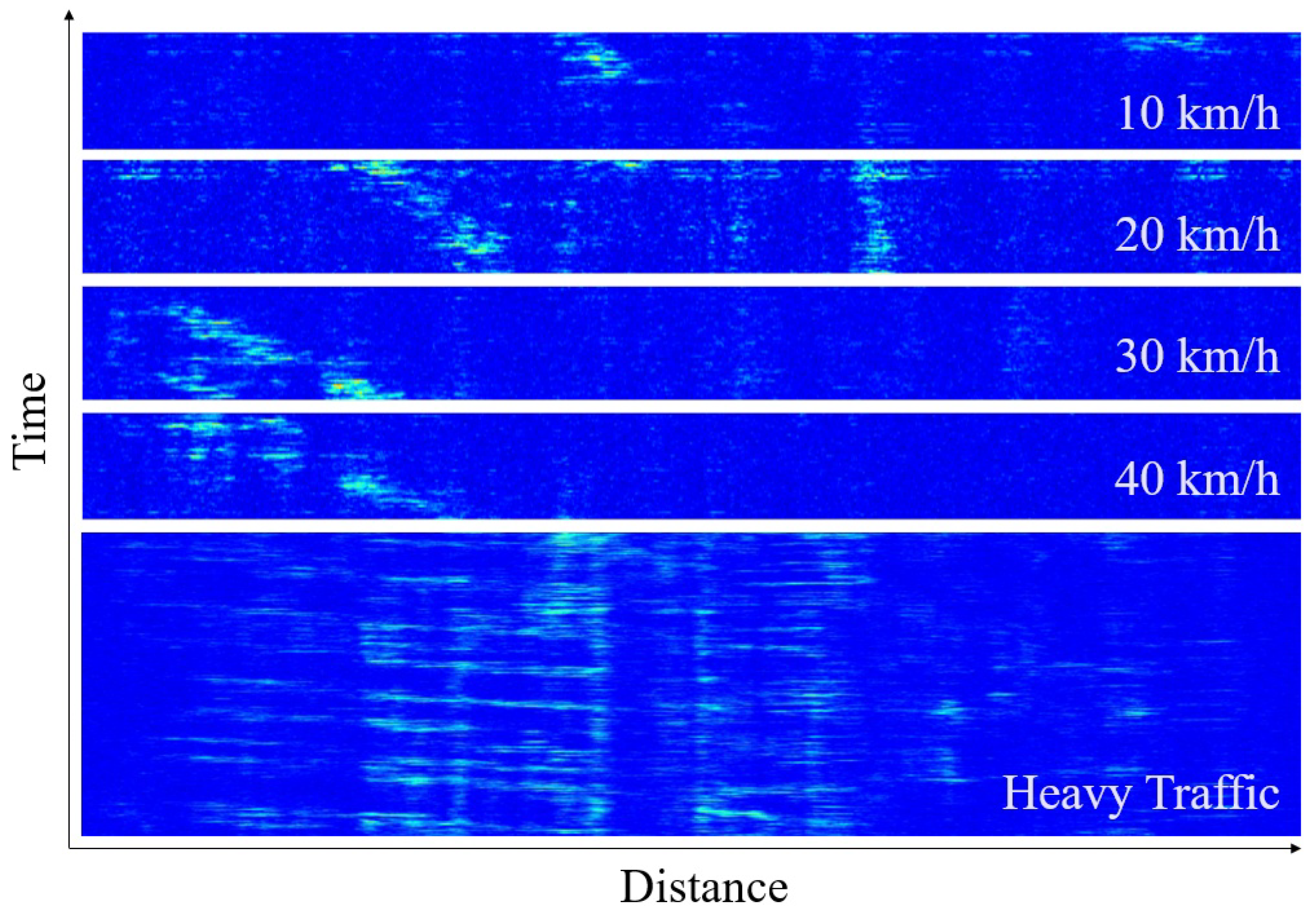
3.3. Dataset
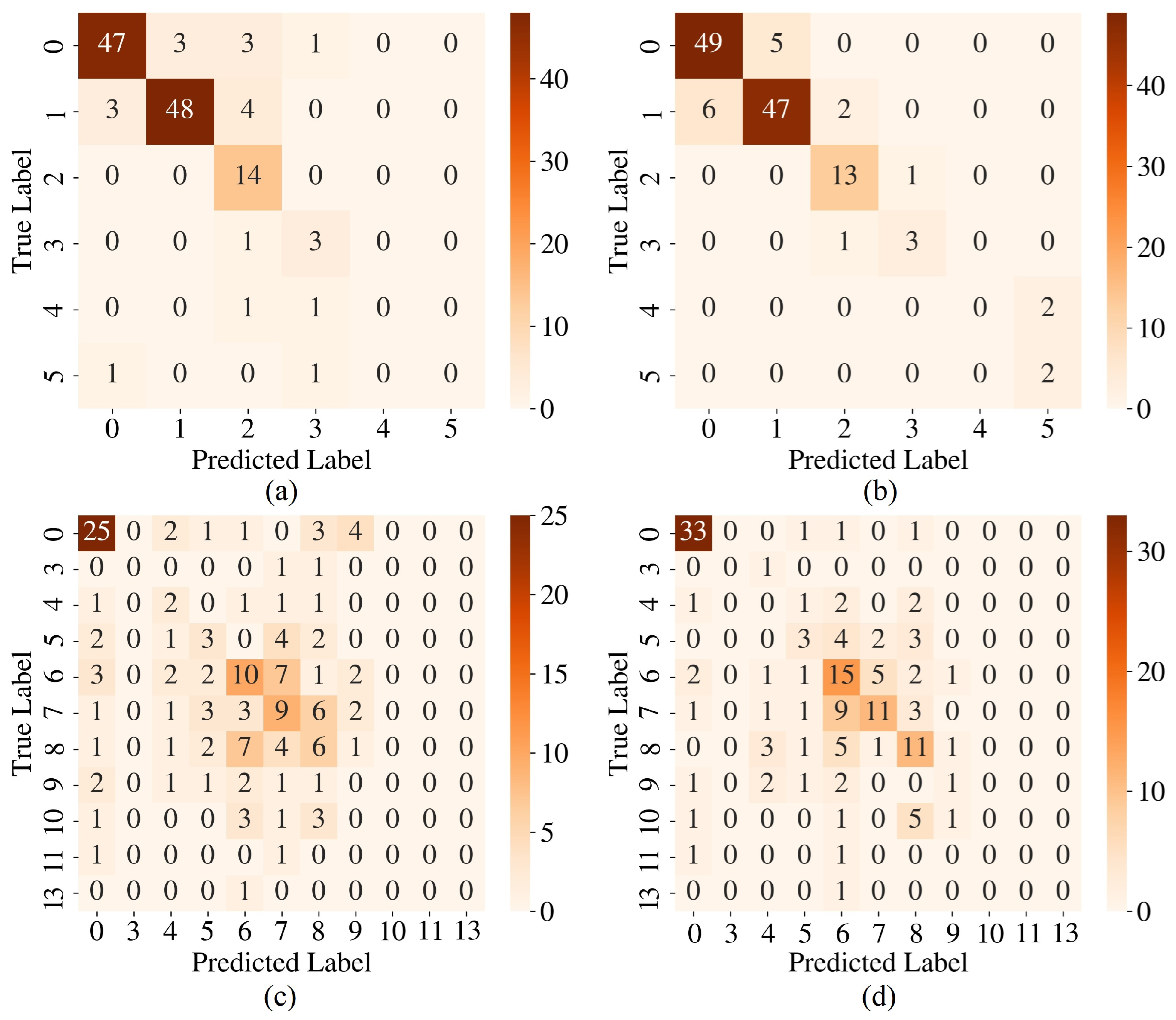
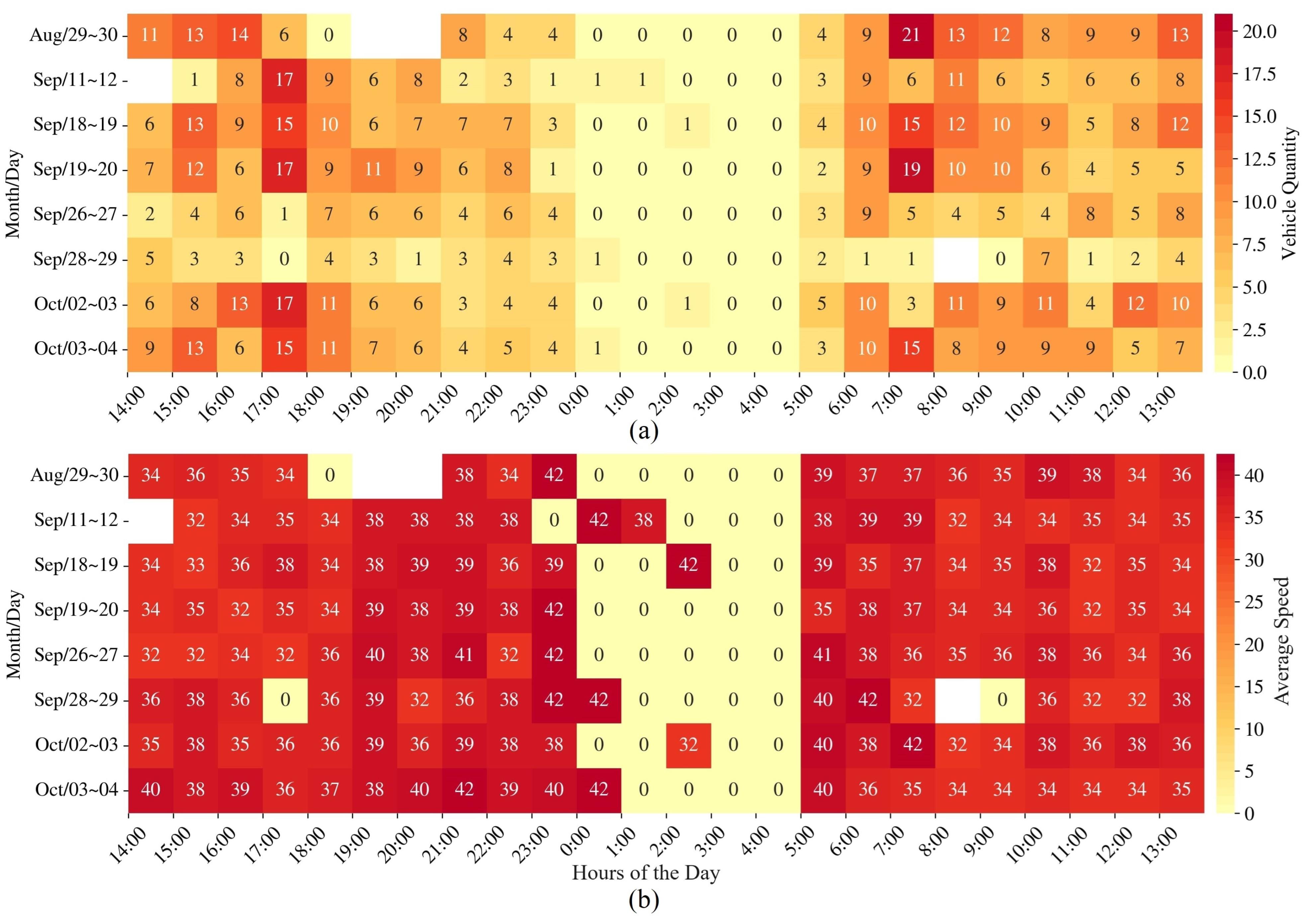
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Letaief, K.B.; Chen, W.; Shi, Y.; Zhang, J.; Zhang, Y.J.A. The Roadmap to 6G: AI Empowered Wireless Networks. IEEE Commun. Mag. 2019, 57, 84–90. [Google Scholar] [CrossRef]
- Wymeersch, H.; Shrestha, D.; de Lima, C.M.; Yajnanarayana, V.; Richerzhagen, B.; Keskin, M.F.; Schindhelm, K.; Ramirez, A.; Wolfgang, A.; de Guzman, M.F.; et al. Integration of Communication and Sensing in 6G: A Joint Industrial and Academic Perspective. In Proceedings of the 2021 IEEE 32nd Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Helsinki, Finland, 13–16 September 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Wild, T.; Braun, V.; Viswanathan, H. Joint Design of Communication and Sensing for Beyond 5G and 6G Systems. IEEE Access 2021, 9, 30845–30857. [Google Scholar] [CrossRef]
- Liu, F.; Cui, Y.; Masouros, C.; Xu, J.; Han, T.X.; Eldar, Y.C.; Buzzi, S. Integrated Sensing and Communications: Toward Dual-Functional Wireless Networks for 6G and Beyond. IEEE J. Sel. Areas Commun. 2022, 40, 1728–1767. [Google Scholar] [CrossRef]
- Boffi, P.; Ferrario, M.; Luch, I.D.; Rizzelli, G.; Gaudino, R. Optical sensing in urban areas by deployed telecommunication fiber networks. In Proceedings of the 2022 International Conference on Optical Network Design and Modeling (ONDM), Warsaw, Poland, 16–19 May 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Mello, D.A.A.; Mayer, K.S.; Escallón-Portilla, A.F.; Arantes, D.S.; Pinto, R.P.; Rothenberg, C.E. When Digital Twins Meet Optical Networks Operations. In Proceedings of the 2023 Optical Fiber Communications Conference and Exhibition (OFC), San Diego, CA, USA, 5–9 March 2023; pp. 1–3. [Google Scholar] [CrossRef]
- Aono, Y.; Ip, E.; Ji, P. More than Communications: Environment Monitoring Using Existing Optical Fiber Network Infrastructure. In Proceedings of the Optical Fiber Communication Conference (OFC) 2020, San Diego, CA, USA, 8–12 March 2020; Optica Publishing Group: Washington, DC, USA, 2020; pp. 1–3. [Google Scholar] [CrossRef]
- Xia, T.J.; Wellbrock, G.A.; Huang, M.F.; Salemi, M.; Chen, Y.; Wang, T.; Aono, Y. First Proof That Geographic Location on Deployed Fiber Cable Can Be Determined by Using OTDR Distance Based on Distributed Fiber Optical Sensing Technology. In Proceedings of the Optical Fiber Communication Conference (OFC) 2020, San Diego, CA, USA, 8–12 March 2020; Optica Publishing Group: Washington, DC, USA, 2020; pp. 1–3. [Google Scholar] [CrossRef]
- Tucker, R.; Ruffini, M.; Valcarenghi, L.; Campelo, D.R.; Simeonidou, D.; Du, L.; Marinescu, M.C.; Middleton, C.; Yin, S.; Forde, T.; et al. Connected OFCity: Technology innovations for a smart city project [Invited]. J. Opt. Commun. Netw. 2017, 9, A245–A255. [Google Scholar] [CrossRef]
- Rao, Y.; Wang, Z.; Wu, H.; Ran, Z.; Han, B. Recent advances in phase-sensitive optical time domain reflectometry (ϕ-OTDR). Photonic Sens. 2021, 11, 1–30. [Google Scholar] [CrossRef]
- Hancke, G.P.; Silva, B.D.C.e.; Hancke, G.P., Jr. The Role of Advanced Sensing in Smart Cities. Sensors 2013, 13, 393–425. [Google Scholar] [CrossRef]
- Jia, Z.; Campos, L.A.; Xu, M.; Zhang, H.; Gonzalez-Herraez, M.; Martins, H.F.; Zhan, Z. Experimental Coexistence Investigation of Distributed Acoustic Sensing and Coherent Communication Systems. In Proceedings of the 2021 Optical Fiber Communications Conference and Exhibition (OFC), San Francisco, CA, USA, 6–11 June 2021; pp. 1–3. [Google Scholar]
- Juarez, J.; Maier, E.; Choi, K.N.; Taylor, H. Distributed fiber-optic intrusion sensor system. J. Light. Technol. 2005, 23, 2081–2087. [Google Scholar] [CrossRef]
- Ren, L.; Jiang, T.; Jia, Z.-g.; Li, D.-s.; Yuan, C.-l.; Li, H.-n. Pipeline corrosion and leakage monitoring based on the distributed optical fiber sensing technology. Measurement 2018, 122, 57–65. [Google Scholar] [CrossRef]
- Fernández-Ruiz, M.R.; Soto, M.A.; Williams, E.F.; Martin-Lopez, S.; Zhan, Z.; Gonzalez-Herraez, M.; Martins, H.F. Distributed acoustic sensing for seismic activity monitoring. APL Photonics 2020, 5, 030901. [Google Scholar] [CrossRef]
- Pastor-Graells, J.; Martins, H.F.; Garcia-Ruiz, A.; Martin-Lopez, S.; Gonzalez-Herraez, M. Single-shot distributed temperature and strain tracking using direct detection phase-sensitive OTDR with chirped pulses. Opt. Express 2016, 24, 13121–13133. [Google Scholar] [CrossRef]
- Tejedor, J.; Macias-Guarasa, J.; Martins, H.F.; Pastor-Graells, J.; Martín-López, S.; Guillén, P.C.; Pauw, G.D.; Smet, F.D.; Postvoll, W.; Ahlen, C.H.; et al. Real Field Deployment of a Smart Fiber-Optic Surveillance System for Pipeline Integrity Threat Detection: Architectural Issues and Blind Field Test Results. J. Light. Technol. 2018, 36, 1052–1062. [Google Scholar] [CrossRef]
- Williams, E.F.; Fernández-Ruiz, M.R.; Magalhaes, R.; Vanthillo, R.; Zhan, Z.; González-Herráez, M.; Martins, H.F. Distributed sensing of microseisms and teleseisms with submarine dark fibers. Nat. Commun. 2019, 10, 5778. [Google Scholar] [CrossRef] [PubMed]
- Peng, F.; Duan, N.; Rao, Y.J.; Li, J. Real-Time Position and Speed Monitoring of Trains Using Phase-Sensitive OTDR. IEEE Photonics Technol. Lett. 2014, 26, 2055–2057. [Google Scholar] [CrossRef]
- Xia, T.J.; Wellbrock, G.A.; Huang, M.F.; Han, S.; Chen, Y.; Salemi, M.; Ji, P.N.; Wang, T.; Aono, Y. Field Trial of Abnormal Activity Detection and Threat Level Assessment with Fiber Optic Sensing for Telecom Infrastructure Protection. In Proceedings of the 2021 Optical Fiber Communications Conference and Exhibition (OFC), San Francisco, CA, USA, 6–11 June 2021; pp. 1–3. [Google Scholar]
- Lu, X.; Soto, M.A.; Thomas, P.J.; Kolltveit, E. Evaluating Phase Errors in Phase-Sensitive Optical Time-Domain Reflectometry Based on I/Q Demodulation. J. Light. Technol. 2020, 38, 4133–4141. [Google Scholar] [CrossRef]
- Adeel, M.; Shang, C.; Hu, D.; Wu, H.; Zhu, K.; Raza, A.; Lu, C. Impact-Based Feature Extraction Utilizing Differential Signals of Phase-Sensitive OTDR. J. Light. Technol. 2020, 38, 2539–2546. [Google Scholar] [CrossRef]
- Uyar, F.; Onat, T.; Unal, C.; Kartaloglu, T.; Ozbay, E.; Ozdur, I. A direct detection fiber optic distributed acoustic sensor with a mean SNR of 7.3 dB at 102.7 km. IEEE Photonics J. 2019, 11, 1–8. [Google Scholar] [CrossRef]
- Kandamali, D.F.; Cao, X.; Tian, M.; Jin, Z.; Dong, H.; Yu, K. Machine learning methods for identification and classification of events in ϕ-OTDR systems: A review. Appl. Opt. 2022, 61, 2975–2997. [Google Scholar] [CrossRef]
- Huang, M.F.; Salemi, M.; Chen, Y.; Zhao, J.; Xia, T.J.; Wellbrock, G.A.; Huang, Y.K.; Milione, G.; Ip, E.; Ji, P.; et al. First Field Trial of Distributed Fiber Optical Sensing and High-Speed Communication Over an Operational Telecom Network. J. Light. Technol. 2020, 38, 75–81. [Google Scholar] [CrossRef]
- Catalano, E.; Coscetta, A.; Cerri, E.; Cennamo, N.; Zeni, L.; Minardo, A. Automatic traffic monitoring by ϕ-OTDR data and Hough transform in a real-field environment. Appl. Opt. 2021, 60, 3579–3584. [Google Scholar] [CrossRef]
- Narisetty, C.; Hino, T.; Huang, M.F.; Ueda, R.; Sakurai, H.; Tanaka, A.; Otani, T.; Ando, T. Overcoming Challenges of Distributed Fiber-Optic Sensing for Highway Traffic Monitoring. Transp. Res. Rec. 2021, 2675, 233–242. [Google Scholar] [CrossRef]
- Wang, T.; Huang, M.F.; Han, S.; Narisetty, C. Employing Fiber Sensing and On-Premise AI Solutions for Cable Safety Protection over Telecom Infrastructure. In Proceedings of the 2022 Optical Fiber Communications Conference and Exhibition (OFC), San Diego, CA, USA, 6–10 March 2022; pp. 1–3. [Google Scholar]
- Liu, S.; Yu, F.; Hong, R.; Xu, W.; Shao, L.; Wang, F. Advances in phase-sensitive optical time-domain reflectometry. Opto-Electron. Adv. 2022, 5, 200078-1. [Google Scholar] [CrossRef]
- Bao, X.; Wang, Y. Recent Advancements in Rayleigh Scattering-Based Distributed Fiber Sensors. Adv. Devices Instrum. 2021, 2021, 8696571. [Google Scholar] [CrossRef]
- Ip, E.; Fang, J.; Li, Y.; Wang, Q.; Huang, M.F.; Salemi, M.; Huang, Y.K. Distributed fiber sensor network using telecom cables as sensing media: Technology advancements and applications [Invited]. J. Opt. Commun. Netw. 2022, 14, A61–A68. [Google Scholar] [CrossRef]
- Colares, R.A.; Conforti, E.; Rittner, L.; Mello, D.A. Field Trial of an ML-Assisted Phase-Sensitive OTDR for Traffic Monitoring in Smart Cities [invited]. In Proceedings of the 2024 24th International Conference on Transparent Optical Networks (ICTON), Bari, Italy, 14–18 July 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Colares, R.A.; Huancachoque, L.; Conforti, E.; Mello, D.A. Demonstration of ϕ-OTDR-based DFOS Assisted by YOLOv8 for Traffic Monitoring in Smart Cities. In Proceedings of the 2024 SBFoton International Optics and Photonics Conference (SBFoton IOPC), Salvador, Brazil, 11–13 November 2024; pp. 1–3. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Sutili, T.; Figueiredo, R.C.; Conforti, E. Laser Linewidth and Phase Noise Evaluation Using Heterodyne Offline Signal Processing. J. Light. Technol. 2016, 34, 4933–4940. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://docs.ultralytics.com/models/yolov8/ (accessed on 1 February 2024).
- Colares, R.A.; Conforti, E.; Mello, D.A.A. Dataset Related to Paper “Fiber Sensing in the 6G Era: Vision Transformers for ϕ-OTDR-Based Road-Traffic Monitoring”. 2024. Available online: https://redu.unicamp.br/dataset.xhtml?persistentId=doi:10.25824/redu/VLHHAW (accessed on 1 February 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters | MAC (G) | RAM (MB) |
|---|---|---|---|
| MNet Car Count | 2,388,614 | 2.40 | 869.18 |
| ViT Car Count | 86,488,454 | 1.61 | 1647.69 |
| MNet Speed | 2,405,186 | 2.40 | 869.25 |
| ViT Speed | 86,498,882 | 1.61 | 1647.73 |
| (a) Car Count | (b) Average Speed | ||
|---|---|---|---|
| Class | Samples | Class | Samples |
| 0 | 482 | 0–4.99 km/h | 251 |
| 1 | 479 | 5–9.99 km/h | 1 |
| 2 | 182 | 10–14.99 km/h | 3 |
| 3 | 35 | 15–19.99 km/h | 9 |
| 4 | 9 | 20–24.99 km/h | 36 |
| 5+ | 11 | 25–29.99 km/h | 76 |
| – | – | 30–34.99 km/h | 171 |
| – | – | 35–39.99 km/h | 162 |
| – | – | 40–44.99 km/h | 137 |
| – | – | 45–49.99 km/h | 49 |
| – | – | 50–54.99 km/h | 51 |
| – | – | 55–59.99 km/h | 10 |
| – | – | 60–64.99 km/h | 1 |
| – | – | 65–70 km/h | 6 |
| Parameter | Example in Filename | Unit |
|---|---|---|
| Vehicle quantity | 3 | vehicles |
| Average speed | 28.12015 | [km/h] |
| Fiber length | 1300 m | [m] |
| Collection period | 300 s | [s] |
| Pulse width | 500 ns | [ns] |
| Pulse period | 100 ms | [ms] |
| Collection mode | byte | string |
| Timestamp | Feb-23-2024_08_49_26 | string |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Colares, R.A.; Rittner, L.; Conforti, E.; Mello, D.A.A. Fiber Sensing in the 6G Era: Vision Transformers for ϕ-OTDR-Based Road-Traffic Monitoring. Appl. Sci. 2025, 15, 3170. https://doi.org/10.3390/app15063170
Colares RA, Rittner L, Conforti E, Mello DAA. Fiber Sensing in the 6G Era: Vision Transformers for ϕ-OTDR-Based Road-Traffic Monitoring. Applied Sciences. 2025; 15(6):3170. https://doi.org/10.3390/app15063170
Chicago/Turabian StyleColares, Robson A., Leticia Rittner, Evandro Conforti, and Darli A. A. Mello. 2025. "Fiber Sensing in the 6G Era: Vision Transformers for ϕ-OTDR-Based Road-Traffic Monitoring" Applied Sciences 15, no. 6: 3170. https://doi.org/10.3390/app15063170
APA StyleColares, R. A., Rittner, L., Conforti, E., & Mello, D. A. A. (2025). Fiber Sensing in the 6G Era: Vision Transformers for ϕ-OTDR-Based Road-Traffic Monitoring. Applied Sciences, 15(6), 3170. https://doi.org/10.3390/app15063170