
Entropy-Optimized Dynamic Text Segmentation and RAG-Enhanced LLMs for Construction Engineering Knowledge Base


Abstract
1. Introduction
- Proposing the use of RAG technology to enhance the ability of LLMs in construction engineering standards and facilitate the cost-effective and efficient establishment of a specialized knowledge base through the utilization of standard texts.
- Presenting the entropy-optimized dynamic text segmentation (EDTS) method for standard texts to ensure the clarity and predictability of information within chunks of limited length.
- Testing the accuracy of LLMs enhanced with domain-specific knowledge texts and revealing the relationship between model size, response accuracy, and execution time, providing a decision-making basis for the trade-off between computational power and precision in engineering practices.
2. Related Work
2.1. Large Language Model
2.2. Prompt Engineering
- Clarify task objectives. To enhance model performance in specialized tasks, it is crucial to explicitly assign roles and define granular actions, thereby narrowing the model’s focus and reducing ambiguity in open-ended tasks. Additionally, breaking complex objectives into sub-steps through task decomposition aligns outputs with domain-specific workflows, enhancing coherence and relevance in the execution of complex tasks.
- Provide sufficient context. To ensure responses are grounded in verified knowledge and minimize hallucination, it is essential to employ domain anchoring by embedding authoritative references or curated data snippets. Furthermore, dynamic context enrichment can be achieved by incorporating real-time updates or scenario-specific examples, such as few-shot learning, allowing the outputs to adapt effectively to evolving professional requirements.
- Set output requirements. To ensure usability in downstream applications such as reports or code generation, it is important to enforce structural constraints through the use of specific formats and validation rules.
- Designing efficient prompts requires users to have a deep understanding of task objectives, domain knowledge, and model characteristics, which makes it difficult for ordinary users to quickly master.
- Current prompt design relies on empirical trial and error, lacking a unified methodology, which results in poor reusability across different domains.
2.3. Retrieval-Augmented Generation
- Reduces hallucinations by grounding responses in retrieved evidence. RAG mitigates hallucinations, which mean the incorrect or fabricated outputs, by directly incorporating verified external data (e.g., documents, databases) into the generation process, ensuring responses align with factual sources.
- Supports knowledge updates without retraining. Unlike traditional LLMs that require costly retraining to integrate new information, RAG dynamically accesses updated knowledge bases (e.g., latest research papers or news archives), enabling real-time adaptation without modifying core model parameters. This mechanism allows users to seamlessly incorporate their private data or regulatory updates, ensuring compliance and relevance [29].
- Enhances multi-domain adaptability via modular retrieval systems. RAG’s architecture decouples retrieval and generation modules, allowing domain-specific retrievers (e.g., legal databases, engineering standards) to be swapped based on task requirements, improving cross-domain versatility [30].
3. Methodology
3.1. Domain Knowledge Base Framework
- Data Collection. For a knowledge base in the field of construction engineering, it is necessary to systematically gather and organize relevant standards, regulations, technical guidelines, and best practice cases. This includes, but is not limited to, national and local building codes, industry standards, and internationally recognized best practice guidelines, ensuring comprehensiveness and authority of the collected materials.
- Document Segmentation. Preprocess the gathered materials, including steps such as file parsing and document segmentation, to facilitate subsequent information retrieval. During this process, original documents are divided into multiple smaller text chunks, enhancing the efficiency and accuracy of information retrieval.
- Vectorization. Convert each text chunk into vector representations, enabling similarity matching with user queries by calculating the similarity between vectors. This process facilitates the provision of highly relevant information to users based on their queries.
- Vector Storage. Store these external knowledge text chunks as vectors within a specially designed vector database to enable rapid retrieval and efficient management. This approach effectively supports real-time information queries based on content similarity, thereby enhancing the professionalism and precision of system responses.
- Question Vectorization. When a user poses a question, the first step is to convert this question into a vector. This transformation enables similarity matching within the vector space, preparing the query for subsequent retrieval processes.
- Semantic Related Chunks. This involves using semantic search methods to identify and retrieve chunk vectors that are closest to the query vector and then converting these vectors back into their original text.
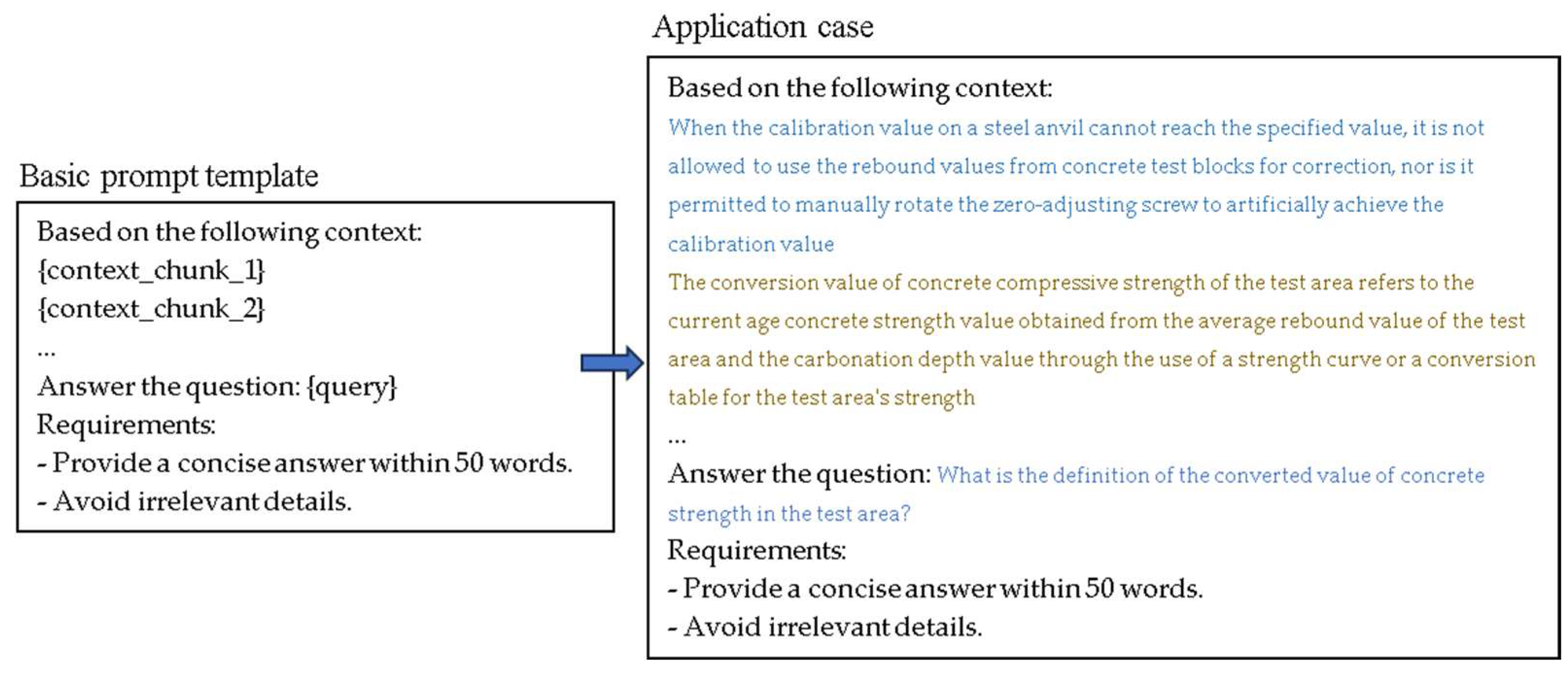
- Integration Context into Prompt. By integrating the user’s question and the retrieved contextual text into prompt, the system ensures that the generated response is grounded in precise and relevant professional knowledge.
- Professional Response. The questions, along with their contextual text, are fed into a LLM. Leveraging the model’s inherent language generation capabilities, it produces response that meets professional requirements.
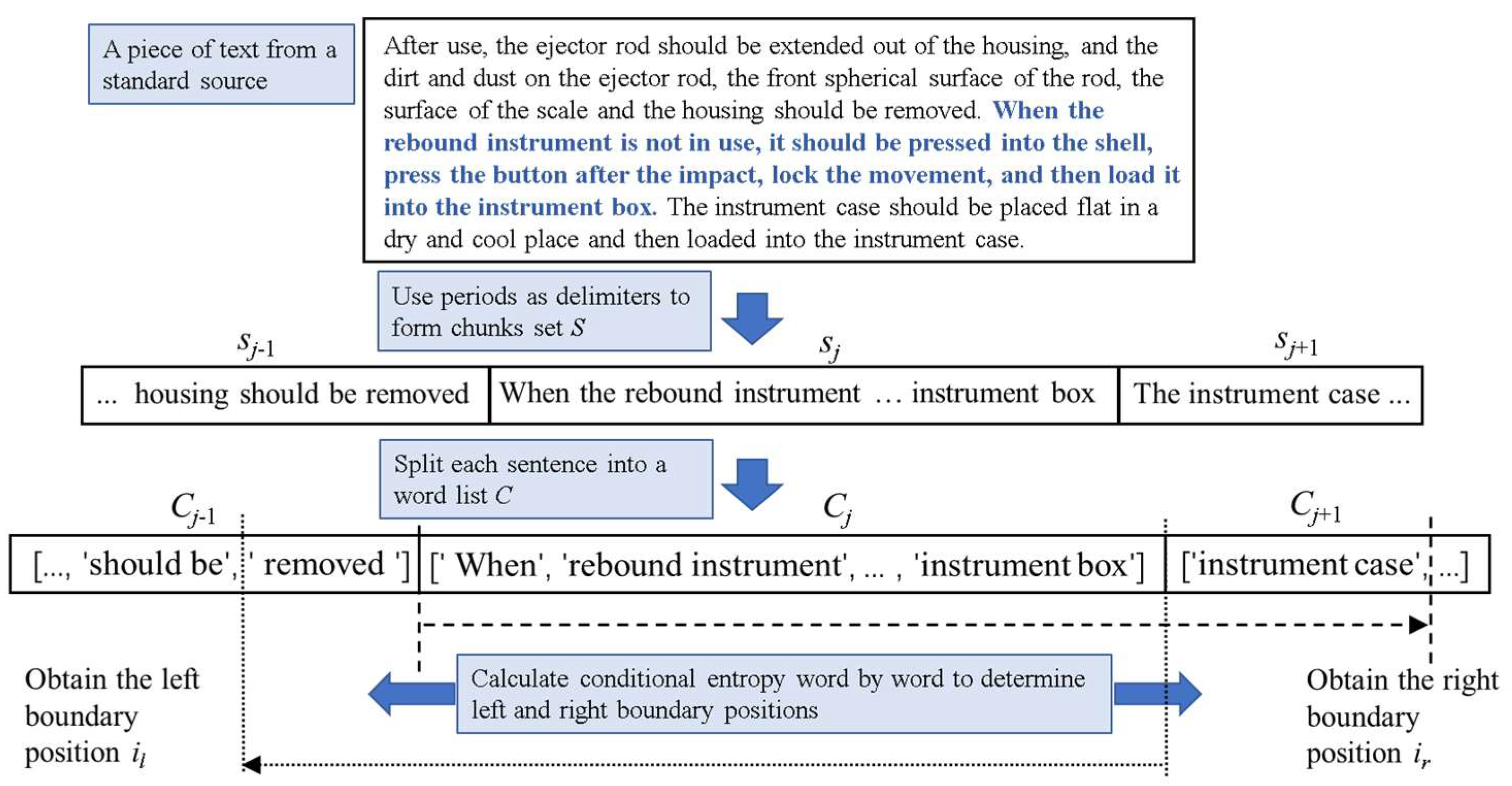
3.2. Entropy-Optimized Dynamic Text Segmentation
- Sentence as core unit: utilizing sentences as foundational semantic units to preserve intrinsic coherence.
- Dynamic context expansion: bidirectionally extending contextual windows (forward/backward) from each sentence boundary through a controlled growth mechanism.
- Entropy-driven boundary detection: Iteratively identifying optimal segmentation points by locating lexical positions with minimal local entropy within the expanded window. Equation (2), which calculates the local information entropy, is defined as follows:
- 4.
- Entropy reduction: Systematically minimizing the entropy of the entire core statement through dynamically adjusting chunk boundaries, ensuring maximally self-contained information units. As shown in Equation (3), select the candidate position that minimizes the conditional entropy as the segmentation boundary.
| Algorithm 1. EDTS Algorithm |
| inputs: content outputs: chunks |
| 1. Read in the entire text content; 2. Count the frequency of each word to form a word probability dictionary, where the key is the word and the value is the probability; 3. Use periods as delimiters to form chunks and the set S = [s1, s2, s3, …, sm]; 4. Assume the current calculation is for sentence sj, the preceding sentence is sj−1, and the following sentence is sj+1; 5. Split sj into a word list W = [w1, w2, w3, …, wn], using jieba segmentation; 6. Calculate the right boundary, use jieba segmentation to split sj+1 into a word list C = [c1, c2, c3, …, ck]; 7. Calculate the joint entropy H(W, c1); 8. Calculate the entropy H(c1); 9. Calculate the conditional entropy H(W|c1), according to Formula (4); 10. Repeat steps (7) to (9) to obtain a sequence of conditional entropies Hr expanding word by word to the right, as well as the list of conditional entropy for the right boundary Hr; 11. According to Formula (3), the boundary position on the right is determined by ir = arg min(Hr); 12. Repeat steps (5) to (11) to obtain the left boundary position il by expanding word by word to the left; 13. Form a word list for a chunk with the starting position at the left boundary il and the ending position at the right boundary ir; 14. Repeat steps (4) to (13) to traverse the sentences in S sequentially, wherein il in the first sentence is the first word of the entire text, and ir in the last sentence is the last word of the entire text; 15. Form a chunk by taking the word at position il as the starting word and the word at position ir as the ending word; 16. Traverse all statements in S and form the final output chunks. |
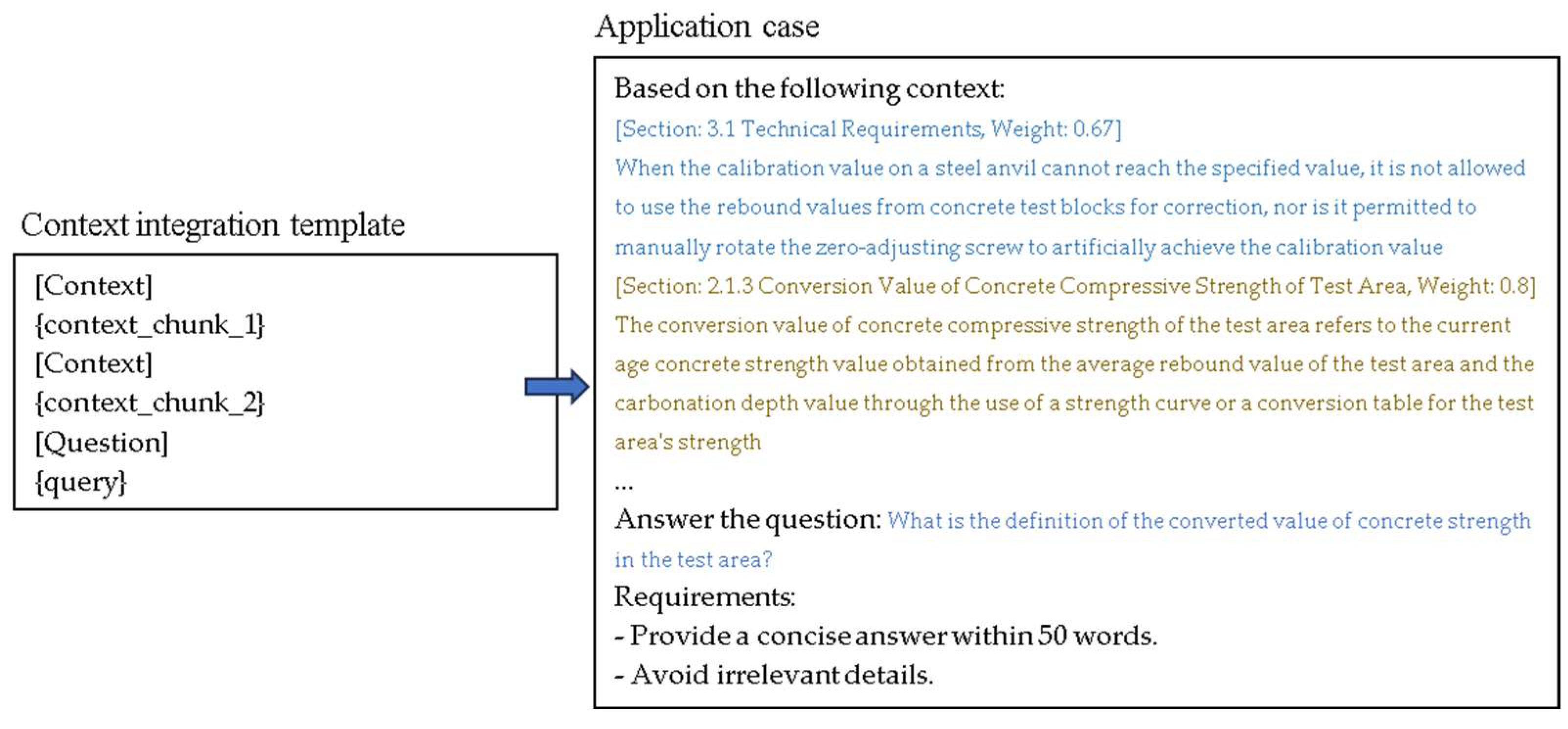
3.3. Chunk Rank Based on Vector Correlation
3.4. Iterative Optimization of Prompt Engineering
- Task Instruction: Clearly specify the type of generation task (e.g., question answering, summarization).
- Retrieval Context: Insert the top-k relevant text chunks as references.
- Query Statement: The user’s original input question or command.
- Format Constraints: Specify the output format (e.g., JSON, bullet points).
4. Test Results and Discussion
4.1. Test Condition
- CPU: Intel Xeon Gold 6226R processor (Cascade Lake architecture, 2.9 GHz base frequency);
- GPU: NVIDIA RTX A5000 with 24 GB GDDR6 memory;
- System memory: 512 GB DDR4-2933 ECC RAM;
- Windows 10 Professional Edition operating system.
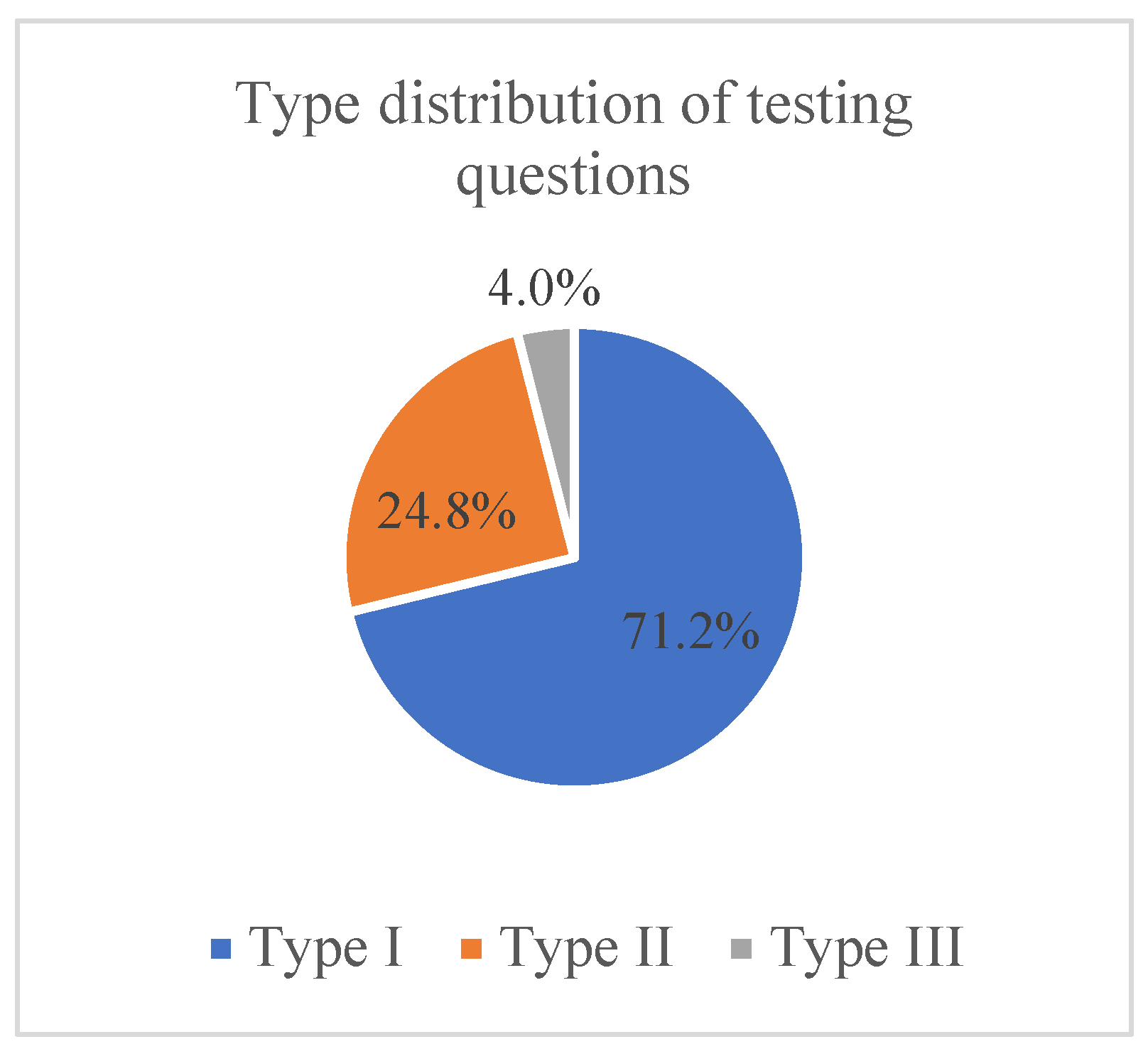
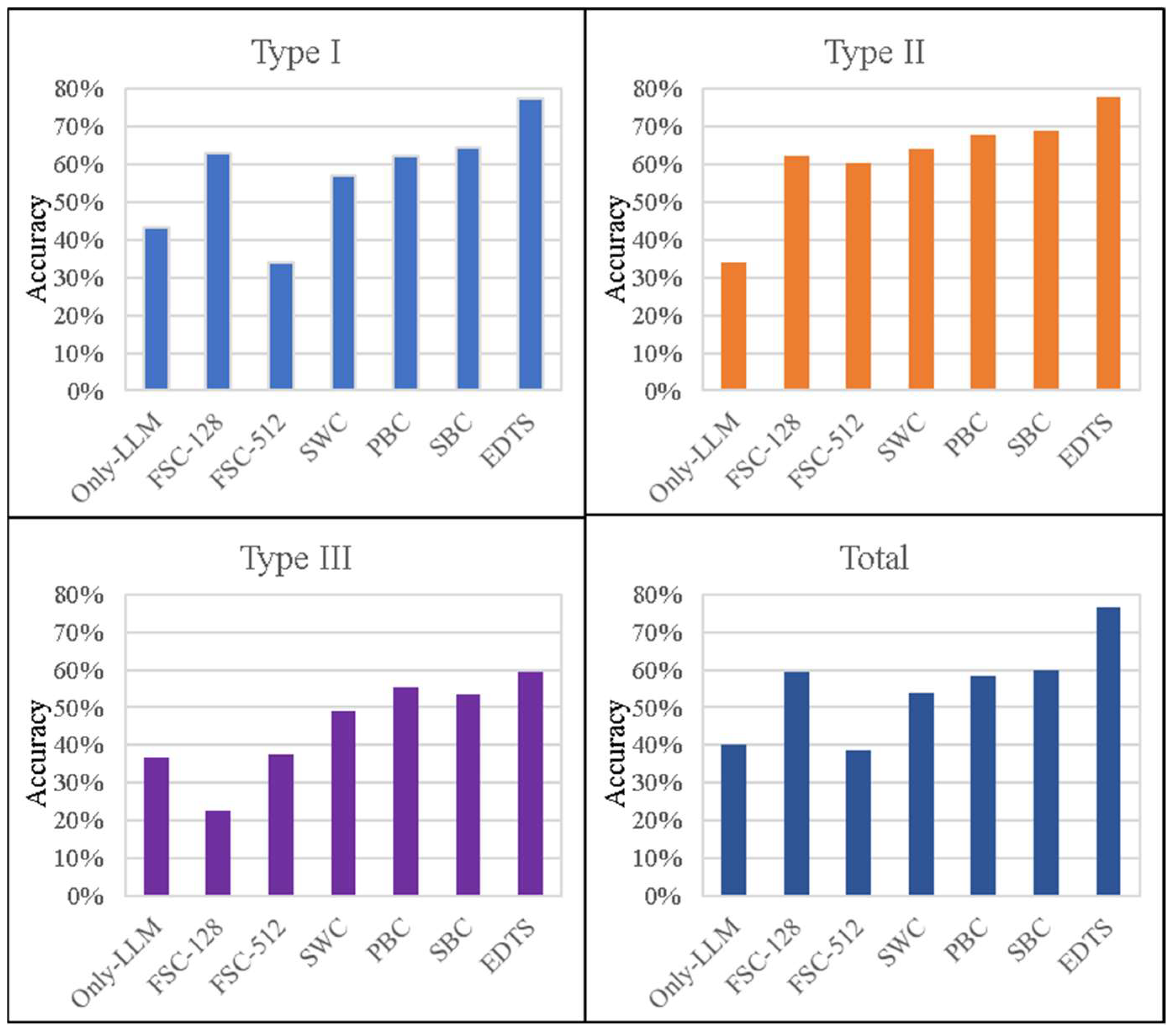
- Accurately answerable questions that allow direct judgment of correctness, such as: “What should be the maximum area of a test area in square meters?”. These questions have standardized numerical answers and are scored as either correct or incorrect.
- Descriptive questions, such as: “What is a test area?”. The answers to these questions are evaluated through similarity assessments to assign a quantitative score.
- Hybrid questions that combine descriptive elements with standardized numerical values. These require evaluating both the numerical accuracy and textual description.
4.2. Test Result Evaluation Method
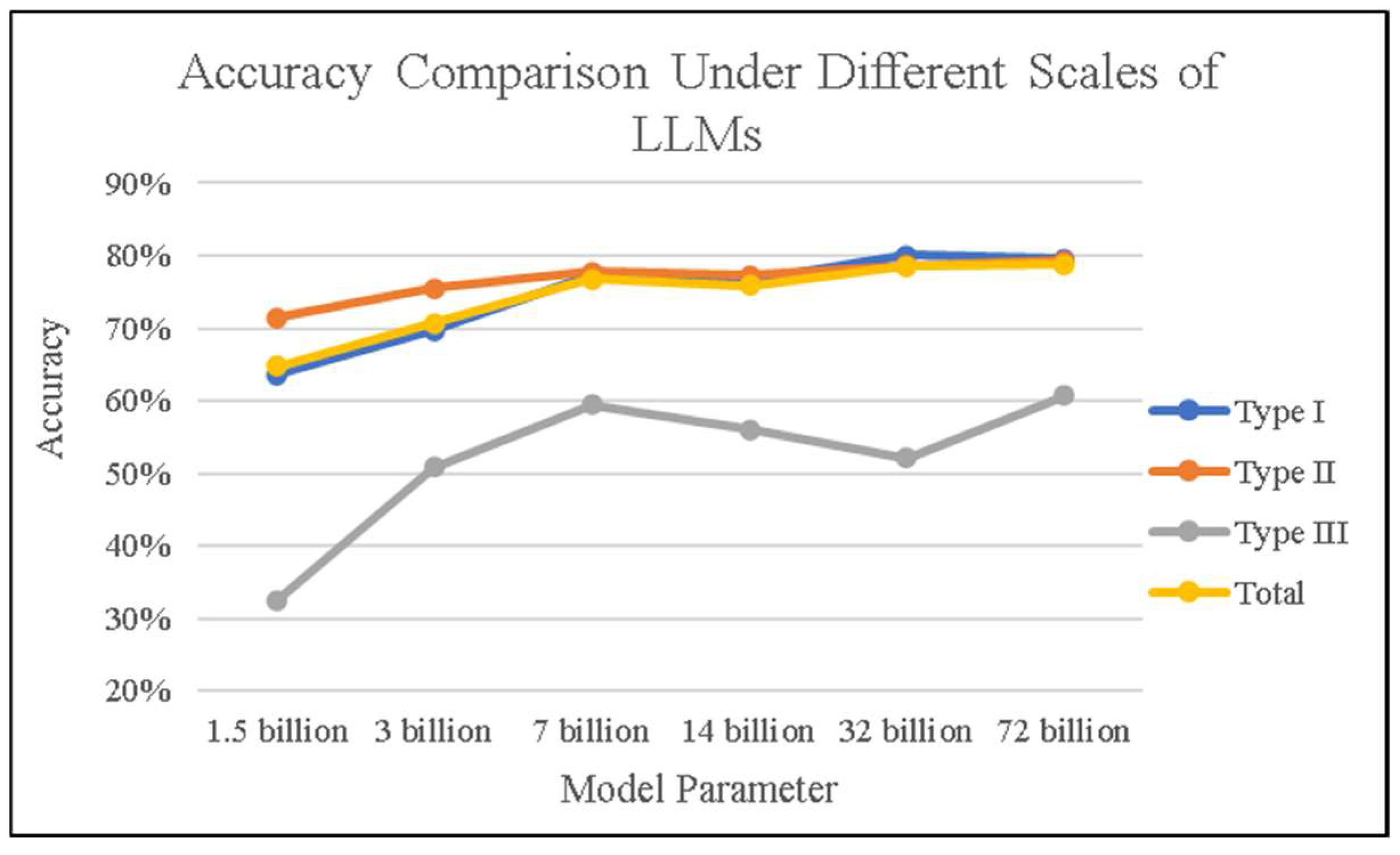
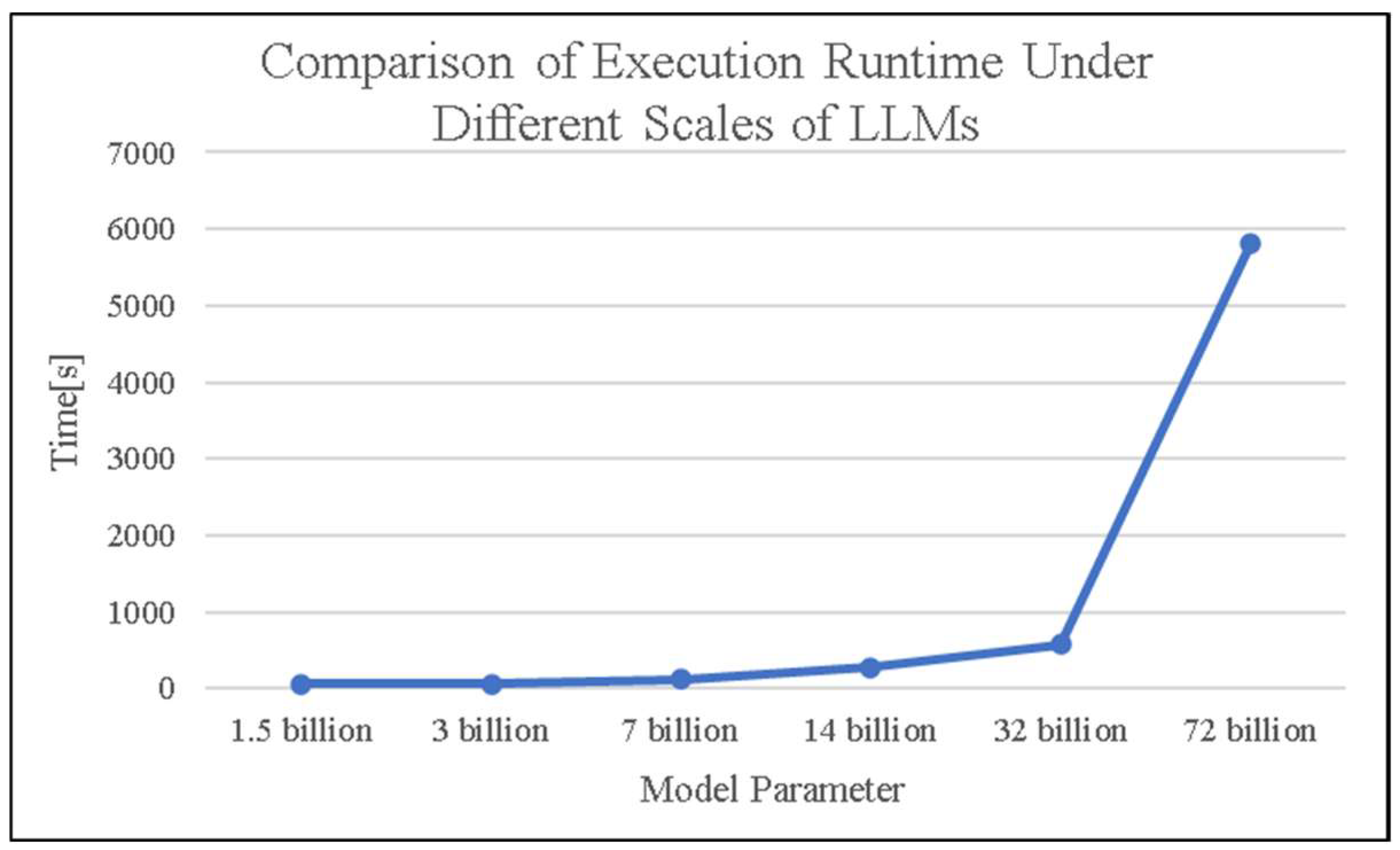
4.3. Test Results
4.4. Update Strategy
- Coexistence of Multiple Versions: Whenever a new version is released or an existing standard is revised, the system stores it as an independent entity rather than simply overwriting the previous version. This approach takes into account both practical application timeliness and compatibility, such as the concurrent execution phases between different versions, while facilitating the tracking of technological evolution. Each document is annotated with metadata recording its effective date, obsolescence status, and revision summary for subsequent querying and tracing purposes.
- Granular Mapping: Every text block will be accompanied by a version identifier, establishing a detailed mapping relationship from version to clause, which aids in the precise identification and citation of specific content under particular versions.
- Priority Setting: Upon feeding updated text blocks into the large model, a prioritization mechanism can be implemented to give higher weight to the most recent standard text blocks. This method not only ensures responses are grounded in the latest knowledge but also enhances the system’s sensitivity and responsiveness to industry dynamic changes.
5. Conclusions
- The integration of domain knowledge texts is not yet comprehensive and requires the gradual incorporation of numerous standards and specifications within the construction engineering field to form a complete domain knowledge base.
- There is a need to integrate dynamic domain knowledge, such as construction logs, inspection technology reports, design notes, and so on.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, Z.; Zhou, Y.C.; Chen, K.Y.; Lu, X.Z.; She, Z.T.; Lin, J.R. A text classification-based approach for evaluating and enhancing the machine interpretability of building codes. Eng. Appl. Artif. Intell. 2024, 127, 107207. [Google Scholar] [CrossRef]
- Lin, J.R.; Chen, K.Y.; Pan, P. Digital and intelligent standards for building and construction engineering: Current status and future. J. Southeast Univ. (Nat. Sci. Ed.) 2024, 55, 16–29. [Google Scholar]
- Liu, Z.S.; Liu, J.J.; Ji, W.Y.; Liu, L. Research on the establishment and application of digital twin-based construction project delivery models. J. Build. Struct. 2024, 45, 97–106. [Google Scholar] [CrossRef]
- Lin, J.R.; Chen, K.Y.; Zheng, Z.; Zhou, Y.; Lu, X. Key technologies and applications of intelligent interpretation of building engineering standards interpretation. Eng. Mech. 2025, 42, 1–14. [Google Scholar] [CrossRef]
- Jiang, C.; Zheng, Z.; Liang, X.; Lin, J.; Ma, Z.; Lu, X. A new interaction paradigm for architectural design driven by large language model: Proof of concept with Rhino7. J. Graph. 2024, 45, 594–600. [Google Scholar] [CrossRef]
- Qin, S.Z.; Zheng, Z.; Gu, Y.; Lu, X. Exploring and Discussion on the Application of Large Language Models in Construction Engineering. Ind. Constr. 2023, 53, 162–169. [Google Scholar] [CrossRef]
- Guo, M.Z.; Zhang, X.X.; Zhao, L.L.; Zhang, Q.Y. Seismic Response Prediction of Structures using Large Language Models. Comput. Eng. Appl. 2024, 1–17. [Google Scholar] [CrossRef]
- Florence, G.; Kikuchi, M.; Ozono, T. Delay risk detection in road construction projects utilizing large language models. In International Conference on Intelligent Systems Design and Applications; Springer: Cham, Switzerland, 2024. [Google Scholar] [CrossRef]
- Jin, X.X.; Lin, X.; Yu, X.R.; Guo, H. Construction progress updating method based on BIM and large language models. Tsinghua Sci. Technol. 2025, 65, 35–44. [Google Scholar] [CrossRef]
- Liang, J.; Zhang, L.P.; Yan, S.; Zhao, Y.; Zhang, Y. Research Progress of Named Entity Recognition Based on Large Language Model. J. Comput. Sci. Explor. 2024, 18, 2594–2615. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July 2019. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. 2023. Available online: https://cdn.openai.com/papers/gpt-4.pdf (accessed on 1 December 2024).
- Gemma Team; Google DeepMind. Gemma: Open Models-Based on Gemini Research and Technology. Available online: https://arxiv.org/pdf/2403.08295 (accessed on 1 December 2024).
- Meta. Llama 3: Foundation for the Next Generation of AI. 2024. Available online: https://www.llama.com (accessed on 3 February 2025).
- Alibaba. Qwen technical report. arXiv 2023, arXiv:2309.16609. [Google Scholar] [CrossRef]
- Baidu. ERNIE 4.0 launch event. 2023. Available online: https://wenxin.baidu.com/ernie (accessed on 1 February 2025).
- iFLYTEK. iFlySpark. 2023. Available online: https://xinghuo.xfyun.cn (accessed on 1 February 2025).
- Vatsal, S.; Dubey, H. A survey of prompt engineering methods in large language models for different nlp tasks. arXiv 2024, arXiv:2407.12994. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Shin, T.; Razeghi, Y.; Iv, R.L.L.; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing 2020, Online, 16–20 November 2020; pp. 4222–4235. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, H.N.G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1.1–1.35. [Google Scholar] [CrossRef]
- Agarwal, U.; Tanmay, K.; Khandelwal, A.; Choudhury, M. Ethical reasoning and moral value alignment of llms depend on the language we prompt them in. arXiv 2024, arXiv:2404.18460. [Google Scholar] [CrossRef]
- Jeong, J. Current research and future directions for off-site construction through LangChain with a large language model. Buildings 2024, 14, 2374. [Google Scholar] [CrossRef]
- Shi, Z.B.; Zhu, L.Y.; Yue, X.Q. Material Information Extraction based on Local Large Language Model and Prompt Engineering. Data Anal. Knowl. Discov. 2024, 8, 23–31. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. arXiv 2020, arXiv:2005.11401. [Google Scholar] [CrossRef]
- Li, X.; Wang, H.; Liu, Z.; Yu, S. Building a coding assistant via the retrieval-augmented language model. ACM Transactions on Information Systems. arXiv 2025, arXiv:2410.16229. [Google Scholar] [CrossRef]
- Borgeaud, S.; Mensch, A.; Hoffmann, J.; Cai, T.; Rutherford, E.; Millican, K.; Van Den Driessche, G.B.; Lespiau, J.B.; Damoc, B.; Clark, A.; et al. Improving language models by retrieving from trillions of tokens. arXiv 2022, arXiv:2112.04426. [Google Scholar] [CrossRef]
- Zhong, Y.; Leng, Y.; Chen, S.; Li, P.; Zou, Z.; Liu, Y.; Wan, J. Accelerating Battery Research with Retrieval-Augmented Large Language Models: Present and Future. Energy Storage Sci. Technol. 2024, 13, 3214–3225. [Google Scholar] [CrossRef]
- Wang, H.Q.; Wei, J.; Jing, H.Y.; Song, H.; Xu, B. Meta-RAG: A Metadata-Driven Retrieval Augmented Generation Framework for the Power Industry. Comput. Eng. 2025, 1–11. [Google Scholar] [CrossRef]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.-T. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) 2020, Online, 16–20 November 2020; pp. 6769–6781. [Google Scholar] [CrossRef]
- Lee, K.; Chang, M.-W.; Toutanova, K. Latent retrieval for weakly supervised open domain question answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) 2019, Florence, Italy, 28 July–2 August 2019; pp. 6086–6096. [Google Scholar] [CrossRef]
- Dai, Z.; Callan, J. Context-aware document term weighting for ad-hoc search. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) 2020, Online, 16–20 November 2020; pp. 49–58. [Google Scholar] [CrossRef]
- Zhao, Y.; Jiang, F.; Li, P. A Bert-Based Hierarchical Adjacent Coherence Text Segmentation Method. Comput. Appl. Softw. 2024, 41, 262–268. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) 2019, Hong Kong, China, 3–7 November 2019; pp. 3730–3740. [Google Scholar] [CrossRef]
- Koshorek, O.; Cohen, A.; Mor, N.; Rotman, M.; Berant, J. Text segmentation as a supervised learning task. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2. [Google Scholar] [CrossRef]
- Jin, Y.; Huang, J. Improved TFIDF algorithm based on information entropy and word length information. J. Zhejiang Univ. Technol. 2021, 49, 203–209. [Google Scholar] [CrossRef]
- Genzel, D.; Charniak, E. Entropy Rate Constancy in Text; Association for Computational Linguistics: Dublin, Ireland, 2002. [Google Scholar] [CrossRef]
- Tang, Y.; Deng, J.; Guo, Z. Candidate term boundary conflict reduction method for Chinese geological text segmentation. Appl. Sci. 2023, 13, 4516. [Google Scholar] [CrossRef]
- Zhou, X.; Gao, Y.Q.; Fan, J.Y. Research on patent retrieval strategy based on BERT word embedding. J. China Soc. Sci. Tech. Inf. 2023, 42, 1347–1357. [Google Scholar] [CrossRef]
- Sufi, F. Generative pre-trained transformer (GPT) in research: A systematic review on data augmentation. Information 2024, 15, 99. [Google Scholar] [CrossRef]
- Yang, Y.; Ye, F.; Xu, D.; Zhang, X.; Xue, J. Construction of digital twin water conservancy knowledge graph integrating large language models and prompt learning. J. Comput. Appl. 2024, 1–11. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Wang, X.; Han, L.F.; Li, Z.; Chen, Z.; Chen, Z. Research on Question Answering System on the Joint of Knowledge Graph and Large Language Models. J. Front. Comput. Sci. Technol. 2023, 17, 2377–2388. [Google Scholar] [CrossRef]
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. IEEE Trans. Big Data 2019, 7, 535–547. [Google Scholar] [CrossRef]
- Wang, S.; He, W.; Wang, F.; Zhao, X.; Zhou, Y. Research on question answering system based on large language model integrating knowledge graph and vector retrieval. Sci. Technol. Eng. 2024, 24, 13902–13910. [Google Scholar] [CrossRef]
- Wu, G.D.; Qin, H.; Hu, Q.X.; Wang, X.N.; Wu, Z.C. Research on large language models and personalized recommendation. CAAI Trans. Intell. Syst. 2024, 19, 1351–1365. [Google Scholar] [CrossRef]
- Zhao, J.F.; Chen, T.; Wang, X.M.; Feng, C. Information Extraction of Unlabeled Patent Based on Knowledge Self-Distillation of Large Language Model. Data Anal. Knowl. Discov. 2025, 8, 133–143. [Google Scholar] [CrossRef]
- Jun, F.E.; Yanghong, C.H.; Jiamin, L.U.; Hailin, T.A.; Zhipeng, L.Y.; Yuchun, Q.I. Construction and Application of Knowledge Graph for Water Engineering Scheduling Based on Large Language Model. J. Front. Comput. Sci. Technol. 2024, 18, 1637–1647. [Google Scholar] [CrossRef]
- Peng, W.; Wu, H.; Xu, L. Keyword weight optimization for short text multi-classification based on attention mechanism. J. Comput. Appl. 2021, 41, 19–24. [Google Scholar] [CrossRef]
- JGJ/T 23-2011; Technical Specification for Inspecting of Concrete Compressive Strength by Rebound Method. Ministry of Housing and Urban-Rural Development of the People’s Republic of China: Beijing, China, 2011.
- Nussbaum, Z.; Morris, J.X.; Duderstadt, B.; Mulyar, A. Nomic embed: Training a reproducible long context text embedder. arXiv 2024, arXiv:2402.01613. [Google Scholar] [CrossRef]
- Nomic AI. Nomic-Embed-Text: Reproducible and Transparent Open-Source Text Embeddings. 2024. Available online: https://www.nomic.ai/ (accessed on 1 February 2025).
- Li, H.; Yang, R.; Xu, S.; Xiao, Y.; Zhao, H. Intelligent checking method for construction schemes via fusion of knowledge graph and large language models. Buildings 2024, 14, 2502. [Google Scholar] [CrossRef]
- Edge, D.; Trinh, H.; Cheng, N.; Bradley, J.; Chao, A.; Mody, A.; Truitt, S.; Metropolitansky, D.; Ness, R.O.; Larson, J. From local to global: A graph rag approach to query-focused summarization. arXiv 2024. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Model Name | Developer | Open Source | Release Date | Max Parameters | Key Features |
|---|---|---|---|---|---|---|
| 1 | ChatGPT [15] | Open AI | No | 2022.11 | N/A | General-purpose dialogue, advanced reasoning, and long-text generation. |
| 2 | Gemma [16] | Google DeepMind | Yes | 2024.2 | 7B | Lightweight open-source model with safety and efficiency focus. |
| 3 | Llama [17] | Meta | Yes | 2023.7 | 400B | Community-driven open-source model, supports multilingual tasks. |
| 4 | Qwen [18] | Alibaba Cloud | Yes | 2023.8 | 110B | Chinese-optimized, excels in math and coding tasks. |
| 5 | ERNIE Bot [19] | Baidu | No | 2023.3 | N/A | Leading Chinese NLP performance, integrated search enhancement. |
| 6 | iFlySpark [20] | iFLYTEK | No | 2023.5 | N/A | Multimodal interaction, specialized in education and healthcare scenarios. |
| No | Method | Implementation Summary | Major Deficiency |
|---|---|---|---|
| 1 | Fixed-size chunking | Define a fixed character or word limit (e.g., 512 or 128 words per chunk). Split the text into equal-sized chunks. | Semantic fragmentation, uneven information density [34] |
| 2 | Sliding window chunking | Define a window size (e.g., 256 words) and a step size (e.g., 64 words). Slide the window across the text to create overlapping chunks. | Redundant information, parameter sensitive [35,36] |
| 3 | Paragraph-based chunking | Split text at paragraph boundaries (e.g., line breaks). | Dependence on formatting quality, uneven paragraph length [37] |
| 4 | Sentence-based chunking | Split text at sentence boundaries (e.g., periods or question marks). | Punctuation dependency, information fragmentation [38] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zhang, D.; Li, J.; Feng, Z.; Zhang, F. Entropy-Optimized Dynamic Text Segmentation and RAG-Enhanced LLMs for Construction Engineering Knowledge Base. Appl. Sci. 2025, 15, 3134. https://doi.org/10.3390/app15063134
Wang H, Zhang D, Li J, Feng Z, Zhang F. Entropy-Optimized Dynamic Text Segmentation and RAG-Enhanced LLMs for Construction Engineering Knowledge Base. Applied Sciences. 2025; 15(6):3134. https://doi.org/10.3390/app15063134
Chicago/Turabian StyleWang, Haiyuan, Deli Zhang, Jianmin Li, Zelong Feng, and Feng Zhang. 2025. "Entropy-Optimized Dynamic Text Segmentation and RAG-Enhanced LLMs for Construction Engineering Knowledge Base" Applied Sciences 15, no. 6: 3134. https://doi.org/10.3390/app15063134
APA StyleWang, H., Zhang, D., Li, J., Feng, Z., & Zhang, F. (2025). Entropy-Optimized Dynamic Text Segmentation and RAG-Enhanced LLMs for Construction Engineering Knowledge Base. Applied Sciences, 15(6), 3134. https://doi.org/10.3390/app15063134