

An Advanced Natural Language Processing Framework for Arabic Named Entity Recognition: A Novel Approach to Handling Morphological Richness and Nested Entities


Abstract
1. Introduction
2. Related Works
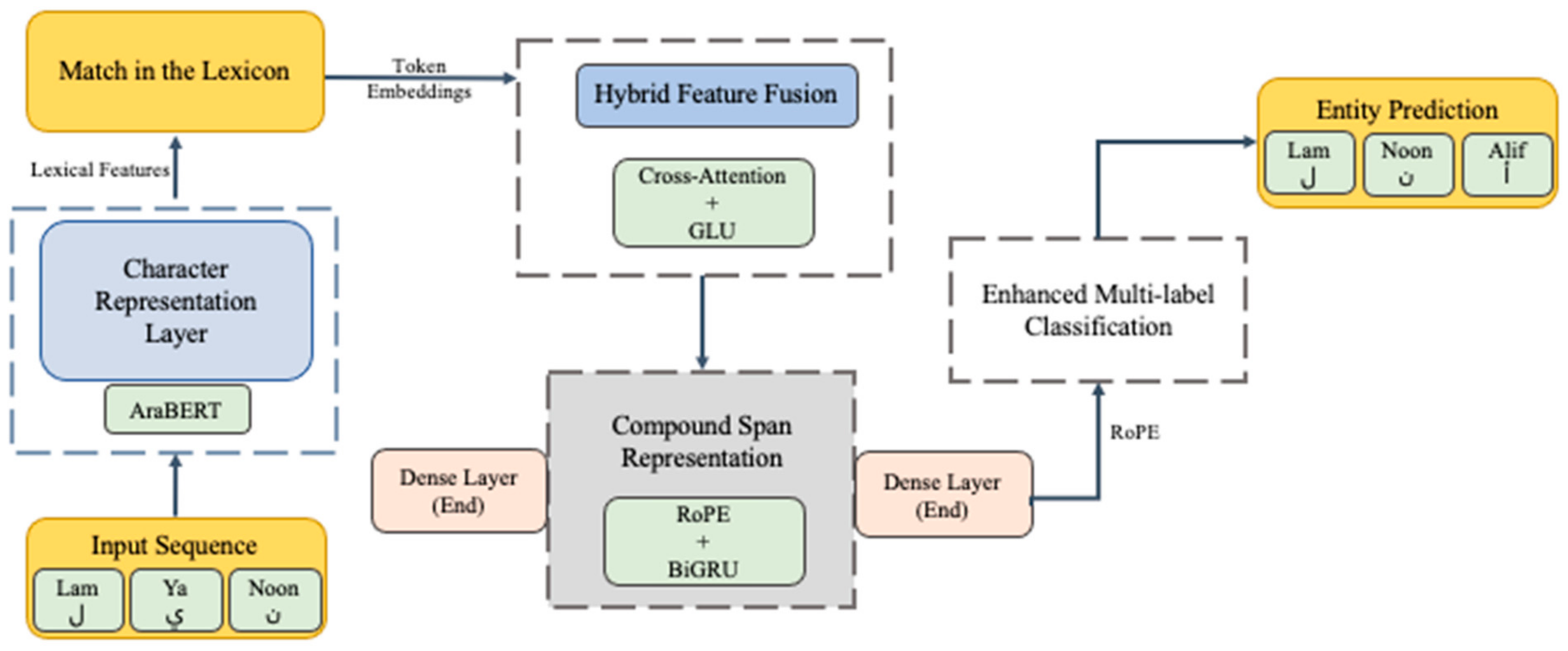
3. Methodology
3.1. Character Representation Layer
3.2. Hybrid Feature Fusion Layer: Cross-Attention + Gated Lexical Integration
3.3. Compound Span Representation Layer: Dense + Recurrent Positional Encoding
3.4. Enhanced Multi-Label Classification Layer: Span-Label Alignment Network
4. Experimental Analysis and Results
4.1. Datasets
- ANERcorp is a widely used benchmark dataset that focuses on flat named entities in general Arabic news articles, including persons, locations, and organizations.
- ACE 2005, in contrast, contains more complex, nested entity structures commonly found in formal newswire texts, making it a suitable testbed for evaluating the proposed model’s nested entity recognition capabilities.
- The custom dataset covers biomedical and legal documents, representing domain-specific content that requires deep semantic understanding and lexicon filtering due to specialized terminology.
4.2. Evaluation Metrics
4.3. Experimental Setup
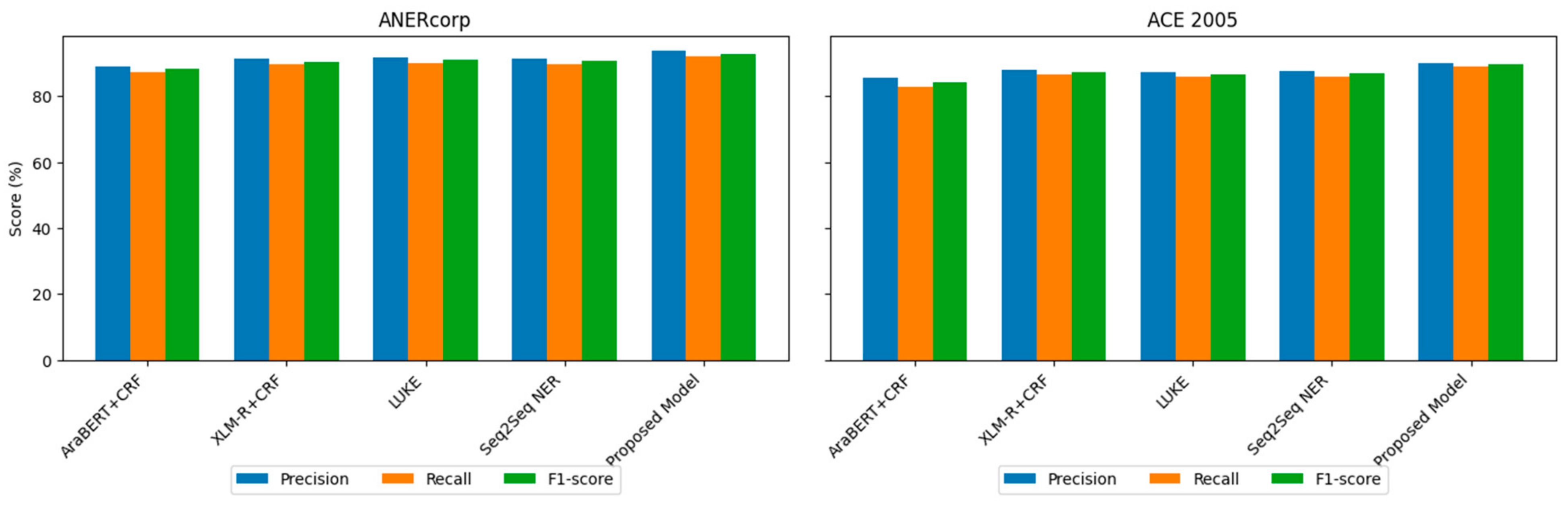
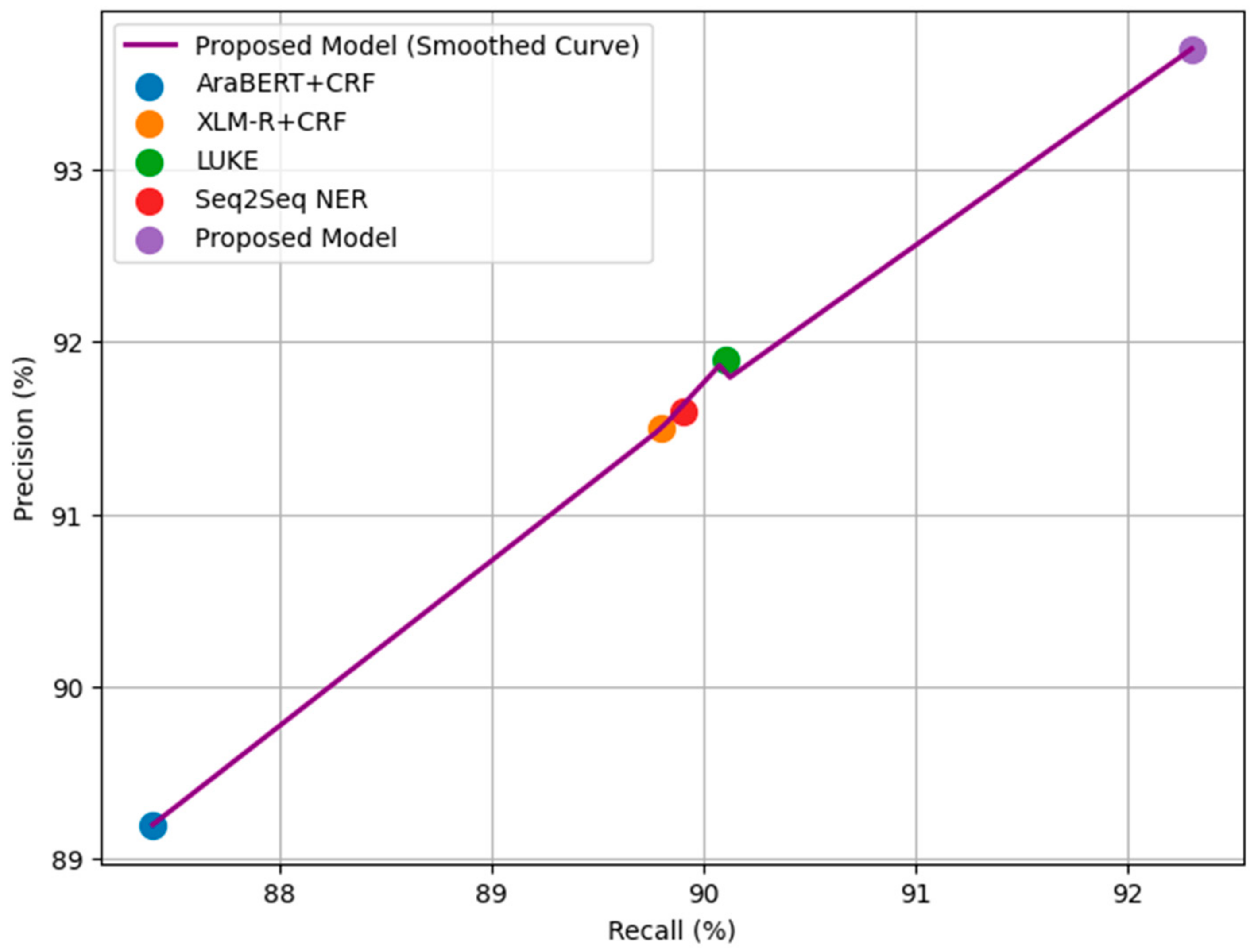
4.3.1. Comparison with Basic Models
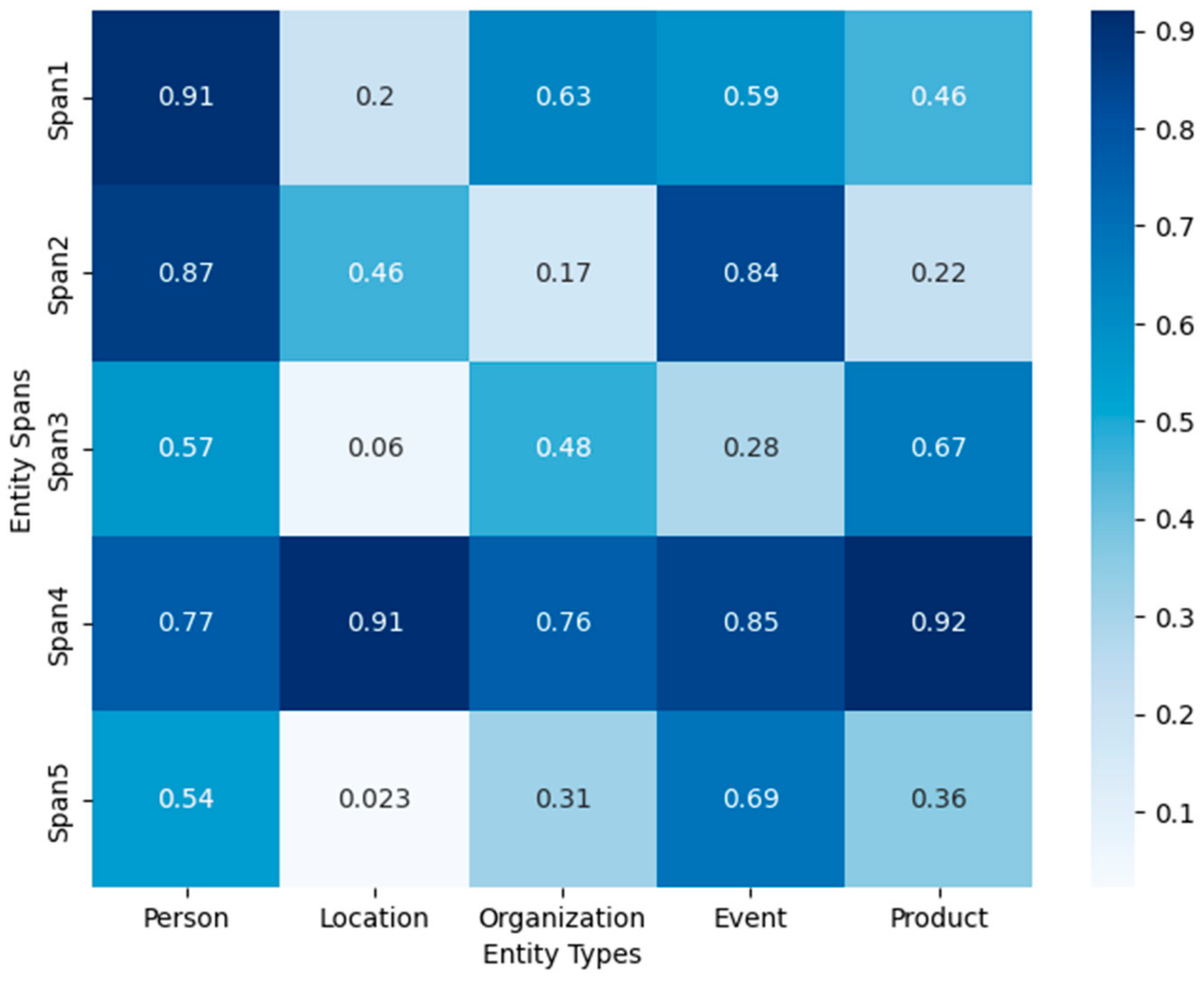
4.3.2. Error Analysis
4.3.3. Case Study
- Person: “الملك سلمان” (King Salman).
- Event: “المؤتمر الدولي للسلام” (The international peace conference).
- Organization: “الأمم المتحدة” (The United Nations).
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- El Khbir, M.; Meziane, F.; Belkredim, F.Z. A span-based approach for Arabic named entity recognition: Application to the WojoodNER shared task. In Proceedings of the Arabic NLP Workshop at ACL 2023, Singapore, 7 December 2023. [Google Scholar]
- Hussein, M.; Abdellatif, M.; Salama, M. AraBINDER: A bi-encoder model with contrastive learning for Arabic named entity recognition. In Proceedings of the Arabic NLP Workshop at ACL 2023, Singapore, 7 December 2023. [Google Scholar]
- Sadallah, A.B.; Ahmed, O.; Mohamed, S.; Hatem, O.; Hesham, D.; Yousef, A.H. ANER: Arabic and Arabizi named entity recognition using transformer-based approach. In Proceedings of the 2023 Intelligent Methods, Systems, and Applications (IMSA), Giza, Egypt, 15–16 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 263–268. [Google Scholar]
- WojoodNER 2023 Shared Task. The WojoodNER Arabic Named Entity Recognition shared task. arXiv 2023, arXiv:2310.16153. [Google Scholar]
- Liqreina, A.; Bouamor, D.; Habash, N. Fine-grained named entity recognition for Arabic: New dataset and models. arXiv 2023. [Google Scholar]
- Shaker, M.; Abdelaziz, A.; El-Tahawy, A. Exploring LSTM and GRU architectures for Arabic named entity recognition. arXiv 2023. [Google Scholar]
- Chen, J.; Wang, P.; Zhang, L.; Lee, S. Multilingual named entity recognition using transfer learning across languages. In Proceedings of the International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 16–21 October 2023. [Google Scholar]
- Li, X.; Meng, Y.; Sun, X.; Han, Q.; Yuan, A.; Li, J. Is Word Segmentation Necessary for Deep Learning of Chinese Representations? arXiv 2019, arXiv:1905.05526. [Google Scholar]
- Wang, Q.; Su, X. Research on named entity recognition methods in Chinese forest disease texts. Appl. Sci. 2022, 12, 3885. [Google Scholar] [CrossRef]
- Youssef, H.; Alghamdi, N.; Alzahrani, F. Leveraging AraBERT for Arabic named entity recognition with morphological features. J. Arab. Comput. Linguist. 2024, 46, 76–91. [Google Scholar]
- Liu, W.; Yang, H.; Zhao, R. Dual-attention mechanisms for named entity recognition in financial texts. J. Financ. Technol. AI 2023. [Google Scholar]
- Sun, X.; Chen, W.; Lin, H.; Zhao, J. Span-based models with enhanced positional encoding for nested entity recognition. J. Artif. Intell. Res. 2023. [Google Scholar]
- Gao, Y.; Liu, H.; Wang, T. Global attention mechanism for overlapping entity recognition. Neural Process. Lett. 2023. [Google Scholar]
- Ahmed, A.; Hussein, K.; Khalifa, M. Data augmentation techniques for underrepresented languages in NER. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore, 6–10 December 2023. [Google Scholar]
- Al-Rashed, H.; Ahmed, M.; Al-Otaibi, F. Enhancing Arabic Named Entity Recognition in Informal Texts through Morphological Analysis. J. Comput. Linguist. Arab. NLP 2024, 15, 45–60. [Google Scholar]
- Zhang, H.; Wang, X.; Liu, J.; Zhang, L.; Ji, L. Enhancing rare entity recognition with lexicons. Inf. Sci. 2023, 625, 385–400. [Google Scholar] [CrossRef]
- Wu, T.; Lin, X.; Zhang, M.; Chen, D. Cross-attention mechanisms for contextual alignment in Arabic named entity recognition. Nat. Lang. Process. AI Rev. 2023. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; Wei, Z.; Huang, X. Simplifying lexicon usage in Chinese NER. In Proceedings of the Association for Computational Linguistics (ACL), Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Singh, R.; Patel, V.; Kumar, S.; Mehta, P. Integrating lexical features into transformer-based named entity recognition models. J. Comput. Linguist. 2024, 52, 45–62. [Google Scholar]
- Park, J.; Kim, H.; Lee, S.; Choi, D. Zero-shot and few-shot learning approaches for named entity recognition in resource-scarce languages. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Bangkok, Thailand, 11–16 August 2024. [Google Scholar]
- Yamada, I.; Asai, A.; Shindo, H.; Takeda, H.; Matsumoto, Y. LUKE: Deep contextualized entity representations with entity-aware self-attention. arXiv 2020, arXiv:2010.01057. [Google Scholar]
- Zhang, Z.; Zuo, Y.; Wu, J. Aspect sentiment triplet extraction: A Seq2Seq approach with span copy enhanced dual decoder. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2729–2742. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year and Author | Focus Area | Technique | Dataset | Key Contribution | Limitations |
|---|---|---|---|---|---|
| Chen et al., 2023 [7] | Multilingual NER | Transfer learning | MultiCoNER | Achieved state-of-the-art performance in 10 languages. | Limited evaluation on morphologically rich languages like Arabic. |
| Li et al., 2024 [8] | Cross-lingual NER | Contrastive learning | WikiAnn | Enhanced NER for low-resource languages. | Does not address domain-specific challenges. |
| Youssef et al., 2024 [10] | Arabic NER | Morphological feature integration | ANERcorp | Enhanced performance using Arabic morphology. | Focused only on formal Arabic texts, neglecting informal domains. |
| Sun et al., 2023 [12] | Nested Entity Recognition | Span-based model | ACE 2005 | Superior nested entity recognition. | No specific adaptation for multilingual or Arabic datasets. |
| Wu et al., 2023 [16] | Cross-Attention for NER | Cross-attention modules | CoNLL 2003 | Improved contextual alignment. | Inefficient for large-scale datasets due to computational complexity. |
| Zhang et al., 2023 [15] | Rare Entity Recognition | External lexicons | Low-resource Datasets | Recognized rare entities efficiently. | Requires high-quality lexicons, which are scarce for many languages. |
| Ma et al., 2023 [17] | Lexicon-enhanced NER | Lexicon-enhanced transformers | Chinese NER Datasets | Improved performance using lexical information. | Limited application to other morphologically complex languages. |
| Dataset | # Sentences | # Tokens | # Entity Types | Nested Entities |
|---|---|---|---|---|
| ANERcorp | 6000 | 150,000 | 3 | No |
| ACE 2005 | 12,000 | 250,000 | 7 | Yes |
| Custom Biomedical | 5000 | 80,000 | 5 | Yes |
| Model | Dataset | Precision (%) | Recall (%) | F1-Score (%) | Exact Match (%) |
|---|---|---|---|---|---|
| AraBERT + CRF | ANERcorp | 89.2 | 87.4 | 88.3 | 85.1 |
| XLM-R + CRF | ANERcorp | 91.5 | 89.8 | 90.6 | 87.2 |
| Proposed Model | ANERcorp | 93.7 | 92.3 | 93.0 | 91.5 |
| NestedNER | ACE 2005 | 85.6 | 82.9 | 84.2 | 80.4 |
| GlobalPointer | ACE 2005 | 88.1 | 86.7 | 87.4 | 84.2 |
| Proposed Model | ACE 2005 | 90.2 | 89.1 | 89.6 | 86.9 |
| Model | Dataset | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| AraBERT + CRF | ANERcorp | 89.2 | 87.4 | 88.3 |
| XLM-R + CRF | ANERcorp | 91.5 | 89.8 | 90.6 |
| LUKE | ANERcorp | 91.9 | 90.1 | 91 |
| Seq2Seq NER | ANERcorp | 91.6 | 89.9 | 90.7 |
| Proposed Model | ANERcorp | 93.7 | 92.3 | 93 |
| AraBERT + CRF | ACE 2005 | 85.6 | 82.9 | 84.2 |
| XLM-R + CRF | ACE 2005 | 88.1 | 86.7 | 87.4 |
| LUKE | ACE 2005 | 87.5 | 85.9 | 86.7 |
| Seq2Seq NER | ACE 2005 | 87.7 | 86.1 | 86.9 |
| Proposed Model | ACE 2005 | 90.2 | 89.1 | 89.6 |
| AraBERT + CRF | Biomedical | 84.7 | 82.5 | 83.6 |
| XLM-R + CRF | Biomedical | 86.3 | 84.1 | 85.2 |
| LUKE | Biomedical | 86.9 | 84.7 | 85.8 |
| Seq2Seq NER | Biomedical | 87.1 | 85 | 86 |
| Proposed Model | Biomedical | 89.5 | 87.3 | 88.4 |
| Model Variant | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| Full Model | 93.7 | 92.3 | 93.0 |
| Without Hybrid Feature Fusion | 91.5 | 90.4 | 90.9 |
| Without Compound Span Representation | 90.8 | 89.3 | 90.0 |
| Without Enhanced Multi-Label Classification | 92.1 | 91.0 | 91.5 |
| Entity Span | Predicted Label | Ground Truth Label | Confidence (%) |
|---|---|---|---|
| “الملك سلمان” | Person | Person | 98.5 |
| “المؤتمر الدولي للسلام” | Event | Event | 96.7 |
| “الأمم المتحدة” | Organization | Organization | 99.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albahli, S. An Advanced Natural Language Processing Framework for Arabic Named Entity Recognition: A Novel Approach to Handling Morphological Richness and Nested Entities. Appl. Sci. 2025, 15, 3073. https://doi.org/10.3390/app15063073
Albahli S. An Advanced Natural Language Processing Framework for Arabic Named Entity Recognition: A Novel Approach to Handling Morphological Richness and Nested Entities. Applied Sciences. 2025; 15(6):3073. https://doi.org/10.3390/app15063073
Chicago/Turabian StyleAlbahli, Saleh. 2025. "An Advanced Natural Language Processing Framework for Arabic Named Entity Recognition: A Novel Approach to Handling Morphological Richness and Nested Entities" Applied Sciences 15, no. 6: 3073. https://doi.org/10.3390/app15063073
APA StyleAlbahli, S. (2025). An Advanced Natural Language Processing Framework for Arabic Named Entity Recognition: A Novel Approach to Handling Morphological Richness and Nested Entities. Applied Sciences, 15(6), 3073. https://doi.org/10.3390/app15063073