
Named Entity Recognition in Online Medical Consultation Using Deep Learning

Abstract
1. Introduction
- An online medical consultation named entity identification dataset for up to 26 medical entity types is constructed, which far exceeds those of the existing studies;
- This study provides important data support for constructing more powerful online medical consultation knowledge graphs and further virtual intelligent health assistants;
- A fusion context mechanism that can fuse the local and global contextual semantic representations is developed;
- This study investigates the performance of the state-of-the-art (SOTA) large language model (LLM) ChatGPT-4o in fine-grained named entity recognition tasks within a specific domain and discusses its applicability to the research problem.
2. Related Work
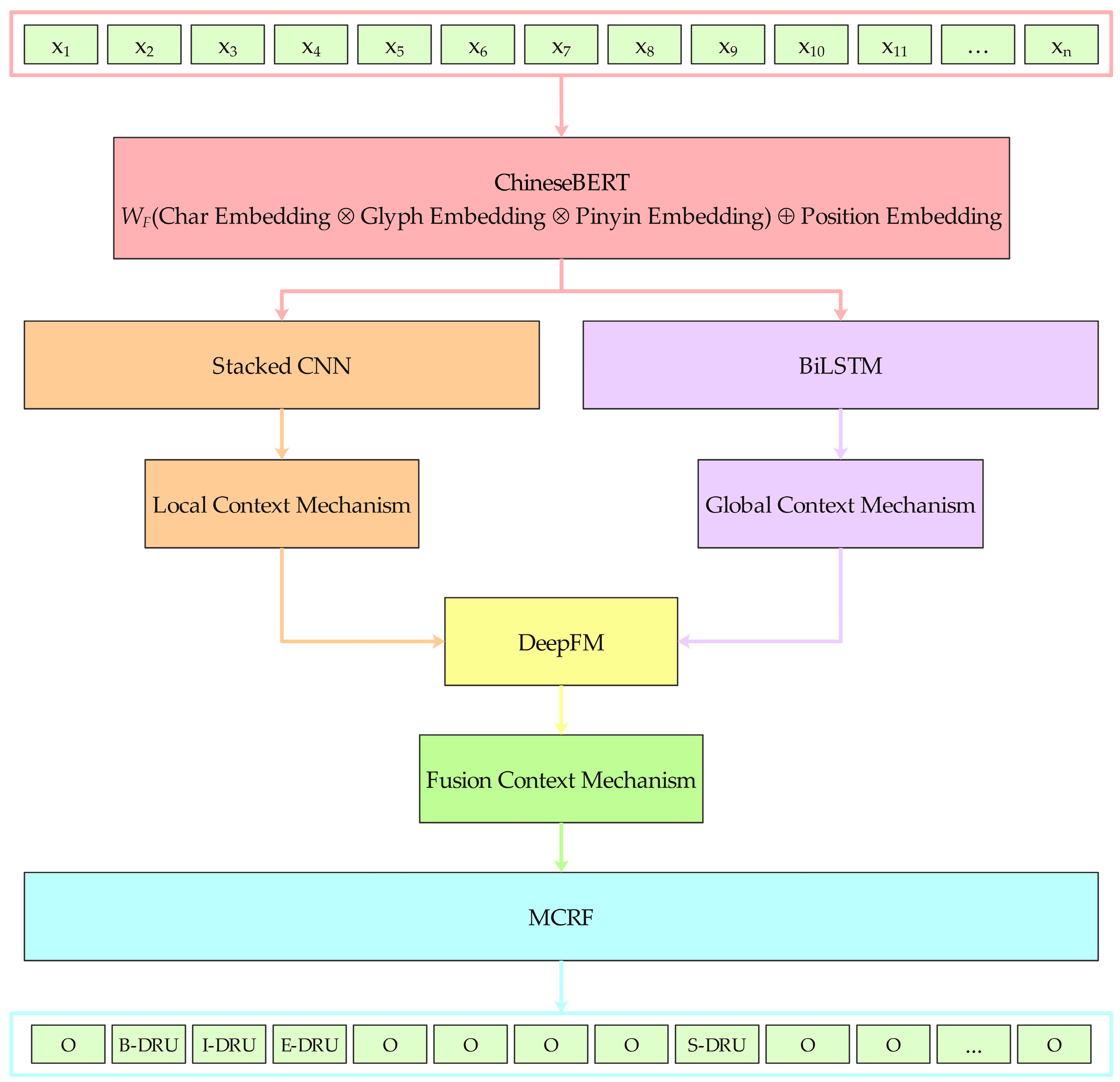
3. The Proposed Approach
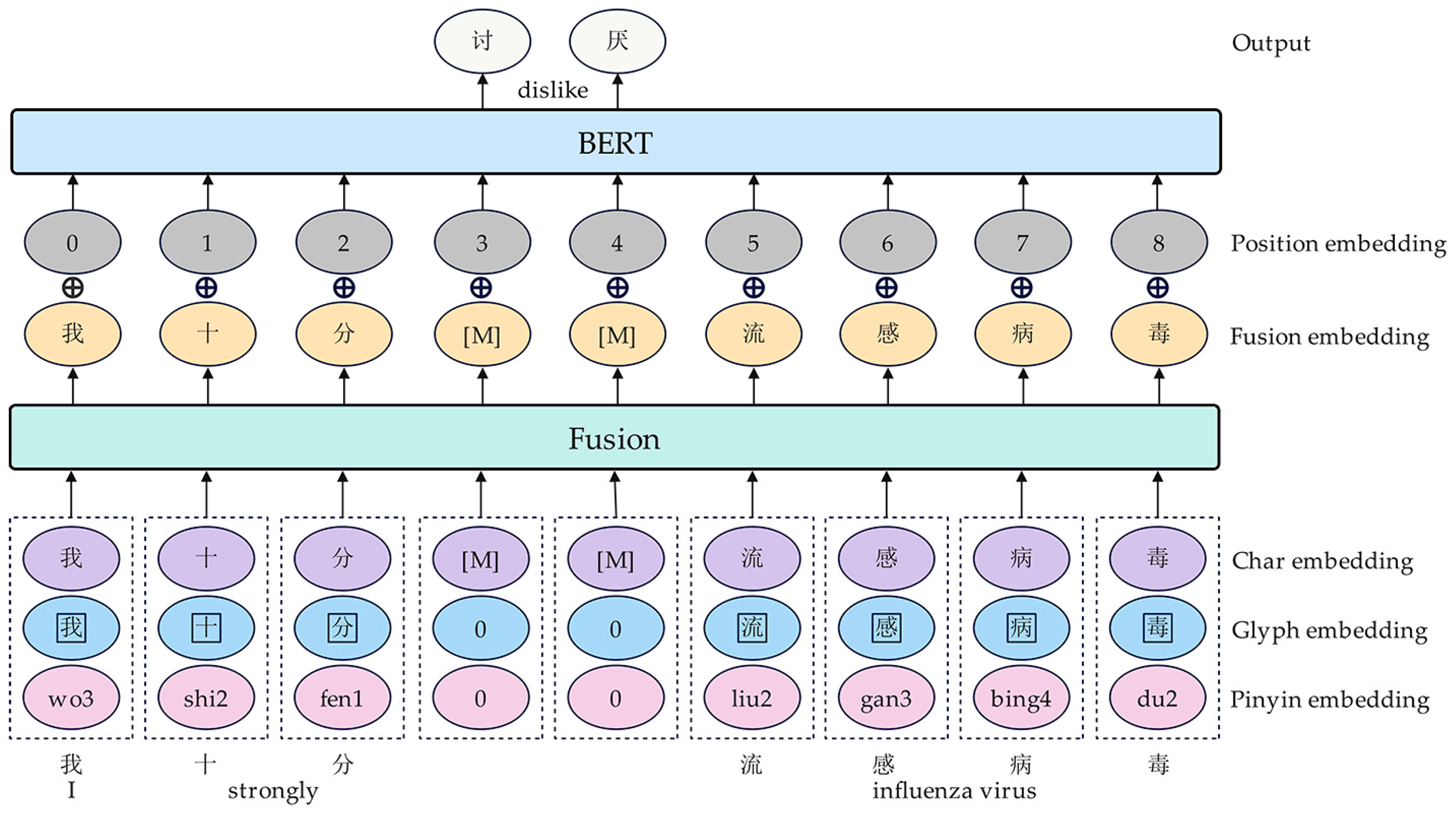
- A data sample sentence is randomly selected from the experimental dataset. In the pretrained model component, ChineseBERT maps this sentence into a real-valued matrix. The matrix’s row count matches the sentence’s character count, while its column count corresponds to the final hidden layer dimension of ChineseBERT. Then, the real-valued matrix is input into the stacked CNN with the local context mechanism component and BiLSTM with the global context mechanism component to model the sentence’s contextual semantic representation from both local and global perspectives simultaneously.
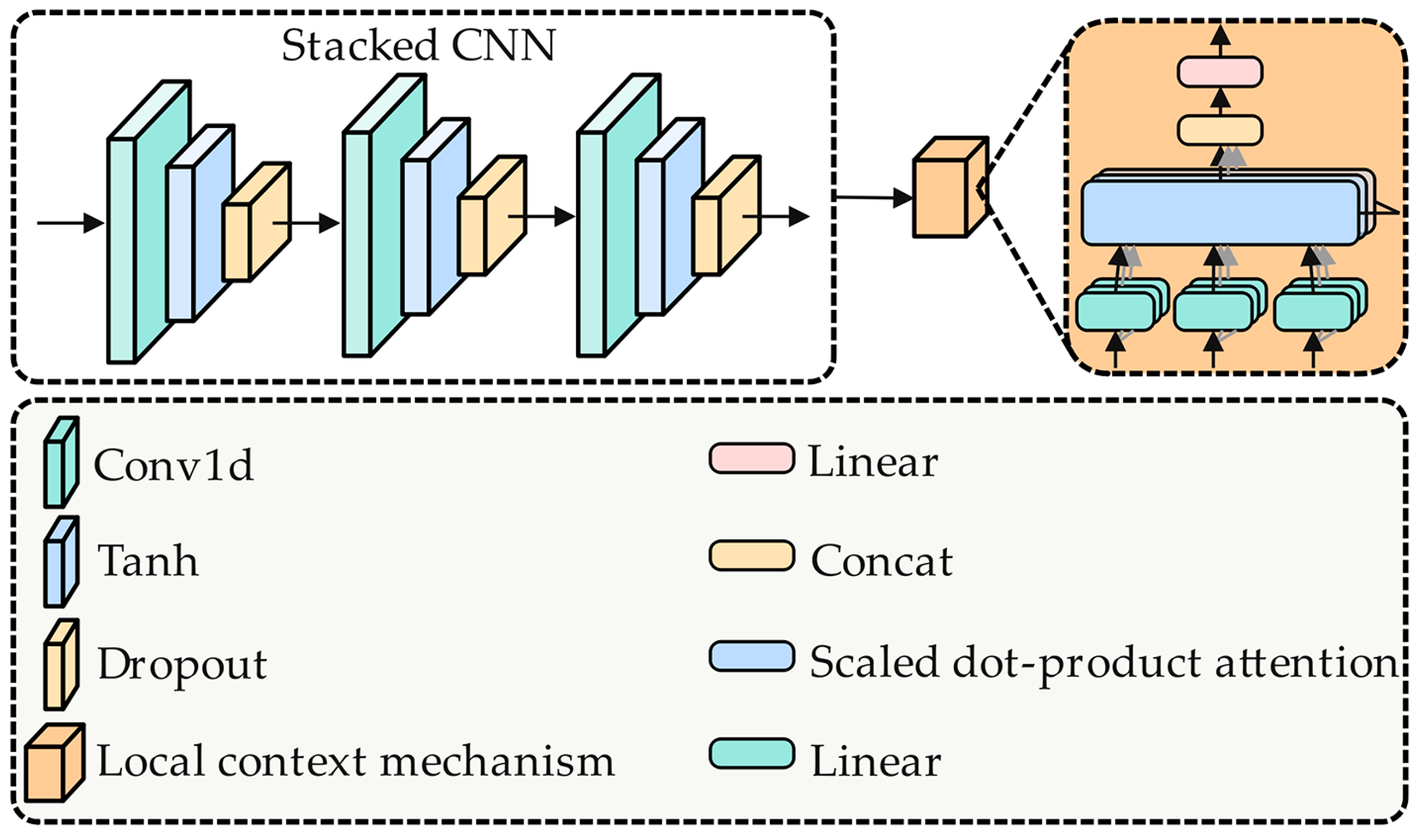
- In the stacked CNN with the local context mechanism component, the real-valued matrix first learns local semantic features from simple to complex layer by layer through a three-layer stacked CNN to improve the local understanding ability of the input sentence. Then, the learned local semantic features are input to the multihead self-attention mechanism in the local context mechanism module. Each head within the multihead self-attention module independently acquires representations from distinct segments of the input sentence. These distinct segments are represented by concatenation and linear transformation. The representation comprehensively considers the information from different perspectives to capture the local contextual semantic representation of the input sentence. Subsequently, the local contextual semantic representation is input to the deep factorization machine with the fusion context mechanism component.
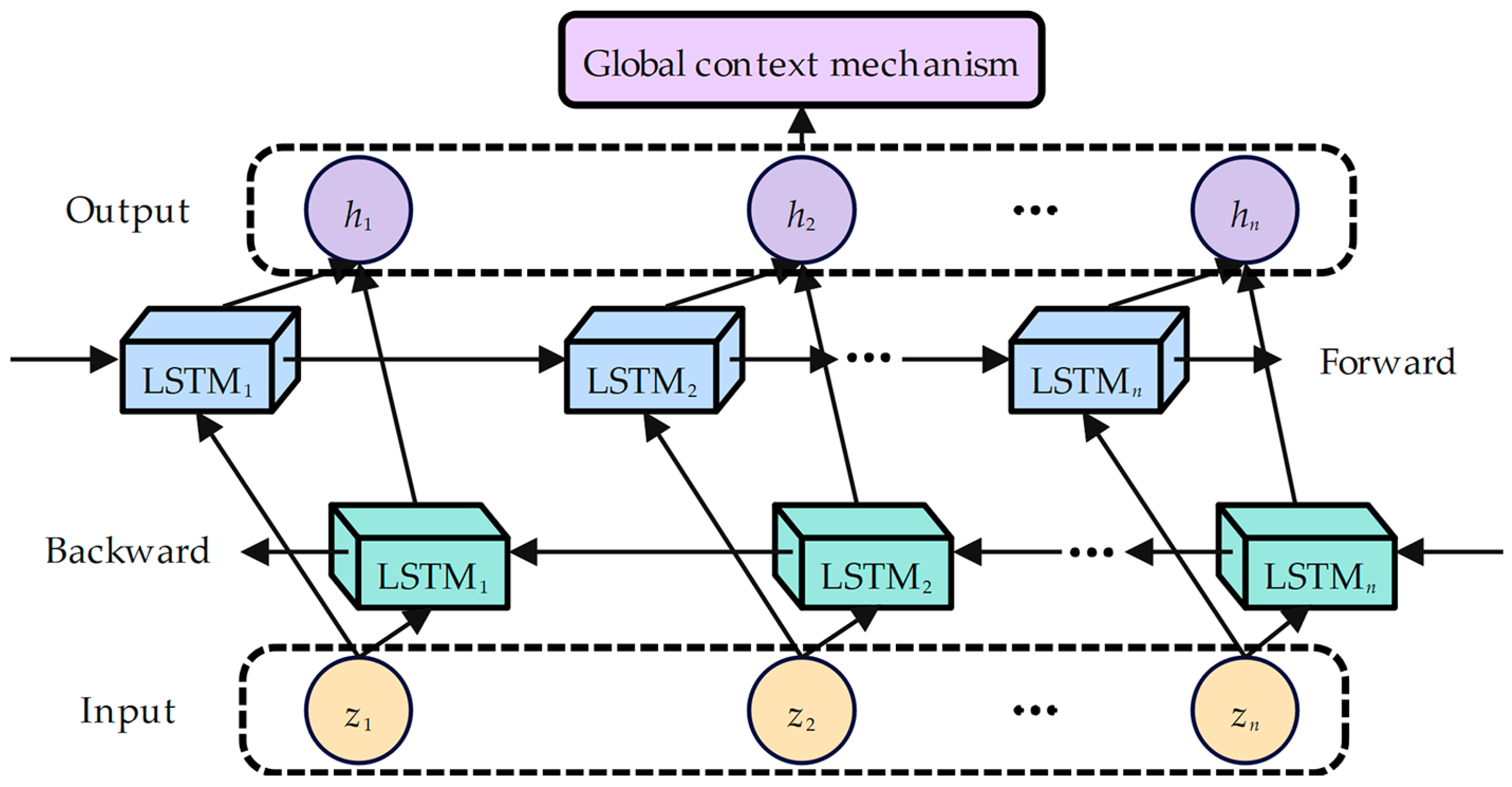
- In BiLSTM with the global context mechanism component, the real-valued matrix first learns global semantic features through BiLSTM’s capture of long-distance dependency to improve the global understanding ability of the input sentence. Then, the learned global semantic features are input into the global context mechanism module to further learn the global contextual semantic representation of the input sentence. Subsequently, the global contextual semantic representation is input to the deep factorization machine with the fusion context mechanism component.
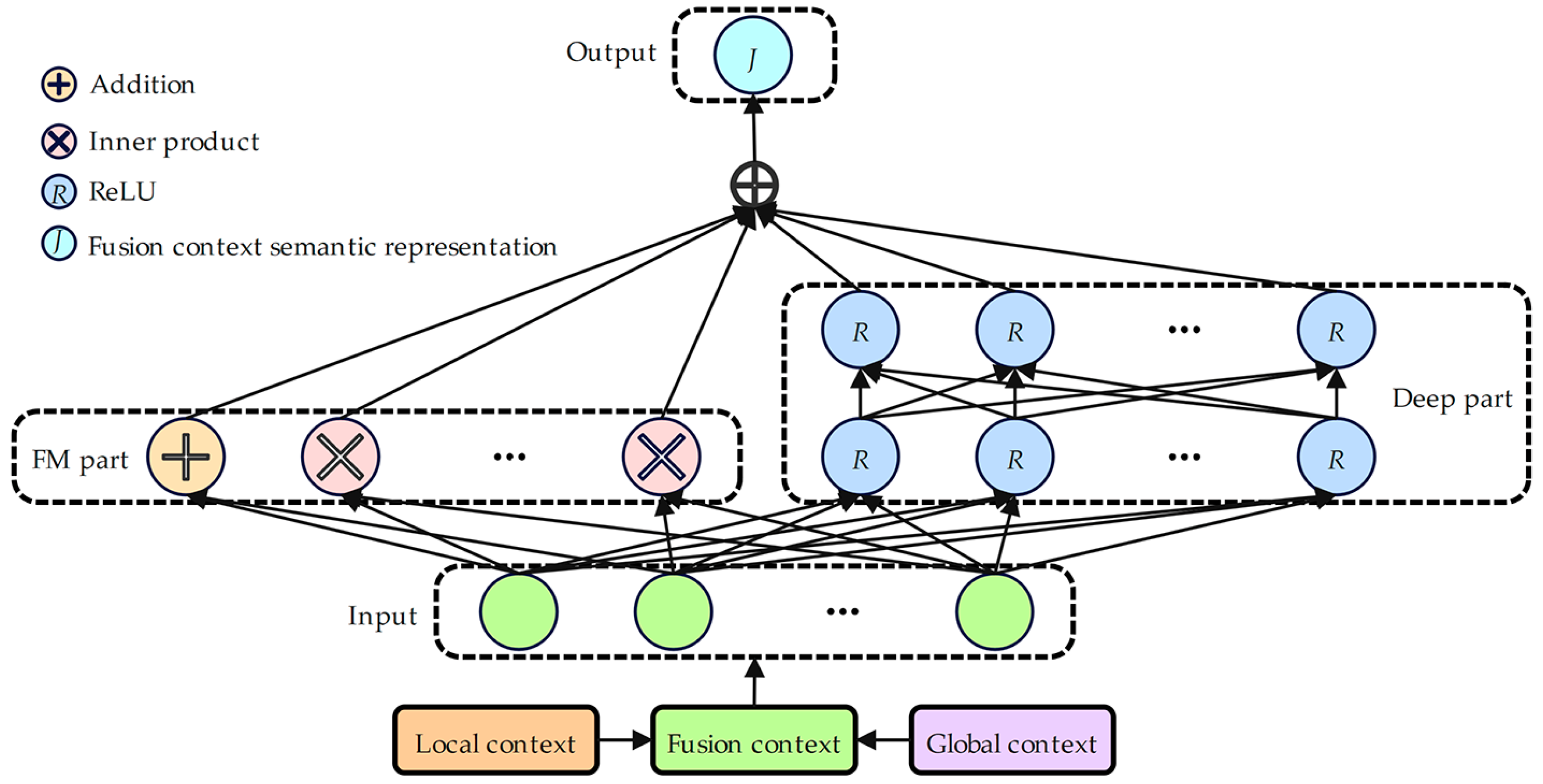
- In the deep factorization machine with the fusion context mechanism component, the factorization machine module of DeepFM is used to capture the first-order and second-order low-order feature interaction relationships, and DeepFM’s deep module is used to capture high-order feature interaction relationships to fully fuse the local and global contextual semantic representations to obtain the fusion contextual semantic representation. Subsequently, the fusion contextual semantic representation is input to the MCRF component.
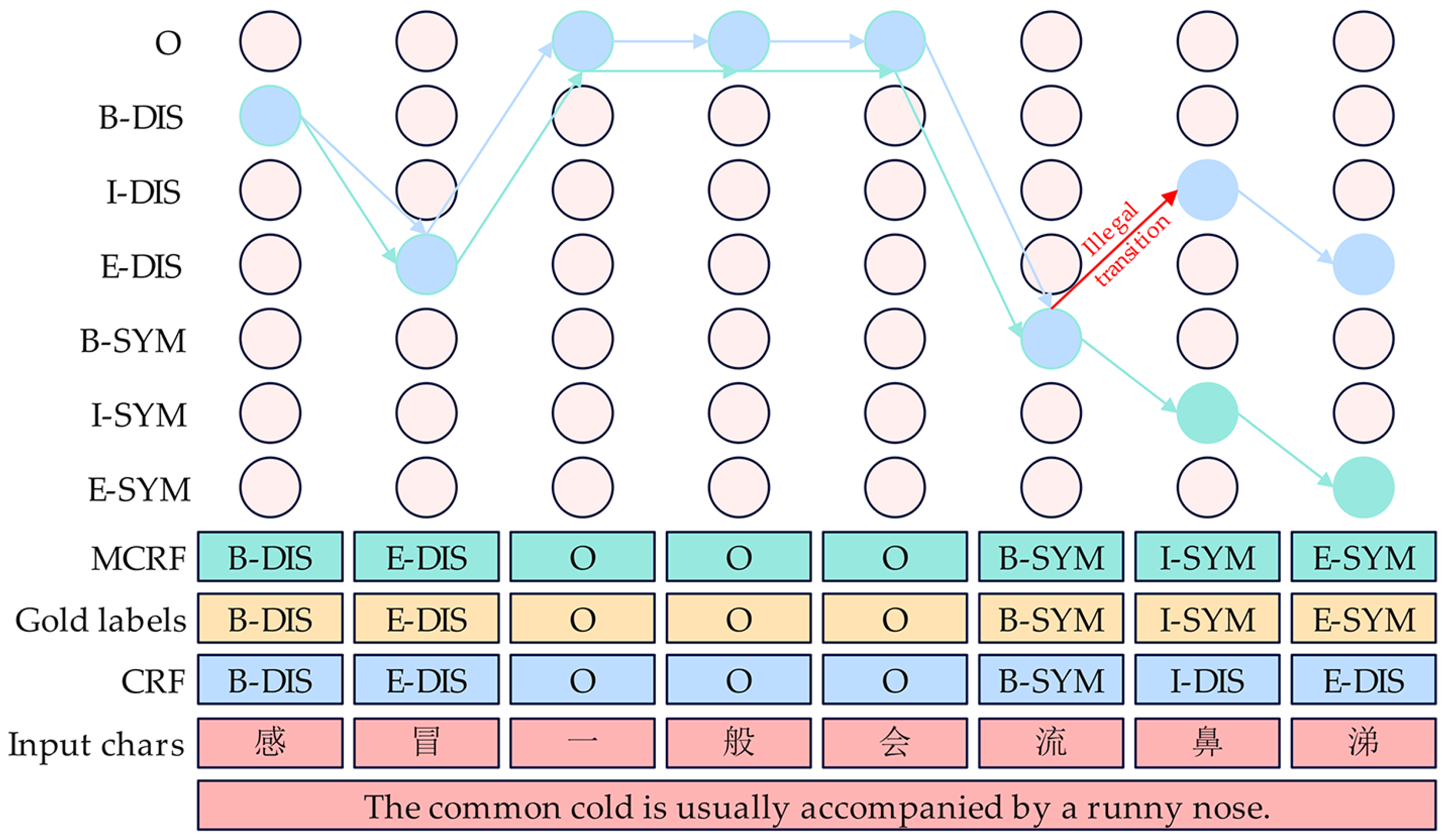
- In the MCRF component, with the help of the Viterbi algorithm and the masked transition matrix, the MCRF decodes the fusion contextual semantic representation into the tag sequence path with the highest probability score, and the occasional generation of illegal tag sequences is effectively prevented.
| Algorithm 1 Our proposed medical named entity recognition framework |
| Input: The given data sample sentence X = {x1, x2, …, xn} Output: The predicted label sequence S 1: for i = 1 to n do 2: zi = ChineseBERT(xi) 3: li = SCNN(zi)//SCNN denotes the stacked convolutional neural network 4: hi = BiLSTM(zi)//BiLSTM denotes the bidirectional long short-term memory 5: LCi = LCM(li)//LCM denotes the local context mechanism 6: GCi = GCM(hi)//GCM denotes the global context mechanism 7: end for 8: LC = {LC1, LC2, …, LCn}//LC denotes the local context 9: GC = {GC1, GC2, …, GCn}//GC denotes the global context 10: FC = LC‖GC//FC denotes the fusion context 11: J = DeepFM(FC)//DeepFM denotes the deep factorization machine 12: S = MCRF(J)//MCRF denotes the masked conditional random field |
3.1. Pretrained Model Component
3.2. Stacked CNN with a Local Context Mechanism Component
3.3. BiLSTM with Global Context Mechanism Component
3.4. Deep Factorization Machine with Fusion Context Mechanism Component
3.5. MCRF Component
4. Research Design and Analysis of Results
4.1. Data Collection and Annotation Approach
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Experimental Results and Discussion
4.4.1. Evaluative Comparison Across Methods
- According to Rows 1–3 in Table 7, the F1 scores of CBERT, CBERT-CRF, and CBERT-MCRF were 80.33%, 82.10%, and 83.42%, respectively. The experimental results show that the model performance can be effectively improved by adding the decoding layer constraint on the CBERT basis. Better performance is obtained because MCRF provides a stronger constraint relationship than CRF and effectively solves the problem of CRF occasionally generating illegal tag sequences.
- According to Rows 3, 5, and 7 in Table 7, the F1 scores of CBERT-MCRF, CBERT-SCNN-MCRF, and CBERT-BiLSTM-MCRF were 83.42%, 84.06%, and 84.37%, respectively. The data indicate that both the SCNN and BiLSTM neural networks can enhance the model’s capability to learn features, with BiLSTM demonstrating a more robust feature learning capacity compared to SCNN. This is because SCNN is more suitable for spatial feature extraction scenarios (such as video processing and image segmentation), while BiLSTM is more suitable for processing sequential data (such as text).
- As Rows 5, 7, and 8 in Table 7 show, the F1 scores of CBERT-SCNN-MCRF, CBERT-BiLSTM-MCRF, and CBERT-SCNN-BiLSTM-MCRF were 84.06%, 84.37%, and 85.17%, respectively. The data indicate that the combination of SCNN and BiLSTM in parallel can complement the advantages of the two methods, which can fully utilize the advantage of SCNN in local feature extraction and fully exploit the advantage of BiLSTM in global feature extraction, thus improving the model’s performance further.
- As Rows 8 and 9 in Table 7 show, the F1 scores of CBERT-SCNN-BiLSTM-MCRF and CBERT-SCNN-Local_Context-BiLSTM-Global_Context-MCRF were 85.17% and 85.24%, respectively. The experimental results show that adding the local context mechanism module after SCNN and the global context mechanism module after BiLSTM can notably enhance model performance, thereby confirming the efficacy of the local context mechanism module in learning local contextual semantic representation and the global context mechanism module in learning global contextual semantic representation.
- As Rows 9 and 13 in Table 7 show, the F1 scores of CBERT-SCNN-Local_Context-BiLSTM-Global_Context-MCRF and CBERT-SCNN-Local_Context-BiLSTM-Global_Context-DeepFM-Fusion_Context-MCRF were 85.24% and 85.47%, respectively. The experimental results show that adding a deep factorization machine with fusion context mechanism component DeepFM-Fusion_Context to the model can better fuse the local contextual semantic representation learned by the stacked CNN with the local context mechanism component, and the global contextual semantic representation learned by BiLSTM with the global context mechanism component, further improving the performance. This is mainly because the factorization machine module in the deep factorization machine with the fusion context mechanism component can capture the low-order (first- and second-order) feature interactions between the local and global contextual semantic representations, while the deep module can capture the high-order feature interactions between the local and global contextual semantic representations to finally obtain the fusion contextual semantic representation.
- As Rows 10 and 11 in Table 7 show, the F1 scores of ChatGPT-4o_26_tags and ChatGPT-4o_5_tags were 42.14% and 54.29%, respectively. The experimental results demonstrate that, under the premise of zero-shot prompting, although large language models (LLMs) have achieved remarkable success in general domains, their performance in specific domains remains suboptimal, with significant gaps compared to traditional methods. Through an in-depth analysis of the prediction results, we found that ChatGPT-4o struggles to recognize fine-grained entity categories that are uncommon in the specific domain. Even for the five common entity categories, ChatGPT-4o often generates hallucinations or makes incorrect judgments in its responses. This may be attributed to the fact that the training corpus of ChatGPT-4o is more focused on general domain generalization, lacking specialized optimization for specific domains. This finding highlights the necessity of training domain-specific entity recognition models for fine-grained named entity recognition tasks in specialized domains, as LLMs under zero-shot prompting are currently inadequate for such tasks.
- As Rows 12 and 13 in Table 7 show, the F1 scores of CBERT-BiLSTM-context (SOTA) and CBERT-SCNN-Local_Context-BiLSTM-Global_Context-DeepFM-Fusion_Context-MCRF were 84.48% and 85.47%, respectively. The data indicate that our proposed approach outperforms the current SOTA method by a significant margin of 0.99%. This is because the SOTA method only considers the extraction of global contextual semantic representation, neglecting the extraction of local contextual semantic representation. It also fails to incorporate a fusion context mechanism that can capture high-order and low-order feature interaction relationships. Furthermore, it does not use a decoding layer constraint, MCRF, to enhance the validity of the predicted tag sequence.
4.4.2. Ablation Study
- As Rows 1 and 2 in Table 8 show, after the approach proposed in this study removed the deep factorization machine with the fusion context mechanism component DeepFM-Fusion_Context, the model’s F1 score dropped by 0.23%, indicating that this component is effective in fusing the local and global context semantic representations.
- As Rows 1 and 3 of Table 8 show, after removing the deep factorization machine with the fusion context mechanism component DeepFM-Fusion_Context from the approach proposed in this study, the local context mechanism module Local_Context and the global context mechanism module Global_Context were further removed and the model’s F1 score dropped by 0.30%, indicating the effectiveness of the Local_Context module and the Global_Context module in improving model performance.
- As Rows 1 and 4 in Table 8 show, after removing the deep factorization machine with the fusion context mechanism component DeepFM-Fusion_Context, the local context mechanism module Local_Context, and the global context mechanism module Global_Context from the approach proposed in this study, on this basis, further removing the stacked CNN (SCNN) module decreased the F1 score of the model by 1.10%, indicating that the local semantic features extracted by this module are important in improving model performance.
- As Rows 1 and 5 of Table 8 show, after removing the deep factorization machine with the fusion context mechanism component DeepFM-Fusion_Context, the local context mechanism module Local_Context, and the global context mechanism module Global_Context from the approach proposed in this study, on this basis, the BiLSTM module was further removed and then the model’s F1 score dropped by 1.41%, indicating that the global semantic features extracted by this module are critical for improving model performance.
- As Rows 1 and 6 of Table 8 show, after the components of the deep factorization machine with the fusion context mechanism DeepFM-Fusion_Context, the stacked CNN with local context mechanism SCNN-Local_Context, and the BiLSTM with global context mechanism BiLSTM-Global_Context were simultaneously removed from the proposed approach, and the model’s F1 score dropped by 2.05%, indicating that these three components synergistically enhance the effectiveness of medical named entity recognition within online medical consultation.
4.4.3. Performance of the Proposed Approach on Different Medical Entity Types
- As Rows 1, 11, and 22 in Table 9 show, the performance indicators for entity types AMO, DRT, and REA not only have low mean values but also very high standard deviations. This is due to the scarcity of these three types of medical entities in the experimental dataset, which prevented the model from adequately learning effective features.
- As Rows 5, 7, 8, 13, 17, 19, and 20 in Table 9 show, the F1 scores of the entity types CON, DEG, DEP, DUR, FRE, PAS, and POS were all above 90%, indicating that the model has a strong ability to identify these entity types. This arises from the relatively small number of unique entities within these types, facilitating the model’s ability to learn their intrinsic feature patterns.
- As Rows 10, 14, 15, 16, 18, 23, and 25 in Table 9 show, the F1 scores of the entity types DRD, EFF, EQU, FOG, MIC, SIG, and SYM were all below 80%. The reason for the weak identification ability of the model to the entity types is that they are easier to express freely in the context of online medical consultation, and the pronounced inconsistency in expression significantly hampers the model’s ability to thoroughly learn the intrinsic feature patterns.
4.4.4. Effects of Hyperparameters
4.4.5. Research Implications and Limitations
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wen, G.; Chen, H.; Li, H.; Hu, Y.; Li, Y.; Wang, C. Cross Domains Adversarial Learning for Chinese Named Entity Recognition for Online Medical Consultation. J. Biomed. Inform. 2020, 112, 103608. [Google Scholar] [CrossRef]
- Yan, Z.; Wang, T.; Chen, Y.; Zhang, H. Knowledge sharing in online health communities: A social exchange theory perspective. Inform. Manag. 2016, 53, 643–653. [Google Scholar] [CrossRef]
- Guo, Q.; Cao, S.; Yi, Z. A medical question answering system using large language models and knowledge graphs. Int. J. Intell. Syst. 2022, 37, 8548–8564. [Google Scholar] [CrossRef]
- Yang, H.; Gao, H. Toward sustainable virtualized healthcare: Extracting medical entities from Chinese online health consultations using deep neural networks. Sustainability 2018, 10, 3292. [Google Scholar] [CrossRef]
- Sudat, S.E.; Robinson, S.C.; Mudiganti, S.; Mani, A.; Pressman, A.R. Mind the Clinical-Analytic Gap: Electronic Health Records and COVID-19 Pandemic Response. J. Biomed. Inform. 2021, 116, 103715. [Google Scholar] [CrossRef]
- Shang, F.; Ran, C. An Entity Recognition Model Based on Deep Learning Fusion of Text Feature. Inform. Process. Manag. 2022, 59, 102841. [Google Scholar] [CrossRef]
- Lybarger, K.; Ostendorf, M.; Thompson, M.; Yetisgen, M. Extracting COVID-19 Diagnoses and Symptoms from Clinical Text: A New Annotated Corpus and Neural Event Extraction Framework. J. Biomed. Inform. 2021, 117, 103761. [Google Scholar] [CrossRef]
- Sun, Z.; Li, X.; Sun, X.; Meng, Y.; Ao, X.; He, Q.; Wu, F.; Li, J. Chinesebert: Chinese pretraining enhanced by glyph and pinyin information. arXiv 2021, arXiv:2106.16038. [Google Scholar]
- Ji, J.; Chen, B.; Jiang, H. Fully-Connected LSTM-CRF on Medical Concept Extraction. Int. J. Mach. Learn. Cyb. 2020, 11, 1971–1979. [Google Scholar] [CrossRef]
- Zeng, Q.T.; Goryachev, S.; Weiss, S.; Sordo, M.; Murphy, S.N.; Lazarus, R. Extracting Principal Diagnosis, Co-Morbidity and Smoking Status for Asthma Research: Evaluation of a Natural Language Processing System. BMC Med. Inform. Decis. Mak. 2006, 6, 30. [Google Scholar] [CrossRef]
- Proux, D.; Rechenmann, F.; Julliard, L.; Pillet, V.; Jacq, B. Detecting Gene Symbols and Names in Biological Texts A First Step Toward Pertinent Information Extraction. Genome Inform. 1998, 9, 72–80. [Google Scholar]
- Settles, B. Biomedical named entity recognition using conditional random fields and rich feature sets. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and Its Applications, Geneva, Switzerland, 28–29 August 2004; pp. 104–107. [Google Scholar]
- Bikel, D.M.; Miller, S.; Schwartz, R.; Weischedel, R. Nymble: A high-performance learning name-finder. In Proceedings of the Fifth Conference on Applied Natural Language Processing, Washington, DC, USA, 31 March–3 April 1997; pp. 194–201. [Google Scholar]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and accurate entity recognition with iterated dilated convolutions. arXiv 2017, arXiv:1702.02098. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Ling, W.; Luís, T.; Marujo, L.; Astudillo, R.F.; Amir, S.; Dyer, C.; Black, A.W.; Trancoso, I. Finding function in form: Compositional character models for open vocabulary word representation. arXiv 2015, arXiv:1508.02096. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Sydney, NSW, Australia, 12–15 December 2013; pp. 3111–3119. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Li, L.; Guo, Y. Biomedical named entity recognition with CNN-BLSTM-CRF. J. Chin. Inform. Process. 2018, 32, 116–122. [Google Scholar]
- Tehseen, A.; Ehsan, T.; Liaqat, H.B.; Kong, X.; Ali, A.; Al-Fuqaha, A. Shahmukhi named entity recognition by using contextualized word embeddings. Expert Syst. Appl. 2023, 229, 120489. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, L.; Ren, G.; Zou, B. Research on named entity recognition of Traditional Chinese Medicine chest discomfort cases incorporating domain vocabulary features. Comput. Biol. Med. 2023, 166, 107466. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, Z.; Wei, W.; Zhang, R.; Mao, X.-L.; Feng, S.; Wang, F.; He, Z.; Jiang, S. Exploiting global contextual information for document-level named entity recognition. Knowl.-Based Syst. 2024, 284, 111266. [Google Scholar] [CrossRef]
- Zha, E.; Zeng, D.; Lin, M.; Shen, Y. Ceptner: Contrastive learning enhanced prototypical network for two-stage few-shot named entity recognition. Knowl.-Based Syst. 2024, 295, 111730. [Google Scholar] [CrossRef]
- Yang, K.; Yang, Z.; Zhao, S.; Yang, Z.; Zhang, S.; Chen, H. Uncertainty-Aware Contrastive Learning for semi-supervised named entity recognition. Knowl.-Based Syst. 2024, 296, 111762. [Google Scholar] [CrossRef]
- Xu, C.; Shen, K.; Sun, H. Supplementary features of BiLSTM for enhanced sequence labeling. arXiv 2023, arXiv:2305.19928. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- Li, R.; Xiao, Q.; Yang, J.; Ren, H.; Chen, Y. Few-Shot Relation Extraction via the Entity Feature Enhancement and Attention-Based Prototypical Network. Int. J. Intell. Syst. 2023, 2023, 1186977. [Google Scholar] [CrossRef]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Wei, T.; Qi, J.; He, S.; Sun, S. Masked Conditional Random Fields for Sequence Labeling. arXiv 2021, arXiv:2103.10682. [Google Scholar]
- Hu, Z.; Ma, X. A novel neural network model fusion approach for improving medical named entity recognition in online health expert question-answering services. Expert Syst. Appl. 2023, 223, 119880. [Google Scholar] [CrossRef]
- Chen, W.; Li, Z.; Fang, H.; Yao, Q.; Zhong, C.; Hao, J.; Zhang, Q.; Huang, X.; Peng, J.; Wei, Z. A benchmark for automatic medical consultation system: Frameworks, tasks and datasets. Bioinformatics 2023, 39, btac817. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Liang, W. Medical name entity recognition based on lexical enhancement and global pointer. Int. J. of Adv. Comput. Sc. 2023, 14, 592–600. [Google Scholar] [CrossRef]
- Saad, S.; Zikun, H. Leveraging Transfer Learning and Label Optimization for Enhanced Traditional Chinese Medicine Ner Performance. Asia-Pac. J. Inf. Technol. Multimed. 2024, 13, 47. [Google Scholar] [CrossRef]
- Zhang, F.; Ma, L.; Wang, J.; Cheng, J. An MRC and adaptive positive-unlabeled learning framework for incompletely labeled named entity recognition. Int. J. Intell. Syst. 2022, 37, 9580–9597. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhao, Q.; Li, J.; Ge, Y.; Ding, X.; Gu, T.; Zou, J.; Lv, S.; Wang, S.; Yang, J.-J. Comparative Analysis of Large Language Models in Chinese Medical Named Entity Recognition. Bioengineering 2024, 11, 982. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, Y.; Mu, J.; Li, W.; Jiao, S.; Wang, Z.; Lv, P.; Zhu, Y. Chinese mineral named entity recognition based on BERT model. Expert Syst. Appl. 2022, 206, 117727. [Google Scholar] [CrossRef]
- Yang, B.; Zhou, C.; Li, S.; Wang, Y. A Chinese named entity recognition method for landslide geological disasters based on deep learning. Eng. Appl. Artif. Intel. 2025, 139, 109537. [Google Scholar] [CrossRef]
- Ke, J.; Wang, W.; Chen, X.; Gou, J.; Gao, Y.; Jin, S. Medical entity recognition and knowledge map relationship analysis of Chinese EMRs based on improved BiLSTM-CRF. Comput. Electr. Eng. 2023, 108, 108709. [Google Scholar] [CrossRef]
- Weischedel, R.; Pradhan, S.; Ramshaw, L.; Palmer, M.; Xue, N.; Marcus, M.; Taylor, A.; Greenberg, C.; Hovy, E.; Belvin, R. Ontonotes release 4.0. LDC2011T03, Philadelphia, Penn.: Linguistic Data Consortium. LDC2011T03 Philadel-Phia Penn. Linguist. Data Consort. 2011, 17, 1–53. [Google Scholar]
- Peng, N.; Dredze, M. Named entity recognition for chinese social media with jointly trained embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 548–554. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method | Performance | Disadvantages |
|---|---|---|---|
| Zeng et al. [10] | Regular expression-based matching rules | Precision (81.47%) | Their method involves complex matching rules and high manual costs and has a low generalization capability. |
| Proux et al. [11] | A series of rules with different properties | Precision (91.40%) | Their method involves complex matching rules and high manual costs and has a low generalization capability. |
| Settles [12] | CRF | F1 score (69.50%) | Their method still requires manual effort for feature engineering before model training, and its generalization capability is insufficient. |
| Bikel et al. [13] | HMM (slightly modified version) | F1 score (93.00%) | Their method still requires manual effort for feature engineering before model training, and its generalization capability is insufficient. |
| Strubell et al. [14] | ID-CNN-CRF | F1 score (90.54%) | Their method considers only the local features of the input data. |
| Huang et al. [15] | BI-LSTM-CRF | F1 score (90.10%) | Their method considers only the global features of the input data. |
| Lample et al. [18] | S-LSTM | F1 score (90.33%) | Their method considers only the global features of the input data. |
| Li and Guo [19] | CNN-BLSTM-CRF | F1 score (89.09%) | Although their method considers both the local and global features of the input data, the local features are processed sequentially as a preliminary step for global feature extraction, without fully accounting for the highly nonlinear relationships between the local and global feature perspectives. |
| Shang and Ran [6] | Fusion multi-feature-CNN-BiLSTM-CRF | F1 score (78.07%) | Although their method considers both the local and global features of the input data, the local features are processed sequentially as a preliminary step for global feature extraction, without fully accounting for the highly nonlinear relationships between the local and global feature perspectives. |
| Tehseen et al. [20] | CNN-BiLSTM-CRF+W2V+ELMo | F1 score (83.75%) | Although their method considers both the local and global features of the input data, the local features are processed sequentially as a preliminary step for global feature extraction, without fully accounting for the highly nonlinear relationships between the local and global feature perspectives. |
| Liu et al. [21] | BiLSTM-CRF-Load | F1 score (92.59%) | Their method considers only the global features of the input data. |
| Yu et al. [22] | GCDoc | F1 score (92.22%) | Their method considers only the global features of the input data. |
| Zha et al. [23] | CEPTNER | F1 score (69.52%) | Their method does not consider the local and global features of the input data; it only performs basic encoding and decoding on the input data. |
| Yang et al. [24] | UACL | F1 score (76.35%) | Their method does not consider the local and global features of the input data; it only performs basic encoding and decoding on the input data. |
| # | Entity Type Abbreviation | Entity Type | Example |
|---|---|---|---|
| 1 | AMO | Amount | 5 mg |
| 2 | BOD | Body | Bladder |
| 3 | CHE | Check | Ultrasound |
| 4 | CLA | Class | Pregnancy |
| 5 | CON | Conditional | Postoperative |
| 6 | CRO | Crowd | Pediatric |
| 7 | DEG | Degree | Mild |
| 8 | DEP | Department | ENT Department |
| 9 | DIS | Disease | Cervical Cancer |
| 10 | DRD | Drug Dosage Forms | Tablet |
| 11 | DRT | Drug Taste | Bitter |
| 12 | DRU | Drug | Vitamin D |
| 13 | DUR | Duration | Long-term |
| 14 | EFF | Traditional Chinese Medicine Efficacy | Kidney Tonic |
| 15 | EQU | Medical Equipment | Insulin Pump |
| 16 | FOG | Food Grouping | Light (Diet) |
| 17 | FRE | Frequency Word | Regular |
| 18 | MIC | Microorganisms | Virus |
| 19 | PAS | Past | History of Alcohol Consumption |
| 20 | POS | Possible | Possible |
| 21 | PRE | Precaution | Induced Labor |
| 22 | REA | Reason | Drinking Alcohol |
| 23 | SIG | Sign | High Echogenicity |
| 24 | SUR | Surgery | Laparoscopic Surgery |
| 25 | SYM | Symptom | Low-grade Fever |
| 26 | TEV | Test Value | Negative |
| Case 1 | |
|---|---|
| Sentence (Chinese) | 你好结石小问题膀胱里面的要看看有肿瘤的可能。 |
| Sentence (English) | Hello, there’s a minor issue with stones, and it’s necessary to examine the bladder for the possibility of a tumor. |
| Gold labels | O, O, B-DIS, E-DIS, O, O, O, B-BOD, E-BOD, O, O, O, O, O, O, O, B-DIS, E-DIS, O, B-POS, E-POS, O |
| Case 2 | |
| Sentence (Chinese) | 你好有没有做过白带检查超声怀孕史。 |
| Sentence (English) | Hello, have you had a vaginal discharge test, ultrasound, or any history of pregnancy? |
| Gold labels | O, O, O, O, O, O, O, B-CHE, I-CHE, I-CHE, E-CHE, B-CHE, E-CHE, B-PAS, I-PAS, E-PAS, O |
| # | Tags | Training | Validation | Testing | Total |
|---|---|---|---|---|---|
| HaoDF | HaoDF | HaoDF | |||
| 1 | AMO | 19 | 5 | 2 | 26 |
| 2 | BOD | 6068 | 2085 | 2056 | 10,209 |
| 3 | CHE | 5812 | 2098 | 2131 | 10,041 |
| 4 | CLA | 113 | 33 | 39 | 185 |
| 5 | CON | 525 | 172 | 152 | 849 |
| 6 | CRO | 278 | 72 | 91 | 441 |
| 7 | DEG | 1859 | 666 | 644 | 3169 |
| 8 | DEP | 1013 | 338 | 357 | 1708 |
| 9 | DIS | 4899 | 1764 | 1639 | 8302 |
| 10 | DRD | 121 | 43 | 33 | 197 |
| 11 | DRT | 52 | 23 | 14 | 89 |
| 12 | DRU | 2777 | 919 | 826 | 4522 |
| 13 | DUR | 315 | 112 | 98 | 525 |
| 14 | EFF | 126 | 44 | 48 | 218 |
| 15 | EQU | 143 | 59 | 44 | 246 |
| 16 | FOG | 171 | 62 | 57 | 290 |
| 17 | FRE | 441 | 145 | 125 | 711 |
| 18 | MIC | 93 | 28 | 34 | 155 |
| 19 | PAS | 301 | 94 | 98 | 493 |
| 20 | POS | 1578 | 500 | 533 | 2611 |
| 21 | PRE | 4572 | 1590 | 1454 | 7616 |
| 22 | REA | 39 | 13 | 12 | 64 |
| 23 | SIG | 594 | 183 | 175 | 952 |
| 24 | SUR | 1723 | 603 | 593 | 2919 |
| 25 | SYM | 2967 | 947 | 1002 | 4916 |
| 26 | TEV | 506 | 185 | 175 | 866 |
| 27 | Sentences | 6000 | 2000 | 2000 | 10,000 |
| Category | Configuration |
|---|---|
| Hardware | CPU: Intel Core i9-13900K @ 3.00 GHz |
| GPU: NVIDIA GeForce RTX 4090 @ 24 GB | |
| RAM: USCORSAIR 32 GB×4 DDR5 @ 6000 MHz ECC | |
| Software | Python: 3.7.15 |
| CUDA: 11.7 | |
| cuDNN: 8.5 | |
| Pytorch: 1.13.0+cu117 | |
| Numpy: 1.18.1 | |
| Pypinyin: 0.38.1 | |
| Tokenizers: 0.9.2 | |
| Transformers: 3.4.0 | |
| Pytorch-lightning: 0.9.0 | |
| Tensorboard: 2.2.0 |
| Parameter Name | Value |
|---|---|
| Max sequence length | 256 |
| Learning rate | 2 × 10−05 |
| Optimizer | Adam |
| Adam epsilon | 1 × 10−08 |
| Hidden dropout ratio | 0.2 |
| Warmup proportion | 0.02 |
| Weight decay | 0.01 |
| Max epochs | 20 |
| Batch size | 1 |
| BiLSTM size | 384 |
| # | Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| 1 | CBERT [36] | 77.54 ± 1.49 | 83.34 ± 0.98 | 80.33 ± 1.24 |
| 2 | CBERT-CRF [36,37] | 79.54 ± 0.97 | 84.83 ± 0.47 | 82.10 ± 0.61 |
| 3 | CBERT-MCRF | 83.84 ± 0.52 | 83.01 ± 1.11 | 83.42 ± 0.81 |
| 4 | CBERT-SCNN-CRF | 80.15 ± 2.29 | 84.47 ± 0.83 | 82.24 ± 1.57 |
| 5 | CBERT-SCNN-MCRF | 84.65 ± 0.41 | 83.47 ± 0.65 | 84.06 ± 0.45 |
| 6 | CBERT-BiLSTM-CRF [21,37,38] | 82.33 ± 0.66 | 85.73 ± 0.48 | 84.00 ± 0.55 |
| 7 | CBERT-BiLSTM-MCRF | 84.38 ± 0.59 | 84.36 ± 0.46 | 84.37 ± 0.31 |
| 8 | CBERT-SCNN-BiLSTM-MCRF | 85.10 ± 0.87 | 85.25 ± 0.94 | 85.17 ± 0.78 |
| 9 | CBERT-SCNN-Local_Context-BiLSTM-Global_Context-MCRF | 84.73 ± 0.33 | 85.77 ± 0.69 | 85.24 ± 0.30 |
| 10 | ChatGPT-4o_26_tags (accessed on 3 February 2025) | 55.01 ± 0.00 | 34.15 ± 0.00 | 42.14 ± 0.00 |
| 11 | ChatGPT-4o_5_tags (accessed on 3 February 2025) | 57.97 ± 0.00 | 51.04 ± 0.00 | 54.29 ± 0.00 |
| 12 | CBERT-BiLSTM-context (SOTA, [25]) | 84.52 ± 0.77 | 84.44 ± 0.69 | 84.48 ± 0.59 |
| 13 | CBERT-SCNN-Local_Context-BiLSTM-Global_Context-DeepFM-Fusion_Context-MCRF (ours) | 85.56 ± 0.73 | 85.38 ± 0.59 | 85.47 ± 0.56 |
| # | Model | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| 1 | CBERT-SCNN-Local_Context-BiLSTM-Global_Context-DeepFM-Fusion_Context-MCRF (ours) | 85.56 ± 0.73 | 85.38 ± 0.59 | 85.47 ± 0.56 |
| 2 | -(DeepFM-Fusion_Context) | 84.73 ± 0.33 | 85.77 ± 0.69 | 85.24(−0.23) ± 0.30 |
| 3 | -(DeepFM-Fusion_Context)-(Local_Context)-(Global_Context) | 85.10 ± 0.87 | 85.25 ± 0.94 | 85.17(−0.30) ± 0.78 |
| 4 | -(DeepFM-Fusion_Context)-(SCNN-Local_Context)-(Global_Context) | 84.38 ± 0.59 | 84.36 ± 0.46 | 84.37(−1.10) ± 0.31 |
| 5 | -(DeepFM-Fusion_Context)-(Local_Context)-(BiLSTM-Global_Context) | 84.65 ± 0.41 | 83.47 ± 0.65 | 84.06(−1.41) ± 0.45 |
| 6 | -(DeepFM-Fusion_Context)-(SCNN-Local_Context)-(BiLSTM-Global_Context) | 83.84 ± 0.52 | 83.01 ± 1.11 | 83.42(−2.05) ± 0.81 |
| # | Tags | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| 1 | AMO | 1.11 ± 2.22 | 20.00 ± 40.00 | 2.11 ± 4.21 |
| 2 | BOD | 88.28 ± 1.40 | 84.87 ± 1.50 | 86.52 ± 0.47 |
| 3 | CHE | 85.41 ± 1.54 | 84.89 ± 1.19 | 85.14 ± 0.86 |
| 4 | CLA | 84.99 ± 4.62 | 87.69 ± 4.10 | 86.16 ± 2.38 |
| 5 | CON | 88.23 ± 2.67 | 94.34 ± 1.74 | 91.18 ± 2.11 |
| 6 | CRO | 88.76 ± 7.94 | 87.25 ± 4.85 | 87.96 ± 6.34 |
| 7 | DEG | 95.45 ± 1.17 | 95.49 ± 0.60 | 95.46 ± 0.32 |
| 8 | DEP | 96.63 ± 1.97 | 96.02 ± 1.42 | 96.33 ± 1.68 |
| 9 | DIS | 84.02 ± 0.74 | 84.88 ± 0.56 | 84.44 ± 0.21 |
| 10 | DRD | 94.86 ± 1.28 | 66.06 ± 4.02 | 77.79 ± 2.44 |
| 11 | DRT | 53.77 ± 28.85 | 48.57 ± 24.50 | 50.72 ± 26.05 |
| 12 | DRU | 81.13 ± 3.62 | 83.53 ± 0.96 | 82.28 ± 2.13 |
| 13 | DUR | 91.28 ± 3.19 | 93.12 ± 1.75 | 92.15 ± 1.78 |
| 14 | EFF | 73.20 ± 2.38 | 68.75 ± 3.49 | 70.79 ± 0.92 |
| 15 | EQU | 89.23 ± 2.52 | 60.93 ± 4.74 | 72.28 ± 3.30 |
| 16 | FOG | 71.86 ± 7.32 | 74.03 ± 6.51 | 72.70 ± 5.75 |
| 17 | FRE | 89.49 ± 3.73 | 92.36 ± 0.98 | 90.85 ± 1.68 |
| 18 | MIC | 78.25 ± 6.96 | 66.47 ± 8.44 | 71.08 ± 2.90 |
| 19 | PAS | 95.27 ± 3.54 | 97.14 ± 1.98 | 96.18 ± 2.68 |
| 20 | POS | 97.75 ± 2.57 | 99.47 ± 0.14 | 98.59 ± 1.35 |
| 21 | PRE | 86.63 ± 1.28 | 87.73 ± 1.58 | 87.17 ± 1.29 |
| 22 | REA | 59.19 ± 18.22 | 61.67 ± 15.46 | 57.08 ± 12.19 |
| 23 | SIG | 45.16 ± 4.51 | 52.23 ± 4.58 | 48.15 ± 2.92 |
| 24 | SUR | 88.98 ± 1.18 | 87.08 ± 0.75 | 88.02 ± 0.83 |
| 25 | SYM | 75.72 ± 3.26 | 75.60 ± 0.99 | 75.60 ± 1.40 |
| 26 | TEV | 82.97 ± 7.07 | 85.40 ± 3.24 | 84.00 ± 4.21 |
| 27 | Average | 85.56 ± 0.73 | 85.38 ± 0.59 | 85.47 ± 0.56 |
| # | Learning Rate | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| 1 | 4 × 10−05 | 9.98 ± 17.29 | 7.68 ± 13.30 | 8.68 ± 15.03 |
| 2 | 3 × 10−05 | 23.16 ± 29.06 | 19.68 ± 26.06 | 21.16 ± 27.28 |
| 3 | 2 × 10−05 | 85.56 ± 0.73 | 85.38 ± 0.59 | 85.47 ± 0.56 |
| 4 | 1 × 10−05 | 85.30 ± 0.95 | 85.13 ± 0.85 | 85.22 ± 0.84 |
| 5 | 9 × 10−06 | 84.68 ± 0.52 | 85.30 ± 0.87 | 84.99 ± 0.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Li, W.; Yang, H. Named Entity Recognition in Online Medical Consultation Using Deep Learning. Appl. Sci. 2025, 15, 3033. https://doi.org/10.3390/app15063033
Hu Z, Li W, Yang H. Named Entity Recognition in Online Medical Consultation Using Deep Learning. Applied Sciences. 2025; 15(6):3033. https://doi.org/10.3390/app15063033
Chicago/Turabian StyleHu, Ze, Wenjun Li, and Hongyu Yang. 2025. "Named Entity Recognition in Online Medical Consultation Using Deep Learning" Applied Sciences 15, no. 6: 3033. https://doi.org/10.3390/app15063033
APA StyleHu, Z., Li, W., & Yang, H. (2025). Named Entity Recognition in Online Medical Consultation Using Deep Learning. Applied Sciences, 15(6), 3033. https://doi.org/10.3390/app15063033