
TransECA-Net: A Transformer-Based Model for Encrypted Traffic Classification


Abstract
Featured Application
Abstract
1. Introduction
- A novel hybrid architecture integrating local feature enhancement with global interaction is proposed.
- A tailored solution for classifying encrypted traffic is developed, effectively overcoming the data dependency and processing limitations characteristic of traditional methods.
- The model markedly enhances efficiency and generalization capabilities for the high-precision, real-time classification of non-VPN encrypted traffic.
2. Related Work
2.1. Port-Based Methods
2.2. Protocol-Analysis-Based Methods
2.3. Feature-Based Methods
2.4. Machine-Learning-Based Methods
2.5. Deep-Learning-Based Methods
2.6. Comparison of GNNs and Transformers for Sequence-Aware Classification
2.7. Transformer Adaptation Strategies for Limited Data
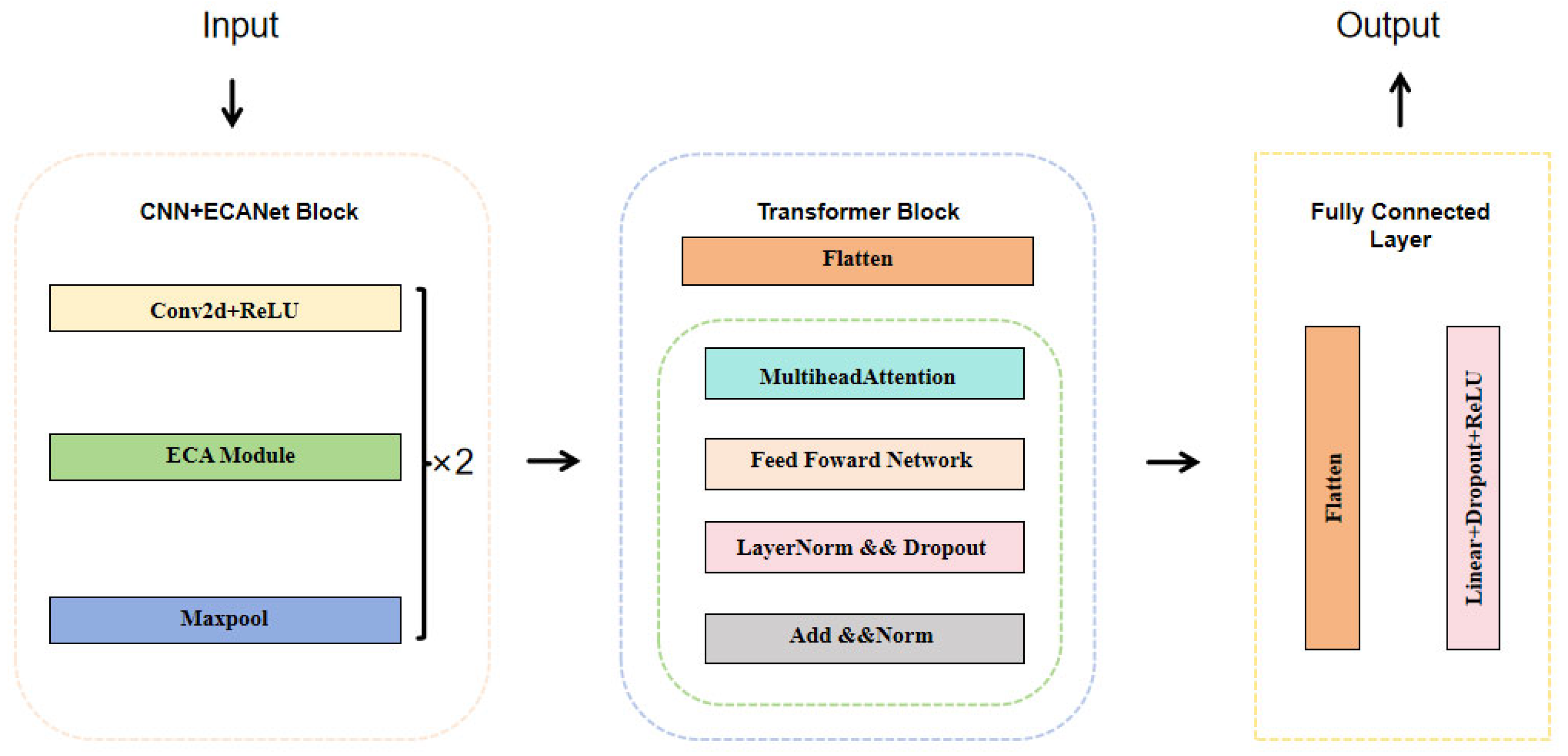
3. Methodology
3.1. CNN–ECANet
- 2D convolutional layer: Initially, a 2D convolutional layer processes the input feature map, configured with 1 input channel and 32 output channels. The layer uses a kernel size of (1, 25), a stride of 1, and “same” padding to ensure that the output dimensions are consistent with those of the input.
- Activation function layer: Following the convolutional layer, an activation function layer applies the ReLU function. This introduction of non-linearity is crucial for enhancing the model’s capacity to learn complex patterns.
- ECAModule: Next, an ECAModule is implemented. This effective channel attention module adaptively modifies the weights of various channels through the application of 1D convolution followed by a Sigmoid activation function. This mechanism enables the model to focus on the most important features in the data.
- Max pooling layer: Subsequently, a max pooling layer is employed to reduce the spatial dimensions of the feature maps. This layer is configured with a kernel size of (1, 3) and a stride of 3, leading to a more compact representation of the features while retaining the essential information.
- Repetition: The previously mentioned configurations are repeated for a second convolutional layer, where the number of output channels is increased to 64. This enhancement allows the model to capture more intricate features and patterns in the input data.
3.2. Transformer
4. Experimental Result
4.1. Dataset
- Traffic types: The dataset includes various types of VPN-encrypted traffic as well as unencrypted regular internet traffic. It covers common network services and applications such as web browsing, email, file transfer, and VoIP (Table 2).
- Realistic scenario simulation: All traffic data were generated in a controlled environment to simulate real-world network communication scenarios.
- Detailed annotations: The dataset is thoroughly labeled, indicating whether the traffic was transmitted via a VPN and specifying which VPN protocol was used.
- Traffic segmentation: Split raw PCAP traffic into session and flow units. To ensure uniform input dimensions for CNN, truncate each session/flow to retain only 784 bytes.
- Traffic cleaning: Remove retransmitted packets, corrupted packets, and non-encrypted traffic.
- Image generation: Convert traffic bytes into a one-dimensional numerical sequence, where each byte corresponds to an integer value between 0 and 255, forming time-series data similar to textual sequences.
- IDX format conversion: Convert byte sequences into IDX3 files (input data) and IDX1 files (labels) to align with frameworks like PyTorch 3.9/TensorFlow (https://tensorflow.google.cn/?hl=zh-cn, accessed on 20 September 2023). Label PCAP files according to ISCX dataset descriptions and remove ambiguous categories (e.g., conflicting portions between “Browser” and “Streaming”), ultimately retaining 12 distinct classes.
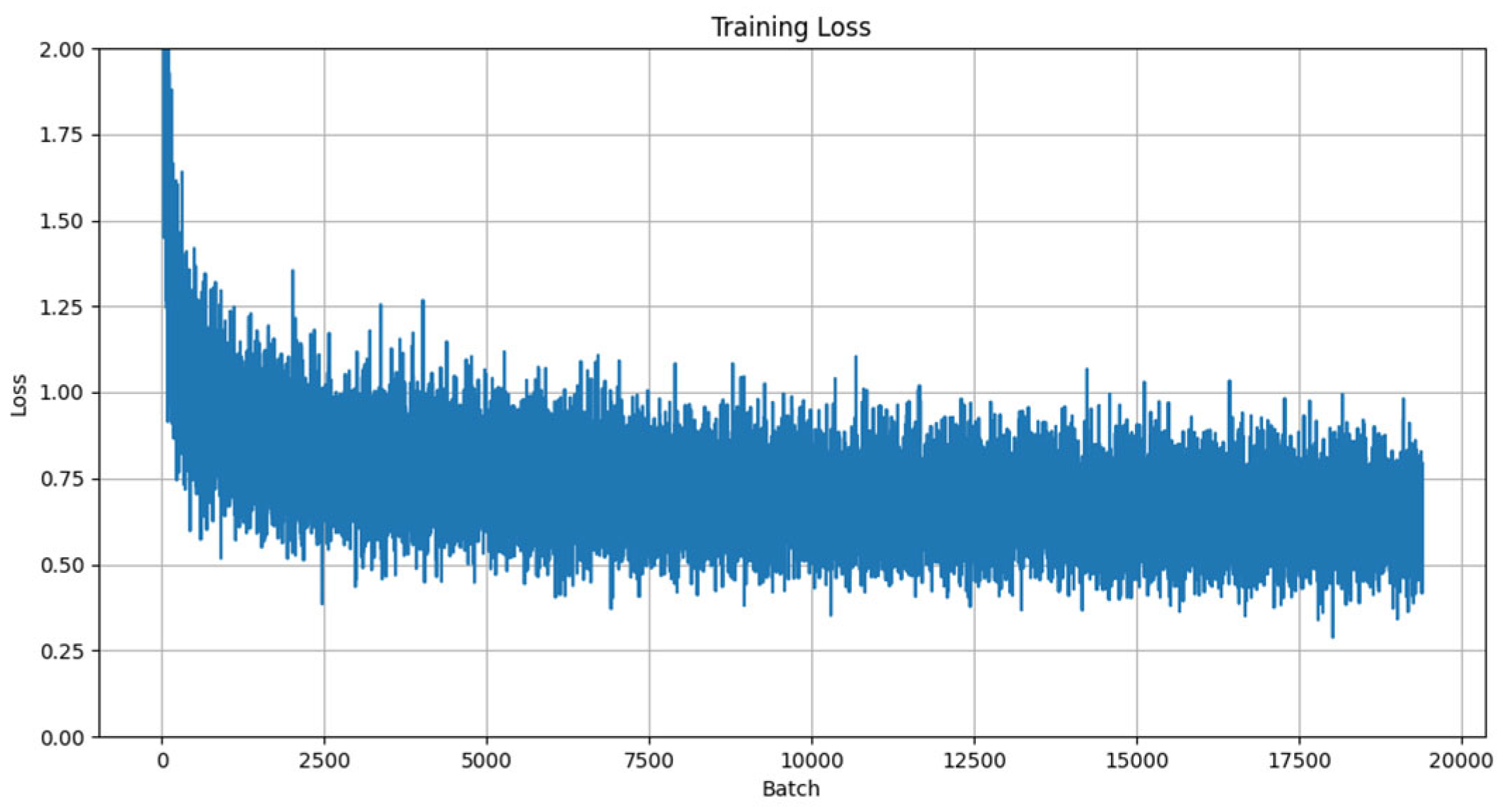
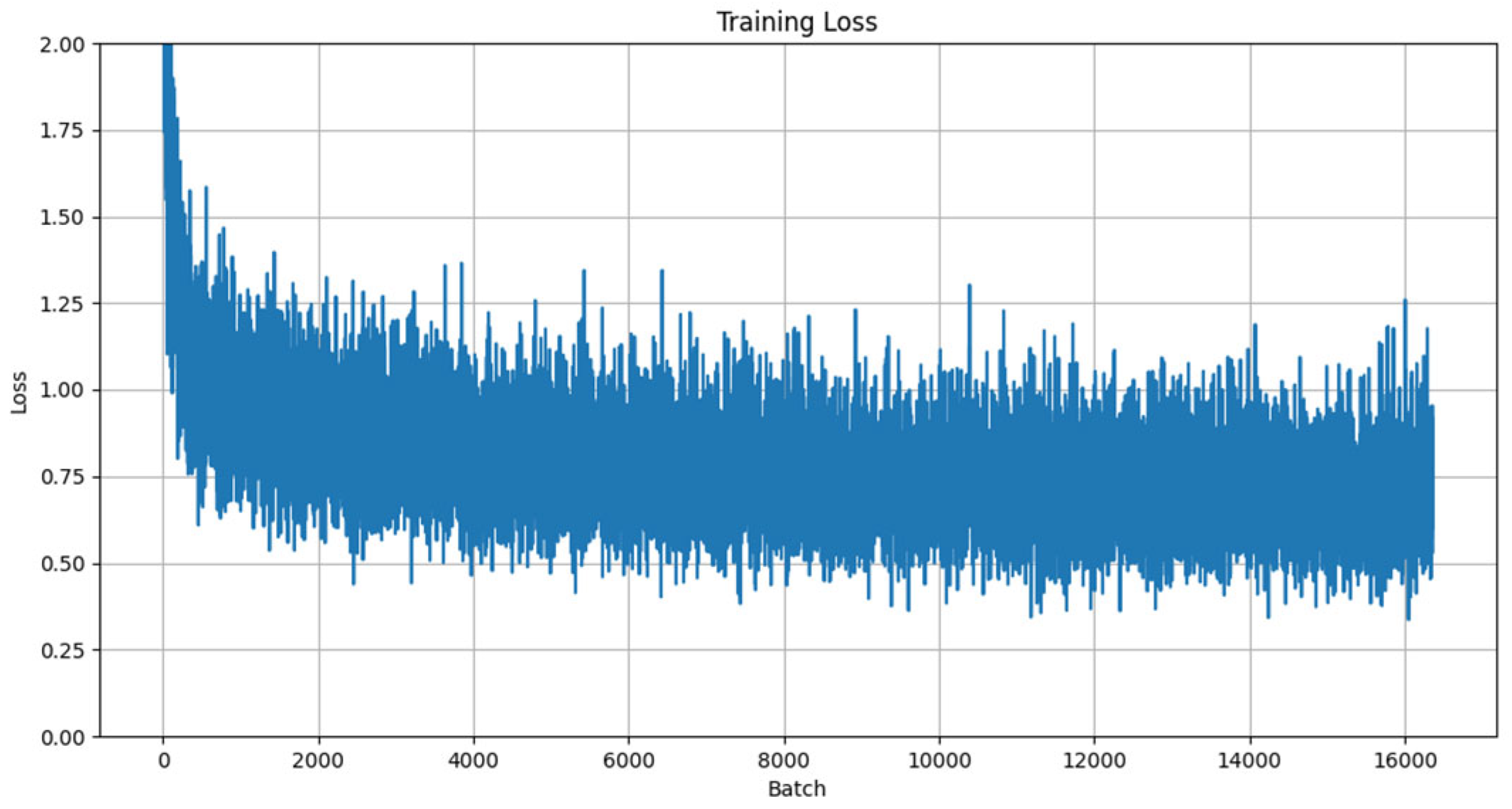
4.2. Basic Experiment
- Learning rate configuration: As demonstrated in [31], the learning rate plays a decisive role in model convergence speed and performance. An initial learning rate of 0.001 was adopted, a value validated by multiple studies as an ideal starting point for deep learning tasks. Additionally, an adaptive learning rate scheduling strategy was implemented to enhance training efficiency through dynamic adjustment mechanisms.
- Batch configuration: Considering GPU parallel-processing capabilities and training stability, the batch size was set to 128. As discussed in [32], this configuration achieves a balance between training speed and model performance while effectively mitigating overfitting risks.
- Training epochs: By monitoring training loss and validation accuracy, the final training epoch count was determined to be 40. Research [33] highlights that the excessive prolongation of training epochs increases overfitting risks; thus, the optimal upper limit was established based on convergence curve analysis.
- Dropout mechanism: Following the sensitivity analysis of network layers in [34], a layered dropout strategy was implemented: 0.5 for fully connected layers and 0.3 for the output layer. This approach employs differentiated regularization to suppress overfitting while enhancing model generalization capabilities.
4.3. Ablation Study and Component Analysis
- Baseline CNN: Retains only the original CNN structure (without ECANet or Transformer).
- CNN + ECANet: Integrates the ECANet module based on CNN.
- Transformer-only: Uses only the standard Transformer architecture (without CNN or ECANet).
- TransECA-Net (full model): A hybrid architecture combining CNN–ECANet and Transformer.
4.4. Comparative Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nascita, A.; Aceto, G.; Ciuonzo, D.; Montieri, A. A Survey on Explainable Artificial Intelligence for Internet Traffic Classification and Prediction, and Intrusion Detection. IEEE Commun. Surv. Tutor. 2024. [Google Scholar] [CrossRef]
- Gang, L.; Zhang, Z. Deep encrypted traffic detection: An anomaly detection framework for encryption traffic based on parallel automatic feature extraction. Comput. Intell. Neurosci. 2023, 2023, 3316642. [Google Scholar]
- De Keersmaeker, F.; Cao, Y.; Kabasele, G.; Sadre, R. A survey of public IoT datasets for network security research. IEEE Commun. Surv. Tutor. 2023, 25, 1808–1840. [Google Scholar] [CrossRef]
- D’Alconzo, A.; Drago, I.; Morichetta, A.; Mellia, M.; Casas, P. A survey on big data for network traffic monitoring and analysis. IEEE Trans. Netw. Serv. Manag. 2019, 16, 800–813. [Google Scholar] [CrossRef]
- Saied, M.; Shawkat, G.; Magda, M. Review of artificial intelligence for enhancing intrusion detection in the internet of things. Eng. Appl. Artif. Intell. 2024, 127, 107231. [Google Scholar] [CrossRef]
- Papadogiannaki, E.; Sotiris, I. A survey on encrypted network traffic analysis applications, techniques, and countermeasures. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Atadoga, A.; Farayola, O.A.; Ayinla, B.S.; Amoo, O.O.; Abrahams, T.O.; Osasona, F. A comparative review of data encryption methods in the USA and Europe. Comput. Sci. IT Res. J. 2024, 5, 447–460. [Google Scholar] [CrossRef]
- Wang, Z.; Vrizlynn, L.L. Thing. Feature mining for encrypted malicious traffic detection with deep learning and other machine learning algorithms. Comput. Secur. 2023, 128, 103143. [Google Scholar] [CrossRef]
- Karakus, M.; Arjan, D. Quality of service (QoS) in software defined networking (SDN): A survey. J. Netw. Comput. Appl. 2017, 80, 200–218. [Google Scholar] [CrossRef]
- Çelebi, M.; Alper, Ö.; Uraz, Y. A comprehensive survey on deep packet inspection for advanced network traffic analysis: Issues and challenges. Niğde Ömer Halisdemir Üniv. Mühendislik Bilim. Derg. 2023, 12, 1–29. [Google Scholar] [CrossRef]
- Dong, S. Multi class SVM algorithm with active learning for network traffic classification. Expert Syst. Appl. 2021, 176, 114885. [Google Scholar] [CrossRef]
- Najm, I.A.; Saeed, A.H.; Ahmad, B.A.; Ahmed, S.R.; Sekhar, R.; Shah, P.; Veena, B.S. Enhanced Network Traffic Classification with Machine Learning Algorithms. In Proceedings of the Cognitive Models and Artificial Intelligence Conference, Istanbul, Turkiye, 25–26 May 2024. [Google Scholar]
- Rezaei, S.; Xin, L. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.F.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yoon, S.-H.; Park, J.; Park, J.-S.; Oh, Y.-S.; Kim, M.-S. Internet Application Traffic Classification Using Fixed IP-Port. In Management Enabling the Future Internet for Changing Business and New Computing Services, Proceedings of the 12th Asia-Pacific Network Operations and Management Symposium, APNOMS, Jeju, South Korea, 23–25 September 2009; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Velan, P.; Čermák, M.; Čeleda, P.; Drašar, M. A survey of methods for encrypted traffic classification and analysis. Int. J. Netw. Manag. 2015, 25, 355–374. [Google Scholar] [CrossRef]
- Stevanovic, M.; Pedersen, J.M. An analysis of network traffic classification for botnet detection. In Proceedings of the IEEE 2015 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), London, UK, 8–9 June 2015. [Google Scholar]
- Huang, S.; Chen, K.; Liu, C.; Liang, A.; Guan, H. A statistical-feature-based approach to internet traffic classification using machine learning. In Proceedings of the IEEE 2009 International Conference on Ultra Modern Telecommunications & Workshops, St. Petersburg, Russia, 12–14 October 2009. [Google Scholar]
- Han, Y.; Kushal, V.; Erdal, O. Robust traffic sign recognition with feature extraction and k-NN classification methods. In Proceedings of the 2015 IEEE International Conference on Electro/Information Technology (EIT), Dekalb, IL, USA, 21–23 May 2015. [Google Scholar]
- Wang, W.; Zhu, M.; Jinlin, W.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017. [Google Scholar]
- Lotfollahi, M.; Zade, R.S.H.; Siavoshani, M.J.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef]
- Wang, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning hierarchical spatial-temporal features using deep neural networks to improve intrusion detection. IEEE Access 2017, 6, 1792–1806. [Google Scholar] [CrossRef]
- Hu, F.; Zhang, S.; Lin, X.; Wu, L.; Liao, N.; Song, Y. Network traffic classification model based on attention mechanism and spatiotemporal features. EURASIP J. Inf. Secur. 2023, 2023, 6. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, L.; Xiao, X.; Li, Q.; Marcaldo, F.; Luo, X.; Liu, Q. TFE-GNN: A temporal fusion encoder using graph neural networks for fine-grained encrypted traffic classification. In Proceedings of the ACM Web Conference 2023, New York, NY, USA, 30 April–4 May 2023. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Sarhangian, F.; Rasha, K.; Muhammad, J. Efficient traffic classification using hybrid deep learning. In Proceedings of the 2021 IEEE International Systems Conference (SysCon), Vancouver, BC, Canada, 15 April–15 May 2021. [Google Scholar]
- Azab, A.; Khasawneh, M.; Alrabaee, S.; Choo, K.-K.R.; Sarsour, M. Network traffic classification: Techniques, datasets, and challenges. Digit. Commun. Netw. 2024, 10, 676–692. [Google Scholar] [CrossRef]
- Loshchilov, I.; Frank, H. Fixing Weight Decay Regularization in Adam. 2018. Available online: https://openreview.net/forum?id=rk6qdGgCZ (accessed on 30 September 2024).
- Khan, A.A.; Chaudhari, O.; Chandra, R. A review of ensemble learning and data augmentation models for class imbalanced problems: Combination, implementation and evaluation. Expert Syst. Appl. 2024, 244, 122778. [Google Scholar] [CrossRef]
- Xie, Z.; Xu, Z.; Zhang, J.; Sato, I.; Sugiyama, M. On the Overlooked Pitfalls of Weight Decay and How to Mitigate Them: A Gradient-Norm Perspective. In Proceedings of the Advances in Neural Information Processing Systems, San Diego, CA, USA, 2–7 December 2024; Volume 36. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 27–29 March 2017. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tak, P.; Tang, P. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Goodfellow, A.C.I. Deep Learning; Goodfellow, I., Bengio, Y., Courville, A., Eds.; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhudinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison Aspect | Transformer | LSTM |
|---|---|---|
| Processing capacity | Strong | Weak |
| Dependency capture | Strong | Weak |
| Computational efficiency | High | Mid |
| Feature learning | Automatically learn the features from the data | Dependence on manual feature extraction |
| Model complexity | Complex | Simple |
| Traffic | VPN-Traffic |
|---|---|
| Browsing | VPN-Browsing |
| VPN-Email | |
| Chat | VPN-Chat |
| Streaming | VPN-Streaming |
| File transfer | VPN-File transfer |
| VoIP | VPN-VoIP |
| TraP2P | VPN-TraP2P |
| Configuration and Environment | |
|---|---|
| CPU | AMD Ryzen 5 5600H with Radeon Graphics 3.30 GHz |
| RAM | 16.0 GB |
| GPU | NVIDIA GeForce RTX3050Ti |
| Operating system | Windows 11 64-bit |
| Integrated development environment | PyCharm |
| Deep learning framework | PyTorch |
| Category | Accuracy | Precision | Recall | Category | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|---|
| Chat | 98.17% | 98.67% | 99.17% | VPN-Chat | 99.83% | 99.50% | 99.83% |
| 99.00% | 99.17% | 99.00% | VPN-Email | 98.33% | 100% | 98.33% | |
| File | 93.56% | 89.56% | 94.33% | VPN-File | 98.49% | 98.98% | 99.49% |
| P2P | 99.46% | 100% | 99.46% | VPN-P2P | 96.74% | 98.89% | 96.74% |
| Streaming | 99.75% | 99.50% | 99.75% | VPN-Streaming | 99.19% | 99.19% | 100% |
| VoIP | 92.20% | 94.37% | 89.33% | VPN-VoIP | 99.50% | 100% | 99.50% |
| Model | Precision | Recall | Number of Parameters | FLOPs |
|---|---|---|---|---|
| Baseline CNN | 93.89% | 93.37% | 1.82 M | 0.36 G |
| CNN + ECANet | 96.88% | 96.21% | 1.90 M | 0.39 G |
| Transformer-only | 95.30% | 94.07% | 2.65 M | 1.24 G |
| TransECA-Net (full model) | 98.64% | 98.13% | 6.89 M | 13.45 G |
| Method | VPN | Non-VPN | ||||
|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | Accuracy | Precision | Recall | |
| 1D-CNN [20] | 94.48% | 94.48% | 93.57% | 83.94% | 83.89% | 84.00% |
| SAE + 1D-CNN [21] | 93.00% | 97.80% | 96.30% | 87.62% | 86.70% | 88.80% |
| CNN + LSTM [23] | 93.69% | 94.57% | 94.33% | 90.91% | 91.69% | 92.00% |
| TFE-GNN [24] | 95.91% | 95.26% | 95.36% | 90.40% | 93.16% | 91.90% |
| OUR | 98.90% | 98.20% | 97.93% | 98.39% | 97.43% | 98.02% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Xie, Y.; Luo, Y.; Wang, Y.; Ji, X. TransECA-Net: A Transformer-Based Model for Encrypted Traffic Classification. Appl. Sci. 2025, 15, 2977. https://doi.org/10.3390/app15062977
Liu Z, Xie Y, Luo Y, Wang Y, Ji X. TransECA-Net: A Transformer-Based Model for Encrypted Traffic Classification. Applied Sciences. 2025; 15(6):2977. https://doi.org/10.3390/app15062977
Chicago/Turabian StyleLiu, Ziao, Yuanyuan Xie, Yanyan Luo, Yuxin Wang, and Xiangmin Ji. 2025. "TransECA-Net: A Transformer-Based Model for Encrypted Traffic Classification" Applied Sciences 15, no. 6: 2977. https://doi.org/10.3390/app15062977
APA StyleLiu, Z., Xie, Y., Luo, Y., Wang, Y., & Ji, X. (2025). TransECA-Net: A Transformer-Based Model for Encrypted Traffic Classification. Applied Sciences, 15(6), 2977. https://doi.org/10.3390/app15062977