1. Introduction
Artificial intelligence solutions are gradually becoming permissible in medical diagnostics. For example, the Polish Code of Medical Ethics [
1], in force since 2025, allows the use of artificial intelligence algorithms when certain conditions are met. The patient must be informed and must express informed consent to the use of artificial intelligence during the diagnostic and therapeutic process. Solutions approved and certified for medical use may be used. It is also important that the final diagnostic and therapeutic decision always be made by a doctor.
The use of artificial intelligence (AI) techniques allows for the analysis of the influence of various factors on the prediction of disease changes. An example of the possibilities of deep learning (DL) techniques is inference for the integration of multimodal data (radiology, pathology, epigenetics, and clinical data) to predict the overall survival of patients with glioma [
2].
Machine learning, and especially deep neural networks (DNNs), can be widely used in ophthalmology OCT image analysis [
3]. Several application areas can be distinguished: segmentation of retinal layers (using U-Net-type networks [
4]); analysis of changes in time using hybrid models (e.g., combining solutions of CNN with sequential recursive NN-type models) [
5]; detection and classification of eye diseases such as age-related macular degeneration (AMD), glaucoma, diabetic retinopathy, or macular holes [
6].
OCT devices for ophthalmological diagnostics often include extensive software for the segmentation of retinal layers and parametric visualization to assess abnormal changes. The correctness of deep learning solutions is comparable to manual image analysis by an ophthalmology specialist. The use of innovative NN models such as the BioImagingLab/INESC TEC [
7] allows precise segmentation of the retinal layer for AMD patients and has demonstrated a moderate to strong correlation between computer and human metrics [
8].
Based on B-scan OCT of the macula area, an experienced ophthalmologist can easily classify retinal pathological changes. However, for screening tests, computer classification using artificial intelligence techniques can be helpful. Datasets of B-scan OCTs prepared in recent years allow the preparation of classifiers that achieve an accuracy above 96% [
3]. It should be noted that the software of OCT devices does not yet typically have such functionality, assuming that the diagnosis will be performed by a specialist.
Modern smartphones have increasingly greater computing capabilities, and built-in cameras take high-resolution photos. We can observe the research progress of smartphone-based optical imaging biosensors in the fields of colorimetry, fluorescence, and microscopic imaging for genetic testing [
9]. The widespread availability of smartphones and broadband transmission has enabled the development of telemedical consultations. This phenomenon can also be observed in the field of ophthalmology [
10]. The ability to send self-taken photos of the anterior segment of the eye and eyelids, e.g., for conditions such as eyelid chalazion (called an eyelid cyst or a meibomian cyst), allows for a quick teleconsultation without traveling to an ophthalmological clinic or hospital. With the right smartphone camera attachments [
11], it is also possible to take photos of the fundus of the eye, thus providing imaging used in diabetic retinopathy.
There are a number of different applications available for smartphones dedicated to diagnosis, treatment, and symptom management in ophthalmology. The review of solutions presented in [
12] shows that mobile applications can be successfully used in the following issues: visual acuity assessment, dry eye diagnostics, color recognition, strabismus assessment, detection of metamorphopsia, pupillometry, or education for ophthalmologists and optometrists. More advanced diagnostics related to glaucoma and diabetes are also possible, in which case the parametric data are entered manually. In general, mobile applications do not use artificial intelligence, i.e., deep neural networks.
For OCT images, smartphone ophthalmic applications are emerging that can support the diagnostic process. Of course, a smartphone does not have the ability to acquire OCT images on its own, but it has enough computing power and can analyze B-scans saved in the device’s memory. The work in [
13] presents a mobile application that allows the classification of four types of B-scan (CNV, DME, DRUSEN, NORMAL). The entire image and a relatively simple CNN network consisting of four sets of 2D convolution layers and max-pooling layers were used for classification. The authors also used YOLOv4 tiny to mark pathological changes in the image. The application and the source code are not available.
In the context of studies on the development of ophthalmic telediagnostics screening, our article presents a comprehensive study of the possibilities of using different neural network architectures. A publicly available application has also been prepared, which allows the user to precisely check the probability of belonging to five classes of pathological changes using three previously selected models. The B-scan was assumed to be available in the memory of the mobile device or would be taken using a smartphone camera from the screen of the OCT device or a printout received by the patient after OCT imaging. The presented analysis and solutions may be helpful for quick evaluation of OCT B-scans, including those archived on older-generation OCT devices.
The main contributions of the authors presented in the article are as follows:
a comparison of the effectiveness of six neural network architectures for automatic classification of OCT B-scans of five groups of lesions;
a comprehensive comparison of the advantages of three solutions for converting neural network models to the constraints of mobile devices;
source code of mobile app design for OCT B-scan classification with software release on GitHub (version 1.0).
The outline of the paper is as follows.
Section 2 describes the dataset and neural networks used in the experiments. The advantages and disadvantages of various approaches for NN implementations in a mobile application are discussed in
Section 3. This section also includes a description of the mobile application’s design. In
Section 4, the experiment setup and classification results are presented.
3. Android-Based Application for OCT Classification
The human eye OCT image classification was implemented in a mobile application for Android phones. The development was performed in Android Studio version 2023.1.1 and the Kotlin programming language.
3.1. Implementing Neural Networks in a Mobile Application
Three different methods of model conversion were analyzed to implement neural networks for image classification on mobile devices: TensorFlow Lite (TF Lite), ONNX, and Firebase ML. Their advantages and disadvantages are discussed below.
TensorFlow Lite is a solution that converts TensorFlow models to a smaller, more efficient machine learning format. In this solution, one can use:
pre-trained models from TensorFlow Lite;
modify existing models;
build one’s own TensorFlow models, then convert them to the TensorFlow Lite format.
The TensorFlow Lite [
19] model is represented in an efficient, portable FlatBuffers format (files with the
.tflite extension). This allows for reduced size and faster inference (via direct access to data without additional analysis/unpacking steps). This solution enables efficient operation on devices with limited computational and memory resources. The advantages and disadvantages of this method are discussed in
Table 4.
The generation of a network model in the .tflite format can be performed using the TensorFlow Lite Model Maker library. This library, using Transfer Learning, reduces the amount of training data required and shortens training time. Another solution is to build a TensorFlow model and use the TensorFlow Lite Converter. In this case, it is possible to optimize the model, for example, through quantization, to adapt the model for operation on a mobile device.
ONNX (
Open Neural Network Exchange) [
20] is an open standard platform for representing machine learning models, used to export or convert models from multiple platforms (such as TensorFlow 2.0, PyTorch 2.1, Keras 1.6, MATLAB 7, etc.) to the standard ONNX format, which can be run on different platforms and devices (clouds, peripherals, CPUs/GPUs, etc.). The advantages and disadvantages of this method are discussed in
Table 5.
Firebase ML [
21] is a mobile Software Development Kit (SDK) that can be used for Android and Apple iOS apps. In this solution, TensorFlow Lite models are used for inference. Inference is the phase in which the deployed model makes predictions, most often on production data. Firebase hosts and serves the model to the app. Inference can be performed in the cloud (Google Cloud) or on the user’s mobile device. The advantages and disadvantages of this method are discussed in
Table 6.
After analyzing the advantages and disadvantages of the discussed methods for implementing neural networks for image classification on mobile devices, TensorFlow Lite was chosen. The prepared TensorFlow Lite model should be integrated with the application interface that will run it on the device to make predictions based on input data. For neural networks requiring significant resources, hardware acceleration via the Android Neural Networks API is possible.
3.2. Graphical User Interface
When launching the mobile application, the user sees the application title
OCT Classifier on the screen. Below the title, two buttons offer the following options: taking a picture using the phone’s rear camera or selecting an image from the gallery (screenshot in
Figure 2):
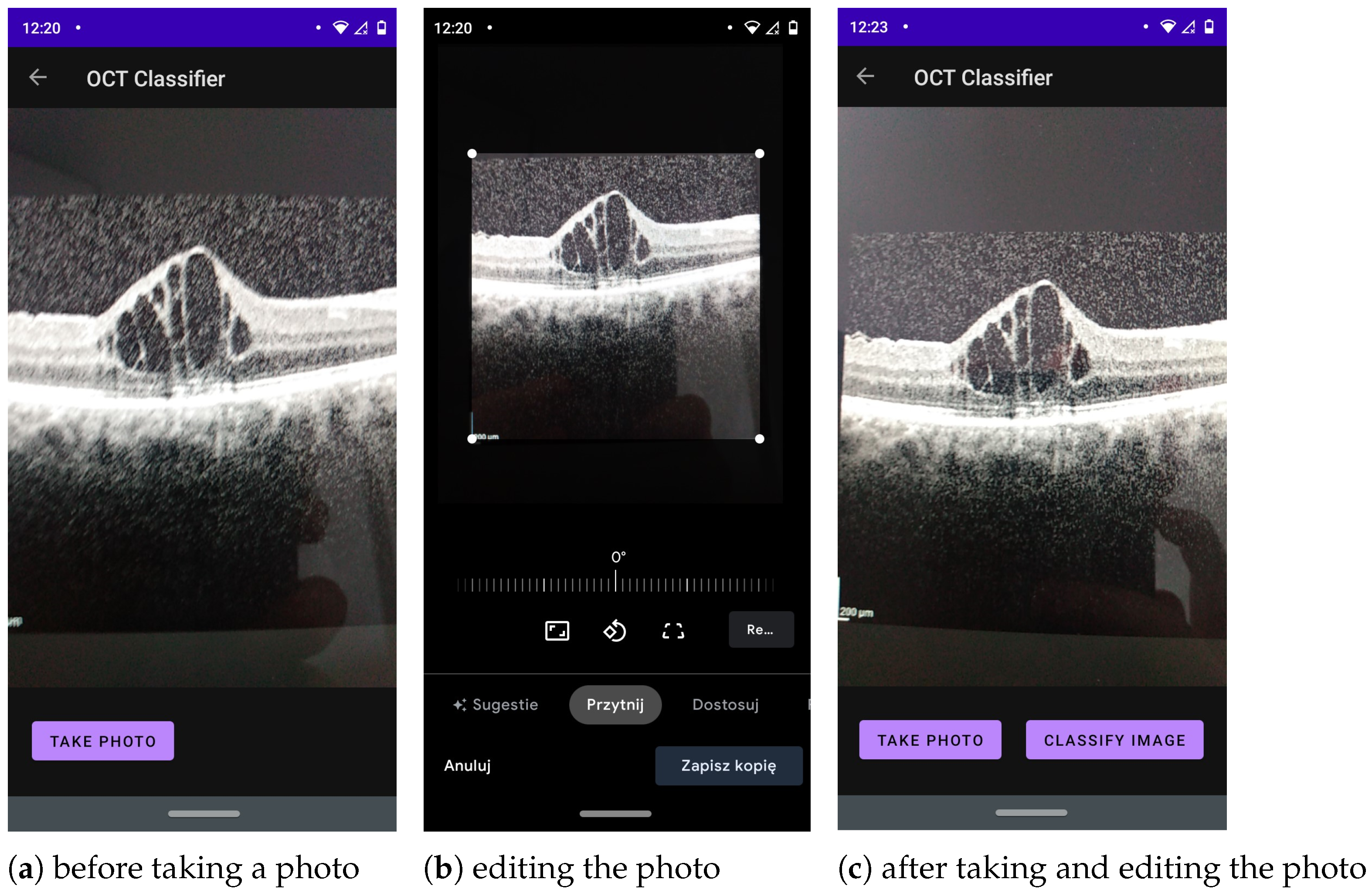
Touching the button labelled
Take a photo takes the user to the application module that allows taking a picture, editing it, and, later, classifying it (this interface is shown in
Figure 3).
Touching the button labelled
Choose image from gallery navigates to a module (whose interface is shown in
Figure 4), where the user can select an image from the gallery and then submit the selected image for classification.
The application must be granted access to the phone’s photos to allow the user to select photos from the phone’s gallery. At this stage, the application also needs permission to write files to save the bitmap of the classified image in the user’s gallery. Additionally, the user has the option of editing a photo captured using the mobile device’s built-in camera before sending it for classification.
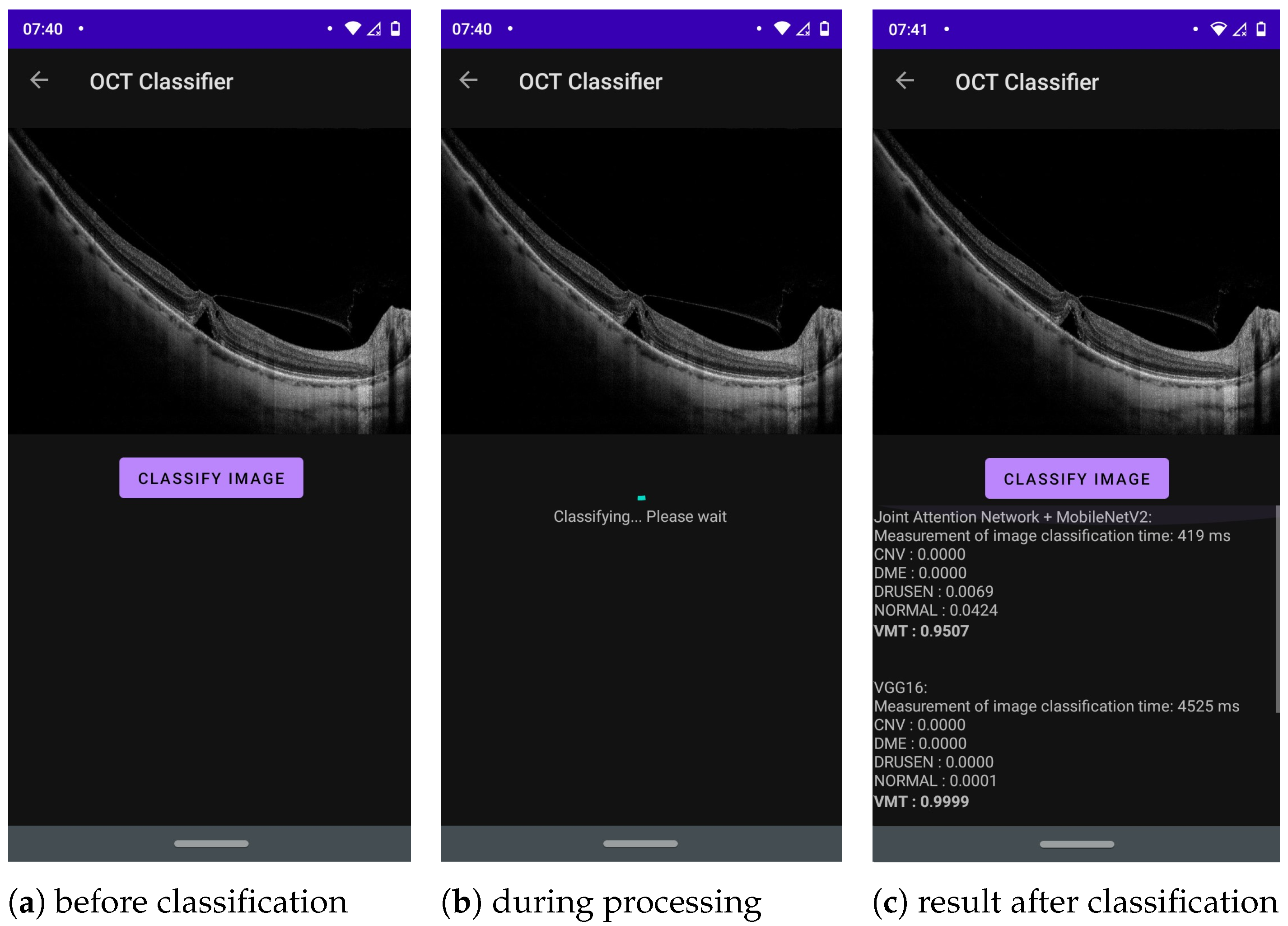
Part of the application where the main image classification occurs can be seen in
Figure 5. At the top of the screen, the user can see an image selected from the gallery or a photo taken earlier with the phone’s camera. Below the image is a button,
Classify image. Touching it runs the built-in NN models converted to TF Lite to classify the selected image into one of five categories: CNV, DME, DRUSEN, NORMAL or VMT. The classification results (class labels with probabilities) and classification times for each network are presented below the button in a scrollable text format. The result with the highest probability for each network is written in bold to immediately draw the user’s attention to the most likely outcome.
4. Experimental Selection of Neural Networks
4.1. Training and Test of the Selected NN Models
The CNN was run with the data split described in
Section 2.1, and training was performed for 100 epochs. The run utilized the Google Colab platform, Google Compute Engine backend with Python 3.10, and a V100 GPU with 16 GB RAM.
Table 7 lists setup parameters for the conducted initial experiments. Furthermore, the following data augmentation techniques (applied randomly) were proven to have a positive impact during training only for Joint Attention Network + MobileNetV2 and OpticNet-71 architectures: horizontal flip, rotation (
°), translation (
), shear (
), and zoom (
).
The results of this experiment are shown in
Table 8. The best result of 89% for all metrics is achieved for the Joint Attention Network with the MobileNetV2 model. The lowest performance of 64% was obtained with the three-layer CNN architecture. Its low efficiency, resulting from the simple and uncomplicated model structure, confirms the need for advanced methods for the task of classifying human eye OCT images. All models had the highest prediction accuracy for the VMT class and the lowest for the DRUSEN and DME classes. The obtained models’ overall insufficient accuracy can be attributed to the small size and imbalance of the dataset (only 4467 images) and data characteristics differing between the OCT manufacturers (e.g., image brightness and contrast).
4.2. Network Tests After Conversion to the TensorFlow Lite Model
All networks were converted to the TensorFlow Lite format and tested on the same set of images. The resulting Accuracy, Precision, Recall, and F1-Score are presented in
Table 9.
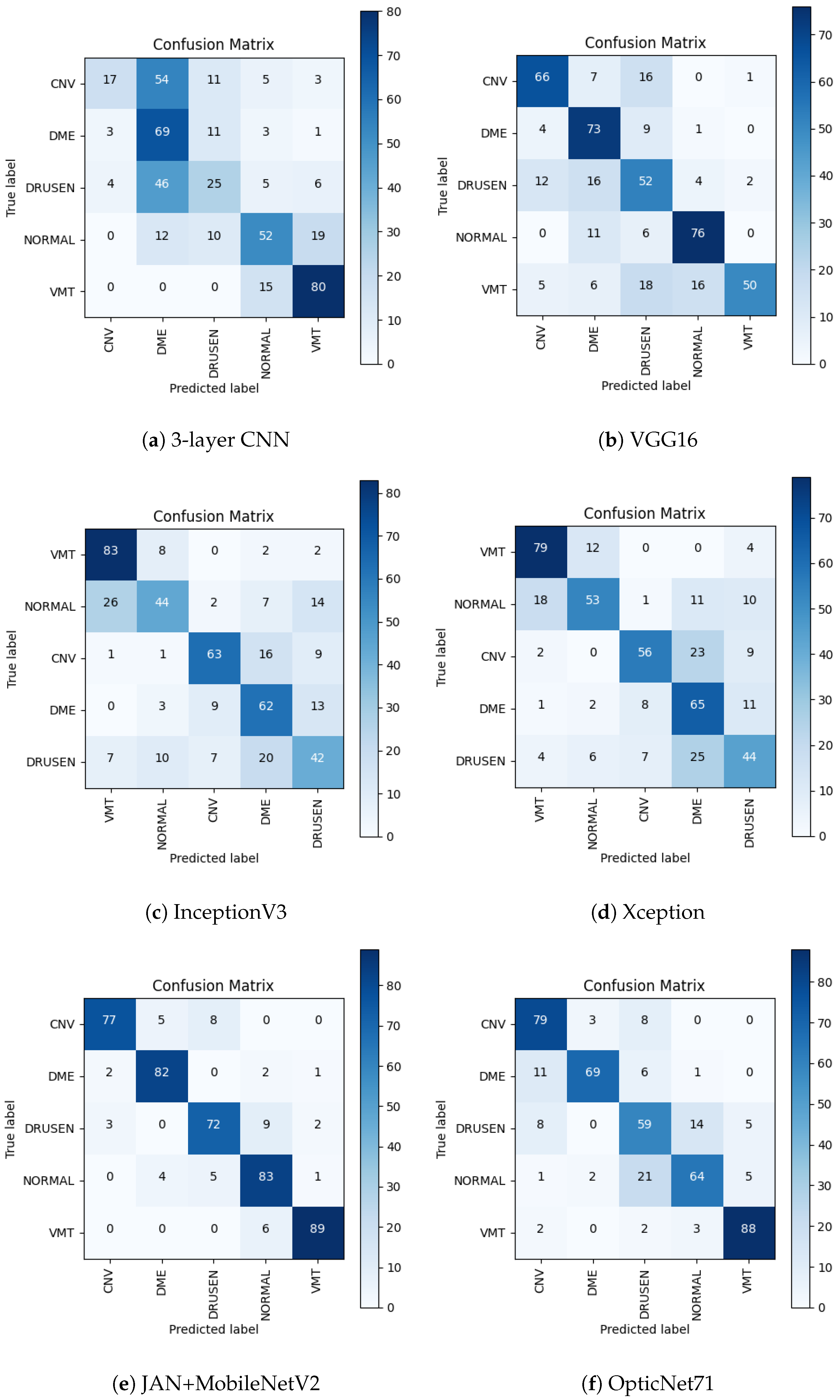
Figure 6 illustrates the obtained confusion matrix for all network architectures.
Comparing the results for the network with three convolutional layers before and after conversion, the accuracy dropped by 10%, and the F1-score dropped by as much as 13%. Analyzing the confusion matrix in
Figure 6a, it can be observed that the VMT class has the greatest number of correct predictions. However, classes CNV and DRUSEN (which are assigned to the DME category) have a significant number of incorrect predictions. The DRUSEN class remained with the fewest correct predictions.
For the VGG16 network, a 13% decrease in both accuracy and F1-score can be observed. After conversion to the TensorFlow Lite format, it can be seen in
Figure 6b that the NORMAL class obtained the largest number of correct predictions, while before the conversion, it was the VMT class. The number of correct predictions for the DME class increased compared to the results before conversion. The VMT and DRUSEN classes resulted in the smallest number of positive predictions.
When comparing the results for both formats, the accuracy and F1-score of the InceptionV3 network dropped by 7% and 8%, respectively. The confusion matrix in
Figure 6c shows that the network in the TensorFlow Lite format obtained the largest number of correct predictions for the VMT class and performed significantly worse with the NORMAL and DRUSEN classes.
In the case of the Xception network, both accuracy and F1-score decreased by 11%. Analyzing the confusion matrix in
Figure 6d, it can be observed that the greatest number of correct predictions were observed for the VMT classes and the fewest for the DRUSEN class. It is worth noting that before conversion, the DME class obtained the smallest number of correct predictions, while after conversion to the TensorFlow Lite format, the number of correct predictions increased.
The results before and after conversion for the Joint Attention Network + MobileNetV2 and OpticNet-71 networks remained the same. Such results may stem from the architecture of these artificial neural networks. Like other networks, OpticNet-71 recognizes VMT disease with the greatest accuracy while having difficulty distinguishing between the NORMAL and DRUSEN classes, as seen in the confusion matrix in
Figure 6f. The confusion matrix for Joint Attention Network + MobileNetV2 shown in
Figure 6e confirms the best classification performance obtained with this model.
In summary, the results from testing the networks before and after conversion to the TensorFlow Lite format allowed the selection of three networks with the highest scores for implementation in the mobile application: the Joint Attention Network + MobileNetV2, OpticNet-71, and VGG16 networks.
4.3. Prediction on Mobile Device
This part of the study examined the performance of the mobile application on three different mobile devices listed in
Table 10.
The aim of the research was to observe the influence of a given mobile device’s camera and its image display method during image acquisition on the results and time of image classification. For each device, application tests were performed under the following three conditions:
OCT scan selected directly from the mobile device gallery—control test.
An OCT scan displayed from a projector, followed by image acquisition using the mobile device’s rear camera; image editing involved cropping to show only the OCT scan, excluding non-tomogram elements of the photo.
An OCT scan displayed on a matte monitor, followed by image acquisition using the mobile device’s rear camera; image editing consisted of cropping, to show only the OCT scan, excluding any non-tomogram elements of the photo.
For each class to which a given image can be assigned, one OCT scan was selected, giving five images in total. These scans were used during tests under three different conditions on all mobile devices. The selected images were not used during the training of the neural networks. The obtained results are listed in
Table 11.
The above classification results show that the control sample (i.e., scans selected from the gallery), provided identical results regardless of the device. Only the duration of the classification varied depending on the available computing power. In all situations, the Joint Attention Network + MobileNetV2 network operated fastest, and VGG16 slowest.
For photos taken with a phone camera, a decrease in classification effectiveness was observed in most cases compared to the control group. Significant differences sometimes occurred between images displayed on the projector and the monitor; however, no common dependencies could be found. A potential reason for the better classification results of OCT scans displayed on the monitor compared to OCT scans displayed on the projector is the better contrast of retina layers.
Although the test sample was small, it can be assumed that the type and resolution of the phone camera should not have a significant impact on the results, since all images are resized to dimensions of pixels. Disturbances occurring in images, resulting from reflections or shadows created during the photographing of the image, seem to be of greater importance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}