2.1. Overall Model Framework
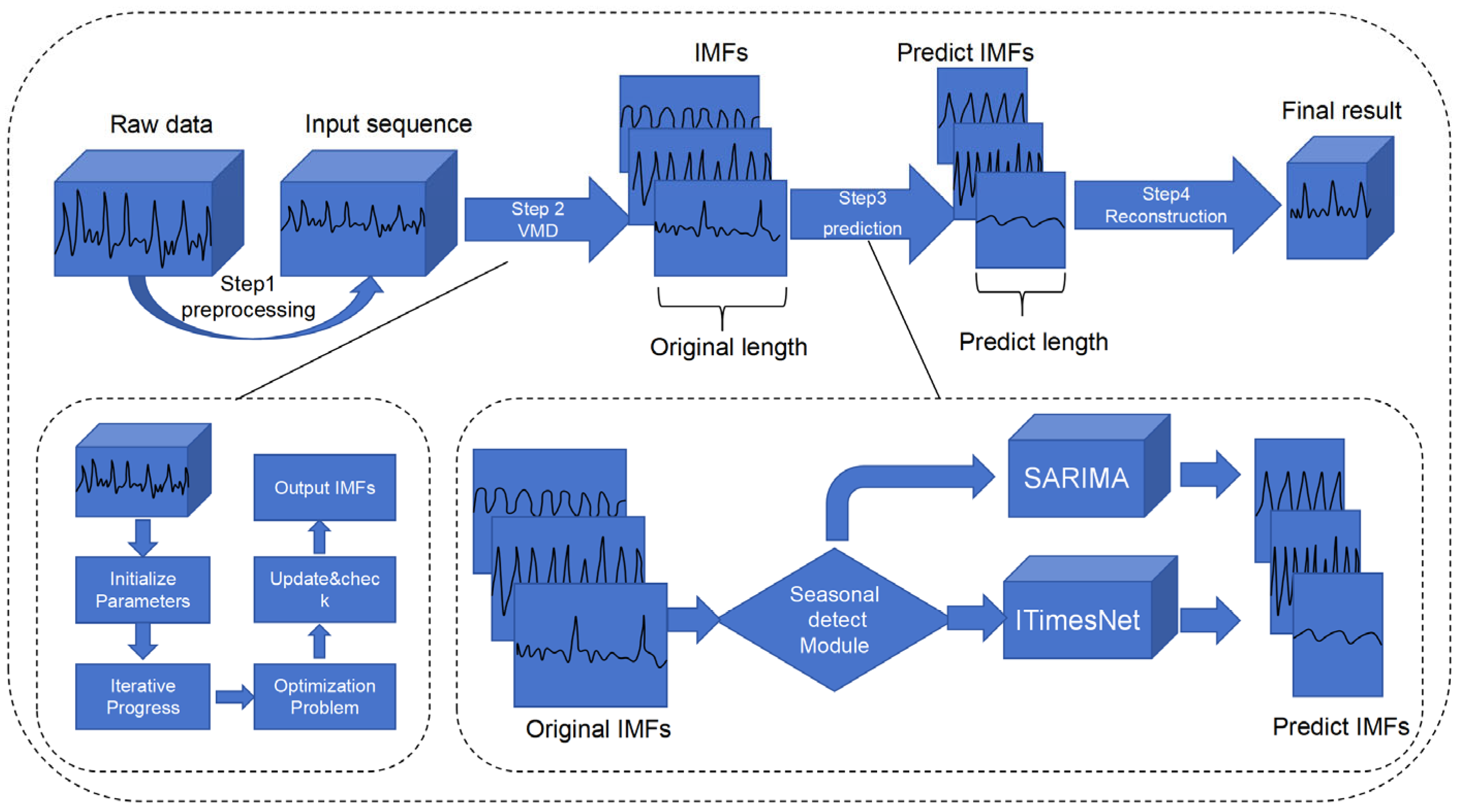
Figure 1 shows the model framework described in this paper. As illustrated in
Figure 1, the overall operation process of this prediction model follows these 4 steps:
(1) Data Preprocessing: initially, the raw data undergo zero-padding operations and normalization to yield a cleaned dataset, which serves as the original input sequence.
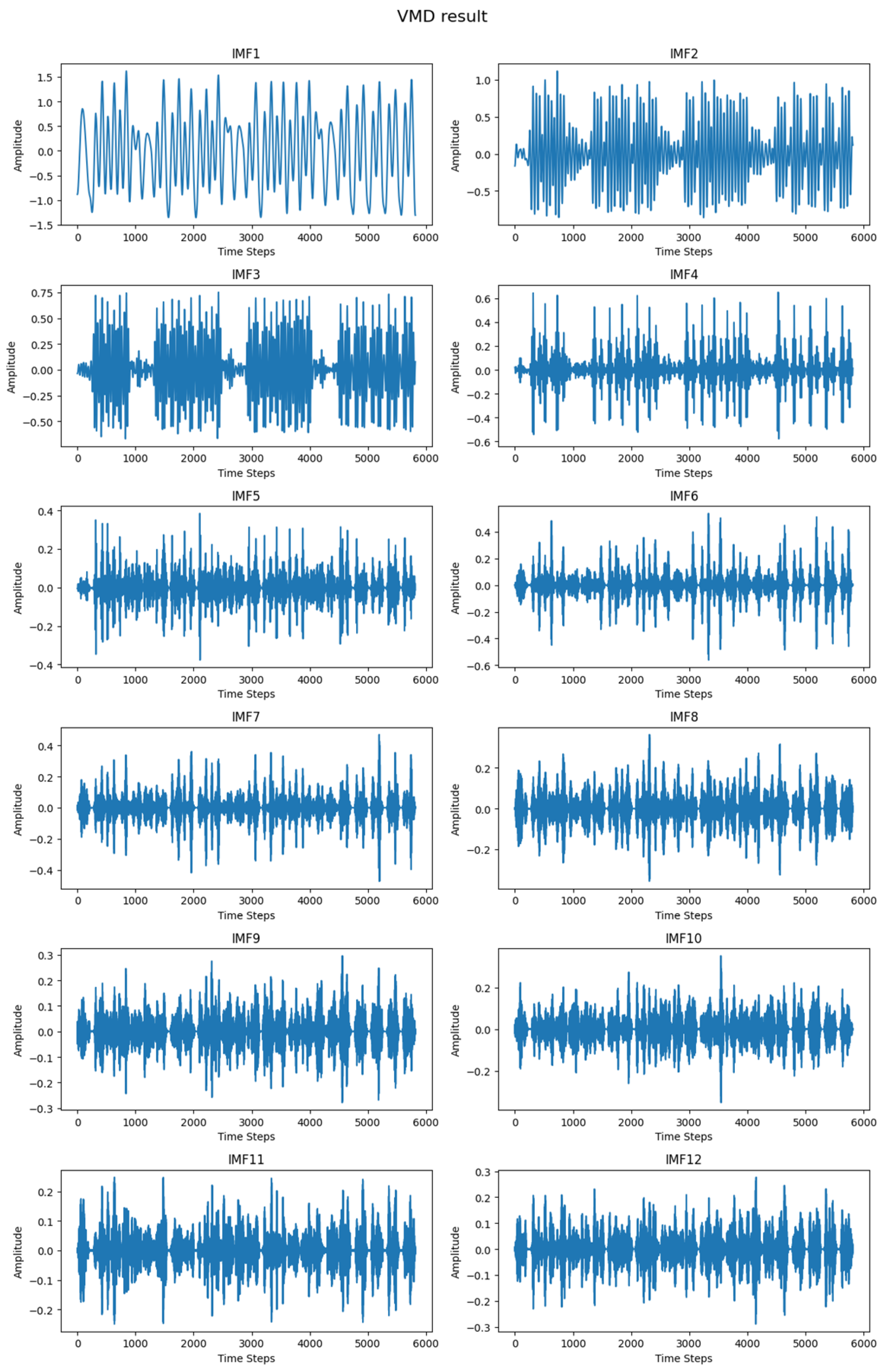
(2) Variational Mode Decomposition (VMD): The cleaned dataset is then subjected to VMD to extract the corresponding Intrinsic Mode Functions (IMFs), obtaining a set of n IMFs. The VMD process involves iterative parameter initialization, optimization, and the update and check mechanism to produce the final IMFs.
(3) IMF Prediction: the obtained IMFs are standardized using the following formula:
Each of the resulting IMFs is then fed into a seasonality detection module. This module utilizes the autocorrelation function (ACF) and partial autocorrelation function (PACF) to identify IMFs with significant seasonal characteristics [
33,
34]. The IMFs exhibiting strong seasonality are input into the SARIMA model, while those without strong seasonality, which exhibit stronger nonlinear and non-periodic patterns, are directed to an improved TimesNet model.
(4) Reconstruction: Finally, after each IMF has been predicted through either SARIMA or TimesNet, all the predicted components are reconstructed to generate the final prediction. This reconstruction step is essential because the VMD decomposes the original sequence into several IMFs, and reconstructing these predicted IMFs allows for the restoration of the overall predicted sequence [
35]. This comprehensive framework captures both strong seasonal components and nonlinear features in the data, thus effectively utilizing all the available information for accurate prediction outcomes.
In this paper, a dataset constructed from real passenger flow data of the Hangzhou subway is used, and the sliding window technique is applied for forecasting. The data are segmented into five-minute intervals, with a total of 232 time steps in a day (covering the data within the statistics time), which serves as the length of the forecasting window (the sliding window length). Additionally, the sliding window can be adjusted based on experimental requirements. For each day forecasted, the window slides by 232 time steps, and the actual values from the previous day are used to update the dataset.
As shown in
Figure 2, we utilized sliding windows of 232 time steps (a full day) to capture passenger flow patterns over different time horizons.
Similarly, the prediction of each component obtained after Variational Mode Decomposition (VMD) also employs the sliding window concept. A detailed description of the VMD module and improved TimesNet model as well as the SARIMA model will be provided in the subsequent sections.
2.2. VMD Module
Variational Mode Decomposition (VMD), first introduced in 2014 by Dragomiretskiy and Zosso, is a technique used to decompose nonlinear, non-stationary data into multiple Intrinsic Mode Functions (IMFs), separating the local characteristics of the data [
36]. VMD decomposes the time series data into Intrinsic Mode Functions (IMFs), each representing a different frequency component. High-frequency IMFs capture short-term fluctuations, while low-frequency IMFs reveal long-term trends. This decomposition helps to isolate noise and enhance the detection of underlying periodic patterns, improving the accuracy of passenger flow predictions. The criteria for identifying an IMF can be summarized as follows:
(1) The number of extrema and the number of zero-crossings must differ at most by one throughout the entire sequence;
(2) At any point, the mean of the envelope defined by the local maxima and the envelope defined by the local minima is zero.
VMD serves as a key step in the subway passenger flow prediction model proposed in this paper. The VMD of a signal
can be represented as follows:
where
are the IMFs, and k represents the number of Intrinsic Mode Functions.
The purpose of VMD is to decompose complex subway passenger flow data into a finite set of IMFs, which each represent different frequency components. These IMFs are then used to reveal deeper characteristics of the subway passenger flow data. The objective of VMD is to minimize the bandwidth of the IMFs by solving the following optimization problem:
where
are the Hilbert transforms of the IMF
, and the operator
refers to the partial derivate with respect to time. The Hilbert transform is used for the instantaneous frequency analysis of the decomposed Intrinsic Mode Functions (IMFs), allowing for a more accurate capture of the nonlinear characteristics in the data. The optimization problem aims to minimize the total bandwidth of the IMFs by solving this equation iteratively. This ensures that the IMFs generated are as narrowband as possible, capturing distinct frequency components from the signal.
In VMD, each IMF is modeled as a mode function
that is the output of a bandpass filter with a fixed center frequency
. The mode function can be expressed as follows:
where
is the amplitude envelope, and
is the instantaneous phase.
VMD is a non-recursive, adaptive, and data-driven method that can decompose nonlinear and non-stationary data into IMFs with limited bandwidth. The center frequencies and bandwidths are iteratively updated by solving the constrained optimization problem to ensure accurate decomposition.
The parameters of these mode functions, including their center frequencies and bandwidths, are determined by solving a constrained optimization problem that minimizes the bandwidth of each IMF and makes their sum as close as possible to the original signal.
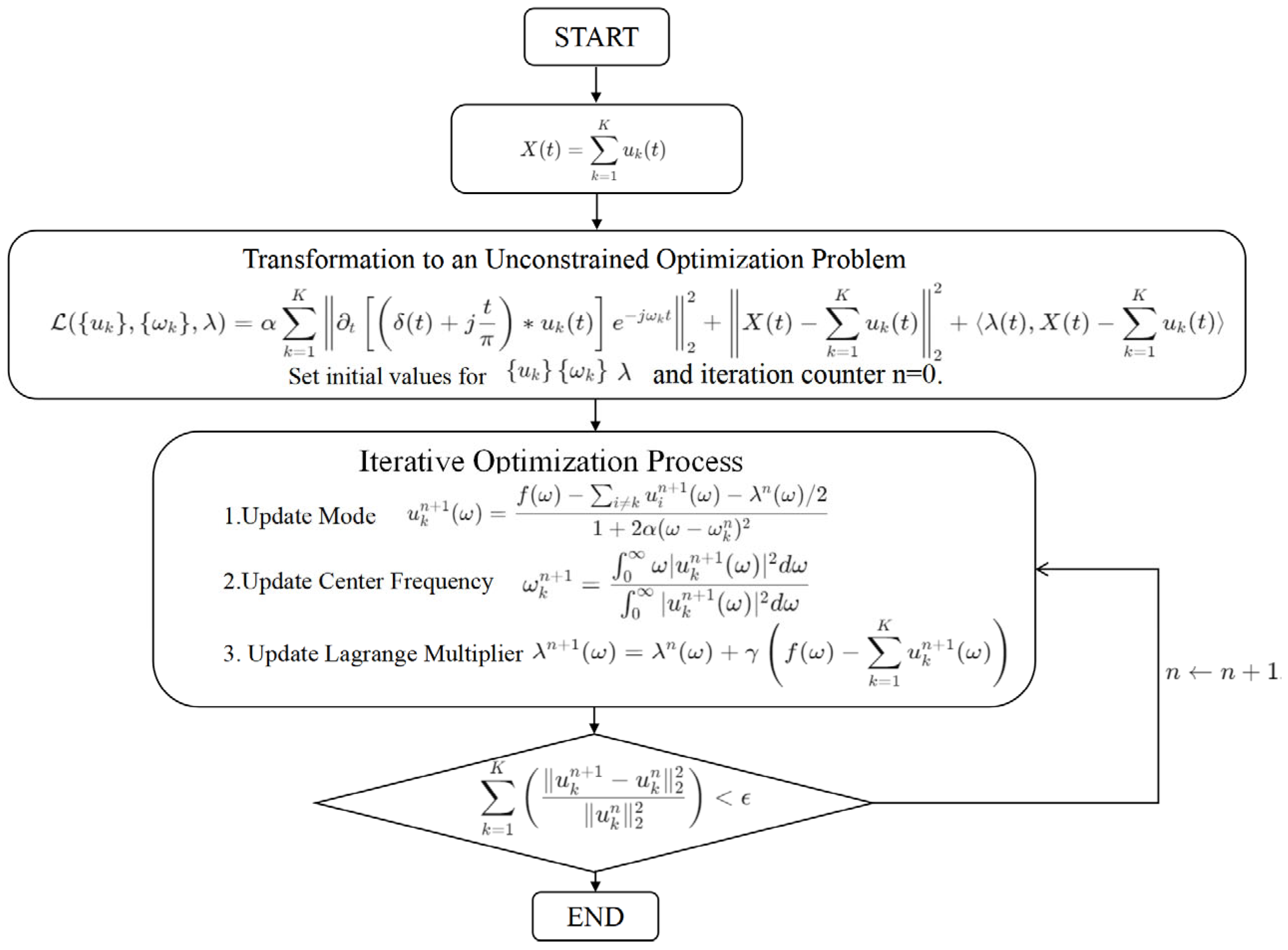
As shown in
Figure 3, the VMD module in this paper executes the following steps:
Step 1: Data Preprocessing. The original metro passenger flow data are normalized to ensure consistent scaling, reducing the influence of different data scales on the analysis and aiding convergence in subsequent optimization. The preprocessed data
are input into the VMD module, where they are first transformed into a variational optimization problem. The original time series
can be represented as follows:
Step2: Transformation to an Unconstrained Optimization Problem. The augmented Lagrangian function for VMD is formulated to minimize the bandwidth of the Intrinsic Mode Functions (IMFs) while constraining the sum of all IMFs to
Here, represents the penalty parameter, and is the Lagrange multiplier used to ensure that the sum of all IMFs matches the original time series.
Step 3: Iterative Optimization Process. A dual optimization strategy is used to iteratively update the estimation of modes their center frequencies , and the Lagrange multiplier until the solution converges.
Step 3.1: Initialization. is initialized, and the iteration counter is set.
Step 3.2: Iterative Updates and Convergence Check. For each iteration , the following updates are performed:
1. Mode
is updated:
Here, represents the Fourier transform of the original signal.
2. The center frequency
is updated:
This update helps estimate the central frequency of each mode to ensure that it accurately captures the frequency characteristics of the IMF.
Step 3.3: The Lagrange multiplier
is updated:
The parameter
controls the adjustment of the Lagrange multiplier, aiding in the convergence of the solution. Convergence check: after each iteration, it is checked whether the solution has converged by evaluating the relative change:
If the convergence criterion is met, the process terminates; otherwise, is incremented, and the process continues.
Step 4: Extraction of IMFs. The output consists of IMFs that collectively represent the original signal. These IMFs are the core components that highlight different intrinsic frequency bands of the time series data, making the signal analysis more interpretable and effective for further modeling.
The VMD algorithm effectively deconstructs complex signals into simpler components that can be analyzed and modeled more easily. In the context of subway passenger flow forecasting, this decomposition allows for a refined analysis of the data’s inherent features, such as daily patterns, peak periods, and anomalies, thereby enhancing the forecasting model’s ability to capture and predict future trends based on historical data.
2.3. Seasonal Detection Module
In the previous section, this paper provided a comprehensive introduction to the VMD process. In the following section, we will elaborate on the seasonal detection model tailored for choosing the appropriate IMFs in subway passenger flow prediction.
Therefore, the model proposed in this article will first input the decomposed sequence data into the “seasonal detection” module to determine if they have strong seasonal characteristics (the specific algorithm in the seasonal detection module is described in detail in the
Supplementary Materials).
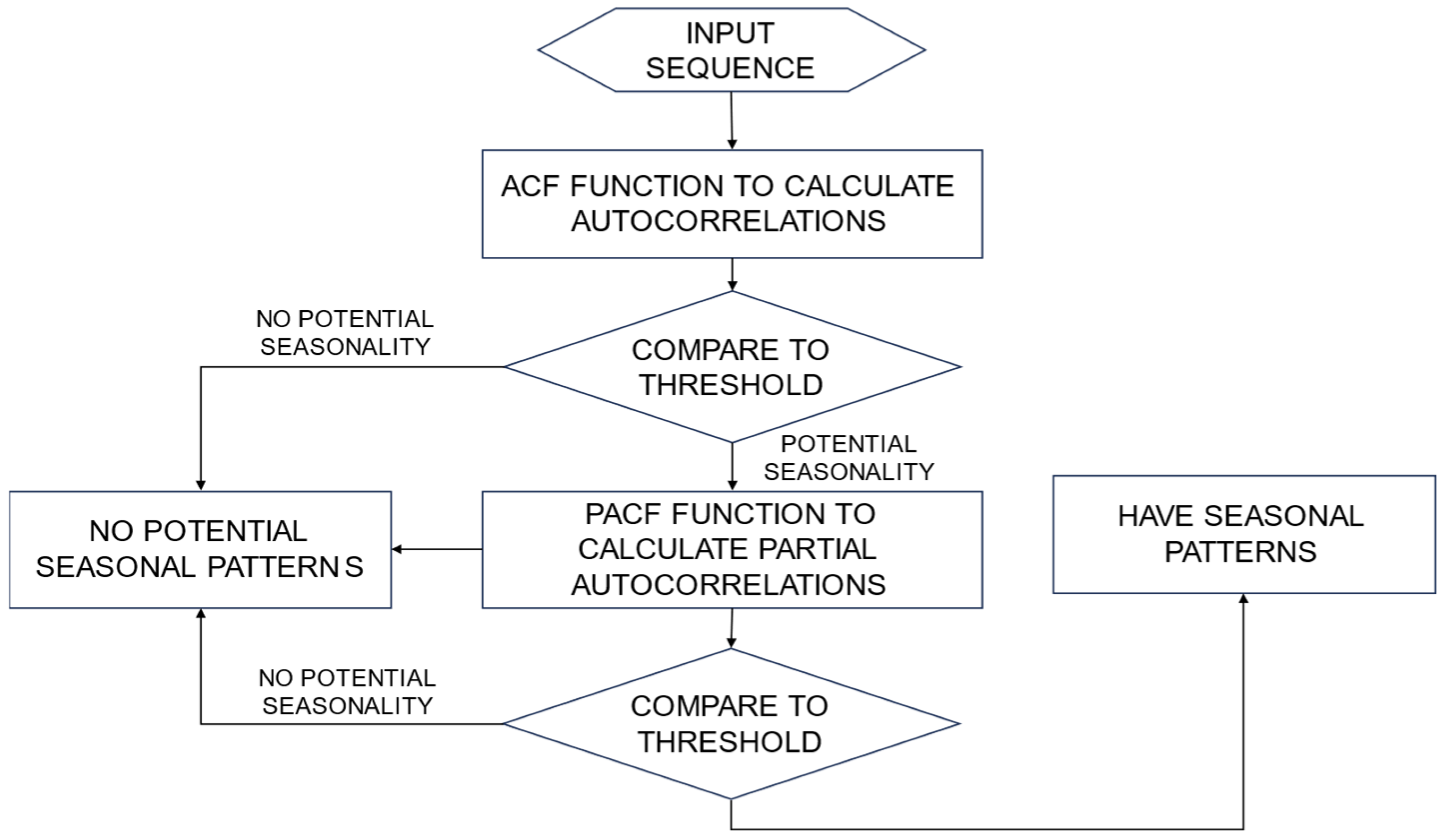
As illustrated in
Figure 4 the seasonality detection module introduced in this study initially receives sequences of Intrinsic Mode Functions (IMFs) as input. It then calculates the autocorrelation function (ACF) to assess the correlation between the time series.
The autocorrelation function (ACF) measures the correlation between observations of a time series that are separated by a specific time lag. The ACF also helps to identify the direct impact of a specific lag on the current observation, independent of the influence of intermediate lags. It provides insights into how past values influence future values.
Series X and its lagged versions are described by the following equation:
Equation (10) quantifies the autocorrelation between the time series and its lagged version. Specifically, it calculates the relationship between the series value and the lagged series for a given lag This equation helps determine whether significant seasonality exists, providing a basis for seasonal analysis in time series.
The ACF values obtained are compared with a predetermined threshold, set at 0.9 for this study. This threshold was selected as a balance between detecting significant correlations and minimizing false positives. A higher threshold, such as 0.95, might be overly restrictive and risk missing relevant seasonal patterns, while a lower threshold could introduce noise, falsely identifying non-seasonal fluctuations as significant. By choosing 0.9, we ensure that only meaningful seasonal trends are detected, allowing for reliable analysis. However, we recognize that the choice of threshold may influence the detection of seasonality, and further exploration of optimal threshold values will be an important focus in future research. If the ACF values exceed this threshold, the module proceeds with further analysis by calculating the partial autocorrelation function (PACF) of the series to confirm the presence of seasonality. The partial autocorrelation function (PACF) measures the correlation between an observation and its lagged value while controlling for the correlations at all shorter lags. This helps to identify the direct impact of a specific lag on the current observation, independent of the influence of intermediate lags.
Specifically, the calculation of PACF values can be expressed as follows:
Here, denotes the covariance given the intermediate variables. The PACF is computed using statistical software to measure the correlation between the series and its lagged versions, excluding the effects of intermediate lags. If the PACF value surpasses the 90% confidence interval, it is interpreted as an indication of significant seasonality. Should the series not exhibit significant seasonality in either the ACF or PACF assessments, the module will conclude the absence of seasonality in the series.
The framework of the seasonal detection model is illustrated in
Figure 4.
Then, adaptively, the appropriate IMFs (Intrinsic Mode Functions) are inputted into the corresponding improved TimesNet and SARIMA (Seasonal Autoregressive Integrated Moving Average) modules.
2.4. Improved TimesNet Module
Subway passenger flow prediction inherently requires time series forecasting. Recent studies have seen a surge of prediction methodologies based on Transformer model variants, such as the Informer model composed of multi-head self-attention mechanisms and the Autoformer model that involves decomposing and then forecasting sequences before recombining data. These models have provided theoretical support for modeling subway passenger flow data prediction in this paper.
In ICLR 2023 (a prominent academic conference in the field of machine learning and AI), the TimesNet model composed of multiple “Timesblock” modules emerged as a state-of-the-art (SOTA) model across various domains of time series modeling. TimesNet is capable of predicting chaotic signals by leveraging its unique design, which focuses on multi-periodicity modeling. Chaotic signals are often characterized by their complexity and sensitivity to initial conditions, making them difficult to predict using conventional time series models. However, TimesNet overcomes this challenge by transforming 1D temporal data into 2D tensors, which capture both intra-period (short-term) and inter-period (long-term) variations. This structure allows the model to disentangle complex patterns and better capture the chaotic nature of the signal.
In the original TimesNet model, the TimesBlock module, which inputs sequence data, simply combines them in parallel to generate the final prediction data. In dealing with different patterns “within the cycle” of the data, the processing of each component is very uniform and standardized, lacking the ability to extract and predict specific characteristics of the data.
The main techniques contained in our I-TimesNet module used in this paper are as follows:
First and foremost, the TimesBlock is the central component of our I-TimesNet model, with its primary function being the identification of multi-periodicity within sequences and the capture of corresponding temporal changes. TimesBlock accomplishes this objective through the following three principal steps: Initially, it mines the data cycles. TimesBlock utilizes the Fast Fourier Transform (FFT) to detect multi-periodicity within the time series. FFT is a robust tool for analyzing the spectral composition of time series data, revealing periodic patterns therein. Specifically, for one-dimensional time series data
, where L is the sequence length and C is the number of variables, the periodic amplitude can be expressed by the following formula:
In Equation (12), the formula represents the computation of the periodic amplitude using the Fast Fourier Transform (FFT) on the 1D time series data
. The result of the FFT is averaged to obtain the overall periodic amplitude
A, which helps in detecting the multi-periodic patterns within the data. To avoid contamination by high-frequency noise, only the first k amplitude values (frequencies) are selected. The specific selection method is as follows:
Here,
refers to the selection of the top k frequencies from the amplitude values. This selection process ensures that only the most significant frequencies, which are relevant for modeling the multi-periodicity, are considered. The combination of the aforementioned formula can be summarized as follows:
Continuing, the second step is the transformation from 1D to 2D sequences: After detecting the multi-periodicity within the time series, TimesBlock reshapes the one-dimensional time series into a set of two-dimensional tensors based on these periods. The specific procedural formula is as follows:
In the above equation, Padding involves appending zeros to the end of the time series to make it compatible with the reshaping process. and denote the number of rows and columns in the transformed 2D tensors, respectively.
Continuing, the following formula can express the input and output process within the TimesBlock module:
Specifically, when
l = 0, the following holds true:
In the TimesBlock module, the softmax function is applied after the FFT for periods to determine the relative importance or weight of each detected frequency (or period) in the input time series. This helps the model to focus on the most relevant periods for further analysis and prediction, ensuring that less significant frequencies do not dominate the output. Specifically, the softmax function ensures that the selected frequencies are normalized, and their values sum to 1, providing a clear probabilistic interpretation of how important each period is in the model’s analysis. This probabilistic weighting aids in the final aggregation and prediction process. The various temporal two-dimensional variants from the k reshaped tensors are captured efficiently utilizing parameter-efficient Inception Blocks within the two-dimensional space. These are then fused based on normalized amplitude values (shown in
Figure 5).
Within the 2D tensors, each column contains time points within a single period, while each row involves time points at the same phase across different periods. This allows for the representation of both intra-period and inter-period variations concurrently in the 2D space.
In the Inception Block module of the TimesNet model, the TimesBlock uses a parameter-efficient Inception Block within the 2D space to capture both intra-period and inter-period changes. Using the Inception V1 convolution, Inception Block is a structure from deep learning for visual models that process multi-scale information in parallel, allowing it to effectively capture and learn 2D features.
In metro passenger flow prediction tasks, models for processing time series data need to capture complex trends and periodic changes. The traditional Inception V1 module uses convolutional kernels of different sizes to capture features at various scales, thereby improving the model’s representation ability [
37]. However, this design has limitations, such as a large number of parameters that may lead to overfitting and insufficient adaptability to dynamic changes in features. To overcome these issues, dynamic convolution is introduced, which adapts to the features of the input data by learning a weighted combination of different convolutional kernels, offering advantages in adaptive feature extraction and parameter efficiency [
38]. Consequently, the design that concatenates dynamic convolution with the Inception V1 module not only inherits the advantages of both but also more effectively processes time series data.
Specifically, the dynamic convolution layer first performs adaptive feature extraction on the input data, adjusting the weights of the convolutional kernels based on the dynamic changes in the data, thereby better capturing the trends and periodic changes in the time series data. Then, the data processed by dynamic convolution pass through the Inception V1 module, which further extracts and fuses features at different scales, enhancing the model’s representation ability. Finally, the GeLU activation function introduces nonlinearity, enhancing the model’s expressive capability, enabling it to capture more complex feature relationships. In metro passenger flow prediction tasks, this design effectively captures the dynamic features of time series data and performs multi-scale feature fusion, thereby improving the accuracy of predictions.
Our improved TimesNet model incorporates dynamic convolution in the Inception Block for enhanced feature extraction. The dynamic convolution can be represented as follows:
where
is the input,
are the learned weights,
is the convolution operation, and
are the filters. The dynamic convolution allows our model to adaptively focus on different features by adjusting the weight
.
In detail, the dynamic convolution equations relevant to our improved TimesNet model are as follows:
where
is the output of the dynamic convolution layer, and
is an activation function (GeLU).
and
are the aggregated convolutional kernel and bias, respectively, which are functions of the input
. Equation (20) is the result of applying the dynamic convolution to the input data
, where the activation function GeLU (Gaussian Error Linear Unit) is applied to the output introducing nonlinearity. The aggregated convolutional kernel
and bias
are computed through kernel aggregation.
Furthermore, the kernel aggregation can be expressed as follows:
Equations (21) and (22) define the kernel aggregation process, where multiple convolution kernels and biases are combined based on the attention weights , which are computed for each kernel. is the number of parallel convolution kernels, and is the attention weight for the k-th kernel, computed based on the input .
Thus, our brand-new Inception Block can be expressed as follows. Initially, the dynamic convolution layer performs feature extraction on the input data
by adaptively adjusting the weights of the convolutional kernels, capturing the dynamic changes in the time series data, which can be expressed as follows:
where
is the number of convolutional kernels,
are the learned weights, and
represents the convolution operation using the kernel
on the input
. Subsequently, the processed data are fed into the Inception V1 module, which further extracts and fuses features at different scales, expressed as follows:
where
represents the convolution operation using a kernel of size
on the output
of the dynamic convolution layer. Finally, the GeLU activation function introduces a nonlinear transformation, enhancing the model’s expressive capability, expressed as follows:
where
represents the GeLU activation function. The GeLU (Gaussian Error Linear Unit) activation function is a nonlinear function commonly used in modern neural networks, especially in Transformer-based models like BERT. The GeLU is defined as follows:
where
is the cumulative distribution function of a standard Gaussian distribution. Unlike the commonly used ReLU (Rectified Linear Unit) activation function, the GeLU introduces a smooth, probabilistic element into the activation. It computes the expected value of
under the assumption that
follows a Gaussian distribution, which allows the model to make smoother transitions between activated and non-activated states. This makes the GeLU particularly effective in handling more complex, nonlinear data. Through this concatenated convolution design, our processed model can more effectively extract details in time series data, improving the accuracy of metro passenger flow predictions. The framework of our improved TimesNet can be found in
Figure 6.
The system of Equations (19)–(26) corresponds to the operations shown in
Figure 6. Dynamic convolution (Equation (19)) is represented by the parallel convolution layers, followed by aggregation (Equations (20)–(22)) and further processing in the Inception V1 block (Equations (23)–(26)).
Following our improved Inception Block in our I-TimesNet model, the subsequent steps can be described as follows:
The output from the Inception Block, denoted as
, is reshaped to match the original sequence length. This is achieved using a truncation method, represented as follows:
where
and
are the dimensions of the reshaped tensor, and
is the truncation operation to adjust the sequence back to its original length.
The reshaped sequence is then weighted using amplitude values derived from a softmax operation:
The final one-dimensional sequence,
, is obtained by aggregating the weighted sequences:
The processed sequence data undergo a final stage of transformation before prediction. Initially, the data are reshaped to align with the requirements of the model’s subsequent components, ensuring the preservation of its temporal structure. This reshaping is achieved through a truncation method that adjusts the sequence length back to its original dimensions. Following this, the sequence is weighted using amplitude values derived from a softmax operation, which balances the contributions of different components within the sequence. This weighted sequence is then subjected to a softmax function to generate the predicted outcomes. This combined step of weighting and prediction encapsulates the final processing stage, enabling our improved TimesNet model to produce accurate predictions by effectively leveraging the temporal features of the metro passenger flow data.
2.5. SARIMA Module
In the context of our proposed method, the SARIMA module can be defined by a mathematical formula that represents its components: autoregressive (AR), differencing (I), moving average (MA), and the seasonal components of each. The generic form of a SARIMA model is typically denoted as follows:
where p is the number of autoregressive terms, d is the number of non-seasonal differences needed for stationarity, q is the number of lagged forecast errors in the prediction equation, P is the number of seasonal autoregressive terms, D is the number of seasonal differences, Q is the number of seasonal moving average terms, and s is the number of periods in a season. Even in seasonally inactive scenarios, Equation (30) provides a general framework that ensures the model is robust across various datasets, including those where seasonality is not a major factor. It serves as a baseline for comparing more complex, seasonally active systems.
Specifically, within our model, the formula for the SARIMA module can be expressed as follows:
where
represents the non-seasonal autoregressive operator,
presents the non-seasonal moving average operator,
is the seasonal moving average operator,
is the time series being modeled, and
is the white noise series.
The above equation can be further decomposed into the following:
For the SARIMA module proposed in this paper, its establishment mainly includes the following steps:
(1) Model identification: According to the training dataset, the appropriate parameters for the corresponding IMFs are automatically determined. This process is automatically completed by fitting various combinations of ARIMA models for different orders and seasonal orders . The models are evaluated based on a given information criterion (the Akaike Information Criterion), and the model with the lowest criterion value is selected.
(2) Using the parameters determined in the previous step, future values of the time series X are predicted with the SARIMA model. The prediction is conducted in a rolling forecast manner, that is, predicting a certain number of future steps, with the model being updated with new data at each step.
(3) The model is continuously predicted and updated upon the receipt of new data. This iterative process continues until predictions have been made for the entire forecast range.
We also considered several boundary conditions during the application of the SARIMA model to ensure the accuracy and relevance of the predictions. These boundary conditions include the following:
- (1)
Stationarity: The SARIMA model assumes that the time series data are stationary. To satisfy this condition, we employed the auto arima function, which automatically determines the differencing required to achieve stationarity if the raw data exhibit non-stationary behavior.
- (2)
Autocorrelation: The autoregressive component of the SARIMA model requires that the time series data exhibit significant autocorrelation. Through the model selection process, auto arima tests various parameter combinations to ensure that the chosen model has sufficient autocorrelation for effective forecasting.
- (3)
Short-term seasonality: We explicitly modeled short-term seasonality by specifying a weekly cycle (m = 7). This reflects the recurring patterns in subway passenger flow that occur within a week, such as weekday versus weekend differences. The seasonal component of the SARIMA model captures these variations to improve forecast accuracy.
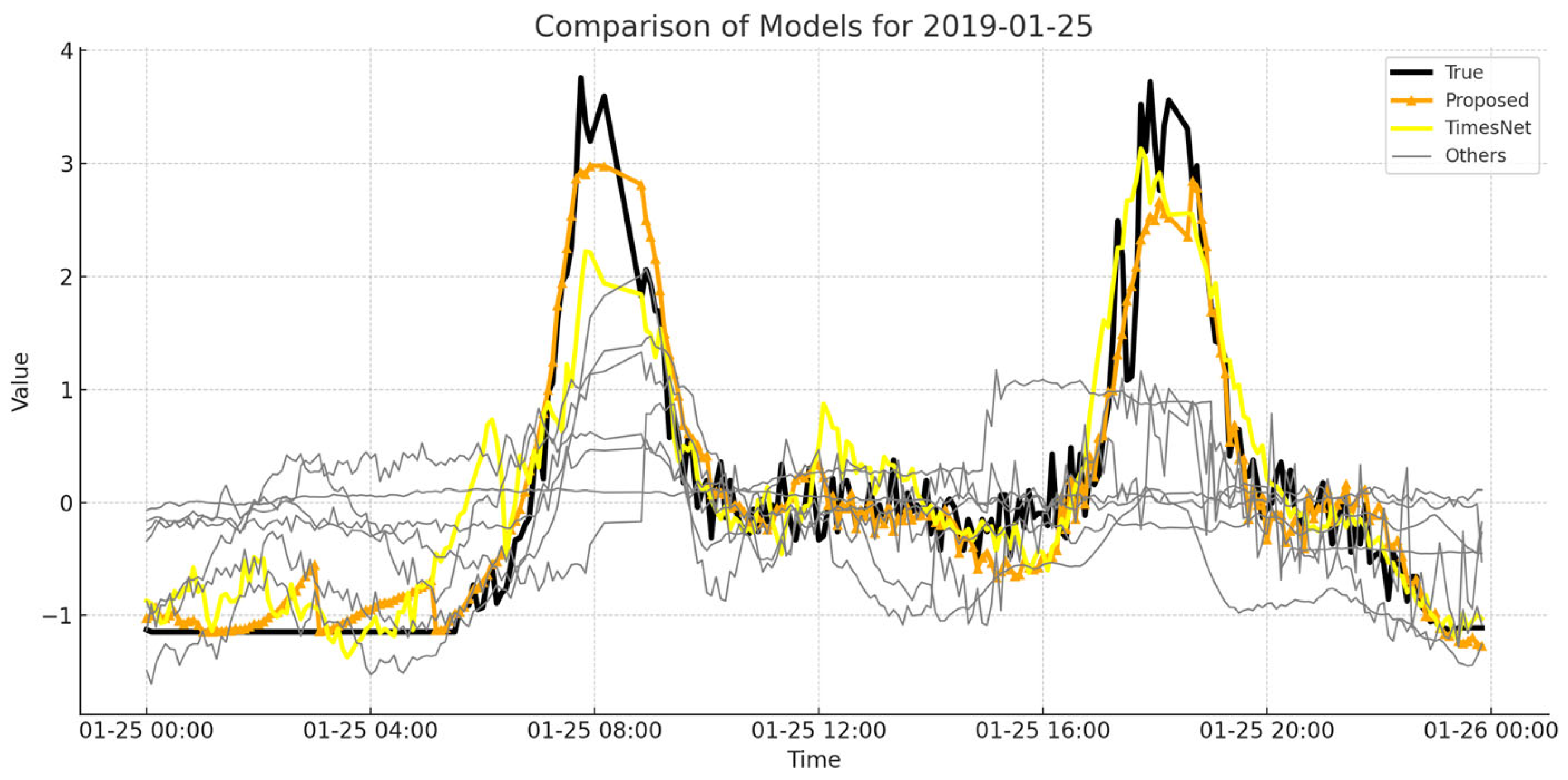
In summary, in this paper, the original subway passenger flow data are first decomposed into multiple Intrinsic Mode Functions (IMFs) using the VMD method. In the seasonal detection module, IMFs exhibiting significant seasonal variations are selectively input into the SARIMA model for forecasting. Meanwhile, the remaining IMFs are input into the Timesblock module and eventually reshaped to obtain the final forecast results. The processing of the original data by VMD allows for the deeper information of the subway passenger flow data to be further mined; the introduction of the SARIMA module enables the forecasting model to better handle the IMFs of subway passenger flow data with seasonal variations, thereby enhancing the accuracy of the forecast. The improved TimesNet model will enhance its predictive performance, allowing for the more precise forecasting of subway passenger flow operations.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}