
Sub-Pixel Displacement Measurement with Swin Transformer: A Three-Level Classification Approach


Abstract
1. Introduction
- A Swin Transformer-based sub-pixel displacement measurement method (ST-SDM) is proposed, which avoids the traditional dependencies on interpolation methods, image gradient calculations, initial value estimations, and iterative calculations. The proposed method significantly enhances the efficiency and accuracy of sub-pixel displacement calculations.
- A square dataset expansion method is introduced to rapidly expand the training dataset for the deep learning model. This method facilitates the rapid augmentation of training data, ensuring that the model is exposed to a diverse and comprehensive training dataset.
- The accuracy and robustness of the ST-SDM model is validated through both simulation experiments and real rigid body experiments. These experiments demonstrate the proposed model’s high accuracy, calculation precision, and efficiency, confirming its effectiveness in practical applications.
2. Related Work
2.1. Principle of Sub-Pixel Shift Search
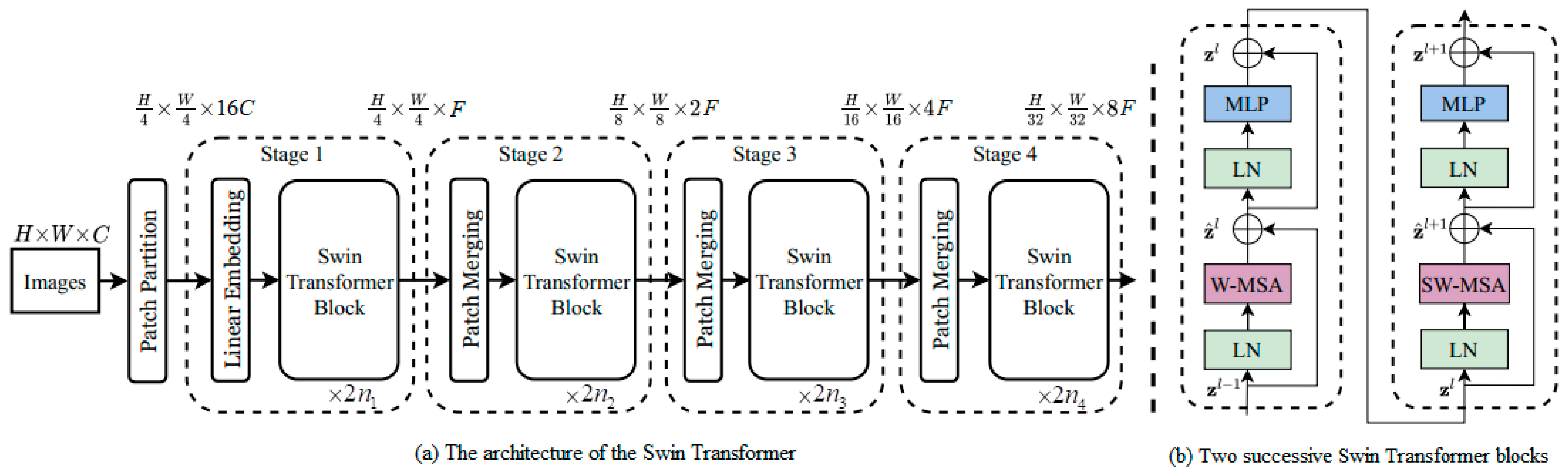
2.2. Swin Transformer
3. Swin Transformer-Based Sub-Pixel Displacement Measurement Method
3.1. Three-Level Classification Method for Calculating Sub-Pixel Displacement
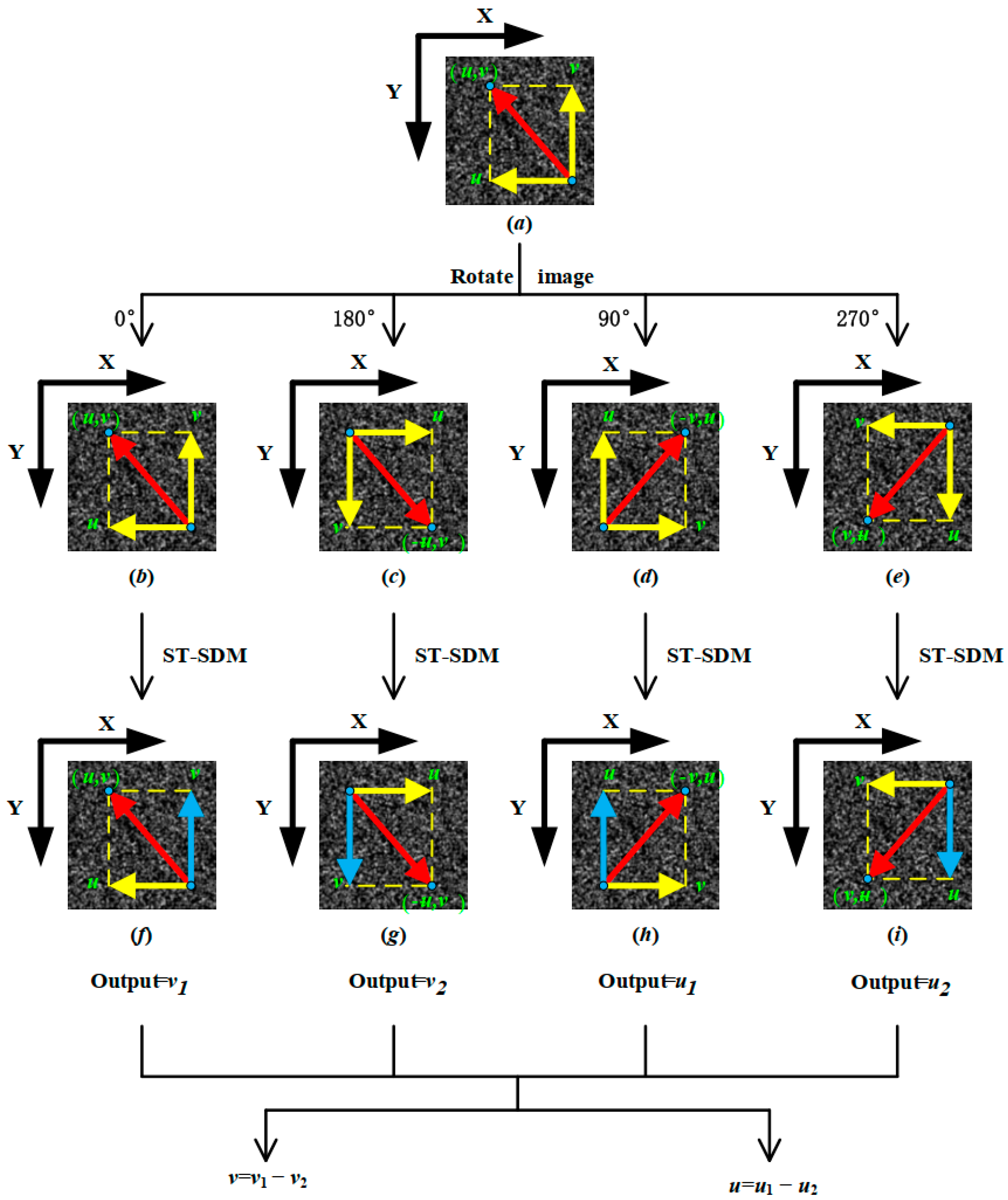
3.2. Rotation-Relative Labeled Value Method
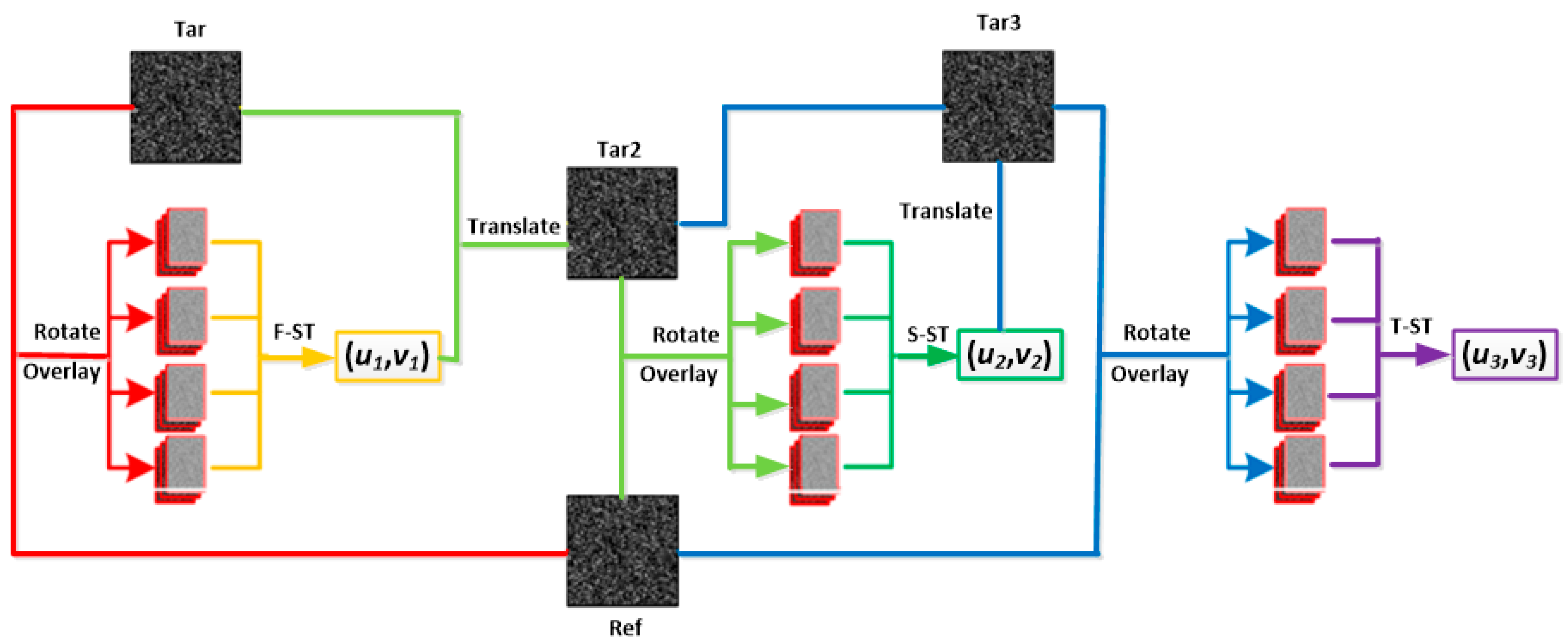
3.3. The Process of the ST-SDM
4. Experiments and Discussions
4.1. Evaluation Metrics
4.2. Simulated Speckle Image Experiments
4.2.1. Simulated Speckle Image Generation
- (1)
- Translation Dataset Generation Method: First, speckle images are generated using the method described earlier, and one of them is randomly selected as the reference image. Next, the selected speckle image is translated to the right along the horizontal direction in steps of 0.01 pixels for a total of 100 steps, generating 100 target images. Finally, using the square dataset expansion method described in Section 4.3.1, the translation dataset is expanded, resulting in a total of 80,200 speckle images.
- (2)
- Stretching Dataset Generation Method: First, speckle images are generated using the method described earlier, and 50 of them are randomly selected as reference images. Next, the selected speckle images are stretched in the horizontal direction with and using Equation (7), and the stretched speckle images are used as target images. Finally, using the square dataset expansion method described in Section 4.3.1, the stretching dataset is expanded, resulting in a total of 20,100 speckle images.
- (3)
- Experimental Dataset Composition: The datasets obtained from the above two steps are combined to form the complete experimental dataset. Of the sample data, 80% are used for training, and the remaining 20% are used for testing.
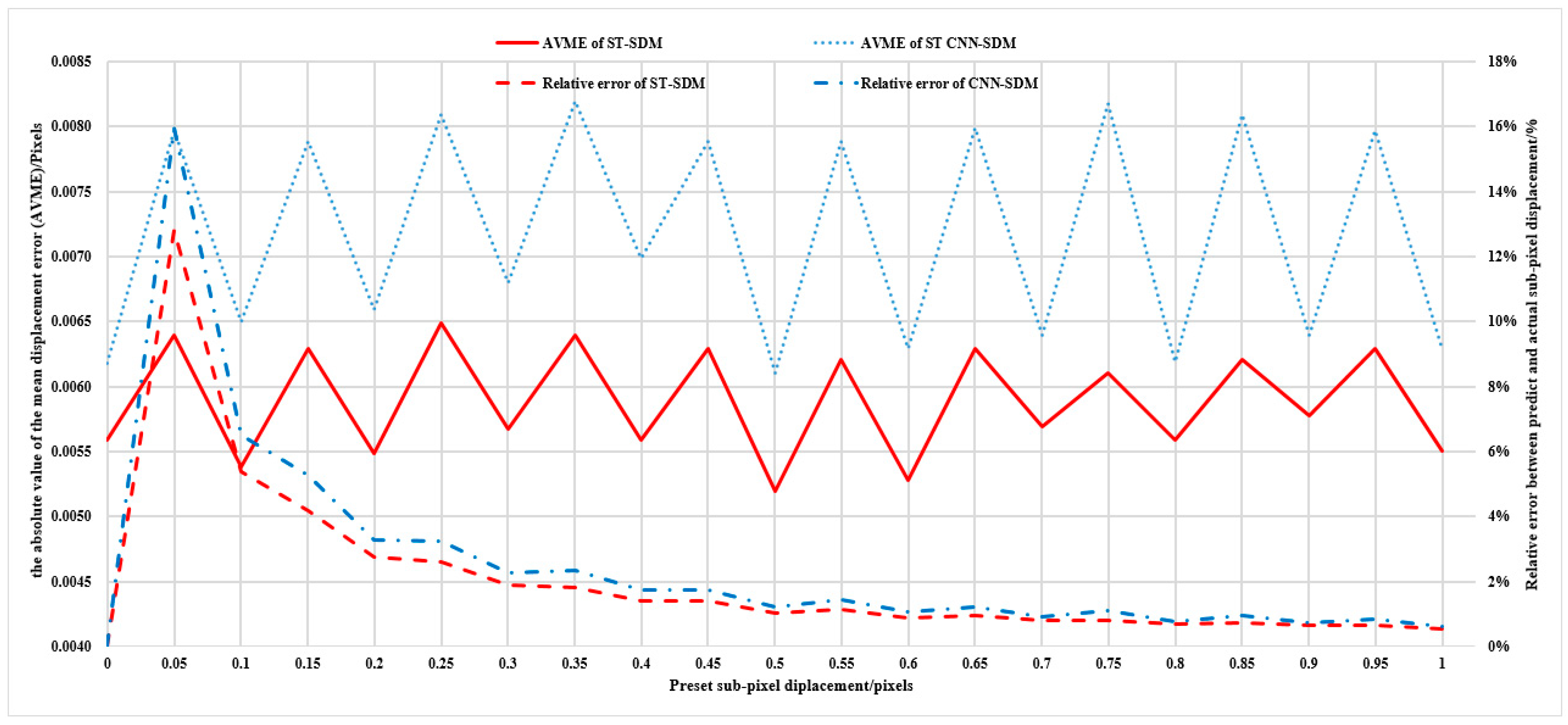
4.2.2. Comparative Analysis of Model Accuracy
4.2.3. Comparative Analysis of Model Calculation Accuracy
4.2.4. Comparative Analysis of Model Computational Efficiency
4.3. Real Rigid Body Translation Experiments
4.3.1. Square Dataset Expansion Method
4.3.2. Experimental Composition and Experimental Procedure
- We made speckles on the glasses. While keeping the spray gun at a constant distance from the glass and perpendicular to it, the matte black paint was uniformly sprayed on the surface of the cleaned glasses to form randomly distributed and uniformly sized speckles on it.
- We prepared the experimental setup. Firstly, the glasses with speckles were fixed on the holder, then the electronically controlled translation stage and the light source equipment were fixed on the optical platform, and finally the CCD camera was fixed on the electronically controlled translation stage.
- We determined the pixel equivalent of the camera system, which is 0.400 mm/pixel in this experiment.
- We obtained the speckle image before displacement. Without applying any displacement, the first speckle images of sizes of 512 pixels ×512 pixels were obtained with the CCD camera, as shown in Figure 11.
- We obtained the speckle image after displacement. Displacement in the direction was applied to the electronically controlled translation stage for 10 steps of 0.1 mm each, and 10 scatter plots were obtained with the CCD camera, each of which had a size of 512 pixels ×512 pixels.
- We conducted the segmentation of speckle images. In order to generate enough training samples, the speckle image before displacement and the speckle image after displacement were divided. The segmentation method is as follows: for each speckle image, with a spacing of 30 pixels in the direction, take an image of a size of 64 pixels × 64 pixels as a sub speckle image, and 15 × 15 = 225 sub speckle images can be obtained. The sub speckle images obtained from the speckle image before displacement were used as the reference images, and the sub speckle images obtained from the speckle image after displacement were used as the target images.
- We generated the dataset. The images obtained in the previous step were expanded using the square dataset expansion method proposed in the previous section, and finally sample data were obtained. We used 80% of the sample data for training and the remaining 20% for testing.
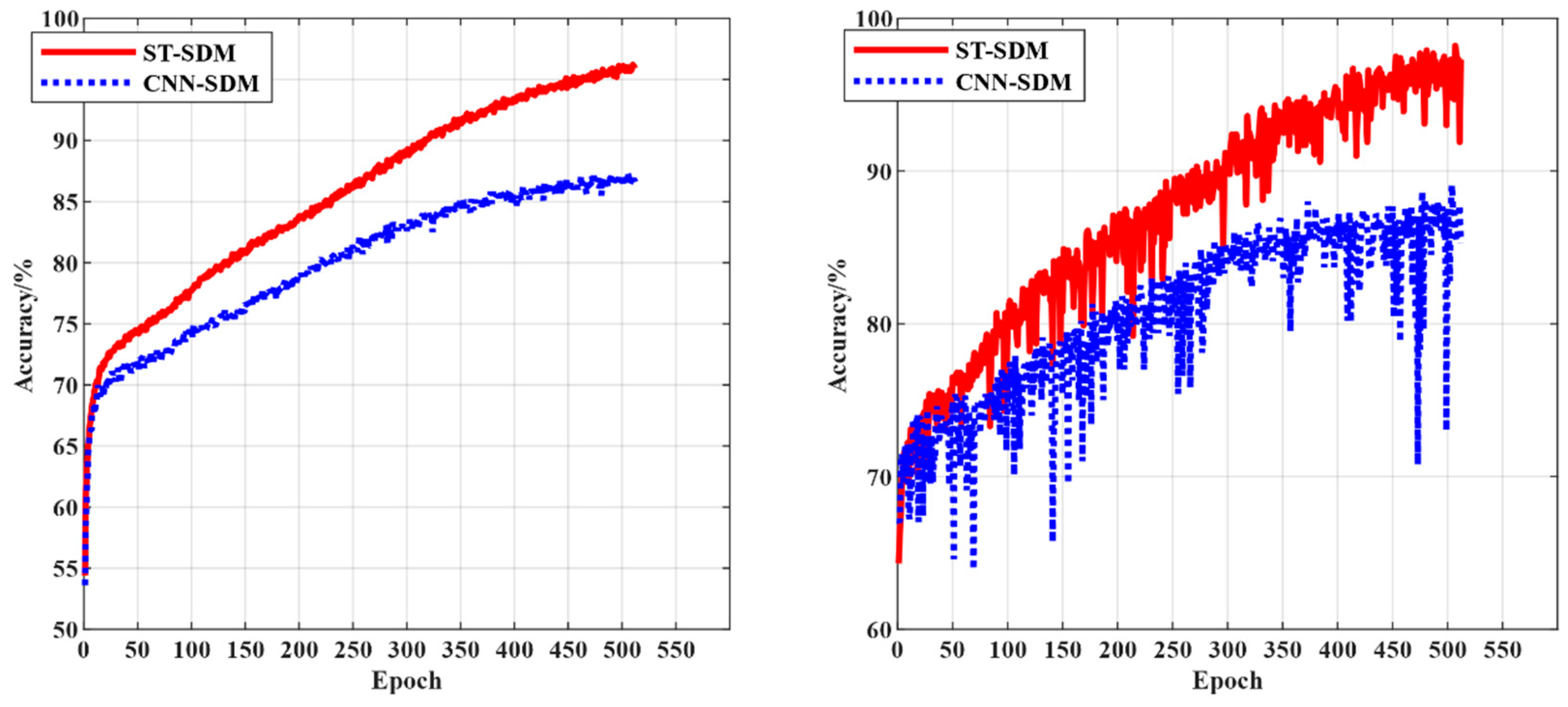
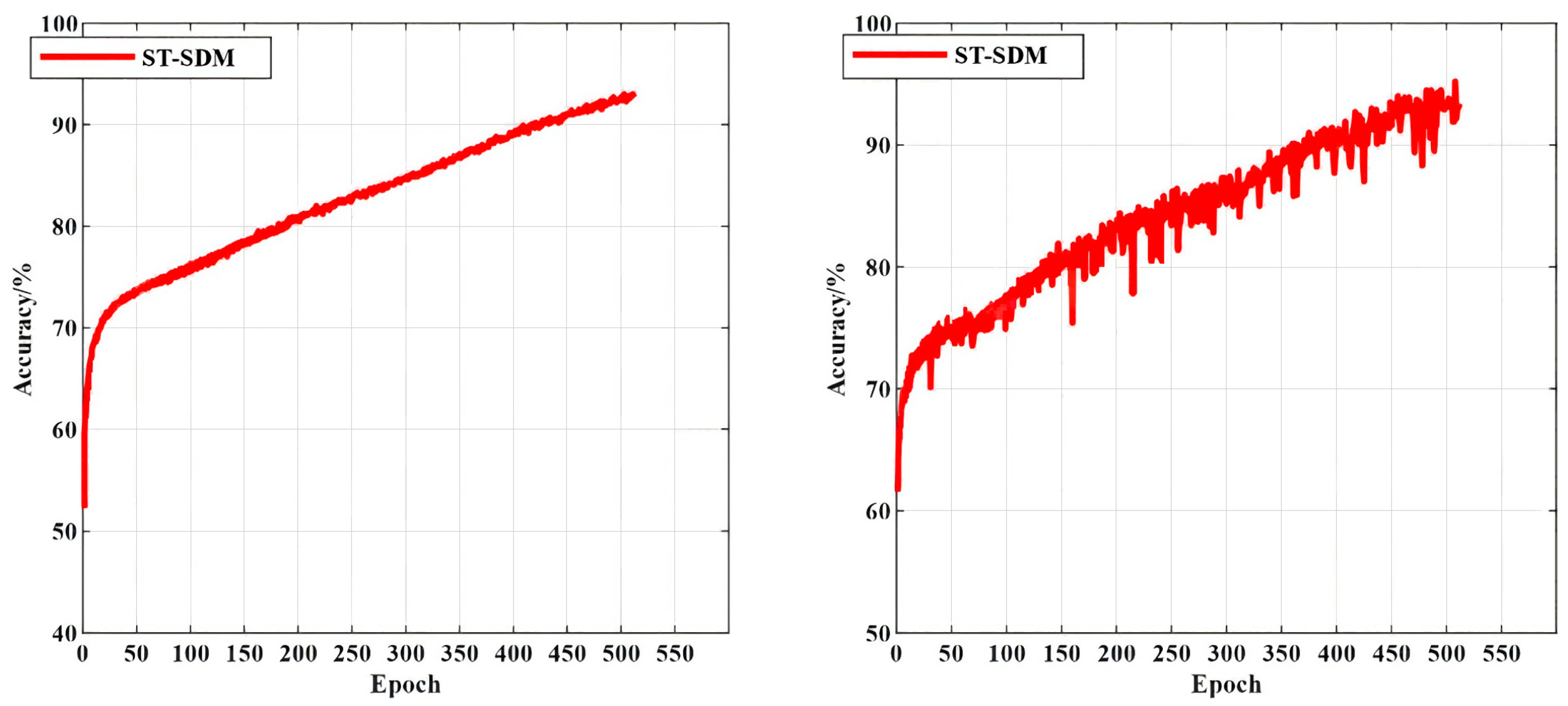
- We conducted a comparison experiment. The ST-SDM model and the CNN-SDM model were trained and tested, respectively, and the experiment results are shown in Figure 12.
4.3.3. Comparative Experimental Analysis
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peters, W.H.; Ranson, W.F. Digital Imaging Techniques in Experimental Stress Analysis. Opt. Eng. 1982, 21, 427–431. [Google Scholar] [CrossRef]
- Chen, D.J.; Chiang, F.P.; Tan, Y.S.; Don, H.S. Digital speckle-displacement measurement using a complex spectrum method. Appl. Opt. 1993, 32, 1839. [Google Scholar] [CrossRef] [PubMed]
- Schreier, H.W.; Sutton, M.A. Systematic errors in digital image correlation due to undermatched subset shape functions. Exp. Mech. 2002, 42, 303–310. [Google Scholar] [CrossRef]
- Wang, H.W.; Kang, Y.L. Improved digital speckle correlation method and its application in fracture analysis of metallic foil. Opt. Eng. 2002, 41, 436–445. [Google Scholar] [CrossRef]
- Tong, X.; Ye, Z.; Xu, Y.; Gao, S.; Xie, H.; Du, Q.; Liu, S.; Xu, X.; Liu, S.; Luan, K.; et al. Image Registration with Fourier-Based Image Correlation: A Comprehensive Review of Developments and Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4062–4081. [Google Scholar] [CrossRef]
- Khoo, S.-W.; Karuppanan, S.; Tan, C.-S. A Review of Surface Deformation and Strain Measurement Using Two-Dimensional Digital Image Correlation. Metrol. Meas. Syst. 2016, 23, 461–480. [Google Scholar] [CrossRef]
- Su, Y.; Zhang, Q.; Xu, X.; Gao, Z. Quality assessment of speckle patterns for DIC by consideration of both systematic errors and random errors. Opt. Lasers Eng. 2016, 86, 132–142. [Google Scholar] [CrossRef]
- Bai, P.; Xu, Y.; Zhu, F.; Lei, D. A novel method to compensate systematic errors due to undermatched shape functions in digital image correlation. Opt. Lasers Eng. 2020, 126, 105907. [Google Scholar] [CrossRef]
- Zhong, F.; Quan, C. Efficient digital image correlation using gradient orientation. Opt. Laser Technol. 2018, 106, 417–426. [Google Scholar] [CrossRef]
- Wang, L.; Bi, S.; Lu, X.; Gu, Y.; Zhai, C. Deformation measurement of high-speed rotating drone blades based on digital image correlation combined with ring projection transform and orientation codes. Measurement 2019, 148, 106899. [Google Scholar] [CrossRef]
- Pan, B.; Li, K.; Tong, W. Fast, Robust and Accurate Digital Image Correlation Calculation Without Redundant Computations. Exp. Mech. 2013, 53, 1277–1289. [Google Scholar] [CrossRef]
- Shao, X.X.; Dai, X.J.; He, X.Y. Noise robustness and parallel computation of the inverse compositional Gauss–Newton algorithm in digital image correlation. Opt. Lasers Eng. 2015, 71, 9–19. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, T.; Jiang, Z.; Kemao, Q.; Liu, Y.; Liu, Z.; Tang, L.; Dong, S. High accuracy digital image correlation powered by GPU-based parallel computing. Opt. Lasers Eng. 2015, 69, 7–12. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, L.; Jiang, Z.; Dong, S.; Chen, W.; Liu, Y.; Liu, Z.; Zhou, L.; Tang, L. Heterogeneous parallel computing accelerated iterative subpixel digital image correlation. Sci. China Technol. Sci. 2018, 61, 74–85. [Google Scholar] [CrossRef]
- Yang, J.; Huang, J.; Jiang, Z.; Dong, S.; Tang, L.; Liu, Y.; Liu, Z.; Zhou, L. SIFT-aided path-independent digital image correlation accelerated by parallel computing. Opt. Lasers Eng. 2020, 127, 105964. [Google Scholar] [CrossRef]
- Chen, Q.; Tie, Z.; Hong, L.; Qu, Y.; Wang, D. Improved Search Algorithm of Digital Speckle Pattern Based on PSO and IC-GN. Photonics 2022, 9, 167. [Google Scholar] [CrossRef]
- Zhou, P.; Goodson, K.E. Subpixel displacement and deformation gradient measurement using digital image/speckle correlation. Opt. Eng. 2001, 40, 1613–1620. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, G.; Ma, S.; Meng, L. Application of an improved subpixel registration algorithm on digital speckle correlation measurement. Opt. Laser Technol. 2003, 35, 533–542. [Google Scholar] [CrossRef]
- Hung, P.C.; Voloshin, A.S. In-plane strain measurement by digital image correlation. J. Braz. Soc. Mech. Sci. Eng. 2003, 25, 215–223. [Google Scholar] [CrossRef]
- Zhao, J.; Zhou, Y.; Zhao, J.; Dong, F.; Jiang, X.; Gong, K. Mover Position Detection for PMSLM Based on Line-Scanning Fence Pattern and Subpixel Polynomial Fitting Algorithm. IEEE/ASME Trans. Mechatron. 2020, 25, 44–54. [Google Scholar] [CrossRef]
- Bruck, H.A.; McNeill, S.R.; Sutton, M.A.; Peters, W.H. Digital Image Correlation Using Newton-Raphson Method of Partial Differential Correction. Exp. Mech. 1989, 29, 261–267. [Google Scholar] [CrossRef]
- Baker, S.; Matthews, I. Equivalence and efficiency of image alignment algorithms. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Sutton, M.A.; Orteu, J.J.; Schreier, H.W. Image Correlation for Shape, Motion and Deformation Measurements: Basic Concepts, Theory and Applications; Springer: New York, NY, USA, 2009; pp. 70–79. [Google Scholar]
- Pitter, M.; See, C.W.; Somekh, M. Subpixel Microscopic Deformation Analysis Using Correlation and Artificial Neural Networks. Opt. Express 2001, 8, 322–327. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Tan, Q. Subpixel In-Plane Displacement Measurement Using Digital Image Correlation and Artificial Neural Networks. In Proceedings of the 2010 Symposium on Photonics and Optoelectronics SOPO 2010, Chengdu, China, 19–21 June 2010. [Google Scholar] [CrossRef]
- Min, H.-G.; On, H.-I.; Kang, D.-J.; Park, J.-H. Strain Measurement During Tensile Testing Using Deep Learning-Based Digital Image Correlation. Meas. Sci. Technol. 2020, 31, 015014. [Google Scholar] [CrossRef]
- Boukhtache, S.; Abdelouahab, K.; Berry, F.; Blaysat, B.; Grédiac, M.; Sur, F. When Deep Learning Meets Digital Image Correlation-ScienceDirect. Opt. Lasers Eng. 2020, 136, 106308. [Google Scholar] [CrossRef]
- Huang, J.; Sun, C.; Lin, X. Displacement Field Measurement of Speckle Images Using Convolutional Neural Network. Acta Opt. Sin. 2021, 41, 2012002. [Google Scholar] [CrossRef]
- Ma, C.; Ren, Q.; Zhao, J. Optical-numerical method based on a convolutional neural network for full-field subpixel displacement measurements. Opt. Express 2021, 29, 9137. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Weng, J.; Shi, Y.; Gu, W.; Mao, Y.; Wang, Y.; Liu, W.; Zhang, J. An Improved Deep Learning Approach for Detection of Thyroid Papillary Cancer in Ultrasound Images. Sci. Rep. 2018, 8, 6600. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of Deep-Learning Approaches for Remote Sensing Observation Enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef]
- Seeja, R.D.; Suresh, A. Deep Learning Based Skin Lesion Segmentation and Classification of Melanoma Using Support Vector Machine (SVM). Asian Pac. J. Cancer Prev. 2019, 20, 1555–1561. [Google Scholar] [CrossRef]
- Boukhtache, S.; Abdelouahab, K.; Bahou, A.; Berry, F.; Blaysat, B.; Grédiac, M.; Sur, F. A lightweight convolutional neural network as an alternative to DIC to measure in-plane displacement fields. Opt. Lasers Eng. 2023, 167, 107367. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Kim, J.H.; Heo, B.; Lee, J.S. Joint Global and Local Hierarchical Priors for Learned Image Compression. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition CVPR 2022, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision ICCV 2021, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | AVME (×10−3 Pixels) | RMSE (×10−3 Pixels) | |
|---|---|---|---|
| Minimum | Maximum | ||
| SF | 13.80 | 24.9 | 16.00 |
| GC | 6.00 | 13.5 | 8.00 |
| FANR | 1.00 | 4.31 | 1.00 |
| IC-GN | 0.90 | 4.24 | 0.97 |
| IV-ICGN | 0.31 | 3.56 | 0.90 |
| CNN-SDM | 6.10 | 8.20 | 0.84 |
| ST-SDM | 5.20 | 6.50 | 0.42 |
| Sub-Pixel Displacement Measurement Method | ST-SDM | CNN-SDM |
|---|---|---|
| Average time spent per image (S) | 0.106 | 0.368 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Xu, X.; Tie, Z. Sub-Pixel Displacement Measurement with Swin Transformer: A Three-Level Classification Approach. Appl. Sci. 2025, 15, 2868. https://doi.org/10.3390/app15052868
Lin Y, Xu X, Tie Z. Sub-Pixel Displacement Measurement with Swin Transformer: A Three-Level Classification Approach. Applied Sciences. 2025; 15(5):2868. https://doi.org/10.3390/app15052868
Chicago/Turabian StyleLin, Yongxing, Xiaoyan Xu, and Zhixin Tie. 2025. "Sub-Pixel Displacement Measurement with Swin Transformer: A Three-Level Classification Approach" Applied Sciences 15, no. 5: 2868. https://doi.org/10.3390/app15052868
APA StyleLin, Y., Xu, X., & Tie, Z. (2025). Sub-Pixel Displacement Measurement with Swin Transformer: A Three-Level Classification Approach. Applied Sciences, 15(5), 2868. https://doi.org/10.3390/app15052868