
DGBL-YOLOv8s: An Enhanced Object Detection Model for Unmanned Aerial Vehicle Imagery

Abstract
1. Introduction
- (1)
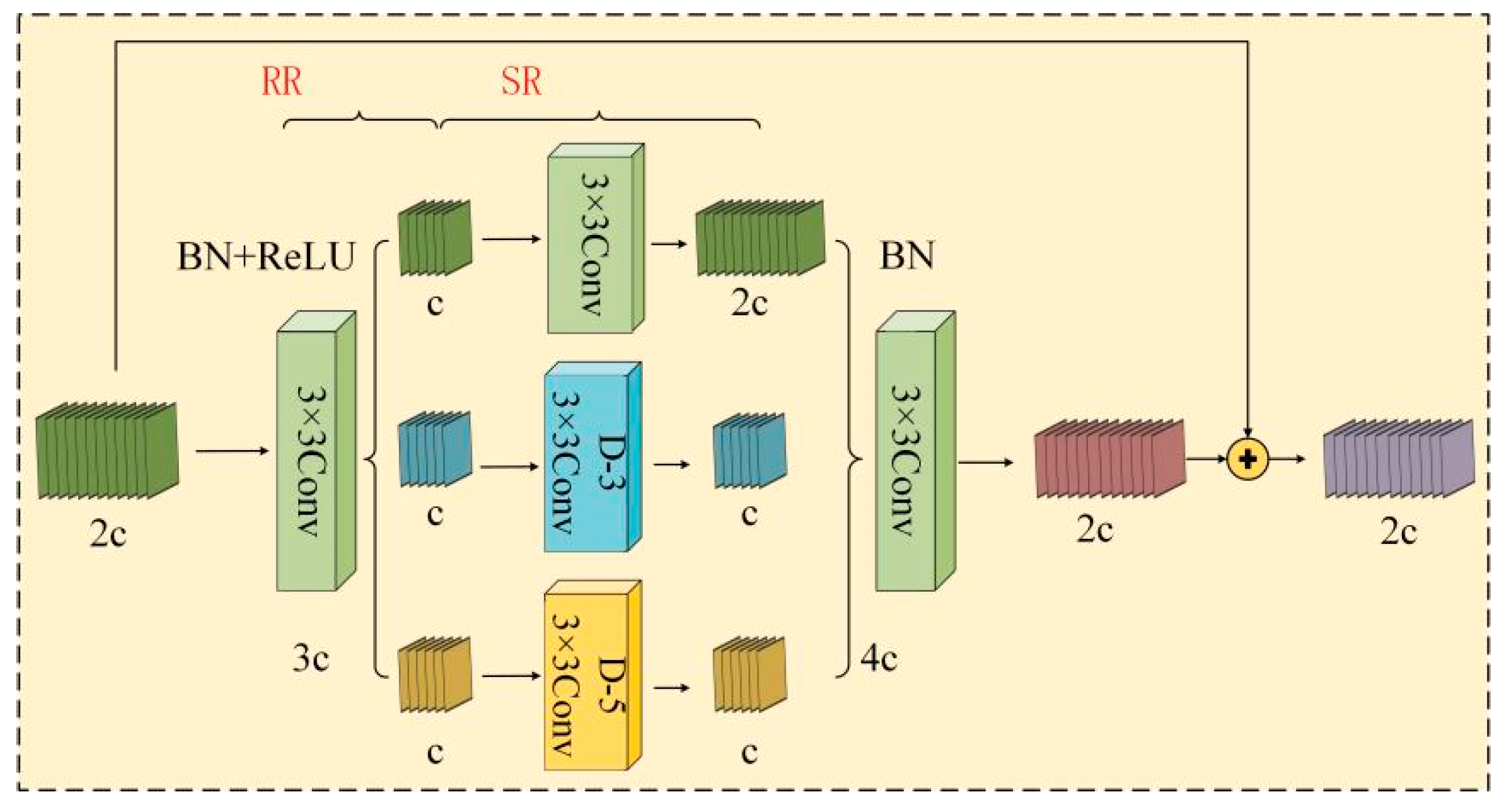
- Based on the Dilation-wise Residual (DWR) module from the DWRSeg network [11], a C2f-DWR module is designed to enhance multi-scale contextual information acquisition. This module enhances the C2f module’s capacity to fuse multi-level feature maps, allowing the model to extract finer target details and richer contextual information.
- (2)
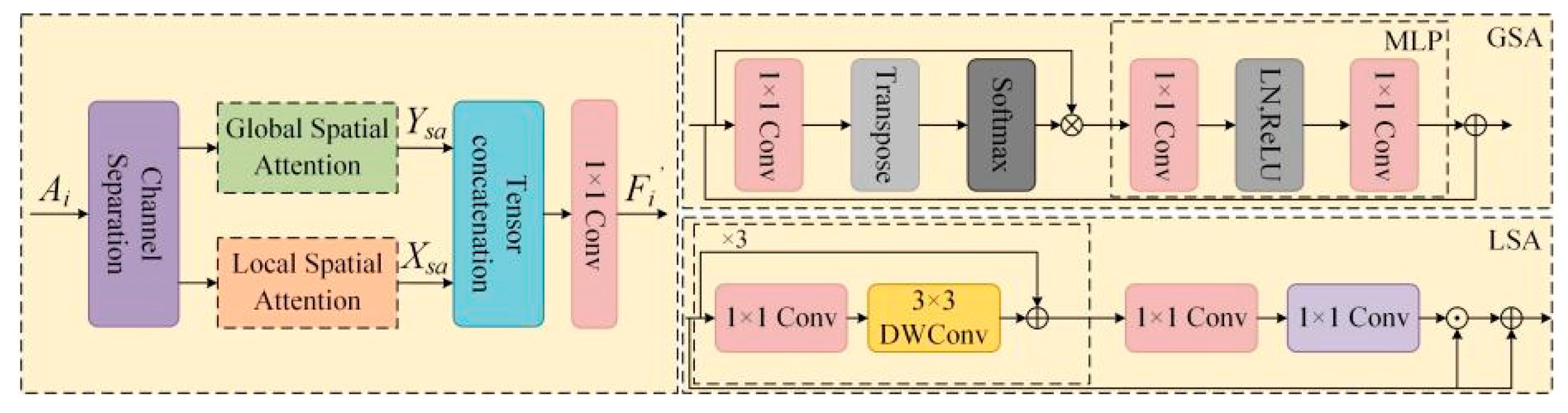
- A Global-to-Local Spatial Aggregation Bidirectional Feature Pyramid Network (GLSA-BiFPN) is designed for the neck structure. This structure combines the Bidirectional Feature Pyramid Network (BiFPN) [12] and the Global-to-Local Spatial Aggregation (GLSA) module [13] to strengthen feature fusion and improve small target detection capabilities.
- (3)
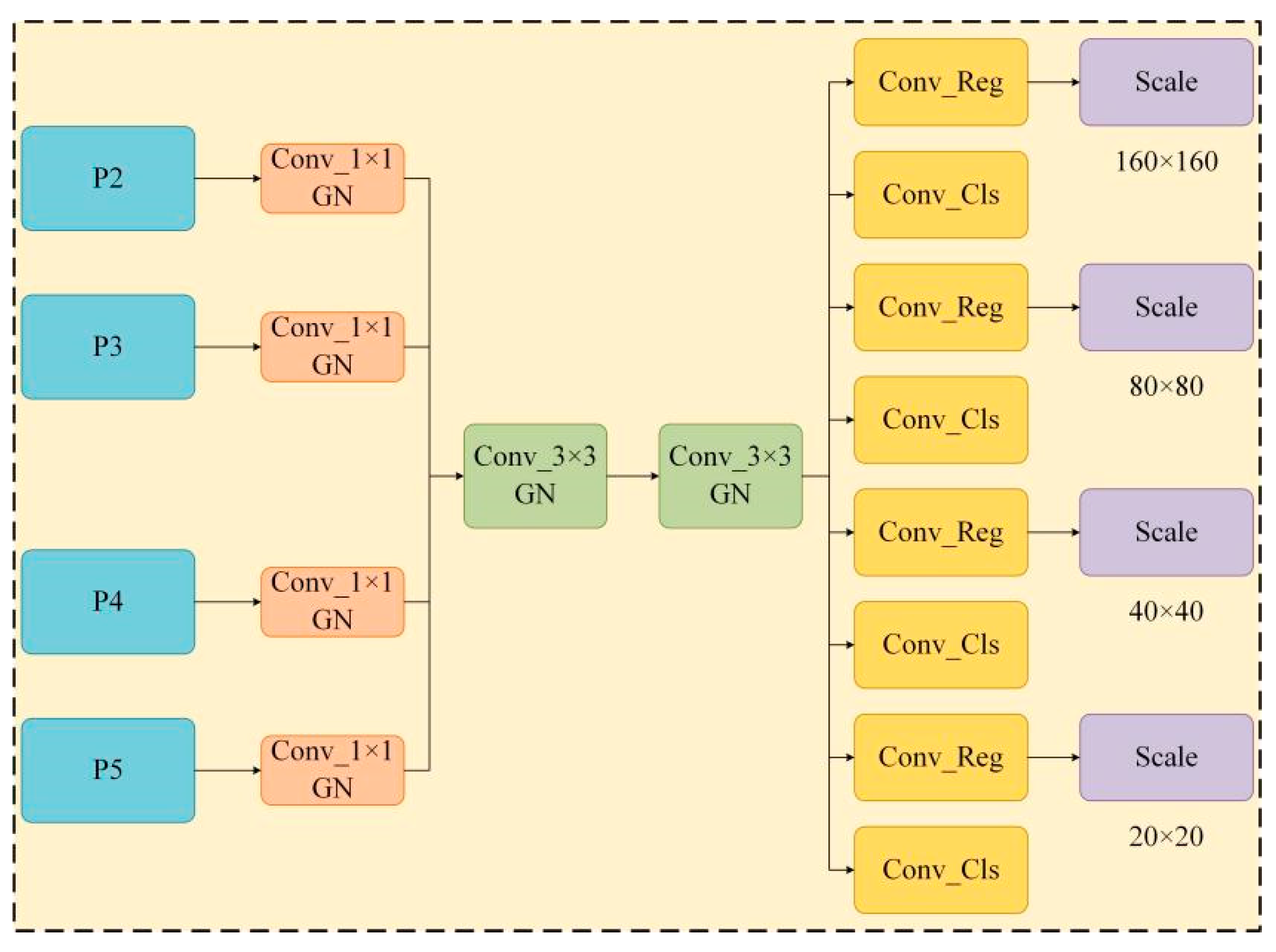
- A lightweight shared convolutional detection head (LSCDH) is constructed based on shared convolution and group normalization (GN) [14], with an additional target detection head. This design enhances the network’s ability to extract shallow information while reducing model parameters.
2. Related Works
2.1. Methods Based on Network Architecture Improvements
2.2. Methods Based on Attention Mechanisms and Feature Enhancement
2.3. Methods Based on Loss Function and Training Strategy Optimization
3. Methods
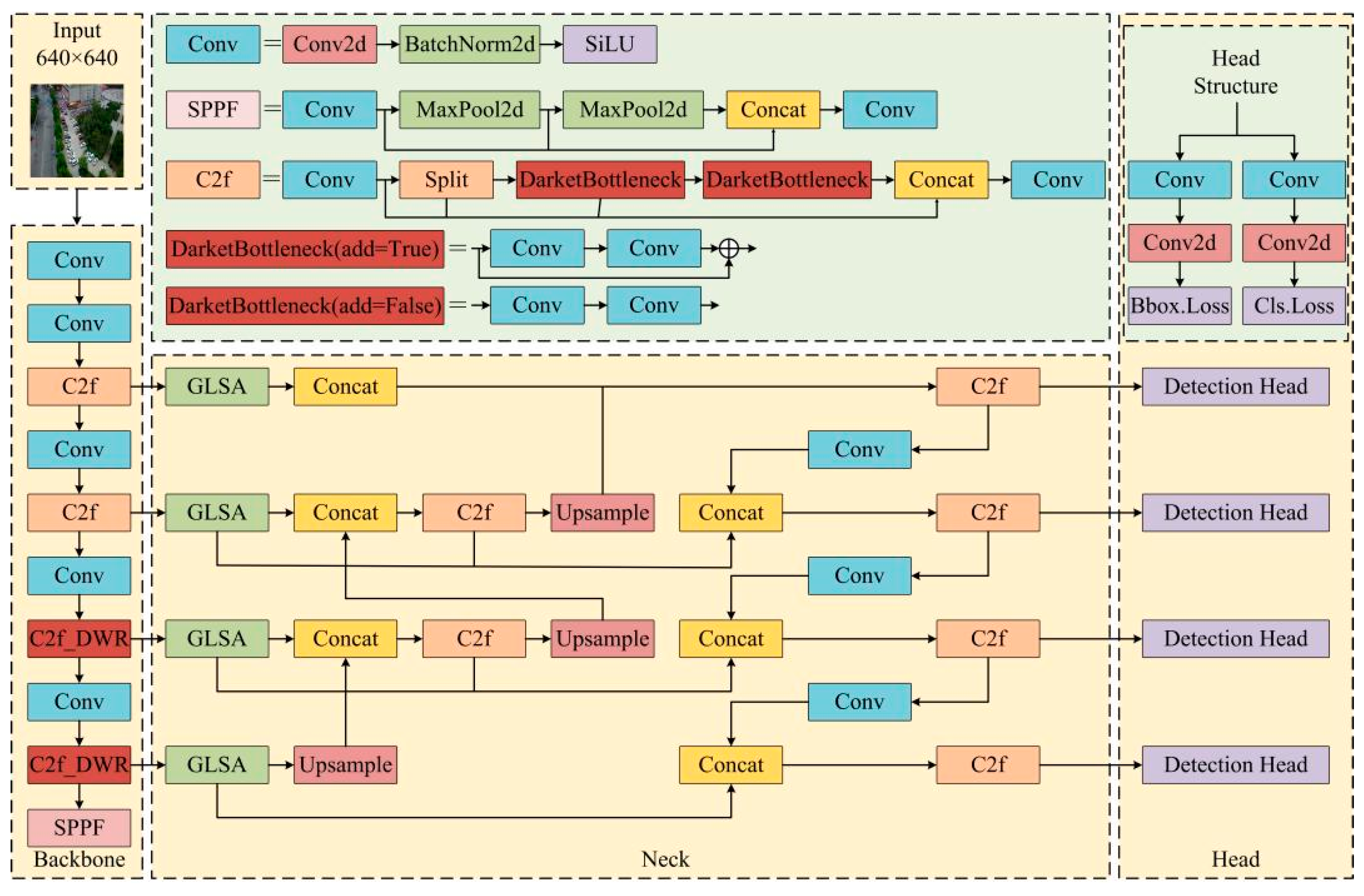
3.1. Introduction of DGBL-YOLOv8 Object Detection Algorithm
3.1.1. The C2f_DWR Module
3.1.2. Structure of the GLBA-BiFPN
3.1.3. Lightweight Shared Convolutional Detection Head
4. Experiment and Result Analysis
4.1. VisDrone2019 Dataset
4.2. Experimental Environment
4.3. Evaluation Index
4.4. Process of Experiment
4.4.1. Ablation Experiment
4.4.2. Comparative Experiments
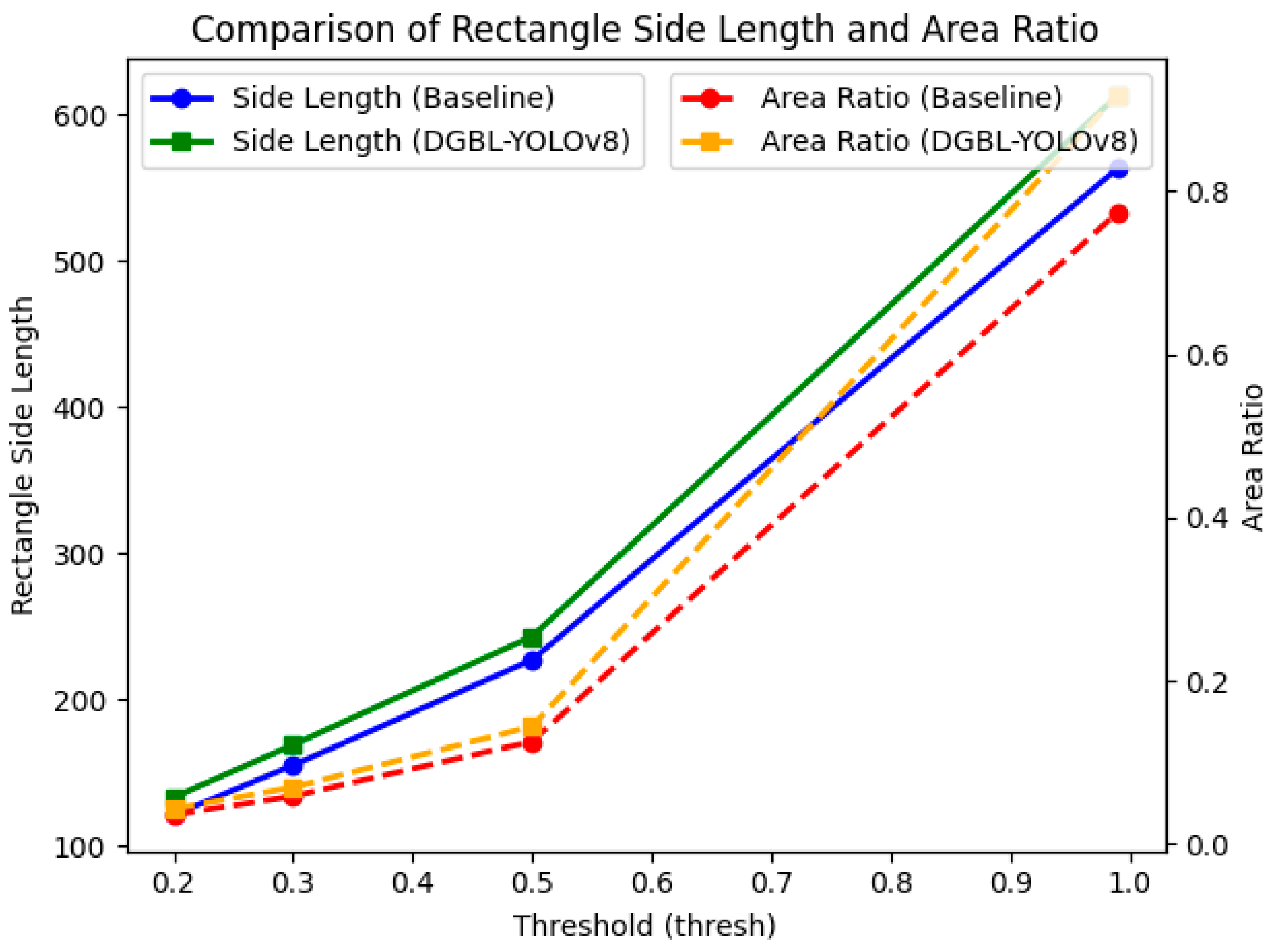
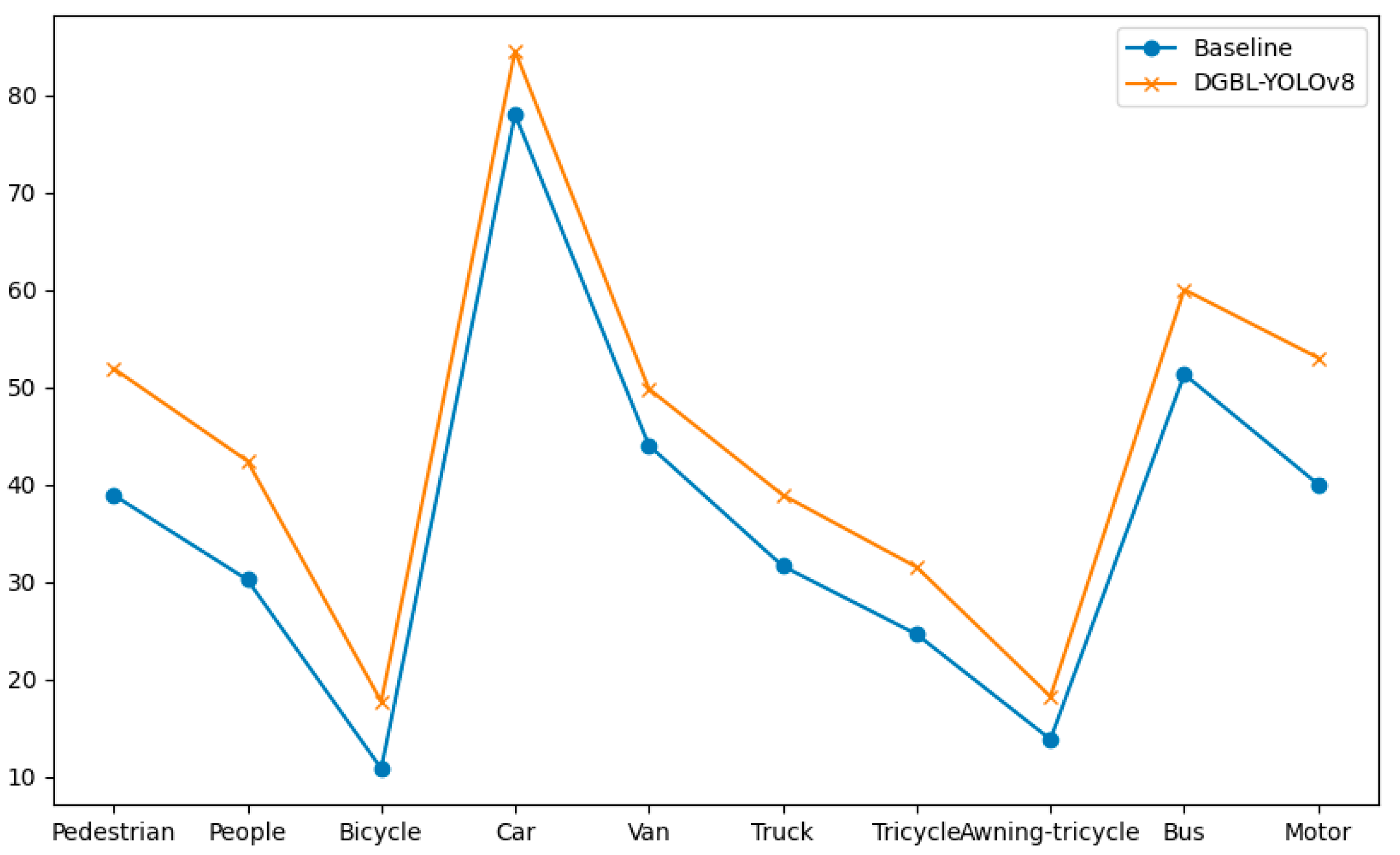
4.5. Analysis of Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mittal, P.; Singh, R.; Sharma, A. Deep learning-based object detection in low-altitude UAV datasets: A survey. Image Vis. Comput. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Lyu, Z.; Jin, H.; Zhen, T.; Sun, F.; Xu, H. Small object recognition algorithm of grain pests based on SSD feature fusion. IEEE Access 2021, 9, 43202–43213. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Wei, H.; Liu, X.; Xu, S.; Dai, Z.; Dai, Y.; Xu, X. DWRSeg: Rethinking Efficient Acquisition of Multi-Scale Contextual Information for Real-Time Semantic Segmentation. arXiv 2022, arXiv:2212.01173. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Tang, F.; Xu, Z.; Huang, Q.; Wang, J.; Hou, X.; Su, J.; Liu, J. DuAT: Dual-aggregation transformer network for medical image segmentation. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Xiamen, China, 13–15 October 2023; pp. 343–356. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. Uav-yolo: Small object detection on unmanned aerial vehicle perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao HY, M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Li, Z.; Fan, B.; Xu, Y.; Sun, R. Improved YOLOv5 for aerial images based on attention mechanism. IEEE Access 2023, 11, 96235–96241. [Google Scholar] [CrossRef]
- Wang, J.; Gao, J.; Zhang, B. A small object detection model in aerial images based on CPDD-YOLOv8. Sci. Rep. 2025, 15, 770. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.D.; Zhen, G.Y.; Chu, C.Q. Unmanned Aerial Vehicle Image Target Detection Algorithm BasedonYOLOv8. J. Comput. Eng. 2024, 50, 113–120. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Computation | |
|---|---|---|
| Standard Convolution | Iin × Iout × m × m | P × Q × Iin × Iout × m × m |
| Depth Convolution | Iin × m × m | P × Q × Iin × m × m |
| Point-wise Convolution | Iin × Iout | Iin × Iout |
| Environment | Type |
|---|---|
| Operation system | Ubuntu 11.4.0 |
| GPU | NVIDIA GeForce RTX 3090 |
| Programming language | Python 3.10.14 |
| CUDA | 12.1 |
| Module platform | Pytorch 2.2.2 |
| IDE platform | Pycharm |
| Parameter Names | Settings |
|---|---|
| Epoch | 100 |
| Pretrain | Closed |
| Input images size | 640 × 640 |
| Batchsize | 16 |
| Workers | 8 |
| lr0 | 0.01 |
| Optimizer | SGD |
| Momentum | 0.937 |
| Weight_decay | 0.0005 |
| Data augmentation | mosaic |
| Baseline | C2f_DWR | GLSA-BiFPN | LSCDH | P/% | R/% | mAP50/% | Para/M | Model Size/MB |
|---|---|---|---|---|---|---|---|---|
| v8s-0 | 47.0 | 35.7 | 36.3 | 11.1 | 21.5 | |||
| v8s-1 | √ | 48.9 | 36.4 | 37.2 | 10.9 | 21.0 | ||
| v8s-2 | √ | 49.0 | 37.5 | 38.0 | 7.9 | 15.5 | ||
| v8s-3 | √ | 52.0 | 41.6 | 42.6 | 9.6 | 18.7 | ||
| v8s-4 | √ | √ | 49.3 | 37.2 | 37.9 | 7.7 | 15.0 | |
| v8s-5 | √ | √ | 50.6 | 41.7 | 42.8 | 9.4 | 18.3 | |
| v8s-6 | √ | √ | 53.9 | 42.9 | 44.7 | 7.4 | 14.7 | |
| v8s-7 | √ | √ | √ | 53.6 | 42.6 | 44.8 | 7.2 | 14.2 |
| Baseline | P/% | R/% | mAP50/% | Para/M | Model Size/MB |
|---|---|---|---|---|---|
| Faster-RCNN | 34.6 | 17.0 | 14.4 | 136.7 | 260.8 |
| SSD | 35.0 | 16.7 | 14.2 | 22.8 | 45.6 |
| YOLOv3-Tiny | 26.3 | 17.4 | 14.6 | 64.4 | 122.8 |
| YOLOv4 | 30.5 | 16.0 | 15.7 | 61.9 | 118.2 |
| YOLOv5 | 43.4 | 34.4 | 32.9 | 7.0 | 16.0 |
| YOLOv8s | 47.0 | 35.7 | 36.3 | 11.1 | 21.5 |
| DGBL-YOLOv8s | 53.6 | 42.6 | 44.8 | 7.2 | 14.2 |
| Number | Baseline | GFLOPs |
|---|---|---|
| I | YOLOv8s | 28.5 |
| II | DWR | 28.1 |
| III | GLSA-BiFPN | 26.7 |
| IV | LSCDH | 45.7 |
| V | DGBL-YOLOv8s | 53.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Yi, H. DGBL-YOLOv8s: An Enhanced Object Detection Model for Unmanned Aerial Vehicle Imagery. Appl. Sci. 2025, 15, 2789. https://doi.org/10.3390/app15052789
Wang C, Yi H. DGBL-YOLOv8s: An Enhanced Object Detection Model for Unmanned Aerial Vehicle Imagery. Applied Sciences. 2025; 15(5):2789. https://doi.org/10.3390/app15052789
Chicago/Turabian StyleWang, Chonghao, and Huaian Yi. 2025. "DGBL-YOLOv8s: An Enhanced Object Detection Model for Unmanned Aerial Vehicle Imagery" Applied Sciences 15, no. 5: 2789. https://doi.org/10.3390/app15052789
APA StyleWang, C., & Yi, H. (2025). DGBL-YOLOv8s: An Enhanced Object Detection Model for Unmanned Aerial Vehicle Imagery. Applied Sciences, 15(5), 2789. https://doi.org/10.3390/app15052789