In this section, we validate the proposed model’s performance by comparing it to several baseline methods, including the Close-In (CI) model, CNN, RNN, GNN, Transformer, and AutoML. Additionally, we evaluate the ensemble models with GA-optimized and PSO-optimized output weights. The goal is to assess the reliability and robustness of the neural network ensemble model optimized by the WOA for path loss prediction in HSR seats. We examine how integrating multiple networks and output weight optimization enhances prediction accuracy. The models are tested on the same dataset, and key performance metrics such as RMSE, MAE, MAPE, and R2 are used for evaluation.
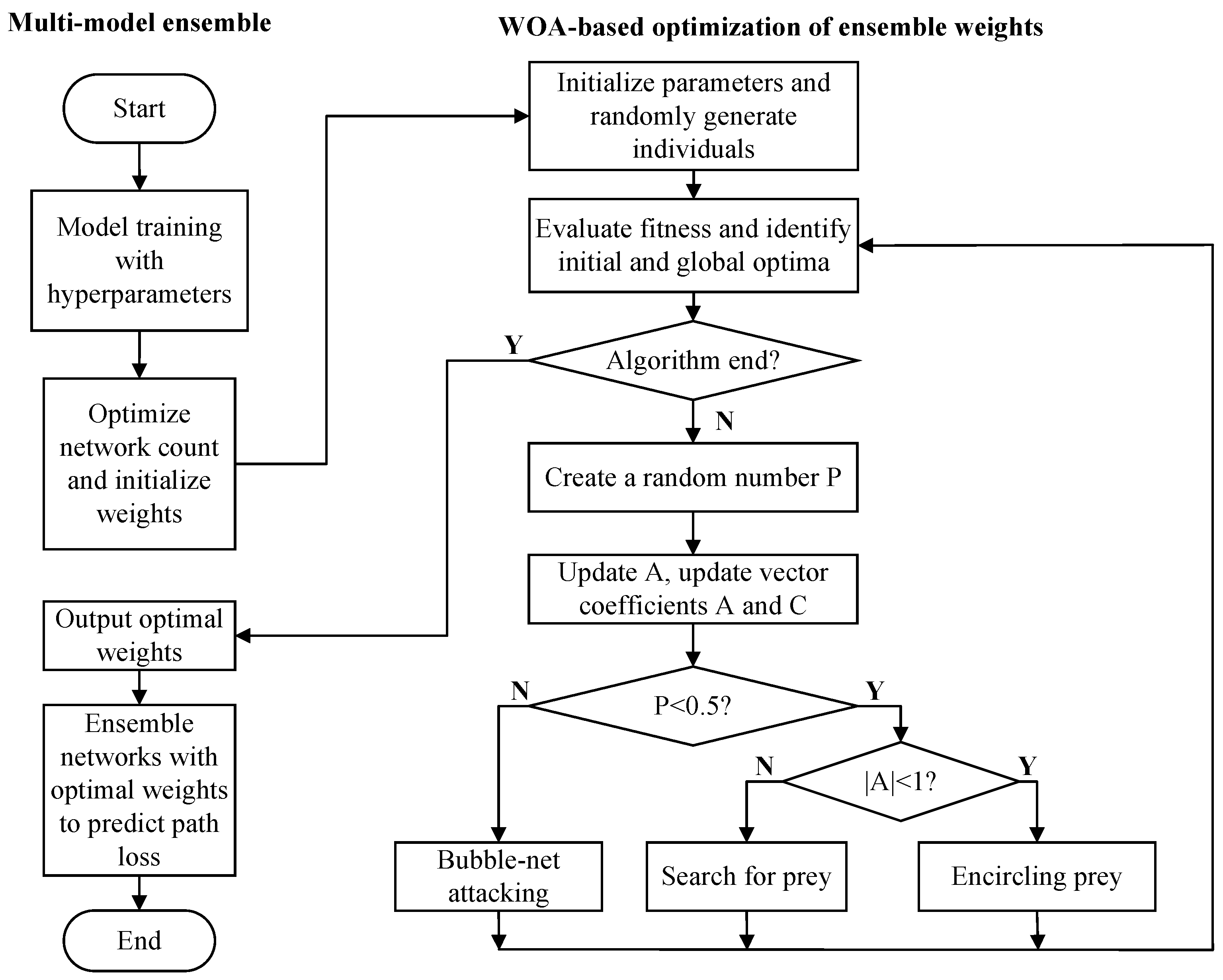
4.1. Optimization and Selection of the Best Neural Network Ensemble
To ensure reliable model evaluation, we divide the high-precision dataset into three subsets: the training set (80%), the validation set (10%), and the test set (10%). All data is normalized using min-max normalization, mapping input and output variables to the range [0, 1]. The mean and standard deviation of each feature were calculated across all sets to confirm consistent distributions. Additionally, a K-S test was performed, and the p-values were found to be greater than 0.05, indicating no significant differences between the sets and validating the balanced data split.
In addition, K-Fold Cross-Validation is applied to enhance generalization assessment. The training set is split into K non-overlapping subsets, with one subset used for validation and the remaining K-1 subsets for training. This process is repeated K times, and the final evaluation metric is obtained by averaging the results across all iterations. This approach reduces bias from a single dataset split and provides a more robust performance assessment. This study sets K to 5 and selects the model that achieves the best performance across evaluation metrics.
During training, key strategies are implemented to ensure efficient and accurate convergence. The optimizer is used with an adaptive learning rate, starting at 0.01, which adjusts automatically to improve convergence and avoid local optima. Early stopping is applied, terminating training if the validation loss does not decrease for five consecutive epochs, preventing overfitting while maintaining computational efficiency. To further enhance generalization, L2 regularization (weight decay) with a coefficient of 0.0001 is introduced to penalize large weights, promoting smoother weight distribution.
The choice of activation function plays a crucial role in the model’s learning ability, influencing convergence speed and accuracy. Comparative experiments on the proposed model show that while ReLU helps mitigate the vanishing gradient problem and accelerates early convergence, tanh ultimately delivers superior overall performance. Specifically, compared to ReLU, tanh reduces RMSE and MAE by 0.44 dB and 0.43 dB, respectively, lowers MAPE by 0.43%, and improves R2 by 0.08. Based on these findings, tanh is selected as the activation function for this study.
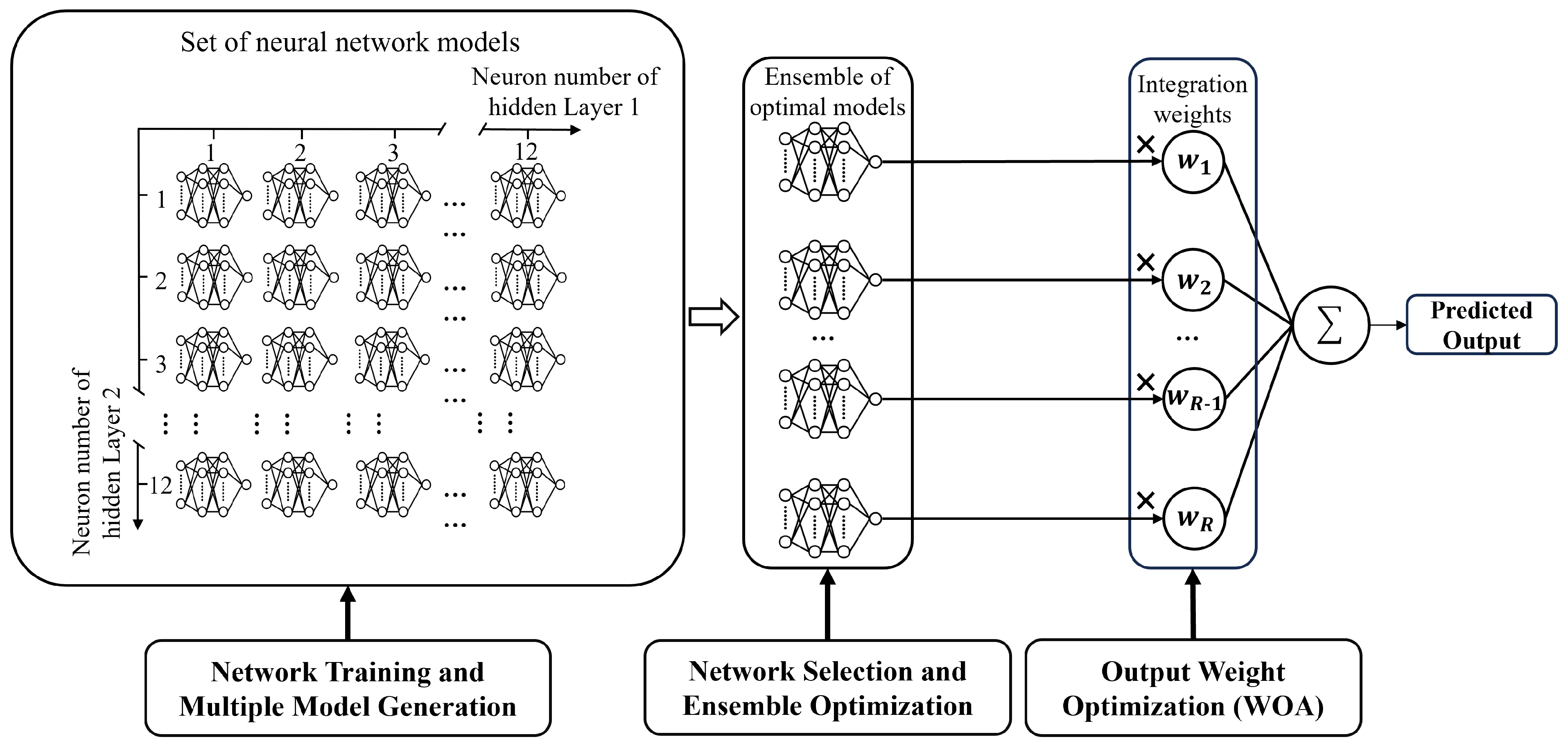
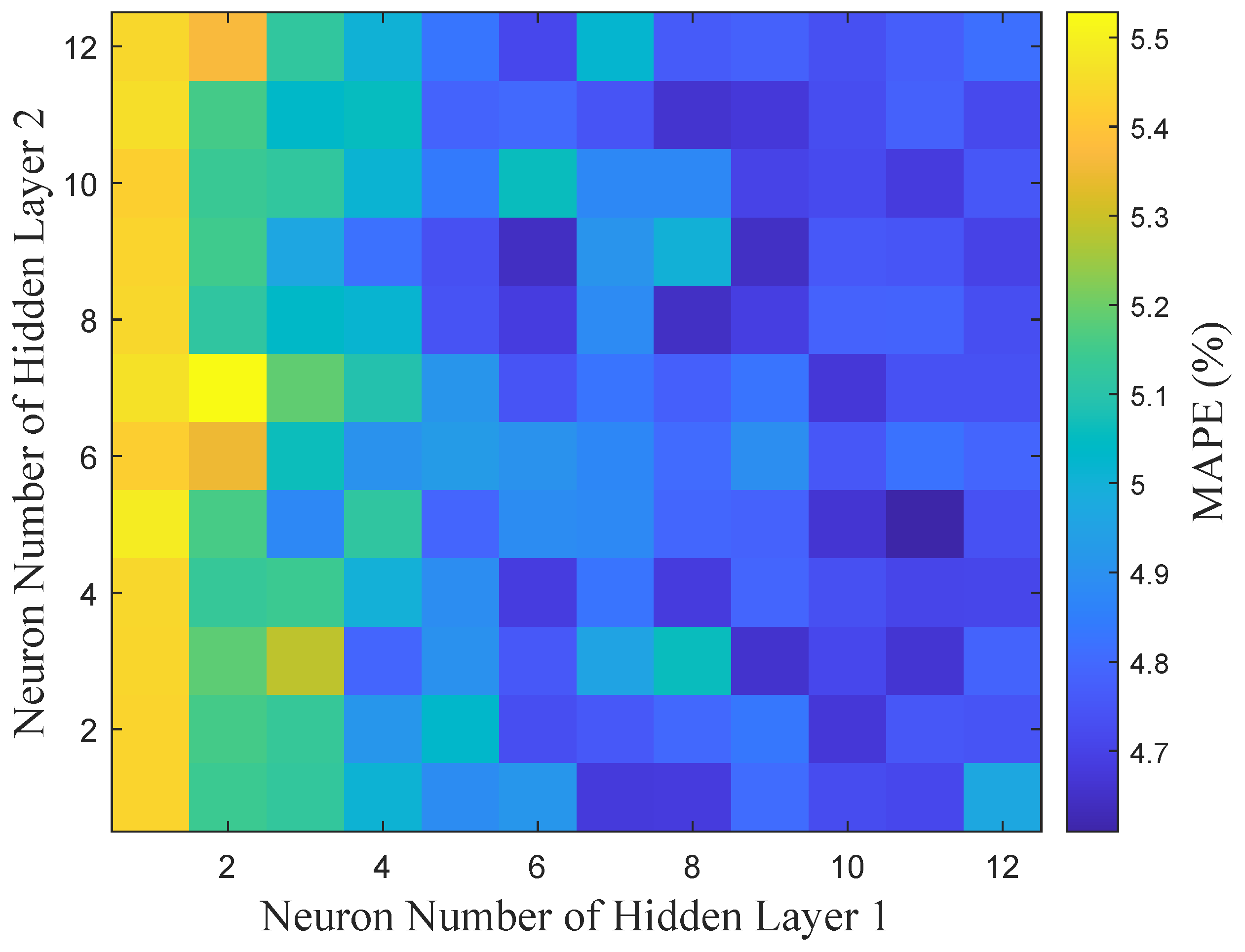
After performing cross-validation, the model is further refined by exploring different network architectures. The experiments compared the performance of models with one, two, and three hidden layers, revealing that while adding a second hidden layer improved performance, further layers led to diminishing returns and overfitting. Therefore, a two-hidden-layer architecture was selected for the final model. Based on empirical guidelines [
36], each hidden layer consists of a maximum of 12 neurons. This results in 144 distinct neural network configurations generated through various combinations of hyperparameters. These models are trained and evaluated on the model selection and ensemble optimization set to identify the best-performing architecture. The performance distribution of these 144 models is shown in
Figure 9.
The number of neurons in the hidden layers plays a crucial role in determining the model’s complexity and learning capacity. More neurons allow the model to capture intricate features but increase the risk of overfitting, while fewer neurons may lead to insufficient feature learning, affecting prediction accuracy. This trade-off explains the variations in MAPE performance observed in
Figure 9.
As shown in
Table 3, the performance of the neural network ensemble model under different hidden layer configurations is presented in detail. While the number of neurons does affect model performance, increasing the number of neurons does not always lead to improved performance. This suggests that model performance depends not only on the number of neurons but also on structural complexity and overfitting control. Too many neurons can introduce unnecessary complexity, reducing generalization ability and degrading performance. Therefore, balancing model complexity and generalization is crucial for optimizing neural network design.
Based on the above results, this study further explores the effect of using the average ensemble strategy (i.e., taking the average of the prediction results of multiple networks) under different neural networks to find the optimal number of neural networks. The basic idea of the average integration strategy is that by combining the prediction results of multiple neural networks, the uncertainty and volatility of the prediction of a single network can be reduced, thus improving the generalization ability and prediction accuracy of the whole model. As shown in
Figure 10.
As the number of ensemble networks increases, model diversity initially improves, enhancing feature representation and reducing MAPE. However, an excessive number of networks increases computational complexity and the risk of overfitting, which may lead to performance degradation. The results demonstrate that the optimal balance between diversity and complexity is achieved with four networks, where the lowest MAPE is observed. Therefore, this study sets the number of integrated neural networks to four to ensure optimal performance and generalization ability.
4.2. WOA-Based Output Weight Optimization
In path loss prediction, integrating multiple neural network models improves prediction accuracy, and further enhancement of overall performance can be achieved by optimizing the weight combinations of these models. The WOA used in this study configures the output weights of the models to effectively reduce prediction error. The optimized weights are applied to the integrated model and validated on the test set to further confirm its applicability in real-world scenarios. The algorithm parameters are shown in
Table 4.
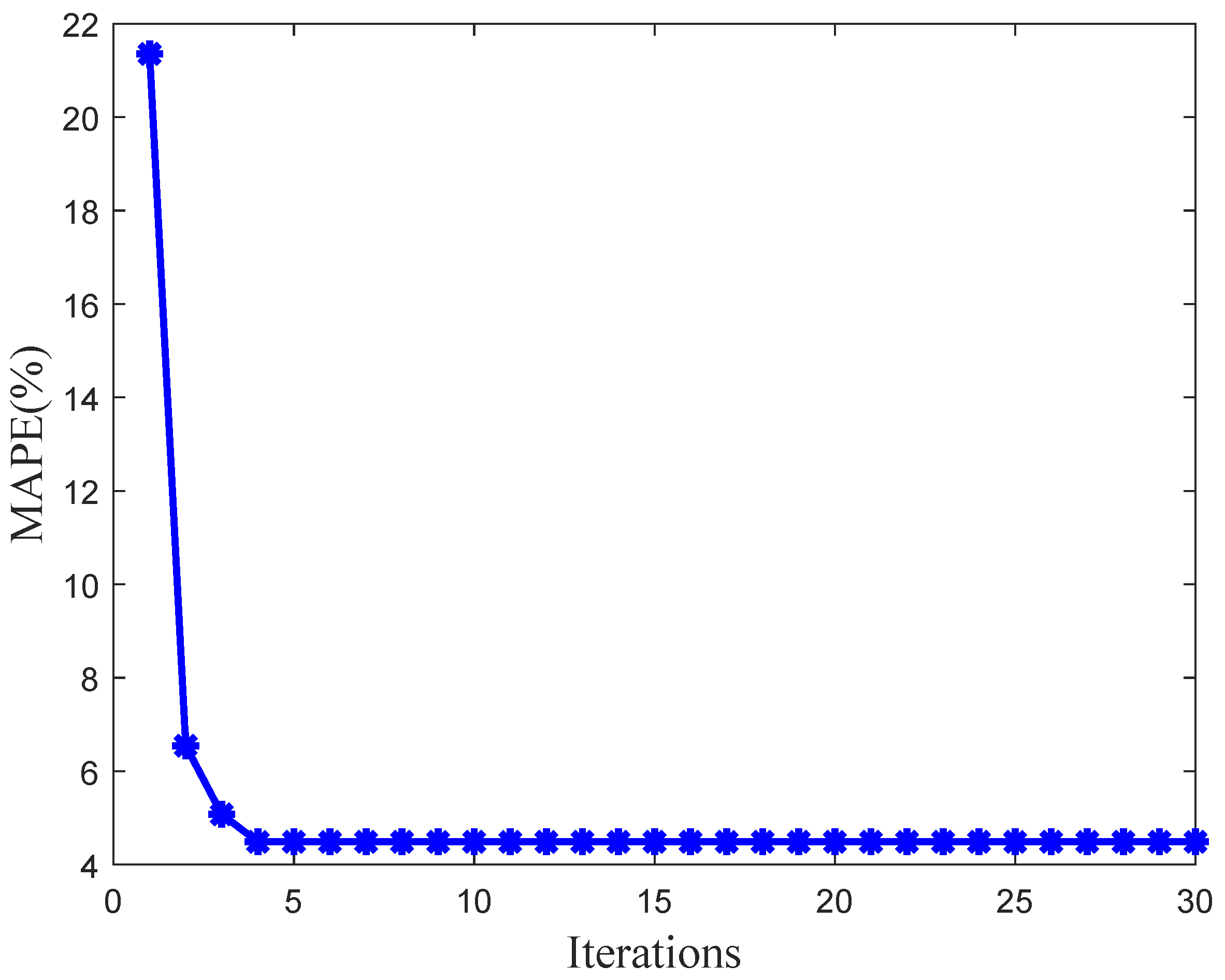
Figure 11 illustrates the variation of MAPE across generations during the WOA optimization process. The results show a rapid decline in MAPE during the initial generations, followed by stabilization after the fourth generation.
In the early iterations, WOA explores a broad solution space, quickly reducing MAPE as it searches for optimal weight combinations. As convergence progresses, the rate of improvement slows, and MAPE stabilizes, indicating that the algorithm has approached the optimal solution. This rapid convergence highlights WOA’s efficiency in weight optimization, demonstrating its capability to effectively minimize errors in the early stages and achieve stable performance in later iterations.
According to
Table 5, the weight configurations of the four finally selected neural networks in the integrated model are as follows: the 1st neural network weights 0.3484, indicating its significant role in the prediction results; the 2nd neural network weights 0.0035, contributing the least, reflecting its limited impact in the integrated model; the 3rd neural network weights 0.4153, contributing the most and significantly affecting the final prediction results; the 4th neural network has a weight of 0.2326, showing a moderate level of contribution. This weight configuration fully reflects the relative importance of each neural network in the integrated model. The integrated model optimizes the combination of predictions from multiple networks through differentiated weight allocation, thereby improving overall performance.
4.3. Computational Cost
Computational cost is a key consideration in model training and optimization. In this study, the computational cost of the model is mainly affected by the complexity of the neural network structure, the size of the dataset, and the optimization algorithm.
The experiments were carried out on computers equipped with the following hardware: the CPU is AMD Ryzen 5 7500F, manufactured by Advanced Micro Devices, Inc. (AMD), located in Sunnyvale, CA, USA with 8 cores and 16 threads; the GPU is NVIDIA GeForce RTX 4080, manufactured by NVIDIA Corporation, located in Santa Clara, CA, USA with 16 GB of video memory; the RAM is 32 GB; the storage is 1 TB NVMe SSD; and the operating system is Windows 11 Professional. The results show that the average BPNN training time is 1.55 s, and the overall time for filtering the integrated BPNN model combination is 17.31 s; the WOA optimization output weight time is 18.14 s.
4.4. Comparative Testing of Baseline Methods
In this experiment, to fully evaluate the performance of the proposed methods, we implemented six benchmark models: (1) CI, (2) CNN, (3) RNN, (4) GNN, (5) Transformer, (6) AutoML. Additionally, we included two ensemble models optimized using optimization algorithms to adjust the output weights of the models: (7) GA-Optimized Ensemble and (8) PSO-Optimized Ensemble. Suitable hyperparameter tuning techniques were applied to determine the optimal configuration for each model. Below is a detailed description of these models.
4.4.1. Path Loss Prediction Method Based on CI Modeling
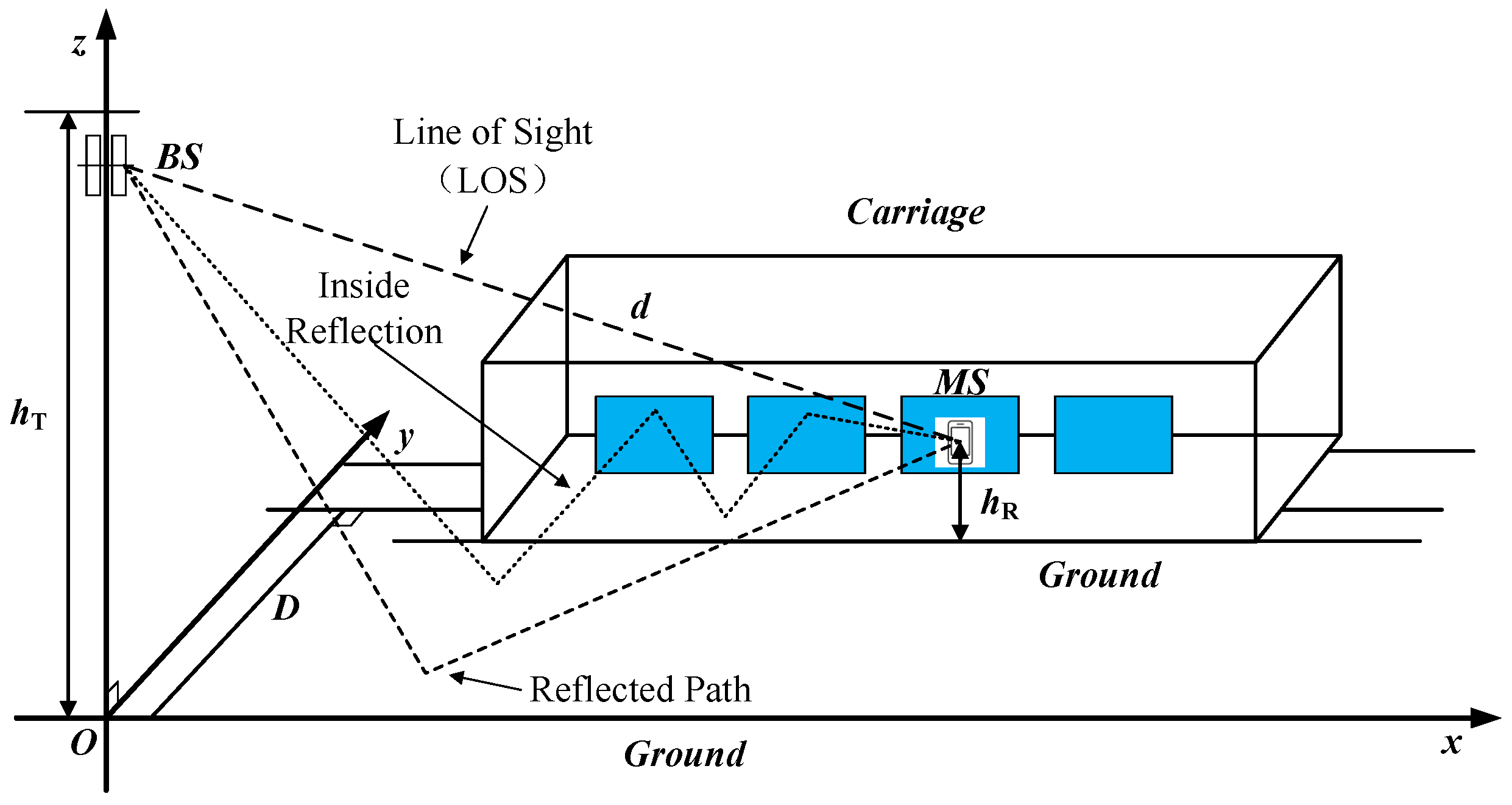
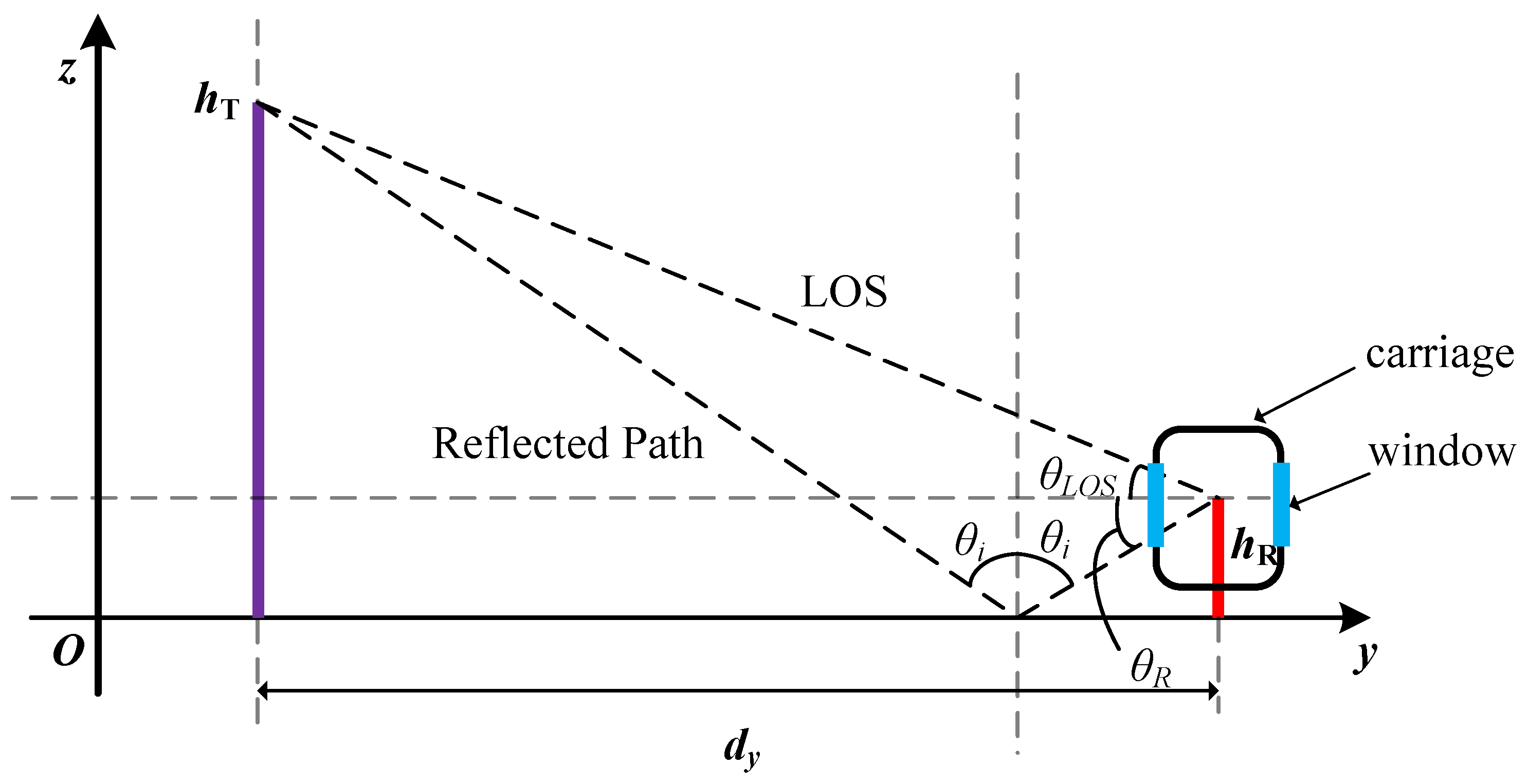
The CI model is an essential tool for designing and planning wireless communication systems. The primary purpose of the CI model is to predict the propagation loss of wireless signals in space based on the environmental characteristics and signal propagation conditions to evaluate the distribution of coverage and signal strength. This paper contains three different channels: the base station to the train, through the train window, and multiple reflections in the train. Its channel model is in the form of a cascade. To find the mathematical expression of the channel cascade, relying on the free-space neighboring reference distance model, this paper sets the model as follows:
where
represents the relative reference distance in free space, usually taken as 1 m.
represents the wavelength, and
represents a Gaussian random variable with a mean of 0 and a standard deviation of
.
n represents the composite factor comprising glass loss, vehicle reflections, etc. In this paper, a CI model is fitted to the seat path loss. After fitting, the value of
n is 4.38.
4.4.2. Path Loss Prediction Method Based on CNN
Convolutional neural networks have shown great potential in handling various data-related tasks and have been used for path loss prediction in several studies [
19,
20,
21]. We implemented a CNN model using PyTorch version 2.3.0 with hyperparameters, including the number of convolutional layers, the number of filters per layer, the convolutional kernel size, the pooling kernel size, and the activation function.
Table 6 presents the optimal combination of hyperparameters for the convolutional neural network determined through the hyperparameter optimization process.
4.4.3. Path Loss Prediction Method Based on RNN
Recurrent neural networks are well suited for processing sequential data and have applications in some scenarios related to path loss prediction [
17,
22]. We implemented a recurrent neural network model using PyTorch version 2.3.0 with hyperparameters that include the input feature dimensions, the number of hidden layer units, the type of activation function, and the setting of the fully connected layers.
Table 7 shows the optimal combination of hyperparameters for the recurrent neural network determined through the hyperparameter optimization process.
4.4.4. Path Loss Prediction Method Based on GNN
Graph neural networks have recently been explored for path loss prediction in [
23]. We implemented this network based on PyTorch version 2.3.0 using appropriate graph neural network-related libraries. The hyperparameters of this network are the number of graph convolution layers, the number of hidden units per layer, the activation function, the K-value of the K-nearest neighbor, the learning rate, the weight decay coefficient, and the type of loss function.
Table 8 presents the optimal combination of hyperparameters for the graph neural network determined through the hyperparameter optimization process.
4.4.5. Path Loss Prediction Method Based on Transformer
Transformer has emerged as a novel and powerful architecture in recent years, and its application in path loss prediction shows great potential. We implemented this model using the PyTorch version 2.3.0 framework, leveraging relevant libraries for Transformer architectures. The hyperparameters of this network include the number of Transformer encoder layers, the model embedding dimension, the number of attention heads, the activation function, the learning rate, the weight decay coefficient, and the type of loss function.
Table 9 shows the optimal combination of hyperparameters for the Transformer network determined through the hyperparameter optimization process.
4.4.6. Path Loss Prediction Method Based on AutoML Tool
Automated Machine Learning has emerged as a revolutionary approach in the field of machine learning. It automates the often complex processes of model selection and hyperparameter tuning. In this study, we harnessed the power of the TPOTRegressor from the spot library to tackle the path loss prediction problem.
The parameters of the TPOTRegressor are crucial in determining the effectiveness and efficiency of the automated model search.
Table 10 presents the key hyperparameters and their selected values for our path loss prediction task:
After setting the parameters, the AutoML tool automatically searched for the optimal machine-learning pipeline and found an ensemble model for path loss prediction. This ensemble model combines Stochastic Gradient Descent (SGD) and Random Forest regression.
Table 11 presents the key parameter settings of the two regression methods:
4.4.7. Path Loss Prediction Method Based on GA—Optimized Ensemble Model
Genetic Algorithm is employed to optimize the output weights of the multi-neural network ensemble model for predicting path loss in high-speed train carriages. This method aims to improve the prediction accuracy by identifying the optimal combination of weights for the ensemble model.
Table 12 shows the optimal combination of parameters for the GA-optimized output weights.
4.4.8. Path Loss Prediction Method Based on PSO—Optimized Ensemble Model
Particle Swarm Optimization is applied to optimize the output weights of the multi-neural network ensemble model for path loss prediction. PSO is a meta-heuristic optimization algorithm that finds the best combination of output weights in a multi-dimensional space.
Table 13 shows the optimal combination of parameters for the PSO-optimized output weights.
4.5. Predicted Results
Table 14 shows the performance of different path loss prediction methods on the test set. According to the data, the neural network integration model optimized by WOA output weights, proposed in this paper, performs exceptionally well in predicting the path loss of HSR seats. Compared to CI, CNN, RNN, GNN, Transformer, AutoML, and the ensemble models with GA-Optimized and PSO-Optimized output weights, the proposed model significantly outperforms the others in four key metrics: RMSE, MAE, MAPE, and R
2.
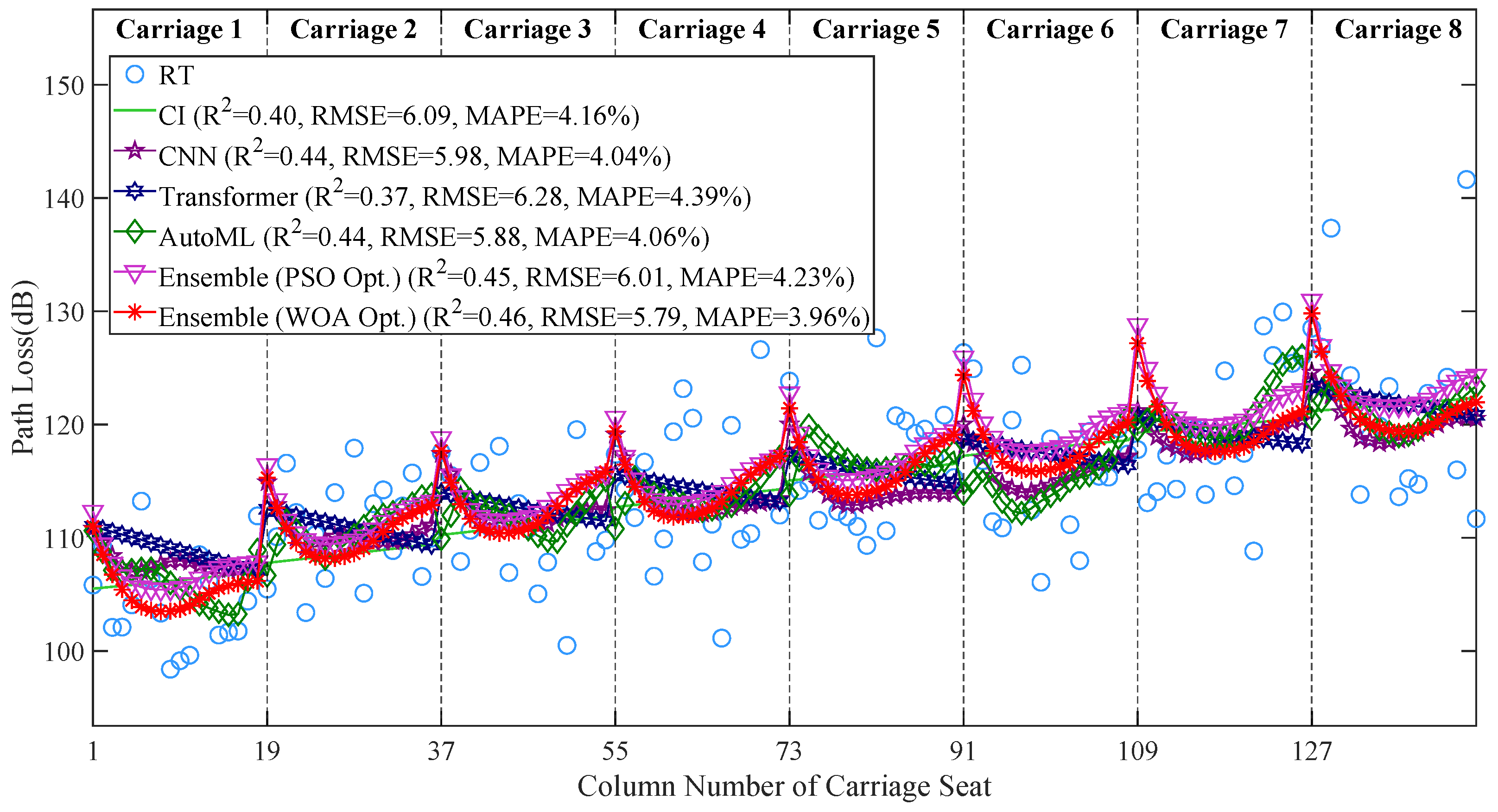
To further assess the robustness of the proposed model, we select representative data points from location E, with the receiving antenna positioned at height III. The prediction results are compared and analyzed against those of the CI model, CNN, Transformer, AutoML, and the ensemble model optimized using the PSO. As illustrated in
Figure 12, the legend provides detailed annotations, where Ensemble (PSO Opt.) represents the ensemble model optimized using the PSO, and Ensemble (WOA Opt.) denotes the ensemble model optimized using the WOA. Additionally, the performance metrics for each method, calculated based on their predictions relative to the RT values, are displayed in the legend for clarity.
As shown in the figure, the WOA-optimized ensemble model stands out, with key performance metrics of R2 = 0.46, RMSE = 5.79 dB, and MAPE = 3.96%, all of which outperform the other models. Furthermore, the model exhibits minimal fluctuation in prediction curves across different carriages, demonstrating excellent robustness. Unlike other models, which show significant deviation from the actual values or poor stability, this model maintains consistent performance despite changes in carriage position, highlighting its superior ability to withstand environmental interference and maintain stability across different spatial locations.
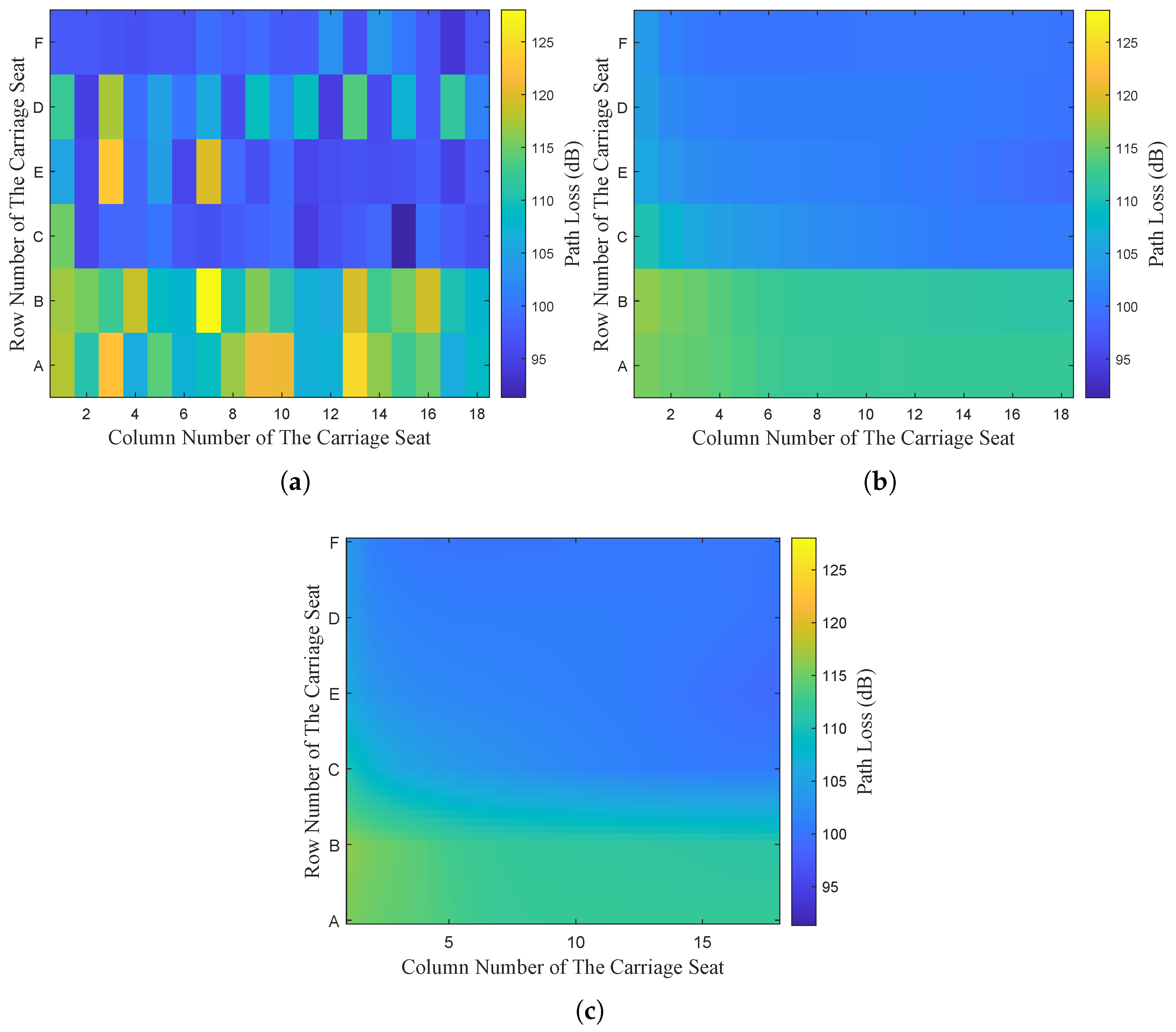
To deeply analyze the predictive effect of the models in a single carriage, the data at the height III position in the first carriage is selected to show the comparison between the original data and the predicted value of the path loss.
Figure 13a shows the distribution of the path loss data in the block obtained by applying WI simulation.
Figure 13b shows the distribution of path loss predictions generated by the integrated neural network prediction method proposed in this paper. Based on the prediction results in
Figure 13b,
Figure 13c uses a linear interpolation method to interpolate the signal path loss across the entire compartment plane, which is used to predict the path loss distribution over a broader range within the compartment.
In
Figure 13, the horizontal axis represents the number of seat rows in the compartment, the vertical axis represents the position, and the color shade directly reflects the magnitude of the predicted or actual path loss. The predicted values of the path loss of the model in this paper are consistent with the original data in terms of distribution, indicating that the model has a high accuracy in predicting the path loss at the height III position of a single compartment. The feasibility of the model in predicting the field strength distribution in the compartment is demonstrated.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}