
A High-Speed Finger Vein Recognition Network with Multi-Scale Convolutional Attention

Abstract
1. Introduction
2. Related Works
- 1.
- This study proposes an efficient finger vein recognition network called FMFVNet to meet the requirements of finger vein recognition tasks for both accuracy and efficiency. Experimental results demonstrate that the proposed model achieves a higher recognition accuracy and lower inference time compared to other methods while maintaining fewer parameters and a lower computational complexity.
- 2.
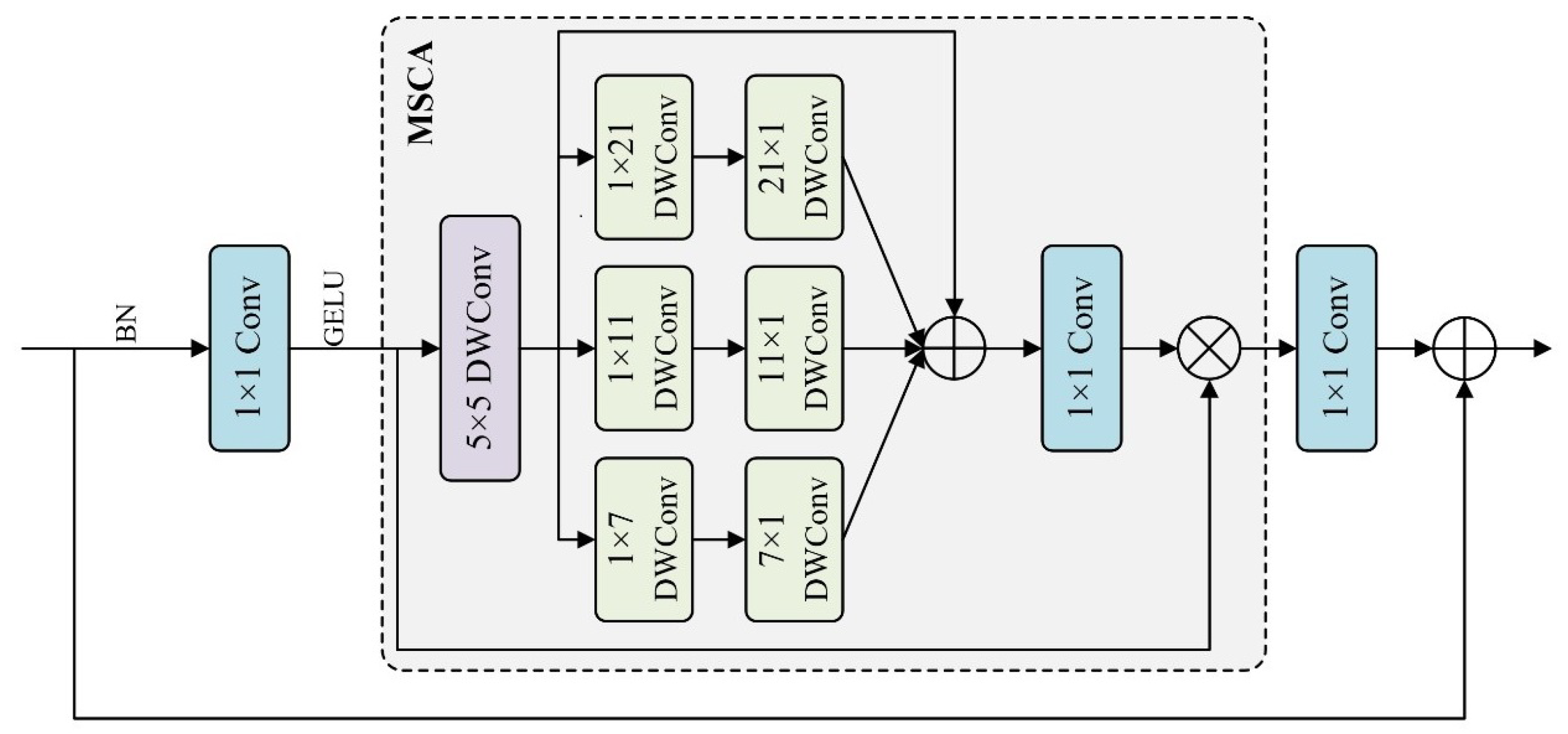
- In this study, MSCA is introduced for finger vein recognition. By incorporating multi-branch deep strip convolutions of different scales, the model captures rich details of finger vein images at multiple scales, focusing more on vein feature extraction. Experimental results show that integrating MSCA effectively improves the recognition accuracy of the finger vein recognition model.
- 3.
- To validate the model’s performance, we conducted comparative tests using the FV-USM dataset from Universiti Teknologi Malaysia and the SDUMLA-HMT dataset from Shandong University. Furthermore, an ablation study was conducted to thoroughly analyze the impact of the MSCA module on FMFVNet. The experimental results indicate that the proposed FMFVNet achieves outstanding performance across various finger vein databases and exhibits a strong generalization ability.
3. Materials and Methods
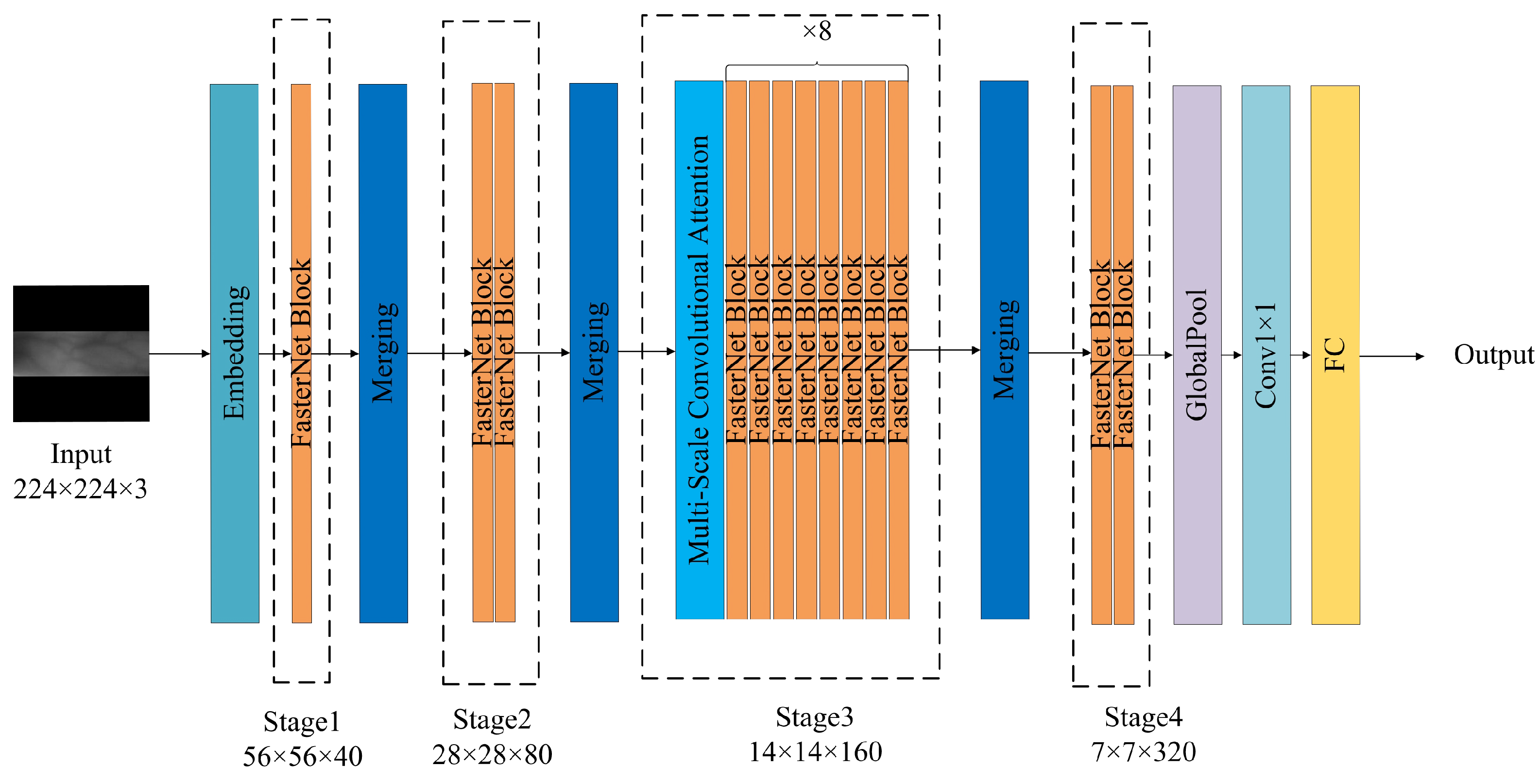
3.1. Network Architecture
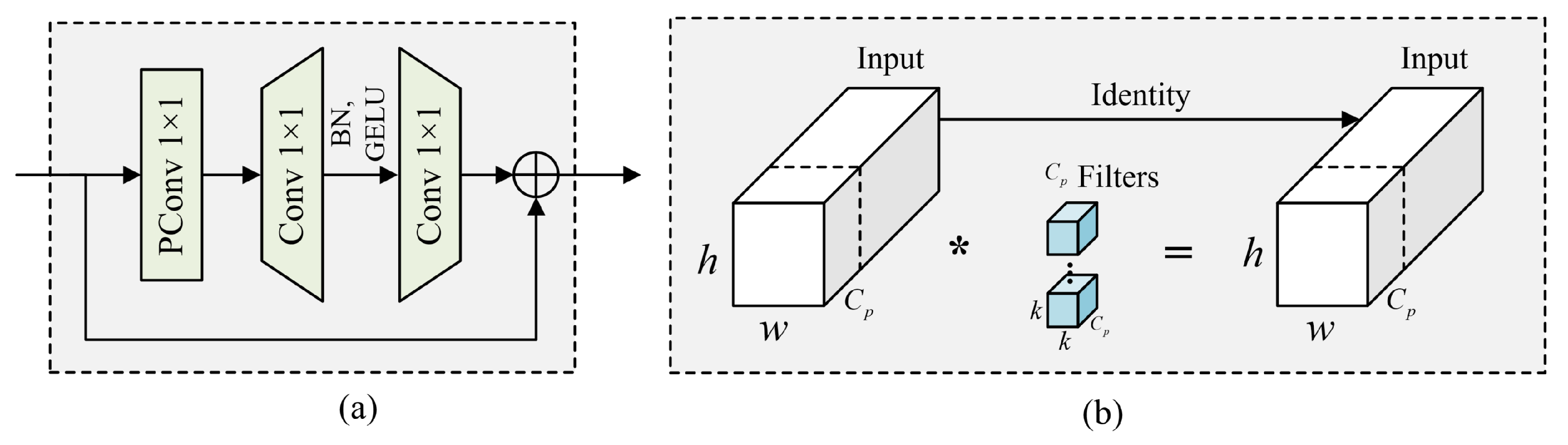
3.2. FasterNet Block
3.3. Multi-Scale Convolutional Attention (MSCA)
4. Experiments and Results
4.1. Dataset
4.2. Experimental Configuration
4.3. Comparative Experiments with Different Models
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sundararajan, K.; Woodard, D.L. Deep learning for biometrics: A survey. ACM Comput. Surv. 2018, 51, 65. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Sridharan, S.; Tistarelli, M.; Nixon, M. Super-resolution for biometrics: A comprehensive survey. Pattern Recognit. 2018, 78, 23–42. [Google Scholar] [CrossRef]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. IEEE Trans. Inf. Forensics Secur. 2019, 15, 144–159. [Google Scholar] [CrossRef]
- Wang, C.; Muhammad, J.; Wang, Y.; He, Z.; Sun, Z. Towards complete and accurate iris segmentation using deep multi-task attention network for non-cooperative iris recognition. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2944–2959. [Google Scholar] [CrossRef]
- Jeevan, G.; Zacharias, G.C.; Nair, M.S.; Rajan, J. An empirical study of the impact of masks on face recognition. Pattern Recognit. 2022, 122, 108308. [Google Scholar] [CrossRef]
- Hashimoto, J. Finger vein authentication technology and its future. In Proceedings of the 2006 Symposium on VLSI Circuits, Honolulu, HI, USA, 13–17 June 2006; pp. 5–8. [Google Scholar]
- Zhou, Y.; Kumar, A. Human identification using palm-vein images. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1259–1274. [Google Scholar] [CrossRef]
- Yanagawa, T.; Aoki, S.; Oyama, T. Diversity of human finger vein patterns and its application to personal identification. Bull. Inform. Cybern. 2009, 41, 1–9. [Google Scholar] [CrossRef]
- Syazana-Itqan, K.; Syafeeza, A.R.; Saad, N.M.; Hamid, N.A.; Saad, W.H.B.M. A review of finger-vein biometrics identification approaches. Indian J. Sci. Technol. 2016, 9, 19. [Google Scholar] [CrossRef]
- Miura, N.; Nagasaka, A.; Miyatake, T. Feature extraction of finger-vein patterns based on repeated line tracking and its application to personal identification. Mach. Vis. Appl. 2004, 15, 194–203. [Google Scholar] [CrossRef]
- Mohsin, A.H.; Zaidan, A.A.; Zaidan, B.B.; Albahri, A.S.; Albahri, O.S.; Alsalem, M.A.; Mohammed, K.I. Real-time remote health monitoring systems using body sensor information and finger vein biometric verification: A multi-layer systematic review. J. Med. Syst. 2018, 42, 238. [Google Scholar] [CrossRef]
- Zirjawi, N.; Kurtanovic, Z.; Maalej, W. A survey about user requirements for biometric authentication on smartphones. In Proceedings of the 2015 IEEE 2nd Workshop on Evolving Security and Privacy Requirements Engineering (ESPRE), Ottawa, ON, Canada, 31 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S. A review of video surveillance systems. J. Vis. Commun. Image Represent. 2021, 77, 103116. [Google Scholar] [CrossRef]
- Kono, M. A new method for the identification of individuals by using vein pattern matching of a finger. In Proceedings of the 5th Symposium on Pattern Measurement, Yamaguchi, Japan, 20–22 January 2000; pp. 9–12. [Google Scholar]
- Miura, N.; Nagasaka, A.; Miyatake, T. Extraction of finger-vein patterns using maximum curvature points in image profiles. IEICE Trans. Inf. Syst. 2007, 90, 1185–1194. [Google Scholar] [CrossRef]
- Park, K.R. Finger vein recognition by combining global and local features based on SVM. Comput. Inform. 2011, 30, 295–309. [Google Scholar]
- Lu, Y.; Xie, S.J.; Yoon, S.; Park, D.S. Finger vein identification using polydirectional local line binary pattern. In Proceedings of the International Conference on ICT Convergence (ICTC), Jeju, Korea, 14–16 October 2013; pp. 61–65. [Google Scholar]
- Mohd Asaari, M.S.; Suandi, S.A.; Rosdi, B.A. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics. Expert Syst. Appl. 2014, 41, 3367–3382. [Google Scholar] [CrossRef]
- Li, J.; Ma, H.; Lv, Y.; Zhao, D.; Liu, Y. Finger vein feature extraction based on improved maximum curvature description. In Proceedings of the Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 7566–7571. [Google Scholar]
- Song, W.; Kim, T.; Kim, H.C.; Choi, J.H.; Kong, H.-J.; Lee, S.-R. A finger-vein verification system using mean curvature. Pattern Recognit. Lett. 2011, 32, 1541–1547. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Hou, Q.; Cheng, M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P. Deeply supervised salient object detection with short connections. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 815–828. [Google Scholar] [CrossRef]
- Tamang, L.D.; Kim, B.W. Deep D2C-Net: Deep learning-based display-to-camera communications. Opt. Express 2021, 29, 11494–11511. [Google Scholar] [CrossRef]
- Huang, H.; Liu, S.; Zheng, H.; Ni, L.; Zhang, Y.; Li, W. DeepVein: Novel finger vein verification methods based on deep convolutional neural networks. In Proceedings of the IEEE International Conference on Identity, Security and Behavior Analysis (ISBA), New Delhi, India, 22–24 February 2017; pp. 1–8. [Google Scholar]
- Song, J.M.; Kim, W.; Park, K.R. Finger-vein recognition based on deep DenseNet using composite image. IEEE Access 2019, 7, 66845–66863. [Google Scholar] [CrossRef]
- Qin, H.; Wang, P. Finger-vein verification based on LSTM recurrent neural networks. Appl. Sci. 2019, 9, 1687. [Google Scholar] [CrossRef]
- Noh, K.J.; Choi, J.; Hong, J.S.; Park, K.R. Finger-vein recognition based on densely connected convolutional network using score-level fusion with shape and texture images. IEEE Access 2020, 8, 96748–96766. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, Z.; Li, M.; Wu, H. GAN-based image augmentation for finger-vein biometric recognition. IEEE Access 2019, 7, 183118–183132. [Google Scholar] [CrossRef]
- Hou, B.; Yan, R. Convolutional autoencoder model for finger-vein verification. IEEE Trans. Instrum. Meas. 2020, 69, 2067–2074. [Google Scholar] [CrossRef]
- Zhong, Y.; Li, J.; Chai, T.; Prasad, S.; Zhang, Z. Different dimension issues in deep feature space for finger-vein recognition. In Proceedings of the Chinese Conference on Biometric Recognition, Shanghai, China, 10–12 September 2021; pp. 295–303. [Google Scholar]
- Ren, H.; Sun, L.; Guo, J.; Han, C.; Wu, F. Finger vein recognition system with template protection based on convolutional neural network. Knowl.-Based Syst. 2021, 227, 107159. [Google Scholar] [CrossRef]
- Li, X.; Zhang, B.-B. FV-ViT: Vision transformer for finger vein recognition. IEEE Access 2023, 11, 75451–75461. [Google Scholar] [CrossRef]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. SegNeXt: Rethinking convolutional attention design for semantic segmentation. arXiv 2022, arXiv:2209.08575. [Google Scholar]
- Liu, J.; Ma, H.; Guo, Z. Multi-Scale convolutional neural network for finger vein recognition. Infrared Phys. Technol. 2024, 143, 105624. [Google Scholar] [CrossRef]
- Bhushan, K.; Singh, S.; Kumar, K.; Kumar, P. Deep learning based automated vein recognition using Swin Transformer and Super Graph Glue model. Knowl.-Based Syst. 2025, 310, 112929. [Google Scholar] [CrossRef]
- Bai, H.; Tan, Y.; Li, Y.-J. Mask-guided network for finger vein feature extraction and biometric identification. Biomed. Opt. Express 2024, 15, 6845–6863. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. arXiv 2023, arXiv:2303.03667. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Yin, Y.; Liu, L.; Sun, X. SDUMLA-HMT: A multimodal biometric database. In Proceedings of the 6th Chinese Conference on Biometric Recognition, Beijing, China, 3–4 December 2011; Springer: Cham, Switzerland, 2011; pp. 260–268. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Input Size | Output Channels | Output Size | Operation |
|---|---|---|---|---|
| Embedding Layer | 40 | Conv | ||
| Stage 1 | 40 | FasterNet Block | ||
| Merging Layer | 80 | Conv | ||
| Stage 2 | 80 | FasterNet Block | ||
| Merging Layer | 160 | Conv | ||
| Stage 3 | 160 | MSCA + FasterNet Block | ||
| Merging Layer | 320 | Conv | ||
| Stage 4 | 320 | FasterNet Block | ||
| Global Pooling Layer | 320 | Global Average Pooling | ||
| 1 × 1 Conv | 1280 | Conv |
| Methods | ACC (%) | |
|---|---|---|
| FV-USM | SDUMLA-HMT | |
| MobileNetV2 | 99.19 | 98.36 |
| EfficientNet-B0 | 99.19 | 98.67 |
| ResNet-50 | 99.39 | 98.85 |
| Swin-T | 98.58 | 98.42 |
| LFVRN-CE [30] | 98.58 | 97.74 |
| Coding SA [31] | 99.39 | 96.01 |
| FV-ViT [32] | 99.59 | 94.51 |
| FMFVNet | 99.80 | 99.06 |
| Method (ms) | Params (M) | FLOPs |
|---|---|---|
| MobileNetV2 | 3.47 | 300.84 M |
| EfficientNet-B0 | 5.24 | 385.88 M |
| ResNet-50 | 24.81 | 4.13 G |
| Swin-T | 28.27 | 4.32 G |
| FMFVNet | 3.53 | 358.46 M |
| Method | Inference Time (ms) |
|---|---|
| MobileNetV2 | 2.21 |
| EfficientNet-B0 | 3.02 |
| ResNet-50 | 2.63 |
| Swin-T | 4.69 |
| FMFVNet | 1.75 |
| MSCA | ACC (%) | |
|---|---|---|
| FV-USM | SDUMLA-HMT | |
| – | 99.19 | 98.36 |
| ✔ | 99.80 | 99.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Liu, P.; Su, C.; Tong, S. A High-Speed Finger Vein Recognition Network with Multi-Scale Convolutional Attention. Appl. Sci. 2025, 15, 2698. https://doi.org/10.3390/app15052698
Zhang Z, Liu P, Su C, Tong S. A High-Speed Finger Vein Recognition Network with Multi-Scale Convolutional Attention. Applied Sciences. 2025; 15(5):2698. https://doi.org/10.3390/app15052698
Chicago/Turabian StyleZhang, Ziyun, Peng Liu, Chen Su, and Shoufeng Tong. 2025. "A High-Speed Finger Vein Recognition Network with Multi-Scale Convolutional Attention" Applied Sciences 15, no. 5: 2698. https://doi.org/10.3390/app15052698
APA StyleZhang, Z., Liu, P., Su, C., & Tong, S. (2025). A High-Speed Finger Vein Recognition Network with Multi-Scale Convolutional Attention. Applied Sciences, 15(5), 2698. https://doi.org/10.3390/app15052698