

Human Action Recognition Based on 3D Convolution and Multi-Attention Transformer


Abstract
1. Introduction
- 1.
- A brand-new two-stream network structure containing a C3D temporal network and a multi-scale Transformer spatial network has been constructed, which fully utilizes the correlation between spatial and temporal information to extract spatiotemporal features with interactive relationships, effectively improving the action recognition ability with long-term dependencies.
- 2.
- A multi-scale convolution module is introduced to replace the original FFN module in the Transformer; after inputting context-based relative position encoding, adaptive integrated multi-scale features with stronger representation capabilities are obtained, effectively improving the recognition accuracy of the model in complex environments.
- 3.
- A more efficient feature fusion strategy has been designed, and the spatiotemporal feature fusion method of the two-stream network has been improved by using weighted fusion, which enhances the model’s ability to model complex spatiotemporal interaction relationships and further improves the recognition accuracy in complex environments.
- 4.
- Experimental results on the datasets of UCF101 and HMDB51 demonstrate that our algorithm is a highly accurate human action recognition model.
2. Related Work
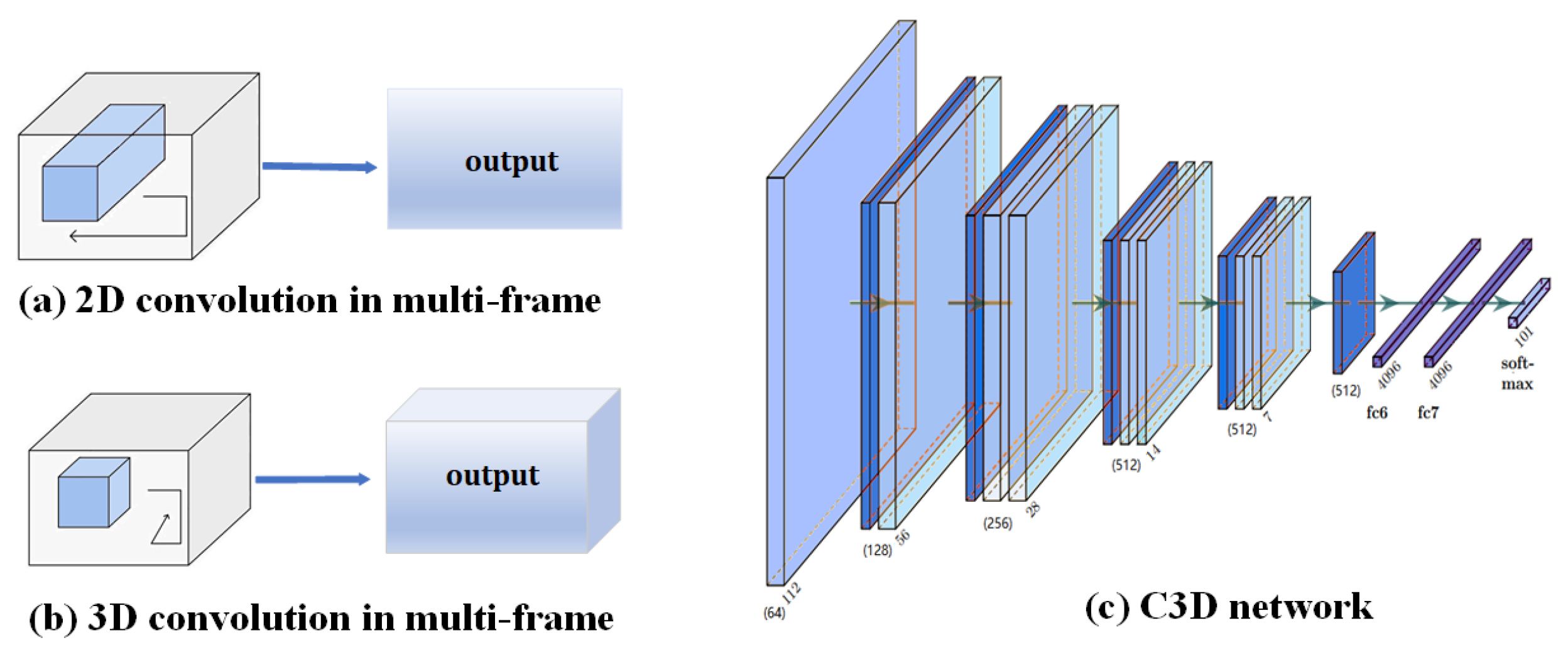
2.1. Action Recognition Based on 3D Convolution
2.2. Action Recognition Based on Two-Stream Networks
2.3. Action Recognition Based on Transformer Model
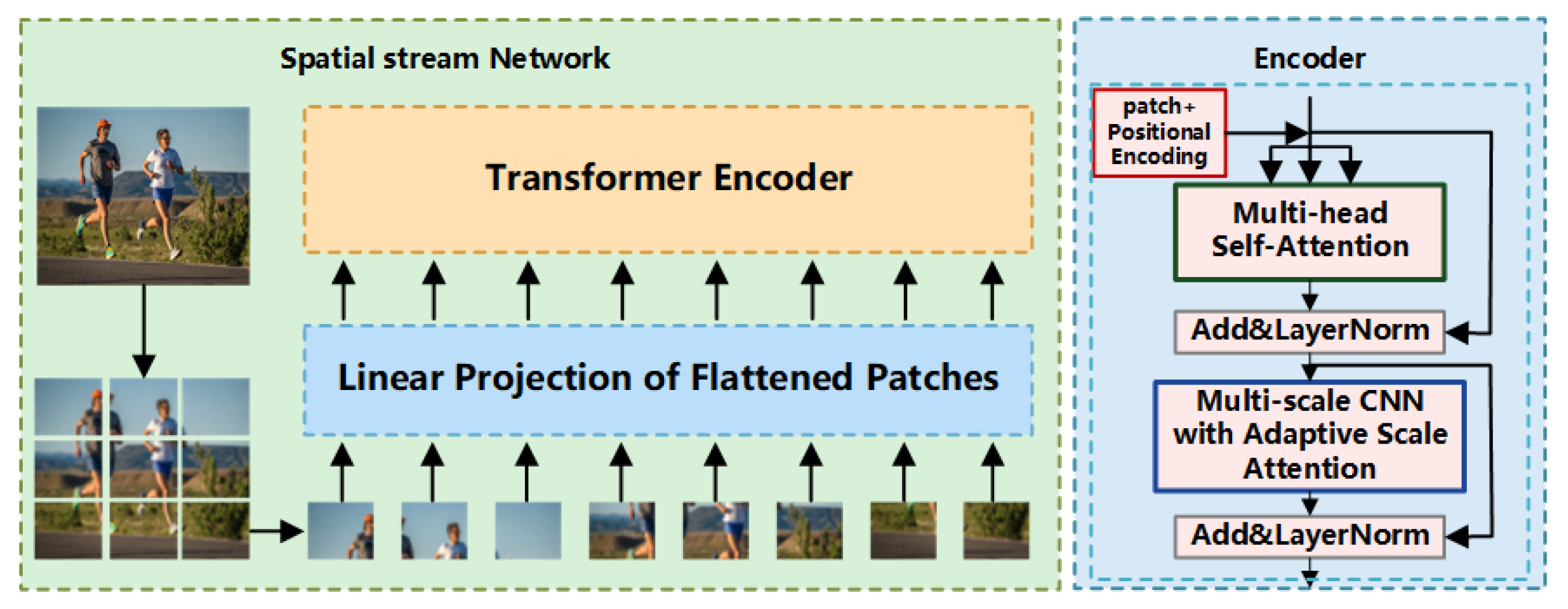
3. Transformer and C3D-Based Two-Stream Network Modeling
3.1. C3D Time-Stream Convolutional Neural Network
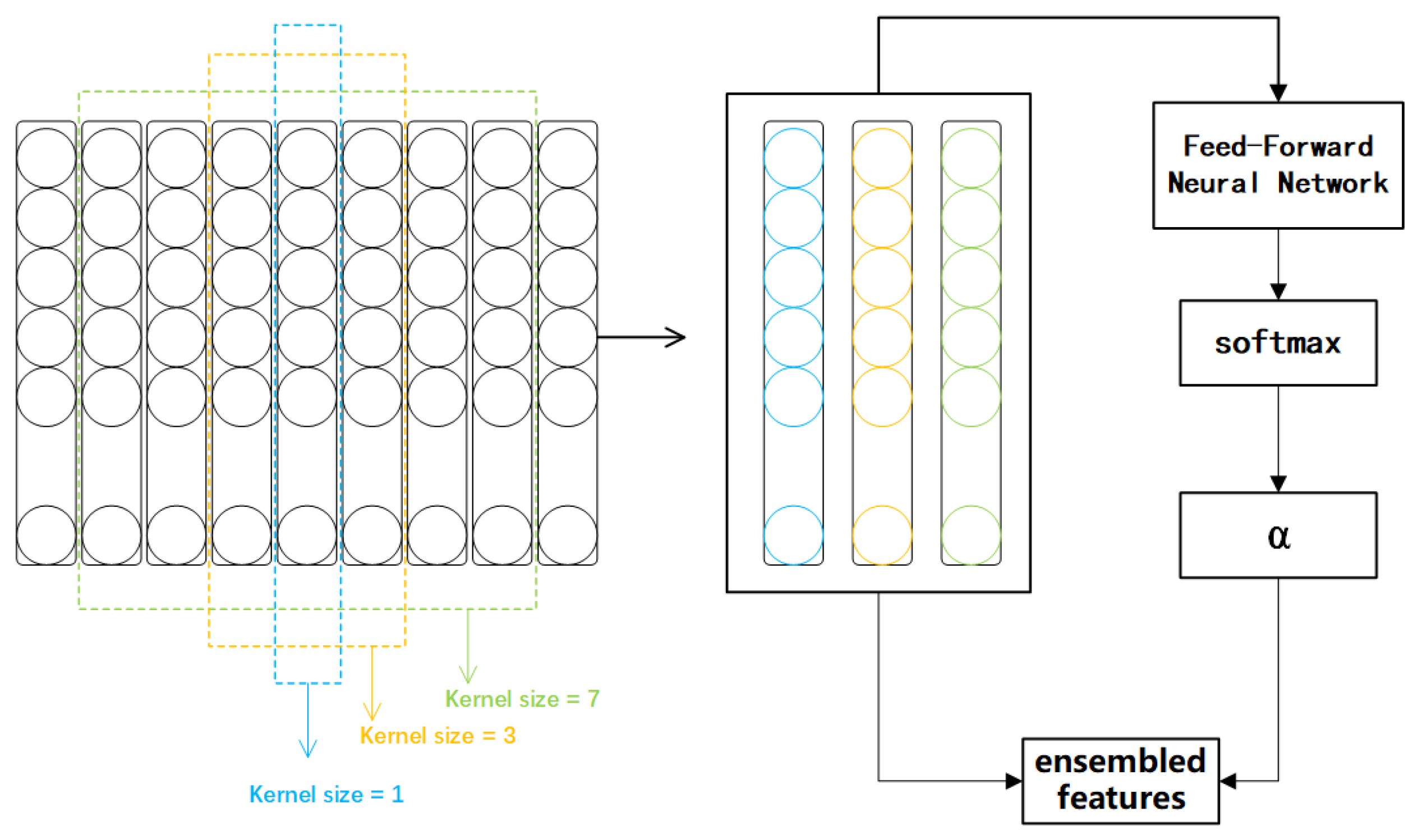
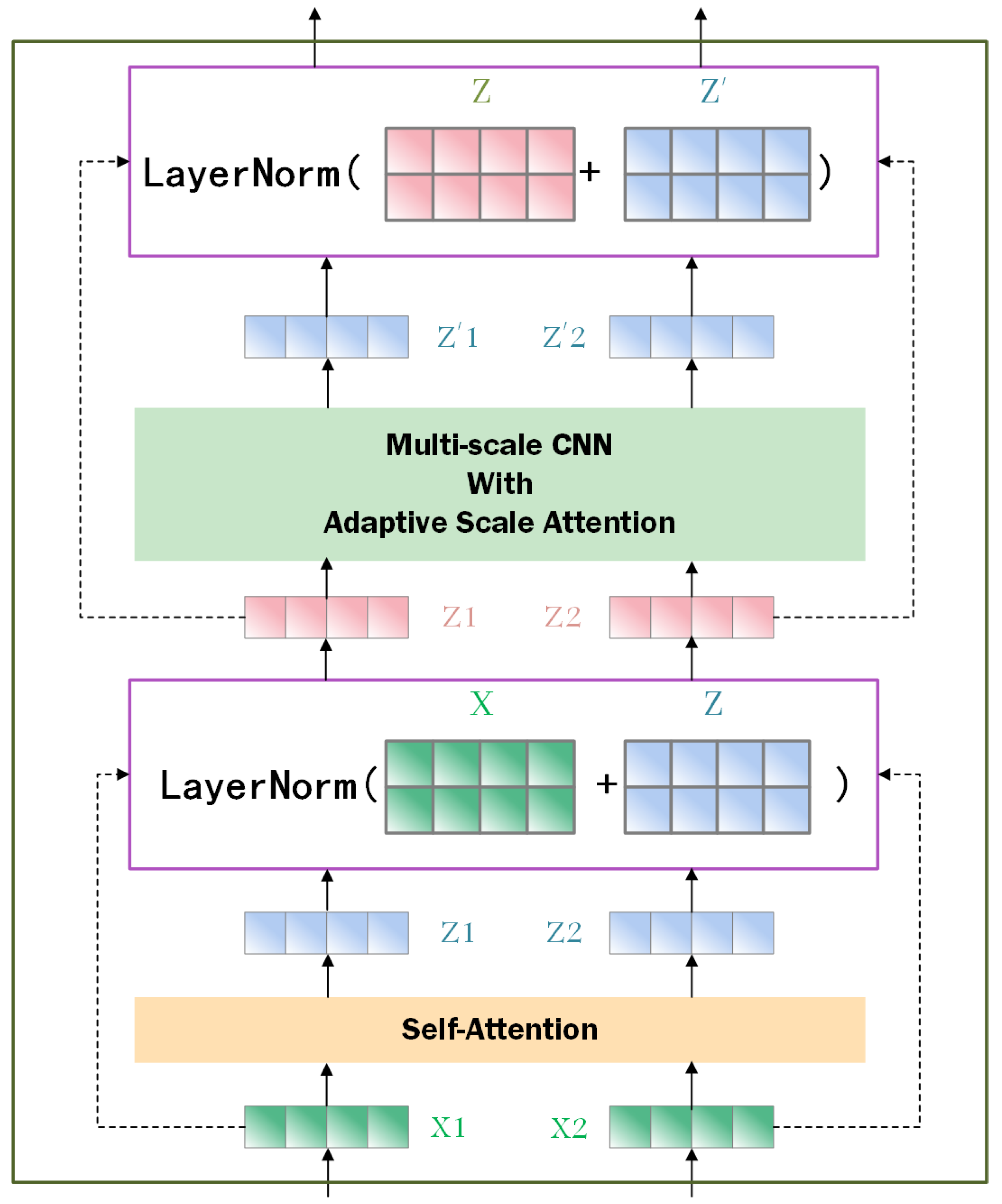
3.2. Multi-Scale Convolution Transformer
3.3. Positional Encoding
3.4. Multi-Scale Residual Model
4. Feature Fusion
4.1. Summing Fusion Approach
4.2. Average Fusion Approach
4.3. Maximum Fusion Approach
4.4. Weighted Fusion Approach
4.5. Fusion Mode Experiment
5. Experimental Results and Analyses
5.1. Datasets
5.2. Experimental Implementation Details
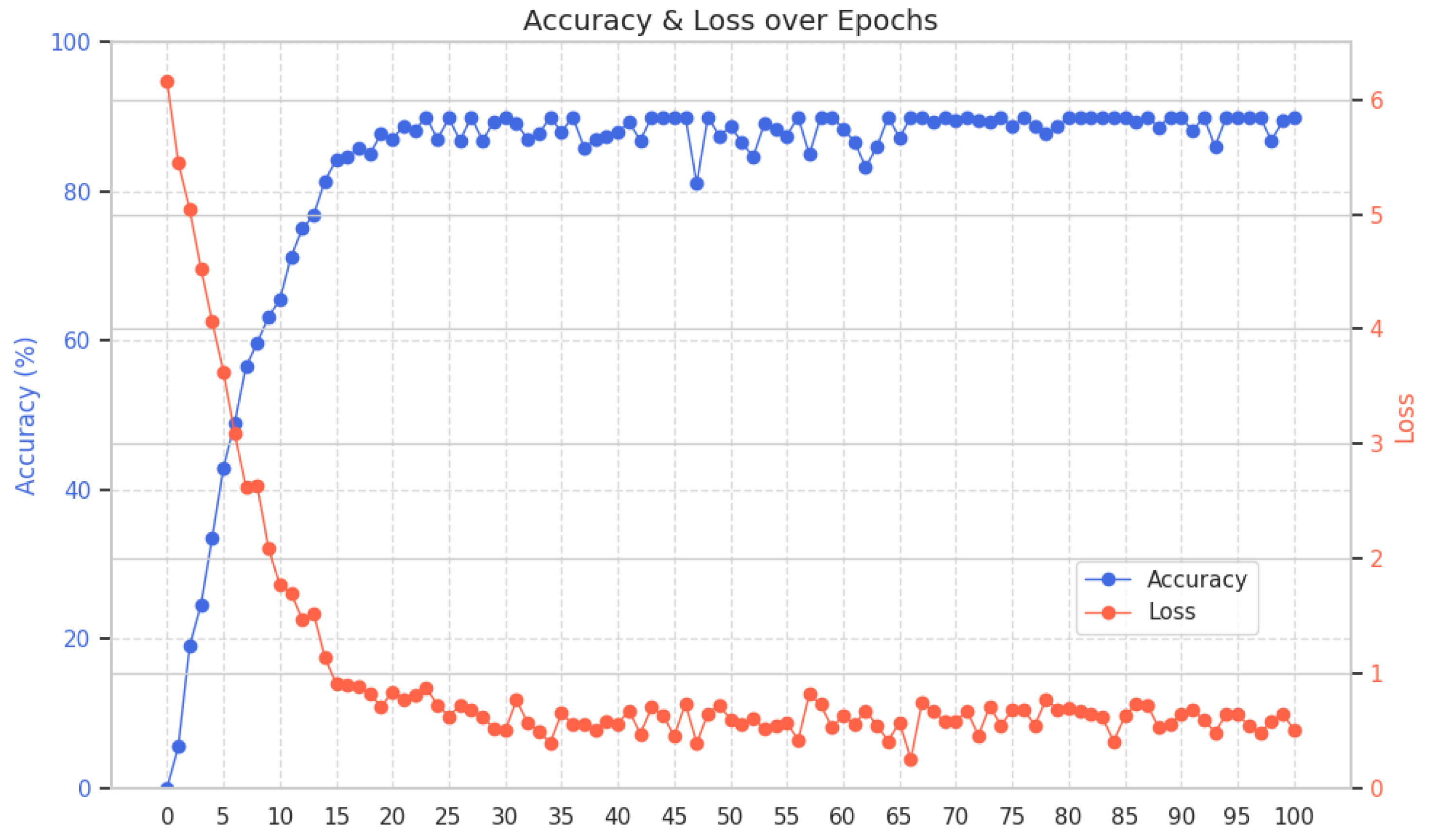
5.3. Ablation Experiment
6. Conclusions and Future Works
6.1. Conclusions
6.2. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Duan, H.; Zhao, Y.; Chen, K.; Lin, D.; Dai, B. Revisiting skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2969–2978. [Google Scholar]
- Ou, Y.; Chen, Z. 3D Deformable Convolution Temporal Reasoning network for action recognition. J. Vis. Commun. Image R. 2023, 93, 103804. [Google Scholar] [CrossRef]
- Bai, J.; Yang, Z.; Peng, B.; Li, W. Research on 3D convolutional neural network and its application to video understanding. J. Electron. Inf. Technol. 2023, 6, 2273–2283. [Google Scholar]
- Pang, C.; Lu, X.; Lyu, L. Skeleton-based action recognition through contrasting two-stream spatial temporal networks. IEEE Trans. Multimed. 2023, 25, 8699–8711. [Google Scholar] [CrossRef]
- Xie, Z.; Gong, Y.; Ji, J.; Ma, Z.; Xie, M. Mask guided two-stream network for end-to-end few-shot action recognition. Neurocomputing 2024, 583, 127582. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, Z.; Li, J.; Xie, X.; Chen, K.; Wang, X.; Shi, G. STDM-transformer: Spacetime dual multi-scale transformer network for skeleton based action recognition. Neurocomputing 2024, 563, 126903. [Google Scholar] [CrossRef]
- Wu, H.; Ma, X.; Li, Y. Transformer-based multiview spatiotemporal feature interactive fusion for human action recognition in depth videos. Signal Process. Image Commun. 2025, 131, 117244. [Google Scholar] [CrossRef]
- Xie, J.; Meng, Y.; Zhao, Y.; Nguyen, A.; Yang, X.; Zheng, Y. Dynamic Semantic-Based Spatial Graph Convolution Network for Skeleton-Based Human Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 6225–6233. [Google Scholar]
- Liu, H.; Liu, Y.; Ren, M.; Wang, H.; Wang, Y.; Sun, Z. Revealing Key Details to See Differences: A Novel Prototypical Perspective for Skeleton-based Action Recognition. arXiv 2024, arXiv:2411.18941. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5534–5542. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Yang, F.; Li, S.; Sun, C.; Li, X.; Xiao, Z. Action recognition in rehabilitation: Combining 3D convolution and LSTM with spatiotemporal attention. Front. Physiol. 2024, 15, 1472380. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision(ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar]
- Tao, L.; Wang, X.; Yamasaki, T. Rethinking Motion Representation: Residual Frames With 3D ConvNets. IEEE Trans. Image Proces. 2020, 30, 9231–9244. [Google Scholar] [CrossRef]
- Li, S.; Wang, Z.; Liu, Y.; Zhang, Y.; Zhu, J.; Cui, X.; Liu, J. FSformer: Fast-Slow Transformer for video action recognition. Image Vis. Comput. 2023, 137, 104740. [Google Scholar] [CrossRef]
- Zhou, A.; Ma, Y.; Ji, W.; Zong, M.; Yang, P.; Wu, M.; Liu, M. Multi-head attention-based two-stream EfficientNet for action recognition. Multimed. Syst. 2023, 29, 487–498. [Google Scholar] [CrossRef]
- Pareek, G.; Nigam, S.; Singh, R. Modeling transformer architecture with attention layer for human activity recognition. Neural Comput. Appl. 2024, 36, 5515–5528. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, R. Relative-position embedding based spatially and temporally decoupled Transformer for action recognition. Pattern Recognit. 2024, 145, 109905. [Google Scholar] [CrossRef]
- Qiu, H.; Hou, B.; Ren, B.; Zhang, X. Spatio-temporal tuples transformer for skeleton-based action recognition. arXiv 2022, arXiv:2201.02849. [Google Scholar]
- Do, J.; Kim, M. SkateFormer: Skeletal-Temporal Transformer for Human Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 9 September–4 October 2024; pp. 401–420. [Google Scholar]
- Liu, H.; Liu, Y.; Chen, Y.; Yuan, C.; Li, B.; Hu, W. TranSkeleton: Hierarchical Spatial–Temporal Transformer for Skeleton-Based Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 8, 4137–4148. [Google Scholar] [CrossRef]
- Sun, W.; Ma, Y.; Wang, R. k-NN attention-based video vision transformer for action recognition. Neurocomputing 2024, 574, 127256. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, J.; Li, Y. ActionFormer: Localizing Moments of Actions with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 492–510. [Google Scholar]
- Zheng, Y.; Li, Z.; Wang, Z.; Wu, L. Transformer-Based Two-Stream Network for Global and Local Motion Estimation. In Proceedings of the IEEE International Conference on Pattern Recognition and Machine Learning (PRML), Urumqi, China, 4–6 August 2023; pp. 328–334. [Google Scholar]
- Yang, J.; Dong, X.; Liu, L.; Zhang, C.; Shen, J.; Yu, D. Recurring the Transformer for Video Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14043–14053. [Google Scholar]
- Neimark, D.; Bar, O.; Zohar, M.; Asselmann, D. Video Transformer Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 3156–3165. [Google Scholar]
- Wang, X.; Chen, K.; Zhao, Z.; Shi, G.; Xie, X.; Jiang, X.; Yang, Y. Multi-Scale Adaptive Skeleton Transformer for action recognition. Comput. Vis. Image Underst. 2025, 250, 104229. [Google Scholar] [CrossRef]
- Kong, J.; Bian, Y.; Jiang, M. MTT: Multi-Scale Temporal Transformer for Skeleton-Based Action Recognition. IEEE Signal Process. Lett. 2022, 29, 528–532. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE Conference on Computer Vision(ICCV), Sydney, Australia, 1–8 December 2011; pp. 2556–2563. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 23–26 August 2004; pp. 32–36. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705. 06950. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Morgado, P.; Vasconcelos, N.; Misra, I. Audio-visual Instance Discrimination with Cross-Modal-Agreement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2021; pp. 12475–12486. [Google Scholar]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G. TDN: Temporal Difference Networks for Efficient Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1895–1904. [Google Scholar]
- Liu, Z.; Li, Z.; Wang, R.; Zong, M.; Ji, W. Spatiotemporal saliency-based multi-stream networks with attention-aware LSTM for action recognition. Neural Comput. Appl. 2020, 18, 14593–14602. [Google Scholar] [CrossRef]
- Manh, N.D.D.; Hang, D.V.; Wang, J.C. YOWOv3: An Efficient and Generalized Framework for Human Action Detection and Recognition. arXiv 2024, arXiv:2408.02623v2. [Google Scholar]
- Wang, J.; Peng, X.; Qiao, Y. Cascade multi-head attention networks for action recognition. Comput. Vis. Image Underst. 2020, 192, 102898. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Integration Approach | Recognition Accuracy (ACC)/% |
|---|---|
| Seek peace and integration | 87.6 |
| Average fusion | 84.3 |
| Maximum fusion | 85.5 |
| Weighted integration | 88.6 |
| Modeling | Recognition Accuracy (ACC)/% |
|---|---|
| Two-stream | 88.6 |
| C3D-Two-stream | 91.8 |
| Multi-Transformer-Two-stream | 90.5 |
| C3D+Multi-Scale Transformer | 92.9 |
| Modeling | UCF101 (ACC)/% | HMDB51 (ACC)/% |
|---|---|---|
| Two-stream [34] | 87.6 | 59.4 |
| P3D [4] | 88.6 | - |
| C3D [12] | 85.4 | 56.8 |
| VTN [27] | 92.7 | 72.3 |
| IDT [35] | 85.9 | 57.2 |
| AVID-CAM [36] | 87.5 | - |
| TDN [37] | 91.5 | 75.3 |
| STS [38] | 90.1 | 62.4 |
| YOWOv3 [39] | 95.4 | 68.8 |
| TDD [40] | 90.3 | 63.2 |
| Ours | 92.9 | 74.6 |
| Ours-DA | 94.2 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Li, W.; He, B.; Wang, C.; Qu, L. Human Action Recognition Based on 3D Convolution and Multi-Attention Transformer. Appl. Sci. 2025, 15, 2695. https://doi.org/10.3390/app15052695
Liu M, Li W, He B, Wang C, Qu L. Human Action Recognition Based on 3D Convolution and Multi-Attention Transformer. Applied Sciences. 2025; 15(5):2695. https://doi.org/10.3390/app15052695
Chicago/Turabian StyleLiu, Minghua, Wenjing Li, Bo He, Chuanxu Wang, and Lianen Qu. 2025. "Human Action Recognition Based on 3D Convolution and Multi-Attention Transformer" Applied Sciences 15, no. 5: 2695. https://doi.org/10.3390/app15052695
APA StyleLiu, M., Li, W., He, B., Wang, C., & Qu, L. (2025). Human Action Recognition Based on 3D Convolution and Multi-Attention Transformer. Applied Sciences, 15(5), 2695. https://doi.org/10.3390/app15052695