
Collaborative Learning Groupings Incorporating Deep Knowledge Tracing Optimization Strategies


Abstract
1. Introduction
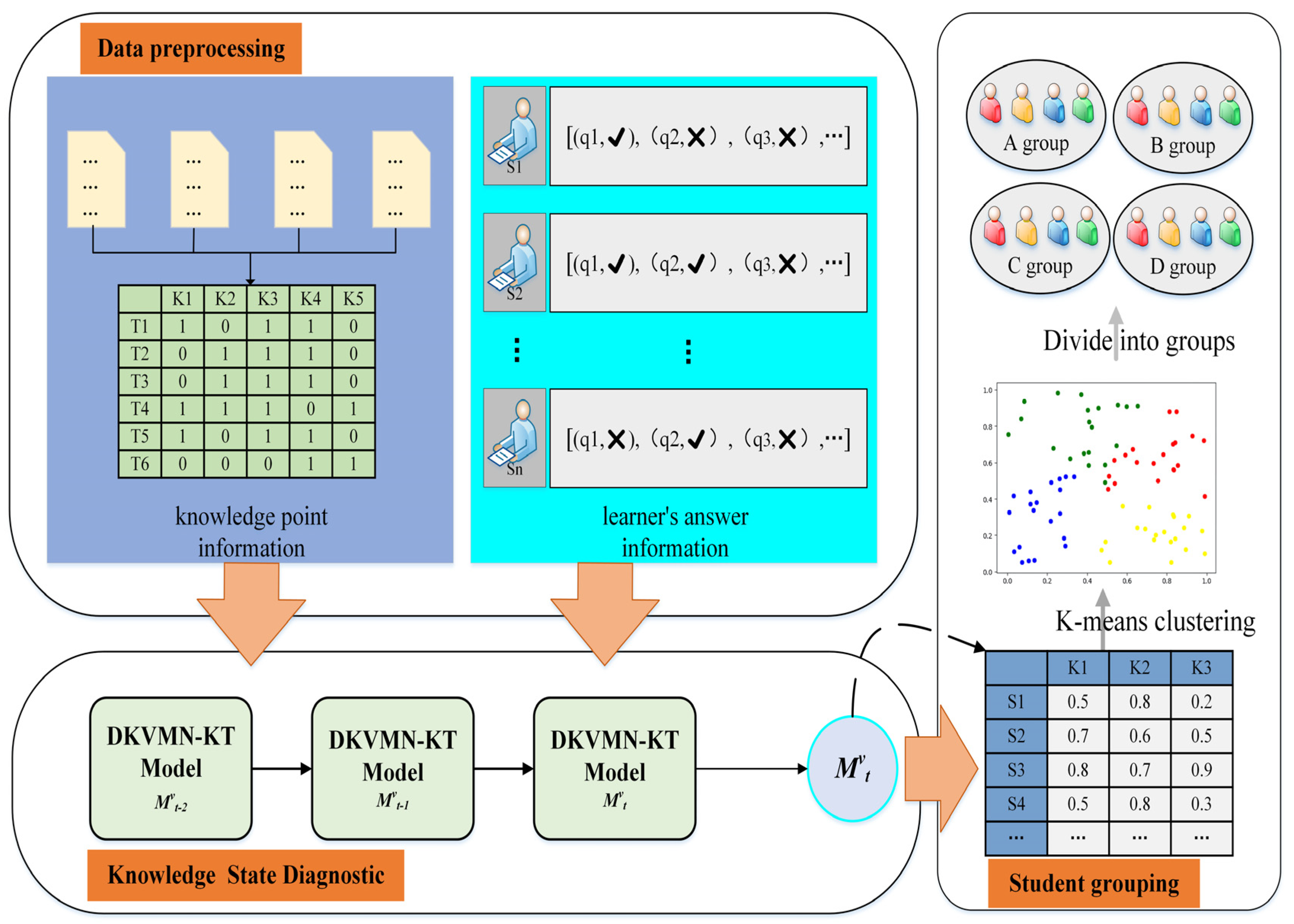
- We considered students’ knowledge mastery levels in the grouping process of collaborative learning and presented an innovative approach that incorporated deep knowledge tracing optimization strategies. The approach included three key modules: a data processing module, a knowledge state diagnosis module, and a student grouping module.
- A dynamic key–value memory network with exercise knowledge characteristics (DKVMN-EKC) model was proposed to improve the existing dynamic key–value memory network (DKVMN) model. DKVMN-EKC effectively represents students’ actual knowledge points and precisely evaluates their mastery levels of knowledge points.
- Considering the knowledge level of the students, the efficacy of the grouping approach was rigorously evaluated by comparing multiple groups of experiments.
2. Related Work
2.1. Collaborative Learning Grouping
2.2. Diagnostic Approaches for Students’ Knowledge States
2.2.1. Cognitive Diagnosis Based Knowledge State Diagnosis
2.2.2. Probabilistic Graph-Based Knowledge State Diagnosis
2.2.3. Deep Learning-Based Knowledge State Diagnosis
3. Collaborative Learning Grouping Approach Incorporating Deep Knowledge Tracing Optimization Strategies
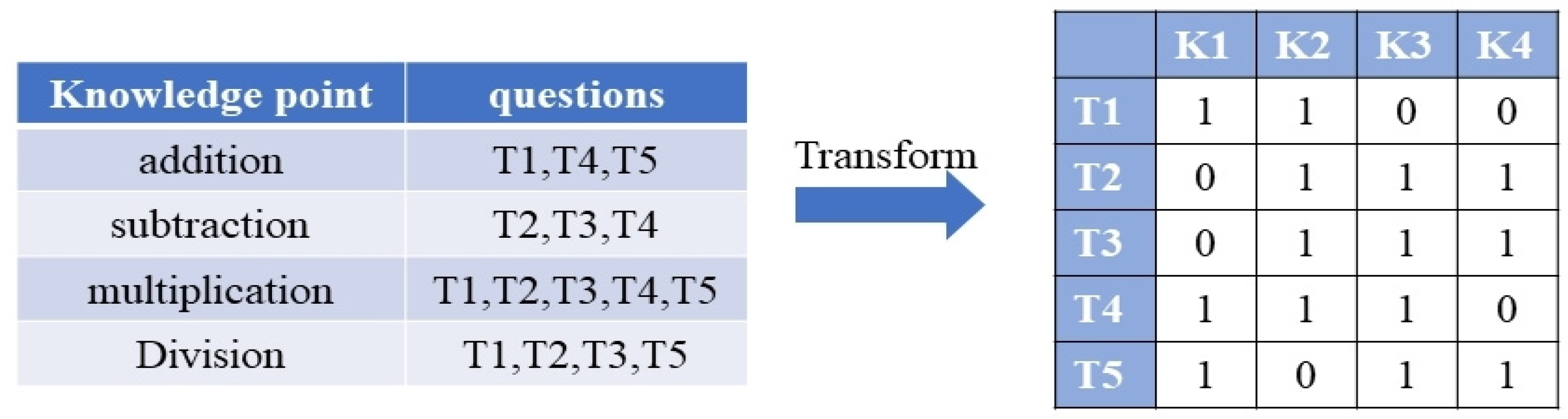
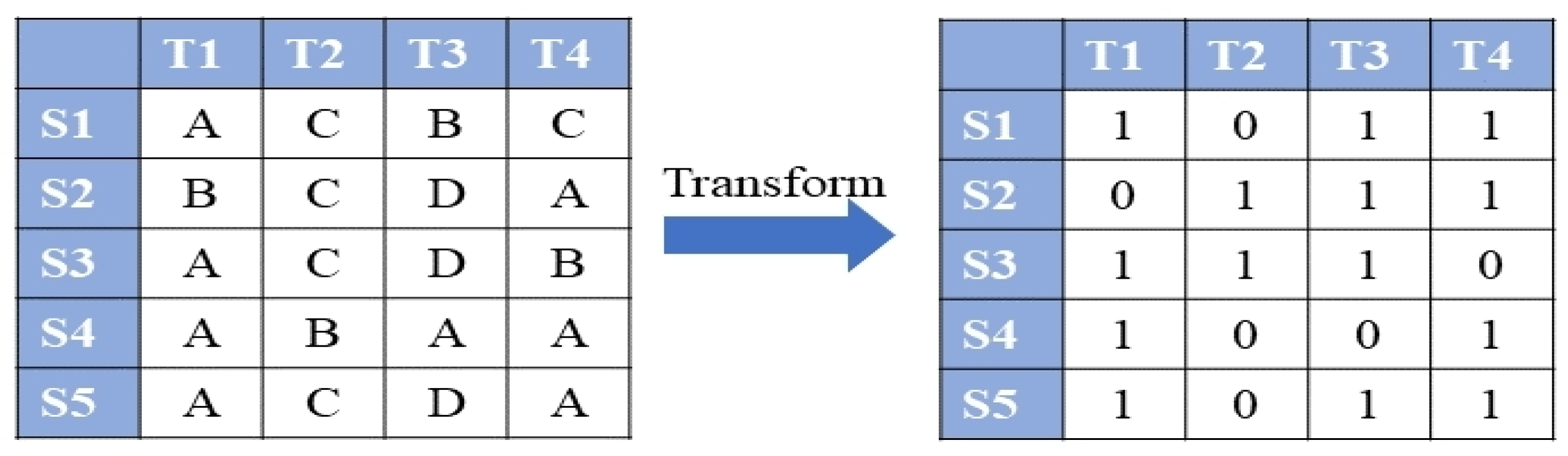
3.1. Data Preprocessing
3.1.1. Data Collection
3.1.2. Data Transformation
3.1.3. Data Cleaning
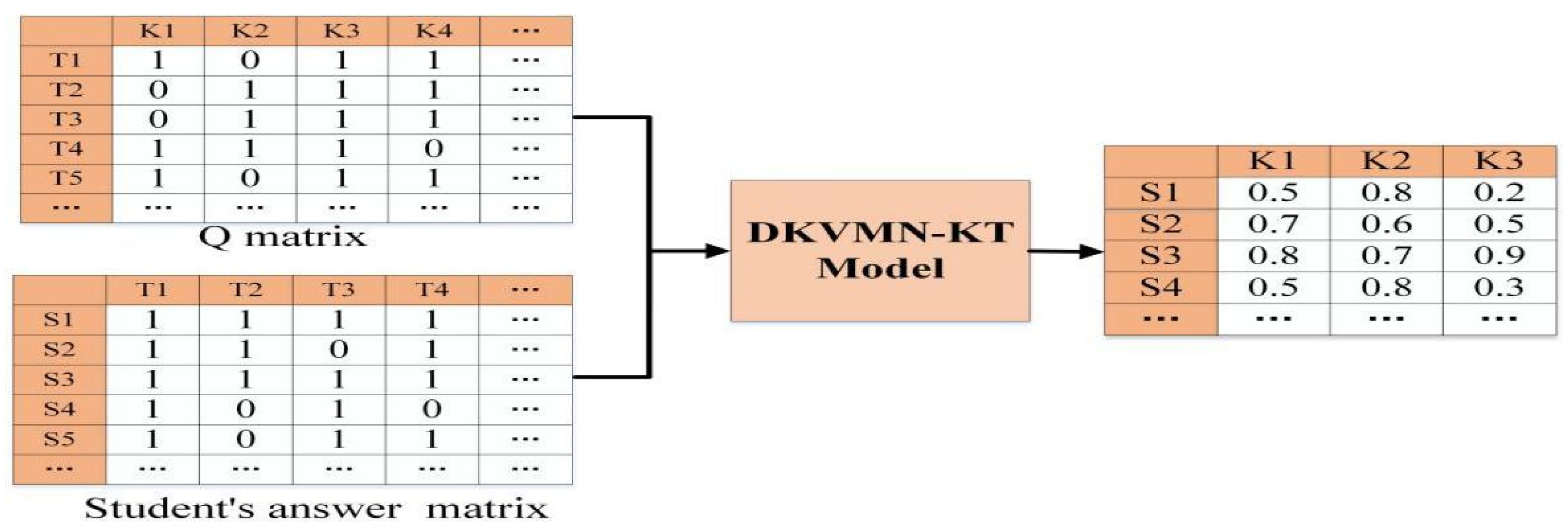
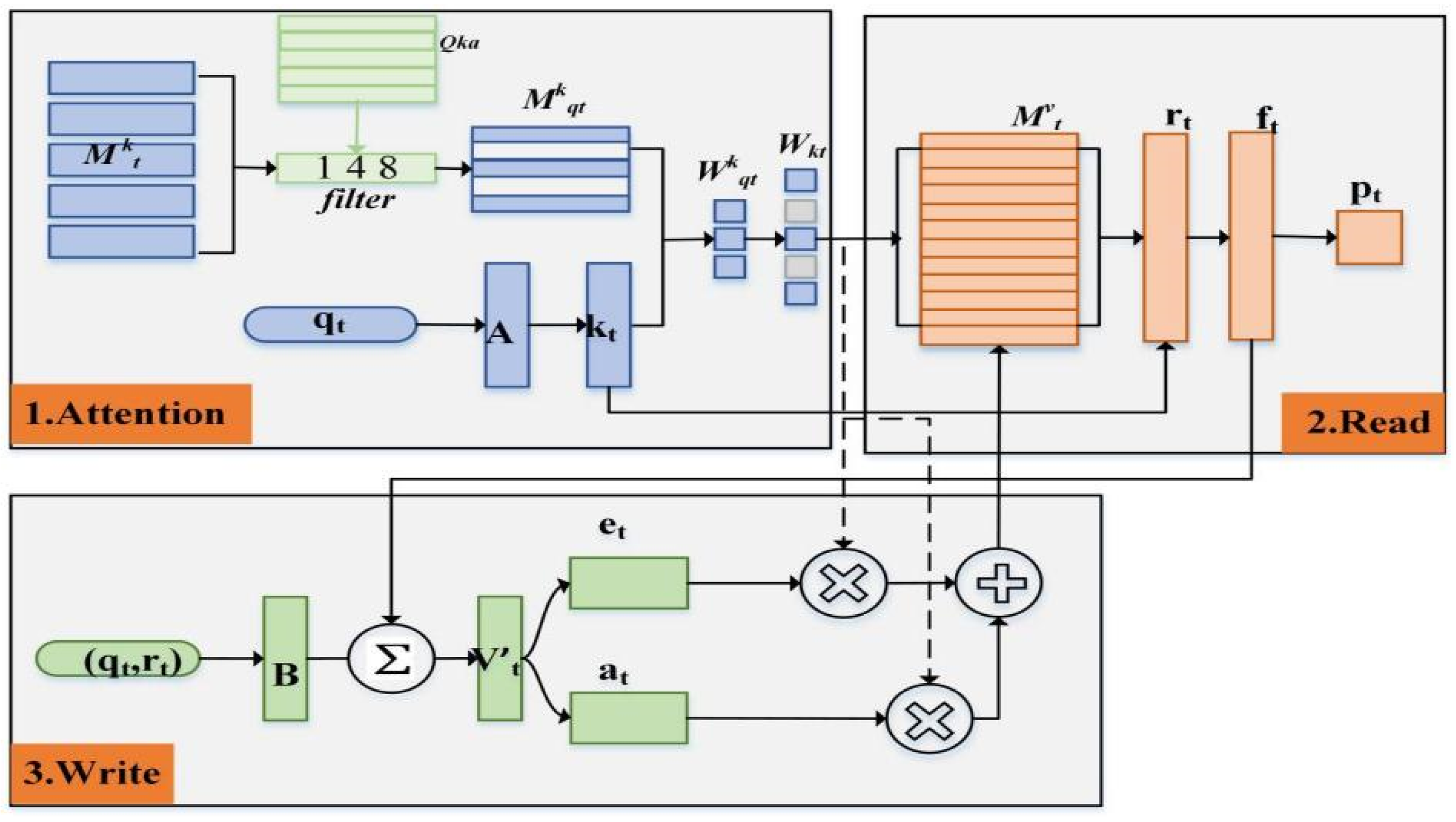
3.2. Knowledge State Diagnostic
3.2.1. Attention Mechanism
3.2.2. Read Operations
3.2.3. Write Operations
3.3. Student Grouping
| Algorithm 1. K-means-based clustering algorithm for students. |
| Input: Output: |
| 2: repeat |
| The number of n in is denoted as n |
| do |
| of the distance |
| ) // The closest cluster that is under the maximum number is marked into the appropriate cluster 8: end for do // Calculate the new mean vector then // |
| otherwise, leave the current mean vector unchanged |
| 13: end if |
| 14: end for |
| 15: until None of the current mean vectors have been updated |
4. Evaluation of Student Knowledge State Diagnosis
4.1. Dataset
4.2. Performance Comparison
- DINA model [27]: This is a common model for modeling students’ knowledge states in the field of educational psychology. It uses a Q matrix to map the relationship between exercises and knowledge points and considers the two influencing factors of errors and guesses to obtain a binary estimate of students’ knowledge states.
- IRT model [28]: This model is based on the relationship between a student’s ability and the percentage of correct responses. It integrates the student’s ability with the situation in the question paper (difficulty, differentiation, etc.) and assesses the student’s unidimensional ability values to diagnose potential traits.
- DKVMN model [23]: This model represents and tracks the conceptual state of each knowledge point using a dynamic key–value pair memory network to characterize a student’s knowledge state as a high-dimensional continuous feature. It is the basis for the DKVMN-EKC model.
- The DKVMN-EKC model surpassed the DINA model for all three datasets, with the most significant improvement in Item II, where the AUC improved by 0.16 and the ACC improved by 0.05. The DINA model represents students’ mastery of knowledge points as discrete two-dimensional variables. However, unlike the DKVMN-EKC model, it disregards the dynamic shifts in students’ knowledge and mastery states during the response process. Instead, it only considers two influencing factors: student error and guessing, which are modeled in an excessively simplified manner.
- The DKVMN-EKC model outperformed the IRT model on all three datasets, with the most significant improvement in Item II, where the AUC improved by 0.22 and ACC improved by 0.05. The IRT model uses a continuous variable to assess students’ latent characteristics with difficulty in diagnosing students’ mastery of their individual knowledge points, in contrast to the DKVMN-EKC model.
- Compared to the DKVMN model, the DKVMN-EKC model performed slightly worse on both the Math2 and Item II datasets but was still within acceptable limits. This is because, compared to the DKVMN model, the DKVMN-EKC model introduces a Q matrix, which inevitably leads to a degree of matrix sparsity; thus, the performance of the model is slightly degraded. However, it compensates for the inability of the DKVMN model to model real knowledge points and calculate students’ personalized knowledge growth. Taken together, the model proposed in this study not only retains the function-fitting capability of the DKVMN model but also models real knowledge points, enhancing the model’s interpretability, and being able to effectively model students’ knowledge mastery levels.
5. Evaluation of Student Groups
5.1. Experiment Subjects
5.2. Experiment Materials and Procedures
5.3. Experiment Evaluation Indicators
5.4. Collaborative Learning Groupings Effectiveness Comparison
5.4.1. Fairness of the Grouping Approach
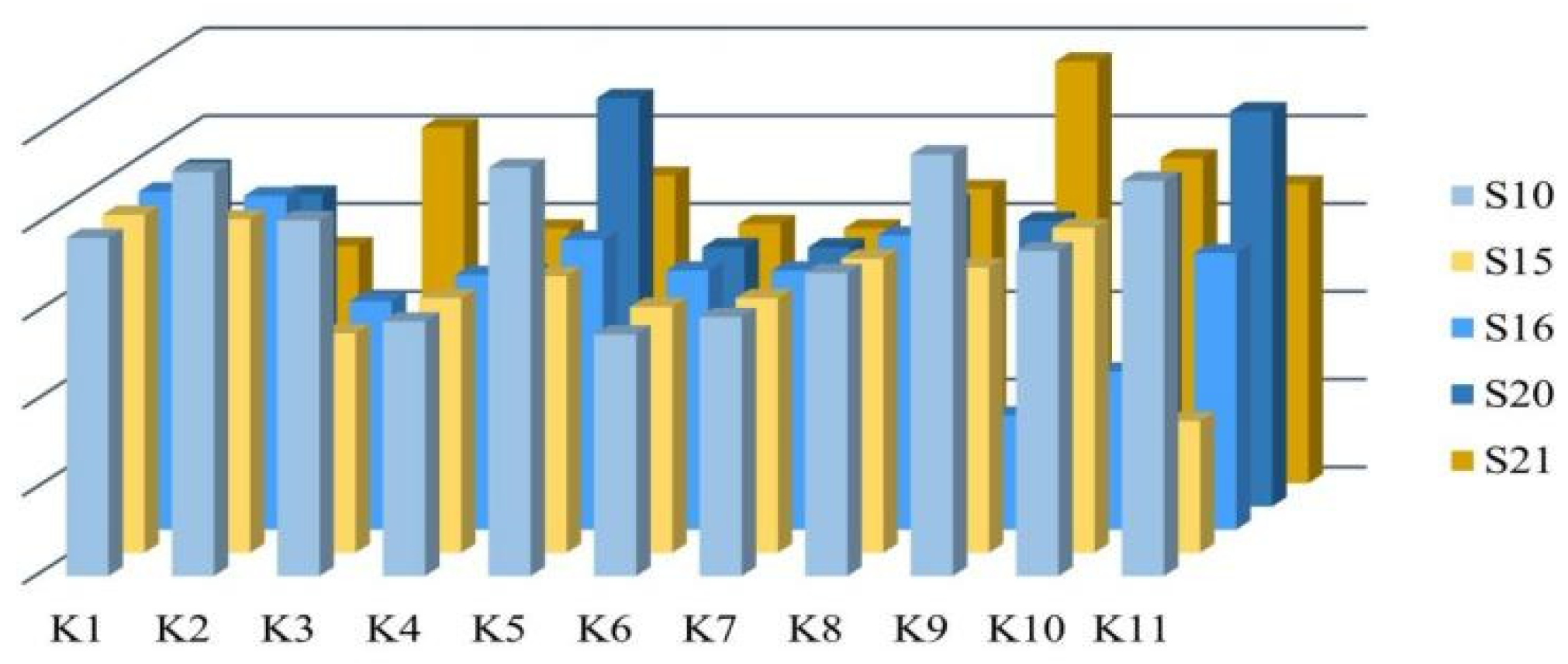
- The mean knowledge acquisition values of students in the quality groups should be consistent with the mean knowledge acquisition of the average student as far as possible. Table 5, Table 6 and Table 7 record the mean knowledge acquisition values of the learning groups formed based on the three different characteristics for each knowledge point. Figure 7 illustrates the mean knowledge acquisition values of Group 1 and the IOT students for the three grouping approaches, with the closest line to the mean being the group formed by our model.
- 2.
- The total average deviation for each knowledge level should be minimized. From the experimental results, for the four knowledge points of the basic elements of circuits (K1), basic knowledge of resistors (K3), electrical power (K9), and Ohm’s law (K11), the total average deviation of the learning group formed based on the DKVMN-EKC model is lower than that of the other two approaches. The total mean deviation of the DKVMN-EKC model-based learning groups was between that of the other two approaches for three knowledge points: resistor classification and symbol (K4), resistor type and parameters (K5), and current (K6). The other two grouping approaches had two or three knowledge points with relatively small total mean deviations.
5.4.2. Heterogeneity of the Grouping Approach
- The conventional grouping approach, which relies solely on raw scores as a measure of students’ knowledge level and is widely employed in related research [13,14], has significant limitations. It merely utilizes superficial data from students’ answers, failing to delve into their cognitive processes or effectively harness the wealth of information contained within their responses.
- While the DINA model-based learning groups establish a relationship between students’ answers and their internal cognitive characteristics, they have significant limitations. These groups rely solely on discrete two-dimensional variables to represent students’ knowledge mastery levels, which are reduced to the binary states of mastery and non-mastery. Clearly, this approach fails to accurately capture the complexities and nuances of real-world scenarios, thereby limiting its effectiveness in representing students’ true knowledge mastery.
- Learning groups formed based on the DKVMN-EKC model: First, in terms of model optimization, DKVMN-EKC is an improvement on the DKVMN model, which uses memory-enhanced network modeling, with the key matrix storing information about knowledge points, and the value matrix storing information about the student’s mastery of each knowledge point. Compared with the DKT model, to represent all the students’ knowledge mastery states, the DKVMN model uses two matrices to store information that is more explanatory than the DKT model; further, the current DKVMN model stores the potential knowledge points modeled by the neural network rather than the real knowledge points of exercises, and therefore introduces a Q matrix that incorporates the real knowledge points of the students. Moreover, the calculation of knowledge growth for the DKVMN model only considers the current responses of the students multiplied by an already trained embedding matrix and ignores the influence of the students’ cognitive processes. Although it has the same response, the students’ knowledge levels are different and the obtained knowledge growth should be different; hence, the model introduces the students’ previous knowledge states to the knowledge growth calculation to derive different knowledge increments for each student. Second, in terms of the cognitive diagnostic process, the DKVMN-EKC model uses the student’s response sequence and the Q matrix as inputs, and the Q matrix is used as a filter for the key matrix, enabling the model to incorporate information about the real knowledge points. The DKVMN-EKC model uses the student’s response sequence to simulate the student’s dynamic learning process, and the value matrix stores the student’s continuous knowledge mastery state for each knowledge point. Third, in terms of the formation results, the students’ mastery states formed using the DKVMN-EKC model are less granular. The model not only yields whether the students have mastery of the knowledge points but also accurately measures the degree of the students’ knowledge mastery using continuous values to represent the students’ knowledge mastery state. The model then uses the K-means algorithm to divide all the student objects into clusters, where the knowledge mastery level of the students in each cluster is similar, but not similar to the students in other clusters. The positive interactions between students lead to improved learning outcomes.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, K.A. Cooperative learning: Effective teamwork for engineering classrooms. In Proceedings of the Proceedings Frontiers in Education 1995 25th Annual Conference. Engineering Education for the 21st Century, Atlanta, GA, USA, 6 August 2002; IEEE: New York, NY, USA; Volume 1. [Google Scholar]
- Hu, X.Y.; Li, Y.L.; Xu, X.H. Practical Strategies for Optimizing Group Learning Effects: A Case Study of Educational Communication Course; South China Normal University (Social Science Edition): Guangzhou, China, 2009; Volume 1, p. 107. [Google Scholar]
- Li, Z.J.; Qiu, D.F. Student’s self-regulated learning: The conditions and strategies of teaching. Glob. Educ. 2017, 1, 47–57. [Google Scholar]
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep knowledge tracing. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/hash/bac9162b47c56fc8a4d2a519803d51b3-Abstract.html (accessed on 3 February 2025).
- Lindow, J.A.; Wilkinson, L.C.; Peterson, P.L. Antecedents and consequences of verbal disagreements during small-group learning. J. Educ. Psychol. 1985, 77, 658–667. [Google Scholar] [CrossRef]
- Barth-Cohen, L.A.; Wittmann, M.C. Aligning coordination class theory with a new context: Applying a theory of individual learning to group learning. Sci. Educ. 2017, 101, 333–363. [Google Scholar] [CrossRef]
- Molina, A.I.; Arroyo, Y.; Lacave, C.; Redondo, M.A. Learn-CIAN: A visual language for the modelling of group learning processes. Br. J. Educ. Technol. 2018, 49, 1096–1112. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Q.; Wu, R.; Chen, E.; Hu, G. Collaborative Learning Team Formation: ACognitive Modeling Perspective. In Proceedings of the International Conference on Database Systems for Advanced Applications, Xi’an, China, 16–19 April 2016. [Google Scholar]
- Gibbs. Learning in Teams: A Tutor Guide; Oxford Centre for Staff and Learning Development: Oxford, UK, 1995. [Google Scholar]
- Ounnas, A.; Davis, H.; Millard, D. A framework for semantic group formation. In Proceedings of the 2008 Eighth IEEE International Conference on Advanced Learning Technologies, Santander, Spain, 1–5 July 2008; IEEE: New York, NY, USA; pp. 34–38. [Google Scholar]
- Lin, Y.T.; Huang, Y.M.; Cheng, S.C. An automatic group composition system for composing collaborative learning groups using enhanced particle swarm optimization. Comput. Educ. 2010, 55, 1483–1493. [Google Scholar] [CrossRef]
- Ullmann, M.R.; Ferreira, D.J.; Camilo, C.G.; Caetano, S.S.; de Assis, L. Formation of learning groups in cmoocs using particle swarm optimization. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015; IEEE: New York, NY, USA; pp. 3296–3304. [Google Scholar]
- Chen, C.M.; Kuo, C.H. An optimized group formation scheme to promote collaborative problem-based learning. Comput. Educ. 2019, 133, 94–115. [Google Scholar] [CrossRef]
- Miranda, P.B.; Mello, R.F.; Nascimento, A.C. A multi-objective optimization approach for the group formation problem. Expert Syst. Appl. 2020, 162, 113828. [Google Scholar] [CrossRef]
- Tatsuoka, K.K. Architecture of knowledge structures and cognitive diagnosis: A statistical pattern recognition and classification approach. In Cognitively Diagnostic Assessment; Routledge: Oxfordshire, UK, 2012; pp. 327–359. [Google Scholar]
- Junker, B.W.; Sijtsma, K. Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Appl. Psychol. Meas. 2001, 25, 258–272. [Google Scholar] [CrossRef]
- Tu, D.B.; Cai, Y.; Dai, H.Q.; Ding, S.L. A polytomous cognitive diagnosis model: P-DINA model. Acta Psychol. Sin. 2010, 42, 1011–1020. [Google Scholar] [CrossRef]
- Tianpeng, Z.; Wenjie, Z.; Lei, G. Cognitive diagnosis modelling based on response times. J. Psychol. Sci. 2023, 46, 478. [Google Scholar]
- Zhang, K.; Yao, Y. A three learning states Bayesian knowledge tracing model. Knowl.-Based Syst. 2018, 148, 189–201. [Google Scholar] [CrossRef]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. User-Adapt. Interact. 1994, 4, 253–278. [Google Scholar] [CrossRef]
- Käser, T.; Klingler, S.; Schwing, A.G.; Gross, M. Dynamic Bayesian networks for student modeling. IEEE Trans. Learn. Technol. 2017, 10, 450–462. [Google Scholar] [CrossRef]
- Spaulding, S.; Breazeal, C. Affect and inference in Bayesian knowledge tracing with a robot tutor. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction Extended Abstracts, Chicago, IL, USA, 2–3 March 2015; pp. 219–220. [Google Scholar]
- Zhang, J.; Shi, X.; King, I.; Yeung, D.Y. Dynamic key-value memory networks for knowledge tracing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 765–774. [Google Scholar]
- Pandey, S.; Karypis, G. A self-attentive model for knowledge tracing. arXiv 2019, arXiv:1907.06837. [Google Scholar]
- Capó, M.; Pérez, A.; Lozano, J.A. An efficient split-merge re-start for the K-means algorithm. IEEE Trans. Knowl. Data Eng. 2020, 34, 1618–1627. [Google Scholar] [CrossRef]
- Wu, R.; Liu, Q.; Liu, Y.; Chen, E.; Su, Y.; Chen, Z.; Hu, G. Cognitive modelling for predicting examinee performance. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 June 2015; Available online: http://staff.ustc.edu.cn/~qiliuql/files/Publications/Runze-IJCAI2015.pdf (accessed on 3 February 2025).
- Tatsuoka, K.K. Rule space: An approach for dealing with misconceptions based on item response theory. J. Educ. Meas. 1983, 20, 345–354. [Google Scholar] [CrossRef]
- Hambleton, R.K.; Swaminathan, H. Item Response Theory: Principles and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Garshasbi, S.; Mohammadi, Y.; Graf, S.; Garshasbi, S.; Shen, J. Optimal learning group formation: A multi-objective heuristic search strategy for enhancing inter-group homogeneity and intra-group heterogeneity. Expert Syst. Appl. 2019, 118, 506–521. [Google Scholar] [CrossRef]
- Rogers, J.; Nehme, M. Motivated to collaborate: A self-determination framework to improve group-based learning. Leg. Educ. Rev. 2019, 29, 1. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Records | Students | Questions | Knowledge Points |
|---|---|---|---|---|
| Math1 | 63,135 | 4209 | 15 | 11 |
| Math2 | 62,576 | 3911 | 16 | 16 |
| Item II | 33,600 | 1120 | 30 | 11 |
| Model | Math1 | Math2 | Item II | |||
|---|---|---|---|---|---|---|
| AUC | ACC | AUC | ACC | AUC | ACC | |
| DINA | 0.66 | 0.63 | 0.68 | 0.64 | 0.59 | 0.69 |
| IRT | 0.69 | 0.64 | 0.71 | 0.65 | 0.53 | 0.70 |
| DKVMN | 0.74 | 0.68 | 0.77 | 0.69 | 0.77 | 0.75 |
| DKVMN-EKC | 0.74 | 0.68 | 0.76 | 0.69 | 0.75 | 0.74 |
| Knowledge Point | Questions |
|---|---|
| Basic elements of circuit composition (K1) | T1, T11, and T26 |
| Circuit operating state (K2) | T2, T12, T24, T25, and T30 |
| Basic knowledge of resistance (K3) | T3, T9, and T13 |
| Resistor classification and symbols (K4) | T14 and T27 |
| Resistor type and parameters (K5) | T4, T5, T15, T16, T17, and T18 |
| Current (K6) | T6 and T19 |
| Voltage (K7) | T28 |
| Electric potential (K8) | T20 and T30 |
| Electrical power (K9) | T9, T10, T21, and T29 |
| Electrical energy (K10) | T10 and T22 |
| Ohm’s law (K11) | T7, T8, T20, T23, T24, T25, and T30 |
| Student ID | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | K11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | 0.71 | 0.79 | 0.50 | 0.53 | 0.63 | 0.56 | 0.59 | 0.67 | 0.65 | 0.74 | 0.71 |
| S2 | 0.77 | 0.57 | 0.50 | 0.58 | 0.62 | 0.55 | 0.58 | 0.69 | 0.25 | 0.36 | 0.33 |
| S3 | 0.77 | 0.61 | 0.81 | 0.58 | 0.93 | 0.55 | 0.59 | 0.69 | 0.96 | 0.74 | 0.65 |
| S4 | 0.77 | 0.71 | 0.52 | 0.53 | 0.62 | 0.55 | 0.59 | 0.69 | 0.65 | 0.74 | 0.90 |
| S5 | 0.71 | 0.71 | 0.52 | 0.53 | 0.62 | 0.56 | 0.59 | 0.31 | 0.65 | 0.74 | 0.70 |
| S6 | 0.77 | 0.91 | 0.52 | 0.49 | 0.71 | 0.59 | 0.58 | 0.67 | 0.65 | 0.74 | 0.65 |
| S7 | 0.77 | 0.71 | 0.81 | 0.58 | 0.93 | 0.55 | 0.59 | 0.69 | 0.96 | 0.74 | 0.90 |
| S8 | 0.77 | 0.61 | 0.50 | 0.58 | 0.71 | 0.59 | 0.59 | 0.69 | 0.65 | 0.74 | 0.44 |
| S9 | 0.77 | 0.61 | 0.81 | 0.58 | 0.93 | 0.55 | 0.59 | 0.69 | 0.96 | 0.74 | 0.65 |
| S10 | 0.77 | 0.92 | 0.81 | 0.58 | 0.93 | 0.55 | 0.59 | 0.69 | 0.96 | 0.74 | 0.90 |
| S11 | 0.77 | 0.92 | 0.81 | 0.58 | 0.93 | 0.59 | 0.59 | 0.31 | 0.96 | 0.74 | 0.70 |
| S12 | 0.77 | 0.54 | 0.52 | 0.58 | 0.65 | 0.55 | 0.59 | 0.28 | 0.65 | 0.74 | 0.60 |
| S13 | 0.28 | 0.57 | 0.52 | 0.58 | 0.93 | 0.55 | 0.59 | 0.69 | 0.65 | 0.74 | 0.72 |
| S14 | 0.28 | 0.61 | 0.50 | 0.58 | 0.71 | 0.59 | 0.59 | 0.31 | 0.65 | 0.74 | 0.63 |
| S15 | 0.77 | 0.76 | 0.50 | 0.58 | 0.63 | 0.56 | 0.58 | 0.67 | 0.65 | 0.74 | 0.30 |
| S16 | 0.77 | 0.76 | 0.52 | 0.58 | 0.66 | 0.59 | 0.59 | 0.67 | 0.26 | 0.36 | 0.63 |
| S17 | 0.77 | 0.76 | 0.50 | 0.58 | 0.93 | 0.59 | 0.59 | 0.69 | 0.65 | 0.74 | 0.69 |
| S18 | 0.77 | 0.91 | 0.50 | 0.58 | 0.93 | 0.55 | 0.59 | 0.67 | 0.65 | 0.74 | 0.62 |
| S19 | 0.77 | 0.80 | 0.81 | 0.58 | 0.71 | 0.55 | 0.59 | 0.69 | 0.96 | 0.74 | 0.39 |
| S20 | 0.77 | 0.71 | 0.27 | 0.53 | 0.93 | 0.59 | 0.59 | 0.69 | 0.65 | 0.74 | 0.90 |
| S21 | 0.29 | 0.54 | 0.81 | 0.58 | 0.70 | 0.59 | 0.58 | 0.67 | 0.96 | 0.74 | 0.68 |
| S22 | 0.77 | 0.76 | 0.50 | 0.58 | 0.42 | 0.60 | 0.59 | 0.69 | 0.65 | 0.74 | 0.36 |
| S23 | 0.77 | 0.91 | 0.50 | 0.58 | 0.93 | 0.56 | 0.59 | 0.67 | 0.65 | 0.74 | 0.65 |
| S24 | 0.77 | 0.91 | 0.50 | 0.58 | 0.93 | 0.55 | 0.58 | 0.28 | 0.65 | 0.74 | 0.70 |
| S25 | 0.29 | 0.76 | 0.81 | 0.58 | 0.93 | 0.59 | 0.59 | 0.67 | 0.96 | 0.74 | 0.63 |
| S26 | 0.77 | 0.91 | 0.81 | 0.53 | 0.62 | 0.59 | 0.59 | 0.67 | 0.96 | 0.74 | 0.88 |
| S27 | 0.29 | 0.71 | 0.50 | 0.58 | 0.62 | 0.55 | 0.59 | 0.28 | 0.65 | 0.74 | 0.70 |
| S28 | 0.77 | 0.92 | 0.52 | 0.58 | 0.74 | 0.55 | 0.59 | 0.69 | 0.65 | 0.74 | 0.90 |
| S29 | 0.77 | 0.92 | 0.81 | 0.58 | 0.93 | 0.55 | 0.59 | 0.69 | 0.96 | 0.74 | 0.90 |
| S30 | 0.29 | 0.79 | 0.50 | 0.58 | 0.63 | 0.55 | 0.58 | 0.67 | 0.65 | 0.74 | 0.71 |
| Avg. | 0.67 | 0.75 | 0.60 | 0.57 | 0.77 | 0.57 | 0.59 | 0.60 | 0.73 | 0.71 | 0.67 |
| Group ID | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | K11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.77 | 0.69 | 0.52 | 0.57 | 0.83 | 0.58 | 0.59 | 0.69 | 0.63 | 0.66 | 0.66 |
| 2 | 0.67 | 0.81 | 0.57 | 0.58 | 0.77 | 0.56 | 0.59 | 0.53 | 0.63 | 0.66 | 0.66 |
| 3 | 0.76 | 0.80 | 0.57 | 0.57 | 0.77 | 0.56 | 0.59 | 0.53 | 0.71 | 0.74 | 0.66 |
| 4 | 0.67 | 0.76 | 0.69 | 0.58 | 0.77 | 0.56 | 0.59 | 0.60 | 0.84 | 0.74 | 0.56 |
| 5 | 0.58 | 0.77 | 0.69 | 0.57 | 0.76 | 0.57 | 0.59 | 0.61 | 0.84 | 0.74 | 0.75 |
| 6 | 0.56 | 0.70 | 0.57 | 0.54 | 0.72 | 0.57 | 0.59 | 0.68 | 0.71 | 0.74 | 0.73 |
| Error a | 7.99 | 4.60 | 6.49 | 1.35 | 3.21 | 0.81 | 0.00 | 6.38 | 8.66 | 3.79 | 6.11 |
| Group ID | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | K11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.67 | 0.67 | 0.58 | 0.56 | 0.72 | 0.57 | 0.59 | 0.69 | 0.69 | 0.66 | 0.64 |
| 2 | 0.65 | 0.76 | 0.50 | 0.56 | 0.66 | 0.57 | 0.59 | 0.53 | 0.65 | 0.74 | 0.60 |
| 3 | 0.77 | 0.81 | 0.57 | 0.57 | 0.77 | 0.57 | 0.59 | 0.60 | 0.71 | 0.74 | 0.74 |
| 4 | 0.67 | 0.82 | 0.75 | 0.58 | 0.93 | 0.57 | 0.59 | 0.53 | 0.90 | 0.74 | 0.72 |
| 5 | 0.67 | 0.80 | 0.63 | 0.56 | 0.77 | 0.57 | 0.59 | 0.6 | 0.70 | 0.66 | 0.76 |
| 6 | 0.58 | 0.67 | 0.57 | 0.58 | 0.77 | 0.56 | 0.59 | 0.68 | 0.71 | 0.74 | 0.56 |
| Error a | 5.55 | 6.31 | 7.70 | 0.91 | 8.19 | 0.41 | 0.00 | 6.36 | 8.02 | 3.79 | 7.46 |
| Group ID | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | K11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.67 | 0.74 | 0.58 | 0.57 | 0.77 | 0.58 | 0.59 | 0.68 | 0.70 | 0.66 | 0.68 |
| 2 | 0.67 | 0.64 | 0.57 | 0.58 | 0.82 | 0.57 | 0.59 | 0.69 | 0.63 | 0.66 | 0.62 |
| 3 | 0.67 | 0.72 | 0.57 | 0.56 | 0.79 | 0.57 | 0.59 | 0.52 | 0.71 | 0.74 | 0.63 |
| 4 | 0.75 | 0.75 | 0.63 | 0.55 | 0.75 | 0.56 | 0.59 | 0.53 | 0.77 | 0.74 | 0.73 |
| 5 | 0.67 | 0.86 | 0.67 | 0.57 | 0.82 | 0.57 | 0.59 | 0.60 | 0.84 | 0.74 | 0.65 |
| 6 | 0.58 | 0.82 | 0.57 | 0.58 | 0.67 | 0.56 | 0.59 | 0.60 | 0.71 | 0.74 | 0.71 |
| Error a | 4.92 | 7.08 | 3.85 | 1.08 | 5.13 | 0.71 | 0.00 | 6.56 | 6.51 | 3.79 | 4.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Chen, Y.; Liao, W.; Wang, X. Collaborative Learning Groupings Incorporating Deep Knowledge Tracing Optimization Strategies. Appl. Sci. 2025, 15, 2692. https://doi.org/10.3390/app15052692
Li H, Chen Y, Liao W, Wang X. Collaborative Learning Groupings Incorporating Deep Knowledge Tracing Optimization Strategies. Applied Sciences. 2025; 15(5):2692. https://doi.org/10.3390/app15052692
Chicago/Turabian StyleLi, Haojun, Yaohan Chen, Weixia Liao, and Xuhui Wang. 2025. "Collaborative Learning Groupings Incorporating Deep Knowledge Tracing Optimization Strategies" Applied Sciences 15, no. 5: 2692. https://doi.org/10.3390/app15052692
APA StyleLi, H., Chen, Y., Liao, W., & Wang, X. (2025). Collaborative Learning Groupings Incorporating Deep Knowledge Tracing Optimization Strategies. Applied Sciences, 15(5), 2692. https://doi.org/10.3390/app15052692